
In den letzten drei Beiträgen dieser Serie haben wir erklärt, wie man ein Deep-Learning-Modell trainiert, um ein Auto anhand seiner Marke und seines Modells zu klassifizieren, basierend auf einem Bild des Autos (Teil 1), wie man dieses Modell aus einem Docker-Container mit TensorFlow Serving einsetzt (Teil 2) und wie man die Vorhersagen des Modells erklärt (Teil 3). In diesem Beitrag lernt ihr, wie ihr mit Dash eine ansprechende Oberfläche um unseren Auto-Modell-Classifier herum bauen könnt.
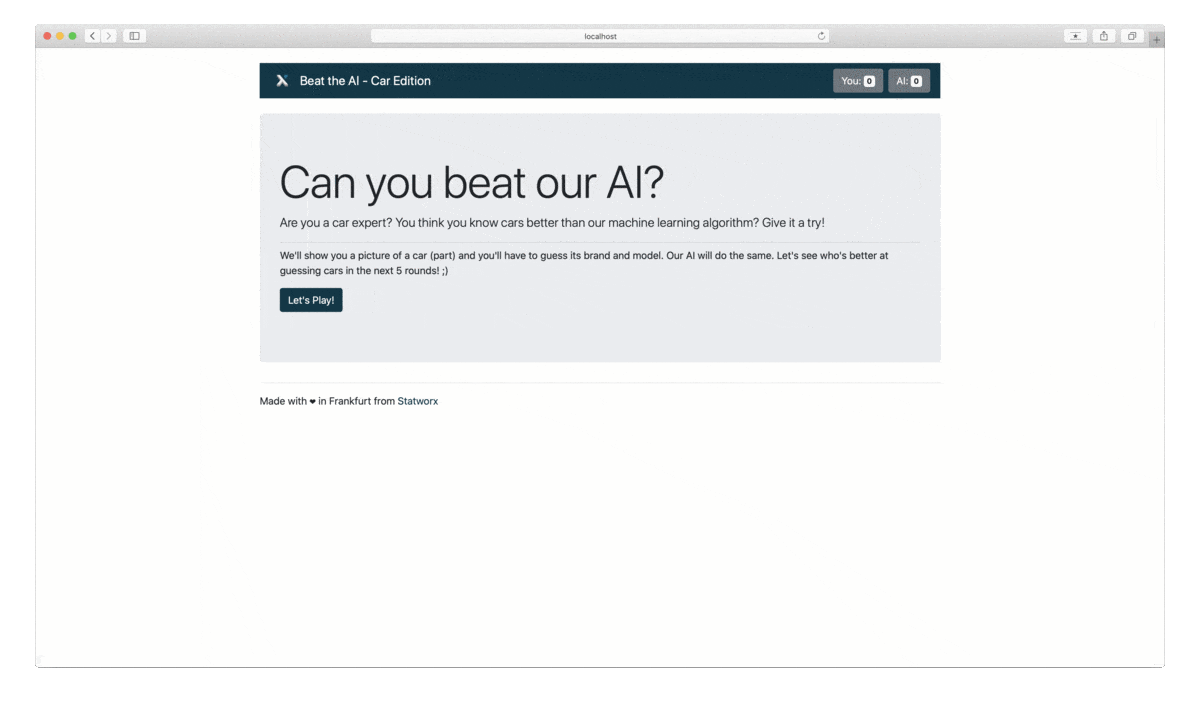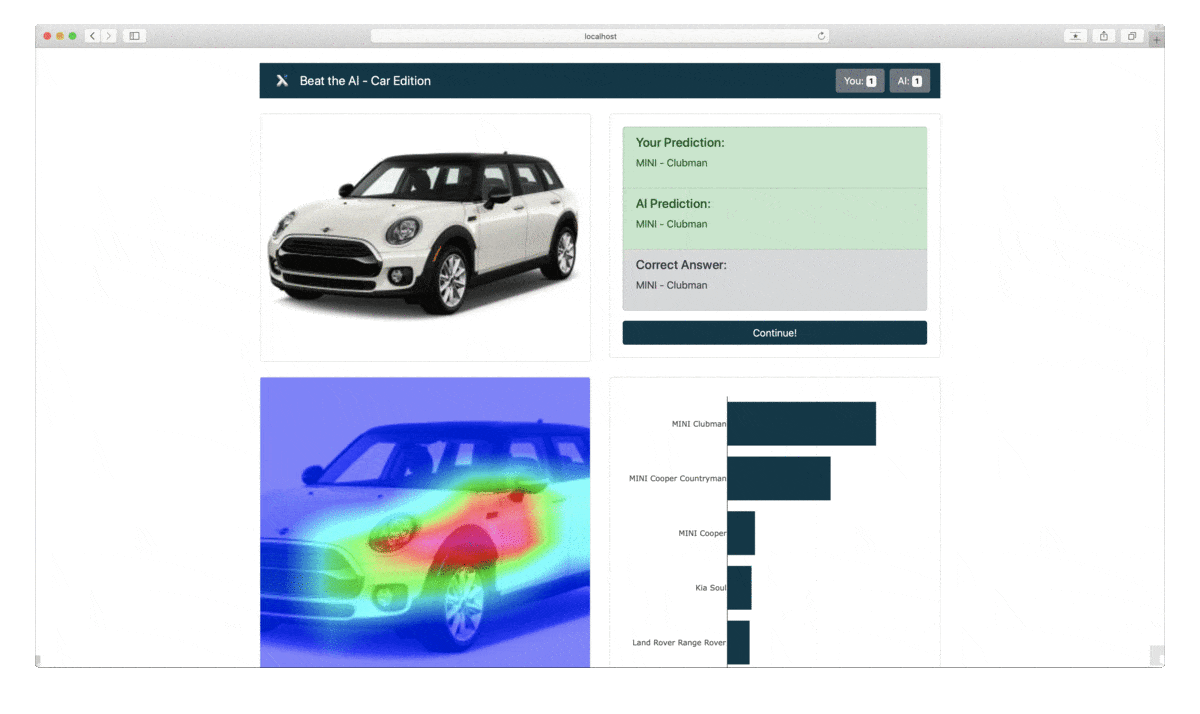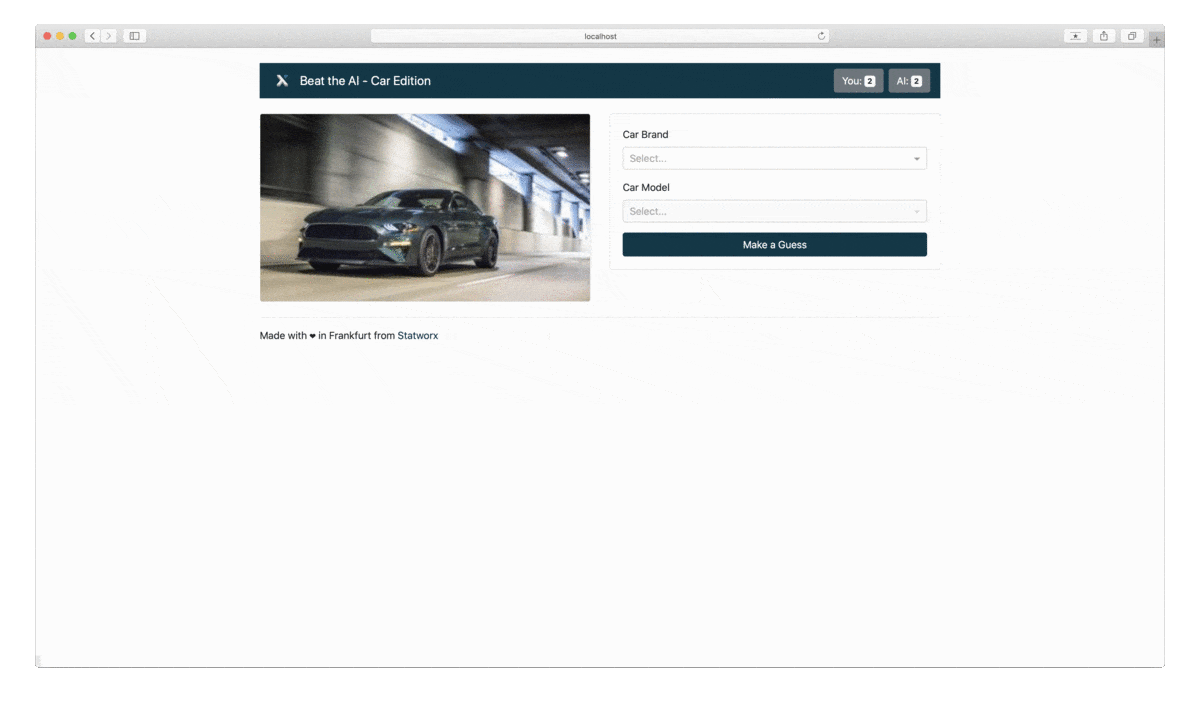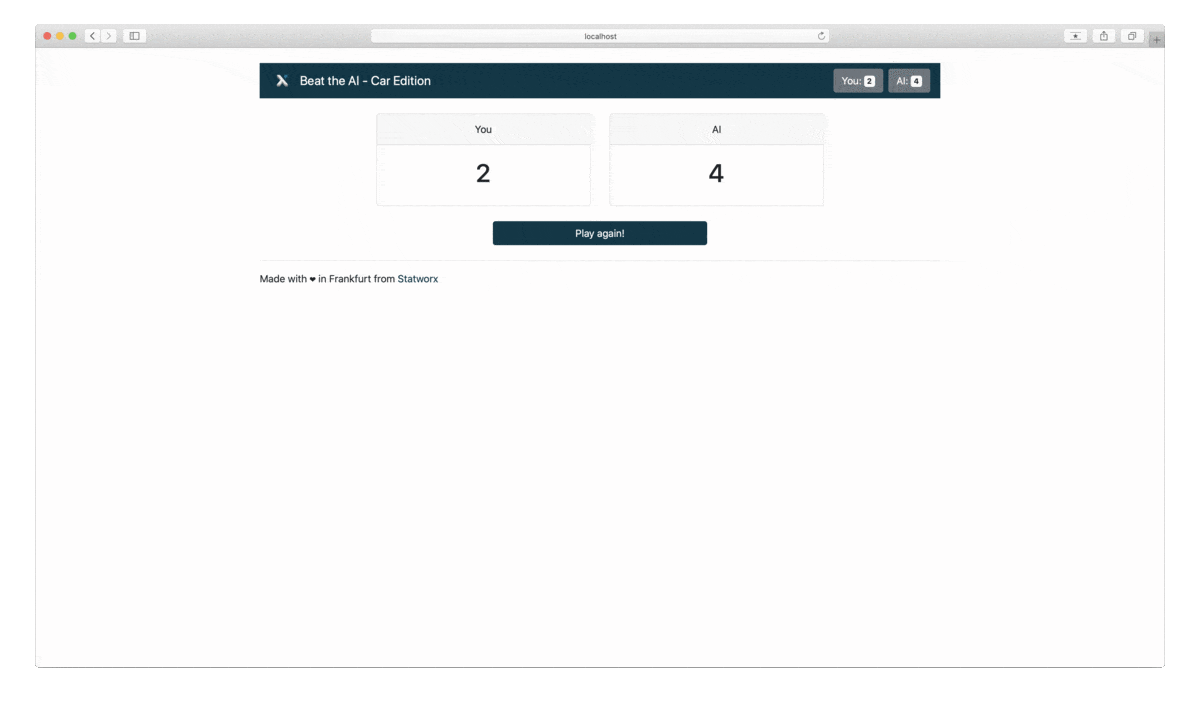
Wir werden unsere Machine Learning-Vorhersagen und -Erklärungen in ein lustiges und spannendes Spiel verwandeln. Wir präsentieren den Anwender*innen zunächst ein Bild von einem Auto. Die Anwender*innen müssen erraten, um welches Automodell und welche Marke es sich handelt – das Machine-Learning-Modell wird das Gleiche tun. Nach 5 Runden wird ausgewertet, wer die Automarke besser vorhersagen kann: die Anwender*innen oder das Modell.
Das Tech Stack: Was ist Dash?
Dash ist, wie der Name schon sagt, eine Software zum Erstellen von Dashboards in Python. In Python, fragen ihr euch? Ja – ihr müsst nichts direkt in HTML oder Javascript programmieren (obwohl ein grundlegendes Verständnis von HTML sicherlich hilfreich ist). Eine hervorragende Einführung findet ihr in dem ausgezeichneten Blogpost meines Kollegen Alexander Blaufuss.
Um das Layout und Styling unserer Web-App zu vereinfachen, verwenden wir auch Dash Bootstrap Components. Sie folgen weitgehend der gleichen Syntax wie die standardmäßigen Dash-Komponenten und fügen sich nahtlos in das Dash-Erlebnis ein.
