Animierte Plots mit ggplot und gganimate


Wusstest du, dass du statische ggplot-Diagramme mit dem Paket gganimate von RStudis's Thomas Lin Pedersen und David Robinson in dynamische Animationen verwandeln kannst? Die Ergebnisse sind wirklich beeindruckend! Meine Kollegen bei statworx und ich sind begeistert, wie einfach sich verschiedene Diagrammtypen in superflüssige Animationen umwandeln lassen. In diesem Beitrag gebe ich dir einen kurzen Überblick über einige der tollen Funktionen von gganimate. Ich hoffe, du findest sie genauso spannend wie wir!
Passend zum Valentinstag werfen wir einen Blick auf den Datensatz des Speed-Dating-Experiments, zusammengestellt von den Professoren Ray Fisman und Sheena Iyengar der Columbia Business School. Vielleicht lernen wir dabei nicht nur etwas über gganimate, sondern auch, wie wir unseren Valentin finden können. Wenn du Lust hast, kannst du die Daten von Kaggle herunterladen.
Grundanimation definieren: transition_*
Wie werden statische Diagramme zum Leben erweckt? Im Grunde erstellt gganimate verschiedene Datensubsets, die einzeln geplottet und in aufeinanderfolgenden Frames angezeigt werden, um die Animation zu erzeugen. Das Besondere an gganimate ist, dass es das sogenannte Tweening übernimmt und die Übergangsdatenpunkte zwischen den Frames berechnet.
Die transition_* Funktionen bestimmen, wie die Datensubsets generiert werden und prägen damit den Charakter der Animation. In diesem Blogpost schauen wir uns drei Übergangstypen an: transition_states(), transition_reveal() und transition_filter(). Aber fangen wir ganz vorne an.
Mit transition_states() teilen wir die Daten in Subsets gemäß den Kategorien, die dem states-Argument übergeben werden. Wenn mehrere Zeilen eines Datensatzes zur gleichen Beobachtungseinheit gehören und entsprechend identifizierbar sein sollen, muss eine Gruppierungsvariable angegeben werden. Alternativ kann ein Identifikator einer anderen Ästhetik zugeordnet werden.
Um die Lesbarkeit dieses Beitrags zu gewährleisten, sind alle Texte zur Interpretation der Speed-Dating-Daten kursiv. Wenn dich dieser Teil nicht interessiert, kannst du ihn einfach überspringen. Für die Datenvorbereitung verweise ich auf mein GitHub.
Zunächst betrachten wir, wonach die Teilnehmer des Speed-Dating-Experiments bei einem Partner suchen. Die Teilnehmer sollten die Bedeutung von Attributen bei einem potenziellen Date bewerten, indem sie ein Budget von 100 Punkten auf verschiedene Merkmale verteilen. Höhere Werte deuten auf eine höhere Wichtigkeit hin. Sie sollten die Attribute sowohl aus ihrer eigenen Sicht als auch aus der vermuteten Perspektive ihrer gleichgeschlechtlichen Altersgenossen bewerten.
