Web Scraping 101 in Python with Requests & BeautifulSoup


Intro
Information is everywhere online. Unfortunately, some of it is hard to access programmatically. While many websites offer an API, they are often expensive or have very strict rate limits, even if you’re working on an open-source and/or non-commercial project or product.
That’s where web scraping can come into play. Wikipedia defines web scraping as follows:
Web scraping, web harvesting, or web data extraction data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol [HTTP], or through a web browser.
“Web scraping” wikipedia.org
In practice, web scraping encompasses any method allowing a programmer to access the content of a website programmatically, and thus, (semi-) automatically.
Here are three approaches (i.e. Python libraries) for web scraping which are among the most popular:
- Sending an HTTP request, ordinarily via Requests, to a webpage and then parsing the HTML (ordinarily using BeautifulSoup) which is returned to access the desired information. Typical Use Case: Standard web scraping problem, refer to the case study.
- Using tools ordinarily used for automated software testing, primarily Selenium, to access a websites‘ content programmatically. Typical Use Case: Websites which use Javascript or are otherwise not directly accessible through HTML.
- Scrapy, which can be thought of as more of a general web scraping framework, which can be used to build spiders and scrape data from various websites whilst minimizing repetition. Typical Use Case: Scraping Amazon Reviews.
While you could scrape data using any other programming language as well, Python is commonly used due to its ease of syntax as well as the large variety of libraries available for scraping purposes in Python.
After this short intro, this post will move on to some web scraping ethics, followed by some general information on the libraries which will be used in this post. Lastly, everything we have learned so far will be applied to a case study in which we will acquire the data of all companies in the portfolio of Sequoia Capital, one of the most well-known VC firms in the US. After checking their website and their robots.txt, scraping Sequoia’s portfolio seems to be allowed; refer to the section on robots.txt and the case study for details on how I went about determining this.
In the scope of this blog post, we will only be able to have a look at one of the three methods above. Since the standard combination of Requests + BeautifulSoup is generally the most flexible and easiest to pick up, we will give it a go in this post. Note that the tools above are not mutually exclusive; you might, for example, get some HTML text with Scrapy or Selenium and then parse it with BeautifulSoup.
Web Scraping Ethics
One factor that is extremely relevant when conducting web scraping is ethics and legality. I’m not a lawyer, and specific laws tend to vary considerably by geography anyway, but in general web scraping tends to fall into a grey area, meaning it is usually not strictly prohibited, but also not generally legal (i.e. not legal under all circumstances). It tends to depend on the specific data you are scraping.
In general, websites may ban your IP address anytime you are scraping something they don’t want you to scrape. We here at statworx don’t condone any illegal activity and encourage you to always check explicitly when you’re not sure if it’s okay to scrape something. For that, the following section will come in handy.
Understanding robots.txt
The robot exclusion standard is a protocol which is read explicitly by web crawlers (such as the ones used by big search engines, i.e. mostly Google) and tells them which parts of a website may be indexed by the crawler and which may not. In general, crawlers or scrapers aren’t forced to follow the limitations set forth in a robots.txt, but it would be highly unethical (and potentially illegal) to not do so.
The following shows an example robots.txt file taken from Hackernews, a social newsfeed run by YCombinator which is popular with many people in startups.
The Hackernews robots.txt specifies that all user agents (thus the * wildcard) may access all URLs, except the URLs that are explicitly disallowed. Because only certain URLs are disallowed, this implicitly allows everything else. An alternative would be to exclude everything and then explicitly specify only certain URLs which can be accessed by crawlers or other bots.
Also, notice the crawl delay of 30 seconds which means that each bot should only send one request every 30 seconds. It is good practice, in general, to let your crawler or scraper sleep in regular (rather large) intervals since too many requests can bring down sites down, even when they come from human users.
When looking at the robots.txt of Hackernews, it is also quite logical why they disallowed some specific URLs: They don’t want bots to pose as users by for example submitting threads, voting or replying. Anything else (e.g. scraping threads and their contents) is fair game, as long as you respect the crawl delay. This makes sense when you consider the mission of Hackernews, which is mostly to disseminate information. Incidentally, they also offer an API that is quite easy to use, so if you really needed information from HN, you would just use their API.
