Be Safe!
Im Zeitalter der Open-Source-Softwareprojekte sind Angriffe auf verwundbare Software allgegenwärtig. Python ist die beliebteste Sprache für Data Science und Engineering und wird daher zunehmend zum Ziel von Angriffen durch bösartige Bibliotheken. Außerdem können öffentlich zugängliche Anwendungen durch Angriffe auf Schwachstellen im Quellcode ausgenutzt werden.
Aus diesem Grund ist es wichtig, dass Dein Code keine CVEs (Common Vulnerabilities and Exposures) enthält oder andere Bibliotheken verwendet, die bösartig sein könnten. Das gilt besonders, wenn es sich um öffentlich zugängliche Software handelt, z. B. eine Webanwendung. Bei statworx suchen wir nach Möglichkeiten, die Qualität unseres Codes durch den Einsatz automatischer Scan-Tools zu verbessern. Deshalb besprechen wir den Wert von zwei Code- und Paketscannern für Python.
Automatische Überprüfung
Es gibt zahlreiche Tools zum Scannen von Code und seinen Abhängigkeiten. Hier werde ich einen Überblick über die beliebtesten Tools geben, die speziell für Python entwickelt wurden. Solche Tools fallen in eine von zwei Kategorien:
- Statische Anwendungssicherheitstests (SAST): suchen nach Schwachstellen im Code und verwundbaren Paketen
- Dynamische Anwendungssicherheitstests (DAST): suchen nach Schwachstellen, die während der Laufzeit auftreten
Im Folgenden werde ich bandit und safety anhand einer kleinen, von mir entwickelten streamlit-Anwendung vergleichen. Beide Tools fallen in die Kategorie SAST, da sie die Anwendung nicht laufen lassen müssen, um ihre Prüfungen durchzuführen. Dynamische Anwendungstests sind komplizierter und werden vielleicht in einem späteren Beitrag behandelt.
Die Anwendung
Um den Zusammenhang zu verdeutlichen, hier eine kurze Beschreibung der Anwendung: Sie wurde entwickelt, um die Konvergenz (oder deren Fehlen) in den Stichprobenverteilungen von Zufallsvariablen zu visualisieren, die aus verschiedenen theoretischen Wahrscheinlichkeitsverteilungen gezogen wurden. Die Nutzer:innen können die Verteilung (z. B. Log-Normal) auswählen, die maximale Anzahl der Stichproben festlegen und verschiedene Stichprobenstatistiken (z. B. Mittelwert, Standardabweichung usw.) auswählen.
Bandit
Bandit ist ein quelloffener Python-Code-Scanner, der nach Schwachstellen im Deinem Code – und nur in Deinem Code – sucht. Er zerlegt den Code in seinen abstrakten Syntaxbaum und führt Plugins gegen diesen aus, um auf bekannte Schwachstellen zu prüfen. Neben anderen Tests prüft es einfachen SQL-Code, der eine Öffnung für SQL-Injektionen bieten könnte, im Code gespeicherte Passwörter und Hinweise auf häufige Angriffsmöglichkeiten wie die Verwendung der Bibliothek „Pickle“.
Bandit ist für die Verwendung mit CI/CD konzipiert und gibt einen Exit-Status von 1 aus, wenn es auf Probleme stößt, wodurch die Pipeline beendet wird. Es wird ein Bericht erstellt, der Informationen über die Anzahl der Probleme enthält, die nach Vertrauenswürdigkeit und Schweregrad in drei Stufen unterteilt sind: niedrig, mittel und hoch. In diesem Fall findet bandit keine offensichtlichen Sicherheitslücken in unserem Code.
Run started:2022-06-10 07:07:25.344619
Test results:
No issues identified.
Code scanned:
Total lines of code: 0
Total lines skipped (#nosec): 0
Run metrics:
Total issues (by severity):
Undefined: 0
Low: 0
Medium: 0
High: 0
Total issues (by confidence):
Undefined: 0
Low: 0
Medium: 0
High: 0
Files skipped (0):Umso wichtiger ist es, Bandit für die Verwendung in Deinem Projekt sorgfältig zu konfigurieren. Manchmal kann es eine Fehlermeldung auslösen, obwohl Du bereits weißt, dass dies zur Laufzeit kein Problem darstellen würde. Wenn Du zum Beispiel eine Reihe von Unit-Tests hast, die pytest verwenden und als Teil Deiner CI/CD-Pipeline laufen, wird Bandit normalerweise eine Fehlermeldung auslösen, da dieser Code die assert-Anweisung verwendet, die nicht für Code empfohlen wird, der nicht ohne das -O-Flag läuft.
Um dieses Verhalten zu vermeiden, kannst Du:
1. Scans gegen alle Dateien durchführen, aber den Test über die Befehlszeilenschnittstelle ausschließen.
2. eine Konfigurationsdatei yaml erstellen, um den Test auszuschließen.
Hier ist ein Beispiel:
# bandit_cfg.yml
skips: ["B101"] # skips the assert checkDann können wir bandit wie folgt ausführen: bandit -c bandit_yml.cfg /path/to/python/files und die unnötigen Warnungen werden nicht auftauchen.
Safety
Entwickelt vom Team von pyup.io, läuft dieser Paketscanner gegen eine kuratierte Datenbank, die aus manuell überprüften Einträgen besteht, die auf öffentlich verfügbaren CVEs und Changelogs basieren. Das Paket ist für Python >= 3.5 verfügbar und kann kostenlos installiert werden. Standardmäßig verwendet es <a href="https://github.com/pyupio/safety-db">Safety DB</a>, die frei zugänglich ist. Pyup.io bietet auch bezahlten Zugang zu einer häufiger aktualisierten Datenbank.
Die Ausführung von safety check --full-report -r requirements.txt im Wurzelverzeichnis des Pakets gibt uns die folgende Ausgabe (aus Gründen der Lesbarkeit gekürzt):
+==============================================================================+
| |
| /$$$$$$ /$$ |
| /$$__ $$ | $$ |
| /$$$$$$$ /$$$$$$ | $$ \__//$$$$$$ /$$$$$$ /$$ /$$ |
| /$$_____/ |____ $$| $$$$ /$$__ $$|_ $$_/ | $$ | $$ |
| | $$$$$$ /$$$$$$$| $$_/ | $$$$$$$$ | $$ | $$ | $$ |
| \____ $$ /$$__ $$| $$ | $$_____/ | $$ /$$| $$ | $$ |
| /$$$$$$$/| $$$$$$$| $$ | $$$$$$$ | $$$$/| $$$$$$$ |
| |_______/ \_______/|__/ \_______/ \___/ \____ $$ |
| /$$ | $$ |
| | $$$$$$/ |
| by pyup.io \______/ |
| |
+==============================================================================+
| REPORT |
| checked 110 packages, using free DB (updated once a month) |
+============================+===========+==========================+==========+
| package | installed | affected | ID |
+============================+===========+==========================+==========+
| urllib3 | 1.26.4 | <1.26.5 | 43975 |
+==============================================================================+
| Urllib3 1.26.5 includes a fix for CVE-2021-33503: An issue was discovered in |
| urllib3 before 1.26.5. When provided with a URL containing many @ characters |
| in the authority component, the authority regular expression exhibits |
| catastrophic backtracking, causing a denial of service if a URL were passed |
| as a parameter or redirected to via an HTTP redirect. |
| https://github.com/advisories/GHSA-q2q7-5pp4-w6pg |
+==============================================================================+Der Bericht enthält die Anzahl der überprüften Pakete, die Art der als Referenz verwendeten Datenbank und Informationen über jede gefundene Schwachstelle. In diesem Beispiel ist eine ältere Version des Pakets urllib3 von einer Schwachstelle betroffen, die technisch gesehen von einem Angreifer für einen Denial-of-Service-Angriff genutzt werden könnte.
Integration in den Workflow
Sowohl bandit als auch safety sind als GitHub Actions verfügbar. Die stabile Version von safety bietet auch Integrationen für TravisCI und GitLab CI/CD.
Natürlich kannst Du beide Pakete immer manuell von PyPI auf Deinem Runner installieren, wenn keine fertige Integration wie eine GitHub Actions verfügbar ist. Da beide Programme von der Kommandozeile aus verwendet werden können, kannst Du sie auch lokal in einen Pre-Commit-Hook integrieren, wenn die Verwendung auf Deiner CI/CD-Plattform nicht in Frage kommt.
Die CI/CD-Pipeline für die obige Anwendung wurde mit GitHub Actions erstellt. Nach der Installation der erforderlichen Pakete der Anwendung wird zuerst bandit und dann safety ausgeführt, um alle Pakete zu scannen. Wenn alle Pakete aktualisiert sind, werden die Schwachstellen-Scans bestanden und das Docker-Image wird erstellt.
| Package check | Code Check |
|---|---|
 |
 |
Fazit
Ich würde dringend empfehlen, sowohl bandit als auch safety in Deiner CI/CD-Pipeline zu verwenden, da sie Sicherheitsüberprüfungen für Deinen Code und Deine Abhängigkeiten bieten. Bei modernen Anwendungen ist die manuelle Überprüfung jedes einzelnen Pakets, von dem Deine Anwendung abhängt, einfach nicht machbar, ganz zu schweigen von all den Abhängigkeiten, die diese Pakete haben! Daher ist automatisiertes Scannen unumgänglich, wenn Du ein gewisses Maß an Bewusstsein darüber haben willst, wie unsicher Dein Code ist.
Während bandit Deinen Code auf bekannte Exploits untersucht, prüft es keine der in Deinem Projekt verwendeten Bibliotheken. Hierfür benötigen Sie safety, da es die bekannten Sicherheitslücken in den Bibliotheken, von denen die Anwendung abhängt, aufzeigt. Zwar sind beide Frameworks nicht völlig idiotensicher, aber es ist immer noch besser, über einige CVEs informiert zu werden als über gar keine. Auf diese Weise kannst Du entweder Deinen anfälligen Code korrigieren oder eine anfällige Paketabhängigkeit auf eine sicherere Version aktualisieren.
Wenn Du Deinen Code sicher und Deine Abhängigkeiten vertrauenswürdig hältst, kannst Du potenziell verheerende Angriffe auf Deine Anwendung abwehren.
Einführung
Je komplexer ein beliebiges Data Science Projekt in Python wird, desto schwieriger wird es in der Regel, den Überblick darüber zu behalten, wie alle Module miteinander interagieren. Wenn man in einem Team an einem größeren Projekt arbeitet, wie es hier bei STATWORX oft der Fall ist, kann die Codebasis schnell so groß werden, dass die Komplexität abschreckend wirken kann. In einem typischen Szenario arbeitet jedes Teammitglied in seiner „Ecke“ des Projekts, so dass jeder nur über ein solides lokales Wissen über den Code des Projekts verfügt, aber möglicherweise nur eine vage Vorstellung von der Gesamtarchitektur des Projekts hat. Im Idealfall sollte jedoch jeder, der an dem Projekt beteiligt ist, einen guten globalen Überblick über das Projekt haben. Damit meine ich nicht, dass man wissen muss, wie jede Funktion intern funktioniert, sondern eher, dass man die Zuständigkeit der Hauptmodule kennt und weiß, wie sie miteinander verbunden sind.
Ein visuelles Hilfsmittel, um die globale Struktur kennenzulernen, kann ein Call Graph sein. Ein Call Graph ist ein gerichteter Graph, der anzeigt, welche Funktion welche Funktion aufruft. Er wird aus den Daten eines Python-Profilers wie cProfile erstellt.
Da sich ein solcher Graph in einem Projekt, an dem ich arbeite, als hilfreich erwiesen hat, habe ich ein Paket namens project_graph erstellt, das einen solchen Call Graph für ein beliebiges Python-Skript erstellt. Das Paket erstellt ein Profil des gegebenen Skripts über cProfile, konvertiert es in einen gefilterten Punktgraphen über gprof2dot und exportiert es schließlich als .png-Datei.
Warum sind Projektgrafiken nützlich?
Als erstes kleines Beispiel soll dieses einfache Modul dienen.
# test_script.py
import time
from tests.goodnight import sleep_five_seconds
def sleep_one_seconds():
time.sleep(1)
def sleep_two_seconds():
time.sleep(2)
for i in range(3):
sleep_one_seconds()
sleep_two_seconds()
sleep_five_seconds()Nach der Installation (siehe unten) wird durch Eingabe von project_graph test_script.py in die Kommandozeile die folgende png-Datei neben dem Skript platziert:

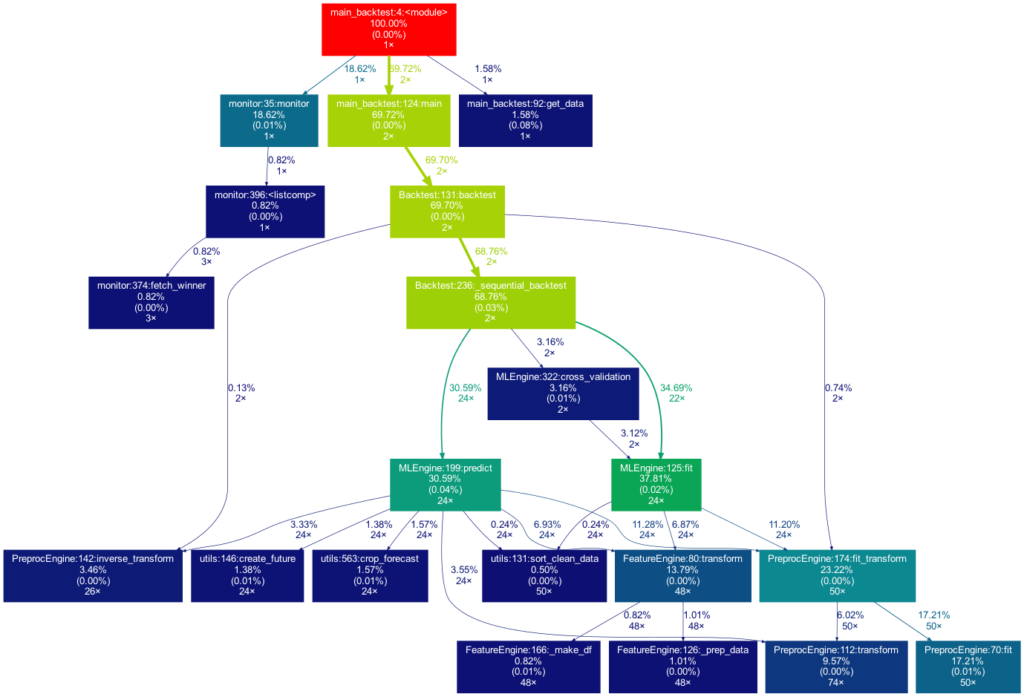
Das zu profilierende Skript dient immer als Ausgangspunkt und ist die Wurzel des Baums. Jedes Kästchen ist mit dem Namen einer Funktion, dem Gesamtprozentsatz der in der Funktion verbrachten Zeit und der Anzahl ihrer Aufrufe beschriftet. Die Zahl in Klammern gibt an, wieviel Zeit innerhalb einer Funktion verbracht wurde, jedoch ohne die Zeit in weiteren Unterfunktion zu berücksichtigen.
In diesem Fall wird die gesamte Zeit in der Funktion sleep des externen Moduls time verbracht, weshalb die Zahl 0,00% beträgt. In selbstgeschriebenen Funktionen wird nur selten viel Zeit verbracht, da die Arbeitslast eines Skripts in der Regel schnell auf sehr einfache Funktionen der Python-Implementierung selbst rausläuft. Neben den Pfeilen ist auch die Zeit angegeben, die eine Funktion an die andere weitergibt, zusammen mit der Anzahl der Aufrufe. Die Farben (ROT-GRÜN-BLAU, absteigend) und die Dicke der Pfeile zeigen die Relevanz der verschiedenen Stellen im Programm an.
Beachten Sie, dass sich die Prozentsätze der drei obigen Funktionen nicht zu 100 % aufaddieren. Der Grund dafür ist, dass der Graph so eingestellt ist, dass er nur selbst geschriebene Funktionen enthält. In diesem Fall hat das Importieren des Moduls time den Python-Interpreter dazu veranlasst, 0,04% der Zeit für eine Funktion des Moduls importlib aufzuwenden.
Auswertung mit externen Packages
Betrachten wir ein zweites Beispiel:
# test_script_2.py
import pandas as pd
from tests.goodnight import sleep_five_seconds
# some random madness
for i in range(1000):
a_frame = pd.DataFrame([[1,2,3]])
sleep_five_seconds()In diesem Skript wird ein Teil der Arbeit in einem externen Paket erledigt, das auf der Top-Ebene und nicht in einer benutzerdefinierten Funktion aufgerufen wird. Um dies im Graphen zu erfassen, können wir das externe Paket (pandas) mit der Flag -x hinzufügen. Die Initialisierung eines Pandas DataFrame wird jedoch in vielen Pandas-internen Funktionen durchgeführt. Offen gesagt, bin ich persönlich nicht an den inneren Verwicklungen von pandas interessiert, weshalb ich möchte, dass der Baum nicht zu tief in die Pandas-Mechanik „hineinwächst“. Diesem Umstand kann man Rechnung tragen, indem man nur Funktionen auftauchen lässt, die einen minimalen Prozentsatz der Laufzeit in ihnen verbringen. Genau dies kann mit der -m-Flag erreicht werden.
In Kombination ergibt project_graph -m 8 -x pandas test_script_2.py das folgende Ergebnis:

Spaß(-Beispiele) beiseite, nun wollen wir uns ernsteren Dingen zuwenden. Ein echtes Data Science Projekt könnte wie dieses aussehen:
Dieses Mal ist der Baum viel größer. Er ist sogar noch größer als in der Abbildung zu sehen, da viel mehr selbst geschriebene Funktionen aufgerufen werden. Sie werden jedoch aus Gründen der Übersichtlichkeit aus dem Baum entfernt, da Funktionen, für die weniger als 0,5 % der Gesamtzeit aufgewendet werden, herausgefiltert werden (dies ist die Standardeinstellung für die -m Flag). Beachten Sie, dass ein solches Diagramm auch bei der Suche nach Leistungsengpässen sehr vorteilhaft ist. Man sieht sofort, welche Funktionen den größten Teil der Arbeitslast tragen, wann sie aufgerufen werden und wie oft sie aufgerufen werden. Das kann Sie davor bewahren, Ihr Programm an den falschen Stellen zu optimieren und dabei den Elefanten im Raum zu übersehen.
Wie man project graph verwendet
Installation
Gehen Sie in Ihrer Projektumgebung wie folgt vor:
brew install graphviz
pip install git+https://github.com/fior-di-latte/project_graph.gitVerwendung
Wechseln Sie in der Projektumgebung in das aktuelle Arbeitsverzeichnis des Projekts (das ist wichtig!) und geben Sie für die Standardverwendung ein:
project_graph myscript.pyWenn Ihr Skript einen argparser enthält, verwenden Sie (vergessen Sie nicht die Anführungsstriche!):
project_graph "myscript.py <arg1> <arg2> (...)"Wenn Sie den gesamten Graphen sehen wollen, einschließlich aller externen Pakete, verwenden Sie:
project_graph -a myscript.pyWenn Sie eine andere Sichtbarkeitsschwelle als 1% verwenden wollen, benutzen Sie:
project_graph -m <percent_value> myscript.pyWenn Sie schließlich externe Pakete in den Graphen aufnehmen wollen, können Sie sie wie folgt angeben:
project_graph -x <package1> -x <package2> (...) myscript.pySchluss & Hinweise
Dieses Paket hat einige Schwächen, von denen die meisten behoben werden können, z.B. durch Formatierung des Codes in einen funktionsbasierten Stil, durch Trimmen mit der -m-Flag oder durch Hinzufügen von Paketen mit der-x-Flag. Wenn etwas seltsam erscheint ist der erste Schritt wahrscheinlich die Verwendung der -a-Flag zur Fehlersuche. Wesentliche Einschränkungen sind die folgenden:
- Es funktioniert nur auf Unix-Systemen.
