Schaffe Mehrwert für Deine Data Science Projekte
Data Science und datengetriebene Entscheidungen sind für viele Unternehmen zu einem zentralen Bestandteil ihres Tagesgeschäfts geworden, der in den kommenden Jahren nur noch an Wichtigkeit zunehmen wird. Bis Ende 2022 werden viele Unternehmen eine Cloud-Strategie eingeführt haben:
„70 % der Unternehmen werden bis 2022 über eine formale Cloud-Strategie verfügen, und diejenigen, die diese nicht einführen, werden es schwer haben.“
– Gartner-Forschung
Dadurch, dass sich Cloud-Technologien zu einem Grundbaustein in allen Arten von Unternehmen entwickeln, werden sie auch immer leichter verfügbar. Dies senkt die Einstiegshürde für die Entwicklung Cloud-nativer Anwendungen.
In diesem Blogeintrag werden wir uns damit beschäftigen, wie und warum wir Data Science Projekte am besten in der Cloud durchführen. Ich gebe einen Überblick über die erforderlichen Schritte, um ein Data Science Projekt in die Cloud zu verlagern, und gebe einige Best Practices aus meiner eigenen Erfahrung weiter, um häufige Fallstricke zu vermeiden.
Ich erörtere keine spezifischen Lösungsmuster für einzelne Cloud-Anbieter, stelle keine Vergleiche auf und gehe auch nicht im Detail auf Best Practices für Machine Learning und DevOps ein.
Data Science Projekte profitieren von der Nutzung öffentlicher Cloud-Dienste
Ein gängiger Ansatz für Data Science Projekte besteht darin, zunächst lokal Daten zu bearbeiten und Modelle auf Snapshot-basierten Daten zu trainieren und auszuwerten. Dies hilft in einem frühen Stadium Schritt zu halten, solange noch unklar ist, ob Machine Learning das identifizierte Problem überhaupt lösen kann. Nach der Erstellung einer ersten Modellversion, die den Anforderungen des Unternehmens entspricht, soll das Modell eingesetzt werden und somit Mehrwert schaffen.
Zum Einsatz eines Modells in Produktion gibt es normalerweise zwei Möglichkeiten: 1) Einsatz des Modells in einer on-premises Infrastruktur oder 2) Einsatz des Modells in einer Cloud-Umgebung bei einem Cloud-Anbieter Deiner Wahl. Die lokale Bereitstellung des Modells on-premises mag zunächst verlockend klingen, und es gibt Fälle, in denen dies eine umsetzbare Option ist. Allerdings können die Kosten für den Aufbau und die Wartung einer Data Science-spezifischen Infrastruktur recht hoch sein. Dies resultiert aus den unterschiedlichen Anforderungen, die von spezifischer Hardware über die Bewältigung von Spitzenbelastung während Trainingsphasen bis hin zu zusätzlichen, voneinander abhängigen Softwarekomponenten reichen.
Verschiedene Cloud-Konfigurationen bieten unterschiedliche Freiheitsgrade
Bei der Nutzung der Cloud wird zwischen «Infrastructure as a Service» (IaaS), «Container as a Service» (CaaS), «Platform as a Service» (PaaS) und «Software as a Service» (SaaS) unterschieden, wobei man in der Regel Flexibilität gegen Wartungsfreundlichkeit tauscht. Die folgende Abbildung veranschaulicht die Unterschiedlichen Abdeckungen auf den einzelnen Serviceebenen.

- «On-Premises» musst Du dich um alles selbst kümmern: Bestellung und Einrichtung der erforderlichen Hardware, Einrichtung Deiner Datenpipeline und Entwicklung, Ausführung und Überwachung Deiner Anwendungen.
- Bei «Infrastructure as a Service» kümmert sich der Anbieter um die Hardwarekomponenten und liefert eine virtuelle Maschine mit einer festen Version eines Betriebssystems (OS).
- Bei «Containers as a Service» bietet der Anbieter eine Container-Plattform und eine Orchestrierungslösung an. Du kannst Container-Images aus einer öffentlichen Registry verwenden, diese anpassen oder eigene Container erstellen.
- Bei «Platform as a Service»-Diensten musst Du in der Regel nur noch Deine Daten einbringen, um mit der Entwicklung Deiner Anwendung loszulegen. Falls es sich um eine serverlose Lösung handelt, sind auch keine Annahmen zur Servergröße nötig.
- «Software as a Service»-Lösungen als höchstes Service-Level sind auf einen bestimmten Zweck zugeschnitten und beinhalten einen sehr geringen Aufwand für Einrichtung und Wartung. Dafür bieten sie aber nur eine stark begrenzte Flexibilität, denn neue Funktionen müssen in der Regel beim Anbieter angefordert werden.
Öffentliche Cloud-Dienste sind bereits auf die Bedürfnisse von Data Science Projekten zugeschnitten
Zu den Vorteilen der Public-Cloud gehören Skalierbarkeit, Entkopplung von Ressourcen und Pay-as-you-go-Modelle. Diese Vorteile sind bereits ein Plus für Data Science Anwendungen, z. B. für die Skalierung von Ressourcen für den Trainingsprozess. Darüber hinaus haben alle drei großen Cloud-Anbieter einen Teil ihres Servicekatalogs auf Data Science Anwendungen zugeschnitten, jeder von ihnen mit seinen eigenen Stärken und Schwächen.
Dazu gehören nicht nur spezielle Hardware wie GPUs, sondern auch integrierte Lösungen für ML-Operationen wie automatisierte Bereitstellungen, Modellregistrierungen und die Überwachung von Modellleistung und Datendrift. Viele neue Funktionen werden ständig entwickelt und zur Verfügung gestellt. Um mit diesen Innovationen und Funktionen on-premises Schritt zu halten, musst Du eine beträchtliche Anzahl von Ressourcen aufwenden, ohne dass sich dies direkt auf Dein Geschäft auswirkt.
Wenn Du an einer ausführlichen Diskussion über die Bedeutung der Cloud für den Erfolg von KI-Projekten interessiert bist, dann schau Dir doch dieses White Paper auf dem statworx Content Hub an.
