Wie lernen neuronale Netze?


Für Außenstehende umgeben neuronale Netze eine mystische Aura. Obwohl die Funktionsweise der elementaren Bausteine neuronaler Netze, Neuronen genannt, bereits seit vielen Jahrzehnten bekannt sind, stellt das Training von neuronalen Netzen Anwender auch heute noch vor Herausforderungen. Insbesondere im Bereich Deep Learning, in dem sehr tiefe oder anderweitig komplexe Netzarchitekturen geschätzt werden, spielt die Art und Weise wie das Netz aus den vorhandenen Daten lernt, eine zentrale Rolle für den Erfolg des Trainings.
In diesem Beitrag sollen die beiden grundlegenden Bausteine des Lernens von neuronalen Netzen beleuchtet werden: (1) Gradient Descent, eine iterative Methode zur Minimierung von Funktionen sowie (2) Backpropagation, ein Verfahren, mit dem in neuronalen Netzen die Stärke und Richtung der Anpassungen der Modellparameter berechnet werden können. Im Zusammenspiel beider Methoden sind wir heute in der Lage, verschiedenste Modelltypen und Architekturen zu entwickeln und auf vorhandenen Daten zu trainieren.
Formaler Aufbau eines Neurons
Ein Neuron $j$ berechnet seinen Output $o_j$ als gewichtete Summe der Eingangssignale $x$, die anschließend durch die sog. Aktivierungsfunktion des Neurons, $g(x)$ transformiert wird. Je nachdem, welche Aktivierungsfunktion für $g()$ gewählt wird, verändert sich der funktionale Output des Neurons. Die folgende Abbildung soll den Aufbau eines einzelnen Neurons schematisch darstellen.
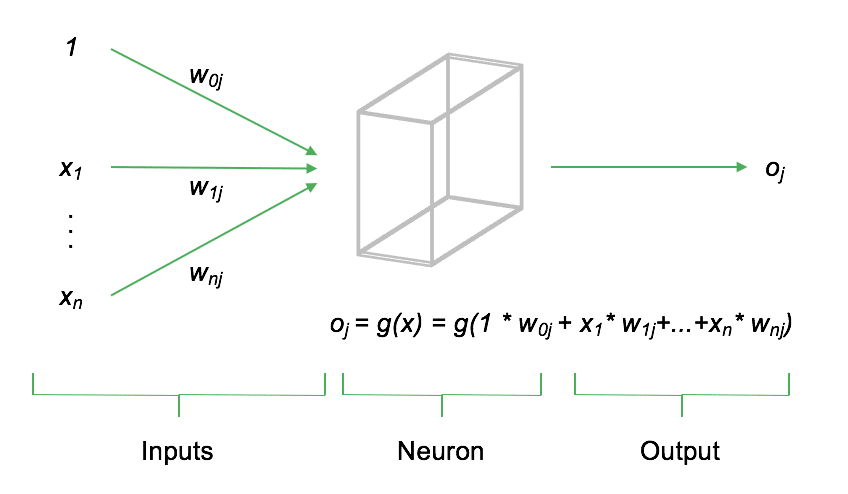
Neben den Inputs $x_1,...,x_n$ beinhaltet jedes Neuron einen sog. Bias. Der Bias steuert das durchschnittliche Aktivierungsniveau und ist elementarer Bestandteil des Neurons. Jeder Input sowie der Bias fließen als gewichtete Summe in das Neuron ein. Anschließend wird die gewichtete Summe durch die Aktivierungsfunktion des Neurons nichtlinear transformiert. Heute wird insbesondere die sog. Rectified Linear Unit (ReLU) als Aktivierungsfunktion verwendet. Diese ist definiert als $g(x)=max(0,x)$. Andere Aktivierungsfunktionen sind bspw. die Sigmoidfunktion, definiert als $g(x)=frac{1}{1+e^{-x}}$ oder der Tangens Hyperbolicus, $g(x)=1-frac{2}{e^{2x}+1}$.
Der folgende Python Code soll exemplarisch den Ablauf zur Berechnung des Outputs eines Neurons aufzeigen.
