
faced the usual situation where we needed to transform a proof of concept (POC) into something that could be used in production. The “new” aspect of this transformation was that the POC was loaded with a tiny amount (a few hundred megabytes) but had to make ready for a waste amount of data (terabytes). The focus was to build pipelines of data which connect all the single pieces and automate the whole workflow from the database, ETL (Extract-Transform-Load) and calculations, to the actual application. Thus, the simple master-script which calls one script after another was not an option anymore. It was relatively clear that a program or a framework which uses DAG’s was necessary. So, within this post, I will swiftly go over what a DAG is in this context, what alternatives we considered and which one we have chosen in the end. Further, there will be a
What’s a DAG?
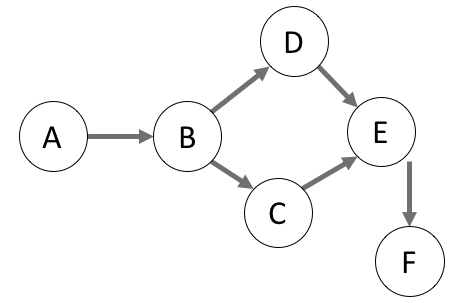
Directed Acyclic Graph
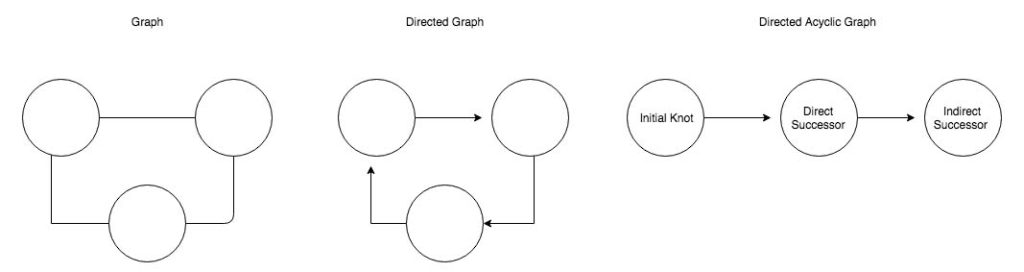
In programming, we can use this model and define every single task as a knot in the graph. Every job that can be done independently will be an initial knot with no predecessors and as such will have no relation point towards him. From there on we will link those tasks which are directly dependent on it. Continuing this process and connecting all task to the graph we can manifest a whole project into a visual guide. Even though this might be trivial for simple projects like ‘First do A then B and finally C’, once our workflow reaches a certain size or needs to be scalable, this won’t be the case anymore. Following this, it is advisable to express it in a DAG such that all the direct and indirect dependencies are expressed. This representation isn’t just a way to show the context visually such that non-technical people could grasp what is happening, but also gives a useful overview of all processes which could run concurrently, and which sequentially.
Just imagine if you have a workflow made up out of several dozen tasks (like the one above) some of which need to run sequentially and some that could run in parallel. Just imagine if one of these tasks failed without the DAG it wouldn’t be clear what should happen next. Which one needs to wait until the failed one finally succeed? Which can keep running since they do not depend on it? With a DAG this question can be answered quickly and doesn’t even come up if a program is keeping track of it. Due to this convenience, a lot of software and packages adopted this representation to automate workflows.
What were we looking for?
As mentioned, we were looking for a piece of software, a framework or at least a library as an orchestrator which works based on a DAG as we would need to keep track of the whole jobs manually otherwise – when does a task start, what if a task fails – what does it mean to the whole workflow. This is especially necessary as the flow needed to be executed every week and therefore monitoring it by hand would be tedious. Moreover, due to the weekly schedule an inbuilt or advanced scheduler would be a huge plus. Why Advanced? – There are simple schedulers like cron which are great for starting a specific job at a specific time but would not integrate with the workflow. So, one that also keeps track of the DAG would be great. Finally, it would also be required that we could extend the workflow easily. As it needed to be scalable it would be helpful if we could call a script – e.g., to clean data- several times just with a different argument – for different batches of data- as different nodes in the workflow without much overhead and code.
What were our options?
Once we settled on the decision that we need to implement an orchestrator which is based on a DAG, a wide variety of software, framework and packages popped up in the Google search. It was necessary to narrow down the amount of possibility so only a few were left which we could examine in depth. We needed something that was neither to heavily based on a GUI since it limits the flexibility and scalability. Nor should it be too code-intensive or in an inconvenient programming language since it could take long to pick it up and get everybody on board. So, options like Jenkins or WAF were thrown out right away. Eventually, we could narrow it down to three options:
Option 1 – Native Solution: Cloud-Orchestrator
Since the POC was deployed on a cloud, the first option was, therefore, rather obvious – we could use one of the cloud native orchestrators. They offered us a simple GUI to define our DAGs, a scheduler and were designed to pipe data like in our case. Even though this sounds good, the inevitable problem was that such GUIs are restricted, one would need to pay for the transactions, and there would be no fun at all without coding. Nevertheless, we kept the solution as a backup plan.
