Web Scraping 101 in Python mit Requests & BeautifulSoup


Intro
Informationen sind überall im Internet zu finden. Leider ist es schwierig, programmatisch auf einige davon zuzugreifen. Zwar bieten viele Websites eine API an, doch sind diese oft teuer oder haben sehr strenge Tarifbeschränkungen, selbst wenn Sie an einem Open-Source- und/oder nicht kommerziellen Projekt oder Produkt arbeiten.
Hier kann Web Scraping ins Spiel kommen. Wikipedia definiert Web Scraping wie folgt:
Web scraping, web harvesting, or web data extraction data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol [HTTP], or through a web browser.
“Web scraping” wikipedia.org
In der Praxis umfasst Web Scraping jede Methode, die es Programmierer:innen ermöglicht, programmatisch und damit (halb-)automatisch auf den Inhalt einer Website zuzugreifen.
Hier sind drei Ansätze (d.h. Python-Bibliotheken) für Web Scraping, die zu den beliebtesten gehören:
- Senden einer HTTP-Anfrage, üblicherweise über Requests, an eine Webseite und anschließendes Parsen des zurückgegebenen HTML (üblicherweise mit BeautifulSoup), um auf die gewünschten Informationen zuzugreifen. Typischer Use Case: Standard-Web-Scraping-Problem, siehe Fallstudie in diesem Beitrag.
- Verwendung von Tools, die normalerweise für automatisierte Softwaretests verwendet werden, hauptsächlich Selenium, um programmatisch auf den Inhalt einer Website zuzugreifen. Typischer Anwendungsfall: Websites, die Javascript verwenden oder anderweitig nicht direkt über HTML zugänglich sind.
- Scrapy, das eher als allgemeines Web-Scraping-Framework betrachtet werden kann, mit dem Spiders erstellt und Daten von verschiedenen Websites gescraped werden können, wobei Wiederholungen minimiert werden. Typischer Anwendungsfall: Scraping von Amazon-Rezensionen.
Obwohl man Daten auch mit jeder anderen Programmiersprache scrapen könnte, wird Python aufgrund seiner einfachen Syntax und der großen Vielfalt an Bibliotheken, die für Scraping-Zwecke in Python zur Verfügung stehen, am häufigsten verwendet.
Nach dieser kurzen Einführung geht es in diesem Beitrag um einige ethische Aspekte des Web-Scraping, gefolgt von allgemeinen Informationen über die Bibliotheken, die in diesem Beitrag verwendet werden. Schließlich wird alles, was wir bisher gelernt haben, auf eine Fallstudie angewandt, in der wir die Daten aller Unternehmen im Portfolio von Sequoia Capital, einer der bekanntesten VC-Firmen in den USA, erfassen werden. Nach einer Überprüfung der Website und der robots.txt scheint das Scraping des Sequoia-Portfolios erlaubt zu sein; wie ich das herausgefunden habe, erfahren Sie im Abschnitt über robots.txt und in der Fallstudie.
Im Rahmen dieses Blogbeitrags können wir uns nur eine der drei oben genannten Methoden ansehen. Da die Standardkombination von Requests + BeautifulSoup im Allgemeinen am flexibelsten und am einfachsten zu handhaben ist, werden wir sie in diesem Beitrag ausprobieren. Beachten Sie, dass die oben genannten Tools sich nicht gegenseitig ausschließen; Sie könnten z.B. einen HTML-Text mit Scrapy oder Selenium erhalten und ihn dann mit BeautifulSoup parsen.
Web Scraping Ethik
Zwei Faktoren, die bei der Durchführung von Web-Scraping äußerst wichtig sind, sind Ethik und Rechtmäßigkeit. Ich bin kein Jurist, und die spezifischen Gesetze variieren je nach Land beträchtlich, aber im Allgemeinen fällt Web Scraping in eine Grauzone, d.h. es ist in der Regel nicht streng verboten, aber auch nicht generell legal (d.h. nicht unter allen Umständen legal). Das hängt in der Regel von den Daten ab, die Sie auslesen.
Im Allgemeinen können Websites Ihre IP-Adresse sperren, wenn Sie etwas auslesen, was nicht erwünscht ist. Wir hier bei statworx dulden keine illegalen Aktivitäten und empfehlen Ihnen, immer ausdrücklich nachzufragen, wenn Sie sich nicht sicher sind, ob das Scrapen von Daten zulässig ist. Hierfür ist der folgende Abschnitt sehr nützlich.
robots.txt verstehen
Der robot exclusion standard ist ein Protokoll, das von Web-Crawlern (z. B. von den großen Suchmaschinen, d. h. hauptsächlich Google) ausdrücklich gelesen wird und ihnen mitteilt, welche Teile einer Website vom Crawler indiziert werden dürfen und welche nicht. Im Allgemeinen sind Crawler oder Scraper nicht gezwungen, die in einer robots.txt festgelegten Einschränkungen zu befolgen, aber es wäre höchst unmoralisch (und potenziell illegal), dies nicht zu tun.
