Datenbanken in R – Einfach, schnell und sicher


Wer mit großen Datenmengen in seinem beruflichen Alltag zu tun hat, der weiß, wie nützlich Datenbanken sein können. Als elektronisches Verwaltungssystem sind Datenbanken darauf ausgelegt, effizient und widerspruchsfrei mit großen Datenmengen umzugehen. Zudem sorgt eine Datenbank im Unternehmen dafür, dass jeder Mitarbeiter auf einen einheitlichen und aktuellen Datenstand zurückgreifen kann. Änderungen in der Datenbasis werden somit allen Beteiligten direkt zuteil. Das ist insbesondere dann von Vorteil, wenn Daten computergestützt automatisch verarbeitet werden.
Mit diesen Paketen meistern Sie den Umgang mit Datenbanken
R bietet verschiedene Pakete zum Umgang mit Datenbanken und ermöglicht es somit auf eine komfortable Art, sich aus R heraus mit Datenbank zu verbinden und diese in den Data Science Prozess zu integrieren. So können wir uns zum Beispiel mit den Paketen DBI und RMySQL bequem und einfach mit unserer Testdatenbank test_db verbinden und uns die darin liegende Testtabelle flights anschauen, welche Informationen zu Abflügen am New Yorker Flughafen des Jahres 2013 enthält.
# Pakete laden
library(DBI) # Funktionen zum Umgang mit Datenbanken
library(RMySQL) # MySQL Treiber
library(dplyr) # Für %>%
# Konnektor-objekt erzeugen
con %
dbGetQuery("SELECT month, day, carrier, origin, dest, air_time
FROM flights LIMIT 3")
# month day carrier origin dest air_time
# 1 1 1 UA EWR IAH 227
# 2 1 1 UA LGA IAH 227
# 3 1 1 AA JFK MIA 160
# Verbindung schließen
dbDisconnect(con)
# [1] TRUE Wie wir sehen, genügen wenige Zeilen Code, um den Inhalt der Datenbanktabelle einzusehen. Der Umgang mit Datenbanken, auch über die R API, hat jedoch einen kleinen Knackpunkt: Für den Umgang mit Datenbanken muss man SQL beherrschen. Das ist an sich kein großes Problem, da SQL als deklarative Sprache recht intuitiv ist. So ist die im Beispiel aufgeführte Query auch einfach zu verstehen. Das Ganze ändert sich jedoch, wenn die Daten auf der Datenbank zu groß sind, um diese über ein einfaches SELECT * FROM abzufragen. In diesem Fall ist es notwendig, erste Aggregationen auf der Datenbank durchzuführen. Sind diese komplex, kann SQL zur echten Hürde eines Data Scientisten werden.Bei STATWORX greifen wir ständig auf Datenbanken zurück, um unsere prädiktiven Systeme nahtlos in die Datenprozesse unserer Kunden integrieren zu können. Man muss jedoch kein SQL-Experte sein, um dies zu tun. Einzelne Packages helfen, mit Datenbanken sicher und souverän umzugehen.Im Folgenden werden drei Pakete vorgestellt, die die Arbeit mit Datenbanken sicherer, stabiler und einfacher machen.
Verbindungen clever verwalten mit pool
Beim Umgang mit Datenbanken sind oft auch etwas technischere Themen von Relevanz.So kann das Verwalten der Verbindungen sehr mühsam sein, wenn diese dynamisch, zum Beispiel in einer Shiny App, erzeugt werden. Dies kann zum Absturz einer App führen, da manche Datenbanken per Default nur 16 gleichzeitige Verbindungen erlauben. Konnektoren müssen daher immer auch geschlossen werden, sollten diese nicht mehr gebraucht werden. Das Schließen wird im Beispielcode oben zum Schluss durchgeführt.Um Konnektoren stabiler zu verwalten, kann das Paket pool verwendet werden.Das pool-Paket erzeugt eine Art intelligenten Konnektor, einen sogenannten Objekt-Pool. Das Praktische daran ist, dass sich der Pool einmal zu Beginn des Aufrufs um das Erzeugen von Konnektoren kümmert und diese das möglichst effizient verwaltet, d.h. Verbindungen zur Datenbank möglichst optimal auslastet. Ein Vorteil im Umgang mit dem pool-Paket ist, dass sich die Funktionalitäten zum DBI-Paket kaum unterscheiden. Dies wollen wir einmal genauer anhand eines Beispiels betrachten.
