A successful data culture is the key for companies to derive the greatest possible benefit from the constantly growing amount of data. The trend towards making decisions based on data is unstoppable. But how do managers manage to empower their teams to use data effectively?
A vibrant data culture: the fuel for corporate success
Data culture is more than just a buzzword – it is the basis for data-driven decision-making. When all departments in a company use data to improve work processes and decision-making, an atmosphere is created in which competent handling of data is standard practice.
Why is this so important? Data is fuel for business success: 76 percent of participants in the BARC Data Culture Survey 22 stated that their company strives for a data culture. And 75 percent of managers see data culture as the most important competence.

The decisive role of managers
An established data culture is not only a success factor for the company, but also a way to promote innovation and motivate employees. Managers play a central role here by acting as trailblazers and actively supporting change. They must clearly communicate the benefits of a data culture, establish clear guidelines for data protection and data quality and offer targeted training and regular communication on progress. Clear responsibility for data culture is crucial, as 31% of companies with a weak data culture do not have a dedicated department or person with this responsibility.
Challenges and solutions
The path to a successful data culture is littered with hurdles. Managers have to face various challenges:
- Resistance to change: A transition to a data culture can be met with resistance. Managers must clearly communicate the benefits and offer training to involve their employees in the change process.
- Lack of data governance: Guidelines and standards for handling data are crucial. If these are missing, data quality will be reduced in the worst case. This leads to wrong decisions. This is where data cleansing and validation methods and regular audits are needed.
- Concerns regarding data protection: Data protection and data access are often in conflict. Clear guidelines and security measures must be introduced in order to gain the trust of employees.
- Lack of resources and support: Without the necessary resources, building a data culture can fail. Companies must provide targeted training and demonstrate the business benefits in economic metrics to gain the support of their executives
Best practices for a strong data culture
To effectively establish a data culture, companies can rely on the following best practices:
Critical thinking: Promoting critical thinking and ethical standards is crucial. Data and AI solutions will become tools of everyday life everywhere. Therefore, human intelligence remains the most important skill in dealing with technology.
Measuring and planning: Data culture can only be built up step by step. Companies should measure and evaluate data-driven behavior in order to assess progress. The stronger the data culture, the more omnipresent data-driven decision-making becomes.
Establishment of key roles: Companies should create special functions or roles for employees who link the data strategy with the corporate strategy and act as central multipliers to promote the data culture among employees.
The development of a strong data culture requires clear leadership, clear guidelines and the commitment of the entire organization. Managers play a crucial role in successfully shaping the change to a data-driven culture.
Building a strong data culture: our strategic approach
At statworx, we specialize in establishing robust data cultures in companies. Our strategy is based on proven frameworks, best practices and our extensive experience to lay the foundations for a successful data culture in your organization.
- Data Culture Strategy: Working hand in hand with our clients’ teams, we develop the strategic roadmap required to foster a thriving data culture. This includes building the foundational structures that are essential to maximizing the potential of your company’s data.
- Data culture training: We focus on empowering your workforce with the skills and knowledge to operate in the data and AI space. Our training programs aim to equip employees with the skills that are essential for building a strong data culture. This enables companies to realize the full potential of data and artificial intelligence.
- Change management and support: Embedding a data culture requires sustained change management efforts. We work with client teams to establish long-term change programs aimed at initiating and consolidating a robust data culture within the organization. Our goal is to ensure that the transformation remains embedded in the DNA of the organization to ensure continued success.
With our comprehensive range of services, we strive to lead companies into a future where data becomes a strategic asset that unlocks new opportunities and enables informed decision-making at all levels. We have written about this in detail in our white paper “Data culture as a management task in companies“ (currently only available in German), which also contains a data culture checklist. Our services relating to data culture can be found on our Data Culture topic page.
We are at the beginning of 2024, a time of fundamental change and exciting progress in the world of artificial intelligence. The next few months are seen as a critical milestone in the evolution of AI as it transforms from a promising future technology to a permanent reality in the business and everyday lives of millions. Together with the AI Hub Frankfurt, the central AI network in the Rhine-Main region, we are therefore presenting our trend forecast for 2024, the AI Trends Report 2024.
The report identifies twelve dynamic AI trends that are unfolding in three key areas: Culture and Development, Data and Technology, and Transparency and Control. These trends paint a picture of the rapid changes in the AI landscape and highlight the impact on companies and society.
Our analysis is based on extensive research, industry-specific expertise and input from experts. We highlight each trend to provide a forward-looking insight into AI and help companies prepare for future challenges and opportunities. However, we emphasize that trend forecasts are always speculative in nature and some of our predictions are deliberately bold.
Directly to the AI Trends Report 2024!
What is a trend?
A trend is different from both a short-lived fashion phenomenon and media hype. It is a phenomenon of change with a “tipping point” at which a small change in a niche can cause a major upheaval in the mainstream. Trends initiate new business models, consumer behavior and forms of work and thus represent a fundamental change to the status quo. It is crucial for companies to mobilize the right knowledge and resources before the tipping point in order to benefit from a trend.
12 AI trends that will shape 2024
In the AI Trends Report 2024, we identify groundbreaking developments in the field of artificial intelligence. Here are the short versions of the twelve trends, each with a selected quote from our experts.
Part 1: Culture and development
From the 4-day week to omnimodality and AGI: 2024 promises great progress for the world of work, for media production and for the possibilities of AI as a whole.
Thesis I: AI expertise within the company
Companies that deeply embed AI expertise in their corporate culture and build interdisciplinary teams with tech and industry knowledge will secure a competitive advantage. Centralized AI teams and a strong data culture are key to success.
Stefanie Babka, Global Head of Data Culture, Merck
Thesis II: 4-day working week thanks to AI
Thanks to AI automation in standard software and company processes, the 4-day working week has become a reality for some German companies. AI tools such as Microsoft’s Copilot increase productivity and make it possible to reduce working hours without compromising growth.
