
Spätestens durch den US-Präsidentschaftswahlkampf rückte der Microblogging Dienst Twitter stärker in den öffentlichen Fokus. Wem es allerdings nicht reicht, einfach nur durch das Soziale Netzwerk zu stöbern, der kann mit ein paar wenigen Tricks vom Datenreichtum Twitters profitieren.
Datenzugang
Twitter, so wie viele andere Online-Dienste, bietet sog. APIs („Application Programming Interface“) an. Durch diese können Interessierte ganz einfach einen Link zwischen der Datenbank der Online Plattform und dem eigenen Analysetool (z.B. R, Python) einrichten.
Um den Datenzugang seitens Twitter zu ermöglichen, müssen Interessierte allerdings einen aktiven Twitter Account haben. Mit diesem können dann eigene Apps erstellt werden. Im Folgenden werden wir nun einmal exemplarisch alle Schritte nach dem Erstellen eines aktiven Twitter Accounts durchgehen.
Wir haben einen aktiven Twitter Account und erstellen uns nun eine App. Hierzu besuchen wir zuerst apps.twitter.com und erstellen eine neue App.
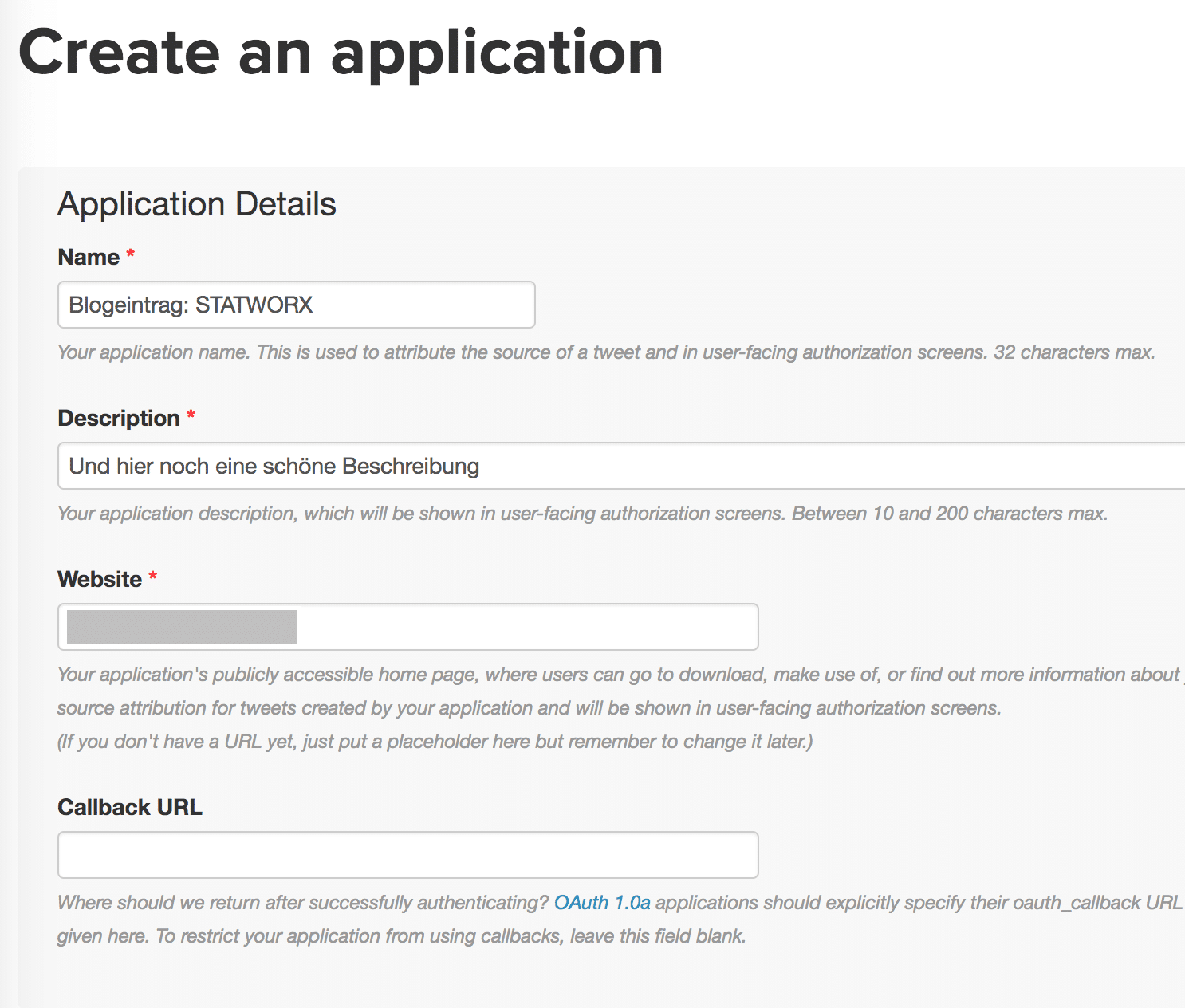
Beim Ausfüllen der Maske müssen wir darauf achten, dass der gewählte Name einzigartig ist. Die Beschreibung kann natürlich generisch sein. Sollte man keine eigene Website besitzen, so kann man ganz einfach einen generischen Placeholder wählen. Die Callback URL können wir vorerst auslassen.
