Gut in Form - Der richtige Datentyp in R, Stata und SPSS


Ist der Datensatz in das gewünschte Statistikprogramm eingeladen, gibt es meist noch einige Stolperfallen, bevor man mit der Anwendung der Methode beginnen kann. Dies liegt oft daran, dass die Variablen nicht dem richtigen Typ zugewiesen sind. Wurden Werte, die eigentlich Zahlen sind, als Strings (Zeichenketten) abgespeichert, können beispielsweise keine Lagemaße der Verteilung berechnet werden. Nach dem Import der Daten sollte deshalb im nächsten Schritt der Datentyp der Variablen überprüft werden, der von der Statistiksoftware meist automatisch – und nicht immer richtig - zugewiesen wird.
Datensatz
Im vorherigen Beitrag wurden die verwendeten Daten bereits kurz vorgestellt. Es handelt sich dabei um die Aufzeichnung des Süßigkeitenkonsums von vier STATWORX-Mitarbeitern, deren realer Name durch den jeweiligen Lieblingsstatistiker ersetzt wurde. Der Kopf der Daten ist unten abgebildet.

Datentypen
In der Informatik gibt es unzählige Datentypen, die vor allem durch ihren Speicherbedarf identifiziert werden. Die Aufzählung der Variablentypen wird hier stark vereinfacht vorgestellt. Generell können Variablen qualitativ als Strings (Zeichenketten) oder quantitativ in Zahlenform vorliegen. Zweitere lassen sich in Ganzzahlen und Dezimalzahlen unterscheiden.
Ein Spezialfall von Strings ist der Faktor. Dies ist eine ordinale Variable, die nur eine begrenzte Anzahl an Ausprägungen aufweist. Dabei wird jede Ausprägung als ein numerischer Wert dargestellt und mit Wertelabels versehen. Beispiel ist die Frage nach der Zufriedenheit mit einem Produkt, wobei mit den Zahlen 1 bis 5 die Zufriedenheit von „sehr unzufrieden“ bis „sehr zufrieden“ ausgedrückt werden kann.
Zu unterschieden ist außerdem das Messniveau von Daten. Daten können sowohl nominal sein, also ohne Reihenfolge, wie das Geschlecht oder ordinal, also geordnet und somit mit einer festen Reihenfolge, wie bei der Verwendung von Altersklassen. Weitere Messniveaus sind die Intervall- und die Verhältnisskala. Bei der Verhältnisskala bilden gleiche Intervalle auf der Skala gleiche Differenzen ab. Der Unterschied zwischen dem Wert 10 und 20 gibt also die gleiche Abweichung an wie die Differenz zwischen 30 und 40. Außerdem gibt es einen natürlichen Nullpunkt. Ein Beispiel hierfür ist das Längenmaß. Bei der Intervallskala gibt es zwar auch gleiche Abstände zwischen den einzelnen Ausprägungen, jedoch keinen absoluten Nullpunkt. Ein übliches Beispiel hierfür ist die Temperaturmessung in Grad Celsius.
Bei Strings können innerhalb der Statistiksoftware interne Typen vorhanden sein, die die Zeichenkette näher klassifizieren, wie beispielsweise ein Datumsformat.
R
Die Struktur der Daten kann in R mit str() abgefragt werden. Für den Süßigkeiten-Datensatz erhalten wir folgendes Ergebnis:

Der Typ einzelner Variablen (bzw. Vektoren) kann mit class() abgefragt werden. Es zeigt sich, dass die meisten Typen bereits richtig erkannt wurden. Generell können beliebige Datentypen mit den Funktionen as.datentyp() zugewiesen werden, beispielsweise as.numeric() oder as.character().
Die Mitarbeiter-Variable weist nur vier Ausprägungen auf. R hat dies erkannt und die Variable automatisch als Faktor mit den Werten 1 bis 4 kodiert und die Ausprägungen mit „Bayes“, „Gauss“, usw. benannt. So kann Speicherplatz gespart werden. Dass die Variable automatisch in einen Faktor umgewandelt wird liegt daran, dass bei data.frame die stringsAsFactors-Option automatisch auf TRUE gesetzt wird.
Die vier Variablen zum Süßigkeiten-Verzehr sind alle richtig als numerische Werte erkannt worden. Was jedoch auf den ersten Blick nicht klar wird, ist, dass die PickUp-Variable nicht angibt, wie viele Riegel am Tag verspeist wurden, sondern welche Sorte der Mitarbeiter am liebsten mag. Dabei soll der Wert 1 für die Sorte “Choco” stehen, 2 für “Choco & Caramel” und 3 für “Choco & Milch”. Ziel ist eine Faktorvariable, wie es auch bei den Mitarbeitern der Fall ist. Die Umsetzung ist in der Codebox unten zu finden. Je nachdem, ob der Faktor ordinale Werte aufweist oder nicht, kann die factor()- oder ordered()-Funktion verwendet werden. Die die Sorten keine Reihenfolge aufweisen, wird hier die factor()- Funktion verwendet.
