Experimente zur Bilderkennung durch die Genderbrille
Im ersten Teil unserer Serie haben wir uns mit einer einfachen Frage beschäftigt: Wie würde sich unser Aussehen verändern, wenn wir Fotos von uns entlang des Genderspektrums bewegen würden? Aus diesen Experimenten entstand die Idee, genderneutrale Gesichtsbilder aus vorhandenen Fotos zu erstellen. Gibt es einen Punkt in der Mitte, an dem wir unser „Gender”, unser Geschlecht, als neutral wahrnehmen? Und außerdem: Wann würde eine KI ein Gesicht als genderneutral wahrnehmen?
Bewusstsein für die Technologie, die wir täglich nutzen
Die Bilderkennung ist ein wichtiges Thema. Diese Technologie entwickelt sich täglich weiter und wird in einer Vielzahl von Anwendungen eingesetzt – oft ohne, dass Benutzer:innen wissen, wie die Technologie funktioniert. Ein aktuelles Beispiel ist der „Bold-Glamour-Filter“ auf TikTok. Bei Anwendung mit weiblich aussehenden Gesichtern ändern sich Gesichtsmerkmale und Make-up drastisch. Im Gegensatz dazu ändern sich männlich aussehende Gesichter deutlich weniger. Dieser Unterschied lässt vermuten, dass die KI hinter den Filtern mit unausgewogenen Daten entwickelt wurde. Die Technologie dahinter basiert höchstwahrscheinlich auf sogenannten „General Adversarial Networks“ (GANs), also dieselbe Art von KI, die wir in diesem Artikel untersuchen.
Als eine Gesellschaft bewusster Bürger:innen sollten wir alle die Technologie verstehen, die solche Anwendungen ermöglicht. Um das Bewusstsein dafür zu schärfen, untersuchen wir die Erzeugung und Klassifizierung von Gesichtsbildern durch eine genderspezifische Brille. Anstatt mehrere Schritte entlang des Spektrums zu erforschen, besteht unser Ziel dieses Mal darin, geschlechtsneutrale Versionen von Gesichtern zu erzeugen.
Wie man genderneutrale Gesichter mit StyleGAN generiert
Ein Deep-Learning-Modell zur Geschlechtsidentifizierung
Es ist alles andere als trivial, einen Punkt zu bestimmen, ab dem das Gender eines Gesichts als neutral gilt. Nachdem wir uns auf unsere eigene (natürlich nicht unvoreingenommene) Interpretation von Gender in Gesichtern verlassen hatten, wurde uns schnell klar, dass wir eine konsistente und weniger subjektive Lösung benötigen. Als KI-Spezialist:innen dachten wir sofort an datengetriebene Ansätze. Ein solcher Ansatz kann mit einem auf Deep Learning basierenden Bildklassifikator umgesetzt werden.
Solche Klassifikationsmodelle werden in der Regel auf großen Datensätzen mit gekennzeichneten Bildern trainiert, um zwischen festgelegten Kategorien zu unterscheiden. Bei der Klassifizierung von Gesichtern sind Kategorien wie Gender (in der Regel nur weiblich und männlich) und ethnische Zugehörigkeit übliche Kategorien. In der Praxis werden solche Modelle oft wegen ihres Missbrauchspotenzials und ihrer Unfairness kritisiert. Bevor wir Beispiele für diese Probleme erörtern, werden wir uns zunächst auf unser weniger kritisches Szenario konzentrieren. In unserem Anwendungsfall ermöglichen es uns Klassifikationsmodelle, die Erstellung von genderneutralen Portraits vollständig zu automatisieren. Um dies zu erreichen, können wir folgendermaßen eine Lösung implementieren:
Wir verwenden einen GAN-basierten Ansatz, um Portraits zu erzeugen, die auf einem gegebenen Inputbild basieren. Dazu verwenden wir die latenten Richtungen des gelernten Genderspektrums des GAN, um das Bild in Richtung eines eher weiblichen oder männlichen Aussehens zu bewegen. Eine detaillierte Untersuchung dieses Prozesses ist im ersten Teil unserer Serie zu finden. Aufbauend auf diesem Ansatz wollen wir uns auf die Verwendung eines binären Gender-Klassifikators konzentrieren, um die Suche nach einem genderneutralen Aussehen vollständig zu automatisieren.
Dazu verwenden wir den von Furkan Gulsen entwickelten Klassifikator, um das Gender der GAN-generierten Version unseres Eingabebildes zu erraten. Der Klassifikator gibt einen Wert zwischen Null und Eins aus, um die Wahrscheinlichkeit darzustellen, dass das Bild ein weibliches bzw. männliches Gesicht darstellt. Dieser Wert sagt uns, in welche Richtung (eher männlich oder eher weiblich) wir uns bewegen müssen, um uns einer geschlechtsneutralen Version des Bildes anzunähern. Nachdem wir einen kleinen Schritt in die ermittelte Richtung gemacht haben, wiederholen wir den Vorgang, bis wir zu einem Punkt gelangen, an dem der Klassifikator das Gender des Gesichts nicht mehr sicher bestimmen kann. Dieser Punkt ist erreicht, sobald der Klassifikator die männliche als auch die weibliche Kategorie für gleich wahrscheinlich hält.
Die folgenden Beispiele illustrieren diesen Status und repräsentieren unsere Ergebnisse. Auf der linken Seite ist das Originalbild zu sehen. Rechts sehen wir die genderneutrale Version des Portraits, welches der Klassifikator mit gleicher Wahrscheinlichkeit als männlich oder weiblich interpretiert. Wir haben versucht, das Experiment für Mitglieder verschiedener Ethnien und Altersgruppen zu wiederholen.
Resultat: Originalportrait und KI-generierter, genderneutraler Output





Bist du neugierig, wie der Code funktioniert oder wie du selbst aussehen würdest? Du kannst den Code, mit dem wir diese Bildpaare erzeugt haben, unter diesem Link ausprobieren. Drücke einfach nacheinander auf jeden Play-Button und warte, bis du das grüne Häkchen siehst.
Hinweis: Wir haben ein bestehendes GAN, einen Bild-Encoder und einen Gesichter-Klassifikator verwendet, um einen genderneutralen Output zu generieren. Eine detaillierte Untersuchung dieses Prozesses ist hier zu finden.
Wahrgenommene Genderneutralität scheint eine Folge von gemischten Gesichtszügen zu sein
Oben sehen wir die Originalportraits verschiedener Personen auf der linken Seite und rechts ihr genderneutrales Gegenstück – von uns erstellt. Subjektiv fühlen sich einige „neutraler“ an als andere. In einigen der Bilder bleiben besonders stereotype Gendermerkmale erhalten, wie z. B. Make-up bei den Frauen und eine eckige Kieferpartie bei den Männern. Als besonders überzeugend empfinden wir die Ergebnisse von Bild 2 und Bild 4. Bei diesen Bildpaaren ist es nicht nur schwieriger, die ursprüngliche Person zurückzuverfolgen, sondern es ist auch viel schwieriger zu entscheiden, ob das Gesicht eher männlich oder weiblich wirkt. Man könnte argumentieren, dass die genderneutralen Gesichter eine ausgewogene, abgeschwächte Mischung aus männlichen und weiblichen Gesichtszügen besitzen. Wenn man beispielsweise Teile der genderneutralen Version von Bild 2 herausgreift und sich darauf konzentriert, erscheinen die Augen- und Mundpartien eher weiblich, während die Kieferlinie und die Gesichtsform eher männlich wirken. Bei der genderneutralen Version von Bild 3 mag das Gesicht allein recht neutral aussehen, aber die kurzen Haare lenken davon ab, so dass der Gesamteindruck in Richtung männlich geht.
Die Trainingsdaten für die Bilderzeugung wurden heftig kritisiert, weil sie nicht repräsentativ für die bestehende Bevölkerung sind, insbesondere was die Unterrepräsentation verschiedener Ethnien und Gender betrifft. Trotz „Cherry Picking“ und einer begrenzten Auswahl an Beispielen sind wir der Meinung, dass unser Ansatz in den obigen Ergebnissen keine schlechteren Beispiele für Frauen oder People of Color hervorgebracht hat.
Gesellschaftliche Bedeutung solcher Modelle
Wenn wir über das Thema der Genderwahrnehmung sprechen, sollten wir nicht vergessen, dass Menschen sich einem anderen Gender zugehörig fühlen können als ihrem biologischen Geschlecht. In diesem Artikel verwenden wir Modelle zur Genderklassifizierung und interpretieren die Ergebnisse. Unsere Einschätzungen werden jedoch wahrscheinlich von der Wahrnehmung anderer Menschen abweichen. Dies ist eine wesentliche Überlegung bei der Anwendung solcher Bildklassifizierungsmodelle und eine, die wir als Gesellschaft diskutieren müssen.
Wie kann Technologie alle gleich behandeln?
Eine Studie des Guardian hat ergeben, dass Bilder von Frauen, die in denselben Situationen wie Männer dargestellt werden, von den KI-Klassifizierungsdiensten von Microsoft, Google und AWS mit größerer Wahrscheinlichkeit als anzüglich eingestuft werden. Die Ergebnisse dieser Untersuchung sind zwar schockierend, aber nicht überraschend. Damit ein Klassifizierungsalgorithmus lernen kann, was anstößige Inhalte sind, müssen Trainingsdaten von Bild- und Label-Paaren erstellt werden. Diese Aufgabe übernehmen Menschen. Sie werden durch ihre eigene soziale Voreingenommenheit beeinflusst und assoziieren beispielsweise Darstellungen von Frauen schneller mit Sexualität. Außerdem sind Kriterien wie „Anzüglichkeit“ schwer zu quantifizieren, geschweige denn zu definieren.
Auch wenn diese Modelle nicht ausdrücklich auf die Unterscheidung zwischen den Geschlechtern trainiert werden, besteht kaum ein Zweifel daran, dass sie unerwünschte Vorurteile gegenüber Frauen verbreiten, die aus ihren Trainingsdaten stammen. Ebenso können gesellschaftliche Vorurteile, die Männer betreffen, an KI-Modelle weitergegeben werden. Bei der Anwendung auf Millionen von Online-Bildern von Menschen wird das Problem der Geschlechterungleichheit noch verstärkt.
Verwendung in der Strafverfolgung wirft Probleme auf
Ein weiteres Szenario für den Missbrauch von Bildklassifizierungstechnologie besteht in der Strafverfolgung. Fehlklassifizierungen sind problematisch und werden in einem Artikel von The Independent als weit verbreitet dargestellt. Als die Erkennungssoftware von Amazon in einer Studie aus dem Jahr 2018 mit einem Konfidenzniveau von 80 % verwendet wurde, ordnete die Software 105 von 1959 Teilnehmer:innen fälschlicherweise Fahndungsfotos von Verbrecher:innen zu. Angesichts der oben beschriebenen Probleme mit der Verarbeitung von Bildern, auf denen Männer und Frauen abgebildet sind, könnte man sich ein ernüchterndes Szenario vorstellen, wenn man das Verhalten von Frauen im öffentlichen Raum beurteilt. Wenn Männer und Frauen für dieselben Handlungen oder Positionen unterschiedlich beurteilt werden, würde dies das Recht aller auf Gleichbehandlung vor dem Gesetz beeinträchtigen. Der Bayerische Rundfunk hat eine interaktive Seite veröffentlicht, auf der die unterschiedlichen Einstufungen der KI-Klassifizierungsdienste mit der eigenen Einschätzung verglichen werden können.
Verwendung genderneutraler Bilder zur Vermeidung von Vorurteilen
Neben den positiven gesellschaftlichen Potenzialen der Bildklassifizierung wollen wir auch einige mögliche praktische Anwendungen ansprechen, die sich aus der Möglichkeit ergeben, mehr als nur zwei Gender abzudecken. Eine Anwendung, die uns in den Sinn kam, ist die Verwendung von „genderlosen“ Bildern, um Vorurteile zu vermeiden. Ein solcher Filter würde einen Verlust an Individualität bedeuten, sodass er nur in Kontexten anwendbar wäre, in denen der Nutzen der Verringerung von Vorurteilen die Kosten dieses Verlusts überwiegt.
