Bei statworx erforschen wir kontinuierlich neue Ideen und Möglichkeiten im Bereich der künstlichen Intelligenz. Die letzten Monate waren von Generativen Modellen geprägt, insbesondere von solchen, die von OpenAI entwickelt wurden (z.B. ChatGPT, DALL-E 2), aber auch von Open-Source-Projekten wie Stable Diffusion. ChatGPT ist ein Text-zu-Text-Modell, während DALL-E 2 und Stable Diffusion Text-zu-Bild-Modelle sind, die auf der Grundlage einer kurzen Textbeschreibung des Benutzers beeindruckende Bilder erstellen. Während der Evaluierung dieser Forschungstrends entdeckten wir eine großartige Möglichkeit, unsere von HP zur Verfügung gestellte GPU-Workstation zu nutzen, damit unsere #statcrew ihre eigenen digitalen Avatare erstellen kann.
Das steckt hinter dem Text-zu-Bild-Generator Stable Diffusion
Text-Bild-Generatoren wie Stable Diffusion und DALL-E 2 basieren auf Diffusionsarchitekturen von künstlichen neuronalen Netzen. Die umfangreichen Trainingsdaten aus dem Internet erfordern oft Monate an Trainingszeit auf Hochleistungsrechnern, um eine optimale Performance zu erreichen. Eine erfolgreiche Implementierung ist daher lediglich durch den Einsatz von Supercomputern möglich. Aber auch nach dem Training benötigen die OpenAI-Modelle immer noch einen Supercomputer, um neue Bilder zu generieren, da ihre Größe die Kapazität von herkömmlichen Computern übersteigt. OpenAI hat Schnittstellen bereitgestellt, um den Zugang zu seinen Modellen zu erleichtern (https://openai.com/product#made-for-developers). Jedoch wurden die Modelle selbst nicht öffentlich freigegeben.
Stable Diffusion hingegen wurde als Text-zu-Bild-Generator entwickelt, ist aber so groß, dass es auf dem eigenen Computer ausgeführt werden kann. Das Open-Source-Projekt ist ein Gemeinschaftsprojekt mehrerer Forschungsinstitute. Seine öffentliche Verfügbarkeit ermöglicht es Forschern und Entwicklern, das trainierte Modell durch sogenanntes fine-tuning für ihre eigenen Zwecke anzupassen. Stable Diffusion ist klein genug, um auf einem Computer ausgeführt zu werden, aber das fine-tuning ist auf einer Workstation (wie der von HP mit zwei NVIDIA RTX8000 GPUs) wesentlich schneller. Obwohl es deutlich kleiner ist als z. B. DALL-E2, ist die Qualität der erzeugten Bilder immer noch hervorragend.
Die genannten Modelle werden durch die Verwendung von Prompts gesteuert, welche eine Beschreibung des gewünschten Bildes in Form von Text enthalten und dadurch das Modell zur Generierung des entsprechenden Bildes angeregt. Für künstliche Intelligenz ist Text direkt nicht verständlich, da alle Algorithmen auf mathematischen Operationen beruhen, die nicht direkt auf Text angewendet werden können.
Daher besteht eine gängige Methode darin, ein so genanntes Embedding zu erzeugen, d. h. Text in mathematische Vektoren umzuwandeln. Das Verständnis des Textes ergibt sich aus dem Training des Übersetzungsmodells von Text zu Embeddings. Die hochdimensionalen Embedding-Vektoren werden so erzeugt, dass der Abstand der Vektoren zueinander die Beziehung der Originaltexte darstellt. Ähnliche Methoden werden auch für Bilder verwendet, und es werden spezielle Modelle für diese Aufgabe trainiert.
CLIP: Ein hybrides Modell von OpenAI zur Bild-Text-Integration mit kontrastivem Lernansatz
Ein solches Modell ist CLIP, ein von OpenAI entwickeltes Hybridmodell, das die Stärken von Bilderkennungsmodellen und Sprachmodellen kombiniert. Das Grundprinzip von CLIP besteht darin, Embeddings für passende Text- und Bildpaare zu erzeugen. Diese Embedding-Vektoren der Texte und Bilder werden so berechnet, dass der Abstand der Vektordarstellungen der passenden Paare minimiert wird. Eine Besonderheit von CLIP ist, dass es mit Hilfe eines kontrastiven Lernansatzes trainiert wird, bei dem zwei verschiedene Eingaben miteinander verglichen werden und die Ähnlichkeit zwischen ihnen maximiert wird, während die Ähnlichkeit, der nicht übereinstimmenden Paare im selben Durchgang minimiert wird. Dadurch kann das Modell robustere und übertragbare Repräsentationen von Bildern und Texten erlernen, was zu einer verbesserten Leistung bei einer Vielzahl von Aufgaben führt.
Anpassen der Bildgenerierung durch Textual Inversion
Mit CLIP als Vorverarbeitungsschritt der Stable Diffusion-Pipeline, die das Embedding der Prompts erstellt, eröffnet sich eine leistungsstarke und effiziente Möglichkeit, dem Modell neue Objekte oder Stile beizubringen. Dieser Spezialfall des fine-tuning wird als Textual Inversion bezeichnet. Abbildung 1 zeigt diesen Trainingsprozess. Mit mindestens drei Bildern eines Objekts oder Stils und einem eindeutigen Textbezeichner kann Stable Diffusion so gesteuert werden, dass es Bilder dieses spezifischen Objekts oder Stils erzeugt.
Im ersten Schritt wird ein <tag> gewählt, der das Objekt repräsentieren soll.
In diesem Fall ist das Objekt als Johannes definiert, und es werden mehrere Bilder von ihm zur Verfügung gestellt. In jedem Trainingsschritt wird ein zufälliges Bild aus den zur Verfügung gestellten Bildern ausgewählt. Zusätzlich wird eine erklärbare Aufforderung wie „rendering of <tag>“ bereitgestellt, und in jedem Trainingsschritt wird eine zufällige Auswahl dieser Aufforderungen getroffen. Der Teil <tag> wird durch den definierten Begriff (in diesem Fall <Johannes>) ausgetauscht.
Durch Anwendung der Textual Inversion Methode wird das Vokabular des Modells erweitert. Nach Durchführung ausreichender Trainingsiterationen kann das neu feinabgestimmte Modell in die Stable Diffusion-Pipeline integriert werden. Dies führt zu einem neuen Bild von Johannes, wenn der Begriff <Johannes> im Prompt des Nutzers vorkommt. Dem generierten Bild können anschließend je nach Eingabeaufforderung Stile und andere Objekte hinzugefügt werden.
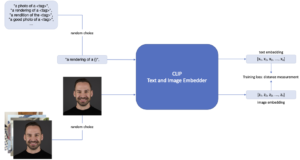
Abbildung 1: Fine-tuning von CLIP mit Textual Inversion.
So sieht es aus, wenn wir KI-generierte Avatare unserer #statcrew erstellen
Wir haben bei statworx allen interessierten Kollegen und Kolleginnen ermöglicht, ihre digitalen Avatare in verschiedensten Kontexten zu positionieren.
Mit der zur Verfügung stehenden HP-Workstation konnten wir die integrierten NVIDIA RTX8000 GPUs nutzen und damit die Trainingszeit im Vergleich zu einer Desktop-CPU um den Faktor 15 reduzieren. Wie man an den Beispielen unten sehen kann, hat es der unserer statcrew viel Spaß gemacht, eine Reihe von Bildern in unterschiedlichen Situationen zu erzeugen. Die folgenden Bilder zeigen ein paar ausgewählte Porträts.
![]()
Prompts von links oben nach rechts unten
- <Andreas> looks a lot like christmas, santa claus, snow
- Robot <Paul>
- <Markus> as funko, trending on artstation, concept art, <Markus>, funko, digital art, box (, superman / batman / mario, nintendo, super mario)
- <Johannes> is very thankful, art, 8k, trending on artstation, vinyl·
- <Markus> riding a unicorn, digital art, trending on artstation, unicorn, (<Markus> / oil paiting)·
- <Max> in the new super hero movie, movie poster, 4k, huge explosions in the background, everyone is literally dying expect for him
- a blonde emoji that looks like <Alex>
- harry potter, hermione granger from harry potter, portrait of <Sarah>, concept art, highly detailed
Stable Diffusion und Textual Inversion stellen spannende Entwicklungen auf dem Gebiet der künstlichen Intelligenz dar. Sie bieten neue Möglichkeiten für die Erstellung einzigartiger und personalisierter Avatare, sind aber auch auf verschiedene Stile anwendbar. Wenn wir diese und andere KI-Modelle weiter erforschen, können wir die Grenzen des Möglichen erweitern und neue und innovative Lösungen für reale Probleme schaffen.
Bilderquelle: Adobe Stock 546181349
Wir gehen in die zweite Runde!
Die enorme Entwicklung von Sprachmodellen wie ChatGPT hat unsere Erwartungen übertroffen. Unternehmen sollten daher verstehen, wie sie von diesen Fortschritten profitieren können.
Im Rahmen unseres auf Führungspositionen ausgerichteten Workshops “ChatGPT for Leaders”, vermitteln wir kompaktes und sofort anwendbares Fachwissen, bieten die Möglichkeit mit anderen Führungskräften und Branchenexperten über die Chancen und Risiken von ChatGPT zu diskutieren und zeigen anhand von Anwendungsfällen, wie Sie Prozesse in Ihrem Unternehmen automatisieren können. Freuen Sie sich auf spannende Vorträge, unter anderem von Timo Klimmer, Global Blackbelt – AI, bei Microsoft und Fabian Müller, COO bei statworx.
Mehr Informationen und eine Anmeldemöglichkeit gibt es hier: ChatGPT for Leaders Workshop
Es ist kein Geheimnis, dass die neuesten Sprachmodelle wie ChatGPT unsere kühnsten Erwartungen weit übertroffen haben. Es ist beeindruckend und erscheint einigen fast unheimlich, dass ein Sprachmodell sowohl ein breites Wissen besitzt als auch die Fähigkeit hat, (fast) jede Frage glaubhaft zu beantworten. Wenige Stunden nach Veröffentlichung dieses Modells begannen bereits die Spekulationen darüber, welche Tätigkeitsfelder durch diese Modelle bereichert, oder womöglich sogar ersetzt werden können, welche Anwendungsfälle sich umsetzen lassen und welche der vielen neuen durch ChatGPT entstandenen Start-Up Ideen sich durchsetzen wird.
Es steht außer Frage, dass die kontinuierliche Weiterentwicklung der Künstlichen Intelligenz an Dynamik gewinnt. Während ChatGPT auf einer dritten Modellgeneration basiert, steht ein “GPT-4” bereits in den Startlöchern und Konkurrenzprodukte warten ebenfalls auf ihren großen Moment.
Als Entscheidungsträger in einem Unternehmen ist es jetzt wichtig zu verstehen, wie diese Fortschritte tatsächlich wertsteigernd eingesetzt werden können. In diesem Blogbeitrag widmen wir uns daher den Hintergründen statt dem Hype, geben Beispiele für konkrete Anwendungsfälle in der Unternehmenskommunikation, und legen insbesondere dar, wie eine Implementierung dieser KI-Systeme erfolgreich erfolgen kann.
Was ist ChatGPT?
Stellt man ChatGPT diese Frage, so erhält man die folgende Antwort:
“Chat GPT ist ein großer Sprachmodell, der von OpenAI trainiert wurde, um natürliche Sprache zu verstehen und zu generieren. Es nutzt die Technologie des Deep Learning und der künstlichen Intelligenz, um menschenähnliche Konversationen mit Benutzern zu führen.”
ChatGPT ist der neueste Vertreter aus einer Klasse an KI-Systemen, die menschliche Sprache (also Texte) verarbeiten. Hierbei spricht man von „Natural Language Processing“, kurz NLP. Es ist das Produkt einer ganzen Kette von Innovationen, die im Jahr 2017 mit einer neuen KI-Architektur begann. In den darauffolgenden Jahren wurden auf dieser Basis die ersten KI-Modelle entwickelt, die in Punkto Sprachverständnis das menschliche Niveau erreichten. In den letzten zwei Jahren lernten die Modelle dann zu schreiben und mit Hilfe von ChatGPT sogar mit dem Benutzer ganze Konversationen zu führen. Im Vergleich zu anderen Modellen zeichnet sich ChatGPT dadurch aus, glaubhafte und passende Antworten auf Nutzeranfragen zu generieren.
Neben ChatGPT gibt es inzwischen viele weitere Sprachmodelle in unterschiedlichen Formen: open-source, proprietär, mit Dialogoption oder auch mit anderen Fähigkeiten. Dabei stellte sich schnell heraus, dass diese Fähigkeiten mit größeren Modellen und mehr (insbesondere qualitativ hochwertigen) Daten kontinuierlich gewachsen sind. Anders als vielleicht ursprünglich zu erwarten war, scheint es dabei kein oberes Limit zu geben. Im Gegenteil: je größer die Modelle, desto mehr Fähigkeiten gewinnen sie!
Diese sprachlichen Fähigkeiten und die Vielseitigkeit von ChatGPT sind erstaunlich, doch der Einsatz derartig großer Modelle ist nicht gerade ressourcenschonen. Große Modelle wie ChatGPT werden von externen Anbietern betrieben, die für jede Anfrage an das Modell in Rechnung stellen. Außerdem erzeugt jede Anfrage an größere Modelle nicht nur mehr Kosten, sondern verbraucht auch mehr Strom und belastet damit die Umwelt.
Dabei erfordern zum Beispiel die meisten Chatanfragen von Kunden kein umfassendes Wissen über die gesamte Weltgeschichte oder die Fähigkeit, auf jede Frage amüsante Antworten zu geben. Stattdessen können bestehende Chatbot-Dienste, die auf Unternehmensdaten zugeschnitten sind, durchaus prägnante und akkurate Antworten zu einem Bruchteil der Kosten liefern.
Moderne Sprachmodelle im Unternehmenseinsatz
Warum wollen dennoch viele Entscheidungsträger in den Einsatz von großen Sprachmodelle wie ChatGPT investieren?
Die Antwort liegt in der Integration in organisatorische Prozesse. Große generative Modelle wie ChatGPT ermöglichen uns erstmals den Einsatz von KI in jeder Phase der geschäftlichen Interaktion. Zunächst in der eingehenden Kundenkommunikation, der Kommunikationsplanung und -organisation, dann in der ausgehenden Kundenkommunikation und der Interaktionsdurchführung, und letztendlich im Bereich der Prozessanalyse und -verbesserung.
Im Folgenden gehen wir genauer darauf ein, wie KI diese Kommunikationsprozesse optimieren und rationalisieren kann. Dabei wird schnell deutlich werden, dass es hier nicht nur darum geht, ein einziges fortschrittliches KI-Modell anzuwenden. Stattdessen zeigt sich, dass nur eine Kombination von mehreren Modellen die Problemstellungen sinnvoll angehen kann und in allen Phasen der Interaktion den gewünschten wirtschaftlichen Nutzen bringt.
KI-Systeme gewinnen beispielsweise in der Kommunikation mit Lieferanten oder mit anderen Stakeholdern zunehmend an Relevanz. Um den revolutionären Einfluss von neuen KI-Modellen möglichst konkret darzustellen, betrachten wir jedoch die Art von Interaktion, die für jedes Unternehmen lebensnotwendig ist: Die Kommunikation mit dem Kunden.
Use Case 1: Eingehende Kundenkommunikation mit KI
Herausforderung
Kundenanfragen gelangen über verschiedene Kanäle (E-Mails, Kontaktformulare über die Website, Apps etc.) in das CRM-System und initiieren interne Prozesse und Arbeitsschritte. Leider ist der Prozess oft ineffizient und führt zu Verzögerungen und erhöhten Kosten, da Anfragen falsch zugewiesen oder in einem einzigen zentralen Postfach landen. Bestehende CRM-Systeme sind meist nicht vollständig in die organisatorischen Arbeitsabläufe integriert und erfordern weitere interne Prozesse, die auf organisch gewachsenen Routinen oder organisatorischem Wissen einer kleinen Anzahl von Mitarbeitenden basieren. Dies mindert die Effizienz und führt zu mangelnder Kundenzufriedenheit und hohen Kosten.
Lösung
Kundenkommunikation kann für Unternehmen eine Herausforderung darstellen, aber KI-Systeme können dabei helfen, diese zu automatisieren und zu verbessern. Mithilfe von KI kann die Planung, Initiierung und Weiterleitung von Kundeninteraktionen effektiver gestaltet werden. Das System kann automatisch Inhalte und Informationen analysieren und auf der Grundlage geeigneter Eskalationsniveaus entscheiden, wie die Interaktion am besten abgewickelt werden kann. Moderne CRM-Systeme sind bereits in der Lage, Standardanfragen mithilfe von kostengünstigen Chatbots oder Antwortvorlagen zu bearbeiten. Aber wenn die KI erkennt, dass eine anspruchsvollere Anfrage vorliegt, kann sie einen KI-Agenten wie ChatGPT oder einen Kundendienstmitarbeiter aktivieren, um die Kommunikation zu übernehmen.
Mit den heutigen Errungenschaften im NLP-Bereich kann ein KI-System aber weitaus mehr. Relevante Informationen können aus Kundenanfragen extrahiert und an die zuständigen Personen im Unternehmen weitergeleitet werden. So kann beispielsweise ein Key-Account-Manager Empfänger der Kundennachricht sein, während gleichzeitig ein technisches Team mit den notwendigen Details informiert wird. Auf diese Weise können komplexere Szenarien, die Organisation des Supports, die Verteilung der Arbeitslast und die Benachrichtigung von Teams über Koordinierungsbedarf bewältigt werden. Dabei werden diese Abläufe nicht manuell definiert werden, sondern vom KI-System gelernt.
Lesen Sie auch unser Whitepaper, in dem wir 4 Blueprints für KI-Modelle in der Kommunikation mit Kunden und Lieferanten vorstellen
Die Implementierung eines integrierten Systems kann die Effizienz von Unternehmen steigern, Verzögerungen und Fehler reduzieren und letztlich zu höherem Umsatz und Gewinn führen.
Use Case 2: Ausgehende Kundenkommunikation mit KI
Herausforderung
Kunden setzen voraus, dass ihre Anfragen umgehend, transparent und präzise beantwortet werden. Eine verzögerte oder inkorrekte Reaktion, ein mangelndes Informationsniveau oder eine unkoordinierte Kommunikation zwischen verschiedenen Abteilungen stellen Vertrauensbrüche dar, die sich langfristig negativ auf die Kundenbeziehung auswirken können.
Bedauerlicherweise sind negative Erfahrungen bei vielen Unternehmen an der Tagesordnung. Dies liegt häufig daran, dass die in bestehenden Lösungen implementierten Chatbots Standardantworten und Templates verwenden und nur selten in der Lage sind, Kundenanfragen umfassend und abschließend zu beantworten. Im Gegensatz dazu verfügen fortgeschrittene KI-Agenten wie ChatGPT über eine höhere kommunikative Fähigkeit, die eine reibungslose Kundenkommunikation ermöglicht.
Wenn die Anfrage dann doch zu den richtigen Mitarbeitenden aus dem Kundendienst gelangt, kommt es zu neuen Herausforderungen. Fehlende Informationen führen regelmäßig zu sequenziellen Anfragen zwischen Abteilungen, und daher zu Verzögerungen. Sobald Prozesse – gewollt oder ungewollt – parallel laufen, besteht die Gefahr von inkohärenter Kommunikation mit dem Kunden. Schlussendlich mangelt es sowohl intern als auch extern an Transparenz.
Lösung
KI-Systeme können Unternehmen in allen Bereichen unterstützen.
Fortgeschrittene Modelle wie ChatGPT verfügen über die notwendigen sprachlichen Fähigkeiten, um viele Kundenanfragen vollständig zu bearbeiten. Sie sind in der Lage, mit Kunden zu kommunizieren und gleichzeitig interne Anfragen zu stellen. Dadurch fühlen sich Kunden nicht länger von einem Chatbot abgewimmelt. Die technischen Innovationen des letzten Jahres ermöglichen es KI-Agenten, Anfragen nicht nur schneller, sondern teilweise auch präziser zu beantworten. Dies trägt zur Entlastung des Kundendienstes und interner Prozessbeteiligter bei und führt letztlich zu einer höheren Kundenzufriedenheit.
KI-Modelle können zudem menschliche Mitarbeiter bei der Kommunikation unterstützen. Wie eingangs erwähnt, mangelt es häufig schlichtweg daran, akkurate und präzise Informationen in kürzester Zeit verfügbar zu machen. Unternehmen sind bestrebt, Informationssilos aufzubrechen, um den Zugang zu relevanten Informationen zu erleichtern. Dies kann jedoch zu längeren Bearbeitungszeiten im Kundendienst führen, da die notwendigen Informationen erst zusammengetragen werden müssen. Ein wesentliches Problem besteht darin, dass Informationen in unterschiedlichsten Formen vorliegen können, beispielsweise als Text, tabellarische Daten, in Datenbanken oder sogar in Form von Strukturen wie vorheriger Dialogketten.
Moderne KI-Systeme können mit unstrukturierten und multimodalen Informationsquellen umgehen. Sogenannte Retrieval-Systeme stellen die Verbindung zwischen Kundenanfragen und diversen Informationsquellen her. Der zusätzliche Einsatz von generativen Modellen wie GPT-3 erlaubt dann, die gefundenen Informationen effizient in verständlichen Text zu synthetisieren. So lassen sich zu jeder Kundenanfrage individuelle „Wikipedia Artikel“ generieren. Alternativ kann der Kundendienstmitarbeiter seinerseits seine Fragen an einen Chatbot richten, der die nötigen Informationen unmittelbar und verständlich zur Verfügung stellt.
Es ist offensichtlich, dass ein integriertes KI-System nicht nur den Kundendienst, sondern auch weitere technische Abteilungen entlastet. Diese Art von System hat das Potenzial, die Effizienz im gesamten Unternehmen zu steigern.
Use Case 3: Analyse der Kommunikation mit KI
Herausforderung
Robuste und effiziente Prozesse entstehen nicht von selbst, sondern durch kontinuierliches Feedback und ständige Verbesserungen. Der Einsatz von KI-Systemen ändert nichts an diesem Prinzip. Eine Organisation benötigt einen Prozess der kontinuierlichen Verbesserung, um effiziente interne Kommunikation sicherzustellen, Verzögerungen im Kundenservice effektiv zu verwalten und ergebnisorientierte Verkaufsgespräche zu führen.
Im Dialog nach Außen steht das Unternehmen aber vor einem Problem: Sprache ist eine Black Box. Worte haben eine unübertroffene Informationsdichte, gerade weil ihre Nutzung in Kontext und Kultur tief verwurzelt ist. Damit entziehen sich Unternehmen aber einer klassischen statistisch-kausalen Analyse, denn Feinheiten der Kommunikation lassen sich nur schwer quantifizieren.
Bestehende Lösungen verwenden deshalb Proxyvariablen, um den Erfolg zu messen und Experimente durchzuführen. Zwar lassen sich übergeordnete KPIs wie Zufriedenheitsrankings extrahieren, diese müssen aber beim Kunden abgefragt werden und haben häufig wenig Aussagekraft. Gleichzeitig bleibt oft offen, was an der Kundenkommunikation konkret geändert werden kann, um diese KPIs zu verändern. Es scheitert schon daran, Interaktionen im Detail zu analysieren, herauszufinden was die Dimensionen und Stellschrauben sind, und was schlussendlich optimiert werden kann. Der überwiegende Teil dessen, was Kunden unmittelbar über sich preisgeben möchten, existiert in Text und Sprache und entzieht sich der Analyse. Diese Problematik ergibt sich sowohl beim Einsatz von KI-Assistenzsystemen als auch beim Einsatz von Kundendienstmitarbeitenden.
Lösung
Während moderne Sprachmodelle aufgrund ihrer generativen Fähigkeiten viel Aufmerksamkeit erhalten haben, haben auch ihre analytischen Fähigkeiten enorme Fortschritte gemacht. Die Fähigkeit von KI-Modellen, auf Kundenanfragen zu antworten, zeigt ein fortgeschrittenes Verständnis von Sprache, was für die Verbesserung integrierter KI-Systeme unerlässlich ist. Eine weitere Anwendung besteht in der Analyse von Konversationen, einschließlich der Analyse von Kunden und eigenen Mitarbeitenden oder KI-Assistenten.
Durch den Einsatz von künstlicher Intelligenz können Kunden präziser segmentiert werden, indem ihre Kommunikation detailliert analysiert wird. Hierbei werden bedeutende Themen erfasst und die Kundenmeinungen ausgewertet. Mittels semantischer Netzwerke kann das Unternehmen erkennen, welche Assoziationen verschiedene Kundengruppen mit Produkten verknüpfen. Zudem werden generative Modelle eingesetzt, um Wünsche, Ideen oder Meinungen aus einer Fülle von Kundenstimmen zu identifizieren. Stellen Sie sich vor, Sie könnten persönlich die gesamte Kundenkommunikation im Detail durchgehen, anstatt auf synthetische KPIs vertrauen zu müssen – genau das ermöglichen KI-Modelle.
Natürlich bieten KI-Systeme auch die Möglichkeit, eigene Prozesse zu analysieren und zu optimieren. Hierbei ist die KI-gestützte Dialoganalyse ein vielversprechendes Anwendungsgebiet, das derzeit intensiv in der Forschung behandelt wird. Diese Technologie ermöglicht beispielsweise die Untersuchung von Verkaufsgesprächen hinsichtlich erfolgreicher Abschlüsse. Hierbei werden Bruchpunkte der Konversation, Stimmungs- und Themenwechsel analysiert, um den optimalen Verlauf einer Konversation zu identifizieren. Diese Art von Feedback ist nicht nur für KI-Assistenten, sondern auch für Mitarbeitende äußerst wertvoll, da es sogar während einer laufenden Konversation eingespielt werden kann.
Zusammengefasst kann gesagt werden, dass sich mit dem Einsatz von KI-Systemen die Breite, die Tiefe, und die Geschwindigkeit der Feedbackprozesse verbessert. Dies ermöglicht der Organisation agil auf Trends, Wünsche und Kundenmeinungen zu reagieren und interne Prozesse noch weitreichender zu optimieren.
Lesen Sie auch unser Whitepaper, in dem wir 4 Blueprints für KI-Modelle in der Kommunikation mit Kunden und Lieferanten vorstellen
Stolpersteine, die es zu beachten gilt
Die Anwendung von KI-Systemen hat also das Potential, die Kommunikation mit Kunden grundlegend zu revolutionieren. Ein ähnliches Potential lässt sich auch bei anderen Bereichen zeigen, zum Beispiel im Einkauf. Im Begleitmaterial finden Sie weitere Use-Cases, die zum Beispiel in den Bereichen Knowledge-Management und Procurement anwendbar sind.
Allerdings zeigt sich, dass selbst fortgeschrittenste KI-Modelle noch nicht in Isolation einsatzfähig sind. Um von Spielerei zum effektiven Einsatz zu kommen, braucht es Erfahrung, Augenmaß und ein abgestimmtes System aus KI-Modellen.
Die Integration von Sprachmodellen ist noch wichtiger als die Modelle selbst. Da Sprachmodelle als Schnittstelle zwischen Computern und Menschen agieren, müssen sie besonderen Anforderungen genügen. Insbesondere müssen Systeme, die in Arbeitsprozesse eingreifen, von den gewachsenen Strukturen des Unternehmens lernen. Als Schnittstellentechnologie müssen Aspekte wie Fairness, Vorurteilsfreiheit und Faktenkontrolle in das System integriert werden. Darüber hinaus benötigt das gesamte System eine direkte Eingriffsmöglichkeit für Mitarbeiter, um Fehler aufzuzeigen und bei Bedarf die KI-Modelle neu auszurichten. Dieses „Active-Learning“ ist noch kein Standard, aber es kann den Unterschied zwischen theoretischer und praktischer Effizienz ausmachen.
Der Einsatz von mehreren Modellen die sowohl vor Ort, als auch direkt bei Fremdanbietern laufen, stellt neue Ansprüche an die Infrastruktur. Ebenfalls gilt zu beachten, dass der essenzielle Informationstransfer nicht ohne gründliche Behandlung von personenbezogenen Daten möglich ist. Dies gilt insbesondere, wenn kritische Firmeninformationen eingebunden werden müssen. Wie eingangs beschrieben, gibt es inzwischen viele Sprachmodelle mit unterschiedlichen Fähigkeiten. Daher muss die Architektur der Lösung und die Modelle entsprechend der Anforderungen ausgewählt und kombiniert werden. Schließlich stellt sich die Frage, ob man auf Anbieter von Lösungen zurückgreift, oder eigene (Teil-)Modelle entwickelt. Derzeit gibt es (entgegen von einigen Marketingaussagen) keine Standardlösung, die allen Anforderungen gerecht wird. Je nach Anwendungsfall gibt es Anbieter von kosteneffizienten Teillösungen. Eine Entscheidung erfordert Kenntnis dieser Anbieter, ihrer Lösung und deren Limitationen.
Fazit
Zusammenfassend kann festgehalten werden, dass der Einsatz von KI-Systemen in der Kundenkommunikation eine Verbesserung und Automatisierung der Prozesse bewirken kann. Eine zentrale Zielsetzung für Unternehmen sollte die Optimierung und Rationalisierung ihrer Kommunikationsprozesse sein. KI-Systeme können dabei unterstützen, indem sie die Planung, Initiation und Weiterleitung von Kundeninteraktionen effektiver gestalten und bei komplexeren Anfragen entweder einen KI-Agenten wie ChatGPT oder einen Kundendienstmitarbeiter aktivieren. Durch die gezielte Kombination von verschiedenen Modellen kann eine sinnvolle Problemlösung in allen Phasen der Interaktion erzielt werden, die den angestrebten wirtschaftlichen Nutzen generiert.
Lesen Sie auch unser Whitepaper, in dem wir 4 Blueprints für KI-Modelle in der Kommunikation mit Kunden und Lieferanten vorstellen
Es weihnachtet sehr bei statworx: In der Mittagspause laufen Weihnachtslieder, das Büro ist festlich geschmückt und die Weihnachtsfeier war bereits ein voller Erfolg. Aber statworx wäre kein Beratungs- und Entwicklungsunternehmen im Bereich Data Science, Machine Learning und KI, wenn wir unsere Expertise und Leidenschaft nicht auch in unsere Weihnachtsvorbereitungen einbringen würden.
Umgeben vom Duft von frischgebackenen Plätzchen und Weihnachtspunsch, kam uns die Idee, einen KI-basierten Weihnachtsrezept-Generator zu entwickeln, der mithilfe von OpenAI Modellen, Texte jeglicher Art vervollständigen und visualisieren kann. Mit GPT-3 genügt die Beschreibung eines Rezeptes, um daraus eine vollständige Zutatenliste sowie eine Kochanleitung zu generieren. Anschließend wird der komplette Text als Bildbeschreibung an DALL-E 2 übergeben, welches diesen in einem hochauflösenden Bild darstellt. Die Anwendung beider Modelle geht natürlich im Berufsalltag weit über den Unterhaltungswert hinaus, jedoch halten wir ein weihnachtliches und spielerisches Kennenlernen mit den Modellen bei Plätzchen und Glühwein für optimal.
Bevor wir gemeinsam kreativ werden und den Weihnachtsrezept-Generator testen, werfen wir in diesem Blogbeitrag zunächst noch einen kurzen Blick auf die dahintersteckenden Modelle.
Die Blätter fallen aber die KI blüht mithilfe von GPT-3 auf
Das Entwicklungstempo der Large-Language-Models und Text-to-Image Modelle der letzten zwei Jahre hat längst die Schallmauer durchbrochen und auch bei uns alle Mitarbeitenden mitgerissen. Von Avataren und internen Memes über synthetische Daten auf Projekten hat nicht nur die Güte der Ergebnisse einen Wandel herbeigeführt, sondern auch die Handhabung der Modelle. Wo einst performanter Code, statistische Auswertungen und viele griechische Buchstaben umhergeschwirrt sind, findet nun die Bedienung einiger Modelle fast schon in Form eines Austauschs oder einer Interaktion statt. Mittels Texten oder stichworthaltigen Aufforderungen entstehen die sogenannten Prompts.

