Verwendung von Reinforcement Learning zum Spielen von Super Mario Bros auf NES mit TensorFlow


Reinforcement Learning ist derzeit eines der heißesten Themen im Machine Learning. Für eine kürzlich besuchte Konferenz (das großartige Data Festival in München) haben wir ein Reinforcement-Learning-Modell entwickelt, das lernt, Super Mario Bros auf dem NES zu spielen, sodass Besucher:innen an unserem Stand gegen den Agenten im Hinblick auf die Zeit zur Level-Vervollständigung antreten konnten.

Die Aktion war ein voller Erfolg und die Leute hatten viel Spaß an diesem „Mensch gegen Maschine“-Wettbewerb. Es gab nur einen Teilnehmer, der es schaffte, die KI zu schlagen – indem er eine geheime Abkürzung nahm, die dem Agenten nicht bekannt war. Auch die Entwicklung des Modells in Python war ein großer Spaß. Daher habe ich beschlossen, einen Blogartikel darüber zu schreiben, der einige der grundlegenden Konzepte des Reinforcement Learning sowie die konkrete Umsetzung unseres Super-Mario-Agenten in TensorFlow behandelt (Achtung: ich habe TensorFlow 1.13.1 verwendet, TensorFlow 2.0 war zum Zeitpunkt des Schreibens noch nicht veröffentlicht).
Rückblick: Reinforcement Learning
Die meisten Machine-Learning-Modelle haben eine explizite Verbindung zwischen Eingabe- und Ausgabewerten, die sich während des Trainings nicht verändert. Deshalb ist es schwierig, Systeme zu modellieren oder vorherzusagen, bei denen die Eingaben oder Zielgrößen selbst von früheren Vorhersagen abhängen. Dabei ist genau das in der realen Welt oft der Fall: autonomes Fahren, Maschinensteuerung, Prozessautomatisierung etc. – in vielen Situationen haben Entscheidungen, die von Modellen getroffen werden, Auswirkungen auf die Umgebung und somit auch auf die nächsten Aktionen. Klassische überwachtes Lernen (Supervised Learning) ist in solchen Szenarien nur begrenzt einsetzbar. Stattdessen braucht es Modelle, die mit zeitabhängigen und miteinander verflochtenen Eingaben und Ausgaben umgehen können. Hier kommt Reinforcement Learning ins Spiel.
Beim Reinforcement Learning interagiert das Modell (der sogenannte Agent) mit seiner Umgebung, indem es in jedem Zustand der Umgebung eine Handlung (aus dem sogenannten Action Space) auswählt, die entweder positive oder negative Belohnungen (Rewards) auslöst. Diese Belohnungen sind ein abstraktes Signal dafür, ob eine Handlung „gut“ oder „schlecht“ war. Dabei kann die Belohnung unmittelbar oder zeitlich verzögert erfolgen. Durch das Lernen aus Kombinationen von Zuständen der Umgebung, Handlungen und dazugehörigen Belohnungen (sogenannten Transitionen) versucht der Agent, eine optimale Menge an Entscheidungsregeln (die Policy) zu erlernen, um den gesamten Ertrag (Reward) in jedem Zustand zu maximieren.
Q-Learning und Deep Q-Learning
Im Reinforcement Learning wird häufig das Konzept des Q-Learning verwendet. Q-Learning basiert auf sogenannten Q-Werten, die dem Agenten helfen, die optimale Handlung im aktuellen Zustand der Umgebung zu bestimmen. Q-Werte sind „diskontierte“ zukünftige Belohnungen, die der Agent im Training durch Handlungen und Übergänge zwischen Zuständen sammelt. Diese Q-Werte sollen während des Trainings approximiert werden – entweder durch einfaches Erkunden der Umgebung oder mittels eines Funktionsapproximators wie eines Deep Neural Networks (wie in unserem Fall). Meistens wählt man in einem Zustand diejenige Handlung mit dem höchsten Q-Wert, also mit der höchsten zukünftigen diskontierten Belohnung im gegebenen Zustand.
Wenn ein neuronales Netz als Q-Funktions-Approximator verwendet wird, lernt es, indem der Unterschied zwischen den vorhergesagten Q-Werten und den „wahren“ Q-Werten – also der Repräsentation der optimalen Entscheidung im aktuellen Zustand – berechnet wird. Basierend auf diesem Loss werden die Netzwerkgewichte mittels Gradientenabstieg aktualisiert, wie bei jedem anderen neuronalen Netz auch. Wiederholt man diesen Vorgang oft genug, konvergiert das Netz gegen einen Zustand, in dem es die Q-Werte für den nächsten Zustand, gegeben den aktuellen Zustand, gut approximieren kann. Ist diese Approximation ausreichend, wählt der Agent einfach die Handlung mit dem höchsten Q-Wert. Auf diese Weise ist er in der Lage, in jeder Situation diejenige Aktion auszuwählen, die die größte Belohnung erwarten lässt.
