Einführung TensorFlow


TensorFlow ist aktuell eines der wichtigsten Frameworks zur Programmierung von neuronalen Netzen, Deep Learning Modellen und anderen Machine Learning Algorithmen. Es basiert auf einem C++ Low Level Backend, das jedoch über eine Python Library gesteuert wird. TensorFlow lässt sich sowohl auf CPU als auch GPU (Clustern) ausführen. Seit kurzem existiert auch ein R Package, mit dem TensorFlow genutzt werden kann. TensorFlow ist keine Software für Deep Learning oder Data Science Einsteiger sondern richtet sich klar an erfahrene Anwender, die über solide Programmierkenntnisse verfügen. Seit einiger Zeit gibt es jedoch Keras, eine High Level API, die mit vereinfachten Funktionen auf TensorFlow aufbaut und die Implementierung von Standardmodellen schnell und einfach gestaltet. Dies ist nicht nur für Deep Learning Einsteiger interessant sondern auch für Experten, die durch den Einsatz von Keras ihre Modelle schneller und effizienter prototypen können.
Der folgende Beitrag soll die zentralen Elemente und Konzepte von TensorFlow näher erläutern und anhand eines Praxisbeispiels verdeutlichen. Der Fokus liegt dabei nicht auf der formalen mathematischen Darstellung der Funktionsweise neuronaler Netze, sondern auf den grundlegenden Konzepten und Terminologien von TensorFlow sowie deren Umsetzung in Python.
Tensoren
In der ursprünglichen Bedeutung beschreibt ein Tensor den Absolutbetrag sog. Quaterionen, komplexer Zahlen, die den Wertebereich reeler Zahlen erweitern. Heutzutage ist diese Bedeutung jedoch nicht mehr gebräuchlich. Unter einem Tensor versteht man heute eine Verallgemeinerung von Skalaren, Vektoren und Matrizen. Ein zweidimensionaler Tensor ist also eine Matrix mit Zeilen und Spalten (also zwei Dimensionen). Insbesondere höherdimensionale Matrizen werden häufig als Tensoren bezeichnet. Die Bedeutung Tensor ist grundsätzlich jedoch unabhängig von der Anzahl der vorliegenden Dimensionen. Somit kann ein Vektor also als 1-dimensionaler Tensor beschrieben werden. In TensorFlow fließen also Tensoren - durch den sog. Graphen.
Der Graph
Die grundlegende Funktionsweise von TensorFlow basiert auf einem sog. Graphen. Dieser bezeichnet eine abstrakte Darstellung des zugrunde liegenden mathematischen Problems in Form eines gerichteten Diagramms. Das Diagramm besteht aus Knoten und Kanten die miteinander verbunden sind. Die Knoten des Graphen repräsentieren in TensorFlow Daten und mathematische Operationen. Durch die richtige Verbindung der Knoten kann ein Graph erstellt werden, der die notwendigen Daten und mathematischen Operationen zur Erstellung eines neuronalen Netzes beinhaltet. Das folgende Beispiel soll die grundlegende Funktionsweise verdeutlichen:
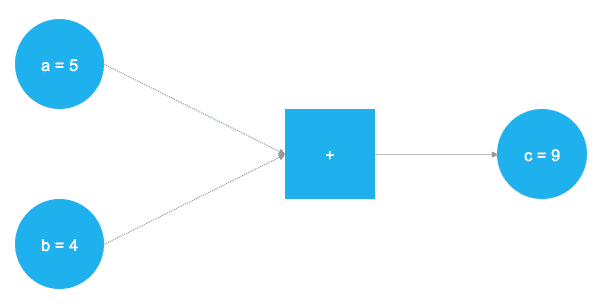
In der obenstehenden Abbildung sollen zwei Zahlen addiert werden. Die beiden Zahlen werden in den Variablen a und b gespeichert. Die Variablen fließen durch den Graphen bis zur quadratischen Box, an der eine Addition durchgeführt wird. Das Ergebnis der Addition wird in der Variablen c gespeichert. Die Variablen a, b und c können als Platzhalter, in TensorFlow "placeholder" genannt, verstanden werden. Alle Zahlen, die für a und b eingesetzt werden, werden nach dem gleichen Ablauf verarbeitet. Diese abstrakte Darstellung der durchzuführenden mathematischen Operationen in der Kern von TensorFlow. Der folgende Code zeigt die Umsetzung dieses einfachen Beispiels in Python:
# TensorFlow laden
import tensorflow as tf
# a und b als Platzhalter definieren
a = tf.placeholder(dtype=tf.int8)
b = tf.placeholder(dtype=tf.int8)
# Die Addition definieren
c = tf.add(a, b)
# Den Graphen initialisieren
graph = tf.Session()
# Den Graphen an der Stelle c ausführen
graph.run(c)
