Wie man Gradient Boosting um den Faktor Zwei beschleunigt


Einführung
Bei statworx helfen wir nicht nur Kunden dabei, eine geeignete Datenstrategie zu finden, zu entwickeln und umzusetzen, sondern wir verbringen auch Zeit damit, Forschung zu betreiben, um unseren eigenen Werkzeugstapel zu verbessern. Auf diese Weise können wir der Open-Source-Community etwas zurückgeben.
Ein besonderer Schwerpunkt meiner Forschung liegt auf baumbasierten Ensemble-Methoden. Diese Algorithmen sind unverzichtbare Werkzeuge im Bereich des prädiktiven Lernens und du findest sie als eigenständiges Modell oder als Bestandteil eines Ensembles in fast jeder überwachten Lern-Herausforderung auf Kaggle. Bekannte Modelle sind der Random Forest von Leo Breiman, Extrem zufällig ausgewählte Bäume (Extra-Trees) von Pierre Geurts, Damien Ernst & Louis Wehenkel und Multiple Additive Regression Trees (MART; auch bekannt als Gradient Boosted Trees) von Jerome Friedman.
Besonders interessiert hat mich, wie sehr Randomisierungstechniken dazu beigetragen haben, die Vorhersageleistung in all den oben genannten Algorithmen zu verbessern. Bei Random Forest und Extra-Trees ist es ziemlich offensichtlich. Hier ist die Randomisierung der Grund, warum die Ensembles eine Verbesserung gegenüber dem Bagging bieten; durch die Dekorrelation der Basislerner verringert sich die Varianz des Ensembles und damit der Vorhersagefehler. Letztendlich erreicht man die Dekorrelation durch das „Aufschütteln“ der Basisbäume, wie es in den beiden Ensembles getan wird. Allerdings profitiert auch MART von der Randomisierung. Im Jahr 2002 veröffentlichte Friedman ein weiteres Papier über Boosting, das zeigt, dass du die Vorhersageleistung von gebooteten Bäumen verbessern kannst, indem du jeden Baum nur auf einer zufälligen Teilmenge deiner Daten trainierst. Als Nebeneffekt verkürzt sich auch die Trainingszeit. Darüber hinaus schlugen Rashmi und Gilad im Jahr 2015 vor, eine Methode namens Dropout zum Boosting-Ensemble hinzuzufügen: eine Methode, die in neuronalen Netzen gefunden und verwendet wird.
Die Idee hinter Random Boost
Inspiriert von theoretischen Lesungen über randomization techniques im Boosting habe ich einen neuen Algorithmus entwickelt, den ich Random Boost (RB) nannte. Im Wesentlichen wächst Random Boost sequenziell Regression-Bäume mit zufälliger Tiefe. Genauer gesagt ist der Algorithmus fast identisch mit und hat genau die gleichen Eingabeargumente wie MART. Der einzige Unterschied ist der Parameter $d_{max}$. In MART bestimmt $d_{max}$ die maximale Tiefe aller Bäume im Ensemble. In Random Boost stellt das Argument die obere Grenze der möglichen Baumgrößen dar. In jeder Boosting-Iteration $i$ wird eine zufällige Zahl $d_i$ zwischen 1 und $d_{max}$ gezogen, die dann die maximale Tiefe des Baums $T_i(d_i)$ definiert.
Im Vergleich zu MART hat dies zwei Vorteile:
Erstens ist RB im Durchschnitt schneller als MART, wenn es mit dem gleichen Wert für die Baumgröße ausgestattet ist. Wenn RB und MART mit einem Wert für die maximale Baumtiefe gleich $d_{max}$ trainiert werden, wird Random Boost in vielen Fällen von Natur aus Bäume der Größe $d$<$d_{max}$ wachsen lassen. Wenn du davon ausgehst, dass bei MART alle Bäume auf ihre volle Größe $d_{max}$ wachsen (d. h. es gibt genug Daten in jedem inneren Knoten, sodass das Baumwachstum nicht vor Erreichen der maximalen Größe stoppt), kannst du eine Formel ableiten, die den relativen Rechengewinn von RB gegenüber MART zeigt:
$t_{rel}(d_{max}) = frac{t_{mathrm{RB}}(d_{max})}{t_{mathrm{MART}}(d_{max})} approx frac{2}{d_{max}}left(1 - left(frac{1}{2}right)^{d_{max}} right).$
$t_{RB}(d_{max})$ ist zum Beispiel die Trainingszeit eines RB-Boosting-Ensembles mit dem Baumgrößenparameter gleich $d_{max}$.
