
Warum sich Sorgen machen? KI und die Klimakrise
Nach dem neuesten Bericht des Weltklimarats (IPCC) im August 2021 „ist es eindeutig, dass menschlicher Einfluss die Atmosphäre, das Meer und das Land erwärmt hat“ [1]. Zudem schreitet der Klimawandel schneller voran als gedacht. Basierend auf den neuesten Berechnungen ist die globale Durchschnittstemperatur zwischen 2010 und 2019 im Vergleich zu dem Zeitraum zwischen 1850 und 1900 aufgrund des menschlichen Einflusses um 1.07°C gestiegen. Außerdem war die CO2 Konzentration in der Atmosphäre in dieser Zeit „höher als zu irgendeiner Zeit in mindestens 2 Millionen Jahren“ [1].
Dessen ungeachtet nehmen die globalen CO2 Emissionen weiter zu, auch wenn es 2020 einen kleinen Rückgang gab [2], der wahrscheinlich auf das Coronavirus und die damit zusammenhängenden ökonomischen Auswirkungen zurückzuführen ist. Im Jahr 2019 wurden weltweit insgesamt 36.7 Gigatonnen (Gt) CO2 ausgestoßen [2]. Eine Gt entspricht dabei einer Milliarden Tonnen. Um das 1.5 °C Ziel noch mit einer geschätzten Wahrscheinlichkeit von 80% zu erreichen, blieben Anfang 2020 nur noch 300 Gt übrig [1]. Da 2020 und 2021 bereits vorüber sind und unter Annahme von circa 35 Gt CO2 Emissionen für jedes Jahr, beträgt das verbleibende CO2 -Budget nur rund 230 Gt. Bleibt der jährliche Ausstoß konstant, wäre dieses in den nächsten sieben Jahren aufgebraucht.
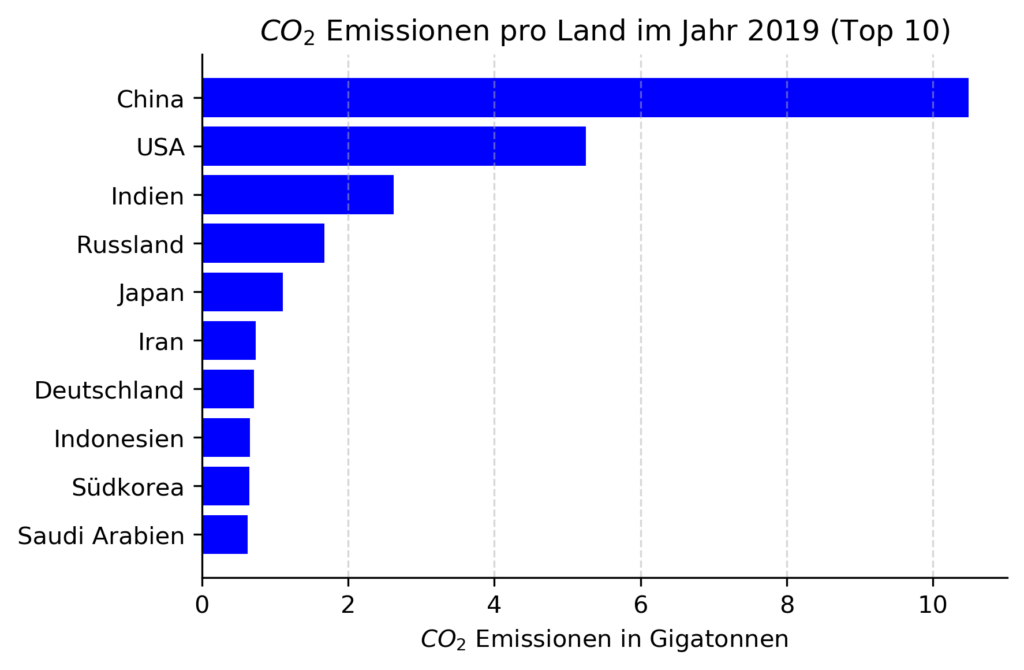
Im Jahr 2019 verursachten China, die USA und Indien die größten CO2-Emissionen. Deutschland ist zwar nur für ungefähr 2% aller globalen CO2 Emissionen verantwortlich, liegt mit 0.7 Gt aber immer noch auf dem siebten Platz (siehe nachfolgende Grafik). Zusammen genommen sind die 10 Länder mit dem größten CO2-Ausstoß für circa zwei Drittel aller CO2-Emissionen weltweit verantwortlich [2]. Die meisten dieser Länder sind hoch industrialisiert, wodurch es sehr wahrscheinlich ist, dass sie künstliche Intelligenz (KI) in den nächsten Jahrzenten verstärkt nutzen werden, um Ihre eigene Wirtschaft zu stärken.
