Paradigmenwechsel in NLP: 5 Ansätze, um bessere Prompts zu schreiben


Bei statworx befassen wir uns intensiv damit, wie wir von großen Sprachmodellen (LLMs) die bestmöglichen Resultate erhalten. In diesem Blogbeitrag stelle ich fünf Ansätze vor, die sich sowohl in der Forschung als auch in unseren eigenen Experimenten mit LLMs bewährt haben. Während sich dieser Text auf das manuelle Design von Prompts zur Textgenerierung beschränkt, werden Bildgenerierung und automatisierte Promptsuche das Thema zukünftiger Beiträge sein.
Mega-Modelle läuten neues Paradigma ein
Die Ankunft des revolutionären Sprachmodells GPT-3 stellte nicht nur für das Forschungsfeld der Sprachmodellierung (NLP) einen Wendepunkt dar, sondern hat ganz nebenbei einen Paradigmenwechsel in der KI-Entwicklung eingeläutet: Prompt-Learning. Vor GPT-3 war der Standard das Fine-Tuning von mittelgroßen Sprachmodellen wie BERT, was dank erneutem Training mit eigenen Daten das vortrainierte Modell an den gewünschten Anwendungsfall anpassen sollte. Derartiges Fine-Tuning erfordert exemplarische Daten für die gewünschte Anwendung, sowie die rechnerischen Möglichkeiten das Modell zumindest teilweise neu zu trainieren.
Die neuen großen Sprachmodelle wie OpenAIs GPT-3 und BigSciences BLOOM hingegen wurden von ihren Entwicklerteams bereits mit derart großen Mengen an Ressourcen trainiert, dass diese Modelle ein neues Maß an Unabhängigkeit in ihrem Anwendungszweck erreicht haben: Diese LLMs benötigen nicht länger aufwändiges Fine-Tuning, um ihren spezifischen Zweck zu erlernen, sondern erzeugen bereits mithilfe von gezielter Instruktion („Prompt“) in natürlicher Sprache beeindruckende Resultate.
Wir befinden uns also inmitten einer Revolution in der KI-Entwicklung: Dank Prompt-Learning findet die Interaktion mit Modellen nicht länger über Code statt, sondern in natürlicher Sprache. Für die Demokratisierung der Sprachmodellierung bedeutet dies einen gigantischen Schritt vorwärts. Texte zu generieren oder neustens sogar Bilder zu erstellen, erfordert dadurch nicht mehr als rudimentäre Sprachkenntnisse. Allerdings heißt das nicht, dass damit auch überzeugende oder beeindruckende Resultate allen zugänglich sind. Hochwertige Outputs verlangen nach hochwertigen Inputs. Für uns Nutzer:innen bedeutet dies, dass die technische Planung in NLP nicht mehr der Modellarchitektur oder den Trainingsdaten gilt, sondern dem Design der Anweisungen, die Modelle in natürlicher Sprache erhalten. Willkommen im Zeitalter des Prompt-Engineerings.
