Wie man eine Machine Learning API mit Python und Flask erstellt


Wolltest du schon einmal dein Machine-Learning-Modell anderen Menschen zur Verfügung stellen, wusstest aber nicht wie? Oder hast du vielleicht einfach nur von dem Begriff API gehört und willst wissen, was dahintersteckt? Dann ist dieser Beitrag genau das Richtige für dich!
Hier bei statworx nutzen und schreiben wir täglich APIs. Für diesen Artikel habe ich aufgeschrieben, wie du deine eigene API für ein von dir erstelltes Machine-Learning-Modell bauen kannst – und was einige der wichtigsten Konzepte wie REST bedeuten. Nach dem Lesen dieses kurzen Artikels wirst du wissen, wie man innerhalb eines Python-Programms Anfragen an deine API stellt. Viel Spaß beim Lesen und Lernen!
Was ist eine API?
API steht für Application Programming Interface (Programmierschnittstelle). Sie erlaubt es Nutzer*innen, mit der zugrunde liegenden Funktionalität eines Codes über eine Schnittstelle zu interagieren. Es gibt eine Vielzahl von APIs, und die Chancen stehen gut, dass du schon einmal von der Art API gehört hast, um die es in diesem Blogpost geht: die Web-API.
Dieser spezielle Typ von API erlaubt es Nutzerinnen, über das Internet mit Funktionalitäten zu interagieren. In unserem Beispiel bauen wir eine API, die Vorhersagen über unser trainiertes Machine-Learning-Modell bereitstellt. In einer realen Anwendung könnte diese API in eine Art Anwendung eingebettet sein, in der eine Nutzer*in neue Daten eingibt und im Gegenzug eine Vorhersage erhält. APIs sind sehr flexibel und leicht zu warten, was sie zu einem praktischen Werkzeug im Alltag von Data Scientists oder Data Engineers macht.
Ein Beispiel für eine öffentlich verfügbare Machine-Learning-API ist Time Door. Sie stellt Tools für Zeitreihenanalysen bereit, die du in deine Anwendungen integrieren kannst. APIs können außerdem dazu verwendet werden, Daten allgemein bereitzustellen – nicht nur Machine-Learning-Modelle.
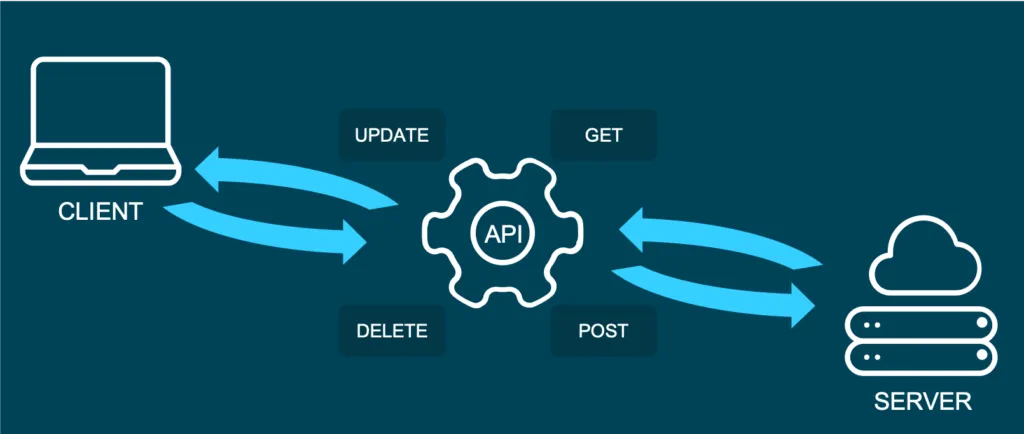
Und was ist REST?
Representational State Transfer (oder REST) ist ein Ansatz, der eine bestimmte Art der Kommunikation über Webdienste beschreibt. Wenn man einige der REST-Best Practices verwendet, um eine API zu implementieren, spricht man von einer „REST API“. Es gibt auch andere Ansätze zur Web-Kommunikation (wie das Simple Object Access Protocol: SOAP), aber REST benötigt im Allgemeinen weniger Bandbreite, was es vorzugswürdig macht, um Machine-Learning-Modelle bereitzustellen.
In einer REST API sind die vier wichtigsten Arten von Anfragen:
- GET
- PUT
- POST
- DELETE
Für unsere kleine Machine-Learning-Anwendung konzentrieren wir uns hauptsächlich auf die POST-Methode, da sie sehr vielseitig ist und viele Clients keine GET-Methoden senden können.