Mit KI den CO2-Ausstoß reduzieren
Was genau hat jetzt KI mit dem Ausstoß von CO2 zu tun? Die Antwort ist: Einiges! Prinzipiell ist die Anwendung von KI wie zwei Seiten derselben Medaille [3]. Auf der einen Seite hat KI großes Potenzial, CO2-Emissionen durch genauere Vorhersagen oder die Verbesserung von Prozessen in vielen Industrien zu reduzieren. Beispielsweise kann KI zur Vorhersage extremer Wetterereignisse, der Optimierung von Lieferketten oder der Überwachung von Mooren eingesetzt werden [4, 5].
Nach einer aktuellen Schätzung von Microsoft und PwC kann die Verwendung von KI im Umweltbereich den Ausstoß der weltweiten Treibhausgase um bis zu 4.4% im Jahr 2030 senken [6]. Absolut gesehen handelt es sich dabei um eine Reduzierung der weltweiten Treibhausgasemissionen von 0.9 bis 2.4 Gt CO2e. Dies entspricht dem, aufgrund aktueller Werte prognostizierten, Ausstoß von Australien, Kanada und Japan im Jahr 2030 zusammen [7]. Der Begriff Treibhausgase beinhaltet hier zusätzlich zu CO2 noch andere Gase wie Methan, die ebenfalls den Treibhauseffekt der Erde verstärken. Um all diese Gase einfach zu messen, werden sie oft als CO2-Äquivalente angeben und als CO2e abgekürzt.
Der CO2-Fußabdruck von KI
Obwohl KI großes Potenzial hat, CO2-Emissionen zu reduzieren, stößt die Anwendung von KI selbst CO2 aus. Dies ist die Kehrseite der Medaille. Im Vergleich zum Jahr 2012 ist die geschätzte Menge an Rechenaufwand für das Training von Deep Learning (DL) Modellen im Jahr 2018 um das 300.000-fache gestiegen (siehe nachfolgende Grafik, [8]). Die Erforschung, das Training und die Anwendung von KI-Modellen benötigen daher eine immer größere Menge an Strom, aber natürlich auch an Hardware. Beides setzt letztlich CO2-Emissionen frei und verstärkt somit den Klimawandel.
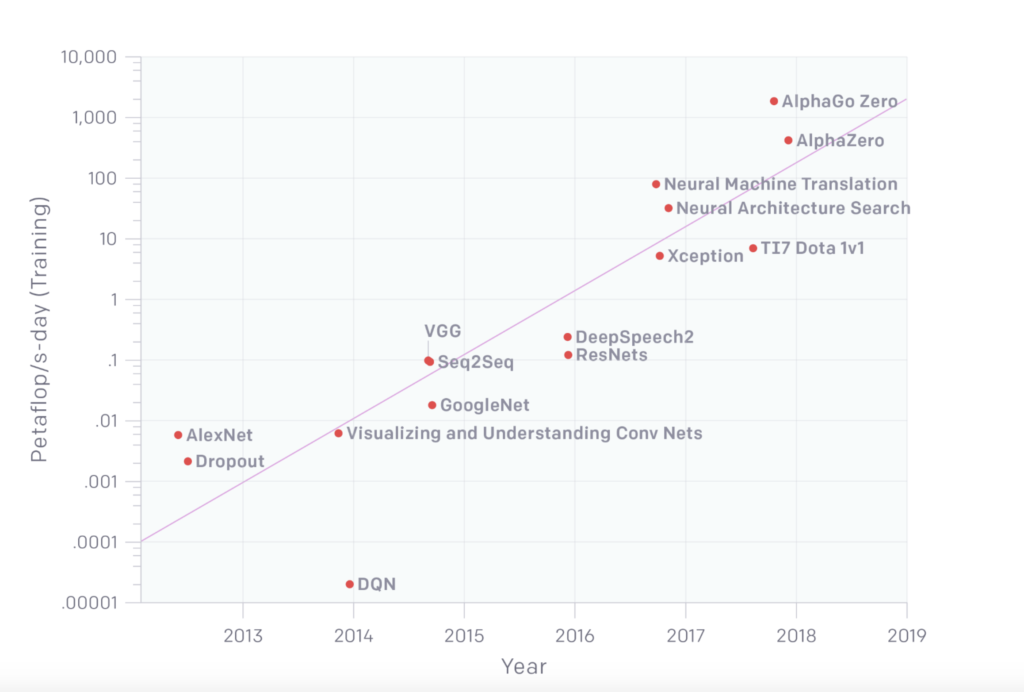
Anmerkung: Die Grafik wurde ursprünglich in [8] veröffentlicht.
