
Intelligente Chatbots sind eine der spannendsten und heute schon sichtbarsten Anwendungen von Künstlicher Intelligenz. ChatGPT und Konsorten erlauben seit Anfang 2023 den unkomplizierten Dialog mit großen KI-Sprachmodellen, was bereits eine beeindruckende Bandbreite an Hilfestellungen im Alltag bietet. Ob Nachhilfe in Statistik, eine Rezeptidee für ein Dreigängemenü mit bestimmten Zutaten oder ein Haiku zum Vereinsjubiläum: Moderne Chatbots liefern Antworten im Nu. Ein Problem haben sie aber noch: Obwohl diese Modelle einiges gelernt haben während des Trainings, sind sie eigentlich keine Wissensdatenbanken. Deshalb liefern sie oft inhaltlichen Unsinn ab – wenn auch überzeugenden.
Mit der Möglichkeit, einem großen Sprachmodell eigene Dokumente zur Verfügung zu stellen, lässt sich dieses Problem aber angehen – und genau danach hat uns unser Partner Microsoft zu einem außergewöhnlichen Anlass gefragt.
Microsofts Cloud Plattform Azure hat sich in den letzten Jahren als erstklassige Plattform für den gesamten Machine-Learning-Prozess erwiesen. Um den Einstieg in Azure zu erleichtern, hat uns Microsoft gebeten, eine spannende KI-Anwendung in Azure umzusetzen und bis ins Detail zu dokumentieren. Dieser sogenannte MicroHack soll Interessierten eine zugängliche Ressource für einen spannenden Use Case bieten.
Unseren Microhack haben wir dem Thema „Retrieval-Augmented Generation“ gewidmet, um damit große Sprachmodelle auf das nächste Level zu heben. Die Anforderungen waren simpel: Baut einen KI-Chatbot in Azure, lasst ihn Informationen aus euren eigenen Dokumenten verarbeiten, dokumentiert jeden Schritt des Projekts und veröffentlicht die Resultate auf dem
offiziellen MicroHacks GitHub Repository als Challenges und Lösungen – frei zugänglich für alle.
Moment, wieso muss KI Dokumente lesen können?
Große Sprachmodelle (LLMs) beeindrucken nicht nur mit ihren kreativen Fähigkeiten, sondern auch als Sammlungen komprimierten Wissens. Während des extensiven Trainingsprozesses eines LLMs lernt das Modell nicht bloß die Grammatik einer Sprache, sondern auch Semantik und inhaltliche Zusammenhänge; kurz gesagt lernen große Sprachmodelle Wissen. Ein LLM kann dadurch befragt werden und überzeugende Antworten generieren – mit einem Haken. Während die gelernten Sprachfertigkeiten eines LLMs oft für die große Mehrheit an Anwendungen taugen, kann das vom gelernten Wissen meist nicht behauptet werden. Ohne erneutem Training auf weiteren Dokumenten bleibt der Wissensstand eines LLMs statisch.
Dies führt zu folgenden Problemen:
- Das trainierte LLMs weist zwar ein großes Allgemeinwissen – oder auch Fachwissen – auf, kann aber keine Auskunft über Wissen aus nicht-öffentlich zugänglichen Quellen geben.
- Das Wissen eines trainierten LLMs ist schnell veraltet: Der sogenannte „Trainings-Cutoff“ führt dazu, dass das LLM keine Aussagen über Ereignisse, Dokumente oder Quellen treffen kann, die sich erst nach dem Trainingsstart ereignet haben oder später entstanden sind.
- Die technische Natur großer Sprachmodelle als Text-Vervollständigungs-Maschinen führt dazu, dass diese Modelle gerne Sachverhalte erfinden, wenn sie eigentlich keine passende Antwort gelernt haben. Sogenannte „Halluzinationen“ führen dazu, dass die Antworten eines LLMs ohne Überprüfung nie komplett vertrauenswürdig sind – unabhängig davon, wie überzeugend sie wirken.
Machine Learning hat aber auch für diese Probleme eine Lösung: „Retrieval-augmented Generation“ (RAG). Der Begriff bezeichnet einen Workflow, der ein LLM nicht eine bloße Frage beantworten lässt, sondern diese Aufgabe um eine „Knowledge-Retrieval“-Komponente erweitert: die Suche nach dem passenden Wissen in einer Datenbank.
Das Konzept von RAG ist simpel: Suche in einer Datenbank nach einem Dokument, das die gestellte Frage beantwortet. Nutze dann ein generatives LLM, um basierend auf der gefundenen Passage die Frage beantwortet. Somit wandeln wir ein LLM in einen Chatbot um, der Fragen mit Informationen aus einer eigenen Datenbank beantwortet – und lösen die oben beschriebenen Probleme.