Wir werden diese Bewertungen für alle Attribute plotten. Da wir die individuellen Wünsche mit den vermuteten Wünschen der Altersgenossen vergleichen möchten, wechseln wir zwischen beiden Bewertungssets. Die Farbe zeigt immer die persönlichen Wünsche eines Teilnehmers an. Eine Blase repräsentiert die Bewertung eines spezifischen Teilnehmers für ein bestimmtes Attribut und wechselt zwischen den eigenen Wünschen und den vermuteten Wünschen der Altersgenossen.
## Static Plot
# ...characteristic vs. (presumed) rating...
# ...color&size mapped to own rating, grouped by ID
plot1 <- ggplot(df_what_look_for,
aes(x = value,
y = variable,
color = own_rating, # bubbels are always colord according to own whishes
size = own_rating,
group = iid)) + # identifier of observations across states
geom_jitter(alpha = 0.5, # to reduce overplotting: jitttering & alpha
width = 5) +
scale_color_viridis(option = "plasma", # use virdis' plasma scale
begin = 0.2, # limit range of used hues
name = "Own Rating") +
scale_size(guide = FALSE) + # no legend for size
labs(y = "", # no axis label
x = "Allocation of 100 Points", # x-axis label
title = "Importance of Characteristics for Potential Partner") +
theme_minimal() + # apply minimal theme
theme(panel.grid = element_blank(), # remove all lines of plot raster
text = element_text(size = 16)) # increase font size
## Animated Plot
plot1 +
transition_states(states = rating) # animate contrast subsets acc. to variable rating
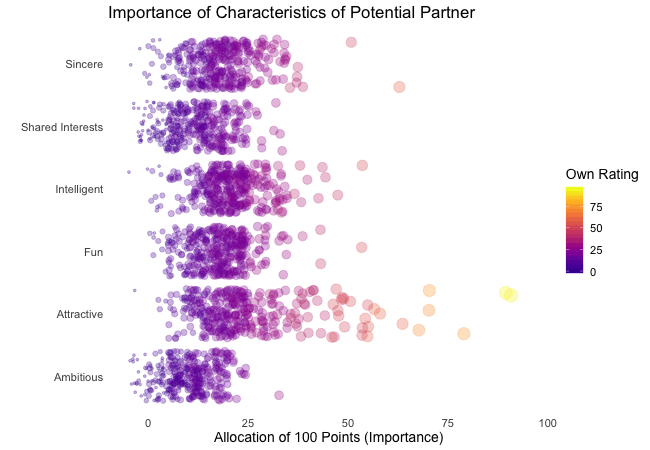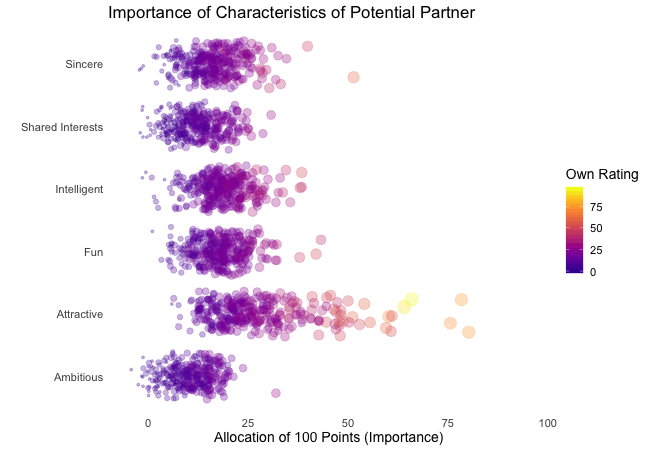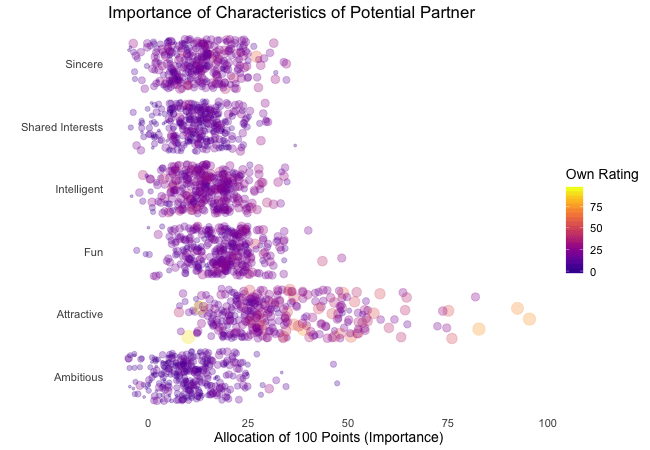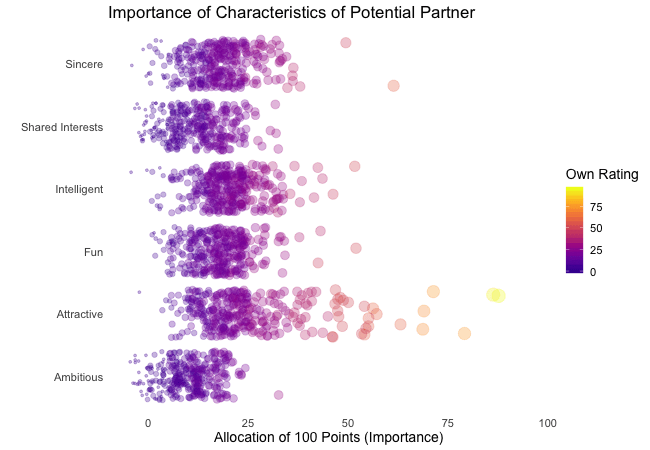
Wenn ihr zunächst etwas verwirrt seid, welcher Zustand welcher ist, habt bitte etwas Geduld, denn wir werden die dynamischen Bezeichnungen im Abschnitt über „Rahmenvariablen“ näher erläutern.
Es ist klar, dass unterschiedliche Menschen nach unterschiedlichen Qualitäten bei einem Partner suchen. Oft wird Attraktivität über andere Eigenschaften gestellt, obwohl ihre Bedeutung stark zwischen den Individuen variiert. Interessanterweise sind sich die Menschen bewusst, dass die Bewertungen ihrer Altersgenossen von ihren eigenen Ansichten abweichen könnten. Die kollektiven Annahmen über andere sind nicht völlig daneben, aber sie haben eine höhere Varianz als die tatsächlichen Bewertungen.
Also gibt es Hoffnung, dass irgendwo jemand nach einem ebenso ehrgeizigen oder intelligenten Partner sucht wie wir. Doch nicht immer zählen nur die inneren Werte.
gganimate bietet die Möglichkeit, die Details der Animation nach unseren Vorstellungen zu gestalten. Mit dem Argument transition_length können wir die relative Länge des Übergangs von einem zum anderen Datensubset festlegen und mit state_length, wie lange jedes Subset der Originaldaten angezeigt wird. Nur wenn das wrap-Argument auf TRUE gesetzt ist, wird der letzte Frame wieder in den ersten Frame der Animation verwandelt, wodurch eine endlose Schleife entsteht.
