Experimenting with image classification through the gender lens
In the first part of our series we discussed a simple question: How would our looks change if we were to move images of us across the gender spectrum? Those experiments lead us the idea of creating gender neutral face images from existing photos. Is there a “mid-point” where we perceive ourselves as gender-neutral? And – importantly – at what point would an AI perceive a face as such?
Becoming more aware of technology we use daily
Image classification is an important topic. Technology advances daily and is employed in a myriad of applications – often without the user being aware of how the technology works. A current example is the Bold Glamour filter on TikTok. When applied on female-looking faces, facial features and amount of makeup change drastically. In contrast to this, male-looking faces change much less. This difference suggests that the data used to develop the AI behind the filters was unbalanced. The technology behind it is most likely based on GANs, like the one we explore in this article.
As a society of conscious citizens, all of us should have a grasp of the technology that makes this possible. To help establish more awareness we explore face image generation and classification through a gender lens. Rather than explore several steps along the spectrum, this time our aim is to generate gender-neutral versions of faces.
How to generate gender-neutral faces using StyleGAN
Utilizing a deep learning-based classifier for gender identification
To determine a point at which a face’s gender is considered neutral is anything but trivial. After relying on our own (of course not bias-free) interpretation of gender in faces, we quickly realized that we needed a more consistent and less subjective solution. As AI-specialists, we immediately thought of data-driven approaches. One such approach can be implemented using a deep learning-based image classifier.
These classifiers are usually trained on large datasets of labelled images to distinguish between given categories. In the case of face classification, categories like gender (usually only female and male) and ethnicity are commonly found in classifier implementations. In practice, such classifiers are often criticized for their potential for misuse and biases. Before discussing examples of those problems, we will first focus on our less critical application scenario. For our use-case, face classifiers allow us to fully automate the creation of gender-neutral face images. To achieve this, we can implement a solution in the following way:
We use a GAN-based approach to generate face images that look like a given input image and then use the latent directions of the GAN to move the image towards a more female or male appearance. You can find all a detailed exploration of this process in the first part of our series. Building on top of this approach, we want to focus on the usage of a binary gender classifier to fully automate the search of a gender-neutral appearance.
For that we use the classifier developed by Furkan Gulsen to guess the gender of the GAN-generated version of our input image. The classifier outputs a value between zero and one to represent the likelihood of the image depicting a female or male face respectively. This value tells us in which direction (more male or more female) to move to approach a more gender-neutral version of the image. After taking a small step in the identified direction we repeat the process until we get to a point at which the classifier can no longer confidently identify the face’s gender but deems both male and female genders equally likely.
Below you will find a set of image pairs that represent our results. On the left, the original image is shown. On the right, we see the gender-neutral version of our input image, that the classifier interpreted as equally likely to be male as female. We tried to repeat the experiment for members of different ethnicities and age groups.
Results: original input and AI-generated gender-neutral output





Are you curious how the code works or what you would look like? You can try out the code we used to generate these image pairs by going to this link. Just press on each play button one by one and wait until you see the green checkmark.
Image processing note: Image processing note: We used an existing GAN, image encoder, and face classifier to generate gender-neutral output. A detailed exploration of this process can be found here
Perceived gender-neutrality seems to be a result of mixed facial features
Above, we see the original portraits of people on the left and their gender-neutral counterpart – created by us – on the right. Subjectively, some feel more “neutral” than others. In several of the pictures, particularly stereotypical gender markers remain, such as makeup for the women and a square jawline for the men. Outputs we feel turned out rather convincing are images 2 and 4. Not only do these images feel more difficult to “trace back” to the original person, but it is also much harder to decide whether it looks more male or female. One could argue that the gender-neutral faces are a balanced toned-down mix of male and female facial features. For example, with image 2 when singling out and focusing on the gender-neutral version the eye and mouth area seems more female, while the jawline and face shape seem more male. In the gender-neutral version of image 3, the face alone may look quite neutral, but the short hair distracts from this, rendering the whole impression in the direction of male.
Training sets for image generation have been heavily criticized for not being representative of the existing population, especially regarding the underrepresentation of examples for different ethnicities and genders. Despite “cherry-picking” and a limited range of examples, we feel that our approach did not bring worse examples for women or non-white people in the results above.
Societal implications of such models
When talking about the topic of gender perception, we should not forget that people may feel they belong to a gender different from their biological sex. In this article, we use gender classification models and interpret the results. However, our judgements will likely differ from other peoples’ perception. This is an essential consideration in the implementation of such image classification models and one we must discuss as a society.
How can technology treat everybody equal?
A study by the Guardian found that images of females portrayed in the same situations as males are more likely to be considered racy by AI classification services offered by Microsoft, Google, and AWS. While the results of the investigation are shocking, they come as no surprise. For a classification algorithm to learn what constitutes sexually explicit content, a training set of image-label pairs must be created. Human labellers perform this task. They are influenced by their own societal bias, for example more quickly associating depictions women with sexuality. Moreover, criteria such as “raciness” are hard to quantify let alone define.
While these models may not explicitly be trained to discriminate between genders there is little doubt that they propagate undesirable biases against women originating from their training data. Similarly, societal biases that affect men can be passed on to AI models, too, resulting in discrimination against males. When applied to millions of online images of people, the issue of gender disparity is amplified.
Use in criminal law enforcement poses issues
Another scenario of misuse of image classification technology exists in the realm of law enforcement. Misclassification is problematic and proven prevalent in an article by The Independent. When Amazon’s Recognition software was used at the default 80% confidence level in a 2018 study, the software falsely matched 105 out of 1959 participants with mugshots of criminals. Seeing the issues with treatment of images depicting males and females above, one could imagine a disheartening scenario when judging actions of females in the public space. If men and women are judged differently for performing the same actions or being in the same positions, it would impact everybody’s right to equal treatment before the law. Bayerischer Rundfunk, a German media outlet, published an interactive page (only in German) where AI classification services’ differing classifications can be compared to one’s own assessment .
Using gender-neutral images to circumvent human bias
Besides the positive societal potentials of image classification, we also want to address some possible practical applications arising from being able to cover more than just two genders. An application that came to our minds is the use of “genderless” images to prevent human bias. Such a filter would imply losing individuality, so they would only be applicable in contexts where the benefit of reducing bias outweighs the cost of that loss.
Imagining a browser extension for the hiring process
HR screening could be an area where gender-neutral images may lead to less gender-based discrimination. Gone are the times of faceless job applications: if your LinkedIn profile has a profile picture it is 14 times more likely to get viewed. When examining candidate profiles, recruiters should ideally be free of subconscious, unintentional gender bias. Human nature prevents this. One could thus imagine a browser extension that generates a gender-neutral version of profile photos on professional social networking sites like LinkedIn or Xing. This could lead to more parity and neutrality in the hiring process, where only skills and character should count, and not one’s gender – or one’s looks for that matter (pretty privilege).
Conclusion
We set out to automatically generate gender-neutral versions from any input face image.
Our implementation indeed automates the creation of gender-neutral faces. We used an existing GAN, image encoder and face image classifier. Our experiments with real peoples’ portraits show that the approach works well in many cases and produces realistically looking face images that clearly resemble the input image while remaining gender neutral.
In some cases, we still found that the supposedly neutral images contain artifacts from technical glitches or still have their recognizable gender. Those limitations likely arise from the nature of the GANs latent space or the lack of artificially generated images in the classifiers training data. We are confident that further work can resolve most of those issues for real-world applications.
Society’s ability to have an informed discussion on advances in AI is crucial
Image classification has far-reaching consequences should be evaluated and discussed by society, not just a few experts. Any image classification service that is used to sort people into categories should be examined closely. What must be avoided is that members of society come to harm. Establishing responsible use of such systems, governance and constant evaluation are essential. An additional solution could be creating structures for the reasoning behind decisions using Explainable AI best practices to lay out why certain decisions were made. As a company in the field of AI, we at statworx look to our AI-principles as a guide.
Image Sources:
AdobeStock 210526825 – Wayhome Studio
AdobeStock 243124072 – Damir Khabirov
AdobeStock 387860637 – insta_photos
AdobeStock 395297652 – Nattakorn
AdobeStock 480057743 – Chris
AdobeStock 573362719 – Xavier Lorenzo
AdobeStock 546222209 – Rrose Selavy
At statworx, we are constantly exploring new ideas and possibilities in the field of artificial intelligence. Recent months have been marked by generative models, particularly those developed by OpenAI (e.g., ChatGPT, DALL-E 2) but also open-source projects like Stable Diffusion. ChatGPT is a text-to-text model while DALL-E 2 and Stable Diffusion are text-to-image models, which create impressive images based on a short text description provided by the user. During the evaluation of those research trends, we discovered a great way to use our GPU to allow the statcrew to generate their own digital avatars.
The technology behind text-to-image generator Stable Diffusion
But first, let’s dive into the background of our work. Text-to-image generators, such as DALL-E 2 and Stable Diffusion, are based on diffusion architectures of artificial neural networks. It often takes months to train them on a vast amount of data from the internet, and this is only possible with supercomputers. However, even after training, the OpenAI models still require a supercomputer to generate new images, as their size exceeds the capacity of personal computers. OpenAI has made their models available through interfaces (https://openai.com/product#made-for-developers), but the model weights themselves have not been publicly released.
Stable Diffusion, on the other hand, was developed as a text-to-image generator but has a size that allows it to be executed on a personal computer. The open-source project is a joined collaboration of several research institutes. Its public availability allows researchers and developers to adapt the trained model for their own purposes by fine-tuning. Stable Diffusion is small enough to be executed on a personal computer, but fine-tuning it is significantly faster on a workstation (like ours provided by HP with two NVIDIA RTX8000 GPUs). Although it is significantly smaller than, for example, DALL-E2, the quality of the generated images is still outstanding.
All these models are controlled using prompts, which are text inputs that describe the image to be generated. Those text inputs are named prompts. For artificial intelligence, text is not natively understandable, because all these algorithms are based on mathematical operations which cannot be applied to text directly. Therefore, a common method is to generate what is known as an embedding, which means converting text into mathematical vectors. The understanding of text comes from the training of the translation model from text to embeddings. The high dimensional embedding vectors are generated in a way that the distance of the vectors to each other represents the relationship of the original texts. Similar methods are also used for images, and special models are trained to perform this task.
CLIP: A hybrid model of OpenAI for image-text integration with contrastive learning approach
One such model is CLIP, a hybrid model developed by OpenAI that combines the strengths of image recognition models and language models. The basic principle of CLIP is to embed matching text and image pairs. Those embedding vectors of the texts and images are calculated so that the distance of the vector representations of the matching pairs is minimized. A distinctive feature of CLIP is that it is trained using a contrastive learning approach, in which two different inputs are compared to each other, and the similarity between them is maximized while the similarity of non-matching pairs is minimized in the same run. This allows the model to learn more robust and transferable representations of images and texts, resulting in improved performance across a variety of tasks.
Customize image generation through Textual Inversion
With CLIP as a preprocessing step of the Stable Diffusion pipeline that creates the embeddings of the user prompts, it opens a powerful and efficient opportunity to teach the model new objects or styles. This fine-tuning is called textual inversion. Figure 1 shows this training process. With a minimum of three images of an object or style and a unique text identifier, Stable Diffusion can be steered to generate images of this specific object or style. In the first step a <tag> is chosen that aims to represent the object. In this case the object is Johannes, and a few pictures of Johannes are provided. In each training step one random image is chosen from the pictures. Further, a more explainable prompt like a “rendering of <tag>” is provided and in each training step one of those prompts is randomly chosen. The part <tag> is exchanged by the defined tag (in this case <Johannes>). With textual inversion the model’s dictionary is expanded and after sufficient training steps the new fine-tuned model can be plugged into the Stable Diffusion pipeline. This leads to a new image of Johannes whenever the tag <Johannes> is part of the user prompt. Styles and other objects can be added to the generated image, depending on the prompt.
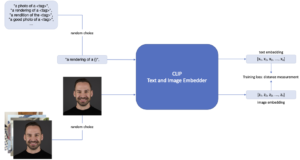
Figure 1: Fine-tuning CLIP with textual inversion.
This is what it looks like when we create AI-generated avatars of our #statcrew
At statworx, we did so with all interested colleagues which enabled them to set their digital avatars in the most diverse contexts. With the HP workstation at hand, we could use the integrated NVIDIA RTX8000 GPUs and hereby reduce the training time by a factor of 15 compared to a desktop CPU. As you can see from the examples below, the statcrew enjoyed it to generate a bunch of images in the most different situations. The following pictures show a few selected portraits of your most trusted AI consultants. 🙂
![]()
Prompts from top left to bottom right:
- <Andreas> looks a lot like christmas, santa claus, snow
- Robot <Paul>
- <Markus> as funko, trending on artstation, concept art, <Markus>, funko, digital art, box (, superman / batman / mario, nintendo, super mario)
- <Johannes> is very thankful, art, 8k, trending on artstation, vinyl·
- <Markus> riding a unicorn, digital art, trending on artstation, unicorn, (<Markus> / oil paiting)·
- <Max> in the new super hero movie, movie poster, 4k, huge explosions in the background, everyone is literally dying expect for him
- a blonde emoji that looks like <Alex>
- harry potter, hermione granger from harry potter, portrait of <Sarah>, concept art, highly detailed
Stable Diffusion together with Textual Inversion represent exciting developments in the field of artificial intelligence. They offer new possibilities for creating unique and personalized avatars but it’s also applicable to styles. By continuing to explore these and other AI models, we can push the boundaries of what is possible and create new and innovative solutions to real-world problems. Stay tuned!
Image Source: Adobe Stock 546181349
What to expect:
The tremendous development of language models like ChatGPT has exceeded our expectations. Enterprises should therefore understand how they can benefit from these advances.
In our workshop “ChatGPT for Leaders”, which is geared towards executive positions, we provide compact and immediately applicable expertise, offer the opportunity to discuss the opportunities and risks of ChatGPT with other executives and industry experts, and use use cases to show how you can automate processes in your company. Look forward to exciting presentations, including from Timo Klimmer, Global Blackbelt – AI, at Microsoft and Fabian Müller, COO at statworx.
More information and a registration option is available here: ChatGPT for Leaders Workshop
What to expect:
The konaktiva at the Technical University of Darmstadt is one of the oldest and largest student business contact fairs and is organized annually by students. With over 10,000 visitors last year and more than 200 booths, konaktiva is the ideal opportunity for companies, students and graduates to get in touch with each other.
This year statworx is again represented at konaktiva with a booth and several colleagues. We will be at the fair on one of the three days (May 9th to May 11th) and will announce the exact date here as soon as we receive the information.
We are looking forward to meet interested students and graduates to inform them about different job opportunities – from internships to permanent positions – at statworx as well as to share our experiences from our daily work. However, getting to know each other does not only take place at the booth – it is also possible to get in touch with us in pre-scheduled one-on-one meetings and to clarify individual questions.
Participation is free of charge for visitors.
It’s no secret that the latest language models like ChatGPT have far exceeded our wildest expectations. It’s impressive and even somewhat eerie to think that a language model possesses both a broad knowledge base and the ability to convincingly answer (almost) any question. Just a few hours after the release of this model, speculation began about which fields of activity could be enriched or even replaced by these models, which use cases can be implemented, and which of the many new start-up ideas arising from ChatGPT will prevail.
There is no doubt that the continuous development of artificial intelligence is gaining momentum. While ChatGPT is based on a third-generation model, a “GPT-4” is already on the horizon, and competing products are also waiting for their big moment.
As decision-makers in a company, it is now important to understand how these advancements can actually be used to add value. In this blog post, we will focus on the background instead of the hype, provide examples of specific use cases in corporate communication, and particularly explain how the implementation of these AI systems can be successful.
What is ChatGPT?
If you ask ChatGPT this question, you will receive the following answer:
“ChatGPT is a large language model trained by OpenAI to understand and generate natural language. It uses deep learning and artificial intelligence technology to conduct human-like conversations with users.”
ChatGPT is the latest representative from a class of AI systems that process human language (i.e. texts). This is called “Natural Language Processing”, or NLP for short. It is the product of a whole chain of innovations that began in 2017 with a new AI architecture. In the following years, the first AI models were developed based on this architecture that reached human-level language understanding. In the last two years, the models learned to write and even have whole conversations with the user using ChatGPT. Compared to other models, ChatGPT stands out for generating credible and appropriate responses to user requests.
In addition to ChatGPT, there are now many other language models in different forms: open source, proprietary, with dialog options or other capabilities. It quickly became apparent that these capabilities continued to grow with larger models and more (especially high-quality) data. Unlike perhaps originally expected, there seems to be no upper limit. On the contrary, the larger the models, the more capabilities they gain!
These linguistic abilities and the versatility of ChatGPT are amazing, but the use of such large models is not exactly resource-friendly. Large models like ChatGPT are operated by external providers who charge for each request to the model. In addition, every request to larger models not only generates more costs but also consumes more electricity and thus affects the environment.
For example, most chat requests from customers do not require comprehensive knowledge of world history or the ability to give amusing answers to every question. Instead, existing chatbot services tailored to business data can deliver concise and accurate answers at a fraction of the cost.
Modern Language Models in Business Applications
Despite the potential environmental and financial costs associated with large language models like ChatGPT, many decision-makers still want to invest in them. The reason lies in their integration into organizational processes. Large generative models like ChatGPT enable us to use AI in every phase of business interaction: incoming customer communication, communication planning and organization, outgoing customer communication and interaction execution, and finally, process analysis and improvement.
In the following, we will explain in detail how AI can optimize and streamline these communication processes. It quickly becomes clear that it is not just a matter of applying a single advanced AI model. Instead, it becomes apparent that only a combination of multiple models can effectively address the challenges and deliver the desired economic benefits in all phases of interaction.
For example, AI systems are becoming increasingly relevant in communication with suppliers or other stakeholders. However, to illustrate the revolutionary impact of new AI models more concretely, let us consider the type of interaction that is vital for every company: communication with the customer.
Use Case 1: Incoming Customer Communication with AI.
Challenge
Customer inquiries are received through various channels (emails, contact forms on the website, apps, etc.) and initiate internal processes and workflows within the CRM system. Unfortunately, the process is often inefficient and leads to delays and increased costs due to inquiries being misdirected or landing in a single central inbox. Existing CRM systems are often not fully integrated into organizational workflows and require additional internal processes based on organic routines or organizational knowledge of a small number of employees. This reduces efficiency and leads to poor customer satisfaction and high costs.
Solution
Customer communication can be a challenge for businesses, but AI systems can help automate and improve it. With the help of AI, the planning, initiation, and routing of customer interactions can be made more effective. The system can automatically analyze content and information and decide how best to handle the interaction based on appropriate escalation levels. Modern CRM systems are already able to process standard inquiries using low-cost chatbots or response templates. But if the AI recognizes that a more complex inquiry is present, it can activate an AI agent like ChatGPT or a customer service representative to take over the communication.
With today’s advances in the NLP field, an AI system can do much more. Relevant information can be extracted from customer inquiries and forwarded to the appropriate people in the company. For example, a key account manager can be the recipient of the customer message while a technical team is informed with the necessary details. In this way, more complex scenarios, the organization of support, the distribution of workloads, and the notification of teams about coordination needs can be handled. These processes are not manually defined but learned by the AI system.
More details such as technical architecture, vendors, pros and cons of models, requirements and timelines can be found in the following download:
The implementation of an integrated system can increase the efficiency of a company, reduce delays and errors, and ultimately lead to higher revenue and profit.
Use Case 2: Outgoing Customer Communication with AI.
Challenge
Customers expect their inquiries to be promptly, transparently, and precisely answered. A delayed or incorrect response, a lack of information, or uncoordinated communication between different departments are breaches of trust that can have a negative long-term effect on customer relationships.
Unfortunately, negative experiences are commonplace in many companies. This is often because existing solutions’ chatbots use standard answers and templates and are only rarely able to fully and conclusively answer customer inquiries. In contrast, advanced AI agents like ChatGPT have higher communication capabilities that enable smooth customer communication.
When the request does reach the right customer service employees, new challenges arise. Missing information regularly leads to sequential requests between departments, resulting in delays. Once processes, intentionally or unintentionally, run in parallel, there is a risk of incoherent communication with the customer. Ultimately, both internally and externally, transparency is lacking.
Solution
AI systems can support companies in all areas. Advanced models like ChatGPT have the necessary linguistic abilities to fully process many customer inquiries. They can communicate with customers and at the same time ask internal requests. This makes customers no longer feel brushed off by a chatbot. The technical innovations of the past year allow AI agents to answer requests not only faster but also more accurately. This relieves the customer service and internal process participants and ultimately leads to higher customer satisfaction.
AI models can also support human employees in communication. As mentioned at the beginning, there is often simply a lack of accurate and precise information available in the shortest possible time. Companies are striving to break down information silos to make access to relevant information easier. However, this can lead to longer processing times in customer service, as the necessary information must first be collected. An essential problem is that information can be presented in various forms, such as text, tabular data, in databases, or even in the form of structures like previous dialogue chains.
Modern AI systems can handle unstructured and multimodal information sources. Retrieval systems connect customer requests to various information sources. The additional use of generative models like GPT-3 then allows the found information to be efficiently synthesized into understandable text. Individual “Wikipedia articles” can be generated for each customer request. Alternatively, the customer service employee can ask a chatbot for the necessary information, which is immediately and understandably provided.
It is evident that an integrated AI system not only relieves customer service but also other technical departments. This type of system has the potential to increase efficiency throughout the company.
Use Case 3: Analysis of communication with AI
Challenge
Robust and efficient processes do not arise on their own, but through continuous feedback and constant improvements. The use of AI systems does not change this principle. An organization needs a process of continuous improvement to ensure efficient internal communication, effectively manage delays in customer service, and conduct result-oriented sales conversations.
However, in outward dialogue, companies face a problem: language is a black box. Words have unparalleled information density precisely because their use is deeply rooted in context and culture. This means that companies evade classical statistical-causal analysis because communication nuances are difficult to quantify.
Existing solutions therefore use proxy variables to measure success and conduct experiments. While overarching KPIs such as satisfaction rankings can be extracted, they must be obtained from the customer and often have little meaning. At the same time, it is often unclear what can be specifically changed in customer communication to modify these KPIs. It is difficult to analyze interactions in detail, identify dimensions and levers, and ultimately optimize them. The vast majority of what customers want to reveal about themselves immediately exists in text and language and evades analysis. This problem arises both with the use of AI assistance systems and with customer service representatives.
Solution
While modern language models have received much attention due to their generative capabilities, their analytical capabilities have also made enormous strides. The ability of AI models to respond to customer inquiries demonstrates an advanced understanding of language, which is essential for improving integrated AI systems. Another application is the analysis of conversations, including the analysis of customers and their own employees or AI assistants.
By using artificial intelligence, customers can be more precisely segmented by analyzing their communication in detail. Significant themes are captured and customer opinions are evaluated. Semantic networks can be used to identify which associations different customer groups have with products. In addition, generative models are used to identify desires, ideas, or opinions from a wealth of customer voices. Imagine being able to personally go through all customer communication in detail instead of having to rely on synthetic KPIs – that’s exactly what AI models make possible.
Of course, AI systems also offer the ability to analyze and optimize their own processes. AI-supported dialogue analysis is a promising area of application that is currently being intensively researched. This technology enables, for example, the examination of sales conversations with regard to successful closures. Breaking points in the conversation, changes in mood and topics are analyzed to identify the optimal course of a conversation. This type of feedback is extremely valuable not only for AI assistants but also for employees because it can even be played during a conversation.
In summary, the use of AI systems improves the breadth, depth, and speed of feedback processes. This allows the organization to be agile in responding to trends, desires, and customer opinions and to further optimize internal processes.
More details such as technical architecture, vendors, pros and cons of models, requirements and timelines can be found in the following download:
Obstacles to consider when implementing AI systems
The application of AI systems has the potential to fundamentally revolutionize communication with customers. Similar potential can also be demonstrated in other areas, such as procurement and knowledge management, which are discussed in more detail in the accompanying materials.
However, it is clear that even the most advanced AI models are not yet ready for deployment in isolation. To move from experimentation to effective implementation, it takes experience, good judgment, and a well-coordinated system of AI models.
The integration of language models is even more important than the models themselves. Since language models act as the interface between computers and humans, they must meet specific requirements. In particular, systems that intervene in work processes must learn from the established structures of the company. As interface technology, aspects such as fairness, impartiality, and fact-checking must be integrated into the system. In addition, the entire system needs a direct intervention capability for employees to identify errors and realign the AI models if necessary. This “active learning” is not yet standard, but it can make the difference between theoretical and practical efficiency.
The use of multiple models that run both on-site and directly from external providers presents new demands on the infrastructure. It is also important to consider that essential information transfer is not possible without careful treatment of personal data, especially when critical company information must be included. As described earlier, there are now many language models with different capabilities. Therefore, the solution’s architecture and models must be selected and combined according to the requirements.
Finally, there is the question of whether to rely on solution providers or develop your own (partial) models. Currently, there is no standard solution that meets all requirements, despite some marketing claims. Depending on the application, there are providers of cost-effective partial solutions. Making a decision requires knowledge of these providers, their solutions, and their limitations.
Conclusion
In summary, it can be stated that the use of AI systems in customer communication can improve and automate processes. A central objective for companies should be the optimization and streamlining of their communication processes. AI systems can support this by making the planning, initiation, and forwarding of customer interactions more effective and by either activating a chatbot like ChatGPT or a customer service representative for more complex inquiries. By combining different models in a targeted manner, meaningful problem-solving can be achieved in all phases of interaction, generating the desired economic benefits.
More details such as technical architecture, vendors, pros and cons of models, requirements and timelines can be found in the following download:
We, the members of the computer vision working group at statworx, had set ourselves the goal of building more competencies in our field with the help of exciting projects. For this year’s statworx Alumni Night, which took place at the beginning of September, we came up with the idea of a greeting robot that would welcome the arriving employees and alumni of our company with a personal message. To realize this project, we planned to develop a facial recognition model on a Waveshare JetBot. The Jetbot is powered by an NVIDIA Jetson Nano, a small, powerful computer with a 128-core GPU for fast execution of advanced AI algorithms. Many popular AI frameworks such as Tensorflow, PyTorch, Caffe, and Keras are supported. The project seemed to be a good opportunity for both experienced and inexperienced members of our working group to build knowledge in computer vision and gain experience in robotics.
Face recognition using the JetBot required solving several interrelated problems:
- Face Detection: Where is the face located in the image?
First, the face must be located on the provided image. Only this part of the image is relevant for all subsequent steps. - Face embedding: What are the unique features of the face?
Next, unique features must be identified and encoded in an embedding that is used to distinguish it from other people. An associated challenge is for the model to learn how to deal with slopes of the face and poor lighting. Therefore, before creating the embedding, the pose of the face must be determined and corrected so that the face is centered. - Name determination: Which embedding is closest to the recognized face?
Finally, the embedding of the face must be compared with the embeddings of all the people the model already knows to determine the name of the person. - UI with welcome message
We developed a UI for the welcome message. For this, we had to create a mapping beforehand that maps the name to a welcome message. - Configuration of the JetBot
The last step was to configure the JetBot and transfer the model to the JetBot.
Training such a face recognition model is very computationally intensive, as millions of images of thousands of different people are used to obtain a powerful neural network. However, once the model is trained, it can generate embeddings for any face (known or unknown). Therefore, we were fortunately able to use existing face recognition models and only had to create embeddings from the faces of our colleagues and alumni. Nevertheless, I’ll briefly explain the training steps to give an understanding of how these face recognition models work.
We used the Python package face_recognition, which wraps the face recognition functionality of dlib to make it easier to work with. Its neural network was trained on a dataset of about 3 million images and achieved 99.38% accuracy on the Labeled Faces in the Wild (LFW) dataset, outperforming other models.
From an image to the encoded face (Face Detection)
The localization of a face on an image is done by the Histogram of Oriented Gradients (HOG) algorithm. In this process, each individual pixel of the image is compared with the pixels in the immediate vicinity and replaced by an arrow pointing in the direction in which the image becomes darker. These arrows represent the gradients and show the progression from light to dark across the entire image. To create a clearer structure, the arrows are aggregated at a higher level. The image (a) is divided into small squares of 16×16 pixels each and replaced with the arrow direction that occurs most frequently (b). Using the HOG-encoded version of the image, the image sector that is closest to a HOG-encoded face (c) can now be found. Only this part of the image is relevant for the following steps.

Figure 1: Turning an image to a HOG pattern
source: https://commons.wikimedia.org/wiki/File:Dlib_Learned-HOG-Detector.jpg
Making faces learnable with embeddings
For the face recognition model to be able to assign different images of a person to the same face despite some images being tilted or suffering from poor lighting, the pose of the face needs to be determined and used for projection so that the eyes and lips are always in the same position of the resulting image. This is done using the Face Landmark Estimation algorithm, which can find specific landmarks in a face using machine learning. This allows us to locate the eyes and mouth and adjust them using basic image transformations such as rotation and scaling, so that the facial features are as centered as possible.

Figure 2: Face landmarks (left) and projection of the face (right)
In the next step, a neural network is used to create an embedding of the centered face image. The neural network learns meaningful embeddings by looking at three face images simultaneously within one training step: Two images of a known person and one image of another person. The neural network creates the embeddings of the three images and optimizes its weights so that the embeddings of the images of the same person are approximated and differ more with the embedding of the other person. After repeating this step millions of times for different images of different people, the neural network learns to generate representative embeddings. The network architecture of dlib‘s face recognition model is based on ResNet-34 from the paper Deep Residual Learning for Image Recognition by He et al., with fewer layers and several filters reduced by half. The generated embeddings are 128-dimensional.
Matching faces with learned embeddings in real time
Fortunately, we could use the existing model from dlib for our robot. For the model to recognize the faces of the current and former statcrew, we only had to create embeddings of everyone’s faces. For this we used the official statworx portraits and saved the resulting embedding together with each respective name. If an unknown image is then fed into the model, the face is detected, centered and turned into an embedding. The created embedding is then matched with the stored embeddings of the known people and if there is a high similarity, the name of this person is returned. If there is no similar embedding, there is no match with the knows faces. More images of a person and thus multiple embeddings per person would improve the performance of the model. However, our tests showed that our faces were recognized quite reliably even with only one image per person. After this step, we now had a good model that recognized faces in the camera in real time and displayed the associated name.
A warm welcome via a UI
Our plan was to equip the robot with a small screen or speaker so the welcome message could be seen or heard. As a starting point, we settled on connecting the robot to a monitor and building a UI to display the message. First, we developed a simple UI which displayed the welcome message in front of a background with the statworx company values and projected the camera image in the lower right corner. For each person to receive a personalized message, we had to create a json file that defined the mapping from the names to the welcome message. For unfamiliar faces, we had created the welcome message “Welcome Stranger!”. Because of the many namesakes at statworx, everyone with the name Alex also received a unique identifier:
Last hurdles before commissioning the robot
Since the model and the UI were only running locally so far, there was still the task of transferring the model to the robot with its integrated camera. Unfortunately, we found out that this was more complicated than expected. We were faced with memory problems time and again, meaning that we had to reconfigure the robot a total of three times before we could successfully deploy the model. The instructions for configuring the robot, which helped us succeed in the end, can be found here: https://jetbot.org/master/software_setup/sd_card.html. The memory problems could mostly be solved with a reboot.
The use of the welcome robot at the Alumni Night
Our welcome robot was a great success at the Alumni Night! Our guests were very surprised and happy about the personalized message.

Figure 3: Welcoming guests to the statworx-Alumni-Night
The project was also a big success for the Computer Vision cluster. During the project, we learned a lot about face recognition models and all the challenges associated with them. Working with the JetBot was particularly exciting and we are already planning more projects with the robot for next year.
At statworx, we deal intensively with how to get the best possible results from large language models (LLMs). In this blog post, I present five approaches that have proven successful both in research and in our own work with LLMs. While this text is limited to the manual design of prompts for text generation, image generation and automated prompt search will be the topic of future posts.
Mega models herald new paradigm
The arrival of the revolutionary language model GPT-3 was not only a turning point for the research field of language modeling (NLP) but has incidentally heralded a paradigm shift in AI development: prompt learning. Prior to GPT-3, the standard was fine-tuning of medium-sized language models such as BERT, which, thanks to re-training with new data, would adapt the pre-trained model to the desired use case. Such fine-tuning requires exemplary data for the desired application, as well as the computational capabilities to at least partially re-train the model.
The new large language models such as OpenAI’s GPT-3 and BigScience’s BLOOM, on the other hand, have already been trained by their development teams with such enormous amounts of resources that these models have achieved a new level of independence in their intended use: These LLMs no longer require elaborate fine-tuning to learn their specific purpose, but already produce impressive results using targeted instruction (“prompt”) in natural language.
So, we are in the midst of a revolution in AI development: Thanks to prompt learning, interaction with models no longer takes place via code, but in natural language. This is a giant step forward for the democratization of language modeling. Generating text or, most recently, even creating images requires no more than rudimentary language skills. However, this does not mean that compelling or impressive results are accessible to all. High quality outputs require high quality inputs. For us users, this means that engineering efforts in NLP are no longer focused on model architecture or training data, but on the design of the instructions that models receive in natural language. Welcome to the age of prompt engineering.
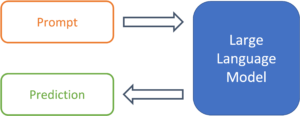
Figure 1: From prompt to prediction with a large language model.
Prompts are more than just snippets of text
Templates facilitate the handling of prompts
Since LLMs have not been trained on a specific use case, it is up to the prompt design to provide the model with the exact task. So-called “prompt templates” are used for this purpose. A template defines the structure of the input that is passed on to the model. Thus, the template takes over the function of fine-tuning and determines the expected output of the model for a specific use case. Using sentiment analysis as an example, a simple prompt template might look like this:
The expressed sentiment in text [X] is: [Z]
The model thus searches for a token z, that, based on the trained parameters and the text in location [X], maximizes the probability of the masked token in location [Z]. The template thus specifies the desired context of the problem to be solved and defines the relationship between the input at position [X] and the output to be predicted at position [Z]. The modular structure of templates enables the systematic processing of a large number of texts for the desired use case.
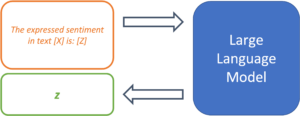
Figure 2: Prompt templates define the structure of a prompt.
Prompts do not necessarily need examples
The template presented is an example of a so-called “0-Shot” prompt, since there is only an instruction, without any demonstration with examples in the template. Originally, LLMs were called “Few-Shot Learners” by the developers of GPT-3, i.e., models whose performance can be maximized with a selection of solved examples of the problem (Brown et al., 2020). However, a follow-up study showed that with strategic prompt design, 0-shot prompts, without a large number of examples, can achieve comparable performance (Reynolds & McDonell, 2021). Thus, since different approaches are also used in research, the next section presents 5 strategies for effective prompt template design.
5 Strategies for Effective Prompt Design
Task demonstration
In the conventional few-shot setting, the problem to be solved is narrowed down by providing several examples. The solved example cases are supposed to take a similar function as the additional training samples during the fine-tuning process and thus define the specific use case of the model. Text translation is a common example for this strategy, which can be represented with the following prompt template:
French: „Il pleut à Paris“
English: „It’s raining in Paris“
French: „Copenhague est la capitale du Danemark“
English: „Copenhagen is the capital of Denmark“
[…]
French: [X]
English: [Z]
While the solved examples are good for defining the problem setting, they can also cause problems. “Semantic contamination” refers to the phenomenon of the LLM interpreting the content of the translated sentences as relevant to the prediction. Examples in the semantic context of the task produce better results – and those out of context can lead to the prediction Z being “contaminated” in terms of its content (Reynolds & McDonell, 2021). Using the above template for translating complex facts, the model might well interpret the input sentence as a statement about a major European city in ambiguous cases.
Task Specification
Recent research shows that with good prompt design, even the 0-shot approach can yield competitive results. For example, it has been demonstrated that LLMs do not require pre-solved examples at all, as long as the problem is defined as precisely as possible in the prompt (Reynolds & McDonell, 2021). This specification can take different forms, but it is always based on the same idea: to describe as precisely as possible what is to be solved, but without demonstrating how.
A simple example of the translation case would be the following prompt:
Translate from French to English [X]: [Z]
This may already work, but the researchers recommend making the prompt as descriptive as possible and explicitly mentioning translation quality:
A French sentence is provided: [X]. The masterful French translator flawlessly translates the sentence to English: [Z]
This helps the model locate the desired problem solution in the space of the learned tasks.
![]()
Figure 3: A clear task description can greatly increase the forecasting quality.
This is also recommended in use cases outside of translations. A text can be summarized with a simple command:
Summarize the following text: [X]: [Z]
However, better results can be expected with a more concrete prompt:
Rephrase this sentence with easy words so a child understands it,
emphasize practical applications and examples: [X]: [Z]
The more accurate the prompt, the greater the control over the output.
Prompts as constraints
Taken to its logical conclusion, the approach of controlling the model simply means constraining the model’s behavior through careful prompt design. This perspective is useful because during training, LLMs learn to complete many different sorts of texts and can thus solve a wide range of problems. With this design strategy, the basic approach to prompt design changes from describing the problem to excluding undesirable results by constraining model behavior. Which prompt leads to the desired result and only to the desired result? The following prompt indicates a translation task, but beyond that, it does not include any approaches to prevent the sentence from simply being continued into a story by the model.
Translate French to English Il pleut à Paris
One approach to improve this prompt is to use both semantic and syntactic means:
Translate this French sentence to English: “Il pleut à Paris.”
The use of syntactic elements such as the colon and quotation marks makes it clear where the sentence to be translated begins and ends. Also, the specification by sentence expresses that it is only about a single sentence. These measures reduce the likelihood that this prompt will be misunderstood and not treated as a translation problem.
Use of “memetic proxies”
This strategy can be used to increase the density of information in a prompt and avoid long descriptions through culturally understood context. Memetic proxies can be used in task descriptions and use implicitly understood situations or personae instead of detailed instructions:
A primary school teacher rephrases the following sentence: [X]: [Z]
This prompt is less descriptive than the previous example of rephrasing in simple words. However, the situation described contains a much higher density of information: The mentioning of an elementary school teacher already implies that the outcome should be understandable to children and thus hopefully increases the likelihood of practical examples in the output. Similarly, prompts can describe fictional conversations with well-known personalities so that the output reflects their worldview or way of speaking:
In this conversation, Yoda responds to the following question: [X]
Yoda: [Z]
This approach helps to keep prompts short by using implicitly understood context and to increase the information density within a prompt. Memetic proxies are also used in prompt design for other modalities. In image generation models such as DALL-e 2, the suffix “Trending on Artstation” often leads to higher quality results, although semantically no statements are made about the image to be generated.
Metaprompting
Metaprompting is how the research team of one study describes the approach of enriching prompts with instructions that are tailored to the task at hand. They describe this as a way to constrain a model with clearer instructions so that the task at hand can be better accomplished (Reynolds & McDonell, 2021). The following example can help to solve mathematical problems more reliably and to make the reasoning path comprehensible:
[X]. Let us solve this problem step-by-step: [Z]
Similarly, multiple choice questions can be enriched with metaprompts so that the model actually chooses an option in the output rather than continuing the list:
[X] in order to solve this problem, let us analyze each option and choose the best: [Z]
Metaprompts thus represent another means of constraining model behavior and results.
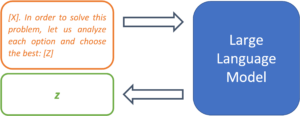
Figure 4: Metaprompts can be used to define procedures for solving problems.
Outlook
Prompt learning is a very young paradigm, and the closely related prompt engineering is still in its infancy. However, the importance of sound prompt writing skills will undoubtedly only increase. Not only language models such as GPT-3, but also the latest image generation models require their users to have solid prompt design skills in order to create convincing results. The strategies presented are both research and practice proven approaches to systematically writing prompts that are helpful for getting better results from large language models.
In a future blog post, we will use this experience with text generation to unlock best practices for another category of generative models: state-of-the-art diffusion models for image generation, such as DALL-e 2, Midjourney, and Stable Diffusion.
Sources
Brown, Tom B. et al. 2020. “Language Models Are Few-Shot Learners.” arXiv:2005.14165 [cs]. http://arxiv.org/abs/2005.14165 (March 16, 2022).
Reynolds, Laria, and Kyle McDonell. 2021. “Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm.” http://arxiv.org/abs/2102.07350 (July 1, 2022).
Text classification is one of the most common applications of natural language processing (NLP). It is the task of assigning a set of predefined categories to a text snippet. Depending on the type of problem, the text snippet could be a sentence, a paragraph, or even a whole document. There are many potential real-world applications for text classification, but among the most common ones are sentiment analysis, topic modeling and intent, spam, and hate speech detection.
The standard approach to text classification is training a classifier in a supervised regime. To do so, one needs pairs of text and associated categories (aka labels) from the domain of interest as training data. Then, any classifier (e.g., a neural network) can learn a mapping function from the text to the most likely category. While this approach can work quite well for many settings, its feasibility highly depends on the availability of those hand-labeled pairs of training data.
Though pre-trained language models like BERT can reduce the amount of data needed, it does not make it obsolete altogether. Therefore, for real-world applications, data availability remains the biggest hurdle.
Zero-Shot Learning
Though there are various definitions of zero-shot learning1, it can broadly speaking be defined as a regime in which a model solves a task it was not explicitly trained on before.
It is important to understand, that a “task” can be defined in both a broader and a narrower sense: For example, the authors of GPT-2 showed that a model trained on language generation can be applied to entirely new downstream tasks like machine translation2. At the same time, a narrower definition of task would be to recognize previously unseen categories in images as shown in the OpenAI CLIP paper3.
But what all these approaches have in common is the idea of extrapolation of learned concepts beyond the training regime. A powerful concept, because it disentangles the solvability of a task from the availability of (labeled) training data.
Zero-Shot Learning for Text Classification
Solving text classification tasks with zero-shot learning can serve as a good example of how to apply the extrapolation of learned concepts beyond the training regime. One way to do this is using natural language inference (NLI) as proposed by Yin et al. (2019)4. There are other approaches as well like the calculation of distances between text embeddings or formulating the problem as a cloze
In NLI the task is to determine whether a hypothesis is true (entailment), false (contradiction), or undetermined (neutral) given a premise5. A typical NLI dataset consists of sentence pairs with associated labels in the following form:
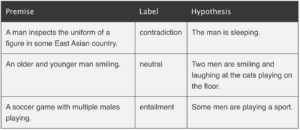
Examples from http://nlpprogress.com/english/natural_language_inference.html
Yin et al. (2019) proposed to use large language models like BERT trained on NLI datasets and exploit their language understanding capabilities for zero-shot text classification. This can be done by taking the text of interest as the premise and formulating one hypothesis for each potential category by using a so-called hypothesis template. Then, we let the NLI model predict whether the premise entails the hypothesis. Finally, the predicted probability of entailment can be interpreted as the probability of the label.
Zero-Shot Text Classification with Hugging Face 🤗
Let’s explore the above-formulated idea in more detail using the excellent Hugging Face implementation for zero-shot text classification.
We are interested in classifying the sentence below into pre-defined topics:
topics = ['Web', 'Panorama', 'International', 'Wirtschaft', 'Sport', 'Inland', 'Etat', 'Wissenschaft', 'Kultur']
test_txt = 'Eintracht Frankfurt gewinnt die Europa League nach 6:5-Erfolg im Elfmeterschießen gegen die Glasgow Rangers'Thanks to the 🤗 pipeline abstraction, we do not need to define the prediction task ourselves. We just need to instantiate a pipeline and define the task as zero-shot-text-classification. The pipeline will take care of formulating the premise and hypothesis as well as deal with the logits and probabilities from the model.
As written above, we need a language model that was pre-trained on an NLI task. The default model for zero-shot text classification in 🤗 is bart-large-mnli. BART is a transformer encoder-decoder for sequence-2-sequence modeling with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder6. The mnli suffix means that BART was then further fine-tuned on the MultiNLI dataset7.
But since we are using German sentences and BART is English-only, we need to replace the default model with a custom one. Thanks to the 🤗 model hub, finding a suitable candidate is quite easy. In our case, mDeBERTa-v3-base-xnli-multilingual-nli-2mil7 is such a candidate. Let’s decrypt the name shortly for a better understanding: it is a multilanguage version of DeBERTa-v3-base (which is itself an improved version of BERT/RoBERTa8) that was then fine-tuned on two cross-lingual NLI datasets (XNLI8 and multilingual-NLI-26lang10).
With the correct task and the correct model, we can now instantiate the pipeline:
from transformers import pipeline
model = 'MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7'
pipe = pipeline(task='zero-shot-classification', model=model, tokenizer=model)Next, we call the pipeline to predict the most likely category of our text given the candidates. But as a final step, we need to replace the default hypothesis template as well. This is necessary since the default is again in English. We, therefore, define the template as 'Das Thema is {}'. Note that, {} is a placeholder for the previously defined topic candidates. You can define any template you like as long as it contains a placeholder for the candidates:
template_de = 'Das Thema ist {}'
prediction = pipe(test_txt, topics, hypothesis_template=template_de)Finally, we can assess the prediction from the pipeline. The code below will output the three most likely topics together with their predicted probabilities:
print(f'Zero-shot prediction for: \n {prediction["sequence"]}')
top_3 = zip(prediction['labels'][0:3], prediction['scores'][0:3])
for label, score in top_3:
print(f'{label} - {score:.2%}')Zero-shot prediction for:
Eintracht Frankfurt gewinnt die Europa League nach 6:5-Erfolg im Elfmeterschießen gegen die Glasgow Rangers
Sport - 77.41%
International - 15.69%
Inland - 5.29%As one can see, the zero-shot model produces a reasonable result with “Sport” being the most likely topic followed by “International” and “Inland”.
Below are a few more examples from other categories. Like before, the results are overall quite reasonable. Note how for the second text the model predicts an unexpectedly low probability of “Kultur”.
further_examples = ['Verbraucher halten sich wegen steigender Zinsen und Inflation beim Immobilienkauf zurück',
'„Die bitteren Tränen der Petra von Kant“ von 1972 geschlechtsumgewandelt und neu verfilmt',
'Eine 541 Millionen Jahre alte fossile Alge weist erstaunliche Ähnlichkeit zu noch heute existierenden Vertretern auf']
for txt in further_examples:
prediction = pipe(txt, topics, hypothesis_template=template_de)
print(f'Zero-shot prediction for: \n {prediction["sequence"]}')
top_3 = zip(prediction['labels'][0:3], prediction['scores'][0:3])
for label, score in top_3:
print(f'{label} - {score:.2%}')Zero-shot prediction for:
Verbraucher halten sich wegen steigender Zinsen und Inflation beim Immobilienkauf zurück
Wirtschaft - 96.11%
Inland - 1.69%
Panorama - 0.70%
Zero-shot prediction for:
„Die bitteren Tränen der Petra von Kant“ von 1972 geschlechtsumgewandelt und neu verfilmt
International - 50.95%
Inland - 16.40%
Kultur - 7.76%
Zero-shot prediction for:
Eine 541 Millionen Jahre alte fossile Alge weist erstaunliche Ähnlichkeit zu noch heute existierenden Vertretern auf
Wissenschaft - 67.52%
Web - 8.14%
Inland - 6.91%The entire code can be found on GitHub. Besides the examples from above, you will find there also applications of zero-shot text classifications on two labeled datasets including an evaluation of the accuracy. In addition, I added some prompt-tuning by playing around with the hypothesis template.
Concluding Thoughts
Zero-shot text classification offers a suitable approach when either training data is limited (or even non-existing) or as an easy-to-implement benchmark for more sophisticated methods. While explicit approaches, like fine-tuning large pre-trained models, certainly still outperform implicit approaches, like zero-shot learning, their universal applicability makes them very appealing.
In addition, we should expect zero-shot learning, in general, to become more important over the next few years. This is because the way we will use models to solve tasks will evolve with the increasing importance of large pre-trained models. Therefore, I advocate that already today zero-shot techniques should be considered part of every modern data scientist’s toolbox.
Sources:
1 https://joeddav.github.io/blog/2020/05/29/ZSL.html
2 https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
3 https://arxiv.org/pdf/2103.00020.pdf
4 https://arxiv.org/pdf/1909.00161.pdf
5 http://nlpprogress.com/english/natural_language_inference.html
6 https://arxiv.org/pdf/1910.13461.pdf
7 https://huggingface.co/datasets/multi_nli
8 https://arxiv.org/pdf/2006.03654.pdf
9 https://huggingface.co/datasets/xnli
10 https://huggingface.co/datasets/MoritzLaurer/multilingual-NLI-26lang-2mil7
Artificially enhancing face images is all the rage
What can AI contribute?
In recent years, image filters have become wildly popular on social media. These filters let anyone adjust their face and the surroundings in different ways, leading to entertaining results. Often, filters enhance facial features that seem to match a certain beauty standard. As AI experts, we asked ourselves what is possible to achieve in the topic of face representations using our tools. One issue that sparked our interest is gender representations. We were curious: how does the AI represent gender differences when creating these images? And on top of that: can we generate gender-neutral versions of existing face images?
Using StyleGAN on existing images
When thinking about what existing images to explore, we were curious to see how our own faces would be edited. Additionally, we decided to use several celebrities as inputs – after all, wouldn’t it be intriguing to observe world-famous faces morphed into different genders?
Currently, we often see text-prompt-based image generation models like DALL-E in the center of public discourse. Yet, the AI-driven creation of photo-realistic face images has long been a focus of researchers due to the apparent challenge of creating natural-looking face images. Searching for suitable AI models to approach our idea, we chose the StyleGAN architectures that are well known for generating realistic face images.
Adjusting facial features using StyleGAN
One crucial aspect of this AI’s architecture is the use of a so-called latent space from which we sample the inputs of the neural network. You can picture this latent space as a map on which every possible artificial face has a defined coordinate. Usually, we would just throw a dart at this map and be happy about the AI producing a realistic image. But as it turns out, this latent space allows us to explore various aspects of artificial face generation. When you move from one face’s location on that map to another face’s location, you can generate mixtures of the two faces. And as you move in any arbitrary direction, you will see random changes in the generated face image.
This makes the StyleGAN architecture a promising approach for exploring gender representation in AI.
Can we isolate a gender direction?
So, are there directions that allow us to change certain aspects of the generated image? Could a gender-neutral representation of a face be approached this way? Pre-existing works have found semantically interesting directions, yielding fascinating results. One of those directions can alter a generated face image to have a more feminine or masculine appearance. This lets us explore gender representation in images.
The approach we took for this article was to generate multiple images by making small steps in each gender’s direction. That way, we can compare various versions of the faces, and the reader can, for example, decide which image comes closest to a gender-neutral face. It also allows us to examine the changes more clearly and look for unwanted characteristics in the edited versions.
Introducing our own faces to the AI
The described method can be utilized to alter any face generated by the AI towards a more feminine or masculine version. However, a crucial challenge remains: Since we want to use our own images as a starting point, we must be able to obtain the latent coordinate (in our analogy, the correct place on the map) for a given face image. Sounds easy at first, but the used StyleGAN architecture only allows us to go one way, from latent coordinate to generated image, not the other way around. Thankfully, other researchers have explored this very problem. Our approach thus heavily builds on the python notebook found here. The researchers built another “encoder”-AI that takes a face image as input and finds its corresponding coordinate in the latent space.
And with that, we finally have all parts necessary to realize our goal: exploring different gender representations using an AI. In the photo sequences below, the center image is the original input image. Towards the left, the generated faces appear more female; towards the right, they seem more male. Without further ado, we present the AI-generated images of our experiment:
Results: photo series from female to male






Unintended biases
After finding the corresponding images in the latent space, we generated artificial versions of the faces. We then moved them along the chosen gender direction, creating “feminized” and “masculinized” faces. Looking at the results, we see some unexpected behavior in the AI: it seems to recreate classic gender stereotypes.
Big smiles vs. thick eyebrows
Whenever we edited an image to look more feminine, we gradually see an opening mouth with a stronger smile and vice versa. Likewise, eyes grow larger and wide open in the female direction. The Drake and Kim Kardashian examples illustrate a visible change in skin tone from darker to lighter when moving along the series from feminine to masculine. The chosen gender direction appears to edit out curls in the female direction (as opposed to the male direction), as exemplified by the examples of Marylin Monroe and blog co-author Isabel Hermes. We also asked ourselves whether the lack of hair extension in Drake’s female direction would be remedied if we extended his photo series. Examining the overall extremes, eyebrows are thinned out and arched on the female and straighter and thicker on the male side. Eye and lip makeup increase heavily on faces that move in the female direction, making the area surrounding the eyes darker and thinning out eyebrows. This may be why we perceived the male versions we generated to look more natural than the female versions.
Finally, we would like to challenge you, as the reader, to examine the photo series above closely. Try to decide which image you perceive as gender-neutral, i.e., as much male as female. What made you choose that image? Did any of the stereotypical features described above impact your perception?
A natural question that arises from image series like the ones generated for this article is whether there is a risk that the AI reinforces current gender stereotypes.
Is the AI to blame for recreating stereotypes?
Given that the adjusted images recreate certain gender stereotypes like a more pronounced smile in female images, a possible conclusion could be that the AI was trained on a biased dataset. And indeed, to train the underlying StyleGAN, image data from Flickr was used that inherits the biases from the website. However, the main goal of this training was to create realistic images of faces. And while the results might not always look as we expect or want, we would argue that the AI did precisely that in all our tests.
To alter the images, however, we used the beforementioned latent direction. In general, those latent directions rarely change only a single aspect of the created image. Instead, like walking in a random direction on our latent map, many elements of the generated face usually get changed simultaneously. Identifying a direction that alters only a single aspect of a generated image is anything but trivial. For our experiment, the chosen direction was created primarily for research purposes without accounting for said biases. It can therefore introduce unwanted artifacts in the images alongside the intended alterations. Yet it is reasonable to assume that a latent direction exists that allows us to alter the gender of a face created by the StyleGAN without affecting other facial features.
Overall, the implementations we build upon use different AIs and datasets, and therefore the complex interplay of those systems doesn’t allow us to identify the AI as a single source for these issues. Nevertheless, our observations suggest that doing due diligence to ensure the representation of different ethnic backgrounds and avoid biases in creating datasets is paramount.

Abb. 7: Picture from “A Sex Difference in Facial Contrast and its Exaggeration by Cosmetics” by Richard Russel
Subconscious bias: looking at ourselves
A study by Richard Russel deals with human perception of gender in faces. Ask yourself, which gender would you intuitively assign to the two images above? It turns out that most people perceive the left person as male and the right person as female. Look again. What separates the faces? There is no difference in facial structure. The only difference is darker eye and mouth regions. It becomes apparent that increased contrast is enough to influence our perception. Suppose our opinion on gender can be swayed by applying “cosmetics” to a face. In that case, we must question our human understanding of gender representations and whether they are simply products of our life-long exposure to stereotypical imagery. The author refers to this as the “Illusion of Sex”.
This bias relates to the selection of latent “gender” dimension: To find the latent dimension that changes the perceived gender of a face, StyleGAN-generated images were divided into groups according to their appearance. While this was implemented based on yet another AI, human bias in gender perception might well have impacted this process and have leaked through to the image rows illustrated above.
Conclusion
Moving beyond the gender binary with StyleGANs
While a StyleGAN might not reinforce gender-related bias in and of itself, people still subconsciously harbor gender stereotypes. Gender bias is not limited to images – researchers have found the ubiquity of female voice assistants reason enough to create a new voice assistant that is neither male nor female: GenderLess Voice.
One example of a recent societal shift is the debate over gender; rather than binary, gender may be better represented as a spectrum. The idea is that there is biological gender and social gender. Being included in society as who they are is essential for somebody who identifies with a gender that differs from that they were born with.
A question we, as a society, must stay wary of is whether the field of AI is at risk of discriminating against those beyond the assigned gender binary. The fact is that in AI research, gender is often represented as binary. Pictures fed into algorithms to train them are either labeled as male or female. Gender recognition systems based on deterministic gender-matching may also cause direct harm by mislabelling members of the LGBTQIA+ community. Currently, additional gender labels have yet to be included in ML research. Rather than representing gender as a binary variable, it could be coded as a spectrum.
Exploring female to male gender representations
We used StyleGANs to explore how AI represents gender differences. Specifically, we used a gender direction in the latent space. Researchers determined this direction to display male and female gender. We saw that the generated images replicated common gender stereotypes – women smile more, have bigger eyes, longer hair, and wear heavy makeup – but importantly, we could not conclude that the StyleGAN model alone propagates this bias. Firstly, StyleGANs were created primarily to generate photo-realistic face images, not to alter the facial features of existing photos at will. Secondly, since the latent direction we used was created without correcting for biases in the StyleGANs training data, we see a correlation between stereotypical features and gender.
Next steps and gender neutrality
We asked ourselves which faces we perceived as gender neutral among the image sequences we generated. For original images of men, we had to look towards the artificially generated female direction and vice versa. This was a subjective choice. We see it as a logical next step to try to automate the generation of gender-neutral versions of face images to explore further the possibilities of AI in the topic of gender and society. For this, we would first have to classify the gender of the face to be edited and then move towards the opposite gender to the point where the classifier can no longer assign an unambiguous label. Therefore, interested readers will be able to follow the continuation of our journey in a second blog article in the coming time.
If you are interested in our technical implementation for this article, you can find the code here and try it out with your own images.
Resources
Photo Credits
AdobeStock 210526825 – Wayhome Studio
AdobeStock 243124072 – Damir Khabirov
AdobeStock 387860637 – insta_photos
AdobeStock 395297652 – Nattakorn
AdobeStock 480057743 – Chris
AdobeStock 573362719 – Xavier Lorenzo
AdobeStock 575284046 – Jose Calsina
What to expect:
You always wanted to know how AI can be used to make our world more sustainable? Then you shouldn’t miss the “Green AIdeas” after-work event.
The event offers AI companies a stage for their ideas and best practices as well as an exchange platform for inspiration, use cases and challenges around the topic of AI and sustainability.
In addition to discussion panels and the guided tour through the sustainable data center, you will have the opportunity to participate in one of the exciting AI & Sustainability talks.
One of these talks on “Sustainable Machine Learning – What impact do Machine Learning models have on the environment and what countermeasures can be taken?” will be held by our statworx AI experts Isabel Hermes and Dominique Lade.
The talk will cover topics such as:
- What machine learning has to do with sustainability
- How to identify and reduce emissions from AI applications
- How machine learning can be made more sustainable
The best part is that everything is for free.
Click here to register: https://mautic.cloudandheat.com/green-aideas-registration
We look forward to seeing you on September 8!