- Es zeigt keinen wahrheitsgetreuen Graphen an, wenn es mit Multiprocessing verwendet wird. Der Grund dafür ist, dass cProfile nicht mit Multiprocessing kompatibel ist. Wenn Multiprocessing verwendet wird, wird nur der Root-Prozess profiliert, was zu falschen Berechnungszeiten im Graphen führt. Wechseln Sie zu einer nicht-parallelen Version des Zielskripts.
- Die Profilerstellung eines Skripts kann zu einem beträchtlichen Overhead bei der Berechnung führen. Es kann sinnvoll sein, die in Ihrem Skript geleistete Arbeit zu verringern (d. h. die Menge der Eingabedaten zu reduzieren). In diesem Fall kann die in den Funktionen verbrachte Zeit natürlich massiv verzerrt werden, wenn die Funktionen nicht linear skalieren.
- Verschachtelte Funktionen werden im Diagramm nicht angezeigt. Insbesondere ein Dekorator verschachtelt implizit Ihre Funktion und versteckt sie daher. Das heißt, wenn Sie einen externen Dekorator verwenden, vergessen Sie nicht, das Paket des Dekorators über die
-xFlag hinzuzufügen (zum Beispielproject_graph -x numba myscript.py). - Wenn Ihre selbst geschriebene Funktion ausschließlich von einer Funktion eines externen Pakets aufgerufen wird, müssen Sie das externe Paket manuell mit der
-xFlag hinzufügen. Andernfalls wird Ihre Funktion nicht im Baum auftauchen, da ihr Parent eine externe Funktion ist und daher nicht berücksichtigt wird.
Sie können das kleine Paket gerne für Ihr eigenes Projekt verwenden, sei es für Leistungsanalysen, Code-Einführungen für neue Teammitglieder oder aus reiner Neugier. Was mich betrifft, so finde ich es sehr befriedigend, eine solche Visualisierung meiner Projekte zu sehen. Wenn Sie Probleme bei der Verwendung haben, zögern Sie nicht, mich auf Github zu kontaktieren (https://github.com/fior-di-latte/project_graph/).
PS: Wenn Sie nach einem ähnlichen Paket in R suchen, sehen Sie sich Jakobs Beitrag über Flussdiagramme von Funktionen an.
Du willst Python lernen? Oder bist du ein R-Profi und dir entfallen bei der Arbeit mit Python regelmäßig die wichtigen Funktionen und Befehle? Oder vielleicht brauchst du von Zeit zu Zeit eine kleine Gedächtnisstütze beim Programmieren? Genau dafür wurden Cheatsheets erfunden!
Cheatsheets helfen dir in all diesen Situationen weiter. Unser erstes Cheatsheet mit den Grundlagen von Python ist der Start einer neuen Blog-Serie, in der weitere Cheatsheets in unserem einzigartigen STATWORX Stil folgen werden.
Du kannst also neugierig sein auf unsere Serie von neuen Python-Cheatsheets, die sowohl Grundlagen als auch Pakete und Arbeitsfelder, die für Data Science relevant sind, behandeln werden.
Unsere Cheatsheets stehen euch zum kostenfreien Download frei zur Verfügung, ohne Anmeldung oder sonstige Paywall.


Warum haben wir neue Cheatsheets erstellt?
Als erfahrene R User sucht man schier endlos nach entsprechend modernen Python Cheatsheets, ähnlich denen, die du von R Studio kennst.
Klar, es gibt eine Vielzahl von Cheatsheets für jeden Themenbereich, die sich aber in Design und Inhalt stark unterscheiden. Sobald man mehrere Cheatsheets in unterschiedlichen Designs verwendet, muss man sich ständig neu orientieren und verliert so insgesamt viel Zeit. Für uns als Data Scientists ist es wichtig, einheitliche Cheatsheets zu haben, anhand derer wir schnell die gewünschte Funktion oder den Befehl finden können.
Diesem nervigen Zusammensuchen von Informationen wollen wir entgegenwirken. Daher möchten wir auf unserem Blog zukünftig regelmäßig neue Cheatsheets in einer Designsprache veröffentlichen – und euch alle an dieser Arbeitserleichterung teilhaben lassen.
Was enthält das erste Cheatsheet?
Unser erstes Cheatsheet in dieser Reihe richtet sich in erster Linie an Python-Neulinge, an R-Nutzer, die Python seltener verwenden, oder an Leute, die gerade erst anfangen, mit Python zu arbeiten.
Es erleichtert den Einstieg und Überblick in Python. Die grundlegende Syntax, die Datentypen und der Umgang mit diesen werden vorgestellt und grundlegende Kontrollstrukturen eingeführt. So kannst du schnell auf die Inhalte zugreifen, die du z.B. in unserer STATWORX Academy gelernt hast oder dir die Grundlagen für dein nächstes Programmierprojekt ins Gedächtnis rufen.
Was behandelt das STATWORX Cheatsheet Episode 2?
Das nächste Cheatsheet behandelt den ersten Schritt eines Data Scientists in einem neuen Projekt: Data Wrangling. Außerdem erwartet dich ein Cheatsheet für pandas über das Laden, Auswählen, Manipulieren, Aggregieren und Zusammenführen von Daten. Happy Coding!
Did you ever want to make your machine learning model available to other people, but didn’t know how? Or maybe you just heard about the term API, and want to know what’s behind it? Then this post is for you!
Here at STATWORX, we use and write APIs daily. For this article, I wrote down how you can build your own API for a machine learning model that you create and the meaning of some of the most important concepts like REST. After reading this short article, you will know how to make requests to your API within a Python program. So have fun reading and learning!
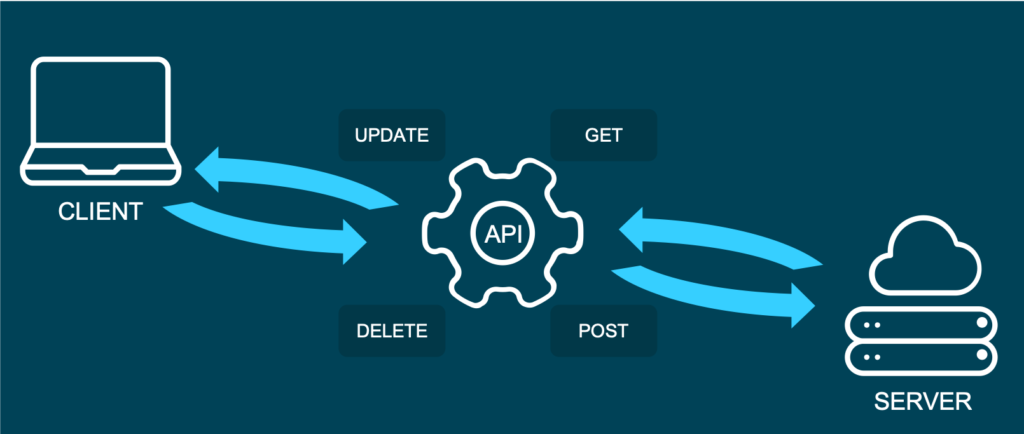
What is an API?
API is short for Application Programming Interface. It allows users to interact with the underlying functionality of some written code by accessing the interface. There is a multitude of APIs, and chances are good that you already heard about the type of API, we are going to talk about in this blog post: The web API.
This specific type of API allows users to interact with functionality over the internet. In this example, we are building an API that will provide predictions through our trained machine learning model. In a real-world setting, this kind of API could be embedded in some type of application, where a user enters new data and receives a prediction in return. APIs are very flexible and easy to maintain, making them a handy tool in the daily work of a Data Scientist or Data Engineer.
An example of a publicly available machine learning API is Time Door. It provides Time Series tools that you can integrate into your applications. APIs can also be used to make data available, not only machine learning models.
And what is REST?
Representational State Transfer (or REST) is an approach that entails a specific style of communication through web services. When using some of the REST best practices to implement an API, we call that API a „REST API“. There are other approaches to web communication, too (such as the Simple Object Access Protocol: SOAP), but REST generally runs on less bandwidth, making it preferable to serve your machine learning models.
In a REST API, the four most important types of requests are:
- GET
- PUT
- POST
- DELETE
For our little machine learning application, we will mostly focus on the POST method, since it is very versatile, and lots of clients can’t send GET methods.
It’s important to mention that APIs are stateless. This means that they don’t save the inputs you give during an API call, so they don’t preserve the state. That’s significant because it allows multiple users and applications to use the API at the same time, without one user request interfering with another.
The Model
For this How-To-article, I decided to serve a machine learning model trained on the famous iris dataset. If you don’t know the dataset, you can check it out here. When making predictions, we will have four input parameters: sepal length, sepal width, petal length, and finally, petal width. Those will help to decide which type of iris flower the input is.
For this example I used the scikit-learn implementation of a simple KNN (K-nearest neighbor) algorithm to predict the type of iris:
# model.py
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.externals import joblib
import numpy as np
def train(X,y):
# train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
knn = KNeighborsClassifier(n_neighbors=1)
# fit the model
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
acc = accuracy_score(y_test, preds)
print(f'Successfully trained model with an accuracy of {acc:.2f}')
return knn
if __name__ == '__main__':
iris_data = datasets.load_iris()
X = iris_data['data']
y = iris_data['target']
labels = {0 : 'iris-setosa',
1 : 'iris-versicolor',
2 : 'iris-virginica'}
# rename integer labels to actual flower names
y = np.vectorize(labels.__getitem__)(y)
mdl = train(X,y)
# serialize model
joblib.dump(mdl, 'iris.mdl')As you can see, I trained the model with 70% of the data and then validated with 30% out of sample test data. After the model training has taken place, I serialize the model with the joblib library. Joblib is basically an alternative to pickle, which preserves the persistence of scikit estimators, which include a large number of numpy arrays (such as the KNN model, which contains all the training data). After the file is saved as a joblib file (the file ending thereby is not important by the way, so don’t be confused that some people call it .model or .joblib), it can be loaded again later in our application.
The API with Python and Flask
To build an API from our trained model, we will be using the popular web development package Flask and Flask-RESTful. Further, we import joblib to load our model and numpy to handle the input and output data.
In a new script, namely app.py, we can now set up an instance of a Flask app and an API and load the trained model (this requires saving the model in the same directory as the script):
from flask import Flask
from flask_restful import Api, Resource, reqparse
from sklearn.externals import joblib
import numpy as np
APP = Flask(__name__)
API = Api(APP)
IRIS_MODEL = joblib.load('iris.mdl')The second step now is to create a class, which is responsible for our prediction. This class will be a child class of the Flask-RESTful class Resource. This lets our class inherit the respective class methods and allows Flask to do the work behind your API without needing to implement everything.
In this class, we can also define the methods (REST requests) that we talked about before. So now we implement a Predict class with a .post() method we talked about earlier.
The post method allows the user to send a body along with the default API parameters. Usually, we want the body to be in JSON format. Since this body is not delivered directly in the URL, but as a text, we have to parse this text and fetch the arguments. The flask _restful package offers the RequestParser class for that. We simply add all the arguments we expect to find in the JSON input with the .add_argument() method and parse them into a dictionary. We then convert it into an array and return the prediction of our model as JSON.
class Predict(Resource):
@staticmethod
def post():
parser = reqparse.RequestParser()
parser.add_argument('petal_length')
parser.add_argument('petal_width')
parser.add_argument('sepal_length')
parser.add_argument('sepal_width')
args = parser.parse_args() # creates dict
X_new = np.fromiter(args.values(), dtype=float) # convert input to array
out = {'Prediction': IRIS_MODEL.predict([X_new])[0]}
return out, 200You might be wondering what the 200 is that we are returning at the end: For APIs, some HTTP status codes are displayed when sending requests. You all might be familiar with the famous 404 - page not found code. 200 just means that the request has been received successfully. You basically let the user know that everything went according to plan.
In the end, you just have to add the Predict class as a resource to the API, and write the main function:
API.add_resource(Predict, '/predict')
if __name__ == '__main__':
APP.run(debug=True, port='1080')The '/predict' you see in the .add_resource() call, is the so-called API endpoint. Through this endpoint, users of your API will be able to access and send (in this case) POST requests. If you don’t define a port, port 5000 will be the default.
You can see the whole code for the app again here:
# app.py
from flask import Flask
from flask_restful import Api, Resource, reqparse
from sklearn.externals import joblib
import numpy as np
APP = Flask(__name__)
API = Api(APP)
IRIS_MODEL = joblib.load('iris.mdl')
class Predict(Resource):
@staticmethod
def post():
parser = reqparse.RequestParser()
parser.add_argument('petal_length')
parser.add_argument('petal_width')
parser.add_argument('sepal_length')
parser.add_argument('sepal_width')
args = parser.parse_args() # creates dict
X_new = np.fromiter(args.values(), dtype=float) # convert input to array
out = {'Prediction': IRIS_MODEL.predict([X_new])[0]}
return out, 200
API.add_resource(Predict, '/predict')
if __name__ == '__main__':
APP.run(debug=True, port='1080')Run the API
Now it’s time to run and test our API!
To run the app, simply open a terminal in the same directory as your app.py script and run this command.
python run app.pyYou should now get a notification, that the API runs on your localhost in the port you defined. There are several ways of accessing the API once it is deployed. For debugging and testing purposes, I usually use tools like Postman. We can also access the API from within a Python application, just like another user might want to do to use your model in their code.
We use the requests module, by first defining the URL to access and the body to send along with our HTTP request:
import requests
url = 'http://127.0.0.1:1080/predict' # localhost and the defined port + endpoint
body = {
"petal_length": 2,
"sepal_length": 2,
"petal_width": 0.5,
"sepal_width": 3
}
response = requests.post(url, data=body)
response.json()The output should look something like this:
Out[1]: {'Prediction': 'iris-versicolor'}That’s how easy it is to include an API call in your Python code! Please note that this API is just running on your localhost. You would have to deploy the API to a live server (e.g., on AWS) for others to access it.
Conclusion
In this blog article, you got a brief overview of how to build a REST API to serve your machine learning model with a web interface. Further, you now understand how to integrate simple API requests into your Python code. For the next step, maybe try securing your APIs? If you are interested in learning how to build an API with R, you should check out this post. I hope that this gave you a solid introduction to the concept and that you will be building your own APIs immediately. Happy coding!
Entwickelt als eine Open-Source-Bibliothek von Plotly, baut das Python Framework Dash auf Flask, Plotly.js und React.js auf. Das Framework ermöglicht die Erstellung von interaktiven Webapplikationen in purem Python und eignet sich besonders für das Teilen von Datenanalysen.
Solltest du Interesse an der Erstellung von interaktiven Grafiken mit Python haben, kann ich den Blog meines Kollegen Markus, , sehr empfehlen.
Ein grundlegendes Verständnis von HTML und CSS ist für die Erstellung von Webapplikationen empfohlen. Um diesem Blog folgen zu können, werden wir alle notwendigen externen Ressourcen zur Verfügung stellen und die Rollen von HTML und CSS in einem Dash(board) erläutern.
Der Source Code ist auf verfügbar.
Vorraussetzungen
Das Projekt besteht aus einem Stylesheet style.css, den Beispieldaten stockdata2.csv und der eigentlichen Dash-Applikation app.py.
Laden des Stylesheet
Die Verwendung eines Stylesheets ist für die Funktionalitäten des Dashboards nicht notwendig. Damit das Dashboard jedoch so aussieht, wie in unseren Beispielen, kann die Datei von unserem heruntergeladen werden. Das verwendete Stylesheet is eine leicht veränderte Version des Stylesheets der . Dash lädt automatisch .css-Dateien, die sich im Unterordner assets befinden.
dashapp
|--assets
|-- style.css
|--data
|-- stockdata2.csv
|-- app.pyDie Dokumentation zu externen Ressourcen (u.a. Stylesheets) kann unter folgendem Link gefunden werden: https://dash.plot.ly/external-resources
Laden der Daten
Für unser Dashboard verwenden wir den Datensatz . Der Datensatz hat folgende Struktur:
| date | stock | value | change |
|---|---|---|---|
| 2007-01-03 | MSFT | 23.95070 | -0.1667 |
| 2007-01-03 | IBM | 80.51796 | 1.0691 |
| 2007-01-03 | SBUX | 16.14967 | 0.1134 |
import pandas as pd
# Load data
df = pd.read_csv('data/stockdata2.csv', index_col=0, parse_dates=True)
df.index = pd.to_datetime(df['Date'])Erste Schritte – Wie man eine Dash-App startet
Nach der Installation von Dash (Anleitung kann gefunden werden) können wir die App starten. Die folgenden Zeilen importieren die benötigten Pakete dash und dash_html_components. Ohne eine Definition eines Layouts der App, kann die Applikation nicht gestartet werden. Eine leere html.Div genügt, um die App zu starten.
import dash
import dash_html_components as htmlWeb Applikation Framework
# Initialise the app
app = dash.Dash(__name__)
# Define the app
app.layout = html.Div()
# Run the app
if __name__ == '__main__':
app.run_server(debug=True)Wie eine .css-Datei das Layout beeinflusst
Das Modul dash_html_components beinhaltet verschiedene HTML-Komponenten. Mehr Informationen zu den Komponenten unter: https://dash.plot.ly/dash-html-components
HTML-Komponenten können über das children-Attribut verschachtelt werden.
app.layout = html.Div(children=[
html.Div(className='row', # Define the row element
children=[
html.Div(className='four columns div-user-controls'), # Define the left element
html.Div(className='eight columns div-for-charts bg-grey') # Define the right element
])
])Das erste html.Div() hat ein untergeordnetes Element (eng. child). Das Element is ein weiteres html.Div() mit dem Namen (className) row, welches der Container für unseren Inhalt sein wird. Die weiteren untergeordneten Elemente sind four-columns div-user-controls und eight columns div-for-charts bg-grey.
Der Stil der div-Komponenten stammt aus unserer style.css-Datei.
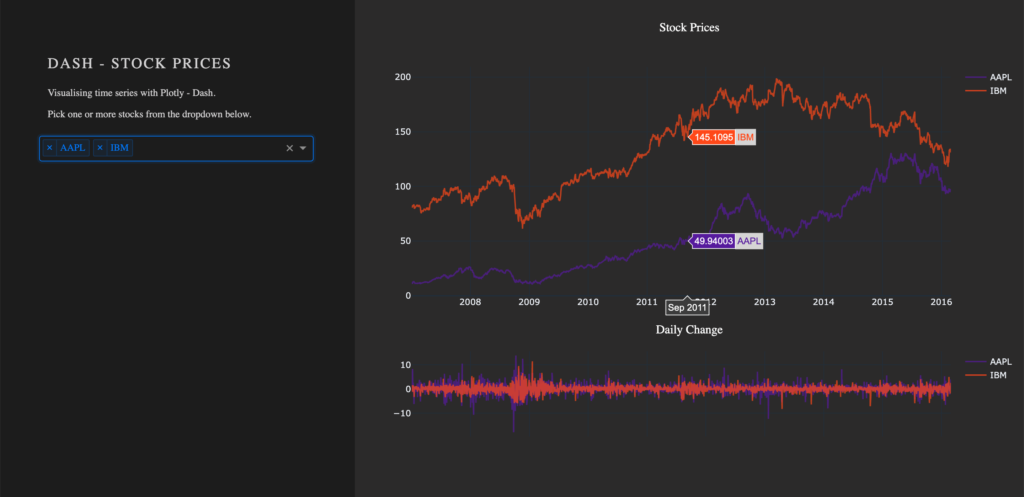
Wir starten damit, dass wir der App weitere Informationen zur Verfügung stellen, wie Titel und Beschreibung. Zum Element four columns div-user-controls fügen wir die Komponenten H2 für die Überschrift und P als Paragraph hinzu.
children = [
html.H2('Dash - STOCK PRICES'),
html.P('''Visualising time series with Plotly - Dash'''),
html.P('''Pick one or more stocks from the dropdown below.''')