Um es etwas praktischer zu machen, sagt die Formel voraus, dass RB für $d_{max}=2, 3$ und $4$ jeweils $75%, 58%$ bzw. $47%$ der Rechenzeit von MART benötigt. Diese Vorhersagen sollten jedoch als RB's Best-Case-Szenario angesehen werden, da MART auch nicht unbedingt vollständige Bäume wachsen lässt. Dennoch deuten die Berechnungen darauf hin, dass Effizienzgewinne erwartet werden können (mehr dazu später).
Zweitens gibt es auch Gründe anzunehmen, dass die Randomisierung über Baumtiefen einen positiven Effekt auf die Vorhersageleistung haben kann. Wie bereits erwähnt, leidet Boosting aus verschiedenen Gründen unter Überkapazität. Einer davon ist die Wahl eines zu komplexen Basislerners in Bezug auf die Tiefe. Wenn beispielsweise angenommen wird, dass die dominante Interaktion im datengenerierenden Prozess von Ordnung drei ist, würde man einen Baum mit entsprechender Tiefe in MART wählen, um diese Interaktions-Tiefe zu erfassen. Dies kann jedoch übermäßig sein, da vollständig gewachsene Bäume mit einer Tiefe von $3$ acht Blätter haben und daher Rauschen in den Daten lernen, wenn es nur wenige solcher hochrangiger Interaktionen gibt. Vielleicht wäre in diesem Fall ein Baum mit Tiefe $3$, aber weniger als acht Blättern optimal. Dies wird in MART nicht berücksichtigt, wenn man nicht jeden Boosting-Iteration einen Pruning-Schritt hinzufügen möchte, was auf Kosten von zusätzlichem Rechenaufwand geht. Random Boost könnte ein effizienteres Mittel zur Lösung dieses Problems bieten. Mit Wahrscheinlichkeit $1 / d_{max}$ wird ein Baum gewachsen, der in der Lage ist, den hochrangigen Effekt zu erfassen, jedoch auch Rauschen lernt. In allen anderen Fällen konstruiert Random Boost kleinere Bäume, die nicht das Überkapazitätsverhalten zeigen und sich auf Interaktionen geringerer Ordnung konzentrieren können. Wenn Überkapazität bei MART aufgrund unterschiedlicher Interaktionen in den Daten, die von einer kleinen Anzahl hochrangiger Interaktionen geregelt werden, ein Problem darstellt, könnte Random Boost besser abschneiden als MART. Darüber hinaus dekorreliert Random Boost auch Bäume durch die zusätzliche Quelle von Zufälligkeit, die einen varianzreduzierenden Effekt auf das Ensemble hat.
Das Konzept von Random Boost stellt eine leichte Änderung von MART dar. Ich habe das sklearn-Paket als Grundlage für meinen Code verwendet. Daher wird der Algorithmus basierend auf sklearn.ensemle.GradientBoostingRegressor und sklearn.ensemle.GradientBoostingClassifier entwickelt und genau auf die gleiche Weise verwendet (d. h. Argumentnamen stimmen genau überein und CV kann mit sklearn.model_selection.GridSearchCV durchgeführt werden). Der einzige Unterschied ist, dass das RandomBoosting*-Objekt max_depth verwendet, um Baumtiefen zufällig für jede Iteration zu ziehen. Als Beispiel kannst du es so verwenden:
rb = RandomBoostingRegressor(learning_rate=0.1, max_depth=4, n_estimators=100)
rb = rb.fit(X_train, y_train)
rb.predict(X_test)
Für den vollständigen Code, schau dir meinen GitHub-Account an.