Das folgende Beispiel zeigt eine robots.txt-Datei von Hackernews, einem sozialen Newsfeed, der von YCombinator betrieben wird und bei vielen Menschen in Startups beliebt ist.
In der robots.txt von Hackernews ist festgelegt, dass alle User Agents (daher der Platzhalter *) auf alle URLs zugreifen dürfen, mit Ausnahme der URLs, die ausdrücklich verboten sind. Da nur bestimmte URLs verboten sind, ist damit implizit alles andere erlaubt. Eine Alternative wäre, alles auszuschließen und dann explizit nur bestimmte URLs anzugeben, auf die Crawler oder andere Bots zugreifen können.
Beachten Sie auch die Crawl-Verzögerung von 30 Sekunden, was bedeutet, dass jeder Bot nur eine Anfrage alle 30 Sekunden senden sollte. Es ist im Allgemeinen eine gute Praxis, Ihren Crawler oder Scraper in regelmäßigen (ziemlich großen) Abständen schlafen zu lassen, da zu viele Anfragen Websites zum Absturz bringen können, selbst wenn sie von menschlichen Nutzenden stammen.
Wenn man sich die robots.txt von Hackernews ansieht, ist es auch ziemlich logisch, warum sie einige bestimmte URLs nicht zulassen: Sie wollen nicht, dass Bots sich als User ausgeben, indem sie z.B. Themen einreichen, abstimmen oder antworten. Alles andere (z.B. das Scrapen von Themen und deren Inhalten) ist erlaubt, solange die Crawl-Verzögerung eingehalten wird. Das macht Sinn, wenn man die Aufgabe von Hackernews bedenkt, die hauptsächlich darin besteht, Informationen zu verbreiten. Übrigens bieten sie auch eine API an, die recht einfach zu benutzen ist. Wenn Sie also wirklich Informationen von HN benötigen, würden Sie einfach ihre API benutzen.
In der Gist unten finden Sie die robots.txt von Google, die (natürlich) viel restriktiver ist als die von Hackernews. Schauen Sie selbst nach, denn sie ist viel länger als unten gezeigt, aber im Wesentlichen ist es Bots nicht erlaubt, eine Suche bei Google durchzuführen, wie in den ersten beiden Zeilen angegeben. Nur bestimmte Teile einer Suche sind erlaubt, wie "about" und "static". Wenn eine allgemeine URL verboten ist, wird sie überschrieben, wenn eine spezifischere URL erlaubt wird (z.B. wird das Verbot von /search durch das spezifischere Zulassen von /search/about überschrieben).
User-Agent: *
Disallow: /x?
Disallow: /vote?
Disallow: /reply?
Disallow: /submitted?
Disallow: /submitlink?
Disallow: /threads?
Crawl-delay: 30
Im Folgenden werden wir einen Blick auf die spezifischen Python-Pakete werfen, die im Rahmen dieser Fallstudie verwendet werden, nämlich Requests und BeautifulSoup.
Requests
Requests ist eine Python-Bibliothek, mit der man auf einfache Weise HTTP-Anfragen stellen kann. Im Allgemeinen hat Requests zwei Hauptanwendungsfälle: Anfragen an eine API und das Abrufen von Roh-HTML-Inhalten von Websites (d.h. Scraping).
Wenn Sie eine Anfrage senden, sollten Sie immer den Statuscode überprüfen (insbesondere beim Scraping), um sicherzustellen, dass Ihre Anfrage erfolgreich bearbeitet wurde. Eine nützliche Übersicht über die Statuscodes finden Sie hier. Im Idealfall sollte Ihr Statuscode 200 sein (was bedeutet, dass Ihre Anfrage erfolgreich war). Der Statuscode kann Ihnen auch Auskunft darüber geben, warum Ihre Anfrage nicht zugestellt werden konnte, z.B. weil Sie zu viele Anfragen gesendet haben (Statuscode 429) oder die berüchtigte Seite nicht gefunden wurde (Statuscode 404).
Use Case 1: API Requests
Die obige Gist zeigt eine einfache API-Anfrage, die an die NYT-API gerichtet ist. Wenn Sie diese Anfrage auf Ihrem eigenen Rechner replizieren möchten, müssen Sie zunächst ein Konto auf der Seite NYT Dev erstellen und dann den erhaltenen Schlüssel der Konstante KEY zuweisen.
Die Daten, die Sie von einer REST-API erhalten, liegen im JSON-Format vor, das in Python als eine dict-Datenstruktur dargestellt wird. Daher müssen Sie diese Daten noch ein wenig "parsen", bevor Sie sie in einem Tabellenformat haben, das z.B. in einer CSV-Datei dargestellt werden kann, d.h. Sie müssen auswählen, welche Daten für Sie relevant sind.
Use Case 2: Scraping
Die folgenden Zeilen fragen den HTML-Code der Wikipedia-Seite zum Thema Web Scraping ab. Das Statuscode-Attribut des Response-Objekts enthält den mit der Anfrage verbundenen Statuscode.
