Die versteckten Risiken von Black-Box Algorithmen
Unzählige Lebensläufe in kürzester Zeit sichten, bewerten und Empfehlungen für geeignete Kandidat:innen abgeben – das ist mit künstlicher Intelligenz im Bewerbungsmanagement mittlerweile möglich. Denn fortschrittliche KI-Techniken können auch komplexe Datenmengen effizient analysieren. Im Personalmanagement kann so nicht nur wertvolle Zeit bei der Vorauswahl eingespart, sondern auch Bewerber:innen schneller kontaktiert werden. Künstliche Intelligenz hat auch das Potenzial, Bewerbungsprozesse fairer und gerechter zu gestalten.
Die Praxis zeigt jedoch, dass auch künstliche Intelligenzen nicht immer „fairer“ sind. Vor einigen Jahren sorgte beispielsweise ein Recruiting-Algorithmus von Amazon für Aufsehen. Die KI diskriminierte Frauen bei der Auswahl von Kandidat:innen. Und auch bei Algorithmen zur Gesichtserkennung von People of Color kommt es immer wieder zu Diskriminierungsvorfällen.
Ein Grund dafür ist, dass komplexe KI-Algorithmen auf Basis der eingespeisten Daten selbstständig Vorhersagen und Ergebnisse berechnen. Wie genau sie zu einem bestimmten Ergebnis kommen, ist zunächst nicht nachvollziehbar. Daher werden sie auch als Black-Box Algorithmen bezeichnet. Im Fall von Amazon hat dieser auf Basis der aktuellen Belegschaft, die vorwiegend männlich war, geeignete Bewerber:innenprofile ermittelt und damit voreingenommene Entscheidungen getroffen. Auf diese oder ähnliche Weise können Algorithmen Stereotypen reproduzieren und Diskriminierung verstärken.
Prinzipien für vertrauenswürdige KI
Der Amazon-Vorfall zeigt, dass Transparenz bei der Entwicklung von KI-Lösungen von hoher Relevanz ist, um die ethisch einwandfreie Funktionsweise sicherzustellen. Deshalb ist Transparenz auch eines der insgesamt sieben statworx Principles für vertrauenswürdige KI. Die Mitarbeitenden von statworx haben gemeinsam folgende KI-Prinzipien definiert: Menschen-zentriert, transparent, ökologisch, respektvoll, fair, kollaborativ und inklusiv. Diese dienen als Orientierung für die alltägliche Arbeit mit künstlicher Intelligenz. Allgemeingültige Standards, Regeln und Gesetzte gibt es nämlich bisher nicht. Dies könnte sich jedoch bald ändern.
Die europäische Union (EU) diskutiert seit geraumer Zeit einen Gesetzesentwurf zur Regulierung von künstlicher Intelligenz. Dieser Entwurf, der so genannte AI-Act, hat das Potenzial zum Gamechanger für die globale KI-Branche zu werden. Denn nicht nur europäische Unternehmen werden von diesem Gesetzesentwurf anvisiert. Betroffen wären alle Unternehmen, die KI-Systeme auf dem europäischen Markt anbieten, dessen KI-generierter Output innerhalb der EU genutzt wird oder KI-Systeme zur internen Nutzung innerhalb der EU betreiben. Die Anforderungen, die ein KI-System dann erfüllen muss, hängen von dessen Anwendungsbereich ab.
Recruiting-Algorithmen werden auf Grund ihres Einsatzbereichs voraussichtlich als Hochrisiko-KI eingestuft. Demnach müssten Unternehmen bei der Entwicklung, der Veröffentlichung aber auch beim Betrieb der KI-Lösung umfassende Auflagen erfüllen. Unter anderem sind Unternehmen in der Pflicht, Qualitätsstandards für genutzte Daten einzuhalten, technische Dokumentationen zu erstellen und Risikomanagement zu etablieren. Bei Verstoß drohen hohe Bußgelder bis zu 6% des globalen jährlichen Umsatzes. Daher sollten sich Unternehmen schon jetzt mit den kommenden Anforderungen und ihren KI-Algorithmen auseinandersetzen. Ein sinnvoller erster Schritt können Explainable AI Methoden (XAI) sein. Mit Hilfe dieser können Black-Box-Algorithmen nachvollzogen und die Transparenz der KI-Lösung erhöht werden.
Die Black-Box mit Explainable AI Methoden entschlüsseln
Durch XAI-Methoden können Entwickler:innen die konkreten Entscheidungsprozesse von Algorithmen besser interpretieren. Das heißt, es wird transparent, wie ein Algorithmus Muster und Regeln gebildet hat und Entscheidungen trifft. Dadurch können mögliche Probleme wie beispielsweise Diskriminierung im Bewerbungsprozess nicht nur entdeckt, sondern auch korrigiert werden. Somit trägt XAI nicht nur zur stärkeren Transparenz von KI bei, sondern begünstigt auch deren ethisch unbedenklichen Einsatz und fördert so die Konformität einer KI mit dem kommenden AI-Act.
Einige XAI-Methoden sind sogar modellagnostisch, also anwendbar auf beliebige KI-Algorithmen vom Entscheidungsbaum bis hin zum Neuronalen Netz. Das Forschungsfeld rund um XAI ist in den letzten Jahren stark gewachsen, weshalb es mittlerweile eine große Methodenvielfalt gibt. Dabei zeigt unsere Erfahrung aber: Es gibt große Unterschiede zwischen verschiedenen Methoden hinsichtlich Verlässlichkeit und Aussagekraft ihrer Ergebnisse. Außerdem eignen sich nicht alle Methoden gleichermaßen zur robusten Anwendung in der Praxis und zur Gewinnung des Vertrauens externer Stakeholder. Daher haben wir unsere Top 3 Methoden anhand der folgenden Kriterien für diesen Blogbeitrag ermittelt:
- Ist die Methode modellagnostisch, funktioniert sie also für alle Arten von KI-Modellen?
