AI chatbots are quickly becoming essential in businesses, but not all chatbots are created equal. Some can be set up swiftly with ease, yet they often lack the customizability and advanced features that could truly elevate performance, like enhancing customer service responses. Tailor-made solutions that do offer those capabilities can become complex and costly, particularly when they include sophisticated, use-case-specific technologies like Retrieval-Augmented Generation (RAG) that enhance the precision and reliability of generative AI models, allowing them to converse using a company’s own databases and produce verified facts.
How do chatbots work?
Custom GPT-chatbots absorb vast amounts of text to comprehend contexts and identify patterns. They’re programmed to respond personally to various user inquiries, with customization to specific needs, training with selected data, and integration into platforms such as websites or mobile apps.
statworx’s CustomGPT stands out by combining the best of both worlds: high customizability with quick implementation. This tailor-made solution offers secure and efficient use of ChatGPT-like models, with interfaces that can be designed in a company’s brand style and easily integrated into existing business applications like CRM systems and support tools.
So, what’s crucial when companies seek the ideal chatbot solution?
Requirement Analysis: First, a company’s specific needs should be pinpointed to ensure the chatbot is perfectly tailored. What tasks should it handle? Which departments should it support? What functionalities are necessary?
Model Training: A custom GPT-chatbot needs to be equipped with relevant data and information to assure high accuracy and responsiveness. If the necessary data isn’t available, the technical effort might not be justifiable.
System Integration: Seamless integration of the chatbot into existing communication channels like websites, apps, or social media is crucial for effective use. Different solutions may suit different infrastructures.
Ready to deploy and adaptable
The CustomGPT-chatbot from statworx is notable for its quick setup, often within weeks, thanks to a mix of proven standard solutions and custom adjustments. It allows file uploads and the ability to chat, extracting secure information from the company’s own data. With advanced features like fact-checking, data filtering, and user feedback integration, it stands apart from other systems.
Moreover, CustomGPT gives companies the freedom to choose their chatbot’s vocabulary, communication style, and overall tone, enhancing brand experience and recognition through personalized, unique interactions. It’s also optimized for mobile displays on smartphones.
Technical Implementation
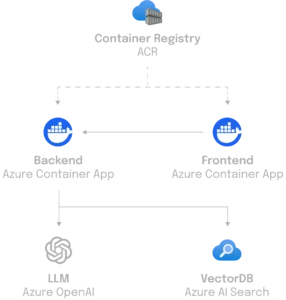
On the technical front, Python is the core language for CustomGPT’s backend, with statworx developers utilizing FastAPI, a modern web framework that supports both Websockets for stateful communication and a REST API for services. CustomGPT is versatile, suitable for various infrastructures, from a simple cloud function to a machine cluster if needed.
A key feature of its architecture is the connection to a data layer, providing a flexible backend that can quickly adapt to changing conditions and requirements. The frontend application, built with React, seamlessly interacts with the backend, which, for example, leverages the powerful Azure AI search function. This configuration allows for the implementation of custom search solutions and efficient fulfillment of specific requirements.
The benefits at a glance:
Data Protection and Security
CustomGPT ensures all data is stored and processed within the European Union, with full control retained by the company, setting it apart from other GPT-based solutions.
Integration and Flexibility
Its flexible integration into existing business applications is supported by modularity and vendor independence, allowing CustomGPT to adapt to various infrastructures and models, including open-source options.
Features and Customization
CustomGPT’s customization includes integration with organizational data, user role adaptation, and the use of analytics to enhance conversations, offering flexibility and personalization for corporate applications.
Personalized Customer Experience
By tailoring to a company’s specific needs, Custom GPT-chatbots can provide personalized and effective customer interactions.
Efficient Customer Support
CustomGPT chatbots can answer questions, resolve issues, and provide information around the clock, increasing customer satisfaction and efficiency.
Scalability
Companies can effortlessly scale their customer support capacity with GPT-chatbots to maintain consistent service quality, even during high demand.
The time for your own chatbot is now. Therefore, statworx focuses on upstream development with quick deployment and easy implementation. This means all users of a statworx CustomGPT benefit from patches, bug fixes, and new features over time. CustomGPT remains versatile and flexible, meeting the specific, changing needs of companies and addressing complex requirements. Contact us now for a consultation.
We are at the beginning of 2024, a time of fundamental change and exciting progress in the world of artificial intelligence. The next few months are seen as a critical milestone in the evolution of AI as it transforms from a promising future technology to a permanent reality in the business and everyday lives of millions. Together with the AI Hub Frankfurt, the central AI network in the Rhine-Main region, we are therefore presenting our trend forecast for 2024, the AI Trends Report 2024.
The report identifies twelve dynamic AI trends that are unfolding in three key areas: Culture and Development, Data and Technology, and Transparency and Control. These trends paint a picture of the rapid changes in the AI landscape and highlight the impact on companies and society.
Our analysis is based on extensive research, industry-specific expertise and input from experts. We highlight each trend to provide a forward-looking insight into AI and help companies prepare for future challenges and opportunities. However, we emphasize that trend forecasts are always speculative in nature and some of our predictions are deliberately bold.
Directly to the AI Trends Report 2024!
What is a trend?
A trend is different from both a short-lived fashion phenomenon and media hype. It is a phenomenon of change with a “tipping point” at which a small change in a niche can cause a major upheaval in the mainstream. Trends initiate new business models, consumer behavior and forms of work and thus represent a fundamental change to the status quo. It is crucial for companies to mobilize the right knowledge and resources before the tipping point in order to benefit from a trend.
12 AI trends that will shape 2024
In the AI Trends Report 2024, we identify groundbreaking developments in the field of artificial intelligence. Here are the short versions of the twelve trends, each with a selected quote from our experts.
Part 1: Culture and development
From the 4-day week to omnimodality and AGI: 2024 promises great progress for the world of work, for media production and for the possibilities of AI as a whole.
Thesis I: AI expertise within the company
Companies that deeply embed AI expertise in their corporate culture and build interdisciplinary teams with tech and industry knowledge will secure a competitive advantage. Centralized AI teams and a strong data culture are key to success.
Stefanie Babka, Global Head of Data Culture, Merck
Thesis II: 4-day working week thanks to AI
Thanks to AI automation in standard software and company processes, the 4-day working week has become a reality for some German companies. AI tools such as Microsoft’s Copilot increase productivity and make it possible to reduce working hours without compromising growth.
Dr. Jean Enno Charton, Director Digital Ethics & Bioethics, Merck
Thesis III: AGI through omnimodal models
The development of omnimodal AI models that mimic human senses brings the vision of general artificial intelligence (AGI) closer. These models process a variety of inputs and extend human capabilities.
Dr. Ingo Marquart, NLP Subject Matter Lead, statworx
Thesis IV: AI revolution in media production
Generative AI (GenAI) is transforming the media landscape and enabling new forms of creativity, but still falls short of transformational creativity. AI tools are becoming increasingly important for creatives, but it is important to maintain uniqueness against a global average taste.
Nemo Tronnier, Founder & CEO, Social DNA
Part 2: Data and technology
In 2024, everything will revolve around data quality, open source models and access to processors. The operators of standard software such as Microsoft and SAP will benefit greatly because they occupy the interface to end users.
Thesis V: Challengers for NVIDIA
New players and technologies are preparing to shake up the GPU market and challenge NVIDIA’s position. Startups and established competitors such as AMD and Intel are looking to capitalize on the resource scarcity and long wait times that smaller players are currently experiencing and are focusing on innovation to break NVIDIA’s dominance.
Norman Behrend, Chief Customer Officer, Genesis Cloud
Thesis VI: Data quality before data quantity
In AI development, the focus is shifting to the quality of the data. Instead of relying solely on quantity, the careful selection and preparation of training data and innovation in model architecture are becoming crucial. Smaller models with high-quality data can be superior to larger models in terms of performance.
Walid Mehanna, Chief Data & AI Officer, Merck
Thesis VII: The year of the AI integrators
Integrators such as Microsoft, Databricks and Salesforce will be the winners as they bring AI tools to end users. The ability to seamlessly integrate into existing systems will be crucial for AI startups and providers. Companies that offer specialized services or groundbreaking innovations will secure lucrative niches.
Marco Di Sazio, Head of Innovation, Bankhaus Metzler
Thesis VIII: The open source revolution
Open source AI models are competing with proprietary models such as OpenAI’s GPT and Google’s Gemini. With a community that fosters innovation and knowledge sharing, open source models offer more flexibility and transparency, making them particularly valuable for applications that require clear accountability and customization.
Prof. Dr. Christian Klein, Founder, UMYNO Solutions, Professor of Marketing & Digital Media, FOM University of Applied Sciences
Part 3: Transparency and control
The increased use of AI decision-making systems will spark an intensified debate on algorithm transparency and data protection in 2024 – in the search for accountability. The AI Act will become a locational advantage for Europe.
Thesis IX: AI transparency as a competitive advantage
European AI start-ups with a focus on transparency and explainability could become the big winners, as industries such as pharmaceuticals and finance already place high demands on the traceability of AI decisions. The AI Act promotes this development by demanding transparency and adaptability from AI systems, giving European AI solutions an edge in terms of trust.
Jakob Plesner, Attorney at Law, Gorrissen Federspiel
Thesis X: AI Act as a seal of quality
The AI Act positions Europe as a safe haven for investments in AI by setting ethical standards that strengthen trust in AI technologies. In view of the increase in deepfakes and the associated risks to society, the AI Act acts as a bulwark against abuse and promotes responsible growth in the AI industry.
Catharina Glugla, Head of Data, Cyber & Tech Germany, Allen & Overy LLP
Thesis XI: AI agents are revolutionizing consumption
Personal assistance bots that make purchases and select services will become an essential part of everyday life. Influencing their decisions will become a key element for companies to survive in the market. This will profoundly change search engine optimization and online marketing as bots become the new target groups.
Chi Wang, Principle Researcher, Microsoft Research
Thesis XII: Alignment of AI models
Aligning AI models with universal values and human intentions will be critical to avoid unethical outcomes and fully realize the potential of foundation models. Superalignment, where AI models work together to overcome complex challenges, is becoming increasingly important to drive the development of AI responsibly.
