
Im letzten Beitrag zu dieser Reihe hatten wir bereits gelernt, wie man RStudio mit der Twitter API verbindet. In diesem Beitrag werden wir uns nun das zurückgegebene Objekt des API Calls genauer anschauen. Wie bereits beim letzten Mal angedeutet gibt der Call ein Listenobjekt zurück. Diese zu strukturieren ist der erste wichtige Schritt auf dem Weg zur Analyse der Daten. Im Folgenden werden wir getrennt die Objekte für Tweets und Profile betrachten.
Tweet Objekt
So ziemlich jeder weiß was ein Tweet ist. Einfach ein kurzes Gedanken-Snippet, ein Zitat, oder manchmal auch – unglücklicherweise – ein offizielles Statement eines Amtsinhabers oder einer Amtsinhaberin. Aus einer Datenperspektive ist ein solcher Tweet natürlich durchaus komplexer. Neben der inhaltlichen Ebene besteht ein Tweet aus extrem vielen Informationen, von welchen die meisten direkt von R abgezogen werden können. Diese Informationen, wie zum Beispiel die Zeit oder der Ort des Tweets, Anzahl der Retweets, oder Anzahl der Likes können für Analysen äußerst hilfreich sein.

In dem Listenobjekt ist jeder Slot durch einen eigenen Tweet belegt. Der obige Tweet z.B. kommt mit einer ganzen Menge zusätzlicher Informationen.
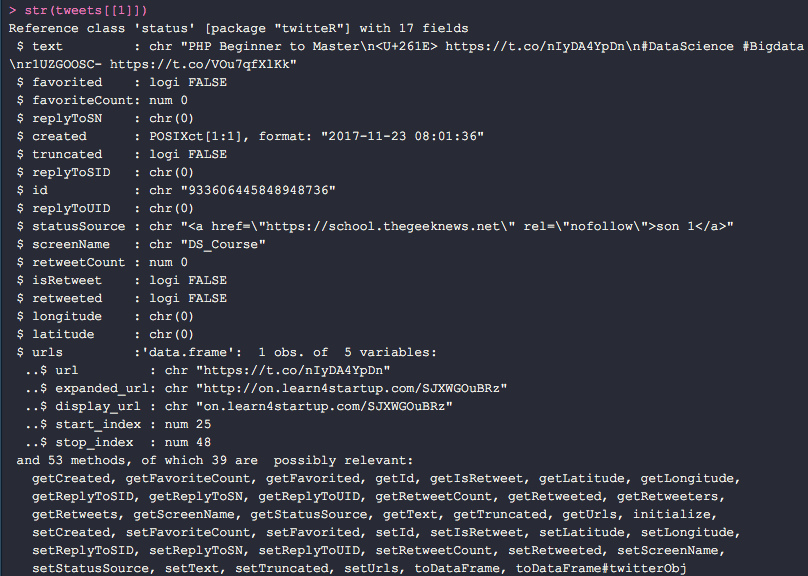
Neben dem reinen Inhalt des Tweets (text) zieht R ebenfalls die Anzahl der Likes (favoriteCount), die Zeit in der getweeted wurde (created) und zum Beispiel die Anzahl der Retweets (retweetCount).
User Objekt
Neben einfachen Tweets haben wir beim letzten Mal schon gelernt, wie wir Profile minen können. Sicherlich jeder Social Network User hat schon die ein oder andere Stalking-Tour hinter sich. Auch hier verbergen sich hinter einem Profil durchaus mehr Daten, als bei bloßem Profilbesuchen zu vermuten wäre. Mit dem API Call ziehen wir diese Informationen direkt ab.
![]()
Für unseren eigenen Twitter Account z.B. bekommen wir eine Masse an zusätzlichen Informationen. Auch diese sind in einem Listen-Objekt gespeichert.
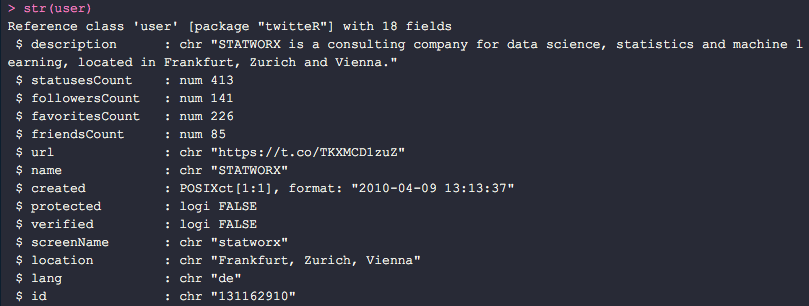
Das Objekt enthält z.B. die Beschreibung des Twitter-Accounts (description), die Anzahl der Tweets (statusesCount), Anzahl der Follower (followersCount), Anzahl der Likes (favoritesCount), aber auch auf die Sekunde genau, den Zeitpunkt des Launches des Accounts (created).
Analyse von Tweets
Da die Analyse von Tweets deutlich populärer ist, werden wir uns im Rest des Blogeintrags erstmal anschauen, wie wir Tweets analysieren können.
Hat man die Struktur des heraus gegebenen Objekts erst einmal verstanden, so ist es leicht eine Analysestrategie zu erörtern. Eine beliebte Analysemethodik von Tweets ist das sog. Text Mining. Mein Kollege David hat hierzu einen schönen Blogeintrag verfasst. Da solltet ihr auf jeden Fall reinschauen (in guter Twitter-Manier: #productplacement).
Beginnen wir einfach mal damit die letzten 50 Tweets mit #DataScience abzufragen. Um eine Textanalyse zu starten, müssen wir natürlich erst das Textelement des Tweets herausfiltern.
# zuerst fragen wir die Tweets ab (hier ohne Retweets und nur auf Englisch)
tweets <- searchTwitter("#DataScience –filter:retweets", n=50, lang="en")
# nun konvertieren wir die Tweets zu einem data.frame
tweets_df <- twListToDF(tweets)
Um nun die Tweets für die Textanalyse vorzubereiten, müssen wir erstmal die Tweets bereinigen. Schauen wir uns zuerst einen exemplarischen Tweet an.