- Liefert die Methode globale Ergebnisse, sagt also etwas über das Modell als Ganzes aus?
- Wie aussagekräftig sind die resultierenden Erklärungen?
- Wie gut ist das theoretische Fundament der Methode?
- Können böswillige Akteure die Resultate manipulieren oder sind sie vertrauenswürdig?
Unsere Top 3 XAI Methoden im Überblick
Anhand der oben genannten Kriterien haben wir drei verbreitete und bewährte Methoden zur detaillierten Darstellung ausgewählt: Permutation Feature Importance (PFI), SHAP Feature Importance und Accumulated Local Effects (ALE). Im Folgenden erklären wir für jede der drei Methoden den Anwendungszweck und deren grundlegende technische Funktionsweise. Außerdem gehen wir auf die Vor- und Nachteile beim Einsatz der drei Methoden ein und illustrieren die Anwendung anhand des Beispiels einer Recruiting-KI.
Mit Permutation Feature Importance effizient Einflussfaktoren identifizieren
Ziel der Permutation Feature Importance (PFI) ist es, herauszufinden, welche Variablen im Datensatz besonders entscheidend dafür sind, dass das Modell genaue Vorhersagen trifft. Im Falle des Recruiting-Beispiels kann die PFI-Analyse darüber aufklären, auf welche Informationen sich das Modell für seine Entscheidung besonders verlässt. Taucht hier z.B. das Geschlecht als einflussreicher Faktor auf, kann das die Entwickler:innen alarmieren. Aber auch in der Außenwirkung schafft die PFI-Analyse Transparenz und zeigt externen Anwender:innen an, welche Variablen für das Modell besonders relevant sind. Für die Berechnung der PFI benötigt man zunächst zwei Dinge:
- Eine Genauigkeitsmetrik wie z.B. die Fehlerrate (Anteil falscher Vorhersagen an allen Vorhersagen)
- Einen Testdatensatz, der zur Ermittlung der Genauigkeit verwendet werden kann.
Im Testdatensatz wird zunächst eine Variable nach der anderen durch das Hinzufügen von zufälligem Rauschen („Noise“) gewissermaßen verschleiert und dann die Genauigkeit des Modells über den bearbeiteten Testdatensatz bestimmt. Nun ist naheliegend, dass die Variablen, deren Verschleierung die Modellgenauigkeit am stärksten beeinträchtigen, besonders wichtig für die Genauigkeit des Modells sind. Sind alle Variablen nacheinander analysiert und sortiert, erhält man eine Visualisierung wie die in Abbildung 1. Anhand unseres künstlich erzeugten Beispieldatensatzes lässt sich folgendes erkennen: Berufserfahrung spielte keine große Rolle für das Modell, die Eindrücke aus dem Vorstellungsgespräch hingegen schon.
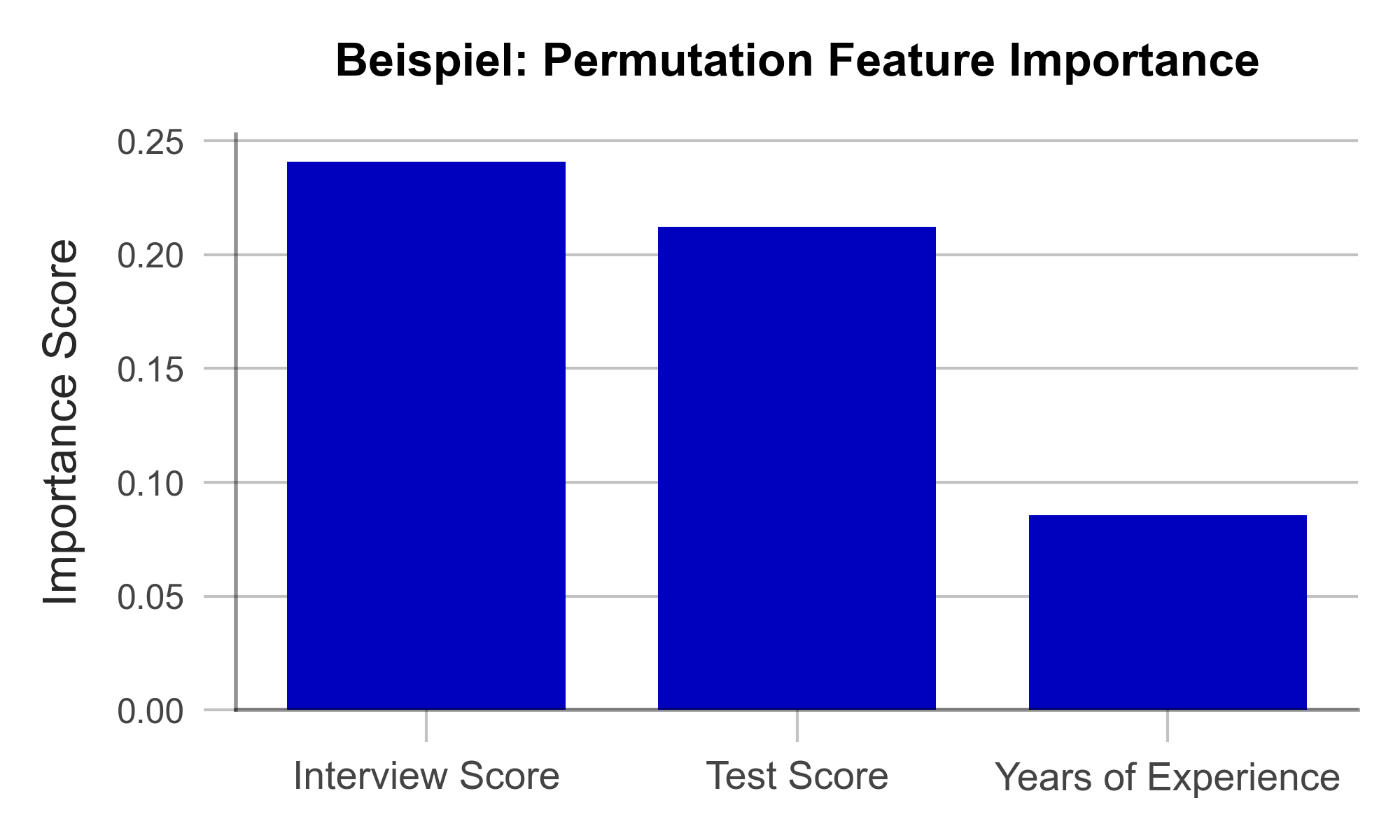
Abbildung 1 – Permutation Feature Importance am Beispiel einer Recruiting-KI (Daten künstlich erzeugt).
