
At STATWORX, we are very passionate about the field of deep learning. In this blog series, we want to illustrate how an end-to-end deep learning project can be implemented. We use TensorFlow 2.x library for the implementation. The topics of the series include:
- Transfer learning for computer vision.
- Model deployment via TensorFlow Serving.
- Interpretability of deep learning models via Grad-CAM.
- Integrating the model into a Dash dashboard.
In the first part, we will show how you can use transfer learning to tackle car image classification. We start by giving a brief overview of transfer learning and the ResNet and then go into the implementation details. The code presented can be found in this github repository.
Introduction: Transfer Learning & ResNet
What is Transfer Learning?
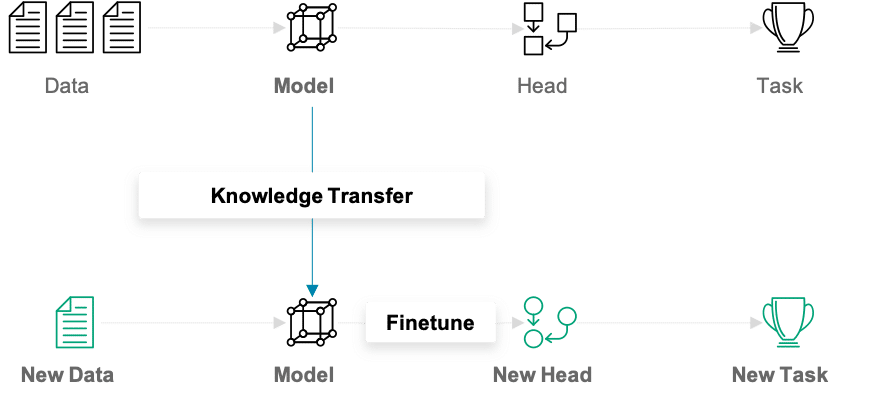
In traditional (machine) learning, we develop a model and train it on new data for every new task at hand. Transfer learning differs from this approach in that knowledge is transferred from one task to another. It is a useful approach when one is faced with the problem of too little available training data. Models that are pretrained for a similar problem can be used as a starting point for training new models. The pretrained models are referred to as base models.
In our example, a deep learning model trained on the ImageNet dataset can be used as the starting point for building a car model classifier. The main idea behind transfer learning for deep learning models is that the first layers of a network are used to extract important high-level features, which remain similar for the kind of data treated. The final layers (also known as the head) of the original network are replaced by a custom head suitable for the problem at hand. The weights in the head are initialized randomly, and the resulting network can be trained for the specific task.
There are various ways in which the base model can be treated during training. In the first step, its weights can be fixed. If the learning progress suggests the model not being flexible enough, certain layers or the entire base model can be “unfrozen” and thus made trainable. A further important aspect to note is that the input must be of the same dimensionality as the data on which the model was trained on – if the first layers of the base model are not modified.
Next, we will briefly introduce the ResNet, a popular and powerful CNN architecture for image data. Then, we will show how we used transfer learning with ResNet to do car model classification.
What is ResNet?
Training deep neural networks can quickly become challenging due to the so-called vanishing gradient problem. But what are vanishing gradients? Neural networks are commonly trained using back-propagation. This algorithm leverages the chain rule of calculus to derive gradients at deeper layers of the network by multiplying gradients from earlier layers. Since gradients get repeatedly multiplied in deep networks, they can quickly approach infinitesimally small values during back-propagation.
ResNet is a CNN network that solves the vanishing gradient problem using so-called residual blocks (you find a good explanation of why they are called ‘residual’ here). The unmodified input is passed on to the next layer in the residual block by adding it to a layer’s output (see right figure). This modification makes sure that a better information flow from the input to the deeper layers is possible. The entire ResNet architecture is depicted in the right network in the left figure below. It is plotted alongside a plain CNN and the VGG-19 network, another standard CNN architecture.
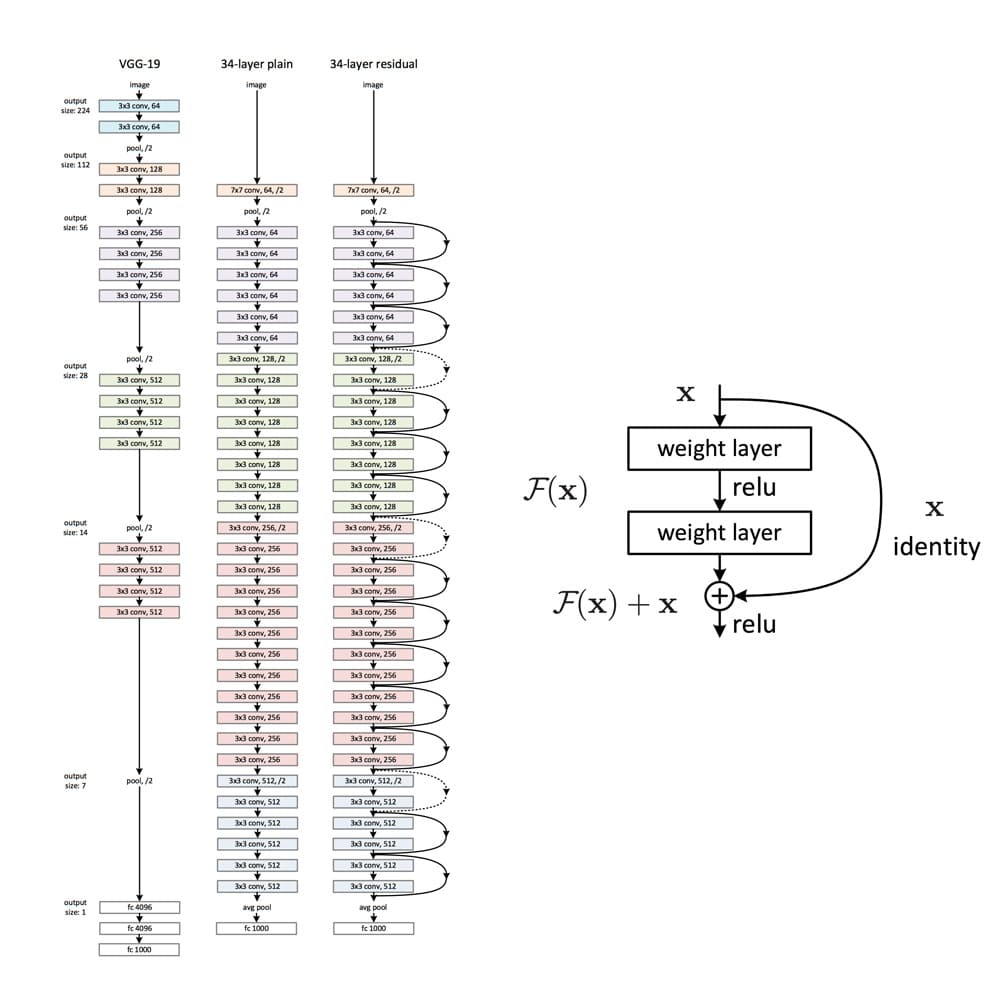
ResNet has proved to be a powerful network architecture for image classification problems. For example, an ensemble of ResNets with 152 layers won the ILSVRC 2015 image classification contest. Pretrained ResNet models of different sizes are available in the tensorflow.keras.application module, namely ResNet50, ResNet101, ResNet152 and their corresponding second versions (ResNet50V2, …). The number following the model name denotes the number of layers the networks have. The available weights are pretrained on the ImageNet dataset. The models were trained on large computing clusters using hardware accelerators for significant time periods. Transfer learning thus enables us to leverage these training results using the obtained weights as a starting point.
Classifying Car Models
As an illustrative example of how transfer learning can be applied, we treat the problem of classifying the car model given an image of the car. We will start by describing the dataset set we used and how we can filter out unwanted examples in the dataset. Next, we will go over how a data pipeline can be setup using tensorflow.data. In the second section, we will talk you through the model implementation and point out what aspects to be particularly careful about during training and prediction.
Data Preparation
We used the dataset described in this github repo, where you can also download the entire dataset. The author built a datascraper to scrape all car images from the car connection website. He explains that many images are from the interior of the cars. As they are not wanted in the dataset, they are filtered out based on pixel color. The dataset contains 64’467 jpg images, where the file names contain information on the car’s make, model, build year, etc. For a more detailed insight on the dataset, we recommend you consult the original github repo. Three sample images are shown below.

While checking through the data, we observed that the dataset still contained many unwanted images, e.g., pictures of wing mirrors, door handles, GPS panels, or lights. Examples of unwanted images can be seen below.

Thus, it is beneficial to additionally prefilter the data to clean out more of the unwanted images.
Filtering Unwanted Images Out of the Dataset
There are multiple possible approaches to filter non-car images out of the dataset:
- Use a pretrained model
- Train another model to classify car/no-car
- Train a generative network on a car dataset and use the discriminator part of the network
We decided to pursue the first approach since it is the most direct one and outstanding pretrained models are easily available. If you want to follow the second or third approach, you could, e.g., use this dataset to train the model. The referred dataset only contains images of cars but is significantly smaller than the dataset we used.
We chose the ResNet50V2 in the tensorflow.keras.applications module with the pretrained “imagenet” weights. In a first step, we must figure out the indices and classnames of the imagenet labels corresponding to car images.
# Class labels in imagenet corresponding to cars
CAR_IDX = [656, 627, 817, 511, 468, 751, 705, 757, 717, 734, 654, 675, 864, 609, 436]
CAR_CLASSES = ['minivan', 'limousine', 'sports_car', 'convertible', 'cab', 'racer', 'passenger_car', 'recreational_vehicle', 'pickup', 'police_van', 'minibus', 'moving_van', 'tow_truck', 'jeep', 'landrover', 'beach_wagon']
Next, the pretrained ResNet50V2 model is loaded.
from tensorflow.keras.applications import ResNet50V2
model = ResNet50V2(weights='imagenet')
We can then use this model to make predictions for images. The images fed to the prediction method must be scaled identically to the images used for training. The different ResNet models are trained on different input scales. It is thus essential to apply the correct image preprocessing. The module keras.application.resnet_v2 contains the method preprocess_input, which should be used when using a ResNetV2 network. This method expects the image arrays to be of type float and have values in [0, 255]. Using the appropriately preprocessed input, we can then use the built-in predict method to obtain predictions given an image stored at filename:
from tensorflow.keras.applications.resnet_v2 import preprocess_input
image = tf.io.read_file(filename)
image = tf.image.decode_jpeg(image)
image = tf.cast(image, tf.float32)
image = tf.image.resize_with_crop_or_pad(image, target_height=224, target_width=224)
image = preprocess_input(image)
predictions = model.predict(image)
There are various ideas of how the obtained predictions can be used for car detection.
- Is one of the
CAR_CLASSESamong the top k predictions? - Is the accumulated probability of the
CAR_CLASSESin the predictions greater than some defined threshold? - Specific treatment of unwanted images (e.g., detect and filter out wheels)
We show the code for comparing the accumulated probability mass over the CAR_CLASSES.
def is_car_acc_prob(predictions, thresh=THRESH, car_idx=CAR_IDX):
"""
Determine if car on image by accumulating probabilities of car prediction and comparing to threshold
Args:
predictions: (?, 1000) matrix of probability predictions resulting from ResNet with imagenet weights
thresh: threshold accumulative probability over which an image is considered a car
car_idx: indices corresponding to cars
Returns:
np.array of booleans describing if car or not
"""
predictions = np.array(predictions, dtype=float)
car_probs = predictions[:, car_idx]
car_probs_acc = car_probs.sum(axis=1)
return car_probs_acc > thresh
The higher the threshold is set, the stricter the filtering procedure is. A value for the threshold that provides good results is THRESH = 0.1. This ensures we do not lose too many true car images. The choice of an appropriate threshold remains subjective, so do as you feel.
The Colab notebook that uses the function is_car_acc_prob to filter the dataset is available in the github repository.
While tuning the prefiltering procedure, we observed the following:
- Many of the car images with light backgrounds were classified as “beach wagons”. We thus decided to also consider the “beach wagon” class in imagenet as one of the
CAR_CLASSES. - Images showing the front of a car are often assigned a high probability of “grille”, which is the grating at the front of a car used for cooling. This assignment is correct but leads the procedure shown above to not consider certain car images as cars since we did not include “grille” in the
CAR_CLASSES. This problem results in the trade-off of either leaving many close-up images of car grilles in the dataset or filtering out several car images. We opted for the second approach since it yields a cleaner car dataset.
After prefiltering the images using the suggested procedure, 53’738 of 64’467 initially remain in the dataset.
Overview of the Final Datasets
The prefiltered dataset contains images from 323 car models. We decided to reduce our attention to the top 300 most frequent classes in the dataset. That makes sense since some of the least frequent classes have less than ten representatives and can thus not be reasonably split into a train, validation, and test set. Reducing the dataset to images in the top 300 classes leaves us with a dataset containing 53’536 labeled images. The class occurrences are distributed as follows:

The number of images per class (car model) ranges from 24 to slightly below 500. We can see that the dataset is very imbalanced. It is essential to keep this in mind when training and evaluating the model.
Building Data Pipelines with tf.data
Even after prefiltering and reducing to the top 300 classes, we still have numerous images left. This poses a potential problem since we can not simply load all images into the memory of our GPU at once. To tackle this problem, we will use tf.data.
tf.data and especially the tf.data.Dataset API allows creating elegant and, at the same time, very efficient input pipelines. The API contains many general methods which can be applied to load and transform potentially large datasets. tf.data.Dataset is especifically useful when training models on GPU(s). It allows for data loading from the HDD, applies transformation on-the-fly, and creates batches that are than sent to the GPU. And this is all done in a way such as the GPU never has to wait for new data.
The following functions create a tf.data.Dataset instance for our particular problem:
def construct_ds(input_files: list,
batch_size: int,
classes: list,
label_type: str,
input_size: tuple = (212, 320),
prefetch_size: int = 10,
shuffle_size: int = 32,
shuffle: bool = True,
augment: bool = False):
"""
Function to construct a tf.data.Dataset set from list of files
Args:
input_files: list of files
batch_size: number of observations in batch
classes: list with all class labels
input_size: size of images (output size)
prefetch_size: buffer size (number of batches to prefetch)
shuffle_size: shuffle size (size of buffer to shuffle from)
shuffle: boolean specifying whether to shuffle dataset
augment: boolean if image augmentation should be applied
label_type: 'make' or 'model'
Returns:
buffered and prefetched tf.data.Dataset object with (image, label) tuple
"""
# Create tf.data.Dataset from list of files
ds = tf.data.Dataset.from_tensor_slices(input_files)
# Shuffle files
if shuffle:
ds = ds.shuffle(buffer_size=shuffle_size)
# Load image/labels
ds = ds.map(lambda x: parse_file(x, classes=classes, input_size=input_size, label_type=label_type))
# Image augmentation
if augment and tf.random.uniform((), minval=0, maxval=1, dtype=tf.dtypes.float32, seed=None, name=None) < 0.7:
ds = ds.map(image_augment)
# Batch and prefetch data
ds = ds.batch(batch_size=batch_size)
ds = ds.prefetch(buffer_size=prefetch_size)
return ds
We will now describe the methods in the tf.data we used:
from_tensor_slices()is one of the available methods for the creation of a dataset. The created dataset contains slices of the given tensor, in this case, the filenames.- Next, the
shuffle()method considersbuffer_sizeelements one at a time and shuffles these items in isolation from the rest of the dataset. If shuffling of the complete dataset is required,buffer_sizemust be larger than the bumber of entries in the dataset. Shuffling is only performed ifshuffle=True. map()allows to apply arbitrary functions to the dataset. We created a functionparse_file()that can be found in the github repo. It is responsible for reading and resizing the images, inferring the labels from the file name and encoding the labels using a one-hot encoder. If the augment flag is set, the data augmentation procedure is activated. Augmentation is only applied in 70% of the cases since it is beneficial to also train the model on non-modified images. The augmentation techniques used inimage_augmentare flipping, brightness, and contrast adjustments.- Finally, the
batch()method is used to group the dataset into batches ofbatch_sizeelements and theprefetch()method enables preparing later elements while the current element is being processed and thus improves performance. If used after a call tobatch(),prefetch_sizebatches are prefetched.
Model Fine Tuning
Having defined our input pipeline, we now turn towards the model training part. Below you can see the code that can be used to instantiate a model based on the pretrained ResNet, which is available in tf.keras.applications:
from tensorflow.keras.applications import ResNet50V2
from tensorflow.keras import Model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
class TransferModel:
def __init__(self, shape: tuple, classes: list):
"""
Class for transfer learning from ResNet
Args:
shape: Input shape as tuple (height, width, channels)
classes: List of class labels
"""
self.shape = shape
self.classes = classes
self.history = None
self.model = None
# Use pre-trained ResNet model
self.base_model = ResNet50V2(include_top=False,
input_shape=self.shape,
weights='imagenet')
# Allow parameter updates for all layers
self.base_model.trainable = True
# Add a new pooling layer on the original output
add_to_base = self.base_model.output
add_to_base = GlobalAveragePooling2D(data_format='channels_last', name='head_gap')(add_to_base)
# Add new output layer as head
new_output = Dense(len(self.classes), activation='softmax', name='head_pred')(add_to_base)
# Define model
self.model = Model(self.base_model.input, new_output)
A few more details on the code above:
- We first create an instance of class
tf.keras.applications.ResNet50V2. Withinclude_top=Falsewe tell the pretrained model to leave out the original head of the model (in this case designed for the classification of 1000 classes on ImageNet). base_model.trainable = Truemakes all layers trainable.- Using
tf.kerasfunctional API, we then stack a new pooling layer on top of the last convolution block of the original ResNet model. This is a necessary intermediate step before feeding the output to the final classification layer. - The final classification layer is then defined using
tf.keras.layers.Dense. We define the number of neurons to be equal to the number of desired classes. And the softmax activation function makes sure that the output is a pseudo probability in the range of(0,1].
The full version of TransferModel (see github) also contains the option to replace the base model with a VGG16 network, another standard CNN for image classification. In addition, it also allows to unfreeze only specific layers, meaning we can make the corresponding parameters trainable while leaving the others fixed. As a default, we have made all parameters trainable here.
After we defined the model, we need to configure it for training. This can be done using tf.keras.Model‘s compile()-method:
def compile(self, **kwargs):
"""
Compile method
"""
self.model.compile(**kwargs)
We then pass the following keyword arguments to our method:
loss = "categorical_crossentropy"for multi-class classification,optimizer = Adam(0.0001)for using the Adam optimizer fromtf.keras.optimizerswith a relatively small learning rate (more on the learning rate below), andmetrics = ["categorical_accuracy"]for training and validation monitoring.
