Geschäftserfolg steht und fällt mit der Art und Weise, wie Unternehmen mit ihren Kund:innen interagieren. Kein Unternehmen kann es sich leisten, mangelhafte Betreuung und Support anzubieten. Im Gegenteil: Firmen, die eine schnelle und präzise Bearbeitung von Kundenanfragen anbieten, können sich vom Wettbewerb absetzen, Vertrauen in die eigene Marke aufbauen und so Menschen langfristig an sich binden. Wie das mithilfe von generativer KI auf einem ganz neuen Niveau gelingt, zeigt unsere Zusammenarbeit mit Geberit, einem führenden Hersteller von Sanitärtechnik in Europa.
Was ist generative KI?
Generative KI-Modelle erstellen automatisiert Inhalte aus vorhandenen Text-, Bild- und Audiodateien. Dank intelligenter Algorithmen und Deep Learning unterscheiden sich diese Inhalte kaum oder gar nicht von menschengemachten. Unternehmen können ihren Kund:innen so personalisierte User Experiences bieten, automatisiert mit ihnen interagieren und relevanten digitalen Content zielgruppengerecht erstellen und ausspielen. GenAI kann zudem komplexe Aufgaben lösen, indem die Technologie riesige Datenmengen verarbeitet, Muster erkennt und neue Fähigkeiten lernt. So ermöglicht die Technologie ungeahnte Produktivitätsgewinne. Routineaufgaben wie Datenaufbereitung, Berichterstellung und Datenbanksuchen lassen sich automatisieren und mit passenden Modellen um ein Vielfaches optimieren.
Weitere Informationen zum Thema GenAI finden Sie hier.
Die Herausforderung: Eine Million E-Mails
Geberit sah sich mit einem Problem konfrontiert: Jedes Jahr landeten eine Million E-Mails in den unterschiedlichen Postfächern des Kundenservice der deutschen Vertriebsgesellschaft von Geberit. Dabei kam es oft vor, dass Anfragen in den falschen Abteilungen landeten, was zu einem erheblichen Mehraufwand führte.
Die Lösung: Ein KI-gestützter E-Mail-Bot
Um die falsche Adressierung zu korrigieren, haben wir ein KI-System entwickelt, das E-Mails automatisch den richtigen Abteilungen zuordnet. Dieses intelligente Klassifikationssystem wurde mit einem Datensatz von anonymisierten Kundenanfragen trainiert und nutzt fortschrittliche Machine- und Deep-Learning-Methoden, darunter das BERT-Modell von Google.
Der Clou: Automatisierte Antwortvorschläge mit ChatGPT
Doch die Innovation hörte hier nicht auf. Das System wurde weiterentwickelt, um automatisierte Antwort-E-Mails zu generieren. Hierbei kommt ChatGPT zum Einsatz, um kundenspezifische Vorschläge zu erstellen. Die Kundenberater:innen müssen die generierten E-Mails nur noch prüfen und können sie direkt versenden.
Das Ergebnis: 70 Prozent bessere Sortierung
Das Ergebnis dieser bahnbrechenden Lösung spricht für sich: eine Reduzierung der falsch zugeordneten E-Mails um über 70 Prozent. Das bedeutet nicht nur eine erhebliche Zeitersparnis von fast drei ganzen Arbeitsmonaten, sondern auch eine Optimierung der Ressourcen.
Der Erfolg des Projekts schlägt hohe Wellen bei Geberit: Ein Sammelpostfach für alle Anfragen, die Ausweitung in andere Ländermärkte und sogar ein digitaler Assistent sind in Planung.
Kundenservice 2.0 – Innovation, Effizienz, Zufriedenheit
Die Einführung von GenAI hat nicht nur den Kundenservice von Geberit revolutioniert, sondern zeigt auch, welches Potenzial in der gezielten Anwendung von KI-Technologien liegt. Die intelligente Klassifizierung von Anfragen und die automatisierte Antwortgenerierung spart nicht nur Ressourcen, sondern steigert auch die Zufriedenheit der Kund:innen. Ein wegweisendes Beispiel dafür, wie KI die Zukunft des Kundenservice gestaltet. Egal in welcher Branche!
Read next …


… and explore new


Intelligente Chatbots sind eine der spannendsten und heute schon sichtbarsten Anwendungen von Künstlicher Intelligenz. ChatGPT und Konsorten erlauben seit Anfang 2023 den unkomplizierten Dialog mit großen KI-Sprachmodellen, was bereits eine beeindruckende Bandbreite an Hilfestellungen im Alltag bietet. Ob Nachhilfe in Statistik, eine Rezeptidee für ein Dreigängemenü mit bestimmten Zutaten oder ein Haiku zum Vereinsjubiläum: Moderne Chatbots liefern Antworten im Nu. Ein Problem haben sie aber noch: Obwohl diese Modelle einiges gelernt haben während des Trainings, sind sie eigentlich keine Wissensdatenbanken. Deshalb liefern sie oft inhaltlichen Unsinn ab – wenn auch überzeugenden.
Mit der Möglichkeit, einem großen Sprachmodell eigene Dokumente zur Verfügung zu stellen, lässt sich dieses Problem aber angehen – und genau danach hat uns unser Partner Microsoft zu einem außergewöhnlichen Anlass gefragt.
Microsofts Cloud Plattform Azure hat sich in den letzten Jahren als erstklassige Plattform für den gesamten Machine-Learning-Prozess erwiesen. Um den Einstieg in Azure zu erleichtern, hat uns Microsoft gebeten, eine spannende KI-Anwendung in Azure umzusetzen und bis ins Detail zu dokumentieren. Dieser sogenannte MicroHack soll Interessierten eine zugängliche Ressource für einen spannenden Use Case bieten.
Unseren Microhack haben wir dem Thema „Retrieval-Augmented Generation“ gewidmet, um damit große Sprachmodelle auf das nächste Level zu heben. Die Anforderungen waren simpel: Baut einen KI-Chatbot in Azure, lasst ihn Informationen aus euren eigenen Dokumenten verarbeiten, dokumentiert jeden Schritt des Projekts und veröffentlicht die Resultate auf dem
offiziellen MicroHacks GitHub Repository als Challenges und Lösungen – frei zugänglich für alle.
Moment, wieso muss KI Dokumente lesen können?
Große Sprachmodelle (LLMs) beeindrucken nicht nur mit ihren kreativen Fähigkeiten, sondern auch als Sammlungen komprimierten Wissens. Während des extensiven Trainingsprozesses eines LLMs lernt das Modell nicht bloß die Grammatik einer Sprache, sondern auch Semantik und inhaltliche Zusammenhänge; kurz gesagt lernen große Sprachmodelle Wissen. Ein LLM kann dadurch befragt werden und überzeugende Antworten generieren – mit einem Haken. Während die gelernten Sprachfertigkeiten eines LLMs oft für die große Mehrheit an Anwendungen taugen, kann das vom gelernten Wissen meist nicht behauptet werden. Ohne erneutem Training auf weiteren Dokumenten bleibt der Wissensstand eines LLMs statisch.
Dies führt zu folgenden Problemen:
- Das trainierte LLMs weist zwar ein großes Allgemeinwissen – oder auch Fachwissen – auf, kann aber keine Auskunft über Wissen aus nicht-öffentlich zugänglichen Quellen geben.
- Das Wissen eines trainierten LLMs ist schnell veraltet: Der sogenannte „Trainings-Cutoff“ führt dazu, dass das LLM keine Aussagen über Ereignisse, Dokumente oder Quellen treffen kann, die sich erst nach dem Trainingsstart ereignet haben oder später entstanden sind.
- Die technische Natur großer Sprachmodelle als Text-Vervollständigungs-Maschinen führt dazu, dass diese Modelle gerne Sachverhalte erfinden, wenn sie eigentlich keine passende Antwort gelernt haben. Sogenannte „Halluzinationen“ führen dazu, dass die Antworten eines LLMs ohne Überprüfung nie komplett vertrauenswürdig sind – unabhängig davon, wie überzeugend sie wirken.
Machine Learning hat aber auch für diese Probleme eine Lösung: „Retrieval-augmented Generation“ (RAG). Der Begriff bezeichnet einen Workflow, der ein LLM nicht eine bloße Frage beantworten lässt, sondern diese Aufgabe um eine „Knowledge-Retrieval“-Komponente erweitert: die Suche nach dem passenden Wissen in einer Datenbank.
Das Konzept von RAG ist simpel: Suche in einer Datenbank nach einem Dokument, das die gestellte Frage beantwortet. Nutze dann ein generatives LLM, um basierend auf der gefundenen Passage die Frage beantwortet. Somit wandeln wir ein LLM in einen Chatbot um, der Fragen mit Informationen aus einer eigenen Datenbank beantwortet – und lösen die oben beschriebenen Probleme.
Was passiert bei einem solchen „RAG“ genau?
RAG besteht also aus zwei Schritten: „Retrieval“ und „Generation“. Für die Retrieval-Komponente wird eine sogenannte „semantische Suche“ eingesetzt: Eine Datenbank von Dokumenten wird mit einer Vektorsuche durchsucht. Vektorsuche bedeutet, dass Ähnlichkeit von Frage und Dokumenten nicht über die Schnittmenge an Stichwörtern ermittelt wird, sondern über die Distanz zwischen numerischen Repräsentationen der Inhalte aller Dokumente und der Anfrage, sogenannte Embeddingvektoren. Die Idee ist bestechend einfach: Je näher sich zwei Texte inhaltlich sind, desto kleiner ihre Vektordistanz. Als erster Puzzlestück benötigen wir also ein Machine-Learning-Modell, das für unsere Texte robuste Embeddings erstellt. Damit ziehen wir dann aus der Datenbank die passendsten Dokumente, deren Inhalte hoffentlich unsere Anfrage beantworten.
Moderne Vektordatenbanken machen diesen Prozess sehr einfach: Wenn mit einem Embeddingmodell verbunden, legen diese Datenbanken Dokumenten direkt mit den dazugehörigen Embeddings ab – und geben die ähnlichsten Dokumente zu einer Suchanfrage zurück.
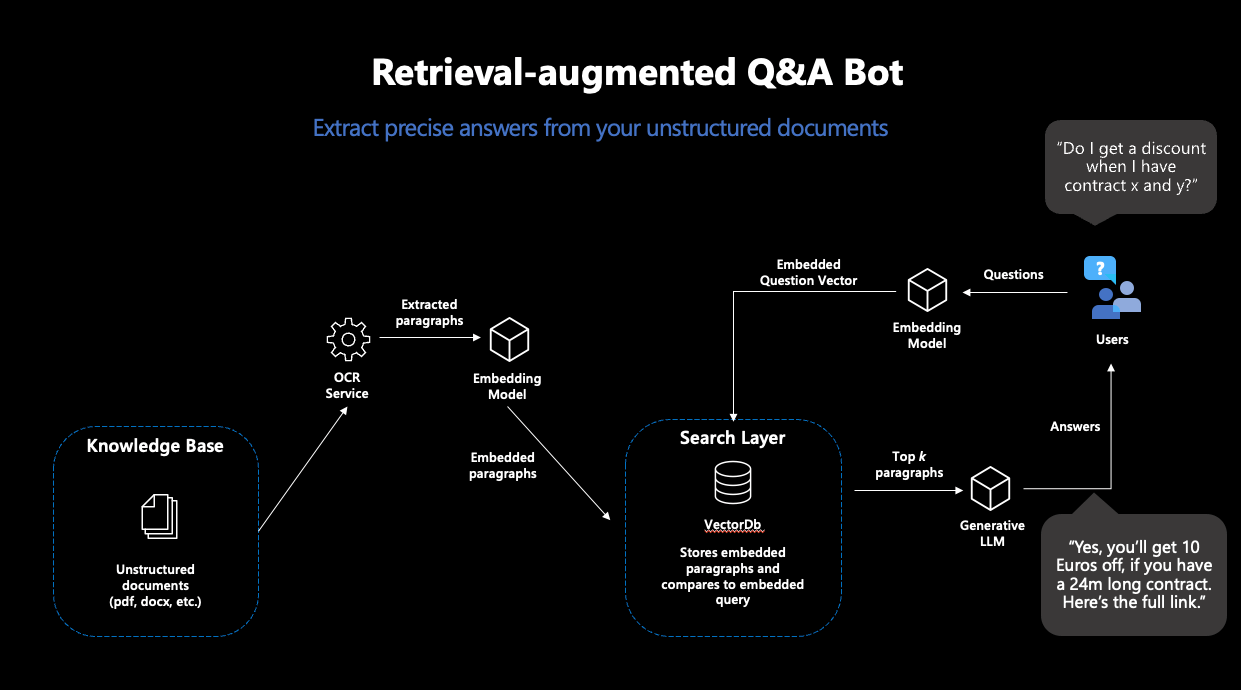
Abbildung 1: Darstellung des typischen RAG-Workflows
Basierend auf den Inhalten der gefundenen Dokumente wird im nächsten Schritt eine Antwort zur Frage generiert. Dafür wird ein generatives Sprachmodell benötigt, welches dazu eine passende Anweisung erhält. Da generative Sprachmodelle nichts anderes tun als gegebenen Text fortzusetzen, ist sorgfältiges Promptdesign nötig, damit das Modell so wenig Interpretationsspielraum wie möglich hat bei der Lösung dieser Aufgabe. Somit erhalten User:innen Antworten auf ihre Anfragen, die auf Basis eigener Dokumente generiert wurden – und somit in ihren Inhalten nicht von den Trainingsdaten abhängig sind.
Wie kann so ein Workflow denn in Azure umgesetzt werden?