Die Durchführung Deines Projekts in der Cloud erfolgt in nur 5 einfachen Schritten
Wenn Du mit der Nutzung der Cloud für Data Science Projekte beginnen möchtest, musst Du im Vorfeld einige wichtige Entscheidungen treffen und entsprechende Schritte unternehmen. Wir werden uns jeden dieser Schritte genauer ansehen.
1. Auswahl der Cloud-Serviceebene
Bei der Wahl der Serviceebene sind die gängigsten Muster für Data-Science-Anwendungen CaaS oder PaaS. Der Grund dafür ist, dass «Infrastructure as a Service» hohe Kosten verursachen kann, die aus der Wartung virtueller Maschinen oder dem Aufbau von Skalierbarkeit über VMs hinweg resultieren. SaaS-Dienste hingegen sind bereits auf ein bestimmtes Geschäftsproblem zugeschnitten und sind einfach in Betrieb zu nehmen, anstatt ein eigenes Modell und eine eigene Anwendung zu entwickeln.
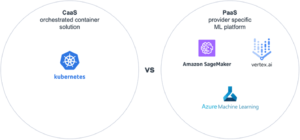
CaaS bietet den Hauptvorteil, dass Container auf jeder Containerplattform eines beliebigen Anbieters bereitgestellt werden können. Und wenn die Anwendung nicht nur aus dem Machine Learning Modell besteht, sondern zusätzliche Mikrodienste oder Front-End-Komponenten benötigt, können diese alle mit CaaS gehostet werden. Der Nachteil ist, dass, ähnlich wie bei einer On-Premises-Einführung, Container-Images für MLops-Tools wie Model Registry, Pipelines und Modell-Performance-Monitoring nicht standardmäßig verfügbar sind und mit der Anwendung erstellt und integriert werden müssen. Je größer die Anzahl der verwendeten Tools und Bibliotheken ist, desto höher ist die Wahrscheinlichkeit, dass künftige Versionen irgendwann Inkompatibilitäten aufweisen oder sogar überhaupt nicht mehr zusammenpassen.
PaaS-Dienste wie Azure Machine Learning, Google Vertex AI oder Amazon SageMaker hingegen haben all diese Funktionalitäten bereits integriert. Der Nachteil dieser Dienste ist, dass sie alle mit komplexen Kostenstrukturen einhergehen und spezifisch für den jeweiligen Cloud-Anbieter sind. Je nach Projektanforderungen können sich die PaaS-Dienste in einigen speziellen Fällen als zu restriktiv erweisen.
Beim Vergleich von CaaS und PaaS geht es meist um den Kompromiss zwischen Flexibilität und einem höheren Grad an Anbieterbindung. Eine stärkere Bindung an den Anbieter ist mit einem Aufpreis verbunden, der für die enthaltenen Funktionen, die größere Kompatibilität und die höhere Entwicklungsgeschwindigkeit zu entrichten ist. Eine höhere Flexibilität wiederum geht mit einem höheren Integrations- und Wartungsaufwand einher.
2. Daten in der Cloud verfügbar machen
In der Regel besteht der erste Schritt zur Bereitstellung Deiner Daten darin, einen Schnappschuss der Daten in einen Cloud-Objektspeicher hochzuladen. Diese sind gut mit anderen Diensten integriert und können später mit geringem Aufwand durch eine geeignetere Datenspeicherlösung ersetzt werden. Sobald die Ergebnisse des Machine Learning Modells aus geschäftlicher Sicht geeignet sind, sollten Data Engineers einen Prozess einrichten, um Deine Daten automatisch auf dem neuesten Stand zu halten.
3. Aufbau einer Pipeline für die Vorverarbeitung
Ein entscheidender Schritt bei jedem Data Science Projekt ist der Aufbau einer robusten Pipeline für die Datenvorverarbeitung. Dadurch wird sichergestellt, dass Deine Daten sauber und bereit für die Modellierung sind, was Dir auf lange Sicht Zeit und Mühe erspart. Ein bewährtes Verfahren ist die Einrichtung einer CICD-Pipeline (Continuous Integration and Continuous Delivery), um die Bereitstellung und das Testen Deiner Vorverarbeitung zu automatisieren und sie in Deinen DevOps-Zyklus einzubinden. Die Cloud hilft Dir, Deine Pipelines automatisch zu skalieren, um jede für das Training Deines Modells benötigte Datenmenge zu bewältigen.
4. Training und Evaluierung des Modells
In dieser Phase wird die Preprocessing-Pipeline durch Hinzufügen von Modellierungskomponenten erweitert. Dazu gehört auch die Abstimmung von Hyperparametern, die wiederum von Cloud-Diensten durch die Skalierung von Ressourcen und die Speicherung der Ergebnisse der einzelnen Trainingsexperimente zum leichteren Vergleich unterstützt wird. Alle Cloud-Anbieter bieten einen automatisierten Dienst für Machine Learning an. Dieser kann entweder genutzt werden, um schnell die erste Version eines Modells zu erstellen und die Leistung mit den Daten über mehrere Modelltypen hinweg zu vergleichen. Auf diese Weise kannst Du schnell beurteilen, ob die Daten und die Vorverarbeitung ausreichen, um das Geschäftsproblem zu lösen. Außerdem kann das Ergebnis als Benchmark für Data Scientists verwendet werden. Das beste Modell sollte in einer Modellregistrierung gespeichert werden, damit es einsatzbereit und transparent ist.
Falls ein Modell bereits lokal oder on-premises trainiert wurde, ist es möglich, das Training zu überspringen und das Modell einfach in die Modellregistrierung zu laden.
5. Bereitstellung des Modells für die Business Unit
Der letzte und wahrscheinlich wichtigste Schritt ist die Bereitstellung des Modells für Deine Business Unit, damit diese einen Nutzen daraus ziehen kann. Alle Cloud-Anbieter bieten Lösungen an, um das Modell mit geringem Aufwand skalierbar bereitzustellen. Schließlich werden alle Teile, die in den früheren Schritten von der automatischen Bereitstellung der neuesten Daten über die Anwendung der Vorverarbeitung und die Einspeisung der Daten in das bereitgestellte Modell erstellt wurden, zusammengeführt.
Jetzt haben wir die einzelnen Schritte für das Onboarding Deines Data Science Projekts durchlaufen. Mit diesen 5 Schritten bist Du auf dem besten Weg, Deinen Data-Science-Workflow in die Cloud zu verlagern. Um einige der üblichen Fallstricke zu vermeiden, möchte ich hier einige Erkenntnisse aus meinen persönlichen Erfahrungen weitergeben, die sich positiv auf den Erfolg Deines Projekts auswirken können.
Erleichtere Dir den Umstieg auf die Cloud mit diesen nützlichen Tipps
Beginne frühzeitig mit der Nutzung der Cloud.
Wenn Du früh damit beginnst, kann sich Dein Team mit den Funktionen der Plattform vertraut machen. Auf diese Weise kannst Du die Möglichkeiten der Plattform optimal nutzen und potenzielle Probleme und umfangreiche Umstrukturierungen vermeiden.
Stelle sicher, dass Deine Daten zugänglich sind.
Dies mag selbstverständlich erscheinen, aber es ist wichtig, dass Deine Daten beim Wechsel in die Cloud leicht zugänglich sind. Dies gilt insbesondere dann, wenn Du Deine Daten lokal generierst und anschliessend in die Cloud übertragen musst.
Erwäge den Einsatz von serverlosem Computing.
Serverless Computing ist eine großartige Option für Data Science Projekte, da es Dir ermöglicht, Deine Ressourcen nach Bedarf zu skalieren, ohne dass Du Server bereitstellen oder verwalten musst.
Vergiss nicht die Sicherheit.
Zwar bieten alle Cloud-Anbieter einige der modernsten IT-Sicherheitseinrichtungen an, doch einige davon sind bei der Konfiguration leicht zu übersehen und können Dein Projekt einem unnötigen Risiko aussetzen.
Überwache Deine Cloud-Kosten.
Bei der Optimierung von on-premises Lösungen geht es oft um die Spitzenauslastung von Ressourcen, da Hardware oder Lizenzen begrenzt sind. Mit Skalierbarkeit und Pay-as-you-go verschiebt sich dieses Paradigma stärker in Richtung Kostenoptimierung. Die Kostenoptimierung ist in der Regel nicht die erste Maßnahme, die man zu Beginn eines Projekts ergreift, aber wenn man die Kosten im Auge behält, können unangenehme Überraschungen vermeiden und die Cloud-Anwendung zu einem späteren Zeitpunkt noch kosteneffizienter gestalten werden.
Lass Deine Data Science Projekte mit der Cloud abheben
Wenn Du Dein nächstes Data Science Projekt in Angriff nimmst, ist die frühzeitige Nutzung der Cloud eine gute Option. Die Cloud ist skalierbar, flexibel und bietet eine Vielzahl von Diensten, mit denen Du das Beste aus Deinem Projekt herausholen kannst. Cloud-basierte Architekturen sind eine moderne Art der Anwendungsentwicklung, die in Zukunft noch mehr an Bedeutung gewinnen wird.
Wenn Du die vorgestellten Schritte befolgst, wirst Du auf diesem Weg unterstützt und kannst mit neusten Trends und Entwicklungen Schritt halten. Außerdem kannst Du mit meinen Tipps viele der üblichen Fallstricke vermeiden, die oft auf diesem Weg auftreten. Wenn Du also nach einer Möglichkeit suchst, das Beste aus Deinem Data Science Projekt herauszuholen, ist die Cloud definitiv eine Überlegung wert.
Warum sich Sorgen machen? KI und die Klimakrise
Nach dem neuesten Bericht des Weltklimarats (IPCC) im August 2021 „ist es eindeutig, dass menschlicher Einfluss die Atmosphäre, das Meer und das Land erwärmt hat“ [1]. Zudem schreitet der Klimawandel schneller voran als gedacht. Basierend auf den neuesten Berechnungen ist die globale Durchschnittstemperatur zwischen 2010 und 2019 im Vergleich zu dem Zeitraum zwischen 1850 und 1900 aufgrund des menschlichen Einflusses um 1.07°C gestiegen. Außerdem war die CO2 Konzentration in der Atmosphäre in dieser Zeit „höher als zu irgendeiner Zeit in mindestens 2 Millionen Jahren“ [1].
Dessen ungeachtet nehmen die globalen CO2 Emissionen weiter zu, auch wenn es 2020 einen kleinen Rückgang gab [2], der wahrscheinlich auf das Coronavirus und die damit zusammenhängenden ökonomischen Auswirkungen zurückzuführen ist. Im Jahr 2019 wurden weltweit insgesamt 36.7 Gigatonnen (Gt) CO2 ausgestoßen [2]. Eine Gt entspricht dabei einer Milliarden Tonnen. Um das 1.5 °C Ziel noch mit einer geschätzten Wahrscheinlichkeit von 80% zu erreichen, blieben Anfang 2020 nur noch 300 Gt übrig [1]. Da 2020 und 2021 bereits vorüber sind und unter Annahme von circa 35 Gt CO2 Emissionen für jedes Jahr, beträgt das verbleibende CO2 -Budget nur rund 230 Gt. Bleibt der jährliche Ausstoß konstant, wäre dieses in den nächsten sieben Jahren aufgebraucht.
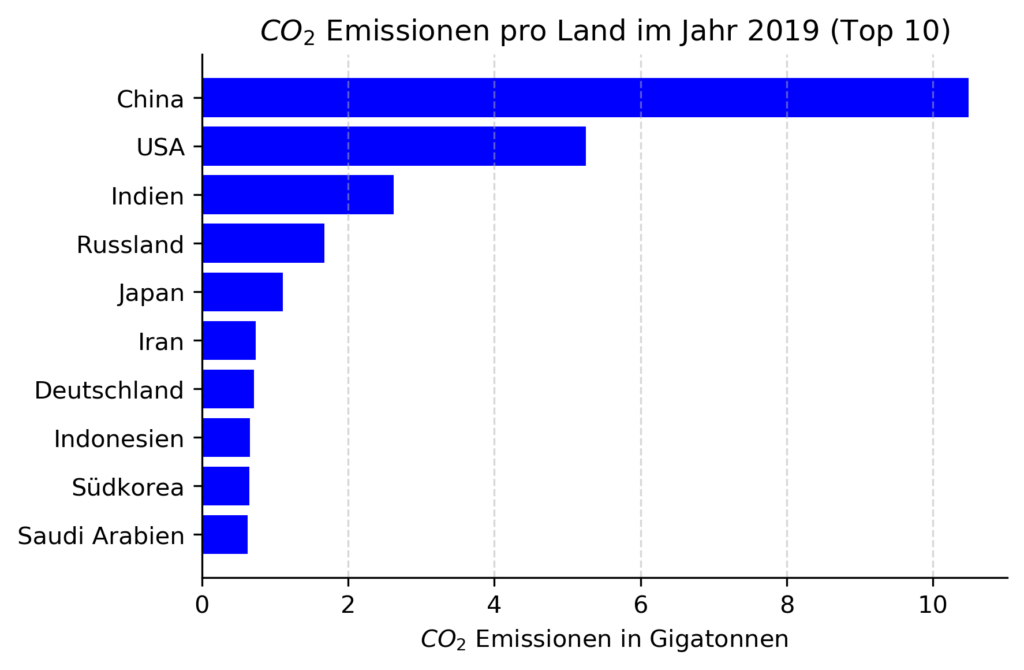
Im Jahr 2019 verursachten China, die USA und Indien die größten CO2-Emissionen. Deutschland ist zwar nur für ungefähr 2% aller globalen CO2 Emissionen verantwortlich, liegt mit 0.7 Gt aber immer noch auf dem siebten Platz (siehe nachfolgende Grafik). Zusammen genommen sind die 10 Länder mit dem größten CO2-Ausstoß für circa zwei Drittel aller CO2-Emissionen weltweit verantwortlich [2]. Die meisten dieser Länder sind hoch industrialisiert, wodurch es sehr wahrscheinlich ist, dass sie künstliche Intelligenz (KI) in den nächsten Jahrzenten verstärkt nutzen werden, um Ihre eigene Wirtschaft zu stärken.
Mit KI den CO2-Ausstoß reduzieren
Was genau hat jetzt KI mit dem Ausstoß von CO2 zu tun? Die Antwort ist: Einiges! Prinzipiell ist die Anwendung von KI wie zwei Seiten derselben Medaille [3]. Auf der einen Seite hat KI großes Potenzial, CO2-Emissionen durch genauere Vorhersagen oder die Verbesserung von Prozessen in vielen Industrien zu reduzieren. Beispielsweise kann KI zur Vorhersage extremer Wetterereignisse, der Optimierung von Lieferketten oder der Überwachung von Mooren eingesetzt werden [4, 5].
Nach einer aktuellen Schätzung von Microsoft und PwC kann die Verwendung von KI im Umweltbereich den Ausstoß der weltweiten Treibhausgase um bis zu 4.4% im Jahr 2030 senken [6]. Absolut gesehen handelt es sich dabei um eine Reduzierung der weltweiten Treibhausgasemissionen von 0.9 bis 2.4 Gt CO2e. Dies entspricht dem, aufgrund aktueller Werte prognostizierten, Ausstoß von Australien, Kanada und Japan im Jahr 2030 zusammen [7]. Der Begriff Treibhausgase beinhaltet hier zusätzlich zu CO2 noch andere Gase wie Methan, die ebenfalls den Treibhauseffekt der Erde verstärken. Um all diese Gase einfach zu messen, werden sie oft als CO2-Äquivalente angeben und als CO2e abgekürzt.
Der CO2-Fußabdruck von KI
Obwohl KI großes Potenzial hat, CO2-Emissionen zu reduzieren, stößt die Anwendung von KI selbst CO2 aus. Dies ist die Kehrseite der Medaille. Im Vergleich zum Jahr 2012 ist die geschätzte Menge an Rechenaufwand für das Training von Deep Learning (DL) Modellen im Jahr 2018 um das 300.000-fache gestiegen (siehe nachfolgende Grafik, [8]). Die Erforschung, das Training und die Anwendung von KI-Modellen benötigen daher eine immer größere Menge an Strom, aber natürlich auch an Hardware. Beides setzt letztlich CO2-Emissionen frei und verstärkt somit den Klimawandel.
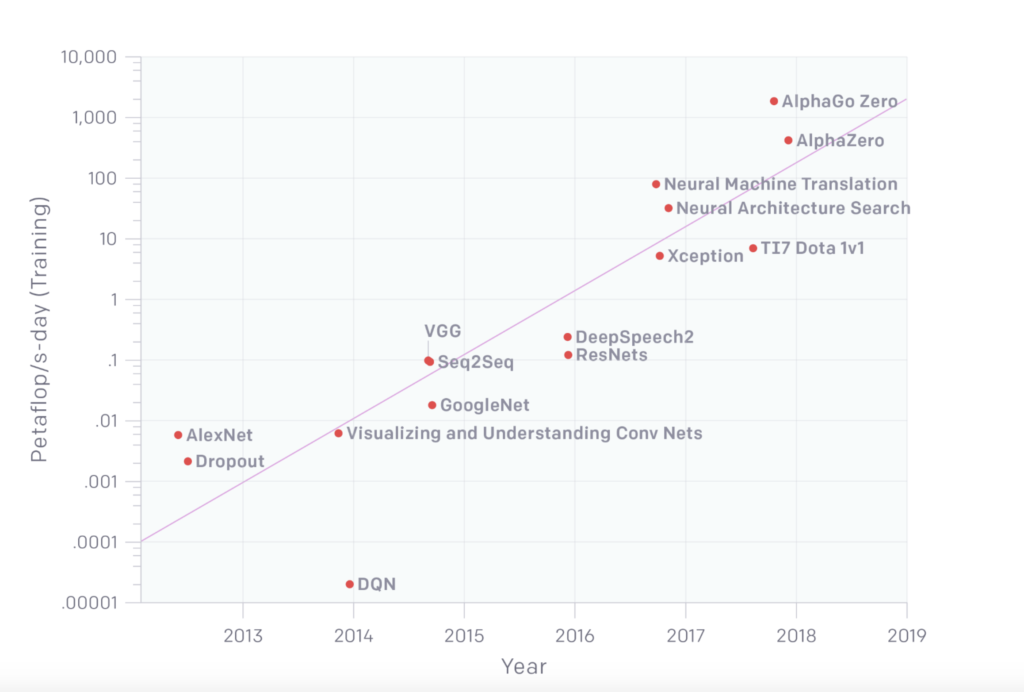
Anmerkung: Die Grafik wurde ursprünglich in [8] veröffentlicht.
Leider ist es mir nicht gelungen, eine Studie ausfindig zu machen, die den CO2-Fußabdruck von KI insgesamt schätzt. Allerdings gibt es diverse Studien, die den CO2– oder CO2e-Ausstoß von Natural Language Processing (NLP) Modellen schätzen. Diese sind in den vergangenen Jahren immer akkurater und somit populärer geworden [9]. Basierend auf der nachfolgenden Tabelle hat das abschließende Training von Googles BERT Modell ungefähr so viel CO2e freigesetzt, wie ein Passagier bei einer Flugreise von New York nach San Francisco. Das Training anderer Modelle, wie bspw. des Transformerbig-Modells, haben zwar wesentlich weniger CO2e-Emissionen verursacht, doch ist das abschließende Training von KI-Modellen nur der letzte Baustein beim Finden des besten Modells. Bevor ein Modell zum letzten Mal trainiert wird, sind häufig bereits viele verschiedene Modelle getestet worden, um so die besten Parameterwerte zu bestimmen. Diese neuronale Architektursuche hat beim Transformerbig-Modell entsprechend viele CO2e-Emissionen verursacht, insgesamt circa fünf Mal so viele wie ein durchschnittliches Auto in seiner gesamten Lebenszeit. Wirf jetzt mal einen Blick auf die CO2e-Emissionen des GPT-3 Modells und stell dir vor, wie hoch der CO2e-Ausstoß bei der dazugehörigen neuronalen Architektursuche gewesen sein muss.
| Emissionen durch Menschen | Emissionen durch KI | ||
|---|---|---|---|
| Beispiel | CO2e Emissionen (Tonnen) | Training von NLP Modellen | CO2e Emissionen (Tonnen) |
| Ein Passagier bei Flugreise New York San Francisco |
0.90 | Transformerbig | 0.09 |
| Durchschnittlicher Mensch ein Jahr |
5.00 | BERTbase | 0.65 |
| Durchschnittlicher Amerikaner ein Jahr |
16.40 | GPT-3 | 84.74 |
| Durchschnittliches Auto während Lebenszeit inkl. Benzin |
57.15 | Neuronale Architektursuche für Transformerbig |
284.02 |
Anmerkung: Alle Werte sind aus [9] entnommen, außer der Werte für GPT-3 [17].
Was du als Data Scientist tun kannst, um deinen CO2-Fußabdruck zu verringern
Insgesamt gibt es ganz unterschiedliche Möglichkeiten, wie du als Data Scientist den CO2-Fußabdruck beim Training und Anwendung von KI-Modellen reduzieren kannst. Aktuell sind im KI-Bereich Machine Learning (ML) und Deep Learning (DL) am populärsten, deswegen findest du nachfolgend verschiedene Ansätze, um den CO2-Fußabdruck dieser Art KI-Modelle zu messen und zu reduzieren.
1. Sei dir der negativen Auswirkungen bewusst und berichte darüber
Es mag einfach klingen, aber sich der negativen Konsequenzen bewusst zu sein, die sich durch die Suche, das Training sowie die Anwendung von ML und DL Modellen ergeben, ist der erste Schritt, deinen CO2-Fußabdruck zu reduzieren. Zu verstehen, wie sich KI negativ auf die Umwelt auswirkt, ist entscheidend, um bereit zu sein, den zusätzlichen Aufwand bei der Messung und systematische Erfassung von CO2-Emissionen zu betreiben. Dies widerrum ist nötig, um den Klimawandel zu bekämpfen [8, 9, 10]. Solltest du also den ersten Teil über KI und die Klimakrise übersprungen haben, gehh zurück und lies ihn. Es lohnt sich!
2. Miss den CO2-Ausstoß deines Codes
Um die CO2-Emissionen deiner ML und DL Modelle transparent darzulegen, müssen diese zuerst gemessen werden. Zurzeit gibt es leider noch kein standardisiertes Konzept, um alle Nachhaltigkeitsaspekte von KI zu messen. Eines wird allerdings gerade entwickelt [11]. Bis dieses fertiggestellt ist, kannst du bereits beginnen, den Energieverbrauch und die damit verbundenen CO2-Emissionen deiner KI-Modelle offen zu legen [12]. Mit TensorFlow und PyTorch sind die ausgereiftesten Pakete für die Berechnung von ML und DL Modellen wahrscheinlich in der Programmiersprache Python verfügbar. Obwohl Python nicht die effizienteste Programmiersprache ist [13], war es im September 2021 erneut die populärste im PYPL Index [14]. Dementsprechend gibt es sogar drei Python Pakete, die du nutzen kannst, um den CO2-Fußabdruck beim Training deiner Modelle zu messen:
- CodeCarbon [15, 16]
- CarbonTracker [17]
- Experiment Impact Tracker [18]
Meiner Auffassung nach sind die beiden Pakete, CodeCarbon und CarbonTracker, am einfachsten anzuwenden. Außerdem lässt sich CodeCarbon problemlos mit TensorFlow und CarbonTracker mit PyTorch kombinieren. Aus diesen Gründen findest du für jedes der beiden Pakete nachfolgend ein Beispiel.