]

Die Basics des App-Layouts
Ein weiteres Feature von Flask (und somit Dash) ist das . Das Feature macht es möglich, eine Änderung im Code ohne einen Neustart der App sehen zu können.
Zusätzlich wird durch debug=True ein Feld rechts in der unteren Ecke der App angezeigt, worin wir auf Fehlermeldungen und den Callback Graph zugriff haben. Wir werden im letzten Abschnitt des Artikels auf Callback Graph zurück kommen, nachdem wir interaktive Funktionalitäten implementiert haben.

Erstellen von Grafiken in Dash – Wie man eine Plotly-Grafik anzeigt
Nachdem wir die grundlegenden Container für unsere App erstellt haben, erstellen wir jetzt einen Plotly-Graphen. Die Komponente dcc.Graph aus den dash_core_components nutzt das gleiche figure-Argument wie das plotly.py Paket. Dash übersetzt jeden Aspekt des Charts zu einem Schlüssel-Wert-Paar, welches von der darunterliegenden JavaScript-Bibliothek Plotly.js verarbeitet wird.
Im folgenden Abschnitt verwenden wir die Expressversion von plotly.py und das Paket Dash Core Components. Nach der Installation von Dash sollte plotly in der Entwicklungsumgebung bereits verfügbar sein.
import dash_core_components as dcc
import plotly.express as pxbeinhaltet eine Kollektion von nützlichen und einfach zu bedienenden Komponenten, welche zur Interaktivität und Funktionalität des Dashboard beitragen.
ist die Expressversion von plotly.py, welche die Erstellung von Plotly-Grafiken vereinfacht, mit der Einschränkung dass es die Flexibilität verringert.
Um einen Plot in der rechten Seite unserer App zu zeichnen, wird ein dcc.Graph() als ein Unterelement dem html.Div() mit dem Namen eight columns div-for-charts bg-grey hinzugefügt. Die Komponente dcc.Graph() kann für jede von plotly-gestützte Visualisierung genutzt werden. In unserem Fall wird die figure von px.line() aus dem Paket plotly.express erstellt. Das Layout der Grafik ändern wir durch die Methode update_layout(). Um den Hintergrund der Grafik transparent zu machen, setzen wir die Farbe auf rgba(0, 0, 0, 0). Ohne den Hintergrund transparent zu setzen, würde eine große weiße Box in der Mitte unserer App stehen. Da dcc.Graph() lediglich die Grafik anzeigt, können wir nach der Erstellung die Eigenschaften der Grafik nicht ohne weiteres ändern.
dcc.Graph(id='timeseries',
config={'displayModeBar': False},
animate=True,
figure=px.line(df,
x='Date',
y='value',
color='stock',
template='plotly_dark').update_layout(
{'plot_bgcolor': 'rgba(0, 0, 0, 0)',
'paper_bgcolor': 'rgba(0, 0, 0, 0)'})
)
Erstellen einer Dropdown-Liste
Eine weitere Komponente ist dcc.Dropdown(), welche genutzt wird – du kannst es dir vielleicht denken –, um eine Dropdown-Liste zu erstellen. Die verfügbaren Optionen in einem Dropdown werden entweder durch eine (Python) Liste gegeben oder innerhalb einer Funktion definiert.
Für unsere Dropdown-Liste erstellen wir eine Funktion, welche eine Liste von Dictionaries ausgibt. Die Liste besteht aus den Dictionaries mit den Schlüsseln label und value. Hierdurch werden die Optionen unserer Dropdown-Liste definiert. Der Wert von label ist der angezeigte Text in der App und der Wert von value kann innerhalb der App als Input für Funktionen verwendet werden. Solltest du beispielsweise den vollen Namen des Unternehmens anzeigen, kann der Wert von label auf Microsoft gesetzt werden. Der Einfachheit halber wählen wir für label und value die gleichen Werte.
Füge die folgende Funktion zum Skript hinzu, bevor du das Layout der App definierst:
# Creates a list of dictionaries, which have the keys 'label' and 'value'.
def get_options(list_stocks):
dict_list = []
for i in list_stocks:
dict_list.append({'label': i, 'value': i})
return dict_listNach unserer Funktion get_option, können wir das Element dcc.Dropdown() von den Dash Core Components zu unserer App hinzufügen. Füge html.Div() als untergeordenetes Element zur Liste der Elemente in four columns div-user-controls hinzu und setze das Argument className=div-for-dropdown. html.Div() hat ein Unterelement, dcc.Dropdown().
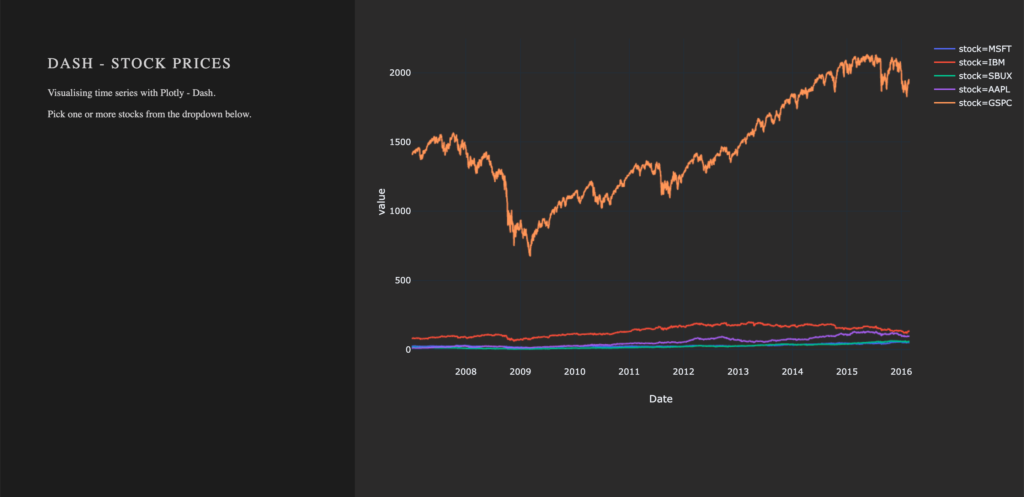
Wir möchten die Möglichkeit habe, nicht nur einen einzelnen Wert, sondern mehrere Werte zur gleichen Zeit auszuwählen und setzen daher das Argument multi=True. Da die App jedoch nicht leer erscheinen soll, setzen wir zudem einen initialen Wert für value.
html.Div(className='div-for-dropdown',
children=[
dcc.Dropdown(id='stockselector',
options=get_options(df['stock'].unique()),
multi=True,
value=[df['stock'].sort_values()[0]],
style={'backgroundColor': '#1E1E1E'},
className='stockselector')
],
style={'color': '#1E1E1E'})id und options Argumente des dcc.Dropdown() sind wichtig für den nächsten Abschnitt. Um unterschiedliche Styles der Dropdown-Liste auszuprobieren, folge diesem
Mit Callbacks arbeiten
Wie man der App interaktive Funktionalitäten hinzufügt
Callbacks (eng. für Rückruffunktion) sind für die Interaktivität in einem Dashboard verantwortlich. Sie nehmen Inputs entgegen, z.B. die ausgewählten Optionen einer Dropdown-Liste und leiten die Werte zu einer Funktion weiter. Der Output der Funktion wird durch den Callback an ein definiertes Element geleitet. Wir werden im nächsten Schritt eine Funktion schreiben, welche eine Grafik basierend auf den Namen von Unternehmen ausgibt. In unserer Implementierung wird die erstellte Grafik an eine dcc.Graph()-Komponente geleitet.
Momenten hat die Auswahl der Dropdown-Liste noch keinen Einfluss auf die angezeigte Grafik. Um diese Funktionalität zu implementieren werden wir einen Callback nutzen. Der Callback übernimmt die Kommunikation zwischen der Dropdown-Liste mit der ID id='stockselector' und dem Graphen 'timeseries'. Zur Vorbereitung entfernen wir die zuvor erstellte Grafik, da wir die figure dynamisch erstellen möchten.
In unserer App möchten wir zwei Graphen haben, weshalb wir eine weitere dcc.Graph()-Komponente erstellen und mit dem Argument id='change' identifizierbar machen.
- Entfernen der
figurevon der Komponentedcc.Graph(id='timeseries') - Hinzufügen der Komponente
dcc.Graph(id='change') - Beide Komponenten sollten Unterelemente von
eight columns div-for-charts bg-greysein.
dcc.Graph(id='timeseries', config={'displayModeBar': False})
dcc.Graph(id='change', config={'displayModeBar': False})Callbacks erhöhen die Interaktivität deiner Anwendung. Sie können Eingaben von Komponenten entgegennehmen, z. B. bestimmte Aktien, die über ein Dropdown-Menü ausgewählt werden, diese Eingaben an eine Funktion weitergeben und die von der Funktion zurückgegebenen Werte an Komponenten zurückgeben.
In unserer Implementierung wird ein Callback ausgelöst, sobald der Nutzer eine Aktie im Dropdown auswählt. Der Callback nimmt den Wert des dcc.Dropdown() entgegen (Input) und leitet den Wert an die Funktionen update_timeseries() und update_change() weiter. Die Funktionen filtern die Daten und erstellen eine auf den Inputs basierende Grafik. Der Callback leitet anschließend den Output der Funktionen (Grafik) an die als Output spezifizierten Elemente weiter.
Der Callback ist als Decorator für eine Funktion implementiert. Mehrere Inputs und Outputs sind möglich. Wir werden jedoch bei einem Input und einem Output bleiben. Wir importieren die Objekte dash.dependencies import Input, Output.
Füge die folgende Zeile zu deinemSkript hinzu.
from dash.dependencies import Input, Output und Output() nehmen die id einer Komponente (bspw. dcc.Graph(id='timeseries') hat die id 'timeseries') sowie die Eigenschaft einer Komponente (hier figure) als Argument entgegen.
Beispiel Callback:
# Update Time Series
@app.callback(Output('id of output component', 'property of output component'),
[Input('id of input component', 'property of input component')])
def arbitrary_function(value_of_first_input):
'''
The property of the input component is passed to the function as value_of_first_input.
The functions return value is passed to the property of the output component.
'''
return arbitrary_outputWenn wir durch unseren stockselector eine Zeitreihe für einen oder mehrere Aktien anzeigen möchten, benötigen wir eine Funktion. Der value unseres Inputs ist die Liste von ausgewählten Unternehmen aus der Dropdown-Liste.
Implementieren von Callbacks
Die Funktion zeichnet die Linien (eng. traces) der Plotly-Grafik, basierend auf den übergebenen Aktiennamen werden die Linien gezeichnet und zusammen als eine figure ausgegeben, welche von dcc.Graph() angezeigt werden kann. Die Inputs für unsere Funktion werden in der Reihenfolge übergeben, in welcher Sie im Callback gesetzt wurden. (Bemerkung: Seit Dash 2.0 muss dies nicht immer der Fall sein.)
Update der Grafik (figure) für die time series:
@app.callback(Output('timeseries', 'figure'),
[Input('stockselector', 'value')])
def update_timeseries(selected_dropdown_value):
''' Draw traces of the feature 'value' based one the currently selected stocks '''
# STEP 1
trace = []
df_sub = df
# STEP 2
# Draw and append traces for each stock
for stock in selected_dropdown_value:
trace.append(go.Scatter(x=df_sub[df_sub['stock'] == stock].index,
y=df_sub[df_sub['stock'] == stock]['value'],
mode='lines',
opacity=0.7,
name=stock,
textposition='bottom center'))
# STEP 3
traces = [trace]
data = [val for sublist in traces for val in sublist]
# Define Figure
# STEP 4
figure = {'data': data,
'layout': go.Layout(
colorway=["#5E0DAC", '#FF4F00', '#375CB1', '#FF7400', '#FFF400', '#FF0056'],
template='plotly_dark',
paper_bgcolor='rgba(0, 0, 0, 0)',
plot_bgcolor='rgba(0, 0, 0, 0)',
margin={'b': 15},
hovermode='x',
autosize=True,
title={'text': 'Stock Prices', 'font': {'color': 'white'}, 'x': 0.5},
xaxis={'range': [df_sub.index.min(), df_sub.index.max()]},
),
}
return figureSTEP 1
- Ein
tracewird für jede Aktie gezeichnet. Erstellen einer leerenlistfür jedentraceder Plotly-Grafik.
STEP 2
In einem for-loop, wird ein trace für die Plotly-Grafik von go.Scatter erstellt. (go stammt aus dem Import import plotly.graph_objects as go)
- Iteriere über die selektierten Aktien im Drodown, zeichne ein
traceund hänge dastracean die Liste aus Step 3 an.
STEP 3
- Ebne (eng. flatten) die Liste.
STEP 4
Plotly-Grafiken sind Dictionaries mit den Schlüsseln data und layout. Der Wert von data ist unsere Liste mit den erstellten traces. Das layout wird mit go.Layout() definiert.
- Füge die
traceszu unsererfigure(Grafik) hinzu - Definiere das Layout der
figure
Diese gleichen Schritte werden für unsere zweite Grafik durchgeführt, mit dem Unterschied, dass die Daten auf der y-Achse auf change gesetzt werden.
Update der Grafik change:
@app.callback(Output('change', 'figure'),
[Input('stockselector', 'value')])
def update_change(selected_dropdown_value):
''' Draw traces of the feature 'change' based one the currently selected stocks '''
trace = []
df_sub = df
# Draw and append traces for each stock
for stock in selected_dropdown_value:
trace.append(go.Scatter(x=df_sub[df_sub['stock'] == stock].index,
y=df_sub[df_sub['stock'] == stock]['change'],
mode='lines',
opacity=0.7,
name=stock,
textposition='bottom center'))
traces = [trace]
data = [val for sublist in traces for val in sublist]
# Define Figure
figure = {'data': data,
'layout': go.Layout(
colorway=["#5E0DAC", '#FF4F00', '#375CB1', '#FF7400', '#FFF400', '#FF0056'],
template='plotly_dark',
paper_bgcolor='rgba(0, 0, 0, 0)',
plot_bgcolor='rgba(0, 0, 0, 0)',
margin={'t': 50},
height=250,
hovermode='x',
autosize=True,
title={'text': 'Daily Change', 'font': {'color': 'white'}, 'x': 0.5},
xaxis={'showticklabels': False, 'range': [df_sub.index.min(), df_sub.index.max()]},
),
}
return figureStarte die App erneut. In der App können nun über die Dropdown-Liste die verschiedenen Aktien ausgewählt werden. Für jedes selektierte Element wird ein Line-Plot gezeichnet und angezeigt. Standardmäßig hat die Dropdown-Komponente einige Funktionalitäten, wie bspw. die Suchfunktion, weshalb die Selektion von einzelnen Elementen auch bei vielen Auswahlmöglichkeiten sehr einfach ist.
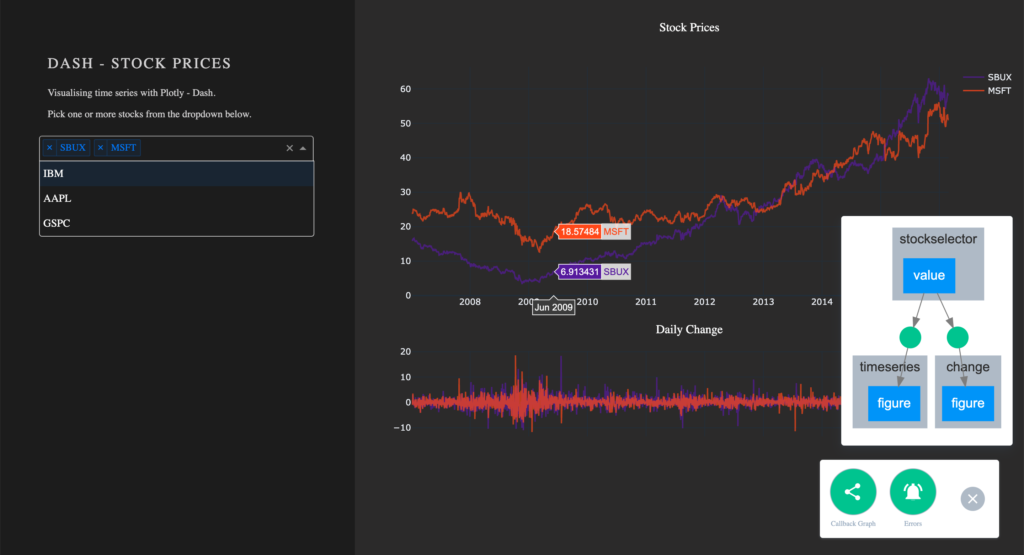
Visualisieren von Callbacks – Callback Graph
Mit den implementierten Callbacks ist die App fertig. Werfen wir nun einen Blick auf den sogenannten Callback Graph. Wenn die App mit debug=True gestartet wird, erscheint in der unteren rechten Ecke ein Feld. Hierüber kann eine visuelle Repräsentation des Callback Graph angezeigt werden, welchen wir im Skript definiert haben. Der Graph zeigt, dass die Komponenten timeseries und change eine figure anzeigen, die auf den ausgewählten Werten im stockselector basieren.
Sollten Callbacks nicht so funktionieren, wie es geplant wurde, ist dieses Tool sehr hilfreich beim Debuggen.
Fazit
Fassen wir die wichtigsten Elemente von Dash zusammen. Um die App zu starten, benötigt man nur ein paar Zeilen Code. Ein grundlegendes Verständnis von HTML und CSS genügt, um den Stil eines Dashboards anzupassen. Interaktive Grafiken können ohne Probleme implementiert werden, da Dash für das Arbeiten mit interaktiven Plotly-Grafiken entwickelt wurde. Über Callbacks, welche den Input von Nutzenden an Funktionen weiterleiten, werden unterschiedliche Komponenten miteinander verbunden.
Wenn dir der Blogartikel gefallen hat, kontaktiere mich gerne über oder per . Ich bin neugierig, welche weiteren Anwendungsmöglichkeiten das Framework bietet und freue mich auf Fragen zu Daten, Machine Learning und KI sowie den spannenden Lösungen, an denen wir bei arbeiten.
Vielen Dank!
Mein Blogbeitrag zielt auf Data Science Einsteiger ab, die vor der Wahl stehen, welche Programmiersprache sie als Erstes lernen wollen. Wir bei statworx arbeiten mit den zwei beliebtesten Sprachen R und Python. Beide Sprachen haben ihre Stärken und Schwächen, weshalb man idealerweise beide beherrschen sollte. Für den Einstieg empfehlen wir eine Sprache zu erlernen und sich dann in der anderen fortzubilden. Um die Entscheidung zu erleichtern, mit welcher Programmiersprache man beginnen möchte, stelle ich Euch beide vor und vergleiche sie anschließend miteinander.