Dr. Jean Enno Charton, Director Digital Ethics & Bioethics, Merck
Thesis III: AGI through omnimodal models
The development of omnimodal AI models that mimic human senses brings the vision of general artificial intelligence (AGI) closer. These models process a variety of inputs and extend human capabilities.
Dr. Ingo Marquart, NLP Subject Matter Lead, statworx
Thesis IV: AI revolution in media production
Generative AI (GenAI) is transforming the media landscape and enabling new forms of creativity, but still falls short of transformational creativity. AI tools are becoming increasingly important for creatives, but it is important to maintain uniqueness against a global average taste.
Nemo Tronnier, Founder & CEO, Social DNA
Part 2: Data and technology
In 2024, everything will revolve around data quality, open source models and access to processors. The operators of standard software such as Microsoft and SAP will benefit greatly because they occupy the interface to end users.
Thesis V: Challengers for NVIDIA
New players and technologies are preparing to shake up the GPU market and challenge NVIDIA’s position. Startups and established competitors such as AMD and Intel are looking to capitalize on the resource scarcity and long wait times that smaller players are currently experiencing and are focusing on innovation to break NVIDIA’s dominance.
Norman Behrend, Chief Customer Officer, Genesis Cloud
Thesis VI: Data quality before data quantity
In AI development, the focus is shifting to the quality of the data. Instead of relying solely on quantity, the careful selection and preparation of training data and innovation in model architecture are becoming crucial. Smaller models with high-quality data can be superior to larger models in terms of performance.
Walid Mehanna, Chief Data & AI Officer, Merck
Thesis VII: The year of the AI integrators
Integrators such as Microsoft, Databricks and Salesforce will be the winners as they bring AI tools to end users. The ability to seamlessly integrate into existing systems will be crucial for AI startups and providers. Companies that offer specialized services or groundbreaking innovations will secure lucrative niches.
Marco Di Sazio, Head of Innovation, Bankhaus Metzler
Thesis VIII: The open source revolution
Open source AI models are competing with proprietary models such as OpenAI’s GPT and Google’s Gemini. With a community that fosters innovation and knowledge sharing, open source models offer more flexibility and transparency, making them particularly valuable for applications that require clear accountability and customization.
Prof. Dr. Christian Klein, Founder, UMYNO Solutions, Professor of Marketing & Digital Media, FOM University of Applied Sciences
Part 3: Transparency and control
The increased use of AI decision-making systems will spark an intensified debate on algorithm transparency and data protection in 2024 – in the search for accountability. The AI Act will become a locational advantage for Europe.
Thesis IX: AI transparency as a competitive advantage
European AI start-ups with a focus on transparency and explainability could become the big winners, as industries such as pharmaceuticals and finance already place high demands on the traceability of AI decisions. The AI Act promotes this development by demanding transparency and adaptability from AI systems, giving European AI solutions an edge in terms of trust.
Jakob Plesner, Attorney at Law, Gorrissen Federspiel
Thesis X: AI Act as a seal of quality
The AI Act positions Europe as a safe haven for investments in AI by setting ethical standards that strengthen trust in AI technologies. In view of the increase in deepfakes and the associated risks to society, the AI Act acts as a bulwark against abuse and promotes responsible growth in the AI industry.
Catharina Glugla, Head of Data, Cyber & Tech Germany, Allen & Overy LLP
Thesis XI: AI agents are revolutionizing consumption
Personal assistance bots that make purchases and select services will become an essential part of everyday life. Influencing their decisions will become a key element for companies to survive in the market. This will profoundly change search engine optimization and online marketing as bots become the new target groups.
Chi Wang, Principle Researcher, Microsoft Research
Thesis XII: Alignment of AI models
Aligning AI models with universal values and human intentions will be critical to avoid unethical outcomes and fully realize the potential of foundation models. Superalignment, where AI models work together to overcome complex challenges, is becoming increasingly important to drive the development of AI responsibly.
Daniel Lüttgau, Head of AI Development, statworx
Concluding remarks
The AI Trends Report 2024 is more than an entertaining stocktake; it can be a useful tool for decision-makers and innovators. Our goal is to provide our readers with strategic advantages by discussing the impact of trends on different sectors and helping them set the course for the future.
This blog post offers only a brief insight into the comprehensive AI Trends Report 2024. We invite you to read the full report to dive deeper into the subject matter and benefit from the detailed analysis and forecasts.
At the beginning of December, the central EU institutions reached a provisional agreement on a legislative proposal to regulate artificial intelligence in the so-called trilogue. The final legislative text with all the details is now being drafted. As soon as this has been drawn up and reviewed, the law can be officially adopted. We have compiled the current state of knowledge on the AI Act.
As part of the ordinary legislative procedure of the European Union, a trilogue is an informal interinstitutional negotiation between representatives of the European Parliament, the Council of the European Union and the European Commission. The aim of a trialogue is to reach a provisional agreement on a legislative proposal that is acceptable to both the Parliament and the Council, the co-legislators. The provisional agreement must then be adopted by each of these bodies in formal procedures.
Legislation with a global impact
A special feature of the upcoming law is the so-called market location principle: according to this, companies worldwide that offer or operate artificial intelligence on the European market or whose AI-generated output is used within the EU will be affected by the AI Act.
Artificial intelligence is defined as machine-based systems that can autonomously make predictions, recommendations or decisions and thus influence the physical and virtual environment. This applies, for example, to AI solutions that support the recruitment process, predictive maintenance solutions and chatbots such as ChatGPT. The legal requirements that different AI systems must fulfill vary greatly depending on their classification into risk classes.
The risk class determines the legal requirements
The EU’s risk-based approach comprises a total of four risk classes:
- low,
- limited,
- high,
- and unacceptable risk.