Leider ist es mir nicht gelungen, eine Studie ausfindig zu machen, die den CO2-Fußabdruck von KI insgesamt schätzt. Allerdings gibt es diverse Studien, die den CO2– oder CO2e-Ausstoß von Natural Language Processing (NLP) Modellen schätzen. Diese sind in den vergangenen Jahren immer akkurater und somit populärer geworden [9]. Basierend auf der nachfolgenden Tabelle hat das abschließende Training von Googles BERT Modell ungefähr so viel CO2e freigesetzt, wie ein Passagier bei einer Flugreise von New York nach San Francisco. Das Training anderer Modelle, wie bspw. des Transformerbig-Modells, haben zwar wesentlich weniger CO2e-Emissionen verursacht, doch ist das abschließende Training von KI-Modellen nur der letzte Baustein beim Finden des besten Modells. Bevor ein Modell zum letzten Mal trainiert wird, sind häufig bereits viele verschiedene Modelle getestet worden, um so die besten Parameterwerte zu bestimmen. Diese neuronale Architektursuche hat beim Transformerbig-Modell entsprechend viele CO2e-Emissionen verursacht, insgesamt circa fünf Mal so viele wie ein durchschnittliches Auto in seiner gesamten Lebenszeit. Wirf jetzt mal einen Blick auf die CO2e-Emissionen des GPT-3 Modells und stell dir vor, wie hoch der CO2e-Ausstoß bei der dazugehörigen neuronalen Architektursuche gewesen sein muss.
| Emissionen durch Menschen | Emissionen durch KI | ||
|---|---|---|---|
| Beispiel | CO2e Emissionen (Tonnen) | Training von NLP Modellen | CO2e Emissionen (Tonnen) |
| Ein Passagier bei Flugreise New York San Francisco |
0.90 | Transformerbig | 0.09 |
| Durchschnittlicher Mensch ein Jahr |
5.00 | BERTbase | 0.65 |
| Durchschnittlicher Amerikaner ein Jahr |
16.40 | GPT-3 | 84.74 |
| Durchschnittliches Auto während Lebenszeit inkl. Benzin |
57.15 | Neuronale Architektursuche für Transformerbig |
284.02 |
Anmerkung: Alle Werte sind aus [9] entnommen, außer der Werte für GPT-3 [17].
Was du als Data Scientist tun kannst, um deinen CO2-Fußabdruck zu verringern
Insgesamt gibt es ganz unterschiedliche Möglichkeiten, wie du als Data Scientist den CO2-Fußabdruck beim Training und Anwendung von KI-Modellen reduzieren kannst. Aktuell sind im KI-Bereich Machine Learning (ML) und Deep Learning (DL) am populärsten, deswegen findest du nachfolgend verschiedene Ansätze, um den CO2-Fußabdruck dieser Art KI-Modelle zu messen und zu reduzieren.
1. Sei dir der negativen Auswirkungen bewusst und berichte darüber
Es mag einfach klingen, aber sich der negativen Konsequenzen bewusst zu sein, die sich durch die Suche, das Training sowie die Anwendung von ML und DL Modellen ergeben, ist der erste Schritt, deinen CO2-Fußabdruck zu reduzieren. Zu verstehen, wie sich KI negativ auf die Umwelt auswirkt, ist entscheidend, um bereit zu sein, den zusätzlichen Aufwand bei der Messung und systematische Erfassung von CO2-Emissionen zu betreiben. Dies widerrum ist nötig, um den Klimawandel zu bekämpfen [8, 9, 10]. Solltest du also den ersten Teil über KI und die Klimakrise übersprungen haben, gehh zurück und lies ihn. Es lohnt sich!
