Data-Dashboard mit Bokeh


Ein wesentliches Problem von größeren und heterogenen Daten ist häufig ihre Interpretation. Als Data Scientist stellt man sich auch deshalb unter anderem folgende Fragen:
- Wie sind die Daten strukturiert?
- Was sind besondere Merkmale?
- Wie lassen sich die Daten graphisch aufbereiten?
Selbstverständlich lässt sich diese Liste noch um beliebige Fragestellungen erweitern. Als Hilfestellung zur Lösung der letzten Frage soll folgender Blog Artikel dienen. Anhand eines einfachen Datensatzes möchten wir euch zeigen, wie man mit einem überschaubaren Aufwand ein Dashboard mit der Python-Bibliothek Bokeh aufbauen kann. Dieses lässt sich dann nicht nur zur einfachen Visualisierung von Daten verwenden, sondern natürlich auch für einen Live Betrieb auf einer Website oder Ähnlichem.
Welche Voraussetzungen solltet ihr mitbringen?
Zur Umsetzung dieses kleinen Projektes solltet ihr eine aktuelle Version von Python 3 auf Eurem PC installiert haben. Falls nicht, ist es am einfachsten, Anaconda zu installieren – hiermit seid ihr bestens für dieses Projekt ausgestattet. Durch das Setup werden nicht nur Python, sondern auch viele weitere Bibliotheken wie Bokeh installiert. Zudem bietet es sich an, dass ihr bereits ein wenig Erfahrung in der grundsätzlichen Funktionsweise von Python sammeln konntet und vor der Benutzung der Kommandozeile/Terminal nicht zurückschreckt. Für die Erstellung des Dashboards solltet ihr zudem über einen passenden Texteditor/IDE wie z.B. Atom, PyCharm oder Jupyter verfügen. Ein Jupyter Notebook könnt ihr - sofern ihr Anaconda installiert habt - sehr einfach starten und müsst keine zusätzlichen Installationen vornehmen. Die Vorteile von Jupyter zeigt unser Data Scientist Marvin in einem Blogbeitrag.
Bokeh - Eine kurze Einführung in die Namensherkunft
Die ursprüngliche Bedeutung von Bokeh kommt aus der Fotografie und leitet sich von dem japanischen Wort boke ab. Es bedeutet so viel wie Unschärfe. Die Namenskomposition mit dem Wort boke und dem Buchstaben h ist auf Mike Johnston zurückzuführen, sie sollte die englische Aussprache vereinfachen.
Nun jedoch zurück zur eigentlichen Anwendung von Bokeh. Die Bibliothek ermöglicht es relativ einfach interaktive Grafiken in Anlehnung an D3.js zu erstellen, in denen z.B. per Mausklick Ausschnitte größer dargestellt und diese dann gespeichert werden können. Für Anwendung der Datenexploration ist diese Funktion eine gute Möglichkeit, sein Datenverständnis zu verbessern.
Unser Datensatz
Für das Dashboard wollen wir nicht fiktive Zahlen generieren und uns diese anzeigen lassen, sondern einen möglichst realen Datensatz verwenden. Hierzu begeben wir uns in die Gastronomie. Ein Kellner hat sich die Mühe gemacht, sein nach seinem Feierabend erhaltenes Trinkgeld und einige weitere Daten zu seinen Kunden zu notieren. Der Datensatz ist in der Grafikbibliothek Seaborn enthalten und lässt sich so einfach herunterladen.
import seaborn as sns
tips = sns.load_datset('tips')
Betrachten wir die ersten Zeilen des Datensatzes, so zeigt sich, dass der Kellner eine überschaubare Anzahl von verschiedenen Variablen erfasst hat. Ein Vorteil der Daten ist ihre unterschiedliche Struktur, so sind Variablen mit unterschiedlichen Skalen enthalten, welche wir für verschiedene Visualisierung in unserem Dashboard nutzen können.