In den meisten Deep-Reinforcement-Learning-Modellen sind tatsächlich zwei neuronale Netze involviert: das Online- und das Target-Netzwerk. Der Grund dafür ist, dass beim Training der Loss eines einzelnen Netzwerks gegen sich ständig ändernde Ziele (Q-Werte) berechnet wird, die wiederum auf den Gewichten des Netzes selbst basieren. Das erschwert die Optimierung oder kann sogar zur Nicht-Konvergenz führen. Das Target-Netzwerk ist im Grunde eine Kopie des Online-Netzes mit eingefrorenen Gewichten, die nicht direkt trainiert werden. Stattdessen werden die Gewichte des Target-Netzes nach einer bestimmten Anzahl an Trainingsschritten mit denen des Online-Netzes synchronisiert. Dadurch liefern die Ausgaben des Target-Netzes „stabile“ Zielwerte, die sich nicht nach jedem Schritt ändern – was die Konvergenz des Optimierungsproblems unterstützt.
Deep Double Q-Learning
Ein weiteres mögliches Problem beim Q-Learning besteht darin, dass durch die Auswahl des maximalen Q-Werts zur Bestimmung der besten Aktion während des Trainings manchmal außergewöhnlich hohe Q-Werte entstehen. Grundsätzlich ist das nicht immer ein Problem, kann jedoch zu einem werden, wenn es zu einer starken Konzentration auf bestimmte Aktionen kommt, was wiederum dazu führt, dass weniger vorteilhafte, aber „ausprobierenswerte“ Aktionen vernachlässigt werden. Wenn Letztere dauerhaft ignoriert werden, kann das Modell in einer lokal optimalen Lösung stecken bleiben oder – noch schlimmer – immer wieder dieselben Aktionen auswählen. Ein Ansatz zur Lösung dieses Problems ist die Einführung einer aktualisierten Version des Q-Learning, genannt Double Q-Learning.
Beim Double Q-Learning werden die Aktionen in jedem Zustand nicht einfach dadurch gewählt, dass die Aktion mit dem höchsten Q-Wert des Target-Netzwerks ausgewählt wird. Stattdessen wird der Auswahlprozess in drei getrennte Schritte unterteilt: (1) Zunächst berechnet das Target-Netzwerk die Ziel-Q-Werte des Zustands nach Durchführung der Aktion. Dann (2) berechnet das Online-Netzwerk die Q-Werte des Zustands nach der Aktion und wählt die beste Aktion durch Auffinden des maximalen Q-Werts. Schließlich (3) werden die Ziel-Q-Werte mit den Q-Werten des Target-Netzwerks berechnet, allerdings an den durch das Online-Netzwerk bestimmten Aktionsindizes. Das stellt sicher, dass keine Überschätzung der Q-Werte auftreten kann, da diese nicht auf sich selbst aktualisiert werden.
Gym-Umgebungen
Um eine Reinforcement-Learning-Anwendung zu erstellen, benötigen wir zwei Dinge: (1) eine Umgebung, mit der der Agent interagieren und aus der er lernen kann, und (2) den Agenten, der den/die Zustand/Zustände der Umgebung beobachtet und geeignete Aktionen auf Basis von Q-Werten auswählt, die (idealerweise) hohe Belohnungen für den Agenten ergeben. Eine Umgebung wird typischerweise als sogenanntes Gym bereitgestellt, eine Klasse, die den notwendigen Code enthält, um die Zustände und Belohnungen der Umgebung als Funktion der Aktionen des Agenten zu simulieren sowie weitere Informationen bereitzustellen, z. B. über den möglichen Aktionsraum. Hier ein Beispiel für eine einfache Environment-Klasse in Python:
class Environment:
""" A simple environment skeleton """
def __init__(self):
# Initializes the environment
pass
def step(self, action):
# Changes the environment based on agents action
return next_state, reward, done, info
def reset(self):
# Resets the environment to its initial state
pass
def render(self):
# Show the state of the environment on screen
pass
Die Umgebung hat drei Hauptfunktionen innerhalb der Klasse: (1) step() führt den Umgebungs-Code als Funktion der vom Agenten gewählten Aktion aus und gibt den nächsten Zustand der Umgebung, die Belohnung in Bezug auf die Aktion, ein Done-Flag (welches angibt, ob ein Endzustand erreicht wurde) sowie ein Dictionary mit zusätzlichen Informationen über die Umgebung und ihren Zustand zurück, (2) reset() setzt die Umgebung in ihren Ausgangszustand zurück und (3) render() zeigt den aktuellen Zustand auf dem Bildschirm an (z. B. durch Darstellung des aktuellen Frames des Super-Mario-Bros-Spiels).