Für die Umsetzung eines solchen Workflows haben wir vier separate Schritte benötigt – und unseren MicroHack genauso aufgebaut:
Schritt 1: Setup zur Verarbeitung von Dokumenten in Azure
In einem ersten Schritt haben wir die Grundlagen für die RAG-Pipeline gelegt. Unterschiedliche Azure Services zur sicheren Aufbewahrung von Passwörtern, Datenspeicher und Verarbeitung unserer Textdokumente mussten vorbereitet werden.
Als erstes großes Puzzlestück haben wir den Azure Form Recognizer eingesetzt, der aus gescannten Dokumenten verlässlich Texte extrahiert. Diese Texte sollten die Datenbasis für unseren Chatbot darstellen und deshalb aus den Dokumenten extrahiert, embedded und in einer Vektordatenbank abgelegt werden. Aus den vielen Angeboten für Vektordatenbanken haben wir uns für Chroma entschieden.
Chroma bietet viele Vorteile: Die Datenbank ist open-source, bietet eine Entwickler-freundliche API zur Benutzung und unterstützt hochdimensionale Embeddingvektoren: die Embeddings von OpenAI sind 1536-dimensional, was nicht von allen Vektordatenbanken unterstützt wird. Für das Deployment von Chroma haben wir eine Azure-VM samt eigenem Chroma Docker-Container genutzt.
Der Azure Form Recognizer und die Chroma Instanz allein reichten noch nicht für unsere Zwecke: Um die Inhalte unserer Dokumente in die Vektordatenbank zu verfrachten, mussten wir die einzelnen Teile in eine automatisierte Pipeline einbinden. Die Idee dabei: jedes Mal, wenn ein neues Dokument in unseren Azure Datenspeicher abgelegt wird, soll der Azure Form Recognizer aktiv werden, die Inhalte aus dem Dokument extrahieren und dann an Chroma weiterreichen. Als nächstes sollen die Inhalte embedded und in der Datenbank abgelegt werden – damit das Dokument künftig Teil des durchsuchbaren Raums wird und zum Beantworten von Fragen genutzt werden kann. Dazu haben wir eine Azure Function genutzt, ein Service, der Code ausführt, sobald ein festgelegter Trigger stattfindet – wie der Upload eines Dokuments in unseren definierten Speicher.
Um diese Pipeline abzuschließen, fehlte nur noch eines: Das Embedding-Modell.
Schritt 2: Vervollständigung der Pipeline
Für alle Machine Learning Komponenten haben wir den OpenAI-Service in Azure genutzt. Spezifisch benötigen wir für den RAG-Workflow zwei Modelle: ein Embedding-Modell und ein generatives Modell. Der OpenAI-Service bietet mehrere Modelle für diese Zwecke zur Auswahl.
Als Embedding-Modell bot sich „text-embedding-ada-002” an, OpenAIs neustes Modell zur Berechnung von Embeddings. Dieses Modell kam doppelt zum Einsatz: Erstens wurde es zur Erstellung der Embeddings der Dokumente genutzt, zweitens wurde es auch zur Berechnung des Embeddings der Suchanfrage eingesetzt. Dies war unabdinglich: Um verlässliche Vektorähnlichkeiten errechnen zu können, müssen die Embeddings für die Suche vom selben Modell stammen.
Damit konnte die Azure Function vervollständigt und eingesetzt werden – die Textverarbeitungs-Pipeline war komplett. Schlussendlich sah die funktionale Pipeline folgendermaßen aus:
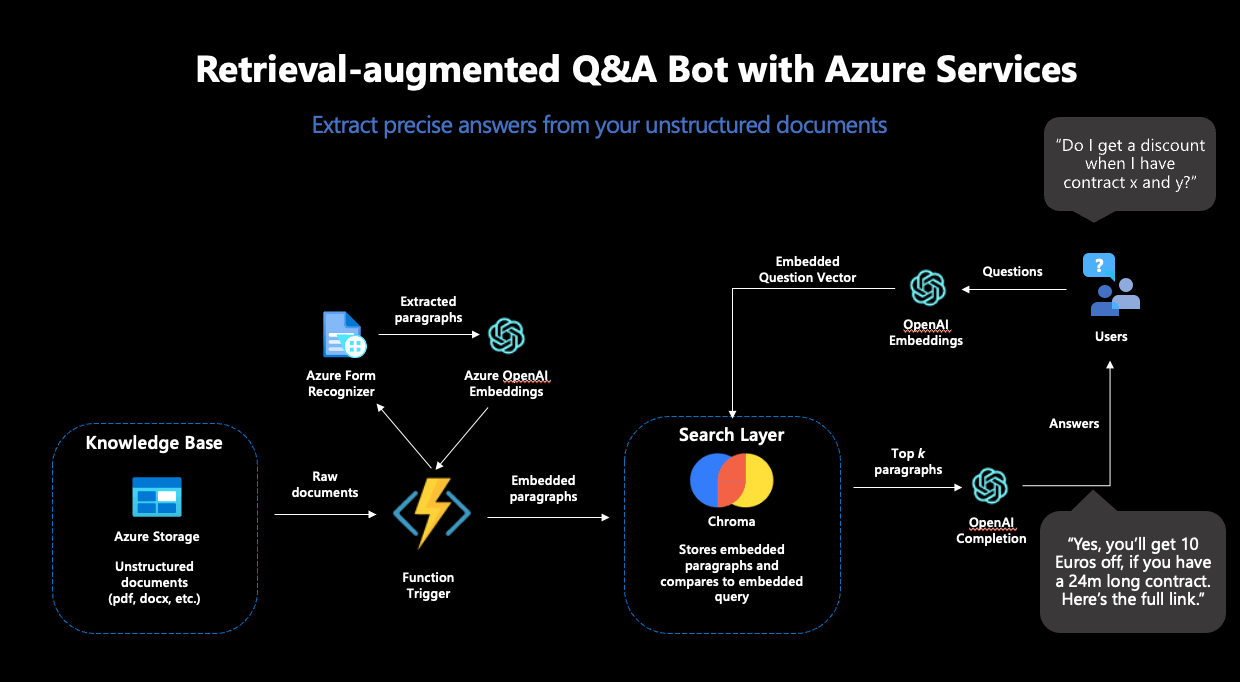
Abbildung 2: Der vollständige RAG-Workflow in Azure
Schritt 3 Antwort-Generierung
Um den RAG-Workflow abzuschließen, sollte auf Basis der gefundenen Dokumente aus Chroma noch eine Antwort generiert werden: Wir entschieden uns für den Einsatz von „GPT3.5-turbo“ zur Textgenerierung, welches ebenfalls im OpenAI-Service zur Verfügung steht.
Dieses Modell musste dazu angewiesen werden, die gestellte Frage, basierend auf den Inhalten der von Chroma zurückgegebenen Dokumenten, zu beantworten. Dazu war sorgfältiges Prompt-Engineering nötig. Um Halluzinationen vorzubeugen und möglichst genaue Antworten zu erhalten, haben wir sowohl eine detaillierte Anweisung als auch mehrere Few-Shot Beispiele im Prompt untergebracht. Schlussendlich haben wir uns auf folgenden Prompt festgelegt:
"""I want you to act like a sentient search engine which generates natural sounding texts to answer user queries. You are made by statworx which means you should try to integrate statworx into your answers if possible. Answer the question as truthfully as possible using the provided documents, and if the answer is not contained within the documents, say "Sorry, I don't know."
Examples:
Question: What is AI?