Überblick R und Python
Sowohl Python als auch R sind Open-Source-Programmiersprachen. Das bedeutet, dass die Quellcodes öffentlich zugänglich sind und gratis verwendet werden können. Während Python eine General Purpose Programmiersprache (Allzwecksprache) ist, wurde R für statistische Analysen entwickelt. Daher weisen die Nutzer der Sprachen oftmals unterschiedliche Hintergründe auf. Verallgemeinernd kann man sagen, dass Softwareentwickler Python nutzen und Statistiker R.
| R | Python | |
|---|---|---|
| Veröffentlichung | 1993 | 1991 |
| Entwickler | R Core Team | Python Software Foundation |
| Package Management | CRAN | Conda (empfohlen für Einsteiger) |
Eine Fülle an Erweiterungen
Beide Sprachen verfügen über einen Grundstock an Funktionen, die mit Paketen (packages) erweitert werden können.
Das Comprehensive R Archive Network (CRAN) ist eine Plattform für R Pakete. Um ein Paket auf CRAN bereit zu stellen, müssen eine ganze Reihe an Richtlinien eingehalten werden. CRAN gewährleistet dadurch, dass alle Pakete, die dort zum Download zur Verfügung stehen auch tatsächlich funktionieren. Insgesamt stehen auf CRAN 10.000 Pakete zur Verfügung. Da R die Standard-Sprache für Statistiker ist, findet man in CRAN für fast jedes Problem im Bereich Statistik eine passende Lösung. Es ist also genau die richtige Anlaufstelle für die neuesten statistischen Methoden und Analysen.
Bei Python gibt es zwei Paket-Verwaltungsplattformen: conda und PyPI (Python Package Index). Auch für Python gibt es über 10.000 Pakete, die im Gegensatz zu R einen sehr breiten Anwendungsbereich abdecken. Da es zu Komplikationen kommen kann, wenn Python Pakete global installiert werden, nutzt man dafür virtuelle Umgebungen. Die sorgen für reibungslose Abläufe innerhalb der verschiedenen Pakete und bei Abhängigkeiten von Paket zu Paket. Für Anfänger ist es daher nicht so einfach, sich da zurecht zu finden.
Mit Hilfe von Paketen besteht die Möglichkeit in R Python Code auszuführen sowie vice versa. Falls dich das interessiert, check den Blogbeitrag von meinem Kollegen Manuel ab. Er stellt das Paket reticulate vor.
IDEs als Hilfestellung
Programmierer nutzen oftmals eine integrierte Entwicklungsumgebung (IDE), die ihnen die Arbeit durch kleine aber feine Hilfsmittel erleichtert.
Für R Nutzer hat sich RStudio als Standard-IDE durchgesetzt. Die IDE wird vom gleichnamigen Unternehmen vertrieben, das kommerziell hinter R steht. RStudio bietet nicht nur ein angenehmes Arbeitsumfeld, sondern entwickelt auch aktiv Pakete und Erweiterungen für die R Sprache. Vom RStudio-Team stammen beispielsweise wichtige Pakete wie tidyverse, packrat und devtools sowie beliebte Erweiterungen wie shiny (Dashboards) und RMarkdown (Berichte).
Python Nutzer haben die Wahl zwischen verschiedenen IDEs (PyCharm, Visual Studio Code, Spyder, …). Allerdings gibt es kein Unternehmen, das hinter Python steht und vergleichbar mit RStudio wäre. Dennoch werden dank der Bemühungen der riesigen Community und der Python Software Foundation ständig neue Erweiterungen für Python zusammengestellt.
Die Kunst der Datenvisualisierung
Die meist verwendeten Pakete für Datenvisualisierung mit Python sind matplotlib und seaborn. Dashboards lassen sich in Python mit dash erstellen.
Aber R hat bei der Datenvisualisierung einen Trumpf im Ärmel: Das Paket ggplot2, das auf dem Buch The Grammar of Graphics von Leland Wilkinson basiert. Mit diesem Paket kannst Du ansprechende und maßgeschneiderte Grafiken erstellen, die Du wiederum auf Dashboards mit Hilfe von shiny für Andere zugänglich machen kannst.
Beide Programmiersprachen bieten die Möglichkeit, schöne Grafiken leicht zu erstellen. Trotzdem überzeugt das R Paket ggplot2 mit seiner Flexibilität und seinen visuellen Möglichkeiten.
Pluspunkte für Lesbarkeit
Python wurde nach dem Motto Readability counts konzipiert. Somit können auch Leute, die nicht mit der Programmiersprache vertraut sind, interpretieren was im Code gemacht wird.
Das ist in R Code eher nicht der Fall. Die Sprache ist weniger intuitiv aufgebaut als Python. Aufgrund der guten Lesbarkeit bietet Python daher einen leichteren Einstieg ins Programmieren.
Schnelligkeit in verschiedenen Observationsgrößen
Als nächstes vergleiche ich, wie lange es dauert in R und Python einen simulierten Datensatz zu erstellen. Für eine faire Gegenüberstellung sollten die Bedingungen möglichst gleich sein. Die Daten werden mit den Paketen Xy und XyPy in R und Python respektive simuliert. Für die Zeitmessung habe ich microbenchmark in R und timeit in Python benutzt. Um die Simulation schnellstmöglich zu generieren, wird der Prozess parallelisiert auf acht Kernen (R: parallel, Python: multiprocessing).
Für das Experiment wird ein Datensatz mit 100 Observationen und 50 Variablen 100 Mal simuliert. Die Zeit, die der Rechner benötigt, um die Simulation durchzuführen, wird für jede Simulation einzeln gemessen. Und das wird dann für 1.000, 10.000, 100.000 und 1.000.000 Observationen wiederholt.
Die R und Python Code Snippets sind unten abgebildet.
# R
# devtools::install_github("andrebleier/Xy")
# install.packages("parallel")
# install.packages("microbenchmark")
# Load packages
library(Xy)
library(microbenchmark)
library(parallel)
# Extract function definition from for loop
sim_this <- function(n_sim) {
sim <- microbenchmark(Xy(n = n_sim,
numvars = c(50,0),
catvars = 0),
times = 100, unit = "s")
data.frame(n = n_sim,
mean = summary(sim)[, 4])
}
# Time measurement for different number of simulations
n_sim <- c(1e2, 1e3, 1e4, 1e5, 1e6)
sim_in_r <- data.frame(n = rep(0, length(n_sim)),
t = rep(0, length(n_sim)))
for(i in 1:length(n_sim)){
out <- mclapply(n_sim[i],
FUN = sim_this,
mc.cores = 8)
sim_in_r[i, 1] <- out[[1]][1]
sim_in_r[i, 2] <- out[[1]][2]
}
# Python
# In terminal: pip install xypy
import multiprocessing as mp
import numpy as np
import timeit
from xypy import Xy
# Predefine function of interest
def sim_this(n_sim):
return(timeit.timeit( lambda: Xy(n = int(n_sim),
numvars = [50, 0],
catvars = [0, 0],
weights = [5, 10],
stn = 4.0,
cor = [0, 0.1],
interactions = 1,
noisevars = 5), number = 100))
# Paralleled computation
pool = mp.Pool(processes = 8)
n_sim = np.array([1e2, 1e3, 1e4, 1e5, 1e6])
results = [pool.map(sim_this, n_sim)]
Die durchschnittliche Dauer, sortiert nach Datensatzgröße, wird für R und Python im unteren Plot dargestellt. Die X-Achse wird hier auf einer logarithmischen Skala mit Basis 10 dargestellt, um die Grafik übersichtlicher zu machen.
Während R bei einer Datensatzgröße von 100 und 1.000 Observationen etwas schneller ist, hängt Python R bald darauf deutlich ab.
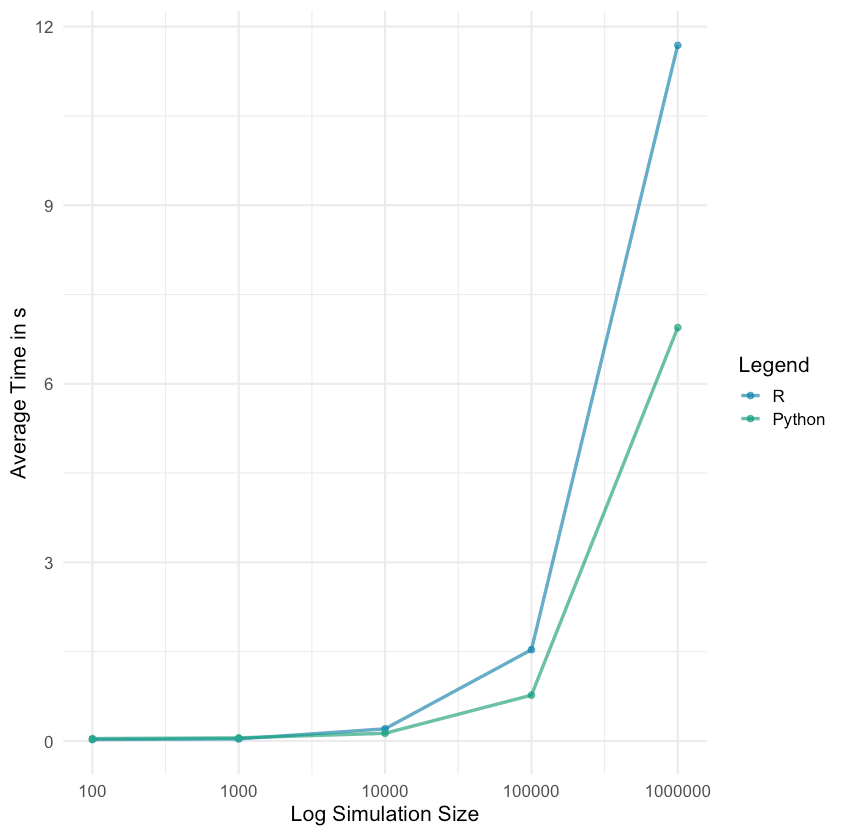
Für weitere Vergleiche kann ich die folgenden STATWORX Blogbeiträge empfehlen: pandas vs. data.table und pandas vs. data.table part 2, dabei wird der Fokus auf Datenmanipulation gelegt.
Der Standard bei Deep Learning
Wenn Dich vor allem Deep Learning Methoden interessieren, eignet sich Python als Sprache besser. Die meisten Deep Learning Bibliotheken wurden in Python geschrieben und implementiert.
Auch in R ist Deep Learning möglich, aber die R Deep Learning Community ist deutlich kleiner. Implementationen wie Keras und TensorFlow lassen sich zwar auch in R aufrufen, dies läuft dann aber über Pakete von Drittanbietern. Die Pakete bieten daher nicht die volle Flexibilität für die Nutzer, z.B. sind nicht alle TensorFlow Funktionen erhältlich. Zu dem kommt der Aspekt der Schnelligkeit. Deep Learning mit Python ist schneller als mit R.
Umfrage in der Community: Wie ticken die Anwender?
Als angehende Data Scientists ist Kaggle eine wichtige Plattform für Euch. Dort kann man an spannenden Machine Learning Wettkämpfen teilnehmen, selbst experimentieren und aus den Erfahrungen der Community lernen.
2018 hat Kaggle eine Machine Learning & Data Science Umfrage durchgeführt. Die Umfrage war zwei Wochen lang online und es gingen insgesamt 23.859 Antworten ein. Aus den Ergebnissen dieser Umfrage habe ich verschiedene Plots erstellt, aus denen sich einige interessante Schlüsse im Hinblick auf mein Blogthema ziehen lassen. Der Code zu den einzelnen Plots ist öffentlich zugänglich auf Github.
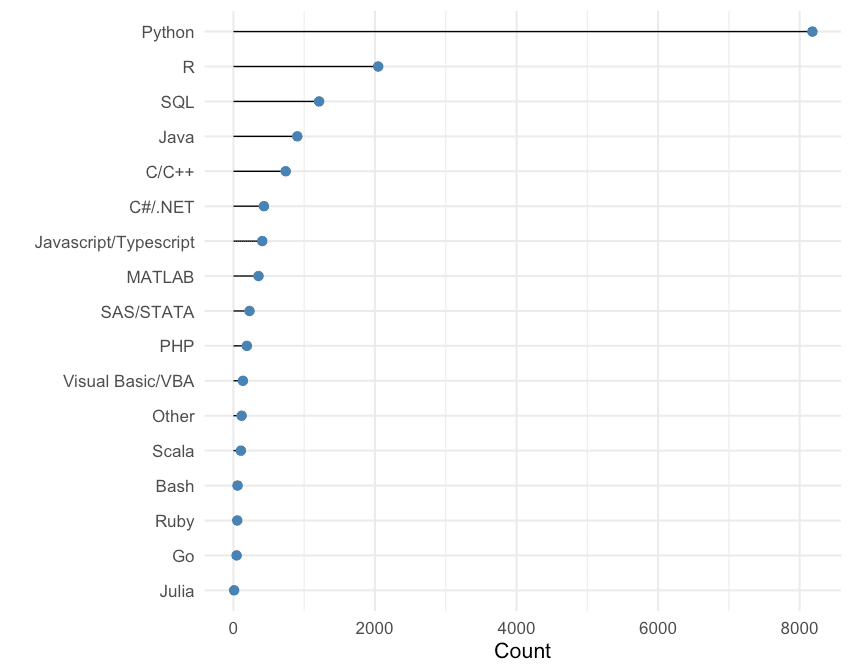
Exkurs: Python & R im Vergleich zu anderen Sprachen
Bevor wir uns auf R und Python stürzen, schauen wir uns an, wie die beiden im Vergleich zu anderen Programmiersprachen abschneiden. Jeder Umfragenteilnehmer gab an, welche Sprache er vorrangig benutzt. Im unteren Plot wurde nach Sprache aggregiert und das Ergebnis lautet: Die große Mehrzahl der Teilnehmer benutzt vor allem Python! Gefolgt von R auf dem zweiten Platz. In dieser Umfrage unterscheiden wir nicht zwischen den Arbeitsbereichen, weshalb Python – als General Purpose Programmiersprache – vermutlich so stark hervorsticht.
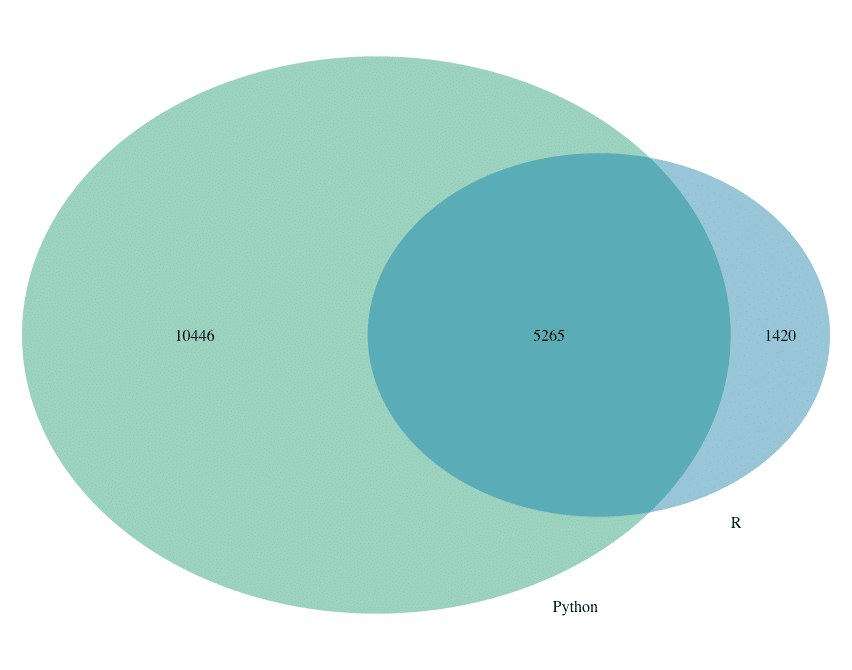
Die Gegenüberstellung R & Python
Im direkten Vergleich zwischen R und Python sieht man, dass sehr viele R-Nutzer auch Python benutzen. Wohingegen die Python-Nutzer oftmals ausschließlich mit Python arbeiten.
Wenn man die Nutzung der Sprachen nach Arbeitsbereich vergleicht, sieht man eine klare Dominanz von Python. In allen Arbeitsfeldern, bis auf Statistiker, wird mehrheitlich Python benutzt.

Die Teilnehmer wurden außerdem gefragt: Welche Sprache empfiehlst Du angehenden Data Scientists zuerst zu lernen? Die Antworten auf die Frage sind in der unteren Tabelle zusammengefasst.
| Sprache | Empfehlung | Nutzer | Differenz |
|---|---|---|---|
| Python | 14.181 | 8.180 | 6.001 |
| R | 2.342 | 2.046 | 296 |
| SQL | 914 | 1.211 | -297 |
| C++ | 339 | 739 | -400 |
| Matlab | 256 | 355 | -99 |
| Java | 184 | 903 | -719 |
| Scala | 74 | 106 | -32 |
| Javascript | 72 | 408 | -336 |
| SAS | 69 | 228 | -159 |
| VBA | 38 | 135 | -97 |
| Go | 26 | 46 | -20 |
| Other | 161 | 117 | 44 |
Wenn man die Anzahl Empfehlungen und die Anzahl Nutzer vergleicht, dann sieht man, dass R und Python die einzigen Sprachen sind, die eine positive Differenz aufweisen.
Auch bei dieser Frage liegt Python (14.181) wieder weit vor R (2.342).
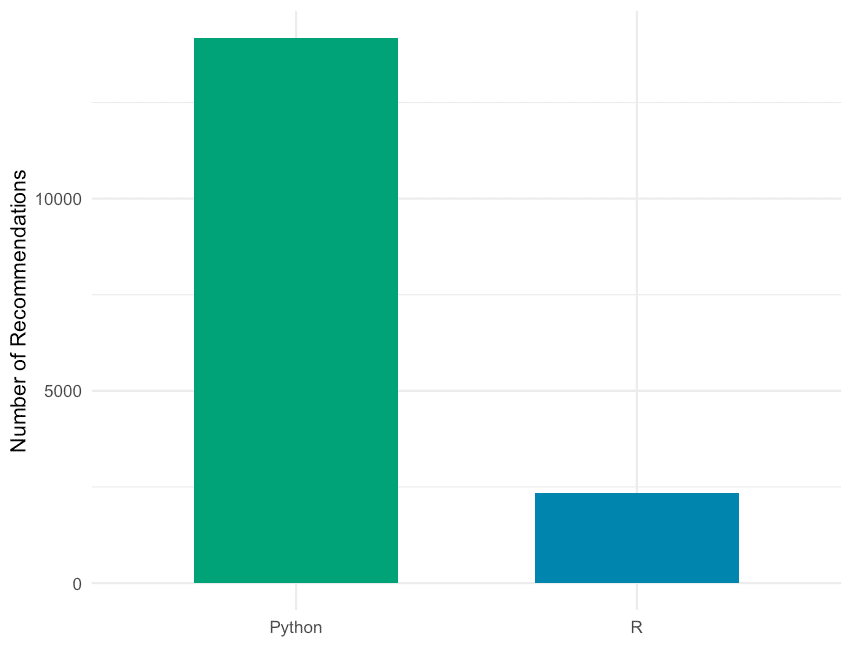
Fazit
Eine Sache vorweg: beide Sprachen sind sehr mächtig. Daher kann man keine falsche Wahl treffen! Die Wahl der Sprache hängt davon ab, welche Projekte man verwirklichen möchte.
