
In diesem Blogeintrag aus der „Gut in Form”-Reihe wird gezeigt, wie sich Datenreshapes in R, Stata und SPSS umsetzten lassen. Diese Datenreshapes dienen dazu, die vorliegenden Daten zu transformieren und so die optimale Darstellung zu erhalten, wenn pro Einheit mehrere Informationen zu einer Begebenheit vorliegen.
Was vielleicht etwas kompliziert klingt, soll anhand eines Beispiels erläutert werden: Es soll ein Datensatz erstellt werden, der Informationen zur Tagesdurchschnittstemperatur am 01.01.2018 in allen europäischen Hauptstädten enthält. Die Städte repräsentieren also die Einheiten, die am Anfang des Beitrags erwähnt werden, die Temperaturen entsprechen den Informationen. Hat man nur Informationen zu einem Tag, so gibt es nur einen vernünftigen Weg die Daten darzustellen. Es gibt zwei Variablen, Stadt und Temperatur, und jede Stadt steht in einer eigenen Zeile.
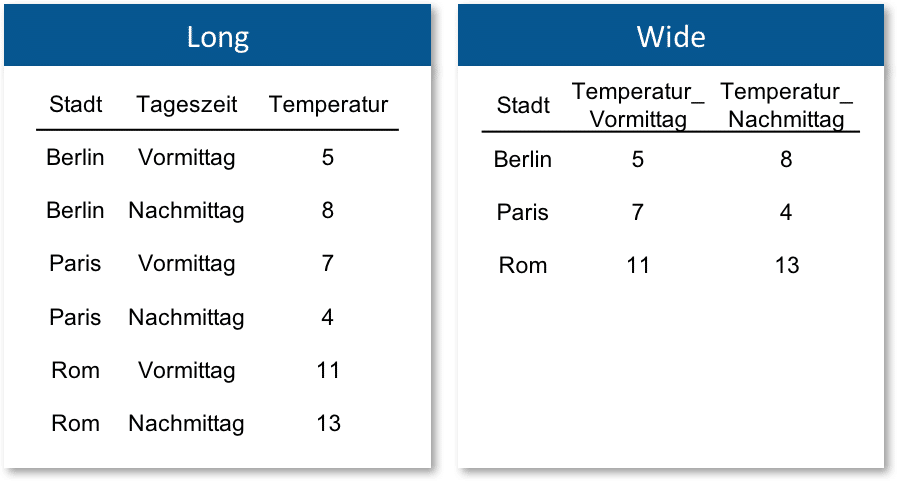
Hat man jedoch pro Stadt Informationen für zwei Tagezeiten (vormittags/nachmittags), so stellt sich die Frage nach der Darstellung. Man spricht hier von einem sogenannten Panel-Design. Generell gibt es zwei Formate, um dies darzustellen: das Long- und das Wide-Format. Die Transformation zwischen den Formaten wird auch Reshape genannt.
Beim Long-Format wird jede einzelne Information/Messung in einer eigenen Zeile dargestellt. Für unser kleines Beispiel heißt das, dass zusätzlich zur Stadt- und Temperatur-Variable eine neue hinzukommt, die Tageszeit, an dem die Temperatur gemessen wurde, angibt. Pro Stadt können im Datensatz so mehrere Fälle (Zeilen) bestehen. In der untenstehenden Darstellung ist dies für mögliche Temperatur in einem Ausschnitt dargestellt.
Beim Wide-Format existiert für jede Einheit nur eine Zeile. Das bedeutet jedoch auch, dass es nicht mehr nur eine, sondern mehrere Variablen zur Information gibt. Für das Beispiel heißt das konkret, dass für jede Tageszeit, zu der Informationen vorliegen, eine Variable angelegt werden muss. Im Gegensatz zum Long-Format geht die Struktur der Daten eher in die Breite, daher auch die Bezeichnung als „Wide“.
Natürlich kann es auch vorkommen, dass nicht zu allen Begebenheiten/Messungen Informationen für alle Einheiten vorliegen. Im Long-Format fällt dies nicht eindeutig auf, im Wide-Format dagegen eher. Für die Datenaufbereitung ist dies unerheblich. Wie methodisch mit solch einem unbalanciertem Design umgegangen wird, ist nicht Bestandteil dieser Blogreihe.