Refer to the Gist below for the robots.txt of Google, which is (obviously) much more restrictive than that of Hackernews. Check it out for yourself, since it is much longer than shown below, but essentially, no bots are allowed to perform a search on Google, specified on the first two lines. Only certain parts of a search are allowed, such as „about“ and „static“. If there is a general URL which is disallowed, it is overwritten if a more specific URL is allowed (e.g. the disallowing of /search is overridden by the more specific allowing of /search/about).
User-Agent: *
Disallow: /x?
Disallow: /vote?
Disallow: /reply?
Disallow: /submitted?
Disallow: /submitlink?
Disallow: /threads?
Crawl-delay: 30
Moving on, we will take a look at the specific Python packages which will be used in the scope of this case study, namely Requests and BeautifulSoup.
Requests
Requests is a Python library used to easily make HTTP requests. Generally, Requests has two main use cases, making requests to an API and getting raw HTML content from websites (i.e., scraping).
Whenever you send any type of request, you should always check the status code (especially when scraping), to make sure your request was served successfully. You can find a useful overview of status codes here. Ideally, you want your status code to be 200 (meaning your request was successful). The status code can also tell you why your request was not served, for example, that you sent too many requests (status code 429) or the infamous not found (status code 404).
Use Case 1: API Requests
The Gist above shows a basic API request directed to the NYT API. If you want to replicate this request on your own machine, you have to first create an account at the NYT Dev page and then assign the key you receive to the KEY constant.
The data you receive from a REST API will be in JSON format, which is represented in Python as a dict data structure. Therefore, you will still have to „parse“ this data a bit before you actually have it in a table format which can be represented in e.g. a CSV file, i.e. you have to select which data is relevant for you.
Use Case 2: Scraping
The following lines request the HTML of Wikipedia’s page on web scraping. The status code attribute of the Response object contains the status code related to the request.
After executing these lines, you still only have the raw HTML with all tags included. This is usually not very useful, since most of the time when scraping with Requests, we are looking for specific information and text only, as human readers are not interested in HTML tags or other markups. This is where BeautifulSoup comes in.
BeautifulSoup
BeautifulSoup is a Python library used for parsing documents (i.e. mostly HTML or XML files). Using Requests to obtain the HTML of a page and then parsing whichever information you are looking for with BeautifulSoup from the raw HTML is the quasi-standard web scraping „stack“ commonly used by Python programmers for easy-ish tasks.
Going back to the Gist above, parsing the raw HTML returned by Wikipedia for the web scraping site would look similar to the below.
In this case, BeautifulSoup extracts all headlines, i.e. all headlines in the Contents section at the top of the page. Try it out for yourself!
As you can see below, you can easily find the class attribute of an HTML element using the inspector of any web browser.
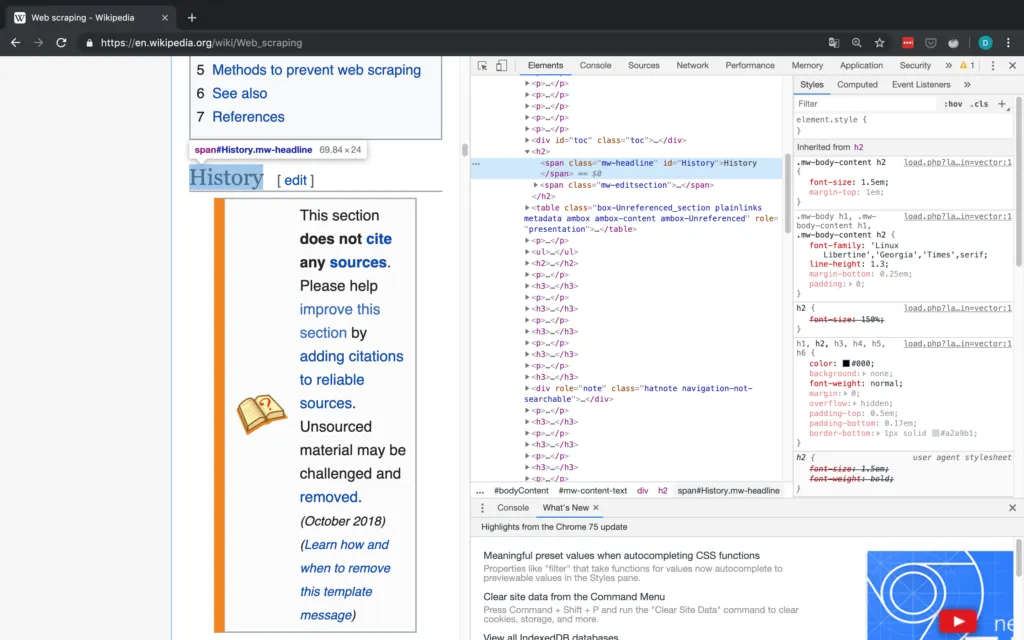
This kind of matching is (in my opinion), one of the easiest ways to use BeautifulSoup: You simply specify the HTML tag (in this case, span) and another attribute of the content which you want to find (in this case, this other attribute is class). This allows you to match arbitrary sections of almost any webpage. For more complicated matches, you can also use regular expressions (REGEX).
