Gut in Form - So klappts mit der Datenaufbereitung in R, Stata und SPSS


In der “Gut in Form”-Serie werden in den nächsten Wochen verschiedene Möglichkeiten gezeigt, um die Daten optimal für die Analyse vorzubereiten. Die Durchführung wird dabei jeweils in R, Stata und SPSS vorgestellt. So werden auch Vor- oder Nachteile der verschiedenen Programme sichtbar.
Datenimport und -export
Egal wie gut die Methodenkenntnisse sind, haben die Daten nicht die gewünschte Form, lässt sich das einfachste statistische Verfahren nicht anwenden. Noch schlimmer ist es, wenn durch die Form der Daten der falsche Test durchgeführt wird. Dies kann beispielsweise beim Unterschied zwischen verbundenen und unabhängigen Stichproben zum Problem werden, wie es in dem Beitrag über den t-Test gezeigt wurde. Dadurch kann sich das Ergebnis sowie die Interpretation drastisch verändern, was dem Anwender mitunter gar nicht auffällt.
In diesem Eintrag geht es zunächst um Möglichkeiten die Daten in das entsprechende Statistikprogramm einzulesen und (nach der Bearbeitung) wieder zu exportieren. Dies gehört zwar nicht zur klassischen Datenaufbereitung, bildet jedoch den ersten Schritt vor bzw. den letzten nach der Datenaufbereitung. In den folgenden Einträgen werden beispielsweise Datentypen, -restrukturierungen und –verschmelzungen sowie der Umgang mit Strings und Datumsformaten besprochen.
Datensatz
Der Datensatz, an dessen Beispiel die Aufbereitung dargestellt wird, soll natürlich zum Thema “Gut in Form” passen. Deshalb haben wir unseren Süßigkeitenkonsum in zwei Wochen notiert. Um niemanden bloßzustellen, werden keinen echten Namen genannt, sondern nur die des jeweiligen Lieblingsstatistikers. Untenstehend sind die ersten Zeilen des Datensatzes “Sweets”, geordnet nach Tagen, dargestellt.

Die Struktur und Variablentypen werden in späteren Beiträgen besprochen. Zunächst gehen wir der Frage nach, wie man zu diesen eingelesenen Daten gelangt.
Datenimport
Um überhaupt mit der Datenaufbereitung beginnen zu können, muss der Datensatz zuerst in das entsprechende Programm importiert werden. Unabhängig von der verwendeten Software muss auf das Datenformat geachtet werden. Hier gibt es unzählige Möglichkeiten und Wege. In der Praxis ist die häufigste Problemstellung wohl der Import vom xls(x)-, csv-Format sowie dem Dateiformat der verwendeten Software. Das Einlesen der jeweils drei Formate wird nun für R, Stata und SPSS vorgestellt. Hierbei wird angenommen, dass die Datei, unabhängig vom Format, als “sweets” benannt ist.
Nach jedem Import sollte unbedingt überprüft werden, ob dieser geglückt ist. Die Variablen- sowie Fallzahl muss mit der des Originals übereinstimmen. Für jede Software wird deshalb die Datenansicht nach dem Einlesen dargestellt.
R
Am einfachsten gestaltet sich hier der Import eines RData-Files. Außer dem Dateinamen und –pfad muss hier meist kein Argument spezifiziert werden.
Das Einlesen einer csv-Datei gelingt am schnellsten mit der read.csv2()-Funktion, eine Spezialform von read.table(). Dabei sollte auf das Trennzeichen und den Dezimaltrenner geachtet werden, welche bei Bedarf mit den Argumenten sep und dec angepasst werden können. Außerdem sollte das Argument header auf TRUE gesetzt werden, falls in der ersten Zeile die Variablennamen stehen.
Für den Import einer Excel-Datei (vom Typ xlsx) kann die read.xlsx2()-Funktion verwendet werden. Hier muss das Tabellenblatt und optional ein bestimmter Bereich spezifiziert werden.
Die genannten Funktionen sind nur jeweils eine von vielen Möglichkeiten zum Import des entsprechenden Dateityps.