Möglichkeiten eines Bokeh Dashboards
Nachdem wir nun einen ersten Überblick über unsere Daten gewonnen haben, gilt es das Dashboard mit Bokeh aufzubauen. Grundsätzlich gibt es hierbei zwei Möglichkeiten:
- Erstellung eines HTML Dokuments inkl. aller Abbildungen
- Starten eines Bokeh Servers
Die erste Möglichkeit bietet den Vorteil, dass ein Dashboard sehr einfach in Form eines HTML Dokuments gespeichert werden kann, allerdings sind interaktive Gestaltungsmöglichkeiten nur beschränkt umsetzbar, sodass wir in diesem Blog Beitrag die zweite Möglichkeit genauer vorstellen. Das Starten des Bokeh Servers läuft folgendermaßen ab:
- Terminal/Bash-Konsole öffnen
- mit cd in das Verzeichnis des Python-Skriptes wechseln
- Dashboard mit
bokeh serve --show name-des-skriptes.pystarten
Der Befehl --show ist nicht zwingend für das Dashboard erforderlich, bringt aber den Vorteil mit sich, dass das Dashboard direkt im Browser angzeigt wird.
Erstellung des Bokeh Dashboards
Kommen wir nun dazu, wie man das Dashboard aufbauen kann. Neben den verschiedenen Visualisierungen kann das Dashboard mit den Widgets wie ein Baukasten modular aufgebaut werden. Auf der Website von bokeh finden sich eine Vielzahl von unterschiedlichen Widgets, womit sich die Funktionen beliebig erweitern lassen. Ziel von unserem Dashboard sollen es sein, dass es folgende Eigenschaften erfüllt:
- Zwei unterschiedliche Visualisierungen
- Interaktionselemente zur Auswahl von Daten für unsere Darstellungen
Als Visualisierungen wollen wir zum einen ein Histogramm/Säulendiagramm und zum anderen einen Scatter-Plot in unser Dashboard aufnehmen. Hierzu importieren wir die Klasse figure mit dieser können wir beide Visualisierung umsetzen. Hierzu drei Anmerkungen:
- Für Bokeh Grafiken ist es entscheidend, um welche Art von Skala es sich bei den Daten handelt. Wir haben in unserem Fall sowohl Daten mit einer Nominalskala, als auch Daten mit einer Verhältnisskala. Wir erstellen daher ein Histogramm sowie ein Säulendiagramm für die unterschiedlichen Fälle.
- Bevor wir ein Histogramm mit Bokeh darstellen können, müssen wir zunächst noch die Klassengrößen und die jeweilige Anzahl der Beobachtungen in den Klassen festlegen, da dies nicht direkt in Bokeh erfolgen kann, setzen wir diesen Schritt mit numpy und der Funktion
np.histogram()um. - Zudem überführen wir unsere Daten in ein Dictionary, damit wir dieses später leicht ändern und das Dashboard interaktiv gestalten können.
Der folgende Python-Code zeigt, wie man das in Verbindung mit dem Bokeh Server und unserem Datensatz umsetzen kann.
import numpy as np
from seaborn import load_dataset
from bokeh.io import curdoc
from bokeh.layouts import row
from bokeh.models import ColumnDataSource
from bokeh.plotting import figure
# Festlegen des Dashboard Titles
curdoc().title = "Histogramm/Säulendiagramm"
# Datenset laden
tips = load_dataset("tips")
# VISUALISIERUNGEN
# Histogramm mit Numpy erstellen
top_hist, x_hist = np.histogram(tips.total_bill)
# Daten in Dict überführen
source_hist = ColumnDataSource(data=dict(x=x_hist[:-1], top=top_hist))
# Allgemeinen Plot erstellen
hist = figure(plot_height=400, plot_width=400,
title="Histogramm",
x_axis_label='total_bill',
y_axis_label='Absolute Häufigkeit')
# Darstellung des Säulendiagramms
hist.vbar(x='x', top='top', width=0.5, source=source_hist)
# Kategoriale Variablen
kat_data = tips.smoker.value_counts()
x_kat = list(kat_data.index)
top_kat = kat_data.values
# Daten in Dict überführen
source_kat = ColumnDataSource(data=dict(x=x_kat, top=top_kat))
# Allgemeinen Plot erstellen
bar = figure(x_range= x_kat, plot_height=400, plot_width=400,
title="Säulendiagramm",
x_axis_label='smoker',
y_axis_label='Absolute Häufigkeit')
# Darstellung des Säulendiagramm
bar.vbar(x='x', top='top', width=0.1, source=source_kat)
# Hinzufügen der beiden Visualisierungen in das Hauptdokument
curdoc().add_root(row(hist, bar))
Als nächstes fügen wir unseren Scatter-Plot zu unserem Dashboard hinzu, hierfür erstellen wir auch wieder eine figure mit einem zugehörigen Daten-Dictionary. Dieses können wir dann zu unserem Dashboard einfach hinzufügen.