2. Miss den CO2-Ausstoß deines Codes
Um die CO2-Emissionen deiner ML und DL Modelle transparent darzulegen, müssen diese zuerst gemessen werden. Zurzeit gibt es leider noch kein standardisiertes Konzept, um alle Nachhaltigkeitsaspekte von KI zu messen. Eines wird allerdings gerade entwickelt [11]. Bis dieses fertiggestellt ist, kannst du bereits beginnen, den Energieverbrauch und die damit verbundenen CO2-Emissionen deiner KI-Modelle offen zu legen [12]. Mit TensorFlow und PyTorch sind die ausgereiftesten Pakete für die Berechnung von ML und DL Modellen wahrscheinlich in der Programmiersprache Python verfügbar. Obwohl Python nicht die effizienteste Programmiersprache ist [13], war es im September 2021 erneut die populärste im PYPL Index [14]. Dementsprechend gibt es sogar drei Python Pakete, die du nutzen kannst, um den CO2-Fußabdruck beim Training deiner Modelle zu messen:
- CodeCarbon [15, 16]
- CarbonTracker [17]
- Experiment Impact Tracker [18]
Meiner Auffassung nach sind die beiden Pakete, CodeCarbon und CarbonTracker, am einfachsten anzuwenden. Außerdem lässt sich CodeCarbon problemlos mit TensorFlow und CarbonTracker mit PyTorch kombinieren. Aus diesen Gründen findest du für jedes der beiden Pakete nachfolgend ein Beispiel.
Um beide Pakete zu testen, habe ich den MNIST Datensatz verwendet und jeweils ein einfaches Multilayer Perceptron (MLP) mit zwei Hidden Layern und jeweils 256 Neuronen trainiert. Um sowohl eine CPU- als auch GPU-basierte Berechnung zu testen, habe ich das Modell mit TensorFlow und CodeCarbon auf meinem lokalen PC (15 Zoll MacBook Pro mit 6 Intel Core i7 CPUs aus dem Jahr 2018) und das mit PyTorch und CarbonTracker in einem Google Colab unter Verwendung einer Tesla K80 GPU trainiert. Beginnen wir mit den Ergebnissen für TensorFlow und CodeCarbon.
# benötigte Pakete importieren
import tensorflow as tf
from codecarbon import EmissionsTracker
# Modeltraining vorbereiten
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256, activation=“relu“),
tf.keras.layers.Dense(256, activation=“relu“),
tf.keras.layers.Dense(10, activation=“softmax“),
]
)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer=“adam“, loss=loss_fn, metrics=[„accuracy“])
# Modell trainieren und CO2 Emissionen berechnen
tracker = EmissionsTracker()
tracker.start()
model.fit(x_train, y_train, epochs=10)
emissions: float = tracker.stop()
print(emissions)Nach der Ausführung des Codes erstellt CodeCarbon automatisch eine CSV-Datei, welche verschiedene Ergebnisparameter beinhaltet, wie Berechnungszeit in Sekunden, totaler Stromverbrauch durch die verwendete Hardware in kWh und die damit verbundenen CO2-Emissionen in kg. Das Training meines Modells dauerte insgesamt 112.15 Sekunden, verbrauchte 0.00068 kWh und verursachte 0.00047 kg CO2-Emissionen.
Als Grundlage für die Berechnungen mit PyTorch und CarbonTracker habe ich dieses Google Colab Notebook verwendet. Um auch hier ein Multilayer Perceptron zu berechnen und die dabei entstehenden CO2-Emissionen zu messen, habe ich einige Details des Notebooks geändert. Als erstes habe ich in Schritt 2 („Define Network“) das Convolutional Neural Network in ein Multilayer Perceptron geändert (Den Namen der Klasse „CNN“ habe ich beibehalten, damit der restliche Code im Notebook noch funktioniert.):
class CNN(nn.Module):
"""Ein einfaches MLP Modell."""