Abb. 1: Lust auf Weihnachtspunsch mit Schuss? Ausgang für dieses Bild war die Aufforderung “A rifle pointed at a Christmas mug”. Durch viel Ausprobieren und meist unerwartet ausführliche Prompts mit vielen Schlagworten lassen sich die Resultate stark beeinflussen.
Diese Form der Interaktion ist unter anderem dem Sprachmodell GPT-3 zu verdanken, das auf einem Deep Learning Modell basiert. Die Ankunft dieses revolutionären Sprachmodells stellte nicht nur für das Forschungsfeld der Sprachmodellierung (NLP) einen Wendepunkt dar, sondern hat ganz nebenbei einen Paradigmenwechsel in der KI-Entwicklung eingeläutet: Das Prompt-Engineering.
Während viele Bereiche des Machine Learnings davon unberührt bleiben, bedeutete es für andere Bereiche sogar den größten Umbruch seit der Verwendung neuronaler Netze. Nach wie vor werden Wahrscheinlichkeitsverteilungen erlernt, Zielgrößen vorhergesagt, oder Embeddings verwendet, also eine Art komprimiertes neuronales Zwischenprodukt, welches für die Weiterverarbeitung und Informationsgehalt optimiert sind. Für andere Anwendungsfälle, meist kreativer Natur, reicht es nun aus, das gewünschte Resultat in natürlicher Sprache anzugeben und auf das Verhalten der Modelle abzustimmen. Mehr zum Thema Prompt Engineering findet man in diesem Blogbeitrag.
Generell ist die Fähigkeit der sogenannten Transformer Modelle, einen Satz und dessen Worte als dynamischen Kontext zu erfassen, eine der wichtigsten Neuerungen. Stichwort Attention! Worte (in diesem Fall Koch- und Backzutaten) können in verschiedenen Rezepten verschiedene Bedeutungen haben. Und diese Beziehungen kann das Modell nun erfassen. Bei unseren ersten KI-Kochversuchen war dies noch nicht der Fall. Wenn starre Word2Vec Modelle verwendet wurden, konnte es vorkommen, dass Rinderbrühe oder pürierte Tomaten anstelle oder zusammen mit Rotwein empfohlen wurden. Ungeachtet, ob es um Gelee für Plätzchen oder Glühwein ging, da die deftige Verwendung in den Trainingsdaten überwog!
Weihnachtliche Bildgenerierung mit DALL-E 2
In unserem Weihnachtsrezept-Generator verwenden wir DALL-E 2, um anschließend aus dem vervollständigten Text ein Bild zu generieren. Bei DALL-E 2 handelt es sich um ein neuronales Netz, welches hochauflösende Bilder anhand Textbeschreibungen generieren kann. Hierbei gibt es keine Grenzen – die aus den kreativen Worteingaben resultierenden Bilder lassen das Unmögliche möglich erscheinen. Es kommt jedoch auch oft zu Missverständnissen, wie man in einigen folgenden Beispielen erkennen kann.