# Import RData-File
load(file = "dateipfad/sweets.RData")
# Import csv-File
read.csv2(file = "dateipfad/sweets.csv")
#Import xlsx-File, sofern Daten im 1. Tabellenblatt
library(xlsx)
read.xlsx2(file = "dateipfad/sweets.xlsx“, sheetIndex = 1)
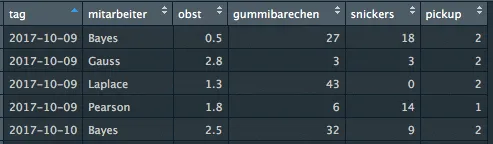
Die oben stehende Abbildung zeigt die eingelesenen Daten. Die Anzahl an Variablen sowie Fällen (hier nicht ersichtlich) stimmt mit dem Original überein. Ob die Variablen jedoch den für die Auswertungen richtigen Datentyp aufweisen, wird erst im späteren geklärt.
Stata
In Stata kann jeweils nur ein Datensatz geöffnet sein. Will man neue Daten laden, müssen die aktuellen geschlossen werden. Beim Einlesen der Daten in Stata sollte deshalb beachtet werden, dass eine Fehlermeldung ausgegeben wird, wenn bereits ein Datensatz geöffnet und ein weiterer geladen werden soll. Ist man sich also sicher, dass man den aktuellen Datensatz nicht mehr braucht, so kann man die clear-Option angeben.
Das Datenformat bei Stata heißt “dta” und kann mit dem use-Befehl geladen werden. Hierbei muss nur der Dateipfad angegeben werden.
Andere Datentypen können mit import eingelesen werden. Mit import delimited können csv- (und txt-) Files geladen werden. Der Trenner kann bei Bedarf mit der delimiters-Option angepasst werden.
Der Import einer Excel-Datei erfolgt mit import excel, wobei der Tabellenname mit sheet und der Zellbereich mit cellrange definiert werden kann. Variablennamen in der ersten Zeile müssen auch hier mit firstrow definiert werden.
* Import dta-File
use "dateipfad/sweets.dta”, clear
* Import csv-File
import delimited "dateipfad/sweets.csv”, firstrow clear
* Import xlsx-File, sofern Daten in 1. Tabellenblatt
import excel "dateipfad/sweets.xlsx", sheet("Tabelle1") firstrow clear
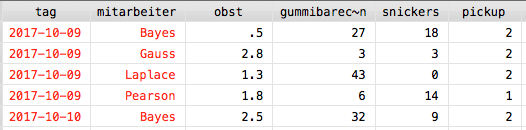
In Stata kann anhand der farbigen Darstellung der Variablen grob der Datentyp abgelesen werden. Bei einer roten Schrift handelt es sich um Strings, in schwarz werden Zahlen aller Art dargestellt und in blau Faktoren. Zwar wird der Datentyp an dieser Stelle noch nicht behandelt, beim Import sollte jedoch darauf geachtet werden, dass die (Dezimal-)Zahlen richtig erkannt werden. Für den konkreten Fall bedeutet das, dass die Variable “obst” in schwarz und nicht rot dargestellt wird.
SPSS
Der Umgang mit SPSS wird in dieser Blog-Serie lediglich über die Verwendung von Syntax beschrieben, nicht über die Dialogfelder. Das SPSS-eigene Datenformat nennt sich “sav”. Wie bei den vorherigen Programmen muss zum Einlesen des eigenen Formates nur der Dateipfad spezifiziert werden.
Die Syntax zum Import eines CSV-Files ist etwas komplizierter, besonders bei einer großen Anzahl an Variablen im Datensatz. Hier muss das Trennzeichen verpflichtend angegeben werden. Muss nur eine Datei eingelesen werden, empfiehlt es sich die Syntax über die Dialogfelder zu erzeugen.
Auch der Befehl zum Einlesen von xlsx-Files ist um einiges länger als bei den bisherigen Statistikprogrammen, weshalb auch hier die Arbeit mit den Dialogfeldern den Import erleichtern kann.