a und b mittels tf.placeholder() definiert. Da TensorFlow auf einem C++ Backend basiert, müssen die Datentypen der Platzhalter im Voraus fix definiert und können nicht zur Laufzeit angepasst werden. Dies geschieht innerhalb der Funktion tf.placeholder() mit dem Argument dtype=tf.int8, was einem 8-bit Integer (Ganzzahl) entspricht. Über die Funktion tf.add()werden nun die beiden Platzhalter miteinander addiert und in der Variable c gespeichert. Mittels tf.Session() wird der Graph initialisiert und anschließend durch graph.run(c) an der Stelle c ausgeführt. Natürlich handelt es sich bei diesem Beispiel um eine triviale Operation. Die benötigten Schritte und Berechnungen in neuronalen Netzen sind deutlich komplexer. Die prinzipielle Funktionsweise der graphenbasierten Ausführung bleibt jedoch bestehen.
Platzhalter
Wie bereits zuvor beschrieben, spielen Platzhalter in TensorFlow eine zentrale Rolle. Platzhalter beinhalten in der Regel alle Daten, die zum Training des neuronalen Netzes benötigt werden. Hierbei handelt es sich normalerweise um Inputs (die Eingangssignale des Modells) und Outputs (die zu vorhersagenden Variablen).
# Platzhalter definieren
X = tf.placeholder(dtype=tf.float32, shape=[None, p])
Y = tf.placeholder(dtype=tf.float32, shape=[None])
Im obigen Codebeispiel werden zwei Platzhalter definiert. X soll als Platzhalter für die Inputs des Modells dienen, Y als Platzhalter für die tatsächlich beobachteten Outputs in den Daten. Neben dem Datentyp der Platzhalter muss noch die Dimension der Tensoren definiert werden, die in den Platzhaltern gespeichert werden. Dies wird über das Funktionsargument shape gesteuert. Im Beispiel handelt es sich bei den Inputs um einen Tensor der Dimension [None, p] und bei dem Output um einen eindimensionalen Tensor. Der Parameter None weist TensorFlow an, diese Dimension flexibel zu halten, da im aktuellen Stadium noch unklar ist, welche Ausdehnung die Daten zum Trainieren des Modells haben werden.
Variablen
Neben Platzhaltern sind Variablen ein weiteres Kernkonzept der Funktionsweise von TensorFlow. Während Platzhalter zum Speichern der Input- und Outputdaten verwendet werden, sind Variablen flexibel und können Ihre Werte während der Laufzeit der Berechnung verändern. Der wichtigste Anwendungsbereich für Variablen in neuronalen Netzen sind die Gewichtungsmatrizen der Neuronen (Weights) und Biasvektoren (Biases), die während des Trainings stetig an die Daten angepasst werden. Im folgenden Codeblock werden die Variablen für ein einschichtiges, Feedforward Netz definiert.
# Anzahl der zu Inputs und Outputs
n_inputs = 10
n_outputs = 1
# Anzahl der Neuronen
n_neurons = 64
# Hidden Layer: Variablen für Weights und Biases
w_hidden = tf.Variable(weight_initializer([n_inputs, n_neurons]))
bias_hidden = tf.Variable(bias_initializer([n_neurons]))
# Output layer: Variablen für Weights und Biases
w_out = tf.Variable(weight_initializer([n_neurons, n_outputs]))
bias_out = tf.Variable(bias_initializer([n_outputs]))
Im Beispielcode werden n_inputs = 10 Inputs und n_outputs = 1 Outputs definiert. Die Anzahl der Neuronen im Hidden Layer beträgt n_neurons = 64. Im nächsten Schritt werden die benötigten Variablen instanziert. Für ein einfaches Feedforward Netz werden zunächst die Gewichtungsmatrizen und Biaswerte zwischen Input- und Hidden Layer benötigt. Diese werden in den Objekten w_hidden und bias_hidden mittels der Funktion tf.Variable() angelegt. Innerhalb von tf.Variable() wird weiterhin die Funktion weight_initializer() verwendet, auf die wir im nächsten Abschnitt genauer eingehen. Nach der Definition der benötigten Variablen zwischen Input- und Hidden Layer werden noch die Weights und Biases zwischen Hidden- und Output Layer instanziert.
