Faktorenanalyse mit binären Items in SPSS


Die Annahme multivariat normalverteilter Items bei der Durchführung einer exploratorischen Faktorenanalyse (EFA) verhindert, streng genommen, die Verwendung von binär skalierten Items (0/1-Codierung). Zwar entspricht der Pearson-Korrelationskoeffizient zwischen zwei binären Items dem Phi-Koeffizienten, der Stärke und Richtung des Zusammenhangs zwischen zwei binären Items misst, jedoch ist aufgrund des limitierten Wertebereichs eines binären Items die geforderte Verteilungsannahme einer multivariaten Normalverteilung klar verletzt.
Verwendung von binären Items bei Faktorenanalysen
Um binäre Items in einer EFA verwenden zu können muss eine sog. polychorische (bzw. im Falle zwei binärer Items die daraus resultierende tetrachorische) Korrelation zwischen jedem Itempaar berechnet werden und die resultierende Korrelationsmatrix in die EFA-Prozedur überführt werden. Polychorische Korrelationen sind spezielle Korrelationskoeffizienten für ordinale Daten, die davon ausgehen, dass hinter einem Item eine nicht beobachtete (latente) Variable liegt, deren Wertebereich in die Intervalle der ordinalen Variable „aufgeteilt“ wurde. Das Verfahren versucht nun, die Korrelation zwischen den latenten Variablen zu schätzen und nicht anhand deren ordinalen Ausprägungen.
Durchführung der Faktorenanalyse mit binären Items
Da bis dato in SPSS keine polychorische/tetrachorische Korrelation implementiert ist, muss die Schätzung der entsprechenden Korrelationsmatrix in einer anderen Software erfolgen. In einem vor Kurzem durchgeführten Projekt haben wir die Schätzung der tetrachorischen Korrelation in der Open Source Software R implementiert und die resultierende Korrelationsmatrix in SPSS zur Durchführung der EFA weiterverwendet. Im Folgenden gehen wir kurz, anhand eines exemplarischen Beispiels, auf die wichtigsten Schritte im Rahmen dieses Vorgehens ein.
Schritt 1: Vorbereitungen zur Analyse
Das R-Paket „foreign“ ermöglicht es, neben anderen Dateiformaten, SPSS-Daten (.sav) zu importieren. Zur Installation wird der Befehlt install.packages(“foreign”) verwendet. Des Weiteren wird zu Schätzung der polychorischen Korrelation das R-Paket „polycor“ benötigt.
Schritt 2: Datenimport von SPSS nach R
Nach dem Laden beider Pakete kann mittels der R Funktion read.spss() der SPSS-Datensatz nach R importiert werden. Möglicherweise erscheint ein Warnhinweis bzgl. falscher Zeichenkodierungen o.ä. Dies kann in der Regel ignoriert werden.
Schritt 3: Berechnung der tetrachorischen Korrelation
Zum Abspeichern der berechneten Korrelationen wird in R ein leeres Matrix-Objekt angelegt, in dem anschließend, mittels einer doppelten Schleife, für jedes Itempaar die polychorische Korrelation berechnet wird. Hierfür wird der Befehl polychor() verwendet. Darauf hin muss noch die Diagonale der Korrelationsmatrix mit dem Wert 1 befüllt werden.
Schritt 4: Export der Korrelationsmatrix