Als universelle Programmiersprache ist Python für diverse Anwendungsgebiete geeignet. Weshalb ich Dir grundsätzlich empfehle mit Python anzufangen. Falls aber statistische Auswertungen oder Datenvisualisierungen bei Deinen Projekten im Vordergrund stehen, hat R gegenüber Python einen Vorteil.
Wie schon erwähnt haben beide Sprachen ihre Vor- und Nachteile. Als fortgeschrittener Data Scientist solltest Du idealerweise beide Sprachen beherrschen.
Ich hoffe, dass Dir dieser Beitrag bei der Suche nach dem richtigen Einstieg in die Data Science Welt weiterhilft.
Happy Coding!
Falls Du Interesse an Schulungen hast, kannst du dir gerne unter AI Academy unsere Kurse durchschauen.
Referenzen
- https://cran.r-project.org/
- https://www.python.org/
- https://wiki.c2.com/?PythonPhilosophy
- https://plot.ly/
- https://www.rstudio.com/
- https://pipenv.readthedocs.io/en/latest/
- https://conda.io/en/latest/
- https://www.kaggle.com
- https://www.springer.com/us/book/9780387245447
- https://www.statworx.com/ai-academy/
Intro
Informationen sind überall im Internet zu finden. Leider ist es schwierig, programmatisch auf einige davon zuzugreifen. Zwar bieten viele Websites eine API an, doch sind diese oft teuer oder haben sehr strenge Tarifbeschränkungen, selbst wenn Sie an einem Open-Source- und/oder nicht kommerziellen Projekt oder Produkt arbeiten.
Hier kann Web Scraping ins Spiel kommen. Wikipedia definiert Web Scraping wie folgt:
Web scraping, web harvesting, or web data extraction data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol [HTTP], or through a web browser.
“Web scraping” wikipedia.org
In der Praxis umfasst Web Scraping jede Methode, die es Programmierer:innen ermöglicht, programmatisch und damit (halb-)automatisch auf den Inhalt einer Website zuzugreifen.
Hier sind drei Ansätze (d.h. Python-Bibliotheken) für Web Scraping, die zu den beliebtesten gehören:
- Senden einer HTTP-Anfrage, üblicherweise über Requests, an eine Webseite und anschließendes Parsen des zurückgegebenen HTML (üblicherweise mit BeautifulSoup), um auf die gewünschten Informationen zuzugreifen. Typischer Use Case: Standard-Web-Scraping-Problem, siehe Fallstudie in diesem Beitrag.
- Verwendung von Tools, die normalerweise für automatisierte Softwaretests verwendet werden, hauptsächlich Selenium, um programmatisch auf den Inhalt einer Website zuzugreifen. Typischer Anwendungsfall: Websites, die Javascript verwenden oder anderweitig nicht direkt über HTML zugänglich sind.
- Scrapy, das eher als allgemeines Web-Scraping-Framework betrachtet werden kann, mit dem Spiders erstellt und Daten von verschiedenen Websites gescraped werden können, wobei Wiederholungen minimiert werden. Typischer Anwendungsfall: Scraping von Amazon-Rezensionen.
Obwohl man Daten auch mit jeder anderen Programmiersprache scrapen könnte, wird Python aufgrund seiner einfachen Syntax und der großen Vielfalt an Bibliotheken, die für Scraping-Zwecke in Python zur Verfügung stehen, am häufigsten verwendet.
Nach dieser kurzen Einführung geht es in diesem Beitrag um einige ethische Aspekte des Web-Scraping, gefolgt von allgemeinen Informationen über die Bibliotheken, die in diesem Beitrag verwendet werden. Schließlich wird alles, was wir bisher gelernt haben, auf eine Fallstudie angewandt, in der wir die Daten aller Unternehmen im Portfolio von Sequoia Capital, einer der bekanntesten VC-Firmen in den USA, erfassen werden. Nach einer Überprüfung der Website und der robots.txt scheint das Scraping des Sequoia-Portfolios erlaubt zu sein; wie ich das herausgefunden habe, erfahren Sie im Abschnitt über robots.txt und in der Fallstudie.
Im Rahmen dieses Blogbeitrags können wir uns nur eine der drei oben genannten Methoden ansehen. Da die Standardkombination von Requests + BeautifulSoup im Allgemeinen am flexibelsten und am einfachsten zu handhaben ist, werden wir sie in diesem Beitrag ausprobieren. Beachten Sie, dass die oben genannten Tools sich nicht gegenseitig ausschließen; Sie könnten z.B. einen HTML-Text mit Scrapy oder Selenium erhalten und ihn dann mit BeautifulSoup parsen.
Web Scraping Ethik
Zwei Faktoren, die bei der Durchführung von Web-Scraping äußerst wichtig sind, sind Ethik und Rechtmäßigkeit. Ich bin kein Jurist, und die spezifischen Gesetze variieren je nach Land beträchtlich, aber im Allgemeinen fällt Web Scraping in eine Grauzone, d.h. es ist in der Regel nicht streng verboten, aber auch nicht generell legal (d.h. nicht unter allen Umständen legal). Das hängt in der Regel von den Daten ab, die Sie auslesen.
Im Allgemeinen können Websites Ihre IP-Adresse sperren, wenn Sie etwas auslesen, was nicht erwünscht ist. Wir hier bei STATWORX dulden keine illegalen Aktivitäten und empfehlen Ihnen, immer ausdrücklich nachzufragen, wenn Sie sich nicht sicher sind, ob das Scrapen von Daten zulässig ist. Hierfür ist der folgende Abschnitt sehr nützlich.
robots.txt verstehen
Der robot exclusion standard ist ein Protokoll, das von Web-Crawlern (z. B. von den großen Suchmaschinen, d. h. hauptsächlich Google) ausdrücklich gelesen wird und ihnen mitteilt, welche Teile einer Website vom Crawler indiziert werden dürfen und welche nicht. Im Allgemeinen sind Crawler oder Scraper nicht gezwungen, die in einer robots.txt festgelegten Einschränkungen zu befolgen, aber es wäre höchst unmoralisch (und potenziell illegal), dies nicht zu tun.
Das folgende Beispiel zeigt eine robots.txt-Datei von Hackernews, einem sozialen Newsfeed, der von YCombinator betrieben wird und bei vielen Menschen in Startups beliebt ist.
In der robots.txt von Hackernews ist festgelegt, dass alle User Agents (daher der Platzhalter *) auf alle URLs zugreifen dürfen, mit Ausnahme der URLs, die ausdrücklich verboten sind. Da nur bestimmte URLs verboten sind, ist damit implizit alles andere erlaubt. Eine Alternative wäre, alles auszuschließen und dann explizit nur bestimmte URLs anzugeben, auf die Crawler oder andere Bots zugreifen können.
Beachten Sie auch die Crawl-Verzögerung von 30 Sekunden, was bedeutet, dass jeder Bot nur eine Anfrage alle 30 Sekunden senden sollte. Es ist im Allgemeinen eine gute Praxis, Ihren Crawler oder Scraper in regelmäßigen (ziemlich großen) Abständen schlafen zu lassen, da zu viele Anfragen Websites zum Absturz bringen können, selbst wenn sie von menschlichen Nutzenden stammen.
Wenn man sich die robots.txt von Hackernews ansieht, ist es auch ziemlich logisch, warum sie einige bestimmte URLs nicht zulassen: Sie wollen nicht, dass Bots sich als User ausgeben, indem sie z.B. Themen einreichen, abstimmen oder antworten. Alles andere (z.B. das Scrapen von Themen und deren Inhalten) ist erlaubt, solange die Crawl-Verzögerung eingehalten wird. Das macht Sinn, wenn man die Aufgabe von Hackernews bedenkt, die hauptsächlich darin besteht, Informationen zu verbreiten. Übrigens bieten sie auch eine API an, die recht einfach zu benutzen ist. Wenn Sie also wirklich Informationen von HN benötigen, würden Sie einfach ihre API benutzen.
In der Gist unten finden Sie die robots.txt von Google, die (natürlich) viel restriktiver ist als die von Hackernews. Schauen Sie selbst nach, denn sie ist viel länger als unten gezeigt, aber im Wesentlichen ist es Bots nicht erlaubt, eine Suche bei Google durchzuführen, wie in den ersten beiden Zeilen angegeben. Nur bestimmte Teile einer Suche sind erlaubt, wie „about“ und „static“. Wenn eine allgemeine URL verboten ist, wird sie überschrieben, wenn eine spezifischere URL erlaubt wird (z.B. wird das Verbot von /search durch das spezifischere Zulassen von /search/about überschrieben).
Im Folgenden werden wir einen Blick auf die spezifischen Python-Pakete werfen, die im Rahmen dieser Fallstudie verwendet werden, nämlich Requests und BeautifulSoup.
Requests
Requests ist eine Python-Bibliothek, mit der man auf einfache Weise HTTP-Anfragen stellen kann. Im Allgemeinen hat Requests zwei Hauptanwendungsfälle: Anfragen an eine API und das Abrufen von Roh-HTML-Inhalten von Websites (d.h. Scraping).
Wenn Sie eine Anfrage senden, sollten Sie immer den Statuscode überprüfen (insbesondere beim Scraping), um sicherzustellen, dass Ihre Anfrage erfolgreich bearbeitet wurde. Eine nützliche Übersicht über die Statuscodes finden Sie hier. Im Idealfall sollte Ihr Statuscode 200 sein (was bedeutet, dass Ihre Anfrage erfolgreich war). Der Statuscode kann Ihnen auch Auskunft darüber geben, warum Ihre Anfrage nicht zugestellt werden konnte, z.B. weil Sie zu viele Anfragen gesendet haben (Statuscode 429) oder die berüchtigte Seite nicht gefunden wurde (Statuscode 404).
Use Case 1: API Requests
Die obige Gist zeigt eine einfache API-Anfrage, die an die NYT-API gerichtet ist. Wenn Sie diese Anfrage auf Ihrem eigenen Rechner replizieren möchten, müssen Sie zunächst ein Konto auf der Seite NYT Dev erstellen und dann den erhaltenen Schlüssel der Konstante KEY zuweisen.
Die Daten, die Sie von einer REST-API erhalten, liegen im JSON-Format vor, das in Python als eine dict-Datenstruktur dargestellt wird. Daher müssen Sie diese Daten noch ein wenig „parsen“, bevor Sie sie in einem Tabellenformat haben, das z.B. in einer CSV-Datei dargestellt werden kann, d.h. Sie müssen auswählen, welche Daten für Sie relevant sind.
Use Case 2: Scraping
Die folgenden Zeilen fragen den HTML-Code der Wikipedia-Seite zum Thema Web Scraping ab. Das Statuscode-Attribut des Response-Objekts enthält den mit der Anfrage verbundenen Statuscode.
Nach dem Ausführen dieser Zeilen haben Sie immer noch nur den rohen HTML-Code mit allen enthaltenen Tags. Dies ist in der Regel nicht sehr nützlich, da wir beim Scraping mit Requests meist nur nach bestimmten Informationen und Text suchen, da menschliche Lesende nicht an HTML-Tags oder anderen Markups interessiert sind. An dieser Stelle kommt BeautifulSoup ins Spiel.
BeautifulSoup
BeautifulSoup ist eine Python-Bibliothek, die zum Parsen von Dokumenten (d.h. hauptsächlich HTML- oder XML-Dateien) verwendet wird. Die Verwendung von Requests, um den HTML-Code einer Seite zu erhalten, und das anschließende Parsen der gesuchten Informationen mit BeautifulSoup aus dem rohen HTML-Code ist der Quasi-Standard für Web-Scraping, der von Python-Programmierern häufig für einfache Aufgaben verwendet wird.
Um auf die obige Gist zurückzukommen, würde das Parsen des von Wikipedia zurückgegebenen HTML-Rohmaterials für die Web-Scraping-Site ähnlich wie unten aussehen.
In diesem Fall extrahiert BeautifulSoup alle Überschriften, d.h. alle Überschriften im Abschnitt „Inhalt“ oben auf der Seite. Probieren Sie es selbst aus!
Wie Sie unten sehen, können Sie das Klassenattribut eines HTML-Elements leicht mit dem Inspektor eines beliebigen Webbrowsers finden.
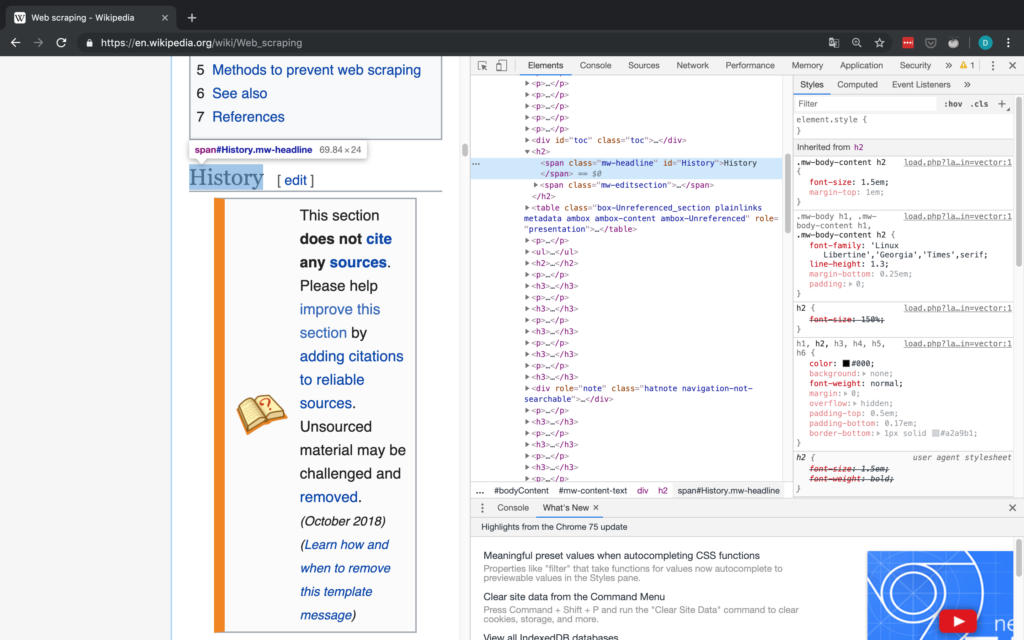
Diese Art des Abgleichs ist (meiner Meinung nach) eine der einfachsten Möglichkeiten, BeautifulSoup zu verwenden: Sie geben einfach das HTML-Tag (in diesem Fall span) und ein anderes Attribut des Inhalts an, das Sie finden wollen (in diesem Fall ist dieses andere Attribut class). Auf diese Weise können Sie beliebige Abschnitte fast jeder Webseite abgleichen. Für kompliziertere Übereinstimmungen können Sie auch reguläre Ausdrücke (REGEX) verwenden.
Sobald Sie die Elemente haben, aus denen Sie den Text extrahieren möchten, können Sie auf den Text zugreifen, indem Sie deren Textattribut auslesen.
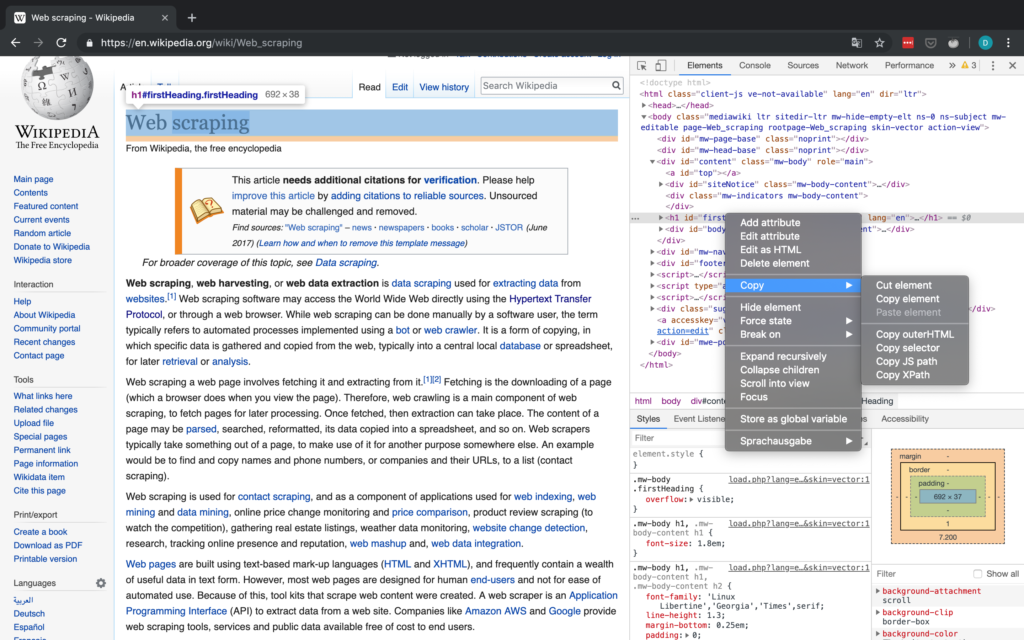
Inspector
Als kurzer Exkurs ist es wichtig, eine Einführung in die in Chrome zu geben (sie sind in jedem Browser verfügbar, ich habe mich nur für Chrome entschieden), mit denen Sie den Inspektor verwenden können, der Ihnen Zugriff auf den HTML-Code einer Website gibt und mit dem Sie auch Attribute wie den XPath- und CSS-Selektor kopieren können. All dies kann beim Scraping-Prozess hilfreich oder sogar notwendig sein (vor allem bei der Verwendung von Selenium). Der Arbeitsablauf in der Fallstudie sollte Ihnen einen grundlegenden Eindruck davon vermitteln, wie Sie mit dem Inspector arbeiten können. Ausführlichere Informationen über den Inspector finden Sie auf der oben verlinkten offiziellen Google-Website, die zahlreiche Informationen enthält.
Abbildung 2 zeigt die grundlegende Schnittstelle des Inspektors in Chrome.
Fallstudie: Sequoia Capital
Eigentlich wollte ich diese Fallstudie zunächst mit der New York Times durchführen, da sie über eine API verfügt und somit die von der API erhaltenen Ergebnisse mit den Ergebnissen des Scrapings hätten verglichen werden können. Leider haben die meisten Nachrichtenorganisationen sehr restriktive robots.txt, die insbesondere die Suche nach Artikeln nicht zulassen. Daher beschloss ich, das Portfolio einer der großen VC-Firmen in den USA, Sequoia, zu scrapen, da deren robots.txt permissiv ist und ich außerdem denke, dass Startups und die Risikokapital-Szene im Allgemeinen sehr interessant sind.
Robots.txt
Werfen wir zunächst einen Blick auf die robots.txt von Sequoia:
Glücklicherweise erlauben sie verschiedene Zugriffsarten – mit Ausnahme von drei URLs, was für unsere Zwecke ausreichend ist. Wir werden dennoch eine Crawl-Verzögerung von 15-30 Sekunden zwischen den einzelnen Anfragen einbauen.
Als Nächstes wollen wir uns die Daten ansehen, die wir abrufen wollen. Wir interessieren uns für das Portfolio von Sequoia, also ist https://www.sequoiacap.com/companies/ die URL, die wir suchen.