Vision einer Browsererweiterung für den Bewerbungsprozess
Die Personalauswahl könnte ein Bereich sein, in dem genderneutrale Bilder zu weniger genderbasierter Diskriminierung führen könnten. Vorbei sind die Zeiten der gesichtslosen Bewerbungen: Wenn ein LinkedIn-Profil ein Profilbild hat, ist die Wahrscheinlichkeit, dass es angesehen wird, 14-mal höher . Bei der Prüfung von Bewerbungsprofilen sollten Personalverantwortliche idealerweise frei von unbewussten, ungewollten genderspezifischen Vorurteilen sein. Die menschliche Natur verhindert dies. So könnte man sich eine Browsererweiterung vorstellen, die eine genderneutrale Version von Profilfotos auf professionellen Social-Networking-Seiten wie LinkedIn oder Xing generiert. Dies könnte zu mehr Gleichheit und Neutralität im Einstellungsprozess führen, bei dem nur die Fähigkeiten und der Charakter zählen sollten, nicht aber das Geschlecht – oder das Aussehen (ein schönes Privileg).
Schlusswort
Wir haben uns zum Ziel gesetzt, automatisch genderneutrale Versionen aus einem beliebigen Portrait zu erzeugen.
Unsere Implementierung automatisiert in der Tat die Erstellung von genderneutralen Gesichtern. Wir haben ein bestehendes GAN, einen Bild-Encoder und einen Gesichter-Klassifikator verwendet. Unsere Experimente mit den Portraits oben zeigen, dass der Ansatz in vielen Fällen gut funktioniert und realistisch aussehende Gesichtsbilder erzeugt, die dem Eingabebild deutlich ähneln und dabei genderneutral bleiben.
In einigen Fällen haben wir jedoch festgestellt, dass die vermeintlich neutralen Bilder Artefakte von technischen Störungen enthalten oder noch ihr erkennbares Gender haben. Diese Einschränkungen ergeben sich wahrscheinlich aus der Beschaffenheit des latenten Raums des GANs oder aus dem Mangel an künstlich erzeugten Bildern in den Trainingsdaten des Klassifikators. Wir sind zuversichtlich, dass weitere Arbeiten die meisten dieser Probleme für reale Anwendungen lösen können.
Die Fähigkeit der Gesellschaft, eine fundierte Diskussion über Fortschritte in der KI zu führen, ist von entscheidender Bedeutung
Bildklassifizierung hat weitreichende Folgen und sollte von der Gesellschaft und nicht nur von einigen wenigen Expert:innen bewertet und diskutiert werden. Jeder Bildklassifikationsdienst, der dazu dient, Menschen in Kategorien einzuteilen, sollte genau geprüft werden. Was vermieden werden muss, ist, dass Mitglieder der Gesellschaft zu Schaden kommen. Die Einführung eines verantwortungsvollen Umgangs mit solchen Systemen, die Kontrolle und die ständige Bewertung sind unerlässlich. Eine weitere Lösung könnte darin bestehen, Strukturen für die Begründung von Entscheidungen zu schaffen und dabei die Best Practices von Explainable AI zu nutzen, um darzulegen, warum bestimmte Entscheidungen getroffen wurden. Als Unternehmen im Bereich der KI sehen wir bei statworx unsere KI-Prinzipien als Wegweiser.
Bildnachweise:
AdobeStock 210526825 – Wayhome Studio
AdobeStock 243124072 – Damir Khabirov
AdobeStock 387860637 – insta_photos
AdobeStock 395297652 – Nattakorn
AdobeStock 480057743 – Chris
AdobeStock 573362719 – Xavier Lorenzo
AdobeStock 546222209 – Rrose Selavy
OpenAI hat diese Woche eine neue Version des Sprachmodells hinter ChatGPT veröffentlicht – GPT-4. Die Neuerungen dieses Modells haben das Potenzial, die bisherigen Grenzen des Sprachverständnisses zu erweitern und die Interaktion zwischen Mensch und Maschine auf ein neues Niveau zu bringen. Wir haben uns sofort mit den wichtigsten Neuerungen von GPT-4 beschäftigt und unsere ersten Eindrücke zusammengetragen.
Zu Beginn des Jahres erhielt bereits viel Aufmerksamkeit für seine beeindruckenden Leistungen bei Aufgaben, die die Verarbeitung natürlicher Sprache benötigen. So ist das leistungsstarke Textgenerierungsmodell von OpenAI in der Lage, menschenähnliche Texte zu erzeugen, Code zu vervollständigen oder kurze Gedichte oder Geschichten zu erstellen, auch wenn es noch lange nicht perfekt ist.
Nach eigenen Angaben ist das Modell GPT-4 nun noch kreativer, zuverlässiger und kann komplexe Aufgaben mit größerer Genauigkeit als sein Vorgänger lösen. In einer öffentlichen Demo hat das Modell gezeigt, wie es auf Basis einer einfachen Skizze ein voll funktionsfähiges Websitelayout generieren kann – ein Beispiel für die Fähigkeit von GPT-4, nicht nur Text, sondern auch Bilder zu verarbeiten. Wir werfen einen ersten Blick auf die Neuerungen und Erweiterungen des Sprachmodells.
#1 Neben Text können auch Bilder verarbeitet werden
Das ist neu
GPT-4 ist in der Lage, nicht nur Text, sondern auch visuelle Inhalte in Form von Bildern zu erfassen und zu analysieren. Demnach kann das Modell Bilder beschreiben, interpretieren sowie Zusammenhänge zwischen diesen aufzeigen. Im Rahmen von Vorführungen hat sich gezeigt, dass GPT-4 in der Lage ist, schrittweise Erklärungen von Memes zu liefern oder komplexe Infografiken zusammenzufassen.
Unsere Einschätzung
Die Funktion von GPT-4, Bilder zu verarbeiten, ist momentan lediglich ausgewählten Partnern von OpenAI vorbehalten. Nichtsdestotrotz existieren bereits seit einiger Zeit weitere KI-Systeme, welche die Verknüpfung von Sprache und Bildern ermöglichen. Gerade im Bereich der automatisierten Informationsextraktion aus Dokumenten ist die Erweiterung des Modelinputs auf die visuelle Domäne von Vorteil. So können mit GPT4 auch Informationen berücksichtigt werden, die sich in Abbildungen und Graphen des Dokuments wiederfinden.
#2 Die Performance bei komplexen Aufgaben ist signifikant besser
Das ist neu
GPT-4 hat in zahlreichen Benchmark-Tests im Vergleich zu seinem Vorgänger signifikante Leistungsverbesserungen gezeigt. Insbesondere bei Prüfungen, die in der Regel von Jura- oder naturwissenschaftlichen Studierenden absolviert werden, erzielt das Modell überdurchschnittlich hohe Punktzahlen.
Unsere Einschätzung
Auf den ersten Blick ist das Abschneiden von GPT-4 zweifellos beeindruckend und zeigt, wie gut die KI in der Lage ist, Wissen in Textform wiederzugeben. Man sollte jedoch nicht vergessen, dass die verwendeten Tests konzipiert wurden, um Menschen anhand ihrer Fähigkeiten in einem bestimmten Bereich untereinander zu vergleichen. Anforderungen an eine spezialisierte KI, die für einen bestimmten Teilbereich optimiert wurde, können daher von Leistungsanforderungen an Menschen abweichen.
#3 Der Antwortstil des Models kann je nach Nutzungszweck angepasst werden
Das ist neu
Durch Verwendung einer System Message steht sowohl Entwickler:innen als auch später Nutzer:innen von ChatGPT eine Option zur Verfügung, um den Antwortstil des Sprachmodells anzupassen.
Unsere Einschätzung dazu
Die Möglichkeit das Antwortverhalten von GPT-4 anzupassen, erlaubt Nutzer:innen die Technologie besser auf ihren Anwendungsbereich zuzuschneiden und beispielsweise Serviceerfahrungen zu verbessern. Der Vorteil des gewählten Ansatzes – das Sprachmodell kann einfach für Downstream-Aufgaben optimiert werden, ohne das große Datenmengen oder weitere Trainingsressourcen benötigt werden.
#4 Die verarbeitbare Textmenge verachtfacht sich
Das ist neu
Die Länge des Kontexts, die während des Prozesses der Textgenerierung von GPT-4 genutzt werden kann, steigt in den verschiedenen Versionen auf bis zu 32.000 Wörter oder etwa 50 Seiten an. Somit ist GPT-4 nun in der Lage, Texte mit höherer Kohärenz und einem stärkeren Fokus auf das ursprüngliche Thema zu generieren.
Unsere Einschätzung dazu
Die Fähigkeit, größere Mengen an Texten zu verarbeiten, hat für praktische Anwendungen interessante Auswirkungen. Obwohl ChatGPT bereits über eine sehr gute Zusammenfassungsfähigkeit für kurze Texte verfügt, besteht nun die Möglichkeit, diese Fähigkeit auch auf vollständige Dokumente auszudehnen.
#5 Logische Fehler und Falschaussagen treten weniger häufig auf
Das ist neu
Im direkten Vergleich mit seinem Vorgänger weist der Output von GPT-4 weniger Falschaussagen und Widersprüche auf. Außerdem wurde der Umgang mit Anfragen, die gegen Richtlinien verstoßen, verbessert.
Unsere Einschätzung dazu
Obwohl GPT-4 einige Verbesserungen aufweist, bleibt die Verlässlichkeit des Modeloutputs ein erhebliches Problem, das die Nutzung des Modells einschränkt. Die generierten Texte können nach wie vor von Vorurteilen geprägt sein und Desinformationen enthalten, die sorgfältig geprüft werden sollten.
Ausblick
In der Welt der künstlichen Intelligenz hat OpenAI mit der Veröffentlichung von GPT-4 zweifellos ein spannendes Upgrade seines GPT-3-Modells vorgenommen. Die neuen Funktionen von GPT-4 sind interessant, da sie die Leistung und die Fähigkeiten von KI in vielen Bereichen verbessern können.
Dennoch gibt es einige Einschränkungen und Bedenken, die mit GPT-4 verbunden sind. Im Gegensatz zu früheren Veröffentlichungen ist OpenAI leider deutlich weniger transparent in Bezug auf Modelldetails. So stehen der Öffentlichkeit nur stark begrenzte Informationen über die Modelarchitektur, den Trainingsansatz oder die Datengrundlage des Modells zur Verfügung. Dies macht es beispielsweise schwierig einzuschätzen, inwieweit das Modell Vorurteile übernommen haben könnte, die eine Nutzung beeinflussen.
GPT-4 stellt im Vergleich zu seinem Vorgänger eine Verbesserung dar, aber nicht unbedingt einen großen Schritt nach vorne. Obwohl es einige neue Funktionen gibt, sind diese nicht so revolutionär wie einige erhofft hatten. Es ist daher sehr wichtig, dass wir realistische Erwartungen an die Fähigkeiten von GPT-4 haben und Leistungen und Grenzen des Modells sollten sorgfältig prüfen, bevor wir es in verschiedenen Anwendungen einsetzen. So kann sichergestellt werden, dass die Technologie im Rahmen ihrer derzeitigen Möglichkeiten gewinnbringend eingesetzt wird.
Bei statworx erforschen wir kontinuierlich neue Ideen und Möglichkeiten im Bereich der künstlichen Intelligenz. Die letzten Monate waren von Generativen Modellen geprägt, insbesondere von solchen, die von OpenAI entwickelt wurden (z.B. ChatGPT, DALL-E 2), aber auch von Open-Source-Projekten wie Stable Diffusion. ChatGPT ist ein Text-zu-Text-Modell, während DALL-E 2 und Stable Diffusion Text-zu-Bild-Modelle sind, die auf der Grundlage einer kurzen Textbeschreibung des Benutzers beeindruckende Bilder erstellen. Während der Evaluierung dieser Forschungstrends entdeckten wir eine großartige Möglichkeit, unsere von HP zur Verfügung gestellte GPU-Workstation zu nutzen, damit unsere #statcrew ihre eigenen digitalen Avatare erstellen kann.
Das steckt hinter dem Text-zu-Bild-Generator Stable Diffusion
Text-Bild-Generatoren wie Stable Diffusion und DALL-E 2 basieren auf Diffusionsarchitekturen von künstlichen neuronalen Netzen. Die umfangreichen Trainingsdaten aus dem Internet erfordern oft Monate an Trainingszeit auf Hochleistungsrechnern, um eine optimale Performance zu erreichen. Eine erfolgreiche Implementierung ist daher lediglich durch den Einsatz von Supercomputern möglich. Aber auch nach dem Training benötigen die OpenAI-Modelle immer noch einen Supercomputer, um neue Bilder zu generieren, da ihre Größe die Kapazität von herkömmlichen Computern übersteigt. OpenAI hat Schnittstellen bereitgestellt, um den Zugang zu seinen Modellen zu erleichtern (https://openai.com/product#made-for-developers). Jedoch wurden die Modelle selbst nicht öffentlich freigegeben.