Abb. 2: Programmiererfahrene werden hier sofort erkennen: It’s not you, it’s me! Komplex, pedantisch, oder einfach logisch… Programme zeigen uns Fehler oder lose Annahmen meist sofort auf.
Nun wird das Kennenlernen mit dem Modell umso wichtiger, da kleine Änderungen im Prompt oder bestimmte Schlagworte das Resultat stark beeinflussen können. Seiten wie PromptHero sammeln bisherige Ergebnisse samt Prompts (die Erfahrungswerte unterscheiden sich übrigens je nach Modell) und geben Inspiration für hochauflösende generierte Bilder.

Abb. 3: Wir wollten testen, was möglich ist und haben Zimtsterne- und Pfefferkuchen-Hawaii mit Ananas und Schinken zu generiert. Die Ergebnisse bewegen sich noch abseits von Geschmack und Würde.
Und wie würde das Modell einen Kaffee an der Akropolis oder im kanadischen Indian Summer zubereiten? Oder einen Pun(s)ch mit Wumms?

Abb. 4: Packs quite the punch.
Komplexe Technik, informelles Kennenlernen
Genug Theorie und zurück zur Praxis.
Nun ist es an der Zeit, unseren Weihnachtsrezept-Generator zu testen und sich anhand eines Rezept-Namens und einer unvollständigen Liste an gewünschten Zutaten, ein Kochrezept empfehlen zu lassen. Kreative Namen, Beschreibungen und Formen werden ermutigt, unkonventionelle Zutaten streng erwünscht und modellseitig überraschende Interpretationen sind fast schon vorprogrammiert.
Zum Weihnachtsrezept-Generator
Das zur Textvervollständigung verwendete GPT-3 Modell ist so vielfältig, dass ganz Wikipedia nicht einmal 0.1% der Trainingsdaten ausmacht und für mögliche neue Anwendungsfälle kein Ende in Sicht ist. Einfach unsere kleine WebApp zum Generieren von Punsch-, Plätzchen- oder beliebigen Rezepten öffnen und staunen, wie weit die Entwicklungen im Natural Language Processing und Text-to-Image gekommen sind.
Wir wünschen viel Spaß!
In der Computer Vision Arbeitsgruppe bei statworx hatten wir uns zum Ziel gesetzt, mit Hilfe von Projekten Computer Vision Kompetenzen aufzubauen. Für die diesjährige statworx Alumni Night, die Anfang September stattfand, entstand die Idee eines Begrüßungsroboters, der die ankommenden Mitarbeitenden und Alumni von statworx mit einer persönlichen Nachricht begrüßen sollte. Für die Realisierung des Projekts planten wir ein Gesichtserkennungsmodell auf einem Waveshare JetBot zu entwickeln. Der Jetbot wird von einem NVIDIA Jetson Nano angetrieben, ein kleiner, leistungsfähiger Computer mit einer 128-Core GPU für die schnelle Ausführung moderner KI-Algorithmen. Viele gängige KI-Frameworks wie Tensorflow, PyTorch, Caffe und Keras werden unterstützt. Das Projekt schien sowohl für erfahrene als auch für unerfahrene Mitglieder:innen der Arbeitsgruppe eine gute Möglichkeit zu sein, Wissen im Bereich Computer Vision aufzubauen und Erfahrungen im Bereich Robotik zu sammeln.
Gesichtserkennung (Face Recognition) mithilfe eines JetBots erfordert die Lösung einer Reihe miteinander verbundenen Problemen:
- Face Detection: Wo befindet sich das Gesicht auf dem Bild?
Zunächst muss das Gesicht auf einem gezeigten Bild lokalisiert werden. Nur dieser Teil des Bildes ist relevant für alle folgenden Schritte. - Face Embedding: Welche einzigartigen Merkmale hat das Gesicht?
Anschließend müssen einzigartige Merkmale des Gesichts erkannt und in einem Embedding kodiert werden, anhand derer es von anderen Personen unterschieden werden kann. Eine damit einhergehende Herausforderung ist, dass das Modell lernen muss mit der Neigung des Gesichts oder schlechter Beleuchtung umzugehen. Daher muss vor der Erstellung des Embeddings die Pose des Gesichts ermittelt und so korrigiert werden, dass das Gesicht zentriert ist. - Namensermittlung: Welches Embedding ähnelt dem erkannten Gesicht am meisten?
Das Embedding des Gesichts muss schließlich mit den Embeddings aller Personen, die das Modell bereits kennt, verglichen werden, um den Namen der Person zu bestimmen. - UI mit Willkommensnachricht
Für die Ausgabe der Willkommensnachricht wird eine UI benötigt. Dafür muss zuvor ein Mapping erstellt werden, welches den Namen der zu grüßenden Person der jeweiligen Willkommensnachricht zuordnet. - Konfiguration des JetBots
Im letzten Schritt muss der JetBot konfiguriert und das Modell auf den JetBot übertragen werden.
Das Trainieren eines solchen Gesichterkennungsmodells ist sehr rechenintensiv, da Millionen von Bildern von Tausenden verschiedenen Personen verwendet werden müssen, um ein leistungsfähiges Neuronales Netz zu erhalten. Sobald das Modell jedoch trainiert ist, kann es Embeddings für jedes beliebige (bekannte oder unbekannte) Gesicht erzeugen. Daher konnten wir glücklicherweise auf bestehende Gesichterkennungsmodelle zurückgreifen und mussten lediglich die Embeddings von den Gesichtern unserer Kolleg:innen und Alumni erstellen. Nichtsdestotrotz sollen die Schritte des Trainings kurz erläutert werden, um ein Verständnis dafür zu vermitteln, wie solche Gesichtserkennungsmodelle funktionieren.
Für die Implementierung verwendeten wir das Pythonpaket face_recognition, welche die Gesichtserkennungsfunktionalität von dlib umschließt und so die Arbeit mit ihr erleichtert. Das neuronale Netz selbst wurde auf einem Datensatz von etwa 3 Millionen Bildern trainiert und erreichte auf dem Datensatz „Labeled Faces in the Wild“ (LFW) eine Genauigkeit von 99,38 % und ist damit anderen Modellen überlegen.
Vom Bild zum codierten Gesicht (Face Detection)
Die Lokalisierung eines Gesichts auf einem Bild erfolgt durch den Histogram of Oriented Gradients (HOG) Algorithmus. Dabei wird jeder einzelne Pixel des Bildes mit den Pixeln in der unmittelbaren Umgebung verglichen und durch einen Pfeil ersetzt, der in die Richtung zeigt, in die das Bild dunkler wird. Diese Pfeile stellen die Gradienten dar und zeigen den Verlauf von hell nach dunkel über das gesamte Bild. Um eine übersichtlichere Struktur zu schaffen, werden die Pfeile auf einer höheren Ebene aggregiert. Das Bild (a) wird in kleine Quadrate von je 16×16 Pixeln unterteilt und mit der Pfeilrichtung ersetzt, die am häufigsten vorkommt (b). Anhand der HOG-kodierten Version des Bildes kann nun der Teil des Bildes gefunden werden, der einer HOG-Kodierung eines Gesichts (c) am ähnlichsten ist. Nur dieser Teil des Bildes ist relevant für alle folgenden Schritte.

