KI-Chatbots kommen in immer mehr Unternehmen zum Einsatz. Doch Chatbot ist nicht gleich Chatbot. Manche Lösungen lassen sich zwar schnell und relativ leicht implementieren. Doch mangelt es ihnen an Konfigurierbarkeit (Customizability) und den Funktionalitäten, die wirklich große Leistungssprünge, z. B. bei der Beantwortung von Kundenanfragen im Customer Service, ermöglichen. Customized Lösungen, die genau das bieten, können wiederum aufwändig und teuer werden – besonders, wenn sie über komplexe und use-case-spezifische Retrieval-Augmented Generation (RAG) verfügen sollen. Die Technik verbessert die Genauigkeit und Zuverlässigkeit von generativen KI-Modellen, indem sie es ermöglicht, z. B. mit unternehmenseigenen Datenbanken zu chatten und nur gesicherte Fakten auszugeben.
Wie funktionieren Chatbots?
Custom GPT-Chatbots lernen aus großen Mengen von Texten, um Zusammenhänge zu verstehen und Muster zu erkennen. Sie werden so programmiert, dass sie individuell auf verschiedene Nutzer:innenanfragen eingehen können. Die Erstellung solcher Chatbots umfasst die maßgeschneiderte Anpassung an bestimmte Bedürfnisse, das gezielte Trainieren mit ausgewählten Daten und das Einbinden in Plattformen wie Websites oder mobile Anwendungen.
CustomGPT von statworx zeichnet sich dadurch aus, dass es das Beste aus beiden Welten – hohe Funktionalität durch Customizability und schnelle Implementierung – miteinander verbindet. Die Lösung ist maßgeschneidert und ermöglicht eine sichere und effiziente Nutzung von ChatGPT-ähnlichen Modellen. Das Interface lässt sich im Corporate Design eines Unternehmens gestalten und leicht in bestehende Geschäftsanwendungen wie CRM-Systeme und Support-Tools integrieren.
Worauf kommt es also an, wenn Unternehmen die ideale Chatbot-Lösung für ihre Bedürfnisse suchen?
Anforderungsanalyse: Zunächst sollten die spezifischen Anforderungen des Unternehmens identifiziert werden, um sicherzustellen, dass der Chatbot optimal auf diese zugeschnitten ist. Welche Aufgaben soll der Chatbot bearbeiten? Welche Abteilungen soll er unterstützen? Welche Funktionen braucht er?
Training des Modells: Ein custom GPT-Chatbots muss mit relevanten Daten und Informationen ausgestattet werden, um eine hohe Genauigkeit und Reaktionsfähigkeit sicherzustellen. Wenn diese Daten nicht verfügbar sind, lohnt sich der technische Aufwand wahrscheinlich nicht.
Integration in bestehende Systeme: Die nahtlose Integration des Chatbots in bestehende Kommunikationskanäle wie Websites, Apps oder soziale Medien ist entscheidend für eine effektive Nutzung. Je nach Infrastruktur eignen sich unterschiedliche Lösungen.
Schnell einsatzbereit und immer anpassungsfähig
Der CustomGPT-Chatbot von statworx zeichnet sich durch seine schnelle Einsatzfähigkeit aus, oft schon innerhalb weniger Wochen. Diese Effizienz verdankt er einer Kombination aus bewährten Standardlösungen und maßgeschneiderter Anpassung an die speziellen Bedürfnisse eines Unternehmens. CustomGPT ermöglicht den Upload von Dateien und die Möglichkeit, mit ihnen zu chatten, also gesicherte Informationen aus den unternehmenseigenen Daten zu ziehen. Mit fortschrittlichen Funktionen wie Faktenprüfung, Datenfilterung und der Möglichkeit, Nutzer:innenfeedback zu integrieren, hebt sich der Chatbot von anderen Systemen ab.
Darüber hinaus bietet CustomGPT Unternehmen die Freiheit, das Vokabular, den Kommunikationsstil und den generellen Ton ihres Chatbots zu bestimmen. Dies ermöglicht nicht nur ein nahtloses Markenerlebnis für die Nutzer:innen, sondern verstärkt auch die Wiedererkennung der Unternehmensidentität durch eine persönliche und einzigartige Interaktion. Ein besonderes Highlight: der Chatbot ist optimiert für die mobile Darstellung auf Smartphones.
Technische Umsetzung
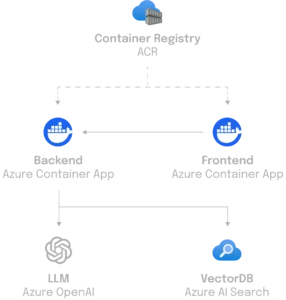
Im Bestreben, eine hochmoderne Anwendung zu schaffen, die sich leicht warten lässt, wurde Python als Kernsprache für das Backend von CustomGPT verwendet. Für die effiziente Handhabung von Anfragen setzen die statworx-Entwickler:innen auf FastAPI, eine moderne Webframework-Lösung, die sowohl Websockets für eine zustandsorientierte Kommunikation als auch eine REST-API für die Dienste bereitstellt. CustomGPT kann flexibel auf unterschiedlichen Infrastrukturen eingesetzt werden – von einer einfachen Cloud-Function bis zu einem Maschinencluster, wenn die Anforderungen dies erfordern.
Ein wesentlicher Aspekt der Architektur ist die Anbindung an eine Datenschicht, um ein flexibles Backend zu bieten, das sich schnell an veränderte Bedingungen und Anforderungen anpassen kann. Die Frontend-Applikation, entwickelt mit React, interagiert nahtlos über Websockets mit dem Backend, welches zum Beispiel die leistungsfähige Azure-AI-Suchfunktion nutzt. Die Konfiguration des Backends ermöglicht es, zusätzliche Use-Cases, wie zum Beispiel maßgeschneiderte Suchlösungen zu implementieren und spezifische Anforderungen effizient zu erfüllen.
Die Vorteile im Überblick:
Datenschutz und Sicherheit
Datenschutz und Datensicherheit sind zentrale Aspekte von CustomGPT. Es gewährleistet, dass alle Daten in der Europäischen Union gespeichert und verarbeitet werden und die vollständige Kontrolle beim Unternehmen liegt. Das ist ein entscheidender Unterschied zu anderen GPT-basierten Lösungen.
Integration und Flexibilität
Die flexible Integration von CustomGPT in bestehende Geschäftsanwendungen ist ein weiterer Vorteil. Dies wird durch Modularität und Anbieterunabhängigkeit unterstützt. Damit kann CustomGPT an verschiedene Infrastrukturen und Modelle angepasst werden, einschließlich Open-Source-Optionen.
Funktionen und Anpassungsmöglichkeiten
Die Anpassungsmöglichkeiten von CustomGPT umfassen die Integration in Organisationsdaten, die Anpassung an Benutzerrollen und die Verwendung von Analytics zur Verbesserung der Konversationen. Durch die Verwendung von Standardmodellen sowie die Möglichkeit, auf Open-Source-Modelle zu setzen, bietet CustomGPT Flexibilität und Individualisierung für Unternehmensanwendungen.
Personalisierte Kundenerfahrung
Durch die Anpassung an die spezifischen Anforderungen eines Unternehmens können Custom GPT-Chatbots eine personalisierte und effektive Interaktion mit Kund:innen gewährleisten.
Effiziente Kundenbetreuung
CustomGPT Chatbots können rund um die Uhr Fragen beantworten, Probleme lösen und Informationen bereitstellen, was zu einer erhöhten Kund:innenzufriedenheit und Effizienz führt.
Skalierbarkeit
Unternehmen können die Kapazität, z. B. ihrer Kund:innenbetreuung mithilfe von GPT-Chatbots problemlos skalieren, um auch bei hohem Aufkommen eine konsistente Servicequalität zu gewährleisten.
Die Zeit für einen eigenen Chatbot ist jetzt! Profitieren Sie von unserer Upstream-Entwicklung mit schneller Bereitstellung und einfacher Implementierung. Als CustomGPT-Kunde stehen Ihnen alle Patches, Bugfixes und neue Funktionalitäten, die im Laufe der Zeit hinzukommen, direkt zur Verfügung. So bleibt Ihr CustomGPT stets so vielseitig und flexibel, dass es den spezifischen, sich ändernden Bedürfnissen gerecht wird und komplexe Anforderungen adressieren kann. Kontaktieren Sie uns jetzt für ein Beratungsgespräch.
Wir stehen am Beginn des Jahres 2024, einer Zeit grundlegender Veränderungen und spannender Fortschritte in der Welt der Künstlichen Intelligenz. Die nächsten Monate gelten als kritischer Meilenstein in der Evolution der KI, in denen sie sich von einer vielversprechenden Zukunftstechnologie zu einer festen Realität im Geschäftsleben und im Alltag von Millionen wandelt. Deshalb präsentieren wir gemeinsamen mit dem AI Hub Frankfurt, dem zentralen KI-Netzwerk der Rhein-Main-Region, unsere Trendprognose für 2024, den AI Trends Report 2024.
Der Report identifiziert zwölf dynamische KI-Trends, die sich in drei Schlüsselbereichen entfalten: Kultur und Entwicklung, Daten und Technologie sowie Transparenz und Kontrolle. Diese Trends zeichnen ein Bild der rasanten Veränderungen in der KI-Landschaft und beleuchten die Auswirkungen auf Unternehmen und Gesellschaft.
Unsere Analyse basiert auf umfangreichen Recherchen, branchenspezifischem Fachwissen und dem Input von Expert:innen. Wir beleuchten jeden Trend, um einen zukunftsweisenden Einblick in die KI zu bieten und Unternehmen bei der Vorbereitung auf künftige Herausforderungen und Chancen zu unterstützen. Wir betonen jedoch, dass Trendprognosen stets einen spekulativen Charakter haben und einige unserer Vorhersagen bewusst gewagt formuliert sind.
Direkt zum AI Trends Report 2024!
Was ist ein Trend?
Ein Trend unterscheidet sich sowohl von einem kurzlebigen Modephänomen als auch von einem medialen Hype. Er ist ein Wandelphänomen mit einem „Tipping Point“, an dem eine kleine Veränderung in einer Nische einen großen Umbruch im Mainstream bewirken kann. Trends initiieren neue Geschäftsmodelle, Konsumverhalten und Arbeitsformen und stellen somit eine grundlegende Veränderung des Status Quo dar. Für Unternehmen ist es entscheidend, vor dem Tipping Point die richtigen Kenntnisse und Ressourcen zu mobilisieren, um von einem Trend profitieren zu können.
12 KI-Trends, die 2024 prägen werden
Im AI Trends Report 2024 identifizieren wir wegweisende Entwicklungen im Bereich Künstlichen Intelligenz. Hier sind die Kurzversionen der zwölf Trends mit jeweils einem ausgewählten Zitat aus den Reihen unserer Expert:innen.
Teil 1: Kultur und Entwicklung
Von der 4-Tage-Woche über Omnimodalität bis AGI: 2024 verspricht große Fortschritt für die Arbeitswelt, für die Medienproduktion und für die Möglichkeiten von KI insgesamt.
These I: KI-Kompetenz im Unternehmen
Unternehmen, die KI-Expertise tief in ihrer Unternehmenskultur verankern und interdisziplinäre Teams mit Tech- und Branchenwissen aufbauen, sichern sich einen Wettbewerbsvorteil. Zentrale KI-Teams und eine starke Data Culture sind Schlüssel zum Erfolg.