* Import sav-File.
GET
FILE='dateipfad/sweets.sav'.
* Import csv-File.
GET DATA
/TYPE=TXT
/FILE'dateipfad/sweets.csv’
/ENCODING='Locale'
/DELCASE=LINE
/DELIMITERS=","
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/IMPORTCASE=ALL
/VARIABLES=
Tag
Mitarbeiter
Obst
Gummibärchen
Snickers
PickUp
CACHE.
EXECUTE.
* Import xlsx-File (unter der Annahme, dass die Daten im Blatt „Tabelle 1“ liegen.
GET DATA /TYPE=XLSX
/FILE='dateipfad/sweets.xlsx'
/SHEET=name 'Tabelle1'
/CELLRANGE=full
/READNAMES=on
/ASSUMEDSTRWIDTH=32767.
EXECUTE.

Die resultierenden Daten entsprechen (vom Aussehen) den Originaldaten. Es zeigt sich, dass SPSS den Dezimaltrenner, sofern die Grundeinstellungen vorhanden sind, automatisch umwandelt.
Übersicht
Datenexport
Nach der Datenaufbereitung müssen die Daten wieder in das gewünschte Format exportiert werden, um die Datenaufbereitung nicht jedes Mal wiederholen zu müssen. Zur besseren Unterscheidung empfiehlt es sich den Datensatz nach der Aufbereitung entsprechend zu benennen. Hier wird nun die Bezeichnung “sweets_final” verwendet.
R
Objekte in R können mit dem save()-Befehl gespeichert werden. Dabei muss das zu speichernde Objekt, sowie der Dateipfad angegeben werden. Als csv-File können die Daten (komplementär zur read.csv2()-Funktion) mittels write.csv2() abgespeichert werden. Alternativ kann auch write.table() verwendet werden.
Auch für den Export nach Excel gibt es die komplementäre write.xlsx2()-Funktion. Bestimmte Ergebnisse oder Plots können auch einzeln mit den workbook-Funktionen nach Excel exportiert werden.
Zusätzlich erlauben die Funktionen write.foreign() und write.dta() den Export in das Datenformat anderer Statistikprogramme.
Achtung: Bei den zuletzt beschrieben Funktionen wird die Zeilennummerierung automatisch als erste Variable (ohne Namen) abgespeichert. Um das zu verhindern, kann das Argument row.names auf FALSE gesetzt werden.
Stata
Auch der Export in das “dta”-Format erfolgt über den Befehl save. Es muss nur der Dateipfad spezifiziert werden. Das Ausspeichern in andere Dateiformat erfolgt über den export-Befehl. Wie beim Import können für csv- und xlsx-Formate entsprechend export delimited und export excel verwendet werden.
Ähnlich zu workbook in R, können bei Stata mittels putexcel-Befehl einzelne Ergebnisse inklusive Formatierung in eine Excel-Arbeitsmappe gespeichert werden. Eine Einführung in diesen Befehl gibt es hier.
SPSS
Daten können ins sav-Format mit dem Befehl save outfile gespeichert werden. Hierbei können beispielsweise noch Variablen spezifiziert werden, die bleiben oder entfernt werden sollen.
Der Export als csv- oder xlsx-Format kann mit dem save translate outfileBefehl durchgeführt werden, hierbei muss der Type als Argument angegeben werden.
Übersicht
Zusammenfassung
Die richtige Struktur der Daten ist unerlässlich für die richtige Anwendung statistischer Methoden. Bevor die Datenstruktur an die Anforderungen der Methodik angepasst werden kann, müssen die Daten korrekt eingelesen werden. Auch der Export in beliebige Formate ist wichtig, um einfach mit Daten weiterarbeiten zu können. Die Vorgehensweise unterscheidet sich dabei zwischen den Statistikprogrammen R, Stata und SPSS. Am einfachsten gestaltet sich das Einlesen des Programm-eigenen Datenformats (RData, dta bzw. sav). Bei Fragen zum Thema Datenaufbereitung, stehen unsere Experten unter info@statworx.com gerne zur Verfügung.