Random Boost versus MART – Eine Simulationsstudie
Um die beiden Algorithmen zu vergleichen, führte ich eine Simulation auf 25 Datensätzen durch, die von einem Random Target Function Generator erzeugt wurden, der von Jerome Friedman in seinem berühmten Boosting-Papier von 2001 eingeführt wurde (Details findest du in seinem Paper. Python-Code findest du hier. Jeder Datensatz (mit 20.000 Beobachtungen) wurde zufällig in einen 25% Testsatz und einen 75% Trainingssatz aufgeteilt. RB und MART wurden über 5-fache CV auf dem gleichen Tuning-Gitter abgestimmt.
learning_rate = 0.1
max_depth = (2, 3, ..., 8)
n_estimators = (100, 105, 110, ..., 195)
Für jeden Datensatz stimmte ich beide Modelle ab, um die beste Parameterkonstellation zu erhalten. Dann trainierte ich jedes Modell erneut an jedem Punkt des Tuning-Gitters und speicherte die Test-MAE sowie die gesamte Trainingszeit in Sekunden. Warum habe ich jedes Modell erneut trainiert und nicht einfach die Vorhersagegenauigkeit der abgestimmten Modelle zusammen mit der gesamten Abstimmungszeit gespeichert? Nun, ich wollte sehen können, wie sich die Trainingszeit mit dem Baumgrößenparameter ändert.
Ein Vergleich der Vorhersagegenauigkeiten
Du kannst die Verteilung der MAEs der besten Modelle auf allen 25 Datensätzen unten sehen.

Offensichtlich schneiden beide Algorithmen ähnlich ab.
Für einen besseren Vergleich berechne ich die relative Differenz zwischen der Vorhersageleistung von RB und MART für jeden Datensatz j, d. h. $j$, i.e. $MAE_{rel,j}=frac{MAE_{RB,j}-MAE_{MART,j}}{MAE_{MART,j}}$. Wenn $MAE_{rel,j}$>$0$, dann hatte RB einen größeren mittleren absoluten Fehler als MART auf Datensatz $j$, und umgekehrt.MAE nach Datensatz mit Boxplot

In den meisten Fällen schnitt RB schlechter ab als MART in Bezug auf die Vorhersagegenauigkeit ($MAE_{rel}$>$0$). Im schlimmsten Fall hatte RB einen 1% höheren MAE als MART. Im Median hat RB einen 0,19% höheren MAE. Ich überlasse es Ihnen zu entscheiden, ob dieser Unterschied praktisch signifikant ist.
Ein Vergleich der Trainingszeiten
Wenn wir uns die Trainingszeit ansehen, erhalten wir ein ziemlich klares Bild. In absoluten Zahlen dauerte es durchschnittlich 433 Sekunden, um alle Parameterkombinationen von RB zu trainieren, im Gegensatz zu 803 Sekunden für MART.durchschnittliche Trainingszeit
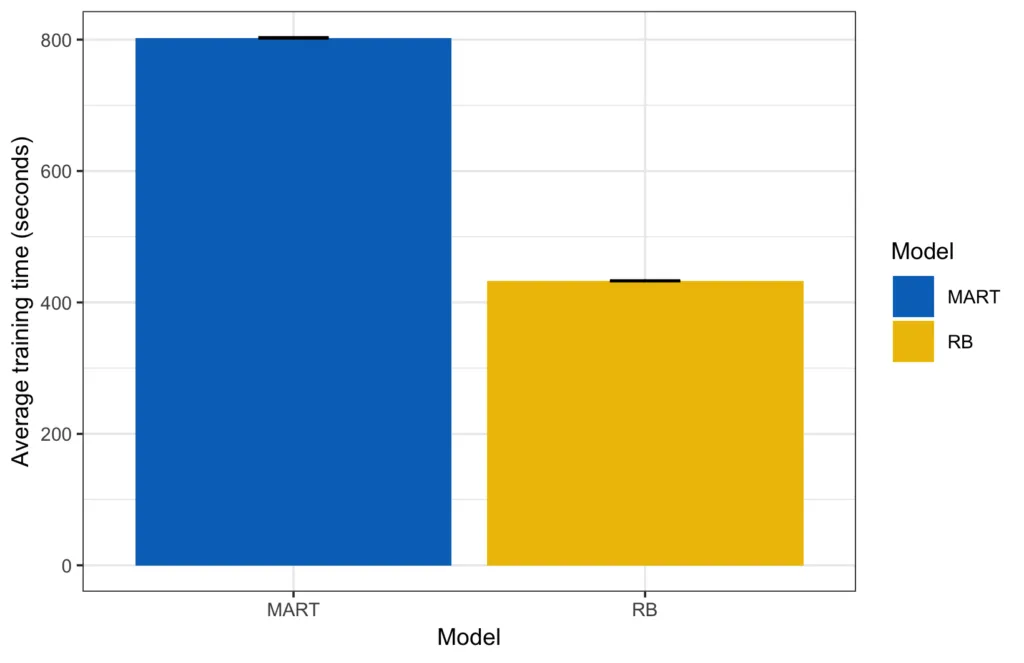
Die kleinen schwarzen Linien oben auf jeder Leiste sind die Fehlerbalken (2-mal die mittlere Standardabweichung; in diesem Fall eher klein).