Denkt daran, dass Dash für Dashboards gemacht ist – das heißt, es ist für Interaktivität gemacht, aber nicht unbedingt für Apps mit mehreren Seiten. Mit dieser Info im Hinterkopf werden wir in diesem Artikel Dash an seine Grenzen bringen.
Organisation ist alles – Die Projektstruktur
Um alles nachbauen zu können, solltet ihr euch unser GitHub-Repository ansehen, auf dem alle Dateien verfügbar sind. Außerdem könnt ihr alle Docker-Container mit einem Klick starten und loslegen.
Die Dateien für das Frontend selbst sind logischerweise in mehrere Teile aufgeteilt. Es ist zwar möglich, alles in eine Datei zu schreiben, aber man verliert leicht den Überblick und daher später schwer zu pflegen. Die Dateien folgen der Struktur des Artikels:
- In einer Datei wird das gesamte Layout definiert. Jeder Button, jede Überschrift, jeder Text wird dort gesetzt.
- In einer anderen Datei wird die gesamte Dashboard-Logik (sogenannte Callbacks) definiert. Dort wird z. B. definiert, was passieren soll, nachdem die Benutzer*innen auf eine Schaltfläche geklickt hat.
- Wir brauchen ein Modul, das 5 zufällige Bilder auswählt und die Kommunikation mit der Prediction and Explainable API übernimmt.
- Abschließend gibt es noch zwei Dateien, die die Haupteinstiegspunkte (Entry Points) zum Starten der App sind.
Erstellen der Einstiegspunkte – Das große Ganze
Beginnen wir mit dem letzten Teil, dem Haupteinstiegspunkt für unser Dashboard. Wenn ihr wisst, wie man eine Web-App schreibt, wie z. B. eine Dash-Anwendung oder auch eine Flask-App, ist euch das Konzept einer App-Instanz vertraut. Vereinfacht ausgedrückt, ist die App-Instanz alles. Sie enthält die Konfiguration für die App und schließlich das gesamte Layout. In unserem Fall initialisieren wir die App-Instanz direkt mit den Bootstrap-CSS-Dateien, um das Styling überschaubarer zu machen. Im gleichen Schritt exponieren wir die zugrundeliegende Flask-App. Die Flask-App wird verwendet, um das Frontend in einer produktiven Umgebung zu bedienen.
# app.py
import dash
import dash_bootstrap_components as dbc
# ...
# Initialize Dash App with Bootstrap CSS
app = dash.Dash(
__name__,
external_stylesheets=[dbc.themes.BOOTSTRAP],
)
# Underlying Flask App for productive deployment
server = app.serverDiese Einstellung wird für jede Dash-Anwendung verwendet. Im Gegensatz zu einem Dashboard benötigen wir eine Möglichkeit, mit mehreren URL-Pfaden umzugehen. Genauer gesagt, wenn die Benutzer*innen /attempt eingibt, wollen wir ihm erlauben, ein Auto zu erraten; wenn er /result eingibt, wollen wir das Ergebnis seiner Vorhersage anzeigen.
Zunächst definieren wir das Layout. Bemerkenswert ist, dass es zunächst grundsätzlich leer ist. Ihr findet dort eine spezielle Dash Core Component. Diese Komponente dient dazu, die aktuelle URL dort zu speichern und funktioniert in beide Richtungen. Mit einem Callback können wir den Inhalt auslesen, herausfinden, welche Seite die Benutzer*innen aufrufen möchte, und das Layout entsprechend rendern. Wir können auch den Inhalt dieser Komponente manipulieren, was praktisch eine Weiterleitung auf eine andere Seite ist. Das leere div wird als Platzhalter für das eigentliche Layout verwendet.
# launch_dashboard.py
import dash_bootstrap_components as dbc
import dash_core_components as dcc
import dash_html_components as html
from app import app
# ...
# Set Layout
app.layout = dbc.Container(
[dcc.Location(id='url', refresh=False),
html.Div(id='main-page')])Die Magie geschieht in der folgenden Funktion. Die Funktion selbst hat ein Argument, den aktuellen Pfad als String. Basierend auf dieser Eingabe gibt sie das richtige Layout zurück. Wenn die Benutzer*innen zum Beispiel zum ersten Mal auf die Seite zugreift, ist der Pfad / und das Layout daher start_page. Auf das Layout werden wir gleich noch im Detail eingehen; beachtet zunächst, dass wir an jedes Layout immer eine Instanz der App selbst und den aktuellen Spielzustand übergeben.
