5 Types of Machine Learning Algorithms With Use Cases


Machine Learning Impact
The conceptual fundamentals for Machine Learning (ML) were developed in the second half of the 20th century. But computational limitations and sparsity of data postponed the enthusiasm around artificial intelligence (AI) to recent years. Since then, computers have become exponentially faster, and cloud services have emerged with nearly limitless resources. The progress in computational power, combined with the abundance of data, makes Machine Learning algorithms applicable in many fields today.
AI systems are beating human domain experts at complex games, such as the board game Go or video games like Dota2. Surprisingly, the algorithms can find ways to solve the task that human experts haven’t even considered. In this sense, humans can learn from their behavior.
All these success stories have to be put in context. ML algorithms are well suited for specialized tasks; however, they still generalize poorly as of today.
One recent exception is an enormous model in Natural Language Processing – the use of a human language (e.g., English) by a computer. The model is called GPT-3 and has performed exceptionally well in multiple tasks. It is an objective of the AI research community to make models applicable for different jobs.
Machine Learning is a branch of Artificial Intelligence
In the early beginnings of artificial intelligence, applications were built on rule-based programs, which means humans encoded their knowledge into the computer. This approach is extremely rigid since only scenarios are covered that the developer considered, and there is no learning taking place. With the significant increase in computing power and the accompanied data generation, algorithms can learn tasks without human interaction. The terms algorithm and model are used interchangeably here.
The process of extracting knowledge from data is called Machine Learning, and it is a subarea of AI. There are various Machine Learning models, and they all use different approaches. Most of them are based on two elements: parameters and an objective function. The objective function returns a value, which signals the performance of the model, and parameters can be thought of as adjustable screws. Hence, the goal is to find those parameters yielding the best possible performance of the model on a specific dataset.
The format of the data determines which algorithms are applicable. Data can be structured or unstructured. Structured data is arranged in a table-like form, whereas unstructured data represents images, audio, or text.
Moreover, data can be labeled or unlabeled. In the case of Labeled data, as one could guess, each data sample has a tag. For example, in figure 1, each image in the dataset is tagged with a description of the animal seen in the picture. Unlabeled data is simply a dataset without any tags. As you can see in figure 1, the dataset no longer has tags with the information that the image represents.

Figure 1: Illustration of labeled and unlabeled data using images.
When working with unstructured data, there often isn’t a natural tag that can be collected. Usually, humans have to go through all examples and tag them with predefined labels. However, models need a lot of data to learn a task – similar to humans, who encounter a lot of information in their first few years of life before they succeed in walking and talking. That’s what motivated Fei Fei Li, former Director of Stanford’s AI Lab, to create a large database with cleanly labeled images, the ImageNet. Currently, ImageNet encompasses more than 14 million images with more than 20,000 categories – you can, for example, find images showing a banana several hundred times. ImageNet became the largest database with labeled images, and it is the starting point for most state-of-the-art Computer Vision models.
We are encountering ML models in our daily lives. Some are practical, like Google Translate; others are fun, like Snapchat Filters. Our interaction with artificial intelligence will most likely increase in the next few years. Given the potential impact of ML models on our future lives, let me present to you the five branches of ML and their key concepts.
Supervised Learning
What is Supervised Learning?
In Supervised Learning tasks, the training of a model is based on data with known labels. Those models take data as input and yield a prediction as output. The predictions are then compared to the truth, which is depicted by the labels. The objective is to minimize the discrepancy between truth and prediction.
Supervised tasks can be divided into two areas: Classification and Regression. Classification problems predict to which class an input belongs. For instance, predicting whether there is a dog or a cat on an image. You can further differentiate between binary classification, where only two classes are involved or multiclass classification involving multiple classes. On the other hand, Regression problems predict a real-valued number. A typical Regression problem is sales forecasting, e.g., predicting how many products will be sold next month.
Use Case
Farmers are growing and supplying perishable goods. One of the decisions a tomato farmer has to take after the harvest is how to bundle his product. Tomatoes that look esthetic should be offered to the end-users, while tomatoes with minor beauty flaws can be sold to intermediate producers, e.g., tomato sauce producers. On the other hand, inedible crops should be filtered out and used as a natural fertilizer.