Eine große Stärke der PFI ist, dass sie einer nachvollziehbaren mathematischen Logik folgt. Die Korrektheit der gelieferten Erklärung kann durch statistische Überlegungen nachgewiesen werden. Darüber hinaus gibt es kaum manipulierbare Parameter im Algorithmus, mit der die Ergebnisse bewusst verzerrt werden könnten. Damit ist die PFI besonders geeignet dafür, das Vertrauen externer Betrachter:innen zu gewinnen. Nicht zuletzt ist die Berechnung der PFI im Vergleich zu anderen Explainable AI Methoden sehr ressourcenschonend.
Eine Schwäche der PFI ist, dass sie unter gewissen Umständen missverständliche Erklärungen liefern kann. Wird einer Variable ein geringer PFI-Wert zugewiesen, heißt das nicht immer, dass die Variable unwichtig für den Sachverhalt ist. Hat z.B. die Note des Bachelorstudiums einen geringen PFI-Wert, so kann das lediglich daran liegen, dass das Modell stattdessen auch die Note des Masterstudiums betrachten kann, da diese oft ähnlich sind. Solche korrelierten Variablen können die Interpretation der Ergebnisse erschweren. Nichtsdestotrotz ist die PFI eine effiziente und nützliche Methode zur Schaffung von Transparenz in Black-Box Modellen.
| Stärken | Schwächen |
|---|---|
| Wenig Spielraum für Manipulation der Ergebnisse | Berücksichtigt keine Interaktionen zwischen Variablen |
| Effiziente Berechnung |
Mit SHAP Feature Importance komplexe Zusammenhänge aufdecken
Die SHAP Feature Importance ist eine Methode zur Erklärung von Black-Box-Modellen, die auf der Spieltheorie basiert. Ziel ist es, den Beitrag jeder Variable zur Vorhersage des Modells zu quantifizieren. Damit ähnelt sie der Permutation Feature Importance auf den ersten Blick stark. Im Gegensatz zur PFI liefert die SHAP Feature Importance aber Ergebnisse, die komplexe Zusammenhänge zwischen mehreren Variablen berücksichtigen können.
SHAP liegt ein Konzept aus der Spieltheorie zugrunde: die Shapley Values. Diese sind ein Fairness-Kriterium, das jeder Variable eine Gewichtung zuweist, die ihrem Beitrag zum Ergebnis entspricht. Naheliegend ist die Analogie zu einem Teamsport, bei dem das Siegerpreisgeld unter allen Spieler:innen fair, also gemäß deren Beitrag zum Sieg, aufgeteilt wird. Mit SHAP kann analog für jede einzelne Beobachtung im Datensatz analysiert werden, welchen Beitrag welche Variable zur Vorhersage des Modells geliefert hat
Ermittelt man nun den durchschnittlichen absoluten Beitrag einer Variable über alle Beobachtungen im Datensatz hinweg, erhält man die SHAP Feature Importance. Abbildung 2 veranschaulicht beispielhaft die Ergebnisse dieser Analyse. Die Ähnlichkeit zur PFI ist klar ersichtlich, auch wenn die SHAP Feature Importance die Bewertung des Vorstellungsgespräches nur auf Platz 2 setzt.
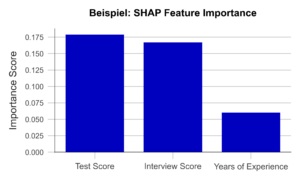
Abbildung 2 – SHAP Feature Importance am Beispiel einer Recruiting KI (Daten künstlich erzeugt).
Ein großer Vorteil dieses Ansatzes ist die Möglichkeit, Interaktionen zwischen Variablen zu berücksichtigen. Durch die Simulation verschiedener Variablen-Kombinationen lässt sich zeigen, wie sich die Vorhersage ändert, wenn zwei oder mehr Variablen gemeinsam variieren. Zum Bespiel sollte die Abschlussnote eines Studiums stets im Zusammenhang mit dem Studiengang und der Hochschule betrachtet werden. Im Gegensatz zur PFI trägt die SHAP Feature Importance diesem Umstand Rechnung. Auch sind Shapley Values, einmal berechnet, die Grundlage einer Bandbreite weiterer nützlicher XAI Methoden.