Für Python ist OpenAI eine zentrale Anlaufstelle zur Suche nach Gym-Umgebungen. Es enthält viele verschiedene Spiele und Problemstellungen, die sich gut für Reinforcement Learning eignen. Darüber hinaus gibt es ein OpenAI-Projekt namens Gym Retro, das Hunderte von Sega- und SNES-Spielen umfasst, die bereit sind, von Reinforcement-Learning-Algorithmen gemeistert zu werden.
Agent
Der Agent verarbeitet den aktuellen Zustand der Umgebung und wählt basierend auf der Auswahlstrategie eine geeignete Aktion aus. Die Policy (Strategie) bildet den Zustand der Umgebung auf eine vom Agenten auszuführende Aktion ab. Die Suche nach der richtigen Policy ist eine zentrale Fragestellung im Reinforcement Learning und beinhaltet häufig die Verwendung von Deep Neural Networks. Der folgende Agent beobachtet einfach den Zustand der Umgebung und gibt action = 1 zurück, wenn state größer als 0 ist, und action = 0 andernfalls.
class Agent:
""" A simple agent """
def __init__(self):
pass
def action(self, state):
if state > 0:
return 1
else:
return 0
Dies ist natürlich eine sehr einfache Policy. In praktischen Reinforcement-Learning-Anwendungen kann der Zustand der Umgebung sehr komplex und hochdimensional sein. Ein Beispiel dafür sind Videospiele. Der Zustand der Umgebung wird durch die Pixel auf dem Bildschirm und die vorherigen Aktionen des Spielers bestimmt. Unser Agent muss eine Policy finden, die die Bildschirm-Pixel auf Aktionen abbildet, die Belohnungen aus der Umgebung generieren.
Environment-Wrappers
Gym-Umgebungen enthalten die meisten Funktionalitäten, die nötig sind, um sie in einem Reinforcement-Learning-Szenario zu verwenden. Es gibt jedoch bestimmte Funktionen, die nicht standardmäßig in der Gym-Umgebung enthalten sind, wie z. B. Bildskalierung, Frame-Skipping und -Stacking, Reward-Clipping und so weiter. Glücklicherweise gibt es sogenannte Gym-Wrappers, die solche Hilfsfunktionen bereitstellen. Ein Beispiel, das für viele Videospiele wie Atari oder NES verwendet werden kann, findet sich hier. Bei Videospiel-Gyms ist es sehr üblich, Wrapper-Funktionen zu verwenden, um eine gute Performance des Agenten zu erzielen. Das folgende Beispiel zeigt einen einfachen Wrapper zum Clipping der Rewards.
import gym
class ClipRewardEnv(gym.RewardWrapper):
""" Example wrapper for reward clipping """
def __init__(self, env):
gym.RewardWrapper.__init__(self, env)
def reward(self, reward):
# Clip reward to {1, 0, -1} by its sign
return np.sign(reward)
Aus dem obigen Beispiel ist ersichtlich, dass es möglich ist, das Standardverhalten der Umgebung zu verändern, indem man deren Kernfunktionen „überschreibt“. Hier werden die Belohnungen der Umgebung mithilfe von np.sign() basierend auf dem Vorzeichen der Belohnung auf $[-1, 0, 1]$ begrenzt.