Stable Diffusion hingegen wurde als Text-zu-Bild-Generator entwickelt, ist aber so groß, dass es auf dem eigenen Computer ausgeführt werden kann. Das Open-Source-Projekt ist ein Gemeinschaftsprojekt mehrerer Forschungsinstitute. Seine öffentliche Verfügbarkeit ermöglicht es Forschern und Entwicklern, das trainierte Modell durch sogenanntes fine-tuning für ihre eigenen Zwecke anzupassen. Stable Diffusion ist klein genug, um auf einem Computer ausgeführt zu werden, aber das fine-tuning ist auf einer Workstation (wie der von HP mit zwei NVIDIA RTX8000 GPUs) wesentlich schneller. Obwohl es deutlich kleiner ist als z. B. DALL-E2, ist die Qualität der erzeugten Bilder immer noch hervorragend.
Die genannten Modelle werden durch die Verwendung von Prompts gesteuert, welche eine Beschreibung des gewünschten Bildes in Form von Text enthalten und dadurch das Modell zur Generierung des entsprechenden Bildes angeregt. Für künstliche Intelligenz ist Text direkt nicht verständlich, da alle Algorithmen auf mathematischen Operationen beruhen, die nicht direkt auf Text angewendet werden können.
Daher besteht eine gängige Methode darin, ein so genanntes Embedding zu erzeugen, d. h. Text in mathematische Vektoren umzuwandeln. Das Verständnis des Textes ergibt sich aus dem Training des Übersetzungsmodells von Text zu Embeddings. Die hochdimensionalen Embedding-Vektoren werden so erzeugt, dass der Abstand der Vektoren zueinander die Beziehung der Originaltexte darstellt. Ähnliche Methoden werden auch für Bilder verwendet, und es werden spezielle Modelle für diese Aufgabe trainiert.
CLIP: Ein hybrides Modell von OpenAI zur Bild-Text-Integration mit kontrastivem Lernansatz
Ein solches Modell ist CLIP, ein von OpenAI entwickeltes Hybridmodell, das die Stärken von Bilderkennungsmodellen und Sprachmodellen kombiniert. Das Grundprinzip von CLIP besteht darin, Embeddings für passende Text- und Bildpaare zu erzeugen. Diese Embedding-Vektoren der Texte und Bilder werden so berechnet, dass der Abstand der Vektordarstellungen der passenden Paare minimiert wird. Eine Besonderheit von CLIP ist, dass es mit Hilfe eines kontrastiven Lernansatzes trainiert wird, bei dem zwei verschiedene Eingaben miteinander verglichen werden und die Ähnlichkeit zwischen ihnen maximiert wird, während die Ähnlichkeit, der nicht übereinstimmenden Paare im selben Durchgang minimiert wird. Dadurch kann das Modell robustere und übertragbare Repräsentationen von Bildern und Texten erlernen, was zu einer verbesserten Leistung bei einer Vielzahl von Aufgaben führt.
Anpassen der Bildgenerierung durch Textual Inversion
Mit CLIP als Vorverarbeitungsschritt der Stable Diffusion-Pipeline, die das Embedding der Prompts erstellt, eröffnet sich eine leistungsstarke und effiziente Möglichkeit, dem Modell neue Objekte oder Stile beizubringen. Dieser Spezialfall des fine-tuning wird als Textual Inversion bezeichnet. Abbildung 1 zeigt diesen Trainingsprozess. Mit mindestens drei Bildern eines Objekts oder Stils und einem eindeutigen Textbezeichner kann Stable Diffusion so gesteuert werden, dass es Bilder dieses spezifischen Objekts oder Stils erzeugt.
Im ersten Schritt wird ein <tag> gewählt, der das Objekt repräsentieren soll.
In diesem Fall ist das Objekt als Johannes definiert, und es werden mehrere Bilder von ihm zur Verfügung gestellt. In jedem Trainingsschritt wird ein zufälliges Bild aus den zur Verfügung gestellten Bildern ausgewählt. Zusätzlich wird eine erklärbare Aufforderung wie „rendering of <tag>“ bereitgestellt, und in jedem Trainingsschritt wird eine zufällige Auswahl dieser Aufforderungen getroffen. Der Teil <tag> wird durch den definierten Begriff (in diesem Fall <Johannes>) ausgetauscht.
Durch Anwendung der Textual Inversion Methode wird das Vokabular des Modells erweitert. Nach Durchführung ausreichender Trainingsiterationen kann das neu feinabgestimmte Modell in die Stable Diffusion-Pipeline integriert werden. Dies führt zu einem neuen Bild von Johannes, wenn der Begriff <Johannes> im Prompt des Nutzers vorkommt. Dem generierten Bild können anschließend je nach Eingabeaufforderung Stile und andere Objekte hinzugefügt werden.
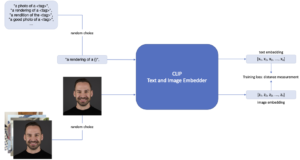
Abbildung 1: Fine-tuning von CLIP mit Textual Inversion.
So sieht es aus, wenn wir KI-generierte Avatare unserer #statcrew erstellen
Wir haben bei statworx allen interessierten Kollegen und Kolleginnen ermöglicht, ihre digitalen Avatare in verschiedensten Kontexten zu positionieren.
Mit der zur Verfügung stehenden HP-Workstation konnten wir die integrierten NVIDIA RTX8000 GPUs nutzen und damit die Trainingszeit im Vergleich zu einer Desktop-CPU um den Faktor 15 reduzieren. Wie man an den Beispielen unten sehen kann, hat es der unserer statcrew viel Spaß gemacht, eine Reihe von Bildern in unterschiedlichen Situationen zu erzeugen. Die folgenden Bilder zeigen ein paar ausgewählte Porträts.
![]()
Prompts von links oben nach rechts unten
- <Andreas> looks a lot like christmas, santa claus, snow
- Robot <Paul>
- <Markus> as funko, trending on artstation, concept art, <Markus>, funko, digital art, box (, superman / batman / mario, nintendo, super mario)
- <Johannes> is very thankful, art, 8k, trending on artstation, vinyl·
- <Markus> riding a unicorn, digital art, trending on artstation, unicorn, (<Markus> / oil paiting)·
- <Max> in the new super hero movie, movie poster, 4k, huge explosions in the background, everyone is literally dying expect for him
- a blonde emoji that looks like <Alex>
- harry potter, hermione granger from harry potter, portrait of <Sarah>, concept art, highly detailed
Stable Diffusion und Textual Inversion stellen spannende Entwicklungen auf dem Gebiet der künstlichen Intelligenz dar. Sie bieten neue Möglichkeiten für die Erstellung einzigartiger und personalisierter Avatare, sind aber auch auf verschiedene Stile anwendbar. Wenn wir diese und andere KI-Modelle weiter erforschen, können wir die Grenzen des Möglichen erweitern und neue und innovative Lösungen für reale Probleme schaffen.
Bilderquelle: Adobe Stock 546181349
Wir gehen in die zweite Runde!
Die enorme Entwicklung von Sprachmodellen wie ChatGPT hat unsere Erwartungen übertroffen. Unternehmen sollten daher verstehen, wie sie von diesen Fortschritten profitieren können.
Im Rahmen unseres auf Führungspositionen ausgerichteten Workshops “ChatGPT for Leaders”, vermitteln wir kompaktes und sofort anwendbares Fachwissen, bieten die Möglichkeit mit anderen Führungskräften und Branchenexperten über die Chancen und Risiken von ChatGPT zu diskutieren und zeigen anhand von Anwendungsfällen, wie Sie Prozesse in Ihrem Unternehmen automatisieren können. Freuen Sie sich auf spannende Vorträge, unter anderem von Timo Klimmer, Global Blackbelt – AI, bei Microsoft und Fabian Müller, COO bei statworx.
Mehr Informationen und eine Anmeldemöglichkeit gibt es hier: ChatGPT for Leaders Workshop
Es ist kein Geheimnis, dass die neuesten Sprachmodelle wie ChatGPT unsere kühnsten Erwartungen weit übertroffen haben. Es ist beeindruckend und erscheint einigen fast unheimlich, dass ein Sprachmodell sowohl ein breites Wissen besitzt als auch die Fähigkeit hat, (fast) jede Frage glaubhaft zu beantworten. Wenige Stunden nach Veröffentlichung dieses Modells begannen bereits die Spekulationen darüber, welche Tätigkeitsfelder durch diese Modelle bereichert, oder womöglich sogar ersetzt werden können, welche Anwendungsfälle sich umsetzen lassen und welche der vielen neuen durch ChatGPT entstandenen Start-Up Ideen sich durchsetzen wird.
Es steht außer Frage, dass die kontinuierliche Weiterentwicklung der Künstlichen Intelligenz an Dynamik gewinnt. Während ChatGPT auf einer dritten Modellgeneration basiert, steht ein “GPT-4” bereits in den Startlöchern und Konkurrenzprodukte warten ebenfalls auf ihren großen Moment.
Als Entscheidungsträger in einem Unternehmen ist es jetzt wichtig zu verstehen, wie diese Fortschritte tatsächlich wertsteigernd eingesetzt werden können. In diesem Blogbeitrag widmen wir uns daher den Hintergründen statt dem Hype, geben Beispiele für konkrete Anwendungsfälle in der Unternehmenskommunikation, und legen insbesondere dar, wie eine Implementierung dieser KI-Systeme erfolgreich erfolgen kann.
Was ist ChatGPT?
Stellt man ChatGPT diese Frage, so erhält man die folgende Antwort:
“Chat GPT ist ein großer Sprachmodell, der von OpenAI trainiert wurde, um natürliche Sprache zu verstehen und zu generieren. Es nutzt die Technologie des Deep Learning und der künstlichen Intelligenz, um menschenähnliche Konversationen mit Benutzern zu führen.”
ChatGPT ist der neueste Vertreter aus einer Klasse an KI-Systemen, die menschliche Sprache (also Texte) verarbeiten. Hierbei spricht man von „Natural Language Processing“, kurz NLP. Es ist das Produkt einer ganzen Kette von Innovationen, die im Jahr 2017 mit einer neuen KI-Architektur begann. In den darauffolgenden Jahren wurden auf dieser Basis die ersten KI-Modelle entwickelt, die in Punkto Sprachverständnis das menschliche Niveau erreichten. In den letzten zwei Jahren lernten die Modelle dann zu schreiben und mit Hilfe von ChatGPT sogar mit dem Benutzer ganze Konversationen zu führen. Im Vergleich zu anderen Modellen zeichnet sich ChatGPT dadurch aus, glaubhafte und passende Antworten auf Nutzeranfragen zu generieren.
Neben ChatGPT gibt es inzwischen viele weitere Sprachmodelle in unterschiedlichen Formen: open-source, proprietär, mit Dialogoption oder auch mit anderen Fähigkeiten. Dabei stellte sich schnell heraus, dass diese Fähigkeiten mit größeren Modellen und mehr (insbesondere qualitativ hochwertigen) Daten kontinuierlich gewachsen sind. Anders als vielleicht ursprünglich zu erwarten war, scheint es dabei kein oberes Limit zu geben. Im Gegenteil: je größer die Modelle, desto mehr Fähigkeiten gewinnen sie!
Diese sprachlichen Fähigkeiten und die Vielseitigkeit von ChatGPT sind erstaunlich, doch der Einsatz derartig großer Modelle ist nicht gerade ressourcenschonen. Große Modelle wie ChatGPT werden von externen Anbietern betrieben, die für jede Anfrage an das Modell in Rechnung stellen. Außerdem erzeugt jede Anfrage an größere Modelle nicht nur mehr Kosten, sondern verbraucht auch mehr Strom und belastet damit die Umwelt.
Dabei erfordern zum Beispiel die meisten Chatanfragen von Kunden kein umfassendes Wissen über die gesamte Weltgeschichte oder die Fähigkeit, auf jede Frage amüsante Antworten zu geben. Stattdessen können bestehende Chatbot-Dienste, die auf Unternehmensdaten zugeschnitten sind, durchaus prägnante und akkurate Antworten zu einem Bruchteil der Kosten liefern.