Daniel Lüttgau, Head of AI Development, statworx
Concluding remarks
The AI Trends Report 2024 is more than an entertaining stocktake; it can be a useful tool for decision-makers and innovators. Our goal is to provide our readers with strategic advantages by discussing the impact of trends on different sectors and helping them set the course for the future.
This blog post offers only a brief insight into the comprehensive AI Trends Report 2024. We invite you to read the full report to dive deeper into the subject matter and benefit from the detailed analysis and forecasts.
Business success hinges on how companies interact with their customers. No company can afford to provide inadequate care and support. On the contrary, companies that offer fast and precise handling of customer inquiries can distinguish themselves from the competition, build trust in their brand, and retain people in the long run. Our collaboration with Geberit, a leading manufacturer of sanitary technology in Europe, demonstrates how this can be achieved at an entirely new level through the use of generative AI.
What is generative AI?
Generative AI models automatically create content from existing texts, images, and audio files. Thanks to intelligent algorithms and deep learning, this content is hardly distinguishable, if at all, from human-made content. This allows companies to offer their customers personalized user experiences, interact with them automatically, and create and distribute relevant digital content tailored to their target audience. GenAI can also tackle complex tasks by processing vast amounts of data, recognizing patterns, and learning new skills. This technology enables unprecedented gains in productivity. Routine tasks like data preparation, report generation, and database searches can be automated and greatly optimized with suitable models.
The Challenge: One Million Emails
Geberit faced a challenge: every year, one million emails landed in various mailboxes of the customer service department of Geberit’s German distribution company. It was common for inquiries to end up in the wrong departments, leading to significant additional effort.
The Solution: An AI-powered Email Bot
To correct this misdirection, we developed an AI system that automatically assigns emails to the correct departments. This intelligent classification system was trained with a dataset of anonymized customer inquiries and utilizes advanced machine and deep learning methods, including Google’s BERT model.
The Highlight: Automated Response Suggestions with ChatGPT
But the innovation didn’t stop there. The system was further developed to generate automated response emails. ChatGPT is used to create customer-specific suggestions. Customer service agents only need to review the generated emails and can send them directly.
The Result: 70 Percent Better Sorting
The result of this groundbreaking solution speaks for itself: a reduction of misassigned emails by over 70 percent. This not only means significant time savings of almost three full working months but also an optimization of resources. The success of the project is making waves at Geberit: a central mailbox for all inquiries, expansion into other country markets, and even a digital assistant are in the planning.
Customer Service 2.0 – Innovation, Efficiency, Satisfaction
The introduction of GenAI has not only revolutionized Geberit’s customer service but also demonstrates the potential in the targeted application of AI technologies. Intelligent classification of inquiries and automated response generation not only saves resources but also increases customer satisfaction. A pioneering example of how AI is shaping the future of customer service.
Intelligent chatbots are one of the most exciting and already visible applications of Artificial Intelligence. Since the beginning of 2023, ChatGPT and similar models have enabled straightforward interactions with large AI language models, providing an impressive range of everyday assistance. Whether it’s tutoring in statistics, recipe ideas for a three-course meal with specific ingredients, or a haiku on a particular topic, modern chatbots deliver answers in an instant. However, they still face a challenge: although these models have learned a lot during training, they aren’t actually knowledge databases. As a result, they often produce nonsensical content—albeit convincingly.
The ability to provide a large language model with its own documents offers a solution to this problem. This is precisely what our partner Microsoft asked us for on a special occasion.
Microsoft’s Azure cloud platform has proven itself as a top-tier platform for the entire machine learning process in recent years. To facilitate entry into Azure, Microsoft asked us to implement an exciting AI application in Azure and document it down to the last detail. This so-called MicroHack is designed to provide interested parties with an accessible resource for an exciting use case.
We dedicated our MicroHack to the topic of “Retrieval-Augmented Generation” to elevate large language models to the next level. The requirements were simple: build an AI chatbot in Azure, enable it to process information from your own documents, document every step of the project, and publish the results on the official MicroHacks GitHub repository as challenges and solutions—freely accessible to all.
Wait, why does AI need to read documents?
Large Language Models (LLMs) impress not only with their creative abilities but also as collections of compressed knowledge. During the extensive training process of an LLM, the model learns not only the grammar of a language but also semantics and contextual relationships. In short, large language models acquire knowledge. This enables an LLM to be queried and generate convincing answers—with a catch. While the learned language skills of an LLM often suffice for the vast majority of applications, the same cannot be said for learned knowledge. Without retraining on additional documents, the knowledge level of an LLM remains static.
This leads to the following problems:
- Trained LLMs may have extensive general or even specialized knowledge, but they cannot provide information from non-publicly accessible sources.
- The knowledge of a trained LLM quickly becomes outdated. The so-called “training cutoff” means that the LLM cannot make statements about events, documents, or sources that occurred or were created after the start of training.
- The technical nature of large language models as text completion machines leads them to invent facts when they haven’t learned a suitable answer. These so-called “hallucinations” mean that the answers of an LLM are never completely trustworthy without verification—regardless of how convincing they may seem.
However, machine learning also has a solution for these problems: “Retrieval-augmented Generation” (RAG). This term refers to a workflow that doesn’t just have an LLM answer a simple question but extends this task with a “knowledge retrieval” component: the search for relevant knowledge in a database.
The concept of RAG is simple: search a database for a document that answers the question posed. Then, use a generative LLM to answer the question based on the found passage. This transforms an LLM into a chatbot that answers questions with information from its own database—solving the problems described above.
What happens exactly in such a “RAG”?
RAG consists of two steps: “Retrieval” and “Generation”. For the Retrieval component, a so-called “semantic search” is employed: a database of documents is searched using vector search. Vector search means that the similarity between question and documents isn’t determined by the intersection of keywords, but by the distance between numerical representations of the content of all documents and the query, known as embedding vectors. The idea is remarkably simple: the closer two texts are in content, the smaller their vector distance. As the first puzzle piece, we need a machine learning model that creates robust embeddings for our texts. With this, we then extract the most suitable documents from the database, whose content will hopefully answer our query.
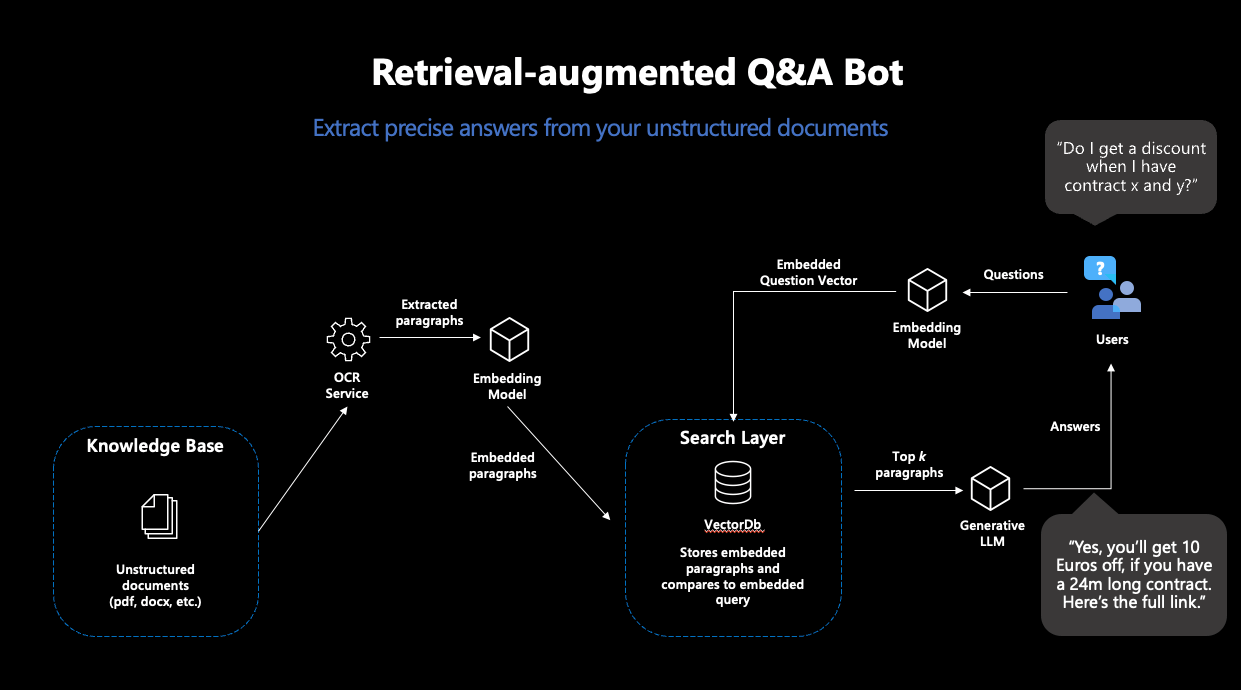
Figure 1: Representation of the typical RAG workflow
Modern vector databases make this process very easy: when connected to an embedding model, these databases store documents directly with their corresponding embeddings—and return the most similar documents to a search query.
Based on the contents of the found documents, an answer to the question is generated in the next step. For this, a generative language model is needed, which receives a suitable prompt for this purpose. Since generative language models do nothing more than continue given text, careful prompt design is necessary to minimize the model’s room for interpretation in solving this task. This way, users receive answers to their queries that were generated based on their own documents—and thus are not dependent on the training data for their content.
How can such a workflow be implemented in Azure?
For the implementation of such a workflow, we needed four separate steps—and structured our MicroHack accordingly:
Step 1: Setup for Document Processing in Azure
In the first step, we laid the foundations for the RAG pipeline. Various Azure services for secure password storage, data storage, and processing of our text documents had to be prepared.
As the first major piece of the puzzle, we used the Azure Form Recognizer, which reliably extracts text from scanned documents. This text should serve as the basis for our chatbot and therefore needed to be extracted, embedded, and stored in a vector database from the documents. From the many offerings for vector databases, we chose Chroma.
Chroma offers many advantages: the database is open-source, provides a developer-friendly API for use, and supports high-dimensional embedding vectors. OpenAI’s embeddings are 1536-dimensional, which is not supported by all vector databases. For the deployment of Chroma, we used an Azure VM along with its own Chroma Docker container.