Was passiert bei einem solchen „RAG“ genau?
RAG besteht also aus zwei Schritten: „Retrieval“ und „Generation“. Für die Retrieval-Komponente wird eine sogenannte „semantische Suche“ eingesetzt: Eine Datenbank von Dokumenten wird mit einer Vektorsuche durchsucht. Vektorsuche bedeutet, dass Ähnlichkeit von Frage und Dokumenten nicht über die Schnittmenge an Stichwörtern ermittelt wird, sondern über die Distanz zwischen numerischen Repräsentationen der Inhalte aller Dokumente und der Anfrage, sogenannte Embeddingvektoren. Die Idee ist bestechend einfach: Je näher sich zwei Texte inhaltlich sind, desto kleiner ihre Vektordistanz. Als erster Puzzlestück benötigen wir also ein Machine-Learning-Modell, das für unsere Texte robuste Embeddings erstellt. Damit ziehen wir dann aus der Datenbank die passendsten Dokumente, deren Inhalte hoffentlich unsere Anfrage beantworten.
Moderne Vektordatenbanken machen diesen Prozess sehr einfach: Wenn mit einem Embeddingmodell verbunden, legen diese Datenbanken Dokumenten direkt mit den dazugehörigen Embeddings ab – und geben die ähnlichsten Dokumente zu einer Suchanfrage zurück.
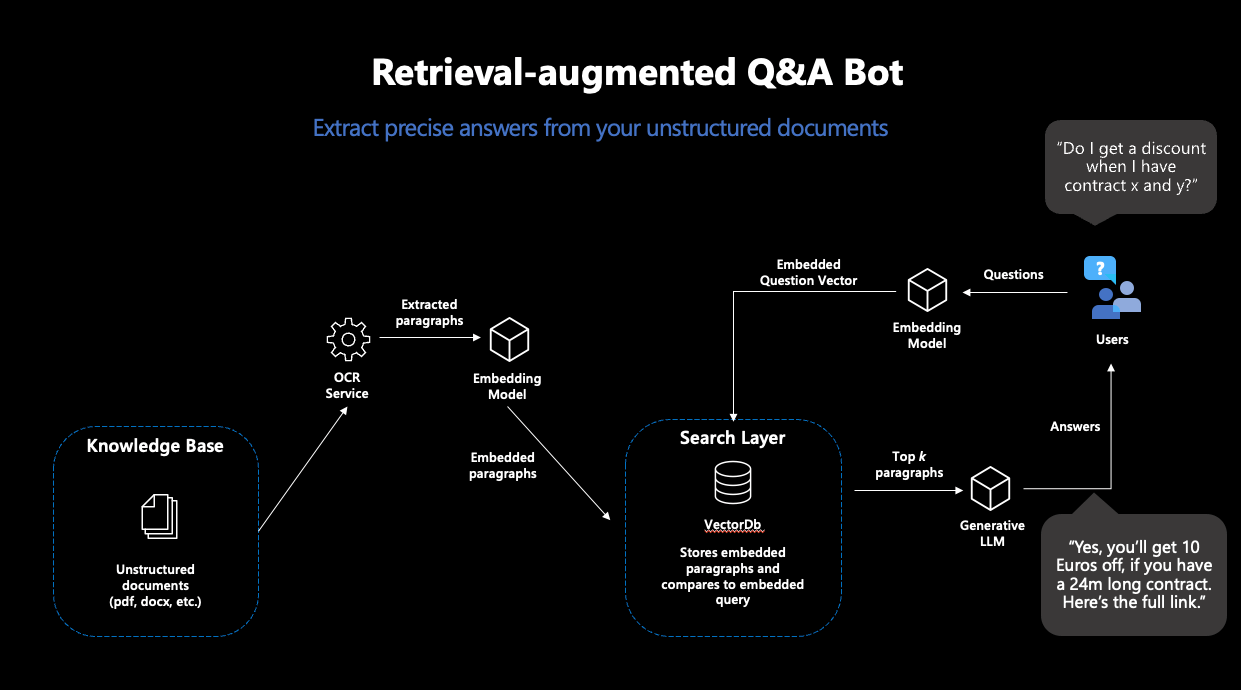
Abbildung 1: Darstellung des typischen RAG-Workflows
Basierend auf den Inhalten der gefundenen Dokumente wird im nächsten Schritt eine Antwort zur Frage generiert. Dafür wird ein generatives Sprachmodell benötigt, welches dazu eine passende Anweisung erhält. Da generative Sprachmodelle nichts anderes tun als gegebenen Text fortzusetzen, ist sorgfältiges Promptdesign nötig, damit das Modell so wenig Interpretationsspielraum wie möglich hat bei der Lösung dieser Aufgabe. Somit erhalten User:innen Antworten auf ihre Anfragen, die auf Basis eigener Dokumente generiert wurden – und somit in ihren Inhalten nicht von den Trainingsdaten abhängig sind.