Die Obst-Variable, soll auf ein Zehntel genau die Anzahl an gegessenen Obststücken darstellen. Leider wurde diese hier als String erkannt. Das liegt häufig am Dezimaltrennzeichen. Außerdem kann das Problem auftauchen, wenn in der Variable Strings, wie „keine Angabe“, enthalten sind.
Bleibt noch die Datumsvariable. Eine Option zur Umformung gängiger Datumsformate ist die as.Date()-Funktion. Mit dem format-Argument sollte die Struktur übergeben werden. In der Codebox unten ist die Umwandlung ins Datumsformat dargestellt. Allerdings gibt es in R noch viele andere, ausgefeiltere Wege, um mit Datumsformaten zu arbeiten, wie beispielsweise das lubridate-Paket.
# Erstellen eines (ungeordneten) Faktors aus der PickUp-Variable
sweets$pickup <- factor(sweets$pickup,
levels = c(1, 2, 3),
labels = c("Choco", "Choco & Caramel", "Choco & Milch"))
# Umwandlung der Obst-Variable ins Zahlenformat
sweets$obst <- as.numeric(sweets$obst)
# Umwandlung der Tag-Variable ins Datumsformat
sweets$tag <- as.Date(sweets$tag, format ="%Y-%m-%d")
Nach der Anpassung der Datentypen zeigt ein erneuter Blick auf die Daten, dass nun alle Variablen den gewünschten Typ aufweisen.

Stata
Generell wird in Stata nach Speichertyp und Anzeigeformat unterschieden. Ersterer zeigt an, wie viel Platz die Variable im Speicher belegt. Hierbei kann auch erkannt werden, ob es sich um eine Zeichenkette (= „str“ ; Zahl am Ende gibt die Länge an) oder um numerische Werte (= „byte“, „float“, „long“, „double“) handelt. Mit dem describe-Befehl kann die Struktur der Variablen angesehen werden.
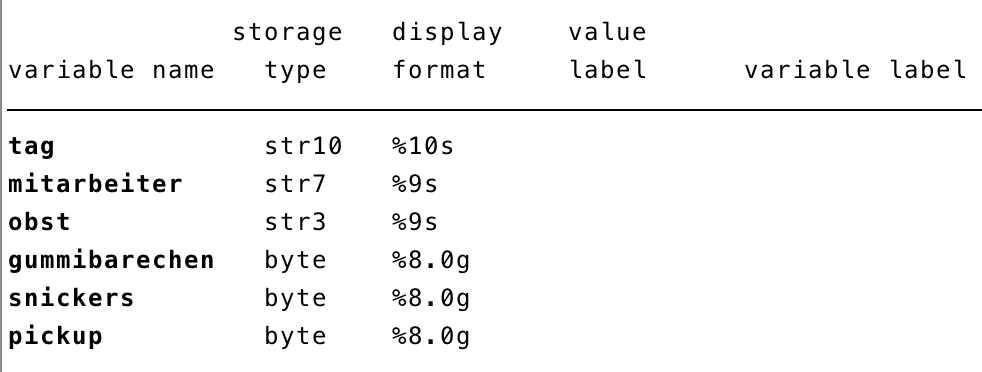
Kommen wir zunächst zur PickUp-Variable, die auch hier als numerisch eingelesen wurde, aber als Faktor definiert werden soll. Dafür muss als erstes, unabhängig von der Variable, eine Benennung definiert werden. Diese kann dann auf eine oder auch mehrere Variablen angewendet werden. In der Codebox unten wird zunächst mit dem label define-Befehl ein Label definiert, dass dann mit dem label values-Befehl auf die Variable angewandt wird.
Zunächst erscheint es vielleicht etwas umständlich, dass Label separat zu definieren und zuzuweisen, es gibt jedoch häufig Labels, die öfter verwendet werden, wie beispielsweise die Benennung der Werte 0 und 1 als „nein“ und „ja“ oder die Benennung einer Zufriedenheitsskala. Übrigens: Die numerischen Werte bei einer bereits gelabelten Variable können mit der Option nolabel beim tabulate-Befehl angesehen werden.