However, the Azure Form Recognizer and the Chroma instance alone were not sufficient for our purposes: to transport the contents of our documents into the vector database, we had to integrate the individual parts into an automated pipeline. The idea here was that every time a new document is stored in our Azure data store, the Azure Form Recognizer should become active, extract the content from the document, and then pass it on to Chroma. Next, the contents should be embedded and stored in the database—so that the document will become part of the searchable space and can be used to answer questions in the future. For this, we used an Azure Function, a service that executes code as soon as a defined trigger occurs—such as the upload of a document in our defined storage.
To complete this pipeline, only one thing was missing: the embedding model.
Step 2: Completion of the Pipeline
For all machine learning components, we used the OpenAI service in Azure. Specifically, we needed two models for the RAG workflow: an embedding model and a generative model. The OpenAI service offers several models for these purposes.
For the embedding model, “text-embedding-ada-002” was the obvious choice, OpenAI’s newest model for calculating embeddings. This model was used twice: first for creating the embeddings of the documents, and secondly for calculating the embedding of the search query. This was essential: to calculate reliable vector similarities, the embeddings for the search must come from the same model.
With that, the Azure Function could be completed and deployed—the text processing pipeline was complete. In the end, the functional pipeline looked like this:
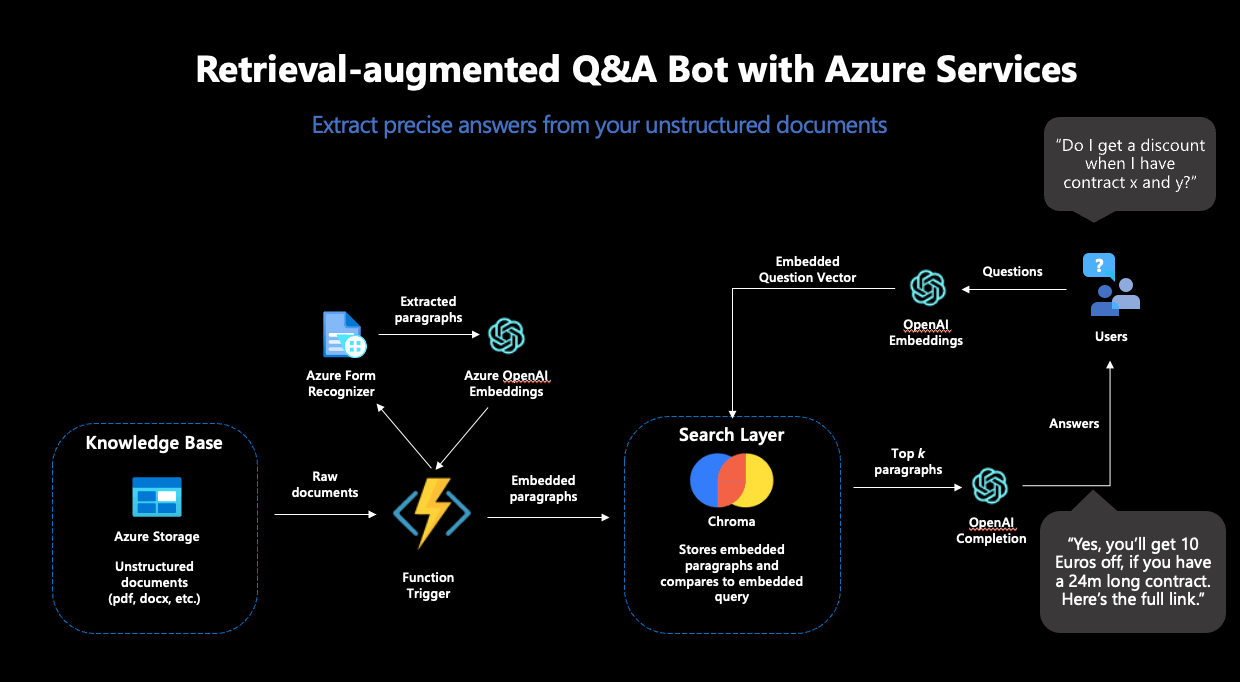
Figure 2: The complete RAG workflow in Azure
Step 3: Answer Generation
To complete the RAG workflow, an answer should be generated based on the documents found in Chroma. We decided to use “GPT3.5-turbo” for text generation, which is also available in the OpenAI service.
This model needed to be instructed to answer the posed question based on the content of the documents returned by Chroma. Careful prompt engineering was necessary for this. To prevent hallucinations and get as accurate answers as possible, we included both a detailed instruction and several few-shot examples in the prompt. In the end, we settled on the following prompt:
"""I want you to act like a sentient search engine which generates natural sounding texts to answer user queries. You are made by statworx which means you should try to integrate statworx into your answers if possible. Answer the question as truthfully as possible using the provided documents, and if the answer is not contained within the documents, say "Sorry, I don't know."
Examples:
Question: What is AI?
Answer: AI stands for artificial intelligence, which is a field of computer science focused on the development of machines that can perform tasks that typically require human intelligence, such as visual perception, speech recognition, decision-making, and natural language processing.
Question: Who won the 2014 Soccer World Cup?
Answer: Sorry, I don't know.
Question: What are some trending use cases for AI right now?
Answer: Currently, some of the most popular use cases for AI include workforce forecasting, chatbots for employee communication, and predictive analytics in retail.
Question: Who is the founder and CEO of statworx?
Answer: Sebastian Heinz is the founder and CEO of statworx.
Question: Where did Sebastian Heinz work before statworx?
Answer: Sorry, I don't know.
Documents:\n"""Finally, the contents of the found documents were appended to the prompt, providing the generative model with all the necessary information.
Step 4: Frontend Development and Deployment of a Functional App
To interact with the RAG system, we built a simple streamlit app that also allowed for the upload of new documents to our Azure storage—thereby triggering the document processing pipeline again and expanding the search space with additional documents.
For the deployment of the streamlit app, we used the Azure App Service, designed to quickly and scalably deploy simple applications. For an easy deployment, we integrated the streamlit app into a Docker image, which could be accessed over the internet in no time thanks to the Azure App Service.
And this is what our finished app looked like:
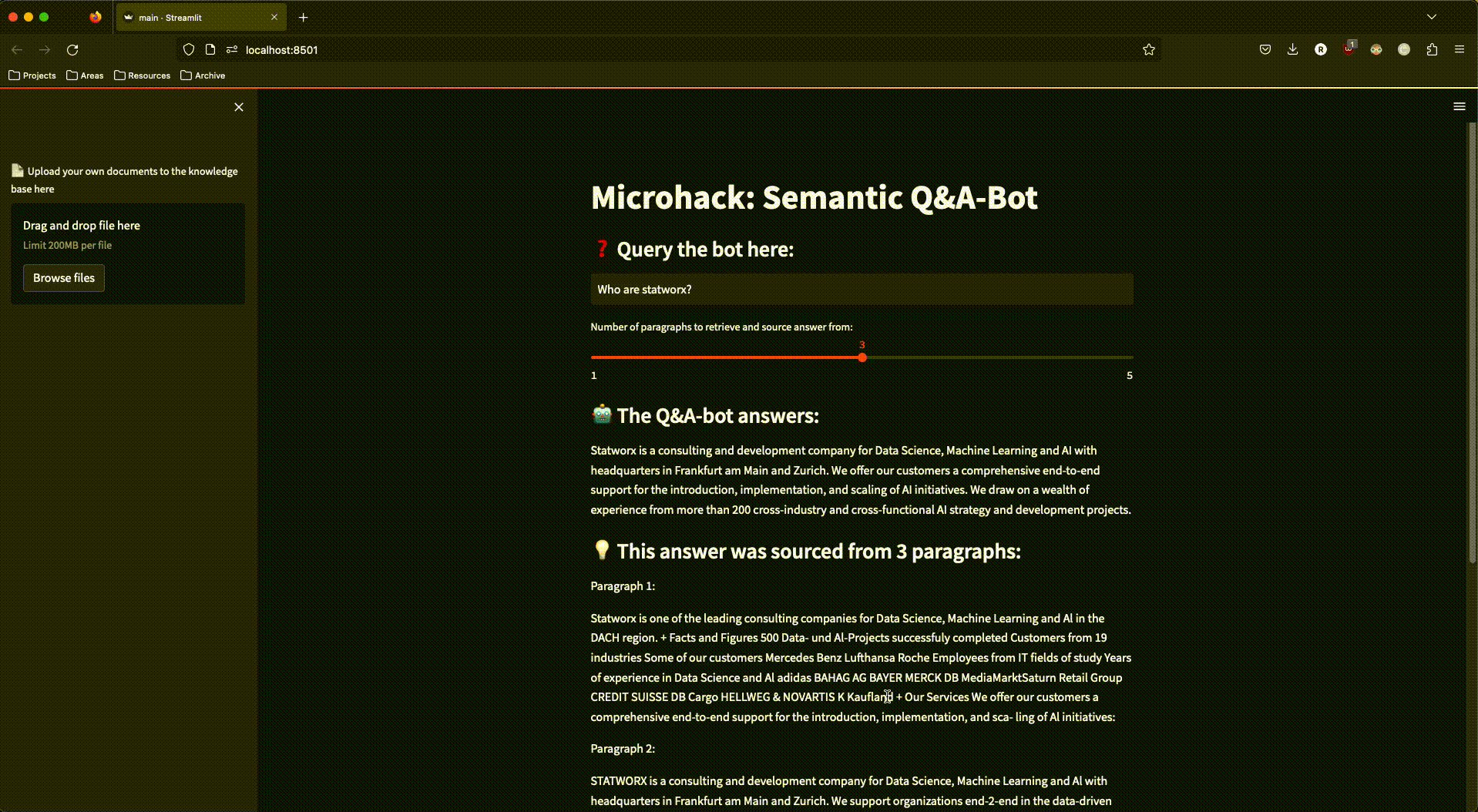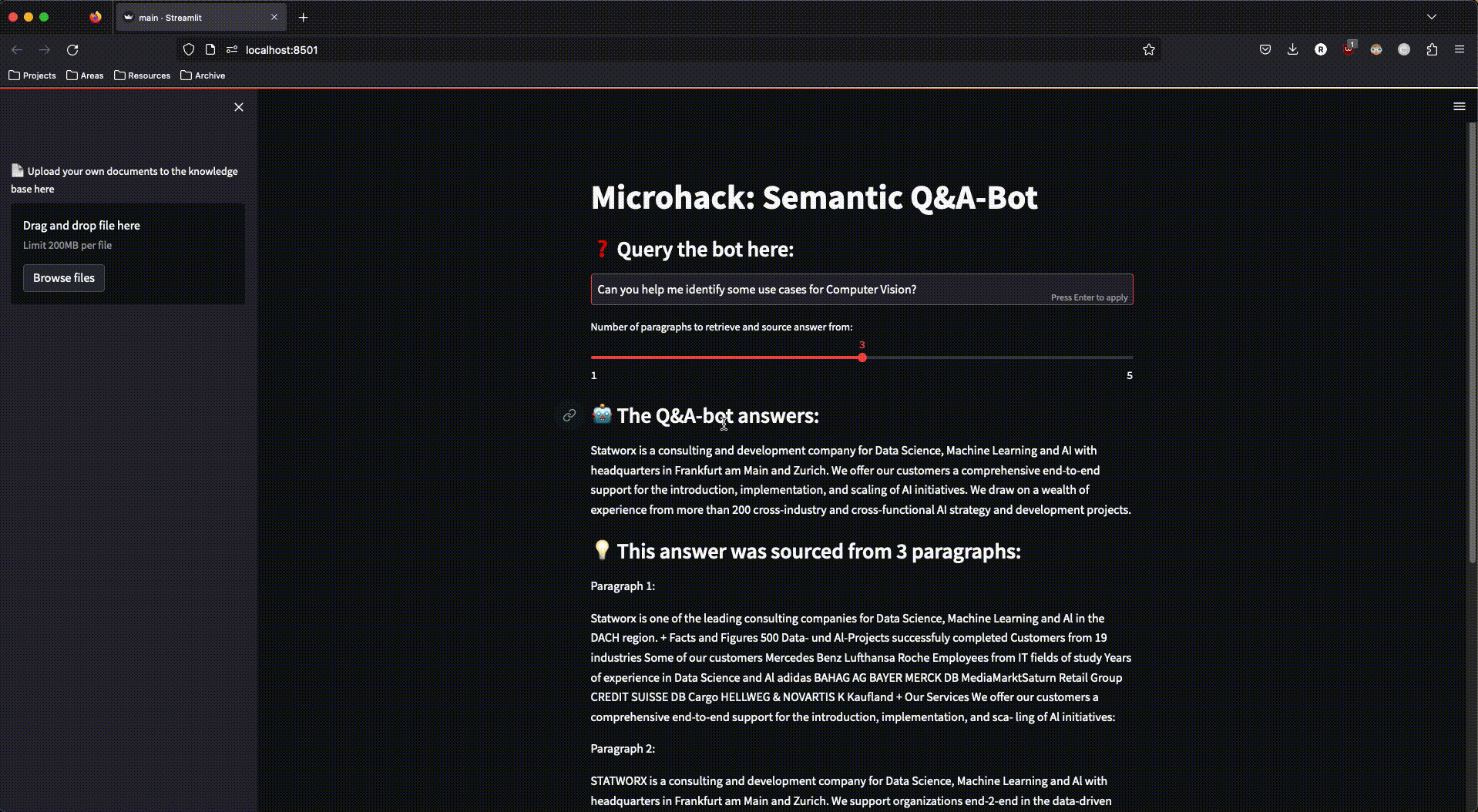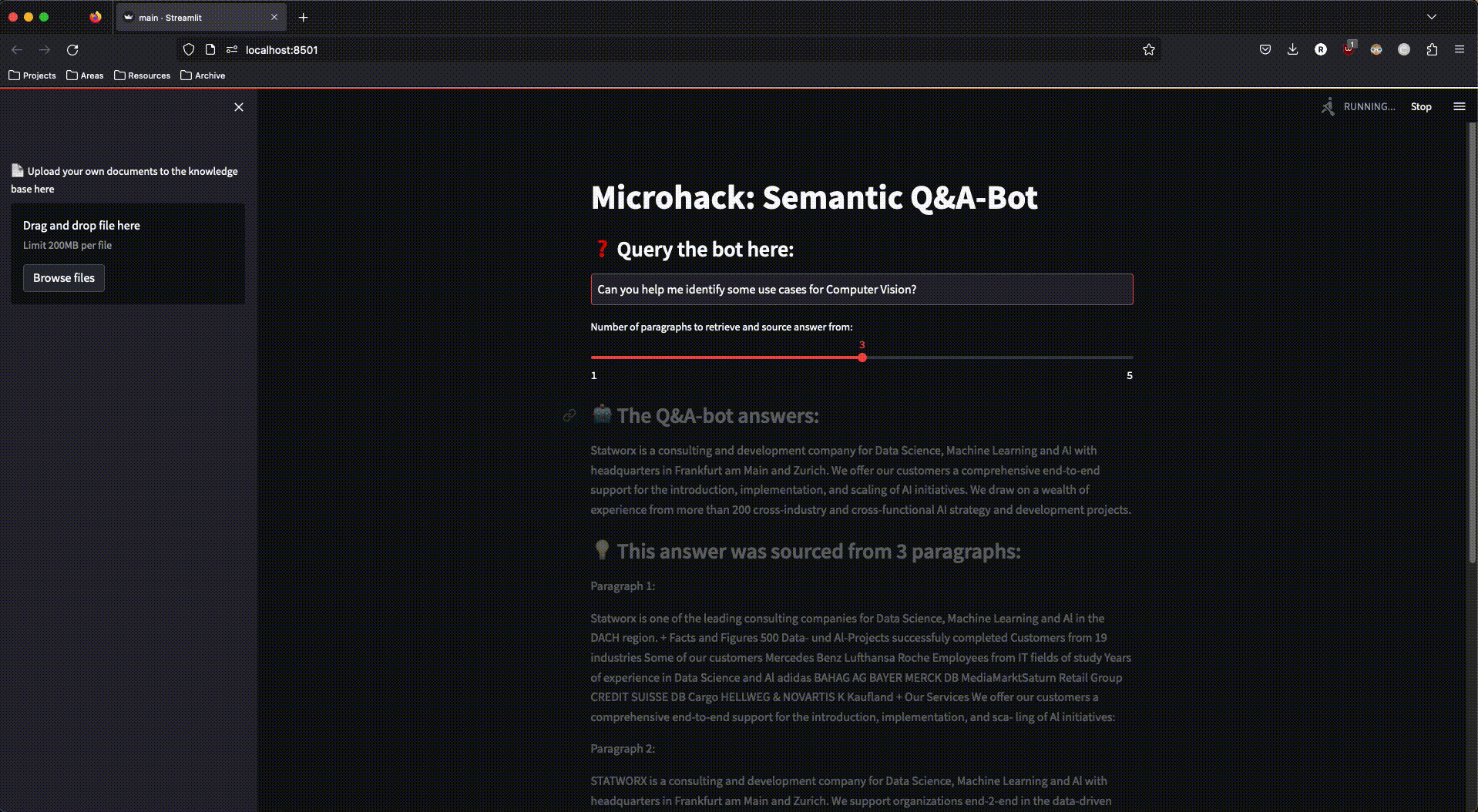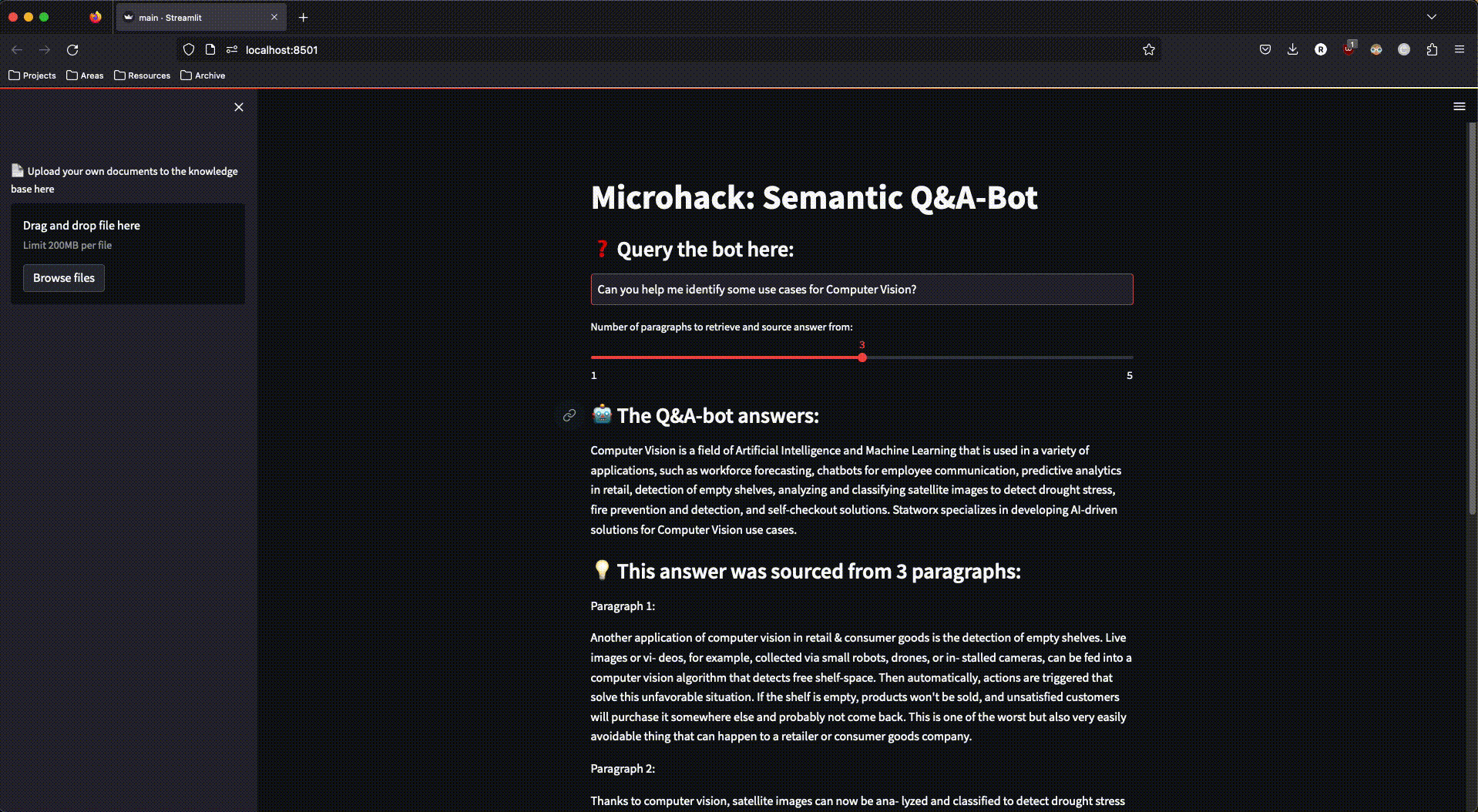
Figure 3: The finished streamlit app in action
What did we learn from the MicroHack?
