Bilder lernen mit Neuronalen Netzen


Convolutional Neural Networks (CNN) sind ein beliebter Architekturtyp neuronaler Netzwerke, die hauptsächlich zur Klassifikation von Bildern und Videos eingesetzt werden. Der Aufbau von Convolutional Networks unterscheidet sich deutlich von dem des Multilayer Perceptron (MLP), das bereits in vorherigen Posts zur Einführung und Programmierung neuronaler Netze besprochen wurde.
Convolutional und Pooling Layers
CNNs verwenden eine spezielle Architektur, die sogenannten Convolutional und Pooling Layers. Der Zweck dieser Schicht ist die Betrachtung eines Inputs aus verschiedenen Perspektiven, bei dem die räumliche Anordnung der Features von Bedeutung ist. Jedes Neuron im Convolutional Layer überprüft einen bestimmten Bereich des Input Feldes mithilfe eines sogenannten Filters. Einen Filter untersucht das Bild auf eine bestimmte Eigenschaft, wie z.B. Farbzusammensetzung oder Kanten und ist prinzipiell nichts Anderes als eine eigens für diese Aufgabe trainierte und zuständige Schicht.
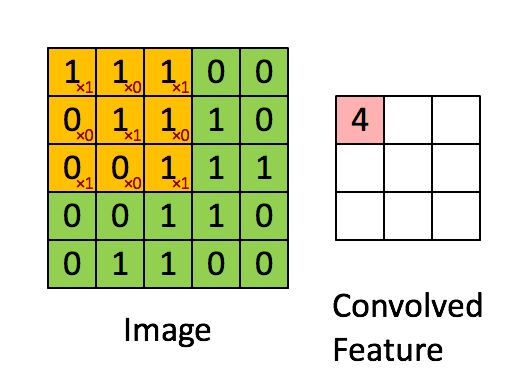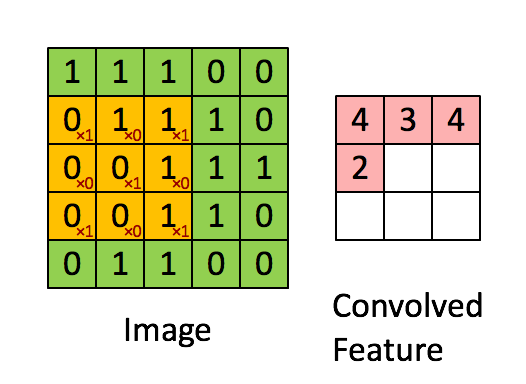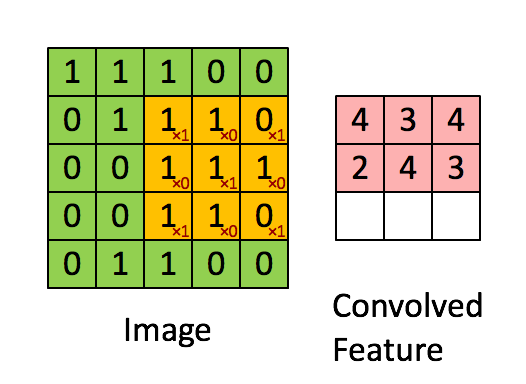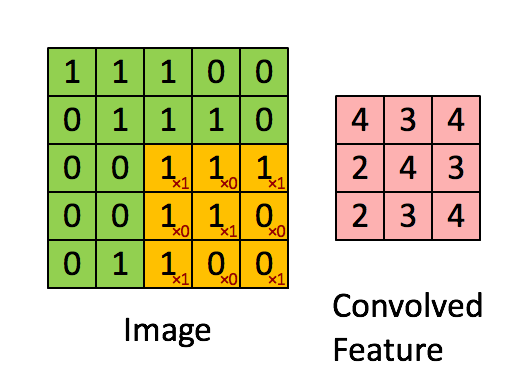
Das Ergebnis eines Filters ist der gewichtete Input für einen Bereich und wird im Convolutional Layer gespeichert. Die Anzahl der Convolutional Layers ist gleich die Anzahl der verwendeten Filter, da jeweils das gesamte Input Bild von jedem Filter geprüft wird. Diese Information wird zwischen den einzelnen Convolutional Layern mit sogenannten Pooling Layern komprimiert. Die Pooling Layer laufen die durch die Filter erstellte Feature Map ab und komprimieren diese. Komprimieren bedeutet in diesem Fall die Reduktion der Pixelanzahl nach einer gegebenen Logik. Diese kann beispielsweise eine Summe oder der Maximalwert eines kleinen Bereichs der Feature Map sein. Dies ähnelt den Convolutional Layern, mit dem Unterschied, dass die Pooling Schichten nicht trainiert werden und ihre Logik somit bestehen bleibt. Danach können noch weitere Convolutional Layer und/oder Pooling Schichten folgen. Anschließend werden die abstrahierten Features in ein voll vernetztes MLP übergeben (siehe Abb). Eine höhere Anzahl von Schichten führt meist zu einem höheren Grad der Abstraktion des Ursprungsbildes. In diesem MLP wird z.B. bei der Bildklassifikation eine abschließende Multiclass Klassifikation durchgeführt und die wahrscheinlichste Klasse zurückgegeben. Multiclass bezeichnet dabei ein Problem bei dem die Zielvariable zu einer von mehreren Klassen gehören kann. Das Gegenstück hierzu ist die binäre Klassifikation, bei der die Zielvariable nur zwei Zustände annehmen kann.

Benchmarking und Evaluation
Bildklassifikation ist einer der Benchmark Cases für die Evaluation aktueller Deep Learning Forschung. Bekannte Datensätze die hierfür verwendet werden sind bspw. MNIST oder CIFAR10 bzw. CIFAR100. Ersterer enthält die Bilder handgeschriebener Ziffern auf Postumschlägen des US Postal Service und ist somit ein Multi-Class Klassifikationsproblem mit 10 Ausprägungen (Ziffern 0-9). Die CIFAR Datensätze beinhalten Bilder von Tieren und Fahrzeugen –in der Version mit 10 Ausprägungen– oder auch von Pflanzen, Menschen oder sogar Elektro-Geräten in dem Datensatz mit 100 Klassen. 10 und 100 stehen dabei für die Anzahl an unterschiedlichen Klassen, die durch Bilder im Datensatz repräsentiert sind. Eine höhere Anzahl an Klassen, stellt in der Regel ein schwierigeres Problem für den Algorithmus dar. Aktuelle state-of-the-art Modelle zur Bildklassifikation erreichen eine Genauigkeit von bis zu 99.8% für MNIST, 96.5% für CIFAR-10 bzw. 75.7% für den CIFAR-100 Datensatz2.
Natürlich bieten die Deep Learning Frameworks Tensorflow und Keras eine Reihe von vorkonfigurierten Bausteinen zur Erstellung von Convolutional Neural Networks. Im kommenden Blogbeitrag veranschaulichen wir die Erstellung eines CNN, mit dem wir versuchen werden, die Kategorien des CIFAR-10 Datensatzes zu erlernen.
Referenzen
- Bildnachweis CNN: Beitrag auf Statsexchange
- Sammlung von CNN-Benchmark Ergebnissen