Datensatz
Der Datensatz wurde bereits in den beiden vorherigen Beiträgen zu den Themen Datenimport und Datentypen vorgestellt. Darin ist für verschiedene STATWORX Mitarbeiter, deren realer Name durch den jeweiligen Lieblingsstatistiker ersetzt wurde, der Süßigkeitenkonsum an zehn aufeinander folgenden Arbeitstagen festgehalten. In der ursprünglichen Version sind neben Tag und Mitarbeiter Informationen zur Anzahl an gegessenen Obststücken, Gummibärchen und Snickers enthalten. Außerdem gibt die Faktor-Variable „Pick Up“ die Lieblingssorte des Schokoriegels jedes Mitarbeiters. Die Lieblingssorte ist (zumindest über die beobachteten zehn Tage) konstant und verändert sich somit nicht.
Um einen besseren Überblick über den Datensatz vor und nach der Umstrukturierung zu erhalten, werden die Angaben zu Gummibärchen und Snickers entfernt, so dass die Anzahl an gegessenen Obststücken die einzige Information ist, die über die Zeit variiert. In diesem Eintrag wird öfter erwähnt werden, dass eine Variable über die Zeit konstant ist oder variiert. Streng genommen ist der Ausdruck „Zeit“ falsch, denn eine Information kann auch über verschiedene Messhintergründe/Begebenheiten konstant sein oder variieren.
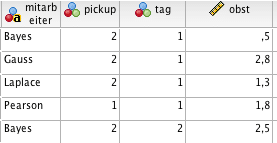
Die ersten fünf Zeilen im Datensatz sind folgend dargestellt:
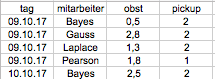
Aus der obigen Erklärung wissen wir, dass die Daten momentan noch im Long-Format vorliegen. Jeder Tag wird in einer eigenen Zeile dargestellt, somit kommt jeder Mitarbeiter öfter vor (hier zehn Mal, weil Beobachtungen zu zehn Tagen vorliegen).
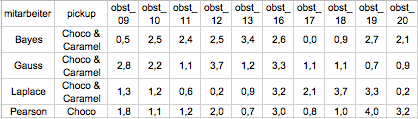
Die Umstrukturierung soll also bewirken, dass pro Mitarbeiter nur noch eine Zeile im Datensatz besteht, dafür sollen zehn Informationen zum Obstkonsum vorhanden sein. Da die Pick Up-Vorliebe über die Zeit konstant ist, wird sie nur einmal dargestellt. Ein Nachteil des Long-Formats ist also, dass einige Informationen auch redundant vorhanden sind. Jetzt wird auch klar, warum wir in diesem Eintrag auf die Informationen zum Verzehr von Snickers und Gummibärchen verzichten: Der Datensatz würde sonst so „breit“, dass man ihn nicht mehr übersichtlich darstellen könnte.
So soll der Datensatz dann im Wide-Format aussehen:
Durchführung
Um einen Datensatz zu transformieren werden bestimmte Variablen benötigt:
Bei der Umwandlung vom Long- zum Wide-Format wird eine Variable benötigt, die die Messung (zu verschiedenen Zeitpunkten/Begebenheiten) enthält. Diese wird im Folgenden als Measurement (Messung) bezeichnet. Im Süßigkeiten Datensatz ist dies die Anzahl an gegessenen Obststücken. Außerdem muss selbstverständlich eine Variable bestehen, die die Begebenheit der Messung klassifiziert, in unserem Datensatz der Tag. Es kann aber auch einen bestimmten Umstand einer Messung bezeichnen, beim Beispiel aus der Einleitung könnten die Temperaturen beispielsweise auch zur gleichen Zeit aber mit Unterschiedlichen Geräten gemessen werden. Die Variable wird im Folgenden Condition (Bedingung) genannt. Wir werden bei der Anwendung in der Software sehen, das zuweilen auch eine Variable vorhanden sein muss, die die Einheit, in unserem Fall die Mitarbeiter, spezifiziert.
Soll ein Datensatz vom Wide- ins Long-Format transformiert werden, so müssen mindestens zwei Variablen mit dem gleichen Datentyp vorhanden sein. Je nach Software muss außerdem pro Einheit eine konstante Benennung oder die Bezeichnung für die neu zu erstellende Condition-Variable definiert werden.
Wie bereits festgestellt wurde, ist der Datensatz, der bisher verwendet wurde, im Long-Format dargestellt. Um Verwirrung zu vermeiden, wird der Datensatz deshalb als „sweets_long“ bezeichnet. Bei der Durchführung in R, Stata und SPSS wird zunächst gezeigt, wie sich der Datensatz ins Wide-Format umwandeln lässt. Zu Demonstrationszwecken wird er dann erneut ins Long-Format transformiert.