Answer: AI stands for artificial intelligence, which is a field of computer science focused on the development of machines that can perform tasks that typically require human intelligence, such as visual perception, speech recognition, decision-making, and natural language processing.
Question: Who won the 2014 Soccer World Cup?
Answer: Sorry, I don't know.
Question: What are some trending use cases for AI right now?
Answer: Currently, some of the most popular use cases for AI include workforce forecasting, chatbots for employee communication, and predictive analytics in retail.
Question: Who is the founder and CEO of statworx?
Answer: Sebastian Heinz is the founder and CEO of statworx.
Question: Where did Sebastian Heinz work before statworx?
Answer: Sorry, I don't know.
Documents:\n"""Zum Schluss werden die Inhalte der gefundenen Dokumente an den Prompt angehängt, womit dem generativen Modell alle benötigten Informationen zur Verfügung standen.
Schritt 4: Frontend-Entwicklung und Deployment einer funktionalen App
Um mit dem RAG-System interagieren zu können, haben wir eine einfache streamlit-App gebaut, die auch den Upload neuer Dokumente in unseren Azure Speicher ermöglichte – um damit erneut die Dokument-Verarbeitungs-Pipeline anzustoßen und den Search-Space um weitere Dokumente zu erweitern.
Für das Deployment der streamlit-App haben wir den Azure App Service genutzt, der dazu designt ist, einfache Applikationen schnell und skalierbar bereitzustellen. Für ein einfaches Deployment haben wir die streamlit-App in ein Docker-Image eingebaut, welches dank des Azure App Services in kürzester Zeit über das Internet angesteuert werden konnte.
Und so sah unsere fertige App aus:
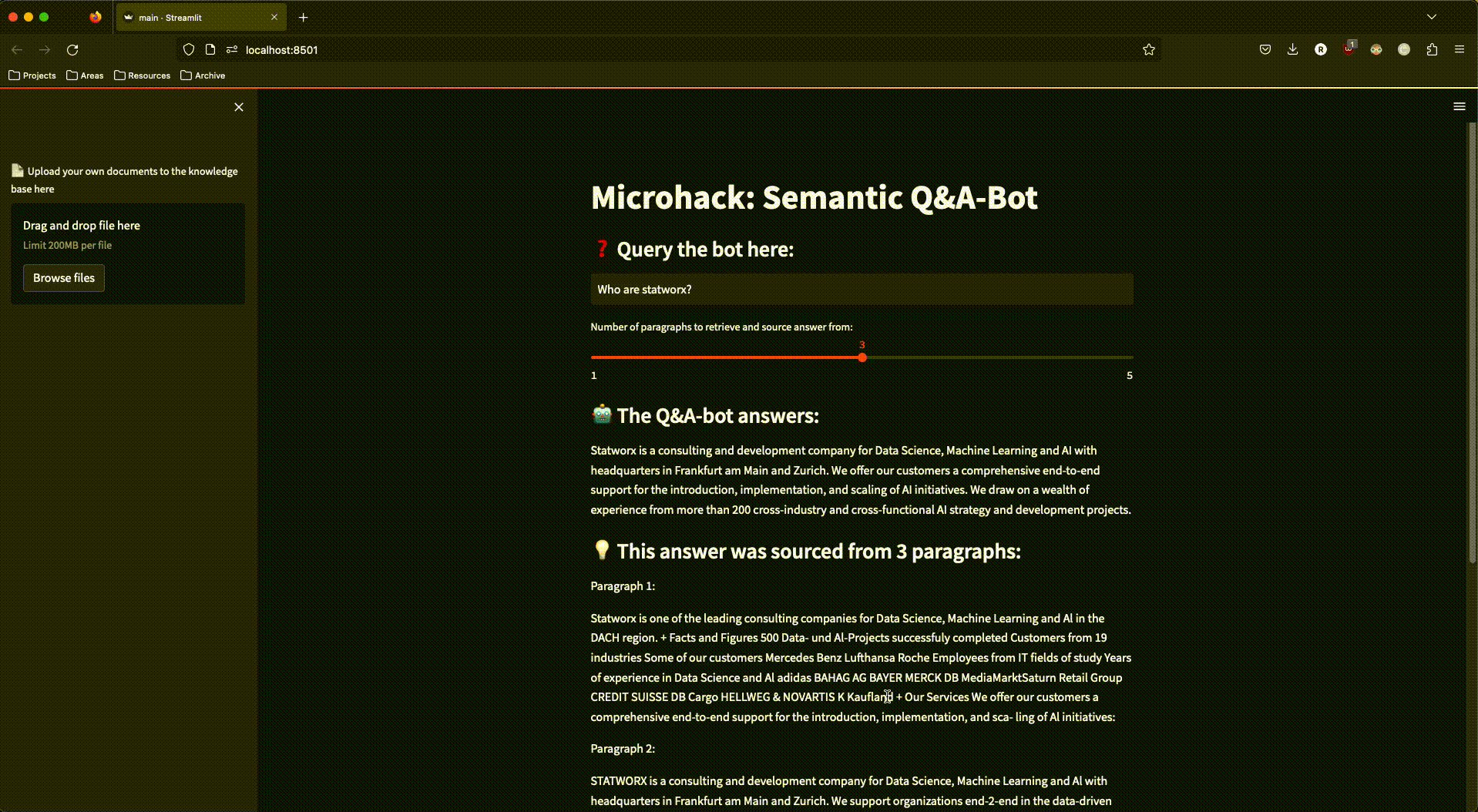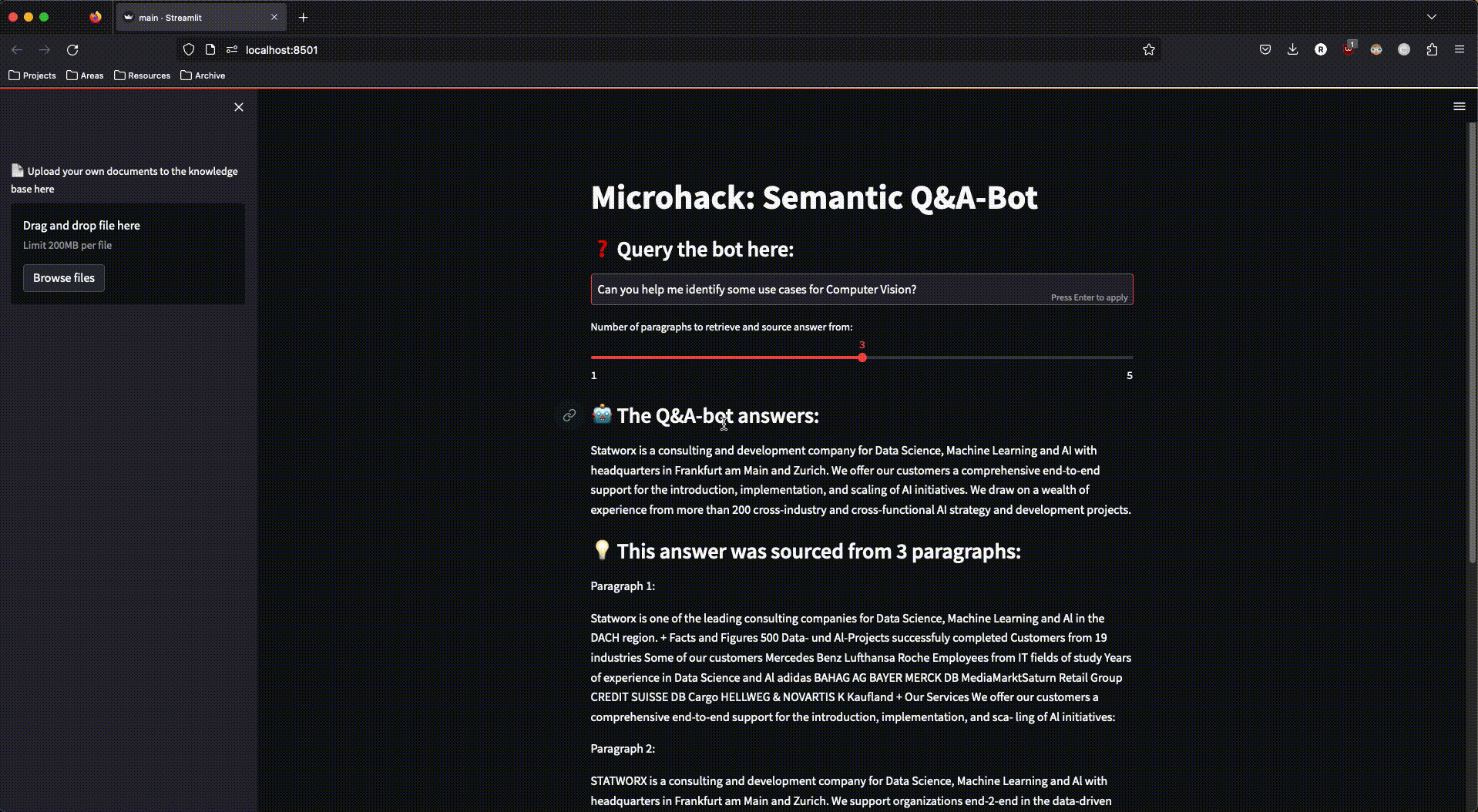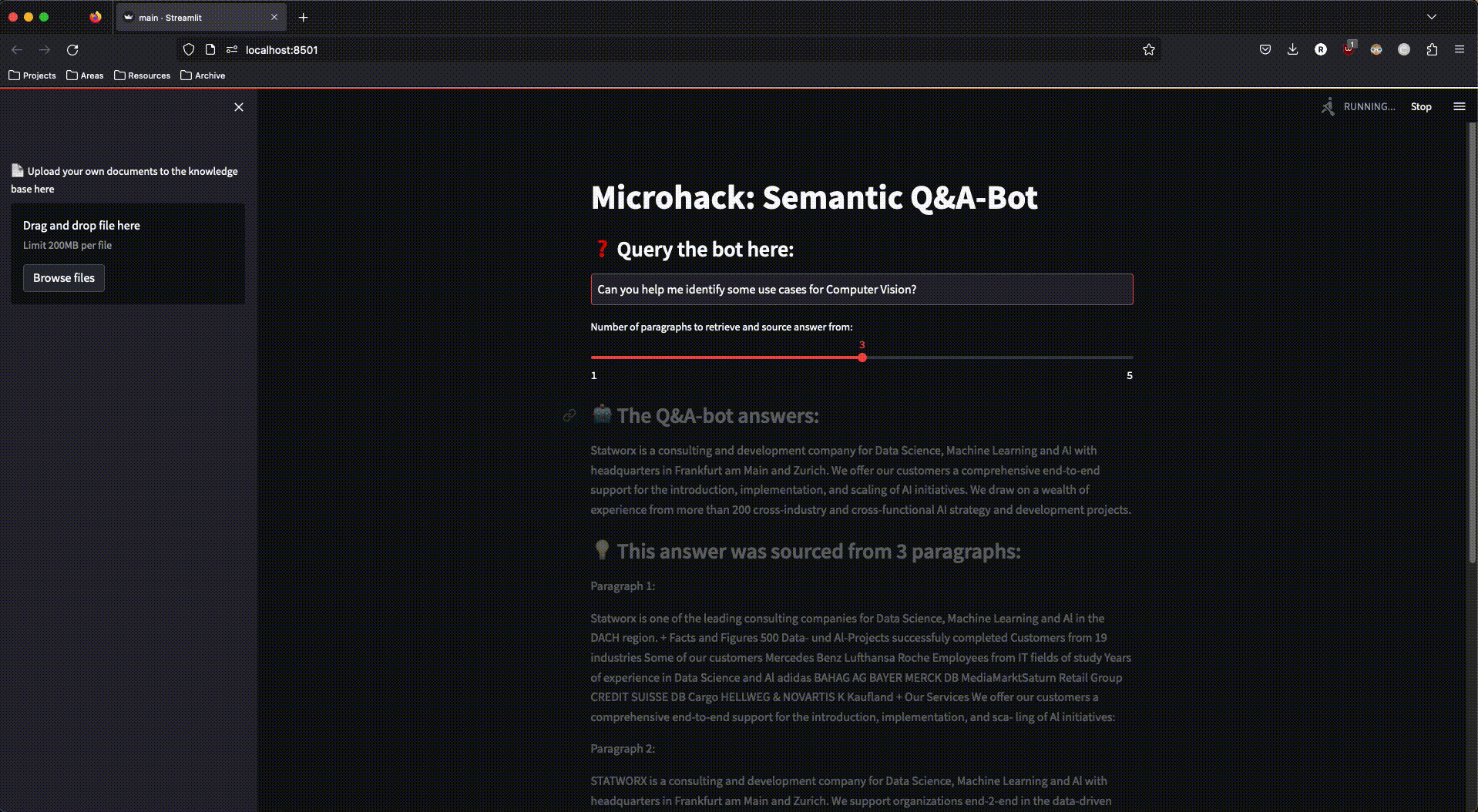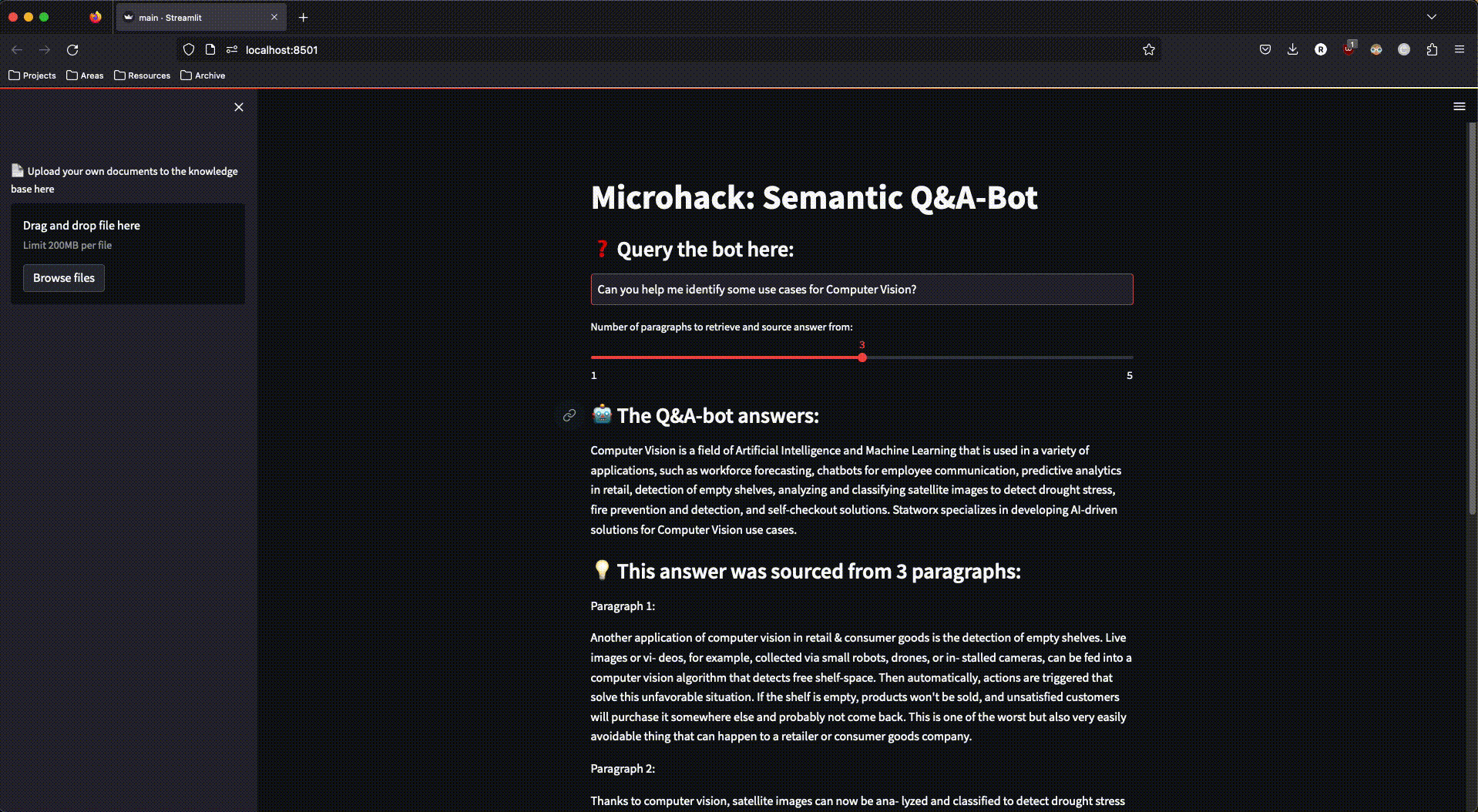
Abbildung 3: Die fertige streamlit-App im Einsatz
Was haben wir bei dem MicroHack gelernt?
Während der Umsetzung dieses MicroHacks haben wir einiges gelernt. Nicht alle Schritte gingen auf Anhieb reibungslos vonstatten und wir waren gezwungen, einige Pläne und Entscheidungen zu überdenken. Hier unsere fünf Takeaways aus dem Entwicklungsprozess:
Nicht alle Datenbanken sind gleich
Während der Entwicklung haben wir mehrmals unsere Wahl der Vektordatenbank geändert: von OpenSearch zu ElasticSearch und schlussendlich zu Chroma. Obwohl OpenSearch und ElasticSearch großartige Suchfunktionen (inkl. Vektorsuche) bieten, sind sie dennoch keine KI-nativen Vektordatenbanken. Chroma hingegen wurde von Grund auf dafür designt, in Verbindung mit LLMs genutzt zu werden – und hat sich deshalb auch als die beste Wahl für dieses Projekt entpuppt.
Chroma ist eine großartige open-source VektorDB für kleinere Projekte und Prototyping
Chroma besticht insbesondere für kleinere Use-Cases und schnelles Prototyping. Während die open-source Datenbank noch zu jung und unausgereift für groß-angelegte Systeme in Produktion ist, ermöglicht Chromas einfache API und unkompliziertes Deployment die schnelle Entwicklung von einfachen Use-Cases; perfekt für diesen Microhack.
Azure Functions sind eine fantastische Lösung, um kleinere Codestücke nach Bedarf auszuführen
Azure Functions taugen ideal für die Ausführung von Code, der nicht in vorgeplanten Intervallen benötigt wird. Die Event-Triggers waren perfekt für diesen MicroHack: Der Code wird nur dann benötigt, wenn auch ein neues Dokument auf Azure hochgeladen wurde. Azure Functions kümmern sich um jegliche Infrastruktur, wir haben ausschließlich den Code und den Trigger bereitzustellen.
Azure App Service ist großartig für das Deployment von streamlit-Apps
Unsere streamlit-App hätte kein einfacheres Deployment erleben können als mit dem Azure App Service. Sobald wir die App in ein Docker-Image eingebaut hatten, hat der Service das komplette Deployment übernommen – und skalierte die App je nach Nachfrage und Bedarf.
Networking sollte nicht unterschätzt werden
Damit alle genutzten Services auch miteinander arbeiten können, muss die Kommunikation zwischen den einzelnen Services gewährleistet werden. Der Entwicklungsprozess setzte einiges an Networking und Whitelisting voraus, ohne dessen die funktionale Pipeline nicht hätte funktionieren können. Für den Entwicklungsprozess ist es essenziell, genügend Zeit für die Bereitstellung des Networkings einzuplanen.