Die Super Mario Bros NES-Umgebung
Für unser Reinforcement-Learning-Experiment mit Super Mario Bros habe ich gym-super-mario-bros verwendet. Die API ist unkompliziert und sehr ähnlich zur OpenAI Gym API. Der folgende Code zeigt einen zufälligen Agenten, der Super Mario spielt. Das führt dazu, dass Mario ziellos über den Bildschirm wackelt – was natürlich nicht zum erfolgreichen Abschluss des Spiels führt.
from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
# Make gym environment
env = gym_super_mario_bros.make('SuperMarioBros-v0')
env = BinarySpaceToDiscreteSpaceEnv(env, SIMPLE_MOVEMENT)
# Play random
done = True
for step in range(5000):
if done:
state = env.reset()
state, reward, done, info = env.step(env.action_space.sample())
env.render()
# Close device
env.close()
Der Agent interagiert mit der Umgebung, indem er zufällige Aktionen aus dem Aktionsraum der Umgebung auswählt. Der Aktionsraum eines Videospiels ist tatsächlich recht groß, da mehrere Tasten gleichzeitig gedrückt werden können. Hier wurde der Aktionsraum auf SIMPLE_MOVEMENT reduziert, was grundlegende Spielaktionen wie Laufen in alle Richtungen, Springen, Ducken usw. abdeckt. BinarySpaceToDiscreteSpaceEnv transformiert den binären Aktionsraum (Dummy-Indikatorvariablen für alle Tasten und Richtungen) in eine einzelne Ganzzahl. So entspricht beispielsweise die Ganzzahl-Aktion 12 dem gleichzeitigen Drücken von „Rechts“ und „A“ (Rennen).
Ein Deep-Learning-Modell als Agent verwenden
Beim Spielen von Super Mario Bros auf dem NES sehen Menschen den Spielbildschirm – genauer gesagt sehen sie aufeinanderfolgende Bilder aus Pixeln, die mit hoher Geschwindigkeit auf dem Bildschirm dargestellt werden. Unser menschliches Gehirn ist in der Lage, den rohen sensorischen Input unserer Augen in elektrische Signale umzuwandeln, die vom Gehirn verarbeitet werden und entsprechende Handlungen auslösen (Knöpfe auf dem Controller drücken), die (hoffentlich) Mario ins Ziel führen.
Beim Training des Agenten rendert das Gym jeden Frame des Spiels als Pixelmatrix entsprechend der jeweiligen Aktion des Agenten. Grundsätzlich können diese Pixel als Input für jedes Machine-Learning-Modell verwendet werden. Im Reinforcement Learning werden jedoch häufig Convolutional Neural Networks (CNNs) eingesetzt, die bei Bildverarbeitungsaufgaben im Vergleich zu anderen ML-Modellen besonders leistungsfähig sind. Ich gehe hier nicht auf die technischen Details von CNNs ein – es gibt eine Fülle großartiger Einführungsartikel, z. B. diesen hier.
Anstatt nur das aktuelle Spielbild als Input für das Modell zu verwenden, ist es üblich, mehrere gestapelte Frames als Input für das CNN zu verwenden. So kann das Modell Veränderungen und „Bewegungen“ zwischen aufeinanderfolgenden Frames erkennen, was bei Verwendung eines einzelnen Frames nicht möglich wäre. Hier hat der Eingabetensor unseres Modells die Größe $[84, 84, 4]$. Das entspricht einem Stapel aus 4 Graustufenbildern, jeweils mit einer Größe von 84x84 Pixeln – dies ist die Standardgröße für 2D-Convolutions.
Die Architektur des Deep-Learning-Modells besteht aus drei Convolutional Layers, gefolgt von einer Flatten-Schicht und einer voll verbundenen Schicht mit 512 Neuronen sowie einer Output-Schicht mit actions = 6 Neuronen. Diese entspricht dem Aktionsraum des Spiels (in diesem Fall RIGHT_ONLY, d. h. Aktionen, um Mario nach rechts zu bewegen – eine Erweiterung des Aktionsraums erhöht üblicherweise die Komplexität des Problems und die Trainingszeit).
Wenn man das TensorBoard-Bild unten genauer betrachtet, erkennt man, dass das Modell tatsächlich nicht nur aus einem, sondern aus zwei identischen Convolutional-Zweigen besteht. Einer ist der Online-Network-Zweig, der andere der Target-Network-Zweig. Das Online-Netzwerk wird mit Gradient Descent trainiert. Das Target-Netzwerk hingegen wird nicht direkt trainiert, sondern alle copy = 10000 Schritte durch Kopieren der Gewichte vom Online-Zweig mit dem Target-Zweig synchronisiert. Der Target-Network-Zweig ist vom Gradient-Descent-Training ausgeschlossen, indem die Funktion tf.stop_gradient() um die Output-Schicht dieses Zweigs gelegt wird. Dies unterbricht den Gradientenfluss an der Output-Schicht, sodass keine Gewichtsaktualisierung entlang dieses Zweigs erfolgt.