Moderne Sprachmodelle im Unternehmenseinsatz
Warum wollen dennoch viele Entscheidungsträger in den Einsatz von großen Sprachmodelle wie ChatGPT investieren?
Die Antwort liegt in der Integration in organisatorische Prozesse. Große generative Modelle wie ChatGPT ermöglichen uns erstmals den Einsatz von KI in jeder Phase der geschäftlichen Interaktion. Zunächst in der eingehenden Kundenkommunikation, der Kommunikationsplanung und -organisation, dann in der ausgehenden Kundenkommunikation und der Interaktionsdurchführung, und letztendlich im Bereich der Prozessanalyse und -verbesserung.
Im Folgenden gehen wir genauer darauf ein, wie KI diese Kommunikationsprozesse optimieren und rationalisieren kann. Dabei wird schnell deutlich werden, dass es hier nicht nur darum geht, ein einziges fortschrittliches KI-Modell anzuwenden. Stattdessen zeigt sich, dass nur eine Kombination von mehreren Modellen die Problemstellungen sinnvoll angehen kann und in allen Phasen der Interaktion den gewünschten wirtschaftlichen Nutzen bringt.
KI-Systeme gewinnen beispielsweise in der Kommunikation mit Lieferanten oder mit anderen Stakeholdern zunehmend an Relevanz. Um den revolutionären Einfluss von neuen KI-Modellen möglichst konkret darzustellen, betrachten wir jedoch die Art von Interaktion, die für jedes Unternehmen lebensnotwendig ist: Die Kommunikation mit dem Kunden.
Use Case 1: Eingehende Kundenkommunikation mit KI
Herausforderung
Kundenanfragen gelangen über verschiedene Kanäle (E-Mails, Kontaktformulare über die Website, Apps etc.) in das CRM-System und initiieren interne Prozesse und Arbeitsschritte. Leider ist der Prozess oft ineffizient und führt zu Verzögerungen und erhöhten Kosten, da Anfragen falsch zugewiesen oder in einem einzigen zentralen Postfach landen. Bestehende CRM-Systeme sind meist nicht vollständig in die organisatorischen Arbeitsabläufe integriert und erfordern weitere interne Prozesse, die auf organisch gewachsenen Routinen oder organisatorischem Wissen einer kleinen Anzahl von Mitarbeitenden basieren. Dies mindert die Effizienz und führt zu mangelnder Kundenzufriedenheit und hohen Kosten.
Lösung
Kundenkommunikation kann für Unternehmen eine Herausforderung darstellen, aber KI-Systeme können dabei helfen, diese zu automatisieren und zu verbessern. Mithilfe von KI kann die Planung, Initiierung und Weiterleitung von Kundeninteraktionen effektiver gestaltet werden. Das System kann automatisch Inhalte und Informationen analysieren und auf der Grundlage geeigneter Eskalationsniveaus entscheiden, wie die Interaktion am besten abgewickelt werden kann. Moderne CRM-Systeme sind bereits in der Lage, Standardanfragen mithilfe von kostengünstigen Chatbots oder Antwortvorlagen zu bearbeiten. Aber wenn die KI erkennt, dass eine anspruchsvollere Anfrage vorliegt, kann sie einen KI-Agenten wie ChatGPT oder einen Kundendienstmitarbeiter aktivieren, um die Kommunikation zu übernehmen.
Mit den heutigen Errungenschaften im NLP-Bereich kann ein KI-System aber weitaus mehr. Relevante Informationen können aus Kundenanfragen extrahiert und an die zuständigen Personen im Unternehmen weitergeleitet werden. So kann beispielsweise ein Key-Account-Manager Empfänger der Kundennachricht sein, während gleichzeitig ein technisches Team mit den notwendigen Details informiert wird. Auf diese Weise können komplexere Szenarien, die Organisation des Supports, die Verteilung der Arbeitslast und die Benachrichtigung von Teams über Koordinierungsbedarf bewältigt werden. Dabei werden diese Abläufe nicht manuell definiert werden, sondern vom KI-System gelernt.
Lesen Sie auch unser Whitepaper, in dem wir 4 Blueprints für KI-Modelle in der Kommunikation mit Kunden und Lieferanten vorstellen
Die Implementierung eines integrierten Systems kann die Effizienz von Unternehmen steigern, Verzögerungen und Fehler reduzieren und letztlich zu höherem Umsatz und Gewinn führen.
Use Case 2: Ausgehende Kundenkommunikation mit KI
Herausforderung
Kunden setzen voraus, dass ihre Anfragen umgehend, transparent und präzise beantwortet werden. Eine verzögerte oder inkorrekte Reaktion, ein mangelndes Informationsniveau oder eine unkoordinierte Kommunikation zwischen verschiedenen Abteilungen stellen Vertrauensbrüche dar, die sich langfristig negativ auf die Kundenbeziehung auswirken können.
Bedauerlicherweise sind negative Erfahrungen bei vielen Unternehmen an der Tagesordnung. Dies liegt häufig daran, dass die in bestehenden Lösungen implementierten Chatbots Standardantworten und Templates verwenden und nur selten in der Lage sind, Kundenanfragen umfassend und abschließend zu beantworten. Im Gegensatz dazu verfügen fortgeschrittene KI-Agenten wie ChatGPT über eine höhere kommunikative Fähigkeit, die eine reibungslose Kundenkommunikation ermöglicht.
Wenn die Anfrage dann doch zu den richtigen Mitarbeitenden aus dem Kundendienst gelangt, kommt es zu neuen Herausforderungen. Fehlende Informationen führen regelmäßig zu sequenziellen Anfragen zwischen Abteilungen, und daher zu Verzögerungen. Sobald Prozesse – gewollt oder ungewollt – parallel laufen, besteht die Gefahr von inkohärenter Kommunikation mit dem Kunden. Schlussendlich mangelt es sowohl intern als auch extern an Transparenz.
Lösung
KI-Systeme können Unternehmen in allen Bereichen unterstützen.
Fortgeschrittene Modelle wie ChatGPT verfügen über die notwendigen sprachlichen Fähigkeiten, um viele Kundenanfragen vollständig zu bearbeiten. Sie sind in der Lage, mit Kunden zu kommunizieren und gleichzeitig interne Anfragen zu stellen. Dadurch fühlen sich Kunden nicht länger von einem Chatbot abgewimmelt. Die technischen Innovationen des letzten Jahres ermöglichen es KI-Agenten, Anfragen nicht nur schneller, sondern teilweise auch präziser zu beantworten. Dies trägt zur Entlastung des Kundendienstes und interner Prozessbeteiligter bei und führt letztlich zu einer höheren Kundenzufriedenheit.
KI-Modelle können zudem menschliche Mitarbeiter bei der Kommunikation unterstützen. Wie eingangs erwähnt, mangelt es häufig schlichtweg daran, akkurate und präzise Informationen in kürzester Zeit verfügbar zu machen. Unternehmen sind bestrebt, Informationssilos aufzubrechen, um den Zugang zu relevanten Informationen zu erleichtern. Dies kann jedoch zu längeren Bearbeitungszeiten im Kundendienst führen, da die notwendigen Informationen erst zusammengetragen werden müssen. Ein wesentliches Problem besteht darin, dass Informationen in unterschiedlichsten Formen vorliegen können, beispielsweise als Text, tabellarische Daten, in Datenbanken oder sogar in Form von Strukturen wie vorheriger Dialogketten.
Moderne KI-Systeme können mit unstrukturierten und multimodalen Informationsquellen umgehen. Sogenannte Retrieval-Systeme stellen die Verbindung zwischen Kundenanfragen und diversen Informationsquellen her. Der zusätzliche Einsatz von generativen Modellen wie GPT-3 erlaubt dann, die gefundenen Informationen effizient in verständlichen Text zu synthetisieren. So lassen sich zu jeder Kundenanfrage individuelle „Wikipedia Artikel“ generieren. Alternativ kann der Kundendienstmitarbeiter seinerseits seine Fragen an einen Chatbot richten, der die nötigen Informationen unmittelbar und verständlich zur Verfügung stellt.
Es ist offensichtlich, dass ein integriertes KI-System nicht nur den Kundendienst, sondern auch weitere technische Abteilungen entlastet. Diese Art von System hat das Potenzial, die Effizienz im gesamten Unternehmen zu steigern.
Use Case 3: Analyse der Kommunikation mit KI
Herausforderung
Robuste und effiziente Prozesse entstehen nicht von selbst, sondern durch kontinuierliches Feedback und ständige Verbesserungen. Der Einsatz von KI-Systemen ändert nichts an diesem Prinzip. Eine Organisation benötigt einen Prozess der kontinuierlichen Verbesserung, um effiziente interne Kommunikation sicherzustellen, Verzögerungen im Kundenservice effektiv zu verwalten und ergebnisorientierte Verkaufsgespräche zu führen.
Im Dialog nach Außen steht das Unternehmen aber vor einem Problem: Sprache ist eine Black Box. Worte haben eine unübertroffene Informationsdichte, gerade weil ihre Nutzung in Kontext und Kultur tief verwurzelt ist. Damit entziehen sich Unternehmen aber einer klassischen statistisch-kausalen Analyse, denn Feinheiten der Kommunikation lassen sich nur schwer quantifizieren.
Bestehende Lösungen verwenden deshalb Proxyvariablen, um den Erfolg zu messen und Experimente durchzuführen. Zwar lassen sich übergeordnete KPIs wie Zufriedenheitsrankings extrahieren, diese müssen aber beim Kunden abgefragt werden und haben häufig wenig Aussagekraft. Gleichzeitig bleibt oft offen, was an der Kundenkommunikation konkret geändert werden kann, um diese KPIs zu verändern. Es scheitert schon daran, Interaktionen im Detail zu analysieren, herauszufinden was die Dimensionen und Stellschrauben sind, und was schlussendlich optimiert werden kann. Der überwiegende Teil dessen, was Kunden unmittelbar über sich preisgeben möchten, existiert in Text und Sprache und entzieht sich der Analyse. Diese Problematik ergibt sich sowohl beim Einsatz von KI-Assistenzsystemen als auch beim Einsatz von Kundendienstmitarbeitenden.
Lösung
Während moderne Sprachmodelle aufgrund ihrer generativen Fähigkeiten viel Aufmerksamkeit erhalten haben, haben auch ihre analytischen Fähigkeiten enorme Fortschritte gemacht. Die Fähigkeit von KI-Modellen, auf Kundenanfragen zu antworten, zeigt ein fortgeschrittenes Verständnis von Sprache, was für die Verbesserung integrierter KI-Systeme unerlässlich ist. Eine weitere Anwendung besteht in der Analyse von Konversationen, einschließlich der Analyse von Kunden und eigenen Mitarbeitenden oder KI-Assistenten.
Durch den Einsatz von künstlicher Intelligenz können Kunden präziser segmentiert werden, indem ihre Kommunikation detailliert analysiert wird. Hierbei werden bedeutende Themen erfasst und die Kundenmeinungen ausgewertet. Mittels semantischer Netzwerke kann das Unternehmen erkennen, welche Assoziationen verschiedene Kundengruppen mit Produkten verknüpfen. Zudem werden generative Modelle eingesetzt, um Wünsche, Ideen oder Meinungen aus einer Fülle von Kundenstimmen zu identifizieren. Stellen Sie sich vor, Sie könnten persönlich die gesamte Kundenkommunikation im Detail durchgehen, anstatt auf synthetische KPIs vertrauen zu müssen – genau das ermöglichen KI-Modelle.
Natürlich bieten KI-Systeme auch die Möglichkeit, eigene Prozesse zu analysieren und zu optimieren. Hierbei ist die KI-gestützte Dialoganalyse ein vielversprechendes Anwendungsgebiet, das derzeit intensiv in der Forschung behandelt wird. Diese Technologie ermöglicht beispielsweise die Untersuchung von Verkaufsgesprächen hinsichtlich erfolgreicher Abschlüsse. Hierbei werden Bruchpunkte der Konversation, Stimmungs- und Themenwechsel analysiert, um den optimalen Verlauf einer Konversation zu identifizieren. Diese Art von Feedback ist nicht nur für KI-Assistenten, sondern auch für Mitarbeitende äußerst wertvoll, da es sogar während einer laufenden Konversation eingespielt werden kann.
Zusammengefasst kann gesagt werden, dass sich mit dem Einsatz von KI-Systemen die Breite, die Tiefe, und die Geschwindigkeit der Feedbackprozesse verbessert. Dies ermöglicht der Organisation agil auf Trends, Wünsche und Kundenmeinungen zu reagieren und interne Prozesse noch weitreichender zu optimieren.
