
Overview and Setting
Python and R have become the most important languages in analytics and data science. Usually, a data scientist can at least navigate one language with relative ease and at STATWORX we luckily have both expertises available. While, with enough will and effort, any coding project can be completed in either language, perhaps they differ in some performance aspects. To assess this question, we chose a task no data scientist can escape – the inevitable data preparation (80% data preparation, 20% analysis as the proverb goes).
While R has a native object type for tabular data – it was made by statisticians after all – Python lacks this feature in the standard library. Relational data can be crunched with the pandas library, which has become the de-facto standard package for tabular data manipulation in Python. It is based on the even more popular framework of numPy, a linear algebra and matrix operation framework. Even though R uses the so-called data frame by default, there has been put some effort into upgrading and enhancing the built-in type. One of the most famous and widely used packages in this regard is data.table. The class data.table excels at combining operations in a performant way since most of its codebase relies on C functions.
We will compare the performance of pandas with that of data.table in a structured and systematic experiment split up to four different cases:
- Data retrieval with a select-like operation
- Data filtering with a conditional select operation
- Data sort operations
- Data aggregation operations
For each of these tasks we will use the same simulated dataset which contains the following data types:
- Integer, in three different distributions (Normal, zero inflated Poisson, Uniform)
- Double, in the same distributions
- String, random lengths within parameters
- Bool, Bernoulli distributed
The computations were performed on a machine with an Intel i7 2.2GHz with 4 physical cores, 16GB RAM, and an SSD hard drive. Software Versions were OS X 10.13.3, Python 3.6.4 and R 3.4.2. The respective library versions used were 0.22 for pandas and 1.10.4-3 for data.table.
Select
In the first step, we checked the speed of accessing several columns in a dataset. We have timed this operation for a single column as well as a group of three columns. The setup is further divided by the position of the columns. For both, the single and multiple column scenarios, we used columns from the beginning, middle, end and for the multiple column case additionally a random location in the dataset.
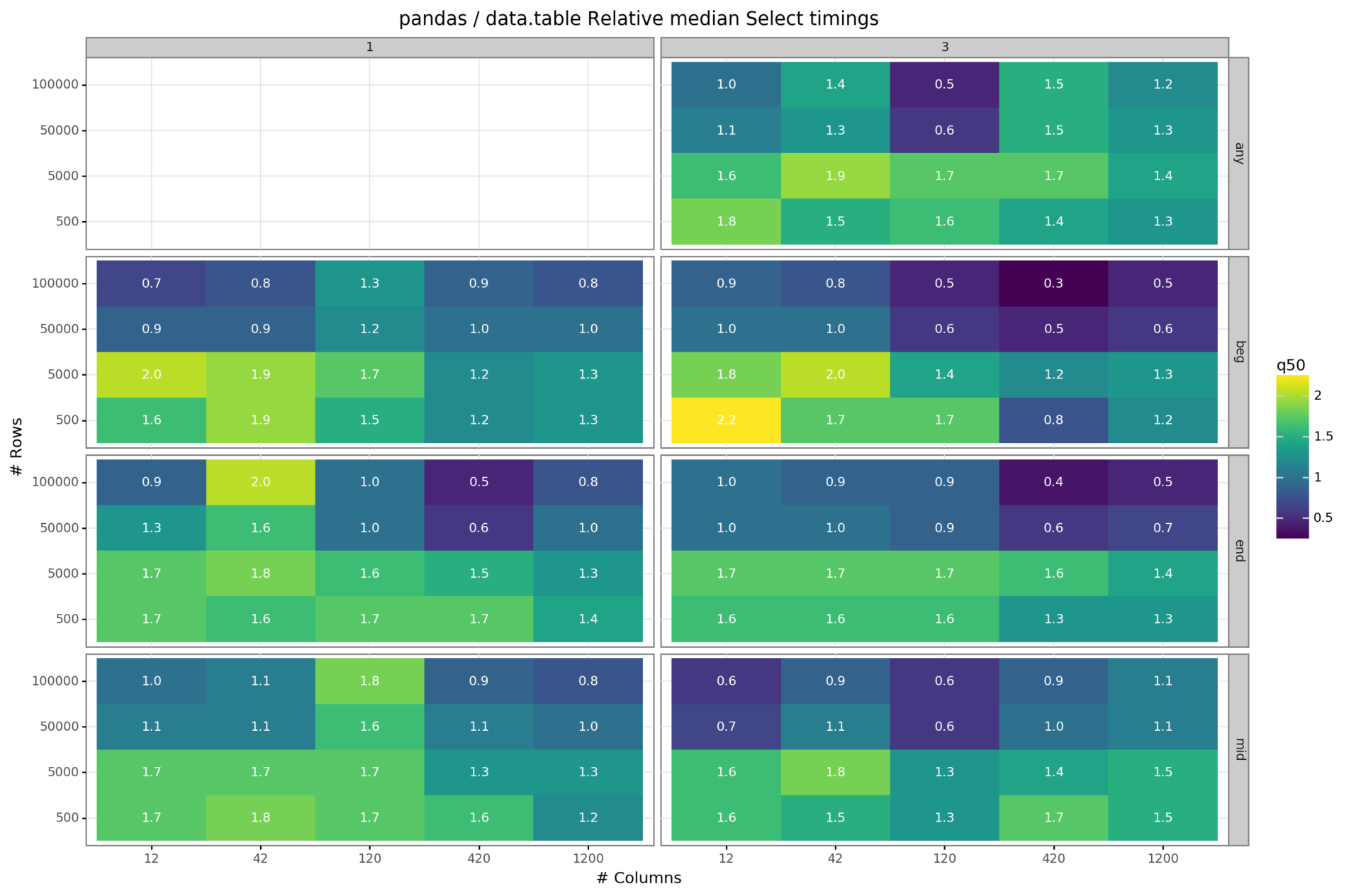
The left side shows the results of the single table queries, while the right grid presents the three-column case. The measured value is the median execution time of pandas relative to the median execution time of data.table. The results are mixed. In the majority of the tested scenarios pandas selection takes roughly 1.5 to 2 times longer than the equivalent data.table query in R. There are also a lot of nearly equal execution speeds across all settings, especially in the scenarios with 50k/100k observations. In absolute terms execution speed for both data.table and pandas was nearly instantaneous. The maximum median value across all queries lies around 2ms for both packages. See the Github project repo of this simulation for additional plots and the source code.
Filter
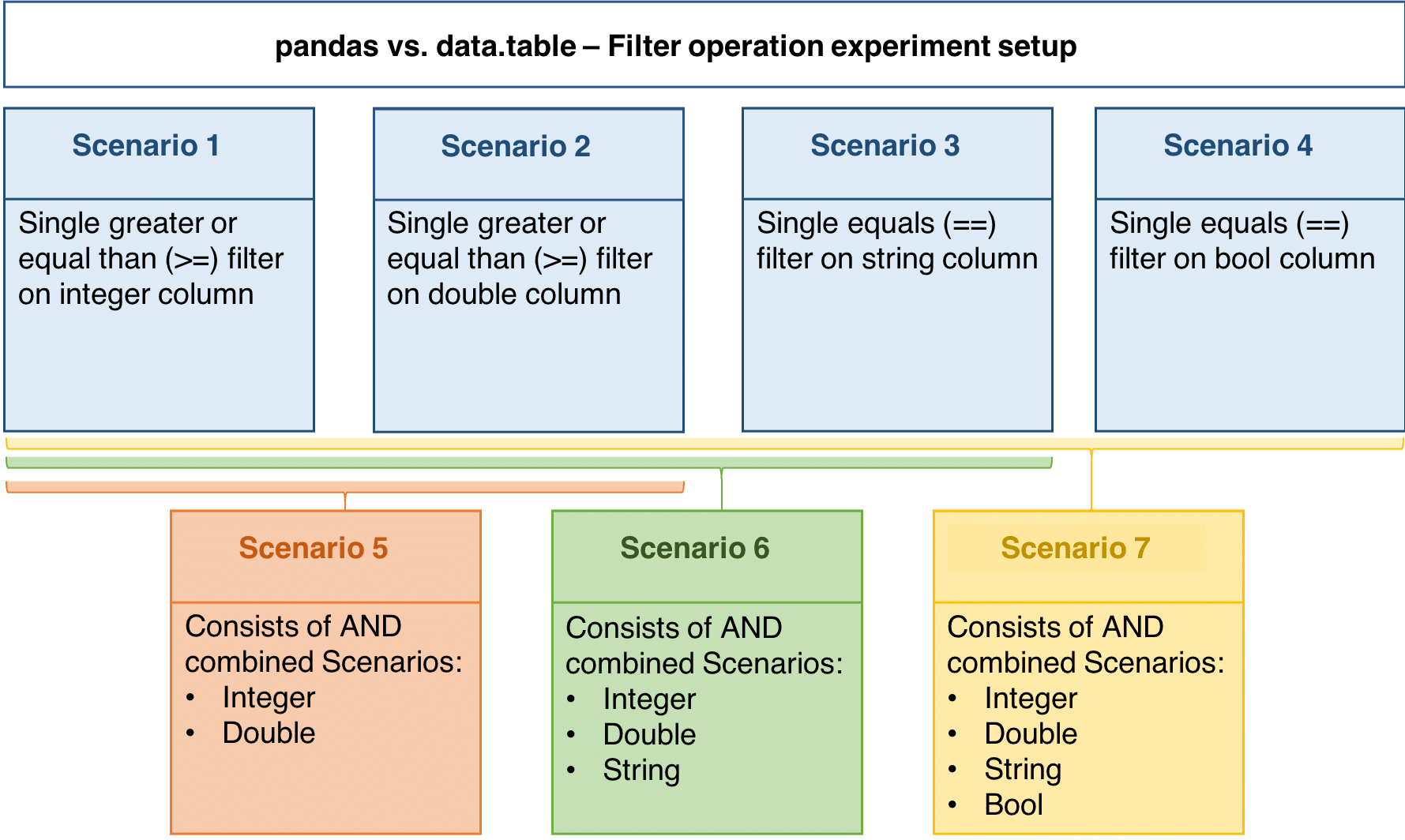
We have tested seven different scenarios using filter operations. Scenario 1 through 4 perform a filter operation on a single column of varying data type (with the aforementioned order – int, double, string, bool). Scenarios 5 – 7 are combinations of the first four with scenario 5 consisting of 1 and 2 and scenario 6 of 1,2 and 3. Scenario 7 includes all single scenarios together in a combined filter query.
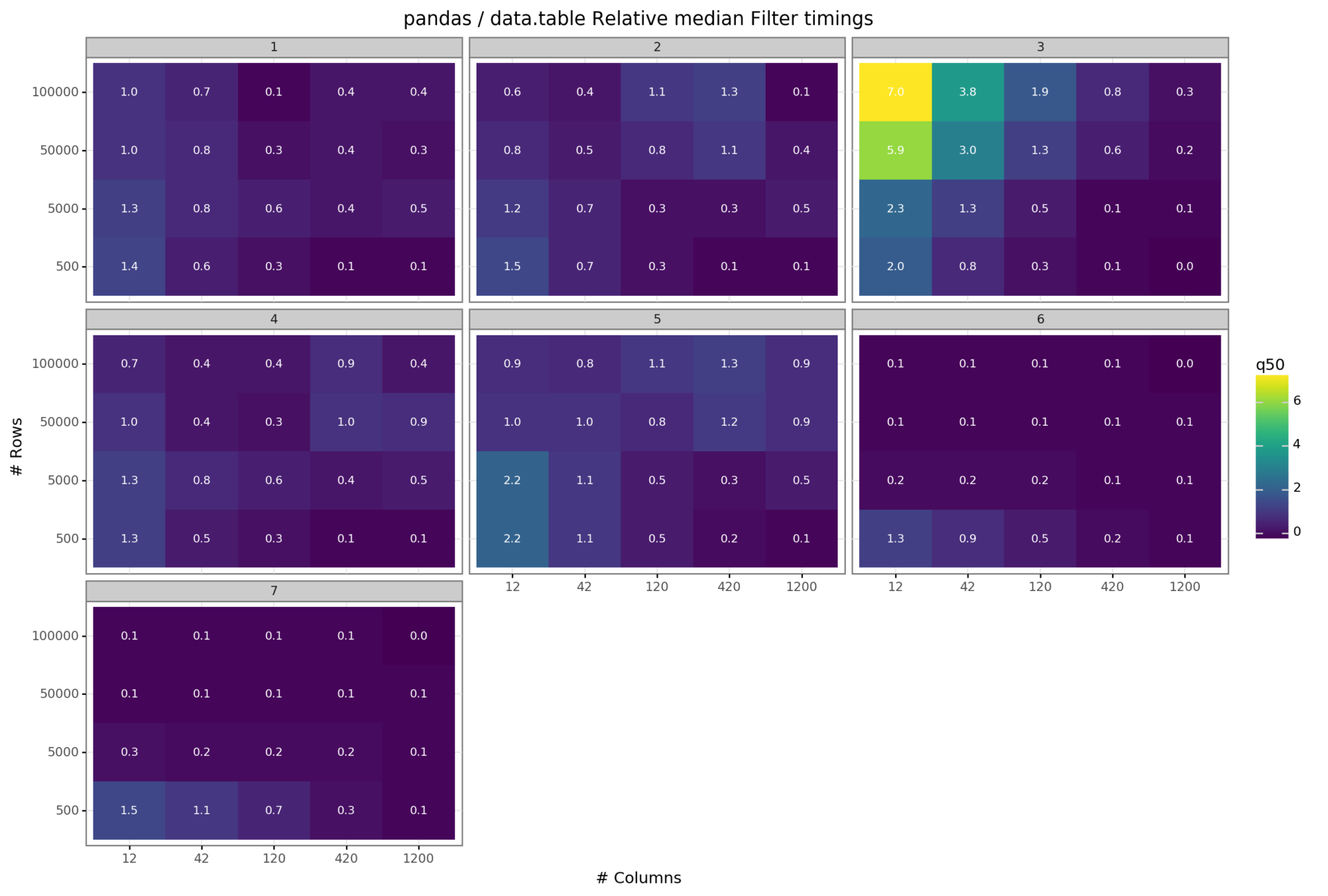
For the given settings pandas yield lower medians for most of the executed scenarios. These relative timings range from nearly identical median timings down to a tenth of the data.table results. Scenario 3 is an exception to this observation. The biggest computation gap between pandas and data.table in absolute terms is the median timing scenario 2 with 100k rows and 1200 columns. The pandas library completed the query in roughly 1.4 seconds, whereas data.table took around 12 seconds. It is unclear where this spike in execution time stems from, as this run seems to be a clear outlier. Other execution times range from 80-600 ms (Again, if you are interested in the detailed numbers check the project repo).
Conclusion, Critique and Outlook
We have seen roughly equal performance for select operations with data.table performing slightly faster in relative terms with very low absolute execution speeds. Pandas, however, copes better with filter operations, since the computation time is overall lower as opposed to the R counterpart.
This experiment does not claim absolute authority but wants to provide a glimpse at general performance of tabular data processing in both languages. There are of course modifications to this experimental setting that would improve the general design. The most important point would possibly be to alternate between different queries per scenario instead of running the same job 100 times all over. If you have any ideas to improve this study, please share your thoughts in an email.
We have learned some interesting facts – both languages, R and Python possess competitive tabular data libraries, which have coped fairly even amongst our two tests. Another observation we were able to make is the reduced query time for more complex filter operations in both packages. This indicates that there seems to be some parallel search in place across all filter conditions which reduces the search space for additional conditions.
Stay tuned for the second part of this series, where we will be examining the more computational intense group-by and arrange operations.
References
- Dowle, Matt, et al. data. table: Extension of data. frame. (2014).
- McKinney, Wes, Data Structures for Statistical Computing in Python, Proceedings of the 9th Python in Science Conference, 51-56. (2010).