
A major problem arises when comparing forecasting methods and models across different time series. This is a challenge we regularly face at STATWORX. Unit-dependent measures like the MAE (Mean Absolute Error) and the RMSE (Root Mean Squared Error) turn out to be unsuitable and hardly helpful if the time series is measured in different units. However, if this is not the case, both measures provide valuable information. The MAE is perfectly interpretable as it embodies the average absolute deviation from the actual values. The RMSE, on the other hand, is not that easy to interpret, more vulnerable to extreme values but still often used in practice.


One of the most commonly used measures that avoid this problem is called MAPE (Mean Absolute Percentage Error). It solves the problem of the mentioned approaches as it does not depend on the unit of the time series. Furthermore, decision-makers without a statistical background can easily interpret and understand this measure. Despite its popularity, the MAPE was and is still criticized.

In this article, I evaluate these critical arguments and prove that at least some of them are highly questionable. The second part of my article concentrates on true weaknesses of the MAPE, some of them well-known but others hiding in the shadows. In the third section, I discuss various alternatives and summarize under which circumstances the use of the MAPE seems to be appropriate (and when it’s not).
What the MAPE is FALSELY blamed for!
It Puts Heavier Penalties on Negative Errors Than on Positive Errors
Most sources dealing with the MAPE point out this “major” issue of the measure. The statement is primarily based on two different arguments. First, they claim that interchanging the actual value with the forecasted value proves their point (Makridakis 1993).
Case 1:  = 150 &
= 150 &  = 100 (positive error)
= 100 (positive error)

Case 2:  = 100 &
= 100 &  = 150 (negative error)
= 150 (negative error)

It is true that Case 1 (positive error of 50) is related to a lower APE (Absolute Percentage Error) than Case 2 (negative error of 50). However, the reason here is not that the error is positive or negative but simply that the actual value changes. If the actual value stays constant, the APE is equal for both types of errors (Goodwin & Lawton 1999). That is clarified by the following example.
Case 3:  = 100 &
= 100 &  = 50
= 50