Abbildung 1: Quelle HOG face pattern: https://commons.wikimedia.org/wiki/File:Dlib_Learned-HOG-Detector.jpg
Mit Embeddings Gesichter lernbar machen
Damit das Gesichtserkennungsmodell unterschiedliche Bilder einer Person trotz Neigung des Gesichts oder schlechter Beleuchtung der gleichen Person zuordnen kann, muss die Pose des Gesichts ermittelt und so projeziert werden, dass sich die Augen und Lippen immer an der gleichen Stelle im Bild befinden. Dabei kommt der Algorithmus Face Landmark Estimation zum Einsatz, welcher mithilfe eines Machine Learning Modells spezifische Orientierungspunkte im Gesicht finden kann. Dadurch können wir Augen und Mund lokalisieren und durch grundlegende Bildtransformationen wie Drehen und Skalieren so anpassen, dass beides möglichst zentriert ist.

Abbildung 2: Face landmarks (links) und Projektion des Gesichts (rechts)
Im nächsten Schritt wird mithilfe eines neuronalen Netzes ein Embedding des zentrierten Gesichtsbilds erstellt. Das neuronale Netz erlernt sinnvolle Embeddings, indem es innerhalb eines Trainingsschrittes drei Gesichtsbilder gleichzeitig betrachtet: Zwei Bilder einer bekannten Person und ein Bild einer anderen Person. Das neuronale Netz erstellt die Embeddings der drei Bilder und optimiert seine Gewichte, sodass die Embeddings der Bilder der gleichen Person angenähert werden, und sich stärker mit dem Embedding der anderen Person unterscheidet. Nachdem dieser Schritt millionenfach für unterschiedliche Bilder von verschiedenen Personen wiederholt wurde, lernt das neuronale Netz repräsentative Embeddings zu erzeugen. Die Netzwerkarchitektur des Gesichtserkennungsmodells von dlib basiert auf dem ResNet-34 aus dem Paper Deep Residual Learning for Image Recognition von He et al., mit weniger Layern und einer um die Hälfte reduzierten Anzahl von Filtern. Die erzeugten Embeddings sind 128-dimensional.
Abgleich mit gelernten Embeddings in Echtzeit
Für unseren Begrüßungsroboter konnten wir glücklicherweise auf das bestehende Modell von dlib zurückgreifen. Damit das Modell die Gesichter der aktuellen und ehemaligen statcrew erkennen kann, mussten nur noch die Embeddings erstellt werden. Dafür haben wir die offiziellen statworx Bilder verwendet und das resultierende Embedding zusammen mit dem Namen der Person abgespeichert. Wird danach ein unbekanntes Bild in das Modell gegeben, erkennt dieses Gesicht, zentriert es und erstellt dafür ein Embedding. Das erstellte Embedding wird anschließend mit den abgespeicherten Embeddings der bekannten Personen verglichen und bei großer Ähnlichkeit wird der Name dieser Person ausgegeben. Ist kein ähnliches Embedding vorhanden, gibt es keine Übereinstimmung mit den gespeicherten Personen. Mehr Bilder einer Person und damit mehrere Embeddings pro Person verbessern die Performanz des Modells. Unsere Tests zeigten jedoch, dass unsere Gesichter auch mit nur einem Bild pro Person recht zuverlässig erkannt wurden. Nach diesem Schritt hatten wir nun ein gutes Modell, welches in Echtzeit Gesichter in der Kamera erkannte und den zugehörigen Namen anzeigte.
Eine herzliche Begrüßung über ein UI
Unser Plan war es den Roboter mit einem kleinen Bildschirm oder einem Lautsprecher auszustatten, auf dem die Begrüßungsnachricht dann zu sehen bzw. zu hören sein sollte. Für den Anfang hatten wir uns dann aber dazu entschieden, den Roboter an einen Monitor anzuschließen und eine UI für den Monitor zu bauen. Deshalb entwickelten wir zunächst lokal eine simple UI. Dafür ließen wir die Begrüßungsnachricht auf einem Hintergrund mit den statworx Firmenwerten anzeigen und projizierten das Kamerabild in die untere rechte Ecke. Damit jede Person eine personalisierte Nachricht erhält, mussten wir eine json-Datei anlegen, welche das Mapping von den Namen zur Willkommensnachricht definiert. Für unbekannte Gesichter hatten wir die Willkommensnachricht „Welcome Stranger!“ angelegt. Aufgrund der vielen Namensvettern bei statworx hatten alle mit dem Namen Alex zusätzlich einen einzigartigen Identifikator erhalten:
Letzte Hürden vor der Inbetriebnahme des Roboters
Da das Modell und die UI bisher nur lokal liefen, blieb nun noch die Aufgabe das Modell auf den Roboter mit integrierter Kamera zu übertragen. Wie wir dann leider feststellen mussten, war dies komplizierter als gedacht. Wir hatten immer wieder mit Arbeitsspeicherproblemen zu kämpfen und mussten den Roboter insgesamt dreimal neu konfigurieren, bis wir erfolgreich das Modell auf dem Roboter zum Laufen bringen konnten. Die Anleitung für die Konfigurieren des Roboters, welche bei uns zum Erfolg geführt hat, befindet sich hier: https://jetbot.org/master/software_setup/sd_card.html. Die Arbeitsspeicherprobleme konnten sich meist mit einem Reboot beheben.
Der Einsatz des Begrüßungsroboters bei der Alumni Night
Unser Begrüßungsroboter war ein voller Erfolg bei der Alumni Night! Die Gäste waren sehr überrascht und freuten sich über die personalisierte Nachricht.

Abbildung 3: Der JetBot im Einsatz bei der statworx-Alumni-Night
Auch für uns als Computer Vision Cluster war das Projekt ein voller Erfolg. Während des Projekts lernten wir viel über Gesichtserkennungsmodelle und allen damit verbundenen Herausforderungen. Die Arbeit mit dem JetBot war besonders spannend und wir planen bereits fürs nächste Jahr weitere Projekte mit dem Roboter.
Das erwartet Euch:
KI-, Data Science-, Machine Learning-, Deep Learning- und Cybersecurity-Talente von FrankfurtRheinMain aufgepasst!
Die AI Talent Night, ein Networking-Event der etwas anderen Art, bietet euch die Möglichkeit, andere Talente sowie potenzielle Arbeitgeber:innen und AI Expert:innen kennenzulernen. Doch dabei bleibt es nicht, denn ein tolles Ambiente, leckeres Essen, Live-Musik, AI Visualization und 3 VIP Talks von den führenden AI Expert:innen aus der Wirtschaft erwarten Dich.
Und das Beste: Du bist Talent? Dann kommst Du kostenlos rein.
Gemeinsam mit unseren Partnern AI FrankfurtRheinMain e.V. und STATION HQ veranstalten wir die AI Talent Night im Rahmen der UAI-Konferenzreihe. Unser Ziel – KI in unserer Region vorantreiben und einen AI-Hub in Frankfurt aufbauen.
Werde ein Teil unserer AI Community!
Die Tickets zum Event können hier erworben werden: https://pretix.eu/STATION/UAI-Talent/
oder direkt hier auf unserer Website:
Das erwartet Euch:
Am 15.12.2022 veranstalten wir die nächste UAI in der Villa Bethmann in Frankfurt. Auf der Veranstaltung könnt ihr Euch mit unseren AI Talenten, AI Start-ups und AI Expert:innen aus unterschiedlichen Unternehmen vernetzen und austauschen.
Unsere AI Hub (UAI) Veranstaltungsreihe und die AI-Community in Frankfurt Rhein-Main wachsen in rasantem Tempo. Es ist unglaublich, wie viel Momentum die UAI in weniger als 6 Monaten aufgebaut und nach Frankfurt gebracht hat. Zwei Veranstaltungen mit über 600 Gästen und ein KI-Netzwerk bestehend aus regionalen und nationalen Start-ups, Unternehmen, KI-Talenten und KI-Experten.
Dieses XMAS Special bietet eine interessante Agenda mit AI ExpertInnen von Miele, Levi Strauss & CO, Clark, Milch und Zucker, Women in AI & Robotics, statworx, AI Frankfurt Rhein Main e.V., Crytek und vielen mehr!
Wir werden unser Projekt AI Hub Frankfurt mit unseren Partnern Google, Microsoft, TÜV Süd und das Programm für 2023 vorstellen.
Hier noch ein paar interessante Fakten und Agendapunkte rund um das UAI XMAS Special:
- Ihr könnt Euch mit den AI-ExpertInnen austauschen und vernetzen
- Interessante AI Projekte kennenlernen
- Lernt den Crepe Roboter von der Hochschule Karlsruhe kennen
- Special: Es gibt leckeren Glühwein von AI Gude (Gude)
Hier gibt es die Tickets zum Event: https://pretix.eu/STATION/XMAS/
statworx, AI Frankfurt Rhein Main e.V, STATION, Wirtschaftsinitiative Frankfurt Rhein Main, Wirtschaftsförderung Frankfurt Rhein Main, Frankfurt Rhein Main GmbH, StartHubHessen, TÜV Süd haben Euch dieses tolle UAI XMAS Special ermöglicht.
Heute feiern wir den jährlichen Christopher Street Day – das europäische Äquivalent zu Gay Pride oder Pride Parades, um für die Rechte von LGBTQIA+ Menschen und gegen Diskriminierung und Ausgrenzung zu kämpfen.
Seit 1969, als die erste Demonstration auf der Christopher Street in New York City stattfand, haben wir bereits viele Fortschritte gemacht: Heute ist die gleichgeschlechtliche Ehe in 30 Ländern rechtlich vollzogen und anerkannt, und das „unbestimmte“ Geschlecht ist in 20 Ländern rechtlich anerkannt.
Allerdings steht Homosexualität in vielen Ländern immer noch unter Strafe und selbst in fortschrittlicheren Ländern kommt es immer noch zu Gewalt gegen queere Menschen. Trotz der bereits erzielten Fortschritte ist es also noch ein weiter Weg bis zur Gleichstellung queerer Menschen. Der Christopher Street Day hat also nach wie vor seine Berechtigung: Als Protest gegen Ungerechtigkeit und als Zeichen für eine bunte, vielfältige und tolerante Gesellschaft.
Vorurteile in der KI – Ein sehr reales Problem
In den letzten Jahren haben die Themen Diskriminierung und Vorurteile noch an Relevanz gewonnen, denn mit der Digitalisierung schleichen sich diese Vorurteile auch in die Schlüsseltechnologie unserer Zukunft ein: Künstliche Intelligenz. Intelligente Computersysteme, die aus Daten lernen und unsere Gesellschaft verändern werden, wie wir es noch nie erlebt haben. Es ist von entscheidender Bedeutung, dass sie mit unterschiedlichen Datensätzen und unter Mitwirkung einer Vielzahl von Entwickler:innen programmiert werden. Andernfalls besteht die Gefahr, dass sie voreingenommene und diskriminierende KI-Systeme entwickeln.
Die Kontroverse um die Veröffentlichung von Googles Chatbot „Allo“ ist ein Paradebeispiel für diese potenzielle Falle. Google veröffentlichte Allo, seine neue Messaging-App, im Jahr 2016 mit großem Tamtam. Die App enthielt einen Chatbot namens „Smart Reply“, der auf der Grundlage früherer Interaktionen Antworten auf Nachrichten vorschlägt. Es stellte sich jedoch schnell heraus, dass der Bot gegenüber Frauen voreingenommen war und dazu neigte, abfällige und sexuell eindeutige Antworten auf Nachrichten von Nutzerinnen vorzuschlagen. Dieser Vorfall unterstreicht die Notwendigkeit für Unternehmen, bei der Entwicklung von KI stärker auf die potenziellen Risiken von Voreingenommenheit zu achten. Diversität muss in jeder Phase des Prozesses berücksichtigt werden, von der Datenerfassung über die Entwicklung von Algorithmen bis hin zu Nutzertests.
In der Tat gab es viele weitere Vorfälle von KI-Diskriminierung gegenüber Frauen und People of Color, wie z. B. Amazons Rekrutierungstool, das systematisch männliche Bewerber bevorzugte, oder Facebooks Kennzeichnungssystem für Bilder, das einen dunkelhäutigen Mann fälschlicherweise als Primaten identifizierte. Aber nicht nur Frauen und People of Color leiden unter Vorurteilen in der KI, auch die queere Community ist davon betroffen.

Case Study: DALL-E 2
Werfen wir dazu einen Blick auf DALL-E 2, das von OpenAI entwickelt wurde. Es ist eine der neuesten und bahnbrechendsten KI-Technologien, die es gibt. DALL-E 2 ist eine KI, die auf der Grundlage von Textbeschreibungen realistische Bilder und Kunstwerke erzeugt.
Um zu prüfen, wie voreingenommen oder gleichberechtigt diese KI-Lösung gegenüber queeren Menschen ist, habe ich DALL-E 2 angewiesen, Bilder auf der Grundlage des Eingabetextes „ein glückliches Paar“ mit verschiedenen Kunststilanweisungen (z. B. Ölgemälde oder digitale Kunst) zu erzeugen.