# Imports
import numpy as np
# ReLU Aktivierungsfunktion
def relu(x):
""" ReLU Aktivierungsfunktion """
return(np.maximum(0, x))
# Funktion für ein einzelnes Neuron
def neuron(w, x):
""" Neuron """
# Gewichtete Summe von w und x
ws = np.sum(np.multiply(w, x))
# Aktivierungsfunktion (ReLU)
out = relu(ws)
# Wert zurückgeben
return(out)
# Gewichtungen und Inputs
w = [0.1, 1.2, 0.5]
x = [1, 10, 10]
# Berechnung Output (ergibt 18.0)
p = neuron(w, x)
array([18.0])
Durch die Anwendung der ReLU Aktivierungsfunktion beträgt der Output des Neurons im obigen Beispiel $18$. Selbstverständlich besteht ein neuronales Netz nicht nur aus einem, sondern sehr vielen Neuronen, die über ihre Gewichtungsfaktoren in Schichten miteinander verbunden sind. Durch die Kombination vieler Neuronen ist das Netz in der Lage, auch hochgradig komplexe Funktionen zu lernen.
Gradient Descent
Einfach gesprochen lernen Neuronale Netze, indem sie iterativ die Modellprognosen mit den tatsächlich beobachteten Daten vergleichen und die Gewichtungsfaktoren im Netz so anpassen, dass in jeder Iteration der Fehler zwischen Modellprognose und Istdaten reduziert wird. Zur Quantifizierung des Modellfehlers wird eine sog. Kostenfunktion (cost function) berechnet. Die Kostenfunktion hat i.d.R. zwei Funktionsargumente: (1) den Output des Modells, $o$ sowie (2) die tatsächlich beobachteten Daten, $y$. Eine typische Kostenfunktion $E$, die in neuronalen Netzen häufig Anwendung findet, ist der mittlere quadratische Fehler (Mean Squared Error, MSE):
$E=frac{1}{n}sum (y_i-o_i)^2$
Der MSE berechnet zunächst für jeden Datenpunkt die quadratische Differenz zwischen $y$ und $o$ und bildet anschließend den Mittelwert. Ein hoher MSE reflektiert somit eine schlechte Anpassung des Modells an die vorliegenden Daten. Ziel des Modelltrainings soll es sein, die Kostenfunktion durch Anpassung der Modellparameter (Gewichtungen) zu minimieren. Woher weiß das neuronale Netz, welche Gewichtungen im Netzwerk angepasst werden müssen, und vor allem, in welche Richtung?
Die Kostenfunktion hängt von allen Parametern im neuronalen Netz ab. Wird auch nur eine Gewichtung minimal verändert, hat dies eine unmittelbare Auswirkung auf alle folgenden Neuronen, den Output des Netzes und somit auch auf die Kostenfunktion. In der Mathematik können die Stärke und Richtung der Veränderung der Kostenfunktion durch Veränderung eines einzelnen Parameters im Netzwerk durch die Berechnung der partiellen Ableitung der Kostenfunktion nach dem entsprechenden Gewichtungsparameter bestimmt werden: $frac{partial E}{partial w_{ij}}$. Da die Kostenfunktion $E$ im neuronalen Netz hierarchisch von den verschiedenen Gewichtungsfaktoren im Netz abhängt, kann nach Anwendung der Kettenregel für Ableitungen folgende Gleichung zur Aktualisierung der Gewichtungen im Netzwerk abgeleitet werden:
$w_{ijt}=w_{ijt-1}-eta frac{partial E}{partial w_{ij}}$
Die Anpassung der Gewichtungsfaktoren von Iteration zu Iteration in Richtung der Minimierung der Kostenfunktion hängt also lediglich von dem Wert des jeweiligen Gewichts aus der vorhergehenden Iteration, der partiellen Ableitung von $E$ nach $w_{ij}$ sowie einer Lernrate (learning rate), $eta$ ab. Die Lernrate steuert dabei, wie groß die Schritte in Richtung der Fehlerminimierung ausfallen. Das oben skizzierte Vorgehen, die Kostenfunktion iterativ auf Basis von Gradienten zu minimieren, wird als Gradient Descent bezeichnet. Die folgende Abbildung soll den Einfluss der Lernrate auf die Minimierung der Kostenfunktion verdeutlichen (in Anlehnung an Yun Le Cun):