Eine Schwäche der Methode ist jedoch, dass sie aufwendiger zu berechnen ist als die PFI. Nur für bestimmte Arten von KI-Algorithmen (z.B. Entscheidungsbäume) gibt es effiziente Implementierungen. Es will also gut überlegt sein, ob für ein gegebenes Problem eine PFI-Analyse genügt, oder ob die SHAP Feature Importance zu Rate gezogen werden sollte.
| Stärken | Schwächen |
|---|---|
| Wenig Spielraum für Manipulation der Ergebnisse | Berechnung ist rechenaufwendig |
| Berücksichtigt komplexe Interaktionen zwischen Variablen |
Mit Accumulated Local Effects einzelne Variablen in den Fokus nehmen
Die Accumulated Local Effects (ALE) Methode ist eine Weiterentwicklung der Partial Dependence Plots (PDP), die sich großer Beliebtheit unter Data Scientists erfreuen. Beide Methoden haben das Ziel, den Einfluss einer bestimmten Variablen auf die Vorhersage des Modells zu simulieren. Damit können Fragen beantwortet werden wie: „Steigen mit zunehmender Berufserfahrung die Chancen auf eine Management Position?“ oder „Macht es einen Unterschied, ob ich eine 1.9 oder eine 2.0 in meinem Abschlusszeugnis habe?“. Im Gegensatz zu den vorherigen zwei Methoden trifft ALE also eine Aussage über die Entscheidungsfindung des Modells, nicht über die Relevanz bestimmter Variablen.
Im einfachsten Fall, dem PDP, wird eine Stichprobe von Beobachtungen ausgewählt und anhand dieser simuliert, welchen Einfluss z.B. eine isolierte Erhöhung der Berufserfahrung auf die Modellvorhersage hätte. Isoliert meint, dass dabei keine der anderen Variablen verändert wird. Der Durchschnitt dieser einzelnen Effekte über die gesamte Stichprobe liefert eine anschauliche Visualisierung (Abbildung 3, oben). Leider sind die Ergebnisse des PDP nicht besonders aussagekräftig, wenn korrelierte Variablen vorliegen. Am Beispiel der Hochschulnoten lässt sich das besonders gut veranschaulichen. So simuliert der PDP hierbei alle möglichen Kombinationen von Noten im Bachelor- und Masterstudium. Dabei entstehen leider Fälle, die in der echten Welt selten vorkommen, z.B. ein ausgezeichnetes Bachelorzeugnis und ein miserabler Masterabschluss. Der PDP hat kein Gespür für unsinnige Fälle, woran auch die Ergebnisse kranken.
Die ALE-Analyse hingegen versucht, dieses Problem durch eine realistischere Simulation zu lösen, die die Zusammenhänge zwischen Variablen adäquat abbildet. Dabei wird die betrachtete Variable, z.B. die Bachelor-Note, in mehrere Abschnitte eingeteilt (z.B. 6.0-5.1, 5.0-4.1, 4.0-3.1, 3.0-2.1 und 2.0-1.0). Nun wird die Simulation der Erhöhung der Bachelor-Note lediglich für Personen in der respektiven Notengruppe durchgeführt. Dies führt dazu, dass unrealistische Kombinationen nicht in die Analyse einfließen. Ein Beispiel für einen ALE-Plot findet sich in Abbildung 3 (unten). Hier zeigt sich anschaulich, dass der ALE-Plot einen negativen Einfluss der Berufserfahrung auf die Anstellungschance identifiziert, während dies dem PDP verborgen bleibt. Ist dieses Verhalten der KI erwünscht? Will man zum Beispiel insbesondere junge Talente einstellen? Oder steckt dahinter vielleicht eine versteckte Altersdiskriminierung? In beiden Fällen hilft der ALE-Plot dabei, Transparenz zu schaffen und ungewünschtes Verhalten rechtzeitig zu erkennen.
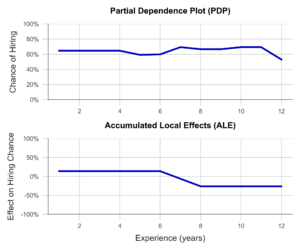
Abbildung 3– Partial Dependence Plot und Accumulated Local Effects am Beispiel einer Recruiting KI (Daten künstlich erzeugt).
Zusammenfassend ist der ALE-Plot eine geeignete Methode, um einen Einblick in den Einfluss einer bestimmten Variable auf die Modellvorhersage zu gewinnen. Dies schafft Transparenz für Nutzende und hilft sogar dabei, ungewünschte Effekte und Bias zu identifizieren und zu beheben. Ein Nachteil der Methode ist, dass der ALE-Plot stets nur eine Variable analysiert. Um also den Einfluss aller Variablen zu verstehen, muss eine Vielzahl von ALE-Plots generiert werden, was weniger übersichtlich ist als z.B. ein PFI- oder ein SHAP Feature Importance Plot.
| Stärken | Schwächen |
|---|---|
| Berücksichtigt komplexe Interaktionen zwischen Variablen | Mit ALE lassen sich nur eine oder zwei Variablen pro Visualisierung analysieren |
| Wenig Spielraum für Manipulation der Ergebnisse |
Mit Explainable AI Methoden Vertrauen aufbauen
In diesem Beitrag haben wir drei Explainable AI Methoden vorgestellt, die dabei helfen können, Algorithmen transparenter und interpretierbarer zu machen. Dies begünstigt außerdem, den Anforderungen des kommenden AI-Acts frühzeitig gerecht zu werden. Denn auch wenn dieser noch nicht verabschiedet ist, empfehlen wir auf Basis des Gesetzesentwurfs sich bereits jetzt mit der Schaffung von Transparenz und Nachvollziehbarkeit für KI-Modelle zu beschäftigen. Viele Data Scientists haben wenig Erfahrung in diesem Feld und benötigen Fortbildung und Einarbeitungszeit, bevor sie einschlägige Algorithmen identifizieren und effektive Lösungen implementieren können. Die weiterführende Beschäftigung mit den vorgestellten Methoden empfehlen wir daher in jedem Fall.
Mit der Permutation Feature Importance (PFI) und der SHAP Feature Importance haben wir zwei Techniken aufgezeigt, um die Relevanz bestimmter Variablen für die Vorhersage des Modells zu bestimmen. Zusammenfassend lässt sich sagen, dass die SHAP Feature Importance eine leistungsstarke Methode zur Erklärung von Black-Box-Modellen ist, die die Interaktionen zwischen Variablen berücksichtigt. Die PFI hingegen ist einfacher zu implementieren, aber weniger leistungsfähig bei korrelierten Daten. Welche Methode im konkreten Fall am besten geeignet ist, hängt von den spezifischen Anforderungen ab.
Auch haben wir mit Accumulated Local Effects (ALE) eine Technik vorgestellt, die nicht die Relevanz von Variablen, sondern sogar deren genauen Einfluss auf die Vorhersage bestimmen und visualisieren kann. Besonders vielversprechend ist die Kombination einer der beiden Feature Importance Methoden mit ausgewählten ALE-Plots zu ausgewählten Variablen. So kann ein theoretisch fundierter und leicht interpretierbarer Überblick über das Modell vermittelt werden – egal, ob es sich um einen Entscheidungsbaum oder ein tiefes Neuronales Netz handelt.
Die Anwendung von Explainable AI ist somit eine lohnende Investition – nicht nur, um intern und extern Vertrauen in die eigenen KI-Lösungen aufzubauen. Vielmehr gehen wir davon aus, dass der geschickte Einsatz interpretationsfördernder Methoden drohende Bußgelder durch die Anforderungen des AI-Acts vermeidet, rechtlichen Konsequenzen vorbeugt, sowie Betroffene vor Schaden schützt – wie im Fall von unverständlicher Recruitingsoftware.
Unserer kostenfreier AI Act Quick Check unterstützt Sie gerne bei der Einschätzung, ob eines Ihrer KI-Systeme vom AI Act betroffen sein könnte: https://www.statworx.com/ai-act-tool/
Quellen & Informationen:
https://www.faz.net/aktuell/karriere-hochschule/buero-co/ki-im-bewerbungsprozess-und-raus-bist-du-17471117.html (letzter Aufruf 03.05.2023)
https://t3n.de/news/diskriminierung-deshalb-platzte-amazons-traum-vom-ki-gestuetzten-recruiting-1117076/ (letzter Aufruf 03.05.2023)
Weitere Informationen zum AI Act: https://www.statworx.com/content-hub/blog/wie-der-ai-act-die-ki-branche-veraendern-wird-alles-was-man-jetzt-darueber-wissen-muss/
Statworx principles: https://www.statworx.com/content-hub/blog/statworx-ai-principles-warum-wir-eigene-ki-prinzipien-entwickeln/
Christoph Molnar: Interpretable Machine Learning: https://christophm.github.io/interpretable-ml-book/
Bildnachweis:
AdobeStock 566672394 – by TheYaksha
Einführung
Forecasts sind in vielen Branchen von zentraler Bedeutung. Ob es darum geht, den Verbrauch von Ressourcen zu prognostizieren, die Liquidität eines Unternehmens abzuschätzen oder den Absatz von Produkten im Einzelhandel vorherzusagen – Forecasts sind ein unverzichtbares Instrument für erfolgreiche Entscheidungen. Obwohl sie so wichtig sind, basieren viele Forecasts immer noch primär auf den Vorerfahrungen und der Intuition von Expert:innen. Das erschwert eine Automatisierung der relevanten Prozesse, eine potenzielle Skalierung und damit einhergehend eine möglichst effiziente Unterstützung. Zudem können Expert:innen aufgrund ihrer Erfahrungen und Perspektiven voreingenommen sein oder möglicherweise nicht über alle relevanten Informationen verfügen, die für eine genaue Vorhersage erforderlich sind.
Diese Gründe führen dazu, dass datengetriebene Forecasts in den letzten Jahren immer mehr an Bedeutung gewonnen haben und die Nachfrage nach solchen Prognosen ist entsprechend stark.
Bei statworx haben wir bereits eine Vielzahl an Projekten im Bereich Forecasting erfolgreich umgesetzt. Dadurch haben wir uns vielen Herausforderungen gestellt und uns mit zahlreichen branchenspezifischen Use Cases vertraut gemacht. Eine unserer internen Arbeitsgruppen, das Forecasting Cluster, begeistert sich besonders für die Welt des Forecastings und bildet sich kontinuierlich in diesem Bereich weiter.
Auf Basis unserer gesammelten Erfahrungen möchten wir diese nun in einem benutzerfreundlichen Tool vereinen, welches je nach Datenlage und Anforderungen jedem ermöglicht, erste Einschätzungen zu spezifischen Forecasting Use Cases zu erhalten. Sowohl Kunden als auch Mitarbeitende sollen in der Lage sein, das Tool schnell und einfach zu nutzen, um eine methodische Empfehlung zu erhalten. Unser langfristiges Ziel ist es, das Tool öffentlich zugänglich zu machen. Jedoch testen wir es zunächst intern, um seine Funktionalität und Nützlichkeit zu optimieren. Dabei legen wir besonderen Wert darauf, dass das Tool intuitiv bedienbar ist und leicht verständliche Outputs liefert.
Obwohl sich unser Recommender-Tool derzeit noch in der Entwicklungsphase befindet, möchten wir einen ersten spannenden Einblick geben.