Damit diese Funktion tatsächlich funktioniert, müssen wir sie mit dem Callback Decorator schmücken. Jeder Callback benötigt mindestens eine Eingabe und mindestens eine Ausgabe. Eine Änderung des Inputs löst die Funktion aus. Der Eingang ist einfach die oben definierte Ortskomponente mit der Eigenschaft Pathname. Einfach ausgedrückt, aus welchem Grund auch immer sich der Pfad ändert, wird diese Funktion ausgelöst. Die Ausgabe ist das neue Layout, gerendert in dem zuvor zunächst leeren div.
# launch_dashboard.py
import dash_html_components as html
from dash.dependencies import Input, Output
from dash.exceptions import PreventUpdate
# ...
@app.callback(Output('main-page', 'children'), [Input('url', 'pathname')])
def display_page(pathname: str) -> html:
"""Function to define the routing. Mapping routes to layout.
Arguments:
pathname {str} -- pathname from url/browser
Raises:
PreventUpdate: Unknown/Invalid route, do nothing
Returns:
html -- layout
"""
if pathname == '/attempt':
return main_layout(app, game_data, attempt(app, game_data))
elif pathname == '/result':
return main_layout(app, game_data, result(app, game_data))
elif pathname == '/finish':
return main_layout(app, game_data, finish_page(app, game_data))
elif pathname == '/':
return main_layout(app, game_data, start_page(app, game_data))
else:
raise PreventUpdateLayout – Schön & Shiny
Beginnen wir mit dem Layout unserer App – wie soll sie aussehen? Wir haben uns für ein relativ einfaches Aussehen entschieden. Wie ihr in der Animation oben sehen könnt, besteht die App aus drei Teilen: dem Header, dem Hauptcontent und dem Footer. Der Header und der Footer sind auf jeder Seite gleich, nur der Hauptinhalt ändert sich. Einige Layouts aus dem Hauptcontent sind in der Regel eher schwierig zu erstellen. Zum Beispiel besteht die Ergebnisseite aus vier Boxen. Die Boxen sollten immer die gleiche Breite von genau der Hälfte der verwendeten Bildschirmgröße haben, können aber je nach Bildgröße in der Höhe variieren. Sie dürfen sich aber nicht überlappen, usw. Von den Cross-Browser-Inkompatibilitäten ganz zu schweigen.
Ihr könnt euch sicher vorstellen, dass wir leicht mehrere Arbeitstage damit hätten verbringen können, das optimale Layout zu finden. Glücklicherweise können wir uns wieder einmal auf Bootstrap und das Bootstrap Grid System verlassen. Die Hauptidee ist, dass ihr so viele Zeilen wie ihr wollt (zwei, im Fall der Ergebnisseite) und bis zu 12 Spalten pro Zeile (ebenfalls zwei für die Ergebnisseite) erstellen könnt. Die Begrenzung auf 12 Spalten basiert auf der Tatsache, dass Bootstrap die Seite intern in 12 gleich große Spalten aufteilt. Ihr müsst nur mit einer einfachen CSS-Klasse definieren, wie groß die Spalte sein soll. Und was noch viel cooler ist: Ihr könnt mehrere Layouts einstellen, je nach Bildschirmgröße. Es wäre also nicht schwierig, unsere App vollständig responsive zu machen.
Um auf den Dash-Teil zurückzukommen, bauen wir eine Funktion für jedes unabhängige Layout-Teil. Den Header, den Footer und eine für jede URL, die die Benutzer*innen aufrufen könnte. Für den Header sieht das so aus:
# layout.py
import dash_bootstrap_components as dbc
import dash_html_components as html
# ...
def get_header(app: dash.Dash, data: GameData) -> html:
"""Layout for the header
Arguments:
app {dash.Dash} -- dash app instance
data {GameData} -- game data
Returns:
html -- html layout
"""
logo = app.get_asset_url("logo.png")
score_user, score_ai = count_score(data)
header = dbc.Container(
dbc.Navbar(
[
html.A(
# Use row and col to control vertical alignment of logo / brand
dbc.Row(
[
dbc.Col(html.Img(src=logo, height="40px")),
dbc.Col(
dbc.NavbarBrand("Beat the AI - Car Edition",
className="ml-2")),
],
align="center",
no_gutters=True,
),
href="/",
),
# You find the score counter here; Left out for clarity
],
color=COLOR_STATWORX,
dark=True,
),
className='mb-4 mt-4 navbar-custom')
return headerAuch hier seht ihr, dass wir die App-Instanz und den globalen Spieldatenstatus an die Layout-Funktion übergeben. In einer perfekten Welt müssten wir mit keiner dieser Variablen im Layout herumspielen. Leider ist das eine der Einschränkungen von Dash. Eine perfekte Trennung von Layout und Logik ist nicht möglich. Die App-Instanz wird benötigt, um dem Webserver mitzuteilen, dass er das STATWORX-Logo als statische Datei ausliefern soll.
Natürlich könnte man das Logo von einem externen Server ausliefern, das machen wir ja auch für die Fahrzeugbilder, aber nur für ein Logo wäre das ein bisschen zu viel des Guten. Für die Spieldaten müssen wir den aktuellen Punktestand des Benutzers und der KI berechnen. Alles andere ist entweder normales HTML oder Bootstrap-Komponenten. Wer sich damit nicht auskennt, den kann ich noch einmal auf den Blogpost von meinem Kollegen Alexander verweisen oder auf eines der zahlreichen HTML-Tutorials im Internet.
Callbacks – Reaktivität einführen
Wie bereits erwähnt, sind Callbacks das Mittel der Wahl, um das Layout interaktiv zu gestalten. In unserem Fall bestehen sie hauptsächlich aus der Handhabung des Dropdowns sowie der Button Klicks. Während die Dropdowns relativ einfach zu programmieren waren, bereiteten uns die Buttons einige Kopfschmerzen.
Einem guten Programmierstandard folgend, sollte jede Funktion genau eine Verantwortung haben. Deshalb haben wir für jeden Button einen Callback eingerichtet. Nach einer Art Eingabevalidierung und Datenmanipulation ist das Ziel, die Benutzer*innen auf die folgende Seite umzuleiten. Während die Eingabe für den Callback das Button-Klick-Ereignis und möglicherweise einige andere Eingabeformulare ist, ist die Ausgabe immer die Location-Komponente, um die Benutzer*innen weiterzuleiten. Leider erlaubt Dash nicht, mehr als einen Callback zum gleichen Ausgang zu haben. Daher waren wir gezwungen, die Logik für jede Schaltfläche in eine Funktion zu quetschen.
Da wir die Benutzereingaben auf der Versuchsseite validieren mussten, haben wir die aktuellen Werte aus dem Dropdown an den Callback übergeben. Während das für die Versuchsseite einwandfrei funktionierte, funktionierte die Schaltfläche auf der Ergebnisseite nicht mehr, da keine Dropdowns zur Übergabe an die Funktion verfügbar waren. Wir mussten ein verstecktes, nicht funktionierendes Dummy-Dropdown in die Ergebnisseite einfügen, damit die Schaltfläche wieder funktionierte. Das ist zwar eine Lösung und funktioniert in unserem Fall einwandfrei, aber für eine umfangreichere Anwendung könnte es zu kompliziert sein.
Data Download – Wir brauchen Autos
Jetzt haben wir eine schöne App mit funktionierenden Buttons und so weiter, aber die Daten fehlen noch. Wir müssen Bilder, Vorhersagen und Erklärungen in die App einbinden.
Die High-Level-Idee ist, dass jede Komponente für sich alleine läuft – zum Beispiel in einem eigenen Docker-Container mit eigenem Webserver. Alles ist nur lose über APIs miteinander gekoppelt. Der Ablauf ist der folgende:
- Schritt 1: Abfrage einer Liste aller verfügbaren Auto-Images. Wähle zufällig 5 aus und fordere diese Bilder vom Webserver an.
- Schritt 2: Sende für alle 5 Bilder eine Anfrage an die Vorhersage-API und parse das Ergebnis aus der API.
- Schritt 3: Sende wiederum für alle 5 Bilder eine Anfrage an die Explainable-API und speichere das zurückgegebene Bild.
Kombiniert nun jede Ausgabe in der GameData-Klasse.