Case 4:  = 100 &
= 100 &  = 150
= 150

The second, equally invalid argument supporting the asymmetry of the MAPE arises from the assumption about the predicted data. As the MAPE is mainly suited to be used to evaluate predictions on a ratio scale, the MAPE is bounded on the lower side by an error of 100% (Armstrong & Collopy 1992). However, this does not imply that the MAPE overweights or underweights some types of errors, but that these errors are not possible.
Its TRUE weaknesses!
It Fails if Some of the Actual Values Are Equal to Zero
This statement is a well-known problem of the focal measure. However, that and the latter argument were the reason for the development of a modified form of the MAPE, the SMAPE (“Symmetric” Mean Absolute Percentage). Ironically, in contrast to the original MAPE, this modified form suffers from true asymmetry (Goodwin & Lawton 1999). I will clarify this argument in the last section of the article.
Particularly Small Actual Values Bias the Mape
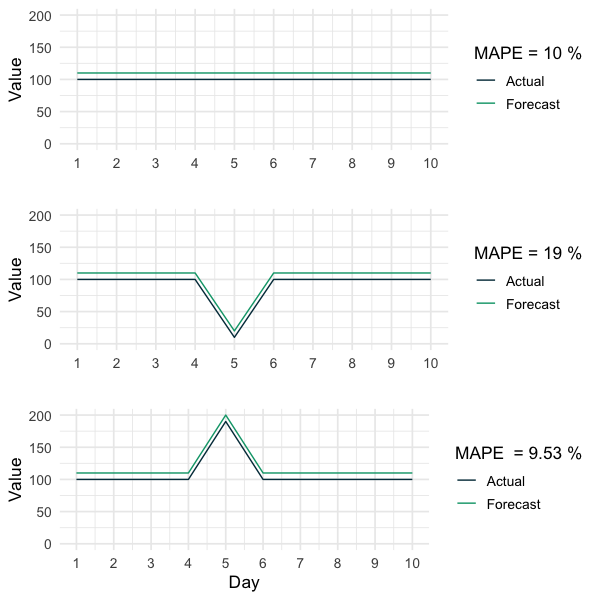
If any true values are very close to zero, the corresponding absolute percentage errors will be extremely high and therefore bias the informativity of the MAPE (Hyndman & Koehler 2006). The following graph clarifies this point. Although all three forecasts have the same absolute errors, the MAPE of the time series with only one extremely small value is approximately twice as high as the MAPE of the other forecasts. This issue implies that the MAPE should be used carefully if there are extremely small observations and directly motivates the last and often ignored the weakness of the MAPE.
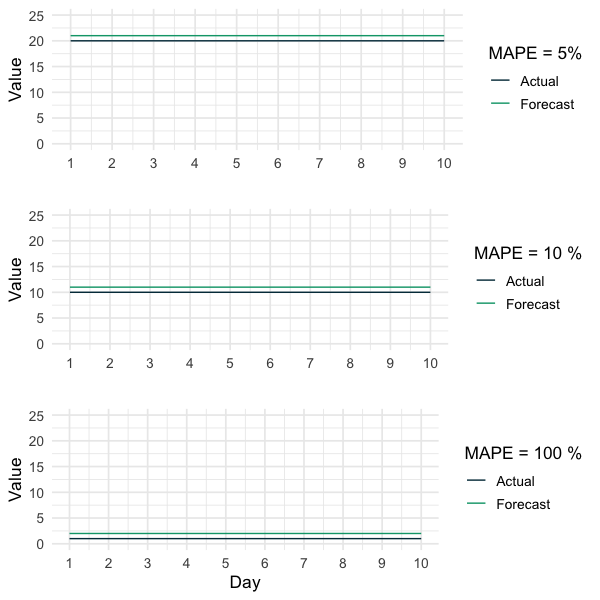
The Mape Implies Only Which Forecast Is Proportionally Better
As mentioned at the beginning of this article, one advantage of using the MAPE for comparison between forecasts of different time series is its unit independence. However, it is essential to keep in mind that the MAPE only implies which forecast is proportionally better. The following graph shows three different time series and their corresponding forecasts. The only difference between them is their general level. The same absolute errors lead, therefore, to profoundly different MAPEs. This article critically questions, if it is reasonable to use such a percentage-based measure for the comparison between forecasts for different time series. If the different time series aren’t behaving in a somehow comparable level (as shown in the following graphic), using the MAPE to infer if a forecast is generally better for one time series than for another relies on the assumption that the same absolute errors are less problematic for time series on higher levels than for time series on lower levels:
“If a time series fluctuates around 100, then predicting 101 is way better than predicting 2 for a time series fluctuating around 1.”
That might be true in some cases. However, in general, this a questionable or at least an assumption people should always be aware of when using the MAPE to compare forecasts between different time series.
Summary
In summary, the discussed findings show that the MAPE should be used with caution as an instrument for comparing forecasts across different time series. A necessary condition is that the time series only contains strictly positive values. Second only some extremely small values have the potential to bias the MAPE heavily. Last, the MAPE depends systematically on the level of the time series as it is a percentage-based error. This article critically questions if it is meaningful to generalize from being a proportionally better forecast to being a generally better forecast.
BETTER alternatives!
The discussed implies that the MAPE alone is often not very useful when the objective is to compare accuracy between different forecasts for different time series. Although relying only on one easily understandable measure appears to be comfortable, it comes with a high risk of drawing misleading conclusions. In general, it is always recommended to use different measures combined. In addition to numerical measures, a visualization of the time series, including the actual and the forecasted values always provides valuable information. However, if one single numeric measure is the only option, there are some excellent alternatives.
Scaled Measures
Scaled measures compare the measure of a forecast, for example, the MAE relative to the MAE of a benchmark method. Similar measures can be defined using RMSE, MAPE, or other measures. Common benchmark methods are the “random walk”, the “naïve” method and the “mean” method. These measures are easy to interpret as they show how the focal model compares to the benchmark methods. However, it is important to keep in mind that relative measures rely on the selection of the benchmark method and on how good the time series can be forecasted by the selected method.

Scaled Errors
Scaled error approaches also try to remove the scale of the data by comparing the forecasted values to those obtained by some benchmark forecast method, like the naïve method. The MASE (Mean Absolute Scaled Error), proposed by Hydnmann & Koehler 2006, is defined slightly differently depending on the seasonality of the time series. In the simple case of a non-seasonal time series, the error of the focal forecast is scaled based on the in-sample MAE from the naïve forecast method. One major advantage is that it can handle actual values of zero and that it is not biased by very extreme values. Once again, it is important to keep in mind that relative measures rely on the selection of the benchmark method and on how good the time series can be forecasted by the selected method.
Non-Seasonal

Seasonal

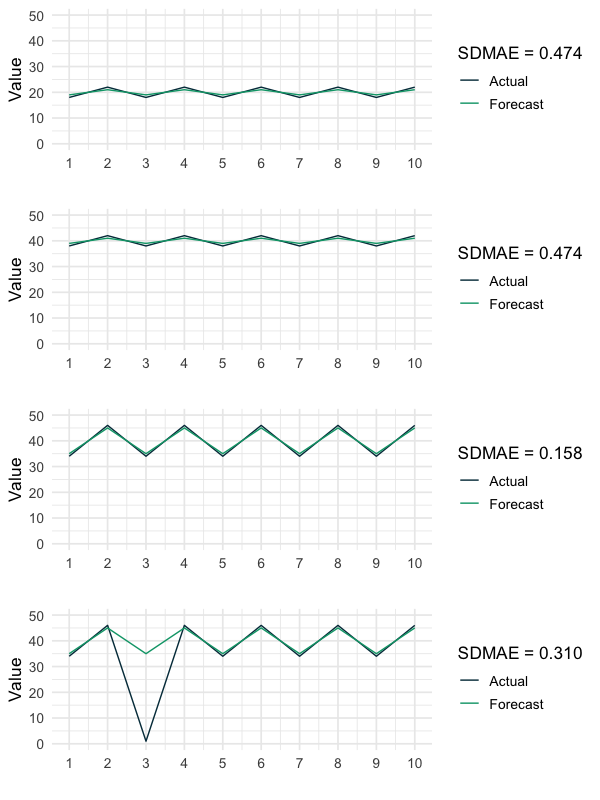
SDMAE
In my understanding, the basic idea of using the MAPE to compare different time series between forecasts is that the same absolute error is assumed to be less problematic for time series on higher levels than for time series on lower levels. Based on the examples shown earlier, I think that this idea is at least questionable.
I argue that how good or bad a specific absolute error is evaluated should not depend on the general level of the time series but on its variation. Accordingly, the following measure the SDMAE (Standard Deviation adjusted Mean Absolute Error) is a product of the discussed issues and my imagination. It can be used for evaluating forecasts for times series containing negative values and does not suffer from actual values being equal to zero nor particularly small. Note that this measure is not defined for time series that do not fluctuate at all. Furthermore, there might be other limitations of this measure, that I am currently not aware of.

Summary
I suggest using a combination of different measures to get a comprehensive understanding of the performance of the different forecasts. I also suggest complementing the MAPE with a visualization of the time series, including the actual and the forecasted values, the MAE, and a Scaled Measure or Scaled Error approach. The SDMAE should be seen as an alternative approach that was not discussed by a broader audience so far. I am thankful for your critical thoughts and comments on this idea.
Worse alternatives!
SMAPE
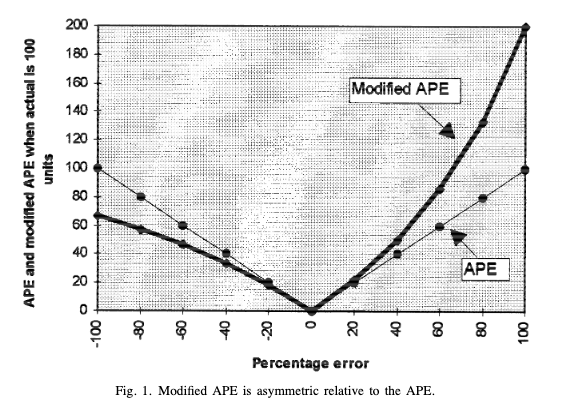
The SMAPE was created, to solve and respond to the problems of the MAPE. However, this did neither solve the problem of extremely small actual values nor the level dependency of the MAPE. The reason is that extremely small actual values are typically related to extremely small predictions (Hyndman & Koehler 2006). Additionally, and in contrast to the unmodified MAPE, the SMAPE raises the problem of asymmetry (Goodwin & Lawton 1999). This is clarified through the following graphic, whereas the ” APE” relates to the MAPE and the “SAPE” relates to the SMAPE. It shows that the SAPE is higher for positive errors than for negative errors and therefore, asymmetric. The SMAPE is not recommended to be used by several scientists (Hyndman & Koehler 2006).

On the asymmetry of the symmetric MAPE (Goodwin & Lawton 1999)
References
- Goodwin, P., & Lawton, R. (1999). On the asymmetry of the symmetric MAPE. International journal of forecasting, 15(4), 405-408.
- Hyndman, R. J., & Koehler, A. B. (2006). Another look at measures of forecast accuracy. International journal of forecasting, 22(4), 679-688.
- Makridakis, S. (1993). Accuracy measures: theoretical and practical concerns. International Journal of Forecasting, 9(4), 527-529.
- Armstrong, J. S., & Collopy, F. (1992). Error measures for generalizing about forecasting methods: Empirical comparisons. International journal of forecasting, 8(1), 69-80.