Häufige Herausforderungen
Modellauswahl
Im Bereich Forecasting gibt es verschiedene Modellierungsansätze. Wir differenzieren dabei zwischen drei zentralen Ansätzen:
- Zeitreihenmodelle
- Baumbasierte Modelle
- Deep Learning Modelle
Es gibt viele Kriterien, die man bei der Modellauswahl heranziehen kann. Wenn es sich um univariate Zeitreihen handelt, die eine starke Saisonalität und Trends aufweisen, sind klassische Zeitreihenmodelle wie (S)ARIMA und ETS sinnvoll. Handelt es sich hingegen um multivariate Zeitreihen mit potenziell komplexen Zusammenhängen und großen Datenmengen, stellen Deep Learning Modelle eine gute Wahl dar. Baumbasierte Modelle wie LightGBM bieten im Vergleich zu Zeitreihenmodellen eine größere Flexibilität, eignen sich aufgrund ihrer Architektur gut für das Thema Erklärbarkeit und haben im Vergleich zu Deep Learning Modellen einen tendenziell geringeren Rechenaufwand.
Saisonalität
Saisonalität stellt wiederkehrende Muster in einer Zeitreihe dar, die in regelmäßigen Abständen auftreten (z.B. täglich, wöchentlich, monatlich oder jährlich). Die Einbeziehung der Saisonalität in der Modellierung ist wichtig, um diese regelmäßigen Muster zu erfassen und die Genauigkeit der Prognosen zu verbessern. Mit Zeitreihenmodellen wie SARIMA, ETS oder TBATS kann die Saisonalität explizit berücksichtigt werden. Für baumbasierte Modelle wie LightGBM kann die Saisonalität nur über die Erstellung entsprechender Features berücksichtigt werden. So können Dummies für die relevanten Saisonalitäten gebildet werden. Eine Möglichkeit Saisonalität in Deep Learning-Modellen explizit zu berücksichtigen, besteht in der Verwendung von Sinus- und Cosinus-Funktionen. Ebenso ist es möglich die Saisonalitätskomponente aus der Zeitreihe zu entfernen. Dazu wird zuerst die Saisonalität entfernt und anschließend eine Modellierung auf der desaisonalisierten Zeitreihe durchgeführt. Die daraus resultierenden Prognosen werden dann mit der Saisonalität ergänzt, indem die genutzte Methodik für die Desaisonalisierung entsprechend angewendet wird. Allerdings erhöht dieser Prozess die Komplexität, was nicht immer erwünscht ist.
Hierarchische Daten
Besonders im Bereich Retail liegen häufig hierarchische Datenstrukturen vor, da die Produkte meist in unterschiedlicher Granularität dargestellt werden können. Hierdurch ergibt sich häufig die Anforderung, Prognosen für unterschiedliche Hierarchien zu erstellen, welche sich nicht widersprechen. Die aggregierten Prognosen müssen daher mit den disaggregierten übereinstimmen. Dabei ergeben sich verschiedene Lösungsansätze. Über Top-Down und Bottom-Up werden Prognosen auf einer Ebene erstellt und nachgelagert disaggregiert bzw. aggregiert. Mit Reconciliation-Methoden wie Optimal Reconciliation werden Prognosen auf allen Ebenen vorgenommen und anschließend abgeglichen, um eine Konsistenz über alle Ebenen zu gewährleisten.
Cold Start
Bei einem Cold Start besteht die Herausforderung darin Produkte zu prognostizieren, die nur wenig oder keine historischen Daten aufweisen. Im Retail Bereich handelt es sich dabei meist um Produktneueinführungen. Da aufgrund der mangelnden Historie ein Modelltraining für diese Produkte nicht möglich ist, müssen alternative Ansätze herangezogen werden. Ein klassischer Ansatz einen Cold Start durchzuführen, ist die Nutzung von Expertenwissen. Expert:innen können erste Schätzungen der Nachfrage liefern, die als Ausgangspunkt für Prognosen dienen können. Dieser Ansatz kann jedoch stark subjektiv ausfallen und lässt sich nicht skalieren. Ebenso kann auf ähnliche Produkte oder auch auf potenzielle Vorgänger-Produkte referenziert werden. Eine Gruppierung von Produkten kann beispielsweise auf Basis der Produktkategorien oder Clustering-Algorithmen wie K-Means erfolgen. Die Nutzung von Cross-Learning-Modellen, die auf Basis vieler Produkte trainiert werden, stellt eine gut skalierbare Möglichkeit dar.
Recommender Concept
Mit unserem Recommender Tool möchten wir die unterschiedlichen Problemstellungen berücksichtigen, um eine möglichst effiziente Entwicklung zu ermöglichen. Dabei handelt es sich um ein interaktives Tool, bei welchem man Inputs auf Basis der Zielvorstellung oder Anforderung und den vorliegenden Datencharakteristiken gibt. Ebenso kann eine Priorisierung vorgenommen werden, sodass bestimmte Anforderungen an der Lösung auch im Output entsprechend priorisiert werden. Auf Basis dieser Inputs werden methodische Empfehlungen generiert, die die Anforderungen an der Lösung in Abhängigkeit der vorliegenden Eigenschaften bestmöglich abdecken. Aktuell bestehen die Outputs aus einer rein inhaltlichen Darstellung der Empfehlungen. Dabei wird auf die zentralen Themenbereiche wie Modellauswahl, Pre-Processing und Feature Engineering mit konkreten Guidelines eingegangen. Das nachfolgende Beispiel gibt dabei einen Eindruck über die konzeptionelle Idee:
Der hier dargestellte Output basiert auf einem realen Projekt. Für das Projekt war vor allem die Implementierung in R und die Möglichkeit einer lokalen Erklärbarkeit von zentraler Bedeutung. Zugleich wurden frequentiert neue Produkte eingeführt, welche ebenso durch die entwickelte Lösung prognostiziert werden sollten. Um dieses Ziel zu erreichen, wurden mehrere globale Modelle mit Hilfe von Catboost trainiert. Dank diesem Ansatz konnten über 200 Produkte ins Training einbezogen werden. Sogar für neu eingeführte Produkte, bei denen keine historischen Daten vorlagen, konnten Forecasts generiert werden.