These classes reflect the extent to which artificial intelligence jeopardizes European values and fundamental rights. As the term “unacceptable” for a risk class already indicates, not all AI systems are permissible. AI systems that belong to the “unacceptable risk” category are prohibited by the AI Act. The following applies to the other three risk classes: the higher the risk, the more extensive and stricter the legal requirements for the AI system.
We explain below which AI systems fall into which risk class and which requirements are associated with them. Our assessments are based on the information contained in the “AI Mandates” document dated June 2023. At the time of publication, this document was the most recently published, comprehensive document on the AI Act.
Ban on social scoring and biometric remote identification
Some AI systems have a significant potential to violate human rights and fundamental principles, which is why they are categorized as “unacceptable risk”. These include:
- Real-time based remote biometric identification systems in publicly accessible spaces (exception: law enforcement agencies may use them to prosecute serious crimes but only with judicial authorization);
- Biometric remote identification systems in retrospect (exception: law enforcement authorities may use them to prosecute serious crimes but only with judicial authorization);
- Biometric categorization systems that use sensitive characteristics such as gender, ethnicity or religion;
- Predictive policing based on so-called profiling – i.e. profiling based on skin color, suspected religious affiliation and similarly sensitive characteristics – geographical location or previous criminal behavior;
- Emotion recognition systems for law enforcement, border control, the workplace and educational institutions;
- Arbitrary extraction of biometric data from social media or video surveillance footage to create facial recognition databases;
- Social scoring leading to disadvantage in social contexts;
- AI that exploits the vulnerabilities of a particular group of people or uses unconscious techniques that can lead to behaviors that cause physical or psychological harm.
These AI systems are to be banned from the European market under the AI Act. Companies whose AI systems could fall into this risk class should urgently address the upcoming requirements and explore options for action. This is because a key result of the trilogue is that these systems will be banned just six months after official adoption.
Numerous requirements for AI with risks to health, safety and fundamental rights
The “high risk” category includes all AI systems that are not explicitly prohibited but nevertheless pose a high risk to health, safety or fundamental rights. The following areas of application and use are explicitly mentioned:
- Biometric and biometric-based systems that do not fall into the “unacceptable risk” risk class;
- Management and operation of critical infrastructure;
- Education and training;
- Access and entitlement to basic private and public services and benefits;
- Employment, human resource management and access to self-employment;
- Law enforcement;
- Migration, asylum and border control;
- Administration of justice and democratic processes
These AI systems are subject to comprehensive legal requirements that must be implemented prior to commissioning and observed throughout the entire AI life cycle:
- Assessment to evaluate the effects on fundamental and human rights
- Quality and risk management
- Data governance structures
- Quality requirements for training, test and validation data
- Technical documentation and record-keeping obligations
- Fulfillment of transparency and provision obligations
- Human supervision, robustness, security and accuracy
- Declaration of conformity incl. CE marking obligation
- Registration in an EU-wide database
AI systems that are used in one of the above-mentioned areas but do not pose a risk to health, safety, the environment or fundamental rights are not subject to the legal requirements. However, this must be proven by informing the competent national authority about the AI system. The authority then has three months to assess the risks of the AI system. The AI can be put into operation within these three months. However, if the examining authority classifies it as high-risk AI, high fines may be imposed.
A special regulation also applies to AI products and AI safety components of products whose conformity is already being tested by third parties on the basis of EU legislation. This is the case for AI in toys, for example. In order to avoid overregulation and additional burdens, these will not be directly affected by the AI Act.
AI with limited risk must comply with transparency obligations
AI systems that interact directly with humans fall into the “limited risk” category. This includes emotion recognition systems, biometric categorization systems and AI-generated or modified content that resembles real people, objects, places or events and could be mistaken for real (“deepfakes”). For these systems, the draft law provides for the obligation to inform consumers about the use of artificial intelligence. This should make it easier for consumers to actively decide for or against their use. A code of conduct is also recommended.
No legal requirements for AI with low risk
Many AI systems, such as predictive maintenance or spam filters, fall into the “low risk” category. Companies that only offer or use such AI solutions will hardly be affected by the AI Act. This is because there are currently no legal requirements for such applications. Only a code of conduct is recommended.
Generative AI such as ChatGPT is regulated separately
Generative AI models and basic models with a wide range of possible applications were not included in the original draft of the AI Act. The regulatory possibilities of such AI models have therefore been the subject of particularly intense debate since the launch of ChatGPT by OpenAI. According to the European Council’s press statement of December 9, these models are now to be regulated on the basis of their risk. In principle, all models must implement transparency requirements. Foundation models with a particular risk – so-called “high-impact foundation models” – will also have to meet additional requirements. How exactly the risk of AI models will be assessed is currently still open. Based on the latest document, the following possible requirements for high-impact foundation models can be estimated:
- Quality and risk management
- Data governance structures
- Technical documentation
- Fulfillment of transparency and information obligations
- Ensuring performance, interpretability, correctability, security, cybersecurity
- Compliance with environmental standards
- Cooperation with downstream providers
- Registration in an EU-wide database
Companies should prepare for the AI Act now
Even though the AI Act has not yet been officially adopted and we do not yet know the details of the legal text, companies should prepare for the transition phase now. In this phase, AI systems and associated processes must be designed to comply with the law. The first step is to assess the risk class of each individual AI system. If you are not yet sure which risk classes your AI systems fall into, we recommend our free AI Act Quick Check. It will help you to assess the risk class.
More information:
- Lunch & Learn „Done Deal“ (only available in German)
- Lunch & Learn „Alles, was du über den AI Act Wissen musst “ (only available in German)
- Factsheet AI Act
Sources:
- Press statement of the European Council: „Artificial intelligence act: Council and Parliament strike a deal on the first rules for AI in the world“
- AI Mandates (June 2023)
- “General approach” of the Council of the European Union: https://www.consilium.europa.eu/en/press/press-releases/2022/12/06/artificial-intelligence-act-council-calls-for-promoting-safe-ai-that-respects-fundamental-rights/
- Legislative proposal (“AI Act”) of the European Commission: https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX%3A52021PC0206
- Ethical guidelines for trustworthy AI: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
Read next …


… and explore new


Have you ever imagined a restaurant where AI powers everything? From the menu to the cocktails, hosting, music, and art? No? Ok, then, please click here.