Nach dem Ausführen dieser Zeilen haben Sie immer noch nur den rohen HTML-Code mit allen enthaltenen Tags. Dies ist in der Regel nicht sehr nützlich, da wir beim Scraping mit Requests meist nur nach bestimmten Informationen und Text suchen, da menschliche Lesende nicht an HTML-Tags oder anderen Markups interessiert sind. An dieser Stelle kommt BeautifulSoup ins Spiel.
BeautifulSoup
BeautifulSoup ist eine Python-Bibliothek, die zum Parsen von Dokumenten (d.h. hauptsächlich HTML- oder XML-Dateien) verwendet wird. Die Verwendung von Requests, um den HTML-Code einer Seite zu erhalten, und das anschließende Parsen der gesuchten Informationen mit BeautifulSoup aus dem rohen HTML-Code ist der Quasi-Standard für Web-Scraping, der von Python-Programmierern häufig für einfache Aufgaben verwendet wird.
Um auf die obige Gist zurückzukommen, würde das Parsen des von Wikipedia zurückgegebenen HTML-Rohmaterials für die Web-Scraping-Site ähnlich wie unten aussehen.
In diesem Fall extrahiert BeautifulSoup alle Überschriften, d.h. alle Überschriften im Abschnitt "Inhalt" oben auf der Seite. Probieren Sie es selbst aus!
Wie Sie unten sehen, können Sie das Klassenattribut eines HTML-Elements leicht mit dem Inspektor eines beliebigen Webbrowsers finden.
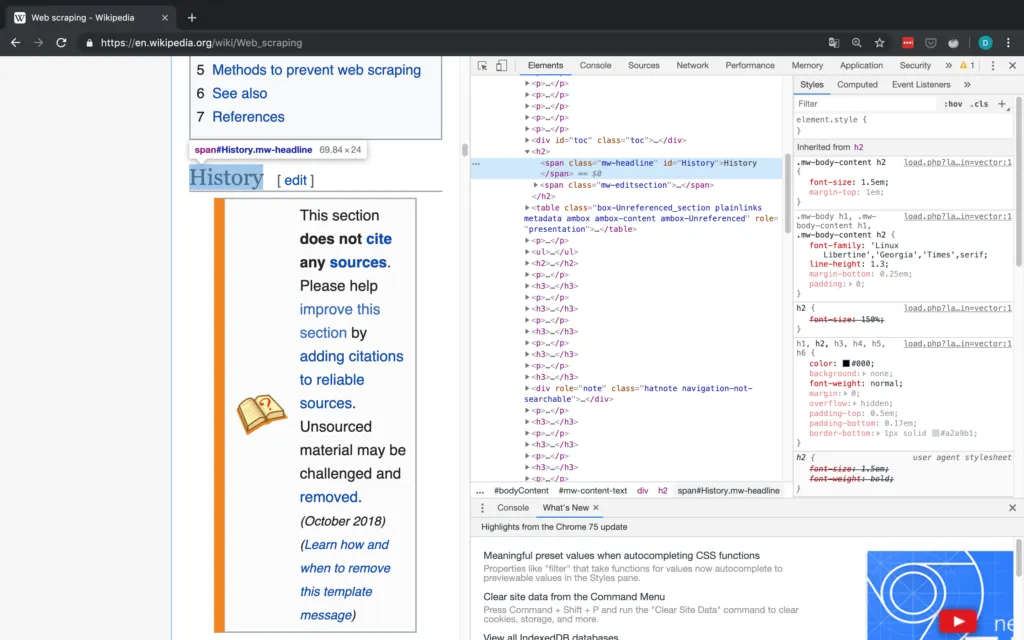
Diese Art des Abgleichs ist (meiner Meinung nach) eine der einfachsten Möglichkeiten, BeautifulSoup zu verwenden: Sie geben einfach das HTML-Tag (in diesem Fall span) und ein anderes Attribut des Inhalts an, das Sie finden wollen (in diesem Fall ist dieses andere Attribut class). Auf diese Weise können Sie beliebige Abschnitte fast jeder Webseite abgleichen. Für kompliziertere Übereinstimmungen können Sie auch reguläre Ausdrücke (REGEX) verwenden.
Sobald Sie die Elemente haben, aus denen Sie den Text extrahieren möchten, können Sie auf den Text zugreifen, indem Sie deren Textattribut auslesen.