Um die Erklärbarkeit der Prognosen sicherzustellen, wurden SHAP Values verwendet. Auf diese Weise konnten die einzelnen Vorhersagen klar und deutlich anhand der genutzten Features erklärt werden.
Zusammenfassung
Die aktuelle Entwicklung ist darauf ausgerichtet ein Tool zu entwickeln, welches auf das Thema Forecasting optimiert ist. Durch die Nutzung wollen wir vor allem die Effizienz bei Forecasting-Projekten steigern. Durch die Kombination von gesammelten Erfahrungen und Expertise soll das Tool unter anderem für die Themen Modellierung, Pre-Processing und Feature Engineering Guidelines bieten. Es wird darauf ausgelegt sein, sowohl von Kunden als auch Mitarbeitenden verwendet zu werden, um schnelle und einfache Abschätzungen sowie methodische Empfehlungen zu erhalten. Eine erste Testversion wird zeitnah für den internen Gebrauch zur Verfügung stehen. Langfristig soll das Tool jedoch auch für externe Nutzer:innen zugänglich gemacht werden. Neben dem derzeit in der Entwicklung befindlichen technischen Output, wird auch ein weniger technischer Output verfügbar sein. Letzterer wird sich auf die wichtigsten Aspekte und deren Aufwände konzentrieren. Insbesondere die Business-Perspektive in Form von erwarteten Aufwänden und potenziellen Trade-Offs von Aufwand und Nutzen soll hierdurch abgedeckt werden.
Profitieren auch Sie von unserer Forecasting Expertise!
Wenn Sie Unterstützung bei der Bewältigung von vorliegenden Herausforderungen bei Forecasting Projekten benötigen oder ein Forecasting Projekt geplant ist, stehen wir gerne mit unserem Know-how und unserer Erfahrung zur Verfügung.
Obwohl wir beim letzten Mal nur um Haaresbreite dem Sog des schwarzen Lochs entkommen sind, welches sich in der Nähe der Welt des Wilcoxon-Rangsummen-Tests befindet (Die ganze Geschichte gibt es hier!), lassen wir uns nicht einschüchtern und setzen unsere Entdeckungsreise durch das nicht-parametrische Universum fort.
Den nächsten Planeten, den wir dabei erkunden wollen, könnte man auf den ersten Blick mit der Welt des Wilcoxon-Rangsummen-Tests verwechseln (Lieber daran interessiert? Dann klicke hier.). Beide Welten haben eine ähnliche Flora und Fauna, doch schaut man genau hin, gibt es kleine, aber bedeutende Unterschiede. Acissej, unsere Botanikerin an Bord und im ganzen Universum von den großfüßigen Blaustirnblatthühnchen gefürchtet, kennt sich in diesem Bereich bestens aus. Sie führt daher unsere Expedition zur Erforschung der Welt des Wilcoxon-Vorzeichen-Tests an.
Zwei Welten – Gemeinsamkeiten und Unterschiede
Bei der Erkundung wird als erstes eine Gemeinsamkeit beider Welten deutlich: Der Wilcoxon-Vorzeichen- und der Wilcoxon-Rangsummen-Test sind jeweils die nicht-parametrische Alternative für den t-Test. Ersterer ist das Pendant zum t-Test für abhängige und letzterer zum t-Test für unabhängige Stichproben (Was ist ein t-Test? Hier erfährst du es.). Nicht-parametrisch bedeutet, dass beide Tests weniger strenge Annahmen über die Verteilung der abhängigen Variable machen. Zusätzlich teilen beide die Eigenschaft, dass sie die Mediane von zwei Gruppen auf signifikante Unterschiede testen. Acissej ergänzt noch scherzend, dass sich der Erfinder beider Tests – Frank Wilcoxon – auch in beiden Bezeichnungen verewigt hat.
Bei den vielen Gemeinsamkeiten beider Welten gibt es jedoch einen großen Unterschied zwischen ihnen: Die Situation, in der die Anwendung des Tests angemessen ist. Der Wilcoxon-Vorzeichen-Test wird ausschließlich bei abhängigen Stichproben angewandt. Doch was genau bedeutet Abhängigkeit überhaupt? Häufig bedeutet es, dass bei verschiedenen Personen ein bestimmtes Merkmal zwei Mal gemessen wurde. In diesem Fall spricht man von Messwiederholung. Abhängigkeit kann aber auch bedeuten, dass man die Werte von zwei Person durch eine Gemeinsamkeit in Verbindung bringen kann. Da fällt Acissej sofort ein gutes Beispiel ein: Wenn sich zwei Mitglieder unserer Crew eine Kajüte teilen müssen und der eine schlechte Laune hat, weißt du sofort, wie es dem anderen geht. Ob Sie wollen oder nicht, Ihre Laune ist voneinander abhängig! Bei Abhängigkeiten zwischen Messungen gilt jedoch, dass man nur solche berücksichtigen kann, die eine gewisse Systematik aufweisen(1). Beispielsweise kann die Laune eines Crewmitgliedes die Laune aller Mitglieder am Bord beeinflussen. Da es aber nicht (einfach) zu erfassen ist, wer sich mit wem unterhält und sich dadurch beeinflusst, ist diese eine Form von Abhängigkeit, die man statistisch nicht berücksichtigen würde.