Lesen Sie auch unser Whitepaper, in dem wir 4 Blueprints für KI-Modelle in der Kommunikation mit Kunden und Lieferanten vorstellen
Stolpersteine, die es zu beachten gilt
Die Anwendung von KI-Systemen hat also das Potential, die Kommunikation mit Kunden grundlegend zu revolutionieren. Ein ähnliches Potential lässt sich auch bei anderen Bereichen zeigen, zum Beispiel im Einkauf. Im Begleitmaterial finden Sie weitere Use-Cases, die zum Beispiel in den Bereichen Knowledge-Management und Procurement anwendbar sind.
Allerdings zeigt sich, dass selbst fortgeschrittenste KI-Modelle noch nicht in Isolation einsatzfähig sind. Um von Spielerei zum effektiven Einsatz zu kommen, braucht es Erfahrung, Augenmaß und ein abgestimmtes System aus KI-Modellen.
Die Integration von Sprachmodellen ist noch wichtiger als die Modelle selbst. Da Sprachmodelle als Schnittstelle zwischen Computern und Menschen agieren, müssen sie besonderen Anforderungen genügen. Insbesondere müssen Systeme, die in Arbeitsprozesse eingreifen, von den gewachsenen Strukturen des Unternehmens lernen. Als Schnittstellentechnologie müssen Aspekte wie Fairness, Vorurteilsfreiheit und Faktenkontrolle in das System integriert werden. Darüber hinaus benötigt das gesamte System eine direkte Eingriffsmöglichkeit für Mitarbeiter, um Fehler aufzuzeigen und bei Bedarf die KI-Modelle neu auszurichten. Dieses „Active-Learning“ ist noch kein Standard, aber es kann den Unterschied zwischen theoretischer und praktischer Effizienz ausmachen.
Der Einsatz von mehreren Modellen die sowohl vor Ort, als auch direkt bei Fremdanbietern laufen, stellt neue Ansprüche an die Infrastruktur. Ebenfalls gilt zu beachten, dass der essenzielle Informationstransfer nicht ohne gründliche Behandlung von personenbezogenen Daten möglich ist. Dies gilt insbesondere, wenn kritische Firmeninformationen eingebunden werden müssen. Wie eingangs beschrieben, gibt es inzwischen viele Sprachmodelle mit unterschiedlichen Fähigkeiten. Daher muss die Architektur der Lösung und die Modelle entsprechend der Anforderungen ausgewählt und kombiniert werden. Schließlich stellt sich die Frage, ob man auf Anbieter von Lösungen zurückgreift, oder eigene (Teil-)Modelle entwickelt. Derzeit gibt es (entgegen von einigen Marketingaussagen) keine Standardlösung, die allen Anforderungen gerecht wird. Je nach Anwendungsfall gibt es Anbieter von kosteneffizienten Teillösungen. Eine Entscheidung erfordert Kenntnis dieser Anbieter, ihrer Lösung und deren Limitationen.
Fazit
Zusammenfassend kann festgehalten werden, dass der Einsatz von KI-Systemen in der Kundenkommunikation eine Verbesserung und Automatisierung der Prozesse bewirken kann. Eine zentrale Zielsetzung für Unternehmen sollte die Optimierung und Rationalisierung ihrer Kommunikationsprozesse sein. KI-Systeme können dabei unterstützen, indem sie die Planung, Initiation und Weiterleitung von Kundeninteraktionen effektiver gestalten und bei komplexeren Anfragen entweder einen KI-Agenten wie ChatGPT oder einen Kundendienstmitarbeiter aktivieren. Durch die gezielte Kombination von verschiedenen Modellen kann eine sinnvolle Problemlösung in allen Phasen der Interaktion erzielt werden, die den angestrebten wirtschaftlichen Nutzen generiert.
Lesen Sie auch unser Whitepaper, in dem wir 4 Blueprints für KI-Modelle in der Kommunikation mit Kunden und Lieferanten vorstellen
Das erwartet euch:
Die konaktiva an der Technischen Universität Darmstadt ist eine der ältesten und größten Unternehmenskontaktmessen und wird jährlich von Studierenden organisiert. Mit über 10.000 Besucher:innen im letzten Jahr und mehr als 200 Ständen ist die konaktiva die ideale Gelegenheit für Unternehmen, Studierende und Absolvent:innen, miteinander in Kontakt zu treten.
Auch dieses Jahr ist statworx wieder mit einem Stand und mehreren Kolleg:innen auf der konaktiva vertreten. Wir sind an einem der drei Tage (9.05. bis 11.05.) auf der Messe anzutreffen und werden das genaue Datum hier bekannt geben, sobald es feststeht.
Wir freuen uns schon sehr darauf, uns mit interessierten Studierenden und Absolvent:innen auszutauschen, und sowohl über verschiedene Einstiegsmöglichkeiten – vom Praktikum bis zur Festanstellung – bei statworx zu informieren als auch aus unserem Arbeitsalltag zu berichten. Das Kennenlernen findet aber nicht ausschließlich am Messestand statt – es ist auch möglich, mit uns in vorterminierten Einzelgesprächen in Kontakt zu kommen und individuelle Fragen zu klären.
Die Teilnahme an der Messe ist für Besucher:innen kostenfrei.
In der Computer Vision Arbeitsgruppe bei statworx hatten wir uns zum Ziel gesetzt, mit Hilfe von Projekten Computer Vision Kompetenzen aufzubauen. Für die diesjährige statworx Alumni Night, die Anfang September stattfand, entstand die Idee eines Begrüßungsroboters, der die ankommenden Mitarbeitenden und Alumni von statworx mit einer persönlichen Nachricht begrüßen sollte. Für die Realisierung des Projekts planten wir ein Gesichtserkennungsmodell auf einem Waveshare JetBot zu entwickeln. Der Jetbot wird von einem NVIDIA Jetson Nano angetrieben, ein kleiner, leistungsfähiger Computer mit einer 128-Core GPU für die schnelle Ausführung moderner KI-Algorithmen. Viele gängige KI-Frameworks wie Tensorflow, PyTorch, Caffe und Keras werden unterstützt. Das Projekt schien sowohl für erfahrene als auch für unerfahrene Mitglieder:innen der Arbeitsgruppe eine gute Möglichkeit zu sein, Wissen im Bereich Computer Vision aufzubauen und Erfahrungen im Bereich Robotik zu sammeln.
Gesichtserkennung (Face Recognition) mithilfe eines JetBots erfordert die Lösung einer Reihe miteinander verbundenen Problemen:
- Face Detection: Wo befindet sich das Gesicht auf dem Bild?
Zunächst muss das Gesicht auf einem gezeigten Bild lokalisiert werden. Nur dieser Teil des Bildes ist relevant für alle folgenden Schritte. - Face Embedding: Welche einzigartigen Merkmale hat das Gesicht?
Anschließend müssen einzigartige Merkmale des Gesichts erkannt und in einem Embedding kodiert werden, anhand derer es von anderen Personen unterschieden werden kann. Eine damit einhergehende Herausforderung ist, dass das Modell lernen muss mit der Neigung des Gesichts oder schlechter Beleuchtung umzugehen. Daher muss vor der Erstellung des Embeddings die Pose des Gesichts ermittelt und so korrigiert werden, dass das Gesicht zentriert ist. - Namensermittlung: Welches Embedding ähnelt dem erkannten Gesicht am meisten?
Das Embedding des Gesichts muss schließlich mit den Embeddings aller Personen, die das Modell bereits kennt, verglichen werden, um den Namen der Person zu bestimmen. - UI mit Willkommensnachricht
Für die Ausgabe der Willkommensnachricht wird eine UI benötigt. Dafür muss zuvor ein Mapping erstellt werden, welches den Namen der zu grüßenden Person der jeweiligen Willkommensnachricht zuordnet. - Konfiguration des JetBots
Im letzten Schritt muss der JetBot konfiguriert und das Modell auf den JetBot übertragen werden.
Das Trainieren eines solchen Gesichterkennungsmodells ist sehr rechenintensiv, da Millionen von Bildern von Tausenden verschiedenen Personen verwendet werden müssen, um ein leistungsfähiges Neuronales Netz zu erhalten. Sobald das Modell jedoch trainiert ist, kann es Embeddings für jedes beliebige (bekannte oder unbekannte) Gesicht erzeugen. Daher konnten wir glücklicherweise auf bestehende Gesichterkennungsmodelle zurückgreifen und mussten lediglich die Embeddings von den Gesichtern unserer Kolleg:innen und Alumni erstellen. Nichtsdestotrotz sollen die Schritte des Trainings kurz erläutert werden, um ein Verständnis dafür zu vermitteln, wie solche Gesichtserkennungsmodelle funktionieren.
Für die Implementierung verwendeten wir das Pythonpaket face_recognition, welche die Gesichtserkennungsfunktionalität von dlib umschließt und so die Arbeit mit ihr erleichtert. Das neuronale Netz selbst wurde auf einem Datensatz von etwa 3 Millionen Bildern trainiert und erreichte auf dem Datensatz „Labeled Faces in the Wild“ (LFW) eine Genauigkeit von 99,38 % und ist damit anderen Modellen überlegen.
Vom Bild zum codierten Gesicht (Face Detection)
Die Lokalisierung eines Gesichts auf einem Bild erfolgt durch den Histogram of Oriented Gradients (HOG) Algorithmus. Dabei wird jeder einzelne Pixel des Bildes mit den Pixeln in der unmittelbaren Umgebung verglichen und durch einen Pfeil ersetzt, der in die Richtung zeigt, in die das Bild dunkler wird. Diese Pfeile stellen die Gradienten dar und zeigen den Verlauf von hell nach dunkel über das gesamte Bild. Um eine übersichtlichere Struktur zu schaffen, werden die Pfeile auf einer höheren Ebene aggregiert. Das Bild (a) wird in kleine Quadrate von je 16×16 Pixeln unterteilt und mit der Pfeilrichtung ersetzt, die am häufigsten vorkommt (b). Anhand der HOG-kodierten Version des Bildes kann nun der Teil des Bildes gefunden werden, der einer HOG-Kodierung eines Gesichts (c) am ähnlichsten ist. Nur dieser Teil des Bildes ist relevant für alle folgenden Schritte.

Abbildung 1: Quelle HOG face pattern: https://commons.wikimedia.org/wiki/File:Dlib_Learned-HOG-Detector.jpg
Mit Embeddings Gesichter lernbar machen
Damit das Gesichtserkennungsmodell unterschiedliche Bilder einer Person trotz Neigung des Gesichts oder schlechter Beleuchtung der gleichen Person zuordnen kann, muss die Pose des Gesichts ermittelt und so projeziert werden, dass sich die Augen und Lippen immer an der gleichen Stelle im Bild befinden. Dabei kommt der Algorithmus Face Landmark Estimation zum Einsatz, welcher mithilfe eines Machine Learning Modells spezifische Orientierungspunkte im Gesicht finden kann. Dadurch können wir Augen und Mund lokalisieren und durch grundlegende Bildtransformationen wie Drehen und Skalieren so anpassen, dass beides möglichst zentriert ist.

Abbildung 2: Face landmarks (links) und Projektion des Gesichts (rechts)
Im nächsten Schritt wird mithilfe eines neuronalen Netzes ein Embedding des zentrierten Gesichtsbilds erstellt. Das neuronale Netz erlernt sinnvolle Embeddings, indem es innerhalb eines Trainingsschrittes drei Gesichtsbilder gleichzeitig betrachtet: Zwei Bilder einer bekannten Person und ein Bild einer anderen Person. Das neuronale Netz erstellt die Embeddings der drei Bilder und optimiert seine Gewichte, sodass die Embeddings der Bilder der gleichen Person angenähert werden, und sich stärker mit dem Embedding der anderen Person unterscheidet. Nachdem dieser Schritt millionenfach für unterschiedliche Bilder von verschiedenen Personen wiederholt wurde, lernt das neuronale Netz repräsentative Embeddings zu erzeugen. Die Netzwerkarchitektur des Gesichtserkennungsmodells von dlib basiert auf dem ResNet-34 aus dem Paper Deep Residual Learning for Image Recognition von He et al., mit weniger Layern und einer um die Hälfte reduzierten Anzahl von Filtern. Die erzeugten Embeddings sind 128-dimensional.