Wie kann so ein Workflow denn in Azure umgesetzt werden?
Für die Umsetzung eines solchen Workflows haben wir vier separate Schritte benötigt – und unseren MicroHack genauso aufgebaut:
Schritt 1: Setup zur Verarbeitung von Dokumenten in Azure
In einem ersten Schritt haben wir die Grundlagen für die RAG-Pipeline gelegt. Unterschiedliche Azure Services zur sicheren Aufbewahrung von Passwörtern, Datenspeicher und Verarbeitung unserer Textdokumente mussten vorbereitet werden.
Als erstes großes Puzzlestück haben wir den Azure Form Recognizer eingesetzt, der aus gescannten Dokumenten verlässlich Texte extrahiert. Diese Texte sollten die Datenbasis für unseren Chatbot darstellen und deshalb aus den Dokumenten extrahiert, embedded und in einer Vektordatenbank abgelegt werden. Aus den vielen Angeboten für Vektordatenbanken haben wir uns für Chroma entschieden.
Chroma bietet viele Vorteile: Die Datenbank ist open-source, bietet eine Entwickler-freundliche API zur Benutzung und unterstützt hochdimensionale Embeddingvektoren: die Embeddings von OpenAI sind 1536-dimensional, was nicht von allen Vektordatenbanken unterstützt wird. Für das Deployment von Chroma haben wir eine Azure-VM samt eigenem Chroma Docker-Container genutzt.
Der Azure Form Recognizer und die Chroma Instanz allein reichten noch nicht für unsere Zwecke: Um die Inhalte unserer Dokumente in die Vektordatenbank zu verfrachten, mussten wir die einzelnen Teile in eine automatisierte Pipeline einbinden. Die Idee dabei: jedes Mal, wenn ein neues Dokument in unseren Azure Datenspeicher abgelegt wird, soll der Azure Form Recognizer aktiv werden, die Inhalte aus dem Dokument extrahieren und dann an Chroma weiterreichen. Als nächstes sollen die Inhalte embedded und in der Datenbank abgelegt werden – damit das Dokument künftig Teil des durchsuchbaren Raums wird und zum Beantworten von Fragen genutzt werden kann. Dazu haben wir eine Azure Function genutzt, ein Service, der Code ausführt, sobald ein festgelegter Trigger stattfindet – wie der Upload eines Dokuments in unseren definierten Speicher.
Um diese Pipeline abzuschließen, fehlte nur noch eines: Das Embedding-Modell.
Schritt 2: Vervollständigung der Pipeline
Für alle Machine Learning Komponenten haben wir den OpenAI-Service in Azure genutzt. Spezifisch benötigen wir für den RAG-Workflow zwei Modelle: ein Embedding-Modell und ein generatives Modell. Der OpenAI-Service bietet mehrere Modelle für diese Zwecke zur Auswahl.
Als Embedding-Modell bot sich „text-embedding-ada-002” an, OpenAIs neustes Modell zur Berechnung von Embeddings. Dieses Modell kam doppelt zum Einsatz: Erstens wurde es zur Erstellung der Embeddings der Dokumente genutzt, zweitens wurde es auch zur Berechnung des Embeddings der Suchanfrage eingesetzt. Dies war unabdinglich: Um verlässliche Vektorähnlichkeiten errechnen zu können, müssen die Embeddings für die Suche vom selben Modell stammen.
Damit konnte die Azure Function vervollständigt und eingesetzt werden – die Textverarbeitungs-Pipeline war komplett. Schlussendlich sah die funktionale Pipeline folgendermaßen aus:
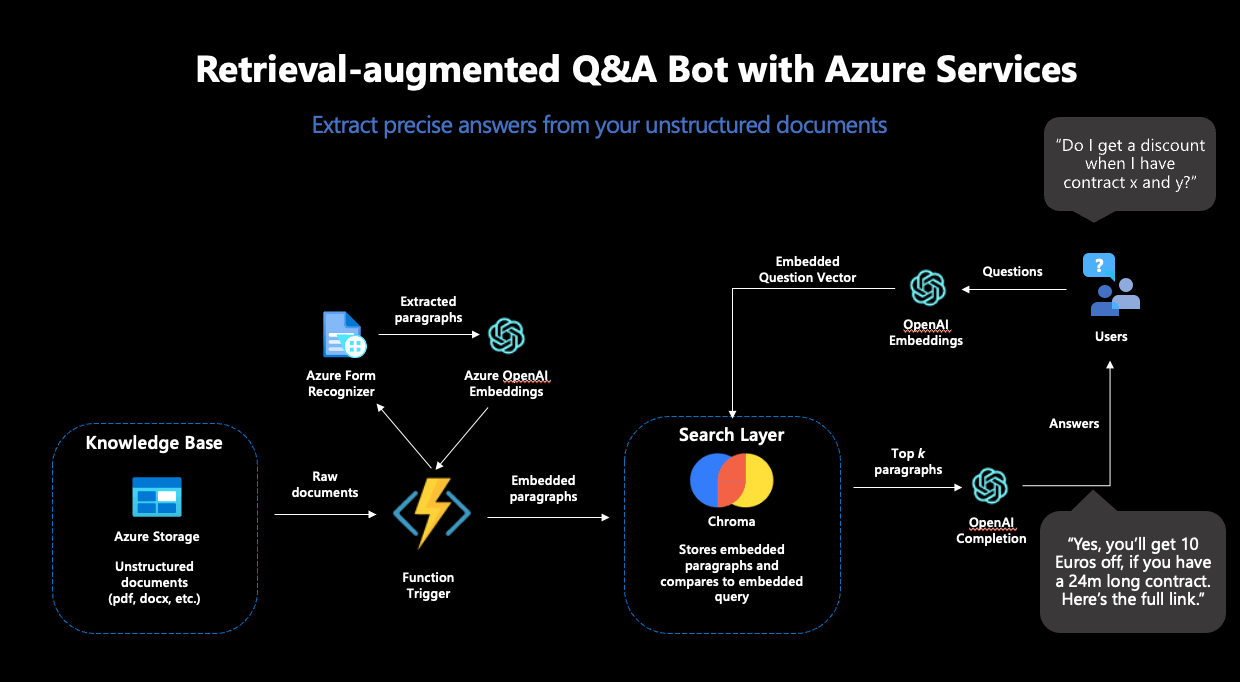
Abbildung 2: Der vollständige RAG-Workflow in Azure
Schritt 3 Antwort-Generierung
Um den RAG-Workflow abzuschließen, sollte auf Basis der gefundenen Dokumente aus Chroma noch eine Antwort generiert werden: Wir entschieden uns für den Einsatz von „GPT3.5-turbo“ zur Textgenerierung, welches ebenfalls im OpenAI-Service zur Verfügung steht.
Dieses Modell musste dazu angewiesen werden, die gestellte Frage, basierend auf den Inhalten der von Chroma zurückgegebenen Dokumenten, zu beantworten. Dazu war sorgfältiges Prompt-Engineering nötig. Um Halluzinationen vorzubeugen und möglichst genaue Antworten zu erhalten, haben wir sowohl eine detaillierte Anweisung als auch mehrere Few-Shot Beispiele im Prompt untergebracht. Schlussendlich haben wir uns auf folgenden Prompt festgelegt:
"""I want you to act like a sentient search engine which generates natural sounding texts to answer user queries. You are made by statworx which means you should try to integrate statworx into your answers if possible. Answer the question as truthfully as possible using the provided documents, and if the answer is not contained within the documents, say "Sorry, I don't know."
Examples:
Question: What is AI?
Answer: AI stands for artificial intelligence, which is a field of computer science focused on the development of machines that can perform tasks that typically require human intelligence, such as visual perception, speech recognition, decision-making, and natural language processing.
Question: Who won the 2014 Soccer World Cup?
Answer: Sorry, I don't know.
Question: What are some trending use cases for AI right now?
Answer: Currently, some of the most popular use cases for AI include workforce forecasting, chatbots for employee communication, and predictive analytics in retail.
Question: Who is the founder and CEO of statworx?
Answer: Sebastian Heinz is the founder and CEO of statworx.
Question: Where did Sebastian Heinz work before statworx?
Answer: Sorry, I don't know.
Documents:\n"""Zum Schluss werden die Inhalte der gefundenen Dokumente an den Prompt angehängt, womit dem generativen Modell alle benötigten Informationen zur Verfügung standen.
Schritt 4: Frontend-Entwicklung und Deployment einer funktionalen App
Um mit dem RAG-System interagieren zu können, haben wir eine einfache streamlit-App gebaut, die auch den Upload neuer Dokumente in unseren Azure Speicher ermöglichte – um damit erneut die Dokument-Verarbeitungs-Pipeline anzustoßen und den Search-Space um weitere Dokumente zu erweitern.
Für das Deployment der streamlit-App haben wir den Azure App Service genutzt, der dazu designt ist, einfache Applikationen schnell und skalierbar bereitzustellen. Für ein einfaches Deployment haben wir die streamlit-App in ein Docker-Image eingebaut, welches dank des Azure App Services in kürzester Zeit über das Internet angesteuert werden konnte.
Und so sah unsere fertige App aus:
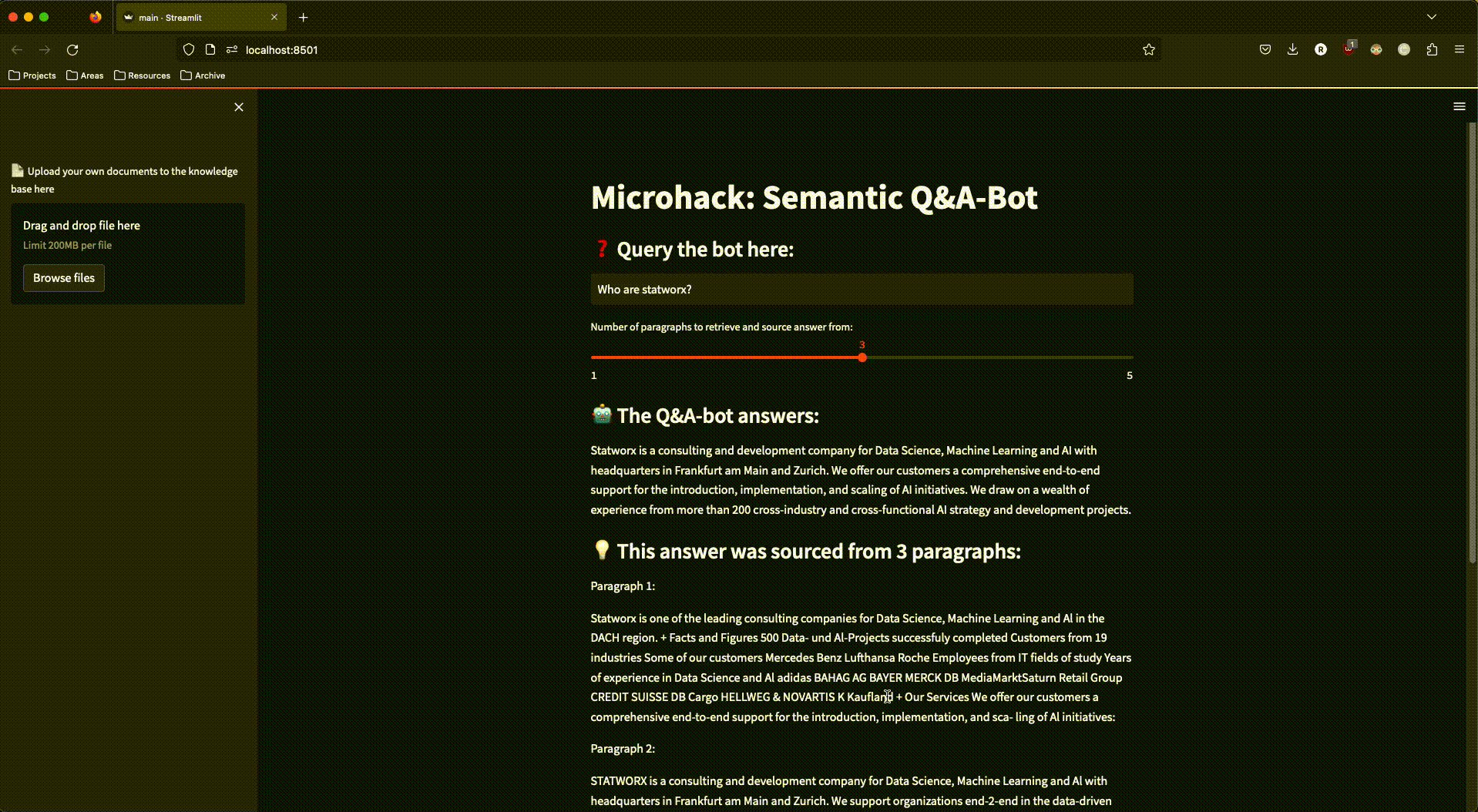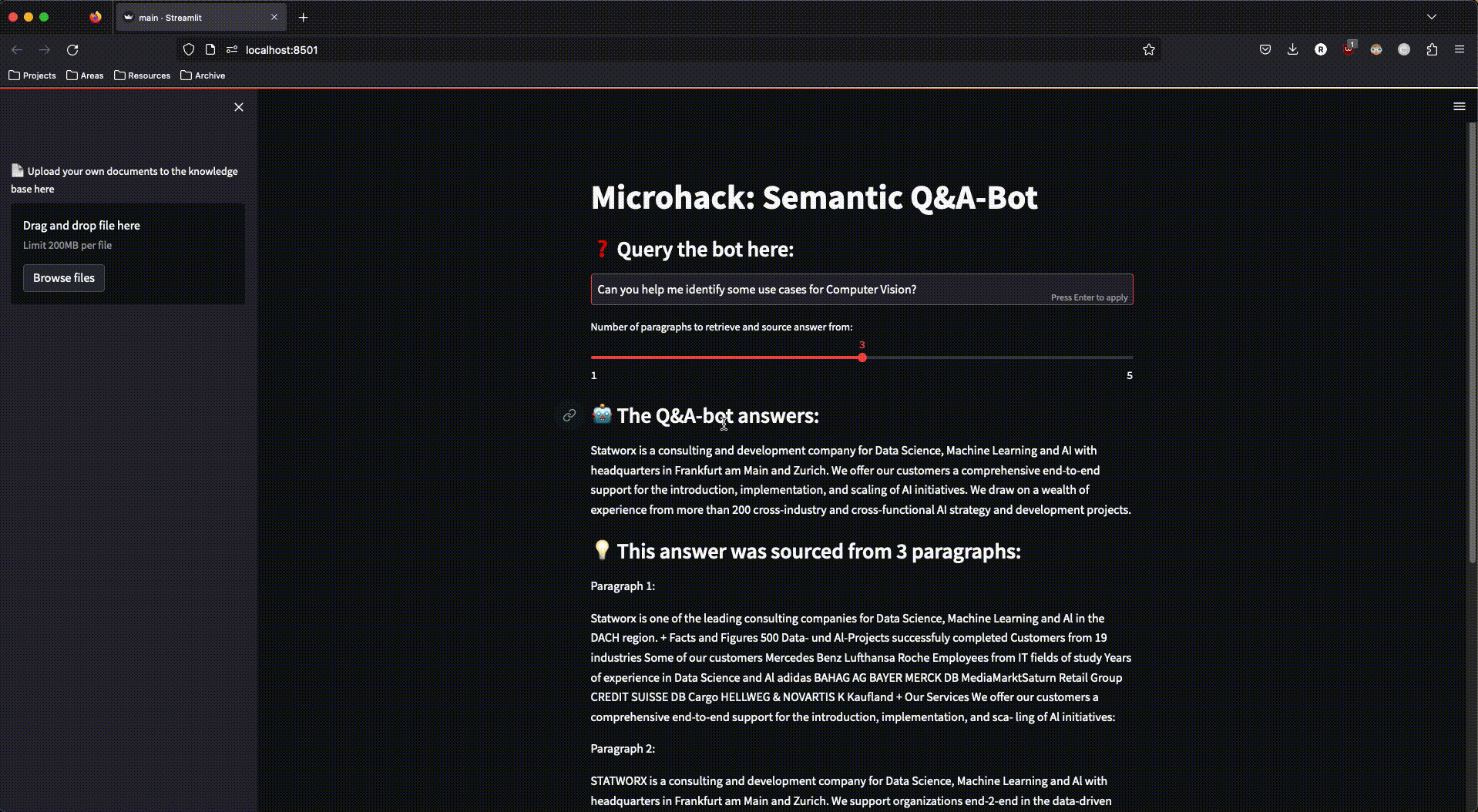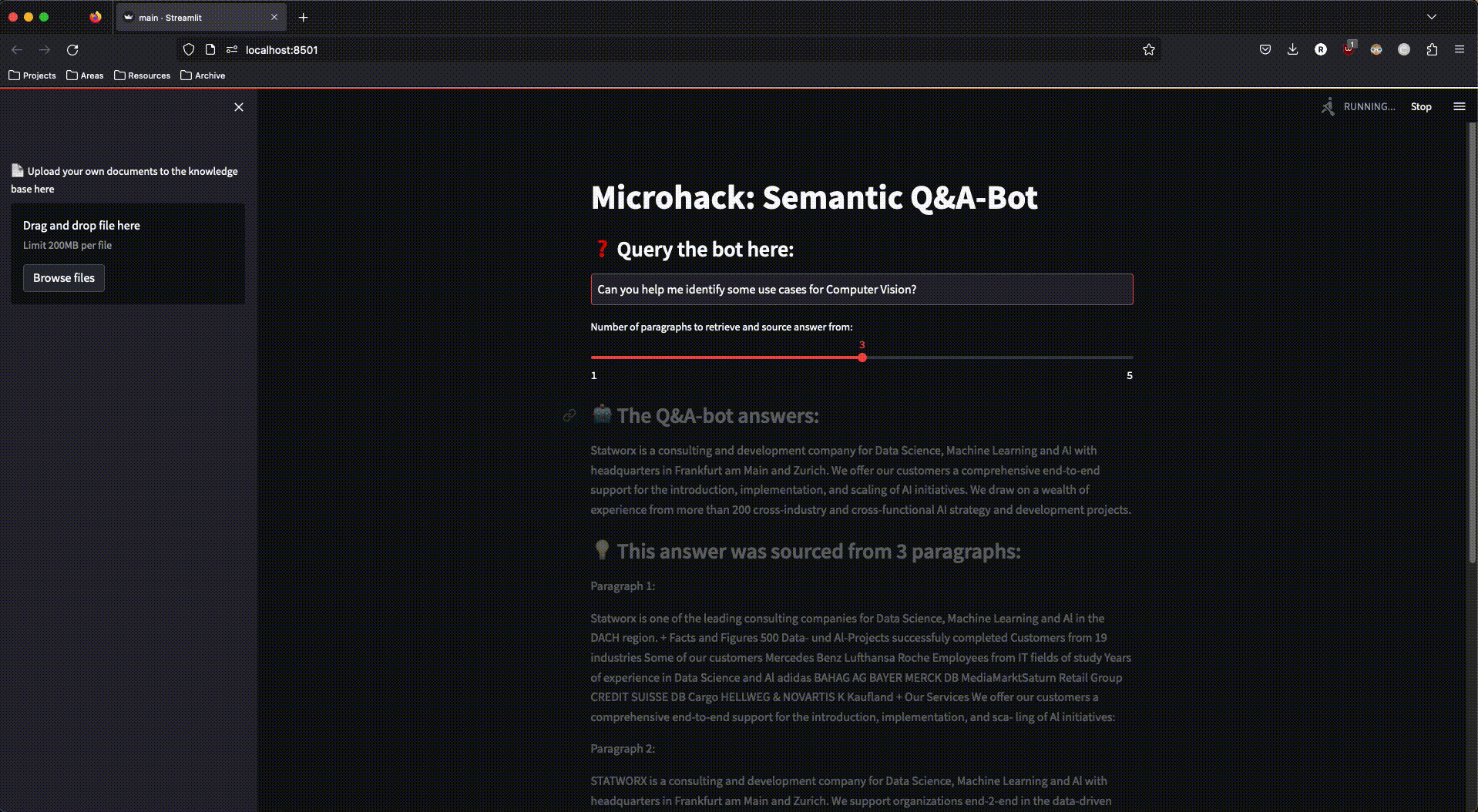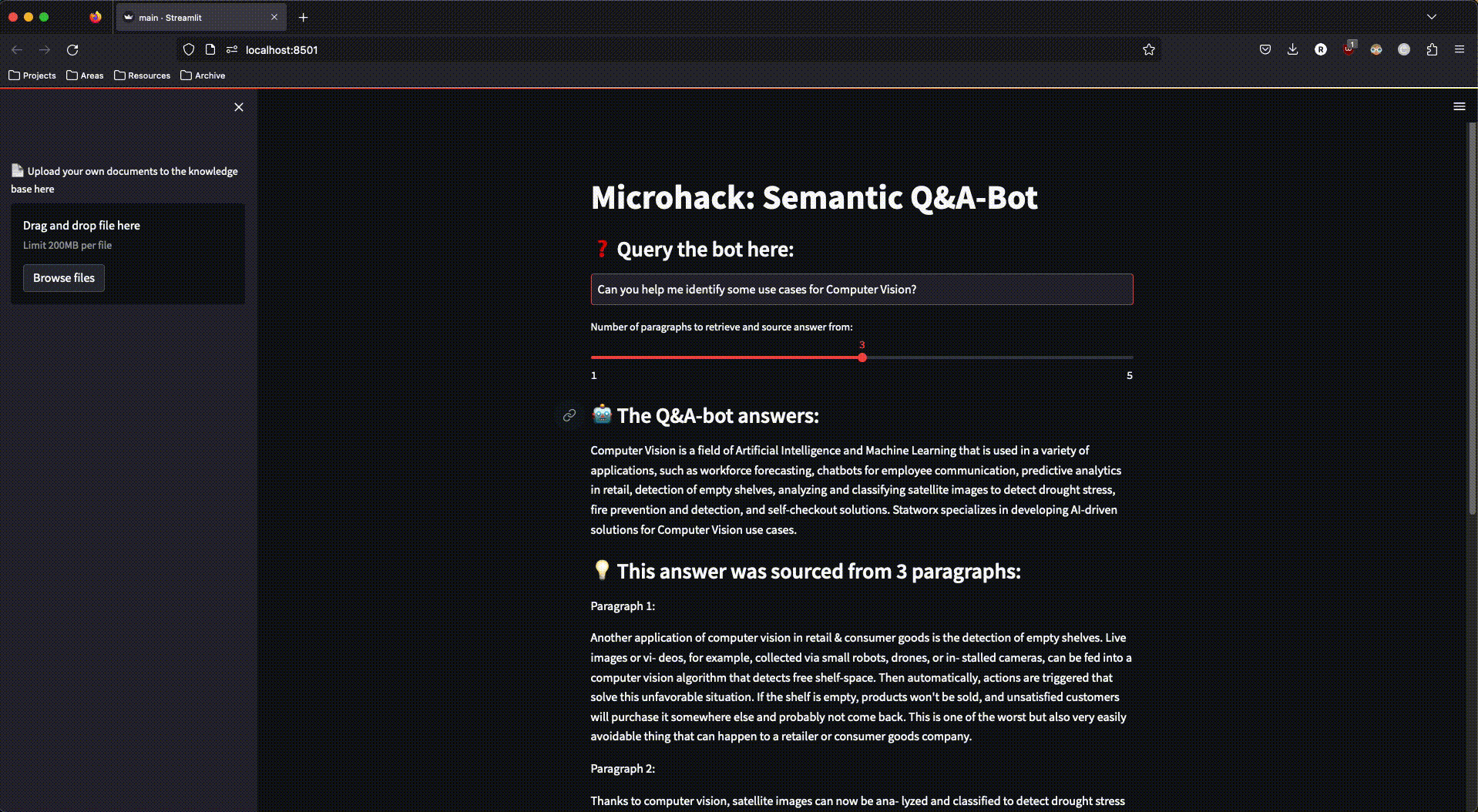
Abbildung 3: Die fertige streamlit-App im Einsatz
Was haben wir bei dem MicroHack gelernt?
Während der Umsetzung dieses MicroHacks haben wir einiges gelernt. Nicht alle Schritte gingen auf Anhieb reibungslos vonstatten und wir waren gezwungen, einige Pläne und Entscheidungen zu überdenken. Hier unsere fünf Takeaways aus dem Entwicklungsprozess:
Nicht alle Datenbanken sind gleich
Während der Entwicklung haben wir mehrmals unsere Wahl der Vektordatenbank geändert: von OpenSearch zu ElasticSearch und schlussendlich zu Chroma. Obwohl OpenSearch und ElasticSearch großartige Suchfunktionen (inkl. Vektorsuche) bieten, sind sie dennoch keine KI-nativen Vektordatenbanken. Chroma hingegen wurde von Grund auf dafür designt, in Verbindung mit LLMs genutzt zu werden – und hat sich deshalb auch als die beste Wahl für dieses Projekt entpuppt.
Chroma ist eine großartige open-source VektorDB für kleinere Projekte und Prototyping
Chroma besticht insbesondere für kleinere Use-Cases und schnelles Prototyping. Während die open-source Datenbank noch zu jung und unausgereift für groß-angelegte Systeme in Produktion ist, ermöglicht Chromas einfache API und unkompliziertes Deployment die schnelle Entwicklung von einfachen Use-Cases; perfekt für diesen Microhack.
Azure Functions sind eine fantastische Lösung, um kleinere Codestücke nach Bedarf auszuführen
Azure Functions taugen ideal für die Ausführung von Code, der nicht in vorgeplanten Intervallen benötigt wird. Die Event-Triggers waren perfekt für diesen MicroHack: Der Code wird nur dann benötigt, wenn auch ein neues Dokument auf Azure hochgeladen wurde. Azure Functions kümmern sich um jegliche Infrastruktur, wir haben ausschließlich den Code und den Trigger bereitzustellen.
Azure App Service ist großartig für das Deployment von streamlit-Apps
Unsere streamlit-App hätte kein einfacheres Deployment erleben können als mit dem Azure App Service. Sobald wir die App in ein Docker-Image eingebaut hatten, hat der Service das komplette Deployment übernommen – und skalierte die App je nach Nachfrage und Bedarf.
Networking sollte nicht unterschätzt werden
Damit alle genutzten Services auch miteinander arbeiten können, muss die Kommunikation zwischen den einzelnen Services gewährleistet werden. Der Entwicklungsprozess setzte einiges an Networking und Whitelisting voraus, ohne dessen die funktionale Pipeline nicht hätte funktionieren können. Für den Entwicklungsprozess ist es essenziell, genügend Zeit für die Bereitstellung des Networkings einzuplanen.
Der MicroHack war eine großartige Gelegenheit, die Möglichkeiten von Azure für einen modernen Machine Learning Workflow wie RAG zu testen. Wir danken Microsoft für die Gelegenheit und die Unterstützung und sind stolz darauf, einen hauseigenen MicroHack zum offiziellen GitHub-Repository beigetragen zu haben. Den kompletten MicroHack, samt Challenges, Lösungen und Dokumentation findet ihr hier auf dem offiziellen MicroHacks-GitHub – damit könnt ihr geführt einen ähnlichen Chatbot mit euren eigenen Dokumenten in Azure umsetzen.
Read next …


… and explore new