„Eine Datenkultur kann man weder kaufen noch anordnen. Man muss die Köpfe, die Herzen und die Herde gewinnen. Wir möchten, dass unsere Mitarbeitenden bewusst Daten erstellen, nutzen und weitergeben. Wir geben ihnen Zugang zu Daten, Analysen und KI und vermitteln das Wissen und die Denkweise, um das Unternehmen auf Basis von Daten zu führen.“
Stefanie Babka, Global Head of Data Culture, Merck
These II :4-Tage-Arbeitswoche durch KI
Dank KI-Automatisierung in Standardsoftware und Unternehmensprozessen ist die 4-Tage-Arbeitswoche für einige deutsche Unternehmen Realität geworden. KI-Tools wie Microsofts Copilot steigern die Produktivität und ermöglichen Arbeitszeitverkürzungen, ohne das Wachstum zu beeinträchtigen.
Dr. Jean Enno Charton, Director Digital Ethics & Bioethics, Merck
These III: AGI durch omnimodale Modelle
Die Entwicklung von omnimodalen KI-Modellen, die menschliche Sinne nachahmen, rückt die Vision einer allgemeinen künstlichen Intelligenz (AGI) näher. Diese Modelle verarbeiten vielfältige Inputs und erweitern menschliche Fähigkeiten.
Dr. Ingo Marquart, NLP Subject Matter Lead, statworx
These IV: KI-Revolution in der Medienproduktion
Generative AI (GenAI) transformiert die Medienlandschaft und ermöglicht neue Formen der Kreativität, bleibt jedoch noch hinter transformatorischer Kreativität zurück. KI-Tools werden für Kreative immer wichtiger, doch es gilt, die Einzigartigkeit gegenüber einem globalen Durchschnittsgeschmack zu wahren.
Nemo Tronnier, Founder & CEO, Social DNA
Teil 2: Daten und Technologie
2024 dreht sich alles um Datenqualität, Open-Source-Modelle und den Zugang zu Prozessoren. Die Betreiber von Standardsoftware wie Microsoft und SAP werden groß profitieren, weil sie die Schnittstelle zu den Endnutzer:innen besetzen.
These V: Herausforderer für NVIDIA
Neue Akteure und Technologien bereiten sich vor, den GPU-Markt aufzumischen und NVIDIAs Position herauszufordern. Startups und etablierte Konkurrenten wie AMD und Intel wollen von der Ressourcenknappheit und den langen Wartezeiten profitieren, die kleinere Player derzeit erleben, und setzen auf Innovation, um NVIDIAs Dominanz zu brechen.
Norman Behrend, Chief Customer Officer, Genesis Cloud
These VI: Datenqualität vor Datenquantität
In der KI-Entwicklung rückt die Qualität der Daten in den Fokus. Statt nur auf Masse zu setzen, wird die sorgfältige Auswahl und Aufbereitung von Trainingsdaten sowie die Innovation in der Modellarchitektur entscheidend. Kleinere Modelle mit hochwertigen Daten können größeren Modellen in der Performance überlegen sein.
Walid Mehanna, Chief Data & AI Officer, Merck
These VII: Das Jahr der KI-Integratoren
Integratoren wie Microsoft, Databricks und Salesforce werden zu den Gewinnern, da sie KI-Tools an Endnutzer:innen bringen. Die Fähigkeit zur nahtlosen Integration in bestehende Systeme wird für KI-Startups und -Anbieter entscheidend sein. Unternehmen, die spezialisierte Dienste oder wegweisende Innovationen bieten, sichern sich lukrative Nischen.
Marco Di Sazio, Head of Innovation, Bankhaus Metzler
These VIII: Die Open-Source-Revolution
Open-Source-KI-Modelle treten in Wettbewerb mit proprietären Modellen wie OpenAIs GPT und Googles Gemini. Mit einer Community, die Innovation und Wissensaustausch fördert, bieten Open-Source-Modelle mehr Flexibilität und Transparenz, was sie besonders wertvoll für Anwendungen macht, die klare Verantwortlichkeiten und Anpassungen erfordern.
Prof. Dr. Christian Klein, Gründer, UMYNO Solutions, Professor für Marketing & Digital Media, FOM Hochschule
Teil 3: Transparenz und Kontrolle
Die verstärkte Nutzung von KI-Entscheidungssystemen wird 2024 eine intensivierte Debatte über Algorithmen-Transparenz und Datenschutz entfachen – auf der Suche nach Verantwortlichkeit. Der AI Act wird dabei zum Standortvorteil für Europa.
These IX: KI-Transparenz als Wettbewerbsvorteil
Europäische KI-Startups mit Fokus auf Transparenz und Erklärbarkeit könnten zu den großen Gewinnern werden, da Branchen wie Pharma und Finance bereits hohe Anforderungen an die Nachvollziehbarkeit von KI-Entscheidungen stellen. Der AI Act fördert diese Entwicklung, indem er Transparenz und Anpassungsfähigkeit von KI-Systemen fordert und damit europäischen KI-Lösungen zu einem Vertrauensvorsprung verhilft.
Jakob Plesner, Rechtsanwalt, Gorrissen Federspiel
These X: AI Act als Qualitätssiegel
Der AI Act positioniert Europa als sicheren Hafen für Investitionen in KI, indem er ethische Standards setzt, die das Vertrauen in KI-Technologien stärken. Angesichts der Zunahme von Deepfakes und der damit verbundenen Risiken für die Gesellschaft wirkt der AI Act als Bollwerk gegen Missbrauch und fördert ein verantwortungsbewusstes Wachstum der KI-Branche.
Catharina Glugla, Head of Data, Cyber & Tech Germany, Allen & Overy LLP
These XI: KI-Agenten revolutionieren den Konsum
Persönliche Assistenz-Bots, die Einkäufe tätigen und Dienstleistungen auswählen, werden zu einem wesentlichen Bestandteil des Alltags. Die Beeinflussung ihrer Entscheidungen wird zum Schlüsselelement für Unternehmen, um auf dem Markt zu bestehen. Dies wird die Suchmaschinenoptimierung und Online-Marketing tiefgreifend verändern, da Bots zu den neuen Zielgruppen werden.
Chi Wang, Principle Researcher, Microsoft Research
These XII: Alignment von KI-Modellen
Die Abstimmung (Alignment) von KI-Modellen auf universelle Werte und menschliche Intentionen wird entscheidend, um unethische Ergebnisse zu vermeiden und das Potenzial von Foundation-Modellen voll auszuschöpfen. Superalignment, bei dem KI-Modelle zusammenarbeiten, um komplexe Herausforderungen zu meistern, wird immer wichtiger, um die Entwicklung von KI verantwortungsvoll voranzutreiben.
Daniel Lüttgau, Head of AI Development, statworx
Schlussbemerkung
Der AI Trends Report 2024 ist mehr als eine unterhaltsame Bestandsaufnahme; er kann ein nützliches Werkzeug für Entscheidungsträger:innen und Innovator:innen sein. Unser Ziel ist es, unseren Leser:innen strategische Vorteile zu verschaffen, indem wir die Auswirkungen der Trends auf verschiedene Sektoren diskutieren und ihnen helfen, die Weichen für die Zukunft zu stellen.
Dieser Blogpost bietet nur einen kurzen Einblick in den umfassenden AI Trends Report 2024. Wir laden Sie ein, den vollständigen Report zu lesen, um tiefer in die Materie einzutauchen und von den detaillierten Analysen und Prognosen zu profitieren.
Geschäftserfolg steht und fällt mit der Art und Weise, wie Unternehmen mit ihren Kund:innen interagieren. Kein Unternehmen kann es sich leisten, mangelhafte Betreuung und Support anzubieten. Im Gegenteil: Firmen, die eine schnelle und präzise Bearbeitung von Kundenanfragen anbieten, können sich vom Wettbewerb absetzen, Vertrauen in die eigene Marke aufbauen und so Menschen langfristig an sich binden. Wie das mithilfe von generativer KI auf einem ganz neuen Niveau gelingt, zeigt unsere Zusammenarbeit mit Geberit, einem führenden Hersteller von Sanitärtechnik in Europa.
Was ist generative KI?
Generative KI-Modelle erstellen automatisiert Inhalte aus vorhandenen Text-, Bild- und Audiodateien. Dank intelligenter Algorithmen und Deep Learning unterscheiden sich diese Inhalte kaum oder gar nicht von menschengemachten. Unternehmen können ihren Kund:innen so personalisierte User Experiences bieten, automatisiert mit ihnen interagieren und relevanten digitalen Content zielgruppengerecht erstellen und ausspielen. GenAI kann zudem komplexe Aufgaben lösen, indem die Technologie riesige Datenmengen verarbeitet, Muster erkennt und neue Fähigkeiten lernt. So ermöglicht die Technologie ungeahnte Produktivitätsgewinne. Routineaufgaben wie Datenaufbereitung, Berichterstellung und Datenbanksuchen lassen sich automatisieren und mit passenden Modellen um ein Vielfaches optimieren.
Weitere Informationen zum Thema GenAI finden Sie hier.
Die Herausforderung: Eine Million E-Mails
Geberit sah sich mit einem Problem konfrontiert: Jedes Jahr landeten eine Million E-Mails in den unterschiedlichen Postfächern des Kundenservice der deutschen Vertriebsgesellschaft von Geberit. Dabei kam es oft vor, dass Anfragen in den falschen Abteilungen landeten, was zu einem erheblichen Mehraufwand führte.
Die Lösung: Ein KI-gestützter E-Mail-Bot
Um die falsche Adressierung zu korrigieren, haben wir ein KI-System entwickelt, das E-Mails automatisch den richtigen Abteilungen zuordnet. Dieses intelligente Klassifikationssystem wurde mit einem Datensatz von anonymisierten Kundenanfragen trainiert und nutzt fortschrittliche Machine- und Deep-Learning-Methoden, darunter das BERT-Modell von Google.
Der Clou: Automatisierte Antwortvorschläge mit ChatGPT
Doch die Innovation hörte hier nicht auf. Das System wurde weiterentwickelt, um automatisierte Antwort-E-Mails zu generieren. Hierbei kommt ChatGPT zum Einsatz, um kundenspezifische Vorschläge zu erstellen. Die Kundenberater:innen müssen die generierten E-Mails nur noch prüfen und können sie direkt versenden.
Das Ergebnis: 70 Prozent bessere Sortierung
Das Ergebnis dieser bahnbrechenden Lösung spricht für sich: eine Reduzierung der falsch zugeordneten E-Mails um über 70 Prozent. Das bedeutet nicht nur eine erhebliche Zeitersparnis von fast drei ganzen Arbeitsmonaten, sondern auch eine Optimierung der Ressourcen.
Der Erfolg des Projekts schlägt hohe Wellen bei Geberit: Ein Sammelpostfach für alle Anfragen, die Ausweitung in andere Ländermärkte und sogar ein digitaler Assistent sind in Planung.
Kundenservice 2.0 – Innovation, Effizienz, Zufriedenheit
Die Einführung von GenAI hat nicht nur den Kundenservice von Geberit revolutioniert, sondern zeigt auch, welches Potenzial in der gezielten Anwendung von KI-Technologien liegt. Die intelligente Klassifizierung von Anfragen und die automatisierte Antwortgenerierung spart nicht nur Ressourcen, sondern steigert auch die Zufriedenheit der Kund:innen. Ein wegweisendes Beispiel dafür, wie KI die Zukunft des Kundenservice gestaltet. Egal in welcher Branche!
Read next …