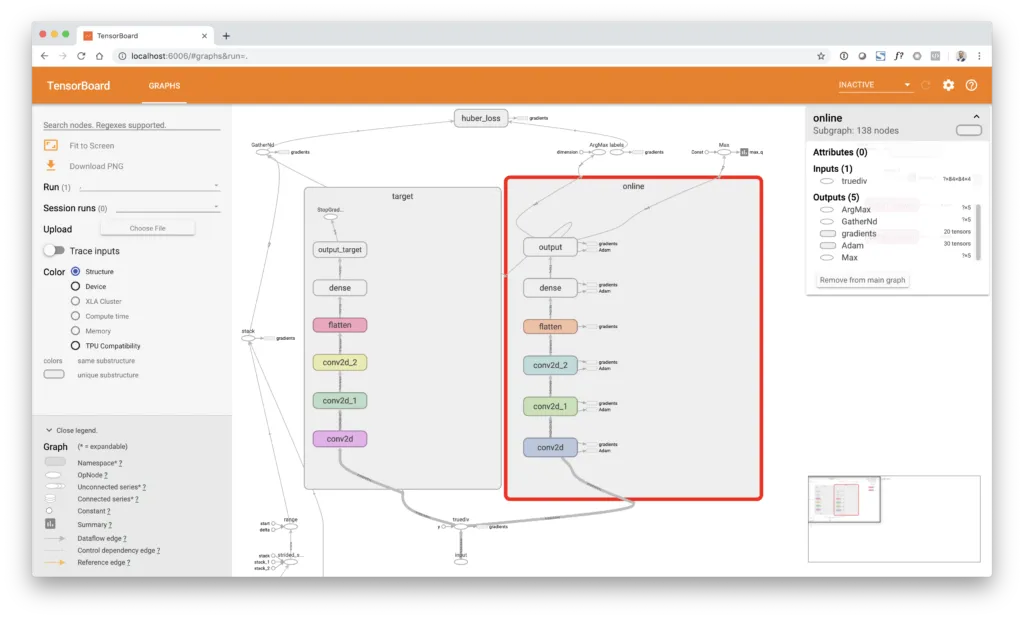
Der Agent lernt, indem er (1) zufällige Stichproben historischer Transitionen entnimmt, (2) die „wahren“ Q-Werte basierend auf den Zuständen der Umgebung nach der Aktion, also next_state, unter Verwendung des Target-Network-Zweigs und der Double-Q-Learning-Regel berechnet, (3) die Ziel-Q-Werte mit einem Diskontierungsfaktor von $\gamma = 0{,}9$ abdiskontiert und (4) einen Batch-Gradient-Descent-Schritt auf Basis der internen Q-Vorhersage des Netzwerks und der tatsächlichen Q-Werte, geliefert durch target_q, durchführt. Um den Trainingsprozess zu beschleunigen, wird der Agent nicht nach jeder Aktion trainiert, sondern nur alle train_each = 3 Frames, was einem Training alle 4 Frames entspricht. Zusätzlich wird nicht jeder Frame in den Replay Buffer gespeichert, sondern nur jeder vierte Frame. Dies wird als Frame Skipping bezeichnet. Genauer gesagt wird eine Max-Pooling-Operation durchgeführt, die die Information zwischen den letzten 4 aufeinanderfolgenden Frames aggregiert. Dies ist dadurch motiviert, dass aufeinanderfolgende Frames nahezu identische Informationen enthalten, die dem Lernproblem keine neue Information hinzufügen und möglicherweise stark autokorrelierte Datenpunkte erzeugen würden.
Apropos korrelierte Daten: Unser Netzwerk wird mittels Adaptive Moment Estimation (ADAM) und Gradient Descent bei einer Lernrate von learning_rate = 0.00025 trainiert, was i.i.d.-Datenpunkte (unabhängig und identisch verteilt) erfordert, um gut zu funktionieren. Das bedeutet, dass wir nicht einfach alle neuen Transitions-Tupel nacheinander zum Training verwenden können, da sie stark korreliert sind. Um dieses Problem zu lösen, verwenden wir ein Konzept namens Experience Replay Buffer. Dabei speichern wir jede Transition unseres Spiels in einem Ringpuffer-Objekt (in Python über die Funktion deque()), aus dem dann zufällig Stichproben gezogen werden, wenn wir unsere Trainingsdaten mit batch_size = 32 entnehmen. Durch die Verwendung einer Zufallsstrategie beim Sampling und eines ausreichend großen Replay Buffers können wir davon ausgehen, dass die resultierenden Datenpunkte (hoffentlich) nicht korreliert sind. Die folgende Codebox zeigt die Klasse DQNAgent.