Es ist wichtig zu verstehen, welche Dimensionen die benötigten Matrizen der Weights und Biases annehmen müssen, damit sie korrekt verarbeitet werden. Als Daumenregel für Gewichtungsmatrizen in einfachen Feedforward Netzen gilt, dass die zweite Dimension des vorhergehenden Layers die erste Dimension des aktuellen Layers darstellt. Was sich zunächst sehr komplex anhört ist schlussendlich nichts anderes als das Weiterreichen von Outputs von Layer zur Layer im Netz. Die Dimension der Biaswerte entspricht normalerweise der Anzahl der Neuronen im aktuellen Layer. Im obigen Beispiel wird somit aus der Anzahl Inputs und der Anzahl Neuronen eine Gewichtungsmatrix der Form [n_inputs, n_neurons] = [10, 64] sowie ein Biasvektor im Hidden Layer der Ausdehnung [bias_hidden] = [64]. Zwischen dem Hidden- und Output Layer hat die Gewichtungsmatrix die Form [n_neurons, n_outputs] = [64, 1] sowie der Biasvektor die Form [1].
Initialisierung
Bei der Definition der Variablen im Codeblock des vorhergehenden Abschnitts wurde die Funktionen weight_initializer() und bias_initializer() verwendet. Die Art und Weise, wie die initialen Gewichtungsmatrizen und Biasvektoren gefüllt werden, hat einen großen Einfluss darauf, wie schnell und wie gut sich das Modell an die vorliegenden Daten anpassen kann. Dies hängt damit zusammen, dass neuronale Netze und Deep Learning Modelle mittels numerischer Optimierungsverfahren trainiert werden, die immer von einer bestimmten Startposition aus beginnen die Parameter des Modells anzupassen. Wenn nun eine vorteilhafte Startposition für das Training des neuronalen Netzes gewählt wird, wirkt sich dies in der Regel positiv auf die Rechenzeit und Anpassungsgüte des Modells aus.
In TensorFlow sind verschiedenste Initialisierungsstrategien implementiert. Angefangen von einfachen Matrizen mit immer dem gleichen Wert, z.B. tf.zeros_initializer() über Zufallswerte, z.B. tf.random_normal_initializer() oder tf.truncated_normal_initializer() bis hin zu komplexeren Funktionen wie tf.glorot_normal_initializer() oder tf.variance_scaling_initializer(). Je nachdem, welche Initialisierung der Gewichte und Biaswerte vorgenommen wird, kann das Ergebnis des Modelltrainings mehr oder weniger stark variieren.
# Initializers
weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=1)
bias_initializer = tf.zeros_initializer()
In unserem Beispiel verwenden wir zwei verschiedene Initialisierungsstrategien für die Gewichte und Biaswerte. Während zur Initialisierung der Gewichtungen tf.variance_scaling_initializer() verwendet wird, nutzen wir tf.zeros_initializer() für die Biaswerte.
Design der Netzwerkarchitektur
Nach der Implementierung der benötigten Gewichtungs- und Biasvariablen wird im nächsten Schritt die Netzwerkarchitektur, auch Topologie genannt, erstellt. Hierbei werden sowohl Platzhalter als auch Variablen in Form von aufeinanderfolgenden Matrizenmultiplikationen miteinander kombiniert.
Weiterhin werden bei der Spezifikation der Topologie auch die Aktivierungsfunktionen der Neuronen festgelegt. Aktivierungsfunktionen führen eine nichtlineare Transformation der Outputs der Hidden Layer durch bevor diese an den nächsten Layer weitergegeben werden. Dadurch wird das gesamte System nichtlinear und kann sich dadurch sowohl an lineare als auch nichtlineare Funktionen anpassen. Es existieren zahllose Aktivierungsfunktionen für neuronale Netze, die sich im Laufe der Zeit entwickelt haben. Heutiger Standard bei der Entwicklung von Deep Learning Modellen ist die sog. Rectified Linear Unit (ReLU), die sich in vielen Anwendungen als vorteilhaft herausgestellt hat.