Es ist wichtig zu erwähnen, dass APIs zustandslos (stateless) sind. Das bedeutet, dass sie die Eingaben, die du während eines API-Aufrufs gibst, nicht speichern – sie speichern also keinen Zustand. Das ist bedeutsam, weil es ermöglicht, dass mehrere Nutzer*innen und Anwendungen die API gleichzeitig nutzen können, ohne dass sich ihre Anfragen gegenseitig beeinflussen.
Das Modell
Für diesen How-To-Artikel habe ich mich entschieden, ein Machine-Learning-Modell bereitzustellen, das auf dem berühmten Iris-Datensatz trainiert wurde. Wenn du den Datensatz nicht kennst, kannst du ihn dir hier anschauen. Beim Erstellen von Vorhersagen haben wir vier Eingabeparameter: Kelchblattlänge (sepal length), Kelchblattbreite (sepal width), Blütenblattlänge (petal length) und schließlich Blütenblattbreite (petal width). Diese helfen dabei zu entscheiden, um welchen Typ der Irisblume es sich handelt.
Für dieses Beispiel habe ich die scikit-learn-Implementierung eines einfachen KNN-Algorithmus (K-nearest neighbor) verwendet, um den Typ der Iris vorherzusagen:
# model.py
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.externals import joblib
import numpy as np
def train(X,y):
# train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
knn = KNeighborsClassifier(n_neighbors=1)
# fit the model
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
acc = accuracy_score(y_test, preds)
print(f'Successfully trained model with an accuracy of {acc:.2f}')
return knn
if __name__ == '__main__':
iris_data = datasets.load_iris()
X = iris_data['data']
y = iris_data['target']
labels = {0 : 'iris-setosa',
1 : 'iris-versicolor',
2 : 'iris-virginica'}
# rename integer labels to actual flower names
y = np.vectorize(labels.__getitem__)(y)
mdl = train(X,y)
# serialize model
joblib.dump(mdl, 'iris.mdl')
Wie du sehen kannst, habe ich das Modell mit 70 % der Daten trainiert und anschließend mit 30 % Out-of-Sample-Testdaten validiert. Nachdem das Modelltraining abgeschlossen ist, serialisiere ich das Modell mit der Bibliothek joblib. Joblib ist im Grunde eine Alternative zu pickle, die die Persistenz von scikit-Estimatoren erhält, welche eine große Anzahl von Numpy-Arrays enthalten (wie z. B. das KNN-Modell, das alle Trainingsdaten beinhaltet). Nachdem die Datei als Joblib-Datei gespeichert wurde (die Dateiendung spielt dabei übrigens keine Rolle, also nicht verwirren lassen, wenn manche sie .model oder .joblib nennen), kann sie später in unserer Anwendung wieder geladen werden.
Die API mit Python und Flask
Um aus unserem trainierten Modell eine API zu bauen, verwenden wir das beliebte Webentwicklungs-Framework Flask sowie Flask-RESTful. Außerdem importieren wir joblib zum Laden unseres Modells und numpy zur Verarbeitung der Eingabe- und Ausgabedaten.
In einem neuen Skript, nämlich app.py, können wir nun eine Instanz einer Flask-App und einer API einrichten und das trainierte Modell laden (dies setzt voraus, dass das Modell im selben Verzeichnis wie das Skript gespeichert ist):
from flask import Flask
from flask_restful import Api, Resource, reqparse
from sklearn.externals import joblib
import numpy as np
APP = Flask(__name__)
API = Api(APP)
IRIS_MODEL = joblib.load('iris.mdl')
Der zweite Schritt besteht nun darin, eine Klasse zu erstellen, die für unsere Vorhersage verantwortlich ist. Diese Klasse wird eine Kindklasse der Flask-RESTful-Klasse Resource sein. Dadurch erbt unsere Klasse die entsprechenden Klassenmethoden und ermöglicht es Flask, die Arbeit hinter deiner API zu übernehmen, ohne dass alles selbst implementiert werden muss.
In dieser Klasse können wir auch die Methoden (REST-Anfragen) definieren, über die wir zuvor gesprochen haben. Jetzt implementieren wir also eine Klasse Predict mit einer .post()-Methode, wie wir sie vorher erwähnt haben.