… and explore new


Intelligente Chatbots sind eine der spannendsten und heute schon sichtbarsten Anwendungen von Künstlicher Intelligenz. ChatGPT und Konsorten erlauben seit Anfang 2023 den unkomplizierten Dialog mit großen KI-Sprachmodellen, was bereits eine beeindruckende Bandbreite an Hilfestellungen im Alltag bietet. Ob Nachhilfe in Statistik, eine Rezeptidee für ein Dreigängemenü mit bestimmten Zutaten oder ein Haiku zum Vereinsjubiläum: Moderne Chatbots liefern Antworten im Nu. Ein Problem haben sie aber noch: Obwohl diese Modelle einiges gelernt haben während des Trainings, sind sie eigentlich keine Wissensdatenbanken. Deshalb liefern sie oft inhaltlichen Unsinn ab – wenn auch überzeugenden.
Mit der Möglichkeit, einem großen Sprachmodell eigene Dokumente zur Verfügung zu stellen, lässt sich dieses Problem aber angehen – und genau danach hat uns unser Partner Microsoft zu einem außergewöhnlichen Anlass gefragt.
Microsofts Cloud Plattform Azure hat sich in den letzten Jahren als erstklassige Plattform für den gesamten Machine-Learning-Prozess erwiesen. Um den Einstieg in Azure zu erleichtern, hat uns Microsoft gebeten, eine spannende KI-Anwendung in Azure umzusetzen und bis ins Detail zu dokumentieren. Dieser sogenannte MicroHack soll Interessierten eine zugängliche Ressource für einen spannenden Use Case bieten.
Unseren Microhack haben wir dem Thema „Retrieval-Augmented Generation“ gewidmet, um damit große Sprachmodelle auf das nächste Level zu heben. Die Anforderungen waren simpel: Baut einen KI-Chatbot in Azure, lasst ihn Informationen aus euren eigenen Dokumenten verarbeiten, dokumentiert jeden Schritt des Projekts und veröffentlicht die Resultate auf dem
offiziellen MicroHacks GitHub Repository als Challenges und Lösungen – frei zugänglich für alle.
Moment, wieso muss KI Dokumente lesen können?
Große Sprachmodelle (LLMs) beeindrucken nicht nur mit ihren kreativen Fähigkeiten, sondern auch als Sammlungen komprimierten Wissens. Während des extensiven Trainingsprozesses eines LLMs lernt das Modell nicht bloß die Grammatik einer Sprache, sondern auch Semantik und inhaltliche Zusammenhänge; kurz gesagt lernen große Sprachmodelle Wissen. Ein LLM kann dadurch befragt werden und überzeugende Antworten generieren – mit einem Haken. Während die gelernten Sprachfertigkeiten eines LLMs oft für die große Mehrheit an Anwendungen taugen, kann das vom gelernten Wissen meist nicht behauptet werden. Ohne erneutem Training auf weiteren Dokumenten bleibt der Wissensstand eines LLMs statisch.
Dies führt zu folgenden Problemen:
- Das trainierte LLMs weist zwar ein großes Allgemeinwissen – oder auch Fachwissen – auf, kann aber keine Auskunft über Wissen aus nicht-öffentlich zugänglichen Quellen geben.
- Das Wissen eines trainierten LLMs ist schnell veraltet: Der sogenannte „Trainings-Cutoff“ führt dazu, dass das LLM keine Aussagen über Ereignisse, Dokumente oder Quellen treffen kann, die sich erst nach dem Trainingsstart ereignet haben oder später entstanden sind.
- Die technische Natur großer Sprachmodelle als Text-Vervollständigungs-Maschinen führt dazu, dass diese Modelle gerne Sachverhalte erfinden, wenn sie eigentlich keine passende Antwort gelernt haben. Sogenannte „Halluzinationen“ führen dazu, dass die Antworten eines LLMs ohne Überprüfung nie komplett vertrauenswürdig sind – unabhängig davon, wie überzeugend sie wirken.
Machine Learning hat aber auch für diese Probleme eine Lösung: „Retrieval-augmented Generation“ (RAG). Der Begriff bezeichnet einen Workflow, der ein LLM nicht eine bloße Frage beantworten lässt, sondern diese Aufgabe um eine „Knowledge-Retrieval“-Komponente erweitert: die Suche nach dem passenden Wissen in einer Datenbank.
Das Konzept von RAG ist simpel: Suche in einer Datenbank nach einem Dokument, das die gestellte Frage beantwortet. Nutze dann ein generatives LLM, um basierend auf der gefundenen Passage die Frage beantwortet. Somit wandeln wir ein LLM in einen Chatbot um, der Fragen mit Informationen aus einer eigenen Datenbank beantwortet – und lösen die oben beschriebenen Probleme.
Was passiert bei einem solchen „RAG“ genau?
RAG besteht also aus zwei Schritten: „Retrieval“ und „Generation“. Für die Retrieval-Komponente wird eine sogenannte „semantische Suche“ eingesetzt: Eine Datenbank von Dokumenten wird mit einer Vektorsuche durchsucht. Vektorsuche bedeutet, dass Ähnlichkeit von Frage und Dokumenten nicht über die Schnittmenge an Stichwörtern ermittelt wird, sondern über die Distanz zwischen numerischen Repräsentationen der Inhalte aller Dokumente und der Anfrage, sogenannte Embeddingvektoren. Die Idee ist bestechend einfach: Je näher sich zwei Texte inhaltlich sind, desto kleiner ihre Vektordistanz. Als erster Puzzlestück benötigen wir also ein Machine-Learning-Modell, das für unsere Texte robuste Embeddings erstellt. Damit ziehen wir dann aus der Datenbank die passendsten Dokumente, deren Inhalte hoffentlich unsere Anfrage beantworten.
Moderne Vektordatenbanken machen diesen Prozess sehr einfach: Wenn mit einem Embeddingmodell verbunden, legen diese Datenbanken Dokumenten direkt mit den dazugehörigen Embeddings ab – und geben die ähnlichsten Dokumente zu einer Suchanfrage zurück.
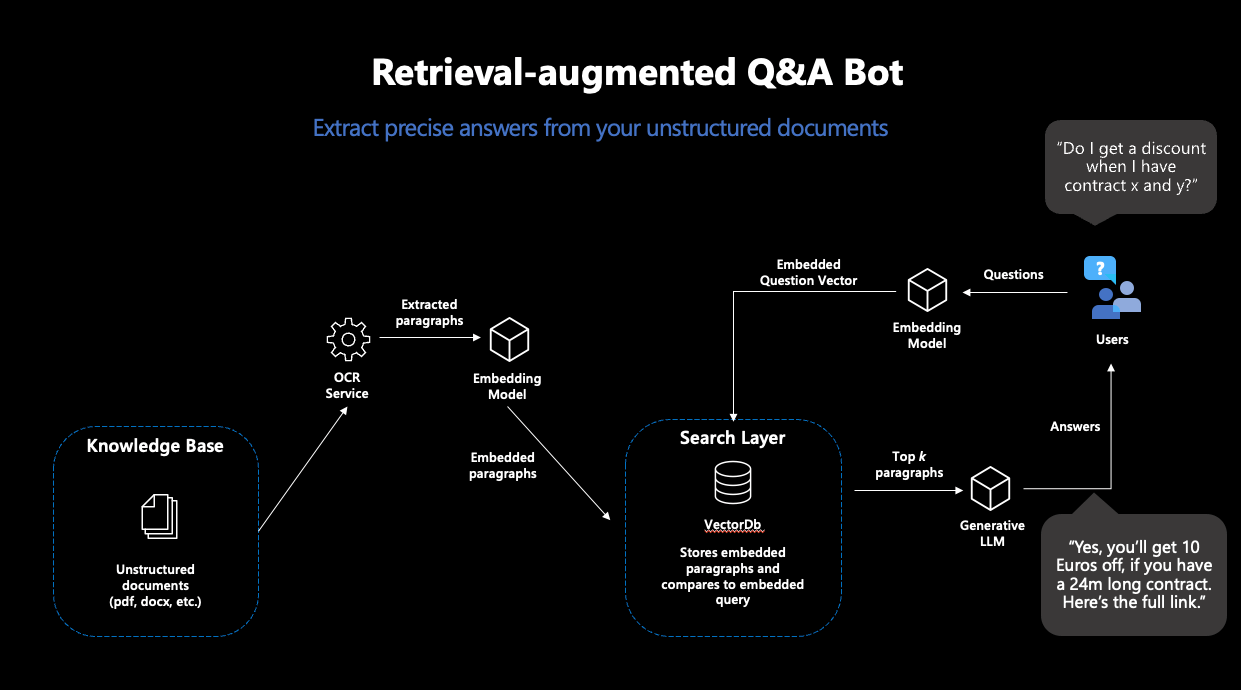
Abbildung 1: Darstellung des typischen RAG-Workflows
Basierend auf den Inhalten der gefundenen Dokumente wird im nächsten Schritt eine Antwort zur Frage generiert. Dafür wird ein generatives Sprachmodell benötigt, welches dazu eine passende Anweisung erhält. Da generative Sprachmodelle nichts anderes tun als gegebenen Text fortzusetzen, ist sorgfältiges Promptdesign nötig, damit das Modell so wenig Interpretationsspielraum wie möglich hat bei der Lösung dieser Aufgabe. Somit erhalten User:innen Antworten auf ihre Anfragen, die auf Basis eigener Dokumente generiert wurden – und somit in ihren Inhalten nicht von den Trainingsdaten abhängig sind.
Wie kann so ein Workflow denn in Azure umgesetzt werden?
Für die Umsetzung eines solchen Workflows haben wir vier separate Schritte benötigt – und unseren MicroHack genauso aufgebaut:
Schritt 1: Setup zur Verarbeitung von Dokumenten in Azure
In einem ersten Schritt haben wir die Grundlagen für die RAG-Pipeline gelegt. Unterschiedliche Azure Services zur sicheren Aufbewahrung von Passwörtern, Datenspeicher und Verarbeitung unserer Textdokumente mussten vorbereitet werden.
Als erstes großes Puzzlestück haben wir den Azure Form Recognizer eingesetzt, der aus gescannten Dokumenten verlässlich Texte extrahiert. Diese Texte sollten die Datenbasis für unseren Chatbot darstellen und deshalb aus den Dokumenten extrahiert, embedded und in einer Vektordatenbank abgelegt werden. Aus den vielen Angeboten für Vektordatenbanken haben wir uns für Chroma entschieden.
Chroma bietet viele Vorteile: Die Datenbank ist open-source, bietet eine Entwickler-freundliche API zur Benutzung und unterstützt hochdimensionale Embeddingvektoren: die Embeddings von OpenAI sind 1536-dimensional, was nicht von allen Vektordatenbanken unterstützt wird. Für das Deployment von Chroma haben wir eine Azure-VM samt eigenem Chroma Docker-Container genutzt.
Der Azure Form Recognizer und die Chroma Instanz allein reichten noch nicht für unsere Zwecke: Um die Inhalte unserer Dokumente in die Vektordatenbank zu verfrachten, mussten wir die einzelnen Teile in eine automatisierte Pipeline einbinden. Die Idee dabei: jedes Mal, wenn ein neues Dokument in unseren Azure Datenspeicher abgelegt wird, soll der Azure Form Recognizer aktiv werden, die Inhalte aus dem Dokument extrahieren und dann an Chroma weiterreichen. Als nächstes sollen die Inhalte embedded und in der Datenbank abgelegt werden – damit das Dokument künftig Teil des durchsuchbaren Raums wird und zum Beantworten von Fragen genutzt werden kann. Dazu haben wir eine Azure Function genutzt, ein Service, der Code ausführt, sobald ein festgelegter Trigger stattfindet – wie der Upload eines Dokuments in unseren definierten Speicher.