# Hidden layer
hidden = tf.nn.relu(tf.add(tf.matmul(X, w_hidden), bias_hidden))
# Output layer
out = tf.transpose(tf.add(tf.matmul(hidden, w_out), bias_out))
ReLU Aktivierungsfunktionen sind in TensorFlow mittels tf.nn.relu() implementiert. Die Aktivierungsfunktion nimmt den Output der Matrizenmultiplikation zwischen Platzhalter und Gewichtungsmatrix sowie der Addition der Biaswerte entgegen und transformiert diese, tf.nn.relu(tf.add(tf.matmul(X, w_hidden), bias_hidden)). Das Ergebnis der nichtlinearen Transformation wird als Output an den nächsten Layer weitergegeben, der diesen als Input einer erneuten Matrizenmultiplikation verwendet. Da es sich beim zweiten Layer bereits um den Output Layer handelt, wird in diesem Beispiel keine erneute ReLU Transformation durchgeführt. Damit die Dimensionalität des Output Layers mit derer der Daten übereinstimmt muss nochmals mittels tf.transpose() eine Transponierung der Matrix vorgenommen werden. Andernfalls kann es zu Problemen bei der Schätzung des Modells kommen.
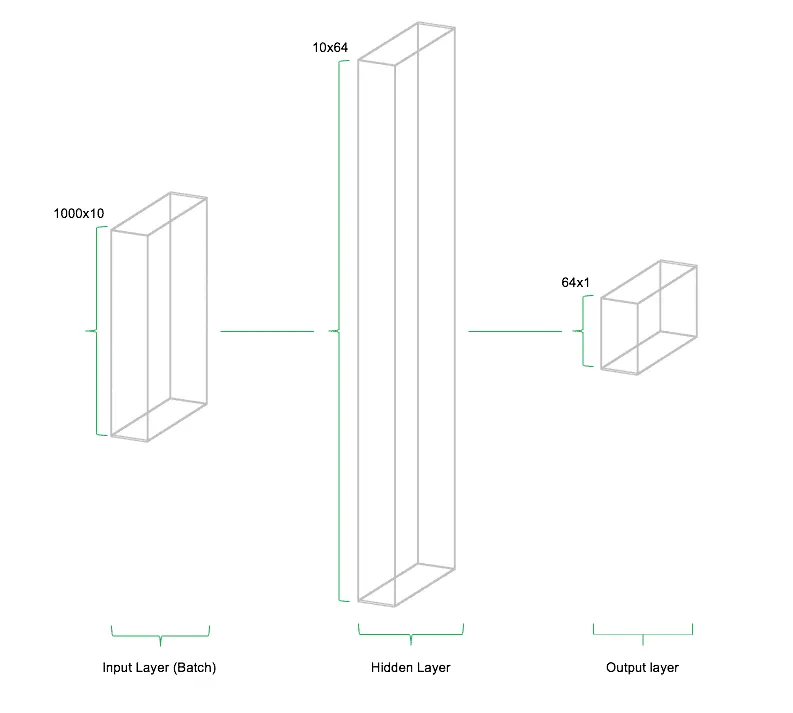
Die oben stehende Abbildung soll die Architektur des Netzwerkes schematisch illustrieren. Das Modell besteht aus drei Teilen: (1) dem Input Layer, (2) dem Hidden Layer sowie (3) dem Output Layer. Diese Architektur nennt man Feedforward Netzwerk. Feedforward beschreibt die Tatsache, dass die Daten nur in eine Richtung durch das Netzwerk fließen. Andere Arten von neuronalen Netzen und Deep Learning Modellen beinhalten Architekturen, die es den Daten erlauben sich auch "rückwärts" oder in Schleifen im Netzwerk zu bewegen.
Kostenfunktion
Die Kostenfunktion (Cost Function) des neuronalen Netzes wird verwendet, um eine Maßzahl zur Bestimmung der Abweichung zwischen der Prognose des Modells und den tatsächlich beobachteten Daten zu berechnen. Hierzu stehen, je nachdem, ob es sich um eine Klassifikation oder Regression handelt, verschiedene Kostenfunktionen zur Verfügung. Für Klassifikationen wird heute zumeist die sog. Kreuzentropie (Cross Entropy) verwendet, für Regressionen die mittlere quadratische Abweichung (Mean Squared Error, MSE). Grundsätzlich kann jede mathematisch differenzierbare Funktion als Kostenfunktion verwendet werden.