Inspector
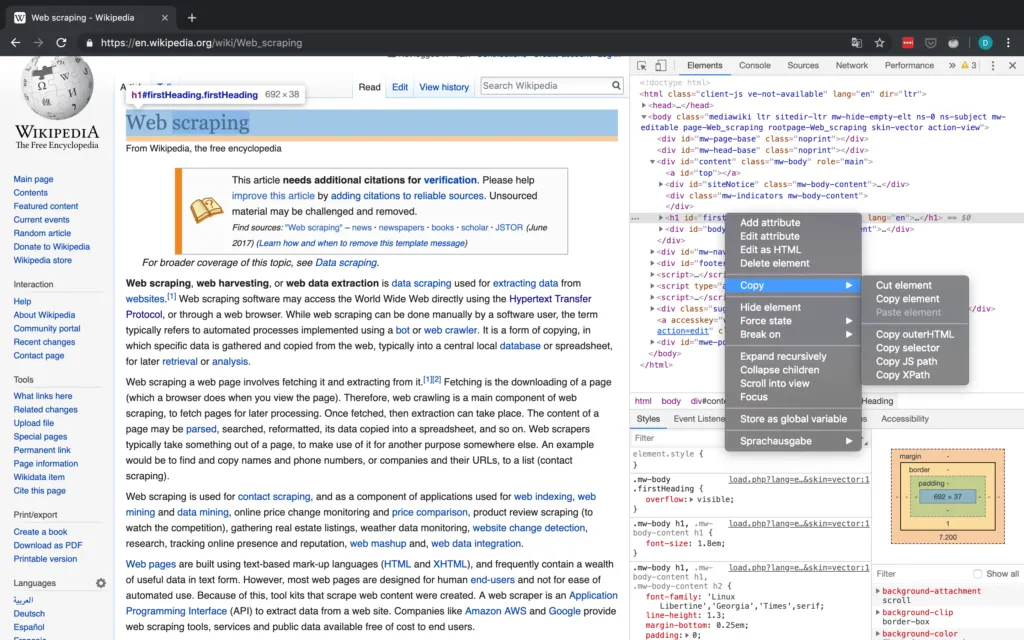
Als kurzer Exkurs ist es wichtig, eine Einführung in die Dev-Tools in Chrome zu geben (sie sind in jedem Browser verfügbar, ich habe mich nur für Chrome entschieden), mit denen Sie den Inspektor verwenden können, der Ihnen Zugriff auf den HTML-Code einer Website gibt und mit dem Sie auch Attribute wie den XPath- und CSS-Selektor kopieren können. All dies kann beim Scraping-Prozess hilfreich oder sogar notwendig sein (vor allem bei der Verwendung von Selenium). Der Arbeitsablauf in der Fallstudie sollte Ihnen einen grundlegenden Eindruck davon vermitteln, wie Sie mit dem Inspector arbeiten können. Ausführlichere Informationen über den Inspector finden Sie auf der oben verlinkten offiziellen Google-Website, die zahlreiche Informationen enthält.
Abbildung 2 zeigt die grundlegende Schnittstelle des Inspektors in Chrome.
Fallstudie: Sequoia Capital
Eigentlich wollte ich diese Fallstudie zunächst mit der New York Times durchführen, da sie über eine API verfügt und somit die von der API erhaltenen Ergebnisse mit den Ergebnissen des Scrapings hätten verglichen werden können. Leider haben die meisten Nachrichtenorganisationen sehr restriktive robots.txt, die insbesondere die Suche nach Artikeln nicht zulassen. Daher beschloss ich, das Portfolio einer der großen VC-Firmen in den USA, Sequoia, zu scrapen, da deren robots.txt permissiv ist und ich außerdem denke, dass Startups und die Risikokapital-Szene im Allgemeinen sehr interessant sind.
Robots.txt
Werfen wir zunächst einen Blick auf die robots.txt von Sequoia:
Glücklicherweise erlauben sie verschiedene Zugriffsarten - mit Ausnahme von drei URLs, was für unsere Zwecke ausreichend ist. Wir werden dennoch eine Crawl-Verzögerung von 15-30 Sekunden zwischen den einzelnen Anfragen einbauen.
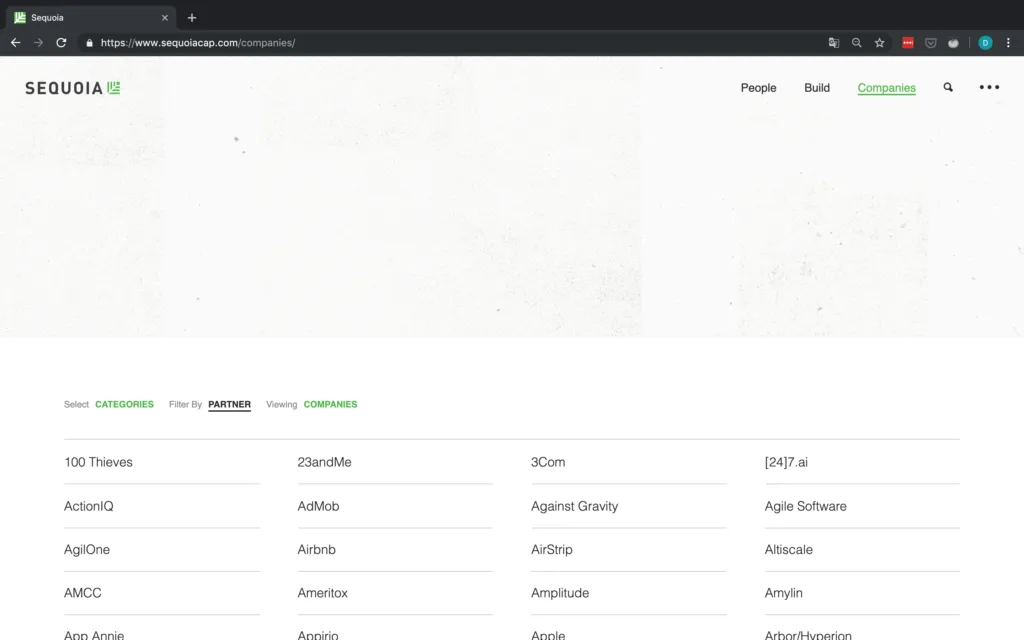
Als Nächstes wollen wir uns die Daten ansehen, die wir abrufen wollen. Wir interessieren uns für das Portfolio von Sequoia, also ist https://www.sequoiacap.com/companies/ die URL, die wir suchen.