R
Die baseR-Methode zum Reshape von Daten ist die Funktion reshape(). Häufig verwendete Funktionen sind außerdem melt() und cast() aus dem reshape2-Paket sowie gather() und spread() aus dem tidyr-Paket: Der Funktionsaufruf wird hier nur bei den letztgenannten besprochen, da die Funktionen als am intuitivsten gelten.
Der Datensatz, der ja bereits im Long-Format vorliegt, kann mit der spead()– Funktion ins Wide-Format umgewandelt werden. Zunächst muss selbstverständlich der Datensatz definiert werden. Spezifiziert werden müssen außerdem, wie bereits erwähnt, die Measurement- und Condition-Variable. Erstere, in unserem Fall „Obst“, wird an das Argument value übergeben. Die Condition-Variable, die von uns durch „Tag“ dargestellt wird, muss beim Argument key definiert werden.
Nach Ausführung des Befehls erhält man folgendes Resultat:

Wie gewünscht hat der Datensatz nur noch vier Beobachtungen, pro Mitarbeiter jedoch zehn Obst-Variablen, sowie eine PickUp-Variable, die über alle Tage konstant ist. Die neu erstellten Obst-Variablen sind alle mit der Bezeichnung der Tage benannt, es wird hier nicht direkt ersichtlich, dass es sich um die Beobachtungen des Obst-Verzehrs handelt. Optional können die Variablennamen deshalb noch angepasst werden. Der zugehörige Befehl ist in der untenstehenden Codebox zu finden. Dadurch sind die Variablen dann „obst_9“ für den 09.10.2017, „obst_10“ für den 10.10.2017 usw. benannt. Leider ist es mit der grundsätzlichen Funktionalität von spead() lediglich möglich eine zeitvariate Variable umzustrukturieren.
Mit gather() können die Informationen wieder ins Wide-Format gebracht werden. Dafür können dieselben Argumente verwendet werden wie beim Funktionsaufruf von spead(). Zusätzlich müssen hier noch zeitkonstante Variablen definiert werden. Dies sind in unserem Fall die Mitarbeiter und die PickUp-Variable. Die Ausführung des Befehls bringt folgendes Resultat:
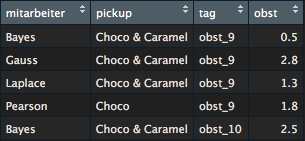
Da die Measurement-Variablen im Vorhinein umbenannt wurden, ist die Tag-Bezeichnung nun „obst_9“ usw. Um wieder mit einem Datum arbeiten zu können, müssten die Faktorstufen dieser Variable umbenannt und ggf. der Variablentyp angepasst werden (siehe für letztgenanntes auch den Blogeintrag zum Thema Datentypen). Ansonsten ist die Umstrukturierung gelungen und im Kern liegt der gleiche Datensatz vor wie zu Beginn.
## Reshape mittels tidyr: gather & spread
# Long zu Wide: Spread
sweets_wide1 <- spread(data = sweets_long, key = tag, value = obst)
# Umbenennung der Variablen
names(sweets_wide1)[3:12] <- paste0("obst_", c(9:13, 16:20))
# Wide zu Long: Gather
sweets_long1 <- gather(data = sweets_wide1, key = tag, value = obst, -c(mitarbeiter, pickup))
Stata
Der Befehl reshape führt in Stata die gleichnamige Operation aus. Nach dem Schlagwort „reshape“ muss das Format spezifiziert werden, in das der Datentyp umgewandelt werden soll, also „wide“ oder „long“. In beiden Fällen muss die Measurement-Variable angegeben werden und im Gegensatz zu R auch eine Variable, die die Einheiten eindeutig kennzeichnet, als für den Süßigkeitendatensatz die Mitarbeiter-Variable, in anderen Fällen kann es jedoch auch eine ID sein. Der generelle Aufbau ist reshape format measurement, i(i) j(j), wobei „format“ durch „long“ oder „wide“ spezifiziert wird, measurement die entsprechende Variable, i die eben genannte Indexvariable darstellt und j die Condition angibt.