Abgleich mit gelernten Embeddings in Echtzeit
Für unseren Begrüßungsroboter konnten wir glücklicherweise auf das bestehende Modell von dlib zurückgreifen. Damit das Modell die Gesichter der aktuellen und ehemaligen statcrew erkennen kann, mussten nur noch die Embeddings erstellt werden. Dafür haben wir die offiziellen statworx Bilder verwendet und das resultierende Embedding zusammen mit dem Namen der Person abgespeichert. Wird danach ein unbekanntes Bild in das Modell gegeben, erkennt dieses Gesicht, zentriert es und erstellt dafür ein Embedding. Das erstellte Embedding wird anschließend mit den abgespeicherten Embeddings der bekannten Personen verglichen und bei großer Ähnlichkeit wird der Name dieser Person ausgegeben. Ist kein ähnliches Embedding vorhanden, gibt es keine Übereinstimmung mit den gespeicherten Personen. Mehr Bilder einer Person und damit mehrere Embeddings pro Person verbessern die Performanz des Modells. Unsere Tests zeigten jedoch, dass unsere Gesichter auch mit nur einem Bild pro Person recht zuverlässig erkannt wurden. Nach diesem Schritt hatten wir nun ein gutes Modell, welches in Echtzeit Gesichter in der Kamera erkannte und den zugehörigen Namen anzeigte.
Eine herzliche Begrüßung über ein UI
Unser Plan war es den Roboter mit einem kleinen Bildschirm oder einem Lautsprecher auszustatten, auf dem die Begrüßungsnachricht dann zu sehen bzw. zu hören sein sollte. Für den Anfang hatten wir uns dann aber dazu entschieden, den Roboter an einen Monitor anzuschließen und eine UI für den Monitor zu bauen. Deshalb entwickelten wir zunächst lokal eine simple UI. Dafür ließen wir die Begrüßungsnachricht auf einem Hintergrund mit den statworx Firmenwerten anzeigen und projizierten das Kamerabild in die untere rechte Ecke. Damit jede Person eine personalisierte Nachricht erhält, mussten wir eine json-Datei anlegen, welche das Mapping von den Namen zur Willkommensnachricht definiert. Für unbekannte Gesichter hatten wir die Willkommensnachricht „Welcome Stranger!“ angelegt. Aufgrund der vielen Namensvettern bei statworx hatten alle mit dem Namen Alex zusätzlich einen einzigartigen Identifikator erhalten:
Letzte Hürden vor der Inbetriebnahme des Roboters
Da das Modell und die UI bisher nur lokal liefen, blieb nun noch die Aufgabe das Modell auf den Roboter mit integrierter Kamera zu übertragen. Wie wir dann leider feststellen mussten, war dies komplizierter als gedacht. Wir hatten immer wieder mit Arbeitsspeicherproblemen zu kämpfen und mussten den Roboter insgesamt dreimal neu konfigurieren, bis wir erfolgreich das Modell auf dem Roboter zum Laufen bringen konnten. Die Anleitung für die Konfigurieren des Roboters, welche bei uns zum Erfolg geführt hat, befindet sich hier: https://jetbot.org/master/software_setup/sd_card.html. Die Arbeitsspeicherprobleme konnten sich meist mit einem Reboot beheben.
Der Einsatz des Begrüßungsroboters bei der Alumni Night
Unser Begrüßungsroboter war ein voller Erfolg bei der Alumni Night! Die Gäste waren sehr überrascht und freuten sich über die personalisierte Nachricht.

Abbildung 3: Der JetBot im Einsatz bei der statworx-Alumni-Night
Auch für uns als Computer Vision Cluster war das Projekt ein voller Erfolg. Während des Projekts lernten wir viel über Gesichtserkennungsmodelle und allen damit verbundenen Herausforderungen. Die Arbeit mit dem JetBot war besonders spannend und wir planen bereits fürs nächste Jahr weitere Projekte mit dem Roboter.
Bei statworx befassen wir uns intensiv damit, wie wir von großen Sprachmodellen (LLMs) die bestmöglichen Resultate erhalten. In diesem Blogbeitrag stelle ich fünf Ansätze vor, die sich sowohl in der Forschung als auch in unseren eigenen Experimenten mit LLMs bewährt haben. Während sich dieser Text auf das manuelle Design von Prompts zur Textgenerierung beschränkt, werden Bildgenerierung und automatisierte Promptsuche das Thema zukünftiger Beiträge sein.
Mega-Modelle läuten neues Paradigma ein
Die Ankunft des revolutionären Sprachmodells GPT-3 stellte nicht nur für das Forschungsfeld der Sprachmodellierung (NLP) einen Wendepunkt dar, sondern hat ganz nebenbei einen Paradigmenwechsel in der KI-Entwicklung eingeläutet: Prompt-Learning. Vor GPT-3 war der Standard das Fine-Tuning von mittelgroßen Sprachmodellen wie BERT, was dank erneutem Training mit eigenen Daten das vortrainierte Modell an den gewünschten Anwendungsfall anpassen sollte. Derartiges Fine-Tuning erfordert exemplarische Daten für die gewünschte Anwendung, sowie die rechnerischen Möglichkeiten das Modell zumindest teilweise neu zu trainieren.
Die neuen großen Sprachmodelle wie OpenAIs GPT-3 und BigSciences BLOOM hingegen wurden von ihren Entwicklerteams bereits mit derart großen Mengen an Ressourcen trainiert, dass diese Modelle ein neues Maß an Unabhängigkeit in ihrem Anwendungszweck erreicht haben: Diese LLMs benötigen nicht länger aufwändiges Fine-Tuning, um ihren spezifischen Zweck zu erlernen, sondern erzeugen bereits mithilfe von gezielter Instruktion („Prompt“) in natürlicher Sprache beeindruckende Resultate.
Wir befinden uns also inmitten einer Revolution in der KI-Entwicklung: Dank Prompt-Learning findet die Interaktion mit Modellen nicht länger über Code statt, sondern in natürlicher Sprache. Für die Demokratisierung der Sprachmodellierung bedeutet dies einen gigantischen Schritt vorwärts. Texte zu generieren oder neustens sogar Bilder zu erstellen, erfordert dadurch nicht mehr als rudimentäre Sprachkenntnisse. Allerdings heißt das nicht, dass damit auch überzeugende oder beeindruckende Resultate allen zugänglich sind. Hochwertige Outputs verlangen nach hochwertigen Inputs. Für uns Nutzer:innen bedeutet dies, dass die technische Planung in NLP nicht mehr der Modellarchitektur oder den Trainingsdaten gilt, sondern dem Design der Anweisungen, die Modelle in natürlicher Sprache erhalten. Willkommen im Zeitalter des Prompt-Engineerings.
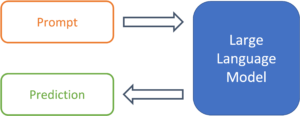
Abbildung 1: Vom Prompt zur Prognose mit einem großen Sprachmodell
Prompts sind mehr als nur Textschnippsel
Templates erleichtern den häufigen Umgang mit Prompts
Da LLMs nicht auf einen spezifischen Anwendungsfall trainiert wurden, liegt es am Promptdesign dem Modell die genaue Aufgabenstellung zu bestimmen. Dazu dienen sogenannte „Prompt Templates“. Ein Template definiert die Struktur des Inputs, der an das Modell weitergereicht wird. Dadurch übernimmt das Template die Funktion des Fine-Tunings und legt den erwarteten Output des Modells für einen bestimmten Anwendungsfall fest. Am Beispiel einer einfachen Sentiment-Analyse könnte ein Prompt-Template so aussehen:
The expressed sentiment in text [X] is: [Z]
Das Modell sucht so nach einem Token z der, basierend auf den trainierten Parametern und dem Text in Position [X], die Wahrscheinlichkeit des maskierten Tokens an Position [Z] maximiert. Das Template legt so den gewünschten Kontext des zu lösenden Problems fest und definiert die Beziehung zwischen dem Input an Stelle [X] und dem zu vorhersagenden Output an Stelle [Z]. Der modulare Aufbau von Templates ermöglicht die systematische Verarbeitung einer Vielzahl von Texten für den erwünschten Anwendungsfall.
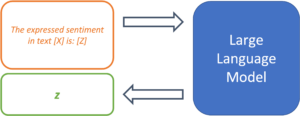
Abbildung 2: Prompt Templates definieren die Struktur eines Prompts.
Prompts benötigen nicht zwingend Beispiele
Das vorgestellte Template ist ein Beispiel eines sogenannten „, da ausschließlich eine Anweisung, ohne jegliche Demonstration mit Beispielen im Template, vorhanden ist. Ursprünglich wurden LLMs von den Entwickler:innen von GPT-3 als „Few-Shot Learners“ bezeichnet, also Modelle, deren Leistung mit einer Auswahl von gelösten Beispielen des Problems maximiert werden kann (Brown et al., 2020). Eine Folgestudie konnte aber zeigen, dass mit strategischem Promptdesign auch 0-Shot Prompts, ohne einer Vielzahl von Beispielen, vergleichbare Leistung erzielen können (Reynolds & McDonell, 2021). Da also auch in der Forschung mit unterschiedlichen Ansätzen gearbeitet wird, stellt der nächste Abschnitt 5 Strategien für effektives Design von Prompt Templates vor.
5 Strategien für effektives Promptdesign
Task Demonstration
Im herkömmlichen Few-Shot Setting wird das zu lösende Problem durch die Bereitstellung von mehreren Beispielen eingegrenzt. Die gelösten Beispielsfälle sollen dabei eine ähnliche Funktion einnehmen wie die zusätzlichen Trainingssamples während des Fine-Tuning Prozesses und somit den spezifischen Anwendungsfall des Modells definieren. Textübersetzung ist ein gängiges Beispiel für diese Strategie, die mit folgendem Prompt Template repräsentiert werden kann:
French: „Il pleut à Paris“
German: „Es regnet in Paris“
French: „Copenhague est la capitale du Danemark“
German: „Kopenhagen ist die Hauptstadt von Dänemark“
[…]
French: [X]
German: [Z]
Die gelösten Beispiele sind zwar gut dazu geeignet das Problemsetting zu definieren, können aber auch für Probleme sorgen. „Semantische Kontamination“ bezeichnet das Problem, dass die Inhalte der übersetzten Sätze als relevant für die Vorhersage interpretiert werden können. Beispiele im semantischen Kontext der Aufgabe produzieren bessere Resultate – und solche außerhalb des Kontexts können dazu führen, dass die Prognose Z inhaltlich „kontaminiert“ wird (Reynolds & McDonell, 2021). Verwendet man das obige Template für die Übersetzung komplexer Sachverhalte, so könnte das Modell in unklaren Fällen wohl den eingegebenen Satz als Aussage über eine europäische Großstadt interpretieren.
Task Specification
Jüngste Forschung zeigt, dass mit gutem Promptdesign auch der 0-Shot Ansatz kompetitive Resultate liefern kann. So wurde demonstriert, dass LLMs gar keine vorgelösten Beispiele benötigen, solange die Problemstellung im Prompt möglichst genau definiert wird (Reynolds & McDonell, 2021). Diese Spezifikation kann unterschiedlich Formen annehmen, ihr liegt aber immer den gleichen Gedanken zugrunde: So genau wie möglich zu beschreiben was gelöst werden soll, aber ohne zu demonstriere wie.
Ein einfaches Beispiel für den Übersetzungsfall wäre folgender Prompt:
Translate from French to German [X]: [Z]
Dies mag bereits funktionieren, die Forscher empfehlen aber den Prompt so deskriptiv wie möglich zu gestalten und auch explizit die Übersetzungsqualität zu nennen:
A French sentence is provided: [X]. The masterful French translator flawlessly translates the sentence to German: [Z]
Dies helfe dem Modell dabei die gewünschte Problemlösung im Raum der gelernten Aufgaben zu lokalisieren.
![]()
Abbildung 3: Ein klarer Aufgabenbeschrieb kann die Prognosegüte stark erhöhen.
Auch in Anwendungsfällen ausserhalb von Übersetzungen ist dies empfehlenswert. Ein Text lässt mit einem einfachen Befehl zusammenfassen:
Summarize the following text: [X]: [Z]
Mit konkreterem Prompt sind aber bessere Resultate zu erwarten:
Rephrase this sentence with easy words so a child understands it,
emphasize practical applications and examples: [X]: [Z]
Je genauer der Prompt, desto grösser die Kontrolle über den Output.
