Data Science in Python – Der Einstieg in Machine Learning mit Scikit-Learn


In unseren bisherigen Artikeln zu Data Science in Python haben wir uns mit der grundlegenden Syntax, Datenstrukturen, Arrays, der Datenvisualisierung und Manipulation/Selektion auseinander gesetzt. Was jetzt noch für den Einstieg fehlt, ist die Möglichkeit Modelle auf die Daten anzuwenden, um so zum einen Muster in diese zu erkennen und zum anderen Prädiktionen abzuleiten. Die Vielfalt an implementierten Modellen in Python und besonders in Scikit-Learn lässt sehr viel Spielraum für eine individuelle Anpassung der Modelle.
Machine Learning Bibliotheken für Python
Die wohl bekannste ML-Bibliothek, die sich in den letzten Jahren sehr stark weiter entwickelt hat, ist TensorFlow von Google. Sie wird vor allem für die Entwicklung und das Training von Neuronalen Netzen verwendet. Weitere bekannte Bibliotheken sind Keras, PyTorch, Caffe sowie MXNet. Weitere Informationen über die Funktionsweise von Neuronalen Netzen finden Sie in einem anderen Blogbeitrag von uns. Allerdings sollte man dabei stets beachten, dass Neuronale Netze nur ein Teilgebiet von Machine Learning darstellen. Auch Entscheidungsbäume, Random Forests und Support Vector Machines zählen zu ML-Modellen. Für Einstieger in diesem Bereich ist es somit sinnvoll sich eine Bibliothek herauszusuchen, die all diese Modelle umfasst und nicht den Fokus auf nur ein Teilgebiet wie Neuronale Netze legt. Scikit-Learn ist eine solche Bibliothek. Mit der stringenten Syntax werden das Entwickeln sowie die Applikation von Daten auf Modelle mehr als vereinfacht.
Einstieg mit Scikit-Learn
Die erste Veröffentlichung von Scikit-Learn fand im Jahr 2010 statt und hat sich seitdem stetig weiter entwickelt. Inzwischen umfasst die Code-Basis mehr als 150 Tsd. Zeien Code. Die Installation erfolgt wie bei den anderen Bibliotheken mit pip oder conda:
pip install scikit-learn
conda install scikit-learn
Scikit-Learn teilt seine verschiedenen Teilbibliotheken anhand der Machine Learning Aufgabenstellung auf:
- Classification (Beispiel: Kunde gehört zu Kategorie A, B, C?)
- Regression (Beispiel: Welcher Absatz kann im nächsten Monat erreicht werden?)
- Clustering (Beispiel: In welche Bereiche können die Kunden gegliedert werden?)
- Dimensionality Reduction
- Model selection
- Preprocessing
Die Teilbibliotheken lassen sich folgendermaßen importieren: import sklearn.cluster as cl. Für die Teilbibliotheken Classification und Regression gilt dies nur begrenzt, da sich ML-Modelle sowohl für die Regression wie für das Clustering nutzen lassen. Die Funktionsweise ist aber ähnlich:
# Neuronales Netz zur Klassifikation
from sklearn.neural_network import MLPClassifier
# Neuronales Netz zur Regression
from sklearn.neural_network import MLPRegressorAufbau des Modelltrainings
Je nachdem welches ML-Problem verfolgt wird, kann man sich mithilfe der obigen Aufteilung schnell einen Überblick verschaffen, welche Modelle in Scikit-Learn verfügbar sind. Die Funktionsweise des Modelltrainings ist dabei immer identisch:
# Import des Entscheidungsbaum
from sklearn import tree
# Beispieldaten
X = [[0, 0], [1, 1]]
Y = [0, 1]
# Initialisierung des Entscheidungsbaum zur Klassifizierung
clf = tree.DecisionTreeClassifier()
# Training des Entscheidungsbaums
clf = clf.fit(X, Y)
# Prädiktion für neue Daten
clf.predict([[2., 2.]])
Als erster Schritt erfolgt die Initialisierung des Modells, hierbei können Modellparameter genauer spezifiziert werden. Diese sind immer in der Dokumentation vorzufinden, wie bspw. hier. Werden keine Parameter angegeben, übernimmt Scikit-Learn die Standardkonfiguration des Modells. Für einen ersten Test, ob ein Modell überhaupt auf die Daten anwendbar ist, kann dies sehr hilfreich sein. Allerdings sollte es natürlich kein sofortiges Auschlusskriterium sein, wenn die Modellgüte nicht den gewünschten Erwartungen entspricht. Im nächsten Schritt wird das Modell mit der fit Methode trainiert, neue Daten können mit der predict Methode in das Modell eingespeist werden.
Nun wollen wir das vorherige Minimal-Beispiel erweitern und mit tatsächlichen Daten arbeiten. Ziel des Trainings des Entscheidungsbaums soll es sein, mithilfe der Features Alter, Geschlecht und Buchungsklasse zu entscheiden, ob ein Passagier den Titanic-Unfall überlebt hat oder nicht. Den Titanic Datensatz hatten wir bereits im Blogbeitrag zu Pandas verwendet.