## Animated Plot
# ...replace default arguments
plot1 +
transition_states(states = rating,
transition_length = 3, # 3/4 of total time for transitions
state_length = 1, # 1/4 of time to display actual data
wrap = FALSE) # no endless loop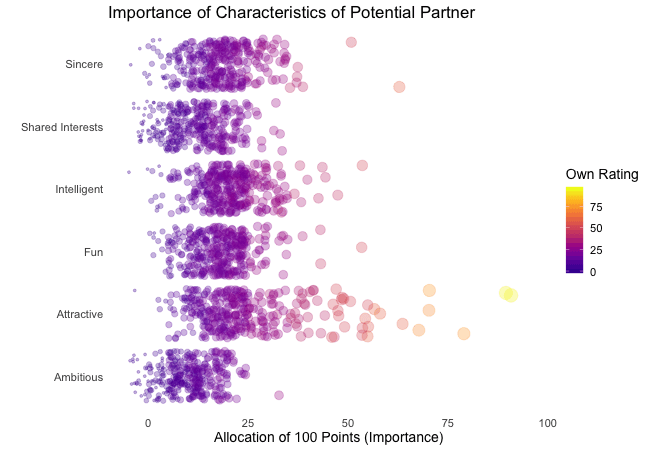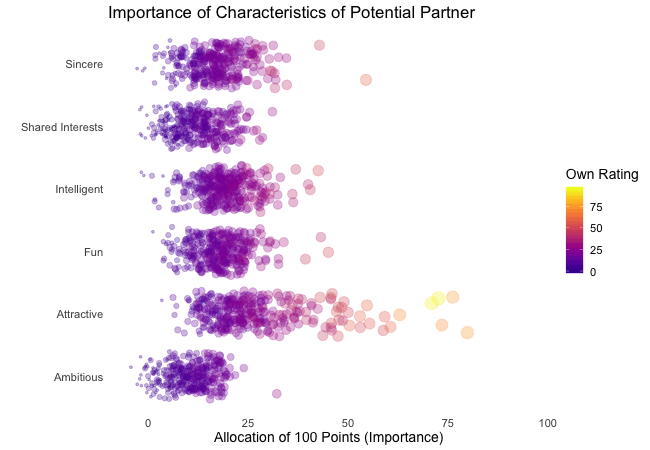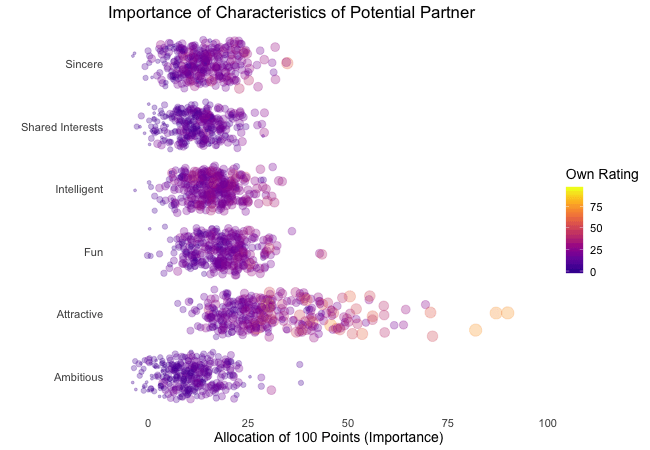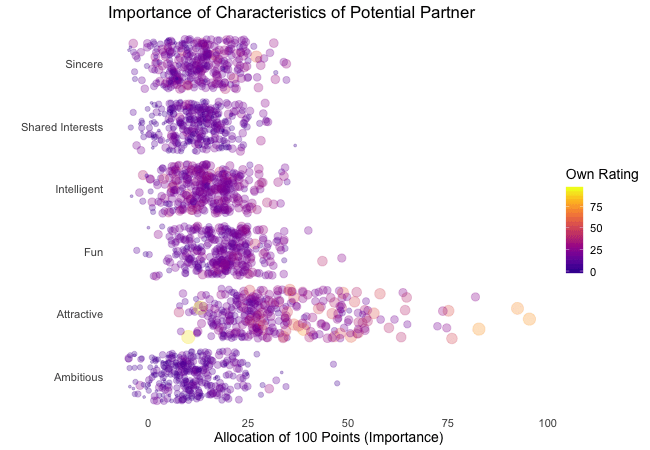
Styling von Übergängen: ease_aes
Wie bereits erwähnt, kümmert sich gganimate um das Tweening und berechnet zusätzliche Datenpunkte, um sanfte Übergänge zwischen den Punkten der tatsächlichen Eingabedaten zu schaffen. Mit ease_aes können wir steuern, welche Easing-Funktion verwendet wird, um Datenpunkte ineinander zu 'verformen'. Die Standardfunktion gilt für alle Ästhetiken eines Plots. Alternativ können Easing-Funktionen einzelnen Ästhetiken zugewiesen werden. Quadric, cubic , sine und exponential Easing-Funktionen stehen zur Verfügung, wobei die linear easing Funktion die Standardfunktion ist. Diese Funktionen können weiter angepasst werden, indem ein Modifikator-Suffix hinzugefügt wird: Mit -in wird die Funktion normal angewendet, mit -out umgekehrt und mit -in-out erst normal und dann umgekehrt.
Hier habe ich eine Easing-Funktion ausprobiert, die das Hüpfen eines Balls modelliert.