Prompts als Einschränkungen
Zu Ende gedacht bedeutet der Ansatz von Kontrolle des Modells schlicht die Einschränkung des Modellverhaltens durch sorgfältiges Promptdesign. Diese Perspektive ist nützlich, denn während dem Training lernen LLMs viele verschiedene Texte fortzuschreiben und können dadurch eine breite Auswahl an Problemen lösen. Mit dieser Designstrategie verändert sich das grundlegende Herangehen ans Promptdesign: vom Beschrieb der Problemstellung zum Ausschluss unerwünschter Resultate durch die Einschränkung des Modellverhaltens. Welcher Prompt führt zum gewünschten Resultat und ausschliesslich zum gewünschten Resultat? Folgender Prompt weist zwar auf eine Übersetzungsaufgabe hin, beinhaltet aber darüber hinaus keine Ansätze zur Verhinderung, dass der Satz durch das Modell einfach zu einer Geschichte fortgesetzt wird.
Translate French to German Il pleut à Paris
Ein Ansatz diesen Prompt zu verbessern ist der Einsatz von sowohl semantischen als auch syntaktischen Mitteln:
Translate this French sentence to German: “Il pleut à Paris.”
Durch die Nutzung von syntaktischen Elementen wie dem Doppelpunkt und den Anführungszeichen wird klar gemacht, wo der zu übersetzende Satz beginnt und endet. Auch drückt die Spezifikation durch sentence aus, dass es nur um einen einzelnen Satz geht. Diese Mittel verringern die Wahrscheinlichkeit, dass dieser Prompt missverstanden und nicht als Übersetzungsproblem behandelt wird.
Nutzung von “memetic Proxies”
Diese Strategie kann genutzt werden, um die Informationsdichte in einem Prompt zu erhöhen und lange Beschreibungen durch kulturell verstandenen Kontext zu vermeiden. Memetic Proxies können in Taskbeschreibungen genutzt werden und nutzen implizit verständliche Situationen oder Personen anstelle von ausführlichen Anweisungen:
A primary school teacher rephrases the following sentence: [X]: [Z]
Dieser Prompt ist weniger deskriptiv als das vorherige Beispiel zur Umformulierung in einfachen Worten. Allerdings besitzt die beschriebene Situation eine viel höhere Dichte an Informationen: Die Nennung eines impliziert bereits, dass das Resultat für Kinder verständlich sein soll und erhöht dadurch hoffentlich auch die Wahrscheinlichkeit von praktischen Beispielen im Output. Ähnlich können Prompts fiktive Gespräche mit bekannten Persönlichkeiten beschreiben, so dass der Output deren Weltbild oder Sprechweise widerspiegelt:
In this conversation, Yoda responds to the following question: [X]
Yoda: [Z]
Dieser Ansatz hilft dabei einen Prompt durch implizit verstandenen Kontext kurz zu halten und die Informationsdichte im Prompt zu erhöhen. Memetic Proxies finden auch im Promptdesign für andere Modalitäten Verwendung. Bei Modellen zur Bildgenerierung wie DALL-e 2 führt das Suffix „Trending on Artstation“ häufig zu Ergebnissen von höherer Qualität, obwohl semantisch eigentlich keine Aussagen über das darzustellende Bild gemacht werden.
Metaprompting
Als Metaprompting beschreibt das Forscherteam einer Studie den Ansatz Prompts durch Anweisungen anzureichern, die auf die jeweilige Aufgabe zugeschnitten sind. Dies beschreiben sie als Weg ein Modell durch klarere Anweisungen einzuschränken, sodass die gestellte Aufgabe besser gelöst werden kann (Reynolds & McDonell, 2021). Folgendes Beispiel kann dabei helfen mathematische Probleme zuverlässiger zu lösen und den Argumentationsweg nachvollziehbar zu machen:
[X]. Let us solve this problem step-by-step: [Z]
Ähnlich lassen sich Multiple Choice Fragen mit Metaprompts anreichern, sodass das Modell im Output auch tatsächlich eine Option wählt, anstatt die Liste fortzusetzen:
[X] in order to solve this problem, let us analyze each option and choose the best: [Z]
Metaprompts stellen somit ein weiteres Mittel dar Modellverhalten und Resultate einzuschränken.
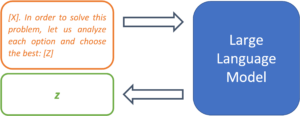
Abbildung 4: Mithilfe von Metaprompts lassen sich Vorgehensweisen zur Problemlösung festlegen.
Ausblick
Prompt Learning ist ein noch sehr junges Paradigma und das damit eng verbundene Prompt Engineering befindet sich noch in den Kinderschuhen. Allerdings wird die Wichtigkeit von fundierten Fähigkeiten zum Schreiben von Prompts zweifellos nur noch zunehmen. Nicht nur Sprachmodelle wie GPT-3, sondern auch neuste Modelle zur Bildgenerierung verlangen von ihren User:innen solide Kenntnisse im Designen von Prompts, um gute Ergebnisse zu kreieren. Die vorgestellten Strategien sind sowohl in der Forschung als auch in der Praxis erprobte Ansätze zum systematischen Schreiben von Prompts, die dabei helfen, bessere Resultate von großen Sprachmodellen zu erhalten.
In einem zukünftigen Blogbeitrag nutzen wir diese Erfahrungen mit Textgenerierung, um Best Practices für eine weitere Kategorie generativer Modelle zu erschliessen: modernste Diffusionsmodelle zur Bildgenerierung, wie DALL-e 2, Midjourney und Stable Diffusion.
Quellen
Brown, Tom B. et al. 2020. “Language Models Are Few-Shot Learners.” arXiv:2005.14165 [cs]. http://arxiv.org/abs/2005.14165 (March 16, 2022).
Reynolds, Laria, and Kyle McDonell. 2021. “Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm.” http://arxiv.org/abs/2102.07350 (July 1, 2022).
Im Trend: Künstliche Verbesserung von Gesichtsbildern
Was trägt künstliche Intelligenz dazu bei?
In den letzten Jahren sind Filter in den sozialen Medien extrem beliebt geworden. Mit diesen Filtern kann jede Person ihr Gesicht und die Umgebung auf unterschiedlichste Weise anpassen, was zu unterhaltsamen Ergebnissen führt. Oftmals verstärken die Filter aber auch Gesichtszüge, die einem bestimmten Schönheitsstandard zu entsprechen scheinen. Als KI-Expert:innen haben wir uns gefragt, was wir mit unseren Tools im Bereich der Gesichtsdarstellung erreichen können. Ein Thema, das unser Interesse geweckt hat, ist die Darstellung von Geschlechtern. Wir wurden neugierig: Wie stellt die KI bei der Erstellung dieser Bilder Geschlechterunterschiede dar? Und darüber hinaus: Können wir geschlechtsneutrale Versionen von bestehenden Gesichtern erzeugen?
Verwendung von StyleGAN auf bestehenden Bildern
Als wir darüber nachdachten, welche vorhandenen Bilder wir untersuchen wollten, haben wir uns überlegt: Wie würden unsere eigenen Gesichter bearbeitet aussehen? Außerdem beschlossen wir, auch mehrere Prominente als Input zu verwenden – wäre es nicht faszinierend, weltberühmte Gesichter dabei zu beobachten, wie sie sich in verschiedene Geschlechter verwandeln?
Gegenwärtig stehen textbasierte Bilderzeugungsmodelle wie DALL-E häufig im Mittelpunkt des öffentlichen Diskurses. Die KI-gesteuerte Erstellung fotorealistischer Gesichtsbilder ist jedoch schon seit langem ein Forschungsschwerpunkt, da es offensichtlich eine Herausforderung ist, natürlich aussehende Bilder von Gesichtern zu erzeugen. Auf der Suche nach geeigneten KI-Modellen für unsere Idee haben wir uns für die StyleGAN-Architekturen entschieden, die für die Erzeugung realistischer Gesichtsbilder bekannt sind.
Anpassung von Gesichtsmerkmalen mit StyleGAN
Ein entscheidender Aspekt der Architektur dieser KI ist die Verwendung eines so genannten latenten Raums, aus dem wir die Eingaben des neuronalen Netzes auswählen. Du kannst dir diesen latenten Raum wie eine Landkarte vorstellen, auf der jedes mögliche generierte Gesicht eine bestimmte Koordinate hat. Normalerweise würden wir einfach einen Dartpfeil auf diese Karte werfen und uns darüber freuen, dass die KI ein realistisches Bild erzeugt. Aber wie sich herausstellt, erlaubt uns dieser latente Raum, noch weitere Aspekte der Erzeugung künstlicher Gesichter zu untersuchen. Wenn Du dich von der Position eines Gesichts auf dieser Karte zur Position eines anderen Gesichts bewegst, kannst Du Mischungen der beiden Gesichter erzeugen. Und wenn Du dich in eine zufällige Richtung bewegst, wirst Du auch zufällige Veränderungen im generierten Bild sehen.
Dies macht die StyleGAN-Architektur zu einem vielversprechenden Ansatz für die Erforschung der Geschlechterdarstellung in der KI.
Können wir eine geschlechtsspezifische Richtung isolieren?
Gibt es also Wege, die es uns erlauben, bestimmte Aspekte des erzeugten Bildes zu verändern? Könnte man sich einer geschlechtsneutralen Darstellung eines Gesichts auf diese Weise nähern? In früheren Arbeiten wurden semantisch interessante Richtungen gefunden, die zu faszinierenden Ergebnissen führten. Eine dieser Richtungen kann ein generiertes Gesichtsbild so verändern, dass es ein weiblicheres oder männlicheres Aussehen erhält. Auf diese Weise können wir die Geschlechterdarstellung in Bildern untersuchen.
Der Ansatz, den wir für diesen Artikel gewählt haben, bestand darin, mehrere Bilder zu erstellen, indem wir kleine Schritte in die Richtung des jeweiligen Geschlechts machten. Auf diese Weise können wir verschiedene Versionen der Gesichter vergleichen, und die Leser:innen können zum Beispiel entscheiden, welches Bild einem geschlechtsneutralen Gesicht am nächsten kommt. Außerdem können wir so die Veränderungen genauer untersuchen und unerwünschte Merkmale in den bearbeiteten Versionen ausfindig machen.
Wir stellen der KI unsere eigenen Gesichter vor
Die beschriebene Methode kann verwendet werden, um jedes von der KI erzeugte Gesicht in eine weiblichere oder männlichere Version zu verändern. Es bleibt jedoch eine entscheidende Herausforderung: Da wir unsere eigenen Bilder als Ausgangspunkt verwenden möchten, müssen wir in der Lage sein, die latente Koordinate (in unserer Analogie den richtigen Ort auf der Landkarte) für ein gegebenes Gesichtsbild zu finden. Das hört sich zunächst einfach an, aber die verwendete StyleGAN-Architektur erlaubt uns nur den Weg in eine Richtung, nämlich von der latenten Koordinate zum generierten Bild, nicht jedoch den weg zurück. Glücklicherweise haben sich bereits Forschende mit genau diesem Problem beschäftigt. Unser Ansatz stützt sich daher stark auf das Python-Notebook, das hier zu finden ist. Die Forschenden haben eine weitere „Encoder“-KI entwickelt, die ein Gesichtsbild als Eingabe erhält und die entsprechende Koordinate im latenten Raum findet.
Somit haben wir endlich alle Teile, die wir brauchen, um unser Ziel zu erreichen: die Erforschung verschiedener Geschlechterdarstellungen innerhalb einer KI. In den Fotosequenzen unten ist das mittlere Bild jeweils das ursprüngliche Eingabebild. Auf der linken Seite erscheinen die generierten Gesichter eher weiblich, auf der rechten Seite eher männlich. Ohne weitere Umschweife präsentieren wir die von der KI generierten Bilder unseres Experiments.
Ergebnisse: Fotoserie von weiblich zu männlich






Unbeabsichtigter Bias
Nachdem wir die entsprechenden Bilder im latenten Raum gefunden hatten, erzeugten wir künstliche Versionen der Gesichter. Wir haben sie dann auf Grundlage der gewählten Geschlechterrichtung verändert und so „feminisierte“ und „maskulinisierte“ Gesichter erzeugt. Die Ergebnisse zeigen ein unerwartetes Verhalten der KI: Sie scheint klassische Geschlechterstereotypen nachzubilden.