Zur weiteren Verwendung wird die Korrelationsmatrix aus R als CSV-Datei exportiert. Dies geschieht mittels write.table(). Hierbei ist darauf zu achten, dass der richtige Dezimaltrenner exportiert wird (SPSS verwendet i.d.R. ein Komma, R verwendet einen Punkt). Im Folgenden finden Sie einen exemplarischen R-Code.
# Benötigte Pakete installieren
install.packages("foreign")
install.packages("polycor")
# Pakete laden
library(foreign)
library(polycor)
# SPSS Daten importieren (Dateipfad anpassen)
data <- read.spss(file="~/Desktop/Binary-Items.sav",
use.value.labels=FALSE, to.data.frame=TRUE)
# Anzahl Zeilen/Spalten Korrelationsmatrix
n <- ncol(data); m <- n
# Leere Korrelationsmatrix anlegen
cormat <- matrix(nrow=n, ncol=m, data=NA)
# Polychorische Korrelationen für jedes Itempaar berechnen
for (i in 1:n){
for(j in 1:m){
cormat[i,j] <- polychor(data[,i], data[,j])
}
}
# Diagonalelemente auf 1 setzen
diag(cormat) <- 1
# Exportieren
write.table(cormat, "~/STATWORX/PolyCorMat.csv", row.names=F, sep=";", dec=",")Schritt 5: Anfertigung MATRIX-Daten in SPSS
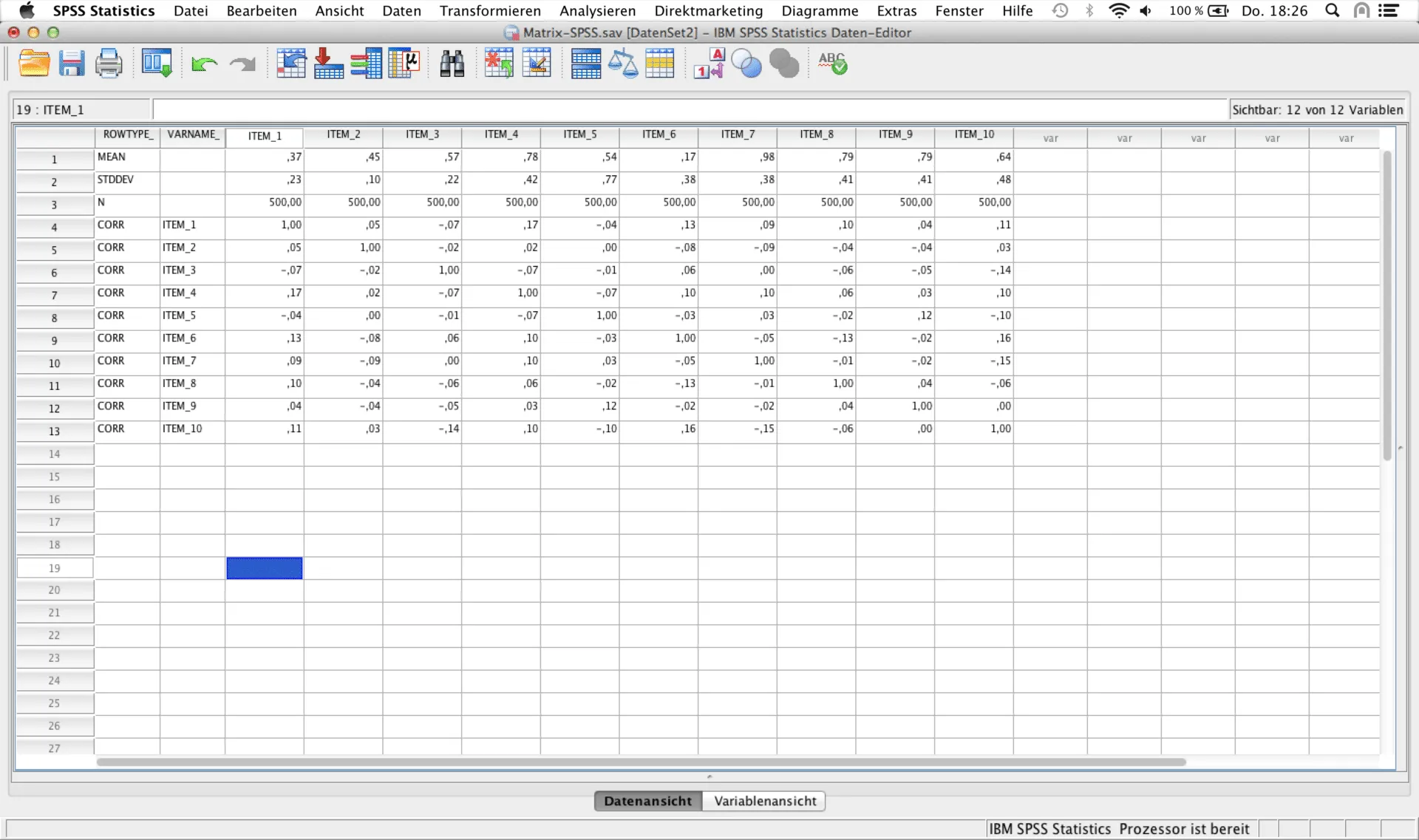
Zur Verwendung der Korrelationsmatrix im Rahmen der FACTOR-Prozedur in SPSS muss manuell eine bestimmte Aufbereitung der Korrelationsmatrix stattfinden damit die Berechnung durchgeführt werden kann (siehe Screenshot unten). Die ersten beiden Spalten enthalten die Attribute ROWTYPE_ und VARNAME_, die vom Benutzer manuell angelegt werden müssen. Die ersten drei Zeilen müssen Mittelwert (MEAN), Standardabweichung (STDDEV) und Anzahl der Beobachtungen (N) der jeweiligen Variablen enthalten. Diese Werte können z.B. anhand der Ausgangsdaten in SPSS erzeugt werden. Die berechneten Korrelationen können z.B. nach Import in Excel mittels Copy und Paste übernommen werden oder direkt in SPSS geladen werden.
Schritt 6: Durchführung der Faktorenanaylse in SPSS
Nachdem die Korrelationsmatrix entsprechend aufbereitet wurde kann nun die eigentliche Faktorenanalyse durchgeführt werden. Diese MUSS mit SPSS-Syntax erfolgen, da nur hier eine benutzerdefinierte Korrelationsmatrix spezifiziert werden kann. Hierbei ist darauf zu achten, dass die Korrelationsmatrix der aktive Datensatz ist. Die Syntax lautet:
FACTOR MATRIX IN (COR=*)
/MISSING LISTWISE
/PRINT UNIVARIATE INITIAL KMO EXTRACTION ROTATION
/FORMAT BLANK(.30)
/PLOT EIGEN
/CRITERIA MINEIGEN(1) ITERATE(25)
/EXTRACTION PAF
/CRITERIA ITERATE(25)
/ROTATION PROMAX(4)
/METHOD=CORRELATION.
Zusammenfassung
Bis dato gibt es in SPSS noch nicht die Möglichkeit binäre Items adäquat in Faktorenanalysen zu verwenden. Dies wird sich wahrscheinlich auch in Zukunft nicht ändern (obwohl SPSS im Rahmen der Restrukturierung des Lizenzmodells nun wieder verstärkt Funktionen implementiert). Durch die Open-Source Software R können aber dennoch in SPSS entsprechende Analysen durchgeführt werden. Natürlich können auch nach der Berechnung der polychorischen Korrelationen in R, die Analyse weiter in R durchgeführt werden. Falls du noch Fragen zur Durchführung einer exploratorischen Faktorenanalyse mit binären Items haben solltest oder ein konkretes Projekt besprechen willst, stehen dir unsere Statistik Experten unter info@statworx.com gerne zur Verfügung.