Die Tiefen der Welt des Wilcoxon-Vorzeichen-Tests
Acissej hat heute extrem gute Laune und das perfekte Beispiel parat, um zu erklären, wie die Welt des Wilcoxon-Vorzeichen-Tests im Detail beschaffen ist. Dazu kramt sie einen Zettel aus ihrer Tasche, auf den wir folgendes Lesen können:
| Pflanzennummer | Größe beim Einpflanzen [cm] | Größe am nächsten Tag [cm] |
|---|---|---|
| 1 | 20,03 | 21,39 |
| 2 | 20,13 | 21 |
| 3 | 20,23 | 21,35 |
| 4 | 20,15 | 20,75 |
| 5 | 20,46 | 20,25 |
| 6 | 20,43 | 20,68 |
| 7 | 20,67 | 20,53 |
| 8 | 20,35 | 21,05 |
| 9 | 20,85 | 20,97 |
| 10 | 20,08 | 20,62 |
| 11 | 20,5 | 20,81 |
| 12 | 21,04 | 20,92 |
| 13 | 20,88 | 20,95 |
| 14 | 19,94 | 20,74 |
| 15 | 20,08 | 20,63 |
Ihr Beispiel handelt natürlich von Pflanzen. Acissej hat ein kleines Experiment durchgeführt und möchte jetzt wissen, ob es geglückt ist. Sie hat gestern 15 neue Pflanzen in ihrer Kajüte eingepflanzt und gemessen, wie groß diese waren. Zum Einpflanzen hat sie aber nicht herkömmlichen Boden, sondern Kaffeesatz verwendet. Auf diese Idee kam sie als sie vor kurzem auf einer anderen Welt gesehen hat, dass die Einheimischen dort Pflanzen auf den Resten anderer Pflanzen züchten. Da sie als Botanikerin weiß, wie viele Nährstoffe in Kaffee enthalten sind und sie selbst jeden Tag mindestens 10 Tassen trinkt, erschien ihr die Verwendung von Kaffeesatz eine geniale Idee. Heute Morgen hat Sie gleich mal nachgemessen und alles auf dem Zettel notiert. Jetzt möchte sie wissen, ob die Pflanzen im Schnitt gewachsen sind, damit sie sie nicht quält, falls alles eine blöde Idee war.
Da „leider“ nur 15 Pflanzen in ihre Kajüte passen und die Messungen voneinander abhängig sind, empfiehlt sich die Anwendung des Wilcoxon-Vorzeichen-Tests. Dieser bildet zuerst die Differenzen aus beiden Zeitpunkten: Größe beim Einpflanzen – Größe am nächsten Tag (siehe Tabelle 2). Anschließend wird für jede Differenz das Vorzeichen notiert und Ränge vergeben. Bei der Vergabe der Ränge wird das Vorzeichen ignoriert (siehe Tabelle 2).
| Pflanzennummer | Differenz | Ränge | Vorzeichen |
|---|---|---|---|
| 1 | -1,36 | 15 | – |
| 2 | -0,87 | 13 | – |
| 3 | -1,12 | 14 | – |
| 4 | -0,6 | 10 | – |
| 5 | 0,21 | 5 | + |
| 6 | -0,25 | 6 | – |
| 7 | 0,14 | 4 | + |
| 8 | -0,7 | 11 | – |
| 9 | -0,12 | 3 | – |
| 10 | -0,54 | 8 | – |
| 11 | -0,31 | 7 | – |
| 12 | 0,12 | 2 | + |
| 13 | -0,07 | 1 | – |
| 14 | -0,8 | 12 | – |
| 15 | -0,55 | 9 | – |
Die Ränge werden letztlich zu zwei Rangsummen aufsummiert. Eine Rangsumme für Ränge mit positiven (T+) und eine für Ränge mit negativen Vorzeichen (T-). Um zu testen, ob sich die Mediane in beiden Gruppen unterscheiden, verwendet der Test die Rangsumme der positiven Differenzen T+. Diese ist in unserem Fall 11. Für T+ wird der dazugehörige p-Wert anschließend mit einer der beiden folgenden Methoden berechnet. Entweder, indem die Rangsumme an der Anzahl der Personen in der Gruppe relativiert und durch ihren Standardfehler geteilt wird oder, indem der p-Wert exakt berechnet wird, mit Hilfe einer Simulation. Da in den Daten jeder Wert nur einmal vorkommt und die Stichprobe insgesamt kleiner als 40 ist, muss die exakte Methode angewendet werden. Der exakte p-Wert für die Pflanzengrößen ist 0,003 und das Ergebnis daher signifikant. Man kann also davon ausgehen, dass der Median der Pflanzengröße nach einem Tag (20,81) signifikant größer ist als zum Zeitpunkt des Einpflanzens (20,35). Somit sind nicht nur die Pflanzen von Acissei im Schnitt gewachsen, sondern wir können auch davon ausgehen, dass Kaffeesatz bei weiteren Pflanzen geeignet ist, um als Nährboden zu fungieren. Auf diese Freude holt sich Acissej doch erstmal einen Kaffee!
Referenzen
- Eid, M., Gollwitzer, M. & Schmitt, M. (2015). Statistik und Forschungsmethoden (4. Überarbeitete und erweiterte Auflage). Weinheim: Beltz. S. 368.
- Wilcoxon, F. (1945). Individual comparisons by ranking methods. Biometrics, 1, 80-83.