Once you have the elements, from which you would like to extract the text, you can access the text by scraping their text attribute.
Inspector
As a short interlude, it's important to give a brief introduction to the Dev tools in Chrome (they are available in any browser, I just chose to use Chrome), which allows you to use the inspector, that gives you access to a websites HTML and also lets you copy attributes such as the XPath and CSS selector. All of these can be helpful or even necessary in the scraping process (especially when using Selenium). The workflow in the case study should give you a basic idea of how to work with the Inspector. For more detailed information on the Inspector, the official Google website linked above contains plenty of information.
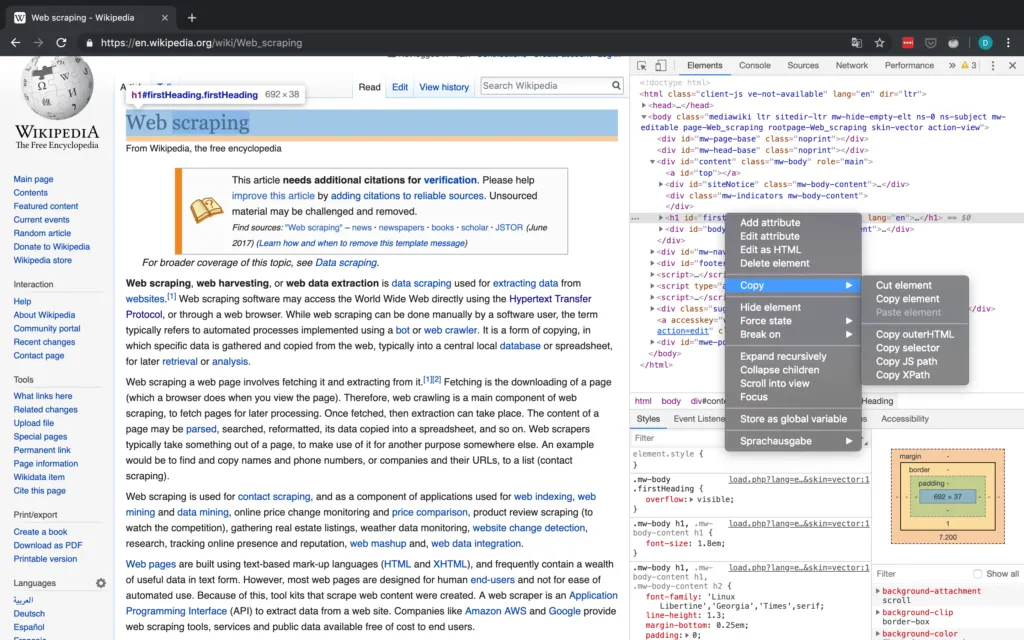
Figure 2 shows the basic interface of the Inspector in Chrome.
Sequoia Capital Case Study
I actually first wanted to do this case study with the New York Times, since they have an API and thus the results received from the API could have been compared to the results from scraping. Unfortunately, most news organizations have very restrictive robots.txt, specifically not permitting searching for articles. Therefore, I decided to scrape the portfolio of one of the big VC firms in the US, Sequoia, since their robots.txt is permissive and I also think that startups and the venture capital scene are very interesting in general.