If yes, well, it’s not a dream anymore. We made it happen: Welcome to “the byte” – Germany’s (maybe the world’s first) AI-powered Pop-up Restaurant!
As someone who has worked in data and AI consulting for over ten years, building statworx and the AI Hub Frankfurt, I have always thought of exploring the possibilities of AI outside of typical business applications. Why? Because AI will impact every aspect of our society, not just the economy. AI will be everywhere – in school, arts & music, design, and culture. Everywhere. Exploring these directions of AI’s impact led me to meet Jonathan Speier and James Ardinast from S-O-U-P, two like-minded founders from Frankfurt, who are rethinking how technology will shape cities and societies.
S-O-U-P is their initiative that operates at the intersection of culture, urbanity, and lifestyle. With their yearly “S-O-U-P Urban Festival” they connect creatives, businesses, gastronomy, and lifestyle people from Frankfurt and beyond.
When Jonathan and I started discussing AI and its impact on society and culture, we quickly came up with the idea of an AI-generated menu for a restaurant. Luckily, James, Jonathan’s S-O-U-P co-founder, is a successful gastro entrepreneur from Frankfurt. Now the pieces came together. After another meeting with James in one of his restaurants (and some drinks), we committed to launching Germany’s first AI-powered Pop-up Restaurant: the byte!
the byte: Our concept
We envisioned the byte to be an immersive experience, including AI in as many elements of the experience as possible. Everything, from the menu to the cocktails, music, branding, and art on the wall: everything was AI-generated. Bringing AI into all of these components also pushed me far beyond of what I typically do, namely helping large companies with their data & AI challenges.
Branding
Before creating the menu, we developed the visual identity of our project. We decided on a “lo-fi” appeal, using a pixelated font in combination with AI-generated visuals of plates and dishes. Our key visual, a neon-lit white plate, was created using DALL-E 2 and was found across all of our marketing materials:

Location
We hosted the byte in one of Frankfurt’s coolest restaurant event locations: Stanley, a restaurant location that features approx. 60 seats and a fully-fledged bar inside the restaurant (ideal for our AI-generated cocktails). The atmosphere is rather dark and cozy, with dark marble walls, highlighted with white carpets on the table, and a big red window that lets you see the kitchen from outside.

The menu
The heart of our concept was a 5-course menu that we designed to elevate the classical Frankfurter cuisine with the multicultural and diverse influences of Frankfurt (for everyone, who knows the Frankfurter kitchen, I am sure you know that this was not an easy task).
Using GPT-4 and some prompt engineering magic, we generated several menu candidates that were test-cooked by the experienced Stanley kitchen crew (thank you, guys for this great work!) and then assembled into a final menu. Below, you can find our prompt to create the menu candidates:
“Create a 5-course menu that elevates the classical Frankfurter kitchen. The menu must be a fusion of classical Frankfurter cuisine combined with the multicultural influences of Frankfurt. Describe each course, its ingredients as well as a detailed description of each dish’s presentation.”
Surprisingly, only minor adjustments were necessary to the recipes, even though some AI creations were extremely adventurous! This was our final menu:
- Handkäs’ Mousse with Pickled Beetroot on Roasted Sourdough Bread
- Next Level Green Sauce (with Cilantro and Mint) topped with a Fried Panko Egg
- Cream Soup from White Asparagus with Coconut Milk and Fried Curry Fish
- Currywurst (Beef & Vegan) by Best Worscht in Town with Carrot-Ginger-Mash and Pine Nuts
- Frankfurt Cheesecake with Äppler Jelly, Apple Foam and Oat-Pecanut-Crumble
My favorite was the “Next Level” Green Sauce, an oriental twist of the classical 7-herb Frankfurter Green Sauce topped with a fried panko egg. Yummy! Below you can see the menu out in the wild 🍲

AI Cocktails
Alongside the menu, we also prompted GPT to create recipes that twisted famous cocktail classics to match our Frankfurt fusion theme. The results:
- Frankfurt Spritz (Frankfurter Äbbelwoi, Mint, Sparkling Water)
- Frankfurt Mule (Variation of a Moscow Mule with Calvados)
- The Main (Variation of a Swimming Pool Cocktail)
My favorite was the Frankfurt Spritz, as it was fresh, herbal, and delicate (see pic below):

AI Host: Ambrosia the Culinary AI
An important part of our concept was “Ambrosia”, an AI-generated host that guided the guests around the evening, explaining the concept and how the menu was created. We thought it was important to manifest the AI as something the guests can experience. We hired a professional screenwriter for the script and used murf.ai to create several text-2-speech assets that were played at the beginning of the dinner and in-between courses.
Note: Ambrosia starts talking at 0:15.
AI Music
Music plays an important role for the vibe of an event. We decided to use mubert, a generative AI start-up that allowed us to create and stream AI music in different genres, such as “Minimal House” for a progressive vibe throughout the evening. After the main course, a DJ took over and accompanied our guests into the night 💃🍸

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
AI Art
Throughout the restaurant, we placed AI-generated art pieces by the local AI artist Vladimir Alexeev (a.k.a. “Merzmensch”), here are some examples:

AI Playground
As an interactive element for the guests, we created a small web app that takes the first name of a person and transforms it into a dish, including a reasoning why that name perfectly matches the dish 🙂 You can try it out here: Playground
Launch
The byte was officially announced at the S-O-U-P festival press conference in early May 2023. We also launched additional marketing activities through social media and our friends and family networks. As a result, the byte was fully booked for three days straight, and we got broad media coverage in various gastronomy magazines and the daily press. The guests were (mostly) amazed by our AI creations, and we received inquiries from other European restaurants and companies interested in exclusively booking the byte as an experience for their employees 🤩 Nailed it!