This is a specialized and repetitive job that Machine Learning algorithms can automate easily. The quality of the tomatoes can be classified using Computer Vision. Each tomato is scanned by a sensor and evaluated by a model. The model assigns each tomato to a specific group.
Before using such models in production, they have to be trained on data. Input for the model would be images of tomatoes with corresponding labels (e.g., end-user, intermediate producer, fertilizer). The output of the model would be the probability measuring the model’s certainty. A high probability signals that the model is confident about the classification. In cases where the model is not sure, a human expert could have a second look at it. This way, there is a prefiltering of clear cases, while inconclusive cases have to be determined individually.
Deploying the model could provide a more efficient process of crop classification. Moreover, the use case applies to numerous quality control/management problems.
Frameworks
The maturity of frameworks for Supervised Learning is high compared to other areas of Machine Learning. Most relevant programming languages have a mature extension dedicated to Supervised Learning tasks. Furthermore, cloud providers and AI platforms reduce the hurdle to benefit from Supervised Learning models with user-friendly interfaces and tools.
Considerations
For Supervised Learning tasks, labeled data is necessary. In many cases, it is expensive to gather labeled data. E.g., in the use case above, at least one human expert had to label each sample by hand. It gets even more costly when considerable knowledge is expected for labeling, such as recognizing tumors on x-ray images. Therefore, various companies have specialized in providing labeling services. Even the big cloud providers – Microsoft, Amazon, and Google – are offering these services. The most prominent one is Amazon Web Services Mechanical Turk.
However, data are abundant – but often unlabeled. In the field of Unsupervised Learning, algorithms were developed to exploit unlabeled data.
Unsupervised Learning
What is Unsupervised Learning?
Unsupervised Learning algorithms focus on solving problems without depending on labeled data. Contrary to Supervised Learning, there is no ground truth available. The performance of the model is evaluated on the input data itself.
This field of Machine Learning can be summarized in three subareas – dimensionality reduction, clustering, and anomaly detection. These subareas are presented in the following.
Datasets can be enormous due to the number of examples and the number of features they contain. In general, the number of examples should be a lot higher than the number of features to ensure that models can find a pattern in the data. There is a problem when features outweigh the number of examples in the data.
Dimensionality reduction algorithms tackle this problem by creating an abstraction of the original dataset while keeping as much information as possible. That means that a dataset with 100 features and just 50 examples can be compressed to a new dataset with 10 features and 50 examples. The new features are constructed in a way that they contain as much information as possible. A small amount of information from the original dataset is sacrificed to ensure that a model yields reliable predictions.
In clustering approaches, we seek to partition the observations into distinct subgroups. The goal is to obtain clusters where observations within clusters are quite similar, while observations in different clusters vary.
Each observation of the dataset can be thought of as a point in a room. The recorded features determine the location of the point. When considering two observations, a distance can be calculated. The distance is then a signal of how similar these two points are.
Clustering algorithms initially create random clusters and iteratively adjust these to minimize the distances of points within a cluster. The resulting clusters contain observations with similar characteristics.
In anomaly detection, the goal is to identify observations that seem strange conditional on the dataset. These observations can also be called outliers or exceptions. An example is fraudulent bank activity, where the payment was attempted from a different country than usual. The attempt is identified as an anomaly and raises a verification process.
Use Case
Big retail companies often provide loyalty cards to collect value points. After each purchase, the card can be scanned to collect these value points. Each month the customer gets a report about his shopping behavior. Which products did the customer buy most often? What is the share of sustainable products the customer purchased? The customer also gets some kind of discount or cashback voucher. The more points a customer collects, the higher the value of the voucher. This can lead to higher customer loyalty and satisfaction since they get rewarded for their behavior. The collected data about the customers’ shopping behavior represents a lot of potential value to the retail company.
It is fair to assume that there is some heterogeneity among customers since all have their shopping behavior. Clustering could be used to identify groups with similar preferences. This is an Unsupervised Learning problem because the groups are unknown beforehand.