Die Unternehmen sind übersichtlich in einem Raster angeordnet, so dass sie recht einfach zu scrapen sind. Wenn Sie auf die Seite klicken, werden die Details zu jedem Unternehmen angezeigt. Beachten Sie auch, wie sich die URL in Abbildung 4 ändert, wenn Sie auf ein Unternehmen klicken! Dies ist besonders für Anfragen wichtig.
Ziel ist es, die folgenden grundlegenden Informationen über jedes Unternehmen zu sammeln und sie als CSV-Datei auszugeben:
- Name des Unternehmens
- URL des Unternehmens
- Beschreibung des Unternehmens
- Meilensteine
- Team
- Partner
Wenn eine dieser Informationen für ein Unternehmen nicht verfügbar ist, fügen wir stattdessen einfach die Zeichenfolge "NA" ein.
Zeit, mit der Inspektion zu beginnen!
Scraping Prozess
Name des Unternehmens
Wenn man sich das Raster ansieht, sieht es so aus, als ob die Informationen über jedes Unternehmen in einem div-Tag mit der Klasse companies _company js-company enthalten sind. Wir sollten also in der Lage sein, mit BeautifulSoup nach dieser Kombination zu suchen.
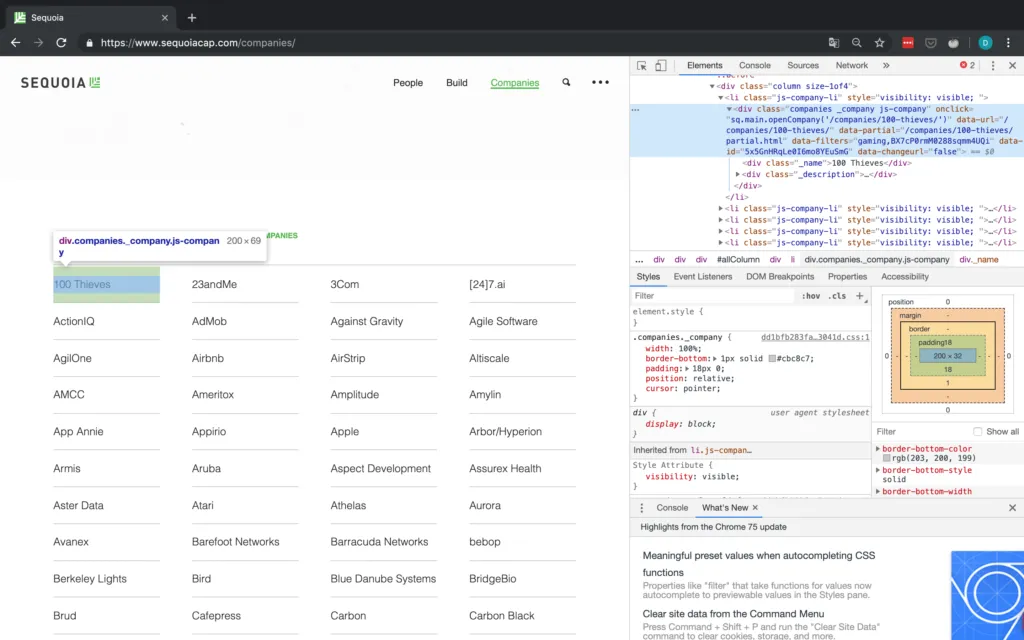
Damit fehlen aber immer noch alle anderen Informationen, d.h. wir müssen irgendwie auf die Detailseiten der einzelnen Unternehmen zugreifen. In Abbildung 5 oben hat jedes Unternehmen ein Attribut namens "data-url". Für 100 Thieves zum Beispiel hat onclick den Wert /companies/100-thieves/. Das ist genau das, was wir brauchen!
Jetzt müssen wir nur noch dieses data-URL-Attribut für jedes Unternehmen an die Basis-URL anhängen (die einfach https://www.sequoiacap.com/ ist), und schon können wir eine weitere Anfrage senden, um die Detailseite jedes Unternehmens aufzurufen.
Schreiben wir also etwas Code, um zunächst den Firmennamen zu ermitteln und dann eine weitere Anfrage an die Detailseite jedes Unternehmens zu senden: Ich werde hier Code schreiben, der mit Text durchsetzt ist. Ein vollständiges Skript finden Sie in meinem Github.
Zunächst kümmern wir uns um alle Importe und richten alle Variablen ein, die wir benötigen. Wir senden auch unsere erste Anfrage an die Basis-URL, die das Raster mit allen Unternehmen enthält und einen BeautifulSoup-Parser instanziiert.