Als nächstes soll nun die Obst-Variable von einer Zeichenkette ins Zahlenformat umgewandelt werden. Dies wird in Stata mit dem destring-Befehl bewerkstelligt. Mit dem tostring-Befehl geht es in die umgekehrte Richtung, also vom Zahlenformat zum String. Bei beiden Befehlen muss mit der generate-Option ein neue Variable definiert werden. Der Grund dafür, dass der Variablentyp falsch erkannt wurde, ist das Komma als Dezimaltrenner (statt einem Punkt). Deshalb muss die dpcomma-Option angegeben werden, welche das Komma als Dezimaltrennzeichen definiert.
Das Datum sollte in den entsprechenden Typ umgewandelt werden, falls dieses für die Analyse wichtig ist, beispielsweise im Rahmen der Zeitreihenanalyse. Auch hier muss eine neue Variable erstellt werden, die den Tag im Datumsformat anzeigt. Wie auch bei R muss nach dem Variablennamen das Format, in der das Datum vorliegt, spezifiziert werden. Die so entstandene Variable wird nun im Stata-eigenen Format definiert. Mit dem Format-Befehl muss dann noch die Struktur ausgewählt werden, mit der das Datum dargestellt werden soll. Bei „%td“ handelt es sich beispielsweise um die Anzeige des Datums ohne Zeitangabe.
Die Mitarbeiter-Variable wird in Stata, im Gegensatz zu R, nicht automatisch als Faktor gespeichert. Sie ist als String gespeichert, was nicht zwingend verändert werden muss. Die Transformation ist dennoch unten dargestellt und kann hilfreich sein, wenn man die Variable aus Speicherplatzgründen umwandeln möchte.
Hierfür kann der encode-Befehl benutzt werden. Mit der label()-Option wird der neuerstellten numerischen Variable gleich das Label übergeben.
* Definition der PickUp-Variable als Faktor
label define chocolabel 1 "Choco" 2 "Choco & Caramel" 3 "Choco & Milch"
label values pickup chocolabel
* Umwandlung der Obst-Variable ins Zahlenformat
destring obst, generate(obst_destring)
* Umwandlung der Tag-Variable ins Datumsformat
gen tag_date = date(tag, "YMD")
format tag_date %td
* Definition der Mitarbeiter-Variable als Faktor
encode mitarbeiter, gen(mitarbeiter_faktor) label()
Nach Ausführung der Befehle wagen wir erneut einen Blick auf die Struktur der Daten. Im Vergleich zum Resultat in R, wurden in Stata viele neue Variable generiert. Selbstverständlich können die ursprünglichen Variablen auch entfernt werden. In R und auch SPSS ist es generell leichter bestehende Variablen zu überschreiben als in Stata. Das ermöglicht einen besseren Überblick über die Daten, kann jedoch auch gefährlich werden, wenn Variablen unabsichtlich überschrieben werden.

SPSS
Als nächstes wird die Anpassung des Datentyps in SPSS vorgestellt. Die Variablenansicht ist gut geeignet, um sich grundlegende Eigenschaften der Daten anzusehen. Für uns ist hier die Spalte "Typ" von Interesse. Diese gibt an, ob es sich beispielsweise um einen String, numerische Werte oder ein Datum handelt. In einer separaten Spalte wird das Messniveau dargestellt.
Über die Variablenansicht können auch händisch Änderungen vorgenommen werden. Dies kann jedoch leichter zu Fehlern führen, außerdem wollen wir hier die Syntax von SPSS vorstellen. So können die Änderungen auch für mehrere Variablen gleichzeitig ausgeführt werden. Zunächst, wie bisher auch, der Blick auf die Struktur der eingelesenen Daten:
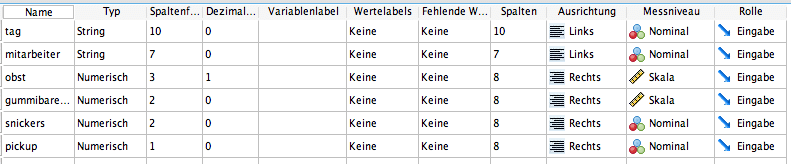
Wieder wird die Datumsvariable nicht im vorgesehenen Typ erkannt. Außerdem soll die Pickup-Variable als gelabelter Faktor definiert werden. Die Obst-Variable mit den Dezimalwerten stellt in der Regel kein Problem dar, weil SPSS sowohl Punkt als auch Komma als Dezimaltrenner anerkennt. Aus diesem Grund wird der Variable auch automatisch eine Dezimalstelle zugeordnet.
Beginnen wir mit der Anpassung der PickUp-Variable. Mit dem VALUES LABELS-Befehl wird den numerischen Werte eine Bezeichnung übergeben. In der Datenansicht von SPSS kann über den Button „Wertelabels“ zwischen Anzeige der numerischen und gelabelten Werte umgeschaltet werden. Weitere Anpassungen müssen für die Variable nicht getroffen werden.