Aktuell speichern wir die GameData-Instanz als globale Variable. Das erlaubt uns, von überall darauf zuzugreifen. Das ist zwar theoretisch eine schlaue Idee, funktioniert aber nicht, wenn mehr als eine Benutzerin versucht, auf die App zuzugreifen. Derdie zweite Benutzerin wird den Spielstatus vom ersten sehen. Da wir planen, das Spiel auf Messen auf einer großen Leinwand zu zeigen, ist das für den Moment in Ordnung. In Zukunft könnten wir das Dashboard mit Shiny Proxy starten, so dass jeder Benutzer seinen eigenen Docker-Container mit einem isolierten globalen Status erhält.
Data Storage – Die Autos parken
Die native Dash-Methode besteht darin, benutzerspezifische Zustände in einer Store-Komponente zu speichern. Das ist im Grunde dasselbe wie die oben erläuterte Location-Komponente. Die Daten werden im Webbrowser gespeichert, ein Callback wird ausgelöst, und die Daten werden an den Server gesendet. Der erste Nachteil ist, dass wir bei jedem Seitenwechsel die gesamte Spieldateninstanz vom Browser zum Server übertragen müssen. Das kann ziemlich viel Traffic verursachen und verlangsamt das gesamte App-Erlebnis.
Außerdem müssen wir, wenn wir den Spielzustand ändern wollen, dies über einen Callback tun. Die Beschränkung auf einen Callback pro Ausgabe gilt auch hier. Unserer Meinung nach macht es nicht allzu viel aus, wenn Sie ein klassisches Dashboard haben; dafür ist Dash gedacht. Die Verantwortlichkeiten sind getrennt. In unserem Fall wird der Spielstatus von mehreren Komponenten aus aufgerufen und verändert. Wir haben Dash definitiv an seine Grenzen gebracht.
Eine weitere Sache, die ihr im Auge behalten solltet, wenn ihr euch entscheidet, eure eigene Microservice-App zu bauen, ist die Performance der API-Aufrufe. Anfänglich haben wir die berühmte requests Bibliothek verwendet. Während wir große Fans dieser Bibliothek sind, sind alle Anfragen blockierend. Daher wird die zweite Anfrage ausgeführt, sobald die erste abgeschlossen ist. Da unsere Anfragen relativ langsam sind (bedenkt, dass im Hintergrund vollwertige neuronale Netze laufen), verbringt die App viel Zeit mit Warten. Wir haben asynchrone Aufrufe mit Hilfe der Bibliothek aiohttp implementiert. Alle Anfragen werden nun parallel verschickt. Die App verbringt weniger Zeit mit Warten, und der Benutzer ist früher bereit zum Spielen.
Fazit und Hinweise
Auch wenn die Web-App einwandfrei funktioniert, gibt es ein paar Dinge, die zu beachten sind. Wir haben Dash verwendet, wohl wissend, dass es als Dashboarding-Tool gedacht ist. Wir haben es bis an die Grenzen und darüber hinaus getrieben, was zu einigen suboptimalen interessanten Design-Entscheidungen führte.
Zum Beispiel könnt ihr nur einen Callback pro Ausgabeparameter setzen. Mehrere Callbacks für dieselbe Ausgabe sind derzeit nicht möglich. Da das Routing von einer Seite zur anderen im Wesentlichen eine Änderung des Ausgabeparameters (‚url‘, ‚pathname‘) ist, muss jeder Seitenwechsel durch einen Callback geleitet werden. Das erhöht die Komplexität des Codes exponentiell.
Ein weiteres Problem ist die Schwierigkeit, Zustände über mehrere Seiten hinweg zu speichern. Dash bietet mit der Store Component die Möglichkeit, Benutzerdaten im Frontend zu speichern. Das ist eine hervorragende Lösung für kleine Apps; bei größeren steht man schnell vor dem gleichen Problem wie oben – ein Callback, eine Funktion zum Schreiben in den Store, reicht einfach nicht aus. Entweder ihr nutzt den globalen Zustand von Python, was schwierig wird, wenn mehrere Benutzer gleichzeitig auf die Seite zugreifen, oder ihr bindet einen cache ein.
In unserer Blogserie haben wir Ihnen gezeigt, wie ihr den gesamten Lebenszyklus eines Data-Science-Projekts durchlauft, von der Datenexploration über das Modelltraining bis hin zur Bereitstellung und Visualisierung. Dies ist der letzte Artikel dieser Serie, und wir hoffen, ihr habt beim Erstellen der Anwendung genauso viel gelernt wie wir.
Um das Durchblättern der vier Artikel zu erleichtern, sind hier die direkten Links: