Mein Kollege An hat bereits eine Grafik veröffentlicht, die seine Reise bei statworx von Data Science zu Data Engineering dokumentiert. Sein Beitrag zeigt, welche Fähigkeiten Data Engineers für ihre tägliche Arbeit benötigen. Falls dir „Data Engineering“ nichts sagt: es handelt sich dabei um den Bereich, der sich mit der Speicherung, Verarbeitung und Übertragung von Daten auf sichere und effiziente Weise befasst.
In diesem Beitrag werde ich die Anforderungen an diese Tätigkeiten näher erläutern. Da es eine ganze Reihe von Themen zu lernen gibt, schlage ich die folgende Reihenfolge vor:
- Eine Programmiersprache
- Die Grundlagen von git und Versionskontrolle
- Die UNIX-Befehlszeile
- REST-APIs und Grundlagen von Netzwerkarchitekturen
- Datenbanksysteme
- Containerisierung
- Die Cloud
Auch wenn dies von eurer persönlichen Lernerfahrung abweichen mag, habe ich festgestellt, dass diese Reihenfolge für Anfänger leichter zu handhaben ist. Wenn ihr an einer kurzen Übersicht über die wichtigsten Data-Engineering-Technologien interessiert seid, könnte euch auch dieser Beitrag meines Kollegen Andre zum Thema gefallen.
Programmieren lernen – welche Sprachen brauche ich?
Wie in anderen datenbezogenen Berufen ist das Programmieren für Data Engineers eine Pflichtübung. Neben SQL verwenden Data Engineers auch andere Programmiersprachen, um ihre Probleme zu lösen. Unter dieser Vielzahl an verwendbaren Programmiersprachen ist Python aber sicherlich eine der besten Optionen. Python hat sich zur Lingua Franca für datenverwandte Aufgaben entwickelt und eignet sich perfekt für die Ausführung von ETL-Aufgaben und das Schreiben von Datenpipelines. Die Sprache ist nicht nur relativ leicht zu erlernen und syntaktisch elegant, sondern bietet auch die Integration mit Tools und Frameworks (wie Apache Airflow, Apache Spark, REST-APIs und relationale Datenbanksysteme wie PostgresSQL), die im Data Engineering entscheidend sind.
Neben der Programmiersprache werdet ihr euch wahrscheinlich auch für eine IDE (Integrated Development Environment) entscheiden. Beliebte Lösungen für Python sind PyCharm und VSCode. Unabhängig von der Wahl wird eure IDE euch wahrscheinlich in die Grundlagen der Versionskontrolle einführen, da die meisten IDEs eine grafische Schnittstelle zur Verwendung von git und Versionskontrolle haben. Sobald ihr mit den Grundlagen vertraut seid, könnt ihr euch mit git und Versionskontrolle vertraut machen.
git & Versionskontrollwerkzeuge – Versionierung des Quellcodes
In einem agilen Team arbeiten in der Regel mehrere Data Engineers an einem Projekt. Daher ist es wichtig sicherzustellen, dass alle Änderungen an Datenpipelines und anderen Teilen der Codebasis nachverfolgt, überprüft und integriert werden können. Dies bedeutet in der Regel, dass der Quellcode in einem entfernten Code-Verwaltungssystem wie GitHub versioniert wird und dass alle Änderungen vor der Produktionsbereitstellung vollständig getestet werden.
Ich empfehle euch dringend, git über die Kommandozeile zu erlernen, um das volle Potenzial auszuschöpfen. Obwohl die meisten IDEs Schnittstellen zu git bieten, sind bestimmte Funktionen möglicherweise nicht vollständig verfügbar. Darüber hinaus bietet das Erlernen von git auf der Kommandozeile einen guten Einstieg, um mehr über Shell-Befehle zu erfahren.
Die UNIX-Befehlszeile – eine grundlegende Fähigkeit
Viele der Aufgaben, die in der Cloud oder auf lokalen Servern und anderen Frameworks ausgeführt werden, werden mit Shell-Befehlen und Skripten gesteuert. In diesen Situationen gibt es keine grafischen Benutzeroberflächen, weshalb Data Engineers mit der Befehlszeile vertraut sein müssen, um Dateien zu bearbeiten, Befehle auszuführen und im System zu navigieren. Ob bash, zsh oder eine andere Shell, die Anforderung Skripte zu schreiben und somit ohne eine Programmiersprache wie Python Aufgaben automatisieren zu können, ist unvermeidlich, insbesondere auf Servern ohne grafische Oberfläche. Da Befehlszeilenprogramme in so vielen verschiedenen Szenarien verwendet werden, sind sie auch für REST-APIs und Datenbanksysteme nützlich.
REST APIs & Netzwerke – wie Dienste miteinander kommunizieren
Moderne Anwendungen sind in der Regel nicht als Monolithen konzipiert. Stattdessen sind die Funktionalitäten oft in separaten Modulen enthalten, die als Microservices ausgeführt werden. Dadurch wird die Gesamtarchitektur flexibler, und das Design kann leichter weiterentwickelt werden, ohne dass die Entwickler den Code aus einer großen Anwendung herausziehen müssen.
Wie aber können solche Module miteinander kommunizieren? Die Antwort liegt im Representational State Transfer (REST) über ein Netzwerk. Das gängigste Protokoll, HTTP, wird von Diensten zum Senden und Empfangen von Daten verwendet. Es ist wichtig, die Grundlagen darüber zu lernen, wie HTTP-Anfragen strukturiert sind, welche HTTP-Verben typischerweise zur Erfüllung von Aufgaben verwendet werden und wie man solche Funktionalitäten praktisch in der Programmiersprache seiner Wahl implementiert. Python bietet Frameworks wie fastAPI und Flask. In diesem Artikel findet ihr ein konkretes Beispiel für den Aufbau einer REST-API mit Flask.
Netzwerke spielen hier ebenfalls eine wichtige Rolle, da sie die Isolierung wichtiger Systeme wie Datenbanken und REST-APIs ermöglichen. Das Konfigurieren von Netzwerken kann manchmal notwendig sein, weshalb ihr die Grundlagen kennen solltet. Sobald ihr mit REST-APIs vertraut seid, ist es sinnvoll, sich mit Datenbanksystemen zu beschäftigen, denn REST-APIs speichern oft selbst keine Daten, sondern fungieren als standardisierte Schnittstellen zum Zugriff auf Daten aus einer Datenbank.
Datenbanksysteme – Daten organisieren
Als Data Engineer werdet ihr einen beträchtlichen Teil eurer Zeit mit dem Betrieb von Datenbanken verbringen, entweder um Daten zu sammeln, zu speichern, zu übertragen, zu bereinigen oder einfach nur abzufragen. Daher müssen Data Engineers über gute Kenntnisse in der Datenbankverwaltung verfügen. Dazu gehört, dass man SQL (Structured Query Language), die grundlegende Sprache für die Interaktion mit Datenbanken, fließend beherrscht und sich mit einigen der gängigsten SQL-Dialekte auskennt, darunter MySQL, SQL Server und PostgreSQL. Neben relationalen Datenbanken müssen Data Engineers auch mit NoSQL-Datenbanken („Not only SQL“) vertraut sein, die sich immer mehr zu den bevorzugten Systemen für Big Data und Echtzeitanwendungen entwickeln. Obwohl die Zahl der NoSQL-Engines zunimmt, sollten Data Engineers daher zumindest die Unterschiede zwischen den NoSQL-Datenbanktypen und die Anwendungsfälle verstehen. Wenn ihr Datenbanken und REST-APIs im Griff habt, müsst ihr sie irgendwie bereitstellen. Hier kommen Container ins Spiel.
Containerisierung – Verpackung Ihrer Software
Bei der Containerisierung wird der Softwarecode mit den Betriebssystembibliotheken und Abhängigkeiten, die für die Ausführung des Codes erforderlich sind, zu einer einzigen leichtgewichtigen ausführbaren Datei – einem Container – zusammengefasst. Diese kann konsistent auf jeder Infrastruktur ausgeführt werden. Da Container portabler und ressourceneffizienter sind als virtuelle Maschinen (VMs), haben sie sich de facto zu den Recheneinheiten moderner Cloud-nativer Anwendungen entwickelt. Um besser zu verstehen, wie Container KI-Lösungen skalierbar machen, könnt ihr unser Whitepaper über Container lesen.
Für die Containerisierung von Anwendungen verwenden die meisten Entwickler Docker, ein Open-Source-Tool zum Erstellen von Images und Ausführen von Containern. Zum Verpacken von Code werden fast immer Befehlszeilentools wie das Docker-CLI (Command Line Interface) verwendet. Aber nicht nur Anwendungen oder REST-APIs können containerisiert werden. Data Engineers führen häufig Datenverarbeitungsaufgaben in Containern aus, um die Laufzeitumgebung zu stabilisieren. Solche Aufgaben müssen geordnet und geplant werden, und hier kommen Orchestrierungswerkzeuge ins Spiel.
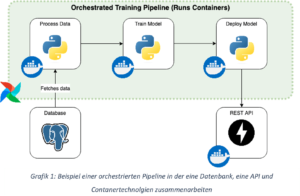
Orchestrierung – Automatisierung der Datenverarbeitung
Eine der Hauptaufgaben von Data Engineers ist die Erstellung von Datenpipelines mit ETL-Technologien und Orchestrierungs-Frameworks. In diesem Abschnitt könnte man viele Technologien aufzählen, da die Zahl der Frameworks ständig steigt.
Data Engineers sollten einige der bekanntesten kennen oder mit ihnen vertraut sein – wie z.B. Apache Airflow, ein beliebtes Orchestrierungs-Framework für die Planung, Erstellung und Verfolgung von Datenpipelines.
Eine Instanz eines solchen Orchestrierungs-Frameworks selbst zu pflegen, kann recht mühsam sein. Wenn der Technologiestapel wächst, wird die Wartung oft zu einem Vollzeitjob. Um diese Belastung zu verringern, bieten Cloud-Anbieter fertige Lösungen an.
Die Cloud – ohne großen Wartungsaufwand in Produktion
Unter den vielen Cloud-Anbietern ist es sinnvoll, sich für einen der drei großen Anbieter zu entscheiden: Amazon Web Services (AWS), Google Cloud Platform (GCP) und Microsoft Azure. Alle bieten verschiedene Dienste an, um Standardaufgaben des Data Engineering zu lösen, wie z. B. die Aufnahme von Daten, die Planung und Orchestrierung von Datenverarbeitungsschritten, die sichere Speicherung von Daten und deren Bereitstellung für Geschäftsanwender und Datenwissenschaftler. Aufgrund der Fülle der Angebote ist es für Data Engineers sinnvoll, sich bei der Auswahl einer Lösung mit der Preisgestaltung des Anbieters vertraut zu machen.
Wenn ihr z.B. ein gutes Verständnis von Datenbanksystemen habt, sollte das Verständnis von Datenbanksystemen in der Cloud nicht allzu schwierig sein. Bestimmte Technologien wie Apache Spark auf Databricks können jedoch ohne Zugang zur Cloud schwer zu erkunden sein. In diesem Fall würde ich empfehlen, ein Konto bei der Cloud-Plattform eurer Wahl einzurichten und mit dem Experimentieren zu beginnen.
Hoher Aufwand, hohe Belohnung
Fassen wir noch einmal zusammen: Um ein Data Engineer zu werden, sollte man Folgendes lernen:
- Eine Programmiersprache
- Die Grundlagen von git und Versionskontrolle
- Die UNIX-Befehlszeile
- REST-APIs und Grundlagen von Netzwerkarchitekturen
- Datenbanksysteme
- Containerisierung
- Die Cloud
Auch wenn dies nach viel Lernaufwand klingt, solltet ihr euch nicht entmutigen lassen. Praktisch alle der oben aufgeführten Fähigkeiten sind auf andere Rollen übertragbar, so dass das Erlernen dieser Fähigkeiten euch fast unabhängig von eurem genauen beruflichen Werdegang helfen wird. Wenn ihr wie ich einen Data Science Hintergrund habt, werden euch einige dieser Themen bereits vertraut sein. Ich persönlich finde Netzwerkarchitekturen am schwierigsten zu begreifen, da die Arbeit oft von IT-Fachleuten auf der Kundenseite erledigt wird.
Ihr fragt euch wahrscheinlich, wie ihr in die Praxis einsteigen könnt. Die Arbeit an eigenen Projekten wird euch helfen, die Grundlagen der meisten dieser Schritte zu erlernen. Zu den üblichen Data-Engineering-Projekten gehören die Einrichtung von Datenbanksystemen und die Orchestrierung von Aufträgen zur regelmäßigen Aktualisierung der Datenbank. Es gibt viele öffentlich zugängliche Datensätze auf kaggle und APIs, wie z.B. die coinbase API, aus denen ihr Daten für euer persönliches Projekt ziehen könnt. So könnt Ihr eure ersten Schritte zunächst lokal erarbeiten und das Projekt anschließend in die Cloud migrieren.
Überwachung von Data-Science-Workflows
Die Zeiten, in denen ein Data Science-Projekt nur aus lose gekoppelten Notebooks für die Datenverarbeitung und das Modelltraining bestand, die die Date Scientists gelegentlich auf ihren Laptops ausführten, sind längst vorbei. Mit zunehmender Reife haben sich die Projekte zu großen Softwareprojekten mit mehreren Beteiligten und Abhängigkeiten sowie unterschiedlichen Modulen mit zahlreichen Klassen und Funktionen entwickelt. Der Data-Science-Workflow, der in der Regel mit der Datenvorverarbeitung, dem Feature-Engineering, dem Modelltraining, dem Tuning, der Evaluierung und schließlich der Inferenz beginnt und als ML-Pipeline bezeichnet wird, wird modularisiert. Diese Modularisierung macht den Prozess skalierbarer und automatisierbar, ergo geeignet für die Ausführung in Container-Orchestrierungssystemen oder in der Cloud-Infrastruktur. Die Extraktion wertvoller modell- oder datenbezogener KPIs kann, wenn sie manuell erfolgt, eine arbeitsintensive Aufgabe sein, umso mehr, wenn sie mit zunehmenden und/oder automatisierten Wiederholungen verbunden ist. Diese Informationen sind wichtig für den Vergleich verschiedener Modelle und die Beobachtung von Trends wie «Distribution-Shift» in den Trainingsdaten. Sie können auch dazu verwendet werden, ungewöhnliche Werte zu erkennen, von unausgewogenen Klassen bis hin zur Löschung von Ausreißern – was auch immer als notwendig erachtet wird, um die Robustheit eines Modells zu gewährleisten. Bibliotheken wie MLFlow können verwendet werden, um all diese Arten von Metriken zu speichern. Außerdem hängt die Operationalisierung von ML-Pipelines stark von der Verfolgung laufbezogener Informationen zur effizienten Fehlerbehebung sowie zur Aufrechterhaltung oder Verbesserung des Ressourcenverbrauchs der Pipeline ab.
Dies gilt nicht nur für die Welt von Data Science. Die heutigen Microservice-basierten Architekturen tragen ebenfalls dazu bei, dass die Wartung und Verwaltung von bereitgestelltem Code eine einheitliche Überwachung erfordert. Dies kann die von einem DevOps-Team benötigten Betriebs- und Wartungsstunden aufgrund eines ganzheitlicheren Verständnisses der beteiligten Prozesse drastisch reduzieren und gleichzeitig fehlerbedingte Ausfallzeiten verringern.
Es ist wichtig zu verstehen, wie verschiedene Formen der Überwachung darauf abzielen, die oben genannten Implikationen anzugehen, und wie modell- und datenbezogene Metriken ebenfalls zu diesem Ziel beitragen können. Zwar hat sich MLFlow als Industriestandard für die Überwachung von ML-bezogenen Metriken etabliert, doch kann auch die Überwachung dieser Metriken zusammen mit allen betrieblichen Informationen interessant sein.
Protokolle vs. Metriken
Protokolle liefern eine ereignisbasierte Momentaufnahme – Metriken geben einen Überblick aus der Vogelperspektive
Ein Protokoll ist eine zu einem bestimmten Zeitpunkt geschriebene Aufzeichnung (z. B. stdout/stderr) eines Ereignisses, das diskontinuierlich und in nicht vordefinierten Intervallen auftritt. Je nach Anwendung enthalten die Protokolle Informationen wie Zeitstempel, Auslöser, Name, Beschreibung und/oder Ergebnis des Ereignisses. Bei den Ereignissen kann es sich um einfache Anfragen oder Benutzeranmeldungen handeln, die der Entwickler des zugrunde liegenden Codes als wichtig erachtet hat. Wenn Sie sich bei diesem Prozess an bewährte Verfahren halten, können Sie sich eine Menge Ärger und Zeit bei der Einrichtung nachgelagerter Überwachungswerkzeuge sparen. Die Verwendung dedizierter Protokollbibliotheken und das Schreiben aussagekräftiger Protokollnachrichten sind hier von Vorteil.
INFO[2021-01-06T17:44:13.368024402-08:00] starting *secrets.YamlSecrets
INFO[2021-01-06T17:44:13.368679356-08:00] starting *config.YamlConfig
INFO[2021-01-06T17:44:13.369046236-08:00] starting *s3.DefaultService
INFO[2021-01-06T17:44:13.369518352-08:00] starting *lambda.DefaultService
ERROR[2021-01-06T17:44:13.369694698-08:00] http server error error="listen tcp 127.0.0.1:6060: bind: address already in use"
Abb. 1: Ereignisprotokolle in Textform
Obwohl die Datenmenge eines einzelnen Protokolls vernachlässigbar ist, können Protokollströme schnell exponentiell ansteigen. Dies führt dazu, dass die Speicherung jedes einzelnen Protokolls nicht gut skalierbar ist, insbesondere in Form von halbstrukturierten Textdaten. Für Debugging oder Auditing kann es jedoch unvermeidlich sein, Protokolle in unveränderter Form zu speichern. Archivspeicherlösungen oder Aufbewahrungsfristen können hier helfen.
In anderen Fällen können das Parsen und Extrahieren von Protokollen in andere Formate, wie z. B. Schlüssel-Wert-Paare, diesen Einschränkungen entgegenwirken. Auf diese Weise kann ein Großteil der Ereignisinformationen erhalten bleiben, während der Speicherbedarf deutlich geringer ist.
{
time: "2021-01-06T17:44:13-08:00",
mode: "reader",
debug_http_error: "listen tcp 127.0.0.1:6061: bind: address already in use"
servicePort: 8089,
duration_ms: 180262
}Abb. 2: Strukturierte Ereignisprotokolle
Eine andere Form der Verringerung dieses Fußabdrucks kann durch Stichprobenmethoden erfolgen, wobei Metriken die prominentesten Vertreter sind.
Eine Metrik ist ein numerisches Maß für ein bestimmtes Ziel (ein bestimmtes Ereignis), das gleichmäßig über Zeitintervalle verteilt ist. Mathematische Aggregationen wie Summen oder Durchschnittswerte sind gängige Transformationen, die solche Metriken datenmäßig relativ klein halten.
{
time: "2022-01-06T17:44:13-08:00",
Duration_ms: 60,
sum_requests: 500,
sum_hits_endpoint_1: 250,
sum_hits_endpoint_2: 117,
avg_duration: 113,
}
Abb. 3: Metriken
Metriken eignen sich daher gut für die schrittweise Verringerung der Datenauflösung auf breitere Frequenzen wie tägliche, wöchentliche oder sogar längere Analysezeiträume. Außerdem lassen sich Metriken in der Regel besser über mehrere Anwendungen hinweg vereinheitlichen, da sie im Vergleich zu rohen Protokollnachrichten stark strukturierte Daten enthalten. Dies verringert zwar die zuvor genannten Probleme, geht aber auf Kosten der Granularität. Daher eignen sich Metriken perfekt für hochfrequente Ereignisse, bei denen die Informationen zu einem einzelnen Ereignis weniger wichtig sind. Die Überwachung von Rechenressourcen ist ein Beispiel dafür. Beide Ansätze haben ihre Berechtigung in jeder Überwachungskonfiguration, da die verschiedenen Anwendungsfälle zu den unterschiedlichen Zielen passen. Anhand eines konkreten Beispiels aus einem kleinen Unternehmen lassen sich die Hauptunterschiede verdeutlichen:
Der Gesamtsaldo eines Bankkontos kann im Laufe der Zeit aufgrund von Abhebungen und Einzahlungen (die zu jedem Zeitpunkt erfolgen können) schwanken. Wenn man nur daran interessiert ist, dass sich Geld auf dem Konto befindet, sollte es ausreichen, eine aggregierte Metrik regelmäßig zu verfolgen. Interessiert man sich jedoch für den Gesamtzufluss im Zusammenhang mit einem bestimmten Kunden, ist die Protokollierung jeder Transaktion unumgänglich.
Architektur und Tool-Stack
In den meisten modernen Cloud-Stacks, wie z. B. Azure Appservice, wird die Protokollierung der Infrastruktur und der Anfrageseite mit dem Dienst selbst ausgeliefert. Mit zunehmendem Volumen kann dies jedoch kostspielig werden. Die Definition der Anwendungsfälle, das Verständnis der Bereitstellungsumgebung und die Abstimmung mit der Protokollierungsarchitektur sind Teil der Aufgaben von DevOps-Teams.
Aus der Sicht eines Entwicklers gibt es eine Vielzahl von Open-Source-Tools, die wertvolle Überwachungslösungen liefern können, die nur einen gewissen Aufwand für die Orchestrierung erfordern. Schlankere Setups können nur aus einem Backend-Server wie einer Zeitreihendatenbank und einem Tool zur Visualisierung bestehen. Komplexere Systeme können mehrere Protokollierungssysteme mit mehreren dedizierten Protokollversendern, Alarmmanagern und anderen Zwischenkomponenten umfassen (siehe Abbildung). Einige dieser Werkzeuge können notwendig sein, um Protokolle überhaupt erst zugänglich zu machen oder um verschiedene Protokollströme zu vereinheitlichen. Das Verständnis der Funktionsweise und des Leistungsbereichs der einzelnen Komponenten ist daher von zentraler Bedeutung.
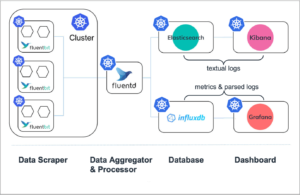
Abb. 4: Überwachungsablauf von Anwendungen, die in einem Kubernetes-Cluster bereitgestellt werden (verändert, aus https://logz.io/blog/fluentd-vs-fluent-bit/)
Datenbank & Entwurf
Protokolle, zumindest wenn sie nach den bewährten Verfahren mit einem Zeitstempel versehen sind, und Metriken sind in der Regel Zeitreihendaten, die in einer Zeitreihendatenbank gespeichert werden können. In Fällen, in denen Textprotokolle unverändert gespeichert werden, verwenden andere Architekturen dokumentenorientierte Speichertypen mit einer leistungsstarken Abfrage-Engine (wie ElasticSearch) als Ergänzung. Neben den speicherbezogenen Unterschieden wird die Backend-Infrastruktur in zwei verschiedene Paradigmen unterteilt: Push und Pull. Diese Paradigmen befassen sich mit der Frage, wer für die anfängliche Aufnahme der Daten verantwortlich ist (Client oder Backend).
Die Entscheidung für das eine oder andere Paradigma hängt vom Anwendungsfall oder der Art der Informationen ab, die persistiert werden sollen. Push-Dienste eignen sich beispielsweise gut für die Ereignisprotokollierung, bei der die Informationen zu einem einzelnen Ereignis wichtig sind. Allerdings sind sie dadurch auch anfälliger für Überlastung durch zu viele Anfragen, was die Robustheit beeinträchtigt. Andererseits sind Pull-Systeme perfekt geeignet, um periodische Informationen abzurufen, die mit der Zusammensetzung von Metriken übereinstimmen.
Dashboard & Warnmeldungen
Um die Daten besser zu verstehen und eventuelle Unregelmäßigkeiten zu erkennen, sind Dashboards sehr nützlich. Überwachungssysteme eignen sich vor allem für einfache, „weniger komplexe“ Abfragen, da die Leistung zählt. Der Zweck dieser Tools ist auf die zu bearbeitenden Probleme spezialisiert, und sie bieten einen begrenzteren Bestand als einige der bekannten Software wie PowerBI. Das macht sie jedoch nicht weniger leistungsfähig in ihrem Einsatzbereich. Tools wie Grafana, das sich hervorragend für den Umgang mit protokollbasierten Metrikdaten eignet, kann sich mit verschiedenen Datenbank-Backends verbinden und maßgeschneiderte Lösungen aus mehreren Quellen erstellen. Tools wie Kibana, die ihre Stärken bei textbasierten Protokoll-Analysen haben, bieten Anwendern ein umfangreiches Abfrage-Toolkit für die Ursachenanalyse und Diagnose. Es ist erwähnenswert, dass beide Tools ihren Anwendungsbereich erweitern, um beide Welten zu unterstützen.
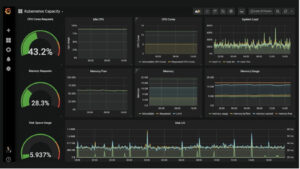
Abb. 5 Grafana Beispiel Dashboard (https://grafana.com/grafana/)
Während sich die Überwachung hervorragend eignet, um Unregelmäßigkeiten zu erkennen (proaktiv) und fehlerhafte Systeme gezielt zu analysieren (reaktiv), können DevOps-Teams sofort handeln, wenn sie über Anwendungsausfälle informiert werden. Alert-Manager bieten die Möglichkeit, nach Ereignissen zu suchen und Alarme über alle möglichen Kommunikationskanäle auszulösen, z. B. über Messaging, Incident-Management-Programme oder per E-Mail.
Scraper, Aggregatoren & Verlader
Da nicht jeder Microservice einen Endpunkt zur Verfügung stellt, an dem Protokolle und protokollbasierte Metriken bewertet oder extrahiert werden können – denken Sie an die Unterschiede zwischen Push und Pull -, müssen Vermittler einspringen. Dienste wie Scraper extrahieren und formatieren Protokolle aus verschiedenen Quellen, Aggregatoren führen eine Art von kombinierten Aktionen (Generierung von Metriken) durch und Shipper können als Push-Dienst für Push-basierte Backends fungieren. Fluentd ist ein perfekter Kandidat, der all die genannten Fähigkeiten in sich vereint und dennoch einen kleinen Fußabdruck beibehält.
End-to-End-Überwachung
Es gibt kostenpflichtige Dienste, die versuchen, ein ganzheitliches System für jede Art von Anwendung, Architektur und unabhängig von Cloud-Anbietern bereitzustellen, was für DevOps-Teams ein entscheidender Vorteil sein kann. Aber auch schlankere Setups können kosteneffiziente und zuverlässige Arbeit leisten.
Wenn man die Notwendigkeit ausschließt, Volltextprotokolle zu sammeln, können viele Standardanwendungsfälle mit einer Zeitreihendatenbank als Backend realisiert werden. InfluxDB ist dafür gut geeignet und einfach aufzusetzen, mit ausgereifter Integrationsfähigkeit in Grafana. Grafana als Dashboard-Tool lässt sich gut mit dem Alter Manager Service von Prometheus kombinieren. Als Vermittler ist fluentd perfekt geeignet, um die textuellen Protokolle zu extrahieren und die notwendigen Transformationen durchzuführen. Da InfluxDB push-basiert ist, kümmert sich fluentd auch darum, dass die Daten in InfluxDB gelangen.
Aufbauend auf diesen Tools deckt die Beispielinfrastruktur alles ab, von der Data Science Pipeline bis zu den später eingesetzten Modell-APIs, mit Dashboards für jeden Anwendungsfall. Bevor ein neuer Trainingslauf für die Produktion freigegeben wird, bieten die eingangs erwähnten ML-Metriken einen guten Einstiegspunkt, um die Legitimität des Modells zu überprüfen. Einfache Nutzerstatistiken, wie die Gesamtzahl der Anfragen und die Anzahl der einzelnen Anfragen, geben einen guten Überblick über die Nutzung des Modells, sobald es eingesetzt wird. Durch die Verfolgung der Antwortzeiten, z. B. eines API-Aufrufs, lassen sich Engpässe leicht aufdecken.
Auf der Ressourcenebene werden die APIs zusammen mit jedem Pipelineschritt überwacht, um Unregelmäßigkeiten wie plötzliche Spitzen im Speicherverbrauch zu beobachten. Durch die Verfolgung der Ressourcen im Zeitverlauf kann auch festgestellt werden, ob die verwendeten VM-Typen über- oder unterausgelastet sind. Durch die Optimierung dieser Metriken lassen sich möglicherweise unnötige Kosten einsparen. Schließlich sollten vordefinierte Fehlerereignisse, wie eine nicht erreichbare API oder fehlgeschlagene Trainingsläufe, einen Alarm auslösen und eine E-Mail versenden.
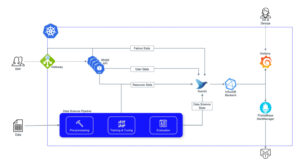
Abb. 6: Eingesetzte Infrastruktur mit Protokoll-Streams und Monitoring-Stack.
Die gesamte Architektur, bestehend aus der Überwachungsinfrastruktur, der Data Science Pipeline und den bereitgestellten APIs, kann in einem (verwalteten) Kubernetes-Cluster ausgeführt werden. Aus einer DevOps-Perspektive ist die Kenntnis von Kubernetes bereits die halbe Miete. Dieser Open-Source-Stack kann nach oben und unten skaliert werden und ist nicht an ein kostenpflichtiges Abonnementmodell gebunden, was große Flexibilität und Kosteneffizienz bietet. Außerdem ist das Onboarding neuer Protokoll-Streams, bereitgestellter Anwendungen oder mehrerer Pipelines mühelos möglich. Sogar einzelne Frameworks können ausgetauscht werden. Wenn zum Beispiel Grafana nicht mehr geeignet ist, verwenden Sie einfach ein anderes Visualisierungstool, das sich mit dem Backend integrieren lässt und den Anforderungen des Anwendungsfalls entspricht.
Fazit
Nicht erst seit Anwendungen modularisiert und in die Cloud verlagert wurden, sind Protokollierung und Monitoring zentrale Bestandteile moderner Infrastrukturen. Dennoch verschlimmern sie sicherlich die Probleme, die entstehen, wenn sie nicht richtig eingerichtet sind. Neben der zunehmenden Operationalisierung des ML-Workflows wächst auch die Notwendigkeit für Unternehmen, gut durchdachte Überwachungslösungen einzurichten, um Modelle, Daten und alles um sie herum im Blick zu behalten.
Es gibt zwar dedizierte Plattformen, die für diese Herausforderungen entwickelt wurden, aber die charmante Idee hinter der vorgestellten Infrastruktur ist, dass sie nur aus einem einzigen Einstiegspunkt für Data Science-, MLOps- und Devops-Teams besteht und in hohem Maße erweiterbar ist.
Schaffe Mehrwert für Deine Data Science Projekte
Data Science und datengetriebene Entscheidungen sind für viele Unternehmen zu einem zentralen Bestandteil ihres Tagesgeschäfts geworden, der in den kommenden Jahren nur noch an Wichtigkeit zunehmen wird. Bis Ende 2022 werden viele Unternehmen eine Cloud-Strategie eingeführt haben:
„70 % der Unternehmen werden bis 2022 über eine formale Cloud-Strategie verfügen, und diejenigen, die diese nicht einführen, werden es schwer haben.“
– Gartner-Forschung
Dadurch, dass sich Cloud-Technologien zu einem Grundbaustein in allen Arten von Unternehmen entwickeln, werden sie auch immer leichter verfügbar. Dies senkt die Einstiegshürde für die Entwicklung Cloud-nativer Anwendungen.
In diesem Blogeintrag werden wir uns damit beschäftigen, wie und warum wir Data Science Projekte am besten in der Cloud durchführen. Ich gebe einen Überblick über die erforderlichen Schritte, um ein Data Science Projekt in die Cloud zu verlagern, und gebe einige Best Practices aus meiner eigenen Erfahrung weiter, um häufige Fallstricke zu vermeiden.
Ich erörtere keine spezifischen Lösungsmuster für einzelne Cloud-Anbieter, stelle keine Vergleiche auf und gehe auch nicht im Detail auf Best Practices für Machine Learning und DevOps ein.
Data Science Projekte profitieren von der Nutzung öffentlicher Cloud-Dienste
Ein gängiger Ansatz für Data Science Projekte besteht darin, zunächst lokal Daten zu bearbeiten und Modelle auf Snapshot-basierten Daten zu trainieren und auszuwerten. Dies hilft in einem frühen Stadium Schritt zu halten, solange noch unklar ist, ob Machine Learning das identifizierte Problem überhaupt lösen kann. Nach der Erstellung einer ersten Modellversion, die den Anforderungen des Unternehmens entspricht, soll das Modell eingesetzt werden und somit Mehrwert schaffen.
Zum Einsatz eines Modells in Produktion gibt es normalerweise zwei Möglichkeiten: 1) Einsatz des Modells in einer on-premises Infrastruktur oder 2) Einsatz des Modells in einer Cloud-Umgebung bei einem Cloud-Anbieter Deiner Wahl. Die lokale Bereitstellung des Modells on-premises mag zunächst verlockend klingen, und es gibt Fälle, in denen dies eine umsetzbare Option ist. Allerdings können die Kosten für den Aufbau und die Wartung einer Data Science-spezifischen Infrastruktur recht hoch sein. Dies resultiert aus den unterschiedlichen Anforderungen, die von spezifischer Hardware über die Bewältigung von Spitzenbelastung während Trainingsphasen bis hin zu zusätzlichen, voneinander abhängigen Softwarekomponenten reichen.
Verschiedene Cloud-Konfigurationen bieten unterschiedliche Freiheitsgrade
Bei der Nutzung der Cloud wird zwischen «Infrastructure as a Service» (IaaS), «Container as a Service» (CaaS), «Platform as a Service» (PaaS) und «Software as a Service» (SaaS) unterschieden, wobei man in der Regel Flexibilität gegen Wartungsfreundlichkeit tauscht. Die folgende Abbildung veranschaulicht die Unterschiedlichen Abdeckungen auf den einzelnen Serviceebenen.

- «On-Premises» musst Du dich um alles selbst kümmern: Bestellung und Einrichtung der erforderlichen Hardware, Einrichtung Deiner Datenpipeline und Entwicklung, Ausführung und Überwachung Deiner Anwendungen.
- Bei «Infrastructure as a Service» kümmert sich der Anbieter um die Hardwarekomponenten und liefert eine virtuelle Maschine mit einer festen Version eines Betriebssystems (OS).
- Bei «Containers as a Service» bietet der Anbieter eine Container-Plattform und eine Orchestrierungslösung an. Du kannst Container-Images aus einer öffentlichen Registry verwenden, diese anpassen oder eigene Container erstellen.
- Bei «Platform as a Service»-Diensten musst Du in der Regel nur noch Deine Daten einbringen, um mit der Entwicklung Deiner Anwendung loszulegen. Falls es sich um eine serverlose Lösung handelt, sind auch keine Annahmen zur Servergröße nötig.
- «Software as a Service»-Lösungen als höchstes Service-Level sind auf einen bestimmten Zweck zugeschnitten und beinhalten einen sehr geringen Aufwand für Einrichtung und Wartung. Dafür bieten sie aber nur eine stark begrenzte Flexibilität, denn neue Funktionen müssen in der Regel beim Anbieter angefordert werden.
Öffentliche Cloud-Dienste sind bereits auf die Bedürfnisse von Data Science Projekten zugeschnitten
Zu den Vorteilen der Public-Cloud gehören Skalierbarkeit, Entkopplung von Ressourcen und Pay-as-you-go-Modelle. Diese Vorteile sind bereits ein Plus für Data Science Anwendungen, z. B. für die Skalierung von Ressourcen für den Trainingsprozess. Darüber hinaus haben alle drei großen Cloud-Anbieter einen Teil ihres Servicekatalogs auf Data Science Anwendungen zugeschnitten, jeder von ihnen mit seinen eigenen Stärken und Schwächen.
Dazu gehören nicht nur spezielle Hardware wie GPUs, sondern auch integrierte Lösungen für ML-Operationen wie automatisierte Bereitstellungen, Modellregistrierungen und die Überwachung von Modellleistung und Datendrift. Viele neue Funktionen werden ständig entwickelt und zur Verfügung gestellt. Um mit diesen Innovationen und Funktionen on-premises Schritt zu halten, musst Du eine beträchtliche Anzahl von Ressourcen aufwenden, ohne dass sich dies direkt auf Dein Geschäft auswirkt.
Wenn Du an einer ausführlichen Diskussion über die Bedeutung der Cloud für den Erfolg von KI-Projekten interessiert bist, dann schau Dir doch dieses White Paper auf dem statworx Content Hub an.
Die Durchführung Deines Projekts in der Cloud erfolgt in nur 5 einfachen Schritten
Wenn Du mit der Nutzung der Cloud für Data Science Projekte beginnen möchtest, musst Du im Vorfeld einige wichtige Entscheidungen treffen und entsprechende Schritte unternehmen. Wir werden uns jeden dieser Schritte genauer ansehen.
1. Auswahl der Cloud-Serviceebene
Bei der Wahl der Serviceebene sind die gängigsten Muster für Data-Science-Anwendungen CaaS oder PaaS. Der Grund dafür ist, dass «Infrastructure as a Service» hohe Kosten verursachen kann, die aus der Wartung virtueller Maschinen oder dem Aufbau von Skalierbarkeit über VMs hinweg resultieren. SaaS-Dienste hingegen sind bereits auf ein bestimmtes Geschäftsproblem zugeschnitten und sind einfach in Betrieb zu nehmen, anstatt ein eigenes Modell und eine eigene Anwendung zu entwickeln.
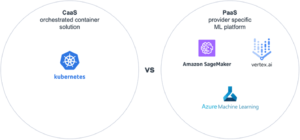
CaaS bietet den Hauptvorteil, dass Container auf jeder Containerplattform eines beliebigen Anbieters bereitgestellt werden können. Und wenn die Anwendung nicht nur aus dem Machine Learning Modell besteht, sondern zusätzliche Mikrodienste oder Front-End-Komponenten benötigt, können diese alle mit CaaS gehostet werden. Der Nachteil ist, dass, ähnlich wie bei einer On-Premises-Einführung, Container-Images für MLops-Tools wie Model Registry, Pipelines und Modell-Performance-Monitoring nicht standardmäßig verfügbar sind und mit der Anwendung erstellt und integriert werden müssen. Je größer die Anzahl der verwendeten Tools und Bibliotheken ist, desto höher ist die Wahrscheinlichkeit, dass künftige Versionen irgendwann Inkompatibilitäten aufweisen oder sogar überhaupt nicht mehr zusammenpassen.
PaaS-Dienste wie Azure Machine Learning, Google Vertex AI oder Amazon SageMaker hingegen haben all diese Funktionalitäten bereits integriert. Der Nachteil dieser Dienste ist, dass sie alle mit komplexen Kostenstrukturen einhergehen und spezifisch für den jeweiligen Cloud-Anbieter sind. Je nach Projektanforderungen können sich die PaaS-Dienste in einigen speziellen Fällen als zu restriktiv erweisen.
Beim Vergleich von CaaS und PaaS geht es meist um den Kompromiss zwischen Flexibilität und einem höheren Grad an Anbieterbindung. Eine stärkere Bindung an den Anbieter ist mit einem Aufpreis verbunden, der für die enthaltenen Funktionen, die größere Kompatibilität und die höhere Entwicklungsgeschwindigkeit zu entrichten ist. Eine höhere Flexibilität wiederum geht mit einem höheren Integrations- und Wartungsaufwand einher.
2. Daten in der Cloud verfügbar machen
In der Regel besteht der erste Schritt zur Bereitstellung Deiner Daten darin, einen Schnappschuss der Daten in einen Cloud-Objektspeicher hochzuladen. Diese sind gut mit anderen Diensten integriert und können später mit geringem Aufwand durch eine geeignetere Datenspeicherlösung ersetzt werden. Sobald die Ergebnisse des Machine Learning Modells aus geschäftlicher Sicht geeignet sind, sollten Data Engineers einen Prozess einrichten, um Deine Daten automatisch auf dem neuesten Stand zu halten.
3. Aufbau einer Pipeline für die Vorverarbeitung
Ein entscheidender Schritt bei jedem Data Science Projekt ist der Aufbau einer robusten Pipeline für die Datenvorverarbeitung. Dadurch wird sichergestellt, dass Deine Daten sauber und bereit für die Modellierung sind, was Dir auf lange Sicht Zeit und Mühe erspart. Ein bewährtes Verfahren ist die Einrichtung einer CICD-Pipeline (Continuous Integration and Continuous Delivery), um die Bereitstellung und das Testen Deiner Vorverarbeitung zu automatisieren und sie in Deinen DevOps-Zyklus einzubinden. Die Cloud hilft Dir, Deine Pipelines automatisch zu skalieren, um jede für das Training Deines Modells benötigte Datenmenge zu bewältigen.
4. Training und Evaluierung des Modells
In dieser Phase wird die Preprocessing-Pipeline durch Hinzufügen von Modellierungskomponenten erweitert. Dazu gehört auch die Abstimmung von Hyperparametern, die wiederum von Cloud-Diensten durch die Skalierung von Ressourcen und die Speicherung der Ergebnisse der einzelnen Trainingsexperimente zum leichteren Vergleich unterstützt wird. Alle Cloud-Anbieter bieten einen automatisierten Dienst für Machine Learning an. Dieser kann entweder genutzt werden, um schnell die erste Version eines Modells zu erstellen und die Leistung mit den Daten über mehrere Modelltypen hinweg zu vergleichen. Auf diese Weise kannst Du schnell beurteilen, ob die Daten und die Vorverarbeitung ausreichen, um das Geschäftsproblem zu lösen. Außerdem kann das Ergebnis als Benchmark für Data Scientists verwendet werden. Das beste Modell sollte in einer Modellregistrierung gespeichert werden, damit es einsatzbereit und transparent ist.
Falls ein Modell bereits lokal oder on-premises trainiert wurde, ist es möglich, das Training zu überspringen und das Modell einfach in die Modellregistrierung zu laden.
5. Bereitstellung des Modells für die Business Unit
Der letzte und wahrscheinlich wichtigste Schritt ist die Bereitstellung des Modells für Deine Business Unit, damit diese einen Nutzen daraus ziehen kann. Alle Cloud-Anbieter bieten Lösungen an, um das Modell mit geringem Aufwand skalierbar bereitzustellen. Schließlich werden alle Teile, die in den früheren Schritten von der automatischen Bereitstellung der neuesten Daten über die Anwendung der Vorverarbeitung und die Einspeisung der Daten in das bereitgestellte Modell erstellt wurden, zusammengeführt.
Jetzt haben wir die einzelnen Schritte für das Onboarding Deines Data Science Projekts durchlaufen. Mit diesen 5 Schritten bist Du auf dem besten Weg, Deinen Data-Science-Workflow in die Cloud zu verlagern. Um einige der üblichen Fallstricke zu vermeiden, möchte ich hier einige Erkenntnisse aus meinen persönlichen Erfahrungen weitergeben, die sich positiv auf den Erfolg Deines Projekts auswirken können.
Erleichtere Dir den Umstieg auf die Cloud mit diesen nützlichen Tipps
Beginne frühzeitig mit der Nutzung der Cloud.
Wenn Du früh damit beginnst, kann sich Dein Team mit den Funktionen der Plattform vertraut machen. Auf diese Weise kannst Du die Möglichkeiten der Plattform optimal nutzen und potenzielle Probleme und umfangreiche Umstrukturierungen vermeiden.
Stelle sicher, dass Deine Daten zugänglich sind.
Dies mag selbstverständlich erscheinen, aber es ist wichtig, dass Deine Daten beim Wechsel in die Cloud leicht zugänglich sind. Dies gilt insbesondere dann, wenn Du Deine Daten lokal generierst und anschliessend in die Cloud übertragen musst.
Erwäge den Einsatz von serverlosem Computing.
Serverless Computing ist eine großartige Option für Data Science Projekte, da es Dir ermöglicht, Deine Ressourcen nach Bedarf zu skalieren, ohne dass Du Server bereitstellen oder verwalten musst.
Vergiss nicht die Sicherheit.
Zwar bieten alle Cloud-Anbieter einige der modernsten IT-Sicherheitseinrichtungen an, doch einige davon sind bei der Konfiguration leicht zu übersehen und können Dein Projekt einem unnötigen Risiko aussetzen.
Überwache Deine Cloud-Kosten.
Bei der Optimierung von on-premises Lösungen geht es oft um die Spitzenauslastung von Ressourcen, da Hardware oder Lizenzen begrenzt sind. Mit Skalierbarkeit und Pay-as-you-go verschiebt sich dieses Paradigma stärker in Richtung Kostenoptimierung. Die Kostenoptimierung ist in der Regel nicht die erste Maßnahme, die man zu Beginn eines Projekts ergreift, aber wenn man die Kosten im Auge behält, können unangenehme Überraschungen vermeiden und die Cloud-Anwendung zu einem späteren Zeitpunkt noch kosteneffizienter gestalten werden.
Lass Deine Data Science Projekte mit der Cloud abheben
Wenn Du Dein nächstes Data Science Projekt in Angriff nimmst, ist die frühzeitige Nutzung der Cloud eine gute Option. Die Cloud ist skalierbar, flexibel und bietet eine Vielzahl von Diensten, mit denen Du das Beste aus Deinem Projekt herausholen kannst. Cloud-basierte Architekturen sind eine moderne Art der Anwendungsentwicklung, die in Zukunft noch mehr an Bedeutung gewinnen wird.
Wenn Du die vorgestellten Schritte befolgst, wirst Du auf diesem Weg unterstützt und kannst mit neusten Trends und Entwicklungen Schritt halten. Außerdem kannst Du mit meinen Tipps viele der üblichen Fallstricke vermeiden, die oft auf diesem Weg auftreten. Wenn Du also nach einer Möglichkeit suchst, das Beste aus Deinem Data Science Projekt herauszuholen, ist die Cloud definitiv eine Überlegung wert.
Be Safe!
Im Zeitalter der Open-Source-Softwareprojekte sind Angriffe auf verwundbare Software allgegenwärtig. Python ist die beliebteste Sprache für Data Science und Engineering und wird daher zunehmend zum Ziel von Angriffen durch bösartige Bibliotheken. Außerdem können öffentlich zugängliche Anwendungen durch Angriffe auf Schwachstellen im Quellcode ausgenutzt werden.
Aus diesem Grund ist es wichtig, dass Dein Code keine CVEs (Common Vulnerabilities and Exposures) enthält oder andere Bibliotheken verwendet, die bösartig sein könnten. Das gilt besonders, wenn es sich um öffentlich zugängliche Software handelt, z. B. eine Webanwendung. Bei statworx suchen wir nach Möglichkeiten, die Qualität unseres Codes durch den Einsatz automatischer Scan-Tools zu verbessern. Deshalb besprechen wir den Wert von zwei Code- und Paketscannern für Python.
Automatische Überprüfung
Es gibt zahlreiche Tools zum Scannen von Code und seinen Abhängigkeiten. Hier werde ich einen Überblick über die beliebtesten Tools geben, die speziell für Python entwickelt wurden. Solche Tools fallen in eine von zwei Kategorien:
- Statische Anwendungssicherheitstests (SAST): suchen nach Schwachstellen im Code und verwundbaren Paketen
- Dynamische Anwendungssicherheitstests (DAST): suchen nach Schwachstellen, die während der Laufzeit auftreten
Im Folgenden werde ich bandit und safety anhand einer kleinen, von mir entwickelten streamlit-Anwendung vergleichen. Beide Tools fallen in die Kategorie SAST, da sie die Anwendung nicht laufen lassen müssen, um ihre Prüfungen durchzuführen. Dynamische Anwendungstests sind komplizierter und werden vielleicht in einem späteren Beitrag behandelt.
Die Anwendung
Um den Zusammenhang zu verdeutlichen, hier eine kurze Beschreibung der Anwendung: Sie wurde entwickelt, um die Konvergenz (oder deren Fehlen) in den Stichprobenverteilungen von Zufallsvariablen zu visualisieren, die aus verschiedenen theoretischen Wahrscheinlichkeitsverteilungen gezogen wurden. Die Nutzer:innen können die Verteilung (z. B. Log-Normal) auswählen, die maximale Anzahl der Stichproben festlegen und verschiedene Stichprobenstatistiken (z. B. Mittelwert, Standardabweichung usw.) auswählen.
Bandit
Bandit ist ein quelloffener Python-Code-Scanner, der nach Schwachstellen im Deinem Code – und nur in Deinem Code – sucht. Er zerlegt den Code in seinen abstrakten Syntaxbaum und führt Plugins gegen diesen aus, um auf bekannte Schwachstellen zu prüfen. Neben anderen Tests prüft es einfachen SQL-Code, der eine Öffnung für SQL-Injektionen bieten könnte, im Code gespeicherte Passwörter und Hinweise auf häufige Angriffsmöglichkeiten wie die Verwendung der Bibliothek „Pickle“.
Bandit ist für die Verwendung mit CI/CD konzipiert und gibt einen Exit-Status von 1 aus, wenn es auf Probleme stößt, wodurch die Pipeline beendet wird. Es wird ein Bericht erstellt, der Informationen über die Anzahl der Probleme enthält, die nach Vertrauenswürdigkeit und Schweregrad in drei Stufen unterteilt sind: niedrig, mittel und hoch. In diesem Fall findet bandit keine offensichtlichen Sicherheitslücken in unserem Code.
Run started:2022-06-10 07:07:25.344619
Test results:
No issues identified.
Code scanned:
Total lines of code: 0
Total lines skipped (#nosec): 0
Run metrics:
Total issues (by severity):
Undefined: 0
Low: 0
Medium: 0
High: 0
Total issues (by confidence):
Undefined: 0
Low: 0
Medium: 0
High: 0
Files skipped (0):Umso wichtiger ist es, Bandit für die Verwendung in Deinem Projekt sorgfältig zu konfigurieren. Manchmal kann es eine Fehlermeldung auslösen, obwohl Du bereits weißt, dass dies zur Laufzeit kein Problem darstellen würde. Wenn Du zum Beispiel eine Reihe von Unit-Tests hast, die pytest verwenden und als Teil Deiner CI/CD-Pipeline laufen, wird Bandit normalerweise eine Fehlermeldung auslösen, da dieser Code die assert-Anweisung verwendet, die nicht für Code empfohlen wird, der nicht ohne das -O-Flag läuft.
Um dieses Verhalten zu vermeiden, kannst Du:
1. Scans gegen alle Dateien durchführen, aber den Test über die Befehlszeilenschnittstelle ausschließen.
2. eine Konfigurationsdatei yaml erstellen, um den Test auszuschließen.
Hier ist ein Beispiel:
# bandit_cfg.yml
skips: ["B101"] # skips the assert checkDann können wir bandit wie folgt ausführen: bandit -c bandit_yml.cfg /path/to/python/files und die unnötigen Warnungen werden nicht auftauchen.
Safety
Entwickelt vom Team von pyup.io, läuft dieser Paketscanner gegen eine kuratierte Datenbank, die aus manuell überprüften Einträgen besteht, die auf öffentlich verfügbaren CVEs und Changelogs basieren. Das Paket ist für Python >= 3.5 verfügbar und kann kostenlos installiert werden. Standardmäßig verwendet es <a href="https://github.com/pyupio/safety-db">Safety DB</a>, die frei zugänglich ist. Pyup.io bietet auch bezahlten Zugang zu einer häufiger aktualisierten Datenbank.
Die Ausführung von safety check --full-report -r requirements.txt im Wurzelverzeichnis des Pakets gibt uns die folgende Ausgabe (aus Gründen der Lesbarkeit gekürzt):
+==============================================================================+
| |
| /$$$$$$ /$$ |
| /$$__ $$ | $$ |
| /$$$$$$$ /$$$$$$ | $$ \__//$$$$$$ /$$$$$$ /$$ /$$ |
| /$$_____/ |____ $$| $$$$ /$$__ $$|_ $$_/ | $$ | $$ |
| | $$$$$$ /$$$$$$$| $$_/ | $$$$$$$$ | $$ | $$ | $$ |
| \____ $$ /$$__ $$| $$ | $$_____/ | $$ /$$| $$ | $$ |
| /$$$$$$$/| $$$$$$$| $$ | $$$$$$$ | $$$$/| $$$$$$$ |
| |_______/ \_______/|__/ \_______/ \___/ \____ $$ |
| /$$ | $$ |
| | $$$$$$/ |
| by pyup.io \______/ |
| |
+==============================================================================+
| REPORT |
| checked 110 packages, using free DB (updated once a month) |
+============================+===========+==========================+==========+
| package | installed | affected | ID |
+============================+===========+==========================+==========+
| urllib3 | 1.26.4 | <1.26.5 | 43975 |
+==============================================================================+
| Urllib3 1.26.5 includes a fix for CVE-2021-33503: An issue was discovered in |
| urllib3 before 1.26.5. When provided with a URL containing many @ characters |
| in the authority component, the authority regular expression exhibits |
| catastrophic backtracking, causing a denial of service if a URL were passed |
| as a parameter or redirected to via an HTTP redirect. |
| https://github.com/advisories/GHSA-q2q7-5pp4-w6pg |
+==============================================================================+Der Bericht enthält die Anzahl der überprüften Pakete, die Art der als Referenz verwendeten Datenbank und Informationen über jede gefundene Schwachstelle. In diesem Beispiel ist eine ältere Version des Pakets urllib3 von einer Schwachstelle betroffen, die technisch gesehen von einem Angreifer für einen Denial-of-Service-Angriff genutzt werden könnte.
Integration in den Workflow
Sowohl bandit als auch safety sind als GitHub Actions verfügbar. Die stabile Version von safety bietet auch Integrationen für TravisCI und GitLab CI/CD.
Natürlich kannst Du beide Pakete immer manuell von PyPI auf Deinem Runner installieren, wenn keine fertige Integration wie eine GitHub Actions verfügbar ist. Da beide Programme von der Kommandozeile aus verwendet werden können, kannst Du sie auch lokal in einen Pre-Commit-Hook integrieren, wenn die Verwendung auf Deiner CI/CD-Plattform nicht in Frage kommt.
Die CI/CD-Pipeline für die obige Anwendung wurde mit GitHub Actions erstellt. Nach der Installation der erforderlichen Pakete der Anwendung wird zuerst bandit und dann safety ausgeführt, um alle Pakete zu scannen. Wenn alle Pakete aktualisiert sind, werden die Schwachstellen-Scans bestanden und das Docker-Image wird erstellt.
| Package check | Code Check |
|---|---|
 |
 |
Fazit
Ich würde dringend empfehlen, sowohl bandit als auch safety in Deiner CI/CD-Pipeline zu verwenden, da sie Sicherheitsüberprüfungen für Deinen Code und Deine Abhängigkeiten bieten. Bei modernen Anwendungen ist die manuelle Überprüfung jedes einzelnen Pakets, von dem Deine Anwendung abhängt, einfach nicht machbar, ganz zu schweigen von all den Abhängigkeiten, die diese Pakete haben! Daher ist automatisiertes Scannen unumgänglich, wenn Du ein gewisses Maß an Bewusstsein darüber haben willst, wie unsicher Dein Code ist.
Während bandit Deinen Code auf bekannte Exploits untersucht, prüft es keine der in Deinem Projekt verwendeten Bibliotheken. Hierfür benötigen Sie safety, da es die bekannten Sicherheitslücken in den Bibliotheken, von denen die Anwendung abhängt, aufzeigt. Zwar sind beide Frameworks nicht völlig idiotensicher, aber es ist immer noch besser, über einige CVEs informiert zu werden als über gar keine. Auf diese Weise kannst Du entweder Deinen anfälligen Code korrigieren oder eine anfällige Paketabhängigkeit auf eine sicherere Version aktualisieren.
Wenn Du Deinen Code sicher und Deine Abhängigkeiten vertrauenswürdig hältst, kannst Du potenziell verheerende Angriffe auf Deine Anwendung abwehren.
Bei all dem Hype um KI in den letzten Jahren darf man nicht außer Acht lassen, dass ein Großteil der Unternehmen bei der erfolgreichen Implementierung von KI-basierten Anwendungen noch hinterherhinken. Dies ist gerade in vielen Industrien, wie z.B. in produzierenden Gewerben, recht offensichtlich (McKinsey).
Eine von Accenture 2019 durchgeführte Studie zum Thema Implementierung von KI in Unternehmungen zeigt, dass über 80% aller Proof of Concepts (PoCs) es nicht in Produktion schaffen. Außerdem gaben nur 5% aller befragten Unternehmen an, eine unternehmensweite KI-Strategie implementiert zu haben.
Diese Erkenntnisse regen zum Nachdenken an: Was genau läuft schief und warum schafft künstliche Intelligenz anscheinend noch nicht die ganzheitliche Transition von erfolgreichen, akademischen Studien zu der realen Welt?
1. Was ist data-centric AI?
„Data-centric AI is the discipline of systematically engineering the data used to build an AI system.“
Zitat von Andrew Ng, data-centric AI Pionier
Der data-centric Ansatz fokussiert sich auf eine stärkere Daten-integrierenden KI (data-first) und weniger auf eine Konzentration auf Modelle (model-first), um die Schwierigkeiten von KI mit der „Realität“ zu bewältigen. Denn, die Trainingsdaten, die meist bei Unternehmen als Ausgangspunkt eines KI-Projekts stehen, haben relativ wenig gemeinsam mit den akribisch kurierten und weit verbreiteten Benchmark Datensets wie MNIST oder ImageNet.
Das Ziel dieses Artikels ist, data-centric im KI-Workflow und Projektkontext einzuordnen, Theorien sowie relevante Frameworks vorzustellen und aufzuzeigen, wie wir bei statworx eine data-first KI-Implementierung angehen.
2. Welche Gedankengänge stecken hinter data-centric?
Vereinfacht dargestellt bestehen KI-Systeme aus zwei entscheidenden Komponenten: Daten und Modell(-Code). Data-centric fokussiert sich mehr auf die Daten, model-centric auf das Modell – duh!
Bei einer stark model-centric lastigen KI werden Daten als ein extrinsischer, statischer Parameter behandelt. Der iterative Prozess eines Data Science Projekts startet praktisch erst nach dem Erhalt der Daten bei den Modell-spezifischen Schritten, wie Feature Engineering, aber vor allem exzessives Trainieren und Fine tunen verschiedener Modellarchitekturen. Dies macht meist das Gros der Zeit aus, das Data Scientists an einem Projekt aufwenden. Kleinere Daten-Aufbereitungsschritte werden meist nur einmalig, ad-hoc am Anfang eines Projekts angegangen.
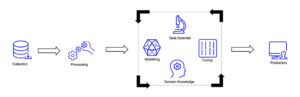
Im Gegensatz dazu versucht data-centric (automatisierte) Datenprozesse als zentralen Teil jedes ML Projekts zu etablieren. Hierunter fallen alle Schritte die ausgehend von den Rohdaten nötig sind, um ein fertiges Trainingsset zu generieren. Durch diese Internalisierung soll eine methodische Überwachbarkeit für verbesserte Qualität sorgen.
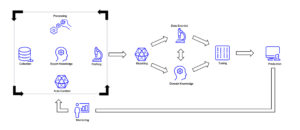
Man kann dabei data-centric Überlegungen in drei übergeordnete Kategorien zusammenfassen. Diese beschreiben lose, welche Aufgabenbereiche bei einem data-centric Ansatz bedacht werden sollten. Im Folgenden wurde versucht, diese bekannte Buzzwords, die im Kontext von data-centric immer wieder auftauchen, thematisch einer Kategorie zuzuordnen.
2.1. Integration von SMEs in den Development Prozess als wichtiges Bindeglied zwischen Data- und Model-Knowledge.
Die Einbindung von Domain Knowledge ist ein integraler Bestandteil von data-centric. Dies hilft Projektteams besser zusammenwachsen zu lassen und so das Wissen der Expert:innen, auch Subject Matter Experts (SMEs) genannt, bestmöglich im KI-Prozess zu integrieren.
- Data Profiling:
Data Scientists sollten nicht als Alleinkämpfer:innen die Daten analysieren und nur ihre Befunde mit den SMEs teilen. Data Scientists können ihre statistischen und programmatischen Fähigkeiten gezielt einsetzen, um SMEs zu befähigen, die Daten eigenständig zu untersuchen und auszuwerten. - Human-in-the-loop Daten & Model Monitoring:
Ähnlich wie beim Profiling soll hierbei durch das Bereitstellen eines Einstiegpunktes gewährleistet werden, das SMEs Zugang zu den relevanten Komponenten des KI-Systems erhalten. Von diesem zentralen Checkpoint können nicht nur Daten sondern auch Modell-relevante Metriken überwacht werden oder Beispiele visualisiert und gecheckt werden. Gleichzeit gewährt ein umfängliches Monitoring die Möglichkeit, nicht nur Fehler zu erkennen, sondern auch die Ursachen zu untersuchen und das möglichst ohne notwendige Programmierkenntnisse.
2.2. Datenqualitätsmanagement als agiler, automatisierter und iterativer Prozess über (Trainings-)Daten
Die Datenaufbereitung wird als Prozess verstanden, dessen kontinuierliche Verbesserung im Vordergrund eines Data Science Projekts stehen sollte. Das Modell, anders als bisher, sollte hingegen erstmal als (relativ) fixer Parameter behandelt werden.
- Data Catalogue, Lineage & Validation:
Die Dokumentation der Daten sollte ebenfalls keine extrinsische Aufgabe sein, die oft nur gegen Ende eines Projekts ad-hoc entsteht und bei jeder Änderung, z.B. eines Modellfeatures, wieder obsolet sein könnte. Änderungen sollen dynamisch reflektiert werden und so die Dokumentation automatisieren. Data Catalogue Frameworks bieten hier die Möglichkeit, Datensätze mit Meta-Informationen anzureichern.
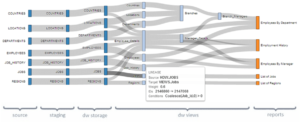
Data Lineage soll im Weiteren dabei unterstützen, bei diversen Inputdaten, verschiedenen Transformations- und Konsolidierungsschritten zwischen roh- und finalem Datenlayer den Überblick zu behalten. Je komplexer ein Datenmodell, desto eher kann ein Lineage Graph Auskunft über das Entstehen der finalen Spalten geben (Grafik unten), beispielsweise ob und wie Filterungen oder bestimmte join Logiken benutzt wurden. Die Validierung (neuer) Daten hilft schließlich eine konsistente Datengrundlage zu gewährleisten. Hier helfen die Kenntnisse aus dem Data Profiling um Validierungsregeln auszuarbeiten und im Prozess zu integrieren.
- Data & Label Cleaning:
Die Notwendigkeit der Datenaufbereitung ist selbsterklärend und als Best Practice ein fester Bestandteil in jedem KI-Projekt. Eine Label-Aufbereitung ist zwar nur bei Klassifikations-Algorithmen relevant, wird aber hier selten als wichtiger pre-processing Schritt mitbedacht. Aufbereitungen können aber mit Hilfe von Machine Learning automatisiert werden. Falsche Labels können es nämlich für Modelle erschweren, exakte patterns zu erlernen.
Auch sollte man sich bewusst machen, dass solange sich die Trainingsdaten ändern, die Datenaufbereitung kein vollkommen abgeschlossener Prozess sein kann. Neue Daten bedeuten oft auch neue Cleaning-Schritte. - Data Drifts in Produktion:
Eine weit verbreitete Schwachstelle von KI-Applikationen tritt meist dann auf, wenn sich Daten nicht so präsentieren, wie es beim Trainieren der Fall war, beispielweise im Zeitverlauf ändern (Data Drifts). Um die Güte von ML Modellen auch langfristig zu gewährleisten, müssen Daten in Produktion kontinuierlich überwacht werden. Hierdurch können Data Drifts frühzeitig ausfindig gemacht werden, um dann Modelle neu auszurichten, wenn z.B. bestimmte Inputvariablen von ihrer ursprünglichen Verteilung zu stark abweichen. - Data Versioning:
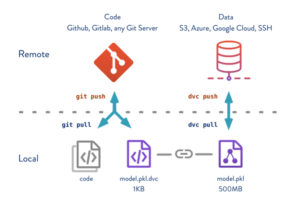
GitHub ist seit Jahren der go to Standard für Code Versionierungen, um mehr Übersicht und Kontrolle zwischen Codeständen zu haben. Aber auch Daten können versioniert werden und so eine ganzheitliche Prozesskontrolle bieten. Ebenfalls können so Code- mit Datenständen verknüpft werden. Dies sorgt nicht nur für bessere Überwachbarkeit, sondern hilft auch dabei, automatisierte Prozesse anzustoßen.
2.3. Generieren von Trainingsdatensätzen als programmatischer Task.
Gerade das Erzeugen von (gelabelten) Trainingsdaten ist einer der größten Roadblocker für viele KI-Projekte. Gerade bei komplexen Problemen, die große Datensätze benötigen, ist der initiale, manuelle Aufwand enorm.
- Data Augmentation:
Bei vielen datenintensiven Deep Learning Modellen wird diese Technik schon seit längerem eingesetzt, um mit bestehenden Daten, artifizielle Daten zu erzeugen. Bei Bilddaten ist dies recht anschaulich erklärbar. Hier werden beispielsweise durch Drehen eines Bildes verschiedene Perspektiven desselben Objektes erzeugt. Aber auch bei NLP und bei „tabularen“ Daten (Excel und Co.) gibt es Möglichkeiten neue Datenpunkte zu erzeugen.
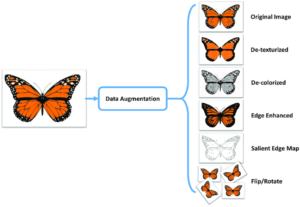
- Automated Data Labeling:
Normalerweise ist Labeling ein sehr arbeitsintensiver Schritt, in dem Menschen Datenpunkte einer vordefinierten Kategorie zuordnen. Einerseits ist dadurch der initiale Aufwand (Kosten) sehr hoch, andererseits fehleranfällig und schwierig zu überwachen. Hier kann ML durch Konzepte wie semi- oder weak supervison Automatisierungshilfe leisten, was den manuellen Aufwand erheblich reduziert. - Data Selection:
Arbeiten mit großen Datensätzen sind im lokalen Trainingskontext schwierig zu handhaben. Gerade dann, wenn diese nicht mehr in den Arbeitsspeicher des Laptops passen. Und selbst wenn, dann dauern Trainingsläufe meist sehr lange. Data Selection versucht die Größe durch ein aktives Subsampling (ob gelabelt oder ungelabelt) zu reduzieren. Aktiv werden hier die „besten“ Beispiele mit der höchsten Vielfalt und Repräsentativität ausgewählt, um die bestmögliche Charakterisierung des Inputs zu gewährleisten – und das automatisiert.
Selbstverständlich ist es nicht in jedem KI-Projekt sinnvoll, alle aufgeführten Frameworks zu bedenken. Es ist Aufgabe eines jedes Development Teams, die nötigen Tools und Schritte im data-centric Kontext zu analysieren und auf Relevanz und Übertragbarkeit zu prüfen. Hier spielen neben datenseitigen Überlegungen auch Business Faktoren eine Hauptrolle, da neue Tools meist auch mehr Projektkomplexität bedeuten.
3. Integration von data-centric bei statworx
Data-centric Überlegungen spielen bei unseren Projekten gerade in der Übergangsphase zwischen PoC und Produktivstellen des Modells vermehrt eine führende Rolle. Denn auch in einigen unserer Projekte ist es schon vorgekommen, dass man nach erfolgreichem PoC mit verschiedenen datenspezifischen Problemen zu kämpfen hatte; meist hervorgerufen durch unzureichende Dokumentation und Validierung der Inputdaten oder ungenügende Integration von SMEs im Datenprozess und Profiling.
Generell versuchen wir daher unseren Kunden die Wichtigkeit des Datenmanagements für die Langlebigkeit und Robustheit von KI-Produkten in Produktion aufzuzeigen und wie hilfreiche Komponenten innerhalb einer KI-Pipeline verknüpft sind.
Gerade unser Data Onboarding – ein Mix aus Profiling, Catalogue, Lineage und Validation, integriert in ein Orchestrations-Framework – ermöglicht uns mit den oben genannten Problemen besser umzugehen und so hochwertigere KI-Produkte bei unseren Kunden zu integrieren.
Zusätzlich hilft dieses Framework dem ganzen Unternehmen, bisher ungenutzte, undokumentierte Datenquellen für verschiedene Use Cases (nicht nur KI) verfügbar zu machen. Dabei ist die enge Zusammenarbeit mit den SMEs auf Kundenseite essenziell, um so effektive und robuste Datenqualitäts-Checks zu implementieren. Die resultierenden Datentöpfe und -prozesse sind somit gut verstanden, sodass Validierungs-Errors vom Kunden verstanden und behoben werden können, was so zu einem langlebigen Einsatz des Service beiträgt.
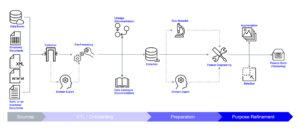
In einer abgespeckten, kundenspezifischen Data Onboarding Integration haben wir mit Hilfe verschiedener Open und Closed Source Tools eine für den Kunden einfach skalierbare und leicht verständliche Plattform geschaffen.
So haben wir beispielsweise Validationchecks mit Great Expectations (GE), einem Open Source Framework, umgesetzt. Dieses Tool bietet neben Python-basierter Integration diverser Tests auch eine Reporting Oberfläche, die nach jedem Durchlauf einen einfach verständlichen Einstiegspunkt in die Resultate bietet.
Diese Architektur kann dann in verschiedenen Kontexten laufen, ob in der Cloud, mit einem Closed Source Software wie Azure Data Factory oder on premises mit Open Source Tools wie Airflow – und kann um weitere Tools jederzeit ergänzt werden.
4. Data-centric im Status Quo von KI
Sowohl model- als auch data-centric beschreiben Handlungsansätze, wie man an ein KI-Projekt herangehen kann.
Model-centric ist in den letzten Jahren recht erwachsen geworden und es haben sich dadurch einige Best Practices in verschiedenen Bereichen entwickelt, auf denen viele Frameworks aufbauen.
Dies hat auch damit zu tun, dass in der akademischen Welt der Fokus sehr stark auf Modellarchitekturen und deren Weiterentwicklung lag (und noch liegt) und diese stark mit führenden KI-Unternehmen korreliert. Gerade im Bereich Computer Vision und Natural Langue Processing konnten kommerzialisierte Meta-Modelle, trainiert auf gigantischen Datensets, die Tür zu erfolgreichen KI Use Cases öffnen. Diese riesigen Modelle können auf kleineren Datenmengen für Endanwendungen gefinetuned werden, bekannt unter Transfer Learning.
Diese Entwicklung hilft allerdings nur einem Teil der gescheiterten Projekte, da gerade im Kontext von industriellen Projekten fehlende Kompatibilität oder Starrheit der Use Cases die Anwendungen von Meta-Modellen erschwert. Die Nicht-Starrheit findet sich häufig in maschinenlastigen Produktionsindustrien, wo sich das Umfeld, in dem Daten produziert werden, stetig ändert und sogar der Austausch einer einzelnen Maschine große Auswirkungen auf ein produktives KI-Modell haben kann. Wenn diese Problematik nicht richtig im KI-Prozess bedacht wurde, entsteht hier ein schwer kalkulierbares Risiko, auch bekannt unter Technical Debt [Quelle: https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf].
Zu guter Letzt stellen die Distributionen bei einigen Use Cases ein inhärentes Problem für ML dar. Modelle haben grundsätzlich Schwierigkeiten mit edge cases, sehr seltene und ungewöhnliche Beobachtungspunkte (die long tails [Quelle: https://medium.com/codex/machine-learning-the-long-tail-paradox-1cc647d4ba4b] einer Verteilung). Beispielweise ist es nicht ungewöhnlich, dass bei Fault Detection das Verhältnis von fehlerhaften zu einwandfreien Bauteilen eins zu mehreren Tausend beträgt. Die Abstraktionsfähigkeit bei ungesehenen, abseits der Norm liegenden Fehlern ist hier meist schlecht.
5. Schluss – Paradigmenwechsel in Sicht?
Diese Probleme zu bewältigen, ist zwar Teil des Versprechens von data-centric, aber präsentiert sich im Moment noch eher unausgereift.
Das lässt sich auch an der Verfügbarkeit und Maturität von Open Source Frameworks darlegen. Zwar gibt es schon vereinzelte, produktionsfertige Anwendungen, aber keine, die die verschiedenen Teilbereiche von data-centric zu vereinheitlichen versucht. Dies führt unweigerlich zu längeren, aufwendigeren und komplexeren KI-Projekten, was für viele Unternehmen eine erhebliche Hürde darstellt. Außerdem sind kaum Datenmetriken vorhanden, die Unternehmen ein Feedback geben, was sie denn genau gerade „verbessern“. Und zweitens, viele der Tools (bsp. Data Catalogue) haben einen eher indirekten, verteilten Nutzen.
Einige Start-ups, die diese Probleme angehen wollen, sind in den letzten Jahren entstanden. Dadurch, dass diese aber (ausschließlich) paid tier Software vermarkten, ist es eher undurchsichtig, inwiefern diese Produkte wirklich die breite Masse an Problemen von verschiedenen Use Cases abdecken können.
Obwohl die Aufführungen oben zeigen, dass Unternehmen generell noch weit entfernt sind von einer ganzheitlichen Integration von data-centric, wurden robuste Daten Strategien in der letzten Zeit immer wichtiger (wie wir bei statworx an unseren Projekten sehen konnten).
Mit vermehrtem akademischem Research in Daten Produkte wird sich dieser Trend sicherlich noch verstärken. Nicht nur weil dadurch neue, robustere Frameworks entstehen, sondern auch weil durch Uni-Absolvent:innen den Unternehmen mehr Wissen in diesem Gebiet zufließt.
Bild-Quellen:
Model-centric arch: eigene
Data-centric arch: eigene
Data lineage: https://www.researchgate.net/figure/Data-lineage-visualization-example-in-DW-environment-using-Sankey-diagram_fig7_329364764
Historisierung Code/Data: https://ardigen.com/7155/
Data Augmentation: https://medium.com/secure-and-private-ai-writing-challenge/data-augmentation-increases-accuracy-of-your-model-but-how-aa1913468722
Data & AI pipeline: eigene
Validieren mit GE: https://greatexpectations.io/blog/ge-data-warehouse/
Das erwartet dich:
Das Ziel der Messe ist es, Studierende der Studiengänge Wirtschaftsinformatik, Wirtschaftsmathematik und Data Science mit Unternehmen zu vernetzen.
Wir sind daher mit einem eigenen Stand vertreten und stellen statworx zudem im Rahmen einer kurzen Präsentation vor.
Bei gutem Wetter findet die Messe in diesem Jahr draußen statt. Die Teilnahme an der Messe ist kostenfrei. Eine Vorab-Anmeldung ist nicht notwendig. Komm einfach vorbei und sprich uns an.
Das erwartet dich:
Die Enter_Zukunft_IT ist eine Karrieremesse des Career Centers und des Fachbereichs Informatik & Mathematik der Goethe-Universität Frankfurt.
Wir sind mit einem eigenen Stand und gleich mehreren Kolleg:innen vertreten und freuen uns schon auf den Austausch mit interessierten Studierenden. Gerne stellen wir die verschiedenen Einstiegsmöglichkeiten bei statworx – vom Praktikum bis zur Festanstellung – vor und berichten aus unserem Arbeitsalltag
Die Teilnahme an der Messe ist für Besucher:innen kostenfrei.
Das erwartet dich:
Die konaktiva an der Technischen Universität Darmstadt ist eine der ältesten und größten studentisch organisierten Unternehmenskontaktmessen Deutschlands. Getreu dem Motto „Studierende treffen Unternehmen“ bringt sie jedes Jahr angehende Absolvent:innen und Unternehmen zusammen.
Auch wir sind dieses Jahr mit einem eigenen Stand und gleich mehreren Kolleg:innen vertreten und wir freuen uns schon auf den Austausch mit interessierten Studierenden. Gerne stellen wir die verschiedenen Einstiegsmöglichkeiten bei statworx – vom Praktikum bis zur Festanstellung – vor und berichten aus unserem Arbeitsalltag.
Darüber hinaus besteht die Möglichkeit uns im Rahmen von vorterminierten Einzelgesprächen abseits des Messetrubels näher kennen zu lernen und individuelle Fragen zu klären.
Die Teilnahme an der Messe ist für Besucher:innen kostenfrei.
Im Bereich Data Science – wie der Name schon sagt – ist das Thema Daten, vom Data Cleaning bis hin zum Feature Engineering, einer der Grundpfeiler. Daten zu haben und auszuwerten ist die eine Seite, doch wie kommt man eigentlich an Daten für neue Problemstellungen?
Wenn man Glück hat, werden die Daten, die man benötigt, bereits zur Verfügung gestellt. Sei es über den Download eines ganzen Datensatzes oder die Verwendung einer API. Häufig muss man allerdings auch Informationen von Webseiten selbst zusammentragen – das nennt man Web Scraping. Je nachdem wie oft man Daten scrapen will, ist es von Vorteil, diesen Schritt zu automatisieren.
In diesem Beitrag soll es genau um diese Automatisierung gehen. Ich werde mittels Web Scraping und GitHub Actions an einem Beispiel aufzeigen, wie man sich selbst Datensätze über einen längeren Zeitraum erstellen kann. Dabei soll der Fokus auf den Erfahrungen liegen, die ich in den letzten Monaten gesammelt habe.
Der verwendete Code sowie die bisher gesammelten Daten befinden sich in diesem GitHub Repo.
Suche nach Daten – Ausgangslage
Bei meiner Recherche für den Blogbeitrag über die Benzinpreise, bin ich auch über Daten zur Auslastung der Parkhäuser in Frankfurt am Main gestoßen. Die Beschaffung dieser Daten legte den Grundstein für diesen Beitrag. Nach einigen Überlegungen und zusätzlicher Recherche kamen mir noch weitere thematisch passende Datenquellen in den Sinn:
- Auslastung der Straßen
- Verspätungen der S- und U-Bahnen
- Events in der Nähe
- Wetterdaten
Schnell stellte sich jedoch heraus, dass ich nicht alle diese Daten bekommen konnte, da sie nicht frei verfügbar sind bzw. es nicht gestattet ist, diese zu speichern. Da ich vorhatte, die gesammelten Daten auf GitHub zu speichern und verfügbar zu machen, war dies ein entscheidender Punkt, welche Daten in Frage kamen. Aus diesen Gründen fielen die Bahndaten vollkommen raus. Für die Straßenauslastung habe ich lediglich Daten für Köln gefunden und ich wollte es vermeiden, die Google API zu nutzen, da das durchaus seine eigenen Herausforderungen mit sich bringt. Es blieben also Event- und Wetterdaten.
Für die Wetterdaten des Deutschen Wetterdienstes kann das rdwd Packet genutzt werden. Da diese Daten bereits historisiert vorliegen, sind sie für diesen Blogbeitrag nebensächlich. Um an die verbleibenden Event- und Parkdaten zu kommen, haben sich die GitHub Actions als sehr nützlich erwiesen – auch wenn sie nicht ganz trivial in der Anwendung sind. Besonders der Umstand, dass diese kostenfrei genutzt werden können, machen sie zu einem empfehlenswerten Tool für solche Projekte.
Scrapen der Daten
Da sich dieser Beitrag nicht mit Details zum Thema Webscraping befassen wird, verweise ich an dieser Stelle auf den Beitrag von meinem Kollegen David.
Die Parkdaten stehen hier im XML-Format bereit und werden alle fünf Minuten aktualisiert. Sobald man die Struktur des XML verstanden hat, müsst ihr nur noch auf den richtigen Index zugreifen und ihr habt die Daten, die ihr möchtet.
In der Funktion get_parking_data() habe ich alles zusammengefasst, was ich benötige. Es wird ein Datensatz zur Area und ein Datensatz zu den einzelnen Parkhäusern erstellt.
Beispiel Datenauszug area
parkingAreaOccupancy;parkingAreaStatusTime;parkingAreaTotalNumberOfVacantParkingSpaces;
totalParkingCapacityLongTermOverride;totalParkingCapacityShortTermOverride;id;TIME
0.08401977;2021-12-01T01:07:00Z;556;150;607;1[Anlagenring];2021-12-01T01:07:02.720Z
0.31417114;2021-12-01T01:07:00Z;513;0;748;4[Bahnhofsviertel];2021-12-01T01:07:02.720Z
0.351417;2021-12-01T01:07:00Z;801;0;1235;5[Dom / Römer];2021-12-01T01:07:02.720Z
0.21266666;2021-12-01T01:07:00Z;1181;70;1500;2[Zeil];2021-12-01T01:07:02.720Z
Beispiel Datenauszug facility
parkingFacilityOccupancy;parkingFacilityStatus;parkingFacilityStatusTime;
totalNumberOfOccupiedParkingSpaces;totalNumberOfVacantParkingSpaces;
totalParkingCapacityLongTermOverride;totalParkingCapacityOverride;
totalParkingCapacityShortTermOverride;id;TIME
0.02;open;2021-12-01T01:02:00Z;4;196;150;350;200;24276[Turmcenter];2021-12-01T01:07:02.720Z
0.11547912;open;2021-12-01T01:02:00Z;47;360;0;407;407;18944[Alte Oper];2021-12-01T01:07:02.720Z
0.0027472528;open;2021-12-01T01:02:00Z;1;363;0;364;364;24281[Hauptbahnhof Süd];2021-12-01T01:07:02.720Z
0.609375;open;2021-12-01T01:02:00Z;234;150;0;384;384;105479[Baseler Platz];2021-12-01T01:07:02.720Z
Für die Eventdaten scrape ich die Seite stadtleben.de. Da es sich um eine HTML handelt, die recht gut strukturiert ist, kann ich über den Tag „kalenderListe“ auf die tabellarische Eventübersicht zugreifen. Das Resultat wird durch die Funktion get_event_data() erstellt.
Beispiel Datenauszug events
eventtitle;views;place;address;eventday;eventdate;request
Magical Sing Along - Das lustigste Mitsing-Event;12576;Bürgerhaus;64546 Mörfelden-Walldorf, Westendstraße 60;Freitag;2022-03-04;2022-03-04T02:24:14.234833Z
Velvet-Bar-Night;1460;Velvet Club;60311 Frankfurt, Weißfrauenstraße 12-16;Freitag;2022-03-04;2022-03-04T02:24:14.234833Z
Basta A-cappella-Band;465;Zeltpalast am Deutsche Bank Park;60528 Frankfurt am Main, Mörfelder Landstraße 362;Freitag;2022-03-04;2022-03-04T02:24:14.234833Z
BeThrifty Vintage Kilo Sale | Frankfurt | 04. & 05. …;1302;Batschkapp;60388 Frankfurt am Main, Gwinnerstraße 5;Freitag;2022-03-04;2022-03-04T02:24:14.234833Z
Automation der Abläufe – GitHub Actions
Das Grundgerüst steht. Ich habe je eine Funktion, die mir die Park- und Eventdaten beim Ausführen in eine .csv Datei schreiben. Da ich die Parkdaten alle fünf Minuten und die Eventdaten zur Sicherheit drei Mal am Tag abfragen möchte, kommen nun GitHub Actions ins Spiel.
Mit dieser Funktion von GitHub können neben Aktionen, die beim Mergen oder Committen auslösen, auch Workflows zeitlich geplant und durchgeführt werden. Hierfür wird eine .yml Datei im Order /.github/workflows erstellt.
Die Hauptbestandteile meines Workflows sind:
- Der
schedule– Alle zehn Minuten sollen die Funktionen ausgeführt werden. - Das OS – Da ich lokal auf einem Mac entwickle, nutze ich hier das
macOS-latest. - Umgebungsvariablen – Hier ist neben meinem GitHub Token auch der Pfad für das Paketmanagement
renventhalten - Die einzelnen
stepsim Workflow selbst
Der Workflow durchläuft die folgenden Schritte:
- Setup R
- Pakete laden mit renv
- Script ausführen um Daten zu scrapen
- Script ausführen um die README zu aktualisieren
- Pushen der neuen Daten zurück ins git
Jeder dieser Schritte ist an sich sehr klein und übersichtlich, jedoch liegt der Teufel wie so oft im Detail.
Limitation und Herausforderungen
Im Laufe der letzten Monate habe ich meinen Workflow immer wieder angepasst und optimiert, um den aufkommenden Fehlern und Problemen Herr zu werden. Nachfolgend also der Überblick über meine kondensierten Erfahrungen mit GitHub Actions.
Schedule Probleme
Wer zeitkritische Aktionen durchführen möchte, sollte auf andere Services zugreifen. GitHub Actions garantieren einem nicht, dass die Jobs exakt getimed werden (oder teilweise überhaupt durchgeführt werden). In der Tabelle sind die Zeiten zwischen zwei erfolgreichen Abfragen angegeben.
| Zeitspanne in Minuten | <= 5 | <= 10 | <= 20 | <= 60 | > 60 |
| Anzahl Abfragen | 1720 | 2049 | 5509 | 3023 | 194 |
Man sieht, dass die geplanten fünf Minuten Intervalle nicht immer eingehalten wurden. Hier sollte ich in Zukunft einen größeren Spielraum einplanen.
Merge Konflikte
Zu Beginn hatte ich zwei Workflows, einen für die Parkdaten und einen für die Events. Wenn diese sich zeitlich überlappt haben, dann kam es zu Merge-Konflikten, da beide Prozesse die README mit einen Zeitstempel updaten. Im Verlauf bin ich umgestiegen auf einen Workflow samt Errorhandling.
Auch wenn ein Durchlauf länger gedauert hat und der nächste bereits gestartet wurde, kam es beim Pushen zu Merge-Konflikten in den .csv-Daten. Lange Durchläufe entstanden häufig durch das R Setup und das Laden der packages. Als Konsequenz habe ich das Schedule-Intervall von fünf auf zehn Minuten erweitert.
Formatanpassungen
Es gab ein paar Situationen, in denen sich die Pfade oder Struktur der gescrapten Daten geändert haben, so dass ich meine Funktionen anpassen musste. Hierbei war die Einstellung, eine E-Mail zu bekommen, falls ein Prozess gescheitert ist, sehr hilfreich.
Fehlende Testmöglichkeiten
Es gibt bisher keine andere Möglichkeit ein Workflow-Script zu testen, als es wirklich laufen zu lassen. So kann man nach einem Tippfehler am Abend zu einer Mailflut mit gefailten Runs am Morgen aufwachen. Das sollte einen dennoch nicht davon abhalten einen lokalen Testlauf durchzuführen.
Kein Datenupdate
Seit Ende Dezember wurden die Parkdaten nicht mehr aktualisiert bzw. bereitgestellt. Das zeigt, dass selbst wenn man einen automatischen Prozess hat, man ihn dennoch weiter überwachen sollte. Ich habe dies erst später festgestellt, wodurch meine Abfragen Ende Dezember immer ins Leere liefen.
Fazit
Trotz der Komplikationen aus dem letzten Kapitel, empfinde ich das Ganze dennoch als einen massiven Erfolg. Während der letzten Monate habe ich mich immer wieder mit dem Thema befasst und die oben beschriebenen Tricks und Kniffe erlernt, die mir auch in Zukunft helfen werden, andere Probleme zu lösen. Ich hoffe, dass auch ihr ein paar wertvolle Hinweise mitnehmen und somit aus meinen Fehlern lernen könnt.
Da ich nun ein gutes halbes Jahr an Daten gesammelt haben, kann ich mich mit der Auswertung befassen. Das wird dann aber erst Gegenstand eines weiteren Blogbeitrages.
Management Summary
Mit Kubernetes steht uns eine Technologie zur Verfügung, welche in vielerlei Hinsicht die Bereitstellung und Wartung von Anwendungen und Rechenlasten, insbesondere das Training und Hosten von Machine Learning Modellen, enorm vereinfacht. Gleichzeitig ermöglicht sie uns, die benötigten Hardware-Ressourcen dazu an den Bedarf anzupassen, und bietet damit eine skalierbare und kostentransparente Lösung.
Dieser Artikel behandelt zuerst den Weg vom Server hin zu dem Management und der Orchestrierung von Containern: isolierte Anwendungen oder Modelle, welche mit all ihren Anforderungen einmal verpackt werden und im Anschluss fast überall ausgeführt werden können. Unabhängig vom Server können diese mit Kubernetes beliebig repliziert werden und ermöglichen somit aufwandslos und schier nahtlos eine durchgehende Erreichbarkeit ihrer Dienste auch unter hoher Last. Ebenfalls kann ihre Anzahl bis auf einen Mindeststand reduziert werden, wenn die Nachfrage vorübergehend oder periodisch schwindet, um Rechenressourcen anderweitig zu nutzen oder unnötige Kosten zu vermeiden.
Aus den Möglichkeiten dieser Infrastruktur geht ein nützliches Architektur-Paradigma hervor, die Microservices. Ehemals zentralisierte Anwendungen werden so in ihre Funktionalitäten heruntergebrochen, welche ein hohes Maß an Wiederverwendbarkeit bieten. Diese können von unterschiedlichen Diensten angesprochen und verwendet werden und skalieren einzeln je nach internem Bedarf. Ein Beispiel hierfür sind große und komplexe Sprachmodelle im Natural Language Processing, welche den Kontext eines Textes unabhängig von dessen weiterer Verwendung erfassen können, und damit vielen downstream Zwecken zugrunde liegen. Andere Microservices (Modelle), wie zur Text-Klassifikation oder Zusammenfassung, können diese aufrufen und die Teilergebnisse weiterverarbeiten.
Nach einer kurzen Einführung der allgemeinen Begrifflichkeiten und Funktionsweise von Kubernetes, sowie mögliche Anwendungsfälle, richtet sich das Augenmerk auf die am weitesten verbreitete Form Kubernetes zu nutzen: mit Cloud Anbietern wie Google GCP, Amazon AWS oder Microsoft Azure. Diese erlauben sog. Kubernetes Clustern, dynamisch mehr oder weniger Ressourcen zu beanspruchen, wenn gleich die entstehenden Kosten auf pay-per-use Basis absehbar bleiben. Auch weitere gängige Dienste wie Datenspeicher, Versionierung und Networking können von den Anbietern einfach eingebunden werden. Letztlich gibt der Beitrag noch einen Ausblick über Tools und Weiterentwicklungen, welche entweder die Nutzung von Kubernetes noch effizienter machen oder das Verfahren hin zu Serverless Architekturen weiter abstrahieren und vereinfachen.
Einleitung
Über die letzten 20 Jahre sind Unmengen neuer Technologien in der Softwareentwicklung und -Bereitstellung zu Tage gekommen, welche nicht nur die Auswahl an Diensten, Programmiersprachen, Bibliotheken oder ähnliches vervielfacht und diversifiziert haben, sondern gar auch bei vielen Anwendungsfällen oder -Gebieten bis hin zu einem Paradigmenwechsel geführt haben.
Betrachtet man so auch die Art und Weise der Bereitstellung von Softwarelösungen, Modellen oder Rechen- und Arbeitslasten über die Jahre, lässt sich erkennen wie auch in diesem Bereich die Neuerungen u.a. zu mehr Flexibilität, Skalierbarkeit und Ressourceneffizienz geführt haben.
Zu Beginn wurden diese als lokale Prozesse direkt auf einem (von mehreren Anwendungen geteilten) Server betrieben, was einige Einschränkungen und Probleme aufwarf: zum einen ist man bei der Auswahl der technischen Werkzeuge an die Begebenheiten der Server und deren Betriebssystem gebunden, zum anderen sind alle Anwendungen, welche auf dem Server gehostet werden, durch dessen Speicher- und Prozessorkapazitäten begrenzt. Somit teilen sie sich nicht nur in Summe die Ressourcen, sondern auch eine eventuelle Prozess-übergreifende Fehleranfälligkeit.
Als erste Weiterentwicklung können Virtuelle Maschinen daraufhin eine weitere Abstraktionsebene bieten: durch das auf dem Server aufgesetzte Emulieren („Virtualisieren“) einer eigenständigen Maschine entsteht für die Entwicklung und das Deployment Modularität und damit größere Freiheit: zum Beispiel in der Wahl des Betriebssystems oder der verwendeten Programmiersprachen und -Bibliotheken. Aus Sicht des „echten“ Servers können die Ressourcen, welche der Anwendung zustehen sollen, besser beschränkt bzw. garantiert werden. Jedoch sind deren Anforderungen auch bedeutend höher, da die Virtuelle Maschine auch das virtuelle Betriebssystem unterhalten muss.
Letztendlich wurde dieses Prinzip durch die Verbreitung von Containern, vor allem Docker, wesentlich verschlankt und vereinfacht. Vereinfacht gesagt baut/konfiguriert man für eine Anwendung oder ein Machine Learning Modell einen eigenen virtuellen, abgegrenzten Server. So enthält jeder Container sein eigenes Dateisystem und gewisse Systembibliotheken, aber nicht das Betriebssystem. Damit wird er technisch zu einem Sandkasten, dessen andere Konfiguration, Code-Abhängigkeiten oder Fehler sich nicht auf den Host-Server auswirken, aber gleichzeitig als relativ „leichtgewichtige“ Prozesse direkt auf diesem laufen können.
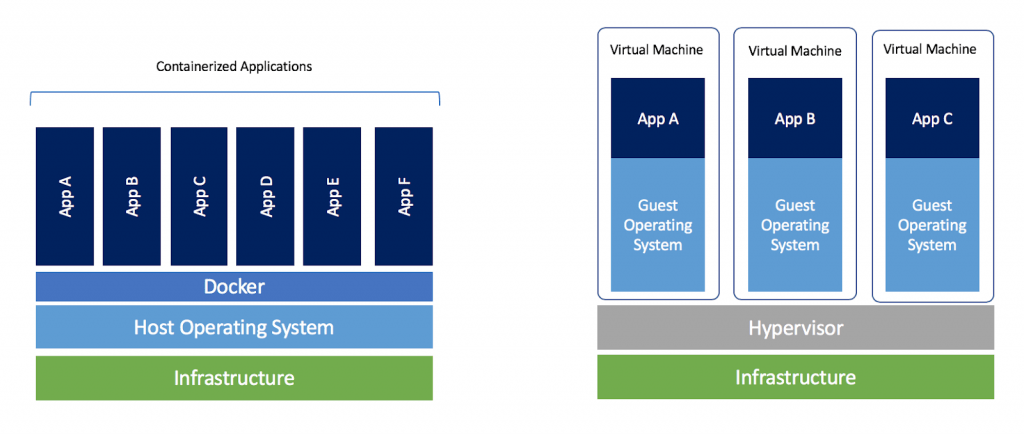
Es besteht also die Möglichkeit, alles für die gewünschte Anwendung zu kopieren, installieren, usw., und dies in einem verpackten Container überall in einem einheitlichen Format bereitzustellen. Dies ist nicht nur für das Produktionsumfeld extrem nützlich, sondern findet bei STATWORX auch gerne in der Entwicklung von komplizierteren Projekten oder der Proof-of-Concept Phase Gebrauch. Zwischenschritte oder -Ergebnisse, wie beispielsweise die Extraktion von Text aus Bildern, können als Container wie ein kleiner Webserver von denjenigen verwendet werden, die an der Weiterverarbeitung des Textes interessiert sind, etwa die Extraktion gewisser zentraler Informationen, oder die Bestimmung von dessen Stimmung oder Absicht.
Diese Unterteilung in sogenannte „Microservices“ mit Hilfe von Containern hilft ungemein bei der Wiederverwendbarkeit der einzelnen Module, bei der Planung und Entwicklung der Architektur komplexer Systeme; sie befreit gleichzeitig die einzelnen Arbeitsschritte von technischen Abhängigkeiten gegenübereinander und erleichtert die Wartungs- und Update-Prozeduren.
Nach diesem kleinen Überblick über die mächtigen und vielseitigen Möglichkeiten der Bereitstellung von Software wird sich der folgende Text damit beschäftigen, wie man diese Container (sprich Anwendungen oder Modelle) verlässlich und skalierbar für Kunden, andere Anwendungen, interne Dienste oder Berechnungen mit Kubernetes bereitstellen kann.
Kubernetes – 8 wesentliche Komponenten
Kubernetes wurde 2014 von Google als open-source Container-Management Software (auch Container-Orchestrierung genannt) vorgestellt. Intern benutzte man bereits seit Jahren eigens entwickelte Tools, um Arbeitslasten und Anwendungen zu verwalten, und sah in der Entwicklung von Kubernetes nicht nur das Zusammenkommen von best practises und lessons learned, sondern auch die Möglichkeit damit ein neues Geschäftsfeld im Cloud Computing zu erschließen.
Der Name Kubernetes (griechisch für Steuermann) wurde angeblich in Bezug auf ein symbolisches Containerschiff ausgewählt, für dessen optimalen Betrieb jener verantwortlich ist.
1. Nodes
Spricht man von einer Kubernetes-Instanz, wird sie als (Kubernetes) Cluster bezeichnet: dieses besteht aus mehreren Servern, genannt Nodes. Eine davon, die sogenannte Master-Node, ist komplett für den administrativen Betrieb zuständig, und ist die Schnittstelle, welche vom Entwickler angesprochen wird. Alle weiteren, genannt Worker-Nodes, sind zu Beginn unbelegt und damit flexibel einsetzbar. Während Nodes tatsächlich physische Instanzen sind, meist in Rechenzentren, sind die nun folgenden Begrifflichkeiten Konzepte von Kubernetes.
2. Pods
Soll eine Anwendung auf dem Cluster bereitgestellt werden, wird im einfachsten Fall der gewünschte Container angegeben, und daraufhin (automatisch) ein sogenannter Pod erstellt und einer Node zugewiesen. Der Pod ähnelt hier einfach einem laufenden Container. Sollen gleich mehrere Instanzen der gleichen Anwendung parallel laufen, etwa um bessere Verfügbarkeit zu bieten, kann die Anzahl der Replicas angegeben werden. Hierbei wird die spezifizierte Anzahl an Pods mit jeweils derselben Anwendung auf die Nodes verteilt. Sollte der Bedarf nach der Anwendung trotz Replicas die Kapazitäten übersteigen, können mit dem Horizontal Autoscaler automatisch noch mehr Pods erstellt werden. Besonders bei Deep Learning Modellen mit verhältnismäßig langer Inferenzzeit können hier Metriken wie CPU- oder GPU-Auslastung überwacht werden, und die Anzahl der Pods vergrößert oder verringert werden, um sowohl Kapazitäten als auch Kosten zu optimieren.
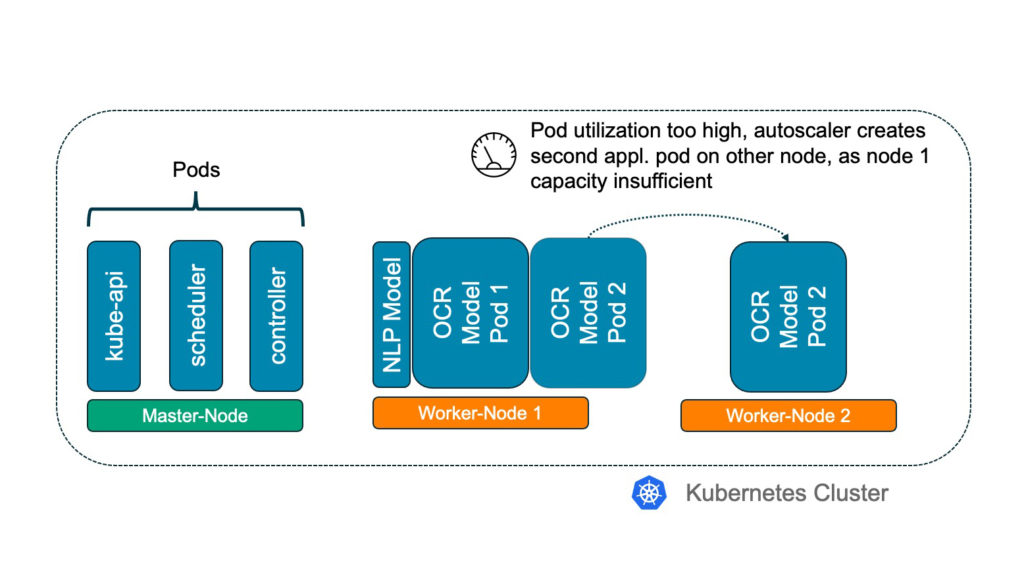
Um nicht zu verwirren: Letztlich ist jeder laufende Container, also jede Arbeitslast, ein Pod. Im Falle der Bereitstellung einer Anwendung geschieht das technisch über ein Deployment, zeitlich begrenzte Rechenlasten sind hingegen Jobs. Persistente Speicher wie Datenbanken werden mit StatefulSets verwaltet. Die folgende Abbildung gibt einen Überblick über die Begriffe:
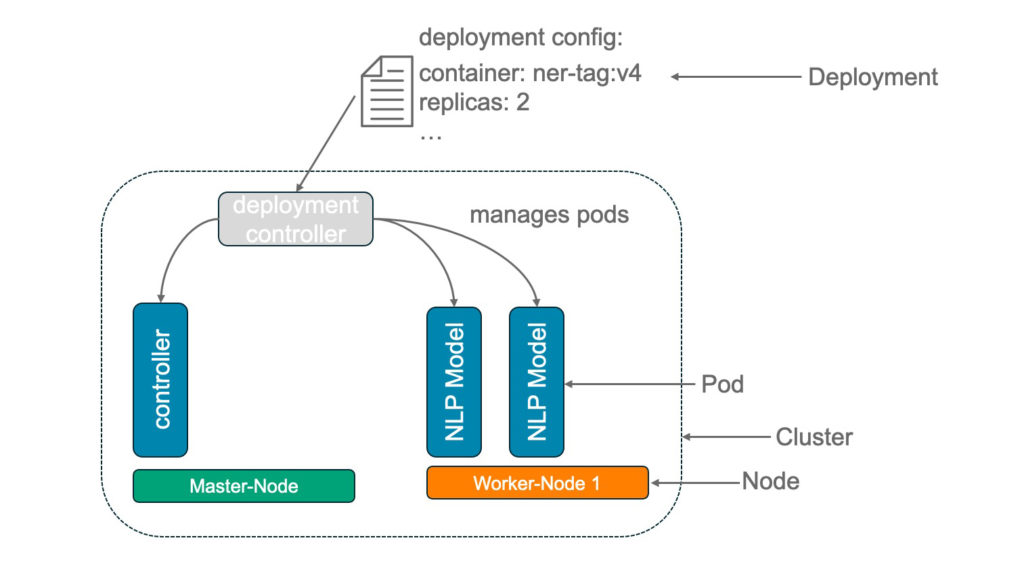
3. Jobs
Mit Kubernetes Jobs können sowohl einmalige als auch wiederkehrende Jobs (sog. CronJobs) in Form eines Container-Deployment auf dem Cluster ausgeführt werden.
Im einfachsten Fall können diese wie ein Skript gesehen werden, welches für Wartungs- oder Aufbereitungsarbeiten von beispielsweise Datenbanken genutzt werden kann. Des Weiteren verwendet man diese auch zum Batch-Processing, wenn zum Beispiel Deep Learning Modelle auf größere Datenmengen angewandt werden sollen und es sich aber nicht lohnt das Modell durchgehend auf dem Cluster zu halten. Der Modell-Container wird hier eigens hochgefahren, erhält Zugriff auf das gewünschte Dataset, führt seine Inferenz darüber aus, speichert die Ergebnisse und fährt sich herunter. Auch für die Herkunft und anschließende Speicherung der Daten ist man hier flexibel, so können eigene oder Cloud Datenbanken, Bucket/Objekt-Speicher oder auch lokale Daten und Logging-Frameworks angebunden werden.
Für wiederkehrende CronJobs kann ein einfaches Zeitschema spezifiziert werden, sodass beispielsweise nachts bestimmte Kundendaten, -transaktionen oder ähnliches verarbeitet werden. Mit Natural Language Processing können so zum Beispiel nachts automatisch Pressespiegel erstellt werden, welche am folgenden Morgen ausgewertet bereitstehen: Nachrichten zu einem Unternehmen, dessen Branche, Wirtschaftsstandorte, Kunden, usw. können aggregiert oder bezogen werden, mit NLP ausgewertet, zusammengefasst, und mit Stimmungsbildern präsentiert oder nach Themen/Inhalten geordnet werden.
Auch arbeitsintensive ETL (Extract Transform Load) Prozesse können so außerhalb der Geschäftszeiten durchgeführt oder vorbereitet werden.
4. Rolling Updates
Soll ein Deployment auf die neuste Version gebracht werden, oder muss ein Rollback auf eine ältere Version vollzogen werden, können in Kubernetes Rolling Updates angestoßen werden. Diese garantieren durchgehende Erreichbarkeit der Anwendungen und Modelle innerhalb einer Continuous Integration/Continuous Deployment Pipeline.
Ein solches Rollout kann reibungslos in einem oder wenigen Schritten angestoßen und überwacht werden. Durch eine Rollout-History besteht auch die Möglichkeit, nicht nur auf eine vorherige Containerversion zurückzuspringen, sondern auch die vorherigen Deployment-Parameter wiederhergestellt werden, sprich Mindest- und Höchstanzahl der Nodes, welche Ressourcengruppe (GPU Nodes, CPU Nodes mit wenig/viel RAM,…), Health-Checks usw.
Wird ein Rolling Update angestoßen, werden die jeweiligen bestehenden Pods so lange am Laufen und erreichbar gehalten, bis dieselbe Anzahl an neuen Pods hochgefahren und zugänglich sind. Hier gibt es sowohl Methoden, um zu garantieren, dass keine Requests verloren gehen, wie auch Parameter, die für den Wechsel eine Mindesterreichbarkeit oder einen maximalen Überschuss an Pods regeln.
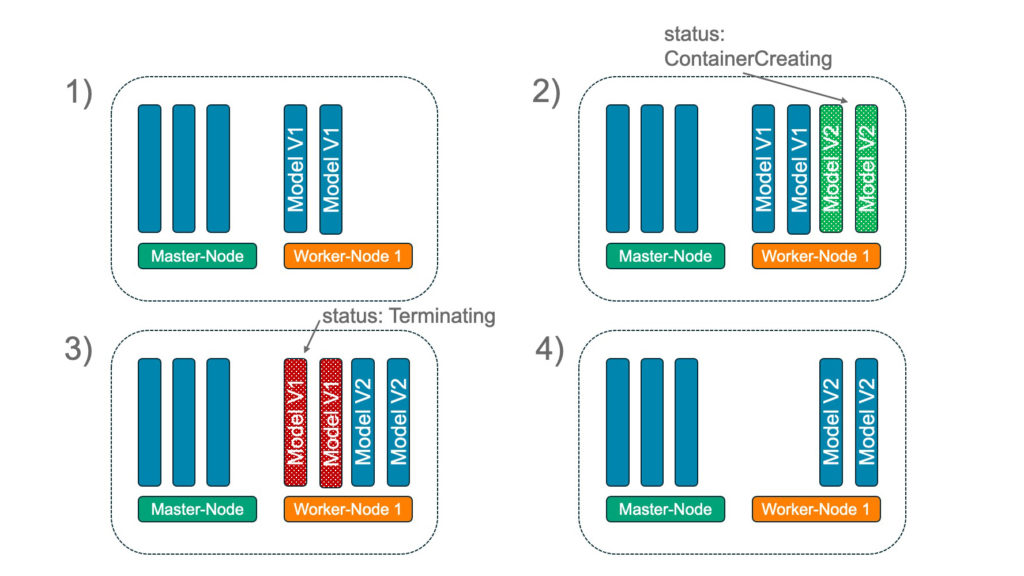
Die Abbildung 5 veranschaulicht das Rolling Update.
1) Die bisher aktuelle Version einer Anwendung liegt mit 2 Replicas auf dem Kubernetes Cluster und ist gewohnt ansprechbar.
2) Ein Rolling Update auf Version V2 wird gestartet, dieselbe Anzahl an Pods wie für V1 werden erstellt.
3) Sobald die neuen Pods den Zustand „Running“ haben und ggf. Health-Checks absolviert wurden, damit also funktional sind, werden die Container der älteren Version heruntergefahren.
4) Die älteren Pods sind entfernt und die Ressourcen wieder freigegeben.
Der DevOps- und Zeitaufwand ist hierbei marginal, intern ändern sich keine Hostnamen oder ähnliches, während der Dienst aus Sicht der Konsumierenden wie bisher in gewohnter Weise ansprechbar ist (gleiche IP, URL, …) und lediglich auf die neuste Version gebracht wurde.
5. Platform/Infrastructure as a Service
Natürlich lässt sich ein Kubernetes Cluster auch lokal auf eigener Hardware on-premises einrichten sowie auf teilweise vorgefertigten Lösungen wie DGX Workbenches.
Einige unserer Kunden haben strikte Richtlinien oder Auflagen bezüglich (Data-) Compliance oder Informationssicherheit, und möchten nicht, dass möglicherweise sensible Daten das Unternehmen verlassen. Weiterhin kann so vermieden werden, dass der Datenverkehr über nicht-europäische Knotenpunkte fließt oder generell in ausländischen Rechenzentren landet.
Erfahrungsgemäß ist dies aber nur in einem sehr geringen Anteil der Fall. Durch Verschlüsselung, Rechtemanagement und SLAs der Betreiber erachten wir die Verwendung von Cloud-Diensten und -Rechenzentren als allgemein sicher und verwenden diese auch für größere Projekte. Diesbezüglich sind auch Deployment, Wartung, CI/CD Pipelines dank Methoden der Containerization (Docker) und Abstraktion (Kubernetes) größtenteils identisch und einfach zu verwenden.
Alle großen Cloud-Betreiber wie Google (GCP), Amazon (AWS) und Microsoft (Azure), aber auch kleinere Anbieter und bald sogar spannende neue deutsche Projekte, bieten sehr ähnliche Kubernetes Dienste an. Dadurch wird es noch einfacher, ein Projekt oder Modell bereitzustellen und vor allem zu skalieren, da durch auto-scaling das Cluster je nach Ressourcenbedarf erweitert oder verkleinert werden kann. Dies entbindet uns aus technischer Sicht größtenteils davon die Nachfrage eines Dienstes abschätzen zu müssen, während die Rentabilität und Kostenstruktur gleichbleiben. Weiterhin können die Dienste auch in unterschiedlichen (geographischen) Zonen gehostet und betrieben werden, um schnellste Erreichbarkeit und Redundanz zu garantieren.
6. Node-Vielfalt
Die Cloud-Betreiber bieten eine große Anzahl unterschiedlicher Node-Typen an, um für alle Anwendungsfälle vom einfacheren Webservice bis hin zu High Performance Computing alle Ressourcenanforderungen zu befriedigen. Besonders im Anwendungsfeld Deep Learning lassen sich so die immer größer werdenden Modelle stets auf der benötigten neuesten Hardware trainieren und bereitstellen.
Während wir beispielsweise für kleinere NLP Zwecke Nodes mit einer durchschnittlichen CPU und geringem Arbeitsspeicher verwenden, lassen sich große Transformer-Modelle im gleichen Cluster auf GPU-Nodes deployen, was deren Verwendung effektiv erst ermöglicht und gleichzeitig die Inferenz (Anwendung des Modells) um Faktor 20 beschleunigen kann. Da neuerdings die Bedeutung dedizierter Hardware für Neuronale Netze stetig zunimmt, bietet Google auch Zugriff auf die eigens entwickelten, für Tensorflow optimierten TPUs an.
Die Organisation und Gruppierung all dieser unterschiedlichen Nodes erfolgt in Kubernetes in sog. Node Pools. Diese können im Deployment ausgewählt bzw. angegeben werden, sodass den Pods der Modelle die richtigen Ressourcen zugeteilt werden.
7. Cluster Autoscaling
Das Ausmaß der Nutzung von Modellen oder Diensten, intern oder durch Kunden, ist oftmals nicht absehbar oder schwankt zeitlich stark. Mit einem Cluster Autoscaler können automatisch neue Nodes erstellt werden, oder nicht benötigte „leerstehende“ Nodes entfernt werden. Auch hier kann ein Minimum an Nodes angegeben werden, welche immer bereitstehen sollen sowie, wenn gewünscht, auch eine maximale Anzahl, die nicht überschritten werden kann, um ggf. die Kosten zu deckeln.
8. Anbindung anderer Dienste
Prinzipiell können Cloud Dienste verschiedener Anbieter kombiniert werden, komfortabler und einfacher ist jedoch die Nutzung eines Anbieters (Beispiel Google GCP). Somit können Dienste wie Datenbuckets, Container-Registry, Lambda Funktionen Cloud-intern ohne große Authentifizierungsprozesse eingebunden und verwendet werden. Des Weiteren ist gerade in einer Microservice-Architektur die Netzwerkkommunikation unter den einzelnen Hosts (Anwendungen, Modelle) wichtig und innerhalb eines Anbieters erleichtert. Hier kann auch Zugangskontrolle/RBAC implementiert werden, sowie mehrere Cluster oder Projekte mit einem Virtuellen Netzwerk überbrückt werden, um die Zuständigkeits- und Kompetenzbereiche besser zu trennen.
Umfeld und zukünftige Entwicklungen
Die steigende Nutzung und Verbreitung von Kubernetes haben ein ganzes Umfeld an nützlichen Tools, wie auch Weiterentwicklungen und weitere Abstraktionen mit sich gebracht, welche dessen Verwendung weiter erleichtern.
Tools und Pipelines basierend auf Kubernetes
Mit Kubeflow lässt sich beispielsweise das Training von Machine Learning Modellen als TensorFlow Training Job anstoßen und fertige Modelle mit TensorFlow Serving bereitstellen.
Der ganze Prozess kann auch in eine Pipeline verpackt werden, welche dann mit Verweis auf Trainings-, Validation- und Testdaten in Speicherbuckets das Training verschiedener Modelle durchführt, überwacht, deren Metriken loggt und die Modell-Performance vergleicht. Der Workflow beinhaltet auch die Aufbereitung der Inputdaten, sodass nach erstmaligem Aufbau der Pipeline einfach Experimente zur Exploration von Modellarchitekturen und Hyperparameter-Tuning angestellt werden können
Serverless
Durch Serverless Deployment Verfahren wie Cloud Run oder Amazon Fargate wird ein weiterer Abstraktionsschritt weg von den technischen Anforderungen unternommen. Hiermit können Container binnen Sekunden deployed werden, und skalieren wie Pods auf einem Kubernetes Cluster, ohne dass man dieses überhaupt erstellen oder warten muss. Dieselbe Infrastruktur wurde also noch einmal in ihrer Benutzung vereinfacht. Nach dem Prinzip pay-per-use wird nur die Zeit berechnet, in welcher der Code wirklich aufgerufen und ausgeführt wird.
Fazit
Kubernetes ist heute zu einer zentralen Säule im Machine Learning Deployment geworden. Der Weg von der Daten- und Modellexploration zum Prototyp und schließlich in die Produktion ist durch Bibliotheken wie PyTorch, TensorFlow und Keras zum einen enorm verschlankt und vereinfacht worden. Gleichzeitig können diese Methoden bei Bedarf aber auch enorm detailliert verwendet werden, um maßgeschneiderte Komponenten zu entwickeln oder mittels Transfer Learning bestehende Modelle einzubinden und anzupassen. Container Technologien wie Docker erlauben im Anschluss, das Ergebnis mit all dessen Anforderungen und Abhängigkeiten zu bündeln und ohne weiteren Aufwand fast überall blitzschnell auszuführen. Im letzten Schritt ist deren Bereitstellung, Wartung und Skalierung mit Kubernetes ebenfalls ungemein vereinfacht und leistungsfähig geworden.
All dies erlaubt uns eigene Produkte sowie Lösungen für Kunden strukturiert zu entwickeln:
- Die Komponenten und die Rahmeninfrastruktur haben eine hohe Wiederverwendbarkeit
- Mit verhältnismäßig geringem Zeit- und Kostenaufwand kann ein erster Meilenstein oder Proof-of-Concept erreicht werden
- Die weiterführende Entwicklungsarbeit folgt auf natürliche Weise weiter diesem Prozess
- Fertige Deployments skalieren ohne zusätzlichen Aufwand, mit Kosten proportional zum Bedarf
- Daraus folgt eine verlässliche Plattform mit planbarer Kostenstruktur
Wenn Sie sich im Anschluss an diesen Artikel weiter über einige zentrale Komponenten informieren möchten, haben wir hier noch einige interessante Beiträge über:
Quellen
- https://trends.google.com/trends/explore?date=all&q=kubernetes,linux%20server,microsoft%20server,docker,virtual%20machine
- https://i1.wp.com/www.docker.com/blog/wp-content/uploads/Blog.-Are-containers-..VM-Image-1-1024×435.png?ssl=1
- https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
- https://www.docker.com/resources/what-container
- https://medium.com/hashmapinc/the-what-why-and-how-of-a-microservices-architecture-4179579423a9
- https://www.geekwire.com/2016/ever-come-kooky-kubernetes-name-heptio/#:~:text=Kubernetes%20(%E2%80%9Ckoo%2Dburr%2D,%E2%80%9Cpilot.%E2%80%9D%20Get%20it%3F
- https://queue.acm.org/detail.cfm?id=2898444
- https://www.techradar.com/news/what-is-kubernetes
- https://kubernetes.io/docs/concepts/overview/components/
- https://kubernetes.io/docs/concepts/workloads/pods/
- https://phoenixnap.com/kb/understanding-kubernetes-architecture-diagrams
- https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/
- https://blog.sebastian-daschner.com/entries/zero-downtime-updates-kubernetes
- https://cloud.google.com/anthos/gke/docs/on-prem/1.5/overview
- https://developer.nvidia.com/blog/maximizing-nvidia-dgx-kubernetes/
- https://www.heise.de/ix/meldung/Statt-AWS-Co-Schwarz-Gruppe-will-Cloud-Anbieter-werden-4724186.html
- https://cloud.google.com/kubernetes-engine/docs/concepts/cluster-autoscaler
- https://cloud.google.com/compute/docs/machine-types
- https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2
- https://www.kubeflow.org/
- https://www.kubeflow.org/docs/pipelines/overview/pipelines-overview/
- https://cloud.google.com/anthos/run