Closing and Next Steps
Creating the byte together with Jonathan and James was an outstanding experience. It further encouraged me that AI will transform not only our economy but all aspects of our daily lives. There is massive potential at the intersection of creativity, culture, and AI that is currently only being tapped.
We definitely want to continue the byte in Frankfurt and other cities in Germany and Europe. Moreover, James, Jonathan, and I are already thinking of new ways to bring AI into culture and society. Stay tuned! 😏
The byte was not just a restaurant; it was an immersive experience. We wanted to create something that had never been done before and did it – in just eight weeks. And that’s the inspiration I want to leave you with today:
Trying new things that move you out of your comfort zone is the ultimate source of growth. You never know what you’re capable of until you try. So, go out there and try something new, like building an AI-powered pop-up restaurant. Who knows, you might surprise yourself. Bon apétit!
Impressions

Media
Genuss Magazin: https://www.genussmagazin-frankfurt.de/gastro_news/Kuechengefluester-26/Interview-James-Ardinast-KI-ist-die-Zukunft-40784.html
Frankfurt Tipp: https://www.frankfurt-tipp.de/ffm-aktuell/s/ugc/deutschlands-erstes-ai-restaurant-the-byte-in-frankfurt.html
Foodservice: https://www.food-service.de/maerkte/news/the-byte-erstes-ki-restaurant-vor-dem-start-55899?crefresh=1
The Hidden Risks of Black-Box Algorithms
Reading and evaluating countless resumes in the shortest possible time and making recommendations for suitable candidates – this is now possible with artificial intelligence in applicant management. This is because advanced AI technologies can efficiently analyze even large volumes of complex data. In HR management, this not only saves valuable time in the pre-selection process but also enables applicants to be contacted more quickly. Artificial intelligence also has the potential to make application processes fairer and more equitable.
However, real-world experience has shown that artificial intelligence is not always “fair”. A few years ago, for example, an Amazon recruiting algorithm stirred up controversy for discriminating against women when selecting candidates. Additionally, facial recognition algorithms have repeatedly led to incidents of discrimination against People of Color.
One reason for this is that complex AI algorithms independently calculate predictions and results based on the data fed into them. How exactly they arrive at a particular result is not initially comprehensible. This is why they are also known as black-box algorithms. In Amazon’s case, the AI determined suitable applicant profiles based on the current workforce, which was predominantly male, and thus made biased decisions. In a similar way, algorithms can reproduce stereotypes and reinforce discrimination.
Principles for Trustworthy AI
The Amazon incident shows that transparency is highly relevant in the development of AI solutions to ensure that they function ethically. This is why transparency is also one of the seven statworx Principles for trustworthy AI. The employees at statworx have collectively defined the following AI principles: Human-centered, transparent, ecological, respectful, fair, collaborative, and inclusive. These serve as orientations for everyday work with artificial intelligence. Universally applicable standards, rules, and laws do not yet exist. However, this could change in the near future.
The European Union (EU) has been discussing a draft law on the regulation of artificial intelligence for some time. Known as the AI Act, this draft has the potential to be a gamechanger for the global AI industry. This is because it is not only European companies that are targeted by this draft law. All companies offering AI systems on the European market, whose AI-generated output is used within the EU, or operate AI systems for internal use within the EU would be affected. The requirements that an AI system must meet depend on its application.
Recruiting algorithms are likely to be classified as high-risk AI. Accordingly, companies would have to fulfill comprehensive requirements during the development, publication, and operation of the AI solution. Among other things, companies are required to comply with data quality standards, prepare technical documentation, and establish risk management. Violations may result in heavy fines of up to 6% of global annual sales. Therefore, companies should already start dealing with the upcoming requirements and their AI algorithms. Explainable AI methods (XAI) can be a useful first step. With their help, black-box algorithms can be better understood, and the transparency of the AI solution can be increased.
Unlocking the Black Box with Explainable AI Methods
XAI methods enable developers to better interpret the concrete decision-making processes of algorithms. This means that it becomes more transparent how an algorithm has formed patterns and rules and makes decisions. As a result, potential problems such as discrimination in the application process can be discovered and corrected. Thus, XAI not only contributes to greater transparency of AI but also favors its ethical use and thus increases the conformity of an AI with the upcoming AI Act.
Some XAI methods are even model-agnostic, i.e. applicable to any AI algorithm from decision trees to neural networks. The field of research around XAI has grown strongly in recent years, which is why there is now a wide variety of methods. However, our experience shows that there are large differences between different methods in terms of the reliability and meaningfulness of their results. Furthermore, not all methods are equally suitable for robust application in practice and for gaining the trust of external stakeholders. Therefore, we have identified our top 3 methods based on the following criteria for this blog post:
- Is the method model agnostic, i.e. does it work for all types of AI models?
- Does the method provide global results, i.e. does it say anything about the model as a whole?
- How meaningful are the resulting explanations?
- How good is the theoretical foundation of the method?
- Can malicious actors manipulate the results or are they trustworthy?
Our Top 3 XAI Methods at a Glance
Using the above criteria, we selected three widely used and proven methods that are worth diving a bit deeper into: Permutation Feature Importance (PFI), SHAP Feature Importance, and Accumulated Local Effects (ALE). In the following, we explain how each of these methods work and what they are used for. We also discuss their advantages and disadvantages and illustrate their application using the example of a recruiting AI.