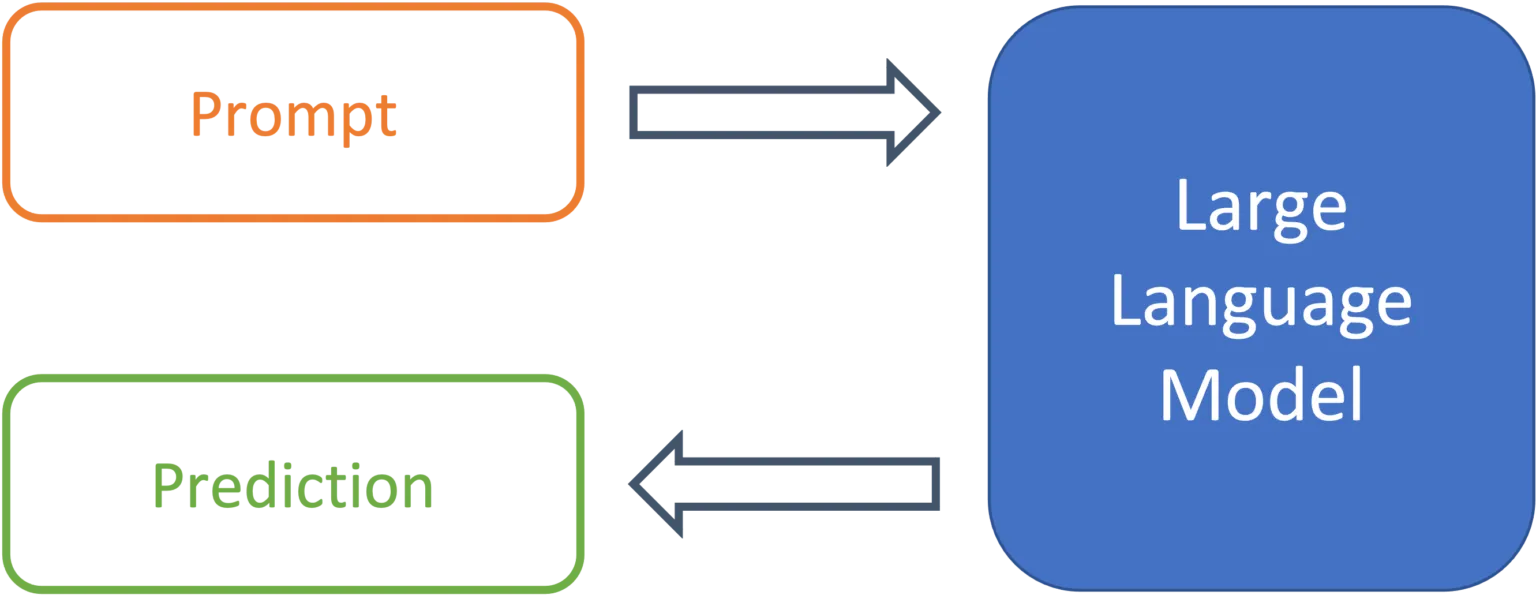
Abbildung 1: Vom Prompt zur Prognose mit einem großen Sprachmodell
Prompts sind mehr als nur Textschnippsel
Templates erleichtern den häufigen Umgang mit Prompts
Da LLMs nicht auf einen spezifischen Anwendungsfall trainiert wurden, liegt es am Promptdesign dem Modell die genaue Aufgabenstellung zu bestimmen. Dazu dienen sogenannte „Prompt Templates“. Ein Template definiert die Struktur des Inputs, der an das Modell weitergereicht wird. Dadurch übernimmt das Template die Funktion des Fine-Tunings und legt den erwarteten Output des Modells für einen bestimmten Anwendungsfall fest. Am Beispiel einer einfachen Sentiment-Analyse könnte ein Prompt-Template so aussehen:
The expressed sentiment in text [X] is: [Z]
Das Modell sucht so nach einem Token z der, basierend auf den trainierten Parametern und dem Text in Position [X], die Wahrscheinlichkeit des maskierten Tokens an Position [Z] maximiert. Das Template legt so den gewünschten Kontext des zu lösenden Problems fest und definiert die Beziehung zwischen dem Input an Stelle [X] und dem zu vorhersagenden Output an Stelle [Z]. Der modulare Aufbau von Templates ermöglicht die systematische Verarbeitung einer Vielzahl von Texten für den erwünschten Anwendungsfall.
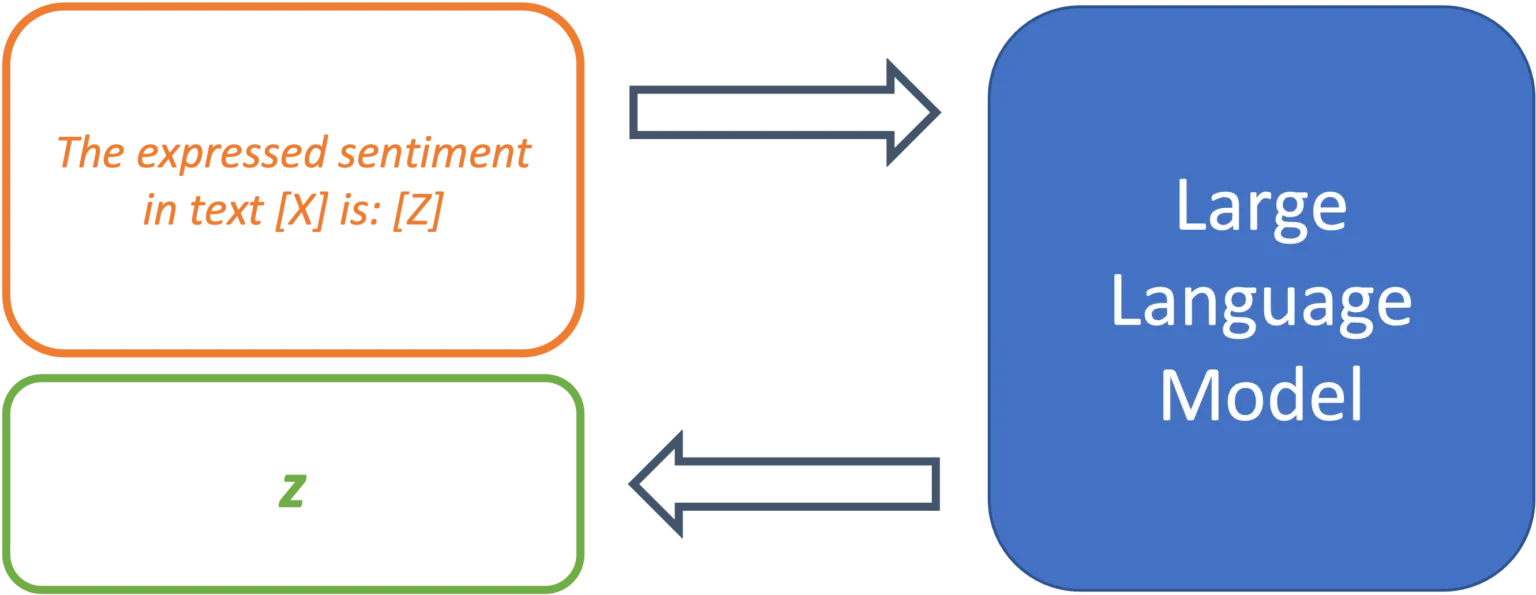
Abbildung 2: Prompt Templates definieren die Struktur eines Prompts.
Prompts benötigen nicht zwingend Beispiele
Das vorgestellte Template ist ein Beispiel eines sogenannten „, da ausschließlich eine Anweisung, ohne jegliche Demonstration mit Beispielen im Template, vorhanden ist. Ursprünglich wurden LLMs von den Entwickler:innen von GPT-3 als „Few-Shot Learners“ bezeichnet, also Modelle, deren Leistung mit einer Auswahl von gelösten Beispielen des Problems maximiert werden kann (Brown et al., 2020). Eine Folgestudie konnte aber zeigen, dass mit strategischem Promptdesign auch 0-Shot Prompts, ohne einer Vielzahl von Beispielen, vergleichbare Leistung erzielen können (Reynolds & McDonell, 2021). Da also auch in der Forschung mit unterschiedlichen Ansätzen gearbeitet wird, stellt der nächste Abschnitt 5 Strategien für effektives Design von Prompt Templates vor.