# Hinzufügen des Scatter Plots
curdoc().add_root(row(hist, bar, scatter))Der Übersicht halber stellen wir nicht mehr den gesamten Programmcode hier dar, sondern nur noch die wesentlichen Auszüge. Den gesamten Quellcode findet ihr in unserem unserem Git Repositroy. Für dieses Beispiel heißt die zugehörige Datei bokeh-hist-bar-scatter.py. Unser Dashboard sieht inzwischen folgendermaßen aus:
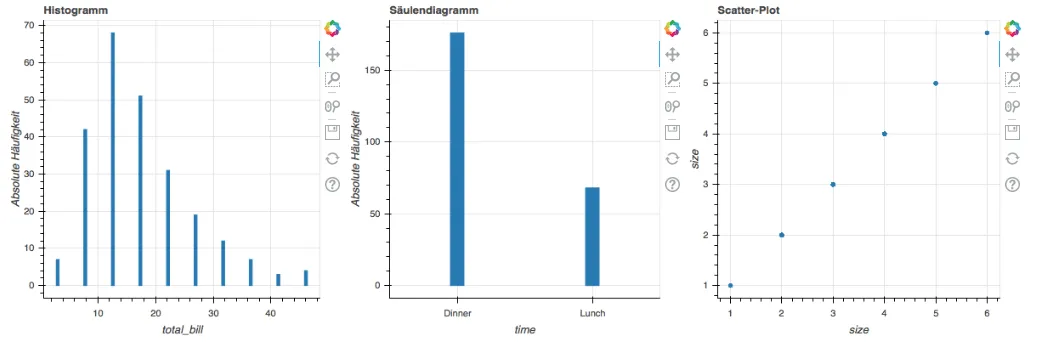
Bis jetzt hat unser Dashboard die erste Anforderung erfüllt, was jetzt noch fehlt, sind die Interaktionselemente auf Englisch: Widgets. Die Funktion der Widgets soll sein, die verschiedenen Variablen für die beiden Plots auszuwählen. Da unser Scatterplot sowohl eine x-, als auch eine y-Achse hat, verwenden wir zwei Select Widgets, um für beide Achsen Daten auszuwählen und beschränken uns auf die Variablen mit Verhältnisskala, also numerischer Natur.

Wie verleiht man dem Dashboard nun die notwendige Interaktion?
Ein wesentliches Manko unseres Dashboards bis jetzt ist es, dass es nur einen Datensatz darstellt, jedoch keine Aktualisierung vornimmt, wenn wir z.B. in den Widgets andere Variablen ausgewählt haben. Das lösen wir nun über die Funktion update_data und eine for-Schleife. Mit der Funktion verändern wir die Daten in unserem Histogramm/Säulendiagramm sowie den Scatter-Plot. Die aktuell gewählten Variablen in unseren Widgets erhalten wir, in dem wir auf das Attribut value zugreifen. Anschließend können wir das dict für unsere Daten aktualisieren. Für die Histogramme ist es entscheidend, ob eine kategoriale Variable vorliegt. Diese Fallunterscheidung decken wir mit der if-Bedinung ab, je nach Variable wird daher entweder das obere oder untere Diagramm aktualisiert. Mit der for-Schleife wird nun sobald eine Veränderung in einem unserer Widgets eintritt, die Funktion update_data ausgeführt.