@nn.compact
def __call__(self, x):
x = x.reshape((x.shape[0], -1)) # flach machen
x = nn.Dense(features=256)(x)
x = nn.relu(x)
x = nn.Dense(features=256)(x)
x = nn.relu(x)
x = nn.Dense(features=10)(x)
x = nn.log_softmax(x)
return xAls zweites habe ich die Installation und den Import von CarbonTracker sowie die Messung der CO2-Emissionen in Schritt 14 („Train and evaluate“) eingefügt:
!pip install carbontracker
from carbontracker.tracker import CarbonTracker
tracker = CarbonTracker(epochs=num_epochs)for epoch in range(1, num_epochs + 1):
tracker.epoch_start()
# Vewendung des separaten PRNG keys, um Bilddaten zu permutieren
rng, input_rng = jax.random.split(rng)
# Optimierung für Trainings Batches
state = train_epoch(state, train_ds, batch_size, epoch, input_rng)
# Evaluation für Testdatensatz nach jeder Epoche
test_loss, test_accuracy = eval_model(state.params, test_ds)
print(' test epoch: %d, loss: %.2f, accuracy: %.2f' % (
epoch, test_loss, test_accuracy * 100))
tracker.epoch_end()
tracker.stop()Nachdem das leicht geänderte Google Colab Notebook bis zum eigentlichen Training des Modells ausgeführt wurde, gab CarbonTracker nach der ersten Trainingsepoche das nachfolgende Ergebnis aus:
train epoch: 1, loss: 0.2999, accuracy: 91.25
test epoch: 1, loss: 0.22, accuracy: 93.42
CarbonTracker:
Actual consumption for 1 epoch(s):
Time: 0:00:15
Energy: 0.000397 kWh
CO2eq: 0.116738 g
This is equivalent to:
0.000970 km travelled by car
CarbonTracker:
Predicted consumption for 10 epoch(s):
Time: 0:02:30
Energy: 0.003968 kWh
CO2eq: 1.167384 g
This is equivalent to:
0.009696 km travelled by carWie erwartet hat die GPU mehr Strom verbraucht und somit auch mehr CO2-Emissionen verursacht. Der Stromverbrauch war um das 6-fache und die CO2-Emissionen um das 2,5-fache Mal höher im Vergleich zu der lokalen Berechnung mit CPUs. Logischerweise hängt beides mit der längeren Berechnungszeit zusammen. Diese betrug zweieinhalb Minuten für die GPU und nur etwas weniger als zwei Minuten für die CPUs. Insgesamt geben beide Pakete alle notwendigen Informationen an, um die CO2-Emissionen und damit zusammenhängende Informationen zu beurteilen und zu berichten.
3. Vergleiche die verschiedenen Regionen von Cloud-Anbietern
In den vergangenen Jahren hat das Training und die Anwendung von ML sowie DL Modellen in der Cloud im Vergleich zu lokalen Berechnungen immer mehr an Bedeutung gewonnen. Sicherlich ist einer der Gründe dafür der zunehmende Bedarf an Rechenleistung [8]. Zugriff auf GPUs in der Cloud ist für viele Unternehmen günstiger und schneller als der Bau eines eigenen Rechenzentrums. Natürlich benötigen auch Rechenzentren von Cloud-Anbietern Hardware und Strom für deren Betrieb. Es wird geschätzt, dass bereits circa 1% des weltweiten Strombedarfs auf Rechenzentren zurückgeht [19]. Da die Nutzung von Hardware, unabhängig vom Standort, immer CO2-Emissionen verursachen kann, ist es auch beim Training und der Anwendung von ML und DL Modellen in der Cloud wichtig, die CO2-Emissionen zu messen.
Aktuell ermöglichen zwei verschiedene Plattformen, die CO2e-Emissionen von Berechnungen in der Cloud zu ermitteln [20, 21]. Die guten Neuigkeiten dabei sind, dass die drei großen Cloud-Anbieter – AWS, Azure und GCP – in beiden Plattformen implementiert sind. Um zu beurteilen, welcher der drei Cloud-Anbieter und welche der verfügbaren europäischen Regionen die geringsten CO2e-Emissionen verursachen, habe ich die erste Plattform – ML CO2 Impact [20] – verwendet, um die CO2e-Emissionen für das abschließende Training von GPT-3 zu berechnen. Das finale Training von GPT-3 benötigte 310 GPUs (NVIDIA Tesla V100 PCIe), die ununterbrochen für 90 Tagen liefen [17]. Als Grundlage für die Berechnungen der CO2e-Emissionen der verschiedenen Cloud-Anbieter und deren Regionen, habe ich die verfügbare Option “Tesla V100-PCIE-16GB” als GPU gewählt. Die Ergebnisse der Berechnungen befinden sich in der nachfolgenden Tabelle.