5 Strategien für effektives Promptdesign
Task Demonstration
Im herkömmlichen Few-Shot Setting wird das zu lösende Problem durch die Bereitstellung von mehreren Beispielen eingegrenzt. Die gelösten Beispielsfälle sollen dabei eine ähnliche Funktion einnehmen wie die zusätzlichen Trainingssamples während des Fine-Tuning Prozesses und somit den spezifischen Anwendungsfall des Modells definieren. Textübersetzung ist ein gängiges Beispiel für diese Strategie, die mit folgendem Prompt Template repräsentiert werden kann:
French: „Il pleut à Paris“
German: „Es regnet in Paris“
French: „Copenhague est la capitale du Danemark“
German: „Kopenhagen ist die Hauptstadt von Dänemark“
[…]
French: [X]
German: [Z]
Die gelösten Beispiele sind zwar gut dazu geeignet das Problemsetting zu definieren, können aber auch für Probleme sorgen. „Semantische Kontamination“ bezeichnet das Problem, dass die Inhalte der übersetzten Sätze als relevant für die Vorhersage interpretiert werden können. Beispiele im semantischen Kontext der Aufgabe produzieren bessere Resultate – und solche außerhalb des Kontexts können dazu führen, dass die Prognose Z inhaltlich „kontaminiert“ wird (Reynolds & McDonell, 2021). Verwendet man das obige Template für die Übersetzung komplexer Sachverhalte, so könnte das Modell in unklaren Fällen wohl den eingegebenen Satz als Aussage über eine europäische Großstadt interpretieren.
Task Specification
Jüngste Forschung zeigt, dass mit gutem Promptdesign auch der 0-Shot Ansatz kompetitive Resultate liefern kann. So wurde demonstriert, dass LLMs gar keine vorgelösten Beispiele benötigen, solange die Problemstellung im Prompt möglichst genau definiert wird (Reynolds & McDonell, 2021). Diese Spezifikation kann unterschiedlich Formen annehmen, ihr liegt aber immer den gleichen Gedanken zugrunde: So genau wie möglich zu beschreiben was gelöst werden soll, aber ohne zu demonstriere wie.