Nachdem wir uns um die grundlegende Buchführung gekümmert und das Wörterbuch eingerichtet haben, in dem wir die Daten auslesen wollen, können wir mit dem eigentlichen Auslesen beginnen, indem wir zunächst die in Abbildung 5 gezeigte Klasse analysieren. Wie in Abbildung 5 zu sehen ist, müssen wir, nachdem wir das "div"-Tag mit der passenden Klasse ausgewählt haben, zu dessen erstem "div"-Unterelement gehen und dann dessen Text auswählen, der dann den Namen des Unternehmens enthält.
Auf der Detailseite haben wir im Grunde alles, was wir wollten. Da wir bereits den Namen des Unternehmens haben, fehlen uns nur noch URL, Beschreibung, Meilensteine, Team und der jeweilige Partner von Sequoia.
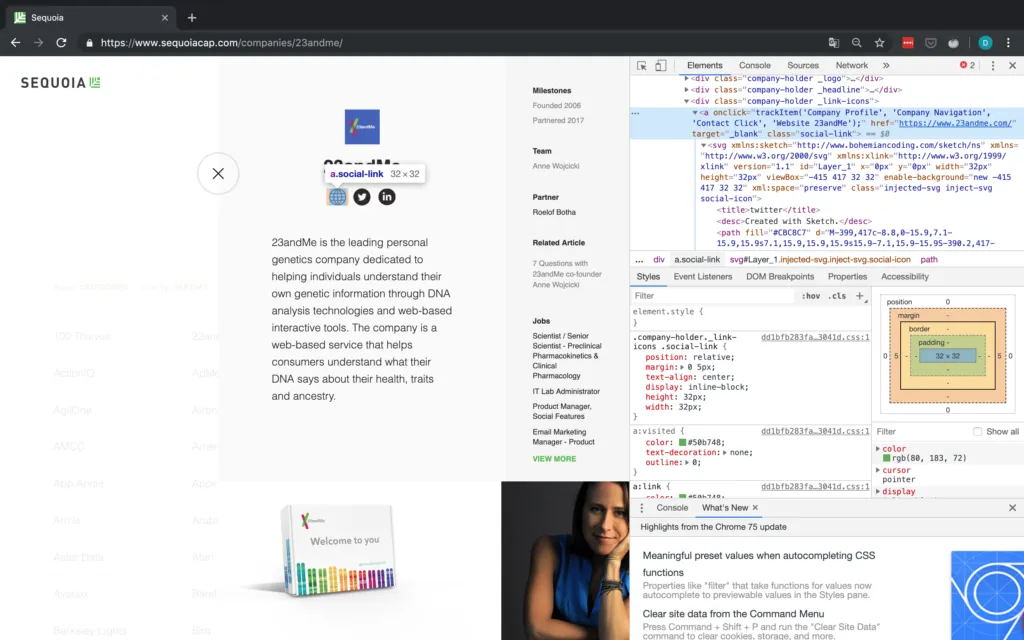
URL des Unternehmens
Für die URL sollten wir nur in der Lage sein, Elemente anhand ihrer Klasse zu finden und dann das erste Element auszuwählen, da es scheint, dass die Website immer der erste soziale Link ist. Die Inspector-Ansicht ist in Abbildung 6 zu sehen.
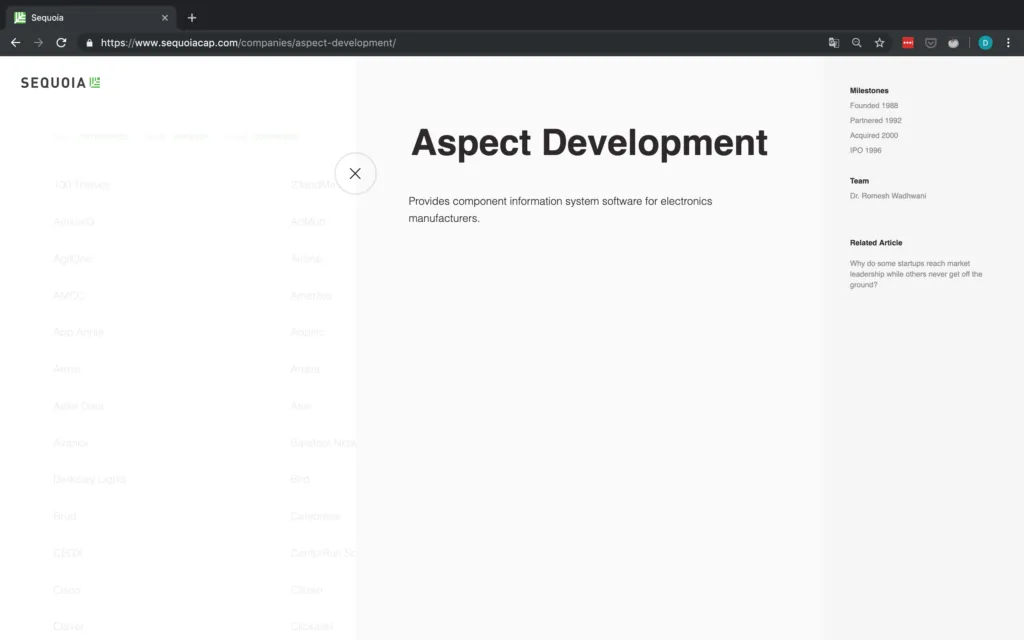
Aber halt - was ist, wenn es keine sozialen Links gibt oder die Website des Unternehmens nicht angegeben ist? Für den Fall, dass die Website nicht angegeben wird, wohl aber eine Social-Media-Seite, betrachten wir diesen Social-Media-Link einfach als die De-facto-Website des Unternehmens. Wenn überhaupt keine sozialen Links vorhanden sind, müssen wir einen NA anhängen. Aus diesem Grund überprüfen wir explizit die Anzahl der gefundenen Objekte, da wir nicht auf das href-Attribut eines Tags zugreifen können, das nicht existiert. Ein Beispiel für ein Unternehmen ohne URL ist in Abbildung 7 dargestellt.
