KI-Chatbots kommen in immer mehr Unternehmen zum Einsatz. Doch Chatbot ist nicht gleich Chatbot. Manche Lösungen lassen sich zwar schnell und relativ leicht implementieren. Doch mangelt es ihnen an Konfigurierbarkeit (Customizability) und den Funktionalitäten, die wirklich große Leistungssprünge, z. B. bei der Beantwortung von Kundenanfragen im Customer Service, ermöglichen. Customized Lösungen, die genau das bieten, können wiederum aufwändig und teuer werden – besonders, wenn sie über komplexe und use-case-spezifische Retrieval-Augmented Generation (RAG) verfügen sollen. Die Technik verbessert die Genauigkeit und Zuverlässigkeit von generativen KI-Modellen, indem sie es ermöglicht, z. B. mit unternehmenseigenen Datenbanken zu chatten und nur gesicherte Fakten auszugeben.
Wie funktionieren Chatbots?
Custom GPT-Chatbots lernen aus großen Mengen von Texten, um Zusammenhänge zu verstehen und Muster zu erkennen. Sie werden so programmiert, dass sie individuell auf verschiedene Nutzer:innenanfragen eingehen können. Die Erstellung solcher Chatbots umfasst die maßgeschneiderte Anpassung an bestimmte Bedürfnisse, das gezielte Trainieren mit ausgewählten Daten und das Einbinden in Plattformen wie Websites oder mobile Anwendungen.
CustomGPT von statworx zeichnet sich dadurch aus, dass es das Beste aus beiden Welten – hohe Funktionalität durch Customizability und schnelle Implementierung – miteinander verbindet. Die Lösung ist maßgeschneidert und ermöglicht eine sichere und effiziente Nutzung von ChatGPT-ähnlichen Modellen. Das Interface lässt sich im Corporate Design eines Unternehmens gestalten und leicht in bestehende Geschäftsanwendungen wie CRM-Systeme und Support-Tools integrieren.
Worauf kommt es also an, wenn Unternehmen die ideale Chatbot-Lösung für ihre Bedürfnisse suchen?
Anforderungsanalyse: Zunächst sollten die spezifischen Anforderungen des Unternehmens identifiziert werden, um sicherzustellen, dass der Chatbot optimal auf diese zugeschnitten ist. Welche Aufgaben soll der Chatbot bearbeiten? Welche Abteilungen soll er unterstützen? Welche Funktionen braucht er?
Training des Modells: Ein custom GPT-Chatbots muss mit relevanten Daten und Informationen ausgestattet werden, um eine hohe Genauigkeit und Reaktionsfähigkeit sicherzustellen. Wenn diese Daten nicht verfügbar sind, lohnt sich der technische Aufwand wahrscheinlich nicht.
Integration in bestehende Systeme: Die nahtlose Integration des Chatbots in bestehende Kommunikationskanäle wie Websites, Apps oder soziale Medien ist entscheidend für eine effektive Nutzung. Je nach Infrastruktur eignen sich unterschiedliche Lösungen.
Schnell einsatzbereit und immer anpassungsfähig
Der CustomGPT-Chatbot von statworx zeichnet sich durch seine schnelle Einsatzfähigkeit aus, oft schon innerhalb weniger Wochen. Diese Effizienz verdankt er einer Kombination aus bewährten Standardlösungen und maßgeschneiderter Anpassung an die speziellen Bedürfnisse eines Unternehmens. CustomGPT ermöglicht den Upload von Dateien und die Möglichkeit, mit ihnen zu chatten, also gesicherte Informationen aus den unternehmenseigenen Daten zu ziehen. Mit fortschrittlichen Funktionen wie Faktenprüfung, Datenfilterung und der Möglichkeit, Nutzer:innenfeedback zu integrieren, hebt sich der Chatbot von anderen Systemen ab.
Darüber hinaus bietet CustomGPT Unternehmen die Freiheit, das Vokabular, den Kommunikationsstil und den generellen Ton ihres Chatbots zu bestimmen. Dies ermöglicht nicht nur ein nahtloses Markenerlebnis für die Nutzer:innen, sondern verstärkt auch die Wiedererkennung der Unternehmensidentität durch eine persönliche und einzigartige Interaktion. Ein besonderes Highlight: der Chatbot ist optimiert für die mobile Darstellung auf Smartphones.
Technische Umsetzung
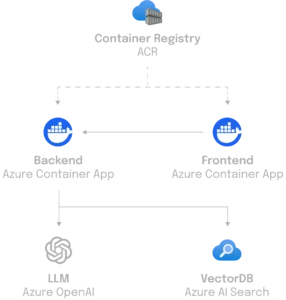
Im Bestreben, eine hochmoderne Anwendung zu schaffen, die sich leicht warten lässt, wurde Python als Kernsprache für das Backend von CustomGPT verwendet. Für die effiziente Handhabung von Anfragen setzen die statworx-Entwickler:innen auf FastAPI, eine moderne Webframework-Lösung, die sowohl Websockets für eine zustandsorientierte Kommunikation als auch eine REST-API für die Dienste bereitstellt. CustomGPT kann flexibel auf unterschiedlichen Infrastrukturen eingesetzt werden – von einer einfachen Cloud-Function bis zu einem Maschinencluster, wenn die Anforderungen dies erfordern.
Ein wesentlicher Aspekt der Architektur ist die Anbindung an eine Datenschicht, um ein flexibles Backend zu bieten, das sich schnell an veränderte Bedingungen und Anforderungen anpassen kann. Die Frontend-Applikation, entwickelt mit React, interagiert nahtlos über Websockets mit dem Backend, welches zum Beispiel die leistungsfähige Azure-AI-Suchfunktion nutzt. Die Konfiguration des Backends ermöglicht es, zusätzliche Use-Cases, wie zum Beispiel maßgeschneiderte Suchlösungen zu implementieren und spezifische Anforderungen effizient zu erfüllen.
Die Vorteile im Überblick:
Datenschutz und Sicherheit
Datenschutz und Datensicherheit sind zentrale Aspekte von CustomGPT. Es gewährleistet, dass alle Daten in der Europäischen Union gespeichert und verarbeitet werden und die vollständige Kontrolle beim Unternehmen liegt. Das ist ein entscheidender Unterschied zu anderen GPT-basierten Lösungen.
Integration und Flexibilität
Die flexible Integration von CustomGPT in bestehende Geschäftsanwendungen ist ein weiterer Vorteil. Dies wird durch Modularität und Anbieterunabhängigkeit unterstützt. Damit kann CustomGPT an verschiedene Infrastrukturen und Modelle angepasst werden, einschließlich Open-Source-Optionen.
Funktionen und Anpassungsmöglichkeiten
Die Anpassungsmöglichkeiten von CustomGPT umfassen die Integration in Organisationsdaten, die Anpassung an Benutzerrollen und die Verwendung von Analytics zur Verbesserung der Konversationen. Durch die Verwendung von Standardmodellen sowie die Möglichkeit, auf Open-Source-Modelle zu setzen, bietet CustomGPT Flexibilität und Individualisierung für Unternehmensanwendungen.
Personalisierte Kundenerfahrung
Durch die Anpassung an die spezifischen Anforderungen eines Unternehmens können Custom GPT-Chatbots eine personalisierte und effektive Interaktion mit Kund:innen gewährleisten.
Effiziente Kundenbetreuung
CustomGPT Chatbots können rund um die Uhr Fragen beantworten, Probleme lösen und Informationen bereitstellen, was zu einer erhöhten Kund:innenzufriedenheit und Effizienz führt.
Skalierbarkeit
Unternehmen können die Kapazität, z. B. ihrer Kund:innenbetreuung mithilfe von GPT-Chatbots problemlos skalieren, um auch bei hohem Aufkommen eine konsistente Servicequalität zu gewährleisten.
Die Zeit für einen eigenen Chatbot ist jetzt! Profitieren Sie von unserer Upstream-Entwicklung mit schneller Bereitstellung und einfacher Implementierung. Als CustomGPT-Kunde stehen Ihnen alle Patches, Bugfixes und neue Funktionalitäten, die im Laufe der Zeit hinzukommen, direkt zur Verfügung. So bleibt Ihr CustomGPT stets so vielseitig und flexibel, dass es den spezifischen, sich ändernden Bedürfnissen gerecht wird und komplexe Anforderungen adressieren kann. Kontaktieren Sie uns jetzt für ein Beratungsgespräch.
Stell dir vor, es ist Freitag und anstatt des üblichen Büroalltags, findest du dich mitten in einem Hackathon für ein Pro-Bono-Projekt wieder, planst einen Ausflug in das Dialogmuseum an der Frankfurter Hauptwache oder befragst Passanten auf der Zeil zu ihren Gedanken über KI und Nachhaltigkeit. Was haben all diese unterschiedlichen Aktivitäten gemeinsam? Sie sind Teil der 4:1-Woche („Vier zu eins“) bei statworx – einem Arbeitsmodell, das Raum für persönliche Entwicklung, innovatives Arbeiten und gesellschaftliches Engagement bietet.
Warum haben wir die 4:1-Woche eingeführt?
Bei statworx standen wir vor einer Herausforderung: Unsere Mitarbeitenden hatten große Ambitionen, sich weiterzubilden, fanden aber wenig Zeit dafür. Die Arbeitswoche war gefüllt mit Projekten und Terminen, und so rückte die persönliche Entwicklung oftmals in den Hintergrund.
Um dieses Dilemma zu lösen, führten wir 2022 eine innovative Arbeitsstruktur ein: die 4:1-Woche. Das Prinzip ist einfach und wirkungsvoll. Vier Tage der Woche sind intensivem Arbeiten an Projekten gewidmet. Der fünfte Tag, der Freitag, steht ganz im Zeichen der Weiterbildung. An diesem Tag findet das Tagesgeschäft in reduzierter Geschwindigkeit statt, und die Mitarbeiter:innen können sich voll und ganz ihrer fachlichen und persönlichen Entwicklung widmen.
Diese neue Struktur hat zu einer spürbaren Veränderung geführt. Sie ermöglicht es jeder und jedem Einzelnen bei statworx, auch in arbeitsreichen Zeiten Fortbildung zu machen und neue Fähigkeiten zu erlernen. Das fördert nicht nur die persönliche Entfaltung, sondern auch die Innovationskraft der Firma. Während die Kundenprojekte von Montag bis Donnerstag die volle Aufmerksamkeit genießen, wird der Freitag zum Raum für Lernen und Inspiration. So wahren wir gemeinsam die Balance zwischen Kundenbedürfnissen und der Entwicklung der Mitarbeitenden.
Welche Weiterbildungsmöglichkeiten bietet statworx an?
statX: Einmal im Monat treffen sich Mitarbeiter:innen auf freiwilliger Basis zum internen Austausch über ihre Erkenntnisse aus Projekten, über persönlich erworbenes Wissen oder über neue Modelle und Ansätze. Die Themen erstrecken sich dabei von Deep Learning mit Audiodaten über den AI Act bis hin zu Anomaly Detection.
Cluster: Die selbstorganisierten Arbeitsgruppen sind der Nährboden für die Entwicklung und Förderung von Fachwissen bei statworx. Derzeit gibt es fünfzehn Cluster, in denen Mitarbeiter:innen die Themen vertiefen, die ihnen besonders am Herzen liegen – und so die Innovationskraft von statworx insgesamt stärken. Hier sind drei Beispiele aus unserem Cluster-Portfolio:
- Bio Medicine Cluster: Erarbeitung von KI-Anwendungsfällen im biomedizinischen und pharmazeutischen Bereich.
- NLP Cluster: Implementierung modernster Modelle, Best Practices und Software für NLP sowie multimodale Anwendung von NLP-Modellen.
- Explainable AI Cluster: Beschäftigung mit Methoden, um Blackbox-KI-Modelle transparent und erklärbar zu machen.
Weiterbildungsbudget: Jedes Teammitglied bei statworx verfügt über ein jährliches Weiterbildungsbudget. Dieses Budget kann für individuelle Weiterbildungsmaßnahmen wie Online-Kurse, externe Trainings, Teilnahme an Konferenzen, Zertifizierungen und vieles mehr genutzt werden.
Technical- und non-technical Trainings: Das ganze Jahr über bieten wir eine Vielzahl von Trainings an, die sowohl Soft- als auch Hard-Skills ausbilden. Von effektiver Kommunikation über konstruktives Feedback bis hin zu Softwareengineering und Scrum sind zahlreiche spannende Themen vertreten.
Woher wissen wir, dass unser 4:1-Konzept funktioniert?
In regelmäßigen Pulse-Surveys und unseren halbjährlichen Umfragen zur Zufriedenheit der Mitarbeitenden sammeln wir anonymisiertes Feedback zum 4:1-Modell. So gewinnen wir Einblicke in die persönlichen Erfahrungen unserer Teammitglieder. In zusätzlichen, direkten Gesprächen mit Mitarbeiter:innen erhalten wir weitere wertvolle Eindrücke, um zu entscheiden, wie wir das Programm zukünftig gestalten und weiterentwickeln möchten.
Unser Zwischenfazit lautet: Mit jedem erworbenen Zertifikat und jeder persönlichen Erfolgsgeschichte bestätigt die 4:1-Woche bei statworx ihre Wirksamkeit. Wir freuen uns darauf, das Konzept kontinuierlich zu verfeinern und noch mehr Mitarbeiter:innen auf ihrer individuellen Lernreise zu unterstützen.