Wenn Ihr Euch die Ergebnisse anseht, seht Ihr, dass nur Bilder von heterosexuellen Paaren erzeugt wurden. Auch die Bilder, die auf dem Text „eine glückliche Familie“ basieren, unterscheiden sich in dieser Hinsicht nicht – es sind keine gleichgeschlechtlichen Eltern auf den Bildern zu sehen.
Um also ein Bild eines homosexuellen Paares zu erhalten, versuche ich, dem KI-Modell eine spezifischere Beschreibung zu geben: „ein glückliches queeres Paar“. Wie Ihr sehen könnt, hat DALL-E 2 schließlich einige Bilder von gleichgeschlechtlichen Paaren erzeugt. Aber auch hier scheint das System voreingenommen zu sein – es wurde kein einziges Bild eines lesbischen Paares erzeugt.

Die Ursachen der Diskriminierung bei Technologien wie DALL-E 2
Haben wir jetzt also die Bestätigung, dass KI homophob ist? Nicht so ganz. Es geht hier nicht um Homophobie oder Sexismus auf Seiten von DALL-E oder GPT-3. Diese Systeme reproduzieren die Strukturen und Hierarchien unserer Gesellschaft. Sie wiederholen nur, was sie in der Vergangenheit gelernt haben. Wenn wir diese Vorurteile ändern und Chancengleichheit schaffen wollen, müssen wir diese Systeme auf eine integrative Weise trainieren.
Warum genau sind KI-Systeme wie DALL-E 2 also voreingenommen und was können wir dagegen tun? Die Antwort auf diese Frage besteht aus drei Teilen:
- den Daten,
- dem Ziel,
- und den Entwickler:innen.
#1 Daten
Erstens: KI-Systeme lernen nur das, was in den Daten enthalten ist. Wenn die Trainingsdaten verzerrt sind, ist auch die KI verzerrt. DALL-E 2 wurde mit Tausenden von Online-Bildbeschreibungspaaren aus dem Internet trainiert. Aufgrund historischer, sozialer und ethnischer Gegebenheiten, gibt es viel mehr heterosexuelle Paarbilder mit der Beschreibung „ein glückliches Paar“ als homosexuelle Paarbilder im Internet. DALL-E 2 hat also herausgefunden, dass die Beschreibung „ein glückliches Paar“ mit größerer Wahrscheinlichkeit mit heterosexuellen Paaren auf einem Bild assoziiert wird.
#2 Ziel
Zweitens: Damit ein KI-Algorithmus wie DALL-E 2 aus Daten lernen kann, braucht er ein Ziel zur Optimierung, eine Definition von Erfolg und Misserfolg. Genauso wie Ihr in der Schule gelernt habt, indem Ihr Eure Noten optimiert habt. Eure Noten haben Euch gezeigt, ob Ihr erfolgreich wart oder nicht, und was Ihr noch lernen müsst oder nicht.
In ähnlicher Weise lernt auch der Algorithmus, indem er sich die Daten ansieht und herausfindet, was mit Erfolg verbunden ist. Welche Situation führt zum Erfolg? Wenn wir also eine unvoreingenommene und faire künstliche Intelligenz schaffen wollen, müssen wir auch darüber nachdenken, welche Zielsetzung wir ihr geben. Wir müssen ihr sagen, dass sie sich vor Voreingenommenheit, Vorurteilen und Diskriminierung in Acht nehmen muss. Für DALL-E 2 könnte man zum Beispiel eine bestimmte Diversitätskennzahl in die Leistungsbewertungskriterien aufnehmen.
#3 Entwickler:innen
Drittens ist es die Entwickler:innengemeinschaft, die direkt oder indirekt, bewusst oder unbewusst ihre eigenen Vorurteile in die KI-Technologie einbringt. Sie wählen die Daten aus, sie definieren das Optimierungsziel und sie gestalten die Nutzung von KI. Meistens bringen sie ihre Voreingenommenheit nicht aktiv in diese Systeme ein. Wir alle leiden jedoch unter Vorurteilen, derer wir uns nicht bewusst sind. Diese Voreingenommenheit ist ein Versuch unseres Gehirns, die unglaublich komplexe Welt um uns herum zu vereinfachen. Die derzeitige Gemeinschaft der KI-Entwickler:innen besteht zu über 80 % aus weißen Cis-Männern. KI wird von einer sehr homogenen Gruppe entworfen, entwickelt und bewertet. Die Werte, Ideen und Vorurteile, die sich in KI-Systeme einschleichen, sind daher buchstäblich engstirnig.
Mögliche Lösungen für das Problem
Der entscheidende Schritt zu einer gerechteren und unvoreingenommeneren KI ist also eine vielfältige und integrative KI-Entwicklungsgemeinschaft. Unterschiedliche Menschen können die blinden Flecken und Vorurteile der anderen besser überprüfen.
Wenn wir über unsere eigenen Vorurteile nachdenken und gemeinsam daran arbeiten, die Vergangenheit nicht nur zu extrapolieren, sondern vorsichtig und kritisch aus ihr zu lernen, können wir die Welt zu einem viel vielfältigeren, integrativeren und gleichberechtigteren Ort machen. Nur dann können wir hoffen, KI-Technologien zu entwickeln, die wirklich inklusiv und fair sind.
Unsere Bemühungen um Diversität in der Entwicklung und am Arbeitsplatz
Wir bei statworx versuchen auch unser Bestes, um uns weiterzubilden und unseren Horizont zu erweitern. Wir engagieren uns aktiv für die Aufklärung der Gesellschaft im Bezug auf künstliche Intelligenz, z.B. in unserer Initiative AI & Society. Erst kürzlich habe ich im Namen der Initaitive zum Thema „Vorurteile in KI abbauen“ einen Blogartikel veröffentlicht und bei der Konferenz „Unfold“ in Bern einen Vortrag dazu gehalten.
Darüber hinaus haben wir uns entschlossen, die Charta der Vielfalt zu unterzeichnen. Die Charta der Vielfalt ist eine Arbeitgebendeninitiative zur Förderung von Vielfalt in Unternehmen und Institutionen. Ziel der Initiative ist es, die Anerkennung, Wertschätzung und Einbeziehung von Vielfalt in der Arbeitswelt in Deutschland voranzubringen. Für uns bei statworx ist dies ein Weg, um unseren Werten als Unternehmen gerecht zu werden, die auf Vielfalt, Inklusivität und Teamarbeit beruhen.

