
Here at STATWORX, a Data Science and AI consulting company, we thrive on creating data-driven solutions that can be acted on quickly and translate into real business value. We provide many of our solutions in some form of web application to our customers, to allow and support them in their data-driven decision-making.
Containerization Allows Flexible Solutions
At the start of a project, we typically need to decide where and how to implement the solution we are going to create. There are several good reasons to deploy the designed solutions directly into our customer IT infrastructure instead of acquiring an external solution. Often our data science solutions use sensitive data. By deploying directly to the customers’ infrastructure, we make sure to avoid data-related compliance or security issues. Furthermore, it allows us to build pipelines that automatically extract new data points from the source and incorporate them into the solution so that it is always up to date.
However, this also imposes some constraints on us. We need to work with the infrastructure provided by our customers. On the one hand, that requires us to develop solutions that can exist in all sorts of different environments. On the other hand, we need to adapt to changes in the customers’ infrastructure quickly and efficiently. All of this can be achieved by containerizing our solutions.
The Advantages of Containerization
Containerization has evolved as a lightweight alternative to virtualization. It involves packaging up software code and all its dependencies in a “container” so that the software can run on practically any infrastructure. Traditionally, an application was developed in a specific computing development environment and then transferred to the production environment, often resulting in many bugs and errors; Especially when these environments were not mirroring each other. For example, when an application is transferred from a local desktop computer to a virtual machine or from a Linux to a Windows operating system.
A container platform like Docker allows us to store the whole application with all the necessary code, system tools, libraries, and settings in a container that can be shipped to and work uniformly in any environment. We can develop our applications dockerized and do not have to worry about the specific infrastructure environment provided by our customers.
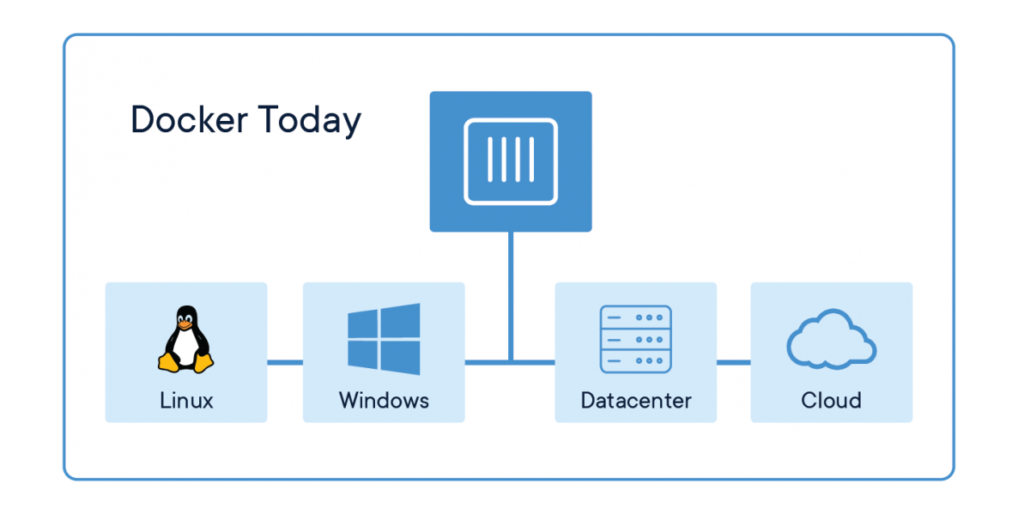
There are some other advantages that come with using Docker in comparison to traditional virtual machines for the deployment of data science applications.
- Efficiency – As the container shares the machines’ OS system kernel and does not require a Guest OS per application, it uses the provided infrastructure more efficiently, resulting in lower infrastructure costs.
- Speed – The start of a container does not require a Guest OS reboot; it can be started, stopped, replicated, and destroyed in seconds. That speeds up the development process, the time to market, and the operational speed. Releasing new software or updates has never been so fast: Bugs can be fixed, and new features implemented in hours or days.
- Scalability – Horizontal scaling allows to start and stop additional container depending on the current demand.
- Security – Docker provides the strongest default isolation capabilities in the industry. Containers run isolated from each other, which means that if one crashes, other containers serving the same applications will still be running.
The Key Benefits of a Microservices Architecture
In connection with the use of Docker for delivering data science solutions, we use another emerging method. Instead of providing a monolithic application that comes with all the required functionalities of an application, we create small, independent services that communicate with each other and together embody the complete application. Usually, we develop WebApps for our customers. As shown in the graphic, the WebApp will communicate directly with the different other backend microservices. Each one is designed for a specific task and has an exposed REST API that allows for different HTTP requests.
Furthermore, the backend microservices are indirectly exposed to the mobile app. An API Gateway routes the requests to the desired microservices. It can also provide an API endpoint that invokes several backend microservices and aggregates the results. Moreover, it can be used for access control, caching, and load balancing. If suitable, you might also decide to place an API Gateway between the WebApp and the backend microservices.
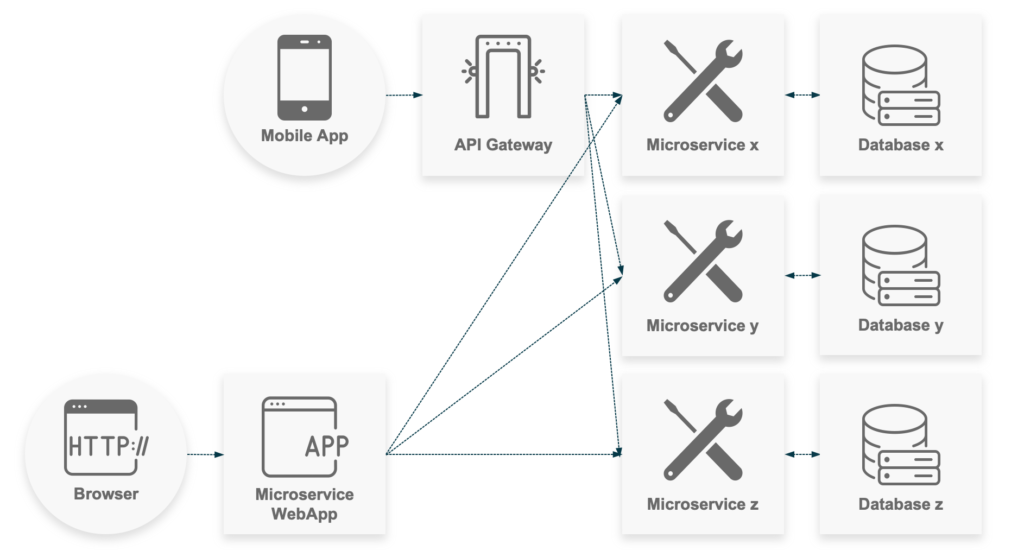
In summary, splitting the application into small microservices has several advantages for us:
- Agility – As services operate independently, we can update or fix bugs for a specific microservice without redeploying the entire application.
- Technology freedom – Different microservices can be based on different technologies or languages, thus allowing us to use the best of all worlds.
- Fault isolation – If an individual microservice becomes unavailable, it will not crash the entire application. Only the function provided by the specific microservice will not be provided.
- Scalability – Services can be scaled independently. It is possible to scale the services which do the work without scaling the application.
- Reusability of service – Often, the functionalities of the services we create are also requested by other departments and other cases. We then expose application user interfaces so that the services can also be used independently of the focal application.
Containerized Microservices – The Best of Both Worlds!
The combination of docker with a clean microservices architecture allows us to combine the mentioned advantages. Each microservice lives in its own Docker container. We deliver fast solutions that are consistent across environments, efficient in terms of resource consumption, and easily scalable and updatable. We are not bound to a specific infrastructure and can adjust to changes quickly and efficiently.
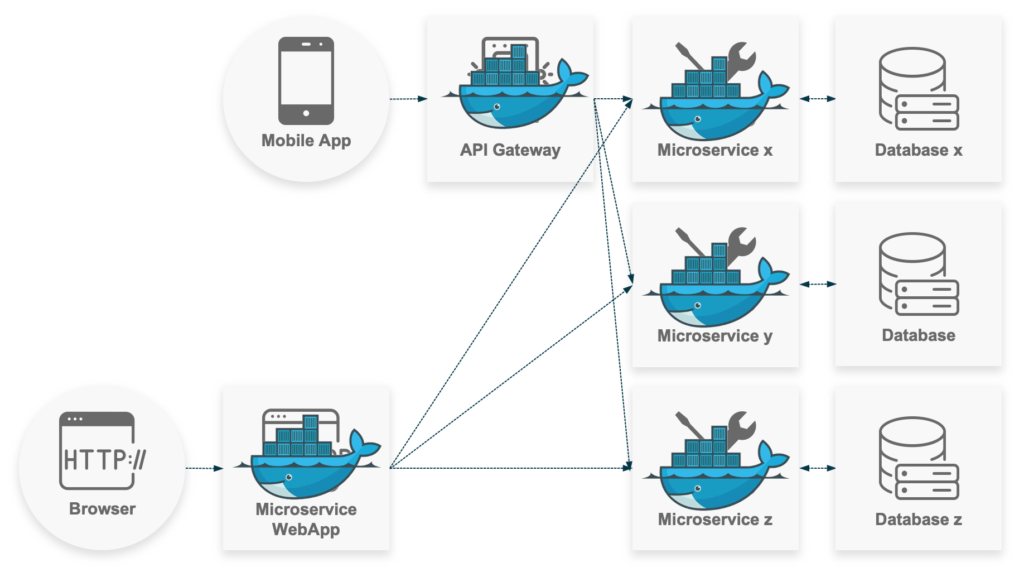
Conclusion
Often the deployment of a data science solution is one of the most challenging tasks within data science projects. But without a proper deployment, there won’t be any business value created. Hopefully, I was able to help you figure out how to optimize the implementation of your data science application. If you need further help bringing your data science solution into production, feel free to contact us!
Sources
- https://docs.microsoft.com/de-de/learn/modules/principles-cloud-computing/2-what-is-cloud-computing
- https://www.ibm.com/cloud/learn/containerization
- https://www.docker.com/resources/what-container
- https://cloud.google.com/containers
- https://blog.kumina.nl/2017/04/the-benefits-of-containers-and-container-technology/
- https://docs.microsoft.com/en-us/dotnet/architecture/microservices/architect-microservice-container-applications/direct-client-to-microservice-communication-versus-the-api-gateway-pattern
- https://www.nginx.com/blog/introduction-to-microservices/