Beschreibung des Unternehmens
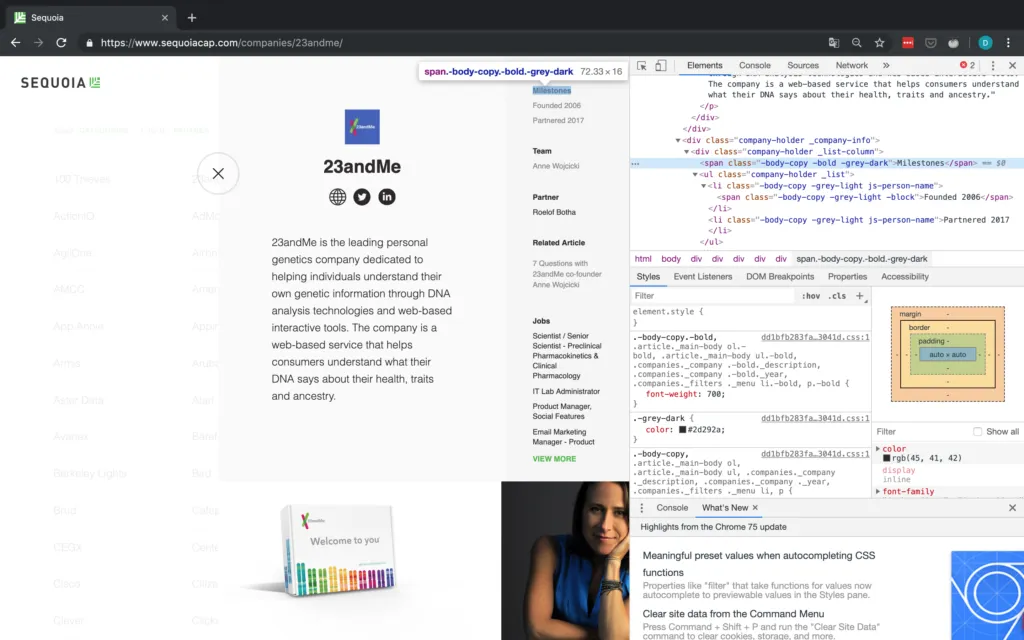
Die letzten drei Elemente befinden sich alle in derselben Struktur und können daher auf dieselbe Weise aufgerufen werden. Wir werden einfach den Text des übergeordneten Elements abgleichen und uns dann von dort aus nach unten vorarbeiten.
Da die spezifischen Textelemente keine guten Erkennungsmerkmale aufweisen, wird der Text des übergeordneten Elements abgeglichen. Sobald wir den Text haben, gehen wir zwei Ebenen nach oben, indem wir das Attribut parent verwenden. Dies bringt uns zum div-Tag, das zu dieser spezifischen Kategorie gehört (z.B. Meilensteine oder Team). Nun müssen wir nur noch zum ul-Tag hinuntergehen, das den eigentlichen Text enthält, an dem wir interessiert sind, und seinen Text abrufen.
Ein Problem bei der Verwendung der Textübereinstimmung ist die Tatsache, dass nur exakte Übereinstimmungen gefunden werden. Dies ist in Fällen von Bedeutung, in denen die gesuchte Zeichenfolge auf verschiedenen Seiten leicht unterschiedlich sein kann. Wie Sie in Abbildung 10 sehen können, gilt dies für unsere Fallstudie hier für den Text Partner. Wenn einem Unternehmen mehr als ein Sequoia-Partner zugewiesen ist, lautet die Zeichenfolge "Partners" statt "Partner". Daher verwenden wir bei der Suche nach dem Element "Partner" ein REGEX, um dies zu umgehen.

Zu guter Letzt ist nicht garantiert, dass alle gewünschten Elemente (d.h. Meilensteine, Team und Partner) tatsächlich für jedes Unternehmen verfügbar sind. Bevor wir also ein Element auswählen, suchen wir zunächst alle Elemente, die mit der Zeichenfolge übereinstimmen, und überprüfen dann die Länge. Wenn es keine übereinstimmenden Elemente gibt, fügen wir NA an, andernfalls erhalten wir die erforderlichen Informationen.