import time
import random
import numpy as np
from collections import deque
import tensorflow as tf
from matplotlib import pyplot as plt
class DQNAgent:
""" DQN agent """
def __init__(self, states, actions, max_memory, double_q):
self.states = states
self.actions = actions
self.session = tf.Session()
self.build_model()
self.saver = tf.train.Saver(max_to_keep=10)
self.session.run(tf.global_variables_initializer())
self.saver = tf.train.Saver()
self.memory = deque(maxlen=max_memory)
self.eps = 1
self.eps_decay = 0.99999975
self.eps_min = 0.1
self.gamma = 0.90
self.batch_size = 32
self.burnin = 100000
self.copy = 10000
self.step = 0
self.learn_each = 3
self.learn_step = 0
self.save_each = 500000
self.double_q = double_q
def build_model(self):
""" Model builder function """
self.input = tf.placeholder(dtype=tf.float32, shape=(None, ) + self.states, name='input')
self.q_true = tf.placeholder(dtype=tf.float32, shape=[None], name='labels')
self.a_true = tf.placeholder(dtype=tf.int32, shape=[None], name='actions')
self.reward = tf.placeholder(dtype=tf.float32, shape=[], name='reward')
self.input_float = tf.to_float(self.input) / 255.
# Online network
with tf.variable_scope('online'):
self.conv_1 = tf.layers.conv2d(inputs=self.input_float, filters=32, kernel_size=8, strides=4, activation=tf.nn.relu)
self.conv_2 = tf.layers.conv2d(inputs=self.conv_1, filters=64, kernel_size=4, strides=2, activation=tf.nn.relu)
self.conv_3 = tf.layers.conv2d(inputs=self.conv_2, filters=64, kernel_size=3, strides=1, activation=tf.nn.relu)
self.flatten = tf.layers.flatten(inputs=self.conv_3)
self.dense = tf.layers.dense(inputs=self.flatten, units=512, activation=tf.nn.relu)
self.output = tf.layers.dense(inputs=self.dense, units=self.actions, name='output')
# Target network
with tf.variable_scope('target'):
self.conv_1_target = tf.layers.conv2d(inputs=self.input_float, filters=32, kernel_size=8, strides=4, activation=tf.nn.relu)
self.conv_2_target = tf.layers.conv2d(inputs=self.conv_1_target, filters=64, kernel_size=4, strides=2, activation=tf.nn.relu)
self.conv_3_target = tf.layers.conv2d(inputs=self.conv_2_target, filters=64, kernel_size=3, strides=1, activation=tf.nn.relu)
self.flatten_target = tf.layers.flatten(inputs=self.conv_3_target)
self.dense_target = tf.layers.dense(inputs=self.flatten_target, units=512, activation=tf.nn.relu)
self.output_target = tf.stop_gradient(tf.layers.dense(inputs=self.dense_target, units=self.actions, name='output_target'))
# Optimizer
self.action = tf.argmax(input=self.output, axis=1)
self.q_pred = tf.gather_nd(params=self.output, indices=tf.stack([tf.range(tf.shape(self.a_true)[0]), self.a_true], axis=1))
self.loss = tf.losses.huber_loss(labels=self.q_true, predictions=self.q_pred)
self.train = tf.train.AdamOptimizer(learning_rate=0.00025).minimize(self.loss)
# Summaries
self.summaries = tf.summary.merge([
tf.summary.scalar('reward', self.reward),
tf.summary.scalar('loss', self.loss),
tf.summary.scalar('max_q', tf.reduce_max(self.output))
])
self.writer = tf.summary.FileWriter(logdir='./logs', graph=self.session.graph)
def copy_model(self):
""" Copy weights to target network """
self.session.run([tf.assign(new, old) for (new, old) in zip(tf.trainable_variables('target'), tf.trainable_variables('online'))])
def save_model(self):
""" Saves current model to disk """
self.saver.save(sess=self.session, save_path='./models/model', global_step=self.step)
def add(self, experience):
""" Add observation to experience """
self.memory.append(experience)
def predict(self, model, state):
""" Prediction """
if model == 'online':
return self.session.run(fetches=self.output, feed_dict={self.input: np.array(state)})
if model == 'target':