# Cost function
mse = tf.reduce_mean(tf.squared_difference(out, Y))
Im obigen Beispiel wird die mittlere quadratische Abweichung als Kostenfunktion implementiert. Hierzu stehen in TensorFlow die beiden Funktionen tf.reduce_mean() sowie tf.squared_difference() zur Verfügung, die einfach miteinander kombiniert werden können. Man sieht, dass die Funktionsargumente von tf.squared_difference() zum einen der Platzhalter Y ist, der die tatsächlich beobachteten Outputs enthält sowie das Objekt out, das die vom Modell erzeugten Prognosen beinhaltet. An der Kostenfunktion laufen also die tatsächlich beobachteten Daten mit den Modellprognosen zusammen und werden miteinander verglichen.
Optimierer
Der Optimierer (Optimizer) hat die Aufgabe, auf Basis der berechneten Modellabweichungen der Kostenfunktion, die Gewichte und Biaswerte des Netzes während des Trainings anzupassen. Um dies zu tun, werden von TensorFlow sog. Gradienten der Kostenfunktion berechnet, die die Richtung anzeigen, in der die Gewichte und Biaswerte angepasst werden müssen, um die Kostenfunktion des Modells zu minimieren. Die Entwicklung von schnellen und stabilen Optimierern ist ein großer Forschungszweig im Bereich neuronaler Netze und Deep Learning.
# Optimizer
opt = tf.train.AdamOptimizer().minimize(mse)
Hier wird der sog. tf.AdamOptimizer()verwendet, der im Moment einer der am häufigsten angewendeten Optimierer ist. Adam steht für Adaptive moment estimation und ist eine methodische Kombination von zwei anderen Optimierungstechniken (AdaGrad und RMSProp). An dieser Stelle gehen wir nicht auf die mathematischen Details der Optimierer ein, da dies den Scope dieser Einführung deutlich sprengen würde. Wichtig zu verstehen ist, dass es verschiedene Optimierer gibt, die auf unterschiedlichen Strategien zur Berechnung der benötigten Anpassungen der Gewichtungs- und Biaswerte basieren.
Session
Die TensorFlow Session ist das Grundgerüst zur Ausführung des Graphen. Die Session wird mit dem Kommando tf.Session() gestartet. Bevor die Session nicht gestartet wurde, kann keine Berechnung innerhalb des Graphen erfolgen.
# Session starten
graph = tf.Session()
In dem Codebeispiel wird eine TensorFlow Session in dem Objekt graph instanziert und kann im Folgenden an einer beliebigen Stelle im Graphen ausgeführt werden. In den aktuellen Entwicklungsversionen (Dev-Builds) von TensorFlow entstehen Ansätze den Code auch ohne die Definition einer Session auszuführen. Aktuell ist dies jedoch nicht im Stable Build enthalten.
Training
Nachdem die notwendigen Bestandteile des neuronalen Netzes definiert wurden, können diese nun im Rahmen des Modelltrainings miteinander verbunden werden. Das Training von neuronalen Netzen läuft heute in der Regel über ein sog. "Minibatch Training" ab. Minibatch bedeutet, dass wiederholt zufällige Stichproben der Inputs und Outputs verwendet werden, um die Gewichtungen und Biaswerte des Netzes anzupassen. Hierzu wird ein Parameter definiert, der die Größe der Zufallsstichprobe (Batches) der Daten steuert. Hierbei ist es häufig so, dass die Daten ohne Zurücklegen gezogen werden, sodass jede Beobachtung im Datensatz für eine Trainingsrunde (auch Epoche genannt) nur einmal dem Netz präsentiert wird. Die Anzahl der Epochen wird ebenfalls als Parameter durch den Anwender definiert.
Die einzelnen Batches werden über die zuvor erstellten Platzhalter X und Y mittels Feed Dictionary in den TensorFlow Graphen übergeben und entsprechend im Modells verwendet. Dies geschieht in Kombination mit der zuvor definierten Session.