Kollegen bestätigen unser vorläufiges Fazit:
„Die 4:1 Woche gibt mir die Möglichkeit, mich neben der Projektarbeit tiefer in Themen und Wissensgebiete einzuarbeiten, für die ich selbst brenne. Deshalb habe ich zusammen mit meinen Kolleg:innen das Bio-Medicine-Cluster ins Leben gerufen. Und meine Software-Engineering-Skills bringe ich im Cluster für Technical Delivery ein, um die technische Bereitstellung unserer Lösungen stetig zu verbessern.“ – Benedikt Batton, Consultant Data Science, AI Development
„Die 4:1 Woche fördert die individuelle fachliche Weiterentwicklung und bietet Platz dafür, über bestehende Abteilungen und Hierarchien hinaus auf innovativen Wegen Wert zu schaffen. In meiner Zeit bei statworx war die Arbeit am Freitag bisher stets eine Quelle der Motivation, Inspiration und Selbstverwirklichung.“ – Max Hilsdorf, Consultant, AI Academy
Du möchtest Teil einer Arbeitskultur sein, die dir Raum für persönliche Entwicklung gibt und ein ausgewogenes Verhältnis zwischen Projektarbeit und Weiterbildung ermöglicht? Dann besuche unsere Karriereseite und bewirb dich jetzt!
Eine erfolgreiche Data Culture ist der Schlüssel für Unternehmen, um aus der ständig wachsenden Menge an Daten den größtmöglichen Nutzen zu ziehen. Der Trend, Entscheidungen auf der Basis von Daten zu treffen, ist unaufhaltsam. Doch wie schaffen es Führungskräfte, ihre Teams dazu zu befähigen, Daten effektiv zu nutzen?
Eine lebendige Data Culture: Der Treibstoff für Unternehmenserfolg
Data Culture ist mehr als ein Schlagwort – sie ist die Grundlage für datengestützte Entscheidungen. Wenn alle Abteilungen eines Unternehmens Daten zur Verbesserung von Arbeitsabläufen und zur Entscheidungsfindung nutzen, entsteht eine Atmosphäre, in der kompetenter Umgang mit Daten zum Standard gehört.
Warum ist das so wichtig? Daten sind Treibstoff für den Geschäftserfolg: 76 Prozent der Teilnehmer:innen des BARC Data Culture Survey 22 gaben an, dass ihr Unternehmen eine Datenkultur anstrebt. Und 75 Prozent der Führungskräfte sehen Data Culture als wichtigste Kompetenz.

Die entscheidende Rolle von Führungskräften
Eine etablierte Data Culture ist nicht nur ein Erfolgsfaktor für das Unternehmen, sondern auch ein Weg, um Innovationen zu fördern und Mitarbeiter:innen zu motivieren. Führungskräfte spielen hier eine zentrale Rolle, indem sie als Wegbereiter auftreten und den Wandel aktiv unterstützen. Sie müssen die Vorteile einer Data Culture klar kommunizieren, klare Richtlinien für Datenschutz und Datenqualität aufstellen und gezielte Schulungen sowie regelmäßige Kommunikation über Fortschritte anbieten. Eine klare Verantwortung für die Datenkultur ist entscheidend, denn 31 Prozent der Unternehmen mit schwach ausgeprägter Data Culture haben keine dedizierte Abteilung oder Person mit dieser Verantwortung.
Herausforderungen und Lösungen
Der Weg zur erfolgreichen Data Culture ist mit Hürden gespickt. Führungskräfte müssen sich verschiedenen Herausforderungen stellen:
- Widerstand gegen Veränderungen: Ein Übergang zu einer Data Culture kann auf Widerstand stoßen. Führungskräfte müssen die Vorteile klar kommunizieren und Schulungen anbieten, um ihre Mitarbeiter:innen in den Veränderungsprozess einzubeziehen.
- Fehlende Data-Governance: Richtlinien und Standards für den Umgang mit Daten sind entscheidend. Fehlen diese, verringert sich schlimmstenfalls die Datenqualität. Das führt zu falschen Entscheidungen. Hier sind Methoden zur Datenbereinigung und -validierung sowie regelmäßige Audits vonnöten.
- Bedenken hinsichtlich des Datenschutzes: Datenschutz und Datenzugang stehen oft im Konflikt. Hier müssen klare Richtlinien und Sicherheitsmaßnahmen eingeführt werden, um das Vertrauen der Mitarbeiter:innen zu gewinnen.
- Fehlende Ressourcen und Unterstützung: Ohne die nötigen Ressourcen kann der Aufbau einer Data Culture scheitern. Unternehmen müssen gezielte Schulungen anbieten und den geschäftlichen Nutzen in wirtschaftlichen Kennzahlen darstellen, um die Unterstützung ihrer Führungskräfte zu gewinnen.
Best Practices für eine starke Data Culture
Um eine Data Culture effektiv zu etablieren, können Unternehmen auf folgende Best Practices setzen:
Kritisches Denken: Die Förderung von kritischem Denken und ethischen Standards ist entscheidend. Data- und KI-Lösungen werden überall Werkzeuge des täglichen Lebens werden. Deshalb bleibt menschliche Intelligenz die wichtigste Kompetenz im Umgang mit Technologie.
Messen und Planen: Data Culture kann nur schrittweise aufgebaut werden. Unternehmen sollten datengesteuertes Verhalten messen und evaluieren, um den Fortschritt zu bewerten. Je stärker die Data Culture, desto omnipräsenter ist datengetriebenes Entscheiden.
Etablierung von Schlüsselrollen: Unternehmen sollten spezielle Funktionen bzw. Rollen schaffen für Mitarbeiter:innen, die die Data Strategy mit der Unternehmensstrategie verknüpfen und als zentrale Multiplikator:innen die Datenkultur bei den Mitarbeiter:innen fördern.
Die Entwicklung einer starken Data Culture erfordert klare Führung, klare Richtlinien und das Engagement der gesamten Organisation. Führungskräfte spielen dabei eine entscheidende Rolle, um den Wandel zu einer datengetriebenen Kultur erfolgreich zu gestalten.
Der Aufbau einer starken Datenkultur: Unser strategischer Ansatz
Bei statworx haben wir uns darauf spezialisiert, robuste Datenkulturen in Unternehmen zu etablieren. Unsere Strategie basiert auf bewährten Rahmenwerken, Best Practices und unserer umfangreichen Erfahrung, um die Grundlagen für eine erfolgreiche Datenkultur in Ihrem Unternehmen zu schaffen.
- Data Culture Strategie: Hand in Hand mit den Teams unserer Kunden entwickeln wir die strategische Roadmap, die erforderlich ist, um eine blühende Datenkultur zu fördern. Dies beinhaltet den Aufbau der grundlegenden Strukturen, die für die Maximierung des Potenzials Ihrer Unternehmensdaten unerlässlich sind.
- Data Culture Trainings: Wir setzen auf die Befähigung Ihrer Belegschaft mit den Fähigkeiten und dem Wissen, um im Bereich Daten und KI zu agieren. Unsere Schulungsprogramme zielen darauf ab, Mitarbeiter:innen mit den Kompetenzen auszustatten, die für den Aufbau einer starken Datenkultur unerlässlich sind. Damit können Unternehmen das volle Potenzial von Daten und Künstlicher Intelligenz ausschöpfen.
- Change-Management und Begleitung: Die Verankerung einer Datenkultur erfordert anhaltende Anstrengungen im Change-Management. Wir arbeiten mit den Kunden-Teams zusammen, um langfristige Änderungsprogramme zu etablieren, die darauf abzielen, eine robuste Datenkultur im Unternehmen zu initiieren und zu festigen. Unser Ziel ist es, sicherzustellen, dass die Transformation in der DNA der Organisation verankert bleibt, um anhaltenden Erfolg zu gewährleisten.
Mit unserem umfassenden Serviceangebot sind wir bestrebt, Unternehmen in eine Zukunft zu führen, in der Daten zu einem strategischen Vermögen werden, das neue Chancen erschließt und fundierte Entscheidungsfindung auf allen Ebenen ermöglicht. Darüber haben wir ausführlich in unserem Whitepaper “Data Culture als Führungsaufgabe in Unternehmen” geschrieben, das auch eine Data-Culture-Checklist enthält. Unsere Angebote rund um das Thema Datenkultur sind auf unserer Themenseite Data Culture zu finden.
Wir stehen am Beginn des Jahres 2024, einer Zeit grundlegender Veränderungen und spannender Fortschritte in der Welt der Künstlichen Intelligenz. Die nächsten Monate gelten als kritischer Meilenstein in der Evolution der KI, in denen sie sich von einer vielversprechenden Zukunftstechnologie zu einer festen Realität im Geschäftsleben und im Alltag von Millionen wandelt. Deshalb präsentieren wir gemeinsamen mit dem AI Hub Frankfurt, dem zentralen KI-Netzwerk der Rhein-Main-Region, unsere Trendprognose für 2024, den AI Trends Report 2024.
Der Report identifiziert zwölf dynamische KI-Trends, die sich in drei Schlüsselbereichen entfalten: Kultur und Entwicklung, Daten und Technologie sowie Transparenz und Kontrolle. Diese Trends zeichnen ein Bild der rasanten Veränderungen in der KI-Landschaft und beleuchten die Auswirkungen auf Unternehmen und Gesellschaft.
Unsere Analyse basiert auf umfangreichen Recherchen, branchenspezifischem Fachwissen und dem Input von Expert:innen. Wir beleuchten jeden Trend, um einen zukunftsweisenden Einblick in die KI zu bieten und Unternehmen bei der Vorbereitung auf künftige Herausforderungen und Chancen zu unterstützen. Wir betonen jedoch, dass Trendprognosen stets einen spekulativen Charakter haben und einige unserer Vorhersagen bewusst gewagt formuliert sind.
Direkt zum AI Trends Report 2024!
Was ist ein Trend?
Ein Trend unterscheidet sich sowohl von einem kurzlebigen Modephänomen als auch von einem medialen Hype. Er ist ein Wandelphänomen mit einem „Tipping Point“, an dem eine kleine Veränderung in einer Nische einen großen Umbruch im Mainstream bewirken kann. Trends initiieren neue Geschäftsmodelle, Konsumverhalten und Arbeitsformen und stellen somit eine grundlegende Veränderung des Status Quo dar. Für Unternehmen ist es entscheidend, vor dem Tipping Point die richtigen Kenntnisse und Ressourcen zu mobilisieren, um von einem Trend profitieren zu können.
12 KI-Trends, die 2024 prägen werden
Im AI Trends Report 2024 identifizieren wir wegweisende Entwicklungen im Bereich Künstlichen Intelligenz. Hier sind die Kurzversionen der zwölf Trends mit jeweils einem ausgewählten Zitat aus den Reihen unserer Expert:innen.
Teil 1: Kultur und Entwicklung
Von der 4-Tage-Woche über Omnimodalität bis AGI: 2024 verspricht große Fortschritt für die Arbeitswelt, für die Medienproduktion und für die Möglichkeiten von KI insgesamt.
These I: KI-Kompetenz im Unternehmen
Unternehmen, die KI-Expertise tief in ihrer Unternehmenskultur verankern und interdisziplinäre Teams mit Tech- und Branchenwissen aufbauen, sichern sich einen Wettbewerbsvorteil. Zentrale KI-Teams und eine starke Data Culture sind Schlüssel zum Erfolg.
„Eine Datenkultur kann man weder kaufen noch anordnen. Man muss die Köpfe, die Herzen und die Herde gewinnen. Wir möchten, dass unsere Mitarbeitenden bewusst Daten erstellen, nutzen und weitergeben. Wir geben ihnen Zugang zu Daten, Analysen und KI und vermitteln das Wissen und die Denkweise, um das Unternehmen auf Basis von Daten zu führen.“
Stefanie Babka, Global Head of Data Culture, Merck
These II :4-Tage-Arbeitswoche durch KI
Dank KI-Automatisierung in Standardsoftware und Unternehmensprozessen ist die 4-Tage-Arbeitswoche für einige deutsche Unternehmen Realität geworden. KI-Tools wie Microsofts Copilot steigern die Produktivität und ermöglichen Arbeitszeitverkürzungen, ohne das Wachstum zu beeinträchtigen.
Dr. Jean Enno Charton, Director Digital Ethics & Bioethics, Merck
These III: AGI durch omnimodale Modelle
Die Entwicklung von omnimodalen KI-Modellen, die menschliche Sinne nachahmen, rückt die Vision einer allgemeinen künstlichen Intelligenz (AGI) näher. Diese Modelle verarbeiten vielfältige Inputs und erweitern menschliche Fähigkeiten.
Dr. Ingo Marquart, NLP Subject Matter Lead, statworx
These IV: KI-Revolution in der Medienproduktion
Generative AI (GenAI) transformiert die Medienlandschaft und ermöglicht neue Formen der Kreativität, bleibt jedoch noch hinter transformatorischer Kreativität zurück. KI-Tools werden für Kreative immer wichtiger, doch es gilt, die Einzigartigkeit gegenüber einem globalen Durchschnittsgeschmack zu wahren.
Nemo Tronnier, Founder & CEO, Social DNA
Teil 2: Daten und Technologie
2024 dreht sich alles um Datenqualität, Open-Source-Modelle und den Zugang zu Prozessoren. Die Betreiber von Standardsoftware wie Microsoft und SAP werden groß profitieren, weil sie die Schnittstelle zu den Endnutzer:innen besetzen.
These V: Herausforderer für NVIDIA
Neue Akteure und Technologien bereiten sich vor, den GPU-Markt aufzumischen und NVIDIAs Position herauszufordern. Startups und etablierte Konkurrenten wie AMD und Intel wollen von der Ressourcenknappheit und den langen Wartezeiten profitieren, die kleinere Player derzeit erleben, und setzen auf Innovation, um NVIDIAs Dominanz zu brechen.
Norman Behrend, Chief Customer Officer, Genesis Cloud
These VI: Datenqualität vor Datenquantität
In der KI-Entwicklung rückt die Qualität der Daten in den Fokus. Statt nur auf Masse zu setzen, wird die sorgfältige Auswahl und Aufbereitung von Trainingsdaten sowie die Innovation in der Modellarchitektur entscheidend. Kleinere Modelle mit hochwertigen Daten können größeren Modellen in der Performance überlegen sein.