Ein einfaches Beispiel für den Übersetzungsfall wäre folgender Prompt:
Translate from French to German [X]: [Z]
Dies mag bereits funktionieren, die Forscher empfehlen aber den Prompt so deskriptiv wie möglich zu gestalten und auch explizit die Übersetzungsqualität zu nennen:
A French sentence is provided: [X]. The masterful French translator flawlessly translates the sentence to German: [Z]
Dies helfe dem Modell dabei die gewünschte Problemlösung im Raum der gelernten Aufgaben zu lokalisieren.
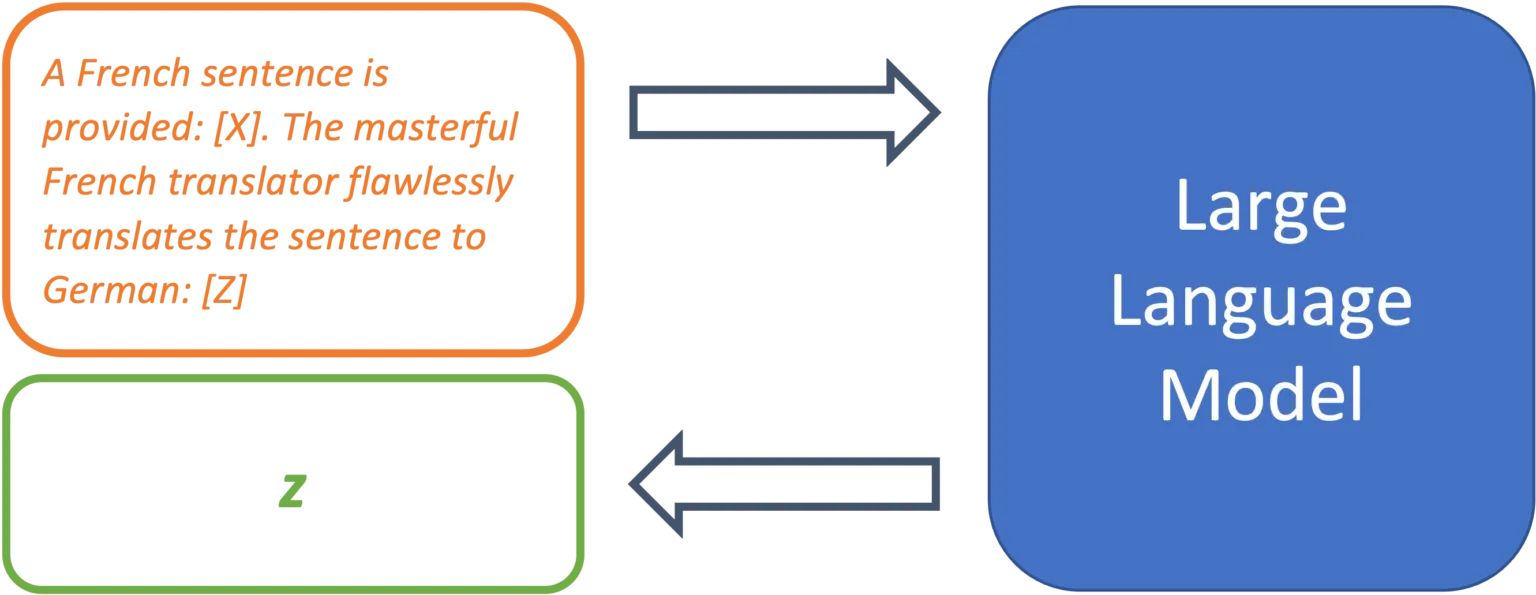
Abbildung 3: Ein klarer Aufgabenbeschrieb kann die Prognosegüte stark erhöhen.
Auch in Anwendungsfällen ausserhalb von Übersetzungen ist dies empfehlenswert. Ein Text lässt mit einem einfachen Befehl zusammenfassen:
Summarize the following text: [X]: [Z]
Mit konkreterem Prompt sind aber bessere Resultate zu erwarten:
Rephrase this sentence with easy words so a child understands it,
emphasize practical applications and examples: [X]: [Z]
Je genauer der Prompt, desto grösser die Kontrolle über den Output.
Prompts als Einschränkungen
Zu Ende gedacht bedeutet der Ansatz von Kontrolle des Modells schlicht die Einschränkung des Modellverhaltens durch sorgfältiges Promptdesign. Diese Perspektive ist nützlich, denn während dem Training lernen LLMs viele verschiedene Texte fortzuschreiben und können dadurch eine breite Auswahl an Problemen lösen. Mit dieser Designstrategie verändert sich das grundlegende Herangehen ans Promptdesign: vom Beschrieb der Problemstellung zum Ausschluss unerwünschter Resultate durch die Einschränkung des Modellverhaltens. Welcher Prompt führt zum gewünschten Resultat und ausschliesslich zum gewünschten Resultat? Folgender Prompt weist zwar auf eine Übersetzungsaufgabe hin, beinhaltet aber darüber hinaus keine Ansätze zur Verhinderung, dass der Satz durch das Modell einfach zu einer Geschichte fortgesetzt wird.
Translate French to German Il pleut à Paris
Ein Ansatz diesen Prompt zu verbessern ist der Einsatz von sowohl semantischen als auch syntaktischen Mitteln:
Translate this French sentence to German: “Il pleut à Paris.”
Durch die Nutzung von syntaktischen Elementen wie dem Doppelpunkt und den Anführungszeichen wird klar gemacht, wo der zu übersetzende Satz beginnt und endet. Auch drückt die Spezifikation durch sentence aus, dass es nur um einen einzelnen Satz geht. Diese Mittel verringern die Wahrscheinlichkeit, dass dieser Prompt missverstanden und nicht als Übersetzungsproblem behandelt wird.
Nutzung von “memetic Proxies”
Diese Strategie kann genutzt werden, um die Informationsdichte in einem Prompt zu erhöhen und lange Beschreibungen durch kulturell verstandenen Kontext zu vermeiden. Memetic Proxies können in Taskbeschreibungen genutzt werden und nutzen implizit verständliche Situationen oder Personen anstelle von ausführlichen Anweisungen:
A primary school teacher rephrases the following sentence: [X]: [Z]
Dieser Prompt ist weniger deskriptiv als das vorherige Beispiel zur Umformulierung in einfachen Worten. Allerdings besitzt die beschriebene Situation eine viel höhere Dichte an Informationen: Die Nennung eines impliziert bereits, dass das Resultat für Kinder verständlich sein soll und erhöht dadurch hoffentlich auch die Wahrscheinlichkeit von praktischen Beispielen im Output. Ähnlich können Prompts fiktive Gespräche mit bekannten Persönlichkeiten beschreiben, so dass der Output deren Weltbild oder Sprechweise widerspiegelt:
In this conversation, Yoda responds to the following question: [X]
Yoda: [Z]
Dieser Ansatz hilft dabei einen Prompt durch implizit verstandenen Kontext kurz zu halten und die Informationsdichte im Prompt zu erhöhen. Memetic Proxies finden auch im Promptdesign für andere Modalitäten Verwendung. Bei Modellen zur Bildgenerierung wie DALL-e 2 führt das Suffix “Trending on Artstation” häufig zu Ergebnissen von höherer Qualität, obwohl semantisch eigentlich keine Aussagen über das darzustellende Bild gemacht werden.
Metaprompting
Als Metaprompting beschreibt das Forscherteam einer Studie den Ansatz Prompts durch Anweisungen anzureichern, die auf die jeweilige Aufgabe zugeschnitten sind. Dies beschreiben sie als Weg ein Modell durch klarere Anweisungen einzuschränken, sodass die gestellte Aufgabe besser gelöst werden kann (Reynolds & McDonell, 2021). Folgendes Beispiel kann dabei helfen mathematische Probleme zuverlässiger zu lösen und den Argumentationsweg nachvollziehbar zu machen:
[X]. Let us solve this problem step-by-step: [Z]
Ähnlich lassen sich Multiple Choice Fragen mit Metaprompts anreichern, sodass das Modell im Output auch tatsächlich eine Option wählt, anstatt die Liste fortzusetzen:
[X] in order to solve this problem, let us analyze each option and choose the best: [Z]
Metaprompts stellen somit ein weiteres Mittel dar Modellverhalten und Resultate einzuschränken.