Breites Lächeln vs. dicke Augenbrauen
Sobald wir ein Bild so bearbeitet haben, dass es weiblicher aussieht, sehen wir allmählich einen sich öffnenden Mund mit einem stärkeren Lächeln und umgekehrt. Zudem werden die Augen in der weiblichen Richtung größer und weiter geöffnet. Die Beispiele von Drake und Kim Kardashian veranschaulichen eine sichtbare Veränderung des Hauttons von dunkler zu heller, wenn man sich entlang der Bildreihe von feminin zu maskulin bewegt. Die gewählte Geschlechterrichtung scheint die Locken in der weiblichen Richtung (im Gegensatz zur männlichen Richtung) zu entfernen, wie die Beispiele von Marylin Monroe und der Co-Autorin dieses Artikels, Isabel Hermes, zeigen.
Wir haben uns auch gefragt, ob eine drastischere Haarverlängerung in Drakes weiblicher Richtung eintreten würde, wenn wir seine Fotoserie nach links erweitern würden. Betrachtet man die allgemeinen Extreme, so sind die Augenbrauen auf der weiblichen Seite ausgedünnt und gewölbt und auf der männlichen Seite gerader und dicker. Augen- und Lippen-Make-up nehmen bei Gesichtern, die sich in die weibliche Richtung bewegen, stark zu, wodurch der Bereich um die Augen dunkler wird und die Augenbrauen dünner werden. Dies könnte der Grund dafür sein, dass wir die von uns erstellten männlichen Versionen als natürlicher empfunden haben als die weiblichen Versionen.
Abschließend möchten wir dich auffordern, die obige Fotoserie genau zu betrachten. Versuche zu entscheiden, welches Bild Du als geschlechtsneutral empfindest, d. h. als ebenso männlich wie weiblich. Warum hast Du dich für dieses Bild entschieden? Hat eines der oben beschriebenen stereotypen Merkmale Deine Wahrnehmung beeinflusst?
Eine Frage, die sich bei Bildserien wie diesen natürlich stellt, ist, ob die Gefahr besteht, dass die KI gängige Geschlechterstereotypen verstärkt.
Ist die KI schuld an der Rekonstruktion von Stereotypen?
Angesichts der Tatsache, dass die angepassten Bilder bestimmte geschlechtsspezifische Stereotypen wiedergeben, wie z. B. ein ausgeprägteres Lächeln bei weiblichen Bildern, könnte eine mögliche Schlussfolgerung sein, dass der Trainingsdatensatz der KI einen Bias aufgewiesen hat. Und in der Tat wurden für das Training des zugrunde liegenden StyleGAN Bilddaten von Flickr verwendet, die die Verzerrungen von der Website übernehmen. Das Hauptziel dieses Trainings war es jedoch, realistische Bilder von Gesichtern zu erstellen. Und obwohl die Ergebnisse vielleicht nicht immer so aussehen, wie wir es erwarten oder wünschen, würden wir behaupten, dass die KI genau das in allen unseren Tests erreicht hat.
Um die Bilder zu verändern, haben wir jedoch die zuvor erwähnte latente Richtung verwendet. Im Allgemeinen ändern diese latenten Richtungen selten nur einen einzigen Aspekt des erzeugten Bildes. Stattdessen werden, wie beim Bewegen in eine zufällige Richtung auf unserer latenten Landkarte, normalerweise viele Elemente des erzeugten Gesichts gleichzeitig verändert. Die Identifizierung einer Richtung, die nur einen einzigen Aspekt eines generierten Bildes verändert, ist alles andere als trivial. Für unser Experiment wurde die gewählte Richtung in erster Linie zu Forschungszwecken erstellt, ohne die genannten Verzerrungen zu berücksichtigen. Sie kann daher neben den beabsichtigten Veränderungen auch unerwünschte Artefakte in die Bilder einbringen. Dennoch kann angenommen werden, dass eine latente Richtung existiert, die es uns ermöglicht, das Geschlecht eines vom StyleGAN erzeugten Gesichts zu verändern, ohne andere Gesichtsmerkmale zu beeinträchtigen.
Insgesamt verwenden die Implementierungen, auf denen wir aufbauen, unterschiedliche KI und Datensätze, und das komplexe Zusammenspiel dieser Systeme erlaubt es uns daher nicht, die KI als einzige Ursache für diese Probleme zu identifizieren. Nichtsdestotrotz legen unsere Beobachtungen nahe, dass es von größter Wichtigkeit ist, bei der Erstellung von Datensätzen die nötige Sorgfalt walten zu lassen, um die Repräsentation verschiedener ethnischer Hintergründe sicherzustellen und Verzerrungen zu vermeiden.

Abb. 7: Beispielbild aus der Studie „A Sex Difference in Facial Contrast and its Exaggeration by Cosmetics“ von Richard Russel
Unbewusste Voreingenommenheit: Blick auf uns selbst
Eine Studie von Richard Russel befasst sich mit der menschlichen Wahrnehmung des Geschlechts in Gesichtern. Welchem Geschlecht würdest Du die beiden Bilder oben intuitiv zuordnen? Es zeigt sich, dass die meisten Menschen die linke Person als männlich und die rechte Person als weiblich wahrnehmen. Schau noch einmal hin. Was unterscheidet die Gesichter? Es gibt keinen Unterschied in der Gesichtsstruktur: Nur die dunkleren Augen- und Mundpartien unterscheiden sich. So wird deutlich, dass ein erhöhter Kontrast ausreicht, um unsere Wahrnehmung zu beeinflussen. Nehmen wir an, unsere Meinung über das Geschlecht kann durch das Auftragen von „Kosmetika“ auf ein Gesicht beeinflusst werden. In diesem Fall müssten wir unser menschliches Verständnis von Geschlechterdarstellungen in Frage stellen und uns damit befassen, ob sie nicht einfach das Produkt unserer lebenslangen Exposition gegenüber stereotypen Bildern sind. Der Studienautor bezeichnet dies als „Illusion des Geschlechts“.
Diese Verzerrung bezieht sich auf die Auswahl der latenten „Geschlechts“-Dimension: Um die latente Dimension zu finden, die das wahrgenommene Geschlecht eines Gesichts verändert, wurden die von StyleGAN generierten Bilder nach ihrem Aussehen in Gruppen eingeteilt. Obwohl dies auf der Grundlage einer anderen KI implementiert wurde, könnte sich die menschliche Voreingenommenheit bei der Geschlechterwahrnehmung durchaus auf diesen Prozess ausgewirkt haben und zu den oben dargestellten Bildreihen durchgesickert sein.
Schluss
Die Geschlechtertrennung überwinden mit StyleGANs
Auch wenn ein StyleGAN an und für sich keine geschlechtsspezifischen Vorurteile verstärkt, so sind Menschen doch unbewusst mit Geschlechterstereotypen behaftet. Geschlechtsspezifische Vorurteile beschränken sich nicht nur auf Bilder – Forscher:innen fanden die Allgegenwart weiblicher Sprachassistenten Grund genug, einen neuen Sprachassistenten zu entwickeln, der weder männlich noch weiblich ist: GenderLess Voice.
Ein Beispiel für einen neueren gesellschaftlichen Wandel ist die Debatte über das Geschlecht, das nicht mehr binär, sondern als Spektrum dargestellt werden kann. Die Idee ist, dass es ein biologisches Geschlecht und ein soziales Geschlecht gibt. Für eine Person, die sich mit einem Geschlecht identifiziert, das sich von dem unterscheidet, mit dem sie geboren wurde, ist es wichtig, in die Gesellschaft aufgenommen zu werden, so wie sie ist.
Eine Frage, die wir als Gesellschaft im Auge behalten müssen, ist, ob der Bereich der KI Gefahr läuft, Menschen jenseits der zugewiesenen binären Geschlechterordnung zu diskriminieren. Tatsache ist, dass in der KI-Forschung das Geschlecht oft binär dargestellt wird. Bilder, die in Algorithmen eingespeist werden, um diese zu trainieren, werden entweder als männlich oder weiblich gekennzeichnet. Geschlechtserkennungssysteme, die auf einer deterministischen Geschlechtszuordnung basieren, können auch direkten Schaden anrichten, indem sie Mitglieder der LGBTQIA+-Gemeinschaft falsch kennzeichnen. Derzeit müssen in der ML-Forschung noch weitere Geschlechtsbezeichnungen berücksichtigt werden. Anstatt das Geschlecht als binäre Variable darzustellen, könnte es als Spektrum kodiert werden.
Erforschung der Geschlechterdarstellung von Frauen und Männern
Wir haben StyleGAN angewandt, um zu untersuchen, wie KI Geschlechterunterschiede darstellt. Konkret haben wir eine Geschlechterrichtung im latenten Raum verwendet. Forscher:innen haben diese Richtung vorher bestimmt, um das männliche und weibliche Geschlecht darzustellen. Wir haben gesehen, dass die generierten Bilder gängige Geschlechterstereotypen wiedergaben – Frauen lächeln mehr, haben größere Augen, längeres Haar und tragen viel Make-up – konnten aber nicht feststellen, dass das StyleGAN-Modell allein diese Verzerrung verbreitet. Erstens wurden die StyleGANs in erster Linie entwickelt, um fotorealistische Gesichtsbilder zu erzeugen und nicht, um die Gesichtszüge vorhandener Fotos nach Belieben zu verändern. Zweitens: Da die von uns verwendete latente Richtung ohne Korrektur für Verzerrungen in den StyleGAN-Trainingsdaten erstellt wurde, sehen wir eine Korrelation zwischen stereotypen Merkmalen und Geschlecht.
Nächste Schritte und Geschlechtsneutralität
Auch haben wir uns gefragt, welche Gesichter wir in den von uns generierten Bildsequenzen als geschlechtsneutral wahrnehmen. Bei Originalbildern von Männern mussten wir in die künstlich erzeugte weibliche Richtung schauen und umgekehrt. Dies war eine subjektive Entscheidung. Wir sehen es als logischen nächsten Schritt an, zu versuchen, die Generierung von geschlechtsneutralen Versionen von Gesichtsbildern zu automatisieren, um die Möglichkeiten der KI im Bereich Geschlecht und Gesellschaft weiter zu erforschen. Dazu müssten wir zunächst das Geschlecht des zu bearbeitenden Gesichts klassifizieren und uns dann bis zu dem Punkt, an dem der Klassifikator keine eindeutige Zuordnung mehr vornehmen kann, dem anderen Geschlecht annähern. Daher können interessierte Leserinnen und Leser die Fortsetzung unserer Reise in einem zweiten Blogartikel in nächster Zeit verfolgen.
Wenn Du dich für unsere technische Umsetzung dieses Artikels interessierst, kannst Du den Code hier finden und ihn mit deinen eigenen Bildern ausprobieren.
Quellen
Bildnachweise
AdobeStock 210526825 – Wayhome Studio
AdobeStock 243124072 – Damir Khabirov
AdobeStock 387860637 – insta_photos
AdobeStock 395297652 – Nattakorn
AdobeStock 480057743 – Chris
AdobeStock 573362719 – Xavier Lorenzo
AdobeStock 575284046 – Jose Calsina
Das erwartet Euch:
Wollten Sie schon immer wissen, wie KI konkret eingesetzt werden kann, um unsere Welt nachhaltiger zu gestalten? Dann sollten Sie die After-Work-Veranstaltung „Green AIdeas“ nicht verpassen.
Das Event bietet KI-Unternehmen eine Bühne für ihre Ideen und Best Practices sowie eine Austauschplattform für Inspiration, konkrete Anwendungsfälle und Herausforderungen rund um das Thema KI und Nachhaltigkeit.
Neben Diskussionsrunden und der Führung durch das nachhaltige Rechenzentrum haben Sie die Möglichkeit, an einem der spannenden KI & Sustainability Impulsvorträge teilzunehmen.
Einer dieser Vorträge zum Thema „Nachhaltiges Machine Learning – Welche Auswirkungen haben Machine Learning Modelle auf die Umwelt und was für Gegenmaßnahmen können getroffen werden?“ wird von unseren statworx KI-Expert:innen Isabel Hermes und Dominique Lade gehalten.
In dem Vortrag lernen Sie unter anderem:
- Was genau maschinelles Lernen mit Nachhaltigkeit zu tun hat
- Wie man die Emissionen von KI-Anwendungen erkennen und reduzieren kann
- Wie maschinelles Lernen umweltverträglicher gestaltet werden kann
Die Teilnahme an der Veranstaltung ist kostenfrei.
Hier geht es zur Anmeldung: https://mautic.cloudandheat.com/green-aideas-registration
Wir freuen uns darauf, Sie am 8. September zu sehen!