| Google Cloud Computing | AWS Cloud Computing | Microsoft Azure | |||
|---|---|---|---|---|---|
| Region | CO2e Emissionen (Tonnen) | Region | CO2e Emissionen (Tonnen) | Region | CO2e Emissionen (Tonnen) |
| europe-west1 | 54.2 | EU – Frankfurt | 122.5 | France Central | 20.1 |
| europe-west2 | 124.5 | EU – Ireland | 124.5 | France South | 20.1 |
| europe-west3 | 122.5 | EU – London | 124.5 | North Europe | 124.5 |
| europe-west4 | 114.5 | EU – Paris | 20.1 | West Europe | 114.5 |
| europe-west6 | 4.0 | EU – Stockholm | 10.0 | UK West | 124.5 |
| europe-north1 | 42.2 | UK South | 124.5 | ||
Zwei Ergebnisse in der Tabelle sind besonders auffällig. Erstens, die ausgewählte Region hat selbst innerhalb eines Cloud-Anbieters einen extrem großen Einfluss auf die geschätzten CO2e-Emissionen. Den größten Unterschied gab es bei GCP, mit einem Faktor von mehr als 30. Dieser große Unterschied ergibt sich auch durch die Region „europe-west6“, welche mit vier Tonnen die insgesamt geringsten CO2e-Emissionen verursacht. Interessanterweise ist ein Faktor der Größe 30 weit mehr als die Faktoren von 5 bis 10, welche in Studien beschrieben werden [12]. Neben den Unterschieden zwischen Regionen sind zweitens die Werte einiger Regionen exakt identisch. Dies spricht dafür, dass eine gewisse Vereinfachung bei den Berechnungen vorgenommen wurde. Die absoluten Werte sollten daher mit Vorsicht betrachtet werden, wobei die Unterschiede weiterhin bestehen bleiben, da allen Regionen die gleiche (vereinfachte) Art der Berechnung zu Grunde liegt.
Neben den reinen CO2e-Emissionen durch Rechenzentren, ist es für die Wahl eines Cloud-Anbieters ebenfalls wichtig, die Nachhaltigkeitsstrategie der Anbieter zu berücksichtigen. In diesem Bereich scheinen GCP und Azure im Vergleich zu AWS die besseren Strategien zu haben [22, 23]. Auch wenn kein Cloud-Anbieter bisher 100% erneuerbare Energien nutzt (siehe Tabelle 2 in [9]), haben GCP und Azure dies mit dem Ausgleich ihres CO2-Ausstoßes sowie Energiezertifikaten bereits in der Theorie erreicht. Aus ökologischer Sicht bevorzuge ich letztlich GCP, weil mich deren Strategie am meisten überzeugt hat. Zudem hat GCP seit 2021 bei der Auswahl der Regionen einen Hinweis eingefügt, welche den geringsten CO2-Ausstoß verursachen [24]. Für mich zeigen solche kleinen Hilfestellungen, welchen Stellenwert das Thema dort einnimmt.
4. Trainiere und nutze KI-Modelle mit Bedacht
Zu guter Letzt gibt es noch viele weitere Tipps und Tricks in Bezug auf das Training und den Einsatz von ML sowie DL Modellen, die dir helfen, deinen CO2-Fußabdruck als Data Scientist zu minimieren.
- Sei sparsam! Neue Forschung, die DL Modelle mit aktuellen Ergebnissen aus den Neurowissenschaften kombiniert, kann die Berechnungszeit um das bis zu 100-fache reduzieren und dadurch extrem viel CO2 einsparen [25].
- Verwende, wenn möglich, einfachere KI-Modelle, die eine vergleichbare Vorhersagegenauigkeit haben, aber weniger rechenintensiv sind. Beispielsweise gibt es das Modell DistilBERT, welches eine kleinere und schnellere Version von BERT ist, aber eine vergleichbare Genauigkeit besitzt [26].