Die post-Methode erlaubt es dem Nutzer, zusammen mit den Standardparametern der API auch einen Body zu senden. In der Regel möchten wir, dass dieser Body im JSON-Format vorliegt. Da dieser Body nicht direkt über die URL übermittelt wird, sondern als Text, müssen wir diesen Text parsen und die Argumente auslesen. Das flask_restful-Paket stellt dafür die Klasse RequestParser zur Verfügung. Wir fügen einfach alle Argumente, die wir im JSON-Eingang erwarten, mit der Methode .add_argument() hinzu und parsen sie anschließend in ein Dictionary. Dieses konvertieren wir dann in ein Array und geben die Vorhersage unseres Modells als JSON zurück.
class Predict(Resource):
@staticmethod
def post():
parser = reqparse.RequestParser()
parser.add_argument('petal_length')
parser.add_argument('petal_width')
parser.add_argument('sepal_length')
parser.add_argument('sepal_width')
args = parser.parse_args() # creates dict
X_new = np.fromiter(args.values(), dtype=float) # convert input to array
out = {'Prediction': IRIS_MODEL.predict([X_new])[0]}
return out, 200
Du fragst dich vielleicht, was es mit der 200 auf sich hat, die wir am Ende zurückgeben: Bei APIs werden beim Senden von Anfragen einige HTTP-Statuscodes angezeigt. Ihr kennt sicher alle den berühmten 404-Code – Seite nicht gefunden. 200 bedeutet einfach, dass die Anfrage erfolgreich empfangen wurde. Man signalisiert dem Benutzer damit, dass alles wie geplant funktioniert hat.
Am Ende musst du nur noch die Klasse Predict als Ressource zur API hinzufügen und die Hauptfunktion schreiben:
API.add_resource(Predict, '/predict')
if __name__ == '__main__':
APP.run(debug=True, port='1080')
Das '/predict', das du im Aufruf von .add_resource() siehst, ist der sogenannte API-Endpunkt. Über diesen Endpunkt können Nutzer deiner API darauf zugreifen und (in diesem Fall) POST-Anfragen senden. Wenn du keinen Port definierst, wird standardmäßig Port 5000 verwendet.
Hier siehst du den gesamten Code der App noch einmal:
# app.py
from flask import Flask
from flask_restful import Api, Resource, reqparse
from sklearn.externals import joblib
import numpy as np
APP = Flask(__name__)
API = Api(APP)
IRIS_MODEL = joblib.load('iris.mdl')
class Predict(Resource):
@staticmethod
def post():
parser = reqparse.RequestParser()
parser.add_argument('petal_length')
parser.add_argument('petal_width')
parser.add_argument('sepal_length')
parser.add_argument('sepal_width')
args = parser.parse_args() # creates dict
X_new = np.fromiter(args.values(), dtype=float) # convert input to array
out = {'Prediction': IRIS_MODEL.predict([X_new])[0]}
return out, 200
API.add_resource(Predict, '/predict')
if __name__ == '__main__':
APP.run(debug=True, port='1080')
API starten
Jetzt ist es an der Zeit, unsere API auszuführen und zu testen!
Um die App zu starten, öffne einfach ein Terminal im gleichen Verzeichnis wie dein app.py-Skript und führe folgenden Befehl aus:
python run app.py
Du solltest jetzt eine Benachrichtigung erhalten, dass die API auf deinem Localhost unter dem von dir definierten Port läuft. Es gibt verschiedene Möglichkeiten, auf die API zuzugreifen, sobald sie läuft. Zum Debuggen und Testen verwende ich normalerweise Tools wie Postman. Wir können aber auch aus einer Python-Anwendung auf die API zugreifen – so wie es auch ein anderer Nutzer tun würde, um dein Modell in seinem Code zu verwenden.
Wir nutzen dafür das requests-Modul, indem wir zuerst die URL definieren, auf die zugegriffen werden soll, und den Body, der mit unserer HTTP-Anfrage gesendet wird.
import requests
url = 'http://127.0.0.1:1080/predict' # localhost and the defined port + endpoint
body = {
"petal_length": 2,
"sepal_length": 2,
"petal_width": 0.5,
"sepal_width": 3
}
response = requests.post(url, data=body)
response.json()
Die Ausgabe sollte in etwa so aussehen:
Out[1]: {'Prediction': 'iris-versicolor'}
So einfach ist es, einen API-Aufruf in deinen Python-Code zu integrieren! Bitte beachte, dass diese API nur auf deinem lokalen Rechner läuft. Du müsstest die API auf einem Live-Server (z. B. bei AWS) bereitstellen, damit andere darauf zugreifen können.
Fazit
In diesem Blogartikel hast du einen kurzen Überblick darüber bekommen, wie man eine REST-API erstellt, um ein Machine-Learning-Modell über eine Webschnittstelle bereitzustellen. Außerdem weißt du jetzt, wie man einfache API-Anfragen in Python-Code integriert. Vielleicht möchtest du als nächsten Schritt deine APIs absichern? Falls du interessiert bist zu lernen, wie man eine API mit R erstellt, solltest du dir diesen Beitrag anschauen. Ich hoffe, dieser Artikel hat dir einen soliden Einstieg in das Thema gegeben – und dass du bald deine eigenen APIs entwickelst. Viel Spaß beim Coden!