# Paket laden
library(pool)
# Pool-Objekt erzeugen
pool %
dbGetQuery("SELECT month, day, carrier, origin, dest, air_time
FROM flights LIMIT 3")
# month day carrier origin dest air_time
# 1 1 1 UA EWR IAH 227
# 2 1 1 UA LGA IAH 227
# 3 1 1 AA JFK MIA 160
# Verbindung schließen
poolClose(pool) Wie wir sehen, hat sich die Syntax kaum verändert. Der einzige Unterschied liegt darin, dass wir den Pool mit den eigens dafür vorgesehenen Funktionen dbPool() und poolClose() verwalten. Um die Konnektoren, die für Datenbankabfragen benötigt werden, kümmert sich der Pool selbst. Dies zeigt die untere Grafik schematisch. Der User sendet – stark vereinfacht gesagt – die Query an den Pool, woraufhin der Pool bestimmt, über welchen Konnektor er die Query an die Datenbank schickt und das Ergebnis zurückgibt.
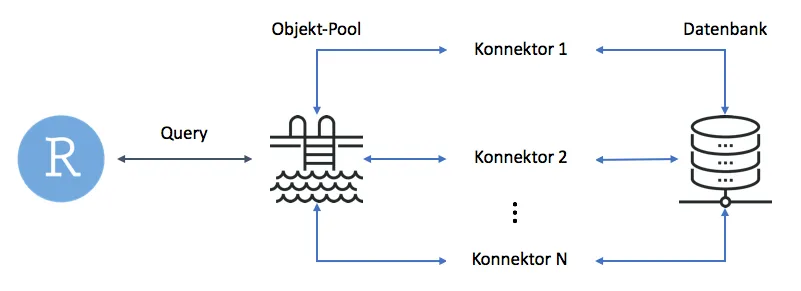
Zugangsdaten verbergen mit config
Beim Erstellen einer Verbindung ist die Eingabe von Zugangsdaten notwendig, die besser an einem geschützten Ort liegen sollten. Dies stellte im obigen Beispiel kein Problem dar, da wir test_db bei uns lokal auf dem PC laufen lassen und die Zugangsdaten somit nicht sensibel sind. Soll der Code zur Erstellung des Konnektors jedoch mit anderen Mitarbeitern geteilt werden, empfiehlt es sich, die Zugangsdaten aus einem R-Objekt auszulesen.Mit config können YAML Konfigurationsdateien aus R heraus eingelesen werden, in denen sich zum Beispiel Zugangsdaten für Datenbanken abspeichern lassen (YAML ist ein für den Menschen lesefreundliches Format, um Daten zu speichern). So müssen wir im ersten Schritt lediglich eine Konfigurationsdatei erstellen, die wir config.yml nennen.
# Konfigurationsdatei erstellen
default:
database_settings:
host: 127.0.0.1
dbname: test_db
user: root
pwd: root
port: 3306
other_setting:
filepath: /path/to/file
username: gauss Zu beachten ist hierbei, dass die erste Zeile der Datei obligatorisch ist. Das YAML Format hat den Vorteil, dass Einstellungen thematisch durch das Einführen von Unterlisten voneinander getrennt werden können. So haben wir im Beispiel eine Unterliste mit den Zugangsdaten zur Datenbank (database_settings) und eine Unterliste mit sonstigen beispielhaften Einstellungen (other_settings) erstellt. Nun können im zweiten Schritt mit der Funktion get() gezielt die Datenbankeinstellungen eingelesen werden.