Walid Mehanna, Chief Data & AI Officer, Merck
These VII: Das Jahr der KI-Integratoren
Integratoren wie Microsoft, Databricks und Salesforce werden zu den Gewinnern, da sie KI-Tools an Endnutzer:innen bringen. Die Fähigkeit zur nahtlosen Integration in bestehende Systeme wird für KI-Startups und -Anbieter entscheidend sein. Unternehmen, die spezialisierte Dienste oder wegweisende Innovationen bieten, sichern sich lukrative Nischen.
Marco Di Sazio, Head of Innovation, Bankhaus Metzler
These VIII: Die Open-Source-Revolution
Open-Source-KI-Modelle treten in Wettbewerb mit proprietären Modellen wie OpenAIs GPT und Googles Gemini. Mit einer Community, die Innovation und Wissensaustausch fördert, bieten Open-Source-Modelle mehr Flexibilität und Transparenz, was sie besonders wertvoll für Anwendungen macht, die klare Verantwortlichkeiten und Anpassungen erfordern.
Prof. Dr. Christian Klein, Gründer, UMYNO Solutions, Professor für Marketing & Digital Media, FOM Hochschule
Teil 3: Transparenz und Kontrolle
Die verstärkte Nutzung von KI-Entscheidungssystemen wird 2024 eine intensivierte Debatte über Algorithmen-Transparenz und Datenschutz entfachen – auf der Suche nach Verantwortlichkeit. Der AI Act wird dabei zum Standortvorteil für Europa.
These IX: KI-Transparenz als Wettbewerbsvorteil
Europäische KI-Startups mit Fokus auf Transparenz und Erklärbarkeit könnten zu den großen Gewinnern werden, da Branchen wie Pharma und Finance bereits hohe Anforderungen an die Nachvollziehbarkeit von KI-Entscheidungen stellen. Der AI Act fördert diese Entwicklung, indem er Transparenz und Anpassungsfähigkeit von KI-Systemen fordert und damit europäischen KI-Lösungen zu einem Vertrauensvorsprung verhilft.
Jakob Plesner, Rechtsanwalt, Gorrissen Federspiel
These X: AI Act als Qualitätssiegel
Der AI Act positioniert Europa als sicheren Hafen für Investitionen in KI, indem er ethische Standards setzt, die das Vertrauen in KI-Technologien stärken. Angesichts der Zunahme von Deepfakes und der damit verbundenen Risiken für die Gesellschaft wirkt der AI Act als Bollwerk gegen Missbrauch und fördert ein verantwortungsbewusstes Wachstum der KI-Branche.
Catharina Glugla, Head of Data, Cyber & Tech Germany, Allen & Overy LLP
These XI: KI-Agenten revolutionieren den Konsum
Persönliche Assistenz-Bots, die Einkäufe tätigen und Dienstleistungen auswählen, werden zu einem wesentlichen Bestandteil des Alltags. Die Beeinflussung ihrer Entscheidungen wird zum Schlüsselelement für Unternehmen, um auf dem Markt zu bestehen. Dies wird die Suchmaschinenoptimierung und Online-Marketing tiefgreifend verändern, da Bots zu den neuen Zielgruppen werden.
Chi Wang, Principle Researcher, Microsoft Research
These XII: Alignment von KI-Modellen
Die Abstimmung (Alignment) von KI-Modellen auf universelle Werte und menschliche Intentionen wird entscheidend, um unethische Ergebnisse zu vermeiden und das Potenzial von Foundation-Modellen voll auszuschöpfen. Superalignment, bei dem KI-Modelle zusammenarbeiten, um komplexe Herausforderungen zu meistern, wird immer wichtiger, um die Entwicklung von KI verantwortungsvoll voranzutreiben.
Daniel Lüttgau, Head of AI Development, statworx
Schlussbemerkung
Der AI Trends Report 2024 ist mehr als eine unterhaltsame Bestandsaufnahme; er kann ein nützliches Werkzeug für Entscheidungsträger:innen und Innovator:innen sein. Unser Ziel ist es, unseren Leser:innen strategische Vorteile zu verschaffen, indem wir die Auswirkungen der Trends auf verschiedene Sektoren diskutieren und ihnen helfen, die Weichen für die Zukunft zu stellen.
Dieser Blogpost bietet nur einen kurzen Einblick in den umfassenden AI Trends Report 2024. Wir laden Sie ein, den vollständigen Report zu lesen, um tiefer in die Materie einzutauchen und von den detaillierten Analysen und Prognosen zu profitieren.
Ticket sichern! Zum AI Trends Report 2024
Gemeinsam mit Nadja Schäfer, Global Lead Data Culture & Data Literacy bei Roche, und David Schlepps, Head of AI Academy bei statworx, tauchen wir ein in die Welt der Data Culture. In unserem AI Trends Report 2024 erklärt Nadja Schäfer, dass es erfolgsentscheidend ist, Datenkultur in der Unternehmensstrategie zu verankern.
Deshalb widmen wir uns im Webinar nun den konkreten Maßnahmen zur Entwicklung einer starken Data Culture – angefangen bei der Einbettung in die Unternehmensstrategie.
Expert:innen:
- Nadja Schäfer, Global Lead Data Culture & Data Literacy, Roche Diagnostics Information Solutions
- David Schlepps, Head of AI Academy, statworx
Themen:
- Was ist Data Culture und warum braucht jedes Unternehmen eine eigene?
- Wie baut Roche seine Data Culture in die Unternehmensstrategie ein?
- Mit welchen Enablement-Maßnahmen lässt sich eine Data Culture aufbauen?
Nutze die Gelegenheit, deine Fragen direkt an Nadja Schäfer und David Schlepps zu stellen und dich mit Gleichgesinnten auszutauschen. Jetzt anmelden!
Alle angemeldeten Teilnehmer:innen erhalten nach dem Event eine Aufzeichnung.
Ticket sichern! Zum AI Trends Report 2024
Die Diskussion um den Einsatz von Künstlicher Intelligenz (KI) am Arbeitsplatz scheint unsere Gesellschaft zu spalten. Aktuell entfaltet sich ein Spannungsfeld: KI wird von den einen als bahnbrechender Fortschritt gefeiert und von anderen als Horrorszenario gefürchtet. Dazwischen scheint es wenig zu geben.
Unsere statworx-Arbeitsgruppe „AI & Society“ hat es sich zur Aufgabe gemacht, dem Diskurs auf den Grund zu gehen, um Antworten auf die drängenden Fragen unserer Gesellschaft zu finden. Dazu führten wir eine nicht-repräsentative Meinungsumfrage – teils online, teils in der Innenstadt von Frankfurt – mit 132 Teilnehmer:innen durch. Wir wollten unter anderem wissen: Was denken die Menschen außerhalb der KI-Bubble über Künstliche Intelligenz im Arbeitsalltag? Wo sehen sie die größten Potenziale und wovor fürchten sie sich? Unser Ziel: Statt nur Meinungen abzufragen, wollen wir die Ängste und Hoffnungen der Menschen verstehen, um daraus Lösungsansätze für einen sozialverträglichen KI-Einsatz ableiten zu können. Dazu untersuchten wir auch andere relevante Studien und Umfragen und die daraus abgeleieteten Empfehlungen.

Was Menschen über KI denken
Geht es um die Nutzung von KI am Arbeitsplatz herrscht eigentlich nur in der Kompetenz-Frage weitestgehend Einigkeit: Unternehmen und Personen, die KI in ihren Arbeitsalltag einsetzen, verschaffen sich Vorteile gegenüber anderen. Darüber hinaus zeigt sich ein undeutliches, teils widersprüchliches Bild auf dem weiten Feld von Studien, Darstellungen der öffentlichen Meinung, persönlicher Ansichten und Emotionen. Ein paar Auszüge daraus:
53 Prozent der von uns befragten Personen wünschen sich, mehr KI-Anwendungen in Studium und Beruf einzusetzen. Gleichzeitig sind sich 45 Prozent der Befragten nicht bewusst, bereits KI-gestützte Services wie Google Maps und Spotify im Alltag zu nutzen. Das zeigt: Es besteht weiter ein großer Aufklärungsbedarf darüber, was der Begriff „Künstliche Intelligenz“ tatsächlich beinhaltet – und was nicht.
Unsere Umfrage zeigt, dass Menschen in verschiedenen Branchen sorgenvoll in die Zukunft von und mit KI blicken. 55 Prozent sagen, dass sie eher besorgt, als begeistert von KI sind. Etwas mehr als die Hälfte der von uns befragten Personen gab sogar an, Angst vor der “allgemeinen Entwicklung” im Bereich KI zu haben. Auch gegenüber dem Institut für Demoskopie Allensbach gaben 40 Prozent an, dass generative KI sie beunruhige. Einer weiteren Studie zufolge finden sogar 58 Prozent der Deutschen KI „unsympathisch“. Das deutet darauf hin, dass ein großer Anteil der Bevölkerung diffuse Ängste und negative Assoziationen in Bezug auf KI hat.
Wenn es um den Einfluss von Künstlicher Intelligenz auf den eigenen Arbeitsalltag geht, vermutet ein Drittel der befragten Personen einen “eher starken” Einfluss. Knapp 60 Prozent wiederum denken, dass KI den eigenen Job “eher wenig” oder “gar nicht” beeinflussen wird. Weniger als ein Drittel erwartet, dass KI die eigene Arbeit interessanter machen wird und nur circa ein Viertel kann sich “mehr Raum für Kreativität” durch KI vorstellen. Diese Tendenzen werden von Ergebnissen einer Onlineumfrage des Marktforschungsinstituts Bilendi unter nichtakademischen Fachkräften mit Berufsausbildung unterstützt: Ein Viertel der Befragten gab an, dass vor allem Unternehmen vom KI-Einsatz profitieren. Beschäftigte würden keine tatsächliche Arbeitsentlastung erfahren, weil durch den technologischen Fortschritt bloß die Menge zu erledigender Aufgaben zunähme. Das zeigt: Die Auswirkungen von KI auf den eigenen Arbeitsalltag werden eher als negativ eingeschätzt. Doch nur ein Fünftel der von Bilendi Befragten glaubt auch, dass KI den eigenen Job irgendwann vollständig ersetzen werde. Auch 58 Prozent unserer Befragten glauben nicht, dass KI zu mehr Arbeitslosigkeit führt, im Gegensatz zu 33 Prozent in der KIRA-Studie, die sich Sorgen um Arbeitsplatzverluste machen.
Worauf wir uns tatsächlich einstellen müssen
Dass die von uns befragten Personen den Impact von Künstlicher Intelligenz vermutlich unterschätzen, zeigt sich in internationalen Vergleichsstudien. Eine Ipsos-Umfrage vom Sommer 2023 illustriert das in Deutschland vorherrschende geringe Bewusstsein für das Transformationspotenzial von KI folgendermaßen:
- 35 Prozent der deutschen Befragten halten es für wahrscheinlich, dass KI ihren derzeitigen Arbeitsplatz in den nächsten 5 Jahren verändern wird (somit vorletzter Platz im Ländervergleich mit einem Durchschnitt von 57 Prozent).
- Nur 19 Prozent der deutschen Befragten glauben, dass KI ihren derzeitigen Arbeitsplatz in den nächsten 5 Jahren ersetzen wird, im Vergleich zu einem Länderdurchschnitt von 36 Prozent.
- Lediglich 23 Prozent der deutschen Befragten denken, dass der verstärkte Einsatz von künstlicher Intelligenz ihre Arbeit in den nächsten 3-5 Jahren verbessern wird, im Gegensatz zum Länderdurchschnitt von 37 Prozent.
- Grundsätzlich vermuten 40 Prozent der Befragten eine Verschlechterung des deutschen Arbeitsmarktes durch die Nutzung von KI, während nur 20% eine Verbesserung erwarten.
Die Ergebnisse zeigen: Unternehmen, aber vor allem ihre Beschäftigten fühlen sich der neuen Herausforderung nicht gewachsen und machen sich kein realistisches Bild von den wirklich erwartbaren Veränderungen durch KI. Es fehlt an Bildungsangeboten und an individuellen Kompetenzen. Ihre diffusen Sorgen gepaart mit Unbedarftheit spitzen sich zu konkreten Herausforderungen für Arbeitgeber zu: Wie sollen Unternehmen mit unterschiedlichen Sichtweisen ihrer Mitarbeitenden auf KI umgehen? Wie (wenn überhaupt) geht man auf die ein, die sich ganz verweigern? Und wie mit jenen, die extrem enthusiastisch bis hin zu übereifrig sind? Wie befähigt man Menschen, souverän mit KI-basierten Tools umzugehen? Welche Abteilung und welche Mitarbeitenden benötigen überhaupt welche KI-Kompetenzen? Und wie bildet man diese individuell passend aus?
Fakt ist: Gerade die Veränderungen im Bereich generativer KI wirken sich massiv auf die Arbeitswelt aus. Einerseits wächst der Bedarf an Fachkräften, die Data-Kompetenz mit Branchenwissen vereinen, und es entstehen ganz neue Jobs wie der des “Prompt Engineers”, andererseits birgt KI-basierte (Teil-)Automatisierung in vielen Branchen die Gefahr großer Stellenstreichungen. Die Ankündigung der BILD-Zeitung, wegen ChatGPT Personal abzubauen, ist wahrscheinlich nur ein Vorbote. Manche Schätzungen gehen sogar davon aus, dass bis zu 80 Prozent der Arbeitsplätze in den kommenden Jahrzehnten automatisiert werden könnten. Die UN und andere Expert:innen halten das zwar für unrealistisch, doch es zeigt auch: Wir wissen nicht, wohin die Reise wirklich gehen wird. Das liegt auch daran, dass Branchen zu unterschiedlich, Berufsprofile mehrdimensional und Menschen (noch) nicht ohne Weiteres ersetzbar sind. Nur weil ein KI-System einen Arbeitsprozess automatisiert, kann es nicht gleich ein komplettes Jobprofil übernehmen. KI-Forscher:innen stimmen dem noch zu: In einer großangelegten Befragung von mehr als 2.700 Forscher:innen äußerten nur zehn Prozent die Erwartung, dass KI uns bis 2027 in allen Aufgaben überlegen sein könnte. Doch die Hälfte der Befragten glaubt auch, dass dieser technologische Durchbruch bis 2047 erreicht werden könnte. Klar ist nur: In Zukunft werden menschliche Arbeitskräfte überall mit KI zusammenarbeiten.