Robots.txt
First, let’s have a look at Sequoia’s robots.txt:
Luckily, they permit access of various kinds – except three URLs, which is fine for our purposes. We will still build in a crawl delay of 15-30 seconds between each request.
Next, let's scope out the actual data which we are trying to scrape. We are interested in the portfolio of Sequoia, so https://www.sequoiacap.com/companies/ is the URL we are after.

The companies are nicely laid out in a grid, making them pretty easy to scrape. Upon clicking, the page shows the details of each company. Also, notice how the URL changes in Figure 4 when clicking on a company! This is important for Requests especially.
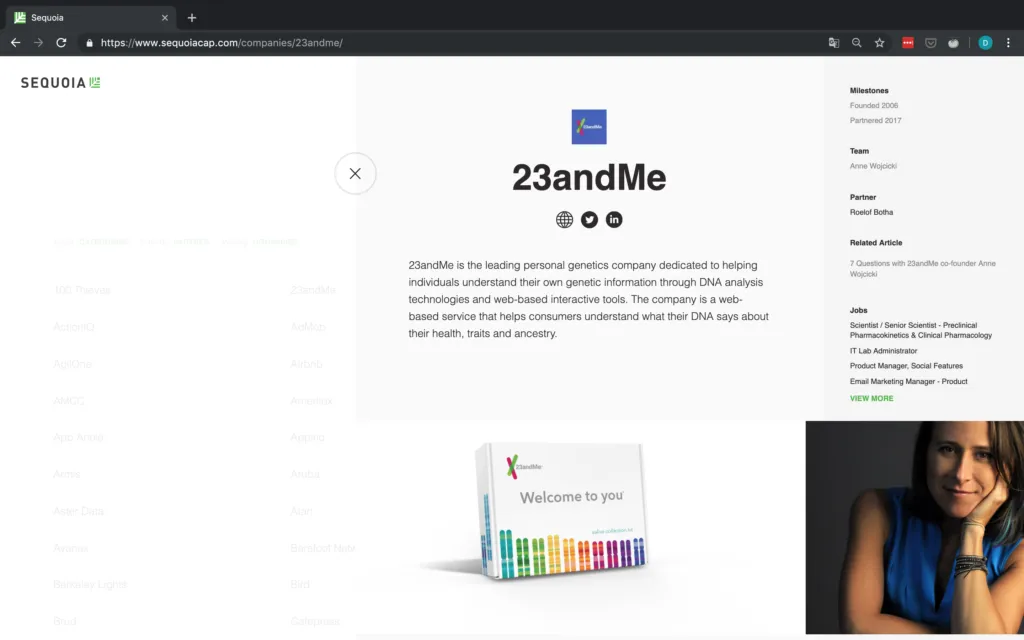
Let's aim for collecting the following basic information on each company and outputting them as a CSV file:
- Name of the company
- URL of the company
- Description
- Milestones
- Team
- Partner
If any of this information is not available for a company, we will simply append the string "NA" instead.
Time to start inspecting!
Scraping Process
Company Name
Upon inspecting the grid it looks like the information on each company is contained within a div tag with the class companies _company js-company. Thus we should just be able to look for this combination with BeautifulSoup.