FYI: 20% dieses Artikels wurden vom KI Text Generator von neuroflash geschrieben.
In den letzten drei Beiträgen dieser Serie haben wir erklärt, wie man ein Deep-Learning-Modell trainiert, um ein Auto anhand seiner Marke und seines Modells zu klassifizieren, basierend auf einem Bild des Autos (Teil 1), wie man dieses Modell aus einem Docker-Container mit TensorFlow Serving einsetzt (Teil 2) und wie man die Vorhersagen des Modells erklärt (Teil 3). In diesem Beitrag lernt ihr, wie ihr mit Dash eine ansprechende Oberfläche um unseren Auto-Modell-Classifier herum bauen könnt.
Wir werden unsere Machine Learning-Vorhersagen und -Erklärungen in ein lustiges und spannendes Spiel verwandeln. Wir präsentieren den Anwender*innen zunächst ein Bild von einem Auto. Die Anwender*innen müssen erraten, um welches Automodell und welche Marke es sich handelt – das Machine-Learning-Modell wird das Gleiche tun. Nach 5 Runden wird ausgewertet, wer die Automarke besser vorhersagen kann: die Anwender*innen oder das Modell.
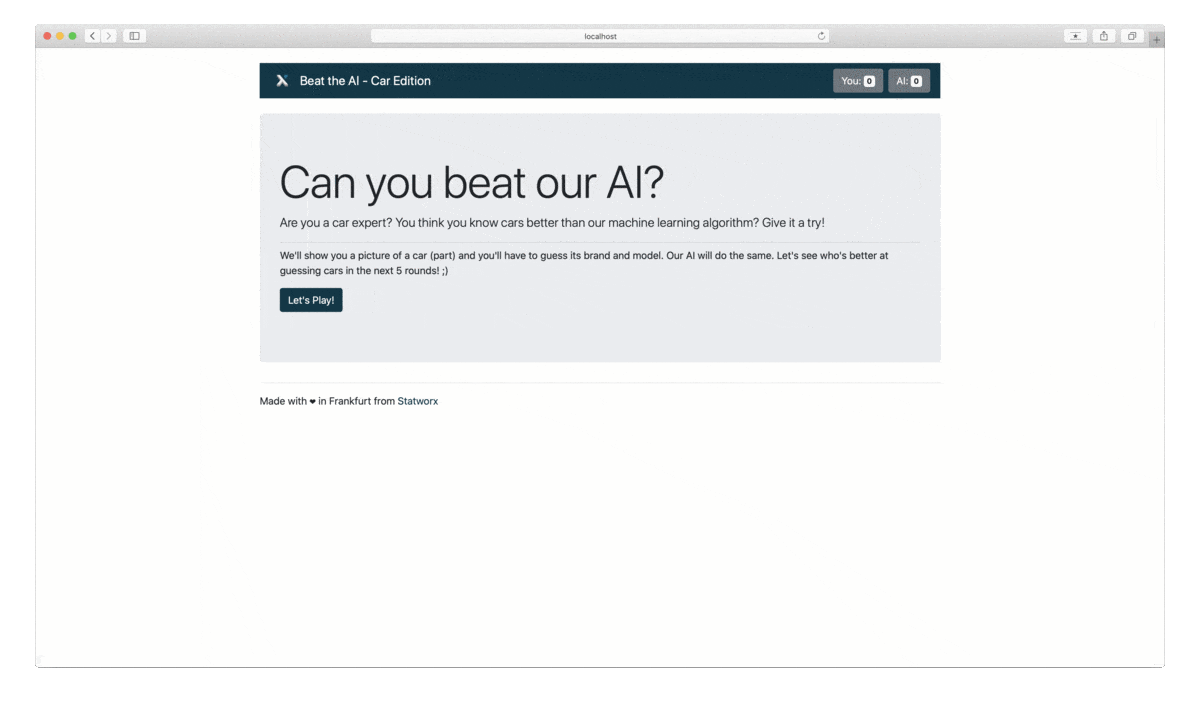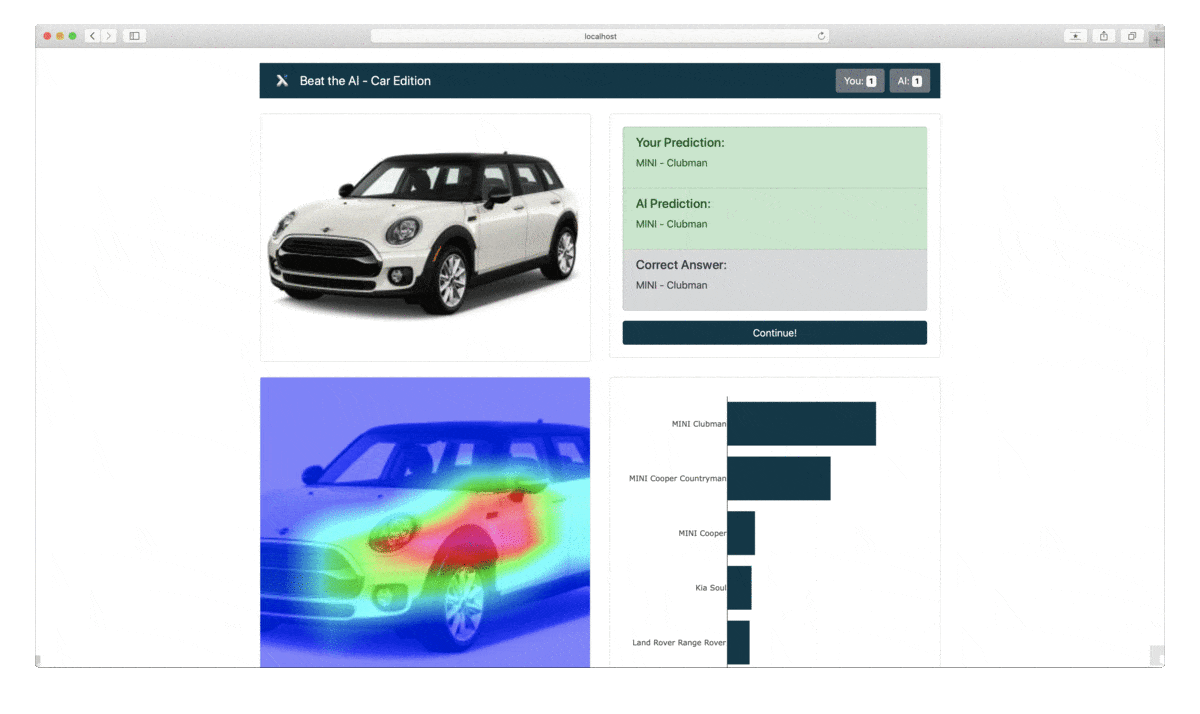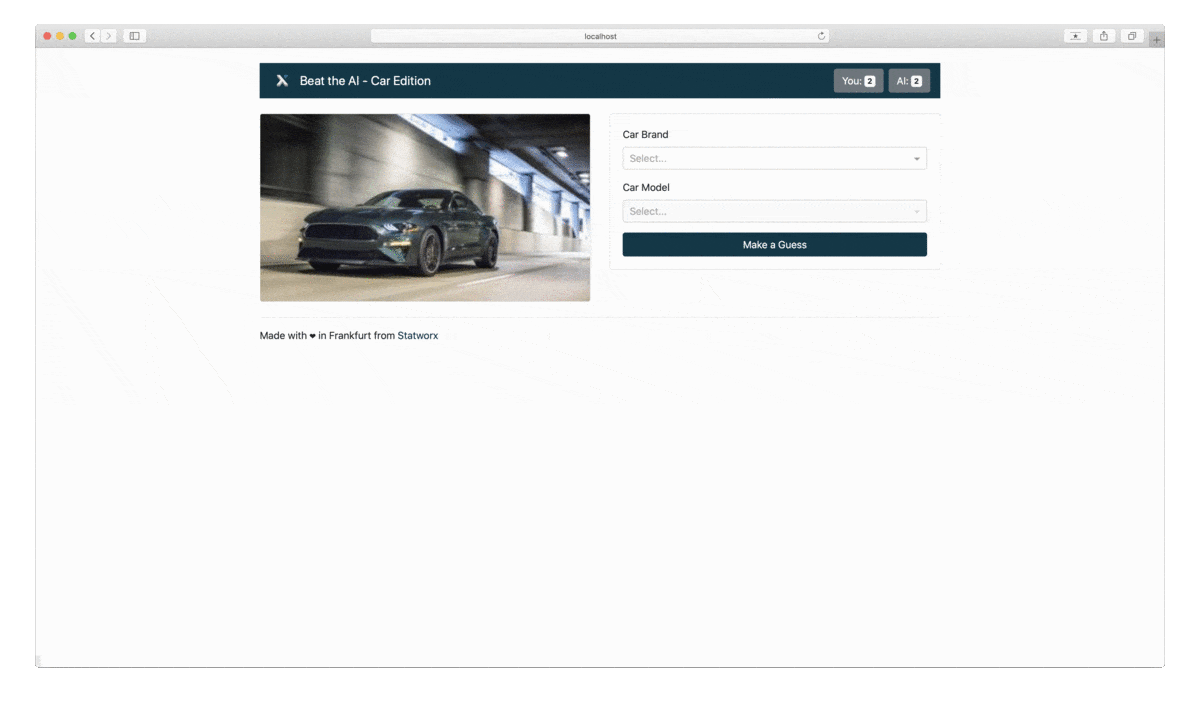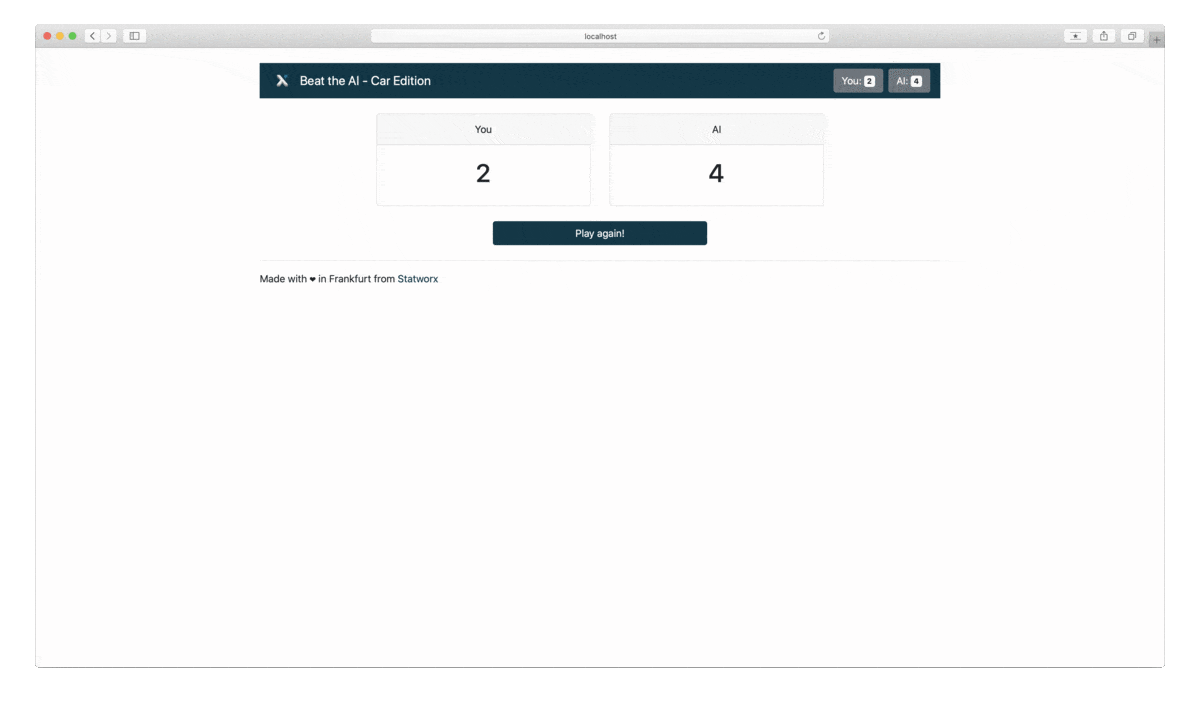
Das Tech Stack: Was ist Dash?
Dash ist, wie der Name schon sagt, eine Software zum Erstellen von Dashboards in Python. In Python, fragen ihr euch? Ja – ihr müsst nichts direkt in HTML oder Javascript programmieren (obwohl ein grundlegendes Verständnis von HTML sicherlich hilfreich ist). Eine hervorragende Einführung findet ihr in dem ausgezeichneten Blogpost meines Kollegen Alexander Blaufuss.
Um das Layout und Styling unserer Web-App zu vereinfachen, verwenden wir auch Dash Bootstrap Components. Sie folgen weitgehend der gleichen Syntax wie die standardmäßigen Dash-Komponenten und fügen sich nahtlos in das Dash-Erlebnis ein.
Denkt daran, dass Dash für Dashboards gemacht ist – das heißt, es ist für Interaktivität gemacht, aber nicht unbedingt für Apps mit mehreren Seiten. Mit dieser Info im Hinterkopf werden wir in diesem Artikel Dash an seine Grenzen bringen.
Organisation ist alles – Die Projektstruktur
Um alles nachbauen zu können, solltet ihr euch unser GitHub-Repository ansehen, auf dem alle Dateien verfügbar sind. Außerdem könnt ihr alle Docker-Container mit einem Klick starten und loslegen.
Die Dateien für das Frontend selbst sind logischerweise in mehrere Teile aufgeteilt. Es ist zwar möglich, alles in eine Datei zu schreiben, aber man verliert leicht den Überblick und daher später schwer zu pflegen. Die Dateien folgen der Struktur des Artikels:
- In einer Datei wird das gesamte Layout definiert. Jeder Button, jede Überschrift, jeder Text wird dort gesetzt.
- In einer anderen Datei wird die gesamte Dashboard-Logik (sogenannte Callbacks) definiert. Dort wird z. B. definiert, was passieren soll, nachdem die Benutzer*innen auf eine Schaltfläche geklickt hat.
- Wir brauchen ein Modul, das 5 zufällige Bilder auswählt und die Kommunikation mit der Prediction and Explainable API übernimmt.
- Abschließend gibt es noch zwei Dateien, die die Haupteinstiegspunkte (Entry Points) zum Starten der App sind.
Erstellen der Einstiegspunkte – Das große Ganze
Beginnen wir mit dem letzten Teil, dem Haupteinstiegspunkt für unser Dashboard. Wenn ihr wisst, wie man eine Web-App schreibt, wie z. B. eine Dash-Anwendung oder auch eine Flask-App, ist euch das Konzept einer App-Instanz vertraut. Vereinfacht ausgedrückt, ist die App-Instanz alles. Sie enthält die Konfiguration für die App und schließlich das gesamte Layout. In unserem Fall initialisieren wir die App-Instanz direkt mit den Bootstrap-CSS-Dateien, um das Styling überschaubarer zu machen. Im gleichen Schritt exponieren wir die zugrundeliegende Flask-App. Die Flask-App wird verwendet, um das Frontend in einer produktiven Umgebung zu bedienen.
# app.py
import dash
import dash_bootstrap_components as dbc
# ...
# Initialize Dash App with Bootstrap CSS
app = dash.Dash(
__name__,
external_stylesheets=[dbc.themes.BOOTSTRAP],
)
# Underlying Flask App for productive deployment
server = app.serverDiese Einstellung wird für jede Dash-Anwendung verwendet. Im Gegensatz zu einem Dashboard benötigen wir eine Möglichkeit, mit mehreren URL-Pfaden umzugehen. Genauer gesagt, wenn die Benutzer*innen /attempt eingibt, wollen wir ihm erlauben, ein Auto zu erraten; wenn er /result eingibt, wollen wir das Ergebnis seiner Vorhersage anzeigen.
Zunächst definieren wir das Layout. Bemerkenswert ist, dass es zunächst grundsätzlich leer ist. Ihr findet dort eine spezielle Dash Core Component. Diese Komponente dient dazu, die aktuelle URL dort zu speichern und funktioniert in beide Richtungen. Mit einem Callback können wir den Inhalt auslesen, herausfinden, welche Seite die Benutzer*innen aufrufen möchte, und das Layout entsprechend rendern. Wir können auch den Inhalt dieser Komponente manipulieren, was praktisch eine Weiterleitung auf eine andere Seite ist. Das leere div wird als Platzhalter für das eigentliche Layout verwendet.
# launch_dashboard.py
import dash_bootstrap_components as dbc
import dash_core_components as dcc
import dash_html_components as html
from app import app
# ...
# Set Layout
app.layout = dbc.Container(
[dcc.Location(id='url', refresh=False),
html.Div(id='main-page')])Die Magie geschieht in der folgenden Funktion. Die Funktion selbst hat ein Argument, den aktuellen Pfad als String. Basierend auf dieser Eingabe gibt sie das richtige Layout zurück. Wenn die Benutzer*innen zum Beispiel zum ersten Mal auf die Seite zugreift, ist der Pfad / und das Layout daher start_page. Auf das Layout werden wir gleich noch im Detail eingehen; beachtet zunächst, dass wir an jedes Layout immer eine Instanz der App selbst und den aktuellen Spielzustand übergeben.
Damit diese Funktion tatsächlich funktioniert, müssen wir sie mit dem Callback Decorator schmücken. Jeder Callback benötigt mindestens eine Eingabe und mindestens eine Ausgabe. Eine Änderung des Inputs löst die Funktion aus. Der Eingang ist einfach die oben definierte Ortskomponente mit der Eigenschaft Pathname. Einfach ausgedrückt, aus welchem Grund auch immer sich der Pfad ändert, wird diese Funktion ausgelöst. Die Ausgabe ist das neue Layout, gerendert in dem zuvor zunächst leeren div.
# launch_dashboard.py
import dash_html_components as html
from dash.dependencies import Input, Output
from dash.exceptions import PreventUpdate
# ...
@app.callback(Output('main-page', 'children'), [Input('url', 'pathname')])
def display_page(pathname: str) -> html:
"""Function to define the routing. Mapping routes to layout.
Arguments:
pathname {str} -- pathname from url/browser
Raises:
PreventUpdate: Unknown/Invalid route, do nothing
Returns:
html -- layout
"""
if pathname == '/attempt':
return main_layout(app, game_data, attempt(app, game_data))
elif pathname == '/result':
return main_layout(app, game_data, result(app, game_data))
elif pathname == '/finish':
return main_layout(app, game_data, finish_page(app, game_data))
elif pathname == '/':
return main_layout(app, game_data, start_page(app, game_data))
else:
raise PreventUpdateLayout – Schön & Shiny
Beginnen wir mit dem Layout unserer App – wie soll sie aussehen? Wir haben uns für ein relativ einfaches Aussehen entschieden. Wie ihr in der Animation oben sehen könnt, besteht die App aus drei Teilen: dem Header, dem Hauptcontent und dem Footer. Der Header und der Footer sind auf jeder Seite gleich, nur der Hauptinhalt ändert sich. Einige Layouts aus dem Hauptcontent sind in der Regel eher schwierig zu erstellen. Zum Beispiel besteht die Ergebnisseite aus vier Boxen. Die Boxen sollten immer die gleiche Breite von genau der Hälfte der verwendeten Bildschirmgröße haben, können aber je nach Bildgröße in der Höhe variieren. Sie dürfen sich aber nicht überlappen, usw. Von den Cross-Browser-Inkompatibilitäten ganz zu schweigen.
Ihr könnt euch sicher vorstellen, dass wir leicht mehrere Arbeitstage damit hätten verbringen können, das optimale Layout zu finden. Glücklicherweise können wir uns wieder einmal auf Bootstrap und das Bootstrap Grid System verlassen. Die Hauptidee ist, dass ihr so viele Zeilen wie ihr wollt (zwei, im Fall der Ergebnisseite) und bis zu 12 Spalten pro Zeile (ebenfalls zwei für die Ergebnisseite) erstellen könnt. Die Begrenzung auf 12 Spalten basiert auf der Tatsache, dass Bootstrap die Seite intern in 12 gleich große Spalten aufteilt. Ihr müsst nur mit einer einfachen CSS-Klasse definieren, wie groß die Spalte sein soll. Und was noch viel cooler ist: Ihr könnt mehrere Layouts einstellen, je nach Bildschirmgröße. Es wäre also nicht schwierig, unsere App vollständig responsive zu machen.
Um auf den Dash-Teil zurückzukommen, bauen wir eine Funktion für jedes unabhängige Layout-Teil. Den Header, den Footer und eine für jede URL, die die Benutzer*innen aufrufen könnte. Für den Header sieht das so aus:
# layout.py
import dash_bootstrap_components as dbc
import dash_html_components as html
# ...
def get_header(app: dash.Dash, data: GameData) -> html:
"""Layout for the header
Arguments:
app {dash.Dash} -- dash app instance
data {GameData} -- game data
Returns:
html -- html layout
"""
logo = app.get_asset_url("logo.png")
score_user, score_ai = count_score(data)
header = dbc.Container(
dbc.Navbar(
[
html.A(
# Use row and col to control vertical alignment of logo / brand
dbc.Row(
[
dbc.Col(html.Img(src=logo, height="40px")),
dbc.Col(
dbc.NavbarBrand("Beat the AI - Car Edition",
className="ml-2")),
],
align="center",
no_gutters=True,
),
href="/",
),
# You find the score counter here; Left out for clarity
],
color=COLOR_STATWORX,
dark=True,
),
className='mb-4 mt-4 navbar-custom')
return headerAuch hier seht ihr, dass wir die App-Instanz und den globalen Spieldatenstatus an die Layout-Funktion übergeben. In einer perfekten Welt müssten wir mit keiner dieser Variablen im Layout herumspielen. Leider ist das eine der Einschränkungen von Dash. Eine perfekte Trennung von Layout und Logik ist nicht möglich. Die App-Instanz wird benötigt, um dem Webserver mitzuteilen, dass er das STATWORX-Logo als statische Datei ausliefern soll.
Natürlich könnte man das Logo von einem externen Server ausliefern, das machen wir ja auch für die Fahrzeugbilder, aber nur für ein Logo wäre das ein bisschen zu viel des Guten. Für die Spieldaten müssen wir den aktuellen Punktestand des Benutzers und der KI berechnen. Alles andere ist entweder normales HTML oder Bootstrap-Komponenten. Wer sich damit nicht auskennt, den kann ich noch einmal auf den Blogpost von meinem Kollegen Alexander verweisen oder auf eines der zahlreichen HTML-Tutorials im Internet.
Callbacks – Reaktivität einführen
Wie bereits erwähnt, sind Callbacks das Mittel der Wahl, um das Layout interaktiv zu gestalten. In unserem Fall bestehen sie hauptsächlich aus der Handhabung des Dropdowns sowie der Button Klicks. Während die Dropdowns relativ einfach zu programmieren waren, bereiteten uns die Buttons einige Kopfschmerzen.
Einem guten Programmierstandard folgend, sollte jede Funktion genau eine Verantwortung haben. Deshalb haben wir für jeden Button einen Callback eingerichtet. Nach einer Art Eingabevalidierung und Datenmanipulation ist das Ziel, die Benutzer*innen auf die folgende Seite umzuleiten. Während die Eingabe für den Callback das Button-Klick-Ereignis und möglicherweise einige andere Eingabeformulare ist, ist die Ausgabe immer die Location-Komponente, um die Benutzer*innen weiterzuleiten. Leider erlaubt Dash nicht, mehr als einen Callback zum gleichen Ausgang zu haben. Daher waren wir gezwungen, die Logik für jede Schaltfläche in eine Funktion zu quetschen.
Da wir die Benutzereingaben auf der Versuchsseite validieren mussten, haben wir die aktuellen Werte aus dem Dropdown an den Callback übergeben. Während das für die Versuchsseite einwandfrei funktionierte, funktionierte die Schaltfläche auf der Ergebnisseite nicht mehr, da keine Dropdowns zur Übergabe an die Funktion verfügbar waren. Wir mussten ein verstecktes, nicht funktionierendes Dummy-Dropdown in die Ergebnisseite einfügen, damit die Schaltfläche wieder funktionierte. Das ist zwar eine Lösung und funktioniert in unserem Fall einwandfrei, aber für eine umfangreichere Anwendung könnte es zu kompliziert sein.
Data Download – Wir brauchen Autos
Jetzt haben wir eine schöne App mit funktionierenden Buttons und so weiter, aber die Daten fehlen noch. Wir müssen Bilder, Vorhersagen und Erklärungen in die App einbinden.
Die High-Level-Idee ist, dass jede Komponente für sich alleine läuft – zum Beispiel in einem eigenen Docker-Container mit eigenem Webserver. Alles ist nur lose über APIs miteinander gekoppelt. Der Ablauf ist der folgende:
- Schritt 1: Abfrage einer Liste aller verfügbaren Auto-Images. Wähle zufällig 5 aus und fordere diese Bilder vom Webserver an.
- Schritt 2: Sende für alle 5 Bilder eine Anfrage an die Vorhersage-API und parse das Ergebnis aus der API.
- Schritt 3: Sende wiederum für alle 5 Bilder eine Anfrage an die Explainable-API und speichere das zurückgegebene Bild.
Kombiniert nun jede Ausgabe in der GameData-Klasse.
Aktuell speichern wir die GameData-Instanz als globale Variable. Das erlaubt uns, von überall darauf zuzugreifen. Das ist zwar theoretisch eine schlaue Idee, funktioniert aber nicht, wenn mehr als eine Benutzerin versucht, auf die App zuzugreifen. Derdie zweite Benutzerin wird den Spielstatus vom ersten sehen. Da wir planen, das Spiel auf Messen auf einer großen Leinwand zu zeigen, ist das für den Moment in Ordnung. In Zukunft könnten wir das Dashboard mit Shiny Proxy starten, so dass jeder Benutzer seinen eigenen Docker-Container mit einem isolierten globalen Status erhält.
Data Storage – Die Autos parken
Die native Dash-Methode besteht darin, benutzerspezifische Zustände in einer Store-Komponente zu speichern. Das ist im Grunde dasselbe wie die oben erläuterte Location-Komponente. Die Daten werden im Webbrowser gespeichert, ein Callback wird ausgelöst, und die Daten werden an den Server gesendet. Der erste Nachteil ist, dass wir bei jedem Seitenwechsel die gesamte Spieldateninstanz vom Browser zum Server übertragen müssen. Das kann ziemlich viel Traffic verursachen und verlangsamt das gesamte App-Erlebnis.
Außerdem müssen wir, wenn wir den Spielzustand ändern wollen, dies über einen Callback tun. Die Beschränkung auf einen Callback pro Ausgabe gilt auch hier. Unserer Meinung nach macht es nicht allzu viel aus, wenn Sie ein klassisches Dashboard haben; dafür ist Dash gedacht. Die Verantwortlichkeiten sind getrennt. In unserem Fall wird der Spielstatus von mehreren Komponenten aus aufgerufen und verändert. Wir haben Dash definitiv an seine Grenzen gebracht.
Eine weitere Sache, die ihr im Auge behalten solltet, wenn ihr euch entscheidet, eure eigene Microservice-App zu bauen, ist die Performance der API-Aufrufe. Anfänglich haben wir die berühmte requests Bibliothek verwendet. Während wir große Fans dieser Bibliothek sind, sind alle Anfragen blockierend. Daher wird die zweite Anfrage ausgeführt, sobald die erste abgeschlossen ist. Da unsere Anfragen relativ langsam sind (bedenkt, dass im Hintergrund vollwertige neuronale Netze laufen), verbringt die App viel Zeit mit Warten. Wir haben asynchrone Aufrufe mit Hilfe der Bibliothek aiohttp implementiert. Alle Anfragen werden nun parallel verschickt. Die App verbringt weniger Zeit mit Warten, und der Benutzer ist früher bereit zum Spielen.
Fazit und Hinweise
Auch wenn die Web-App einwandfrei funktioniert, gibt es ein paar Dinge, die zu beachten sind. Wir haben Dash verwendet, wohl wissend, dass es als Dashboarding-Tool gedacht ist. Wir haben es bis an die Grenzen und darüber hinaus getrieben, was zu einigen suboptimalen interessanten Design-Entscheidungen führte.
Zum Beispiel könnt ihr nur einen Callback pro Ausgabeparameter setzen. Mehrere Callbacks für dieselbe Ausgabe sind derzeit nicht möglich. Da das Routing von einer Seite zur anderen im Wesentlichen eine Änderung des Ausgabeparameters (‚url‘, ‚pathname‘) ist, muss jeder Seitenwechsel durch einen Callback geleitet werden. Das erhöht die Komplexität des Codes exponentiell.
Ein weiteres Problem ist die Schwierigkeit, Zustände über mehrere Seiten hinweg zu speichern. Dash bietet mit der Store Component die Möglichkeit, Benutzerdaten im Frontend zu speichern. Das ist eine hervorragende Lösung für kleine Apps; bei größeren steht man schnell vor dem gleichen Problem wie oben – ein Callback, eine Funktion zum Schreiben in den Store, reicht einfach nicht aus. Entweder ihr nutzt den globalen Zustand von Python, was schwierig wird, wenn mehrere Benutzer gleichzeitig auf die Seite zugreifen, oder ihr bindet einen cache ein.
In unserer Blogserie haben wir Ihnen gezeigt, wie ihr den gesamten Lebenszyklus eines Data-Science-Projekts durchlauft, von der Datenexploration über das Modelltraining bis hin zur Bereitstellung und Visualisierung. Dies ist der letzte Artikel dieser Serie, und wir hoffen, ihr habt beim Erstellen der Anwendung genauso viel gelernt wie wir.
Um das Durchblättern der vier Artikel zu erleichtern, sind hier die direkten Links:
- Transfer Learning mit ResNet
- Deployment von TensorFlow-Modellen in Docker mit TensorFlow Serving
- Erklärbarkeit von Deep Learning Modellen mit Grad-CAM
Im ersten Artikel dieser Serie über die Klassifizierung von Automodellen haben wir ein Modell gebaut, das Transfer Learning verwendet, um das Automodell durch ein Bild eines Autos zu klassifizieren. Im zweiten Beitrag haben wir gezeigt, wie TensorFlow Serving verwendet werden kann, um ein TensorFlow-Modell am Beispiel des Automodell-Classifiers einzusetzen. Diesen dritten Beitrag widmen wir einem weiteren wesentlichen Aspekt von Deep Learning und maschinellem Lernen im Allgemeinen: der Erklärbarkeit von Modellvorhersagen (englisch: Explainable AI).
Wir beginnen mit einer kurzen allgemeinen Einführung in das Thema Erklärbarkeit beim maschinellen Lernen. Als nächstes werden wir kurz auf verbreitete Methoden eingehen, die zur Erklärung und Interpretation von CNN-Vorhersagen verwendet werden können. Anschließend werden wir Grad-CAM, eine gradientenbasierte Methode, ausführlich erklären, indem wir Schritt für Schritt eine Implementierung des Verfahrens durchgehen. Zum Schluss zeigen wir Ergebnisse, die wir mit unserer Grad-CAM-Implementierung für den Auto-Modell-Classifier berechnet haben.
Eine kurze Einführung in die Erklärbarkeit von Machine Learning Modellen
In den letzten Jahren war die Erklärbarkeit ein immer wiederkehrendes Thema – aber dennoch ein Nischenthema – im Machine Learning. In den letzten vier Jahren jedoch hat das Interesse an diesem Thema stark zugenommen. Stark dazu beigetragen hat unter anderem die steigende Anzahl von Machine Learning-Modellen in der Produktion. Einerseits führt dies zu einer wachsenden Zahl von Endnutzern, die verstehen müssen, wie die Modelle Entscheidungen treffen. Andererseits müssen immer mehr Entwickler*innen von Machine Learning verstehen, warum (oder warum nicht) ein Modell auf eine bestimmte Weise funktioniert.
Dieser steigende Bedarf an Erklärbarkeit führte in den letzten Jahren zu einigen sowohl methodisch als auch technisch bemerkenswerten Innovationen:
- LIME (Local Interpretable Model-agnostic Explanations) – eine modellagnostische Erklärungstechnik, die ein interpretierbares lokales Surrogate-Modell verwendet
- SHAP (SHapley Additive exPlanations) – eine von der Spieltheorie inspirierte Methode
- CAM (Class Activation Mapping) – eine Methode zur Kennzeichnung diskriminierender Bildregionen, die von einem CNN zur Identifizierung einer bestimmten Kategorie verwendet werden (z. B. bei Klassifizierungsaufgaben)
Methoden zur Erklärung von CNN-Outputs für Bilddaten
Deep Neural Networks (DNNs) und insbesondere komplexe Architekturen wie CNNs galten lange Zeit als reine Blackbox-Modelle. Wie oben beschrieben änderte sich dies in den letzten Jahren, und inzwischen gibt es verschiedene Methoden, um CNN-Outputs zu erklären. Zum Beispiel implementiert die hervorragende Bibliothek tf-explain eine breite Palette nützlicher Methoden für TensorFlow 2.x. Wir werden nun kurz auf die Ideen der verschiedenen Ansätze eingehen, bevor wir uns Grad-CAM zuwenden:
Activations Visualization
Activations Visualization ist die einfachste Visualisierungstechnik. Hierbei wird die Ausgabe einer bestimmten Layer innerhalb des Netzwerks während des Vorwärtsdurchlaufs ausgegeben. Diese kann hilfreich sein, um ein Gefühl für die extrahierten Features zu bekommen, da die meisten Activations während des Trainings gegen Null tendieren (bei Verwendung der ReLu-Activation). Ein Beispiel für die Ausgabe der ersten Faltungsschicht des Auto-Modell-Classifiers ist unten dargestellt:

Vanilla Gradients
Man kann die Vanilla-Gradients der Ausgabe der vorhergesagten Klassen für das Eingangsbild verwenden, um die Bedeutung der Eingangspixel abzuleiten.
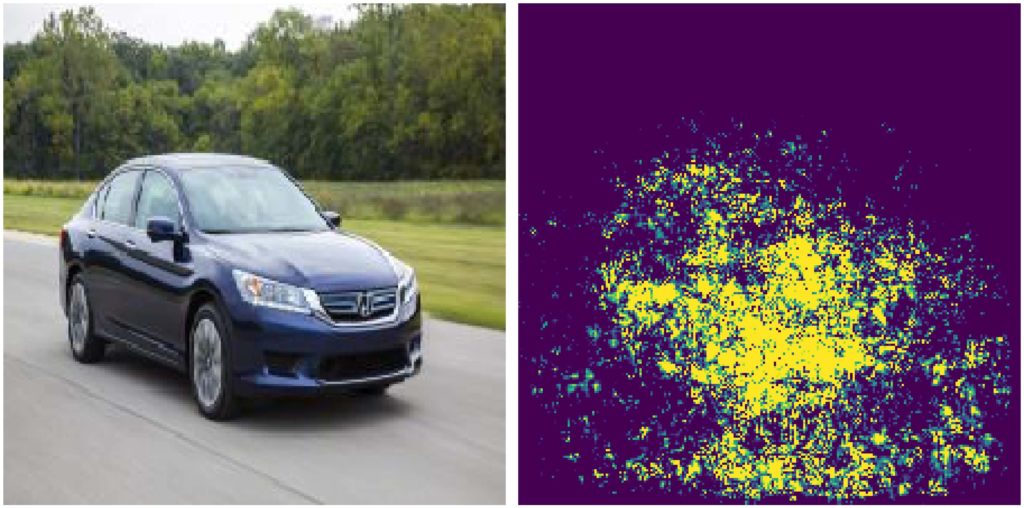
Wir sehen hier, dass der hervorgehobene Bereich hauptsächlich auf das Auto fokussiert ist. Im Vergleich zu den unten besprochenen Methoden ist der diskriminierende Bereich viel weniger eingegrenzt.
Occlusion Sensitivity
Bei diesem Ansatz wird die Signifikanz bestimmter Teile des Eingangsbildes berechnet, indem die Vorhersage des Modells für verschiedene ausgeblendete Teile des Eingangsbildes bewertet wird. Teile des Bildes werden iterativ ausgeblendet, indem sie durch graue Pixel ersetzt werden. Je schwächer die Vorhersage wird, wenn ein Teil des Bildes ausgeblendet ist, desto wichtiger ist dieser Teil für die endgültige Vorhersage. Basierend auf der Unterscheidungskraft der Bildregionen kann eine Heatmap erstellt und dargestellt werden. Die Anwendung der Occlusion Sensitivity für unseren Auto-Modell-Classifier hat keine aussagekräftigen Ergebnisse geliefert. Daher zeigen wir das Beispielbild von tf-explain, welches das Ergebnis der Anwendung des Verfahrens der Occlusion Sensitivity für ein Katzenbild zeigt.