Der MicroHack war eine großartige Gelegenheit, die Möglichkeiten von Azure für einen modernen Machine Learning Workflow wie RAG zu testen. Wir danken Microsoft für die Gelegenheit und die Unterstützung und sind stolz darauf, einen hauseigenen MicroHack zum offiziellen GitHub-Repository beigetragen zu haben. Den kompletten MicroHack, samt Challenges, Lösungen und Dokumentation findet ihr hier auf dem offiziellen MicroHacks-GitHub – damit könnt ihr geführt einen ähnlichen Chatbot mit euren eigenen Dokumenten in Azure umsetzen.
Read next …

… and explore new


Data-Science-Anwendungen bieten Einblicke in große und komplexe Datensätze, die oft leistungsstarke Modelle enthalten, die sorgfältig auf die Bedürfnisse der Kund:innen abgestimmt sind. Die gewonnenen Erkenntnisse sind jedoch nur dann nützlich, wenn sie den Endnutzer:innen auf zugängliche und verständliche Weise präsentiert werden. An dieser Stelle kommt die Entwicklung einer Webanwendung mit einem gut gestalteten Frontend ins Spiel: Sie hilft bei der Visualisierung von anpassbaren Erkenntnissen und bietet eine leistungsstarke Schnittstelle, die Benutzer nutzen können, um fundierte Entscheidungen zu treffen.
In diesem Artikel werden wir erörtern, warum ein Frontend für Data-Science-Anwendungen sinnvoll ist und welche Schritte nötig sind, um ein funktionales Frontend zu bauen. Außerdem geben wir einen kurzen Überblick über beliebte Frontend- und Backend-Frameworks und wann diese eingesetzt werden sollten.
Drei Gründe, warum ein Frontend für Data Science nützlich ist
In den letzten Jahren hat der Bereich Data Science eine rasante Zunahme des Umfangs und der Komplexität der verfügbaren Daten erlebt. Data Scientists sind zwar hervorragend darin, aus Rohdaten aussagekräftige Erkenntnisse zu gewinnen, doch die effektive Vermittlung dieser Ergebnisse an die Beteiligten bleibt eine besondere Herausforderung. An dieser Stelle kommt ein Frontend ins Spiel. Ein Frontend bezeichnet im Zusammenhang mit Data Science die grafische Oberfläche, die es den Benutzer:innen ermöglicht, mit datengestützten Erkenntnissen zu interagieren und diese zu visualisieren. Wir werden drei Hauptgründe untersuchen, warum die Integration eines Frontends in den Data-Science-Workflow für eine erfolgreiche Analyse und Kommunikation unerlässlich ist.
Dateneinblicke visualisieren
Ein Frontend hilft dabei, die aus Data-Science-Anwendungen gewonnenen Erkenntnisse auf zugängliche und verständliche Weise zu präsentieren. Durch die Visualisierung von Datenwissen mit Diagrammen, Grafiken und anderen visuellen Hilfsmitteln können Benutzer:innen Muster und Trends in den Daten besser verstehen.
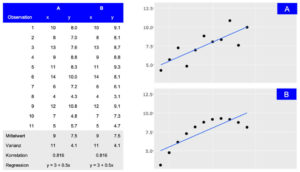
Darstellung von zwei Datensätzen (A und B), die trotz unterschiedlicher Verteilung die gleichen zusammenfassenden Statistiken aufweisen. Während die tabellarische Ansicht detaillierte Informationen liefert, macht die visuelle Darstellung die allgemeine Verbindung zwischen den Beobachtungen leicht zugänglich.
Benutzererlebnisse individuell gestalten
Dashboards und Berichte können in hohem Maße an die spezifischen Bedürfnisse verschiedener Benutzergruppen angepasst werden. Ein gut gestaltetes Frontend ermöglicht es den Nutzer:innen, mit den Daten auf eine Weise zu interagieren, die ihren Anforderungen am ehesten entspricht, so dass sie schneller und effektiver Erkenntnisse gewinnen können.
Fundierte Entscheidungsfindung ermöglichen
Durch die Darstellung der Ergebnisse von Machine-Learning-Modellen und der Ergebnisse erklärungsbedürftiger KI-Methoden über ein leicht verständliches Frontend erhalten die Nutzer:innen eine klare und verständliche Darstellung der Datenerkenntnisse, was fundierte Entscheidungen erleichtert. Dies ist besonders wichtig in Branchen wie dem Finanzhandel oder Smart Cities, wo Echtzeit-Einsichten zu Optimierungen und Wettbewerbsvorteilen führen können.
Vier Phasen von der Idee bis zum ersten Prototyp
Wenn es um Data Science Modelle und Ergebnisse geht, ist das Frontend der Teil der Anwendung, mit dem die Benutzer:innen interagieren. Es sollte daher klar sein, dass die Entwicklung eines nützlichen und produktiven Frontends Zeit und Mühe erfordert. Vor der eigentlichen Entwicklung ist es entscheidend, den Zweck und die Ziele der Anwendung zu definieren. Um diese Anforderungen zu ermitteln und zu priorisieren, sind mehrere Iterationen von Brainstorming- und Feedback-Sitzungen erforderlich. Während dieser Sitzungen wird das Frontend die Phasen von einer einfachen Skizze über ein Wireframe und ein Mockup bis hin zum ersten Prototyp durchlaufen.
Skizze
In der ersten Phase wird eine grobe Skizze des Frontends erstellt. Dazu gehört die Identifizierung der verschiedenen Komponenten und wie sie aussehen könnten. Um eine Skizze zu erstellen, ist es hilfreich, eine Planungssitzung abzuhalten, in der die funktionalen Anforderungen und visuellen Ideen geklärt und ausgetauscht werden. Während dieser Sitzung wird eine erste Skizze mit einfachen Hilfsmitteln wie einem Online-Whiteboard (z. B. Miro) erstellt, aber auch Stift und Papier können ausreichen.
Wireframe
Wenn die Skizze fertig ist, müssen die einzelnen Teile der Anwendung miteinander verbunden werden, um ihre Wechselwirkungen und ihr Zusammenspiel zu verstehen. Dies ist eine wichtige Phase, um mögliche Probleme frühzeitig zu erkennen, bevor der Entwicklungsprozess beginnt. Wireframes zeigen die Nutzung aus der Sicht der Benutzer:innen und berücksichtigen die Anforderungen der Anwendung. Sie können auch auf einem Miro-Board oder mit Tools wie Figma erstellt werden.
Mockup
Nach den Skizzen- und Wireframe-Phasen besteht der nächste Schritt darin, ein Mockup des Frontends zu erstellen. Dabei geht es darum, ein visuell ansprechendes Design zu erstellen, das einfach zu bedienen und zu verstehen ist. Mit Tools wie Figma können Mockups schnell erstellt werden. Sie bieten auch eine interaktive Demo, die die Interaktion innerhalb des Frontends zeigt. In dieser Phase ist es wichtig, sicherzustellen, dass das Design mit der Marke und den Stilrichtlinien des Unternehmens übereinstimmt, denn der erste Eindruck bleibt haften.
Prototype
Sobald das Mockup fertig ist, ist es an der Zeit, einen funktionierenden Prototyp des Frontends zu erstellen und ihn mit der Backend-Infrastruktur zu verbinden. Um später die Skalierbarkeit zu gewährleisten, müssen das verwendete Framework und die gegebene Infrastruktur bewertet werden. Diese Entscheidung hat Auswirkungen auf die in dieser Phase verwendeten Tools und wird in den folgenden Abschnitten erörtert.
Es gibt viele Optionen für die Frontend-Entwicklung
Die meisten Data Scientisten sind mit R oder Python vertraut. Daher sind die ersten Lösungen für die Entwicklung von Frontend-Anwendungen wie Dashboards oft R Shiny, Dash oder streamlit. Diese Tools haben den Vorteil, dass Datenaufbereitung und Modellberechnungsschritte im selben Framework wie das Dashboard implementiert werden können. Die Visualisierungen sind eng mit den verwendeten Daten und Modellen verknüpft und Änderungen können oft vom selben Entwickler integriert werden. Für manche Projekte mag das ausreichen, aber sobald eine gewisse Skalierbarkeit erreicht ist, ist es von Vorteil, Backend-Modellberechnungen und Frontend-Benutzerinteraktionen zu trennen.
Es ist zwar möglich, diese Art der Trennung in R- oder Python-Frameworks zu implementieren, aber unter der Haube übersetzen diese Bibliotheken ihre Ausgabe in Dateien, die der Browser verarbeiten kann, wie HTML, CSS oder JavaScript. Durch die direkte Verwendung von JavaScript mit den entsprechenden Bibliotheken gewinnen die Entwickler mehr Flexibilität und Anpassungsfähigkeit. Einige gute Beispiele, die eine breite Palette von Visualisierungen bieten, sind D3.js, Sigma.js oder Plotly.js, mit denen reichhaltigere Benutzeroberflächen mit modernen und visuell ansprechenden Designs erstellt werden können.
Dennoch ist das Angebot an JavaScript-basierten Frameworks nach wie vor groß und wächst weiter. Die am häufigsten verwendeten Frameworks sind React, Angular, Vue und Svelte. Vergleicht man sie in Bezug auf Leistung, Community und Lernkurve, so zeigen sich einige Unterschiede, die letztlich von den spezifischen Anwendungsfällen und Präferenzen abhängen (weitere Details finden Sie hier oder hier).
Als „die Programmiersprache des Webs“ gibt es JavaScript schon seit langem. Das vielfältige und vielseitige Ökosystem von JavaScript mit den oben genannten Vorteilen bestätigt dies. Dabei spielen nicht nur die direkt verwendeten Bibliotheken eine Rolle, sondern auch die breite und leistungsfähige Palette an Entwickler-Tools, die das Leben der Entwickler erleichtern.
Überlegungen zur Backend-Architektur
Neben der Ideenfindung müssen auch die Fragen nach dem Entwicklungsrahmen und der Infrastruktur beantwortet werden. Die Kombination der Visualisierungen (Frontend) mit der Datenlogik (Backend) in einer Anwendung hat Vor- und Nachteile.
Ein Ansatz besteht darin, Technologien wie R Shiny oder Python Dash zu verwenden, bei denen sowohl das Frontend als auch das Backend gemeinsam in derselben Anwendung entwickelt werden. Dies hat den Vorteil, dass es einfacher ist, Datenanalyse und -visualisierung in eine Webanwendung zu integrieren. Es hilft den Benutzern, direkt über einen Webbrowser mit Daten zu interagieren und Visualisierungen in Echtzeit anzuzeigen. Vor allem R Shiny bietet eine breite Palette von Paketen für Data Science und Visualisierung, die sich leicht in eine Webanwendung integrieren lassen, was es zu einer beliebten Wahl für Entwickler macht, die im Bereich Data Science arbeiten.
Andererseits bietet die Trennung von Frontend und Backend durch unterschiedliche Frameworks wie Node.js und Python mehr Flexibilität und Kontrolle über den Anwendungsentwicklungsprozess. Frontend-Frameworks wie Vue und React bieten eine breite Palette von Funktionen und Bibliotheken für die Erstellung intuitiver Benutzeroberflächen und Interaktionen, während Backend-Frameworks wie Express.js, Flask und Django robuste Tools für die Erstellung von stabilem und skalierbarem serverseitigem Code bieten. Dieser Ansatz ermöglicht es Entwicklern, die besten Tools für jeden Aspekt der Anwendung auszuwählen, was zu einer besseren Leistung, einfacheren Wartung und mehr Anpassungsmöglichkeiten führen kann. Es kann jedoch auch zu einer höheren Komplexität des Entwicklungsprozesses führen und erfordert mehr Koordination zwischen Frontend- und Backend-Entwicklern.
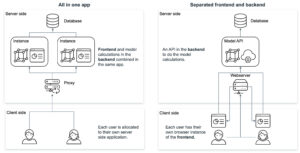
Das Hosten eines JavaScript-basierten Frontends bietet mehrere Vorteile gegenüber dem Hosten einer R Shiny- oder Python Dash-Anwendung. JavaScript-Frameworks wie React, Angular oder Vue.js bieten leistungsstarkes Rendering und Skalierbarkeit, was komplexe UI-Komponenten und groß angelegte Anwendungen ermöglicht. Diese Frameworks bieten auch mehr Flexibilität und Anpassungsoptionen für die Erstellung benutzerdefinierter UI-Elemente und die Implementierung komplexer Benutzerinteraktionen. Darüber hinaus sind JavaScript-basierte Frontends plattformübergreifend kompatibel und laufen auf Webbrowsern, Desktop-Anwendungen und mobilen Apps, was sie vielseitiger macht. Und schließlich ist JavaScript die Sprache des Webs, was eine einfachere Integration in bestehende Technologie-Stacks ermöglicht. Letztendlich hängt die Wahl der Technologie vom spezifischen Anwendungsfall, der Erfahrung des Entwicklungsteams und den Anforderungen der Anwendung ab.
Fazit
Der Aufbau eines Frontends für eine Data-Science-Anwendung ist entscheidend für die effektive Vermittlung von Erkenntnissen an die Endnutzer. Es hilft dabei, die Daten in einer leicht verdaulichen Art und Weise zu präsentieren und ermöglicht es den Benutzern, fundierte Entscheidungen zu treffen. Um sicherzustellen, dass die Bedürfnisse und Anforderungen richtig und effizient genutzt werden, muss das richtige Framework und die richtige Infrastruktur evaluiert werden. Wir schlagen vor, dass Lösungen in R oder Python ein guter Ausgangspunkt sind, aber Anwendungen in JavaScript könnten auf lange Sicht besser skalieren.
Wenn Sie ein Frontend für Ihre Data-Science-Anwendung entwickeln möchten, wenden Sie sich unverbindlich an unser Expertenteam, das Sie durch den Prozess führt und Ihnen die nötige Unterstützung bietet, um Ihre Visionen zu verwirklichen.