Efficiently Identify Influencial Variables with Permutation Feature Importance
The goal of Permutation Feature Importance (PFI) is to find out which variables in the data set are particularly crucial for the model to make accurate predictions. In the case of the recruiting example, PFI analysis can shed light on what information the model relies on to make its decision. For example, if gender emerges as an influential factor here, it can alert the developers to potential bias in the model. In the same way, a PFI analysis creates transparency for external users and regulators. Two things are needed to compute PFI:
- An accuracy metric such as the error rate (proportion of incorrect predictions out of all predictions).
- A test data set that can be used to determine accuracy.
In the test data set, one variable after the other is concealed from the model by adding random noise. Then, the accuracy of the model is determined over the transformed test dataset. From there, we conclude that those variables whose concealment affects model accuracy the most are particularly important. Once all variables are analyzed and sorted, we obtain a visualization like Figure 1. Using our artificially generated sample data set, we can derive the following: Work experience did not play a major role in the model, but ratings from the interview were influencial.
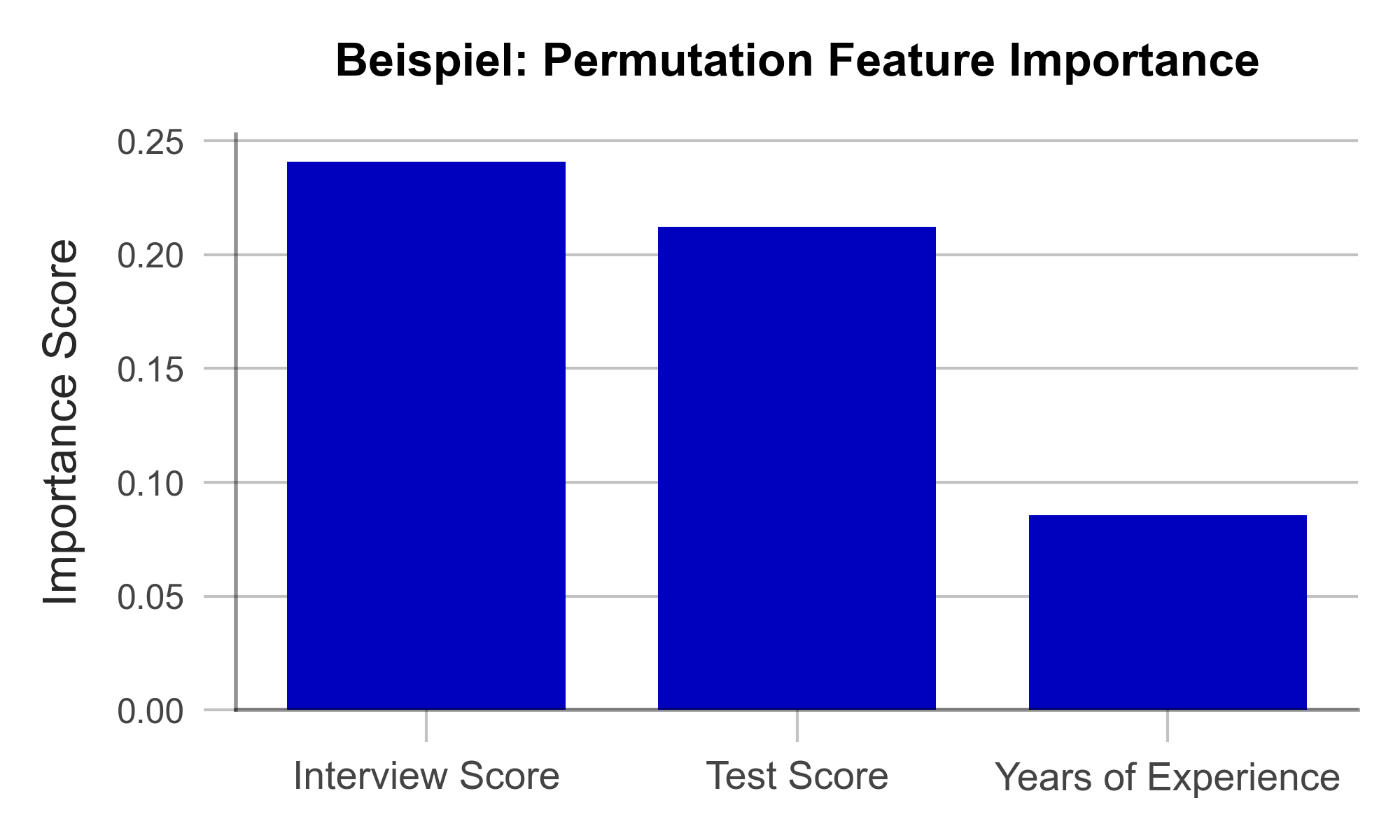
Figure 1 – Permutation Feature Importance using the example of a recruiting AI (data artificially generated).
A great strength of PFI is that it follows a clear mathematical logic. The correctness of its explanation can be proven by statistical considerations. Furthermore, there are hardly any manipulable parameters in the algorithm with which the results could be deliberately distorted. This makes PFI particularly suitable for gaining the trust of external observers. Finally, the computation of PFI is very resource efficient compared to other XAI methods.
One weakness of PFI is that it can provide misleading explanations under some circumstances. If a variable is assigned a low PFI value, it does not always mean that the variable is unimportant to the issue. For example, if the bachelor’s degree grade has a low PFI value, this may simply be because the model can simply look at the master’s degree grade instead since they are usually similar. Such correlated variables can complicate the interpretation of the results. Nonetheless, PFI is an efficient and useful method for creating transparency in black-box models.
| Strengths | Weaknesses |
|---|---|
| Little room for malicious manipulation of results | Does not consider interactions between variables |
| Efficient computation |
Uncover Complex Relationships with SHAP Feature Importance
SHAP Feature Importance is a method for explaining black box models based on game theory. The goal is to quantify the contribution of each variable to the prediction of the model. As such, it closely resembles Permutation Feature Importance at first glance. However, unlike PFI, SHAP Feature Importance provides results that can account for complex relationships between multiple variables.