- Ziehe Transfer Learning und sogenannte Foundation Modelle [10| in Betracht, um die Vorhersagegenauigkeit zu maximieren und Berechnungszeit zu minimieren.
- Ziehe Federated Learning in Betracht, um CO2-Emissionen zu minimieren [27].
- Denke nicht nur an die Vorhersagegenauigkeit deiner Modelle. Effizienz ist ebenfalls ein wichtiges Kriterium. Wäge ab, ob eine 1% höhere Genauigkeit die zusätzlichen Umweltauswirkungen wert sind [9, 12].
- Wenn der beste Bereich für die Hyperparameter deines Modells noch unbekannt sind, nutze eine zufällige oder Bayesianische Suche nach den Hyperparametern anstatt einer Rastersuche [9, 20].
- Wenn dein Modell während der Anwendung regelmäßig neu trainiert wird, wähle das Trainingsintervall bewusst aus. Je nach Anwendungsfall reicht es womöglich aus, das Modell nur jeden Monat und nicht jede Woche neu zu trainieren.
Fazit
Es besteht kein Zweifel daran, dass Menschen und ihre Treibhausgasemissionen das Klima beeinflussen und unseren Planeten erwärmen. KI kann und sollte beim Problem des Klimawandels zur Lösung beitragen. Gleichzeitig müssen wir den CO2-Fußabdruck von KI im Auge behalten, um sicherzustellen, dass es Teil der Lösung und nicht Teil des Problems ist.
Du kannst als Data Scientist dabei einen großen Beitrag leisten. Informiere dich über die positiven Möglichkeiten und die negativen Auswirkungen von KI und kläre andere darüber auf. Außerdem kannst du die CO2-Emissionen deiner Modelle messen und transparent darstellen. Du solltest zudem deine Anstrengungen zur Minimierung des CO2-Fußabdrucks deiner Modelle beschreiben. Letztlich kannst du deinen Cloud-Anbieter bewusst wählen und beispielsweise prüfen, ob es für deinen Anwendungsfall einfachere Modelle gibt, die eine vergleichbare Vorhersagegenauigkeit bieten, aber mit weniger Emissionen.
Wir bei statworx haben vor kurzem die Initiative AI & Environment ins Leben gerufen, um genau solche Aspekte in unserer täglichen Arbeit als Data Scientists einzubauen. Wenn du mehr darüber erfahren möchtest, sprich uns einfach an!
Referenzen
- https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM_final.pdf
- http://www.globalcarbonatlas.org/en/CO2-emissions
- https://doi.org/10.1007/s43681-021-00043-6
- https://arxiv.org/pdf/1906.05433.pdf
- Harnessing Artificial Intelligence
- https://www.pwc.co.uk/sustainability-climate-change/assets/pdf/how-ai-can-enable-a-sustainable-future.pdf
- https://climateactiontracker.org/
- https://arxiv.org/pdf/1907.10597.pdf
- https://arxiv.org/pdf/1906.02243.pdf
- https://arxiv.org/pdf/2108.07258.pdf
- https://algorithmwatch.org/de/sustain/
- https://arxiv.org/ftp/arxiv/papers/2104/2104.10350.pdf
- https://stefanos1316.github.io/my_curriculum_vitae/GKS17.pdf
- https://pypl.github.io/PYPL.html
- https://codecarbon.io/
- https://mlco2.github.io/codecarbon/index.html
- https://arxiv.org/pdf/2007.03051.pdf
- https://github.com/Breakend/experiment-impact-tracker
- https://www.iea.org/reports/data-centres-and-data-transmission-networks
- https://mlco2.github.io/impact/#co2eq
- http://www.green-algorithms.org/
- https://blog.container-solutions.com/the-green-cloud-how-climate-friendly-is-your-cloud-provider
- https://www.wired.com/story/amazon-google-microsoft-green-clouds-and-hyperscale-data-centers/
- https://cloud.google.com/blog/topics/sustainability/pick-the-google-cloud-region-with-the-lowest-co2)
- https://arxiv.org/abs/2112.13896
- https://arxiv.org/abs/1910.01108
- https://flower.dev/blog/2021-07-01-what-is-the-carbon-footprint-of-federated-learning