Nur mangelndes Wissen? Woher die Skepsis gegenüber KI kommt
KI läuft Gefahr zu einem gesellschaftlichen Spaltungsthema zu werden, wenn wir sie nicht sozialverträglich in unsere Arbeitswelt einbetten. Wie sorgen wir dafür, dass das gelingt? Die meisten Studien deuten in die gleiche Richtung: Bildung ist ein wichtiger Schlüssel, um Verständnis für die (rechtlich zulässigen) Fähigkeiten von KI zu schaffen, fundierte Entscheidungen über und mit KI zu treffen und Ängste vor der Technologie abzubauen. Das bestätigt auch unsere Umfrage: Obwohl sie KI bereits häufiger nutzen, haben Führungskräfte den Wunsch nach mehr Wissen; ebenso wie 53 Prozent der Befragten, die gerne mehr KI in ihrer beruflichen Umgebung einsetzen würden. Doch grundlegendes Wissen über die Technologie und ihren verantwortungsvollen Einsatz reicht nicht.
Viele Menschen wollen auch mehr über die Risiken von KI wissen und suchen nach Wegen, sich selbst zu befähigen. Die Aussagen aus dem qualitativen Teil unserer Studie unterstreichen das. Eine Person fordert zum Beispiel, dass der “Umgang mit KI […] allen Altersgruppen verständlich gemacht werden [sollte, damit] keine Wissenskluft entsteht.” Risikobestimmung ist für viele ein kritischer Punkt, wie aus dem Zitat hervorgeht: “Menschen wollen am ehesten mehr zu Risiken von KI wissen – am wenigsten wollen sie wissen, wie KI funktioniert.” Ein hohes Risikobewusstsein attestiert auch die KIRA-Studie. Passend dazu fanden wir in Bezug auf KI-Anwendungen heraus, dass den Befragten hohe Sicherheit am wichtigsten ist. Am wenigsten wichtig ist ihnen schnelle Verfügbarkeit. Interessant ist allerdings: Führungskräfte schätzen “Hohe Sicherheit” etwas niedriger und “Schnelle Verfügbarkeit” etwas höher ein als Angestellte.
Neben den unmittelbaren Risiken durch KI (wie Diskriminierung) sorgen sich Menschen auch aus anderen Gründen, zum Beispiel weil sie Abhängigkeit und Kontrollverlust befürchten, sich überfordert fühlen oder Angst vor Missbrauch und Manipulation haben. Insbesondere die Angst vor möglicher Überwachung durch KI ist prominent: 62 Prozent unserer Befragten und 54 Prozent der Teilnehmer:innen der KIRA-Studie stimmen dem zu. Ähnlich verhält es sich beim Thema Desinformation, das 51 Prozent unserer Befragten und 56 Prozent der KIRA-Studienteilnehmer:innen als mit KI verbunden betrachten. Interessanterweise denken jedoch 59 Prozent unserer Befragten nicht, dass KI die Menschheit bedroht, während 58 Prozent der KIRA-Studienteilnehmer:innen deshalb besorgt sind.
Wer sind die KI-Skeptiker:innen?
Wen die vielen Zahlen und Studien etwas ratlos zurücklassen, der oder die ist nicht allein. Es zeichnet sich kein klares Bild ab. Noch weniger lässt sich ableiten, wie man im Einzelnen vorgehen sollte, um mit KI-Skeptiker:innen umzugehen. Die Diskrepanzen in den Antworten spiegeln die Vielschichtigkeit der Wahrnehmung von KI und ihrer Auswirkungen auf den Arbeitsmarkt wider. Die verschiedenen Perspektiven und Herausforderungen unterstreichen die Notwendigkeit eines umfassenden Dialogs und einer partizipativen Gestaltung der Zukunft im Zeitalter der Künstlichen Intelligenz. Doch mit wem müssen wir wie sprechen?

Eine in der MIT Sloan Management Review veröffentlichten Umfrage unter 140 Führungskräften identifiziert drei Idealtypen von KI-basiertem Entscheidern: Skeptiker, Interagierer und Delegierer. Skeptiker sind nicht bereit, ihre Autonomie im Entscheidungsprozess an KI abzugeben, während Delegierer gerne die Verantwortung der KI überlassen. Intergrierer gehen einen Mittelweg, der je nach Entscheidung eher in die eine oder eher in die andere Richtung tendieren kann. Die drei Typen der Entscheidungsfindung zeigen, dass die Qualität der KI-Empfehlung selbst nur die Hälfte der Gleichung ist bei der Bewertung KI-gestützter Entscheidungsfindung in Organisationen. Der menschliche Filter macht den Unterschied aus, sagen die Autoren Philip Meissner and Christoph Keding. Delegierer sind auch ohne KI eher diejenigen, die Verantwortung an andere übergeben.
Eine EY-Studie kommt zu dem Ergebnis, dass Tech-Skeptiker:innen älter sind und ein geringeres Einkommen haben. Sie sind relativ unzufrieden mit ihrem Leben und befürchten, dass es künftigen Generationen noch schlechter gehen wird. Nur wenige glauben, dass die jungen Menschen von heute ein besseres Leben haben werden als ihre Eltern. Tech-Skeptiker:innen sind besorgt um ihre finanzielle Sicherheit, misstrauen der Regierung und sind nicht von den Vorteilen der Technologie überzeugt. Sie nutzen die Technologie für grundlegende Aufgaben, glauben aber nicht, dass sie die Probleme der Gesellschaft lösen wird. Sie verfügen zwar über grundlegende digitale Fähigkeiten, aber nur wenige sehen einen Sinn darin, diese weiterzuentwickeln. Tech-Skeptiker:innen sind in der Regel gegen die gemeinsame Nutzung von Daten, selbst wenn es einen klaren Zweck gibt.
Daraus können wir auch ableiten: Skepsis ist ein zutiefst menschliches, oft charakterliches Merkmal, das nicht unbedingt für vernunftlogische Argumente zugänglich ist. Ein Eckpfeiler aller Bemühungen muss deshalb transparente, verständnisvolle Kommunikation auf Augenhöhe sein, die das ernst nimmt. Eine Forrester-Umfrage zum Thema KI im Personalwesen identifizierte vier Personengruppen, auf die Führungskräfte ihre Kommunikation abstimmen sollten:
- KI-Skeptiker:innen: am häufigsten in der IT-Branche anzutreffen
- KI-Befürworter:innen: am ehesten im Alter von 26 bis 35 Jahren und im Gesundheitssektor
- KI-Indifferente: am ehesten im Alter von 36-45 Jahren
- KI-Enthusiast:innen: am ehesten 18-25 Jahre alt und arbeiten im Vertrieb
Unabhängig davon, wie zutreffend diese Einteilung für die deutsche Gesellschaft ist, kann die Erstellung von Personas sinnvoll sein, um passende Botschaften zu entwickeln. Jede dieser Gruppen reagiert unterschiedlich auf verschiedene Arten der Kommunikation. So sagt etwa die Hälfte der KI-Befürworter:innen, dass Transparenz in Bezug auf die Frage, ob durch KI Arbeitsplätze im eigenen Unternehmen wegfallen werden oder nicht, ihre Bedenken und Ängste in Bezug auf KI im Personalwesen verringern würde. Nur 18 Prozent derjenigen, die der KI gleichgültig gegenüberstehen, sehen das genauso. Während mehr als die Hälfte der KI-Skeptiker:innen angaben, dass die Kommunikation darüber, wie das Unternehmen KI einsetzt, ihre Bedenken und Ängste lindern würde, sind nur 22 Prozent der KI-Befürworter:innen dieser Meinung. 45 Prozent der vorsichtigen Befürworter:innen und Skeptiker:innen gab an, dass sie das Unternehmen eher verlassen würden, wenn ihre Bedenken über den Einsatz von KI in der Personalabteilung nicht ausgeräumt würden.
Wie schaffen wir KI-Zuversicht?
Was können wir daraus für den Umgang mit KI-Skepsis lernen? Wir befinden uns immer noch an der Spitze des Eisbergs, wenn es um die Nutzung von KI geht. Während Unternehmen ihre KI-Infrastruktur weiter ausbauen, müssen sie auch sicherstellen, dass sich ihre Mitarbeitenden befähigt fühlen, KI in ihren jeweiligen Rollen zu nutzen. Mit anderen Worten: Die Unternehmensführung muss deutlich zeigen, dass sie ihre Mitarbeitenden als Partner:innen und nicht nur als Passagier:innen auf der KI-Reise sieht.

Unsere Einschätzung: Es bedarf der Entwicklung robusterer Richtlinien für verantwortungsvolle KI in Unternehmen und Teams, um Sorgen in Zuversicht umzuwandeln und dem ungewollten Abfluss von Betriebsgeheimnissen oder anderer schutzwürdiger Daten entgegenzuwirken. Dazu gehört maximale Transparenz über den (geplanten) Einsatz von KI. Die Realität ist, dass die meisten Mitarbeiter:innen nicht wirklich verstehen, wie KI funktioniert – viele Entscheidungsträger:innen aber glauben, dass sie es wissen. Upskilling hilft, diese Kluft zu überbrücken. Die gezielte Qualifizierung von Arbeitnehmer:innen fördert einen sicheren und produktiven Einsatz. Wenn Mitarbeiter:innen darüber hinaus auch verstehen – weil es ihnen nachvollziehbar gezeigt wird – wie die Technologie ihr Arbeitsleben verbessern kann, erhöht das ihre Bereitschaft, mitzuziehen. Denn der Großteil von ihnen hofft schon, dass KI ihnen den Zugang zu Informationen erleichtern und ihre Produktivität steigern wird. Und auch diejenigen, die skeptisch sind, sind rationalen Argumenten gegenüber meist aufgeschlossen. Entscheidend ist, wie man sie anspricht. Statt Verständnis und Bereitschaft vorauszusetzen, kann es sich lohnen, sie auf individueller Ebene abzuholen: “Wenn du eine große finanzielle Entscheidung treffen musst, hörst du dann einzig auf dein Bauchgefühl oder versuchst so viele Daten und Informationen wie möglich zu sammeln?” Es muss klar werden, dass es bei (fast allen typischen) KI-Systemen um Technologien geht, die Menschen dienen dazu sollen, bessere, evidenzbasierte Entscheidungen zu treffen – und nicht um irgendeine Roboterdystopie, in der der Mensch zum Mittel wird.
Dafür ist zielgruppengerechte interne Kommunikation wichtig. Unternehmen in denen vornehmlich Tech- und KI-Enthusiasten arbeiten, sind möglicherweise gut beraten, KI als neuen, revolutionären Trend an ihre Mitarbeiter:innen zu kommunizieren. Wenn diese Zielgruppe Wert darauf legt, dass ihr Arbeitgeber modern und hightech ist, sollte sich das auch in der Kommunikation widerspiegeln. Andere Unternehmen, in denen weniger Enthusiasmus und vielleicht stärker konservative, vorsichtige Denkweise herrschen, fahren wahrscheinlich besser damit, KI intern als kontinuierlich Weiterentwicklung und Verbesserung bestehender, bekannter Technologien zu kommunizieren. Möglicherweise sollten sie sogar ganz darauf verzichten, das Label KI zu nutzen und neue Systeme eher an vertraute Namen und Beschreibungen anlehnen. Welche kommunikativen Strategien in welchem Unternehmen (und in welchen Abteilungen) gut funktionieren, lässt sich pauschal nicht sagen. Die oben vorgestellten Personas und ihre Gründe für KI-Skepsis geben jedoch gute Hinweise darauf, wie man interne Stimmungen einfangen und darauf eine passende Kommunikationsstrategie ausrichten kann.
Über die Arbeitsgruppe AI & Society
Als Arbeitsgruppe mit Einblicken in den aktuellen Forschungsstand führen wir gemeinsam mit Expert:innen aus Wirtschaft, Gesellschaft und Forschung die Diskussion. Unsere Arbeitsgruppe ist nicht nur auf die Analyse beschränkt, sondern handelt auch aktiv. „KI Macht Schule“ und der Girls Day sind nur einige Beispiele unserer Bemühungen, die Gesellschaft in den Dialog einzubeziehen und KI erlebbar zu machen. Die Entwicklung von Responsible-AI-Prinzipien und Workshops sind weitere Maßnahmen, um Innovation verantwortungsvoll voranzutreiben.
Alle Ergebnisse auf einen Blick

Quellen
https://arxiv.org/pdf/2401.02843.pdf
https://blog.workday.com/en-us/2023/how-employees-feel-ai-at-work.html
https://www.elektroniknet.de/halbleiter/wer-hat-angst-vor-ki.207613.html
https://www.ey.com/en_gl/government-public-sector/meet-the-tech-skeptics
https://www.faz.net/aktuell/politik/inland/allensbach-warum-deutsche-die-ki-fuerchten-19060081.html
https://t3n.de/news/ki-prognosen-automatisierung-arbeit-1601598/
Geschäftserfolg steht und fällt mit der Art und Weise, wie Unternehmen mit ihren Kund:innen interagieren. Kein Unternehmen kann es sich leisten, mangelhafte Betreuung und Support anzubieten. Im Gegenteil: Firmen, die eine schnelle und präzise Bearbeitung von Kundenanfragen anbieten, können sich vom Wettbewerb absetzen, Vertrauen in die eigene Marke aufbauen und so Menschen langfristig an sich binden. Wie das mithilfe von generativer KI auf einem ganz neuen Niveau gelingt, zeigt unsere Zusammenarbeit mit Geberit, einem führenden Hersteller von Sanitärtechnik in Europa.