Um auf die API zugreifen zu können, brauchen wir nun folgende Information:
- Consumer Key (API-Key)
- Consumer Secret (API-Secret)
- Access Token
- Access Token Secret
Die Consumer Key Elemente können wir ganz einfach unter dem Reiter „Keys and Access Tokens“ einsehen.
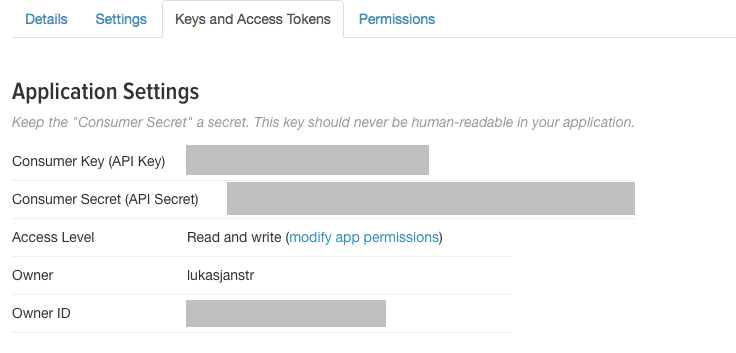
Den Access Token und das Access Token Secret müssen wir zuerst generieren.

Schon ist die App erstellt und wir haben alle Informationen, um unser Analyseprogramm mit der Twitter API zu verbinden.
API Abfrage mit RStudio
Twitter bietet zwei verschiedene APIs an: zum einen die sog. Search oder Rest API und zum anderen die Streaming API. Mit der Rest API können bereits geschriebene Tweets und Profilinformationen abgefragt werden. Mit der Streaming API können kontinuierlich Tweets abgezogen werden. Für den Rest des Blogeintrags schauen wir uns aber zuerst einmal die Rest API an.
RStudio und die Rest API
Um Tweets und Profile über die Rest API direkt von RStudio abzufragen, brauchen wir die folgenden Zeilen Code. Hierbei müssen consumer_key, consumer_secret, access_token und access_secret entsprechend vorher definiert werden.
# Benötigte Packages für den Link zur Rest API
install.packages("twitteR")
library(twitteR)
# Nun kann der Link zur Twitter API aufgesetzt werden
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
Nun steht der Link zwischen RStudio unter der Twitter API. Im nächsten Schritt können wir die ersten Twitterdaten abfragen.
Kurzes Beispiel
Angenommen, wir interessieren uns für Tweets zum Thema Data Science, dann können diese über die twitteR Funktionen abgefragt werden. Mit searchTwitter() ziehen wir hier die letzten beiden Tweets mit dem Hashtag #DataScience ab.
tweets <- searchTwitter("#DataScience", n=2)
Allerdings beschränkt sich die Rest API nicht nur auf Tweets. Wir können auch gezielt Profile minen. Mit getUser() können Profildaten abgefragt werden, hier z.B. für den STATWORX Account.
user <- getUser("@statworx")
Ausblick
In der nächsten Ausgabe werden wir uns mit der Struktur der gespeicherten Objekte befassen. Die Funktionen aus dem twitteR Package erlauben uns, eine Vielzahl von Informationen mit abzuziehen. Beim nächsten Mal verwenden wir diese, um die Informationen zu strukturieren, aufzubereiten und zu analysieren.