CNN Fixations
Ein weiterer interessanter Ansatz namens CNN Fixations wurde in diesem Paper vorgestellt . Die Idee dabei ist, zurück zu verfolgen, welche Neuronen in jeder Schicht signifikant waren, indem man die Activations aus der Vorwärtsrechnung und die Netzwerkgewichte betrachtet. Die Neuronen mit großem Einfluss werden als Fixations bezeichnet. Dieser Ansatz erlaubt es also, die wesentlichen Regionen für das Ergebnis zu finden, ohne wiederholte Modellvorhersagen berechnen zu müssen (wie dies z.B. für die oben erklärte Occlusion Sensitivity der Fall ist).
Das Verfahren kann wie folgt beschrieben werden: Der Knoten, der der Klasse entspricht, wird als Fixation in der Ausgabeschicht gewählt. Dann werden die Fixations für die vorherige Schicht bestimmt, indem berechnet wird, welche der Knoten den größten Einfluss auf die Fixations der nächsthöheren Ebene haben, die im letzten Schritt bestimmt wurden. Die Knotengewichtung wird durch Multiplikation von Activations und Netzwerk-Gewichten errechnet. Wenn ihr an den Details des Verfahrens interessiert seid, schaut euch das Paper oder das entsprechende Github Repo an. Dieses Backtracking wird so lange durchgeführt, bis das Eingabebild erreicht ist, was eine Menge von Pixeln mit beträchtlicher Unterscheidungskraft ergibt. Ein Beispiel aus dem Paper ist unten dargestellt.

CAM
Das in diesem Paper vorgestellte Class Activation Mapping (CAM) ist ein Verfahren, um die diskriminante(n) Region(en) für eine CNN-Vorhersage durch die Berechnung von sogenannten Class Activation Maps zu finden. Ein wesentlicher Nachteil dieses Verfahrens ist, dass das Netzwerk als letzten Schritt vor der Vorhersageschicht ein Global Average Pooling (GAP) verwenden muss. Es ist daher nicht möglich, diesen Ansatz für allgemeine CNN-Architekturen anzuwenden. Ein Beispiel ist in der folgenden Abbildung dargestellt (entnommen aus dem CAM paper):
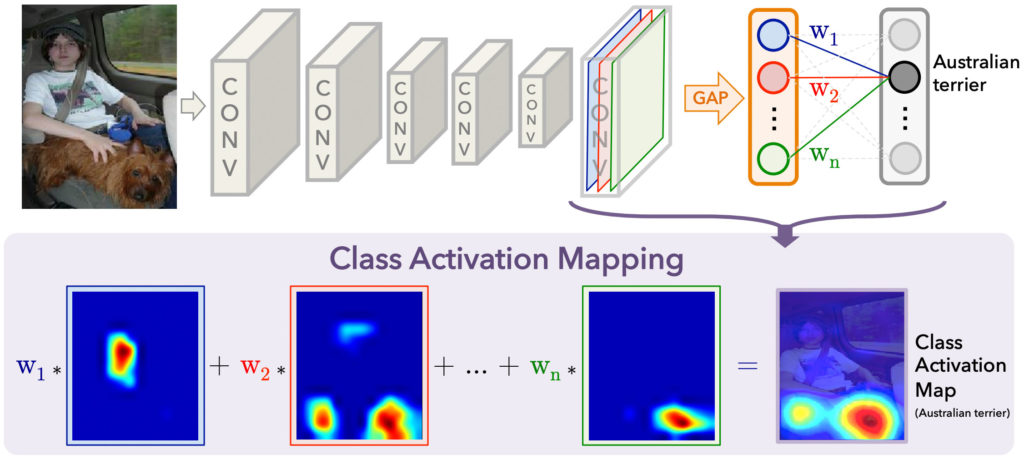
Die Class Activation Map weist jeder Position (x, y) in der letzten Faltungsschicht eine Bedeutung zu, indem sie die Linearkombination der Activations – gewichtet mit den entsprechenden Ausgangsgewichten für die beobachtete Klasse (im obigen Beispiel „Australian Terrier“) – berechnet. Die resultierende Class Activation Mapping wird dann auf die Größe des Eingabebildes hochgerechnet. Dies wird durch die oben dargestellte Heatmap veranschaulicht. Aufgrund der Architektur von CNNs ist die Aktivierung, z. B. oben links für eine beliebige Schicht, direkt mit der oberen linken Seite des Eingabebildes verbunden. Deshalb können wir nur aus der Betrachtung der letzten CNN-Schicht schließen, welche Eingabebereiche wichtig sind.
Bei dem Grad-CAM-Verfahren, das wir unten im Detail besprechen werden, handelt es sich um eine Verallgemeinerung von CAM. Grad-CAM kann auf Netzwerke mit allgemeinen CNN-Architekturen angewendet werden, die mehrere fully connected Layers am Ausgang enthalten.
Grad-CAM
Grad-CAM erweitert die Anwendbarkeit des CAM-Verfahrens durch das Einbeziehen von Gradienteninformationen. Konkret bestimmt der Gradient der Loss-Funktion in Bezug auf die letzte Faltungsschicht das Gewicht für jede der entsprechenden Feature Maps. Wie beim obigen CAM-Verfahren bestehen die weiteren Schritte in der Berechnung der gewichteten Summe der Aktivierungen und dem anschließenden Upsampling des Ergebnisses auf die Bildgröße, um das Originalbild mit der erhaltenen Heatmap darzustellen. Wir werden nun den Code, der zur Ausführung von Grad-CAM verwendet werden kann, zeigen und diskutieren. Der vollständige Code ist hier auf GitHub verfügbar.
import pickle
import tensorflow as tf
import cv2
from car_classifier.modeling import TransferModel
INPUT_SHAPE = (224, 224, 3)
# Load list of targets
file = open('.../classes.pickle', 'rb')
classes = pickle.load(file)
# Load model
model = TransferModel('ResNet', INPUT_SHAPE, classes=classes)
model.load('...')
# Gradient model, takes the original input and outputs tuple with:
# - output of conv layer (in this case: conv5_block3_3_conv)
# - output of head layer (original output)
grad_model = tf.keras.models.Model([model.model.inputs],
[model.model.get_layer('conv5_block3_3_conv').output,
model.model.output])
# Run model and record outputs, loss, and gradients
with tf.GradientTape() as tape:
conv_outputs, predictions = grad_model(img)
loss = predictions[:, label_idx]
# Output of conv layer
output = conv_outputs[0]
# Gradients of loss w.r.t. conv layer
grads = tape.gradient(loss, conv_outputs)[0]
# Guided Backprop (elimination of negative values)
gate_f = tf.cast(output > 0, 'float32')
gate_r = tf.cast(grads > 0, 'float32')
guided_grads = gate_f * gate_r * grads
# Average weight of filters
weights = tf.reduce_mean(guided_grads, axis=(0, 1))
# Class activation map (cam)
# Multiply output values of conv filters (feature maps) with gradient weights
cam = np.zeros(output.shape[0: 2], dtype=np.float32)
for i, w in enumerate(weights):
cam += w * output[:, :, i]
# Or more elegant:
# cam = tf.reduce_sum(output * weights, axis=2)
# Rescale to org image size and min-max scale
cam = cv2.resize(cam.numpy(), (224, 224))
cam = np.maximum(cam, 0)
heatmap = (cam - cam.min()) / (cam.max() - cam.min())Detailbetrachtung des Codes
- Der erste Schritt besteht darin, eine Instanz des Modells zu laden.
- Dann erstellen wir eine neue
keras.Model-Instanz, die zwei Ausgaben hat: Die Aktivierungen der letzten CNN-Schicht ('conv5_block3_3_conv') und die ursprüngliche Modellausgabe. - Als nächstes führen wir eine Vorwärtsrechnung für unser neues
grad_modelaus, wobei wir als Eingabe ein Bild (img) der Form (1, 224, 224, 3) verwenden, das mit der Methoderesnetv2.preprocess_inputvorverarbeitet wurde. Zur Aufzeichnung der Gradienten wirdtf.GradientTapeangelegt und angewendet (die Gradienten werden hierbei imtapeObjekt gespeichert). Weiterhin werden die Ausgaben der Faltungsschicht (conv_outputs) und des heads (predictions) gespeichert. Schließlich können wirlabel_idxverwenden, um den Verlust zu erhalten, der dem Label entspricht, für das wir die diskriminierenden Regionen finden wollen. - Mit Hilfe der
gradient-Methode kann man die gewünschten Gradienten austapeextrahieren. In diesem Fall benötigen wir den Gradienten des Verlustes in Bezug auf die Ausgabe der Faltungsschicht. - In einem weiteren Schritt wird eine guided Backprop angewendet. Dabei werden nur Werte für die Gradienten behalten, bei denen sowohl die Aktivierungen als auch die Gradienten positiv sind. Dies bedeutet im Wesentlichen, dass die Aufmerksamkeit auf die Aktivierungen beschränkt wird, die positiv zu der gewünschten Ausgabevorhersage beitragen.
- Die
weightswerden durch Mittelung der erhaltenen geführten Gradienten für jeden Filter berechnet. - Die Class Activation Map
camwird dann als gewichteter Durchschnitt der Aktivierungen der Feature Map (output) berechnet. Die Methode mit der obigen for-Schleife hilft zu verstehen, was die Funktion im Detail tut. Eine weniger einfache, aber effizientere Art, die CAM-Berechnung zu implementieren, ist die Verwendung vontf.reduce_meanund wird in der kommentierten Zeile unterhalb der Schleifenimplementierung gezeigt. - Schließlich wird das Resampling (Größenänderung) mit der
resize-Methode von OpenCV2 durchgeführt, und die Heatmap wird so skaliert, dass sie Werte in [0, 1] enthält, um sie zu plotten.
Eine Version von Grad-CAM ist auch in tf-explain implementiert.
Beispiele für den Auto-Modell-Classifier
Wir verwenden nun die Grad-CAM-Implementierung, um die Vorhersagen des TransferModel für die Klassifizierung von Automodellen zu interpretieren und zu erklären. Wir beginnen mit der Betrachtung von Fahrzeugbildern, die von vorne aufgenommen wurden.

Die roten Regionen markieren die wichtigsten diskriminierenden Regionen, die blauen Regionen die unwichtigsten. Wir können sehen, dass sich das CNN bei Bildern von vorne auf den Kühlergrill des Autos und den Bereich des Logos konzentriert. Ist das Auto leicht gekippt, verschiebt sich der Fokus mehr auf den Rand des Fahrzeugs. Dies ist auch bei leicht gekippten Bildern von der Rückseite des Fahrzeugs der Fall, wie im mittleren Bild unten gezeigt.

Bei Bildern von der Rückseite des Autos liegt der wichtigste Unterscheidungsbereich in der Nähe des Nummernschilds. Wie bereits erwähnt, hat bei Autos, die aus einem Winkel betrachtet werden, die nächstgelegene Ecke die höchste Trennschärfe. Ein sehr interessantes Beispiel ist die Mercedes-Benz C-Klasse auf der rechten Seite, bei der sich das Modell nicht nur auf die Rückleuchten konzentriert, sondern auch die höchste Trennschärfe auf den Modellschriftzug legt.

Wenn wir Bilder von der Seite betrachten, stellen wir fest, dass die diskriminierende Region auf die untere Hälfte der Autos beschränkt ist. Auch hier bestimmt der Winkel, aus dem das Fahrzeugbild aufgenommen wurde, die Verschiebung der Region in Richtung der vorderen oder hinteren Ecke.
Im Allgemeinen ist die wichtigste Tatsache, dass die diskriminierenden Bereiche immer auf Teile der Autos beschränkt sind. Es gibt keine Bilder, bei denen der Hintergrund eine hohe Unterscheidungskraft hat. Die Betrachtung der Heatmaps und der zugehörigen diskriminierenden Regionen kann als Sanity-Check für CNN-Modelle verwendet werden.
Fazit
Wir haben mehrere Ansätze zur Erklärung von CNN-Klassifikatorausgaben diskutiert. Wir haben Grad-CAM im Detail vorgestellt, indem wir den Code untersucht und uns Beispiele für den Auto-Modell-Classifier angeschaut haben. Am auffälligsten ist, dass die durch das Grad-CAM-Verfahren hervorgehobenen diskriminierenden Regionen immer auf das Auto fokussiert sind und nie auf die Hintergründe der Bilder. Das Ergebnis zeigt, dass das Modell so funktioniert, wie wir es erwarten und spezifische Teile des Autos zur Unterscheidung zwischen verschiedenen Modellen verwendet werden.
Im vierten und letzten Teil dieser Blog-Serie werden wir zeigen, wie der Car Classifier mit Dash in eine Web-Anwendung eingebaut werden kann. Bis bald!