Option 2 – Apaches Hadoop Solutions: Oozie or Azkaban
Oozie and Azkaban are both open-source workflow manager written in Java and designed to integrate with Hadoop Systems. Therefore, they are both designed to execute DAGs, are scalable and have an integrated scheduler. While Oozie tries to offer high flexibility in exchange for usability, Azkaban has the tradeoff the other way around. As such, orchestration is only possible through the WebUI in the case of Azkaban. Oozie, on the other hand, relies on XML-Files or Bash to manage and schedule your work.
Option 3 – Pythonic Solution: Luigi or Airflow
Luigi and Airflow are both workflow managers written in Python and available as open-source frameworks.
Luigi was developed in 2011 by Spotify and was designed to be as general as possible – in contrast to Oozie or Azkaban which were intended for Hadoop. The main difference compared to the other two is that Luigi is code- rather than GUI-based. The executable workflows are all defined by Python code rather than in a user interface. Luigi’s WebUI offers high usabilitiy, like searching, filtering or monitoring the graphs and tasks.
Similar to this is Airflow which was developed by Airbnb and opened up in 2015. Moreover, it was accepted in the Apache Incubator since 2016. Like Luigi, it is also code-based with an interface to increase usability. Furthermore, it comes with an integrated scheduler so that one doesn’t need to rely on cron.
Our decision
Our first criterion for further filtering was that we wanted a code-based orchestrator. Even though interfaces are relatively straightforward to pick up and easy to get used to, it would come at the cost of slower development. Moreover, editing and extending would also be time-consuming if every single adjustment would require clicking instead of reusing function or code snippets. Therefore, we turned down option number one – the local Cloud-Orchestrator. The loss of flexibility shouldn’t be underestimated. Any learning or takeaways with an independent orchestrator could likely apply to any other project. This wouldn’t be the case for a native one, as it is bound to the specific environment.
The most significant difference between the other two options were the languages in which they operate. Luigi and Airflow are Python-based while Oozie and Azkaban are based on Java, and Bash scripts. Also, this decision was easy to determine, as Python is an excellent scripting language, easy to read, fast to learn and simple to write. With the aspect of flexibility and scalability in mind, Python offered us a better utility compared the (compiled) programming language Java. Moreover, the workflow definition needed to be either done in a GUI (again) or with XML. Thus, we could also exclude option two.
The last thing to settle was either to use Spotify’s Luigi or Airbnbs Airflow. It was a decision between taking the mature and stable or go with the young star of the workflow managers. Both projects are still maintained and highly active on GitHub with over several thousand commits, several hundred stars and several hundred of contributors. Nevertheless, there was one aspect which was mainly driving our decision – cron. Luigi can only schedule jobs with the usage of cron, unlike Airflow which has an integrated scheduler. But, what is actually the problem with cron?
Cron works fine if you want one job done at a specified time. However, once you want to schedule several jobs which depend on each other, it gets tricky. Cron does not regard these dependencies whether one task scheduled job needs to wait until the predecessor is finished. Let’s say we want a job to run every five minutes and transport some real-time data from a database. In case everything goes fine, we will not run into trouble. A job will start, it will finish, the next one starts and so on. However, what if the connection to the database isn’t working? Job one will start but never finishes. Five minutes later the second one will do the same while job one will still be active. This might continue until the whole machine is blocked by unfinished jobs or crashes. With Airflow, such a scenario could be easily avoided as it automatically stops starting new jobs when requirements are not met.
Summarizing our decision
We chose apache Airflow over the other alternatives base on:
-
No cron – With Airflow´s included scheduler we don’t need to rely on cron to schedule our DAG and only use one framework (not like Luigi).
-
Code Bases – In Airflow all workflows, dependencies, and schedulings are done in Python code. Therefore, it is rather easy to build complex structures and extend the flows.
-
Language – Python is a language somewhat natural to pick up and was available in our team.
Thus, Airflow fulfills all our needs. With it, we have an orchestrator which keeps track of the workflow we define by code using Python. Therefore, we could also easily extend the workflow in any directions – more data, more batches, more steps in the process or even on multiple machines concurrently won’t be a problem anymore. Further, Airflow also includes a nice visual interface of the workflows such that one could also easily monitor it. Finally, Airflow allows us to renounce crone as it comes with an advanced onboard scheduler. One that can not only start a task but also keeps track of each and is highly customizable in its execution properties.
In the