Was ist generative KI?
Generative KI-Modelle erstellen automatisiert Inhalte aus vorhandenen Text-, Bild- und Audiodateien. Dank intelligenter Algorithmen und Deep Learning unterscheiden sich diese Inhalte kaum oder gar nicht von menschengemachten. Unternehmen können ihren Kund:innen so personalisierte User Experiences bieten, automatisiert mit ihnen interagieren und relevanten digitalen Content zielgruppengerecht erstellen und ausspielen. GenAI kann zudem komplexe Aufgaben lösen, indem die Technologie riesige Datenmengen verarbeitet, Muster erkennt und neue Fähigkeiten lernt. So ermöglicht die Technologie ungeahnte Produktivitätsgewinne. Routineaufgaben wie Datenaufbereitung, Berichterstellung und Datenbanksuchen lassen sich automatisieren und mit passenden Modellen um ein Vielfaches optimieren.
Weitere Informationen zum Thema GenAI finden Sie hier.
Die Herausforderung: Eine Million E-Mails
Geberit sah sich mit einem Problem konfrontiert: Jedes Jahr landeten eine Million E-Mails in den unterschiedlichen Postfächern des Kundenservice der deutschen Vertriebsgesellschaft von Geberit. Dabei kam es oft vor, dass Anfragen in den falschen Abteilungen landeten, was zu einem erheblichen Mehraufwand führte.
Die Lösung: Ein KI-gestützter E-Mail-Bot
Um die falsche Adressierung zu korrigieren, haben wir ein KI-System entwickelt, das E-Mails automatisch den richtigen Abteilungen zuordnet. Dieses intelligente Klassifikationssystem wurde mit einem Datensatz von anonymisierten Kundenanfragen trainiert und nutzt fortschrittliche Machine- und Deep-Learning-Methoden, darunter das BERT-Modell von Google.
Der Clou: Automatisierte Antwortvorschläge mit ChatGPT
Doch die Innovation hörte hier nicht auf. Das System wurde weiterentwickelt, um automatisierte Antwort-E-Mails zu generieren. Hierbei kommt ChatGPT zum Einsatz, um kundenspezifische Vorschläge zu erstellen. Die Kundenberater:innen müssen die generierten E-Mails nur noch prüfen und können sie direkt versenden.
Das Ergebnis: 70 Prozent bessere Sortierung
Das Ergebnis dieser bahnbrechenden Lösung spricht für sich: eine Reduzierung der falsch zugeordneten E-Mails um über 70 Prozent. Das bedeutet nicht nur eine erhebliche Zeitersparnis von fast drei ganzen Arbeitsmonaten, sondern auch eine Optimierung der Ressourcen.
Der Erfolg des Projekts schlägt hohe Wellen bei Geberit: Ein Sammelpostfach für alle Anfragen, die Ausweitung in andere Ländermärkte und sogar ein digitaler Assistent sind in Planung.
Kundenservice 2.0 – Innovation, Effizienz, Zufriedenheit
Die Einführung von GenAI hat nicht nur den Kundenservice von Geberit revolutioniert, sondern zeigt auch, welches Potenzial in der gezielten Anwendung von KI-Technologien liegt. Die intelligente Klassifizierung von Anfragen und die automatisierte Antwortgenerierung spart nicht nur Ressourcen, sondern steigert auch die Zufriedenheit der Kund:innen. Ein wegweisendes Beispiel dafür, wie KI die Zukunft des Kundenservice gestaltet. Egal in welcher Branche!
Read next …


… and explore new


Ticket sichern! Zur Case Study
Das globale Wirtschaftsumfeld wird immer schnelllebiger und volatiler. Aber eines ändert sich nie: Kompetenter, effektiver Customer Support ist und bleibt einer der wichtigsten Schlüssel zu dauerhaftem Geschäftserfolg. Denn guter Service bindet Kund:innen und sorgt dafür, dass sie immer wieder zurückkehren. Doch wie bewältigen Unternehmen die Flut von anspruchsvollen Kundenanfragen, um genau das zu gewährleisten? Hier bietet generative Künstliche Intelligenz (GenAI) bislang unerreichte Möglichkeiten.
Gemeinsam mit Geberit haben wir ein KI-System entwickelt, das Kundenanfragen intelligent sortiert und automatisch Antworten erstellt. Im gemeinsamen Webinar sprechen wir über die innovative Lösung.
Freue dich auf folgende Inhalte:
- Die Meilensteine des Projekts: Wir führen euch von der Herausforderung über die erste Idee bis hin zu unerwarteten Entwicklungen des Projekts.
- Die Funktionsweise unseres KI-Tools: Wir erklären in einfachen Worten, wie die maßgeschneiderte KI-Lösung funktioniert.
- Die Ergebnisse und der Business Impact: Wir zeigen, wie Geberit von der Customer Support Automation profitiert und wie andere Unternehmen das ebenfalls können!
Dich erwarten folgende Speaker:
- Dr. Tilo Sperling, Head of AI-Projects Business Applications, Geberit
- Dominique Lade, Senior Consultant, statworx
Jetzt kostenlos registrieren!
Allen registrierten Teilnehmer:innen wird im Anschluss eine Aufzeichnung des Webinars zugesandt.
Ticket sichern! Zur Case Study
Intelligente Chatbots sind eine der spannendsten und heute schon sichtbarsten Anwendungen von Künstlicher Intelligenz. ChatGPT und Konsorten erlauben seit Anfang 2023 den unkomplizierten Dialog mit großen KI-Sprachmodellen, was bereits eine beeindruckende Bandbreite an Hilfestellungen im Alltag bietet. Ob Nachhilfe in Statistik, eine Rezeptidee für ein Dreigängemenü mit bestimmten Zutaten oder ein Haiku zum Vereinsjubiläum: Moderne Chatbots liefern Antworten im Nu. Ein Problem haben sie aber noch: Obwohl diese Modelle einiges gelernt haben während des Trainings, sind sie eigentlich keine Wissensdatenbanken. Deshalb liefern sie oft inhaltlichen Unsinn ab – wenn auch überzeugenden.
Mit der Möglichkeit, einem großen Sprachmodell eigene Dokumente zur Verfügung zu stellen, lässt sich dieses Problem aber angehen – und genau danach hat uns unser Partner Microsoft zu einem außergewöhnlichen Anlass gefragt.
Microsofts Cloud Plattform Azure hat sich in den letzten Jahren als erstklassige Plattform für den gesamten Machine-Learning-Prozess erwiesen. Um den Einstieg in Azure zu erleichtern, hat uns Microsoft gebeten, eine spannende KI-Anwendung in Azure umzusetzen und bis ins Detail zu dokumentieren. Dieser sogenannte MicroHack soll Interessierten eine zugängliche Ressource für einen spannenden Use Case bieten.
Unseren Microhack haben wir dem Thema „Retrieval-Augmented Generation“ gewidmet, um damit große Sprachmodelle auf das nächste Level zu heben. Die Anforderungen waren simpel: Baut einen KI-Chatbot in Azure, lasst ihn Informationen aus euren eigenen Dokumenten verarbeiten, dokumentiert jeden Schritt des Projekts und veröffentlicht die Resultate auf dem
offiziellen MicroHacks GitHub Repository als Challenges und Lösungen – frei zugänglich für alle.
Moment, wieso muss KI Dokumente lesen können?
Große Sprachmodelle (LLMs) beeindrucken nicht nur mit ihren kreativen Fähigkeiten, sondern auch als Sammlungen komprimierten Wissens. Während des extensiven Trainingsprozesses eines LLMs lernt das Modell nicht bloß die Grammatik einer Sprache, sondern auch Semantik und inhaltliche Zusammenhänge; kurz gesagt lernen große Sprachmodelle Wissen. Ein LLM kann dadurch befragt werden und überzeugende Antworten generieren – mit einem Haken. Während die gelernten Sprachfertigkeiten eines LLMs oft für die große Mehrheit an Anwendungen taugen, kann das vom gelernten Wissen meist nicht behauptet werden. Ohne erneutem Training auf weiteren Dokumenten bleibt der Wissensstand eines LLMs statisch.
Dies führt zu folgenden Problemen:
- Das trainierte LLMs weist zwar ein großes Allgemeinwissen – oder auch Fachwissen – auf, kann aber keine Auskunft über Wissen aus nicht-öffentlich zugänglichen Quellen geben.
- Das Wissen eines trainierten LLMs ist schnell veraltet: Der sogenannte „Trainings-Cutoff“ führt dazu, dass das LLM keine Aussagen über Ereignisse, Dokumente oder Quellen treffen kann, die sich erst nach dem Trainingsstart ereignet haben oder später entstanden sind.
- Die technische Natur großer Sprachmodelle als Text-Vervollständigungs-Maschinen führt dazu, dass diese Modelle gerne Sachverhalte erfinden, wenn sie eigentlich keine passende Antwort gelernt haben. Sogenannte „Halluzinationen“ führen dazu, dass die Antworten eines LLMs ohne Überprüfung nie komplett vertrauenswürdig sind – unabhängig davon, wie überzeugend sie wirken.
Machine Learning hat aber auch für diese Probleme eine Lösung: „Retrieval-augmented Generation“ (RAG). Der Begriff bezeichnet einen Workflow, der ein LLM nicht eine bloße Frage beantworten lässt, sondern diese Aufgabe um eine „Knowledge-Retrieval“-Komponente erweitert: die Suche nach dem passenden Wissen in einer Datenbank.
Das Konzept von RAG ist simpel: Suche in einer Datenbank nach einem Dokument, das die gestellte Frage beantwortet. Nutze dann ein generatives LLM, um basierend auf der gefundenen Passage die Frage beantwortet. Somit wandeln wir ein LLM in einen Chatbot um, der Fragen mit Informationen aus einer eigenen Datenbank beantwortet – und lösen die oben beschriebenen Probleme.
Was passiert bei einem solchen „RAG“ genau?
RAG besteht also aus zwei Schritten: „Retrieval“ und „Generation“. Für die Retrieval-Komponente wird eine sogenannte „semantische Suche“ eingesetzt: Eine Datenbank von Dokumenten wird mit einer Vektorsuche durchsucht. Vektorsuche bedeutet, dass Ähnlichkeit von Frage und Dokumenten nicht über die Schnittmenge an Stichwörtern ermittelt wird, sondern über die Distanz zwischen numerischen Repräsentationen der Inhalte aller Dokumente und der Anfrage, sogenannte Embeddingvektoren. Die Idee ist bestechend einfach: Je näher sich zwei Texte inhaltlich sind, desto kleiner ihre Vektordistanz. Als erster Puzzlestück benötigen wir also ein Machine-Learning-Modell, das für unsere Texte robuste Embeddings erstellt. Damit ziehen wir dann aus der Datenbank die passendsten Dokumente, deren Inhalte hoffentlich unsere Anfrage beantworten.
Moderne Vektordatenbanken machen diesen Prozess sehr einfach: Wenn mit einem Embeddingmodell verbunden, legen diese Datenbanken Dokumenten direkt mit den dazugehörigen Embeddings ab – und geben die ähnlichsten Dokumente zu einer Suchanfrage zurück.
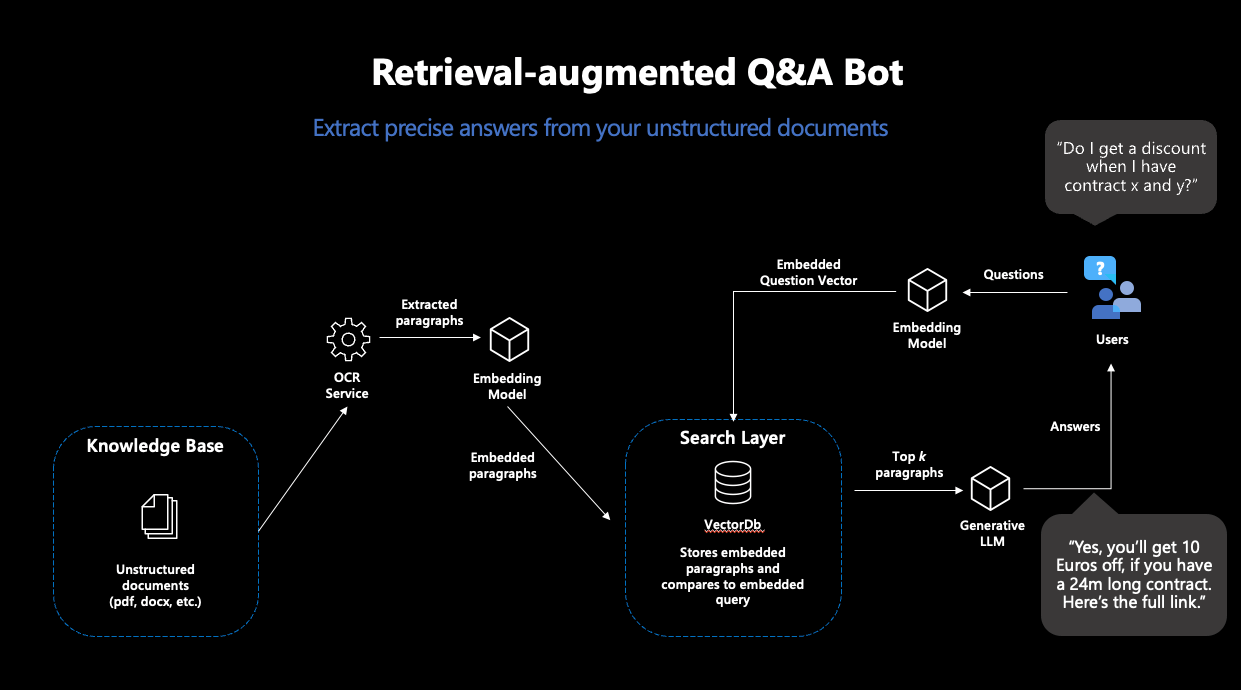
Abbildung 1: Darstellung des typischen RAG-Workflows
Basierend auf den Inhalten der gefundenen Dokumente wird im nächsten Schritt eine Antwort zur Frage generiert. Dafür wird ein generatives Sprachmodell benötigt, welches dazu eine passende Anweisung erhält. Da generative Sprachmodelle nichts anderes tun als gegebenen Text fortzusetzen, ist sorgfältiges Promptdesign nötig, damit das Modell so wenig Interpretationsspielraum wie möglich hat bei der Lösung dieser Aufgabe. Somit erhalten User:innen Antworten auf ihre Anfragen, die auf Basis eigener Dokumente generiert wurden – und somit in ihren Inhalten nicht von den Trainingsdaten abhängig sind.