## Animated Plot
# ...add special easing function
plot1 +
transition_states(states = rating) +
ease_aes("bounce-in") # bouncy easing function, as-is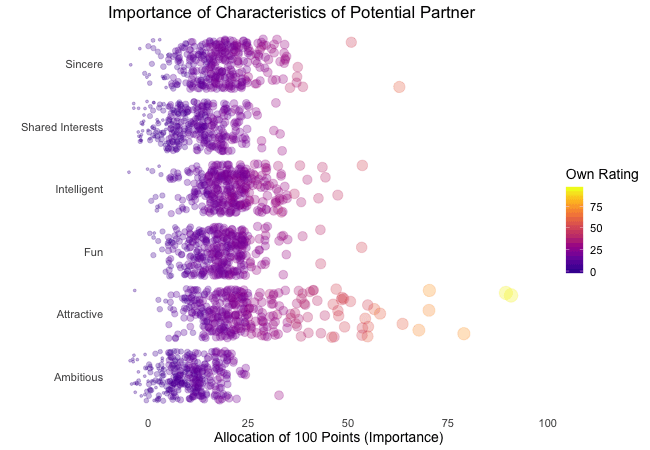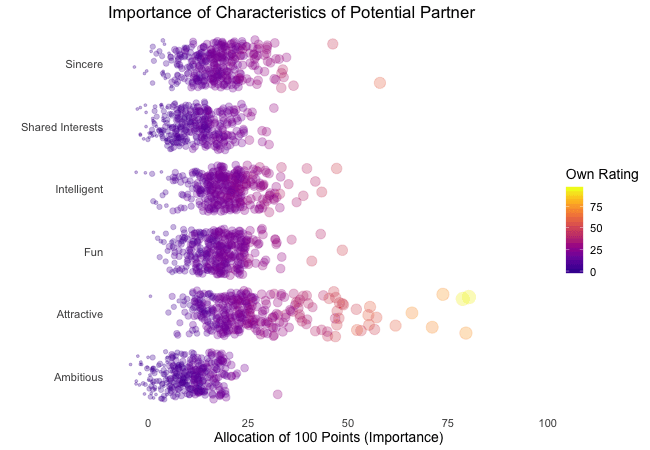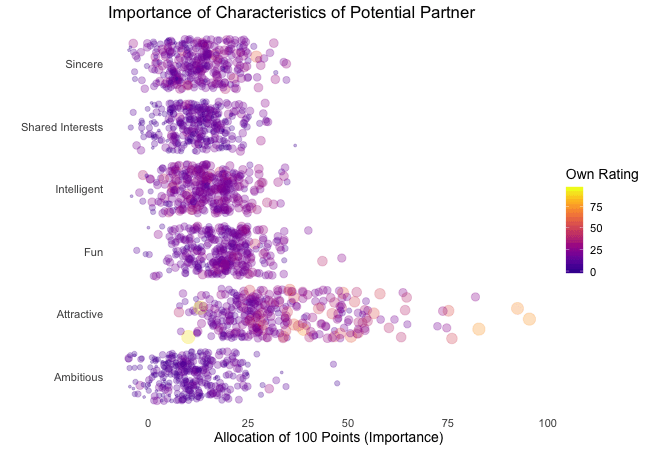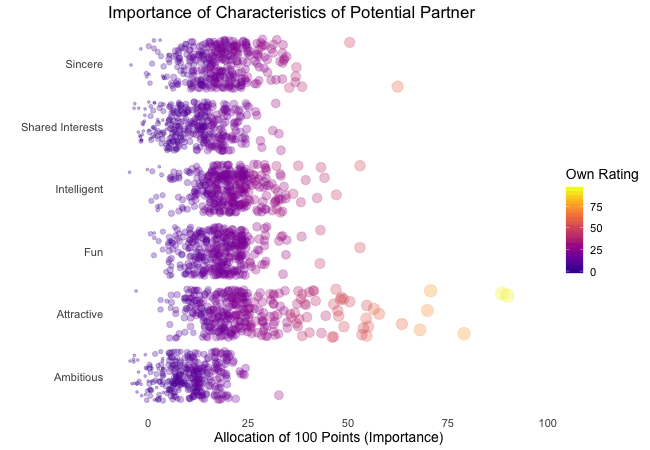
Dynamisches Labeling: {Frame-Variablen}
Damit wir beim Betrachten der Animationen nicht den Überblick verlieren, stellt gganimate sogenannte Frame-Variablen bereit, die Metadaten über die Animation oder den vorherigen/aktuellen/nächsten Frame liefern. Diese Variablen können innerhalb aller Plot-Labels interpretiert werden, wenn sie in geschweifte Klammern gesetzt sind. Zum Beispiel können wir jeden Frame mit dem Wert der states Variablen beschriften, die das aktuell angezeigte Subset der Daten definiert.
## Animated Plot
# ...add dynamic label: subtitle with current/next value of states variable
plot1 +
labs(subtitle = "{closest_state}") + # add frame variable as subtitle
transition_states(states = rating) 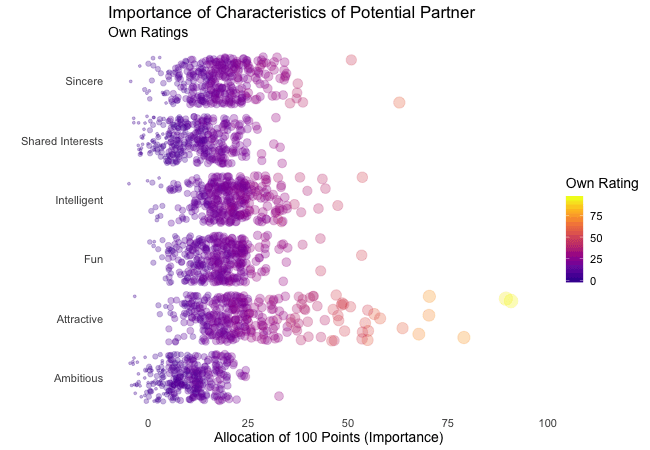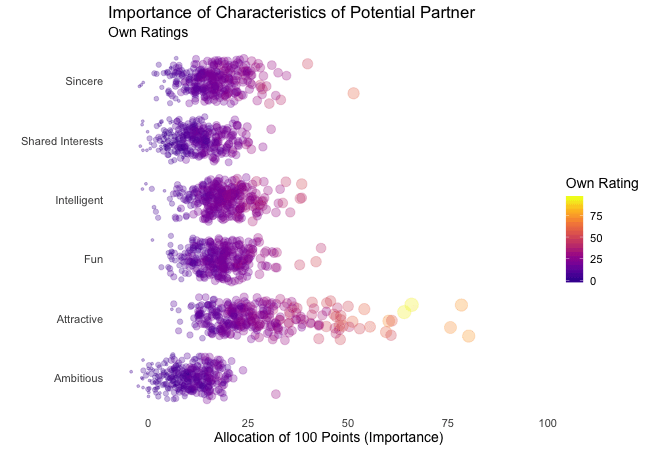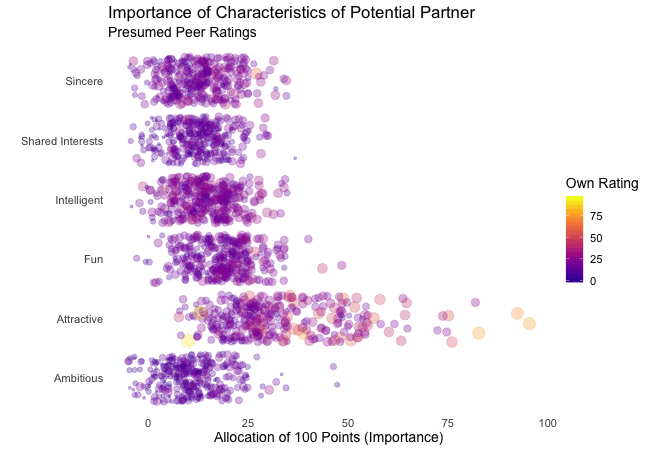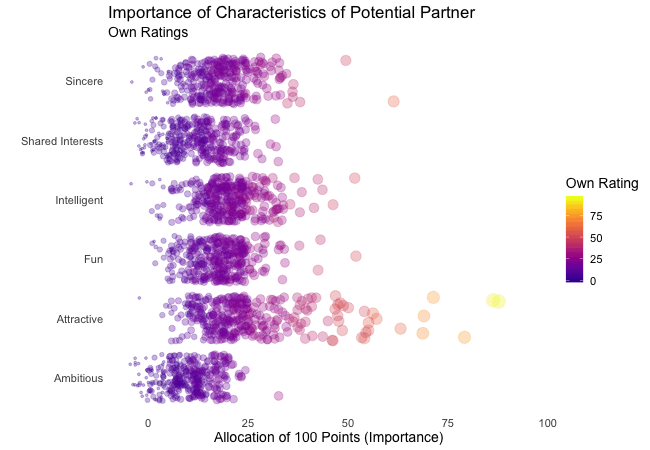
Das Set der verfügbaren Variablen hängt von der Übergangsfunktion ab. Um eine Liste der Frame-Variablen für eine Animation zu erhalten, kann die Funktion frame_vars() aufgerufen werden, um die Namen und Werte der verfügbaren Variablen zu erhalten.
Anzeige vorheriger Daten: shadow_*
Um die Verbindung zwischen verschiedenen Frames zu betonen, können wir einen der 'Schatten' von gganimate verwenden. Standardmäßig wird kein Schatten hinzugefügt shadow_null(). Schatten zeigen Datenpunkte vergangener Frames auf unterschiedliche Weise: shadow_trail() erstellt eine Spur gleichmäßig verteilter Datenpunkte, während shadow_mark() alle Rohdatenpunkte anzeigt.
Wir verwenden shadow_wake(), um ein kleines 'Wach' von vergangenen Datenpunkten zu erzeugen, die allmählich schrumpfen und verblassen. Mit dem Argument wake_length können wir die Länge des Wachs relativ zur Gesamtanzahl der Frames festlegen. Da sich die Wachs überlappen, muss die Transparenz der Geoms möglicherweise angepasst werden. Schatten können die Verständlichkeit bei Plots mit vielen Datenpunkten beeinträchtigen.
plot1B + # same as plot1, but with alpha = 0.1 in geom_jitter
labs(subtitle = "{closest_state}") +
transition_states(states = rating) +
shadow_wake(wake_length = 0.5) # adding shadow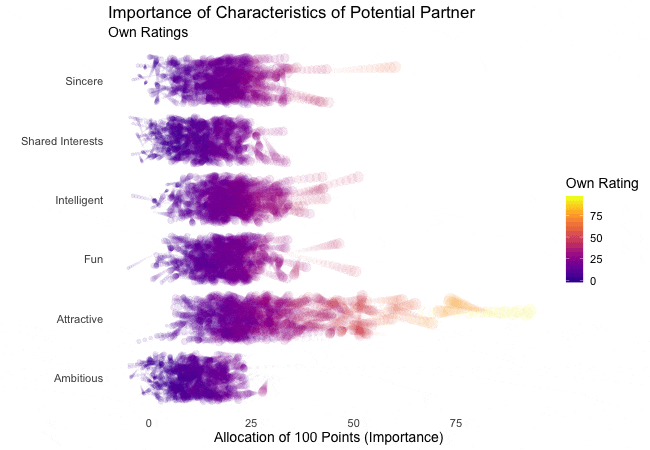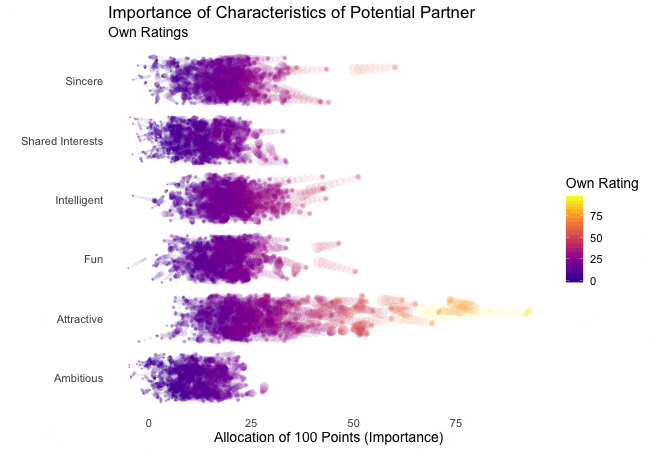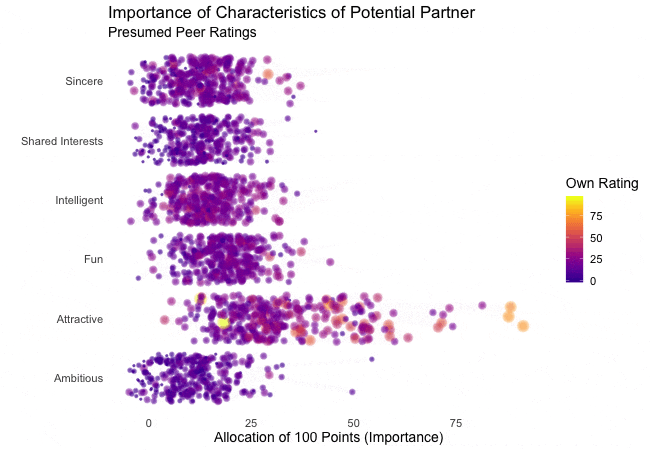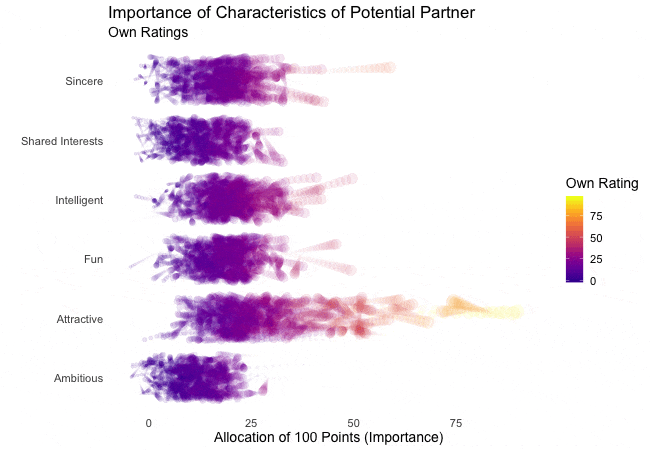
Die Vorteile von transition_*
Die visuellen Darstellungen von animierten Plots sind nicht nur schön anzusehen, sondern bieten auch tatsächliche Vorteile. Ich finde, dass transition_states gegenüber der Facettierung den Vorteil hat, dass es einfacher ist, individuelle Beobachtungen durch Übergänge zu verfolgen. Egal wie viele Unterplots wir erkunden möchten, wir benötigen nicht viel Platz und überladen unser Dokument nicht mit unzähligen Plots.
Ähnlich bietet transition_reveal zusätzlichen Wert für Zeitreihen, indem es nicht nur eine Zeitvariable auf eine Achse mappt, sondern auch die tatsächliche Zeit berücksichtigt: Die Übergangslänge zwischen den individuellen Frames der Eingabedaten entspricht den tatsächlichen Zeitunterschieden der Ereignisse. Um dies zu veranschaulichen, werfen wir einen Blick auf den 'Erfolg' der Speed-Dates über die verschiedenen Events:
## Static Plot
# ... date of event vs. interest in second date for women, men or couples
plot2 <- ggplot(data = df_match,
aes(x = date, # date of speed dating event
y = count, # interest in 2nd date
color = info, # which group: women/men/reciprocal
group = info)) +
geom_point(aes(group = seq_along(date)), # needed, otherwise transition dosen't work
size = 4, # size of points
alpha = 0.7) + # slightly transparent
geom_line(aes(lty = info), # line type according to group
alpha = 0.6) + # slightly transparent
labs(y = "Interest After Speed Date",
x = "Date of Event",
title = "Overall Interest in Second Date") +
scale_linetype_manual(values = c("Men" = "solid", # assign line types to groups
"Women" = "solid",
"Reciprocal" = "dashed"),
guide = FALSE) + # no legend for linetypes
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) + # y-axis in %
scale_color_manual(values = c("Men" = "#2A00B6", # assign colors to groups
"Women" = "#9B0E84",
"Reciprocal" = "#E94657"),
name = "") +
theme_minimal() + # apply minimal theme
theme(panel.grid = element_blank(), # remove all lines of plot raster
text = element_text(size = 16)) # increase font size
## Animated Plot
plot2 +
transition_reveal(along = date)
Angezeigt werden die Prozentsätze der Frauen und Männer, die nach jedem ihrer Speed-Dates an einem zweiten Date interessiert waren, sowie der Prozentsatz der Paare, bei denen beide Partner sich wiedersehen wollten.
Meistens waren Frauen mehr an zweiten Dates interessiert als Männer. Die Anziehung zwischen den Dating-Partnern ging oft nicht in beide Richtungen: Die Fälle, in denen beide Partner eines Paares ein zweites Date wollten, waren immer seltener als das allgemeine Interesse von Männern oder Frauen. Laut den Daten schien im frühen Herbst eine Flaute in der Romantik zu sein. Vielleicht war jeder noch wegen seines Sommerflirts gebrochenen Herzens? Glücklicherweise ist der Valentinstag im Februar.
Eine sehr praktische Option ist transition_filter(). Damit kannst du ausgewählte Erkenntnisse deiner Datenanalyse präsentieren. Die Animation durchläuft dabei Datensubsets, die durch Filterbedingungen definiert sind. Es liegt an dir, welche Subsets du in Szene setzen möchtest. Die Daten werden gemäß logischen Aussagen gefiltert, die in transition_filter() definiert sind. Alle Zeilen, für die eine Aussage zutrifft, werden in das entsprechende Subset aufgenommen. Wir können den logischen Ausdrücken Namen zuweisen, die als Frame-Variablen zugänglich sind. Wenn das keep-Argument auf TRUE gesetzt ist, bleiben die Daten der vorherigen Frames in späteren Frames erhalten.
Ich möchte untersuchen, ob die eigenen Eigenschaften mit den Attributen zusammenhängen, die man bei einem Partner sucht. Ziehen Gegensätze sich an oder wollen Gleichgesinnte zusammen sein?
Unten siehst du die Wichtigkeiten, die die Teilnehmer des Speed-Dating-Experiments verschiedenen Attributen eines potenziellen Partners zugeordnet haben. Kontrastiert werden Subsets von Teilnehmern, die von ihren Dating-Partnern als besonders lustig, attraktiv, aufrichtig, intelligent oder ehrgeizig bewertet wurden. Die Bewertungsskala reichte von 1 = niedrig bis 10 = hoch, daher nehme ich an, dass Werte >7 herausragend sind.
## Static Plot (without geom)
# ...importance ratings for different attributes
plot3 <- ggplot(data = df_ratings,
aes(x = variable, # different attributes
y = own_rating, # importance regarding potential partner
size = own_rating,
color = variable, # different attributes
fill = variable)) +
geom_jitter(alpha = 0.3) +
labs(x = "Attributes of Potential Partner", # x-axis label
y = "Allocation of 100 Points (Importance)", # y-axis label
title = "Importance of Characteristics of Potential Partner", # title
subtitle = "Subset of {closest_filter} Participants") + # dynamic subtitle
scale_color_viridis_d(option = "plasma", # use viridis scale for color
begin = 0.05, # limit range of used hues
end = 0.97,
guide = FALSE) + # don't show legend
scale_fill_viridis_d(option = "plasma", # use viridis scale for filling
begin = 0.05, # limit range of used hues
end = 0.97,
guide = FALSE) + # don't show legend
scale_size_continuous(guide = FALSE) + # don't show legend
theme_minimal() + # apply minimal theme
theme(panel.grid = element_blank(), # remove all lines of plot raster
text = element_text(size = 16)) # increase font size
## Animated Plot
# ...show ratings for different subsets of participants
plot3 +
geom_jitter(alpha = 0.3) +
transition_filter("More Attractive" = Attractive > 7, # adding named filter expressions
"Less Attractive" = Attractive <= 7,
"More Intelligent" = Intelligent > 7,
"Less Intelligent" = Intelligent <= 7,
"More Fun" = Fun > 7,
"Less Fun" = Fun <= 5)
Natürlich ist die Anzahl der außergewöhnlich attraktiven, intelligenten oder lustigen Teilnehmer relativ gering. Überraschenderweise gibt es wenig Unterschiede zwischen den Erwartungen von niedrig- vs. hochbewerteten Teilnehmern. Die Gruppe mit niedrigerer Bewertung umfasst mehr Personen mit extremen Erwartungen. Die individuellen Geschmäcker scheinen unabhängig von den eigenen Eigenschaften zu variieren.