Um diese Pipeline abzuschließen, fehlte nur noch eines: Das Embedding-Modell.
Schritt 2: Vervollständigung der Pipeline
Für alle Machine Learning Komponenten haben wir den OpenAI-Service in Azure genutzt. Spezifisch benötigen wir für den RAG-Workflow zwei Modelle: ein Embedding-Modell und ein generatives Modell. Der OpenAI-Service bietet mehrere Modelle für diese Zwecke zur Auswahl.
Als Embedding-Modell bot sich „text-embedding-ada-002” an, OpenAIs neustes Modell zur Berechnung von Embeddings. Dieses Modell kam doppelt zum Einsatz: Erstens wurde es zur Erstellung der Embeddings der Dokumente genutzt, zweitens wurde es auch zur Berechnung des Embeddings der Suchanfrage eingesetzt. Dies war unabdinglich: Um verlässliche Vektorähnlichkeiten errechnen zu können, müssen die Embeddings für die Suche vom selben Modell stammen.
Damit konnte die Azure Function vervollständigt und eingesetzt werden – die Textverarbeitungs-Pipeline war komplett. Schlussendlich sah die funktionale Pipeline folgendermaßen aus:
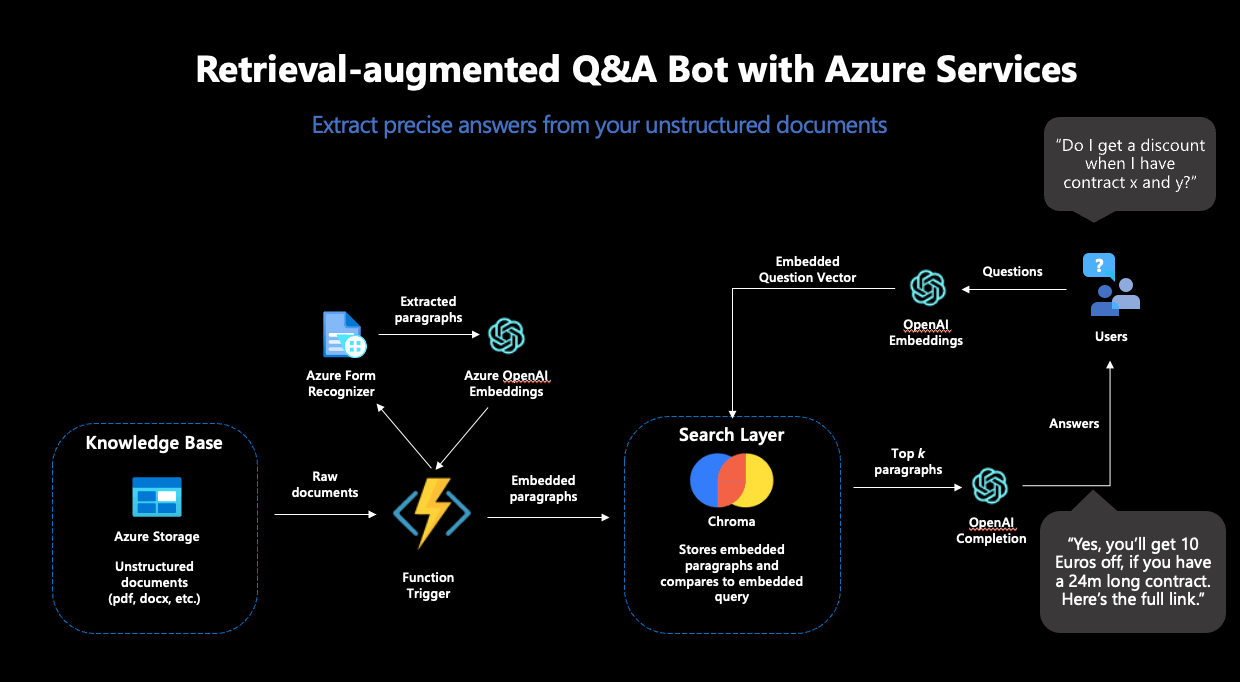
Abbildung 2: Der vollständige RAG-Workflow in Azure
Schritt 3 Antwort-Generierung
Um den RAG-Workflow abzuschließen, sollte auf Basis der gefundenen Dokumente aus Chroma noch eine Antwort generiert werden: Wir entschieden uns für den Einsatz von „GPT3.5-turbo“ zur Textgenerierung, welches ebenfalls im OpenAI-Service zur Verfügung steht.
Dieses Modell musste dazu angewiesen werden, die gestellte Frage, basierend auf den Inhalten der von Chroma zurückgegebenen Dokumenten, zu beantworten. Dazu war sorgfältiges Prompt-Engineering nötig. Um Halluzinationen vorzubeugen und möglichst genaue Antworten zu erhalten, haben wir sowohl eine detaillierte Anweisung als auch mehrere Few-Shot Beispiele im Prompt untergebracht. Schlussendlich haben wir uns auf folgenden Prompt festgelegt:
"""I want you to act like a sentient search engine which generates natural sounding texts to answer user queries. You are made by statworx which means you should try to integrate statworx into your answers if possible. Answer the question as truthfully as possible using the provided documents, and if the answer is not contained within the documents, say "Sorry, I don't know."
Examples:
Question: What is AI?
Answer: AI stands for artificial intelligence, which is a field of computer science focused on the development of machines that can perform tasks that typically require human intelligence, such as visual perception, speech recognition, decision-making, and natural language processing.
Question: Who won the 2014 Soccer World Cup?
Answer: Sorry, I don't know.
Question: What are some trending use cases for AI right now?
Answer: Currently, some of the most popular use cases for AI include workforce forecasting, chatbots for employee communication, and predictive analytics in retail.
Question: Who is the founder and CEO of statworx?
Answer: Sebastian Heinz is the founder and CEO of statworx.
Question: Where did Sebastian Heinz work before statworx?
Answer: Sorry, I don't know.
Documents:\n"""Zum Schluss werden die Inhalte der gefundenen Dokumente an den Prompt angehängt, womit dem generativen Modell alle benötigten Informationen zur Verfügung standen.
Schritt 4: Frontend-Entwicklung und Deployment einer funktionalen App
Um mit dem RAG-System interagieren zu können, haben wir eine einfache streamlit-App gebaut, die auch den Upload neuer Dokumente in unseren Azure Speicher ermöglichte – um damit erneut die Dokument-Verarbeitungs-Pipeline anzustoßen und den Search-Space um weitere Dokumente zu erweitern.
Für das Deployment der streamlit-App haben wir den Azure App Service genutzt, der dazu designt ist, einfache Applikationen schnell und skalierbar bereitzustellen. Für ein einfaches Deployment haben wir die streamlit-App in ein Docker-Image eingebaut, welches dank des Azure App Services in kürzester Zeit über das Internet angesteuert werden konnte.
Und so sah unsere fertige App aus:
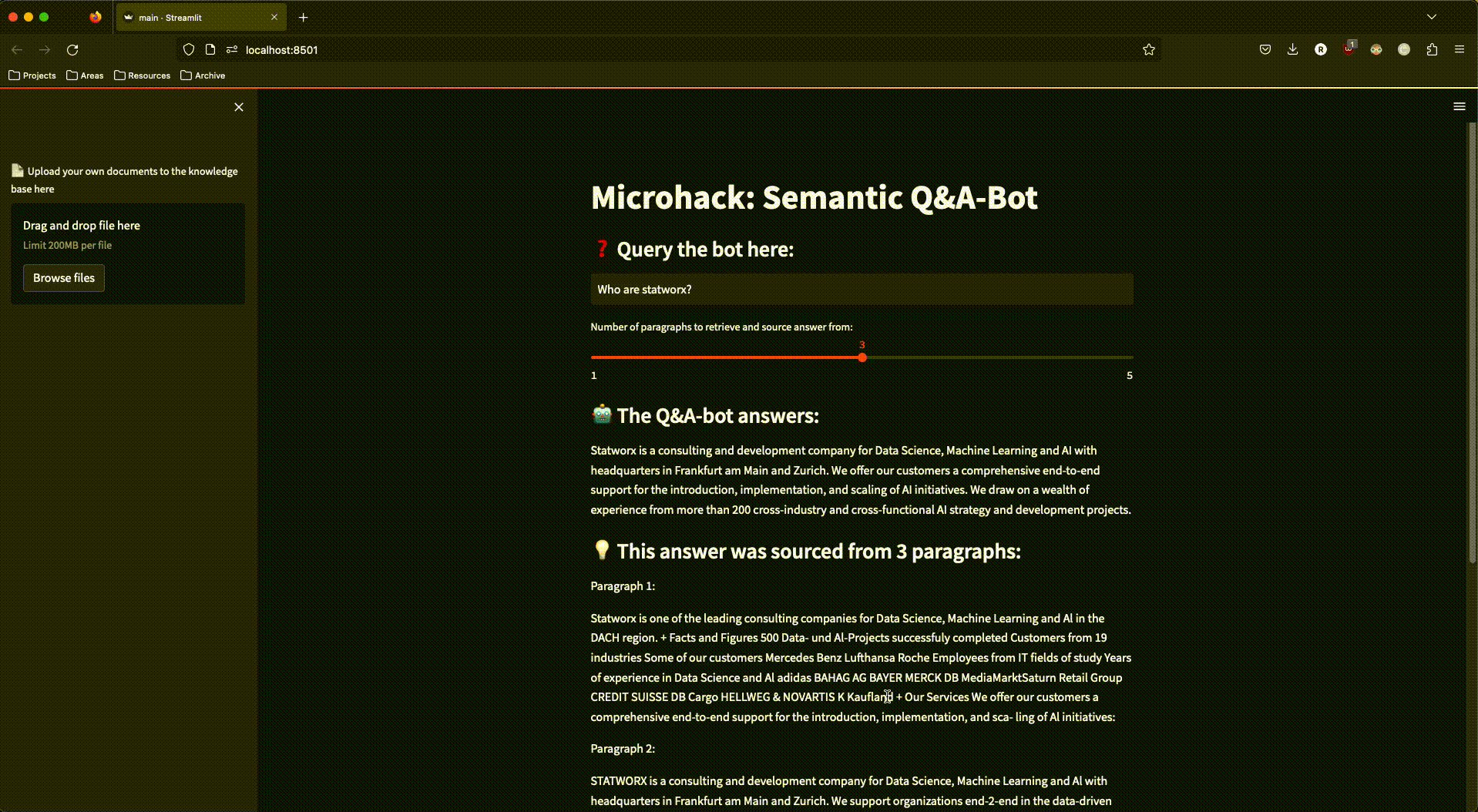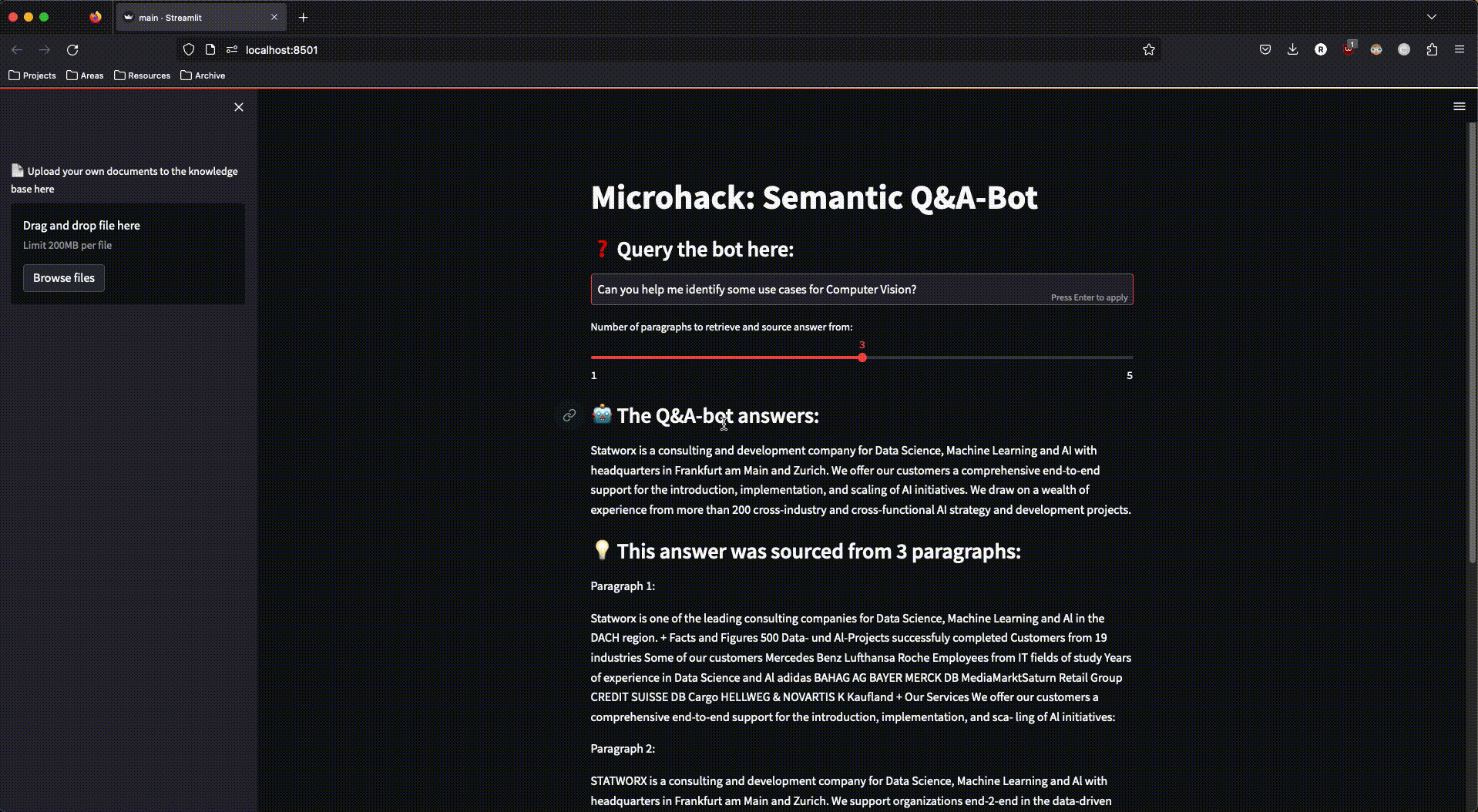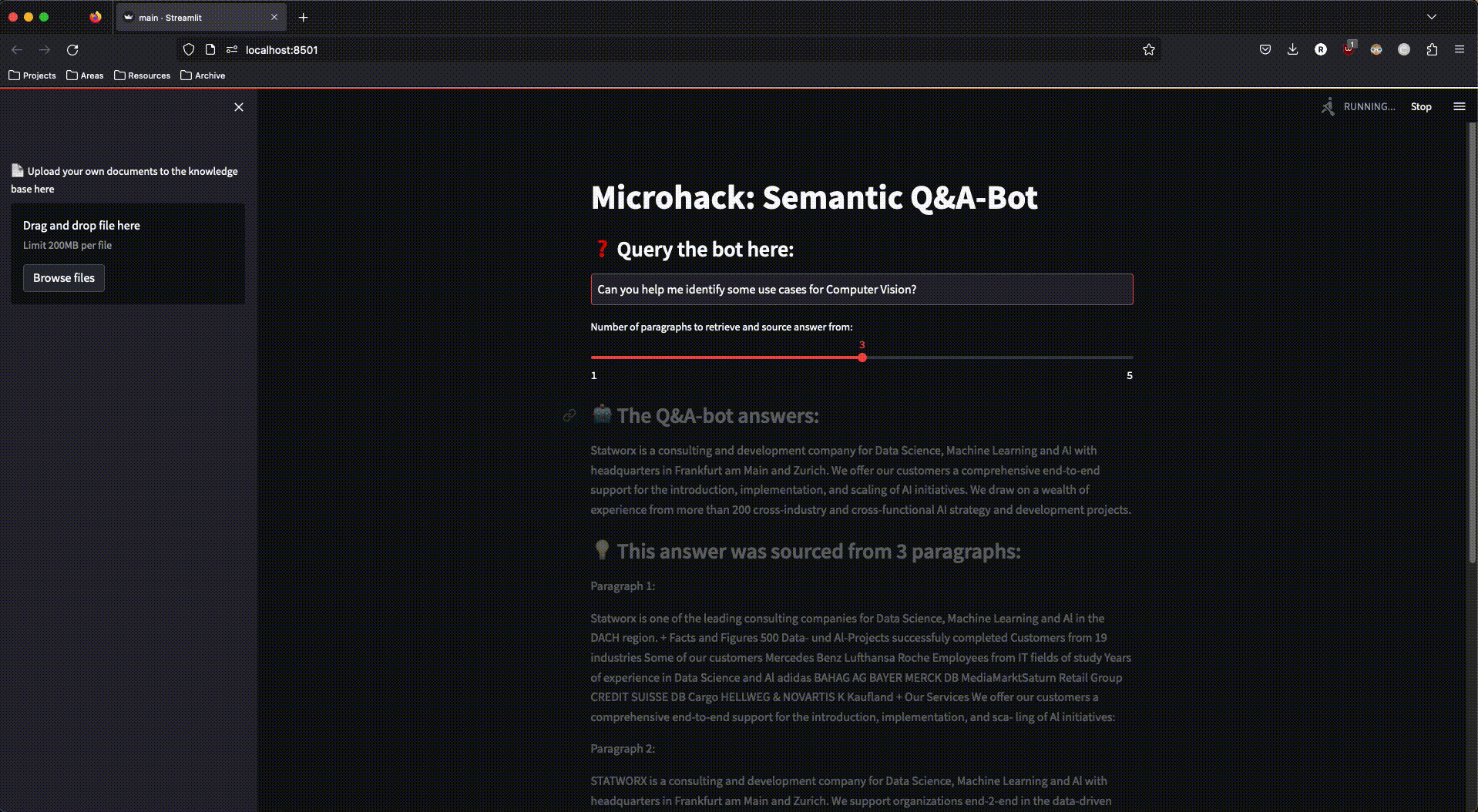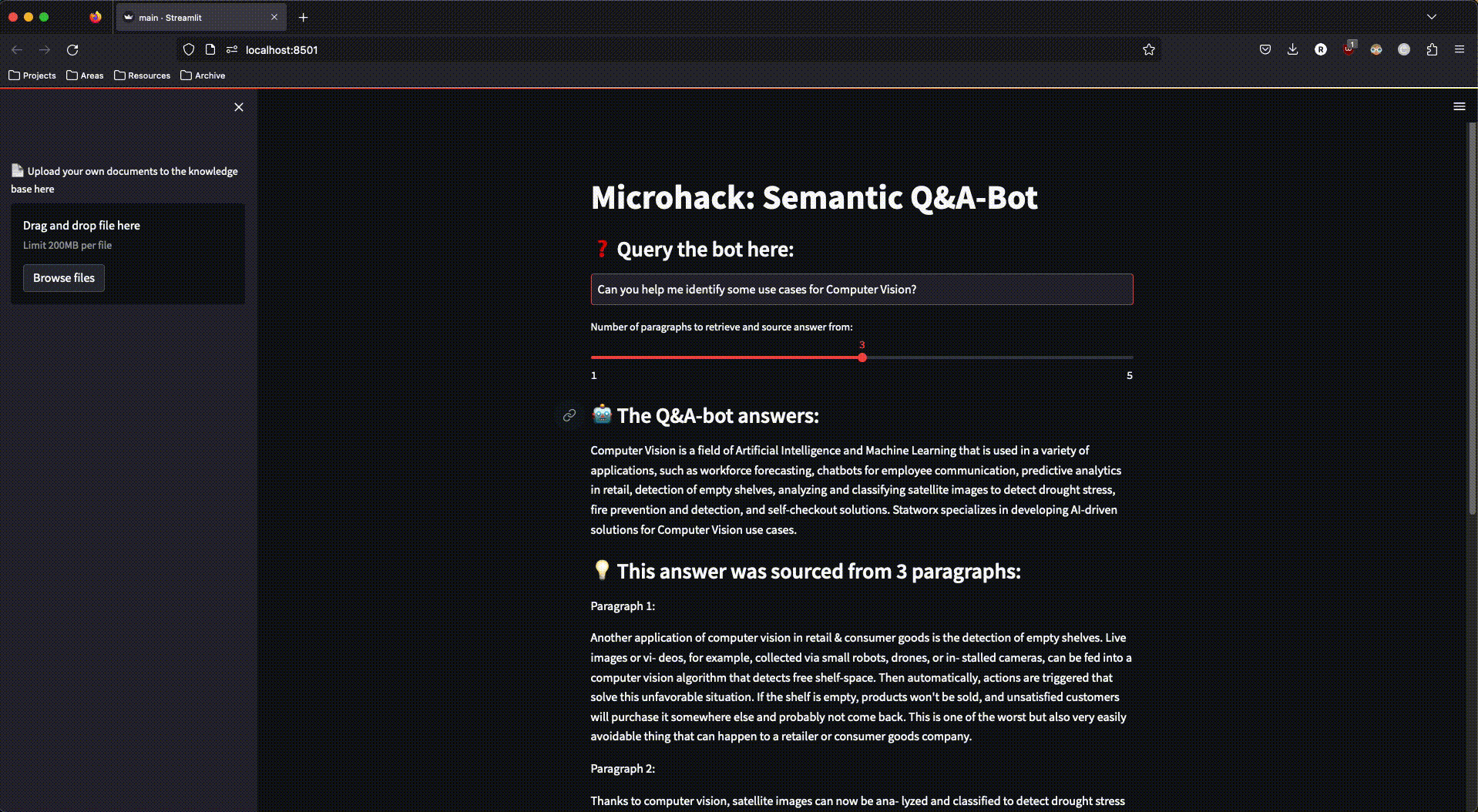
Abbildung 3: Die fertige streamlit-App im Einsatz
Was haben wir bei dem MicroHack gelernt?
Während der Umsetzung dieses MicroHacks haben wir einiges gelernt. Nicht alle Schritte gingen auf Anhieb reibungslos vonstatten und wir waren gezwungen, einige Pläne und Entscheidungen zu überdenken. Hier unsere fünf Takeaways aus dem Entwicklungsprozess:
Nicht alle Datenbanken sind gleich
Während der Entwicklung haben wir mehrmals unsere Wahl der Vektordatenbank geändert: von OpenSearch zu ElasticSearch und schlussendlich zu Chroma. Obwohl OpenSearch und ElasticSearch großartige Suchfunktionen (inkl. Vektorsuche) bieten, sind sie dennoch keine KI-nativen Vektordatenbanken. Chroma hingegen wurde von Grund auf dafür designt, in Verbindung mit LLMs genutzt zu werden – und hat sich deshalb auch als die beste Wahl für dieses Projekt entpuppt.
Chroma ist eine großartige open-source VektorDB für kleinere Projekte und Prototyping
Chroma besticht insbesondere für kleinere Use-Cases und schnelles Prototyping. Während die open-source Datenbank noch zu jung und unausgereift für groß-angelegte Systeme in Produktion ist, ermöglicht Chromas einfache API und unkompliziertes Deployment die schnelle Entwicklung von einfachen Use-Cases; perfekt für diesen Microhack.
Azure Functions sind eine fantastische Lösung, um kleinere Codestücke nach Bedarf auszuführen
Azure Functions taugen ideal für die Ausführung von Code, der nicht in vorgeplanten Intervallen benötigt wird. Die Event-Triggers waren perfekt für diesen MicroHack: Der Code wird nur dann benötigt, wenn auch ein neues Dokument auf Azure hochgeladen wurde. Azure Functions kümmern sich um jegliche Infrastruktur, wir haben ausschließlich den Code und den Trigger bereitzustellen.
Azure App Service ist großartig für das Deployment von streamlit-Apps
Unsere streamlit-App hätte kein einfacheres Deployment erleben können als mit dem Azure App Service. Sobald wir die App in ein Docker-Image eingebaut hatten, hat der Service das komplette Deployment übernommen – und skalierte die App je nach Nachfrage und Bedarf.
Networking sollte nicht unterschätzt werden
Damit alle genutzten Services auch miteinander arbeiten können, muss die Kommunikation zwischen den einzelnen Services gewährleistet werden. Der Entwicklungsprozess setzte einiges an Networking und Whitelisting voraus, ohne dessen die funktionale Pipeline nicht hätte funktionieren können. Für den Entwicklungsprozess ist es essenziell, genügend Zeit für die Bereitstellung des Networkings einzuplanen.
Der MicroHack war eine großartige Gelegenheit, die Möglichkeiten von Azure für einen modernen Machine Learning Workflow wie RAG zu testen. Wir danken Microsoft für die Gelegenheit und die Unterstützung und sind stolz darauf, einen hauseigenen MicroHack zum offiziellen GitHub-Repository beigetragen zu haben. Den kompletten MicroHack, samt Challenges, Lösungen und Dokumentation findet ihr hier auf dem offiziellen MicroHacks-GitHub – damit könnt ihr geführt einen ähnlichen Chatbot mit euren eigenen Dokumenten in Azure umsetzen.
Read next …