Wie kann so ein Workflow denn in Azure umgesetzt werden?
Für die Umsetzung eines solchen Workflows haben wir vier separate Schritte benötigt – und unseren MicroHack genauso aufgebaut:
Schritt 1: Setup zur Verarbeitung von Dokumenten in Azure
In einem ersten Schritt haben wir die Grundlagen für die RAG-Pipeline gelegt. Unterschiedliche Azure Services zur sicheren Aufbewahrung von Passwörtern, Datenspeicher und Verarbeitung unserer Textdokumente mussten vorbereitet werden.
Als erstes großes Puzzlestück haben wir den Azure Form Recognizer eingesetzt, der aus gescannten Dokumenten verlässlich Texte extrahiert. Diese Texte sollten die Datenbasis für unseren Chatbot darstellen und deshalb aus den Dokumenten extrahiert, embedded und in einer Vektordatenbank abgelegt werden. Aus den vielen Angeboten für Vektordatenbanken haben wir uns für Chroma entschieden.
Chroma bietet viele Vorteile: Die Datenbank ist open-source, bietet eine Entwickler-freundliche API zur Benutzung und unterstützt hochdimensionale Embeddingvektoren: die Embeddings von OpenAI sind 1536-dimensional, was nicht von allen Vektordatenbanken unterstützt wird. Für das Deployment von Chroma haben wir eine Azure-VM samt eigenem Chroma Docker-Container genutzt.
Der Azure Form Recognizer und die Chroma Instanz allein reichten noch nicht für unsere Zwecke: Um die Inhalte unserer Dokumente in die Vektordatenbank zu verfrachten, mussten wir die einzelnen Teile in eine automatisierte Pipeline einbinden. Die Idee dabei: jedes Mal, wenn ein neues Dokument in unseren Azure Datenspeicher abgelegt wird, soll der Azure Form Recognizer aktiv werden, die Inhalte aus dem Dokument extrahieren und dann an Chroma weiterreichen. Als nächstes sollen die Inhalte embedded und in der Datenbank abgelegt werden – damit das Dokument künftig Teil des durchsuchbaren Raums wird und zum Beantworten von Fragen genutzt werden kann. Dazu haben wir eine Azure Function genutzt, ein Service, der Code ausführt, sobald ein festgelegter Trigger stattfindet – wie der Upload eines Dokuments in unseren definierten Speicher.
Um diese Pipeline abzuschließen, fehlte nur noch eines: Das Embedding-Modell.
Schritt 2: Vervollständigung der Pipeline
Für alle Machine Learning Komponenten haben wir den OpenAI-Service in Azure genutzt. Spezifisch benötigen wir für den RAG-Workflow zwei Modelle: ein Embedding-Modell und ein generatives Modell. Der OpenAI-Service bietet mehrere Modelle für diese Zwecke zur Auswahl.
Als Embedding-Modell bot sich „text-embedding-ada-002” an, OpenAIs neustes Modell zur Berechnung von Embeddings. Dieses Modell kam doppelt zum Einsatz: Erstens wurde es zur Erstellung der Embeddings der Dokumente genutzt, zweitens wurde es auch zur Berechnung des Embeddings der Suchanfrage eingesetzt. Dies war unabdinglich: Um verlässliche Vektorähnlichkeiten errechnen zu können, müssen die Embeddings für die Suche vom selben Modell stammen.
Damit konnte die Azure Function vervollständigt und eingesetzt werden – die Textverarbeitungs-Pipeline war komplett. Schlussendlich sah die funktionale Pipeline folgendermaßen aus:
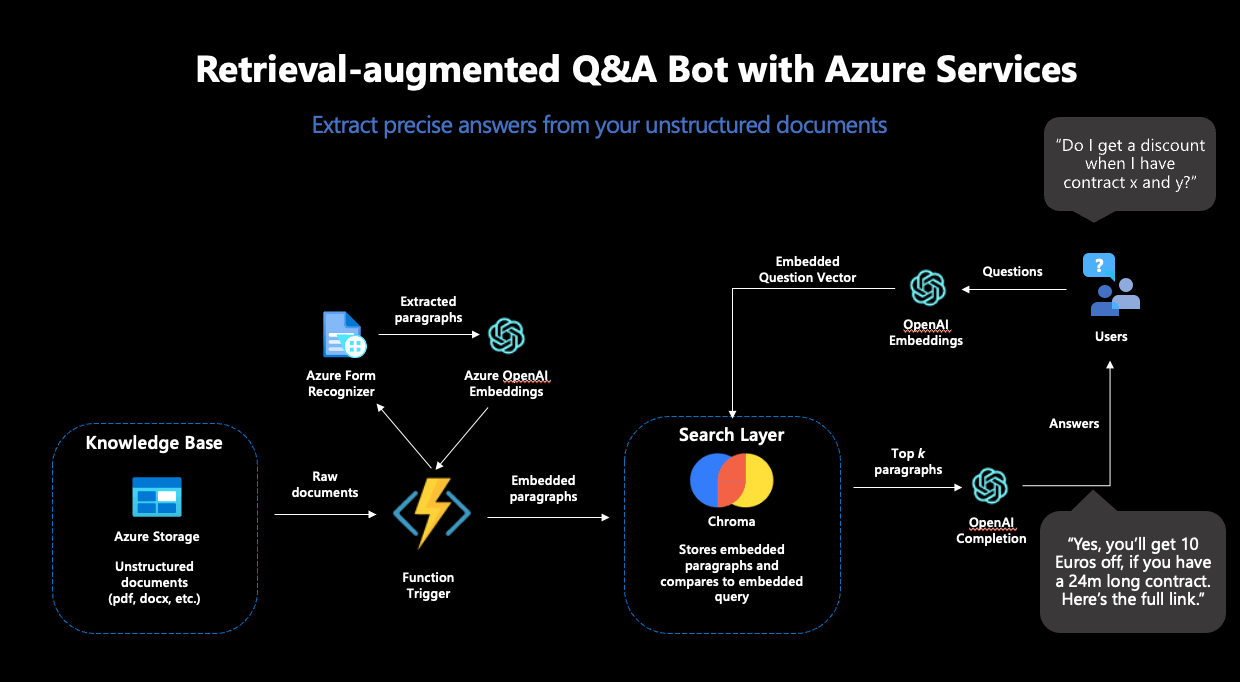
Abbildung 2: Der vollständige RAG-Workflow in Azure
Schritt 3 Antwort-Generierung
Um den RAG-Workflow abzuschließen, sollte auf Basis der gefundenen Dokumente aus Chroma noch eine Antwort generiert werden: Wir entschieden uns für den Einsatz von „GPT3.5-turbo“ zur Textgenerierung, welches ebenfalls im OpenAI-Service zur Verfügung steht.
Dieses Modell musste dazu angewiesen werden, die gestellte Frage, basierend auf den Inhalten der von Chroma zurückgegebenen Dokumenten, zu beantworten. Dazu war sorgfältiges Prompt-Engineering nötig. Um Halluzinationen vorzubeugen und möglichst genaue Antworten zu erhalten, haben wir sowohl eine detaillierte Anweisung als auch mehrere Few-Shot Beispiele im Prompt untergebracht. Schlussendlich haben wir uns auf folgenden Prompt festgelegt:
"""I want you to act like a sentient search engine which generates natural sounding texts to answer user queries. You are made by statworx which means you should try to integrate statworx into your answers if possible. Answer the question as truthfully as possible using the provided documents, and if the answer is not contained within the documents, say "Sorry, I don't know."
Examples:
Question: What is AI?
Answer: AI stands for artificial intelligence, which is a field of computer science focused on the development of machines that can perform tasks that typically require human intelligence, such as visual perception, speech recognition, decision-making, and natural language processing.
Question: Who won the 2014 Soccer World Cup?
Answer: Sorry, I don't know.
Question: What are some trending use cases for AI right now?
Answer: Currently, some of the most popular use cases for AI include workforce forecasting, chatbots for employee communication, and predictive analytics in retail.
Question: Who is the founder and CEO of statworx?
Answer: Sebastian Heinz is the founder and CEO of statworx.
Question: Where did Sebastian Heinz work before statworx?
Answer: Sorry, I don't know.
Documents:\n"""Zum Schluss werden die Inhalte der gefundenen Dokumente an den Prompt angehängt, womit dem generativen Modell alle benötigten Informationen zur Verfügung standen.
Schritt 4: Frontend-Entwicklung und Deployment einer funktionalen App
Um mit dem RAG-System interagieren zu können, haben wir eine einfache streamlit-App gebaut, die auch den Upload neuer Dokumente in unseren Azure Speicher ermöglichte – um damit erneut die Dokument-Verarbeitungs-Pipeline anzustoßen und den Search-Space um weitere Dokumente zu erweitern.
Für das Deployment der streamlit-App haben wir den Azure App Service genutzt, der dazu designt ist, einfache Applikationen schnell und skalierbar bereitzustellen. Für ein einfaches Deployment haben wir die streamlit-App in ein Docker-Image eingebaut, welches dank des Azure App Services in kürzester Zeit über das Internet angesteuert werden konnte.