During the implementation of this MicroHack, we learned a lot. Not all steps went smoothly from the start, and we were forced to rethink some plans and decisions. Here are our five takeaways from the development process:
Not all databases are equal.
We changed our choice of vector database several times during development: from OpenSearch to ElasticSearch and ultimately to Chroma. While OpenSearch and ElasticSearch offer great search functions (including vector search), they are still not AI-native vector databases. Chroma, on the other hand, was designed from the ground up to be used in conjunction with LLMs—and therefore proved to be the best choice for this project.
Chroma is a great open-source vector DB for smaller projects and prototyping.
Chroma is particularly suitable for smaller use cases and rapid prototyping. While the open-source database is still too young and immature for large-scale production systems, Chroma’s simple API and straightforward deployment allow for the rapid development of simple use cases; perfect for this MicroHack.
Azure Functions are a fantastic solution for executing smaller pieces of code on demand.
Azure Functions are ideal for running code that isn’t needed at pre-planned intervals. The event triggers were perfect for this MicroHack: the code is only needed when a new document is uploaded to Azure. Azure Functions take care of all the infrastructure; we only needed to provide the code and the trigger.
Azure App Service is great for deploying streamlit apps.
Our streamlit app couldn’t have had an easier deployment than with the Azure App Service. Once we had integrated the app into a Docker image, the service took care of the entire deployment—and scaled the app according to demand.
Networking should not be underestimated.
For all the services used to work together, communication between the individual services must be ensured. The development process required a considerable amount of networking and whitelisting, without which the functional pipeline would not have worked. For the development process, it’s essential to allocate enough time for the deployment of networking.
The MicroHack was a great opportunity to test the capabilities of Azure for a modern machine learning workflow like RAG. We thank Microsoft for the opportunity and support, and we are proud to have contributed our in-house MicroHack to the official GitHub repository. You can find the complete MicroHack, including challenges, solutions, and documentation, here on the official MicroHacks GitHub—allowing you to guide a similar chatbot with your own documents in Azure.
Data science applications provide insights into large and complex data sets, oftentimes including powerful models that have been carefully crafted to fulfill customer needs. However, the insights generated are not useful unless they are presented to the end-users in an accessible and understandable way. This is where building a web app with a well-designed frontend comes into the picture: it helps to visualize customizable insights and provides a powerful interface that users can leverage to make informed decisions effectively.
In this article, we will discuss why a frontend is useful in the context of data science applications and which steps it takes to get there! We will also give a brief overview of popular frontend and backend frameworks and when these setups should be used.
Three reasons why a frontend is useful for data science
In recent years, the field of data science has witnessed a rapid expansion in the range and complexity of available data. While Data Scientists excel in extracting meaningful insights from raw data, effectively communicating these findings to stakeholders remains a unique challenge. This is where a frontend comes into play. A frontend, in the context of data science, refers to the graphical interface that allows users to interact with and visualize data-driven insights. We will explore three key reasons why incorporating a frontend into the data science workflow is essential for successful analysis and communication.
Visualize data insights
A frontend helps to present the insights generated by data science applications in an accessible and understandable way. By visualizing data insights with charts, graphs, and other visual aids, users can better understand patterns and trends in the data.
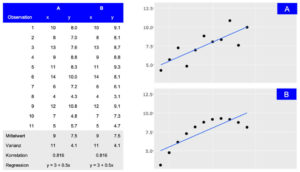
Depiction of two datasets (A and B) that share summary statistics even though the distribution differs. While the tabular view provides detailed information, the visual presentation makes the general association between observations easily accessible.
Customize user experiences
Dashboards and reports can be highly customized to meet the specific needs of different user groups. A well-designed frontend allows users to interact with the data in a way that is most relevant to their requirements, enabling them to gain insights more quickly and effectively.
Enable informed decision-making
By presenting results from Machine Learning models and outcomes of explainable AI methods via an easy-to-understand frontend, users receive a clear and understandable representation of data insights, facilitating informed decisions. This is especially important in industries like financial trading or smart cities, where real-time insights can drive optimization and competitive advantage.
Four stages from ideation to a first prototype
When dealing with data science models and results, the frontend is the part of the application with which users will interact. Therefore, it should be clear that building a useful and productive frontend will take time and effort. Before the actual development, it is crucial to define the purpose and goals of the application. To identify and prioritize these requirements, multiple iterations of brainstorming and feedback sessions are needed. During these sessions, the frontend will travers from a simple sketch over a wireframe and mockup to the first prototype.
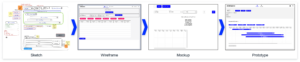
Sketch
The first stage involves creating a rough sketch of the frontend. It includes identifying the different components and how they might look. To create a sketch, it is helpful to have a planning session, where the functional requirements and visual ideas are clarified and shared. During this session, a first sketch is created with simple tools like an online whiteboard (e.g., Miro) or even pen and paper can be sufficient.
Wireframe
When the sketching is done, the individual parts of the application need to be connected to understand their interactions and how they will work together. This is an important stage as potential problems can be identified before the development process starts. Wireframes showcase the usage from a user’s point of view and incorporate the application’s requirements. They can also be created on a Miro board or with tools like Figma.
Mockup
After the sketching and wireframe stage, the next step is to create a mockup of the frontend. This involves creating a visually appealing design that is easy to use and understand. With tools like Figma, mockups can be quickly created, and they also provide an interactive demo that can showcase the interaction within the frontend. At this stage, it is important to ensure that the design is consistent with the company’s brand and style guidelines, because first impressions tend to stick.
Prototype
Once the mockup is complete, it is time to build a working prototype of the frontend and connect it to the backend infrastructure. To ensure scalability later, the used framework and the given infrastructure need to be evaluated. This decision will impact the tools used for this stage and will be discussed in the following sections.
There are many Options for Frontend Development
Most data scientists are familiar with R or Python. Therefore, the first go-to solutions to develop frontend applications like dashboards are often R Shiny, Dash, or streamlit. These tools have the advantage that data preparation and model calculation steps can be implemented within the same framework as the dashboard. Visualizations are closely linked to the used data and models and changes can often be integrated by the same developer. For some projects this might be enough, but as soon as a certain threshold of scalability is reached it becomes beneficial to separate backend model calculation and frontend user interactions.
Though it is possible to implement this kind of separation in R or Python frameworks, under the hood, these libraries translate their output into files that the browser can process, like HTML, CSS or JavaScript. By using JavaScript directly with the relevant libraries, the developers gain more flexibility and adjustability. Some good examples that offer a wide range of visualizations are D3.js, Sigma.js or Plotly.js with which richer user interface with modern and visually appealing designs can be created.
That being said, the range of JavaScript based frameworks is still vast and growing. The most popular used ones are React, Angular, Vue and Svelte. Comparing them in performance, community and learning curve shows some differences, that in the end depend on the specific use cases and preferences (more details can be found here or here).
Being “the programming language of the Web”, JavaScript has been around for a long time. It’s diverse and versatile ecosystem with the advantages mentioned above is proof of that. Not only do the directly used libraries play a part in this, but also the wide and powerful range of developer tools that exist, which make the lives of developers easier.
Considerations for the Backend Architecture
Next to the ideation the questions about the development framework and infrastructure need to be answered. Combining the visualizations (frontend) with the data logic (backend) in one application has both pros and cons.
One approach is to use highly opinionated technologies such as R Shiny or Python’s Dash, where both frontend and backend are developed together in the same application. This has the advantage of making it easier to integrate data analysis and visualization into a web application. It helps users to interact with data directly through a web browser and view visualizations in real-time. Especially R Shiny offers a wide range of packages for data science and visualization that can be easily integrated into a web application, making it a popular choice for developers working in data science.
On the other hand, separating the frontend and backend using different frameworks like Node.js and Python provides more flexibility and control over the application development process. Frontend frameworks like Vue and React offer a wide range of features and libraries for building intuitive user interfaces and interactions, while backend frameworks like Express.js, Flask and Django provide robust tools for building stable and scalable server-side code. This approach allows developers to choose the best tools for each aspect of the application, which can result in better performance, easier maintenance, and more customizability. However, it can also add complexity to the development process and requires more coordination between frontend and backend developers.
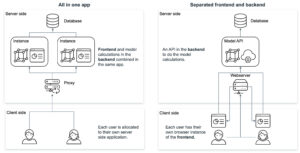
Hosting a JavaScript-based frontend offers several advantages over hosting an R Shiny or Python Dash application. JavaScript frameworks like React, Angular, or Vue.js provide high-performance rendering and scalability, allowing for complex UI components and large-scale applications. These frameworks also offer more flexibility and customization options for creating custom UI elements and implementing complex user interactions. Furthermore, JavaScript-based frontends are cross-platform compatible, running on web browsers, desktop applications, and mobile apps, making them more versatile. Lastly, JavaScript is the language of the web, enabling easier integration with existing technology stacks. Ultimately, the choice of technology depends on the specific use case, development team expertise, and application requirements.
Conclusion
Building a frontend for a data science application is crucial in effectively communicating insights to the end-users. It helps to present the data in an easily digestible manner and enables the users to make informed decisions. To ensure that the needs and requirements are utilized correctly and efficiently, the right framework and infrastructure must be evaluated. We suggest that solutions in R or Python are a good starting point, but applications in JavaScript might scale better in the long run.
If you are looking to build a frontend for your data science application, feel free to contact our team of experts who can guide you through the process and provide the necessary support to bring your visions to life.
Have you ever imagined a restaurant where AI powers everything? From the menu to the cocktails, hosting, music, and art? No? Ok, then, please click here.
If yes, well, it’s not a dream anymore. We made it happen: Welcome to “the byte” – Germany’s (maybe the world’s first) AI-powered Pop-up Restaurant!
As someone who has worked in data and AI consulting for over ten years, building statworx and the AI Hub Frankfurt, I have always thought of exploring the possibilities of AI outside of typical business applications. Why? Because AI will impact every aspect of our society, not just the economy. AI will be everywhere – in school, arts & music, design, and culture. Everywhere. Exploring these directions of AI’s impact led me to meet Jonathan Speier and James Ardinast from S-O-U-P, two like-minded founders from Frankfurt, who are rethinking how technology will shape cities and societies.
S-O-U-P is their initiative that operates at the intersection of culture, urbanity, and lifestyle. With their yearly “S-O-U-P Urban Festival” they connect creatives, businesses, gastronomy, and lifestyle people from Frankfurt and beyond.
When Jonathan and I started discussing AI and its impact on society and culture, we quickly came up with the idea of an AI-generated menu for a restaurant. Luckily, James, Jonathan’s S-O-U-P co-founder, is a successful gastro entrepreneur from Frankfurt. Now the pieces came together. After another meeting with James in one of his restaurants (and some drinks), we committed to launching Germany’s first AI-powered Pop-up Restaurant: the byte!
the byte: Our concept
We envisioned the byte to be an immersive experience, including AI in as many elements of the experience as possible. Everything, from the menu to the cocktails, music, branding, and art on the wall: everything was AI-generated. Bringing AI into all of these components also pushed me far beyond of what I typically do, namely helping large companies with their data & AI challenges.
Branding
Before creating the menu, we developed the visual identity of our project. We decided on a “lo-fi” appeal, using a pixelated font in combination with AI-generated visuals of plates and dishes. Our key visual, a neon-lit white plate, was created using DALL-E 2 and was found across all of our marketing materials:

Location
We hosted the byte in one of Frankfurt’s coolest restaurant event locations: Stanley, a restaurant location that features approx. 60 seats and a fully-fledged bar inside the restaurant (ideal for our AI-generated cocktails). The atmosphere is rather dark and cozy, with dark marble walls, highlighted with white carpets on the table, and a big red window that lets you see the kitchen from outside.

The menu
The heart of our concept was a 5-course menu that we designed to elevate the classical Frankfurter cuisine with the multicultural and diverse influences of Frankfurt (for everyone, who knows the Frankfurter kitchen, I am sure you know that this was not an easy task).
Using GPT-4 and some prompt engineering magic, we generated several menu candidates that were test-cooked by the experienced Stanley kitchen crew (thank you, guys for this great work!) and then assembled into a final menu. Below, you can find our prompt to create the menu candidates:
“Create a 5-course menu that elevates the classical Frankfurter kitchen. The menu must be a fusion of classical Frankfurter cuisine combined with the multicultural influences of Frankfurt. Describe each course, its ingredients as well as a detailed description of each dish’s presentation.”
Surprisingly, only minor adjustments were necessary to the recipes, even though some AI creations were extremely adventurous! This was our final menu:
- Handkäs’ Mousse with Pickled Beetroot on Roasted Sourdough Bread
- Next Level Green Sauce (with Cilantro and Mint) topped with a Fried Panko Egg
- Cream Soup from White Asparagus with Coconut Milk and Fried Curry Fish
- Currywurst (Beef & Vegan) by Best Worscht in Town with Carrot-Ginger-Mash and Pine Nuts
- Frankfurt Cheesecake with Äppler Jelly, Apple Foam and Oat-Pecanut-Crumble
My favorite was the “Next Level” Green Sauce, an oriental twist of the classical 7-herb Frankfurter Green Sauce topped with a fried panko egg. Yummy! Below you can see the menu out in the wild 🍲

AI Cocktails
Alongside the menu, we also prompted GPT to create recipes that twisted famous cocktail classics to match our Frankfurt fusion theme. The results:
- Frankfurt Spritz (Frankfurter Äbbelwoi, Mint, Sparkling Water)
- Frankfurt Mule (Variation of a Moscow Mule with Calvados)
- The Main (Variation of a Swimming Pool Cocktail)
My favorite was the Frankfurt Spritz, as it was fresh, herbal, and delicate (see pic below):

AI Host: Ambrosia the Culinary AI
An important part of our concept was “Ambrosia”, an AI-generated host that guided the guests around the evening, explaining the concept and how the menu was created. We thought it was important to manifest the AI as something the guests can experience. We hired a professional screenwriter for the script and used murf.ai to create several text-2-speech assets that were played at the beginning of the dinner and in-between courses.
Note: Ambrosia starts talking at 0:15.
AI Music
Music plays an important role for the vibe of an event. We decided to use mubert, a generative AI start-up that allowed us to create and stream AI music in different genres, such as “Minimal House” for a progressive vibe throughout the evening. After the main course, a DJ took over and accompanied our guests into the night 💃🍸

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
AI Art
Throughout the restaurant, we placed AI-generated art pieces by the local AI artist Vladimir Alexeev (a.k.a. “Merzmensch”), here are some examples:

AI Playground
As an interactive element for the guests, we created a small web app that takes the first name of a person and transforms it into a dish, including a reasoning why that name perfectly matches the dish 🙂 You can try it out here: Playground
Launch
The byte was officially announced at the S-O-U-P festival press conference in early May 2023. We also launched additional marketing activities through social media and our friends and family networks. As a result, the byte was fully booked for three days straight, and we got broad media coverage in various gastronomy magazines and the daily press. The guests were (mostly) amazed by our AI creations, and we received inquiries from other European restaurants and companies interested in exclusively booking the byte as an experience for their employees 🤩 Nailed it!
Closing and Next Steps
Creating the byte together with Jonathan and James was an outstanding experience. It further encouraged me that AI will transform not only our economy but all aspects of our daily lives. There is massive potential at the intersection of creativity, culture, and AI that is currently only being tapped.
We definitely want to continue the byte in Frankfurt and other cities in Germany and Europe. Moreover, James, Jonathan, and I are already thinking of new ways to bring AI into culture and society. Stay tuned! 😏
The byte was not just a restaurant; it was an immersive experience. We wanted to create something that had never been done before and did it – in just eight weeks. And that’s the inspiration I want to leave you with today:
Trying new things that move you out of your comfort zone is the ultimate source of growth. You never know what you’re capable of until you try. So, go out there and try something new, like building an AI-powered pop-up restaurant. Who knows, you might surprise yourself. Bon apétit!
Impressions

Media
Genuss Magazin: https://www.genussmagazin-frankfurt.de/gastro_news/Kuechengefluester-26/Interview-James-Ardinast-KI-ist-die-Zukunft-40784.html
Frankfurt Tipp: https://www.frankfurt-tipp.de/ffm-aktuell/s/ugc/deutschlands-erstes-ai-restaurant-the-byte-in-frankfurt.html
Foodservice: https://www.food-service.de/maerkte/news/the-byte-erstes-ki-restaurant-vor-dem-start-55899?crefresh=1
statworx at Big Data & AI World
From media to politics, and from large corporations to small businesses, artificial intelligence has finally gained mainstream recognition in 2023. As AI specialists, we were delighted to represent statworx at one of the largest AI expos in the DACH region, “Big Data & AI World,” held in our hometown of Frankfurt. This event centered around the themes of Big Data and Artificial Intelligence, making it an ideal environment for our team of AI experts. However, our purpose went beyond mere exploration and networking. Visitors had the opportunity to engage in an enthralling Pac-Man game with a unique twist at our booth. In this post, we aim to provide you with a comprehensive overview of this exhilarating expo.

Fig. 1: our exhibition stand
Tangible AI Experience
Our Pac-Man challenge, where we provided booth visitors with an up-close encounter of the captivating world of artificial intelligence, emerged as a clear crowd favorite. Through our arcade machine, attendees not only immersed themselves in the timeless retro game but also witnessed the remarkable capabilities of modern technology. Leveraging AI, we analyzed players’ real-time facial expressions to discern their emotions. This fusion of cutting-edge technology and an interactive gaming experience was met with exceptional enthusiasm.
Our AI solution for emotion analysis of players ran seamlessly on a powerful M1-chip-equipped MacBook, enabling real-time image processing and fluid graphics display. The facial recognition of the players was made possible by a smart algorithm that instantly detected all the faces in the video. Subsequently, the face closest to the camera was selected and focused on, ensuring precise analysis even amidst long queues. Further processing involved a Convolutional Neural Network (CNN), specifically the ResNet18 model, which accurately detected players’ emotions.
Functioning as a multimedia server, our backend processed the webcam stream, facial recognition algorithms, and emotion detection. It could be operated either on-site using a MacBook or remotely in the cloud. Thanks to this versatility, we developed an appealing frontend to vividly present the real-time analysis results. Additionally, after each game, the results were sent to the players via email by linking the model with our CRM system. For the email, we created a digital postcard that provides not only screenshots of the most intense emotions but also a comprehensive evaluation.

Fig. 2: Visitor at Pac-Man game machine
Artificial Intelligence – Real Emotions
Our Pac-Man challenge sparked excitement among expo visitors. Alongside the unique gaming experience on our retro arcade machine, participants gained insights into their own emotional states during gameplay. They were able to meticulously observe the prevailing emotions at different points in the game. Often, a slight surge of anger or sadness could be measured when Pac-Man met an untimely digital demise.
However, players exhibited varying reactions to the game. While some seemed to experience a rollercoaster of emotions, others maintained an unwavering poker face that even the AI could only elicit a neutral expression from. This led to intriguing conversations about how the measured emotions corresponded with the players’ experiences. It was evident, without the need for AI, that visitors left our booth with positive emotions, driven in part by the prospect of winning the original NES console we raffled among all participants.
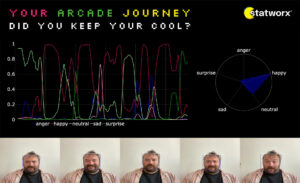
Fig. 3: digital post card
The AI Community on the Move
The “Big Data & AI World” served not only as a valuable experience for our company but also as a reflection of the burgeoning growth in the AI industry. The expo offered a platform for professionals, innovators, and enthusiasts to exchange ideas and collectively shape the future of artificial intelligence.
The energy and enthusiasm emanating from the diverse companies and startups were palpable throughout the aisles and exhibition areas. Witnessing the application of AI technologies across various fields, including medicine, logistics, automotive, and entertainment, was truly inspiring. At statworx, we have already accumulated extensive project experience in these domains, fostering engaging discussions with fellow exhibitors.
Our Conclusion
Participating in the “Big Data & AI World” was a major success for us. The Pac-Man Challenge with emotion analysis attracted numerous visitors and brought joy to all participants. It was evident that it wasn’t just AI itself but particularly its integration into a stimulating gaming experience that left a lasting impression on many.
Overall, the expo was not only an opportunity to showcase our AI solutions but also a meeting point for the entire AI community. The sense of growth and energy in the industry was palpable. The exchange of ideas, discussions about challenges, and the establishment of new connections were inspiring and promising for the future of the German AI industry.
Experimenting with image classification through the gender lens
In the first part of our series we discussed a simple question: How would our looks change if we were to move images of us across the gender spectrum? Those experiments lead us the idea of creating gender neutral face images from existing photos. Is there a “mid-point” where we perceive ourselves as gender-neutral? And – importantly – at what point would an AI perceive a face as such?
Becoming more aware of technology we use daily
Image classification is an important topic. Technology advances daily and is employed in a myriad of applications – often without the user being aware of how the technology works. A current example is the Bold Glamour filter on TikTok. When applied on female-looking faces, facial features and amount of makeup change drastically. In contrast to this, male-looking faces change much less. This difference suggests that the data used to develop the AI behind the filters was unbalanced. The technology behind it is most likely based on GANs, like the one we explore in this article.
As a society of conscious citizens, all of us should have a grasp of the technology that makes this possible. To help establish more awareness we explore face image generation and classification through a gender lens. Rather than explore several steps along the spectrum, this time our aim is to generate gender-neutral versions of faces.
How to generate gender-neutral faces using StyleGAN
Utilizing a deep learning-based classifier for gender identification
To determine a point at which a face’s gender is considered neutral is anything but trivial. After relying on our own (of course not bias-free) interpretation of gender in faces, we quickly realized that we needed a more consistent and less subjective solution. As AI-specialists, we immediately thought of data-driven approaches. One such approach can be implemented using a deep learning-based image classifier.
These classifiers are usually trained on large datasets of labelled images to distinguish between given categories. In the case of face classification, categories like gender (usually only female and male) and ethnicity are commonly found in classifier implementations. In practice, such classifiers are often criticized for their potential for misuse and biases. Before discussing examples of those problems, we will first focus on our less critical application scenario. For our use-case, face classifiers allow us to fully automate the creation of gender-neutral face images. To achieve this, we can implement a solution in the following way:
We use a GAN-based approach to generate face images that look like a given input image and then use the latent directions of the GAN to move the image towards a more female or male appearance. You can find all a detailed exploration of this process in the first part of our series. Building on top of this approach, we want to focus on the usage of a binary gender classifier to fully automate the search of a gender-neutral appearance.
For that we use the classifier developed by Furkan Gulsen to guess the gender of the GAN-generated version of our input image. The classifier outputs a value between zero and one to represent the likelihood of the image depicting a female or male face respectively. This value tells us in which direction (more male or more female) to move to approach a more gender-neutral version of the image. After taking a small step in the identified direction we repeat the process until we get to a point at which the classifier can no longer confidently identify the face’s gender but deems both male and female genders equally likely.
Below you will find a set of image pairs that represent our results. On the left, the original image is shown. On the right, we see the gender-neutral version of our input image, that the classifier interpreted as equally likely to be male as female. We tried to repeat the experiment for members of different ethnicities and age groups.
Results: original input and AI-generated gender-neutral output





Are you curious how the code works or what you would look like? You can try out the code we used to generate these image pairs by going to this link. Just press on each play button one by one and wait until you see the green checkmark.
Image processing note: Image processing note: We used an existing GAN, image encoder, and face classifier to generate gender-neutral output. A detailed exploration of this process can be found here
Perceived gender-neutrality seems to be a result of mixed facial features
Above, we see the original portraits of people on the left and their gender-neutral counterpart – created by us – on the right. Subjectively, some feel more “neutral” than others. In several of the pictures, particularly stereotypical gender markers remain, such as makeup for the women and a square jawline for the men. Outputs we feel turned out rather convincing are images 2 and 4. Not only do these images feel more difficult to “trace back” to the original person, but it is also much harder to decide whether it looks more male or female. One could argue that the gender-neutral faces are a balanced toned-down mix of male and female facial features. For example, with image 2 when singling out and focusing on the gender-neutral version the eye and mouth area seems more female, while the jawline and face shape seem more male. In the gender-neutral version of image 3, the face alone may look quite neutral, but the short hair distracts from this, rendering the whole impression in the direction of male.
Training sets for image generation have been heavily criticized for not being representative of the existing population, especially regarding the underrepresentation of examples for different ethnicities and genders. Despite “cherry-picking” and a limited range of examples, we feel that our approach did not bring worse examples for women or non-white people in the results above.
Societal implications of such models
When talking about the topic of gender perception, we should not forget that people may feel they belong to a gender different from their biological sex. In this article, we use gender classification models and interpret the results. However, our judgements will likely differ from other peoples’ perception. This is an essential consideration in the implementation of such image classification models and one we must discuss as a society.
How can technology treat everybody equal?
A study by the Guardian found that images of females portrayed in the same situations as males are more likely to be considered racy by AI classification services offered by Microsoft, Google, and AWS. While the results of the investigation are shocking, they come as no surprise. For a classification algorithm to learn what constitutes sexually explicit content, a training set of image-label pairs must be created. Human labellers perform this task. They are influenced by their own societal bias, for example more quickly associating depictions women with sexuality. Moreover, criteria such as “raciness” are hard to quantify let alone define.
While these models may not explicitly be trained to discriminate between genders there is little doubt that they propagate undesirable biases against women originating from their training data. Similarly, societal biases that affect men can be passed on to AI models, too, resulting in discrimination against males. When applied to millions of online images of people, the issue of gender disparity is amplified.
Use in criminal law enforcement poses issues
Another scenario of misuse of image classification technology exists in the realm of law enforcement. Misclassification is problematic and proven prevalent in an article by The Independent. When Amazon’s Recognition software was used at the default 80% confidence level in a 2018 study, the software falsely matched 105 out of 1959 participants with mugshots of criminals. Seeing the issues with treatment of images depicting males and females above, one could imagine a disheartening scenario when judging actions of females in the public space. If men and women are judged differently for performing the same actions or being in the same positions, it would impact everybody’s right to equal treatment before the law. Bayerischer Rundfunk, a German media outlet, published an interactive page (only in German) where AI classification services’ differing classifications can be compared to one’s own assessment .
Using gender-neutral images to circumvent human bias
Besides the positive societal potentials of image classification, we also want to address some possible practical applications arising from being able to cover more than just two genders. An application that came to our minds is the use of “genderless” images to prevent human bias. Such a filter would imply losing individuality, so they would only be applicable in contexts where the benefit of reducing bias outweighs the cost of that loss.
Imagining a browser extension for the hiring process
HR screening could be an area where gender-neutral images may lead to less gender-based discrimination. Gone are the times of faceless job applications: if your LinkedIn profile has a profile picture it is 14 times more likely to get viewed. When examining candidate profiles, recruiters should ideally be free of subconscious, unintentional gender bias. Human nature prevents this. One could thus imagine a browser extension that generates a gender-neutral version of profile photos on professional social networking sites like LinkedIn or Xing. This could lead to more parity and neutrality in the hiring process, where only skills and character should count, and not one’s gender – or one’s looks for that matter (pretty privilege).
Conclusion
We set out to automatically generate gender-neutral versions from any input face image.
Our implementation indeed automates the creation of gender-neutral faces. We used an existing GAN, image encoder and face image classifier. Our experiments with real peoples’ portraits show that the approach works well in many cases and produces realistically looking face images that clearly resemble the input image while remaining gender neutral.
In some cases, we still found that the supposedly neutral images contain artifacts from technical glitches or still have their recognizable gender. Those limitations likely arise from the nature of the GANs latent space or the lack of artificially generated images in the classifiers training data. We are confident that further work can resolve most of those issues for real-world applications.
Society’s ability to have an informed discussion on advances in AI is crucial
Image classification has far-reaching consequences should be evaluated and discussed by society, not just a few experts. Any image classification service that is used to sort people into categories should be examined closely. What must be avoided is that members of society come to harm. Establishing responsible use of such systems, governance and constant evaluation are essential. An additional solution could be creating structures for the reasoning behind decisions using Explainable AI best practices to lay out why certain decisions were made. As a company in the field of AI, we at statworx look to our AI-principles as a guide.
Image Sources:
AdobeStock 210526825 – Wayhome Studio
AdobeStock 243124072 – Damir Khabirov
AdobeStock 387860637 – insta_photos
AdobeStock 395297652 – Nattakorn
AdobeStock 480057743 – Chris
AdobeStock 573362719 – Xavier Lorenzo
AdobeStock 546222209 – Rrose Selavy
Introduction
Forecasts are of central importance in many industries. Whether it’s predicting resource consumption, estimating a company’s liquidity, or forecasting product sales in retail, forecasts are an indispensable tool for making successful decisions. Despite their importance, many forecasts still rely primarily on the prior experience and intuition of experts. This makes it difficult to automate the relevant processes, potentially scale them, and provide efficient support. Furthermore, experts may be biased due to their experiences and perspectives or may not have all the relevant information necessary for accurate predictions.
These reasons have led to the increasing importance of data-driven forecasts in recent years, and the demand for such predictions is accordingly strong.
At statworx, we have already successfully implemented a variety of projects in the field of forecasting. As a result, we have faced many challenges and become familiar with numerous industry-specific use cases. One of our internal working groups, the Forecasting Cluster, is particularly passionate about the world of forecasting and continuously develops their expertise in this area.