Idealerweise würde die Lernrate so gesetzt werden, dass mit nur einer Iteration das Minimum der Kostenfunktion erreicht wird (oben links). Da in der Anwendung der theoretisch korrekte Wert nicht bekannt ist, muss die Lernrate vom Anwender definiert werden. Im Falle einer kleinen Lernrate kann man relativ sicher sein, dass ein (zumindest lokales) Minimum der Kostenfunktion erreicht wird. Allerdings steigt in diesem Szenario die Anzahl der benötigten Iterationen bis zum Minimum deutlich an (oben rechts). Für den Fall, dass die Lernrate größer als das theoretische Optimum gewählt wird, destabilisiert sich der Pfad hin zum Minimum zusehends. Zwar sinkt die benötigte Anzahl der Iterationen, es kann aber nicht sichergestellt werden, dass tatsächlich ein lokales oder globales Optimum erreicht wird. Insbesondere in Regionen, in denen die Steigung bzw. Oberfläche der Fehlerkurve sehr flach wird, kann es vorkommen, dass durch eine zu große Schrittweite das Minimum verfehlt wird (unten links). Im Falle einer deutlich zu hohen Lernrate führt dies zu einer Destabilisierung der Minimierung und es wird keine sinnvolle Lösung für die Anpassung der Gewichtungen gefunden (unten rechts). In aktuellen Optimierungsschemata finden auch adaptive Lernraten Anwendung, die die Lernrate im Laufe des Trainings anpassen. So kann bspw. zu Beginn eine höhere Lernrate gewählt werden, die dann im Laufe der Zeit weiter reduziert wird, um stabiler am (lokalen) Optimum zu landen.
# Imports
import numpy as np
# ReLU Aktivierungsfunktion
def relu(x):
""" ReLU Aktivierungsfunktion """
return(np.maximum(0, x))
# Ableitung der Aktivierungsfunktion
def relu_deriv(x):
""" Ableitung ReLU """
return(1)
# Kostenfunktion
def cost(y, p):
""" MSE Kostenfunktion """
mse = np.mean(pow(y-p, 2))
return(mse)
# Ableitung der Kostenfunktion
def cost_deriv(y, p):
""" Ableitung MSE """
return(y-p)
# Funktion für ein einzelnes Neuron
def neuron(w, x):
""" Neuron """
# Gewichtete Summe von w und x
ws = np.sum(np.multiply(w, x))
# Aktivierungsfunktion (ReLU)
out = relu(ws)
# Wert zurückgeben
return(out)
# Initiales Gewicht
w = [5.5]
# Input
x = [10]
# Target
y = [100]
# Lernrate
eta = 0.01
# Anzahl Iterationen
n_iter = 100
# Neuron trainieren
for i in range(n_iter):
# Ausgabe des Neurons berechnen
p = neuron(w, x)
# Ableitungen berechnen
delta_cost = cost_deriv(p, y)
delta_act = relu_deriv(x)
# Gewichtung aktualisieren
w = w - eta * delta_act * delta_cost
# Ergebnis des Trainings
print(w)
array([9.99988047])
Durch das iterative Training des Modells ist es also gelungen, die Gewichtung des Inputs so anzupassen, dass der Abstand zwischen der Modellprognose und dem tatsächlich beobachteten Wert nahe 0 ist. Dies ist einfach nachzurechnen:
$o_j=g(x)=g(w*x)=max(0, 9.9998*10) = max(0, 99.998) = 99.998$
Das Ergebnis liegt also fast bei $100$. Der mittlere quadratische Fehler beträgt $3.9999e-06$ und ist somit ebenfalls nahe $0$. Die folgende Abbildung visualisiert abschließend den MSE im Trainingsverlauf.
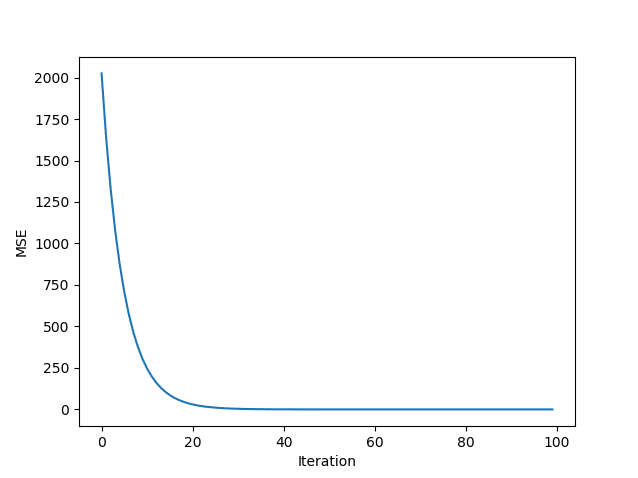
Man sieht deutlich den monoton abnehmenden, mittleren quadratischen Fehler. Nach 30 Iterationen liegt der Fehler praktisch bei null.