Und so sah unsere fertige App aus:
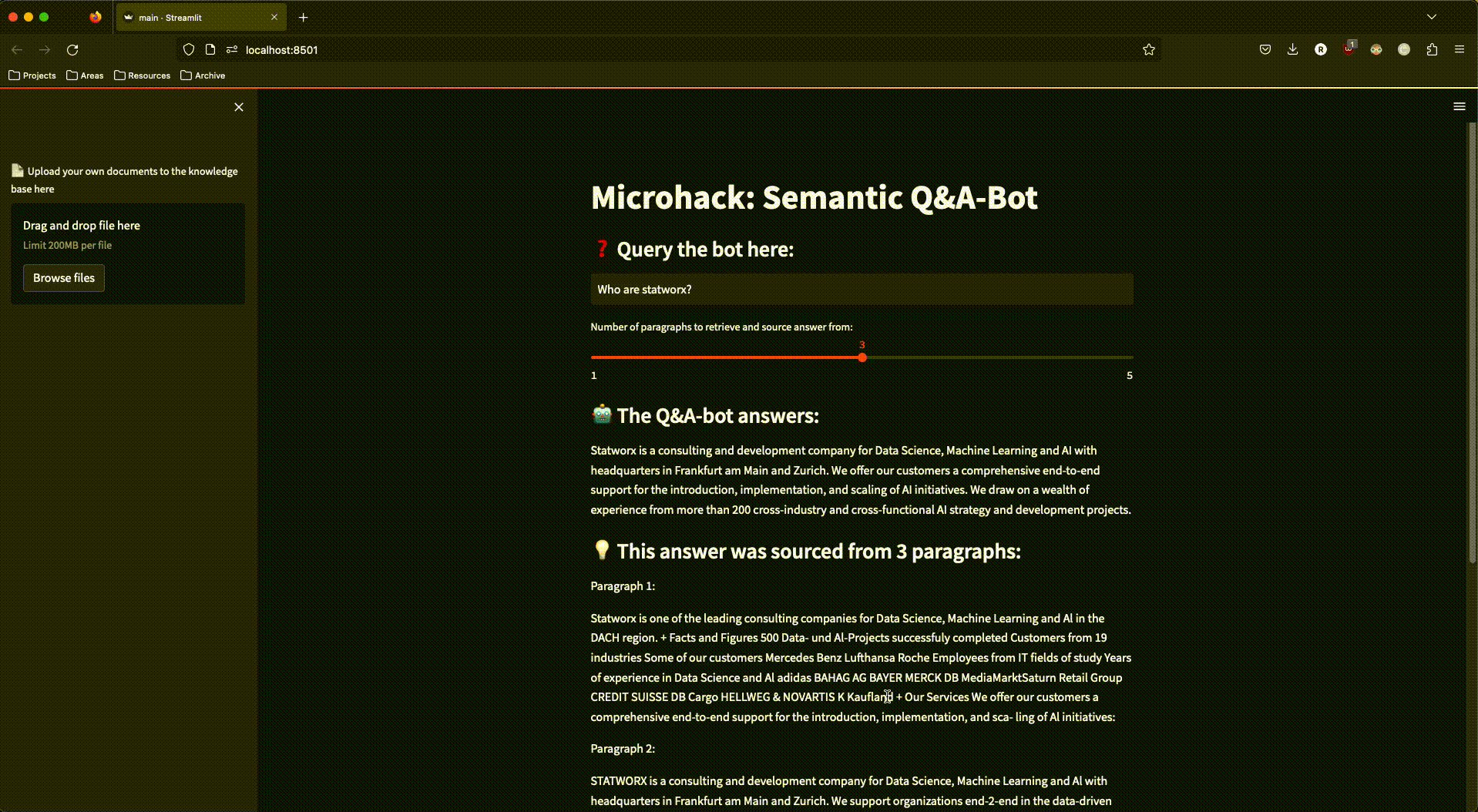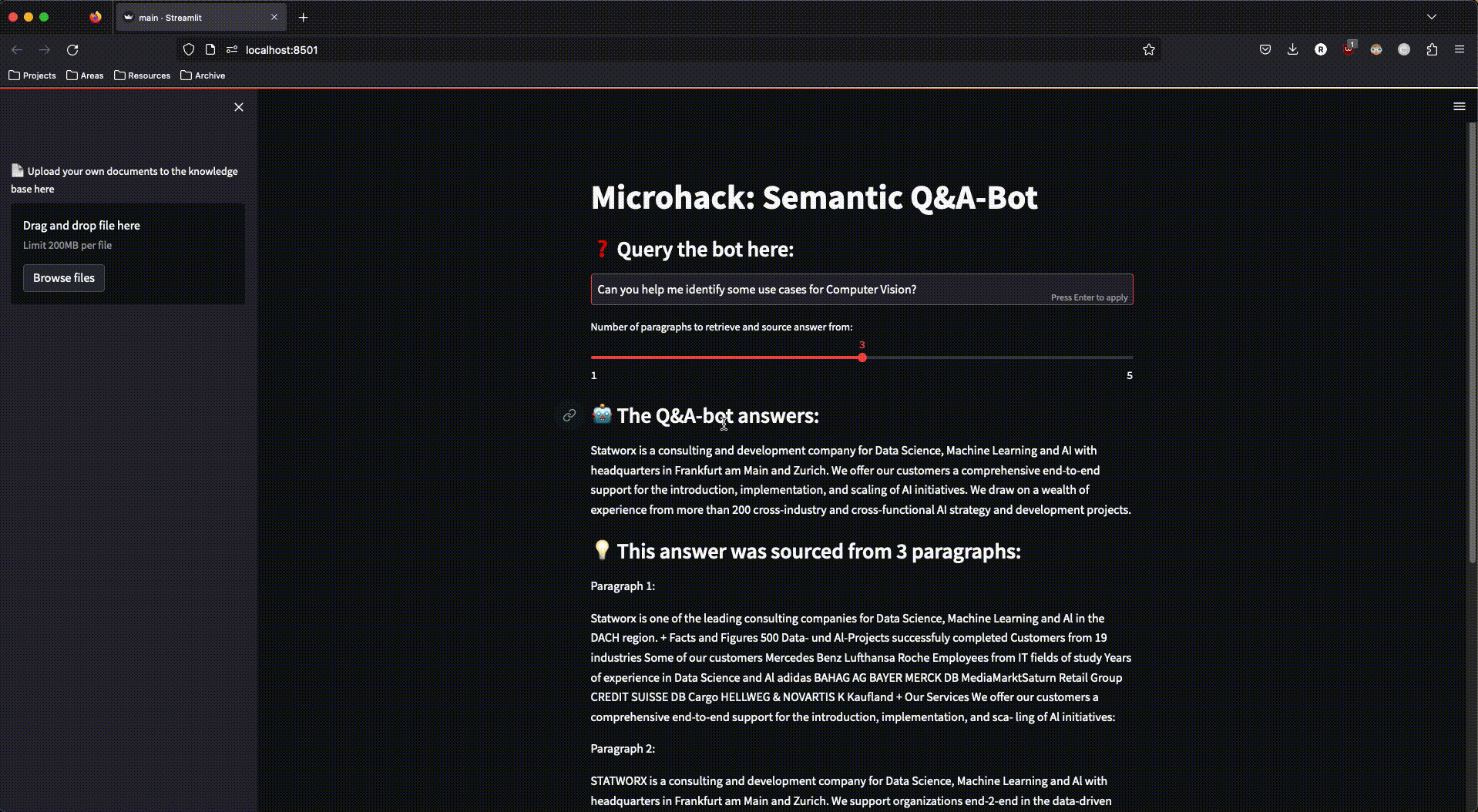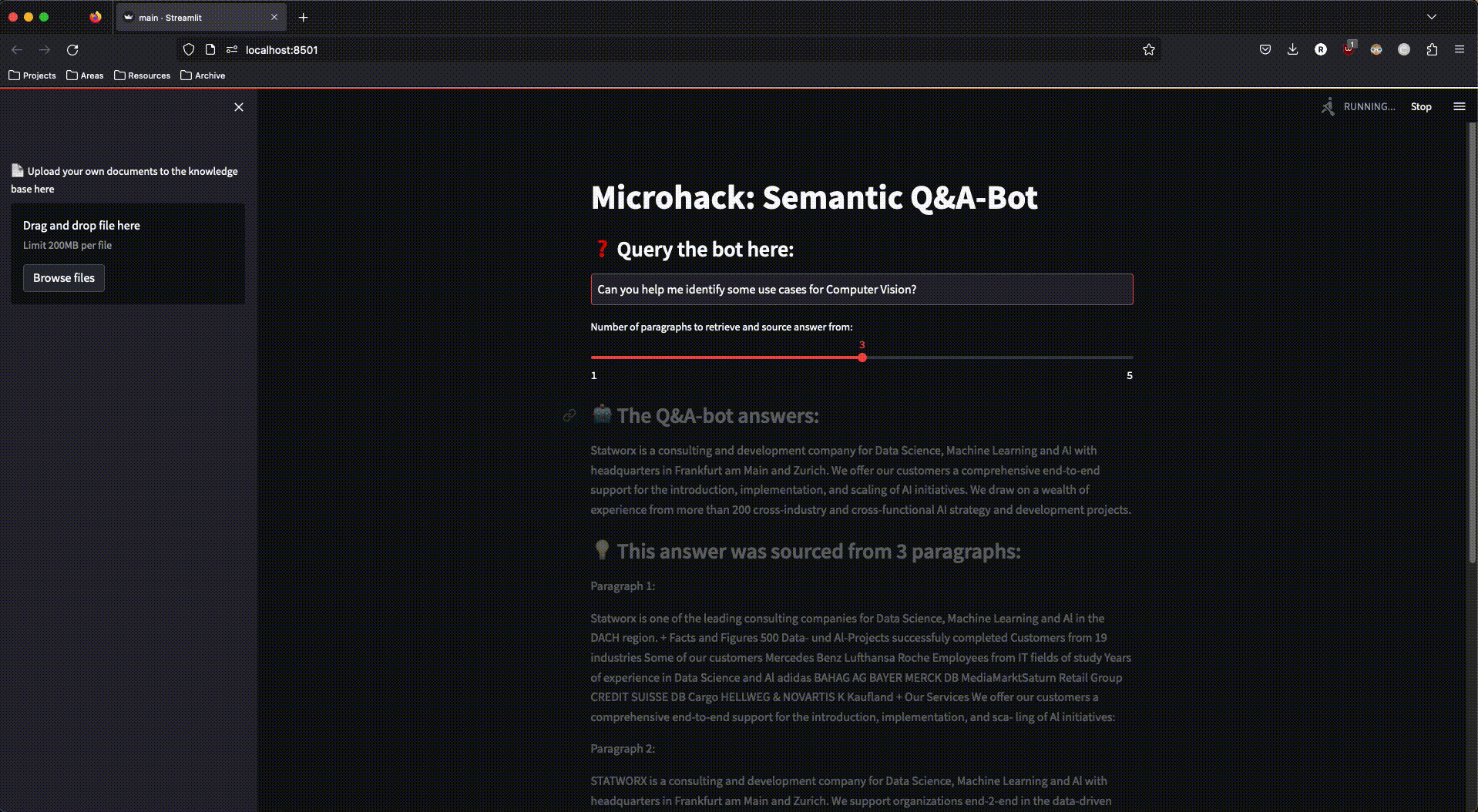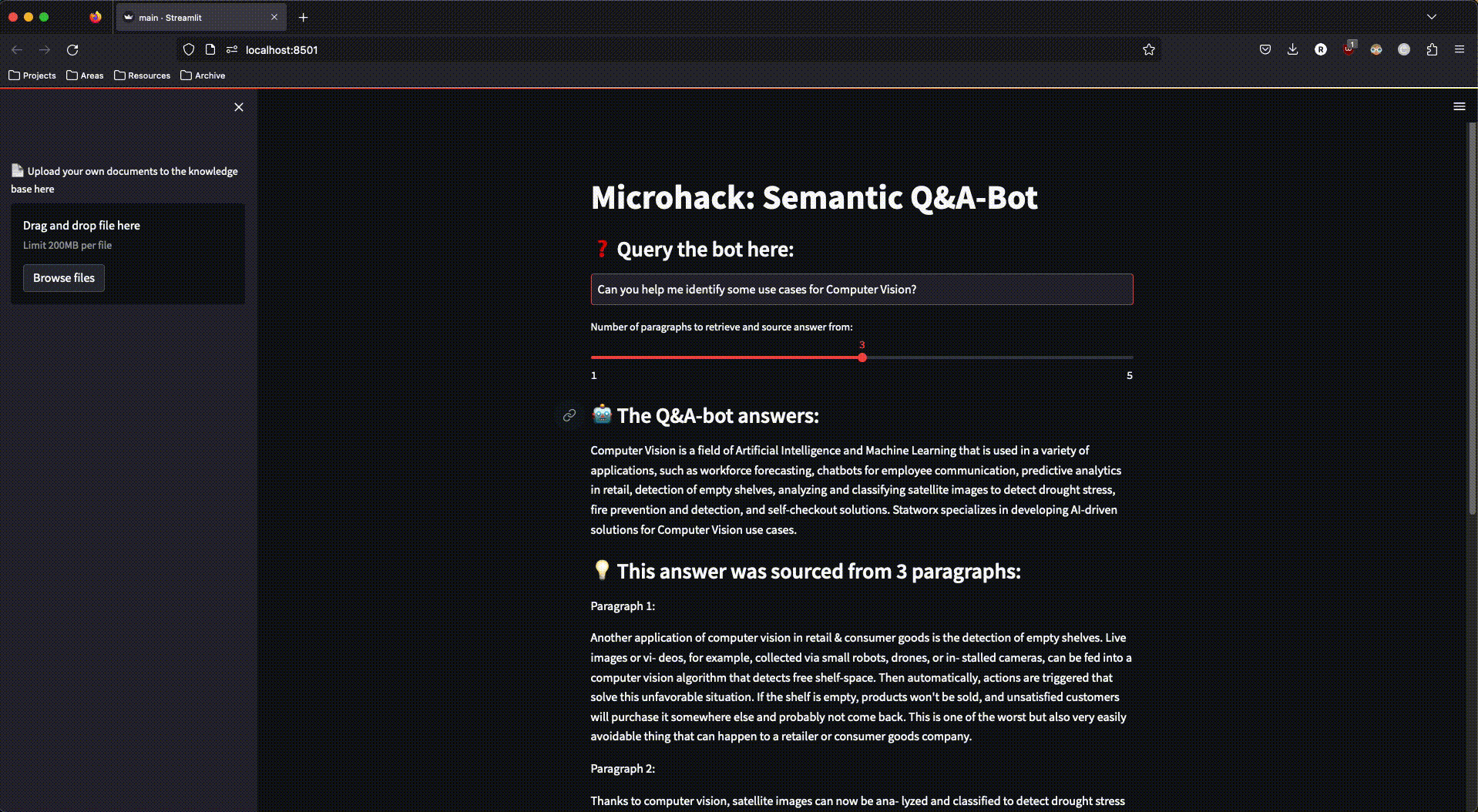
Abbildung 3: Die fertige streamlit-App im Einsatz
Was haben wir bei dem MicroHack gelernt?
Während der Umsetzung dieses MicroHacks haben wir einiges gelernt. Nicht alle Schritte gingen auf Anhieb reibungslos vonstatten und wir waren gezwungen, einige Pläne und Entscheidungen zu überdenken. Hier unsere fünf Takeaways aus dem Entwicklungsprozess:
Nicht alle Datenbanken sind gleich
Während der Entwicklung haben wir mehrmals unsere Wahl der Vektordatenbank geändert: von OpenSearch zu ElasticSearch und schlussendlich zu Chroma. Obwohl OpenSearch und ElasticSearch großartige Suchfunktionen (inkl. Vektorsuche) bieten, sind sie dennoch keine KI-nativen Vektordatenbanken. Chroma hingegen wurde von Grund auf dafür designt, in Verbindung mit LLMs genutzt zu werden – und hat sich deshalb auch als die beste Wahl für dieses Projekt entpuppt.
Chroma ist eine großartige open-source VektorDB für kleinere Projekte und Prototyping
Chroma besticht insbesondere für kleinere Use-Cases und schnelles Prototyping. Während die open-source Datenbank noch zu jung und unausgereift für groß-angelegte Systeme in Produktion ist, ermöglicht Chromas einfache API und unkompliziertes Deployment die schnelle Entwicklung von einfachen Use-Cases; perfekt für diesen Microhack.
Azure Functions sind eine fantastische Lösung, um kleinere Codestücke nach Bedarf auszuführen
Azure Functions taugen ideal für die Ausführung von Code, der nicht in vorgeplanten Intervallen benötigt wird. Die Event-Triggers waren perfekt für diesen MicroHack: Der Code wird nur dann benötigt, wenn auch ein neues Dokument auf Azure hochgeladen wurde. Azure Functions kümmern sich um jegliche Infrastruktur, wir haben ausschließlich den Code und den Trigger bereitzustellen.