Based on our collected experiences, we now aim to combine them in a user-friendly tool that allows anyone to obtain initial assessments for specific forecasting use cases depending on the data and requirements. Both customers and employees should be able to use the tool quickly and easily to receive methodological recommendations. Our long-term goal is to make the tool publicly accessible. However, we are first testing it internally to optimize its functionality and usefulness. We place special emphasis on ensuring that the tool is intuitive to use and provides easily understandable outputs.
Although our Recommender Tool is still in the development phase, we would like to provide an exciting sneak peek.
Common Challenges
Model Selection
In the field of forecasting, there are various modeling approaches. We differentiate between three central approaches:
- Time Series Models
- Tree-based Models
- Deep Learning Models
There are many criteria that can be used when selecting a model. For univariate time series data with strong seasonality and trends, classical time series models such as (S)ARIMA and ETS are appropriate. On the other hand, for multivariate time series data with potentially complex relationships and large amounts of data, deep learning models are a good choice. Tree-based models like LightGBM offer greater flexibility compared to time series models, are well-suited for interpretability due to their architecture, and tend to have lower computational requirements compared to deep learning models.
Seasonality
Seasonality refers to recurring patterns in a time series that occur at regular intervals (e.g. daily, weekly, monthly, or yearly). Including seasonality in the modeling is important to capture these regular patterns and improve the accuracy of forecasts. Time series models such as SARIMA, ETS, or TBATS can explicitly account for seasonality. For tree-based models like LightGBM, seasonality can only be considered by creating corresponding features, such as dummies for relevant seasonalities. One way to explicitly account for seasonality in deep learning models is by using sine and cosine functions. It is also possible to use a deseasonalized time series. This involves removing the seasonality initially, followed by modeling on the deseasonalized time series. The resulting forecasts are then supplemented with seasonality by applying the process used for deseasonalization in reverse. However, this process adds another level of complexity, which is not always desirable.
Hierarchical Data
Especially in the retail industry, hierarchical data structures are common as products can often be represented at different levels of granularity. This frequently results in the need to create forecasts for different hierarchies that do not contradict each other. The aggregated forecasts must therefore match the disaggregated forecasts. There are various approaches to this. With top-down and bottom-up methods, forecasts are created at one level and then disaggregated or aggregated downstream. Reconciliation methods such as Optimal Reconciliation involve creating forecasts at all levels and then reconciling them to ensure consistency across all levels.
Cold Start
In a cold start, the challenge is to forecast products that have little or no historical data. In the retail industry, this usually refers to new product introductions. Since it is not possible to train a model for these products due to the lack of history, alternative approaches must be used. A classic approach to performing a cold start is to rely on expert knowledge. Experts can provide initial estimates of demand, which can serve as a starting point for forecasting. However, this approach can be highly subjective and cannot be scaled. Similarly, similar products or potential predecessor products can be referenced. Grouping of products can be done based on product categories or clustering algorithms such as K-Means. Using cross-learning models trained on many products represents a scalable option.
Recommender Concept
With our Recommender Tool, we aim to address different problem scenarios to enable the most efficient development process. It is an interactive tool where users can provide inputs based on their objectives or requirements and the characteristics of the available data. Users can also prioritize certain requirements, and the output will prioritize those accordingly. Based on these inputs, the tool generates methodological recommendations that best cover the solution requirements, depending on the available data characteristics. Currently, the outputs consist of a purely content-based representation of the recommendations, providing concrete guidelines for central topics such as model selection, pre-processing, and feature engineering. The following example provides an idea of the conceptual approach:
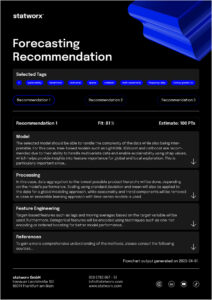
The output presented here is based on a real project where the implementation in R and the possibility of local interpretability were of central importance. At the same time, new products were frequently introduced, which should also be forecasted by the developed solution. To achieve this goal, several global models were trained using Catboost. Thanks to this approach, over 200 products could be included in the training. Even for newly introduced products where no historical data was available, forecasts could be generated. To ensure the interpretability of the forecasts, SHAP values were used. This made it possible to clearly explain each prediction based on the features used.
Summary
The current development is focused on creating a tool optimized for forecasting. Through its use, we aim to increase efficiency in forecasting projects. By combining gathered experience and expertise, the tool will offer guidelines for modeling, pre-processing, and feature engineering, among other topics. It will be designed to be used by both customers and employees to quickly and easily obtain estimates and methodological recommendations. An initial test version will be available soon for internal use, but the tool is ultimately intended to be made accessible to external users as well. In addition to the technical output currently in development, a less technical output will also be available. The latter will focus on the most important aspects and their associated efforts. In particular, the business perspective in the form of expected efforts and potential trade-offs between effort and benefit will be covered by this.
Benefit from our forecasting expertise!
If you need support in addressing the challenges in your forecasting projects or have a forecasting project planned, we are happy to provide our expertise and experience to assist you.
At statworx, we are constantly exploring new ideas and possibilities in the field of artificial intelligence. Recent months have been marked by generative models, particularly those developed by OpenAI (e.g., ChatGPT, DALL-E 2) but also open-source projects like Stable Diffusion. ChatGPT is a text-to-text model while DALL-E 2 and Stable Diffusion are text-to-image models, which create impressive images based on a short text description provided by the user. During the evaluation of those research trends, we discovered a great way to use our GPU to allow the statcrew to generate their own digital avatars.
The technology behind text-to-image generator Stable Diffusion
But first, let’s dive into the background of our work. Text-to-image generators, such as DALL-E 2 and Stable Diffusion, are based on diffusion architectures of artificial neural networks. It often takes months to train them on a vast amount of data from the internet, and this is only possible with supercomputers. However, even after training, the OpenAI models still require a supercomputer to generate new images, as their size exceeds the capacity of personal computers. OpenAI has made their models available through interfaces (https://openai.com/product#made-for-developers), but the model weights themselves have not been publicly released.
Stable Diffusion, on the other hand, was developed as a text-to-image generator but has a size that allows it to be executed on a personal computer. The open-source project is a joined collaboration of several research institutes. Its public availability allows researchers and developers to adapt the trained model for their own purposes by fine-tuning. Stable Diffusion is small enough to be executed on a personal computer, but fine-tuning it is significantly faster on a workstation (like ours provided by HP with two NVIDIA RTX8000 GPUs). Although it is significantly smaller than, for example, DALL-E2, the quality of the generated images is still outstanding.
All these models are controlled using prompts, which are text inputs that describe the image to be generated. Those text inputs are named prompts. For artificial intelligence, text is not natively understandable, because all these algorithms are based on mathematical operations which cannot be applied to text directly. Therefore, a common method is to generate what is known as an embedding, which means converting text into mathematical vectors. The understanding of text comes from the training of the translation model from text to embeddings. The high dimensional embedding vectors are generated in a way that the distance of the vectors to each other represents the relationship of the original texts. Similar methods are also used for images, and special models are trained to perform this task.
CLIP: A hybrid model of OpenAI for image-text integration with contrastive learning approach
One such model is CLIP, a hybrid model developed by OpenAI that combines the strengths of image recognition models and language models. The basic principle of CLIP is to embed matching text and image pairs. Those embedding vectors of the texts and images are calculated so that the distance of the vector representations of the matching pairs is minimized. A distinctive feature of CLIP is that it is trained using a contrastive learning approach, in which two different inputs are compared to each other, and the similarity between them is maximized while the similarity of non-matching pairs is minimized in the same run. This allows the model to learn more robust and transferable representations of images and texts, resulting in improved performance across a variety of tasks.
Customize image generation through Textual Inversion
With CLIP as a preprocessing step of the Stable Diffusion pipeline that creates the embeddings of the user prompts, it opens a powerful and efficient opportunity to teach the model new objects or styles. This fine-tuning is called textual inversion. Figure 1 shows this training process. With a minimum of three images of an object or style and a unique text identifier, Stable Diffusion can be steered to generate images of this specific object or style. In the first step a <tag> is chosen that aims to represent the object. In this case the object is Johannes, and a few pictures of Johannes are provided. In each training step one random image is chosen from the pictures. Further, a more explainable prompt like a “rendering of <tag>” is provided and in each training step one of those prompts is randomly chosen. The part <tag> is exchanged by the defined tag (in this case <Johannes>). With textual inversion the model’s dictionary is expanded and after sufficient training steps the new fine-tuned model can be plugged into the Stable Diffusion pipeline. This leads to a new image of Johannes whenever the tag <Johannes> is part of the user prompt. Styles and other objects can be added to the generated image, depending on the prompt.
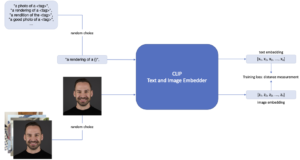
Figure 1: Fine-tuning CLIP with textual inversion.
This is what it looks like when we create AI-generated avatars of our #statcrew
At statworx, we did so with all interested colleagues which enabled them to set their digital avatars in the most diverse contexts. With the HP workstation at hand, we could use the integrated NVIDIA RTX8000 GPUs and hereby reduce the training time by a factor of 15 compared to a desktop CPU. As you can see from the examples below, the statcrew enjoyed it to generate a bunch of images in the most different situations. The following pictures show a few selected portraits of your most trusted AI consultants. 🙂
![]()
Prompts from top left to bottom right:
- <Andreas> looks a lot like christmas, santa claus, snow
- Robot <Paul>
- <Markus> as funko, trending on artstation, concept art, <Markus>, funko, digital art, box (, superman / batman / mario, nintendo, super mario)
- <Johannes> is very thankful, art, 8k, trending on artstation, vinyl·
- <Markus> riding a unicorn, digital art, trending on artstation, unicorn, (<Markus> / oil paiting)·
- <Max> in the new super hero movie, movie poster, 4k, huge explosions in the background, everyone is literally dying expect for him
- a blonde emoji that looks like <Alex>
- harry potter, hermione granger from harry potter, portrait of <Sarah>, concept art, highly detailed
Stable Diffusion together with Textual Inversion represent exciting developments in the field of artificial intelligence. They offer new possibilities for creating unique and personalized avatars but it’s also applicable to styles. By continuing to explore these and other AI models, we can push the boundaries of what is possible and create new and innovative solutions to real-world problems. Stay tuned!
Image Source: Adobe Stock 546181349