Um dir ein besseres Gefühl dafür zu geben, wie jedes Modell auf jedem Datensatz abschneidet, habe ich auch die Trainingszeiten für jede Runde geplottet.

Wenn du jetzt das Trainingszeitverhältnis zwischen MART und RB berechnen ($frac{t_{MART}}{t_{RB}}$), siehst du, dass RB im Durchschnitt etwa 1,8-mal schneller als MART ist.
Eine weitere Perspektive auf den Fall ist das relative Training $t_{rel,j}=frac{t_{RB,j}}{t_{MART,j}}$ zu berechnen, das nur 1 durch die Beschleunigung ist. Beachte, dass diese Maßnahme etwas anders interpretiert werden muss als das relative MAE-Maß oben. Wenn $t_{rel,j}=1$, dann ist RB genauso schnell wie MART, wenn $t_{rel,j}$>$1$, dann dauert es länger, RB zu trainieren als MART, und wenn $t_{rel,j}$<$1$, dann ist RB schneller als MART.
Im Durchschnitt benötigt RB nur etwa 54% der Abstimmungszeit von MART im Median und ist in allen Fällen merklich schneller. Ich habe mich auch gefragt, wie das relative Training mit $d_{max}$ variiert und wie gut die theoretisch abgeleitete untere Grenze von oben zur tatsächlich gemessenen relativen Trainingszeit passt. Deshalb habe ich die relative Trainingszeit über alle 25 Datensätze nach Baumgröße berechnet.
Die theoretischen Zahlen sind optimistisch, aber der relative Leistungsgewinn von RB steigt mit der Baumgröße.
Ergebnisse in Kürze und nächste Schritte
Im Rahmen meiner Forschung zu baumbasierten Ensemble-Methoden habe ich einen neuen Algorithmus namens Random Boost entwickelt. Random Boost basiert auf Jerome Friedmans MART, mit dem kleinen Unterschied, dass es Bäume zufälliger Größe passt. Insgesamt kann diese kleine Änderung das Problem des Overfittings reduzieren und die Berechnung deutlich beschleunigen. Mithilfe eines von Friedman vorgeschlagenen Random Target Function Generator fand ich heraus, dass RB im Durchschnitt etwa doppelt so schnell wie MART ist, mit einer vergleichbaren Vorhersagegenauigkeit in Erwartung.
Da das Durchführen der gesamten Simulation ziemlich viel Zeit in Anspruch nimmt (das Finden der optimalen Parameter und das erneute Training jedes Modells dauert etwa eine Stunde für jeden Datensatz auf meinem Mac), konnte ich nicht Hunderte oder mehr Simulationen für diesen Blogbeitrag durchführen. Das ist das Ziel für zukünftige Forschung zu Random Boost. Außerdem möchte ich den Algorithmus an realen Datensätzen benchmarken.
In der Zwischenzeit können Sie gerne meinen Code ansehen und die Simulationen selbst durchführen. Alles ist auf GitHub. Darüber hinaus, wenn Sie etwas Interessantes finden und es mit mir teilen möchten, zögern Sie nicht, mir eine E-Mail zu schicken.
Referenzen
- Breiman, Leo (2001). Random Forests. Machine Learning, 45, 5–32
- Chang, Tianqi, and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Pages 785-794
- Chapelle, Olivier, and Yi Chang. 2011. “Yahoo! learning to rank challenge overview”. In Proceedings of the Learning to Rank Challenge, 1–24.
- Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, 1189-1232.
- Friedman, J. H. (2002). “Stochastic gradient boosting”. Computational Statistics & Data Analysis 38 (4): 367–378.
- Geurts, Pierre, Damien Ernst, and Louis Wehenkel (2006). “Extremely randomized trees”. Machine learning 63 (1): 3–42.
- Rashmi, K. V., and Ran Gilad-Bachrach (2015). Proceedings of the 18th International Conference on Artificial Intelligence and Statistics (AISTATS) 2015, San Diego, CA, USA. JMLR: W&CP volume 38.