Dadurch ergibt sich für die Transformation von Long zu Wide der in der Codebox angegebene Befehl. Im Gegensatz zu R können auch mehrere Measurement-Variablen angegeben werden. Da Variablen mit Datumsformat in Stata intern nicht so abgespeichert wird wie es angezeigt wird, wird die Obstvariable für die verschiedenen Tage nicht anhand des angezeigten, sondern des intern gespeicherten Datums bezeichnet. Deshalb können auch hier die Variablennamen noch geändert werden. Führt man den unten dargestellten Befehl aus, so erhalten die Daten im Wide-Format folgendermaßen:

Aus Platzgründen werden nur die ersten Obst-Variablen dargestellt.
Für den Reshape in die umgekehrte Richtung (Wide zu Long) muss eine Angabe für j nicht zwingend gegeben sein. Hierbei handelt es sich nur um eine Benennung für die zu erstellende Condition-Variable. Als Measurement können entweder mehrere Variable angegeben werden oder, wie bei Stata generell möglich, eine einheitliche Abkürzung aller entsprechenden Variablen. In unserem Fall ist dies der Wortstock „obst“. Der Ausschnitt des so resultierenden Datensatzes zeigt, dass der ursprüngliche Datensatz wiederhergestellt ist:
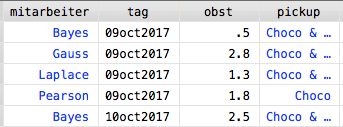
Benötigt man die Restrukturierung nur temporär und will danach wieder ins ursprüngliche Format zurück, so kann ganz einfach der Befehl reshape long um ins Long- oder reshape wide um ins Wide-Format zurückzukehren, verwendet werden.
*Long zu Wide:
reshape wide obst, i(mitarbeiter) j(tag)
*Wide zu Long:
reshape long obst, i(mitarbeiter) j(tag)
SPSS
In SPSS erfolgt die Transformation mit den Befehlen CASETOVARS bzw. VARSTOCASES, je nachdem, ob Fälle in Variablen umgewandelt werden sollen (Long- zu Wide-Format) oder vice versa.
Beim Reshape von Long zu Wide müssen zwei Variablen definiert werden: die ID-Variable und die Indexvariable. Erstere kennzeichnet die Einheiten, im Beispiel also die Mitarbeitervariable. Die Indexvariable kennzeichnet die unterschiedlichen Zeitpunkte/Messungen/Beobachtungen. Dies ist im Beispiel die Tagesvariable. Sobald diese Sonderzeichen oder beispielsweise Punkte enthält, ist eine logische Benennung der zu erstellenden Variablen nicht mehr möglich und es werden die Namen „v1“ usw. vergeben. Anhand des Labels kann der Ursprung jedoch trotzdem erkannt werden.
Bei der Transformation erkennt SPSS automatisch, welche Variablen zeitkonstant sind und welche über die Zeit variieren und somit umstrukturiert werden müssen. Im Wide-Format resultiert der folgende Datensatz. Es ist zu beachten, dass die Variablennamen hier noch nicht angepasst wurden.
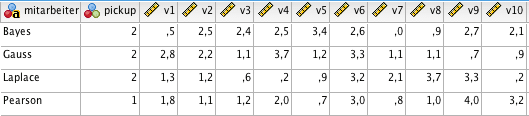
Die Syntax zum Reshape von Wide zu Long ist ebenfalls in der Codebox unten dargestellt. Diese gilt für unser Beispiel, in dem unsere Variablen nur ein Measurement darstellen. Für die Bezeichnung der Tag-Variable wird hier eine Indexierung gewählt, die später noch umgewandelt werden kann, alternativ könnten auch die Variablennamen verwendet werden. Die Indexoption muss dann /INDEX = Index1(obst) lauten.
Auch in SPSS ist es möglich mehrere Variablen umzustrukturieren. Bei der Transformation zum Long-Format können in der Syntax zusätzliche /MAKE-Optionen hinzugefügt werden.
*Long zu Wide:
SORT CASES BY mitarbeiter tag.
CASESTOVARS
/ID=mitarbeiter
/INDEX=tag
/GROUPBY=VARIABLE.
*Wide zu Long:
VARSTOCASES
/ID=id
/MAKE obst FROM v1 v2 v3 v4 v5 v6 v7 v8 v9 v10
/INDEX=tag(10)
/KEEP=mitarbeiter pickup
/NULL=KEEP.
Zusammenfassung
Der Hintergedanke beim Reshape von Daten ist in R, Stata und SPSS gleich. Die Umsetzung unterscheidet sich jedoch besonders auch im Hinblick auf die Variablen/Informationen, die angegeben werden müssen.
Falls es mal mit der Datenaufbereitung nicht so klappt, helfen wir bei STATWORX gerne dabei, gut in Form zu kommen.