
In my last blog post, I have elaborated on the Bagging algorithm and showed its prediction performance via simulation. Here, I want to go into the details on how to simulate the bias and variance of a nonparametric regression fitting method using R. These kinds of questions arise here at STATWORX when developing, for example, new machine learning algorithms or testing established ones which shall generalize well to new unseen data.
Decomposing the mean squared error
We consider the basic regression setup where we observe a real-valued sample  and our aim is to predict an outcome
and our aim is to predict an outcome  based on some predictor variables (“covariates”)
based on some predictor variables (“covariates”)  via a regression fitting method. Usually, we can measure our target only with noise
via a regression fitting method. Usually, we can measure our target only with noise  ,
,

To measure our prediction accuracy, we will use the mean squared error (MSE) which can be decomposed as follows:
![MSE = n^{-1} sum_{i=1}^{n}[E(hat{f}(x_i)) - f(x_i)]^2 + n^{-1} sum_{i=1}^{n}Var(hat{f}(x_i))](https://www.statworx.com/wp-content/ql-cache/quicklatex.com-551aaf44b1c482f2031d75ffe52424ba_l3.png "Rendered by QuickLaTeX.com")

 is our prediction obtained by the regression method at hand.
is our prediction obtained by the regression method at hand.
From the above expression, we observe that the MSE consists of two parts:
 : measures the (squared) difference between the true underlying process and the mean of our predictions, i.e.
: measures the (squared) difference between the true underlying process and the mean of our predictions, i.e. ![[E(hat{f}(x_i)) - f(x_i)]^2.](https://www.statworx.com/wp-content/ql-cache/quicklatex.com-0ee48a199627e0d34eada785418f35c2_l3.png "Rendered by QuickLaTeX.com")
 : measures the variation of our predictions around its mean, i.e.
: measures the variation of our predictions around its mean, i.e. 
In general, it will not be possible to minimize both expressions as they are competing with each other. This is what is called the bias-variance tradeoff. More complex models (e.g. higher order polynomials in polynomial regression) will result in low bias while yielding high variance as we fit characteristic features of the data that are not necessary to predict the true outcome (and vice versa, cf. Figure 1).
Monte Carlo Setup & Simulation Code
To illustrate this, we consider a simple toy model.

where  ,
, ![x_i sim U([0,1])](https://www.statworx.com/wp-content/ql-cache/quicklatex.com-ed15cb00882b2d51f1a0222419969566_l3.png "Rendered by QuickLaTeX.com") and
and 
As a fitting procedure, we will use a cubic smoothing spline (smooth.spline). For the purpose of this blog post, we only need to know that a smoothing spline divides our univariate predictor space into  intervals and fits each one to a cubic polynomial to approximate our target. The complexity of our smoothing spline can be controlled via the degrees of freedom (function argument
intervals and fits each one to a cubic polynomial to approximate our target. The complexity of our smoothing spline can be controlled via the degrees of freedom (function argument df). If you are interested in the (impressive) mathematical details of smoothing splines, check out this script by Ryan Tibshirani.
Figure 1 shows the bias-variance tradeoff from above. For relatively low degrees of freedom we obtain a model (red line) which is too simple and does not approximate the true data generating process well (black dashed line) – Note: for  we obtain the least-squares fit. Here, the bias will be relatively large while the variance will remain low. On the other hand, choosing relatively high degrees of freedoms leads to a model which overfits the data (green line). In this case, we clearly observe that the model is fitting characteristic features of the data which are not relevant for approximating the true data generating process.
we obtain the least-squares fit. Here, the bias will be relatively large while the variance will remain low. On the other hand, choosing relatively high degrees of freedoms leads to a model which overfits the data (green line). In this case, we clearly observe that the model is fitting characteristic features of the data which are not relevant for approximating the true data generating process.

To make this tradeoff more rigorous, we explicitly plot the bias and variance. For this, we conduct a Monte Carlo simulation. As a side note, to run the code snippets below, you only need the stats module which is contained in the standard R module scope.
For validation purposes, we use a training and test dataset (*_test and *_train, respectively). On the training set, we construct the algorithm (obtain coefficient estimates, etc.) while on the test set, we make our predictions.
# set a random seed to make the results reproducible
set.seed(123)
n_sim <- 200
n_df <- 40
n_sample <- 100
# setup containers to store the results
prediction_matrix <- matrix(NA, nrow = n_sim, ncol = n_sample)
mse_temp <- matrix(NA, nrow = n_sim, ncol = n_df)
results <- matrix(NA, nrow = 3, ncol = n_df)
# Train data -----
x_train <- runif(n_sample, -0.5, 0.5)
f_train <- 0.8*x_train+sin(6*x_train)
epsilon_train <- replicate(n_sim, rnorm(n_sample, 0, sqrt(2)))
y_train <- replicate(n_sim,f_train) + epsilon_train
# Test data -----
x_test <- runif(n_sample, -0.5, 0.5)
f_test <- 0.8*x_test+sin(6*x_test)The bias-variance tradeoff can be modelled in R using two for-loops. The outer one will control the complexity of the smoothing splines (counter: df_iter). The Monte Carlo Simulation with 200 iterations (n_sim) to obtain the prediction matrix for the variance and bias is run in the inner loop.
# outer for-loop
for (df_iter in seq(n_df)){
# inner for-loop
for (mc_iter in seq(n_sim)){
cspline <- smooth.spline(x_train, y_train[, mc_iter], df=df_iter+1)
cspline_predict <- predict(cspline, x_test)
prediction_matrix[mc_iter, 1:n_sample] <- cspline_predict![y mse_temp[mc_iter, df_iter] <- mean((cspline_predict](https://www.statworx.com/wp-content/ql-cache/quicklatex.com-90740c778b7a45c616d6fea72b705c8b_l3.png "Rendered by QuickLaTeX.com") y - f_test)^2)
}
var_matrix <- apply(prediction_matrix, 2, FUN = var)
bias_matrix <- apply(prediction_matrix, 2, FUN = mean)
squared_bias <- (bias_matrix - f_test)^2
results[1, df_iter] <- mean(var_matrix)
results[2, df_iter] <- mean(squared_bias)
}
results[3,1:n_df] <- apply(mse_temp, 2, FUN = mean)
y - f_test)^2)
}
var_matrix <- apply(prediction_matrix, 2, FUN = var)
bias_matrix <- apply(prediction_matrix, 2, FUN = mean)
squared_bias <- (bias_matrix - f_test)^2
results[1, df_iter] <- mean(var_matrix)
results[2, df_iter] <- mean(squared_bias)
}
results[3,1:n_df] <- apply(mse_temp, 2, FUN = mean)To model  and
and  from the above MSE-equation, we have to approximate those theoretical (population) terms by means of a Monte Carlo simulation (inner
from the above MSE-equation, we have to approximate those theoretical (population) terms by means of a Monte Carlo simulation (inner for-loop). We run  (
(n_sim) Monte Carlo iterations and save the predictions obtained by the smooth.spline-object in a  prediction matrix. To approximate
prediction matrix. To approximate  at each test sample point
at each test sample point  , by
, by  , we take the average of each column.
, we take the average of each column.  denotes the prediction of the algorithm obtained at some sample point in iteration
denotes the prediction of the algorithm obtained at some sample point in iteration  . Similar considerations can be made to obtain an approximation for
. Similar considerations can be made to obtain an approximation for  .
.