Read next …


… and explore new

Die versteckten Risiken von Black-Box Algorithmen
Unzählige Lebensläufe in kürzester Zeit sichten, bewerten und Empfehlungen für geeignete Kandidat:innen abgeben – das ist mit künstlicher Intelligenz im Bewerbungsmanagement mittlerweile möglich. Denn fortschrittliche KI-Techniken können auch komplexe Datenmengen effizient analysieren. Im Personalmanagement kann so nicht nur wertvolle Zeit bei der Vorauswahl eingespart, sondern auch Bewerber:innen schneller kontaktiert werden. Künstliche Intelligenz hat auch das Potenzial, Bewerbungsprozesse fairer und gerechter zu gestalten.
Die Praxis zeigt jedoch, dass auch künstliche Intelligenzen nicht immer „fairer“ sind. Vor einigen Jahren sorgte beispielsweise ein Recruiting-Algorithmus von Amazon für Aufsehen. Die KI diskriminierte Frauen bei der Auswahl von Kandidat:innen. Und auch bei Algorithmen zur Gesichtserkennung von People of Color kommt es immer wieder zu Diskriminierungsvorfällen.
Ein Grund dafür ist, dass komplexe KI-Algorithmen auf Basis der eingespeisten Daten selbstständig Vorhersagen und Ergebnisse berechnen. Wie genau sie zu einem bestimmten Ergebnis kommen, ist zunächst nicht nachvollziehbar. Daher werden sie auch als Black-Box Algorithmen bezeichnet. Im Fall von Amazon hat dieser auf Basis der aktuellen Belegschaft, die vorwiegend männlich war, geeignete Bewerber:innenprofile ermittelt und damit voreingenommene Entscheidungen getroffen. Auf diese oder ähnliche Weise können Algorithmen Stereotypen reproduzieren und Diskriminierung verstärken.
Prinzipien für vertrauenswürdige KI
Der Amazon-Vorfall zeigt, dass Transparenz bei der Entwicklung von KI-Lösungen von hoher Relevanz ist, um die ethisch einwandfreie Funktionsweise sicherzustellen. Deshalb ist Transparenz auch eines der insgesamt sieben statworx Principles für vertrauenswürdige KI. Die Mitarbeitenden von statworx haben gemeinsam folgende KI-Prinzipien definiert: Menschen-zentriert, transparent, ökologisch, respektvoll, fair, kollaborativ und inklusiv. Diese dienen als Orientierung für die alltägliche Arbeit mit künstlicher Intelligenz. Allgemeingültige Standards, Regeln und Gesetzte gibt es nämlich bisher nicht. Dies könnte sich jedoch bald ändern.
Die europäische Union (EU) diskutiert seit geraumer Zeit einen Gesetzesentwurf zur Regulierung von künstlicher Intelligenz. Dieser Entwurf, der so genannte AI-Act, hat das Potenzial zum Gamechanger für die globale KI-Branche zu werden. Denn nicht nur europäische Unternehmen werden von diesem Gesetzesentwurf anvisiert. Betroffen wären alle Unternehmen, die KI-Systeme auf dem europäischen Markt anbieten, dessen KI-generierter Output innerhalb der EU genutzt wird oder KI-Systeme zur internen Nutzung innerhalb der EU betreiben. Die Anforderungen, die ein KI-System dann erfüllen muss, hängen von dessen Anwendungsbereich ab.
Recruiting-Algorithmen werden auf Grund ihres Einsatzbereichs voraussichtlich als Hochrisiko-KI eingestuft. Demnach müssten Unternehmen bei der Entwicklung, der Veröffentlichung aber auch beim Betrieb der KI-Lösung umfassende Auflagen erfüllen. Unter anderem sind Unternehmen in der Pflicht, Qualitätsstandards für genutzte Daten einzuhalten, technische Dokumentationen zu erstellen und Risikomanagement zu etablieren. Bei Verstoß drohen hohe Bußgelder bis zu 6% des globalen jährlichen Umsatzes. Daher sollten sich Unternehmen schon jetzt mit den kommenden Anforderungen und ihren KI-Algorithmen auseinandersetzen. Ein sinnvoller erster Schritt können Explainable AI Methoden (XAI) sein. Mit Hilfe dieser können Black-Box-Algorithmen nachvollzogen und die Transparenz der KI-Lösung erhöht werden.
Die Black-Box mit Explainable AI Methoden entschlüsseln
Durch XAI-Methoden können Entwickler:innen die konkreten Entscheidungsprozesse von Algorithmen besser interpretieren. Das heißt, es wird transparent, wie ein Algorithmus Muster und Regeln gebildet hat und Entscheidungen trifft. Dadurch können mögliche Probleme wie beispielsweise Diskriminierung im Bewerbungsprozess nicht nur entdeckt, sondern auch korrigiert werden. Somit trägt XAI nicht nur zur stärkeren Transparenz von KI bei, sondern begünstigt auch deren ethisch unbedenklichen Einsatz und fördert so die Konformität einer KI mit dem kommenden AI-Act.
Einige XAI-Methoden sind sogar modellagnostisch, also anwendbar auf beliebige KI-Algorithmen vom Entscheidungsbaum bis hin zum Neuronalen Netz. Das Forschungsfeld rund um XAI ist in den letzten Jahren stark gewachsen, weshalb es mittlerweile eine große Methodenvielfalt gibt. Dabei zeigt unsere Erfahrung aber: Es gibt große Unterschiede zwischen verschiedenen Methoden hinsichtlich Verlässlichkeit und Aussagekraft ihrer Ergebnisse. Außerdem eignen sich nicht alle Methoden gleichermaßen zur robusten Anwendung in der Praxis und zur Gewinnung des Vertrauens externer Stakeholder. Daher haben wir unsere Top 3 Methoden anhand der folgenden Kriterien für diesen Blogbeitrag ermittelt:
- Ist die Methode modellagnostisch, funktioniert sie also für alle Arten von KI-Modellen?
- Liefert die Methode globale Ergebnisse, sagt also etwas über das Modell als Ganzes aus?
- Wie aussagekräftig sind die resultierenden Erklärungen?
- Wie gut ist das theoretische Fundament der Methode?
- Können böswillige Akteure die Resultate manipulieren oder sind sie vertrauenswürdig?
Unsere Top 3 XAI Methoden im Überblick
Anhand der oben genannten Kriterien haben wir drei verbreitete und bewährte Methoden zur detaillierten Darstellung ausgewählt: Permutation Feature Importance (PFI), SHAP Feature Importance und Accumulated Local Effects (ALE). Im Folgenden erklären wir für jede der drei Methoden den Anwendungszweck und deren grundlegende technische Funktionsweise. Außerdem gehen wir auf die Vor- und Nachteile beim Einsatz der drei Methoden ein und illustrieren die Anwendung anhand des Beispiels einer Recruiting-KI.
Mit Permutation Feature Importance effizient Einflussfaktoren identifizieren
Ziel der Permutation Feature Importance (PFI) ist es, herauszufinden, welche Variablen im Datensatz besonders entscheidend dafür sind, dass das Modell genaue Vorhersagen trifft. Im Falle des Recruiting-Beispiels kann die PFI-Analyse darüber aufklären, auf welche Informationen sich das Modell für seine Entscheidung besonders verlässt. Taucht hier z.B. das Geschlecht als einflussreicher Faktor auf, kann das die Entwickler:innen alarmieren. Aber auch in der Außenwirkung schafft die PFI-Analyse Transparenz und zeigt externen Anwender:innen an, welche Variablen für das Modell besonders relevant sind. Für die Berechnung der PFI benötigt man zunächst zwei Dinge:
- Eine Genauigkeitsmetrik wie z.B. die Fehlerrate (Anteil falscher Vorhersagen an allen Vorhersagen)
- Einen Testdatensatz, der zur Ermittlung der Genauigkeit verwendet werden kann.
Im Testdatensatz wird zunächst eine Variable nach der anderen durch das Hinzufügen von zufälligem Rauschen („Noise“) gewissermaßen verschleiert und dann die Genauigkeit des Modells über den bearbeiteten Testdatensatz bestimmt. Nun ist naheliegend, dass die Variablen, deren Verschleierung die Modellgenauigkeit am stärksten beeinträchtigen, besonders wichtig für die Genauigkeit des Modells sind. Sind alle Variablen nacheinander analysiert und sortiert, erhält man eine Visualisierung wie die in Abbildung 1. Anhand unseres künstlich erzeugten Beispieldatensatzes lässt sich folgendes erkennen: Berufserfahrung spielte keine große Rolle für das Modell, die Eindrücke aus dem Vorstellungsgespräch hingegen schon.
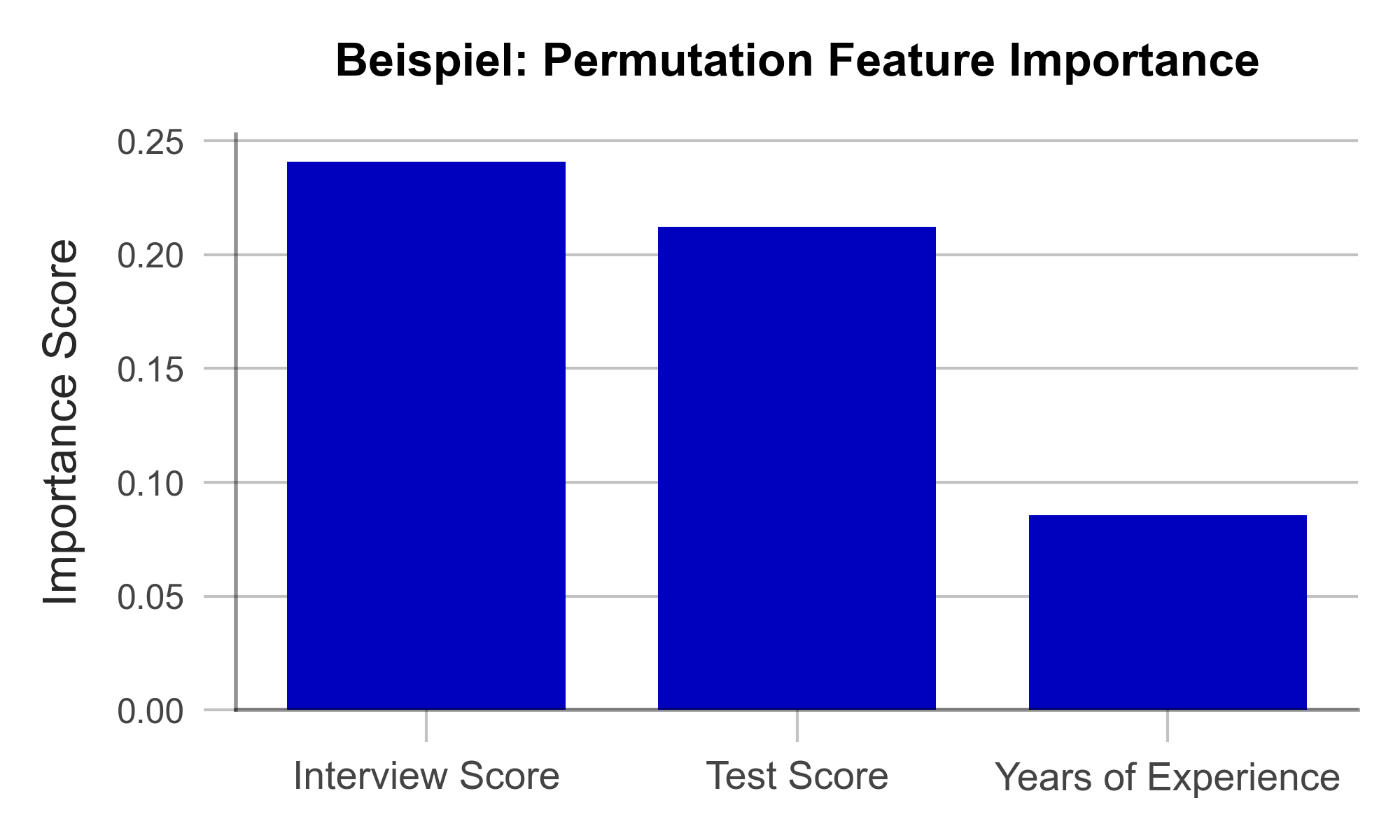
Abbildung 1 – Permutation Feature Importance am Beispiel einer Recruiting-KI (Daten künstlich erzeugt).
Eine große Stärke der PFI ist, dass sie einer nachvollziehbaren mathematischen Logik folgt. Die Korrektheit der gelieferten Erklärung kann durch statistische Überlegungen nachgewiesen werden. Darüber hinaus gibt es kaum manipulierbare Parameter im Algorithmus, mit der die Ergebnisse bewusst verzerrt werden könnten. Damit ist die PFI besonders geeignet dafür, das Vertrauen externer Betrachter:innen zu gewinnen. Nicht zuletzt ist die Berechnung der PFI im Vergleich zu anderen Explainable AI Methoden sehr ressourcenschonend.