def update_data(attrname, old, new):
"""Update der Daten sowie der Beschriftungen"""
# Scatter Diagramm
scatter.xaxis.axis_label = select_x.value
scatter.yaxis.axis_label = select_y.value
x = select_x.value
y = select_y.value
source_scatter.data = dict(x=tips[x], y= tips[y])
# Säulendiagramm
data_cat = tips[select_cat.value]
summary = data_cat.value_counts()
bar.x_range.factors = list(summary.index)
source_kat.data = dict(x=list(summary.index), top=summary.values)
bar.xaxis.axis_label = select_cat.value
# Historamm
data_hist = tips[select_hist.value]
top_hist_new, x_hist_new = np.histogram(data_hist)
source_hist.data = dict(x= x_hist_new[:-1], top=top_hist_new)
hist.xaxis.axis_label = select_hist.value
for w in [select_hist, select_cat, select_x, select_y]:
w.on_change('value', update_data)
Damit ist unser Dashboard nun fertig und hat die Zielsetzung erfüllt. Den Code für das fertige Dashboard findet ihr in der Datei bokeh-dashboard-final.py unter folgendem Link und so sieht es in Aktion aus:
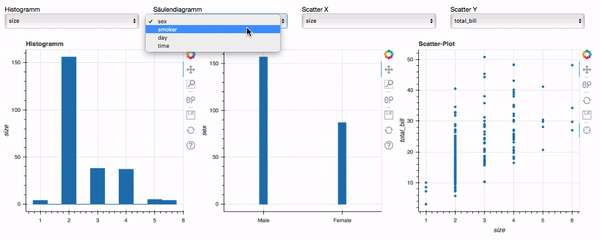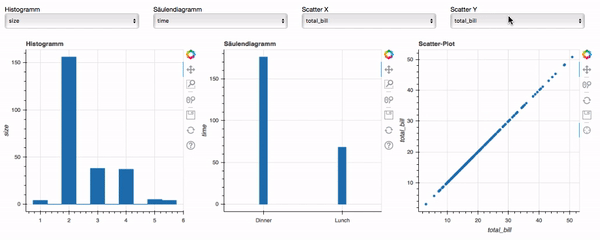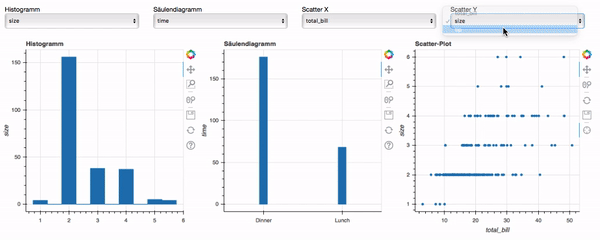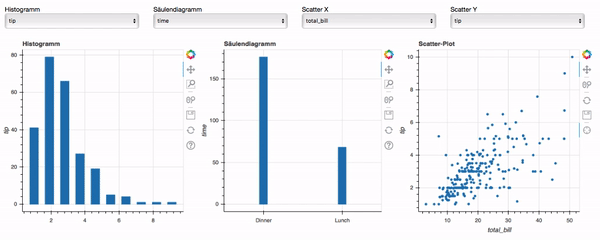
Fazit
Zum Abschluss möchten wir noch ein kurzes Fazit zu unserem Dashboard ziehen. Es hat sich gezeigt, dass folgende Schritte für ein interaktives Bokeh-Dashboard notwendig sind:
- Vorbereitung der Daten und Erstellung von Dictionaries
- Festlegung der Visualisierung und zugehörigen Skalen
- Hinzufügen der passenden Widgets
- Definition einer oder mehrer Funkitonen zur Aktualisierung der Diagramme
Sobald dieses Grundgerüst steht, kann man sein Bokeh-Dashborad beliebig um Widgets und Darstellungen erweitern. Im Hinterkopf sollte man stets die objekteorientierte Arbeitsweise behalten und sich über die verschiedenen Klassen sowie Attribute der Objekte bewusst sein. Durch die Umsetzung in Python ist das Verarbeiten von Daten z.B. mit der Bibliothek pandas einfach möglich. Mit Bokeh spart ihr euch zudem den Aufwand, selber das Layout in HTML-Code festzulegen und auch die Interaktionen in JavaScript zu schreiben. Viel Spaß beim Erstellen eigener Dashboards!
Referenzen:


