Data-Science-Anwendungen bieten Einblicke in große und komplexe Datensätze, die oft leistungsstarke Modelle enthalten, die sorgfältig auf die Bedürfnisse der Kund:innen abgestimmt sind. Die gewonnenen Erkenntnisse sind jedoch nur dann nützlich, wenn sie den Endnutzer:innen auf zugängliche und verständliche Weise präsentiert werden. An dieser Stelle kommt die Entwicklung einer Webanwendung mit einem gut gestalteten Frontend ins Spiel: Sie hilft bei der Visualisierung von anpassbaren Erkenntnissen und bietet eine leistungsstarke Schnittstelle, die Benutzer nutzen können, um fundierte Entscheidungen zu treffen.
In diesem Artikel werden wir erörtern, warum ein Frontend für Data-Science-Anwendungen sinnvoll ist und welche Schritte nötig sind, um ein funktionales Frontend zu bauen. Außerdem geben wir einen kurzen Überblick über beliebte Frontend- und Backend-Frameworks und wann diese eingesetzt werden sollten.
Drei Gründe, warum ein Frontend für Data Science nützlich ist
In den letzten Jahren hat der Bereich Data Science eine rasante Zunahme des Umfangs und der Komplexität der verfügbaren Daten erlebt. Data Scientists sind zwar hervorragend darin, aus Rohdaten aussagekräftige Erkenntnisse zu gewinnen, doch die effektive Vermittlung dieser Ergebnisse an die Beteiligten bleibt eine besondere Herausforderung. An dieser Stelle kommt ein Frontend ins Spiel. Ein Frontend bezeichnet im Zusammenhang mit Data Science die grafische Oberfläche, die es den Benutzer:innen ermöglicht, mit datengestützten Erkenntnissen zu interagieren und diese zu visualisieren. Wir werden drei Hauptgründe untersuchen, warum die Integration eines Frontends in den Data-Science-Workflow für eine erfolgreiche Analyse und Kommunikation unerlässlich ist.
Dateneinblicke visualisieren
Ein Frontend hilft dabei, die aus Data-Science-Anwendungen gewonnenen Erkenntnisse auf zugängliche und verständliche Weise zu präsentieren. Durch die Visualisierung von Datenwissen mit Diagrammen, Grafiken und anderen visuellen Hilfsmitteln können Benutzer:innen Muster und Trends in den Daten besser verstehen.
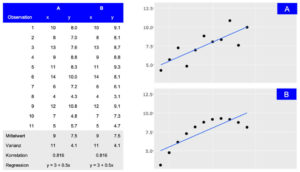
Darstellung von zwei Datensätzen (A und B), die trotz unterschiedlicher Verteilung die gleichen zusammenfassenden Statistiken aufweisen. Während die tabellarische Ansicht detaillierte Informationen liefert, macht die visuelle Darstellung die allgemeine Verbindung zwischen den Beobachtungen leicht zugänglich.
Benutzererlebnisse individuell gestalten
Dashboards und Berichte können in hohem Maße an die spezifischen Bedürfnisse verschiedener Benutzergruppen angepasst werden. Ein gut gestaltetes Frontend ermöglicht es den Nutzer:innen, mit den Daten auf eine Weise zu interagieren, die ihren Anforderungen am ehesten entspricht, so dass sie schneller und effektiver Erkenntnisse gewinnen können.
Fundierte Entscheidungsfindung ermöglichen
Durch die Darstellung der Ergebnisse von Machine-Learning-Modellen und der Ergebnisse erklärungsbedürftiger KI-Methoden über ein leicht verständliches Frontend erhalten die Nutzer:innen eine klare und verständliche Darstellung der Datenerkenntnisse, was fundierte Entscheidungen erleichtert. Dies ist besonders wichtig in Branchen wie dem Finanzhandel oder Smart Cities, wo Echtzeit-Einsichten zu Optimierungen und Wettbewerbsvorteilen führen können.
Vier Phasen von der Idee bis zum ersten Prototyp
Wenn es um Data Science Modelle und Ergebnisse geht, ist das Frontend der Teil der Anwendung, mit dem die Benutzer:innen interagieren. Es sollte daher klar sein, dass die Entwicklung eines nützlichen und produktiven Frontends Zeit und Mühe erfordert. Vor der eigentlichen Entwicklung ist es entscheidend, den Zweck und die Ziele der Anwendung zu definieren. Um diese Anforderungen zu ermitteln und zu priorisieren, sind mehrere Iterationen von Brainstorming- und Feedback-Sitzungen erforderlich. Während dieser Sitzungen wird das Frontend die Phasen von einer einfachen Skizze über ein Wireframe und ein Mockup bis hin zum ersten Prototyp durchlaufen.
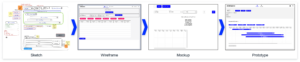
Skizze
In der ersten Phase wird eine grobe Skizze des Frontends erstellt. Dazu gehört die Identifizierung der verschiedenen Komponenten und wie sie aussehen könnten. Um eine Skizze zu erstellen, ist es hilfreich, eine Planungssitzung abzuhalten, in der die funktionalen Anforderungen und visuellen Ideen geklärt und ausgetauscht werden. Während dieser Sitzung wird eine erste Skizze mit einfachen Hilfsmitteln wie einem Online-Whiteboard (z. B. Miro) erstellt, aber auch Stift und Papier können ausreichen.
Wireframe
Wenn die Skizze fertig ist, müssen die einzelnen Teile der Anwendung miteinander verbunden werden, um ihre Wechselwirkungen und ihr Zusammenspiel zu verstehen. Dies ist eine wichtige Phase, um mögliche Probleme frühzeitig zu erkennen, bevor der Entwicklungsprozess beginnt. Wireframes zeigen die Nutzung aus der Sicht der Benutzer:innen und berücksichtigen die Anforderungen der Anwendung. Sie können auch auf einem Miro-Board oder mit Tools wie Figma erstellt werden.
Mockup
Nach den Skizzen- und Wireframe-Phasen besteht der nächste Schritt darin, ein Mockup des Frontends zu erstellen. Dabei geht es darum, ein visuell ansprechendes Design zu erstellen, das einfach zu bedienen und zu verstehen ist. Mit Tools wie Figma können Mockups schnell erstellt werden. Sie bieten auch eine interaktive Demo, die die Interaktion innerhalb des Frontends zeigt. In dieser Phase ist es wichtig, sicherzustellen, dass das Design mit der Marke und den Stilrichtlinien des Unternehmens übereinstimmt, denn der erste Eindruck bleibt haften.
Prototype
Sobald das Mockup fertig ist, ist es an der Zeit, einen funktionierenden Prototyp des Frontends zu erstellen und ihn mit der Backend-Infrastruktur zu verbinden. Um später die Skalierbarkeit zu gewährleisten, müssen das verwendete Framework und die gegebene Infrastruktur bewertet werden. Diese Entscheidung hat Auswirkungen auf die in dieser Phase verwendeten Tools und wird in den folgenden Abschnitten erörtert.
Es gibt viele Optionen für die Frontend-Entwicklung
Die meisten Data Scientisten sind mit R oder Python vertraut. Daher sind die ersten Lösungen für die Entwicklung von Frontend-Anwendungen wie Dashboards oft R Shiny, Dash oder streamlit. Diese Tools haben den Vorteil, dass Datenaufbereitung und Modellberechnungsschritte im selben Framework wie das Dashboard implementiert werden können. Die Visualisierungen sind eng mit den verwendeten Daten und Modellen verknüpft und Änderungen können oft vom selben Entwickler integriert werden. Für manche Projekte mag das ausreichen, aber sobald eine gewisse Skalierbarkeit erreicht ist, ist es von Vorteil, Backend-Modellberechnungen und Frontend-Benutzerinteraktionen zu trennen.
Es ist zwar möglich, diese Art der Trennung in R- oder Python-Frameworks zu implementieren, aber unter der Haube übersetzen diese Bibliotheken ihre Ausgabe in Dateien, die der Browser verarbeiten kann, wie HTML, CSS oder JavaScript. Durch die direkte Verwendung von JavaScript mit den entsprechenden Bibliotheken gewinnen die Entwickler mehr Flexibilität und Anpassungsfähigkeit. Einige gute Beispiele, die eine breite Palette von Visualisierungen bieten, sind D3.js, Sigma.js oder Plotly.js, mit denen reichhaltigere Benutzeroberflächen mit modernen und visuell ansprechenden Designs erstellt werden können.
Dennoch ist das Angebot an JavaScript-basierten Frameworks nach wie vor groß und wächst weiter. Die am häufigsten verwendeten Frameworks sind React, Angular, Vue und Svelte. Vergleicht man sie in Bezug auf Leistung, Community und Lernkurve, so zeigen sich einige Unterschiede, die letztlich von den spezifischen Anwendungsfällen und Präferenzen abhängen (weitere Details finden Sie hier oder hier).
Als „die Programmiersprache des Webs“ gibt es JavaScript schon seit langem. Das vielfältige und vielseitige Ökosystem von JavaScript mit den oben genannten Vorteilen bestätigt dies. Dabei spielen nicht nur die direkt verwendeten Bibliotheken eine Rolle, sondern auch die breite und leistungsfähige Palette an Entwickler-Tools, die das Leben der Entwickler erleichtern.
Überlegungen zur Backend-Architektur
Neben der Ideenfindung müssen auch die Fragen nach dem Entwicklungsrahmen und der Infrastruktur beantwortet werden. Die Kombination der Visualisierungen (Frontend) mit der Datenlogik (Backend) in einer Anwendung hat Vor- und Nachteile.
Ein Ansatz besteht darin, Technologien wie R Shiny oder Python Dash zu verwenden, bei denen sowohl das Frontend als auch das Backend gemeinsam in derselben Anwendung entwickelt werden. Dies hat den Vorteil, dass es einfacher ist, Datenanalyse und -visualisierung in eine Webanwendung zu integrieren. Es hilft den Benutzern, direkt über einen Webbrowser mit Daten zu interagieren und Visualisierungen in Echtzeit anzuzeigen. Vor allem R Shiny bietet eine breite Palette von Paketen für Data Science und Visualisierung, die sich leicht in eine Webanwendung integrieren lassen, was es zu einer beliebten Wahl für Entwickler macht, die im Bereich Data Science arbeiten.
Andererseits bietet die Trennung von Frontend und Backend durch unterschiedliche Frameworks wie Node.js und Python mehr Flexibilität und Kontrolle über den Anwendungsentwicklungsprozess. Frontend-Frameworks wie Vue und React bieten eine breite Palette von Funktionen und Bibliotheken für die Erstellung intuitiver Benutzeroberflächen und Interaktionen, während Backend-Frameworks wie Express.js, Flask und Django robuste Tools für die Erstellung von stabilem und skalierbarem serverseitigem Code bieten. Dieser Ansatz ermöglicht es Entwicklern, die besten Tools für jeden Aspekt der Anwendung auszuwählen, was zu einer besseren Leistung, einfacheren Wartung und mehr Anpassungsmöglichkeiten führen kann. Es kann jedoch auch zu einer höheren Komplexität des Entwicklungsprozesses führen und erfordert mehr Koordination zwischen Frontend- und Backend-Entwicklern.
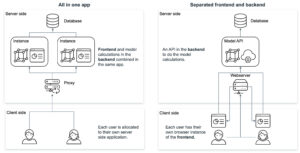
Das Hosten eines JavaScript-basierten Frontends bietet mehrere Vorteile gegenüber dem Hosten einer R Shiny- oder Python Dash-Anwendung. JavaScript-Frameworks wie React, Angular oder Vue.js bieten leistungsstarkes Rendering und Skalierbarkeit, was komplexe UI-Komponenten und groß angelegte Anwendungen ermöglicht. Diese Frameworks bieten auch mehr Flexibilität und Anpassungsoptionen für die Erstellung benutzerdefinierter UI-Elemente und die Implementierung komplexer Benutzerinteraktionen. Darüber hinaus sind JavaScript-basierte Frontends plattformübergreifend kompatibel und laufen auf Webbrowsern, Desktop-Anwendungen und mobilen Apps, was sie vielseitiger macht. Und schließlich ist JavaScript die Sprache des Webs, was eine einfachere Integration in bestehende Technologie-Stacks ermöglicht. Letztendlich hängt die Wahl der Technologie vom spezifischen Anwendungsfall, der Erfahrung des Entwicklungsteams und den Anforderungen der Anwendung ab.
Fazit
Der Aufbau eines Frontends für eine Data-Science-Anwendung ist entscheidend für die effektive Vermittlung von Erkenntnissen an die Endnutzer. Es hilft dabei, die Daten in einer leicht verdaulichen Art und Weise zu präsentieren und ermöglicht es den Benutzern, fundierte Entscheidungen zu treffen. Um sicherzustellen, dass die Bedürfnisse und Anforderungen richtig und effizient genutzt werden, muss das richtige Framework und die richtige Infrastruktur evaluiert werden. Wir schlagen vor, dass Lösungen in R oder Python ein guter Ausgangspunkt sind, aber Anwendungen in JavaScript könnten auf lange Sicht besser skalieren.
Wenn Sie ein Frontend für Ihre Data-Science-Anwendung entwickeln möchten, wenden Sie sich unverbindlich an unser Expertenteam, das Sie durch den Prozess führt und Ihnen die nötige Unterstützung bietet, um Ihre Visionen zu verwirklichen.
Read next …


… and explore new


Entwickelt als eine Open-Source-Bibliothek von Plotly, baut das Python Framework Dash auf Flask, Plotly.js und React.js auf. Das Framework ermöglicht die Erstellung von interaktiven Webapplikationen in purem Python und eignet sich besonders für das Teilen von Datenanalysen.
Solltest du Interesse an der Erstellung von interaktiven Grafiken mit Python haben, kann ich den Blog meines Kollegen Markus, , sehr empfehlen.
Ein grundlegendes Verständnis von HTML und CSS ist für die Erstellung von Webapplikationen empfohlen. Um diesem Blog folgen zu können, werden wir alle notwendigen externen Ressourcen zur Verfügung stellen und die Rollen von HTML und CSS in einem Dash(board) erläutern.
Der Source Code ist auf verfügbar.
Vorraussetzungen
Das Projekt besteht aus einem Stylesheet style.css, den Beispieldaten stockdata2.csv und der eigentlichen Dash-Applikation app.py.
Laden des Stylesheet
Die Verwendung eines Stylesheets ist für die Funktionalitäten des Dashboards nicht notwendig. Damit das Dashboard jedoch so aussieht, wie in unseren Beispielen, kann die Datei von unserem heruntergeladen werden. Das verwendete Stylesheet is eine leicht veränderte Version des Stylesheets der . Dash lädt automatisch .css-Dateien, die sich im Unterordner assets befinden.
dashapp
|--assets
|-- style.css
|--data
|-- stockdata2.csv
|-- app.pyDie Dokumentation zu externen Ressourcen (u.a. Stylesheets) kann unter folgendem Link gefunden werden: https://dash.plot.ly/external-resources
Laden der Daten
Für unser Dashboard verwenden wir den Datensatz . Der Datensatz hat folgende Struktur:
| date | stock | value | change |
|---|---|---|---|
| 2007-01-03 | MSFT | 23.95070 | -0.1667 |
| 2007-01-03 | IBM | 80.51796 | 1.0691 |
| 2007-01-03 | SBUX | 16.14967 | 0.1134 |
import pandas as pd
# Load data
df = pd.read_csv('data/stockdata2.csv', index_col=0, parse_dates=True)
df.index = pd.to_datetime(df['Date'])Erste Schritte – Wie man eine Dash-App startet
Nach der Installation von Dash (Anleitung kann gefunden werden) können wir die App starten. Die folgenden Zeilen importieren die benötigten Pakete dash und dash_html_components. Ohne eine Definition eines Layouts der App, kann die Applikation nicht gestartet werden. Eine leere html.Div genügt, um die App zu starten.
import dash
import dash_html_components as htmlWeb Applikation Framework
# Initialise the app
app = dash.Dash(__name__)
# Define the app
app.layout = html.Div()
# Run the app
if __name__ == '__main__':
app.run_server(debug=True)Wie eine .css-Datei das Layout beeinflusst
Das Modul dash_html_components beinhaltet verschiedene HTML-Komponenten. Mehr Informationen zu den Komponenten unter: https://dash.plot.ly/dash-html-components
HTML-Komponenten können über das children-Attribut verschachtelt werden.
app.layout = html.Div(children=[
html.Div(className='row', # Define the row element
children=[
html.Div(className='four columns div-user-controls'), # Define the left element
html.Div(className='eight columns div-for-charts bg-grey') # Define the right element
])
])Das erste html.Div() hat ein untergeordnetes Element (eng. child). Das Element is ein weiteres html.Div() mit dem Namen (className) row, welches der Container für unseren Inhalt sein wird. Die weiteren untergeordneten Elemente sind four-columns div-user-controls und eight columns div-for-charts bg-grey.
Der Stil der div-Komponenten stammt aus unserer style.css-Datei.
Wir starten damit, dass wir der App weitere Informationen zur Verfügung stellen, wie Titel und Beschreibung. Zum Element four columns div-user-controls fügen wir die Komponenten H2 für die Überschrift und P als Paragraph hinzu.
children = [
html.H2('Dash - STOCK PRICES'),
html.P('''Visualising time series with Plotly - Dash'''),
html.P('''Pick one or more stocks from the dropdown below.''')
]

Die Basics des App-Layouts
Ein weiteres Feature von Flask (und somit Dash) ist das . Das Feature macht es möglich, eine Änderung im Code ohne einen Neustart der App sehen zu können.
Zusätzlich wird durch debug=True ein Feld rechts in der unteren Ecke der App angezeigt, worin wir auf Fehlermeldungen und den Callback Graph zugriff haben. Wir werden im letzten Abschnitt des Artikels auf Callback Graph zurück kommen, nachdem wir interaktive Funktionalitäten implementiert haben.

Erstellen von Grafiken in Dash – Wie man eine Plotly-Grafik anzeigt
Nachdem wir die grundlegenden Container für unsere App erstellt haben, erstellen wir jetzt einen Plotly-Graphen. Die Komponente dcc.Graph aus den dash_core_components nutzt das gleiche figure-Argument wie das plotly.py Paket. Dash übersetzt jeden Aspekt des Charts zu einem Schlüssel-Wert-Paar, welches von der darunterliegenden JavaScript-Bibliothek Plotly.js verarbeitet wird.
Im folgenden Abschnitt verwenden wir die Expressversion von plotly.py und das Paket Dash Core Components. Nach der Installation von Dash sollte plotly in der Entwicklungsumgebung bereits verfügbar sein.
import dash_core_components as dcc
import plotly.express as pxbeinhaltet eine Kollektion von nützlichen und einfach zu bedienenden Komponenten, welche zur Interaktivität und Funktionalität des Dashboard beitragen.
ist die Expressversion von plotly.py, welche die Erstellung von Plotly-Grafiken vereinfacht, mit der Einschränkung dass es die Flexibilität verringert.
Um einen Plot in der rechten Seite unserer App zu zeichnen, wird ein dcc.Graph() als ein Unterelement dem html.Div() mit dem Namen eight columns div-for-charts bg-grey hinzugefügt. Die Komponente dcc.Graph() kann für jede von plotly-gestützte Visualisierung genutzt werden. In unserem Fall wird die figure von px.line() aus dem Paket plotly.express erstellt. Das Layout der Grafik ändern wir durch die Methode update_layout(). Um den Hintergrund der Grafik transparent zu machen, setzen wir die Farbe auf rgba(0, 0, 0, 0). Ohne den Hintergrund transparent zu setzen, würde eine große weiße Box in der Mitte unserer App stehen. Da dcc.Graph() lediglich die Grafik anzeigt, können wir nach der Erstellung die Eigenschaften der Grafik nicht ohne weiteres ändern.
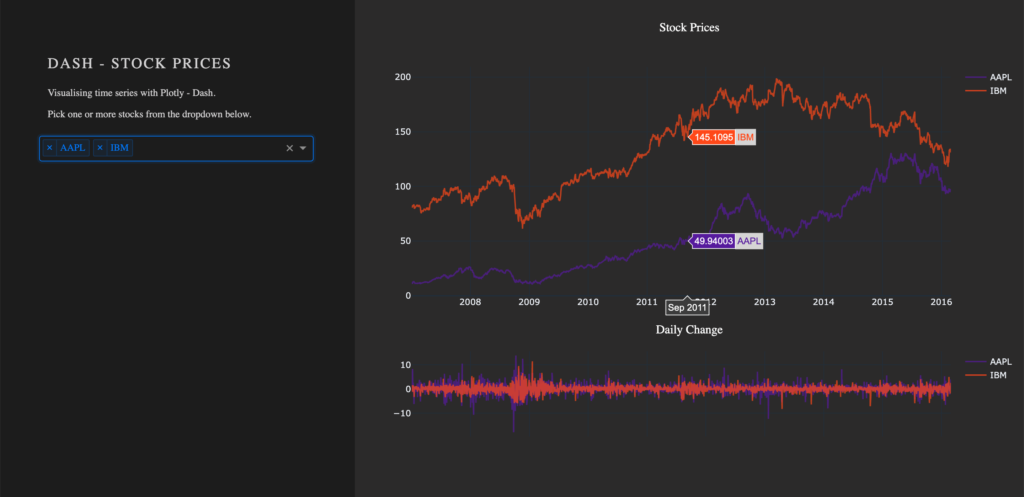
dcc.Graph(id='timeseries',
config={'displayModeBar': False},
animate=True,
figure=px.line(df,
x='Date',
y='value',
color='stock',
template='plotly_dark').update_layout(
{'plot_bgcolor': 'rgba(0, 0, 0, 0)',
'paper_bgcolor': 'rgba(0, 0, 0, 0)'})
)
Erstellen einer Dropdown-Liste
Eine weitere Komponente ist dcc.Dropdown(), welche genutzt wird – du kannst es dir vielleicht denken –, um eine Dropdown-Liste zu erstellen. Die verfügbaren Optionen in einem Dropdown werden entweder durch eine (Python) Liste gegeben oder innerhalb einer Funktion definiert.
Für unsere Dropdown-Liste erstellen wir eine Funktion, welche eine Liste von Dictionaries ausgibt. Die Liste besteht aus den Dictionaries mit den Schlüsseln label und value. Hierdurch werden die Optionen unserer Dropdown-Liste definiert. Der Wert von label ist der angezeigte Text in der App und der Wert von value kann innerhalb der App als Input für Funktionen verwendet werden. Solltest du beispielsweise den vollen Namen des Unternehmens anzeigen, kann der Wert von label auf Microsoft gesetzt werden. Der Einfachheit halber wählen wir für label und value die gleichen Werte.
Füge die folgende Funktion zum Skript hinzu, bevor du das Layout der App definierst:
# Creates a list of dictionaries, which have the keys 'label' and 'value'.
def get_options(list_stocks):
dict_list = []
for i in list_stocks:
dict_list.append({'label': i, 'value': i})
return dict_listNach unserer Funktion get_option, können wir das Element dcc.Dropdown() von den Dash Core Components zu unserer App hinzufügen. Füge html.Div() als untergeordenetes Element zur Liste der Elemente in four columns div-user-controls hinzu und setze das Argument className=div-for-dropdown. html.Div() hat ein Unterelement, dcc.Dropdown().
Wir möchten die Möglichkeit habe, nicht nur einen einzelnen Wert, sondern mehrere Werte zur gleichen Zeit auszuwählen und setzen daher das Argument multi=True. Da die App jedoch nicht leer erscheinen soll, setzen wir zudem einen initialen Wert für value.
html.Div(className='div-for-dropdown',
children=[
dcc.Dropdown(id='stockselector',
options=get_options(df['stock'].unique()),
multi=True,
value=[df['stock'].sort_values()[0]],
style={'backgroundColor': '#1E1E1E'},
className='stockselector')
],
style={'color': '#1E1E1E'})id und options Argumente des dcc.Dropdown() sind wichtig für den nächsten Abschnitt. Um unterschiedliche Styles der Dropdown-Liste auszuprobieren, folge diesem
Mit Callbacks arbeiten
Wie man der App interaktive Funktionalitäten hinzufügt
Callbacks (eng. für Rückruffunktion) sind für die Interaktivität in einem Dashboard verantwortlich. Sie nehmen Inputs entgegen, z.B. die ausgewählten Optionen einer Dropdown-Liste und leiten die Werte zu einer Funktion weiter. Der Output der Funktion wird durch den Callback an ein definiertes Element geleitet. Wir werden im nächsten Schritt eine Funktion schreiben, welche eine Grafik basierend auf den Namen von Unternehmen ausgibt. In unserer Implementierung wird die erstellte Grafik an eine dcc.Graph()-Komponente geleitet.
Momenten hat die Auswahl der Dropdown-Liste noch keinen Einfluss auf die angezeigte Grafik. Um diese Funktionalität zu implementieren werden wir einen Callback nutzen. Der Callback übernimmt die Kommunikation zwischen der Dropdown-Liste mit der ID id='stockselector' und dem Graphen 'timeseries'. Zur Vorbereitung entfernen wir die zuvor erstellte Grafik, da wir die figure dynamisch erstellen möchten.
In unserer App möchten wir zwei Graphen haben, weshalb wir eine weitere dcc.Graph()-Komponente erstellen und mit dem Argument id='change' identifizierbar machen.
- Entfernen der
figurevon der Komponentedcc.Graph(id='timeseries') - Hinzufügen der Komponente
dcc.Graph(id='change') - Beide Komponenten sollten Unterelemente von
eight columns div-for-charts bg-greysein.
dcc.Graph(id='timeseries', config={'displayModeBar': False})
dcc.Graph(id='change', config={'displayModeBar': False})Callbacks erhöhen die Interaktivität deiner Anwendung. Sie können Eingaben von Komponenten entgegennehmen, z. B. bestimmte Aktien, die über ein Dropdown-Menü ausgewählt werden, diese Eingaben an eine Funktion weitergeben und die von der Funktion zurückgegebenen Werte an Komponenten zurückgeben.
In unserer Implementierung wird ein Callback ausgelöst, sobald der Nutzer eine Aktie im Dropdown auswählt. Der Callback nimmt den Wert des dcc.Dropdown() entgegen (Input) und leitet den Wert an die Funktionen update_timeseries() und update_change() weiter. Die Funktionen filtern die Daten und erstellen eine auf den Inputs basierende Grafik. Der Callback leitet anschließend den Output der Funktionen (Grafik) an die als Output spezifizierten Elemente weiter.
Der Callback ist als Decorator für eine Funktion implementiert. Mehrere Inputs und Outputs sind möglich. Wir werden jedoch bei einem Input und einem Output bleiben. Wir importieren die Objekte dash.dependencies import Input, Output.
Füge die folgende Zeile zu deinemSkript hinzu.
from dash.dependencies import Input, Output und Output() nehmen die id einer Komponente (bspw. dcc.Graph(id='timeseries') hat die id 'timeseries') sowie die Eigenschaft einer Komponente (hier figure) als Argument entgegen.
Beispiel Callback:
# Update Time Series
@app.callback(Output('id of output component', 'property of output component'),
[Input('id of input component', 'property of input component')])
def arbitrary_function(value_of_first_input):
'''
The property of the input component is passed to the function as value_of_first_input.
The functions return value is passed to the property of the output component.
'''
return arbitrary_outputWenn wir durch unseren stockselector eine Zeitreihe für einen oder mehrere Aktien anzeigen möchten, benötigen wir eine Funktion. Der value unseres Inputs ist die Liste von ausgewählten Unternehmen aus der Dropdown-Liste.
Implementieren von Callbacks
Die Funktion zeichnet die Linien (eng. traces) der Plotly-Grafik, basierend auf den übergebenen Aktiennamen werden die Linien gezeichnet und zusammen als eine figure ausgegeben, welche von dcc.Graph() angezeigt werden kann. Die Inputs für unsere Funktion werden in der Reihenfolge übergeben, in welcher Sie im Callback gesetzt wurden. (Bemerkung: Seit Dash 2.0 muss dies nicht immer der Fall sein.)
Update der Grafik (figure) für die time series:
@app.callback(Output('timeseries', 'figure'),
[Input('stockselector', 'value')])
def update_timeseries(selected_dropdown_value):
''' Draw traces of the feature 'value' based one the currently selected stocks '''
# STEP 1
trace = []
df_sub = df
# STEP 2
# Draw and append traces for each stock
for stock in selected_dropdown_value:
trace.append(go.Scatter(x=df_sub[df_sub['stock'] == stock].index,
y=df_sub[df_sub['stock'] == stock]['value'],
mode='lines',
opacity=0.7,
name=stock,
textposition='bottom center'))
# STEP 3
traces = [trace]
data = [val for sublist in traces for val in sublist]
# Define Figure
# STEP 4
figure = {'data': data,
'layout': go.Layout(
colorway=["#5E0DAC", '#FF4F00', '#375CB1', '#FF7400', '#FFF400', '#FF0056'],
template='plotly_dark',
paper_bgcolor='rgba(0, 0, 0, 0)',
plot_bgcolor='rgba(0, 0, 0, 0)',
margin={'b': 15},
hovermode='x',
autosize=True,
title={'text': 'Stock Prices', 'font': {'color': 'white'}, 'x': 0.5},
xaxis={'range': [df_sub.index.min(), df_sub.index.max()]},
),
}
return figureSTEP 1
- Ein
tracewird für jede Aktie gezeichnet. Erstellen einer leerenlistfür jedentraceder Plotly-Grafik.