Eine Schwäche der PFI ist, dass sie unter gewissen Umständen missverständliche Erklärungen liefern kann. Wird einer Variable ein geringer PFI-Wert zugewiesen, heißt das nicht immer, dass die Variable unwichtig für den Sachverhalt ist. Hat z.B. die Note des Bachelorstudiums einen geringen PFI-Wert, so kann das lediglich daran liegen, dass das Modell stattdessen auch die Note des Masterstudiums betrachten kann, da diese oft ähnlich sind. Solche korrelierten Variablen können die Interpretation der Ergebnisse erschweren. Nichtsdestotrotz ist die PFI eine effiziente und nützliche Methode zur Schaffung von Transparenz in Black-Box Modellen.
| Stärken | Schwächen |
|---|---|
| Wenig Spielraum für Manipulation der Ergebnisse | Berücksichtigt keine Interaktionen zwischen Variablen |
| Effiziente Berechnung |
Mit SHAP Feature Importance komplexe Zusammenhänge aufdecken
Die SHAP Feature Importance ist eine Methode zur Erklärung von Black-Box-Modellen, die auf der Spieltheorie basiert. Ziel ist es, den Beitrag jeder Variable zur Vorhersage des Modells zu quantifizieren. Damit ähnelt sie der Permutation Feature Importance auf den ersten Blick stark. Im Gegensatz zur PFI liefert die SHAP Feature Importance aber Ergebnisse, die komplexe Zusammenhänge zwischen mehreren Variablen berücksichtigen können.
SHAP liegt ein Konzept aus der Spieltheorie zugrunde: die Shapley Values. Diese sind ein Fairness-Kriterium, das jeder Variable eine Gewichtung zuweist, die ihrem Beitrag zum Ergebnis entspricht. Naheliegend ist die Analogie zu einem Teamsport, bei dem das Siegerpreisgeld unter allen Spieler:innen fair, also gemäß deren Beitrag zum Sieg, aufgeteilt wird. Mit SHAP kann analog für jede einzelne Beobachtung im Datensatz analysiert werden, welchen Beitrag welche Variable zur Vorhersage des Modells geliefert hat
Ermittelt man nun den durchschnittlichen absoluten Beitrag einer Variable über alle Beobachtungen im Datensatz hinweg, erhält man die SHAP Feature Importance. Abbildung 2 veranschaulicht beispielhaft die Ergebnisse dieser Analyse. Die Ähnlichkeit zur PFI ist klar ersichtlich, auch wenn die SHAP Feature Importance die Bewertung des Vorstellungsgespräches nur auf Platz 2 setzt.
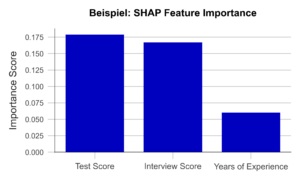
Abbildung 2 – SHAP Feature Importance am Beispiel einer Recruiting KI (Daten künstlich erzeugt).
Ein großer Vorteil dieses Ansatzes ist die Möglichkeit, Interaktionen zwischen Variablen zu berücksichtigen. Durch die Simulation verschiedener Variablen-Kombinationen lässt sich zeigen, wie sich die Vorhersage ändert, wenn zwei oder mehr Variablen gemeinsam variieren. Zum Bespiel sollte die Abschlussnote eines Studiums stets im Zusammenhang mit dem Studiengang und der Hochschule betrachtet werden. Im Gegensatz zur PFI trägt die SHAP Feature Importance diesem Umstand Rechnung. Auch sind Shapley Values, einmal berechnet, die Grundlage einer Bandbreite weiterer nützlicher XAI Methoden.
Eine Schwäche der Methode ist jedoch, dass sie aufwendiger zu berechnen ist als die PFI. Nur für bestimmte Arten von KI-Algorithmen (z.B. Entscheidungsbäume) gibt es effiziente Implementierungen. Es will also gut überlegt sein, ob für ein gegebenes Problem eine PFI-Analyse genügt, oder ob die SHAP Feature Importance zu Rate gezogen werden sollte.
| Stärken | Schwächen |
|---|---|
| Wenig Spielraum für Manipulation der Ergebnisse | Berechnung ist rechenaufwendig |
| Berücksichtigt komplexe Interaktionen zwischen Variablen |
Mit Accumulated Local Effects einzelne Variablen in den Fokus nehmen
Die Accumulated Local Effects (ALE) Methode ist eine Weiterentwicklung der Partial Dependence Plots (PDP), die sich großer Beliebtheit unter Data Scientists erfreuen. Beide Methoden haben das Ziel, den Einfluss einer bestimmten Variablen auf die Vorhersage des Modells zu simulieren. Damit können Fragen beantwortet werden wie: „Steigen mit zunehmender Berufserfahrung die Chancen auf eine Management Position?“ oder „Macht es einen Unterschied, ob ich eine 1.9 oder eine 2.0 in meinem Abschlusszeugnis habe?“. Im Gegensatz zu den vorherigen zwei Methoden trifft ALE also eine Aussage über die Entscheidungsfindung des Modells, nicht über die Relevanz bestimmter Variablen.
Im einfachsten Fall, dem PDP, wird eine Stichprobe von Beobachtungen ausgewählt und anhand dieser simuliert, welchen Einfluss z.B. eine isolierte Erhöhung der Berufserfahrung auf die Modellvorhersage hätte. Isoliert meint, dass dabei keine der anderen Variablen verändert wird. Der Durchschnitt dieser einzelnen Effekte über die gesamte Stichprobe liefert eine anschauliche Visualisierung (Abbildung 3, oben). Leider sind die Ergebnisse des PDP nicht besonders aussagekräftig, wenn korrelierte Variablen vorliegen. Am Beispiel der Hochschulnoten lässt sich das besonders gut veranschaulichen. So simuliert der PDP hierbei alle möglichen Kombinationen von Noten im Bachelor- und Masterstudium. Dabei entstehen leider Fälle, die in der echten Welt selten vorkommen, z.B. ein ausgezeichnetes Bachelorzeugnis und ein miserabler Masterabschluss. Der PDP hat kein Gespür für unsinnige Fälle, woran auch die Ergebnisse kranken.
Die ALE-Analyse hingegen versucht, dieses Problem durch eine realistischere Simulation zu lösen, die die Zusammenhänge zwischen Variablen adäquat abbildet. Dabei wird die betrachtete Variable, z.B. die Bachelor-Note, in mehrere Abschnitte eingeteilt (z.B. 6.0-5.1, 5.0-4.1, 4.0-3.1, 3.0-2.1 und 2.0-1.0). Nun wird die Simulation der Erhöhung der Bachelor-Note lediglich für Personen in der respektiven Notengruppe durchgeführt. Dies führt dazu, dass unrealistische Kombinationen nicht in die Analyse einfließen. Ein Beispiel für einen ALE-Plot findet sich in Abbildung 3 (unten). Hier zeigt sich anschaulich, dass der ALE-Plot einen negativen Einfluss der Berufserfahrung auf die Anstellungschance identifiziert, während dies dem PDP verborgen bleibt. Ist dieses Verhalten der KI erwünscht? Will man zum Beispiel insbesondere junge Talente einstellen? Oder steckt dahinter vielleicht eine versteckte Altersdiskriminierung? In beiden Fällen hilft der ALE-Plot dabei, Transparenz zu schaffen und ungewünschtes Verhalten rechtzeitig zu erkennen.
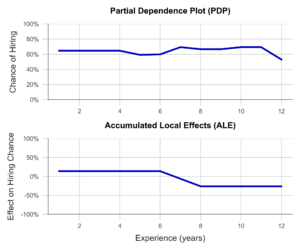
Abbildung 3– Partial Dependence Plot und Accumulated Local Effects am Beispiel einer Recruiting KI (Daten künstlich erzeugt).
Zusammenfassend ist der ALE-Plot eine geeignete Methode, um einen Einblick in den Einfluss einer bestimmten Variable auf die Modellvorhersage zu gewinnen. Dies schafft Transparenz für Nutzende und hilft sogar dabei, ungewünschte Effekte und Bias zu identifizieren und zu beheben. Ein Nachteil der Methode ist, dass der ALE-Plot stets nur eine Variable analysiert. Um also den Einfluss aller Variablen zu verstehen, muss eine Vielzahl von ALE-Plots generiert werden, was weniger übersichtlich ist als z.B. ein PFI- oder ein SHAP Feature Importance Plot.
| Stärken | Schwächen |
|---|---|
| Berücksichtigt komplexe Interaktionen zwischen Variablen | Mit ALE lassen sich nur eine oder zwei Variablen pro Visualisierung analysieren |
| Wenig Spielraum für Manipulation der Ergebnisse |
Mit Explainable AI Methoden Vertrauen aufbauen
In diesem Beitrag haben wir drei Explainable AI Methoden vorgestellt, die dabei helfen können, Algorithmen transparenter und interpretierbarer zu machen. Dies begünstigt außerdem, den Anforderungen des kommenden AI-Acts frühzeitig gerecht zu werden. Denn auch wenn dieser noch nicht verabschiedet ist, empfehlen wir auf Basis des Gesetzesentwurfs sich bereits jetzt mit der Schaffung von Transparenz und Nachvollziehbarkeit für KI-Modelle zu beschäftigen. Viele Data Scientists haben wenig Erfahrung in diesem Feld und benötigen Fortbildung und Einarbeitungszeit, bevor sie einschlägige Algorithmen identifizieren und effektive Lösungen implementieren können. Die weiterführende Beschäftigung mit den vorgestellten Methoden empfehlen wir daher in jedem Fall.
Mit der Permutation Feature Importance (PFI) und der SHAP Feature Importance haben wir zwei Techniken aufgezeigt, um die Relevanz bestimmter Variablen für die Vorhersage des Modells zu bestimmen. Zusammenfassend lässt sich sagen, dass die SHAP Feature Importance eine leistungsstarke Methode zur Erklärung von Black-Box-Modellen ist, die die Interaktionen zwischen Variablen berücksichtigt. Die PFI hingegen ist einfacher zu implementieren, aber weniger leistungsfähig bei korrelierten Daten. Welche Methode im konkreten Fall am besten geeignet ist, hängt von den spezifischen Anforderungen ab.
Auch haben wir mit Accumulated Local Effects (ALE) eine Technik vorgestellt, die nicht die Relevanz von Variablen, sondern sogar deren genauen Einfluss auf die Vorhersage bestimmen und visualisieren kann. Besonders vielversprechend ist die Kombination einer der beiden Feature Importance Methoden mit ausgewählten ALE-Plots zu ausgewählten Variablen. So kann ein theoretisch fundierter und leicht interpretierbarer Überblick über das Modell vermittelt werden – egal, ob es sich um einen Entscheidungsbaum oder ein tiefes Neuronales Netz handelt.
Die Anwendung von Explainable AI ist somit eine lohnende Investition – nicht nur, um intern und extern Vertrauen in die eigenen KI-Lösungen aufzubauen. Vielmehr gehen wir davon aus, dass der geschickte Einsatz interpretationsfördernder Methoden drohende Bußgelder durch die Anforderungen des AI-Acts vermeidet, rechtlichen Konsequenzen vorbeugt, sowie Betroffene vor Schaden schützt – wie im Fall von unverständlicher Recruitingsoftware.
Unserer kostenfreier AI Act Quick Check unterstützt Sie gerne bei der Einschätzung, ob eines Ihrer KI-Systeme vom AI Act betroffen sein könnte: https://www.statworx.com/ai-act-tool/
Quellen & Informationen:
https://www.faz.net/aktuell/karriere-hochschule/buero-co/ki-im-bewerbungsprozess-und-raus-bist-du-17471117.html (letzter Aufruf 03.05.2023)
https://t3n.de/news/diskriminierung-deshalb-platzte-amazons-traum-vom-ki-gestuetzten-recruiting-1117076/ (letzter Aufruf 03.05.2023)
Weitere Informationen zum AI Act: https://www.statworx.com/content-hub/blog/wie-der-ai-act-die-ki-branche-veraendern-wird-alles-was-man-jetzt-darueber-wissen-muss/
Statworx principles: https://www.statworx.com/content-hub/blog/statworx-ai-principles-warum-wir-eigene-ki-prinzipien-entwickeln/
Christoph Molnar: Interpretable Machine Learning: https://christophm.github.io/interpretable-ml-book/
Bildnachweis:
AdobeStock 566672394 – by TheYaksha
Einführung
Forecasts sind in vielen Branchen von zentraler Bedeutung. Ob es darum geht, den Verbrauch von Ressourcen zu prognostizieren, die Liquidität eines Unternehmens abzuschätzen oder den Absatz von Produkten im Einzelhandel vorherzusagen – Forecasts sind ein unverzichtbares Instrument für erfolgreiche Entscheidungen. Obwohl sie so wichtig sind, basieren viele Forecasts immer noch primär auf den Vorerfahrungen und der Intuition von Expert:innen. Das erschwert eine Automatisierung der relevanten Prozesse, eine potenzielle Skalierung und damit einhergehend eine möglichst effiziente Unterstützung. Zudem können Expert:innen aufgrund ihrer Erfahrungen und Perspektiven voreingenommen sein oder möglicherweise nicht über alle relevanten Informationen verfügen, die für eine genaue Vorhersage erforderlich sind.
Diese Gründe führen dazu, dass datengetriebene Forecasts in den letzten Jahren immer mehr an Bedeutung gewonnen haben und die Nachfrage nach solchen Prognosen ist entsprechend stark.
Bei statworx haben wir bereits eine Vielzahl an Projekten im Bereich Forecasting erfolgreich umgesetzt. Dadurch haben wir uns vielen Herausforderungen gestellt und uns mit zahlreichen branchenspezifischen Use Cases vertraut gemacht. Eine unserer internen Arbeitsgruppen, das Forecasting Cluster, begeistert sich besonders für die Welt des Forecastings und bildet sich kontinuierlich in diesem Bereich weiter.