… and explore new


Data-Science-Anwendungen bieten Einblicke in große und komplexe Datensätze, die oft leistungsstarke Modelle enthalten, die sorgfältig auf die Bedürfnisse der Kund:innen abgestimmt sind. Die gewonnenen Erkenntnisse sind jedoch nur dann nützlich, wenn sie den Endnutzer:innen auf zugängliche und verständliche Weise präsentiert werden. An dieser Stelle kommt die Entwicklung einer Webanwendung mit einem gut gestalteten Frontend ins Spiel: Sie hilft bei der Visualisierung von anpassbaren Erkenntnissen und bietet eine leistungsstarke Schnittstelle, die Benutzer nutzen können, um fundierte Entscheidungen zu treffen.
In diesem Artikel werden wir erörtern, warum ein Frontend für Data-Science-Anwendungen sinnvoll ist und welche Schritte nötig sind, um ein funktionales Frontend zu bauen. Außerdem geben wir einen kurzen Überblick über beliebte Frontend- und Backend-Frameworks und wann diese eingesetzt werden sollten.
Drei Gründe, warum ein Frontend für Data Science nützlich ist
In den letzten Jahren hat der Bereich Data Science eine rasante Zunahme des Umfangs und der Komplexität der verfügbaren Daten erlebt. Data Scientists sind zwar hervorragend darin, aus Rohdaten aussagekräftige Erkenntnisse zu gewinnen, doch die effektive Vermittlung dieser Ergebnisse an die Beteiligten bleibt eine besondere Herausforderung. An dieser Stelle kommt ein Frontend ins Spiel. Ein Frontend bezeichnet im Zusammenhang mit Data Science die grafische Oberfläche, die es den Benutzer:innen ermöglicht, mit datengestützten Erkenntnissen zu interagieren und diese zu visualisieren. Wir werden drei Hauptgründe untersuchen, warum die Integration eines Frontends in den Data-Science-Workflow für eine erfolgreiche Analyse und Kommunikation unerlässlich ist.
Dateneinblicke visualisieren
Ein Frontend hilft dabei, die aus Data-Science-Anwendungen gewonnenen Erkenntnisse auf zugängliche und verständliche Weise zu präsentieren. Durch die Visualisierung von Datenwissen mit Diagrammen, Grafiken und anderen visuellen Hilfsmitteln können Benutzer:innen Muster und Trends in den Daten besser verstehen.
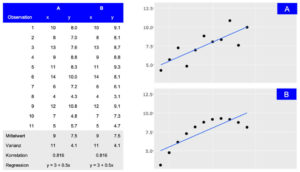
Darstellung von zwei Datensätzen (A und B), die trotz unterschiedlicher Verteilung die gleichen zusammenfassenden Statistiken aufweisen. Während die tabellarische Ansicht detaillierte Informationen liefert, macht die visuelle Darstellung die allgemeine Verbindung zwischen den Beobachtungen leicht zugänglich.
Benutzererlebnisse individuell gestalten
Dashboards und Berichte können in hohem Maße an die spezifischen Bedürfnisse verschiedener Benutzergruppen angepasst werden. Ein gut gestaltetes Frontend ermöglicht es den Nutzer:innen, mit den Daten auf eine Weise zu interagieren, die ihren Anforderungen am ehesten entspricht, so dass sie schneller und effektiver Erkenntnisse gewinnen können.
Fundierte Entscheidungsfindung ermöglichen
Durch die Darstellung der Ergebnisse von Machine-Learning-Modellen und der Ergebnisse erklärungsbedürftiger KI-Methoden über ein leicht verständliches Frontend erhalten die Nutzer:innen eine klare und verständliche Darstellung der Datenerkenntnisse, was fundierte Entscheidungen erleichtert. Dies ist besonders wichtig in Branchen wie dem Finanzhandel oder Smart Cities, wo Echtzeit-Einsichten zu Optimierungen und Wettbewerbsvorteilen führen können.
Vier Phasen von der Idee bis zum ersten Prototyp
Wenn es um Data Science Modelle und Ergebnisse geht, ist das Frontend der Teil der Anwendung, mit dem die Benutzer:innen interagieren. Es sollte daher klar sein, dass die Entwicklung eines nützlichen und produktiven Frontends Zeit und Mühe erfordert. Vor der eigentlichen Entwicklung ist es entscheidend, den Zweck und die Ziele der Anwendung zu definieren. Um diese Anforderungen zu ermitteln und zu priorisieren, sind mehrere Iterationen von Brainstorming- und Feedback-Sitzungen erforderlich. Während dieser Sitzungen wird das Frontend die Phasen von einer einfachen Skizze über ein Wireframe und ein Mockup bis hin zum ersten Prototyp durchlaufen.
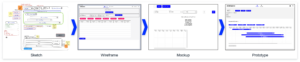
Skizze
In der ersten Phase wird eine grobe Skizze des Frontends erstellt. Dazu gehört die Identifizierung der verschiedenen Komponenten und wie sie aussehen könnten. Um eine Skizze zu erstellen, ist es hilfreich, eine Planungssitzung abzuhalten, in der die funktionalen Anforderungen und visuellen Ideen geklärt und ausgetauscht werden. Während dieser Sitzung wird eine erste Skizze mit einfachen Hilfsmitteln wie einem Online-Whiteboard (z. B. Miro) erstellt, aber auch Stift und Papier können ausreichen.
Wireframe
Wenn die Skizze fertig ist, müssen die einzelnen Teile der Anwendung miteinander verbunden werden, um ihre Wechselwirkungen und ihr Zusammenspiel zu verstehen. Dies ist eine wichtige Phase, um mögliche Probleme frühzeitig zu erkennen, bevor der Entwicklungsprozess beginnt. Wireframes zeigen die Nutzung aus der Sicht der Benutzer:innen und berücksichtigen die Anforderungen der Anwendung. Sie können auch auf einem Miro-Board oder mit Tools wie Figma erstellt werden.
Mockup
Nach den Skizzen- und Wireframe-Phasen besteht der nächste Schritt darin, ein Mockup des Frontends zu erstellen. Dabei geht es darum, ein visuell ansprechendes Design zu erstellen, das einfach zu bedienen und zu verstehen ist. Mit Tools wie Figma können Mockups schnell erstellt werden. Sie bieten auch eine interaktive Demo, die die Interaktion innerhalb des Frontends zeigt. In dieser Phase ist es wichtig, sicherzustellen, dass das Design mit der Marke und den Stilrichtlinien des Unternehmens übereinstimmt, denn der erste Eindruck bleibt haften.
Prototype
Sobald das Mockup fertig ist, ist es an der Zeit, einen funktionierenden Prototyp des Frontends zu erstellen und ihn mit der Backend-Infrastruktur zu verbinden. Um später die Skalierbarkeit zu gewährleisten, müssen das verwendete Framework und die gegebene Infrastruktur bewertet werden. Diese Entscheidung hat Auswirkungen auf die in dieser Phase verwendeten Tools und wird in den folgenden Abschnitten erörtert.
Es gibt viele Optionen für die Frontend-Entwicklung
Die meisten Data Scientisten sind mit R oder Python vertraut. Daher sind die ersten Lösungen für die Entwicklung von Frontend-Anwendungen wie Dashboards oft R Shiny, Dash oder streamlit. Diese Tools haben den Vorteil, dass Datenaufbereitung und Modellberechnungsschritte im selben Framework wie das Dashboard implementiert werden können. Die Visualisierungen sind eng mit den verwendeten Daten und Modellen verknüpft und Änderungen können oft vom selben Entwickler integriert werden. Für manche Projekte mag das ausreichen, aber sobald eine gewisse Skalierbarkeit erreicht ist, ist es von Vorteil, Backend-Modellberechnungen und Frontend-Benutzerinteraktionen zu trennen.
Es ist zwar möglich, diese Art der Trennung in R- oder Python-Frameworks zu implementieren, aber unter der Haube übersetzen diese Bibliotheken ihre Ausgabe in Dateien, die der Browser verarbeiten kann, wie HTML, CSS oder JavaScript. Durch die direkte Verwendung von JavaScript mit den entsprechenden Bibliotheken gewinnen die Entwickler mehr Flexibilität und Anpassungsfähigkeit. Einige gute Beispiele, die eine breite Palette von Visualisierungen bieten, sind D3.js, Sigma.js oder Plotly.js, mit denen reichhaltigere Benutzeroberflächen mit modernen und visuell ansprechenden Designs erstellt werden können.
Dennoch ist das Angebot an JavaScript-basierten Frameworks nach wie vor groß und wächst weiter. Die am häufigsten verwendeten Frameworks sind React, Angular, Vue und Svelte. Vergleicht man sie in Bezug auf Leistung, Community und Lernkurve, so zeigen sich einige Unterschiede, die letztlich von den spezifischen Anwendungsfällen und Präferenzen abhängen (weitere Details finden Sie hier oder hier).
Als „die Programmiersprache des Webs“ gibt es JavaScript schon seit langem. Das vielfältige und vielseitige Ökosystem von JavaScript mit den oben genannten Vorteilen bestätigt dies. Dabei spielen nicht nur die direkt verwendeten Bibliotheken eine Rolle, sondern auch die breite und leistungsfähige Palette an Entwickler-Tools, die das Leben der Entwickler erleichtern.
Überlegungen zur Backend-Architektur
Neben der Ideenfindung müssen auch die Fragen nach dem Entwicklungsrahmen und der Infrastruktur beantwortet werden. Die Kombination der Visualisierungen (Frontend) mit der Datenlogik (Backend) in einer Anwendung hat Vor- und Nachteile.
Ein Ansatz besteht darin, Technologien wie R Shiny oder Python Dash zu verwenden, bei denen sowohl das Frontend als auch das Backend gemeinsam in derselben Anwendung entwickelt werden. Dies hat den Vorteil, dass es einfacher ist, Datenanalyse und -visualisierung in eine Webanwendung zu integrieren. Es hilft den Benutzern, direkt über einen Webbrowser mit Daten zu interagieren und Visualisierungen in Echtzeit anzuzeigen. Vor allem R Shiny bietet eine breite Palette von Paketen für Data Science und Visualisierung, die sich leicht in eine Webanwendung integrieren lassen, was es zu einer beliebten Wahl für Entwickler macht, die im Bereich Data Science arbeiten.
Andererseits bietet die Trennung von Frontend und Backend durch unterschiedliche Frameworks wie Node.js und Python mehr Flexibilität und Kontrolle über den Anwendungsentwicklungsprozess. Frontend-Frameworks wie Vue und React bieten eine breite Palette von Funktionen und Bibliotheken für die Erstellung intuitiver Benutzeroberflächen und Interaktionen, während Backend-Frameworks wie Express.js, Flask und Django robuste Tools für die Erstellung von stabilem und skalierbarem serverseitigem Code bieten. Dieser Ansatz ermöglicht es Entwicklern, die besten Tools für jeden Aspekt der Anwendung auszuwählen, was zu einer besseren Leistung, einfacheren Wartung und mehr Anpassungsmöglichkeiten führen kann. Es kann jedoch auch zu einer höheren Komplexität des Entwicklungsprozesses führen und erfordert mehr Koordination zwischen Frontend- und Backend-Entwicklern.
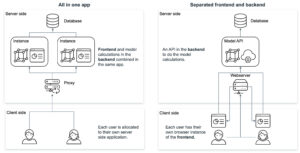
Das Hosten eines JavaScript-basierten Frontends bietet mehrere Vorteile gegenüber dem Hosten einer R Shiny- oder Python Dash-Anwendung. JavaScript-Frameworks wie React, Angular oder Vue.js bieten leistungsstarkes Rendering und Skalierbarkeit, was komplexe UI-Komponenten und groß angelegte Anwendungen ermöglicht. Diese Frameworks bieten auch mehr Flexibilität und Anpassungsoptionen für die Erstellung benutzerdefinierter UI-Elemente und die Implementierung komplexer Benutzerinteraktionen. Darüber hinaus sind JavaScript-basierte Frontends plattformübergreifend kompatibel und laufen auf Webbrowsern, Desktop-Anwendungen und mobilen Apps, was sie vielseitiger macht. Und schließlich ist JavaScript die Sprache des Webs, was eine einfachere Integration in bestehende Technologie-Stacks ermöglicht. Letztendlich hängt die Wahl der Technologie vom spezifischen Anwendungsfall, der Erfahrung des Entwicklungsteams und den Anforderungen der Anwendung ab.
Fazit
Der Aufbau eines Frontends für eine Data-Science-Anwendung ist entscheidend für die effektive Vermittlung von Erkenntnissen an die Endnutzer. Es hilft dabei, die Daten in einer leicht verdaulichen Art und Weise zu präsentieren und ermöglicht es den Benutzern, fundierte Entscheidungen zu treffen. Um sicherzustellen, dass die Bedürfnisse und Anforderungen richtig und effizient genutzt werden, muss das richtige Framework und die richtige Infrastruktur evaluiert werden. Wir schlagen vor, dass Lösungen in R oder Python ein guter Ausgangspunkt sind, aber Anwendungen in JavaScript könnten auf lange Sicht besser skalieren.
Wenn Sie ein Frontend für Ihre Data-Science-Anwendung entwickeln möchten, wenden Sie sich unverbindlich an unser Expertenteam, das Sie durch den Prozess führt und Ihnen die nötige Unterstützung bietet, um Ihre Visionen zu verwirklichen.
Read next …


… and explore new

Habt ihr euch jemals ein Restaurant vorgestellt, in dem alles von KI gesteuert wird? Vom Menü über die Cocktails, das Hosting, die Musik und die Kunst? Nein? Ok, dann klickt bitte hier.
Falls ja, ist eure Traumvorstellung bereits Realität geworden. Wir haben es geschafft: Willkommen im „the byte“ – Deutschlands (vielleicht auch weltweit erstes) KI-gesteuertes Pop-up Restaurant!
Als jemand, der seit über zehn Jahren in der Daten- und KI-Beratung tätig ist und statworx und den AI Hub Frankfurt aufgebaut hat, habe ich immer daran gedacht, die Möglichkeiten von KI außerhalb der typischen Geschäftsanwendungen zu erkunden. Warum? Weil KI jeden Aspekt unserer Gesellschaft beeinflussen wird, nicht nur die Wirtschaft. KI wird überall sein – in Schulen, Kunst und Musik, Design und Kultur. Überall. Bei der Erkundung dieser Auswirkungen von KI traf ich Jonathan Speier und James Ardinast von S-O-U-P, zwei gleichgesinnte Gründer aus Frankfurt, die darüber nachdenken, wie Technologie Städte und unsere Gesellschaft prägen wird.
S-O-U-P ist ihre Initiative, die an der Schnittstelle von Kultur, Urbanität und Lifestyle tätig ist. Mit ihrem jährlichen „S-O-U-P Urban Festival“ bringen sie Kreative, Unternehmen, Gastronomie- und Menschen aus Frankfurt und darüber hinaus zusammen.
Als Jonathan und ich über KI und ihre Auswirkungen auf Gesellschaft und Kultur diskutierten, kamen wir schnell auf die Idee eines KI-generierten Menüs für ein Restaurant. Glücklicherweise ist James, Jonathans Mitbegründer von S-O-U-P, ein erfolgreicher Gastronomie-Unternehmer aus Frankfurt. Nun fügten sich die Puzzlestücke zusammen. Nach einem weiteren Treffen mit James in einem seiner Restaurants (und ein paar Drinks) beschlossen wir, Deutschlands erstes KI-gesteuertes Pop-up-Restaurant zu eröffnen: the byte!
the byte: Unser Konzept
Wir stellten uns the byte als ein immersives Erlebnis vor, bei dem KI in möglichst vielen Elementen des Erlebnisses integriert ist. Alles, vom Menü über die Cocktails, Musik, Branding und Kunst an der Wand: wirklich alles wurde von KI generiert. Die Integration von KI in all diese Komponenten unterschied sich auch für mich sehr von meiner ursprünglichen Aufgabe, Unternehmen bei ihren Daten- und KI-Herausforderungen zu helfen.
Branding
Bevor wir das Menü erstellt haben, entwickelten wir die visuelle Identität unseres Projekts. Wir entschieden uns für einen „Lo-Fi“-Ansatz und verwendeten eine pixel-artige Schrift in Kombination mit KI-generierten Visuals von Tellern und Gerichten. Unser Hauptmotiv, ein neonbeleuchteter weißer Teller, wurde mit Hilfe von DALL-E 2 erstellt und war in all unseren Marketingmaterialien zu finden.

Location
Wir haben the byte in einer der coolsten Restaurant-Event-Locations in Frankfurt veranstaltet: Stanley. Das Stanley ist ein Restaurant mit etwa 60 Sitzplätzen und einer voll ausgestatteten Bar im Inneren (ideal für unsere KI-generierten Cocktails). Die Atmosphäre ist eher dunkel und gemütlich, mit dunklen Marmorplatten an den Wänden, weißen Tischläufern und einem großen roten Fenster, das einen Blick in die Küche ermöglicht.