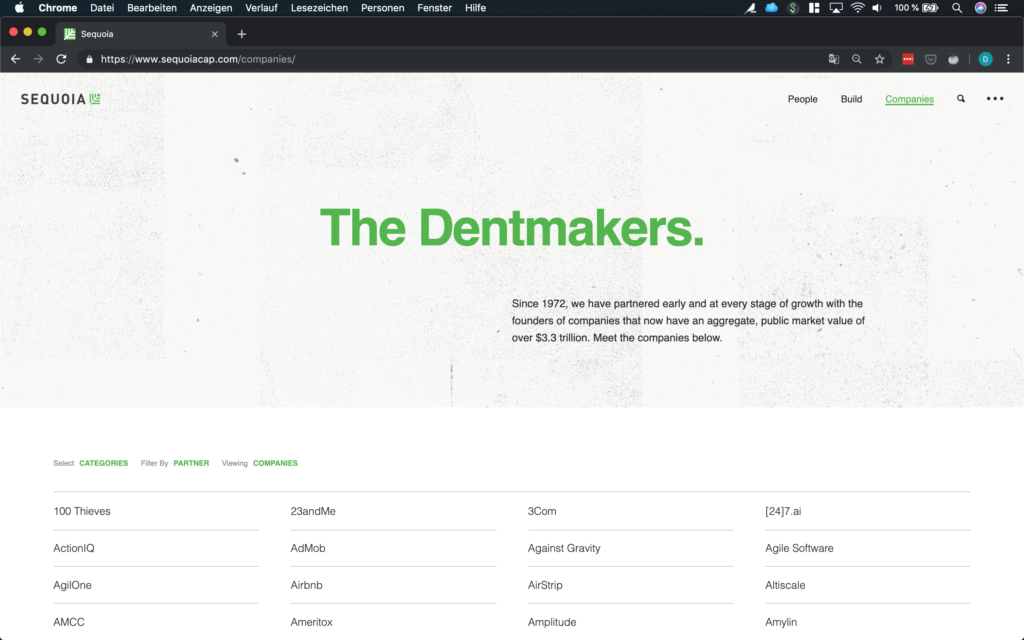
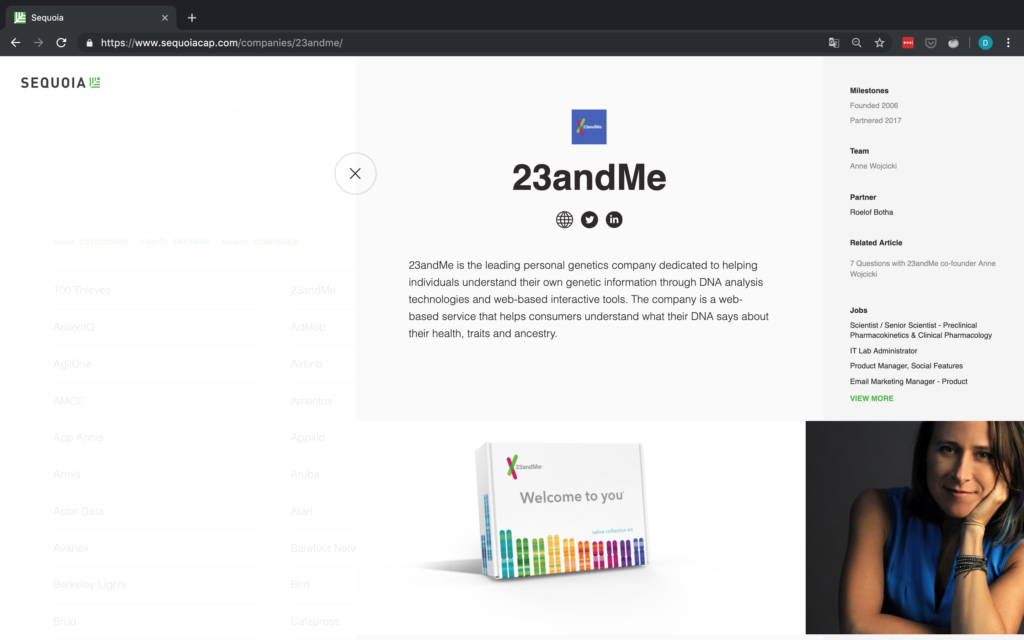
Die Unternehmen sind übersichtlich in einem Raster angeordnet, so dass sie recht einfach zu scrapen sind. Wenn Sie auf die Seite klicken, werden die Details zu jedem Unternehmen angezeigt. Beachten Sie auch, wie sich die URL in Abbildung 4 ändert, wenn Sie auf ein Unternehmen klicken! Dies ist besonders für Anfragen wichtig.
Ziel ist es, die folgenden grundlegenden Informationen über jedes Unternehmen zu sammeln und sie als CSV-Datei auszugeben:
-
Name des Unternehmens
-
URL des Unternehmens
-
Beschreibung des Unternehmens
-
Meilensteine
-
Team
-
Partner
Wenn eine dieser Informationen für ein Unternehmen nicht verfügbar ist, fügen wir stattdessen einfach die Zeichenfolge „NA“ ein.
Zeit, mit der Inspektion zu beginnen!
Scraping Prozess
Name des Unternehmens
Wenn man sich das Raster ansieht, sieht es so aus, als ob die Informationen über jedes Unternehmen in einem div-Tag mit der Klasse companies _company js-company enthalten sind. Wir sollten also in der Lage sein, mit BeautifulSoup nach dieser Kombination zu suchen.
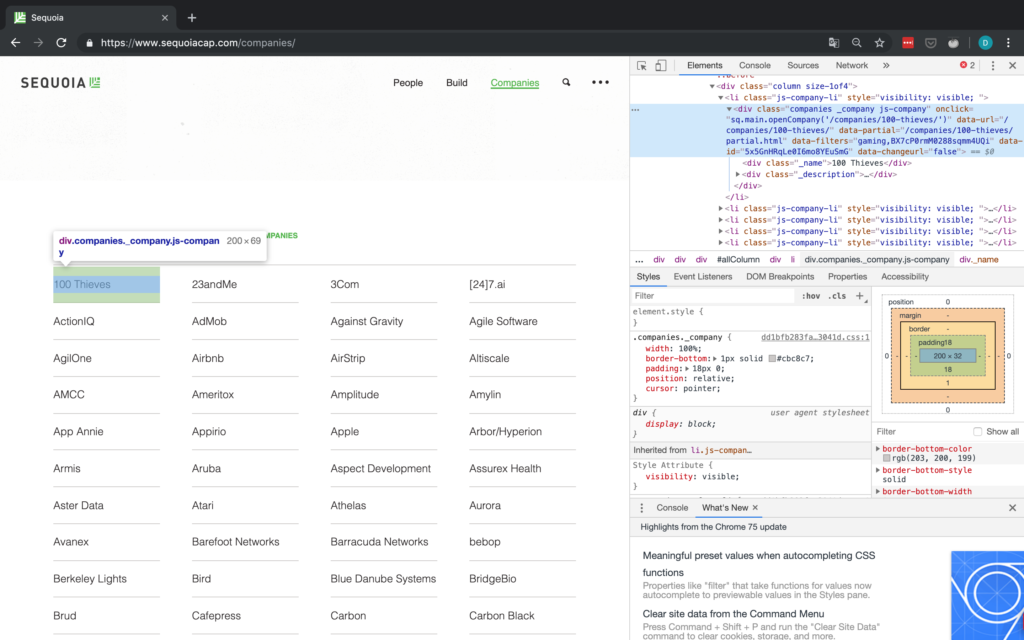
Damit fehlen aber immer noch alle anderen Informationen, d.h. wir müssen irgendwie auf die Detailseiten der einzelnen Unternehmen zugreifen. In Abbildung 5 oben hat jedes Unternehmen ein Attribut namens „data-url“. Für 100 Thieves zum Beispiel hat onclick den Wert /companies/100-thieves/. Das ist genau das, was wir brauchen!
Jetzt müssen wir nur noch dieses data-URL-Attribut für jedes Unternehmen an die Basis-URL anhängen (die einfach https://www.sequoiacap.com/ ist), und schon können wir eine weitere Anfrage senden, um die Detailseite jedes Unternehmens aufzurufen.
Schreiben wir also etwas Code, um zunächst den Firmennamen zu ermitteln und dann eine weitere Anfrage an die Detailseite jedes Unternehmens zu senden: Ich werde hier Code schreiben, der mit Text durchsetzt ist. Ein vollständiges Skript finden Sie in meinem .
Zunächst kümmern wir uns um alle Importe und richten alle Variablen ein, die wir benötigen. Wir senden auch unsere erste Anfrage an die Basis-URL, die das Raster mit allen Unternehmen enthält und einen BeautifulSoup-Parser instanziiert.
Nachdem wir uns um die grundlegende Buchführung gekümmert und das Wörterbuch eingerichtet haben, in dem wir die Daten auslesen wollen, können wir mit dem eigentlichen Auslesen beginnen, indem wir zunächst die in Abbildung 5 gezeigte Klasse analysieren. Wie in Abbildung 5 zu sehen ist, müssen wir, nachdem wir das „div“-Tag mit der passenden Klasse ausgewählt haben, zu dessen erstem „div“-Unterelement gehen und dann dessen Text auswählen, der dann den Namen des Unternehmens enthält.
URL des Unternehmens
Für die URL sollten wir nur in der Lage sein, Elemente anhand ihrer Klasse zu finden und dann das erste Element auszuwählen, da es scheint, dass die Website immer der erste soziale Link ist. Die Inspector-Ansicht ist in Abbildung 6 zu sehen.
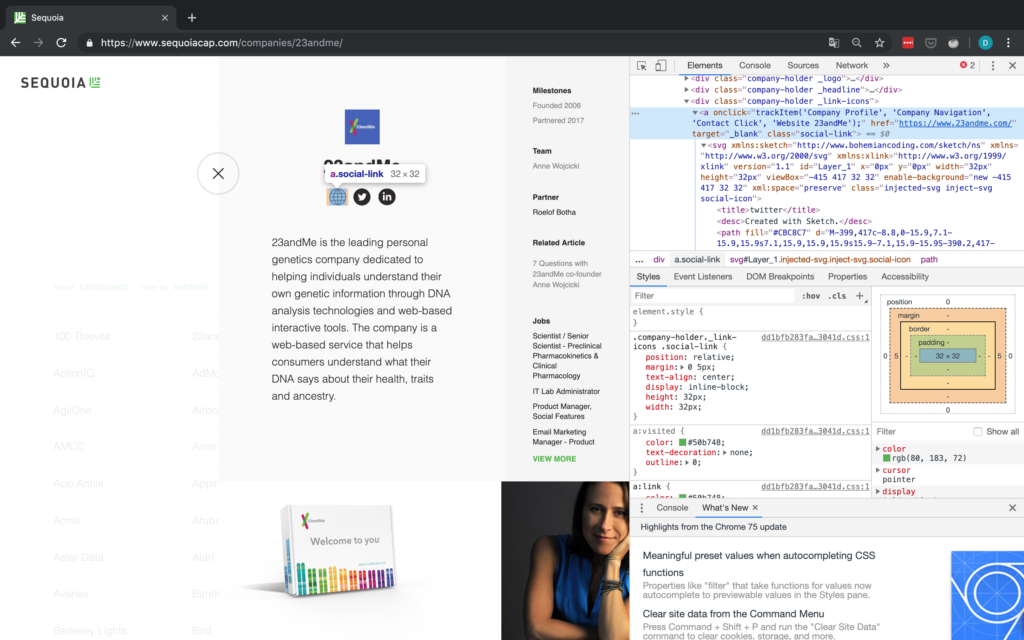
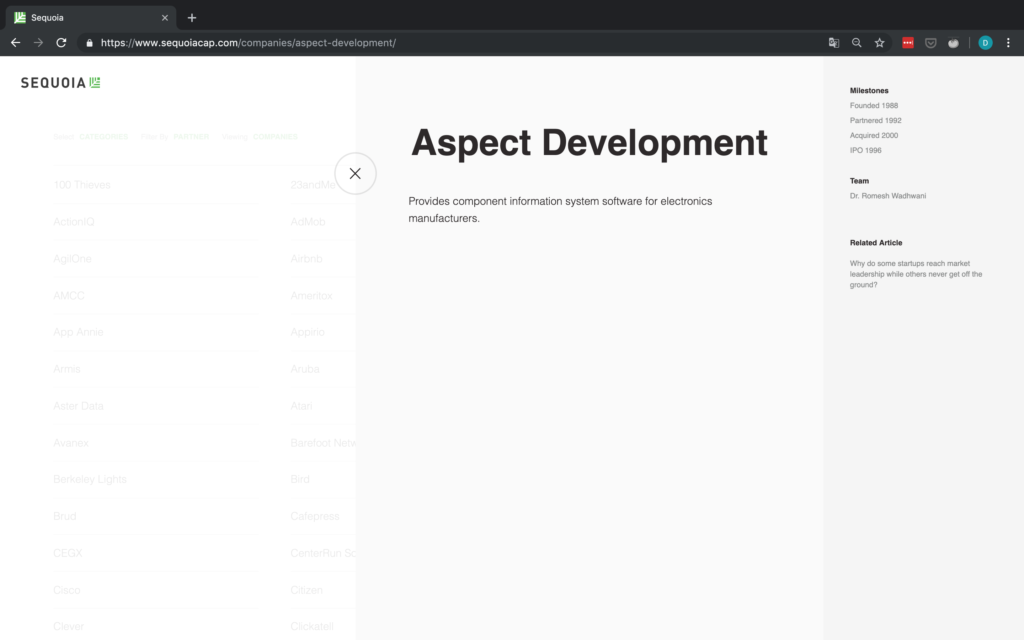
Aber halt – was ist, wenn es keine sozialen Links gibt oder die Website des Unternehmens nicht angegeben ist? Für den Fall, dass die Website nicht angegeben wird, wohl aber eine Social-Media-Seite, betrachten wir diesen Social-Media-Link einfach als die De-facto-Website des Unternehmens. Wenn überhaupt keine sozialen Links vorhanden sind, müssen wir einen NA anhängen. Aus diesem Grund überprüfen wir explizit die Anzahl der gefundenen Objekte, da wir nicht auf das href-Attribut eines Tags zugreifen können, das nicht existiert. Ein Beispiel für ein Unternehmen ohne URL ist in Abbildung 7 dargestellt.
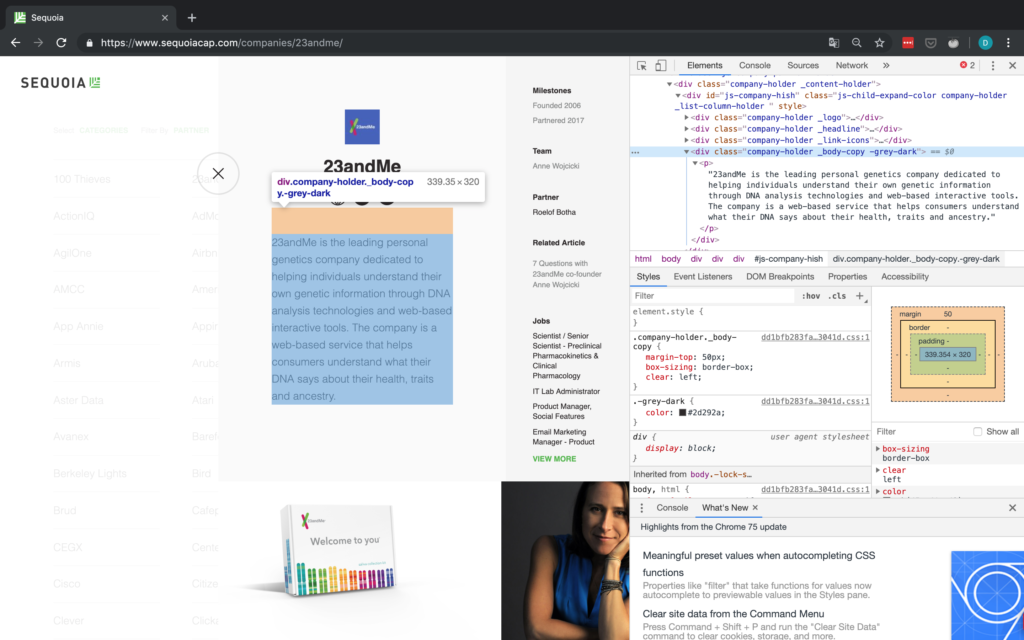
p-Tag, der die Unternehmensbeschreibung enthält, keine zusätzlichen identifier. Daher sind wir gezwungen, zuerst auf den „div“-Tag darüber zuzugreifen und dann zum p -Tag mit der Beschreibung zu gehen und dessen text
Die letzten drei Elemente befinden sich alle in derselben Struktur und können daher auf dieselbe Weise aufgerufen werden. Wir werden einfach den Text des übergeordneten Elements abgleichen und uns dann von dort aus nach unten vorarbeiten.
Da die spezifischen Textelemente keine guten Erkennungsmerkmale aufweisen, wird der Text des übergeordneten Elements abgeglichen. Sobald wir den Text haben, gehen wir zwei Ebenen nach oben, indem wir das Attribut parent verwenden. Dies bringt uns zum div-Tag, das zu dieser spezifischen Kategorie gehört (z.B. Meilensteine oder Team). Nun müssen wir nur noch zum ul-Tag hinuntergehen, das den eigentlichen Text enthält, an dem wir interessiert sind, und seinen Text abrufen.
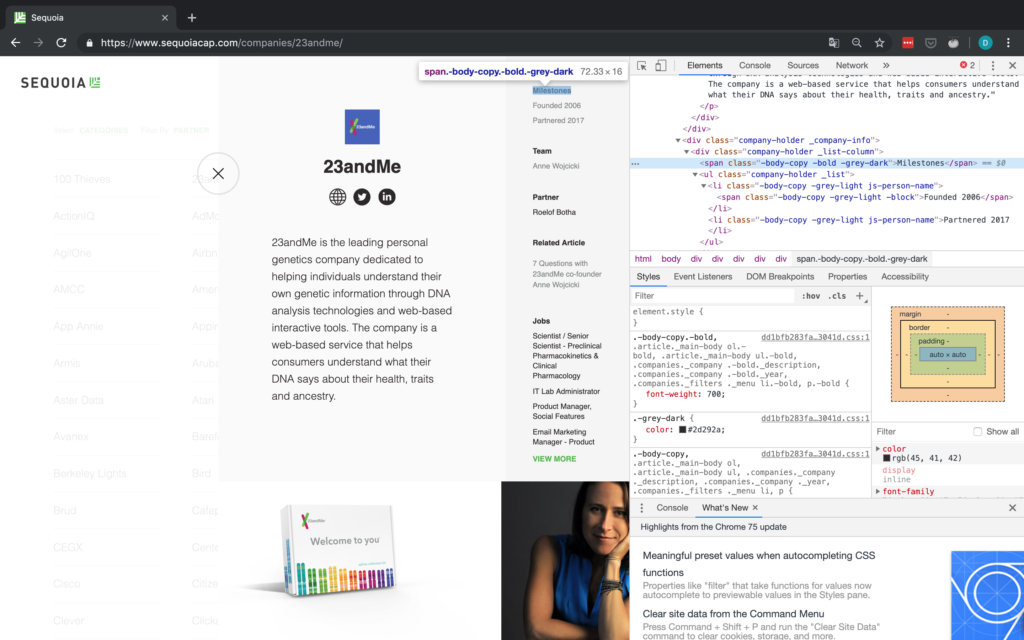
Ein Problem bei der Verwendung der Textübereinstimmung ist die Tatsache, dass nur exakte Übereinstimmungen gefunden werden. Dies ist in Fällen von Bedeutung, in denen die gesuchte Zeichenfolge auf verschiedenen Seiten leicht unterschiedlich sein kann. Wie Sie in Abbildung 10 sehen können, gilt dies für unsere Fallstudie hier für den Text Partner. Wenn einem Unternehmen mehr als ein Sequoia-Partner zugewiesen ist, lautet die Zeichenfolge „Partners“ statt „Partner“. Daher verwenden wir bei der Suche nach dem Element „Partner“ ein REGEX, um dies zu umgehen.