Auf Basis unserer gesammelten Erfahrungen möchten wir diese nun in einem benutzerfreundlichen Tool vereinen, welches je nach Datenlage und Anforderungen jedem ermöglicht, erste Einschätzungen zu spezifischen Forecasting Use Cases zu erhalten. Sowohl Kunden als auch Mitarbeitende sollen in der Lage sein, das Tool schnell und einfach zu nutzen, um eine methodische Empfehlung zu erhalten. Unser langfristiges Ziel ist es, das Tool öffentlich zugänglich zu machen. Jedoch testen wir es zunächst intern, um seine Funktionalität und Nützlichkeit zu optimieren. Dabei legen wir besonderen Wert darauf, dass das Tool intuitiv bedienbar ist und leicht verständliche Outputs liefert.
Obwohl sich unser Recommender-Tool derzeit noch in der Entwicklungsphase befindet, möchten wir einen ersten spannenden Einblick geben.
Häufige Herausforderungen
Modellauswahl
Im Bereich Forecasting gibt es verschiedene Modellierungsansätze. Wir differenzieren dabei zwischen drei zentralen Ansätzen:
- Zeitreihenmodelle
- Baumbasierte Modelle
- Deep Learning Modelle
Es gibt viele Kriterien, die man bei der Modellauswahl heranziehen kann. Wenn es sich um univariate Zeitreihen handelt, die eine starke Saisonalität und Trends aufweisen, sind klassische Zeitreihenmodelle wie (S)ARIMA und ETS sinnvoll. Handelt es sich hingegen um multivariate Zeitreihen mit potenziell komplexen Zusammenhängen und großen Datenmengen, stellen Deep Learning Modelle eine gute Wahl dar. Baumbasierte Modelle wie LightGBM bieten im Vergleich zu Zeitreihenmodellen eine größere Flexibilität, eignen sich aufgrund ihrer Architektur gut für das Thema Erklärbarkeit und haben im Vergleich zu Deep Learning Modellen einen tendenziell geringeren Rechenaufwand.
Saisonalität
Saisonalität stellt wiederkehrende Muster in einer Zeitreihe dar, die in regelmäßigen Abständen auftreten (z.B. täglich, wöchentlich, monatlich oder jährlich). Die Einbeziehung der Saisonalität in der Modellierung ist wichtig, um diese regelmäßigen Muster zu erfassen und die Genauigkeit der Prognosen zu verbessern. Mit Zeitreihenmodellen wie SARIMA, ETS oder TBATS kann die Saisonalität explizit berücksichtigt werden. Für baumbasierte Modelle wie LightGBM kann die Saisonalität nur über die Erstellung entsprechender Features berücksichtigt werden. So können Dummies für die relevanten Saisonalitäten gebildet werden. Eine Möglichkeit Saisonalität in Deep Learning-Modellen explizit zu berücksichtigen, besteht in der Verwendung von Sinus- und Cosinus-Funktionen. Ebenso ist es möglich die Saisonalitätskomponente aus der Zeitreihe zu entfernen. Dazu wird zuerst die Saisonalität entfernt und anschließend eine Modellierung auf der desaisonalisierten Zeitreihe durchgeführt. Die daraus resultierenden Prognosen werden dann mit der Saisonalität ergänzt, indem die genutzte Methodik für die Desaisonalisierung entsprechend angewendet wird. Allerdings erhöht dieser Prozess die Komplexität, was nicht immer erwünscht ist.
Hierarchische Daten
Besonders im Bereich Retail liegen häufig hierarchische Datenstrukturen vor, da die Produkte meist in unterschiedlicher Granularität dargestellt werden können. Hierdurch ergibt sich häufig die Anforderung, Prognosen für unterschiedliche Hierarchien zu erstellen, welche sich nicht widersprechen. Die aggregierten Prognosen müssen daher mit den disaggregierten übereinstimmen. Dabei ergeben sich verschiedene Lösungsansätze. Über Top-Down und Bottom-Up werden Prognosen auf einer Ebene erstellt und nachgelagert disaggregiert bzw. aggregiert. Mit Reconciliation-Methoden wie Optimal Reconciliation werden Prognosen auf allen Ebenen vorgenommen und anschließend abgeglichen, um eine Konsistenz über alle Ebenen zu gewährleisten.
Cold Start
Bei einem Cold Start besteht die Herausforderung darin Produkte zu prognostizieren, die nur wenig oder keine historischen Daten aufweisen. Im Retail Bereich handelt es sich dabei meist um Produktneueinführungen. Da aufgrund der mangelnden Historie ein Modelltraining für diese Produkte nicht möglich ist, müssen alternative Ansätze herangezogen werden. Ein klassischer Ansatz einen Cold Start durchzuführen, ist die Nutzung von Expertenwissen. Expert:innen können erste Schätzungen der Nachfrage liefern, die als Ausgangspunkt für Prognosen dienen können. Dieser Ansatz kann jedoch stark subjektiv ausfallen und lässt sich nicht skalieren. Ebenso kann auf ähnliche Produkte oder auch auf potenzielle Vorgänger-Produkte referenziert werden. Eine Gruppierung von Produkten kann beispielsweise auf Basis der Produktkategorien oder Clustering-Algorithmen wie K-Means erfolgen. Die Nutzung von Cross-Learning-Modellen, die auf Basis vieler Produkte trainiert werden, stellt eine gut skalierbare Möglichkeit dar.
Recommender Concept
Mit unserem Recommender Tool möchten wir die unterschiedlichen Problemstellungen berücksichtigen, um eine möglichst effiziente Entwicklung zu ermöglichen. Dabei handelt es sich um ein interaktives Tool, bei welchem man Inputs auf Basis der Zielvorstellung oder Anforderung und den vorliegenden Datencharakteristiken gibt. Ebenso kann eine Priorisierung vorgenommen werden, sodass bestimmte Anforderungen an der Lösung auch im Output entsprechend priorisiert werden. Auf Basis dieser Inputs werden methodische Empfehlungen generiert, die die Anforderungen an der Lösung in Abhängigkeit der vorliegenden Eigenschaften bestmöglich abdecken. Aktuell bestehen die Outputs aus einer rein inhaltlichen Darstellung der Empfehlungen. Dabei wird auf die zentralen Themenbereiche wie Modellauswahl, Pre-Processing und Feature Engineering mit konkreten Guidelines eingegangen. Das nachfolgende Beispiel gibt dabei einen Eindruck über die konzeptionelle Idee:
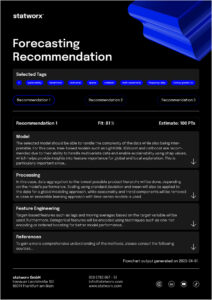
Der hier dargestellte Output basiert auf einem realen Projekt. Für das Projekt war vor allem die Implementierung in R und die Möglichkeit einer lokalen Erklärbarkeit von zentraler Bedeutung. Zugleich wurden frequentiert neue Produkte eingeführt, welche ebenso durch die entwickelte Lösung prognostiziert werden sollten. Um dieses Ziel zu erreichen, wurden mehrere globale Modelle mit Hilfe von Catboost trainiert. Dank diesem Ansatz konnten über 200 Produkte ins Training einbezogen werden. Sogar für neu eingeführte Produkte, bei denen keine historischen Daten vorlagen, konnten Forecasts generiert werden.
Um die Erklärbarkeit der Prognosen sicherzustellen, wurden SHAP Values verwendet. Auf diese Weise konnten die einzelnen Vorhersagen klar und deutlich anhand der genutzten Features erklärt werden.
Zusammenfassung
Die aktuelle Entwicklung ist darauf ausgerichtet ein Tool zu entwickeln, welches auf das Thema Forecasting optimiert ist. Durch die Nutzung wollen wir vor allem die Effizienz bei Forecasting-Projekten steigern. Durch die Kombination von gesammelten Erfahrungen und Expertise soll das Tool unter anderem für die Themen Modellierung, Pre-Processing und Feature Engineering Guidelines bieten. Es wird darauf ausgelegt sein, sowohl von Kunden als auch Mitarbeitenden verwendet zu werden, um schnelle und einfache Abschätzungen sowie methodische Empfehlungen zu erhalten. Eine erste Testversion wird zeitnah für den internen Gebrauch zur Verfügung stehen. Langfristig soll das Tool jedoch auch für externe Nutzer:innen zugänglich gemacht werden. Neben dem derzeit in der Entwicklung befindlichen technischen Output, wird auch ein weniger technischer Output verfügbar sein. Letzterer wird sich auf die wichtigsten Aspekte und deren Aufwände konzentrieren. Insbesondere die Business-Perspektive in Form von erwarteten Aufwänden und potenziellen Trade-Offs von Aufwand und Nutzen soll hierdurch abgedeckt werden.
Profitieren auch Sie von unserer Forecasting Expertise!
Wenn Sie Unterstützung bei der Bewältigung von vorliegenden Herausforderungen bei Forecasting Projekten benötigen oder ein Forecasting Projekt geplant ist, stehen wir gerne mit unserem Know-how und unserer Erfahrung zur Verfügung.
Überwachung von Data-Science-Workflows
Die Zeiten, in denen ein Data Science-Projekt nur aus lose gekoppelten Notebooks für die Datenverarbeitung und das Modelltraining bestand, die die Date Scientists gelegentlich auf ihren Laptops ausführten, sind längst vorbei. Mit zunehmender Reife haben sich die Projekte zu großen Softwareprojekten mit mehreren Beteiligten und Abhängigkeiten sowie unterschiedlichen Modulen mit zahlreichen Klassen und Funktionen entwickelt. Der Data-Science-Workflow, der in der Regel mit der Datenvorverarbeitung, dem Feature-Engineering, dem Modelltraining, dem Tuning, der Evaluierung und schließlich der Inferenz beginnt und als ML-Pipeline bezeichnet wird, wird modularisiert. Diese Modularisierung macht den Prozess skalierbarer und automatisierbar, ergo geeignet für die Ausführung in Container-Orchestrierungssystemen oder in der Cloud-Infrastruktur. Die Extraktion wertvoller modell- oder datenbezogener KPIs kann, wenn sie manuell erfolgt, eine arbeitsintensive Aufgabe sein, umso mehr, wenn sie mit zunehmenden und/oder automatisierten Wiederholungen verbunden ist. Diese Informationen sind wichtig für den Vergleich verschiedener Modelle und die Beobachtung von Trends wie «Distribution-Shift» in den Trainingsdaten. Sie können auch dazu verwendet werden, ungewöhnliche Werte zu erkennen, von unausgewogenen Klassen bis hin zur Löschung von Ausreißern – was auch immer als notwendig erachtet wird, um die Robustheit eines Modells zu gewährleisten. Bibliotheken wie MLFlow können verwendet werden, um all diese Arten von Metriken zu speichern. Außerdem hängt die Operationalisierung von ML-Pipelines stark von der Verfolgung laufbezogener Informationen zur effizienten Fehlerbehebung sowie zur Aufrechterhaltung oder Verbesserung des Ressourcenverbrauchs der Pipeline ab.
Dies gilt nicht nur für die Welt von Data Science. Die heutigen Microservice-basierten Architekturen tragen ebenfalls dazu bei, dass die Wartung und Verwaltung von bereitgestelltem Code eine einheitliche Überwachung erfordert. Dies kann die von einem DevOps-Team benötigten Betriebs- und Wartungsstunden aufgrund eines ganzheitlicheren Verständnisses der beteiligten Prozesse drastisch reduzieren und gleichzeitig fehlerbedingte Ausfallzeiten verringern.
Es ist wichtig zu verstehen, wie verschiedene Formen der Überwachung darauf abzielen, die oben genannten Implikationen anzugehen, und wie modell- und datenbezogene Metriken ebenfalls zu diesem Ziel beitragen können. Zwar hat sich MLFlow als Industriestandard für die Überwachung von ML-bezogenen Metriken etabliert, doch kann auch die Überwachung dieser Metriken zusammen mit allen betrieblichen Informationen interessant sein.
Protokolle vs. Metriken
Protokolle liefern eine ereignisbasierte Momentaufnahme – Metriken geben einen Überblick aus der Vogelperspektive
Ein Protokoll ist eine zu einem bestimmten Zeitpunkt geschriebene Aufzeichnung (z. B. stdout/stderr) eines Ereignisses, das diskontinuierlich und in nicht vordefinierten Intervallen auftritt. Je nach Anwendung enthalten die Protokolle Informationen wie Zeitstempel, Auslöser, Name, Beschreibung und/oder Ergebnis des Ereignisses. Bei den Ereignissen kann es sich um einfache Anfragen oder Benutzeranmeldungen handeln, die der Entwickler des zugrunde liegenden Codes als wichtig erachtet hat. Wenn Sie sich bei diesem Prozess an bewährte Verfahren halten, können Sie sich eine Menge Ärger und Zeit bei der Einrichtung nachgelagerter Überwachungswerkzeuge sparen. Die Verwendung dedizierter Protokollbibliotheken und das Schreiben aussagekräftiger Protokollnachrichten sind hier von Vorteil.
INFO[2021-01-06T17:44:13.368024402-08:00] starting *secrets.YamlSecrets
INFO[2021-01-06T17:44:13.368679356-08:00] starting *config.YamlConfig
INFO[2021-01-06T17:44:13.369046236-08:00] starting *s3.DefaultService
INFO[2021-01-06T17:44:13.369518352-08:00] starting *lambda.DefaultService
ERROR[2021-01-06T17:44:13.369694698-08:00] http server error error="listen tcp 127.0.0.1:6060: bind: address already in use"
Abb. 1: Ereignisprotokolle in Textform
Obwohl die Datenmenge eines einzelnen Protokolls vernachlässigbar ist, können Protokollströme schnell exponentiell ansteigen. Dies führt dazu, dass die Speicherung jedes einzelnen Protokolls nicht gut skalierbar ist, insbesondere in Form von halbstrukturierten Textdaten. Für Debugging oder Auditing kann es jedoch unvermeidlich sein, Protokolle in unveränderter Form zu speichern. Archivspeicherlösungen oder Aufbewahrungsfristen können hier helfen.