Um beide Pakete zu testen, habe ich den MNIST Datensatz verwendet und jeweils ein einfaches Multilayer Perceptron (MLP) mit zwei Hidden Layern und jeweils 256 Neuronen trainiert. Um sowohl eine CPU- als auch GPU-basierte Berechnung zu testen, habe ich das Modell mit TensorFlow und CodeCarbon auf meinem lokalen PC (15 Zoll MacBook Pro mit 6 Intel Core i7 CPUs aus dem Jahr 2018) und das mit PyTorch und CarbonTracker in einem Google Colab unter Verwendung einer Tesla K80 GPU trainiert. Beginnen wir mit den Ergebnissen für TensorFlow und CodeCarbon.
# benötigte Pakete importieren
import tensorflow as tf
from codecarbon import EmissionsTracker
# Modeltraining vorbereiten
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256, activation=“relu“),
tf.keras.layers.Dense(256, activation=“relu“),
tf.keras.layers.Dense(10, activation=“softmax“),
]
)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer=“adam“, loss=loss_fn, metrics=[„accuracy“])
# Modell trainieren und CO2 Emissionen berechnen
tracker = EmissionsTracker()
tracker.start()
model.fit(x_train, y_train, epochs=10)
emissions: float = tracker.stop()
print(emissions)Nach der Ausführung des Codes erstellt CodeCarbon automatisch eine CSV-Datei, welche verschiedene Ergebnisparameter beinhaltet, wie Berechnungszeit in Sekunden, totaler Stromverbrauch durch die verwendete Hardware in kWh und die damit verbundenen CO2-Emissionen in kg. Das Training meines Modells dauerte insgesamt 112.15 Sekunden, verbrauchte 0.00068 kWh und verursachte 0.00047 kg CO2-Emissionen.
Als Grundlage für die Berechnungen mit PyTorch und CarbonTracker habe ich dieses Google Colab Notebook verwendet. Um auch hier ein Multilayer Perceptron zu berechnen und die dabei entstehenden CO2-Emissionen zu messen, habe ich einige Details des Notebooks geändert. Als erstes habe ich in Schritt 2 („Define Network“) das Convolutional Neural Network in ein Multilayer Perceptron geändert (Den Namen der Klasse „CNN“ habe ich beibehalten, damit der restliche Code im Notebook noch funktioniert.):
class CNN(nn.Module):
"""Ein einfaches MLP Modell."""
@nn.compact
def __call__(self, x):
x = x.reshape((x.shape[0], -1)) # flach machen
x = nn.Dense(features=256)(x)
x = nn.relu(x)
x = nn.Dense(features=256)(x)
x = nn.relu(x)
x = nn.Dense(features=10)(x)
x = nn.log_softmax(x)
return xAls zweites habe ich die Installation und den Import von CarbonTracker sowie die Messung der CO2-Emissionen in Schritt 14 („Train and evaluate“) eingefügt:
!pip install carbontracker
from carbontracker.tracker import CarbonTracker
tracker = CarbonTracker(epochs=num_epochs)for epoch in range(1, num_epochs + 1):
tracker.epoch_start()
# Vewendung des separaten PRNG keys, um Bilddaten zu permutieren
rng, input_rng = jax.random.split(rng)
# Optimierung für Trainings Batches
state = train_epoch(state, train_ds, batch_size, epoch, input_rng)
# Evaluation für Testdatensatz nach jeder Epoche
test_loss, test_accuracy = eval_model(state.params, test_ds)
print(' test epoch: %d, loss: %.2f, accuracy: %.2f' % (
epoch, test_loss, test_accuracy * 100))
tracker.epoch_end()
tracker.stop()Nachdem das leicht geänderte Google Colab Notebook bis zum eigentlichen Training des Modells ausgeführt wurde, gab CarbonTracker nach der ersten Trainingsepoche das nachfolgende Ergebnis aus:
train epoch: 1, loss: 0.2999, accuracy: 91.25
test epoch: 1, loss: 0.22, accuracy: 93.42
CarbonTracker:
Actual consumption for 1 epoch(s):
Time: 0:00:15
Energy: 0.000397 kWh
CO2eq: 0.116738 g
This is equivalent to:
0.000970 km travelled by car
CarbonTracker:
Predicted consumption for 10 epoch(s):
Time: 0:02:30
Energy: 0.003968 kWh
CO2eq: 1.167384 g
This is equivalent to:
0.009696 km travelled by carWie erwartet hat die GPU mehr Strom verbraucht und somit auch mehr CO2-Emissionen verursacht. Der Stromverbrauch war um das 6-fache und die CO2-Emissionen um das 2,5-fache Mal höher im Vergleich zu der lokalen Berechnung mit CPUs. Logischerweise hängt beides mit der längeren Berechnungszeit zusammen. Diese betrug zweieinhalb Minuten für die GPU und nur etwas weniger als zwei Minuten für die CPUs. Insgesamt geben beide Pakete alle notwendigen Informationen an, um die CO2-Emissionen und damit zusammenhängende Informationen zu beurteilen und zu berichten.
3. Vergleiche die verschiedenen Regionen von Cloud-Anbietern
In den vergangenen Jahren hat das Training und die Anwendung von ML sowie DL Modellen in der Cloud im Vergleich zu lokalen Berechnungen immer mehr an Bedeutung gewonnen. Sicherlich ist einer der Gründe dafür der zunehmende Bedarf an Rechenleistung [8]. Zugriff auf GPUs in der Cloud ist für viele Unternehmen günstiger und schneller als der Bau eines eigenen Rechenzentrums. Natürlich benötigen auch Rechenzentren von Cloud-Anbietern Hardware und Strom für deren Betrieb. Es wird geschätzt, dass bereits circa 1% des weltweiten Strombedarfs auf Rechenzentren zurückgeht [19]. Da die Nutzung von Hardware, unabhängig vom Standort, immer CO2-Emissionen verursachen kann, ist es auch beim Training und der Anwendung von ML und DL Modellen in der Cloud wichtig, die CO2-Emissionen zu messen.