Der Tweet beginnt mit dem Account-Namen des „Tweeters“. Informationen wie diese stehen uns im Weg, wenn wir einfach nur eine Inhaltsanalyse machen wollen. Ebenfalls stören jegliche Links und Emojis. Die folgenden Zeilen an Code beheben all diese Probleme.
# nun säubern wir die Tweets
for (i in seq(nrow(tweets_df))){
tweets_df$clean_text[i] <- gsub("&", "", tweets_df$text[i])
tweets_df$clean_text[i] <- gsub("(RT|via)((?:bW*@w+)+)", "",
tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("@w+", "", tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("[[:punct:]]", "", tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("[[:digit:]]", "", tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("httpw+", "", tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("[ t]{2,}", "", tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("^s+|s+$", "", tweets_df$clean_text[i])
tweets_df$clean_text[i] <- gsub("n", "", tweets_df$clean_text[i])
}
tweets_df$clean_text <- sapply(tweets_df$clean_text,
function(x) iconv(x, "latin1", "ASCII", sub=""))
Nun liegen uns die jeweiligen Tweets wie ganz normale Strings vor und können auch so behandelt werden. Mit Hilfe des  Packages, können wir den Text nun noch um unnötige Wörter bereinigen.
Packages, können wir den Text nun noch um unnötige Wörter bereinigen.
# Laden des tm Packages
library(tm)
# nun ziehen wir den Corpus der Tweets heraus
tweets_corpus <- Corpus(VectorSource(tweets_df$clean_text))
# und setzten unsere Stopwords
my_stopwords <- c(stopwords("en"))
tweets_corpus <- tm_map(tweets_corpus, removeWords, my_stopwords)
# Nun können wir auch schon unsere Textmatrix blden
tdm <- TermDocumentMatrix(tweets_corpus)
# und zum Beispiel die häufigsten Begriffe betrachten
term_freq <- rowSums(as.matrix(tdm))
term_freq 10)
Diese sind in unserem Fall:

Ausblick
Für die Analyse von Tweets gibt es keine Grenzen – naja, bis auf ein paar, natürlich. Wenn ihr euch stärker für weitere Aspekte der Textanalyse interessiert, dann könnt ihr natürlich die aufbereiteten Tweets z.B. durch eine Sentiment Analyse – wie bei David– jagen. Eurer Fantasie sind hier also kaum Grenzen gesetzt.
In der nächsten Runde werden wir uns mal anschauen, was man mit Twitter-Accounts analysieren könnte und vor Allem, welche Aufbereitungsschritte wichtig sind.