Das Menü
Das Herzstück unseres Konzepts war ein 5-Gänge-Menü, welches wir mit dem Ziel entworfen haben, die klassische Frankfurter Küche mit den multikulturellen und vielfältigen Einflüssen aus Frankfurt zu erweitern (für alle, die die Frankfurter Küche kennen, wissen, dass dies keine leichte Aufgabe war).
Mit Hilfe von GPT-4 und etwas „Prompt Engineering“-Magie, haben wir ein Menü erstellt, das von der erfahrenen Küchencrew des Stanley getestet (vielen Dank für diese großartige Arbeit!) und dann zu einem endgültigen Menü zusammengestellt wurde. Nachfolgend findet ihr unseren Prompt, der verwendet wurde, um die Menüauswahl zu erstellen:
„Create a 5-course menu that elevates the classical Frankfurter kitchen. The menu must be a fusion of classical Frankfurter cuisine combined with the multicultural influences of Frankfurt. Describe each course, its ingredients as well as a detailed description of each dish’s presentation.“
Zu meiner Überraschung waren nur geringfügige Anpassungen an den Rezepten erforderlich, obwohl einige der KI-Kreationen extrem abenteuerlich waren! Hier ist unser endgültiges Menü:
- Handkäs-Mousse mit eingelegter Rote Bete auf geröstetem Sauerteigbrot
- „Next Level“ Grüne Soße (mit Koriander und Minze) mit einem frittierten Panko-Ei
- Cremesuppe aus weißem Spargel mit Kokosmilch und gebratenem Curry-Fisch
- Currywurst (Rind & vegan) by Best Worscht in Town mit Karotten-Ingwer-Püree und Pinienkernen
- Frankfurter Käsekuchen mit Äppler-Gelee, Apfelschaum und Hafer-Pekannuss-Streusel
Mein klarer Favorit war die „Next Level“ Grüne Soße, eine orientalische Variante der klassischen Frankfurter 7-Kräuter-Grünen Soße mit dem panierten Panko-Ei. Lecker!
Hier könnt ihr das Menü in freier Wildbahn sehen 🍲

KI-Cocktails
Neben dem Menü haben wir GPT angewiesen, Rezepte für berühmte Cocktail-Klassiker zu erstellen, die zu unserem Frankfurt-Fusion-Thema passen. Hier sind die Ergebnisse:
- Frankfurt Spritz (Frankfurter Äbbelwoi, Minze, Sprudelwasser)
- Frankfurt Mule (Variation eines Moscow Mule mit Calvados)
- The Main (Variation eines Swimming Pool Cocktails)
Mein Favorit war der Frankfurt Spritz – er war erfrischend, kräuterig und super lecker (siehe Bild unten).

KI-Host: Ambrosia, die kulinarische KI
Ein wichtiger Teil unseres Konzepts war „Ambrosia“, ein KI-generierter Host, die unsere Gäste durch den Abend geführt und das Konzept sowie die Entstehung des Menüs erklärt hat. Es war uns ein wichtiges Anliegen, die KI für die Gäste erlebbar zu machen. Wir engagierten einen professionellen Drehbuchautor für das Skript und verwendeten murf.ai, um Text-zu-Sprach-Elemente zu erstellen, die zu Beginn des Dinners und zwischen den Gängen abgespielt wurden.
Notiz: Ambrosia spricht ab Sekunde 0:15.
KI-Musik
Musik spielt eine wichtige Rolle für die Atmosphäre einer Veranstaltung. Daher haben wir uns für mubert entschieden, ein generatives KI-Start-up, das es uns ermöglichte, Musik in verschiedenen Genres wie „Minimal House“ zu erstellen und zu streamen, und so für eine progressive Stimmung über den gesamten Abend sorgte. Nach dem Hauptgang übernahm ein DJ und begleitete unsere Gäste durch die Nacht. 💃🍸
KI-Kunst
Im gesamten Restaurant platzierten wir KI-generierte Kunstwerke des lokalen KI-Künstlers Vladimir Alexeev (a.k.a. “Merzmensch”). Hier sind einige Beispiele:

KI-Spielplatz
Als interaktives Element für die Gäste haben wir eine kleine Web-App erstellt, die den Vornamen einer Person nimmt und in ein Gericht verwandelt, inklusive einer Begründung, warum dieser Name perfekt zum Gericht passt. Probiert es hier gerne selbst aus: Playground
Launch
the byte wurde offiziell auf der Pressekonferenz des S-O-U-P-Festivals Anfang Mai 2023 angekündigt. Wir starteten auch zusätzliche Marketingaktivitäten über soziale Medien und unser Netzwerk von Freunden und Familie. Als Ergebnis war the byte drei Tage lang vollständig ausgebucht und wir erhielten breite Medienberichterstattung in verschiedenen Gastronomie-Magazinen und der Tagespresse. Die Gäste waren (meistens) von unseren KI-Kreationen begeistert und wir erhielten Anfragen von anderen europäischen Restaurants und Unternehmen, die the byte exklusiv als Erlebnis für ihre Mitarbeiter:innen buchen möchten. 🤩 Nailed it!
Fazit und nächste Schritte
Die Erschaffung von the byte zusammen mit Jonathan und James war eine herausragende Erfahrung. Es hat mich weiter darin bestärkt, dass KI nicht nur unsere Wirtschaft, sondern alle Aspekte unseres täglichen Lebens transformieren wird. Es gibt ein riesiges Potenzial an der Schnittstelle von Kreativität, Kultur und KI, das derzeit erschlossen wird.
Wir möchten the byte definitiv in Frankfurt weiterführen und haben bereits Anfragen aus anderen Städten in Europa erhalten. Außerdem denken James, Jonathan und ich bereits über neue Möglichkeiten nach, KI in Kultur und Gesellschaft einzubringen. Stay tuned! 😏
the byte war nicht nur ein Restaurant, sondern ein fesselndes Erlebnis. Wir wollten etwas erschaffen, was noch nie zuvor gemacht wurde, und das haben wir in nur acht Wochen erreicht. Das ist die Inspiration, die ich euch heute mitgeben möchte:
Neue Dinge auszuprobieren, die einen aus der Komfortzone herausholen, ist die ultimative Quelle des Wachstums. Ihr wisst nie, wozu ihr fähig seid, bis ihr es versucht. Also, geht raus und probiert etwas Neues aus, wie den Aufbau eines KI-gesteuerten Pop-up-Restaurants. Wer weiß, vielleicht überrascht ihr euch selbst. Bon apétit!
Impressionen

Media
Genuss Magazin: https://www.genussmagazin-frankfurt.de/gastro_news/Kuechengefluester-26/Interview-James-Ardinast-KI-ist-die-Zukunft-40784.html
Frankfurt Tipp: https://www.frankfurt-tipp.de/ffm-aktuell/s/ugc/deutschlands-erstes-ai-restaurant-the-byte-in-frankfurt.html
Foodservice: https://www.food-service.de/maerkte/news/the-byte-erstes-ki-restaurant-vor-dem-start-55899?crefresh=1
statworx auf der Big Data & AI World
Von Medien über Politik bis hin zu großen und kleinen Unternehmen – Künstliche Intelligenz hat im Jahr 2023 endlich den Sprung in den Mainstream geschafft. Umso mehr haben wir uns gefreut, dieses Jahr wieder auf einer der größten KI-Messen im DACH-Raum, der „Big Data & AI World“, in unserer Heimatstadt Frankfurt vertreten zu sein. Bei dieser Veranstaltung standen die Themen Big Data und künstliche Intelligenz im Mittelpunkt; ein perfektes Umfeld für uns als KI-Spezialist:innen. Doch wir kamen nicht nur zum Erkunden der Messe und zum Knüpfen von Kontakten: Auch an unserem eigenen Stand konnten Besucher:innen ein faszinierendes Pac-Man-Spiel mit einem besonderen Kniff erleben. In diesem Beitrag möchten wir Ihnen gerne einen Rückblick auf diese aufregende Messe geben.

Abb. 1: unser Messestand
KI zum Anfassen
Unsere Pac-Man Challenge, bei der wir den Standbesucher:innen die faszinierende Welt der künstlichen Intelligenz hautnah präsentierten, stellte sich als wahrer Publikumsliebling heraus. Mit unserem Spielautomaten konnte man sich nicht nur an dem zeitlosen Retro-Spiel versuchen, sondern auch die beeindruckende Leistungsfähigkeit moderner KI-Technologie erleben. So setzten wir nämlich eine KI ein, um die Emotionen in der Mimik der Spieler:innen in Echtzeit zu analysieren. Diese Kombination von modernster Technologie mit einem interaktiven Spielerlebnis kam hervorragend an.
Unsere KI-Lösung zur lief auf einem MacBook mit leistungsstarkem M1-Chip, was die Bildverarbeitung in Echtzeit und flüssige Grafikdarstellung ermöglichte. Die Gesichtserkennung der Spieler:innen wurde durch einen smarten Algorithmus ermöglicht, der sofort alle Gesichter im Video ermittelte. Anschließend wurde das Gesicht, das sich am nächsten an der Kamera befand, ausgewählt und fokussiert. So konnte auch bei einer langen Schlange vor dem Automaten das korrekte Gesicht analysiert werden. Eine weitere Schicht der Verarbeitung erfolgte durch ein Convolutional Neural Network (CNN), speziell das ResNet18-Modell, welches die Emotionen der Spieler:innen erkannte.
Unser Backend fungierte als Multimedia-Server, der den Webcam-Stream, die Gesichtserkennungsalgorithmen und die Emotionserkennung verarbeitete. Es kann sowohl vor Ort auf einem MacBook betrieben werden wie auch remote in der Cloud. Dank dieser Flexibilität konnten wir ein ansprechendes Frontend entwickeln, um die Ergebnisse der Echtzeitanalyse anschaulich darzustellen. Zusätzlich wurden nach jedem Spiel die Resultate mittels E-Mail an die Spieler:innen versandt, indem wir das Modell mit unserem CRM-System verknüpft haben. Für die E-Mail haben wir eine digitale Postkarte erstellt, welche neben Screenshots der intensivsten Emotionen auch eine umfassende Auswertung bereitstellt.

Abb. 2: Besucherin am Pac-Man Spieleautomaten
Künstliche Intelligenz, echte Emotionen
Die Pac-Man Challenge mit Emotionsanalyse sorgte bei den Messebesucher:innen für Begeisterung. Neben der besonderen Spielerfahrung auf unserem Retro-Automaten erhielten die Teilnehmenden nämlich auch einen Einblick in ihre eigenen Emotionen während des Spielens. So konnten die Spieler:innen detailliert ablesen, welche Emotion zu welchem Zeitpunkt im Spiel am präsentesten war. Allzu oft ließ sich ein kleines Aufkommen von Wut oder Traurigkeit messen, wenn Pac-Man unfreiwillig in den digitalen Tod geschickt wurde.
Nicht alle Spieler:innen zeigten jedoch die gleiche Reaktion auf das Spiel. Während manche ein Wechselbad der Gefühle zu erleben schienen, setzten andere ein eisernes Pokerface auf, dem selbst die KI nur einen neutralen Ausdruck entlocken konnte. Somit entstanden viele spannende Gespräche darüber, wie die gemessenen Emotionen zum Erlebnis der Spieler:innen passten. Es bedurfte keiner KI, um zu erkennen, dass die Besucher:innen unseren Stand mit positiven Emotionen verließen – nicht zuletzt in Hoffnung auf den Gewinn der originalen NES-Konsole, die wir unter allen Teilnehmenden verlosten.
Abb. 3: digitale Postkarte
Die KI-Community im Aufbruch
Die „Big Data & AI World“ war nicht nur für uns als Unternehmen eine bereichernde Erfahrung, sondern auch ein Spiegelbild des Aufbruchs, den die KI-Branche derzeit erlebt. Die Messe bot eine Plattform für Fachleute, Innovator:innen und Enthusiast:innen, um sich über die neuesten Entwicklungen auszutauschen und gemeinsam die Zukunft der künstlichen Intelligenz voranzutreiben.
In den Gängen und Ausstellungsbereichen spürte man die Energie und Aufregung, die von den verschiedenen Unternehmen und Start-ups ausgingen. Es war inspirierend zu sehen, wie KI-Technologien in den unterschiedlichsten Bereichen angewendet werden – von der Medizin bis zur Logistik, von der Automobilindustrie bis zur Unterhaltung. Mit all diesen Bereichen haben wir bei statworx bereits Projekterfahrung sammeln können, was die Basis für spannende Fachgespräche mit anderen Aussteller:innen bildete.
Unser Fazit
Die Teilnahme an der „Big Data & AI World “ war für uns als KI-Beratung ein großer Erfolg. Die Pac-Man Challenge mit Emotionsanalyse zog zahlreiche Besucher:innen an und bereitete allen Teilnehmenden viel Freude. Es war deutlich erkennbar, dass nicht die KI als solche, sondern insbesondere deren Einbindung in eine anregende Spielerfahrung bei vielen einen bleibenden Eindruck hinterließ.
Insgesamt war die Messe nicht nur eine Gelegenheit, unsere KI-Lösungen zu präsentieren, sondern auch ein Treffpunkt für die gesamte KI-Community. Der Aufbruch und die Energie in der Branche waren deutlich spürbar. Auch der Austausch von Ideen, Diskussionen über Herausforderungen und das Aufbauen neuer Kontakte war inspirierend und vielversprechend für die Zukunft der deutschen KI-Branche.
Experimente zur Bilderkennung durch die Genderbrille
Im ersten Teil unserer Serie haben wir uns mit einer einfachen Frage beschäftigt: Wie würde sich unser Aussehen verändern, wenn wir Fotos von uns entlang des Genderspektrums bewegen würden? Aus diesen Experimenten entstand die Idee, genderneutrale Gesichtsbilder aus vorhandenen Fotos zu erstellen. Gibt es einen Punkt in der Mitte, an dem wir unser „Gender”, unser Geschlecht, als neutral wahrnehmen? Und außerdem: Wann würde eine KI ein Gesicht als genderneutral wahrnehmen?
Bewusstsein für die Technologie, die wir täglich nutzen
Die Bilderkennung ist ein wichtiges Thema. Diese Technologie entwickelt sich täglich weiter und wird in einer Vielzahl von Anwendungen eingesetzt – oft ohne, dass Benutzer:innen wissen, wie die Technologie funktioniert. Ein aktuelles Beispiel ist der „Bold-Glamour-Filter“ auf TikTok. Bei Anwendung mit weiblich aussehenden Gesichtern ändern sich Gesichtsmerkmale und Make-up drastisch. Im Gegensatz dazu ändern sich männlich aussehende Gesichter deutlich weniger. Dieser Unterschied lässt vermuten, dass die KI hinter den Filtern mit unausgewogenen Daten entwickelt wurde. Die Technologie dahinter basiert höchstwahrscheinlich auf sogenannten „General Adversarial Networks“ (GANs), also dieselbe Art von KI, die wir in diesem Artikel untersuchen.
Als eine Gesellschaft bewusster Bürger:innen sollten wir alle die Technologie verstehen, die solche Anwendungen ermöglicht. Um das Bewusstsein dafür zu schärfen, untersuchen wir die Erzeugung und Klassifizierung von Gesichtsbildern durch eine genderspezifische Brille. Anstatt mehrere Schritte entlang des Spektrums zu erforschen, besteht unser Ziel dieses Mal darin, geschlechtsneutrale Versionen von Gesichtern zu erzeugen.
Wie man genderneutrale Gesichter mit StyleGAN generiert
Ein Deep-Learning-Modell zur Geschlechtsidentifizierung
Es ist alles andere als trivial, einen Punkt zu bestimmen, ab dem das Gender eines Gesichts als neutral gilt. Nachdem wir uns auf unsere eigene (natürlich nicht unvoreingenommene) Interpretation von Gender in Gesichtern verlassen hatten, wurde uns schnell klar, dass wir eine konsistente und weniger subjektive Lösung benötigen. Als KI-Spezialist:innen dachten wir sofort an datengetriebene Ansätze. Ein solcher Ansatz kann mit einem auf Deep Learning basierenden Bildklassifikator umgesetzt werden.
Solche Klassifikationsmodelle werden in der Regel auf großen Datensätzen mit gekennzeichneten Bildern trainiert, um zwischen festgelegten Kategorien zu unterscheiden. Bei der Klassifizierung von Gesichtern sind Kategorien wie Gender (in der Regel nur weiblich und männlich) und ethnische Zugehörigkeit übliche Kategorien. In der Praxis werden solche Modelle oft wegen ihres Missbrauchspotenzials und ihrer Unfairness kritisiert. Bevor wir Beispiele für diese Probleme erörtern, werden wir uns zunächst auf unser weniger kritisches Szenario konzentrieren. In unserem Anwendungsfall ermöglichen es uns Klassifikationsmodelle, die Erstellung von genderneutralen Portraits vollständig zu automatisieren. Um dies zu erreichen, können wir folgendermaßen eine Lösung implementieren:
Wir verwenden einen GAN-basierten Ansatz, um Portraits zu erzeugen, die auf einem gegebenen Inputbild basieren. Dazu verwenden wir die latenten Richtungen des gelernten Genderspektrums des GAN, um das Bild in Richtung eines eher weiblichen oder männlichen Aussehens zu bewegen. Eine detaillierte Untersuchung dieses Prozesses ist im ersten Teil unserer Serie zu finden. Aufbauend auf diesem Ansatz wollen wir uns auf die Verwendung eines binären Gender-Klassifikators konzentrieren, um die Suche nach einem genderneutralen Aussehen vollständig zu automatisieren.
Dazu verwenden wir den von Furkan Gulsen entwickelten Klassifikator, um das Gender der GAN-generierten Version unseres Eingabebildes zu erraten. Der Klassifikator gibt einen Wert zwischen Null und Eins aus, um die Wahrscheinlichkeit darzustellen, dass das Bild ein weibliches bzw. männliches Gesicht darstellt. Dieser Wert sagt uns, in welche Richtung (eher männlich oder eher weiblich) wir uns bewegen müssen, um uns einer geschlechtsneutralen Version des Bildes anzunähern. Nachdem wir einen kleinen Schritt in die ermittelte Richtung gemacht haben, wiederholen wir den Vorgang, bis wir zu einem Punkt gelangen, an dem der Klassifikator das Gender des Gesichts nicht mehr sicher bestimmen kann. Dieser Punkt ist erreicht, sobald der Klassifikator die männliche als auch die weibliche Kategorie für gleich wahrscheinlich hält.
Die folgenden Beispiele illustrieren diesen Status und repräsentieren unsere Ergebnisse. Auf der linken Seite ist das Originalbild zu sehen. Rechts sehen wir die genderneutrale Version des Portraits, welches der Klassifikator mit gleicher Wahrscheinlichkeit als männlich oder weiblich interpretiert. Wir haben versucht, das Experiment für Mitglieder verschiedener Ethnien und Altersgruppen zu wiederholen.
Resultat: Originalportrait und KI-generierter, genderneutraler Output