# Aktuellen Batch in Netzwerk übergeben
graph.run(opt, feed_dict={X: data_x, Y: data_y})
Im obigen Beispiel wird der Optimierungsschritt opt im Graphen durchgeführt. Damit TensorFlow die notwendigen Berechnungen ausführen kann, müssen über das Argument feed_dict Daten in den Graphen übergeben werden, die für die Berechnungen an die Stelle der Platzhalter X und Y treten sollen.
Nach der Übergabe mittels feed_dict wird X über die Multiplikation mit der Gewichtungsmatrix zwischen Input und Hidden Layer in das Netz eingespeist und durch die Aktivierungsfunktion nichtlinear transformiert. Anschließend wird das Ergebnis des Hidden Layers wiederum mit der Gewichtungsmatrix zwischen Hidden und Output Layer multipliziert und an den Output Layer weitergereicht. Hier wird durch die Kostenfunktion die Differenz zwischen der Prognose des Netzes und den tatsächlich beobachteten Werten Y berechnet. Auf Basis des Optimierers werden nun für jeden einzelnen Gewichtungsparameter im Netz die Gradienten berechnet. Die Gradienten wiederum sind die Basis auf denen eine Anpassung der Gewichtungen in Richtung der Minimierung der Kostenfunktion durchgeführt wird. Diesen Vorgang nennt man auch Gradient Descent. Anschließend wird der soeben beschriebene Prozess mit dem nächsten Batch erneut durchgeführt. Das neuronale Netz bewegt sich also in jeder Iteration näher in Richtung der Kostenminimierung, sprich in Richtung einer kleineren Abweichung zwischen Prognose und beobachteten Werten.
Anwendungsbeispiel
Im folgenden Beispiel sollen die zuvor vermittelten Konzepte nun anhand eines praktischen Beispiels dargestellt werden. Zur Durchführung benötigen wir zunächst einige Daten auf Basis derer das Modell trainiert werden kann. Diese können mittels der in sklearn enthaltenen Funktion sklearn.datasets.make_regression() einfach und schnell simuliert werden.
# Anzahl der zu Inputs, Neuronen und Outputs
n_inputs = 10
n_neurons = 64
n_outputs = 1
# Daten für das Modell simulieren
from sklearn.datasets import make_regression
data_x, data_y = make_regression(n_samples=1000, n_features=n_inputs, n_targets=n_outputs)
Wie im obigen Beispiel verwenden wir 10 Inputs und 1 Output zur Erstellung eines neuronalen Netzes zur Prognose des beobachteten Outputs. Anschließend definieren wir Platzhalter, Initialisierung, Variablen, Netzarchitektur, Kostenfunktion, Optimierer und Session in TensorFlow.
# Platzhalter definieren
X = tf.placeholder(dtype=tf.float32, shape=[None, n_inputs])
Y = tf.placeholder(dtype=tf.float32, shape=[None])
# Initializers
weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=1)
bias_initializer = tf.zeros_initializer()
# Hidden Layer: Variablen für Weights und Biases
w_hidden = tf.Variable(weight_initializer([n_inputs, n_neurons]))
bias_hidden = tf.Variable(bias_initializer([n_neurons]))
# Output layer: Variablen für Weights und Biases
w_out = tf.Variable(weight_initializer([n_neurons, n_outputs]))
bias_out = tf.Variable(bias_initializer([n_outputs]))
# Hidden Layer
hidden = tf.nn.relu(tf.add(tf.matmul(X, w_hidden), bias_hidden))
# Output Layer
out = tf.transpose(tf.add(tf.matmul(hidden, w_out), bias_out))
# Kostenfunktion
mse = tf.reduce_mean(tf.squared_difference(out, Y))
# Optimizer
opt = tf.train.AdamOptimizer().minimize(mse)
# Session starten
graph = tf.Session()
Nun beginnt das Training des Modells. Hierfür benötigen wir zunächst einen äußeren Loop, der über die Anzahl der definierten Epochen ausgeführt wird. Innerhalb jeder Iteration des äußeren Loops werden die Daten zufällig in Batches eingeteilt und nacheinander in einem inneren Loop dem Netzwerk präsentiert. Nach Beendigung einer Epoche wird der MSE, also die mittlere quadratische Abweichung des Modells zu den tatsächlich Beobachteten Daten berechnet und ausgegeben.