Styling der (Dis)Appearance von Daten: enter_* / exit_*
Besonders wenn angezeigte Subsets von Daten nicht oder nur teilweise überlappen, kann es vorteilhaft sein, dies visuell zu betonen. Die Funktionen enter_() und exit_() ermöglichen es uns, den Eintritt und Austritt von Datenpunkten zu gestalten, die nicht zwischen den Frames bestehen bleiben.
Es gibt viele kombinierbare Optionen: Datenpunkte können einfach erscheinen oder verschwinden (der Standard), verblassen (enter_fade()/exit_fade()), wachsen oder schrumpfen (enter_grow()/exit_shrink()), ihre Farbe ändern (enter_recolor()/exit_recolor()), fliegen (enter_fly()/exit_fly()) oder treiben (enter_drift()/exit_drift()).
Diese stilistischen Mittel können verwendet werden, um Änderungen in den Daten verschiedener Frames zu betonen. Ich habe exit_fade() verwendet, um nicht weiter eingeschlossene Datenpunkte verblassen zu lassen, während sie aus dem Plotbereich auf einer vertikalen Route hinausfliegen (y_loc = 100. Die Punkte, die wieder in die Stichprobe eintreten, fliegen von unten in den Plot (y_loc = 0):
## Animated Plot
# ...show ratings for different subsets of participants
plot3 +
geom_jitter(alpha = 0.3) +
transition_filter("More Attractive" = Attractive > 7, # adding named filter expressions
"Less Attractive" = Attractive <= 7,
"More Intelligent" = Intelligent > 7,
"Less Intelligent" = Intelligent <= 7,
"More Fun" = Fun > 7,
"Less Fun" = Fun <= 5) +
enter_fly(y_loc = 0) + # entering data: fly in vertically from bottom
exit_fly(y_loc = 100) + # exiting data: fly out vertically to top...
exit_fade() # ...while color is fadingFinetuning und Speichern: animate() & anim_save()
Zum Glück macht gganimate es sehr einfach, unsere Animationen zu finalisieren und zu speichern. Wir können unser fertiges gganimate-Objekt an animate() übergeben, um die Anzahl der zu rendernden Frames (nframes), die Rate der Frames pro Sekunde (fps) und die Dauer der Animation (duration) zu definieren. Wir können auch das Gerät bestimmen, auf dem die einzelnen Frames gerendert werden (Standard ist device = “png”). Zudem können wir Argumente an das Gerät weitergeben, wie z.B. width oder height. Beachte, dass das einfache Drucken eines gganimateobject gleichbedeutend mit der Übergabe an animate() mit Standardargumenten ist. Wenn wir unsere Animation speichern möchten, ist das Argument renderer wichtig: Die Funktion anim_save() ermöglicht es uns, jedes gganimate-Objekt mühelos zu speichern, vorausgesetzt, es wurde mit magick_renderer() oder dem Standard gifski_renderer() gerendert.
Die Funktion anim_save() ist recht einfach. Wir können Dateiname (filename) und Pfad (path) (Standard ist das aktuelle Arbeitsverzeichnis) sowie das Animationsobjekt (Standard ist die zuletzt erstellte Animation) definieren.
# create a gganimate object
gg_animation <- plot3 +
transition_filter("More Attractive" = Attractive > 7,
"Less Attractive" = Attractive <= 7)
# adjust the animation settings
animate(gg_animation,
width = 900, # 900px wide
height = 600, # 600px high
nframes = 200, # 200 frames
fps = 10) # 10 frames per second
# save the last created animation to the current directory
anim_save("my_animated_plot.gif")
Fazit (und einen fröhlichen Valentinstag)
Ich hoffe, dieser Blogbeitrag hat dir gezeigt, wie du gganimate nutzen kannst, um deine eigenen ggplots in schöne und informative Animationen zu verwandeln. Ich habe nur die Oberfläche der gganimate-Funktionen angekratzt, also bitte verstehe diesen Beitrag nicht als eine vollständige Beschreibung der Funktionen oder des Pakets. Es gibt viel zu entdecken, also fang an mit gganimate!
Und noch wichtiger: Warte nicht auf die Liebe. Die Speed-Dating-Daten zeigen, dass wahrscheinlich jemand da draußen nach jemandem wie dir sucht. Also von uns allen hier bei statworx: Happy Valentine’s Day!

## 8 bit heart animation
animation2 <- plot(data = df_eight_bit_heart %>% # includes color and x/y position of pixels
dplyr::mutate(id = row_number()), # create row number as ID
aes(x = x,
y = y,
color = color,
group = id)) +
geom_point(size = 18, # depends on height & width of animation
shape = 15) + # square
scale_color_manual(values = c("black" = "black", # map values of color to actual colors
"red" = "firebrick2",
"dark red" = "firebrick",
"white" = "white"),
guide = FALSE) + # do not include legend
theme_void() + # remove everything but geom from plot
transition_states(-y, # reveal from high to low y values
state_length = 0) +
shadow_mark() + # keep all past data points
enter_grow() + # new data grows
enter_fade() # new data starts without color
animate(animation2,
width = 250, # depends on size defined in geom_point
height = 250, # depends on size defined in geom_point
end_pause = 15) # pause at end of animation