Bist du neugierig, wie der Code funktioniert oder wie du selbst aussehen würdest? Du kannst den Code, mit dem wir diese Bildpaare erzeugt haben, unter diesem Link ausprobieren. Drücke einfach nacheinander auf jeden Play-Button und warte, bis du das grüne Häkchen siehst.
Hinweis: Wir haben ein bestehendes GAN, einen Bild-Encoder und einen Gesichter-Klassifikator verwendet, um einen genderneutralen Output zu generieren. Eine detaillierte Untersuchung dieses Prozesses ist hier zu finden.
Wahrgenommene Genderneutralität scheint eine Folge von gemischten Gesichtszügen zu sein
Oben sehen wir die Originalportraits verschiedener Personen auf der linken Seite und rechts ihr genderneutrales Gegenstück – von uns erstellt. Subjektiv fühlen sich einige „neutraler“ an als andere. In einigen der Bilder bleiben besonders stereotype Gendermerkmale erhalten, wie z. B. Make-up bei den Frauen und eine eckige Kieferpartie bei den Männern. Als besonders überzeugend empfinden wir die Ergebnisse von Bild 2 und Bild 4. Bei diesen Bildpaaren ist es nicht nur schwieriger, die ursprüngliche Person zurückzuverfolgen, sondern es ist auch viel schwieriger zu entscheiden, ob das Gesicht eher männlich oder weiblich wirkt. Man könnte argumentieren, dass die genderneutralen Gesichter eine ausgewogene, abgeschwächte Mischung aus männlichen und weiblichen Gesichtszügen besitzen. Wenn man beispielsweise Teile der genderneutralen Version von Bild 2 herausgreift und sich darauf konzentriert, erscheinen die Augen- und Mundpartien eher weiblich, während die Kieferlinie und die Gesichtsform eher männlich wirken. Bei der genderneutralen Version von Bild 3 mag das Gesicht allein recht neutral aussehen, aber die kurzen Haare lenken davon ab, so dass der Gesamteindruck in Richtung männlich geht.
Die Trainingsdaten für die Bilderzeugung wurden heftig kritisiert, weil sie nicht repräsentativ für die bestehende Bevölkerung sind, insbesondere was die Unterrepräsentation verschiedener Ethnien und Gender betrifft. Trotz „Cherry Picking“ und einer begrenzten Auswahl an Beispielen sind wir der Meinung, dass unser Ansatz in den obigen Ergebnissen keine schlechteren Beispiele für Frauen oder People of Color hervorgebracht hat.
Gesellschaftliche Bedeutung solcher Modelle
Wenn wir über das Thema der Genderwahrnehmung sprechen, sollten wir nicht vergessen, dass Menschen sich einem anderen Gender zugehörig fühlen können als ihrem biologischen Geschlecht. In diesem Artikel verwenden wir Modelle zur Genderklassifizierung und interpretieren die Ergebnisse. Unsere Einschätzungen werden jedoch wahrscheinlich von der Wahrnehmung anderer Menschen abweichen. Dies ist eine wesentliche Überlegung bei der Anwendung solcher Bildklassifizierungsmodelle und eine, die wir als Gesellschaft diskutieren müssen.
Wie kann Technologie alle gleich behandeln?
Eine Studie des Guardian hat ergeben, dass Bilder von Frauen, die in denselben Situationen wie Männer dargestellt werden, von den KI-Klassifizierungsdiensten von Microsoft, Google und AWS mit größerer Wahrscheinlichkeit als anzüglich eingestuft werden. Die Ergebnisse dieser Untersuchung sind zwar schockierend, aber nicht überraschend. Damit ein Klassifizierungsalgorithmus lernen kann, was anstößige Inhalte sind, müssen Trainingsdaten von Bild- und Label-Paaren erstellt werden. Diese Aufgabe übernehmen Menschen. Sie werden durch ihre eigene soziale Voreingenommenheit beeinflusst und assoziieren beispielsweise Darstellungen von Frauen schneller mit Sexualität. Außerdem sind Kriterien wie „Anzüglichkeit“ schwer zu quantifizieren, geschweige denn zu definieren.
Auch wenn diese Modelle nicht ausdrücklich auf die Unterscheidung zwischen den Geschlechtern trainiert werden, besteht kaum ein Zweifel daran, dass sie unerwünschte Vorurteile gegenüber Frauen verbreiten, die aus ihren Trainingsdaten stammen. Ebenso können gesellschaftliche Vorurteile, die Männer betreffen, an KI-Modelle weitergegeben werden. Bei der Anwendung auf Millionen von Online-Bildern von Menschen wird das Problem der Geschlechterungleichheit noch verstärkt.
Verwendung in der Strafverfolgung wirft Probleme auf
Ein weiteres Szenario für den Missbrauch von Bildklassifizierungstechnologie besteht in der Strafverfolgung. Fehlklassifizierungen sind problematisch und werden in einem Artikel von The Independent als weit verbreitet dargestellt. Als die Erkennungssoftware von Amazon in einer Studie aus dem Jahr 2018 mit einem Konfidenzniveau von 80 % verwendet wurde, ordnete die Software 105 von 1959 Teilnehmer:innen fälschlicherweise Fahndungsfotos von Verbrecher:innen zu. Angesichts der oben beschriebenen Probleme mit der Verarbeitung von Bildern, auf denen Männer und Frauen abgebildet sind, könnte man sich ein ernüchterndes Szenario vorstellen, wenn man das Verhalten von Frauen im öffentlichen Raum beurteilt. Wenn Männer und Frauen für dieselben Handlungen oder Positionen unterschiedlich beurteilt werden, würde dies das Recht aller auf Gleichbehandlung vor dem Gesetz beeinträchtigen. Der Bayerische Rundfunk hat eine interaktive Seite veröffentlicht, auf der die unterschiedlichen Einstufungen der KI-Klassifizierungsdienste mit der eigenen Einschätzung verglichen werden können.
Verwendung genderneutraler Bilder zur Vermeidung von Vorurteilen
Neben den positiven gesellschaftlichen Potenzialen der Bildklassifizierung wollen wir auch einige mögliche praktische Anwendungen ansprechen, die sich aus der Möglichkeit ergeben, mehr als nur zwei Gender abzudecken. Eine Anwendung, die uns in den Sinn kam, ist die Verwendung von „genderlosen“ Bildern, um Vorurteile zu vermeiden. Ein solcher Filter würde einen Verlust an Individualität bedeuten, sodass er nur in Kontexten anwendbar wäre, in denen der Nutzen der Verringerung von Vorurteilen die Kosten dieses Verlusts überwiegt.
Vision einer Browsererweiterung für den Bewerbungsprozess
Die Personalauswahl könnte ein Bereich sein, in dem genderneutrale Bilder zu weniger genderbasierter Diskriminierung führen könnten. Vorbei sind die Zeiten der gesichtslosen Bewerbungen: Wenn ein LinkedIn-Profil ein Profilbild hat, ist die Wahrscheinlichkeit, dass es angesehen wird, 14-mal höher . Bei der Prüfung von Bewerbungsprofilen sollten Personalverantwortliche idealerweise frei von unbewussten, ungewollten genderspezifischen Vorurteilen sein. Die menschliche Natur verhindert dies. So könnte man sich eine Browsererweiterung vorstellen, die eine genderneutrale Version von Profilfotos auf professionellen Social-Networking-Seiten wie LinkedIn oder Xing generiert. Dies könnte zu mehr Gleichheit und Neutralität im Einstellungsprozess führen, bei dem nur die Fähigkeiten und der Charakter zählen sollten, nicht aber das Geschlecht – oder das Aussehen (ein schönes Privileg).
Schlusswort
Wir haben uns zum Ziel gesetzt, automatisch genderneutrale Versionen aus einem beliebigen Portrait zu erzeugen.
Unsere Implementierung automatisiert in der Tat die Erstellung von genderneutralen Gesichtern. Wir haben ein bestehendes GAN, einen Bild-Encoder und einen Gesichter-Klassifikator verwendet. Unsere Experimente mit den Portraits oben zeigen, dass der Ansatz in vielen Fällen gut funktioniert und realistisch aussehende Gesichtsbilder erzeugt, die dem Eingabebild deutlich ähneln und dabei genderneutral bleiben.
In einigen Fällen haben wir jedoch festgestellt, dass die vermeintlich neutralen Bilder Artefakte von technischen Störungen enthalten oder noch ihr erkennbares Gender haben. Diese Einschränkungen ergeben sich wahrscheinlich aus der Beschaffenheit des latenten Raums des GANs oder aus dem Mangel an künstlich erzeugten Bildern in den Trainingsdaten des Klassifikators. Wir sind zuversichtlich, dass weitere Arbeiten die meisten dieser Probleme für reale Anwendungen lösen können.
Die Fähigkeit der Gesellschaft, eine fundierte Diskussion über Fortschritte in der KI zu führen, ist von entscheidender Bedeutung
Bildklassifizierung hat weitreichende Folgen und sollte von der Gesellschaft und nicht nur von einigen wenigen Expert:innen bewertet und diskutiert werden. Jeder Bildklassifikationsdienst, der dazu dient, Menschen in Kategorien einzuteilen, sollte genau geprüft werden. Was vermieden werden muss, ist, dass Mitglieder der Gesellschaft zu Schaden kommen. Die Einführung eines verantwortungsvollen Umgangs mit solchen Systemen, die Kontrolle und die ständige Bewertung sind unerlässlich. Eine weitere Lösung könnte darin bestehen, Strukturen für die Begründung von Entscheidungen zu schaffen und dabei die Best Practices von Explainable AI zu nutzen, um darzulegen, warum bestimmte Entscheidungen getroffen wurden. Als Unternehmen im Bereich der KI sehen wir bei statworx unsere KI-Prinzipien als Wegweiser.
Bildnachweise:
AdobeStock 210526825 – Wayhome Studio
AdobeStock 243124072 – Damir Khabirov
AdobeStock 387860637 – insta_photos
AdobeStock 395297652 – Nattakorn
AdobeStock 480057743 – Chris
AdobeStock 573362719 – Xavier Lorenzo
AdobeStock 546222209 – Rrose Selavy
Einführung
Forecasts sind in vielen Branchen von zentraler Bedeutung. Ob es darum geht, den Verbrauch von Ressourcen zu prognostizieren, die Liquidität eines Unternehmens abzuschätzen oder den Absatz von Produkten im Einzelhandel vorherzusagen – Forecasts sind ein unverzichtbares Instrument für erfolgreiche Entscheidungen. Obwohl sie so wichtig sind, basieren viele Forecasts immer noch primär auf den Vorerfahrungen und der Intuition von Expert:innen. Das erschwert eine Automatisierung der relevanten Prozesse, eine potenzielle Skalierung und damit einhergehend eine möglichst effiziente Unterstützung. Zudem können Expert:innen aufgrund ihrer Erfahrungen und Perspektiven voreingenommen sein oder möglicherweise nicht über alle relevanten Informationen verfügen, die für eine genaue Vorhersage erforderlich sind.
Diese Gründe führen dazu, dass datengetriebene Forecasts in den letzten Jahren immer mehr an Bedeutung gewonnen haben und die Nachfrage nach solchen Prognosen ist entsprechend stark.
Bei statworx haben wir bereits eine Vielzahl an Projekten im Bereich Forecasting erfolgreich umgesetzt. Dadurch haben wir uns vielen Herausforderungen gestellt und uns mit zahlreichen branchenspezifischen Use Cases vertraut gemacht. Eine unserer internen Arbeitsgruppen, das Forecasting Cluster, begeistert sich besonders für die Welt des Forecastings und bildet sich kontinuierlich in diesem Bereich weiter.
Auf Basis unserer gesammelten Erfahrungen möchten wir diese nun in einem benutzerfreundlichen Tool vereinen, welches je nach Datenlage und Anforderungen jedem ermöglicht, erste Einschätzungen zu spezifischen Forecasting Use Cases zu erhalten. Sowohl Kunden als auch Mitarbeitende sollen in der Lage sein, das Tool schnell und einfach zu nutzen, um eine methodische Empfehlung zu erhalten. Unser langfristiges Ziel ist es, das Tool öffentlich zugänglich zu machen. Jedoch testen wir es zunächst intern, um seine Funktionalität und Nützlichkeit zu optimieren. Dabei legen wir besonderen Wert darauf, dass das Tool intuitiv bedienbar ist und leicht verständliche Outputs liefert.
Obwohl sich unser Recommender-Tool derzeit noch in der Entwicklungsphase befindet, möchten wir einen ersten spannenden Einblick geben.
Häufige Herausforderungen
Modellauswahl
Im Bereich Forecasting gibt es verschiedene Modellierungsansätze. Wir differenzieren dabei zwischen drei zentralen Ansätzen:
- Zeitreihenmodelle
- Baumbasierte Modelle
- Deep Learning Modelle
Es gibt viele Kriterien, die man bei der Modellauswahl heranziehen kann. Wenn es sich um univariate Zeitreihen handelt, die eine starke Saisonalität und Trends aufweisen, sind klassische Zeitreihenmodelle wie (S)ARIMA und ETS sinnvoll. Handelt es sich hingegen um multivariate Zeitreihen mit potenziell komplexen Zusammenhängen und großen Datenmengen, stellen Deep Learning Modelle eine gute Wahl dar. Baumbasierte Modelle wie LightGBM bieten im Vergleich zu Zeitreihenmodellen eine größere Flexibilität, eignen sich aufgrund ihrer Architektur gut für das Thema Erklärbarkeit und haben im Vergleich zu Deep Learning Modellen einen tendenziell geringeren Rechenaufwand.
Saisonalität
Saisonalität stellt wiederkehrende Muster in einer Zeitreihe dar, die in regelmäßigen Abständen auftreten (z.B. täglich, wöchentlich, monatlich oder jährlich). Die Einbeziehung der Saisonalität in der Modellierung ist wichtig, um diese regelmäßigen Muster zu erfassen und die Genauigkeit der Prognosen zu verbessern. Mit Zeitreihenmodellen wie SARIMA, ETS oder TBATS kann die Saisonalität explizit berücksichtigt werden. Für baumbasierte Modelle wie LightGBM kann die Saisonalität nur über die Erstellung entsprechender Features berücksichtigt werden. So können Dummies für die relevanten Saisonalitäten gebildet werden. Eine Möglichkeit Saisonalität in Deep Learning-Modellen explizit zu berücksichtigen, besteht in der Verwendung von Sinus- und Cosinus-Funktionen. Ebenso ist es möglich die Saisonalitätskomponente aus der Zeitreihe zu entfernen. Dazu wird zuerst die Saisonalität entfernt und anschließend eine Modellierung auf der desaisonalisierten Zeitreihe durchgeführt. Die daraus resultierenden Prognosen werden dann mit der Saisonalität ergänzt, indem die genutzte Methodik für die Desaisonalisierung entsprechend angewendet wird. Allerdings erhöht dieser Prozess die Komplexität, was nicht immer erwünscht ist.