Um die Datumsvariable in das entsprechende Format umzuwandeln muss als erstes mit dem NUMBER-Befehl eine neue Variable erstellt werden. Nach der zu transformierenden Variable wird als zweites Argument die Reihenfolge des Datums erwartet. Eine direkte Umwandlung ist jedoch auch mit dem ALTER TYPE-Befehl möglich. Nähere Informationen zum Datumstyp sind hier zu finden.
Außerdem wird dargestellt, wie sich die String-Variable „Mitarbeiter“ in einen Faktor transformieren lässt. In diesem Beispiel hat der Anwender dadurch, außer geringerem Speicherplatz, keinen Vorteil, handelt es sich jedoch um eine Variable mit ordinalem Messniveau, muss diese Umwandlung erfolgen. Mit dem AUTORECODE-Befehl wird die String-Variable bequem in einen gelabelten, numerischen Faktor umgewandelt. Die Nummerierung erfolgt alphabetisch. Dies stellt hier kein Problem dar, bei einem Faktor mit ordinalem Messniveau kann dies jedoch zur Falle werden, wenn die Nummerierung automatisch erfolgt. Die (leider) einfachste Möglichkeit damit umzugehen ist, alle Werte einzeln mit dem RECODE-Befehl in numerische Größen umzustrukturieren und mit dem bereits bekannten Befehl zu labeln. Aus diesem Grund ist in der Codebox zusätzlich noch dargestellt, wie sich die Strings in Faktoren mit beliebigen Ausprägungen/beliebiger Reihenfolge umwandeln lassen.
Generell lässt sich der Variablentyp mit dem ALTER TYPE-Befehl verändern. Nach den Anpassungen blicken wir wieder auf die Variablentypen in der Variablenansicht.
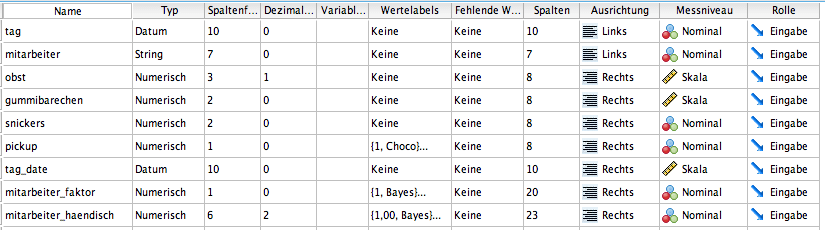
Sowohl die neu erstellte Variable „tage_date“ als auch die transformierte Tag-Variable liegen nun im Datumsformat vor. Aus der String-Mitarbeiter-Variable wurden zwei Faktoren erstellt. Eine der beiden lässt sich sehr einfach generieren (mit AUTORECODE), die Erstellung der zweiten ist eher aufwändiger. Das Resultat der beiden ist jedoch sehr ähnlich: Beide weisen einen numerischen Typ als auch Wertelabels auf. Auch bei der PickUp-Variable werden jetzt Labels angezeigt.
* Definition der PickUp-Variable als Faktor
VALUE LABELS pickup 1 "Choco" 2 "Choco & Caramel" 3 "Choco & Milch".
EXECUTE.
* Umwandlung der Obst-Variable ins Zahlenformat nicht notwendig, Komma automatisch als Dezimaltrenner erkannt.
* Umwandlung der Tag-Variable ins Datumsformat
COMPUTE tag_date=NUMBER(tag, SDATE10).
FORMATS tag_date (SDATE10).
EXECUTE.
* Oder direkte Transformation des Datums:
ALTER TYPE tag (SDATE10).
* Definition der Mitarbeiter-Variable als Faktor
AUTORECODE mitarbeiter /INTO mitarbeiter_faktor.
* Mit beliebiger Nummerierung der Mitarbeiter-Variable
RECODE mitarbeiter (CONVERT) ("Bayes" = 1) ("Pearson" = 2) ("Laplace" = 3) ("Gauss" = 4) INTO mitarbeiter_haendisch.
VALUE LABELS mitarbeiter_haendisch 1 "Bayes" 2 "Pearson" 3 "Laplace" 4 "Gauss".
EXECUTE.
Zusammenfassung
Dieser Blogbeitrag versucht die häufigsten Probleme im Zusammenhang mit Datentypen in R, Stata und SPSS aufzuzeigen. Es zeigt sich, dass der gleiche Schritt zur Datenaufbereitung, nämlich die Anpassung des Variablentyps, in den verschiedenen Softwareprogrammen völlig unterschiedlich umgesetzt wird. Auch die Transformation zwischen Typen innerhalb eines Statistikprogramms ist leider oft nicht intuitiv verständlich.