Backpropagation
Das oben dargestellte Verfahren des steilsten Gradientenabstiegs wird auch heute zur Minimierung der Kostenfunktion von neuronalen Netzen eingesetzt. Allerdings gestaltet sich die Berechnung der benötigten Gradienten in komplexeren Netzarchitekturen deutlich schwieriger als im oben gezeigten Beispiel eines einzelnen Neurons. Der Grund hierfür ist, dass die Gradienten der einzelnen Neuronen voneinander abhängen. Es besteht also eine Verkettung der Wirkungen einzelner Neuronen im Netz. Zur Lösung dieses Problems wird der sog. Backpropagation Algorithmus eingesetzt, der es ermöglicht, die Gradienten in jeder Iteration rekursiv zu berechnen.
Ursprünglich wurde der Backpropagation Algorithmus in den 1970er Jahren entwickelt, fand aber erst deutlich später, im Jahre 1986, Anerkennung durch das bahnbrechende Paper von Rumelhart, Hinton und Williams (1986), in dem Backpropagation erstmalig zum Training von neuronalen Netzen verwendet wurde. Die gesamte formale Herleitung des Backpropagation Algorithmus ist zu komplex, um hier im Detail dargestellt zu werden. Im Folgenden soll der grundsätzliche Ablauf formal skizziert werden.
In Matrizenschreibweise ist der Vektor der Outputs $o$ aller Neuronen eines Layers $l$ definiert als
$o_l=g(w_lo_{l-1}+b_l)$
wobei $w_l$ die Gewichtungsmatrix zwischen den Neuronen der Layer $l$ und $l-1$ ist und $o_{l-1}$ den Output des vorhergehenden Layers bezeichnet. Der Term $b_l$ repräsentiert die Biaswerte des Layers $l$. Die Funktion $g$ ist die Aktivierungsfunktion des Layers. Der Term innerhalb der Klammer wir auch als gewichteter Input $z$ bezeichnet. Es gilt also $o_l=g(z)$ mit $z=w_lo_{l-1}+b_l$. Zudem nehmen wir an, dass das Netzwerk insgesamt aus $L$ Layern besteht. Der Output des Netzes ist also $o_L$. Die Kostenfunktion $E$ des neuronalen Netzes muss so definiert sein, dass sie als Funktion des Outputs $o_L$ sowie der beobachteten Daten $y$ geschreiben werden kann.Die Veränderung der Kostenfunktion in Abhängigkeit des gewichteten Inputs eines Neurons $j$ im Layer $l$ ist definiert als $delta_j=partial E / partial z_j$. Umso größer dieser Wert, desto stärker ist die Kostenfunktion abhängig vom gewichteten Inputs dieses Neurons. Die Veränderung der Kostenfunktion in Abhängigkeit der Outputs des Layers $L$ ist definiert als
$delta_L=frac{partial E}{partial o_L}g'(z_L)$
Die genaue Form von $delta_L$ ist abhängig von der Wahl der Kostenfunktion $E$. Die hier verwendete mittlere quadratische Abweichung lässt sich einfach ableiten nach $o_L$:
$frac{partial E}{partial o_L}=(y-o_l)$
Somit kann der Vektor der Gradienten für die Outputschicht folgendermaßen geschrieben werden:
$delta_L=(y-o_L)g'(z_L)$
Für die vorhergehenden Layer $l=1,...,L-1$ lässt sich der Gradientenvektor schreiben als
$delta_l=(w_{l+1})^T delta_{l+1} g'(z_l)$
Wie man sieht, sind die Gradienten im $l$-ten Layer eine Funktion der Gradienten und Gewichtungen des folgenden Layers $l+1$. Somit ist es unabdingbar, die Berechnung der Gradienten im letzten Layer des Netzes zu beginnen und diese dann iterativ in die vorhergehenden Layer zu propagieren (=Backpropagation). Durch die Kombination von $delta_L$ und $delta_l$ lassen sich somit die Gradienten für alle Layer im neuronalen Netz berechnen.