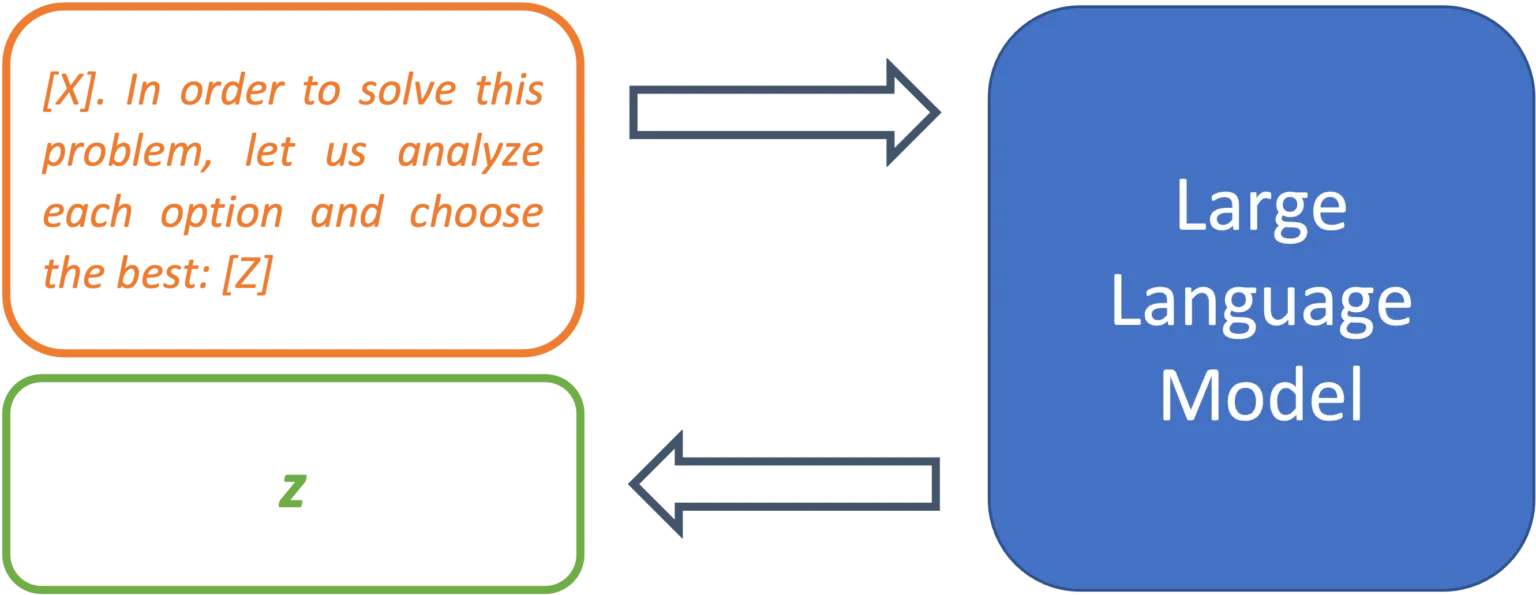
Abbildung 4: Mithilfe von Metaprompts lassen sich Vorgehensweisen zur Problemlösung festlegen.
Ausblick
Prompt Learning ist ein noch sehr junges Paradigma und das damit eng verbundene Prompt Engineering befindet sich noch in den Kinderschuhen. Allerdings wird die Wichtigkeit von fundierten Fähigkeiten zum Schreiben von Prompts zweifellos nur noch zunehmen. Nicht nur Sprachmodelle wie GPT-3, sondern auch neuste Modelle zur Bildgenerierung verlangen von ihren User:innen solide Kenntnisse im Designen von Prompts, um gute Ergebnisse zu kreieren. Die vorgestellten Strategien sind sowohl in der Forschung als auch in der Praxis erprobte Ansätze zum systematischen Schreiben von Prompts, die dabei helfen, bessere Resultate von großen Sprachmodellen zu erhalten.
In einem zukünftigen Blogbeitrag nutzen wir diese Erfahrungen mit Textgenerierung, um Best Practices für eine weitere Kategorie generativer Modelle zu erschliessen: modernste Diffusionsmodelle zur Bildgenerierung, wie DALL-e 2, Midjourney und Stable Diffusion.
Quellen
Brown, Tom B. et al. 2020. “Language Models Are Few-Shot Learners.” arXiv:2005.14165 [cs]. http://arxiv.org/abs/2005.14165 (March 16, 2022).
Reynolds, Laria, and Kyle McDonell. 2021. “Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm.” http://arxiv.org/abs/2102.07350 (July 1, 2022).