# Batch Größe
batch_size = 256
# Anzahl möglicher Batches
max_batch = len(data_y) // batch_size
# Anzahl Epochen
n_epochs = 100
# Training des Modells
for e in range(n_epochs):
# Zufällige Anordnung von X und Y für Minibatch Training
shuffle_indices = np.random.randint(low=0, high=n, size=n)
data_x = data_x[shuffle_indices]
data_y = data_y[shuffle_indices]
# Minibatch training
for i in range(0, max_batch):
# Batches erzeugen
start = i * batch_size
end = start + batch_size
batch_x = data_x[start:end]
batch_y = data_y[start:end]
# Aktuellen Batch in Netzwerk übergeben
net.run(opt, feed_dict={X: batch_x, Y: batch_y})
# Pro Epoche den MSE anzeigen
mse_train = graph.run(mse, feed_dict={X: data_x, Y: data_y})
print('MSE: ' + str(mse))
Insgesamt werden dem Netzwerk 15 Batches pro Epoche präsentiert. Innerhalb von 100 Epochen ist das Modell in der Lage den MSE von anfangs 20.988,60 auf 55,13 zu reduzieren (Anmerkung: diese Werte unterscheiden sich von Ausführung zu Ausführung aufgrund der zufälligen Initialisierung der Gewichte und Biaswerte sowie der zufälligen Ziehung der Batches). Die untenstehende Abbildung zeigt den Verlauf der mittleren quadratischen Abweichung während des Trainings.
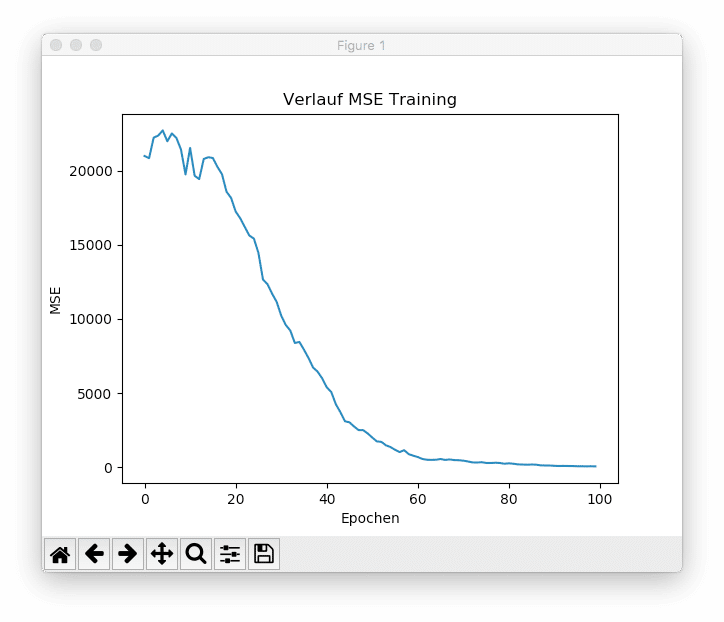
Es ist zu sehen, dass das Modell mit einer ausreichend hohen Anzahl an Epochen in der Lage ist, den Trainingsfehler auf nahe 0 zu reduzieren. Was sich zunächst vorteilhaft anhört ist für echte Machine Learning Projekte ein Problem. Die Kapazität neuronaler Netze ist häufig so hoch, dass sie die Trainingsdaten einfach "auswendig lernen" und auf neuen, ungesehenen Daten schlecht generalisieren. Man spricht hierbei von einem sog. Overfitting der Trainingsdaten. Aus diesem Grund wird häufig bereits während des Trainings der Prognosefehler auf ungesehenen Testdaten überwacht. In der Regel wird das Training des Modells an der Stelle abgebrochen, an der der Prognosefehler der Testdaten wieder anzusteigen beginnt. Dies nennt man Early Stopping.
Zusammenfassung und Ausblick
Mit TensorFlow ist es Google gelungen, einen Meilenstein im Bereich Deep Learning Forschung zu setzen. Durch die geballte intellektuelle Kapazität von Google ist es gelungen eine Software zu erschaffen, die sich bereits nach sehr kurzer Zeit als Quasi-Standard bei der Entwicklung von neuronalen Netzen und Deep Learning Modellen etablieren konnte. Auch bei statworx arbeiten wir in der Data Science Beratung erfolgreich mit TensorFlow, um für unsere Kunden Deep Learning Modelle und neuronale Netze zu entwickeln.