return self.session.run(fetches=self.output_target, feed_dict={self.input: np.array(state)})
def run(self, state):
""" Perform action """
if np.random.rand() < self.eps:
# Random action
action = np.random.randint(low=0, high=self.actions)
else:
# Policy action
q = self.predict('online', np.expand_dims(state, 0))
action = np.argmax(q)
# Decrease eps
self.eps *= self.eps_decay
self.eps = max(self.eps_min, self.eps)
# Increment step
self.step += 1
return action
def learn(self):
""" Gradient descent """
# Sync target network
if self.step % self.copy == 0:
self.copy_model()
# Checkpoint model
if self.step % self.save_each == 0:
self.save_model()
# Break if burn-in
if self.step < self.burnin:
return
# Break if no training
if self.learn_step < self.learn_each:
self.learn_step += 1
return
# Sample batch
batch = random.sample(self.memory, self.batch_size)
state, next_state, action, reward, done = map(np.array, zip(*batch))
# Get next q values from target network
next_q = self.predict('target', next_state)
# Calculate discounted future reward
if self.double_q:
q = self.predict('online', next_state)
a = np.argmax(q, axis=1)
target_q = reward + (1. - done) * self.gamma * next_q[np.arange(0, self.batch_size), a]
else:
target_q = reward + (1. - done) * self.gamma * np.amax(next_q, axis=1)
# Update model
summary, _ = self.session.run(fetches=[self.summaries, self.train],
feed_dict={self.input: state,
self.q_true: np.array(target_q),
self.a_true: np.array(action),
self.reward: np.mean(reward)})
# Reset learn step
self.learn_step = 0
# Write
self.writer.add_summary(summary, self.step)Training des Agenten zum Spielen
Zuerst müssen wir die Umgebung instanziieren. Hier verwenden wir das erste Level von Super Mario Bros, SuperMarioBros-1-1-v0 sowie einen diskreten Ereignisraum mit dem Aktionsraum RIGHT_ONLY. Zusätzlich verwenden wir einen Wrapper, der Frame-Resizing, Stacking und Max-Pooling, Reward-Clipping sowie Lazy Frame Loading auf die Umgebung anwendet.
Wenn das Training beginnt, erkundet der Agent zunächst die Umgebung, indem er zufällige Aktionen ausführt. Dies geschieht, um erste Erfahrungen zu sammeln, die als Ausgangspunkt für den eigentlichen Lernprozess dienen. Nach einer Burn-in-Phase von burin = 100000 Spielframes beginnt der Agent langsam, zufällige Aktionen durch Aktionen zu ersetzen, die durch die CNN-Policy bestimmt werden. Dies wird als Epsilon-Greedy-Policy bezeichnet. Epsilon-Greedy bedeutet, dass der Agent mit Wahrscheinlichkeit $\varepsilon$ eine zufällige Aktion auswählt oder mit Wahrscheinlichkeit $(1 - \varepsilon)$ eine Policy-basierte Aktion. Hier verringert sich Epsilon während des Trainings linear um den Faktor eps_decay = 0.99999975, bis es den Wert eps = 0.1 erreicht, bei dem es für den Rest des Trainings konstant bleibt. Es ist wichtig, zufällige Aktionen im Trainingsprozess nicht vollständig zu eliminieren, um zu vermeiden, dass das Modell in lokal optimalen Lösungen stecken bleibt.
Für jede ausgeführte Aktion gibt die Umgebung vier Objekte zurück: (1) den nächsten Spielzustand, (2) die Belohnung für die Aktion, (3) ein Flag, ob die Episode beendet ist, und (4) ein Info-Dictionary mit zusätzlichen Informationen aus der Umgebung. Nachdem die Aktion ausgeführt wurde, wird ein Tupel der zurückgegebenen Objekte zum Replay-Buffer hinzugefügt und der Agent führt einen Lernschritt durch. Nach dem Lernen wird der aktuelle Zustand mit dem next_state aktualisiert und die Schleife erhöht sich um eine Iteration. Die While-Schleife wird unterbrochen, wenn das done-Flag den Wert True hat. Dies entspricht entweder dem Tod von Mario oder dem erfolgreichen Abschluss des Levels. Hier wird der Agent in 10000 Episoden trainiert.