Zu guter Letzt ist nicht garantiert, dass alle gewünschten Elemente (d.h. Meilensteine, Team und Partner) tatsächlich für jedes Unternehmen verfügbar sind. Bevor wir also ein Element auswählen, suchen wir zunächst alle Elemente, die mit der Zeichenfolge übereinstimmen, und überprüfen dann die Länge. Wenn es keine übereinstimmenden Elemente gibt, fügen wir NA an, andernfalls erhalten wir die erforderlichen Informationen.
Für einen Partner gibt es immer ein Element, so dass wir davon ausgehen, dass keine Partnerinformationen verfügbar sind, wenn es ein oder weniger Elemente gibt. Ich glaube, der Grund dafür, dass immer ein Element mit einem Partner übereinstimmt, ist die in Abbildung 11 gezeigte Option „Filter nach Partner“. Wie Sie sehen, ist beim Scraping oft eine Iteration erforderlich, um mögliche Probleme mit Ihrem Skript zu finden.
Auf die Festplatte schreiben
Zum Abschluss fügen wir alle Informationen zu einem Unternehmen an die Liste an, zu der es in unserem Wörterbuch gehört. Dann konvertieren wir dieses Wörterbuch in einen Pandas DataFrame, bevor wir es auf die Festplatte schreiben.
Geschafft! Wir haben soeben alle Portfolio-Unternehmen von Seqouia und Informationen über sie gesammelt.
* Nun, zumindest alle auf ihrer Website, ich glaube, sie haben ihre eigenen Websites für z.B. Indien und Israel.
Werfen wir einen Blick auf die Daten, die wir gerade gescraped haben:
Sieht gut aus! Wir haben insgesamt 506 Unternehmen erfasst, und auch die Datenqualität sieht wirklich gut aus. Das Einzige, was mir aufgefallen ist, ist, dass einige Unternehmen zwar einen Social Link haben, dieser aber nirgendwo hinführt. In Abbildung 12 sehen Sie ein Beispiel dafür bei Pixelworks. Das Problem ist, dass Pixelworks einen Social Link hat, aber dieser Social Link enthält eigentlich keine URL (das href-Ziel ist leer) und verweist einfach auf das Sequoia-Portfolio.
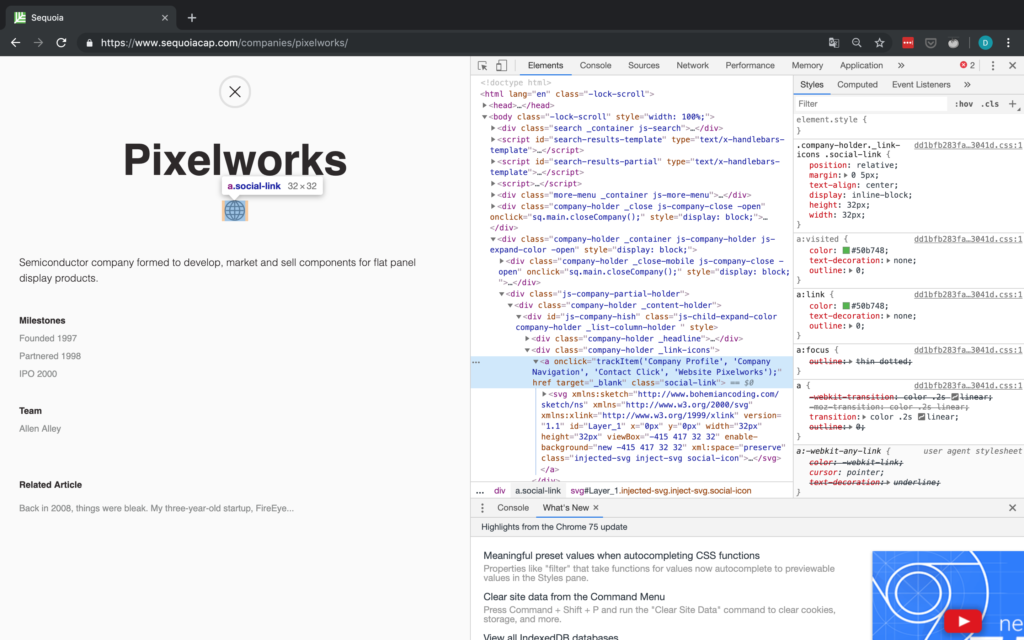
Ich habe dem Skript Code hinzugefügt, um die Leerzeichen durch NAs zu ersetzen, habe aber die Daten so belassen, wie sie sind, um diesen Punkt zu illustrieren.
Fazit
Mit diesem Blogbeitrag wollte ich Ihnen eine gute Einführung in das Web-Scraping im Allgemeinen und speziell in die Verwendung von Requests und BeautifulSoup geben. Jetzt können Sie es in der freien Wildbahn einsetzen, indem Sie Daten auslesen, die für Sie oder jemanden, den Sie kennen, von Nutzen sein können. Achten Sie aber immer darauf, dass Sie sowohl die robots.txt als auch die Nutzungsbedingungen der jeweiligen Seite, die Sie scrapen wollen, lesen und respektieren.
Darüber hinaus können Sie sich auf den offiziellen Websites Ressourcen und Anleitungen zu einigen der oben genannten Methoden wie Scrapy und Selenium ansehen. Sie sollten sich auch selbst herausfordern, indem Sie einige dynamischere Seiten scrapen, die Sie nicht nur mit Requests scrapen können.
Wenn Sie Fragen haben, einen Fehler gefunden haben oder einfach nur über alles, was mit Python und Scraping zu tun hat, plaudern möchten, können Sie uns gerne unter kontaktieren.
Die Datenexploration ist ein wichtiger Schritt in jedem Data Science-Projekt hier bei STATWORX. Um alle relevanten Erkenntnisse zu gewinnen, ziehen wir interaktive Diagramme statischen Diagrammen vor, da wir so die Möglichkeit haben, tiefer in die Daten einzudringen. Das hilft uns, alle Informationen sichtbar zu machen.
In diesem Blogbeitrag zeigen wir dir, wie du die Interaktivität von Plotly Histograms in Python verbessern kannst, wie du in der Grafik unten sehen kannst. Du findest den Code in unserem GitHub Repo.
TL;DR: Kurze Zusammenfassung
- Wir zeigen dir das Standard Histogram von Plotly und sein unerwartetes Verhalten.
- Wir verbessern das interaktive Histogram, damit es unserer menschlichen Intuition entspricht, und zeigen dir den Code.
- Wir erklären den Code Zeile für Zeile und geben dir mehr Informationen über die Implementierung.
Das Problem des Standard Histograms von Plotly
Diese Grafik zeigt dir das Verhalten eines Plotly Histograms, wenn du in eine bestimmte Region hinein zoomst. Du kannst sehen, dass die Balken einfach größer/breiter werden. Das ist nicht das, was wir erwarten! Wenn wir in ein Diagramm reinzoomen, wollen wir tiefer graben und feinere Informationen für einen bestimmten Bereich sehen. Deshalb erwarten wir, dass das Histogram detailliertere Informationen anzeigt. In diesem speziellen Fall erwarten wir, dass das Histogram Bins für die ausgewählte Region anzeigt. Daher muss das Histogram neu gebinnt werden.
Verbesserung des interaktiven Histograms
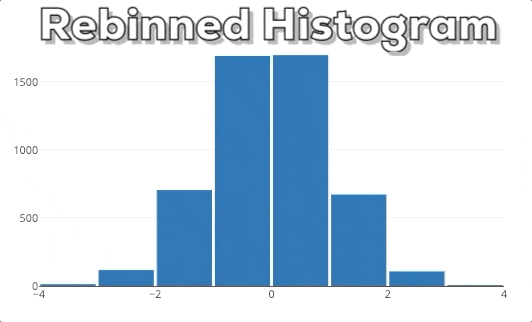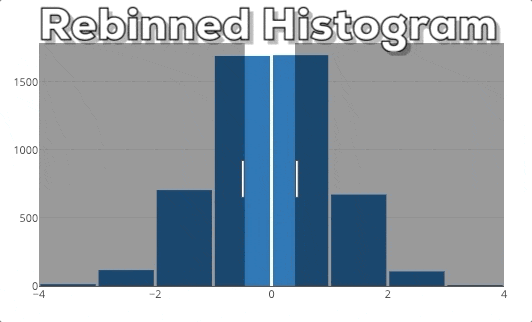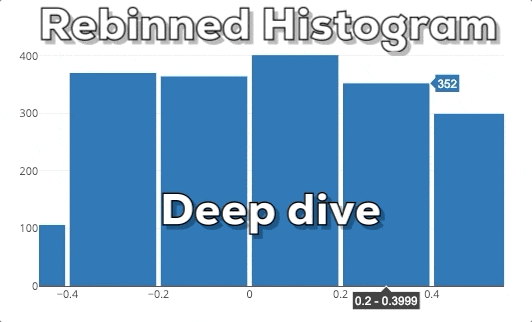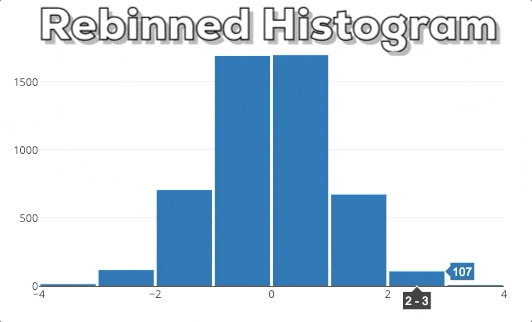
In dieser Grafik kannst du unser erwartetes Endergebnis sehen. Wenn man einen neuen x-Bereich auswählt, soll das Histogram auf der Grundlage des neuen x-Bereichs neu berechnet werden.
Um dieses Verhalten zu implementieren, müssen wir die Grafik ändern, wenn sich der ausgewählte x-Bereich ändert. Dies ist eine neue Funktion von plotly.py 3.0.0, die der großartige Jon Mease der Community zur Verfügung gestellt hat. Du kannst mehr über die neuen Funktionen von Plotly.py 3.0.0 in dieser Ankündigung lesen.
Hinweis: Die Implementierung funktioniert nur innerhalb eines Jupyter-Notebooks oder JupyterLabs, da sie einen aktiven Python-Kernel für den Callback benötigt. Sie funktioniert nicht in einem eigenständigen Python-Skript und auch nicht in einer eigenständigen HTML-Datei. Die Idee für die Umsetzung ist die folgende: Wir erstellen eine interaktive Abbildung und jedes Mal, wenn sich die X-Achse ändert, aktualisieren wir die zugrunde liegenden Daten des Histograms. Whoops, warum haben wir das Binning nicht geändert? Plotly Histograms übernehmen automatisch das Binning für die zugrunde liegenden Daten. Wir können also das Histogram die Arbeit machen lassen und nur die zugrunde liegenden Daten ändern. Das ist zwar ein wenig kontraintuitiv, spart aber eine Menge Arbeit.
Einblick in den vollständigen Code
Hier kommt also endlich der relevante Code ohne unnötige Importe usw. Wenn du den vollständigen Code sehen willst, schau bitte in diese GitHub-Datei.
x_values = np.random.randn(5000)
figure = go.FigureWidget(data=[go.Histogram(x=x_values,
nbinsx=10)],
layout=go.Layout(xaxis={'range': [-4, 4]},
bargap=0.05))
histogram = figure.data[0]
def adjust_histogram_data(xaxis, xrange):
x_values_subset = x_values[np.logical_and(xrange[0] <= x_values,
x_values <= xrange[1])]
histogram.x = x_values_subset
figure.layout.xaxis.on_change(adjust_histogram_data, 'range')
Detaillierte Erklärungen für jede Codezeile
Im Folgenden geben wir einige detaillierte Einblicke und Erklärungen zu jeder Codezeile.
1) Initialisierung der x_values
x_values = np.random.randn(5000)
Wir erhalten 5000 neue zufällige x_values, die nach einer Normalverteilung ausgegeben werden. Die Werte werden von der großartigen Numpy-Bibliothek erstellt, die mit np abgekürzt wird.
2) Erstellen der figure
figure = go.FigureWidget(data=[go.Histogram(x=x_values,
nbinsx=10)],
layout=go.Layout(xaxis={'range': [-4, 4]},
bargap=0.05))
Wir erzeugen eine neue FigureWidget-Instanz. Das FigureWidget-Objekt ist das neue „magische Objekt“, das von Jon Mease eingeführt wurde. Du kannst es in Jupyter Notebook oder JupyterLab wie eine normale Plotly figure anzeigen, aber es gibt einige Vorteile.Du kannst das FigureWidget auf verschiedene Arten in Python manipulieren und du kannst auch auf einige Ereignisse hören und weiteren Python-Code ausführen, was dir eine Menge Möglichkeiten gibt. Diese Flexibilität ist der große Vorteil, den sich Jon Mease ausgedacht hat. Das FigureWidget erhält die Attribute data und layout.
Als data geben wir eine Liste aller traces (sprich: Visualisierungen) an, die wir anzeigen wollen. In unserem Fall wollen wir nur ein einziges Histogram anzeigen. Die x-Werte für das Histogramm sind unsere x_values. Außerdem setzen wir die maximale Anzahl der Bins mit nbinsx auf 10. Plotly verwendet dies als Richtlinie, erzwingt aber nicht, dass der Plot genau nbinsx Bins enthält. Als layout geben wir ein neues Layout-Objekt an und setzen den Bereich der x-Achse (xaxis) auf [-4, 4]. Mit dem Argument bargap können wir das Layout dazu bringen eine Lücke zwischen den einzelnen Balken anzuzeigen. So können wir besser erkennen, wo ein Balken aufhört und der nächste beginnt. In unserem Fall wird dieser Wert auf 0.05 gesetzt.
3) Speichern einer Referenz zum Histogram
histogram = figure.data[0]
Wir erhalten den Verweis auf das Histogram, weil wir das Histogram im letzten Schritt-Updating-the-histogram-data) manipulieren wollen. Wir erhalten nicht die eigentlichen Daten, sondern einen Verweis auf das trace-Objekt von Plotly. Diese Plotly-Syntax ist vielleicht etwas irreführend, aber sie stimmt mit der Definition der Abbildung überein, in der wir auch die „traces“ als „data“ angegeben haben.
4) Überblick zum Callback
def adjust_histogram_data(xaxis, xrange):
x_values_subset = x_values[np.logical_and(xrange[0] <= x_values,
x_values <= xrange[1])]
hist.x = x_values_subset
figure.layout.xaxis.on_change(adjust_histogram_data, 'range')
In diesem Abschnitt legen wir zunächst fest, was wir tun wollen, wenn sich die x-Achse ändert. Danach registrieren wir die Callback-Funktion adjust_histogram_data. Wir werden das weiter aufschlüsseln, aber wir beginnen mit der letzten Zeile, weil Python diese Zeile zur Laufzeit zuerst ausführt. Deshalb ist es sinnvoller, den Code in dieser umgekehrten Reihenfolge zu lesen. Noch ein bisschen mehr Hintergrundwissen zum Callback: Der Code in der Callback-Methode adjust_histogram_data wird aufgerufen, wenn das Ereignis xaxis.on_change tatsächlich eintritt, weil Benutzende mit dem Diagramm interagiert haben. Aber zuerst muss Python die Callback-Methode adjust_histogram_data registrieren. Viel später, wenn das Callback-Ereignis xaxis.on_change eintritt, wird Python die Callback-Methode adjust_histogram_data und ihren Inhalt ausführen. Lies dir diesen Abschnitt 3-4 Mal durch, bis du ihn vollständig verstanden hast.
4a) Registrierung des Callbacks
figure.layout.xaxis.on_change(adjust_histogram_data, 'range')
In dieser Zeile teilen wir dem Figure-Objekt mit, dass es die Callback-Funktion adjust_histogram_data immer dann aufrufen soll, wenn sich die X-Achse ändert. Bitte beachte, dass wir nur den Namen der Funktion adjust_histogram_data ohne die runden Klammern () angeben. Das liegt daran, dass wir nur den Verweis auf die Funktion übergeben müssen und die Funktion nicht aufrufen wollen. Das ist ein häufiger Fehler und sorgt oftmals für Verwirrung. Außerdem geben wir an, dass wir nur an dem Attribut range interessiert sind. Daher wird das figure-Objekt nur diese Information an die Callback-Funktion senden.
Aber wie sieht die Callback-Funktion aus und was ist ihre Aufgabe? Diese Fragen werden in den nächsten Schritten erklärt:
4b) Definieren der Callback-Signatur
def adjust_histogram_data(xaxis, xrange):
Hier beginnen wir, unsere Callback-Funktion zu definieren. Das erste Argument, das an die Funktion übergeben wird, ist das Objekt xaxis, das den Callback ausgelöst hat. Das ist eine Konvention von Plotly und wir müssen diesen Platzhalter nur hier einfügen, obwohl wir ihn nicht benutzen. Das zweite Argument ist der xrange, der die untere und obere Grenze der neuen xrange-Konfiguration enthält. Du fragst dich vielleicht: „Woher kommen die Argumente xaxis und xrange?“ Diese Argumente werden automatisch von figure bereitgestellt, wenn der Callback aufgerufen wird. Wenn du Callbacks zum ersten Mal verwendest, mag dir das wie unergründliche Magie vorkommen. Aber du wirst dich daran gewöhnen…
4c) Aktualisieren der x_values
x_values_subset = x_values[np.logical_and(xrange[0] <= x_values,
x_values <= xrange[1])]
In dieser Zeile definieren wir unsere neuen x_values, die in den meisten Fällen eine Teilmenge der ursprünglichen x_values sind. Wenn die untere und die obere Grenze jedoch sehr weit voneinander entfernt sind, kann es passieren, dass wir alle ursprünglichen x_values auswählen. Die Teilmenge ist also nicht immer eine strenge Teilmenge. Die untere Grenze der xrange wird durch xrange[0] und die obere Grenze durch xrange[1] definiert. Um die Teilmenge der x_values auszuwählen, die innerhalb der unteren und oberen Grenze des Bereichs liegt, verwenden wir die Funktion logical_and von Numpy. Es gibt mehrere Möglichkeiten, wie wir in Python Teilmengen von Daten auswählen können. Zum Beispiel kannst du das auch über Pandas-Selektoren tun, wenn du Pandas Dataframes/Series verwendest.
4d) Aktualisieren der Histogram-Daten
histogram.x = x_values_subset
In dieser Zeile aktualisieren wir die zugrundeliegenden Daten des Histograms und setzen sie auf das neue x_values_subset. Diese Zeile löst die Aktualisierung des Histograms und das automatische Rebinning aus. Das histogram ist der Verweis, den wir in Schritt 3 des Codes erstellt haben, weil wir ihn hier brauchen.