STEP 2
In einem for-loop, wird ein trace für die Plotly-Grafik von go.Scatter erstellt. (go stammt aus dem Import import plotly.graph_objects as go)
- Iteriere über die selektierten Aktien im Drodown, zeichne ein
traceund hänge dastracean die Liste aus Step 3 an.
STEP 3
- Ebne (eng. flatten) die Liste.
STEP 4
Plotly-Grafiken sind Dictionaries mit den Schlüsseln data und layout. Der Wert von data ist unsere Liste mit den erstellten traces. Das layout wird mit go.Layout() definiert.
- Füge die
traceszu unsererfigure(Grafik) hinzu - Definiere das Layout der
figure
Diese gleichen Schritte werden für unsere zweite Grafik durchgeführt, mit dem Unterschied, dass die Daten auf der y-Achse auf change gesetzt werden.
Update der Grafik change:
@app.callback(Output('change', 'figure'),
[Input('stockselector', 'value')])
def update_change(selected_dropdown_value):
''' Draw traces of the feature 'change' based one the currently selected stocks '''
trace = []
df_sub = df
# Draw and append traces for each stock
for stock in selected_dropdown_value:
trace.append(go.Scatter(x=df_sub[df_sub['stock'] == stock].index,
y=df_sub[df_sub['stock'] == stock]['change'],
mode='lines',
opacity=0.7,
name=stock,
textposition='bottom center'))
traces = [trace]
data = [val for sublist in traces for val in sublist]
# Define Figure
figure = {'data': data,
'layout': go.Layout(
colorway=["#5E0DAC", '#FF4F00', '#375CB1', '#FF7400', '#FFF400', '#FF0056'],
template='plotly_dark',
paper_bgcolor='rgba(0, 0, 0, 0)',
plot_bgcolor='rgba(0, 0, 0, 0)',
margin={'t': 50},
height=250,
hovermode='x',
autosize=True,
title={'text': 'Daily Change', 'font': {'color': 'white'}, 'x': 0.5},
xaxis={'showticklabels': False, 'range': [df_sub.index.min(), df_sub.index.max()]},
),
}
return figureStarte die App erneut. In der App können nun über die Dropdown-Liste die verschiedenen Aktien ausgewählt werden. Für jedes selektierte Element wird ein Line-Plot gezeichnet und angezeigt. Standardmäßig hat die Dropdown-Komponente einige Funktionalitäten, wie bspw. die Suchfunktion, weshalb die Selektion von einzelnen Elementen auch bei vielen Auswahlmöglichkeiten sehr einfach ist.
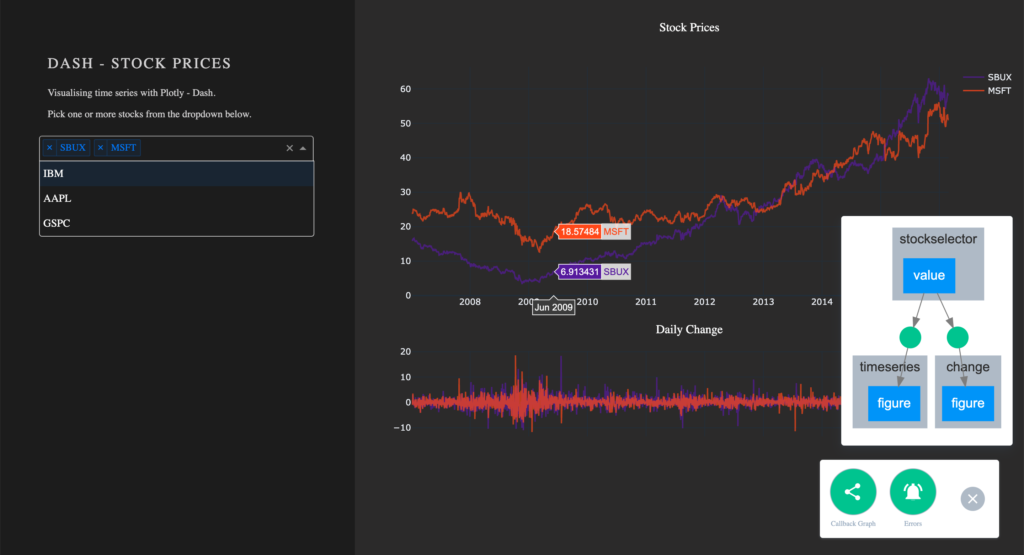
Visualisieren von Callbacks – Callback Graph
Mit den implementierten Callbacks ist die App fertig. Werfen wir nun einen Blick auf den sogenannten Callback Graph. Wenn die App mit debug=True gestartet wird, erscheint in der unteren rechten Ecke ein Feld. Hierüber kann eine visuelle Repräsentation des Callback Graph angezeigt werden, welchen wir im Skript definiert haben. Der Graph zeigt, dass die Komponenten timeseries und change eine figure anzeigen, die auf den ausgewählten Werten im stockselector basieren.
Sollten Callbacks nicht so funktionieren, wie es geplant wurde, ist dieses Tool sehr hilfreich beim Debuggen.
Fazit
Fassen wir die wichtigsten Elemente von Dash zusammen. Um die App zu starten, benötigt man nur ein paar Zeilen Code. Ein grundlegendes Verständnis von HTML und CSS genügt, um den Stil eines Dashboards anzupassen. Interaktive Grafiken können ohne Probleme implementiert werden, da Dash für das Arbeiten mit interaktiven Plotly-Grafiken entwickelt wurde. Über Callbacks, welche den Input von Nutzenden an Funktionen weiterleiten, werden unterschiedliche Komponenten miteinander verbunden.
Wenn dir der Blogartikel gefallen hat, kontaktiere mich gerne über oder per . Ich bin neugierig, welche weiteren Anwendungsmöglichkeiten das Framework bietet und freue mich auf Fragen zu Daten, Machine Learning und KI sowie den spannenden Lösungen, an denen wir bei arbeiten.
Vielen Dank!