In anderen Fällen können das Parsen und Extrahieren von Protokollen in andere Formate, wie z. B. Schlüssel-Wert-Paare, diesen Einschränkungen entgegenwirken. Auf diese Weise kann ein Großteil der Ereignisinformationen erhalten bleiben, während der Speicherbedarf deutlich geringer ist.
{
time: "2021-01-06T17:44:13-08:00",
mode: "reader",
debug_http_error: "listen tcp 127.0.0.1:6061: bind: address already in use"
servicePort: 8089,
duration_ms: 180262
}Abb. 2: Strukturierte Ereignisprotokolle
Eine andere Form der Verringerung dieses Fußabdrucks kann durch Stichprobenmethoden erfolgen, wobei Metriken die prominentesten Vertreter sind.
Eine Metrik ist ein numerisches Maß für ein bestimmtes Ziel (ein bestimmtes Ereignis), das gleichmäßig über Zeitintervalle verteilt ist. Mathematische Aggregationen wie Summen oder Durchschnittswerte sind gängige Transformationen, die solche Metriken datenmäßig relativ klein halten.
{
time: "2022-01-06T17:44:13-08:00",
Duration_ms: 60,
sum_requests: 500,
sum_hits_endpoint_1: 250,
sum_hits_endpoint_2: 117,
avg_duration: 113,
}
Abb. 3: Metriken
Metriken eignen sich daher gut für die schrittweise Verringerung der Datenauflösung auf breitere Frequenzen wie tägliche, wöchentliche oder sogar längere Analysezeiträume. Außerdem lassen sich Metriken in der Regel besser über mehrere Anwendungen hinweg vereinheitlichen, da sie im Vergleich zu rohen Protokollnachrichten stark strukturierte Daten enthalten. Dies verringert zwar die zuvor genannten Probleme, geht aber auf Kosten der Granularität. Daher eignen sich Metriken perfekt für hochfrequente Ereignisse, bei denen die Informationen zu einem einzelnen Ereignis weniger wichtig sind. Die Überwachung von Rechenressourcen ist ein Beispiel dafür. Beide Ansätze haben ihre Berechtigung in jeder Überwachungskonfiguration, da die verschiedenen Anwendungsfälle zu den unterschiedlichen Zielen passen. Anhand eines konkreten Beispiels aus einem kleinen Unternehmen lassen sich die Hauptunterschiede verdeutlichen:
Der Gesamtsaldo eines Bankkontos kann im Laufe der Zeit aufgrund von Abhebungen und Einzahlungen (die zu jedem Zeitpunkt erfolgen können) schwanken. Wenn man nur daran interessiert ist, dass sich Geld auf dem Konto befindet, sollte es ausreichen, eine aggregierte Metrik regelmäßig zu verfolgen. Interessiert man sich jedoch für den Gesamtzufluss im Zusammenhang mit einem bestimmten Kunden, ist die Protokollierung jeder Transaktion unumgänglich.
Architektur und Tool-Stack
In den meisten modernen Cloud-Stacks, wie z. B. Azure Appservice, wird die Protokollierung der Infrastruktur und der Anfrageseite mit dem Dienst selbst ausgeliefert. Mit zunehmendem Volumen kann dies jedoch kostspielig werden. Die Definition der Anwendungsfälle, das Verständnis der Bereitstellungsumgebung und die Abstimmung mit der Protokollierungsarchitektur sind Teil der Aufgaben von DevOps-Teams.
Aus der Sicht eines Entwicklers gibt es eine Vielzahl von Open-Source-Tools, die wertvolle Überwachungslösungen liefern können, die nur einen gewissen Aufwand für die Orchestrierung erfordern. Schlankere Setups können nur aus einem Backend-Server wie einer Zeitreihendatenbank und einem Tool zur Visualisierung bestehen. Komplexere Systeme können mehrere Protokollierungssysteme mit mehreren dedizierten Protokollversendern, Alarmmanagern und anderen Zwischenkomponenten umfassen (siehe Abbildung). Einige dieser Werkzeuge können notwendig sein, um Protokolle überhaupt erst zugänglich zu machen oder um verschiedene Protokollströme zu vereinheitlichen. Das Verständnis der Funktionsweise und des Leistungsbereichs der einzelnen Komponenten ist daher von zentraler Bedeutung.
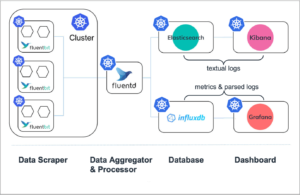
Abb. 4: Überwachungsablauf von Anwendungen, die in einem Kubernetes-Cluster bereitgestellt werden (verändert, aus https://logz.io/blog/fluentd-vs-fluent-bit/)
Datenbank & Entwurf
Protokolle, zumindest wenn sie nach den bewährten Verfahren mit einem Zeitstempel versehen sind, und Metriken sind in der Regel Zeitreihendaten, die in einer Zeitreihendatenbank gespeichert werden können. In Fällen, in denen Textprotokolle unverändert gespeichert werden, verwenden andere Architekturen dokumentenorientierte Speichertypen mit einer leistungsstarken Abfrage-Engine (wie ElasticSearch) als Ergänzung. Neben den speicherbezogenen Unterschieden wird die Backend-Infrastruktur in zwei verschiedene Paradigmen unterteilt: Push und Pull. Diese Paradigmen befassen sich mit der Frage, wer für die anfängliche Aufnahme der Daten verantwortlich ist (Client oder Backend).
Die Entscheidung für das eine oder andere Paradigma hängt vom Anwendungsfall oder der Art der Informationen ab, die persistiert werden sollen. Push-Dienste eignen sich beispielsweise gut für die Ereignisprotokollierung, bei der die Informationen zu einem einzelnen Ereignis wichtig sind. Allerdings sind sie dadurch auch anfälliger für Überlastung durch zu viele Anfragen, was die Robustheit beeinträchtigt. Andererseits sind Pull-Systeme perfekt geeignet, um periodische Informationen abzurufen, die mit der Zusammensetzung von Metriken übereinstimmen.
Dashboard & Warnmeldungen
Um die Daten besser zu verstehen und eventuelle Unregelmäßigkeiten zu erkennen, sind Dashboards sehr nützlich. Überwachungssysteme eignen sich vor allem für einfache, „weniger komplexe“ Abfragen, da die Leistung zählt. Der Zweck dieser Tools ist auf die zu bearbeitenden Probleme spezialisiert, und sie bieten einen begrenzteren Bestand als einige der bekannten Software wie PowerBI. Das macht sie jedoch nicht weniger leistungsfähig in ihrem Einsatzbereich. Tools wie Grafana, das sich hervorragend für den Umgang mit protokollbasierten Metrikdaten eignet, kann sich mit verschiedenen Datenbank-Backends verbinden und maßgeschneiderte Lösungen aus mehreren Quellen erstellen. Tools wie Kibana, die ihre Stärken bei textbasierten Protokoll-Analysen haben, bieten Anwendern ein umfangreiches Abfrage-Toolkit für die Ursachenanalyse und Diagnose. Es ist erwähnenswert, dass beide Tools ihren Anwendungsbereich erweitern, um beide Welten zu unterstützen.
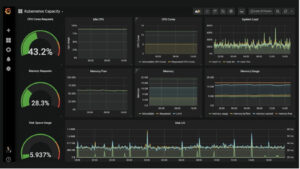
Abb. 5 Grafana Beispiel Dashboard (https://grafana.com/grafana/)
Während sich die Überwachung hervorragend eignet, um Unregelmäßigkeiten zu erkennen (proaktiv) und fehlerhafte Systeme gezielt zu analysieren (reaktiv), können DevOps-Teams sofort handeln, wenn sie über Anwendungsausfälle informiert werden. Alert-Manager bieten die Möglichkeit, nach Ereignissen zu suchen und Alarme über alle möglichen Kommunikationskanäle auszulösen, z. B. über Messaging, Incident-Management-Programme oder per E-Mail.
Scraper, Aggregatoren & Verlader
Da nicht jeder Microservice einen Endpunkt zur Verfügung stellt, an dem Protokolle und protokollbasierte Metriken bewertet oder extrahiert werden können – denken Sie an die Unterschiede zwischen Push und Pull -, müssen Vermittler einspringen. Dienste wie Scraper extrahieren und formatieren Protokolle aus verschiedenen Quellen, Aggregatoren führen eine Art von kombinierten Aktionen (Generierung von Metriken) durch und Shipper können als Push-Dienst für Push-basierte Backends fungieren. Fluentd ist ein perfekter Kandidat, der all die genannten Fähigkeiten in sich vereint und dennoch einen kleinen Fußabdruck beibehält.
End-to-End-Überwachung
Es gibt kostenpflichtige Dienste, die versuchen, ein ganzheitliches System für jede Art von Anwendung, Architektur und unabhängig von Cloud-Anbietern bereitzustellen, was für DevOps-Teams ein entscheidender Vorteil sein kann. Aber auch schlankere Setups können kosteneffiziente und zuverlässige Arbeit leisten.
Wenn man die Notwendigkeit ausschließt, Volltextprotokolle zu sammeln, können viele Standardanwendungsfälle mit einer Zeitreihendatenbank als Backend realisiert werden. InfluxDB ist dafür gut geeignet und einfach aufzusetzen, mit ausgereifter Integrationsfähigkeit in Grafana. Grafana als Dashboard-Tool lässt sich gut mit dem Alter Manager Service von Prometheus kombinieren. Als Vermittler ist fluentd perfekt geeignet, um die textuellen Protokolle zu extrahieren und die notwendigen Transformationen durchzuführen. Da InfluxDB push-basiert ist, kümmert sich fluentd auch darum, dass die Daten in InfluxDB gelangen.
Aufbauend auf diesen Tools deckt die Beispielinfrastruktur alles ab, von der Data Science Pipeline bis zu den später eingesetzten Modell-APIs, mit Dashboards für jeden Anwendungsfall. Bevor ein neuer Trainingslauf für die Produktion freigegeben wird, bieten die eingangs erwähnten ML-Metriken einen guten Einstiegspunkt, um die Legitimität des Modells zu überprüfen. Einfache Nutzerstatistiken, wie die Gesamtzahl der Anfragen und die Anzahl der einzelnen Anfragen, geben einen guten Überblick über die Nutzung des Modells, sobald es eingesetzt wird. Durch die Verfolgung der Antwortzeiten, z. B. eines API-Aufrufs, lassen sich Engpässe leicht aufdecken.
Auf der Ressourcenebene werden die APIs zusammen mit jedem Pipelineschritt überwacht, um Unregelmäßigkeiten wie plötzliche Spitzen im Speicherverbrauch zu beobachten. Durch die Verfolgung der Ressourcen im Zeitverlauf kann auch festgestellt werden, ob die verwendeten VM-Typen über- oder unterausgelastet sind. Durch die Optimierung dieser Metriken lassen sich möglicherweise unnötige Kosten einsparen. Schließlich sollten vordefinierte Fehlerereignisse, wie eine nicht erreichbare API oder fehlgeschlagene Trainingsläufe, einen Alarm auslösen und eine E-Mail versenden.
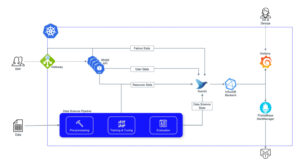
Abb. 6: Eingesetzte Infrastruktur mit Protokoll-Streams und Monitoring-Stack.
Die gesamte Architektur, bestehend aus der Überwachungsinfrastruktur, der Data Science Pipeline und den bereitgestellten APIs, kann in einem (verwalteten) Kubernetes-Cluster ausgeführt werden. Aus einer DevOps-Perspektive ist die Kenntnis von Kubernetes bereits die halbe Miete. Dieser Open-Source-Stack kann nach oben und unten skaliert werden und ist nicht an ein kostenpflichtiges Abonnementmodell gebunden, was große Flexibilität und Kosteneffizienz bietet. Außerdem ist das Onboarding neuer Protokoll-Streams, bereitgestellter Anwendungen oder mehrerer Pipelines mühelos möglich. Sogar einzelne Frameworks können ausgetauscht werden. Wenn zum Beispiel Grafana nicht mehr geeignet ist, verwenden Sie einfach ein anderes Visualisierungstool, das sich mit dem Backend integrieren lässt und den Anforderungen des Anwendungsfalls entspricht.
Fazit
Nicht erst seit Anwendungen modularisiert und in die Cloud verlagert wurden, sind Protokollierung und Monitoring zentrale Bestandteile moderner Infrastrukturen. Dennoch verschlimmern sie sicherlich die Probleme, die entstehen, wenn sie nicht richtig eingerichtet sind. Neben der zunehmenden Operationalisierung des ML-Workflows wächst auch die Notwendigkeit für Unternehmen, gut durchdachte Überwachungslösungen einzurichten, um Modelle, Daten und alles um sie herum im Blick zu behalten.
Es gibt zwar dedizierte Plattformen, die für diese Herausforderungen entwickelt wurden, aber die charmante Idee hinter der vorgestellten Infrastruktur ist, dass sie nur aus einem einzigen Einstiegspunkt für Data Science-, MLOps- und Devops-Teams besteht und in hohem Maße erweiterbar ist.