E.g., three clusters might emerge. One cluster contains customers with a vegetarian diet, meat-eaters, and customers mixing meat and vegetarian substitutes. Based on the three customer profiles, marketing campaigns can be customized cluster-specific.

Figure 2: Clustering customers into three groups based on their shopping behavior.
Frameworks/Maturity
Dimensionality reduction, clustering, and anomaly detection algorithms are relatively mature approaches and available in most Machine Learning packages.
Considerations
Recent research puts a focus on Unsupervised methods. The main reason is that there is an abundance of data available, but just a tiny share is labeled data. Self-Supervised and Semi-Supervised Learning approaches arose from the goal to combine labeled and unlabeled data to learn a task.
Self-Supervised Learning
What is Self-Supervised Learning?
Self-Supervised Learning is a relatively new approach in Machine Learning, mainly applied in Computer Vision and Natural Language Processing. These fields require large datasets to learn a task, but as I discussed earlier, it is expensive to obtain a clean labeled large dataset.
Large amounts of unlabeled data are generated every day – tweets, Instagram posts, and many others. The idea of Self-Supervised Learning is to take advantage of all the available data. The learning task is constructed from a supervised problem using unlabeled data. The key is that the labels for the supervised task are a subset of the input. In other words, the data is transformed so that a piece of the input is used as the label and the model’s objective is to predict the missing piece of the input. This way, the data is supervising itself.
There are different ways to transform input data. A simple one is through rotation. As depicted in figure 2, a transformation is applied to each input image. The modified image is input for the model, and the applied rotation is the target to predict. To predict different rotations for the same image, the model must learn to recognize high-level image semantics – such as sky, terrain, heads, eyes, and the relative position of these parts.
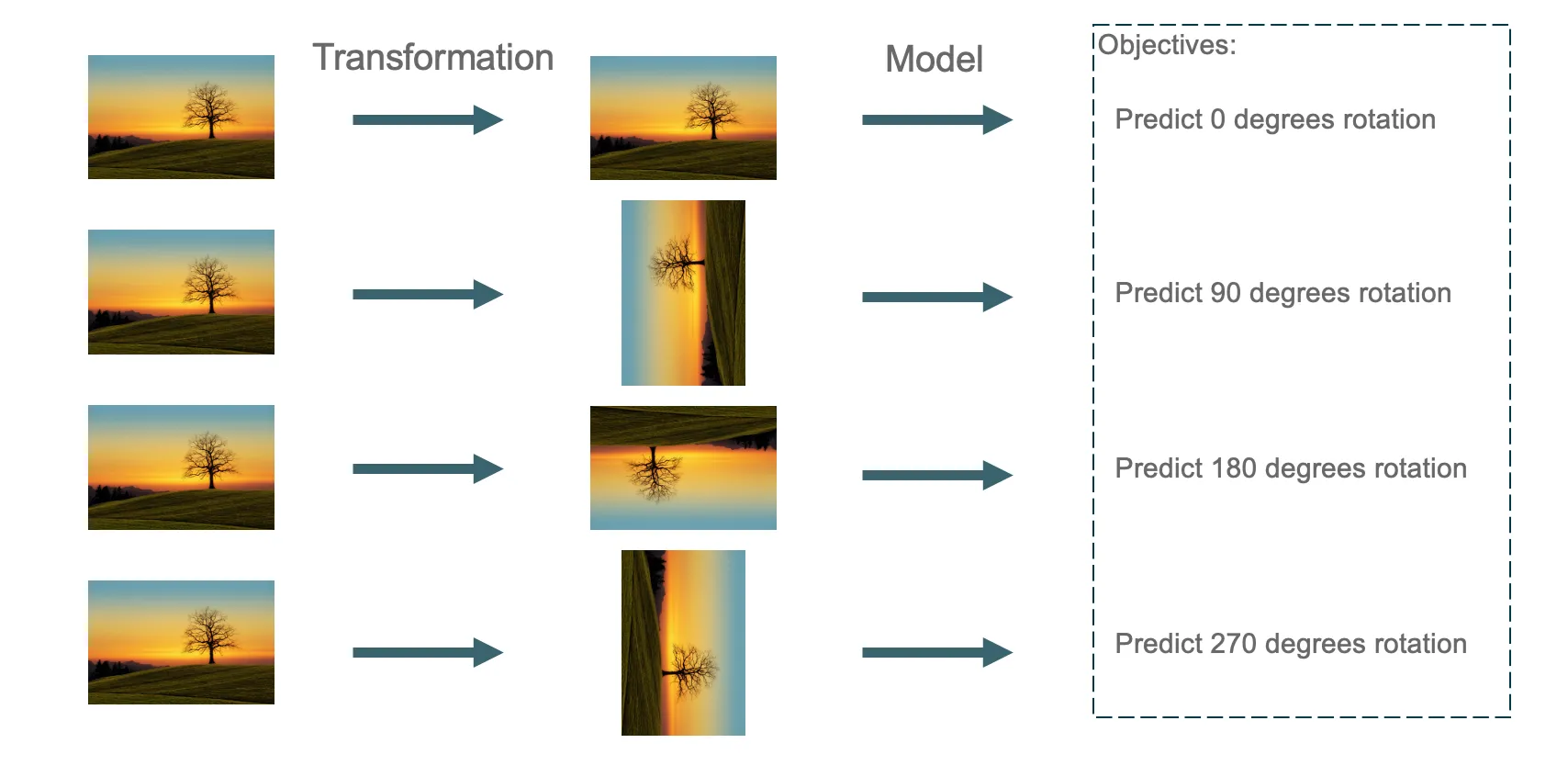
Figure 3: Illustration of Self-Supervised Learning using the rotation of the input image. The model learns to predict the applied rotation.
In conclusion, the performance of the model predicting the rotation of the image is irrelevant; it is just a means to an end. While solving the rotation prediction task, the model implicitly learns a generally good understanding of images. In the context of language models, an initial objective could be to predict the next word in the text. Through this task, the model already learns the structure of a language. This part of the model can be extracted and further used for a more specialized task using Supervised Learning. The benefit is that the model already learned a broad understanding and doesn’t need to start from scratch to learn a task.
Use Case
Speech recognition models can translate human speech into text. It is used in many services, most prominently in home-assistance systems like Alexa.