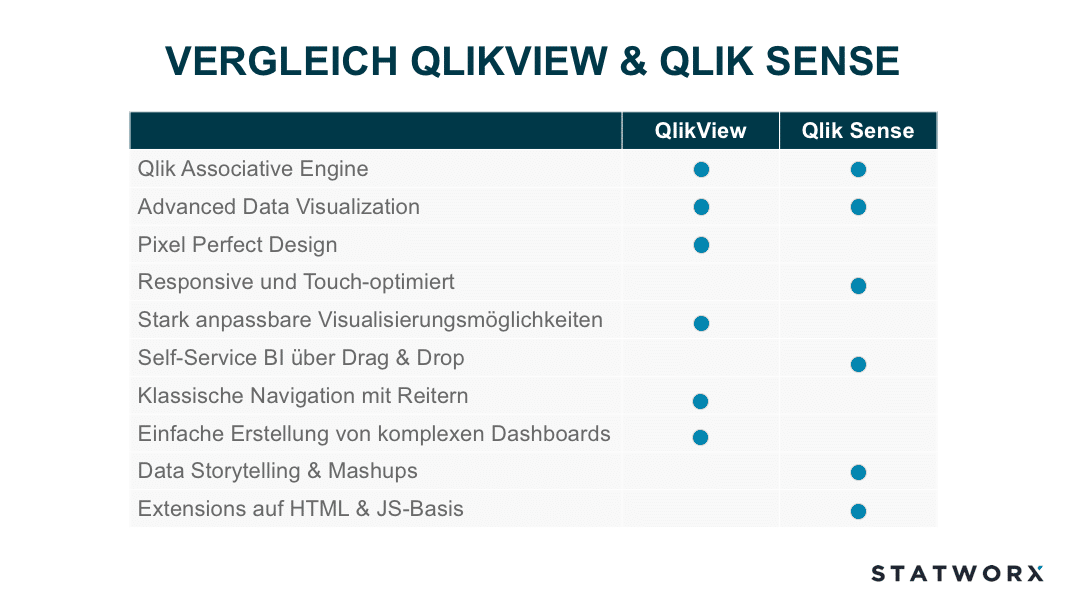
Daten-Visualisierung und -Verständnis sind wichtige Faktoren bei der Durchführung eines Data Science Projekts. Eine visuelle Exploration der Daten unterstützt den Data Scientist beim Verständnis der Daten und liefert häufig wichtige Hinweise über Datenqualität und deren Besonderheiten. Bei STATWORX wenden wir im Bereich Datenvisualsierung eine Vielzahl von unterschiedlichen Tools und Technologien an, wie z.B. Tableau, Qlik, R Shiny oder D3. Seit 2014 hat QlikTech zwei Produkte im Angebot: QlikView und Qlik Sense. Für viele unserer Kunden ist die Entscheidung, ob sie QlikView oder QlikSense einsetzen sollen nicht einfach zu treffen. Was sind die Vor- und Nachteile der beiden Produkte? In diesem Blogbeitrag erläutern wir die Unterschiede zwischen den beiden Tools.

Geschichte und Aufbau von Qlik
Die Erfolgsgeschichte der Firma QlikTech begann in den 90er Jahren mit dem Produkt QlikView, das im Jahre 2014 durch QlikSense offiziell abgelöst werden sollte. Aktuell sind noch beide Produkte am Markt, QlikTech fokussiert sich jedoch stark auf die Weiterentwicklung von QlikSense. Zwischen den Veröffentlichungsterminen der beiden Produkte stieg die Anzahl der Mitarbeiter von QlikTech von 35 auf über 2000. Beiden Produkten liegt dieselbe Kerntechnologie zu Grunde; die Qlik Associative Engine. Diese ermöglicht eine einfache Verknüpfung von unterschiedlichen Datensätzen, die alle In-Memory (im Arbeitsspeicher des Rechners) gehalten werden. Dies ermöglicht einen extrem schnellen Datenzugriff, da der Arbeitsspeicher gegenüber normalen Datenträgern eine erheblich schnellere Lese- und Schreibgeschwindigkeit aufweist. Weiterhin kann die Qlik Associative Engine viele Nutzer und große Datenmengen managen was einer der Hauptgründe ist, warum sich Qlik erfolgreich gegen seine Mitbewerber durchsetzen konnte.
QlikView
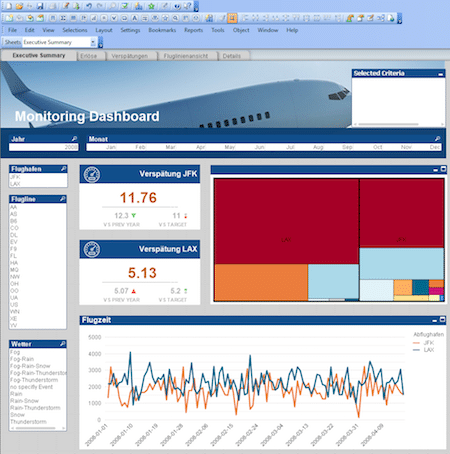
QlikView orientiert sich grundsätzlich am Thema „Guided Analytics“. Hierbei wird dem Endanwender eine App von einem QlikView-Entwickler bereitgestellt, die die notwendigen Überlegungen und Implementierungen rund um das Datenmodell, den inhaltlichen und optischen Aufbau der App sowie die unterschiedlichen Visualisierunge enthält. Der Anwender wiederum hat die komplette Freiheit die Daten durch Filtern, Auswählen, Drill-Down und Cycle Groups zu erkunden, um neue Erkentnisse zu gewinnen und Antworten auf seine Business-Fragen zu finden. Hierbei steht allerdings das Erstellen von eigenen Visualisierungen für den Endanwender nicht im Fokus.
Die Entwicklung von QlikView Applikationen erfordert Erfahrung und Expertise, da die Dashboarderstellung nicht über Drag und Drop möglich ist. Der Endanwender erhält hingegen eine fertige und einsatzbereite Applikation und kann somit umgehend mit seinen BI Analysen starten.
Die fertigen Datenmodelle und die daraus resultierende QVDs können ebenfalls von Qlik Sense geöffnet werden, dies ist allerdings andersherum nicht möglich.