Fazit
In diesem Blogbeitrag haben wir dir gezeigt, wie du das Standard-Histogram von Plotly durch interaktives Binning verbessern kannst. Wir haben dir den Code gegeben und jede Zeile der Implementierung erklärt. Wir hoffen, dass du uns folgen konntest und ein gutes Verständnis für die neuen Möglichkeiten von plotly.py 3.0.0 gewonnen hast.
Vielleicht hast du manchmal das Gefühl, dass du den Code, den du im Internet oder auf Stackoverflow findest, nicht gut verstehst. Wenn du intuitive Erklärungen für Themen aus Data Science-Welt suchst, solltest du dir einige unserer offenen Kurse ansehen, die von unseren Data Science-Expert:innen hier bei STATWORX unterrichtet werden.
Quellen
- Offizielles plotly.py GitHub-Repository https://github.com/plotly/plotly.py
- Offizielle Übersicht über alle neuen Funktionen von plotly.py 3.0.0 https://medium.com/@plotlygraphs/introducing-plotly-py-3-0-0-7bb1333f69c6
In unseren bisherigen Artikeln zu Data Science in Python haben wir uns mit der grundlegenden Syntax, Datenstrukturen, Arrays, der Datenvisualisierung und Manipulation/Selektion auseinander gesetzt. Was jetzt noch für den Einstieg fehlt, ist die Möglichkeit Modelle auf die Daten anzuwenden, um so zum einen Muster in diese zu erkennen und zum anderen Prädiktionen abzuleiten. Die Vielfalt an implementierten Modellen in Python und besonders in Scikit-Learn lässt sehr viel Spielraum für eine individuelle Anpassung der Modelle.
Machine Learning Bibliotheken für Python
Die wohl bekannste ML-Bibliothek, die sich in den letzten Jahren sehr stark weiter entwickelt hat, ist TensorFlow von Google. Sie wird vor allem für die Entwicklung und das Training von Neuronalen Netzen verwendet. Weitere bekannte Bibliotheken sind Keras, PyTorch, Caffe sowie MXNet. Weitere Informationen über die Funktionsweise von Neuronalen Netzen finden Sie in einem anderen Blogbeitrag von uns. Allerdings sollte man dabei stets beachten, dass Neuronale Netze nur ein Teilgebiet von Machine Learning darstellen. Auch Entscheidungsbäume, Random Forests und Support Vector Machines zählen zu ML-Modellen. Für Einstieger in diesem Bereich ist es somit sinnvoll sich eine Bibliothek herauszusuchen, die all diese Modelle umfasst und nicht den Fokus auf nur ein Teilgebiet wie Neuronale Netze legt. Scikit-Learn ist eine solche Bibliothek. Mit der stringenten Syntax werden das Entwickeln sowie die Applikation von Daten auf Modelle mehr als vereinfacht.
Einstieg mit Scikit-Learn
Die erste Veröffentlichung von Scikit-Learn fand im Jahr 2010 statt und hat sich seitdem stetig weiter entwickelt. Inzwischen umfasst die Code-Basis mehr als 150 Tsd. Zeien Code. Die Installation erfolgt wie bei den anderen Bibliotheken mit pip oder conda:
pip install scikit-learn
conda install scikit-learn
Scikit-Learn teilt seine verschiedenen Teilbibliotheken anhand der Machine Learning Aufgabenstellung auf:
- Classification (Beispiel: Kunde gehört zu Kategorie A, B, C?)
- Regression (Beispiel: Welcher Absatz kann im nächsten Monat erreicht werden?)
- Clustering (Beispiel: In welche Bereiche können die Kunden gegliedert werden?)
- Dimensionality Reduction
- Model selection
- Preprocessing
Die Teilbibliotheken lassen sich folgendermaßen importieren: import sklearn.cluster as cl. Für die Teilbibliotheken Classification und Regression gilt dies nur begrenzt, da sich ML-Modelle sowohl für die Regression wie für das Clustering nutzen lassen. Die Funktionsweise ist aber ähnlich:
# Neuronales Netz zur Klassifikation
from sklearn.neural_network import MLPClassifier
# Neuronales Netz zur Regression
from sklearn.neural_network import MLPRegressor
Aufbau des Modelltrainings
Je nachdem welches ML-Problem verfolgt wird, kann man sich mithilfe der obigen Aufteilung schnell einen Überblick verschaffen, welche Modelle in Scikit-Learn verfügbar sind. Die Funktionsweise des Modelltrainings ist dabei immer identisch:
# Import des Entscheidungsbaum
from sklearn import tree
# Beispieldaten
X = [[0, 0], [1, 1]]
Y = [0, 1]
# Initialisierung des Entscheidungsbaum zur Klassifizierung
clf = tree.DecisionTreeClassifier()
# Training des Entscheidungsbaums
clf = clf.fit(X, Y)
# Prädiktion für neue Daten
clf.predict([[2., 2.]])
Als erster Schritt erfolgt die Initialisierung des Modells, hierbei können Modellparameter genauer spezifiziert werden. Diese sind immer in der Dokumentation vorzufinden, wie bspw. hier. Werden keine Parameter angegeben, übernimmt Scikit-Learn die Standardkonfiguration des Modells. Für einen ersten Test, ob ein Modell überhaupt auf die Daten anwendbar ist, kann dies sehr hilfreich sein. Allerdings sollte es natürlich kein sofortiges Auschlusskriterium sein, wenn die Modellgüte nicht den gewünschten Erwartungen entspricht. Im nächsten Schritt wird das Modell mit der fit Methode trainiert, neue Daten können mit der predict Methode in das Modell eingespeist werden.
Nun wollen wir das vorherige Minimal-Beispiel erweitern und mit tatsächlichen Daten arbeiten. Ziel des Trainings des Entscheidungsbaums soll es sein, mithilfe der Features Alter, Geschlecht und Buchungsklasse zu entscheiden, ob ein Passagier den Titanic-Unfall überlebt hat oder nicht. Den Titanic Datensatz hatten wir bereits im Blogbeitrag zu Pandas verwendet.
Nach dem Import der Daten müssen wir zunächst die Variable Geschlecht transformieren, da der Entscheidungsbaum mit Daten im String-Format kein Training vornehmen kann. Anschließend extrahieren wir diejengen Trainingsspalten und entfernen im gleichen Zug fehlende Dateneinträge. Der wichtigste Schritt ist anschließend die Aufteilung in Trainings- sowie Testdaten, schließelich muss die Modellgüte mit den Daten überprüft werden, die das Modell nicht zum Training verwendet hat. Ein Aufteilung in 70% Trainings- / 30% Testdaten kann als gute Faustregel verwendet werden. Anschließend erfolgt das Training des Entscheidungsbaums. In diesem Fall ist die Tiefe des Entscheidungsbaums auf fünf begrenzt. Abschließend wird die Accuarcy für die Testdaten berechnet.
import seaborn as sns
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Laden der Daten
df = sns.load_dataset('titanic')
# Transformation der Variable Geschlecht
labelenc = preprocessing.LabelEncoder()
labelenc.fit(df.sex)
df['sex_transform'] = labelenc.transform(df.sex)
# Auswahl von Daten zum Training
train = df.loc[:,['age', 'fare', 'sex_transform', 'survived']].dropna()
# Aufteilen der Daten in Features und Target
y = train['survived']
X = train.drop('survived', axis=1)
# Aufteilen in Test und Train Daten
X_train, X_test, y_train
y_test = train_test_split(X, y, test_size=0.4, random_state=10, shuffle = True)
# Initialisierung des Entscheidungsbaums
clf = DecisionTreeClassifier(max_depth=5)
# Training des Entscheidungsbaums
clf.fit(X_train, y_train)
# Berechnung der Metrik
clf.score(X_test, y_test)
Dieser Ablauf wird auch für andere Modelle sehr ähnlich sein, da Scikit-Learn für jedes Modell immer ansatzweise dieselben Methoden implementiert hat. Beispielsweise würde es für ein Random Forest Modell wie folgt aussehen:
from sklearn.ensemble import RandomForestClassifier
# Initialisierung des Random Forest Modells
rf = RandomForestClassifier()
# Training des Random Forest Modells
rf.fit(X_train, y_train)
# Berechnung der Metrik
rf.score(X_test, y_test)
Diese Syntax durchzieht die Scikit-Learn Bibliothek wie ein roter Faden.
Tuning der Hyperparameter des Modells
Eine Herausforderung bei der Anwendung von Machine Learning Modellen ist die Bestimmungen der optimlen Parameter des Modells. Die Anzahl von Variationen ist so vielfältig, dass es nicht sinnvoll ist händisch jede einzelne Kombination zu überprüfen. Für diesen Prozess kann die sogenannte GridSearch-Methode verwendet werden. Aus allen Parametern wird ein Netz (Grid) mit allen Kombinationen aufgespannt je mehr Parameter in ihren Ausprägungen geprüft werden sollen, umso größer wird das Netz. Hat man sehr viele Kombinationen, ist es sinnvoll, eine zufällige Parameterkombination auszuwählen, da sich so passende Parameterkombinationen schneller finden lassen und das Verfahren schneller abläuft. Der Vergleich wird durch die folgende Grafik noch einmal verdeutlicht:
Wir stellen nun die vollständige Grid-Search Methode vor:
from sklearn.model_selection import GridSearchCV
# Definition der Paramerkombination
params = {"max_depth": range(3,15), "splitter": ["best", "random"]}
# Erstellen des Grids
grid = GridSearchCV(estimator=clf, param_grid=params,
cv=10, verbose=2, n_jobs=-1)
# Training des Grids
grid.fit(X_train, y_train)
print(grid.best_params_, grid.best_score_)
Die zu evaluierenden Parameterkombinationen werden in Form eines Dict erstellt, wobei der jeweilige Key dem Modellparameter entspricht. Dem Key wird dann eine Liste mit den verschiedenen Optionen übergeben. Also in diesem Fall die Tiefe des Entscheidungsbaums und die Aufteilungsmethode. Das grid-Objekt muss änhlich wie das Modell initialisiert werden. Mit dem Parameter n_jobs wird Optimierung parallel vorgenommen und läuft somit schneller ab. Zum Abschluss kann man sich die beste Parameterkombination für das Modell und den zugehörigen Score ausgeben lassen. Wichtig ist natürlich im Anschluss noch die Evaluation mit den Testdaten vorzunehmen. Welche Paramater für welchen Modelltyp in Frage kommen, ist pauschal so nicht zu beantworten, da dies häufig auch mit den Dateneigenschaften zusammen hängt.
Rückblick
In diesem Blogartikel haben wir die Funktionweise von Machine Learning Modellen anhand des Entscheidungsbaums mit Scikit-Learn dargestellt. Wichtig ist immer, dass Modell zu initialisieren, danach kann man das Modell triainieren (fit), sich Prädiktionen (predict) und die Genauigkeit (score) sich ausgeben lassen. Mit Scikit-Learn kann natürlich noch eine Vielzahl von Modellarten und Anwendungen umgesetzt werden. So lässt sich beispielsweise der kompletten Datenvoverarbeitungs- und Trainingsprozess in Pipelines zusammen fassen. Wie man dies umsetzt, hat mein Kollege Martin in seinem Artikel zusammengefasst. Die Reihe zum Einstieg mit Python in das Themenfeld Data Science endet nun mit diesem Beitrag.
Referenzen
- Bergstra, Bengio (2012): Random Search for Hyper-Parameter Optimization
Nachdem wir in dem vorherigen Artikel eine Einführung in Pandas gegeben haben und somit nun Daten auswählen sowie manipulieren können, soll sich in diesem Artikel alles um die Visualisierung von Daten drehen. Bekanntlicherweise lassen sich mit der passenden Grafik Daten häufig noch besser verstehen und ermöglichen eine andere Art der Interpretation, unabhängig von Mittelwerten und anderen Kennzahlen.
Welche Bibliothek zu Datenvisualisierung in Python?
In dem Bibliotheksdschungel von Python wimmelt es nur so von Bibliotheken, die sich zur Visualisierung eignen. Die Bandbreite reicht von einem einfachen Streudiagramm über die Darstellung der Struktur eines neuronalen Netzes bis zu 3D-Visualisierungen. Die älteste und ausgereifteste Datenvisualisierungs Bibliothek im Python Ökosystem ist Matplotlib. Mit dem Start der Entwicklung im Jahr 2003 hat sie sich kontinuierlich weiterentwickelt und bildet auch die Basis für die Bibliothek seaborn. Sie bietet eine große Fülle an Einstellungs- bzw. Customizing Möglichkeiten und orientiert sich dabei an MATLAB. Der Namenszusammenhang ist offensichtlich ;-).
Start mit Matplotlib
Grafiken mit Matplotlib zu erstellen kann auf zwei Arten erfolgen:
- via
pyplot - Objekt-orientierter Ansatz
An dieser Stelle sei angemerkt, dass es sich bei pyplot um eine Teilbibliothek von matplotlib handelt. Der erste Ansatz ist der meist verbereitete, da dieser einen einfachen Einstieg in Matplotlib ermöglicht. Hingegen bietet sich der zweite für wirklich sehr detailreiche Grafiken an, die viele Anpassungen erfordern, an. In diesem Blog-Beitrag werden die Grafiken ausschließlich mit pyplot erstellen. Die Erstellung orientiert sich dabei an folgender Vorgehensweise:
- Erstellung eines
figure-Objekts inkl.axes-Objekten - Bearbeiten der
axes-Objekte - Ausgabe des Objekts
Folglich bearbeiten wir in Python somit ein Objekt direkt, anstatt wie bei der „Gramma of Graphics“ Schicht für Schicht auf eine Grafik zu legen.
Initialisierung einer Grafik
Der Import von matplotlib typerweise wie folgt:
# Import Matplotlib
import matplotlib.pyplot as plt
Nun gilt es ein figure-Objekt anzulegen. An dieser Stelle sollte man sich zudem überlegen, wie viele Darstellungen man in seinem Objekt integrieren möchte, dies erleichtert den späteren Arbeitsfluss. Im folgenden Codebeispiel wird eine figure mit einer Spalte sowie einer Zeile erstellt.
# Initilaisierung einer Figure
fig, ax = plt.subplots(nrows = 1, ncols = 1)
# Ausgabe der Figure
fig
Die Methode figure liefert zwei Argumente zurück, es handelt sich dabei um die eigentlich figure sowie um ein Axes-Objekt. Dies hängt mit dem objektorientierten Ansatz von Matplotlib zusammen. Umfasst eine figure mehrere Teildarstellungen wie z.B. Histogramme von unterschiedlichen Daten, so kann man die Teildarstellungen einzeln über das Axes-Objekt bearbeiten und das figure-Objekt fasst alle Teildarstellungen zusammen. Die figure umfasst somit die graphische Darstellung und das Axes-Objekt die einzelnen Teildarstellungen. Lässt man sich die erstellte Variable fig ausgeben, so erhält man folgende Darstellung:
Unsere Grafik enthält also bis jetzt nur ein Koordinatensystem. Um den objektorientieren Ansatz noch einmal zu verdeutlichen erstellen wir eine figure mit insgesamt zwei Zeilen und Splaten.
# Erstellen einer Figure mit 4 separaten Grafiken
fig, ax = plt.subplots(nrows = 2, ncols = 2)
Mittels Indexselektion kann man nun die einzelnen Teildarstellungen aus dem Grid auswählen. Somit sollte der objektorientierte Ansatz klar und deutlich geworden sein.
# Auswahl der einzelnen Teildarstellungen
ax[0,0]
ax[0,1]
ax[1,0]
ax[1,1]
Bei der Initialisierung einer Grafik sind natürlich Anpassungen im Hinblick auf die Größe der Grafik denkbar, dies lässt sich wie folgt umsetzen:
# Festlegung der figure Größe
fig, ax = plt.subplots(nrows = 2, ncols = 2, figsize = (10, 12))
Die Grafikgröße wird als Tuple (Breite, Höhe) in Inches angegeben.
Darstellung von Daten
Nachdem wir dargestellt haben wie man eine Grafik in Matplotlib initialisieren kann, soll es nun darum gehen, diese mit Daten zu befüllen. Für den Einstieg nehmen wir die erste figure aus dem Blog-Beitrag. Zur Darstellung von Daten greifen wir auf das Axes-Objekt zu und wählen zu Beginn die Funktion plot. Eine Vielzahl von weiteren Funktionen kann unter diesem Link gefunden werden.
# Erstellen der Grafik
fig, ax = plt.subplots(nrows = 1, ncols = 1)
# Erstellen von Beispieldaten
sample_data = np.random.randint(low = 0, high = 10, size = 10)
# Darstellung der Beispieldaten
ax.plot(sample_data)
# Ausgabe der Figure
fig
An dieser Stelle sei kurz angemerkt, dass Matplotlib im Hintergrund zwei Vorgänge durchgeführt hat:
- Die Skala wurde automatisch an die Daten angepasst.
- Die Darstellung der Daten erfolgte über den Index, d. h. der eigentliche Wert ist auf der y-Achse.
Ist man der Auffassung, dass z.B. ein Streudiagramm besser geeignet wäre, so lässt sich die Grafik einfach ändern. Anstelle von plot schreibt man scatter. Der Codes zeigt, dass in diesem Fall nicht die Daten automatisch über den Index dargestellt wurden, sondern explizit x und y als Argumente übergeben müssen.
# Erstellen der Grafik
fig, ax = plt.subplots(nrows = 1, ncols = 1)
# Erstellen von Beispieldaten
sample_data = np.random.randint(low = 0, high = 10, size = 10)
# Darstellung der Beispieldaten
ax.scatter(x = range(0, len(sample_data)), y=sample_data)
# Ausgabe der Figure
fig
Alle typischen Datenvisualisierungen lassen sich so mit Matplotlib umsetzen.
Beschriftungen und Speichern von Grafiken
Die Darstellung der Daten ist die eine Sache, mit einer passenden Überschrift werden sie dann doch verständlicher.
Als Beispiel wollen wir ein Histogramm mit den Beispieldaten beschriften. Mithilfe der Funktionen set_ kann die Beschriftung einfach vorgenommen werden.
fig, ax = plt.subplots(nrows=1, ncols=1)
sample_data = np.random.randint(low = 0, high = 10, size = 10)
ax.hist(sample_data,width = 0.4)
# Hinzufügen der Beschriftungen
ax.set_xlabel('Beispieldaten')
ax.set_ylabel('Häufigkeiten')
ax.set_title('Histogramm mit Matplotlib')
# Ausgabe der Figure
fig
Wir erhalten folgende Grafik:
Möchte man gerne seine Grafik speichern, so kann man über die Funktion fig.savefig('Pfad der Grafik') dies vornehmen.
Resümee und Ausblick
Dieser Blog Beitrag sollte einen ersten Einstieg in die Python Visualisierungsbibliothek Matplotlib geben und grundlegende Konzepte vermitteln. Die Anpassbarkeit der Grafiken geht weit über die Funktionen, die wir vorgestellt haben, hinaus:
- Anpassung der Farben, Farbverläufe,…
- individuelle Axenbeschriftung/-skalierung
- Annotieren von Grafiken mit Text Boxen
- Änderung der Schriftart
- …
Allgemein ist zu berücksichtigen, die passenden Daten für die Grafiken auszuwählen, wie man das mit Pandas umsetzen kann, lässt sich hier nachlesen. Im nächsten Beitrag in dieser Serie wird es dann um Scikit-Learn gehen, der Einsteiger Machine Learning Bibliothek in Python.