Für einen Partner gibt es immer ein Element, so dass wir davon ausgehen, dass keine Partnerinformationen verfügbar sind, wenn es ein oder weniger Elemente gibt. Ich glaube, der Grund dafür, dass immer ein Element mit einem Partner übereinstimmt, ist die in Abbildung 11 gezeigte Option "Filter nach Partner". Wie Sie sehen, ist beim Scraping oft eine Iteration erforderlich, um mögliche Probleme mit Ihrem Skript zu finden.
Auf die Festplatte schreiben
Zum Abschluss fügen wir alle Informationen zu einem Unternehmen an die Liste an, zu der es in unserem Wörterbuch gehört. Dann konvertieren wir dieses Wörterbuch in einen Pandas DataFrame, bevor wir es auf die Festplatte schreiben.
Geschafft! Wir haben soeben alle Portfolio-Unternehmen von Seqouia und Informationen über sie gesammelt.
* Nun, zumindest alle auf ihrer Website, ich glaube, sie haben ihre eigenen Websites für z.B. Indien und Israel.
Werfen wir einen Blick auf die Daten, die wir gerade gescraped haben:
Sieht gut aus! Wir haben insgesamt 506 Unternehmen erfasst, und auch die Datenqualität sieht wirklich gut aus. Das Einzige, was mir aufgefallen ist, ist, dass einige Unternehmen zwar einen Social Link haben, dieser aber nirgendwo hinführt. In Abbildung 12 sehen Sie ein Beispiel dafür bei Pixelworks. Das Problem ist, dass Pixelworks einen Social Link hat, aber dieser Social Link enthält eigentlich keine URL (das href-Ziel ist leer) und verweist einfach auf das Sequoia-Portfolio.
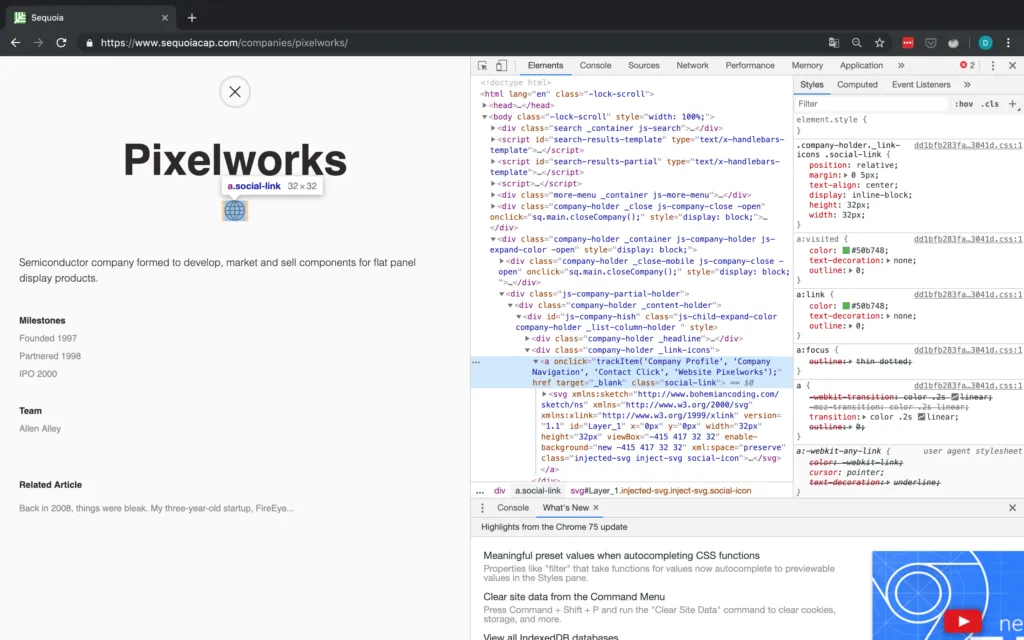
Ich habe dem Skript Code hinzugefügt, um die Leerzeichen durch NAs zu ersetzen, habe aber die Daten so belassen, wie sie sind, um diesen Punkt zu illustrieren.
Fazit
Mit diesem Blogbeitrag wollte ich Ihnen eine gute Einführung in das Web-Scraping im Allgemeinen und speziell in die Verwendung von Requests und BeautifulSoup geben. Jetzt können Sie es in der freien Wildbahn einsetzen, indem Sie Daten auslesen, die für Sie oder jemanden, den Sie kennen, von Nutzen sein können. Achten Sie aber immer darauf, dass Sie sowohl die robots.txt als auch die Nutzungsbedingungen der jeweiligen Seite, die Sie scrapen wollen, lesen und respektieren.
Darüber hinaus können Sie sich auf den offiziellen Websites Ressourcen und Anleitungen zu einigen der oben genannten Methoden wie Scrapy und Selenium ansehen. Sie sollten sich auch selbst herausfordern, indem Sie einige dynamischere Seiten scrapen, die Sie nicht nur mit Requests scrapen können.
Wenn Sie Fragen haben, einen Fehler gefunden haben oder einfach nur über alles, was mit Python und Scraping zu tun hat, plaudern möchten, können Sie uns gerne unter blog@statworx.com kontaktieren.