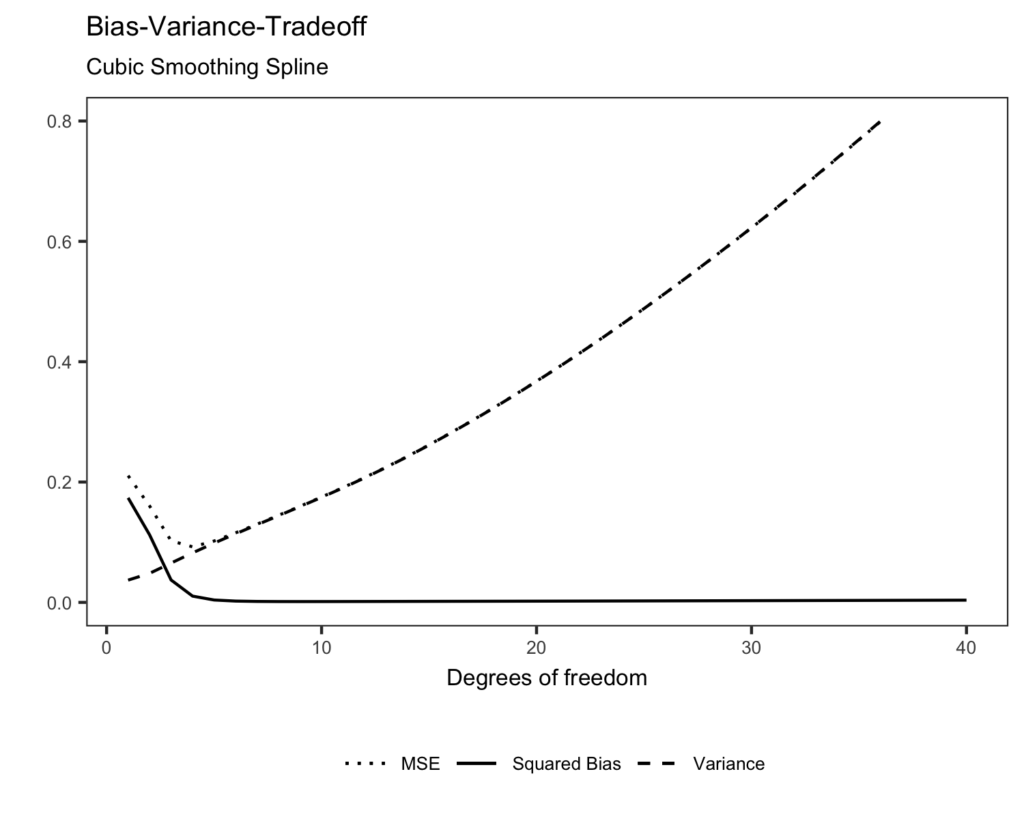
Bias-variance tradeoff as a function of the degrees of freedom
Figure 2 shows the simulated bias-variance tradeoff (as a function of the degrees of freedom). We clearly observe the complexity considerations of Figure 1. Here, the bias is quickly decreasing to zero while the variance exhibits linear increments with increasing degrees of freedoms. Hence, for higher degrees of freedom, the MSE is driven mostly by the variance.
Comparing this Figure with Figure 1, we note that for  , the bias contributes substantially more than the variance to the MSE. If we increase the degrees of freedom to
, the bias contributes substantially more than the variance to the MSE. If we increase the degrees of freedom to  the bias tends to zero, characteristic features of the data are fitted and the MSE consists mostly of the variance.
the bias tends to zero, characteristic features of the data are fitted and the MSE consists mostly of the variance.
With small modifications, you can use this code to explore the bias-variance tradeoff of other regression fitting and also Machine Learning methods such as Boosting or Random Forest. I leave it to you to find out which hyperparameters induce the bias-variance tradeoff in these algorithms.
You can find the full code on my Github Account. If you spot any mistakes or if you are interested in discussing applied statistic and econometrics topics, feel free to contact me.
References
The simulation setup in this blog post follows closely the one from Buhlmann.
- Buhlmann, P. and Yu, B. (2003). Boosting with the L2-loss: Regression and classification. J. Amer. Statist. Assoc. 98, 324–339.