Aktuell ermöglichen zwei verschiedene Plattformen, die CO2e-Emissionen von Berechnungen in der Cloud zu ermitteln [20, 21]. Die guten Neuigkeiten dabei sind, dass die drei großen Cloud-Anbieter – AWS, Azure und GCP – in beiden Plattformen implementiert sind. Um zu beurteilen, welcher der drei Cloud-Anbieter und welche der verfügbaren europäischen Regionen die geringsten CO2e-Emissionen verursachen, habe ich die erste Plattform – ML CO2 Impact [20] – verwendet, um die CO2e-Emissionen für das abschließende Training von GPT-3 zu berechnen. Das finale Training von GPT-3 benötigte 310 GPUs (NVIDIA Tesla V100 PCIe), die ununterbrochen für 90 Tagen liefen [17]. Als Grundlage für die Berechnungen der CO2e-Emissionen der verschiedenen Cloud-Anbieter und deren Regionen, habe ich die verfügbare Option “Tesla V100-PCIE-16GB” als GPU gewählt. Die Ergebnisse der Berechnungen befinden sich in der nachfolgenden Tabelle.
| Google Cloud Computing | AWS Cloud Computing | Microsoft Azure | |||
|---|---|---|---|---|---|
| Region | CO2e Emissionen (Tonnen) | Region | CO2e Emissionen (Tonnen) | Region | CO2e Emissionen (Tonnen) |
| europe-west1 | 54.2 | EU – Frankfurt | 122.5 | France Central | 20.1 |
| europe-west2 | 124.5 | EU – Ireland | 124.5 | France South | 20.1 |
| europe-west3 | 122.5 | EU – London | 124.5 | North Europe | 124.5 |
| europe-west4 | 114.5 | EU – Paris | 20.1 | West Europe | 114.5 |
| europe-west6 | 4.0 | EU – Stockholm | 10.0 | UK West | 124.5 |
| europe-north1 | 42.2 | UK South | 124.5 | ||
Zwei Ergebnisse in der Tabelle sind besonders auffällig. Erstens, die ausgewählte Region hat selbst innerhalb eines Cloud-Anbieters einen extrem großen Einfluss auf die geschätzten CO2e-Emissionen. Den größten Unterschied gab es bei GCP, mit einem Faktor von mehr als 30. Dieser große Unterschied ergibt sich auch durch die Region „europe-west6“, welche mit vier Tonnen die insgesamt geringsten CO2e-Emissionen verursacht. Interessanterweise ist ein Faktor der Größe 30 weit mehr als die Faktoren von 5 bis 10, welche in Studien beschrieben werden [12]. Neben den Unterschieden zwischen Regionen sind zweitens die Werte einiger Regionen exakt identisch. Dies spricht dafür, dass eine gewisse Vereinfachung bei den Berechnungen vorgenommen wurde. Die absoluten Werte sollten daher mit Vorsicht betrachtet werden, wobei die Unterschiede weiterhin bestehen bleiben, da allen Regionen die gleiche (vereinfachte) Art der Berechnung zu Grunde liegt.
Neben den reinen CO2e-Emissionen durch Rechenzentren, ist es für die Wahl eines Cloud-Anbieters ebenfalls wichtig, die Nachhaltigkeitsstrategie der Anbieter zu berücksichtigen. In diesem Bereich scheinen GCP und Azure im Vergleich zu AWS die besseren Strategien zu haben [22, 23]. Auch wenn kein Cloud-Anbieter bisher 100% erneuerbare Energien nutzt (siehe Tabelle 2 in [9]), haben GCP und Azure dies mit dem Ausgleich ihres CO2-Ausstoßes sowie Energiezertifikaten bereits in der Theorie erreicht. Aus ökologischer Sicht bevorzuge ich letztlich GCP, weil mich deren Strategie am meisten überzeugt hat. Zudem hat GCP seit 2021 bei der Auswahl der Regionen einen Hinweis eingefügt, welche den geringsten CO2-Ausstoß verursachen [24]. Für mich zeigen solche kleinen Hilfestellungen, welchen Stellenwert das Thema dort einnimmt.
4. Trainiere und nutze KI-Modelle mit Bedacht
Zu guter Letzt gibt es noch viele weitere Tipps und Tricks in Bezug auf das Training und den Einsatz von ML sowie DL Modellen, die dir helfen, deinen CO2-Fußabdruck als Data Scientist zu minimieren.
- Sei sparsam! Neue Forschung, die DL Modelle mit aktuellen Ergebnissen aus den Neurowissenschaften kombiniert, kann die Berechnungszeit um das bis zu 100-fache reduzieren und dadurch extrem viel CO2 einsparen [25].
- Verwende, wenn möglich, einfachere KI-Modelle, die eine vergleichbare Vorhersagegenauigkeit haben, aber weniger rechenintensiv sind. Beispielsweise gibt es das Modell DistilBERT, welches eine kleinere und schnellere Version von BERT ist, aber eine vergleichbare Genauigkeit besitzt [26].
- Ziehe Transfer Learning und sogenannte Foundation Modelle [10| in Betracht, um die Vorhersagegenauigkeit zu maximieren und Berechnungszeit zu minimieren.
- Ziehe Federated Learning in Betracht, um CO2-Emissionen zu minimieren [27].
- Denke nicht nur an die Vorhersagegenauigkeit deiner Modelle. Effizienz ist ebenfalls ein wichtiges Kriterium. Wäge ab, ob eine 1% höhere Genauigkeit die zusätzlichen Umweltauswirkungen wert sind [9, 12].
- Wenn der beste Bereich für die Hyperparameter deines Modells noch unbekannt sind, nutze eine zufällige oder Bayesianische Suche nach den Hyperparametern anstatt einer Rastersuche [9, 20].
- Wenn dein Modell während der Anwendung regelmäßig neu trainiert wird, wähle das Trainingsintervall bewusst aus. Je nach Anwendungsfall reicht es womöglich aus, das Modell nur jeden Monat und nicht jede Woche neu zu trainieren.
Fazit
Es besteht kein Zweifel daran, dass Menschen und ihre Treibhausgasemissionen das Klima beeinflussen und unseren Planeten erwärmen. KI kann und sollte beim Problem des Klimawandels zur Lösung beitragen. Gleichzeitig müssen wir den CO2-Fußabdruck von KI im Auge behalten, um sicherzustellen, dass es Teil der Lösung und nicht Teil des Problems ist.