Hierarchische Daten
Besonders im Bereich Retail liegen häufig hierarchische Datenstrukturen vor, da die Produkte meist in unterschiedlicher Granularität dargestellt werden können. Hierdurch ergibt sich häufig die Anforderung, Prognosen für unterschiedliche Hierarchien zu erstellen, welche sich nicht widersprechen. Die aggregierten Prognosen müssen daher mit den disaggregierten übereinstimmen. Dabei ergeben sich verschiedene Lösungsansätze. Über Top-Down und Bottom-Up werden Prognosen auf einer Ebene erstellt und nachgelagert disaggregiert bzw. aggregiert. Mit Reconciliation-Methoden wie Optimal Reconciliation werden Prognosen auf allen Ebenen vorgenommen und anschließend abgeglichen, um eine Konsistenz über alle Ebenen zu gewährleisten.
Cold Start
Bei einem Cold Start besteht die Herausforderung darin Produkte zu prognostizieren, die nur wenig oder keine historischen Daten aufweisen. Im Retail Bereich handelt es sich dabei meist um Produktneueinführungen. Da aufgrund der mangelnden Historie ein Modelltraining für diese Produkte nicht möglich ist, müssen alternative Ansätze herangezogen werden. Ein klassischer Ansatz einen Cold Start durchzuführen, ist die Nutzung von Expertenwissen. Expert:innen können erste Schätzungen der Nachfrage liefern, die als Ausgangspunkt für Prognosen dienen können. Dieser Ansatz kann jedoch stark subjektiv ausfallen und lässt sich nicht skalieren. Ebenso kann auf ähnliche Produkte oder auch auf potenzielle Vorgänger-Produkte referenziert werden. Eine Gruppierung von Produkten kann beispielsweise auf Basis der Produktkategorien oder Clustering-Algorithmen wie K-Means erfolgen. Die Nutzung von Cross-Learning-Modellen, die auf Basis vieler Produkte trainiert werden, stellt eine gut skalierbare Möglichkeit dar.
Recommender Concept
Mit unserem Recommender Tool möchten wir die unterschiedlichen Problemstellungen berücksichtigen, um eine möglichst effiziente Entwicklung zu ermöglichen. Dabei handelt es sich um ein interaktives Tool, bei welchem man Inputs auf Basis der Zielvorstellung oder Anforderung und den vorliegenden Datencharakteristiken gibt. Ebenso kann eine Priorisierung vorgenommen werden, sodass bestimmte Anforderungen an der Lösung auch im Output entsprechend priorisiert werden. Auf Basis dieser Inputs werden methodische Empfehlungen generiert, die die Anforderungen an der Lösung in Abhängigkeit der vorliegenden Eigenschaften bestmöglich abdecken. Aktuell bestehen die Outputs aus einer rein inhaltlichen Darstellung der Empfehlungen. Dabei wird auf die zentralen Themenbereiche wie Modellauswahl, Pre-Processing und Feature Engineering mit konkreten Guidelines eingegangen. Das nachfolgende Beispiel gibt dabei einen Eindruck über die konzeptionelle Idee:
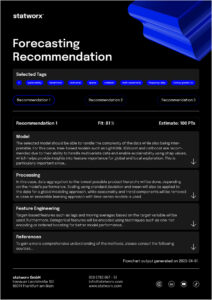
Der hier dargestellte Output basiert auf einem realen Projekt. Für das Projekt war vor allem die Implementierung in R und die Möglichkeit einer lokalen Erklärbarkeit von zentraler Bedeutung. Zugleich wurden frequentiert neue Produkte eingeführt, welche ebenso durch die entwickelte Lösung prognostiziert werden sollten. Um dieses Ziel zu erreichen, wurden mehrere globale Modelle mit Hilfe von Catboost trainiert. Dank diesem Ansatz konnten über 200 Produkte ins Training einbezogen werden. Sogar für neu eingeführte Produkte, bei denen keine historischen Daten vorlagen, konnten Forecasts generiert werden.
Um die Erklärbarkeit der Prognosen sicherzustellen, wurden SHAP Values verwendet. Auf diese Weise konnten die einzelnen Vorhersagen klar und deutlich anhand der genutzten Features erklärt werden.
Zusammenfassung
Die aktuelle Entwicklung ist darauf ausgerichtet ein Tool zu entwickeln, welches auf das Thema Forecasting optimiert ist. Durch die Nutzung wollen wir vor allem die Effizienz bei Forecasting-Projekten steigern. Durch die Kombination von gesammelten Erfahrungen und Expertise soll das Tool unter anderem für die Themen Modellierung, Pre-Processing und Feature Engineering Guidelines bieten. Es wird darauf ausgelegt sein, sowohl von Kunden als auch Mitarbeitenden verwendet zu werden, um schnelle und einfache Abschätzungen sowie methodische Empfehlungen zu erhalten. Eine erste Testversion wird zeitnah für den internen Gebrauch zur Verfügung stehen. Langfristig soll das Tool jedoch auch für externe Nutzer:innen zugänglich gemacht werden. Neben dem derzeit in der Entwicklung befindlichen technischen Output, wird auch ein weniger technischer Output verfügbar sein. Letzterer wird sich auf die wichtigsten Aspekte und deren Aufwände konzentrieren. Insbesondere die Business-Perspektive in Form von erwarteten Aufwänden und potenziellen Trade-Offs von Aufwand und Nutzen soll hierdurch abgedeckt werden.
Profitieren auch Sie von unserer Forecasting Expertise!
Wenn Sie Unterstützung bei der Bewältigung von vorliegenden Herausforderungen bei Forecasting Projekten benötigen oder ein Forecasting Projekt geplant ist, stehen wir gerne mit unserem Know-how und unserer Erfahrung zur Verfügung.
Bei statworx erforschen wir kontinuierlich neue Ideen und Möglichkeiten im Bereich der künstlichen Intelligenz. Die letzten Monate waren von Generativen Modellen geprägt, insbesondere von solchen, die von OpenAI entwickelt wurden (z.B. ChatGPT, DALL-E 2), aber auch von Open-Source-Projekten wie Stable Diffusion. ChatGPT ist ein Text-zu-Text-Modell, während DALL-E 2 und Stable Diffusion Text-zu-Bild-Modelle sind, die auf der Grundlage einer kurzen Textbeschreibung des Benutzers beeindruckende Bilder erstellen. Während der Evaluierung dieser Forschungstrends entdeckten wir eine großartige Möglichkeit, unsere von HP zur Verfügung gestellte GPU-Workstation zu nutzen, damit unsere #statcrew ihre eigenen digitalen Avatare erstellen kann.
Das steckt hinter dem Text-zu-Bild-Generator Stable Diffusion
Text-Bild-Generatoren wie Stable Diffusion und DALL-E 2 basieren auf Diffusionsarchitekturen von künstlichen neuronalen Netzen. Die umfangreichen Trainingsdaten aus dem Internet erfordern oft Monate an Trainingszeit auf Hochleistungsrechnern, um eine optimale Performance zu erreichen. Eine erfolgreiche Implementierung ist daher lediglich durch den Einsatz von Supercomputern möglich. Aber auch nach dem Training benötigen die OpenAI-Modelle immer noch einen Supercomputer, um neue Bilder zu generieren, da ihre Größe die Kapazität von herkömmlichen Computern übersteigt. OpenAI hat Schnittstellen bereitgestellt, um den Zugang zu seinen Modellen zu erleichtern (https://openai.com/product#made-for-developers). Jedoch wurden die Modelle selbst nicht öffentlich freigegeben.
Stable Diffusion hingegen wurde als Text-zu-Bild-Generator entwickelt, ist aber so groß, dass es auf dem eigenen Computer ausgeführt werden kann. Das Open-Source-Projekt ist ein Gemeinschaftsprojekt mehrerer Forschungsinstitute. Seine öffentliche Verfügbarkeit ermöglicht es Forschern und Entwicklern, das trainierte Modell durch sogenanntes fine-tuning für ihre eigenen Zwecke anzupassen. Stable Diffusion ist klein genug, um auf einem Computer ausgeführt zu werden, aber das fine-tuning ist auf einer Workstation (wie der von HP mit zwei NVIDIA RTX8000 GPUs) wesentlich schneller. Obwohl es deutlich kleiner ist als z. B. DALL-E2, ist die Qualität der erzeugten Bilder immer noch hervorragend.
Die genannten Modelle werden durch die Verwendung von Prompts gesteuert, welche eine Beschreibung des gewünschten Bildes in Form von Text enthalten und dadurch das Modell zur Generierung des entsprechenden Bildes angeregt. Für künstliche Intelligenz ist Text direkt nicht verständlich, da alle Algorithmen auf mathematischen Operationen beruhen, die nicht direkt auf Text angewendet werden können.
Daher besteht eine gängige Methode darin, ein so genanntes Embedding zu erzeugen, d. h. Text in mathematische Vektoren umzuwandeln. Das Verständnis des Textes ergibt sich aus dem Training des Übersetzungsmodells von Text zu Embeddings. Die hochdimensionalen Embedding-Vektoren werden so erzeugt, dass der Abstand der Vektoren zueinander die Beziehung der Originaltexte darstellt. Ähnliche Methoden werden auch für Bilder verwendet, und es werden spezielle Modelle für diese Aufgabe trainiert.
CLIP: Ein hybrides Modell von OpenAI zur Bild-Text-Integration mit kontrastivem Lernansatz
Ein solches Modell ist CLIP, ein von OpenAI entwickeltes Hybridmodell, das die Stärken von Bilderkennungsmodellen und Sprachmodellen kombiniert. Das Grundprinzip von CLIP besteht darin, Embeddings für passende Text- und Bildpaare zu erzeugen. Diese Embedding-Vektoren der Texte und Bilder werden so berechnet, dass der Abstand der Vektordarstellungen der passenden Paare minimiert wird. Eine Besonderheit von CLIP ist, dass es mit Hilfe eines kontrastiven Lernansatzes trainiert wird, bei dem zwei verschiedene Eingaben miteinander verglichen werden und die Ähnlichkeit zwischen ihnen maximiert wird, während die Ähnlichkeit, der nicht übereinstimmenden Paare im selben Durchgang minimiert wird. Dadurch kann das Modell robustere und übertragbare Repräsentationen von Bildern und Texten erlernen, was zu einer verbesserten Leistung bei einer Vielzahl von Aufgaben führt.
Anpassen der Bildgenerierung durch Textual Inversion
Mit CLIP als Vorverarbeitungsschritt der Stable Diffusion-Pipeline, die das Embedding der Prompts erstellt, eröffnet sich eine leistungsstarke und effiziente Möglichkeit, dem Modell neue Objekte oder Stile beizubringen. Dieser Spezialfall des fine-tuning wird als Textual Inversion bezeichnet. Abbildung 1 zeigt diesen Trainingsprozess. Mit mindestens drei Bildern eines Objekts oder Stils und einem eindeutigen Textbezeichner kann Stable Diffusion so gesteuert werden, dass es Bilder dieses spezifischen Objekts oder Stils erzeugt.
Im ersten Schritt wird ein <tag> gewählt, der das Objekt repräsentieren soll.
In diesem Fall ist das Objekt als Johannes definiert, und es werden mehrere Bilder von ihm zur Verfügung gestellt. In jedem Trainingsschritt wird ein zufälliges Bild aus den zur Verfügung gestellten Bildern ausgewählt. Zusätzlich wird eine erklärbare Aufforderung wie „rendering of <tag>“ bereitgestellt, und in jedem Trainingsschritt wird eine zufällige Auswahl dieser Aufforderungen getroffen. Der Teil <tag> wird durch den definierten Begriff (in diesem Fall <Johannes>) ausgetauscht.
Durch Anwendung der Textual Inversion Methode wird das Vokabular des Modells erweitert. Nach Durchführung ausreichender Trainingsiterationen kann das neu feinabgestimmte Modell in die Stable Diffusion-Pipeline integriert werden. Dies führt zu einem neuen Bild von Johannes, wenn der Begriff <Johannes> im Prompt des Nutzers vorkommt. Dem generierten Bild können anschließend je nach Eingabeaufforderung Stile und andere Objekte hinzugefügt werden.
Abbildung 1: Fine-tuning von CLIP mit Textual Inversion.
So sieht es aus, wenn wir KI-generierte Avatare unserer #statcrew erstellen
Wir haben bei statworx allen interessierten Kollegen und Kolleginnen ermöglicht, ihre digitalen Avatare in verschiedensten Kontexten zu positionieren.
Mit der zur Verfügung stehenden HP-Workstation konnten wir die integrierten NVIDIA RTX8000 GPUs nutzen und damit die Trainingszeit im Vergleich zu einer Desktop-CPU um den Faktor 15 reduzieren. Wie man an den Beispielen unten sehen kann, hat es der unserer statcrew viel Spaß gemacht, eine Reihe von Bildern in unterschiedlichen Situationen zu erzeugen. Die folgenden Bilder zeigen ein paar ausgewählte Porträts.
![]()
Prompts von links oben nach rechts unten
- <Andreas> looks a lot like christmas, santa claus, snow
- Robot <Paul>
- <Markus> as funko, trending on artstation, concept art, <Markus>, funko, digital art, box (, superman / batman / mario, nintendo, super mario)
- <Johannes> is very thankful, art, 8k, trending on artstation, vinyl·
- <Markus> riding a unicorn, digital art, trending on artstation, unicorn, (<Markus> / oil paiting)·
- <Max> in the new super hero movie, movie poster, 4k, huge explosions in the background, everyone is literally dying expect for him
- a blonde emoji that looks like <Alex>
- harry potter, hermione granger from harry potter, portrait of <Sarah>, concept art, highly detailed
Stable Diffusion und Textual Inversion stellen spannende Entwicklungen auf dem Gebiet der künstlichen Intelligenz dar. Sie bieten neue Möglichkeiten für die Erstellung einzigartiger und personalisierter Avatare, sind aber auch auf verschiedene Stile anwendbar. Wenn wir diese und andere KI-Modelle weiter erforschen, können wir die Grenzen des Möglichen erweitern und neue und innovative Lösungen für reale Probleme schaffen.
Bilderquelle: Adobe Stock 546181349