SHAP is based on a concept from game theory: Shapley values. Shapley values are a fairness criterion that assigns a weight to each variable that corresponds to its contribution to the outcome. This is analogous to a team sport, where the winning prize is divided fairly among all players, according to their contribution to the victory. With SHAP, we can look at every individual obversation in the data set and analyze what contribution each variable has made to the prediction of the model.
If we now determine the average absolute contribution of a variable across all observations in the data set, we obtain the SHAP Feature Importance. Figure 2 illustrates the results of this analysis. The similarity to the PFI is evident, even though the SHAP Feature Importance only places the rating of the job interview in second place.
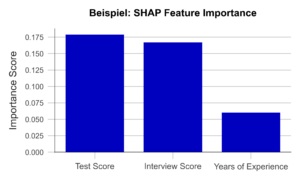
Figure 2 – SHAP Feature Importance using the example of a recruiting AI (data artificially generated).
A major advantage of this approach is the ability to account for interactions between variables. By simulating different combinations of variables, it is possible to show how the prediction changes when two or more variables vary together. For example, the final grade of a university degree should always be considered in the context of the field of study and the university. In contrast to the PFI, the SHAP Feature Importance takes this into account. Also, Shapley Values, once calculated, are the basis of a wide range of other useful XAI methods.
However, one weakness of the method is that it is more computationally expensive than PFI. Efficient implementations are available only for certain types of AI algorithms like decision trees or random forests. Therefore, it is important to carefully consider whether a given problem requires a SHAP Feature Importance analysis or whether PFI is sufficient.
| Strengths | Weaknesses |
|---|---|
| Little room for malicious manipulation of results | Calculation is computationally expensive |
| Considers complex interactions between variables |
Focus in on Specific Variables with Accumulated Local Effects
Accumulated Local Effects (ALE) is a further development of the commonly used Partial Dependence Plots (PDP). Both methods aim at simulating the influence of a certain variable on the prediction of the model. This can be used to answer questions such as “Does the chance of getting a management position increase with work experience?” or “Does it make a difference if I have a 1.9 or a 2.0 on my degree certificate?”. Therefore, unlike the previous two methods, ALE makes a statement about the model’s decision-making, not about the relevance of certain variables.
In the simplest case, the PDP, a sample of observations is selected and used to simulate what effect, for example, an isolated increase in work experience would have on the model prediction. Isolated means that none of the other variables are changed in the process. The average of these individual effects over the entire sample can then be visualized (Figure 3, above). Unfortunately, PDP’s results are not particularly meaningful when variables are correlated. For example, let us look at university degree grades. PDP simulates all possible combinations of grades in bachelor’s and master’s programs. Unfortunately, this results in cases that rarely occur in the real world, e.g., an excellent bachelor’s degree and a terrible master’s degree. The PDP has no sense for unreaslistic cases, and the results may suffer accordingly.
ALE analysis, on the other hand, attempts to solve this problem by using a more realistic simulation that adequately represents the relationships between variables. Here, the variable under consideration, e.g., bachelor’s grade, is divided into several sections (e.g., 6.0-5.1, 5.0-4.1, 4.0-3.1, 3.0-2.1, and 2.0-1.0). Now, the simulation of the bachelor’s grade increase is performed only for individuals in the respective grade group. This prevents unrealistic combinations from being included in the analysis. An example of an ALE plot can be found in Figure 3 (below). Here, we can see that ALE identifies a negative impact of work experience on the chance of employment, which PDP was unable to find. Is this behavior of the AI desirable? For example, does the company want to hire young talent in particular? Or is there perhaps an unwanted age bias behind it? In both cases, the ALE plot helps to create transparency and to identify undesirable behavior.
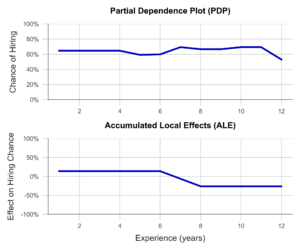
Figure 3- Partial Dependence Plot and Accumulated Local Effects using a Recruiting AI as an example (data artificially generated).
In summary, ALE is a suitable method to gain insight into the influence of a certain variable on the model prediction. This creates transparency for users and even helps to identify and fix unwanted effects and biases. A disadvantage of the method is that ALE can only analyze one or two variables together in the same plot, meaningfully. Thus, to understand the influence of all variables, multiple ALE plots must be generated, which makes the analysis less compact than PFI or a SHAP Feature Importance.
| Strengths | Weaknesses |
|---|---|
| Considers complex interactions between variables | Only one or two variables can be analyzed in one ALE plot |
| Little room for malicious manipulation of results |
Build Trust with Explainable AI Methods
In this post, we presented three Explainable AI methods that can help make algorithms more transparent and interpretable. This also favors meeting the requirements of the upcoming AI Act. Even though it has not yet been passed, we recommend to start working on creating transparency and traceability for AI models based on the draft law as soon as possible. Many Data Scientists have little experience in this field and need further training and time to familiarize with XAI concepts before they can identify relevant algorithms and implement effective solutions. Therefore, it makes sense to familiarize yourself with our recommended methods preemptively.
With Permutation Feature Importance (PFI) and SHAP Feature Importance, we demonstrated two techniques to determine the relevance of certain variables to the prediction of the model. In summary, SHAP Feature Importance is a powerful method for explaining black-box models that considers the interactions between variables. PFI, on the other hand, is easier to implement but less powerful for correlated data. Which method is most appropriate in a particular case depends on the specific requirements.
We also introduced Accumulated Local Effects (ALE), a technique that can analyze and visualize exactly how an AI responds to changes in a specific variable. The combination of one of the two feature importance methods with ALE plots for selected variables is particularly promising. This can provide a theoretically sound and easily interpretable overview of the model – whether it is a decision tree or a deep neural network.