Weitere wichtige Eckpunkte zu QlikView sind:
- eine Vielzahl an unterschiedlichen Datenverbindungsmöglichkeiten vorhanden
- keine Cloud-Lösung erhältlich, QlikView läuft lokal oder auf einem On-Premise Server
- benutzerfreundliche Entwicklungsoberfläche
- baut auf C++ und C# auf
- PDF Reporting durch NPrinting möglich
- Pixel genaues Erstellen von Applikationen
- 2000er Retro-Charme
- schnelle Entwicklungsprozesse und einfache Anpassungsmöglichkeiten
Qlik Sense
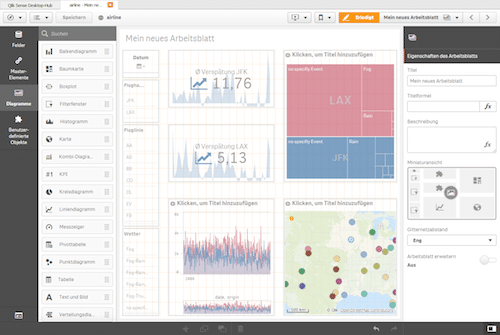
Qlik Sense wurde mit dem Fokus auf Self-Service BI entwickelt und ist Qliks Antwort auf den größten Mitbewerber Tableau. Hierbei wird der Anwender der Applikation weniger gerichtet geleitet sondern ihm die Möglichkeit gegeben seine eigenen Daten zu integrieren, um Apps selbständig zu kreieren. Einer der Vorteile von Self-Service BI ist, dass der Anwender eigenständig neue Visualisierungen erstellen kann, die sich konkret an seinen Fragestellungen orientieren. Allerdings erfordert dies engagierte und neugierige Anwender, die Lust haben ihre Daten zu erkunden. Tools wie QlikSense vereinfachen den Prozess bei der Erstellung von Visualisierungen erheblich, sodass auch unerfahrene Anwender innerhalb kürzester Zeit sinnvolle Darstellungen aus ihren Daten generieren können.
Die Erstellung von Visualisierungen und Layout erfolgt einfach über Drag & Drop. Kennzahlen und Dimensionen können ebenfalls in die Visualisierung gezogen werden. Im Gegensatz zu QlikView stehen nativ moderne Datenvisualisierungsmöglichkeiten zu Verfügung wie beispielsweiße Karten für Geoanalysen.
Jedoch spielen Qlik Experten weiterhin eine wichtige Rolle, da falls es sich nicht um Ad-hoc Analysen handelt eine Anbindung an die bestehende Dateninfrastruktur notwendig ist. Folglich ist es bei großen Datenmengen ebenfalls wichtig, dass das Datenmodell effizient und performant ausgestalltet sind. Um unterschiedliche Berechnung von KPIs zu vermeiden und die Kommunikation von widersprüchlichen Ergebnissen zwischen Abteilungen zu verhindern ist die Bereitstellung von Masterkennzahlen und Dimensionen entscheident. Zusätzlich vermeidet dies die ineffiziente Berechnung von Kennziffern, was bei großen Datenmengen an Bedeutung gewinnt bezüglich Ladezeit. Oft sind komplexere Analysen notwendig, welche nicht durch Drag & Drop möglich sind, sondern Erfahrung und Expertise in weitergehende Funktionen wie Set Analysen erfordert. Nur dadurch kann das volle Potential von Qlik Sense ausgeschöpft werden.
Im Vergleich zu QlikView ist Qlik Sense benutzerfreundlicher gestaltet worden, allerdings schränkt dies die Individualisierungsmöglichkeiten ein, was für erfahrene QlikView-Benutzer beim Umstieg frustrierend sein kann.
Weiterhin gibt es aus der Anwendung von QlikSense heraus noch folgende wichtige Punkte:
- Vielzahl von möglichen Datenverbindungen und Integration eines Data Marketplace
- Cloud Option vorhanden
- vereinfachtes Lizenzmodell
- kostenfreie Desktop-Version
- PDF Reporting durch NPrinting
- verwendet HTML und JavaScript als Grundlage
- anwenderfreundliche, offene API
- Vielzahl an kostenlosen und kostenpflichtigen Extensions, allerdings ist hierbei nicht immer eine Kompatibilität mit der nächsten Qlik Sense Version gewährleistet
- responsive, dadurch geeignet für mobile Devices und touch-freundliche Bedienung
Fazit
Schaut man sich die letzten Updates von QlikView und Qlik Sense an, erkennt man deutlich, dass der Fokus von QlikTech auf Qlik Sense liegt. QlikView soll weiterhin mit Updates versorgt werden, allerdings wird es vorrausichtlich keine neuen Features geben, diese bleiben Qlik Sense vorbehalten. Lange Zeit war der grundlegende Funktionsumfang gleich und die größten Unterschiede gab es hinsichtlich Bedienung und Visualisierungsmöglichkeiten. Allerdings gibt es beispielsweise die neuen In… Funktionen, die Year-to-date Berechnungen vereinfachen, nur in Qlik Sense.
Die Entwicklung von komplexeren Dashboards gestaltet sich unter Qlik Sense im Vergleich zu QlikView als schwieriger. Hier spielt QlikView eindeutig seine Stärke aus. Allerdings erweitern sich die Möglichkeiten diesbezüglich für Qlik Sense mit jedem Update. In den neusten Versionen wurden Optionen integriert um die Grid-Size anzupassen, die Seitenlänge zu erweitern und Scrollen zu ermöglichen oder ein Dashboard mit CI-konformen Farben zu gestalten mittels Custom-Themes. Außerdem bietet Qlik Sense für komplexe Dashboards die Möglichkeit Mashups zu erstellen. Hierbei handelt es sich um Webseiten oder Applikationen in die Qlik Sense Objekte integriert werden. Die Lücke zu QlikView hinsichtlich der Erstellung von Dashboards verkleinert sich somit stetig.
Beide Lösungen werden noch für längere Zeit ihre Daseinsberechtigung haben. Daher wird es für manche Unternehmen weiterhin Sinn machen QlikView und Qlik Sense parallel zu Betreiben und sich anwendungsbezogen für ein Produkt zu entscheiden.