import time
import numpy as np
from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
import gym_super_mario_bros
from gym_super_mario_bros.actions import RIGHT_ONLY
from agent import DQNAgent
from wrappers import wrapper
# Build env (first level, right only)
env = gym_super_mario_bros.make('SuperMarioBros-1-1-v0')
env = BinarySpaceToDiscreteSpaceEnv(env, RIGHT_ONLY)
env = wrapper(env)
# Parameters
states = (84, 84, 4)
actions = env.action_space.n
# Agent
agent = DQNAgent(states=states, actions=actions, max_memory=100000, double_q=True)
# Episodes
episodes = 10000
rewards = []
# Timing
start = time.time()
step = 0
# Main loop
for e in range(episodes):
# Reset env
state = env.reset()
# Reward
total_reward = 0
iter = 0
# Play
while True:
# Show env (diabled)
# env.render()
# Run agent
action = agent.run(state=state)
# Perform action
next_state, reward, done, info = env.step(action=action)
# Remember transition
agent.add(experience=(state, next_state, action, reward, done))
# Update agent
agent.learn()
# Total reward
total_reward += reward
# Update state
state = next_state
# Increment
iter += 1
# If done break loop
if done or info['flag_get']:
break
# Rewards
rewards.append(total_reward / iter)
# Print
if e % 100 == 0:
print('Episode {e} - +'
'Frame {f} - +'
'Frames/sec {fs} - +'
'Epsilon {eps} - +'
'Mean Reward {r}'.format(e=e,
f=agent.step,
fs=np.round((agent.step - step) / (time.time() - start)),
eps=np.round(agent.eps, 4),
r=np.mean(rewards[-100:])))
start = time.time()
step = agent.step
# Save rewards
np.save('rewards.npy', rewards)
Nach jeder Spiel-Episode wird die durchschnittliche Belohnung dieser Episode zur Liste rewards hinzugefügt. Außerdem werden verschiedene Statistiken wie Bilder pro Sekunde (frames per second) und das aktuelle Epsilon alle 100 Episoden ausgegeben.
Wiedergabe
Während des Trainings speichert das Programm das aktuelle Netzwerk alle save_each = 500000 Frames und behält die 10 neuesten Modelle auf der Festplatte. Ich habe während des Trainings mehrere Modellversionen auf meinen lokalen Rechner heruntergeladen und das folgende Video erstellt.
Es ist wirklich beeindruckend, den Lernfortschritt des Agenten zu sehen! Das Training dauerte ungefähr 20 Stunden auf einer GPU-beschleunigten VM in der Google Cloud.
Zusammenfassung und Ausblick
Reinforcement Learning ist ein spannendes Teilgebiet des maschinellen Lernens, das eine Vielzahl möglicher Anwendungen sowohl in der Wissenschaft als auch in der Wirtschaft bietet. Allerdings ist das Training von Reinforcement-Learning-Agenten nach wie vor recht aufwendig und erfordert häufig mühsames Tuning von Hyperparametern und Netzwerkarchitektur, um zufriedenstellende Ergebnisse zu erzielen. In letzter Zeit gab es jedoch Fortschritte, etwa durch RAINBOW (eine Kombination mehrerer RL-Strategien), die auf ein robusteres Framework für das Training von RL-Agenten abzielen – dennoch ist das Feld weiterhin ein aktiver Forschungsbereich. Neben Q-Learning wurden viele weitere interessante Trainingsansätze im Reinforcement Learning entwickelt. Wenn du verschiedene RL-Agenten und Trainingsverfahren ausprobieren möchtest, empfehle ich dir einen Blick auf Stable Baselines – eine großartige Möglichkeit, moderne RL-Methoden und Konzepte einfach zu nutzen.
Wenn du Deep-Learning-Einsteiger bist und mehr lernen möchtest, dann solltest du dir unser brandneues statworx Deep Learning Bootcamp ansehen – eine fünftägige Präsenzveranstaltung, die dir alles vermittelt, was du brauchst, um deine ersten Deep-Learning-Modelle zu entwickeln: Theoretische Grundlagen neuronaler Netze, Backpropagation und Gradient Descent, Programmierung in Python, TensorFlow und Keras, CNNs und andere Bildverarbeitungsmodelle, rekurrente Netze und LSTMs für Zeitreihendaten und NLP sowie fortgeschrittene Themen wie Deep Reinforcement Learning und GANs.
Wenn du Anmerkungen oder Fragen zu meinem Beitrag hast, melde dich gerne bei mir! Du darfst auch gerne meinen Code verwenden (Link zum GitHub-Repo) oder diesen Beitrag mit deinen Kolleginnen und Kollegen in sozialen Netzwerken teilen.
Wenn du an weiteren Inhalten dieser Art interessiert bist, abonniere unsere Mailingliste – damit erhältst du regelmäßig neue Lesetipps und Infos rund um Data Science, Machine Learning und KI direkt von mir und meinem Team bei statworx in dein Postfach!
Und zuletzt: Folge mir auf LinkedIn oder meinem Unternehmen statworx auf Twitter, wenn du mehr von uns sehen möchtest!