The application of Explainable AI is a worthwhile investment – not only to build internal and external trust in one’s own AI solutions. Rather, we expect that the skillful use of interpretation-enhancing methods can help avoid impending fines due to the requirements of the AI Act, prevents legal consequences, and protects those affected from harm – as in the case of incomprehensible recruiting software.
Our free AI Act Quick Check helps you assess whether any of your AI systems could be affected by the AI Act: https://www.statworx.com/en/ai-act-tool/
Sources & Further Information:
https://www.faz.net/aktuell/karriere-hochschule/buero-co/ki-im-bewerbungsprozess-und-raus-bist-du-17471117.html (last opened 03.05.2023)
https://t3n.de/news/diskriminierung-deshalb-platzte-amazons-traum-vom-ki-gestuetzten-recruiting-1117076/ (last opened 03.05.2023)
For more information on the AI Act: https://www.statworx.com/en/content-hub/blog/how-the-ai-act-will-change-the-ai-industry-everything-you-need-to-know-about-it-now/
Statworx principles: https://www.statworx.com/en/content-hub/blog/statworx-ai-principles-why-we-started-developing-our-own-ai-guidelines/
Christoph Molnar: Interpretable Machine Learning: https://christophm.github.io/interpretable-ml-book/
Image Sources
AdobeStock 566672394 – by TheYaksha
Last December, the European Council published a dossier outlining the Council’s preliminary position on the draft law known as the AI Act. This new law is intended to regulate artificial intelligence (AI) and thus becomes a game-changer for the entire tech industry. In the following, we have compiled the most important information from the dossier, which is the current official source on the planned AI Act at the time of publication.
A legal framework for AI
Artificial intelligence has enormous potential to improve and ease all our lives. For example, AI algorithms already support early cancer detection or translate sign language in real time, thereby eliminating language barriers. But in addition to the positive effects, there are risks, as the latest deep fakes from Pope Francis or the Cambridge Analytica scandal illustrate.
The European Union (EU) is currently drafting legislation to regulate artificial intelligence to mitigate the risks of artificial intelligence. With this, the EU wants to protect consumers and ensure the ethically acceptable use of artificial intelligence. The so-called “AI Act” is still in the legislative process but is expected to be passed in 2023 – before the end of the current legislative period. Companies will then have two years to implement the legally binding requirements. Violations will be punished with fines of up to 6% of global annual turnover or €30,000,000 – whichever is higher. Therefore, companies should already start addressing the upcoming legal requirements now.
Legislation with global impact
The planned AI Act is based on the “location principle, ” meaning that not only European companies will be affected by the amendment. Thus, all companies that offer AI systems on the European market or also operate them for internal use within the EU are affected by the AI Act – with a few exceptions. Private use of AI remains untouched by the regulation so far.
Which AI systems are affected?
The definition of AI determines which systems will be affected by the AI Act. For this reason, the AI definition of the AI Act has been the subject of controversial debate in politics, business, and society for a considerable time. The initial definition was so broad that many “normal” software systems would also have been affected. The current proposal defines AI as any system developed through machine learning or logic- and knowledge-based approaches. It remains to be seen whether this definition will ultimately be adopted.
7 Principles for trustworthy AI
The “seven principles for trustworthy AI” are the most important basis of the AI Act. A group of experts from research, the digital economy, and associations developed them on behalf of the European Commission. They include not only technical aspects but also social and ethical factors that can be used to classify the trustworthiness of an AI system:
- Human action & oversight: decision-making should be supported without undermining human autonomy.
- Technical Robustness & security: accuracy, reliability, and security must be preemptively ensured.
- Data privacy & data governance: handling of data must be legally secure and protected.
- Transparency: interaction with AI must be clearly communicated, as must its limitations and boundaries.
- Diversity, non-discrimination & fairness: Avoidance of unfair bias must be ensured throughout the entire AI lifecycle.
- Environmental & societal well-being: AI solutions should have a positive impact on the environment and society as possible.
- Accountability: responsibilities for the development, use, and maintenance of AI systems must be defined.
Based on these principles, the AI Act’s risk-based approach was developed, allowing AI systems to be classified into one of four risk classes: low, limited, high, and unacceptable risk.
Four risk classes for trustworthy AI
The risk class of an AI system indicates the extent to which an AI system threatens the principles of trustworthy AI and which legal requirements the system must fulfill – provided the system is fundamentally permissible. This is because, in the future, not all AI systems will be allowed on the European market. For example, most “social scoring” techniques are assessed as “unacceptable” and will not be allowed by the new law.
For the other three risk classes, the rule of thumb is that the higher the risk of an AI system, the higher the legal requirements for it. Companies that offer or operate high-risk systems will have to meet the most requirements. For example, AI used to operate critical (digital) infrastructure or used in medical devices is considered such. To bring these to market, companies will have to observe high-quality standards for the used data, set up a risk management, affix a CE mark, and more.
AI systems in the “limited risk” class are subject to information and transparency obligations. Accordingly, companies must inform users of chatbots, emotion recognition systems, or deep fakes about the use of artificial intelligence. Predictive maintenance or spam filters are two examples of AI systems that fall into the lowest-risk category “low risk”. Companies that exclusively offer or use such AI solutions will hardly be affected by the upcoming AI Act. There are no legal requirements for these applications yet.
What companies can do for now
Even though the AI Act is still in the legislative process, companies should act now. The first step is to clarify how they will be affected by the AI Act. To help you do this, we have developed the AI Act Quick Check. With this free tool, AI systems can be quickly assigned to a risk class free of charge, and requirements for the system can be derived. Finally, it can be used as a basis to estimate how extensive the realization of the AI Act will be in your own company and to take initial measures. Of course, we are also happy to support you in evaluating and solving company-specific challenges related to the AI Act. Please do not hesitate to contact us!
Benefit from our expertise!
Of course, we are happy to support you in evaluating and solving company-specific challenges related to the AI Act. Please do not hesitate to contact us!