Nach dem Import der Daten müssen wir zunächst die Variable Geschlecht transformieren, da der Entscheidungsbaum mit Daten im String-Format kein Training vornehmen kann. Anschließend extrahieren wir diejengen Trainingsspalten und entfernen im gleichen Zug fehlende Dateneinträge. Der wichtigste Schritt ist anschließend die Aufteilung in Trainings- sowie Testdaten, schließelich muss die Modellgüte mit den Daten überprüft werden, die das Modell nicht zum Training verwendet hat. Ein Aufteilung in 70% Trainings- / 30% Testdaten kann als gute Faustregel verwendet werden. Anschließend erfolgt das Training des Entscheidungsbaums. In diesem Fall ist die Tiefe des Entscheidungsbaums auf fünf begrenzt. Abschließend wird die Accuarcy für die Testdaten berechnet.
import seaborn as sns
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Laden der Daten
df = sns.load_dataset('titanic')
# Transformation der Variable Geschlecht
labelenc = preprocessing.LabelEncoder()
labelenc.fit(df.sex)
df['sex_transform'] = labelenc.transform(df.sex)
# Auswahl von Daten zum Training
train = df.loc[:,['age', 'fare', 'sex_transform', 'survived']].dropna()
# Aufteilen der Daten in Features und Target
y = train['survived']
X = train.drop('survived', axis=1)
# Aufteilen in Test und Train Daten
X_train, X_test, y_train
y_test = train_test_split(X, y, test_size=0.4, random_state=10, shuffle = True)
# Initialisierung des Entscheidungsbaums
clf = DecisionTreeClassifier(max_depth=5)
# Training des Entscheidungsbaums
clf.fit(X_train, y_train)
# Berechnung der Metrik
clf.score(X_test, y_test)
Dieser Ablauf wird auch für andere Modelle sehr ähnlich sein, da Scikit-Learn für jedes Modell immer ansatzweise dieselben Methoden implementiert hat. Beispielsweise würde es für ein Random Forest Modell wie folgt aussehen:
from sklearn.ensemble import RandomForestClassifier
# Initialisierung des Random Forest Modells
rf = RandomForestClassifier()
# Training des Random Forest Modells
rf.fit(X_train, y_train)
# Berechnung der Metrik
rf.score(X_test, y_test)
Diese Syntax durchzieht die Scikit-Learn Bibliothek wie ein roter Faden.
Tuning der Hyperparameter des Modells
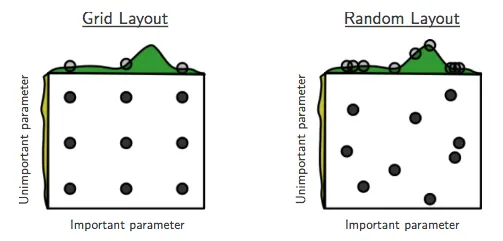
Eine Herausforderung bei der Anwendung von Machine Learning Modellen ist die Bestimmungen der optimlen Parameter des Modells. Die Anzahl von Variationen ist so vielfältig, dass es nicht sinnvoll ist händisch jede einzelne Kombination zu überprüfen. Für diesen Prozess kann die sogenannte GridSearch-Methode verwendet werden. Aus allen Parametern wird ein Netz (Grid) mit allen Kombinationen aufgespannt je mehr Parameter in ihren Ausprägungen geprüft werden sollen, umso größer wird das Netz. Hat man sehr viele Kombinationen, ist es sinnvoll, eine zufällige Parameterkombination auszuwählen, da sich so passende Parameterkombinationen schneller finden lassen und das Verfahren schneller abläuft. Der Vergleich wird durch die folgende Grafik noch einmal verdeutlicht:
Wir stellen nun die vollständige Grid-Search Methode vor:
from sklearn.model_selection import GridSearchCV
# Definition der Paramerkombination
params = {"max_depth": range(3,15), "splitter": ["best", "random"]}
# Erstellen des Grids
grid = GridSearchCV(estimator=clf, param_grid=params,
cv=10, verbose=2, n_jobs=-1)
# Training des Grids
grid.fit(X_train, y_train)
print(grid.best_params_, grid.best_score_)
Die zu evaluierenden Parameterkombinationen werden in Form eines Dict erstellt, wobei der jeweilige Key dem Modellparameter entspricht. Dem Key wird dann eine Liste mit den verschiedenen Optionen übergeben. Also in diesem Fall die Tiefe des Entscheidungsbaums und die Aufteilungsmethode. Das grid-Objekt muss änhlich wie das Modell initialisiert werden. Mit dem Parameter n_jobs wird Optimierung parallel vorgenommen und läuft somit schneller ab. Zum Abschluss kann man sich die beste Parameterkombination für das Modell und den zugehörigen Score ausgeben lassen. Wichtig ist natürlich im Anschluss noch die Evaluation mit den Testdaten vorzunehmen. Welche Paramater für welchen Modelltyp in Frage kommen, ist pauschal so nicht zu beantworten, da dies häufig auch mit den Dateneigenschaften zusammen hängt.
Rückblick
In diesem Blogartikel haben wir die Funktionweise von Machine Learning Modellen anhand des Entscheidungsbaums mit Scikit-Learn dargestellt. Wichtig ist immer, dass Modell zu initialisieren, danach kann man das Modell triainieren (fit), sich Prädiktionen (predict) und die Genauigkeit (score) sich ausgeben lassen. Mit Scikit-Learn kann natürlich noch eine Vielzahl von Modellarten und Anwendungen umgesetzt werden. So lässt sich beispielsweise der kompletten Datenvoverarbeitungs- und Trainingsprozess in Pipelines zusammen fassen. Wie man dies umsetzt, hat mein Kollege Martin in seinem Artikel zusammengefasst. Die Reihe zum Einstieg mit Python in das Themenfeld Data Science endet nun mit diesem Beitrag.
Referenzen
- Bergstra, Bengio (2012): Random Search for Hyper-Parameter Optimization