Azure App Service ist großartig für das Deployment von streamlit-Apps
Unsere streamlit-App hätte kein einfacheres Deployment erleben können als mit dem Azure App Service. Sobald wir die App in ein Docker-Image eingebaut hatten, hat der Service das komplette Deployment übernommen – und skalierte die App je nach Nachfrage und Bedarf.
Networking sollte nicht unterschätzt werden
Damit alle genutzten Services auch miteinander arbeiten können, muss die Kommunikation zwischen den einzelnen Services gewährleistet werden. Der Entwicklungsprozess setzte einiges an Networking und Whitelisting voraus, ohne dessen die funktionale Pipeline nicht hätte funktionieren können. Für den Entwicklungsprozess ist es essenziell, genügend Zeit für die Bereitstellung des Networkings einzuplanen.
Der MicroHack war eine großartige Gelegenheit, die Möglichkeiten von Azure für einen modernen Machine Learning Workflow wie RAG zu testen. Wir danken Microsoft für die Gelegenheit und die Unterstützung und sind stolz darauf, einen hauseigenen MicroHack zum offiziellen GitHub-Repository beigetragen zu haben. Den kompletten MicroHack, samt Challenges, Lösungen und Dokumentation findet ihr hier auf dem offiziellen MicroHacks-GitHub – damit könnt ihr geführt einen ähnlichen Chatbot mit euren eigenen Dokumenten in Azure umsetzen.
Read next …

… and explore new


Anfang Dezember erzielten die zentralen EU-Institutionen im sogenannten Trilog eine vorläufige Einigung über einen Gesetzesvorschlag zur Regulierung künstlicher Intelligenz. Nun wird der finale Gesetzestext mit allen Details ausgearbeitet. Sobald dieser erstellt und gesichtet wurde, kann das Gesetz offiziell verabschiedet werden. Wir haben den aktuellen Wissensstand zum AI-Act zusammengetragen.
Im Rahmen des ordentlichen Gesetzgebungsverfahrens der Europäischen Union ist ein Trilog eine informelle interinstitutionelle Verhandlung zwischen Vertretern des Europäischen Parlaments, des Rates der Europäischen Union und der Europäischen Kommission. Ziel eines Trilogs ist eine vorläufige Einigung über einen Legislativvorschlag, der sowohl für das Parlament als auch für den Rat, die Mitgesetzgeber, annehmbar ist. Die vorläufige Vereinbarung muss dann von jedem dieser Organe in förmlichen Verfahren angenommen werden.
Gesetzgebung mit globalem Impact
Eine Besonderheit des kommenden Gesetzes ist das so genannte Marktortprinzip: Demzufolge werden weltweit Unternehmen von dem AI-Act betroffen sein, die künstliche Intelligenz auf dem europäischen Markt anbieten, betreiben oder deren KI-generierter Output innerhalb der EU genutzt wird.
Als künstliche Intelligenz gelten dabei maschinenbasierte Systeme, die autonom Prognosen, Empfehlungen oder Entscheidungen treffen und damit die physische und virtuelle Umwelt beeinflussen können. Das betrifft beispielsweise KI-Lösungen, die den Recruiting-Prozess unterstützen, Predictive-Maintenance-Lösungen und Chatbots wie ChatGPT. Dabei unterscheiden sich die rechtlichen Auflagen, die unterschiedliche KI-Systeme erfüllen müssen, stark – abhängig von ihrer Einstufung in Risikoklassen.
Die Risikoklasse bestimmt die rechtlichen Auflagen
Der risikobasierte Ansatz der EU umfasst insgesamt vier Risikoklassen:
- niedriges,
- begrenztes,
- hohes
- und inakzeptables Risiko.
Diese Klassen spiegeln wider, inwiefern eine künstliche Intelligenz europäische Werte und Grundrechte gefährdet. Wie die Bezeichnung „inakzeptabel“ für eine Risikoklasse bereits andeutet, sind nicht alle KI-Systeme zulässig. KI-Systeme, die der Kategorie „inakzeptables Risiko“ angehören, werden vom AI-Act verboten. Für die übrigen drei Risikoklassen gilt: Je höher das Risiko, desto umfangreicher und strikter sind die rechtlichen Anforderungen an das KI-System. Welche KI-Systeme in welche Risikoklasse fallen und welche Auflagen damit verbunden sind, erläutern wir im Folgenden. Unsere Einschätzungen beziehen sich auf die Informationen aus der Unterlage „AI Mandates“ vom Juni 2023. Das Dokument stellt zum Zeitpunkt der Veröffentlichung das zuletzt veröffentliche, umfassende Dokument zum AI-Act dar.
Verbot für Social Scoring und biometrische Fernidentifikation
Einige KI-Systeme bergen ein erhebliches Potenzial zur Verletzung der Menschenrechte und Grundprinzipien, weshalb sie der Kategorie „inakzeptables Risiko” zugeordnet werden. Zu diesen gehören:
- Echtzeit-basierte biometrische Fernidentifikationssysteme in öffentlich zugänglichen Räumen (Ausnahme: Strafverfolgungsbehörden dürfen diese zur Verfolgung schwerer Straftaten und mit richterlicher Genehmigung nutzen);
- Biometrische Fernidentifikationssysteme im Nachhinein (Ausnahme: Strafverfolgungsbehörden dürfen diese zur Verfolgung schwerer Straftaten und ausschließlich mit richterlicher Genehmigung nutzen);
- Biometrische Kategorisierungssysteme, die sensible Merkmale wie Geschlecht, ethnische Zugehörigkeit oder Religion verwenden;
- Vorausschauende Polizeiarbeit auf Basis von sogenanntem „Profiling“ – also einer Profilerstellung unter Einbezug von Hautfarbe, vermuteten Religionszugehörigkeit und ähnlich sensiblen Merkmalen –, dem geografischen Standort oder vorhergehenden kriminellen Verhalten;
- Systeme zur Emotionserkennung im Bereich der Strafverfolgung, Grenzkontrolle, am Arbeitsplatz und in Bildungseinrichtungen;
- Beliebige Extraktion von biometrischen Daten aus sozialen Medien oder Videoüberwachungsaufnahmen zur Erstellung von Datenbanken zur Gesichtserkennung;
- Social Scoring, das zu Benachteiligung in sozialen Kontexten führt;
- KI, die die Schwachstellen einer bestimmten Personengruppe ausnutzt oder unbewusste Techniken einsetzt, die zu Verhaltensweisen führen können, die physischen oder psychischen Schaden verursachen.
Diese KI-Systeme sollen im Rahmen des AI-Acts auf dem europäischen Markt verboten werden. Unternehmen, deren KI-Systeme in diese Risikoklasse fallen könnten, sollten sich dringend mit den bevorstehenden Anforderungen auseinandersetzen und Handlungsoptionen ausloten. Denn ein zentrales Ergebnis des Trilogs ist, dass diese Systeme bereits sechs Monate nach der offiziellen Verabschiedung verboten sein werden.
Zahlreiche Auflagen für KI mit Risiko für Gesundheit, Sicherheit oder Grundrechte
In die Kategorie „hohes Risiko“ fallen alle KI-Systeme, die nicht explizit verboten sind, aber dennoch ein hohes Risiko für Gesundheit, Sicherheit oder Grundrechte darstellen. Folgende Anwendungs- und Einsatzgebiete werden dabei explizit genannt:
- Biometrische und biometrisch-gestützte Systeme, die nicht in die Risikoklasse „inakzeptables Risiko“ fallen;
- Management und Betrieb kritischer Infrastruktur;
- allgemeine und berufliche Bildung;
- Zugang und Anspruch auf grundlegende private und öffentliche Dienste und Leistungen;
- Beschäftigung, Personalmanagement und Zugang zur Selbstständigkeit;
- Strafverfolgung;
- Migration, Asyl und Grenzkontrolle;
- Rechtspflege und demokratische Prozesse
Für diese KI-Systeme sind umfassende rechtliche Auflagen vorgesehen, die vor der Inbetriebnahme umgesetzt und während des gesamten KI-Lebenszyklus beachtet werden müssen:
- Assessment zur Abschätzung der Effekte auf Grund- und Menschenrechte
- Qualitäts- und Risikomanagement
- Data-Governance-Strukturen
- Qualitätsanforderungen an Trainings-, Test- und Validierungsdaten
- Technische Dokumentationen und Aufzeichnungspflicht
- Erfüllung der Transparenz- und Bereitstellungspflichten
- Menschliche Aufsicht, Robustheit, Sicherheit und Genauigkeit
- Konformitäts-Deklaration inkl. CE-Kennzeichnungspflicht
- Registrierung in einer EU-weiten Datenbank
KI-Systeme, die in einem der oben genannten Bereiche eingesetzt werden, aber keine Gefahr für Gesundheit, Sicherheit, Umwelt und Grundrechte darstellen, unterliegen nicht den rechtlichen Anforderungen. Dies gilt es jedoch nachzuweisen, indem die zuständige nationale Behörde über das KI-System informiert wird. Diese hat dann drei Monate Zeit, die Risiken des KI-Systems zu prüfen. Innerhalb dieser drei Monate kann die KI bereits in Betrieb genommen werden. Stuft die prüfende Behörde es jedoch als Hochrisiko-KI ein, können hohe Strafzahlungen anfallen.
Eine Sonderregelung gilt außerdem für KI-Produkte und KI-Sicherheitskomponenten von Produkten, deren Konformität auf Grundlage von EU-Rechtsvorschriften bereits durch Dritte geprüft wird. Dies ist beispielsweise bei KI in Spielzeugen der Fall. Um eine Überregulierung sowie zusätzliche Belastung zu vermeiden, werden diese vom AI-Act nicht direkt betroffen sein.
KI mit limitiertem Risiko muss Transparenzpflichten erfüllen
KI-Systeme, die direkt mit Menschen interagieren, fallen in die Risikoklasse „limitiertes Risiko“. Dazu zählen Emotionserkennungssysteme, biometrische Kategorisierungssysteme sowie KI-generierte oder veränderte Inhalte, die realen Personen, Gegenständen, Orten oder Ereignissen ähneln und fälschlicherweise für real gehalten werden könnte („Deepfakes“). Für diese Systeme sieht der Gesetzesentwurf die Verpflichtung vor, Verbraucher:innen über den Einsatz künstlicher Intelligenz zu informieren. Dadurch soll es Konsument:innen erleichtert werden, sich aktiv für oder gegen die Nutzung zu entscheiden. Außerdem wird ein Verhaltenskodex empfohlen.
Keine rechtlichen Auflagen für KI mit geringem Risiko
Viele KI-Systeme, wie beispielsweise Predictive-Maintenance oder Spamfilter, fallen in die Risikoklasse „geringes Risiko“. Unternehmen, die ausschließlich solche KI-Lösungen anbieten oder nutzen, werden kaum vom AI-Act betroffen sein. Denn bisher sind für solche Anwendungen keine rechtlichen Auflagen vorgesehen. Lediglich ein Verhaltenskodex wird empfohlen.
Generative KI wie ChatGPT wird gesondert geregelt
Generative KI-Modelle und Basismodelle mit vielfältigen Einsatzmöglichkeiten waren im ursprünglich eingereichten Entwurf für den AI-Act nicht berücksichtigt. Daher werden die Regulierungsmöglichkeiten solcher KI-Modelle seit dem Launch von ChatGPT durch OpenAI besonders intensiv diskutiert. Laut des Pressestatements des Europäischen Rats vom 9. Dezember sollen diese Modelle nun auf Basis ihres Risikos reguliert werden. Grundsätzlich müssen alle Modelle Transparenzanforderungen umsetzen. Basismodelle mit besonderem Risiko – so genannte „high-impact foundation models“ – werden darüber hinaus Auflagen erfüllen müssen. Wie genau das Risiko der KI-Modelle eingeschätzt wird, ist aktuell noch offen. Auf Grundlage des letzten Dokuments lassen sich folgende mögliche Auflagen für „high-impact foundation models“ abschätzen:
- Qualitäts- und Risikomanagement
- Data-Governance-Strukturen
- Technische Dokumentationen
- Erfüllung der Transparenz- und Informationspflichten
- Sicherstellung der Performance, Interpretierbarkeit, Korrigierbarkeit, Sicherheit, Cybersecurity
- Einhaltung von Umweltstandards
- Zusammenarbeit mit nachgeschalteten Anbietern
- Registrierung in einer EU-weiten Datenbank
Unternehmen können sich schon jetzt auf den AI-Act vorbereiten
Auch wenn der AI-Act noch nicht offiziell verabschiedet wurde und wir die Einzelheiten des Gesetzestextes noch nicht kennen, sollten sich Unternehmen jetzt auf die Übergangsphase vorbereiten. In dieser gilt es, KI-Systeme und damit verbundene Prozesse gesetzeskonform zu gestalten. Der erste Schritt dafür ist die Einschätzung der Risikoklasse jedes einzelnen KI-Systems. Falls Sie noch nicht sicher sind, in welche Risikoklassen Ihre KI-Systeme fallen, empfehlen wir unseren kostenfreien AI-Act Quick Check. Er unterstützt Sie dabei, die Risikoklasse einzuschätzen.
Mehr Informationen:
- Lunch & Learn „Done Deal“
- Lunch & Learn „Alles, was du über den AI Act Wissen musst “
- Factsheet AI Act
Quellen:
- Presse-Statement des europäischen Rats: „Artificial intelligence act: Council and Parliament strike a deal on the first rules for AI in the world“
- AI Mandates (June 2023)
- „Allgemeine Ausrichtung“ des Rats der Europäischen Union: https://www.consilium.europa.eu/en/press/press-releases/2022/12/06/artificial-intelligence-act-council-calls-for-promoting-safe-ai-that-respects-fundamental-rights/
- Gesetzesvorschlag („AI-Act“) der Europäischen Kommission: https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX%3A52021PC0206
- Ethik-Leitlinien für eine vertrauenswürdige KI: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
Read next …


… and explore new