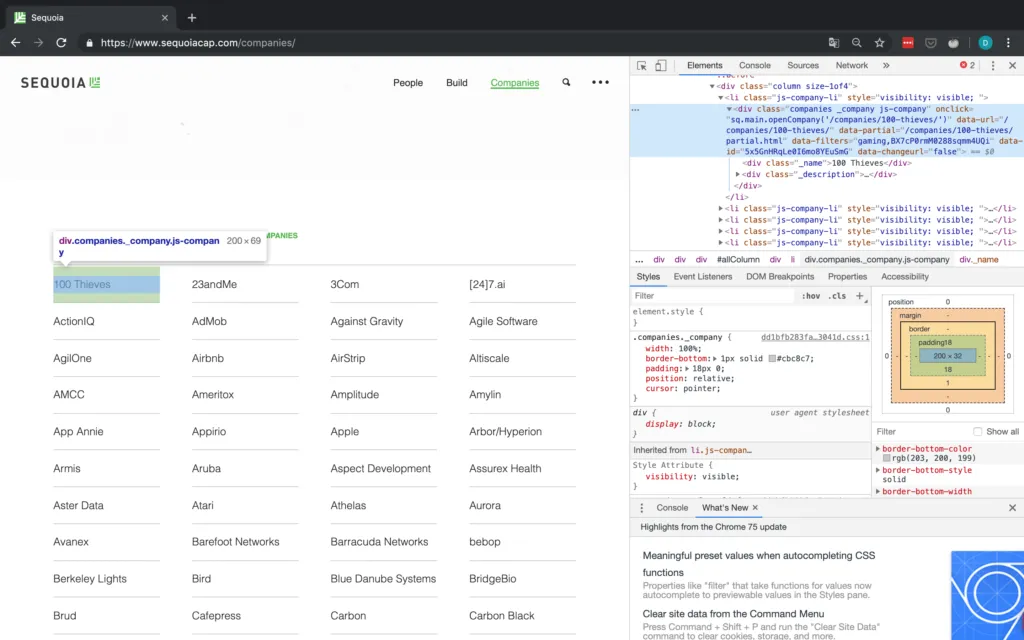
This still leaves us with all the other information missing though, meaning we have to somehow access the detail page of each company. Notice how in Figure 5 above, each company div has an attribute called data-url. For 100 Thieves, for example, onclick has the value /companies/100-thieves/. That's just what we need!
Now, all we have to do is to append this data-URL attribute for each company to the base URL (which is just https://www.sequoiacap.com/) and now we can send yet another request to access the detail page of each company.
So let's write some code to first get the company name and then send another request to the detail page of each company: I will write code interspersed with text here. For a full script, check my Github.
First of all, we take care of all the imports and set up any variables we might need. We also send our first request to the base URL which contains the grid with all companies and instantiates a BeautifulSoup parser.
After we have taken care of basic bookkeeping and setup the dictionary in which we want to scrape the data, we can start working on the actual scraping, first parsing the class shown in Figure 5. As you can see in Figure 5, once we have selected the div tag with the matching class, we have to go to its first div child and then select its text, which then contains the name of the company.
On the detail page, we have basically everything we wanted. Since we already have the name of the company, all we still need are URL, description, milestones, team and the respective partner from Sequoia.
Company URL
For the URL, we should just be able to find elements by their class and then select the first element, since it seems like the website is always the first social link. You can see the inspector view in Figure 6.
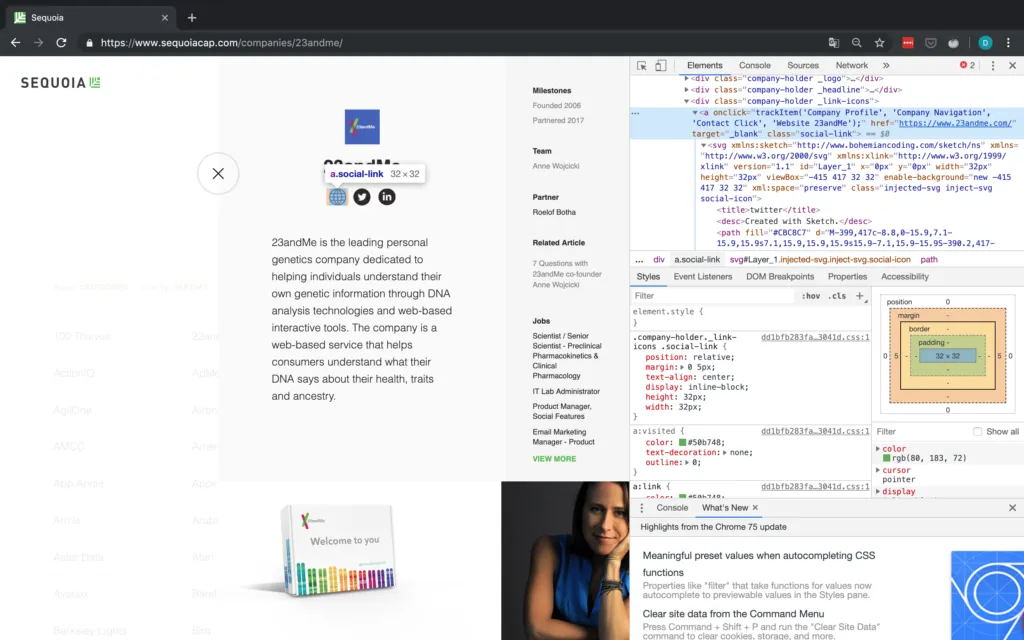
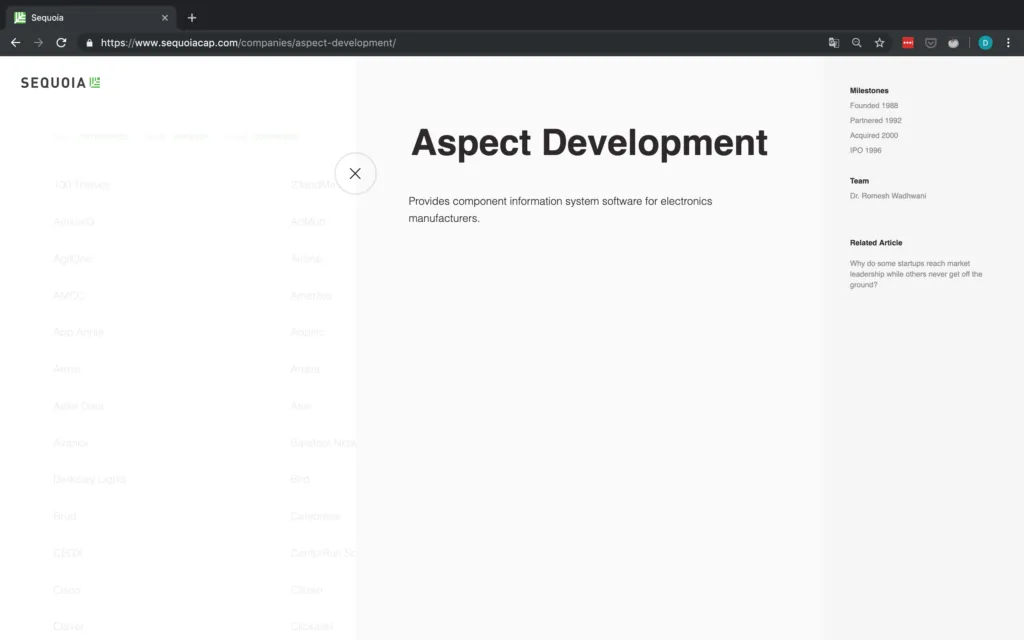
But wait – what if there are no social links or the company website is not provided? In the case that the website is not provided, but a social media page is, we will simply consider this social media link the company's de facto website. If there are no social links provided at all, we have to append an NA. This is why we check explicitly for the number of objects found because we cannot access the href attribute of a tag that doesn't exist. An example of a company without a URL is shown in Figure 7.
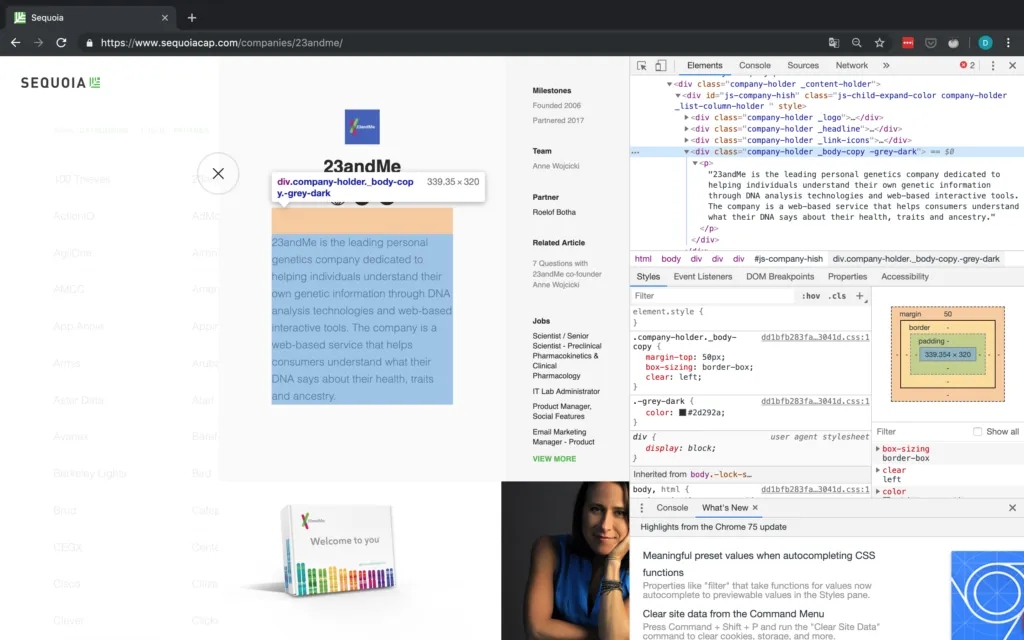
Company description
As you can see in Figure 8, the p tag containing the company description does not have any additional identifiers, therefore we are forced to first access the div tag above it and then go down to the p tag containing the description and selecting its text attribute.
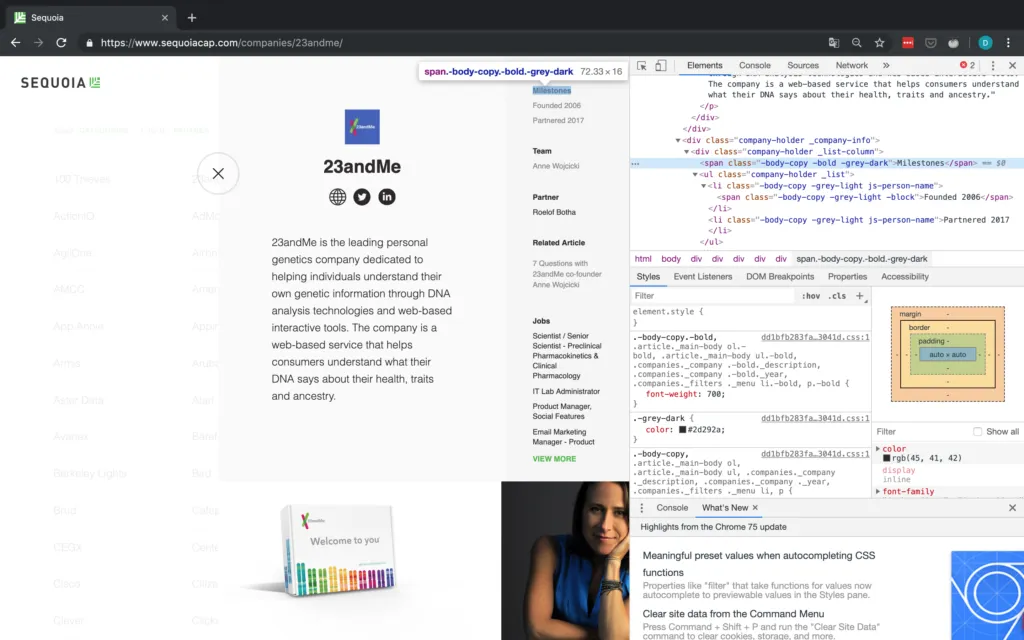
Milestones, Team & Partner(s)
For the last three elements, they are all located in the same structure and can thus be accessed in the same manner. We will simply match the text of their parent element and then work our way down from there.
Since the specific text elements do not have good identifying characteristics, we match the text of their parent element. Once we have the text, we go up two levels, by using the parent attribute. This brings us to the div tag belonging to this specific category (e.g. Milestones or Team). Now all that is left to do is go down to the ul tag containing the actual text we are interested in and getting its text.
One issue with using text match is the fact that only exact matches are found. This matters in cases where the string you are looking for might differ slightly between pages. As you can see in Figure 10, this applies to our case study here for the text Partner. If a company has more than one Sequoia partner assigned to it, the string is "Partners" instead of "Partner". Therefore we use a REGEX when searching for the partner element to get around this.

Last but not least, it is not guaranteed that all the elements we want (i.e. Milestones, Team, and Partner) are in fact available for each company. Thus before actually selecting the element, we first find all elements matching the string and then check the length. If there are no matching elements, we append NA, otherwise, we get the requisite information.
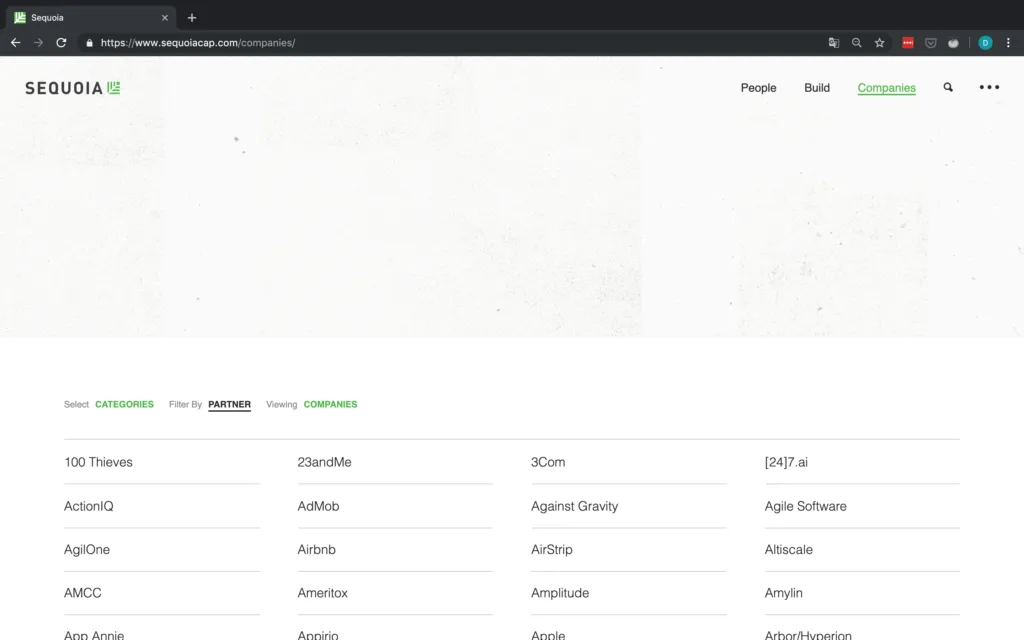
For a partner, there is always one element, thus we assume no partner information is available if there are one or fewer elements. I believe the reason that one element matching partner always shows up is the "Filter by Partner" option shown in Figure 11. As you can see, scraping often requires some iterating to find some potential issues with your script.
Writing to disk
To wrap up, we append all the information corresponding to a company to the list it belongs to within our dictionary. Then we convert this dictionary into a pandas DataFrame before writing it to disk.
Success! We just collected all of Seqouia's portfolio companies and information on them.
* Well, all on their website at least, I believe they have their own respective sites for e.g. India and Israel.
Let's have a look at the data we just scraped:
Looks good! We collected 506 companies in total and the data quality looks really good as well. The only thing I noticed is that some companies have a social link but it does not actually go anywhere. Refer to Figure 12 for an example of this with Pixelworks. The issue is that Pixelworks has a social link but this social link does not actually contain a URL (the href target is blank) and simply links back to the Sequoia portfolio.
I have added code in the script to replace the blanks with NAs but have left the data as is above to illustrate this point.
Conclusion
With this blog post, I wanted to give you a decent introduction to web scraping in general and specifically using Requests & BeautifulSoup. Now go use it in the wild by scraping some data that can be of use to you or someone you know! But always make sure to read and respect both the robots.txt and the terms and conditions of whichever page you are scraping.
Furthermore, you can check out resources and tutorials on some of the other methods shown above on their official websites, such as Scrapy and Selenium. You should also challenge yourself by scraping some more dynamic sites which you can not scrape using only Requests.
If you have any questions, found a bug or just feel like chatting about all things Python and scraping, feel free to contact us at blog@statworx.com.