# Paket laden
library(config)
# Datenbankeinstellungen laden
config <- get(value = "database_settings",
file = "~/Desktop/r-spotlight/config.yml")
str(config)
# List of 5
# $ host : chr "127.0.0.1"
# $ dbname: chr "test_db"
# $ user : chr "root"
# $ pwd : chr "root"
# $ port : int 3306 Beim Erstellen eines Pools müssen wir nun nicht mehr unsere sensiblen Daten offenbaren.
# Pool-Objekt erzeugen
pool <- dbPool(drv = RMySQL::MySQL(),
user = config$user,
password = config$pwd,
host = config$host,
port = config$port,
dbname = config$dbname)
SQL ohne SQL dank dbplyr
dbplyr ist das Datenbank-Back-End von dplyr und kümmert sich schlicht und einfach darum, dass dplyr’s elegante Syntax auch bei der Nutzung von Konnektor-Objekten Anwendung findet. dbplyr wurde in dplyr integriert und muss daher nicht separat geladen werden.
# Paket laden
library(dplyr)
# Eine kleine Query mit dplyr
pool %>%
tbl("flights") %>%
select(month, day, carrier, origin, dest, air_time) %>%
head(n = 3)
# Source: lazy query [?? x 6]
# Database: mysql 5.6.35 [root@127.0.0.1:/test_db]
# month day carrier origin dest air_time
#
# 1 1 1 UA EWR IAH 227
# 2 1 1 UA LGA IAH 227
# 3 1 1 AA JFK MIA 160
Dabei fällt auf, dass es sich bei dem Ergebnis nicht um einen R Data Frame handelt (wie an „Source: lazy query ...“ zu sehen). Vielmehr wird die eingegebene R-Syntax in SQL übersetzt und als Query an die Datenbank geschickt. Es wird somit alles auf der Datenbank berechnet. Den dahinterliegenden SQL-Befehlt kann man sich mit show_query() anzeigen lassen.
# SQL anzeigen lassen
pool %>%
tbl("flights") %>%
select(month, day, carrier, origin, dest, air_time) %>%
head(n = 3) %>%
show_query()
# :SQL:
# SELECT `month` AS `month`, `day` AS `day`, `carrier` AS `carrier`,
# `origin` AS `origin`, `dest` AS `dest`, `air_time` AS `air_time`
# FROM `flights`
# LIMIT 3
Zugegeben: das war noch nicht die Killer-Query, aber das Prinzip sollte klar sein. Mit diesem Tool lassen sich schnell auch deutlich komplexere Querys schreiben. Entsprechend könnten wir nun die mittlere geflogene Distanz pro Fluggesellschaft auf der Datenbank berechnen lassen.
# Eine etwas komplexere Query
qry %
tbl("flights") %>%
group_by(carrier) %>%
summarise(avg_dist = mean(distance)) %>%
arrange(desc(avg_dist)) %>%
head(n = 3)
qry
# Source: lazy query [?? x 2]
# Database: mysql 5.6.35 [root@127.0.0.1:/test_db]
# Ordered by: desc(avg_dist)
# carrier avg_dist
#
# 1 HA 4983.000
# 2 VX 2499.482
# 3 AS 2402.000 Mit collect() können wir uns das Ergebnis des SQL-Statements als R-Objekt abspeichern lassen.# SQL Resultat in R abspeichern
# SQL Resultat in R abspeichern
qry %>%
collect()
# A tibble: 3 x 2
# carrier avg_dist
#
# 1 HA 4983.000
# 2 VX 2499.482
# 3 AS 2402.000
Fazit
Das Arbeiten mit Datenbanken kann durch das Verwenden der richtigen Pakete um einiges einfacher und sicherer gemacht werden. Für das Schreiben komplexer SQL Querys müssen wir dank dplyr nicht länger online SQL-Tutorials pauken, sondern können die freigewordene Zeit für wichtigere Dinge nutzen; zum Beispiel für das Vernaschen der köstlichen Süßigkeiten bei STATWORX, wie Jessica in ihrem Blogbeitrag festgestellt hat.
Referenzen
- Boergs, Barbara (2017). Pool: Object Pooling. R Package Version 0.1.3. URL: https://CRAN.R-project.org/package=pool
- Datenbanken verstehen. Was ist eine Datenbank? URL: http://www.datenbanken-verstehen.de/datenbank-grundlagen/datenbank/
- Wickham, Hadley (2017a). Flights that Departed NYC in 2013. R Package. URL: https://CRAN.R-project.org/package=nycflights13
- Wickham, Hadley (2017b). dbplyr: A 'dplyr' Back End for Databases. R Package Version 1.1.0. URL: https://CRAN.R-project.org/package=dbplyr