Next, we will look at the training procedure. Therefore we define a train-method for our TransferModel-class introduced above:
from tensorflow.keras.callbacks import EarlyStopping
def train(self,
ds_train: tf.data.Dataset,
epochs: int,
ds_valid: tf.data.Dataset = None,
class_weights: np.array = None):
"""
Trains model in ds_train with for epochs rounds
Args:
ds_train: training data as tf.data.Dataset
epochs: number of epochs to train
ds_valid: optional validation data as tf.data.Dataset
class_weights: optional class weights to treat unbalanced classes
Returns
Training history from self.history
"""
# Define early stopping as callback
early_stopping = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=12,
restore_best_weights=True)
callbacks = [early_stopping]
# Fitting
self.history = self.model.fit(ds_train,
epochs=epochs,
validation_data=ds_valid,
callbacks=callbacks,
class_weight=class_weights)
return self.history
As our model is an instance of tensorflow.keras.Model, we can train it using the fit method. To prevent overfitting, early stopping is used by passing it to the fit method as a callback function. The patience parameter can be tuned to specify how soon early stopping should apply. The parameter stands for the number of epochs after which, if no decrease of the validation loss is registered, the training will be interrupted. Further, class weights can be passed to the fit method. Class weights allow treating unbalanced data by assigning the different classes different weights, thus allowing to increase the impact of classes with fewer training examples.
We can describe the training process using a pretrained model as follows: As the weights in the head are initialized randomly, and the weights of the base model are pretrained, the training composes of training the head from scratch and fine-tuning the pretrained model’s weights. It is recommended to use a small learning rate (e.g. 1e-4) since choosing the learning rate too large can destroy the near-optimal pretrained weights of the base model.
The training procedure can be sped up by first training for a few epochs without the base model being trainable. The purpose of these initial epochs is to adapt the heads’ weights to the problem. This speeds up the training since when training only the head, much fewer parameters are trainable and thus updated for every batch. The resulting model weights can then be used as the starting point to train the entire model, with the base model being trainable. For the car classification problem that we are considering here, applying this two-stage training did not achieve notable performance enhancement.
Model Performance Evaluation/Prediction
When using the tf.data.Dataset API, one must pay attention to the nature of the methods used. The following method in our TransferModel class can be used as a prediction method.
def predict(self, ds_new: tf.data.Dataset, proba: bool = True):
"""
Predict class probs or labels on ds_new
Labels are obtained by taking the most likely class given the predicted probs
Args:
ds_new: New data as tf.data.Dataset
proba: Boolean if probabilities should be returned
Returns:
class labels or probabilities
"""
p = self.model.predict(ds_new)
if proba:
return p
else:
return [np.argmax(x) for x in p]
It is essential that the dataset ds_new is not shuffled, or else the predictions obtained will be misaligned with the images obtained when iterating over the dataset a second time. This is the case since the flag reshuffle_each_iteration is true by default in the shuffle method’s implementation. A further effect of shuffling is that multiple calls to the take method will not return the same data. This is important when you want to check out predictions, e.g., for only one batch. A simple example where this can be seen is:
# Use construct_ds method from above to create a shuffled dataset
ds = construct_ds(..., shuffle=True)
# Take 1 batch (e.g. 32 images) of dataset: This returns a new dataset
ds_batch = ds.take(1)
# Predict labels for one batch
predictions = model.predict(ds_batch)
# Predict labels again: The result will not be the same as predictions above due to shuffling
predictions_2 = model.predict(ds_batch)
A function to plot images annotated with the corresponding predictions could look as follows:
def show_batch_with_pred(model, ds, classes, rescale=True, size=(10, 10), title=None):
for image, label in ds.take(1):
image_array = image.numpy()
label_array = label.numpy()
batch_size = image_array.shape[0]
pred = model.predict(image, proba=False)
for idx in range(batch_size):
label = classes[np.argmax(label_array[idx])]
ax = plt.subplot(np.ceil(batch_size / 4), 4, idx + 1)
if rescale:
plt.imshow(image_array[idx] / 255)
else:
plt.imshow(image_array[idx])
plt.title("label: " + label + "\n"
+ "prediction: " + classes[pred[idx]], fontsize=10)
plt.axis('off')
The show_batch_with_pred method works for shuffled datasets as well, since image and label correspond to the same call to the take method.
Evaluating model perfomance can be done using keras.Model's evaluate method.
How Accurate Is Our Final Model?
The model achieves slightly above 70% categorical accuracy for the task of predicting the car model for images from 300 model classes. To better understand the model’s predictions, it is helpful to observe the confusion matrix. Below, you can see the heatmap of the model’s predictions on the validation dataset.
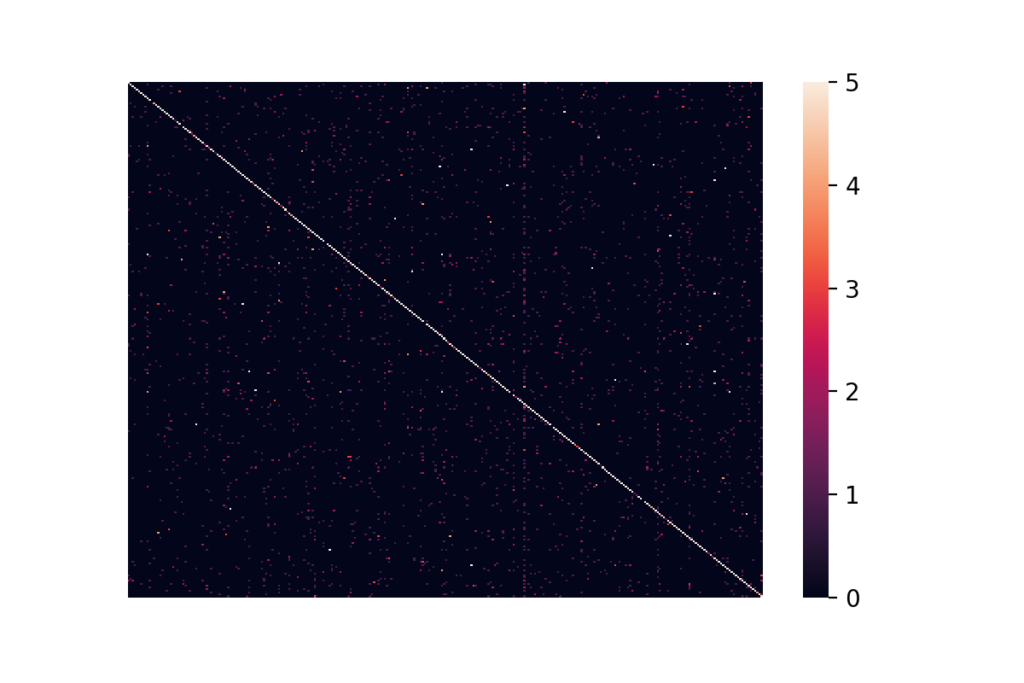
We restricted the heatmap to clip the confusion matrix’s entries to [0, 5], as allowing a further span did not significantly highlight any off-diagonal region. As can be seen from the heat map, one class is assigned to examples of almost all classes. That can be seen from the dark red vertical line two-thirds to the right in the figure above. Other than the class mentioned before, there are no evident biases in the predictions. We want to stress here that the categorical accuracy is generally not sufficient for a satisfactory assessment of the model’s performance, particularly in the case of imbalanced classes.
Conclusion and Next Steps
In this blog post, we have applied transfer learning using the ResNet50V2 to classify the car model from images of cars. Our model achieves 70% categorical accuracy over 300 classes.
We found unfreezing the entire base model and using a small learning rate to achieve the best results. Now, having developed a cool car classification model is great, but how can we use our model in a productive setting? Of course, we could build our custom model API using Flask or FastAPI…
But might there even be an easier, standardized way? In the second article of our series, “Deploying TensorFlow Models in Docker using TensorFlow Serving“, we discuss how this model can be deployed using TensorFlow Serving.