In a Self-Supervised setting, unlabeled data (for example, audiobooks) can be used for pretraining. Through an auxiliary task, the model learns a broad understanding of speech and language. That part of the model is extracted and combined with Supervised Learning techniques. Hence, Self-Supervised Learning can be used to improve the performance of Supervised Learning approaches.
Frameworks
Few frameworks provide access to Self-Supervised Learning models. PyTorch, e.g., provides pre-trained models that can be used for Computer Vision tasks. Besides that, the models can be reproduced – but that is quite a challenging task and can be costly.
Considerations
Recent papers show promising results, but they are often focusing on one area. For instance, Self-Supervised Learning is yielding provable improvements for image classification. Translating the progress to object detection, however, has shown to be quite tricky and not straightforward. Nevertheless, the approaches and improvements are exciting.
Semi-Supervised Learning
What is Semi-Supervised Learning?
Supervised and Unsupervised Learning are combined in Semi-Supervised Learning.
There are different approaches to Semi-Supervised Learning. Usually, it is divided into multiple steps.
First, a model is trained in a Self-Supervised Learning manner. For instance, the model learns a good understanding of a language using unlabeled text data and an auxiliary task (a simple example would be to predict the next word in the text). The elements of the model responsible for succeeding in the auxiliary task can be cut off. The rest of the model contains a high-level understanding of a language.
The truncated model is then trained on the labeled data in a Supervised Learning fashion. Since the model already learned some understanding of a language, it does not need a massive amount of labeled data to learn another specialized task connected to language understanding. Semi-Supervised Learning is primarily applied in the fields of Computer Vision and Natural Language Processing.
Use Case
People are sharing their thoughts and opinions daily on social media. These comments in the form of text can be valuable for companies. Tracking customer satisfaction over time generates a deeper understanding of the customer experience. Sentiment analysis, a subfield of Natural Language Processing, can be used to classify the customer views based on tweets, Facebook comments, or blog posts. Before being able to classify sentiment from text, the model is pretrained on text documents from Wikipedia, books, and many other resources. Usually, the model’s task is to predict the next word in a sentence. The objective is to learn the structure of a language in a first step before specializing in a particular task. After the pretraining, the model parameters are fine-tuned on a dataset with labels. In this scenario, the model is trained on a dataset with tweets, each with a tag, whether the sentiment is negative, neutral, or positive.