Nachdem die Gradienten aller Layer im Netz bekannt sind, kann anschließend ein Update der Gewichtungen im Netz mittels Gradient Descent stattfinden. Dieses Update wird so gewählt, dass die Gewichtungen in entgegengesetzter Richtung zu den berechneten Gradienten stattfinden - und somit die Kostenfunktion reduzieren.
Für das folgende Programmierbeispiel, das exemplarisch den Backpropagation Algorithmus darstellt, erweitern wir unser neuronales Netz aus dem vorherigen Beispiel um ein weiteres Neuron. Somit besteht das Netz nun aus zwei Schichten - dem Hidden Layer sowie dem Output Layer. Der Hidden Layer wird weiterhin mit der ReLU aktiviert, der Output Layer verfügt über eine lineare Aktivierung, er gibt also nur die gewichtete Summe des Neurons weiter.
# Neuron
def neuron(w, x, activation):
""" Neuron """
# Gewichtete Summe von w und x
ws = np.sum(np.multiply(w, x))
# Aktivierungsfunktion (ReLU)
if activation == 'relu':
out = relu(ws)
elif activation == 'linear':
out = ws
# Wert zurückgeben
return(out)
# Initiale Gewichte
w = [1, 1]
# Input
x = [10]
# Target
y = [100]
# Lernrate
eta = 0.001
# Anzahl Iterationen
n_iter = 100
# Container für Gradienten
delta = [0, 0]
# Container für MSE
mse = []
# Anzahl Layer
layers = 2
# Neuron trainieren
for i in range(100):
# Hidden layer
hidden = neuron(w[0], x, activation='relu')
# Output layer
p = neuron(w[1], x=hidden, activation='linear')
# Ableitungen berechnen
d_cost = cost_deriv(p, y)
d_act = relu_deriv(x)
# Backpropagation
for l in reversed(range(layers)):
# Output Layer
if l == 1:
# Gradienten und Update
delta[l] = d_act * d_cost
w[l] = w[l] - eta * delta[l]
# Hidden Layer
else:
# Gradienten und Update
delta[l] = w[l+1] * delta[l+1] * d_act
w[l] = w[l] - eta * delta[l]
# Append MSE
mse.append(cost(y, p))
# Ergebnis des Trainings
print(w)
[array([3.87498172]), array([2.58052067])]
Im Gegensatz zum letzten Beispiel ist die Schleife nun durch Hinzufügen einer weiteren Schleife nun etwas komplexer geworden. Die weitere Schleife bildet die Backpropagation im Netz ab. Über reversed(range(layers)) iteriert die Schleife rückwärts über die Anzahl der Layer und startet somit beim Output Layer. Danach werden die Gradienten gem. oben dargestellter Formel berechnet und anschließend die Gewichtungen mittels Gradient Descent aktualisiert. Multipliziert man die berechneten Gewichtungen erhält man
$3.87498172*10*2.58052067=99.99470$
was wiederum fast genau dem Zielwert von $y=100$ entspricht. Durch die Anwendung von Backpropagation und Gradient Descent hat das (wenn auch sehr minimalistische) neuronale Netz den Zielwert gelernt.
Zusammenfassung und Ausblick
Neuronale Netze lernen heute mittels Gradient Descent (bzw. moderneren Abwandlungen davon) und Backpropagation. Die Entwicklung effizienterer Lernverfahren, die schneller, genauer und stabiler als bestehende Formen von Backpropagation und Gradient Descent sind, gehört zu den zentralen Forschungsbereichen in diesem Fachgebiet. Insbesondere für Deep Learning Modelle, in denen sehr tiefe Modellarchitekturen geschätzt werden müssen, spielt die Auswahl des Lernverfahrens eine zentrale Rolle für die Geschwindigkeit des Trainings sowie für die Genauigkeit des Modells. Die fundamentalen Mechanismen der Lernverfahren für neuronale Netze sind bisher weitestgehend unverändert geblieben. Vielleicht wird aber künftig, angetrieben durch die massive Forschung in diesem Bereich, ein neues Lernverfahren entwickelt, das genauso revolutionär und erfolgreich sein wird wie der Backpropagation Algorithmus. Sebastian Heinz Sebastian Heinz