Frameworks
Semi-Supervised Learning covers all approaches that combine Unsupervised and Supervised Learning. Hence, practitioners can use well established frameworks from both areas.
Considerations
Semi-Supervised Learning is combining unlabeled and labeled data to increase the predictive performance of the model. But a prerequisite is that the size of the unlabeled data is substantially larger compared to the labeled data. Otherwise, just Supervised Learning could be used.
Reinforcement Learning
What is Reinforcement Learning?
In the Reinforcement setting, an agent is interacting with an environment. The agent observes the state of the environment, and based on its observations, it can choose an action. Depending on the chosen action, it gets a reward. If the action was good, the agent will get a high reward and vice versa. The goal of the agent is to maximize its future cumulative reward. In other words, it has to find the best action for each state.
In many cases, the interaction of the agent with the environment is simulated. That way, the agent can experience millions of states and learn the correct behavior.

Figure 4: Illustration of the learning process in Reinforcement Learning
Use Case
Personalized advertisement can improve the efficiency of a new marketing campaign. Instead of displaying ads with a discount for a product, say a car, internet users could be led down a sales funnel before presenting the final deal. In the first step, the ad could describe the availability of favorable financing terms, then, on the next visit, praise an excellent service department, and in the end, present the final discount. This might lead to more clicks of a user over repeated visits and, if well implemented, to more sales.
In the above-described case, an agent would choose which ad should be shown depending on the user’s profile. The profile is based on the user’s interests and preferences derived from online activity. The agent adjusts his actions – displaying different ads – based on the user’s feedback. In this setting, the agent does not get a signal for each action he takes since it takes a while until the user decides to purchase a car. For instance, showing a specific ad might catch the user’s interest but won’t immediately translate into a sale. This is called the credit assignment problem. But the agent can wait for an amount of time. If the case results in a sale, the probability of the taken actions will be increased given the same input. Otherwise, the agent will be discouraged to take the same actions for the same input.
Frameworks
Within the field of Reinforcement Learning, various approaches exist. Hence, there is not a standardized framework available. But gym and baselines – both developed by OpenAI, a nonprofit AI research company – establish themselves as important starting points for Reinforcement Learning applications.
Considerations
The agent is learning based on many interactions with the environment. Conducting these interactions in real-time would take a long time and is often infeasible – e.g., a car autopilot cannot learn in the real world because it is not safe. Therefore, simulations of the real world are created, where the agent can learn through trial and error. To train an agent successfully, the gap between simulation and reality has to be as small as possible.
Apart from the simulation, the conception of the reward is crucial to the agent’s performance. In maximizing his reward, the agent can learn unintended behavior, which leads to higher rewards but does not solve the task.
The learning procedure of the agent is sample inefficient. This means that it needs a lot of interactions to learn a task.
Reinforcement Learning shows promising results in many areas. However, few real-world applications are based on it. This might change in a few years.
Conclusion
The Future of Artificial Intelligence
Artificial Intelligence has come a long way – from rule-based scripts to Machine Learning algorithms that are beating human experts. The field has grown substantially in recent years. ML models are used to tackle different domain problems, and their impact on our lives is increasing steadily.
Nonetheless, there are still important questions that remain unanswered. To create more reliable models, we have to address these questions.
A crucial point is the measurement of intelligence. We do not have a general definition of intelligence yet. The current models that we describe as artificially intelligent are learning by memorizing the data we provide. That already yields astonishing results. Introducing a metric of intelligence and optimizing it will lead to far more powerful models in the future. It is exciting to experience the progress in AI.
Resources
- “Google AI defeats human Go champion”
- “OpenAI Five Defeats Dota 2 World Champions”
- https://www.alexirpan.com/2018/02/14/rl-hard.html
- Reinforcement Learning, Sutton R. and Barto A., 2018