Du kannst als Data Scientist dabei einen großen Beitrag leisten. Informiere dich über die positiven Möglichkeiten und die negativen Auswirkungen von KI und kläre andere darüber auf. Außerdem kannst du die CO2-Emissionen deiner Modelle messen und transparent darstellen. Du solltest zudem deine Anstrengungen zur Minimierung des CO2-Fußabdrucks deiner Modelle beschreiben. Letztlich kannst du deinen Cloud-Anbieter bewusst wählen und beispielsweise prüfen, ob es für deinen Anwendungsfall einfachere Modelle gibt, die eine vergleichbare Vorhersagegenauigkeit bieten, aber mit weniger Emissionen.
Wir bei statworx haben vor kurzem die Initiative AI & Environment ins Leben gerufen, um genau solche Aspekte in unserer täglichen Arbeit als Data Scientists einzubauen. Wenn du mehr darüber erfahren möchtest, sprich uns einfach an!
Referenzen
- https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM_final.pdf
- http://www.globalcarbonatlas.org/en/CO2-emissions
- https://doi.org/10.1007/s43681-021-00043-6
- https://arxiv.org/pdf/1906.05433.pdf
- Harnessing Artificial Intelligence
- https://www.pwc.co.uk/sustainability-climate-change/assets/pdf/how-ai-can-enable-a-sustainable-future.pdf
- https://climateactiontracker.org/
- https://arxiv.org/pdf/1907.10597.pdf
- https://arxiv.org/pdf/1906.02243.pdf
- https://arxiv.org/pdf/2108.07258.pdf
- https://algorithmwatch.org/de/sustain/
- https://arxiv.org/ftp/arxiv/papers/2104/2104.10350.pdf
- https://stefanos1316.github.io/my_curriculum_vitae/GKS17.pdf
- https://pypl.github.io/PYPL.html
- https://codecarbon.io/
- https://mlco2.github.io/codecarbon/index.html
- https://arxiv.org/pdf/2007.03051.pdf
- https://github.com/Breakend/experiment-impact-tracker
- https://www.iea.org/reports/data-centres-and-data-transmission-networks
- https://mlco2.github.io/impact/#co2eq
- http://www.green-algorithms.org/
- https://blog.container-solutions.com/the-green-cloud-how-climate-friendly-is-your-cloud-provider
- https://www.wired.com/story/amazon-google-microsoft-green-clouds-and-hyperscale-data-centers/
- https://cloud.google.com/blog/topics/sustainability/pick-the-google-cloud-region-with-the-lowest-co2)
- https://arxiv.org/abs/2112.13896
- https://arxiv.org/abs/1910.01108
- https://flower.dev/blog/2021-07-01-what-is-the-carbon-footprint-of-federated-learning
Management Summary
Machine Learning Projekte zu deployen und zu überwachen ist ein komplexes Vorhaben. Neben dem konsequenten Dokumentieren von Modellparametern und den dazugehörigen Evaluationsmetriken, besteht die Herausforderung vor allem darin, das gewünschte Modell in eine Produktivumgebung zu überführen. Sofern mehrere Personen an der Entwicklung beteiligt sind, ergeben sich zusätzlich Synchronisationsprobleme in Bezug auf die Entwicklungsumgebungen und Versionsstände der Modelle. Aus diesem Grund werden Tools zum effizienten Management von Modellergebnissen bis hin zu umfangreichen Trainings- und Inferenzpipelines benötigt.
In diesem Artikel werden die typischen Herausforderungen entlang des Machine Learning Workflows dargestellt und mit MLflow eine mögliche Lösungsplattform beschrieben. Zusätzlich stellen wir drei verschiedene Szenarien dar, mit deren Hilfe sich Machine Learning Workflows professionalisieren lassen:
- Einsteigervariante:
Modellparameter und Performance-Metriken werden über eine R/Python API geloggt und in einer GUI übersichtlich dargestellt. Zusätzlich werden die trainierten Modelle als Artefakt abgespeichert und können über APIs bereitgestellt werden. - Fortgeschrittenes Modellmanagement:
Neben dem Tracking von Parametern und Metriken werden bestimmte Modelle geloggt und versioniert. Dies ermöglicht ein kontrolliertes Monitoring und vereinfacht das Deployment von ausgewählten Modellversionen. - Kollaboratives Workflowmanagement:
Das Abkapseln von Machine Learning Projekten als Pakete oder Git Repositories und der damit einhergehenden lokalen Reproduzierbarkeit von Entwicklungsumgebungen, ermöglichen eine reibungslose Entwicklung von Machine Learning Projekten mit mehreren Beteiligten.
Je nach Reifegrad Ihres Machine Learning Projektes können die drei Szenarien als Inspiration für einen potenziellen Machine Learning Workflow dienen. Zum besseren Verständnis haben wir jedes Szenario detailliert ausgearbeitet und geben Empfehlungen hinsichtlich der zu verwendeten APIs und Deployment-Umgebungen.
Herausforderungen entlang des Machine Learning Workflows
Das Training von Machine Learning Modellen wird immer einfacher. Mittlerweile ermöglichen eine Vielzahl von Open Source Tools eine effiziente Datenaufbereitung sowie ein immer einfacheres Modelltraining und Deployment.
Der Mehrwert für Unternehmen entsteht vor allem durch das systematische Zusammenspiel von Modelltraining, in Form von Modellidentifikation, Hyperparametertuning und Fitting auf den Trainingsdaten, und Deployment, also dem Bereitstellen des Modells zur Berechnung von Vorhersagen. Insbesondere in frühen Phasen der Entwicklung von Machine Learning Initiativen wird dieses Zusammenspiel häufig nicht als kontinuierlicher Prozess etabliert. Ein Modell kann jedoch nur dann langfristig Mehrwerte generieren, wenn ein stabiler Produktionsprozess vom Modelltraining, über dessen Validierung bis hin zum Test und Deployment implementiert wird. Sofern dieser Prozess korrekt implementiert wird können bei der operativen Inbetriebnahme des Modells komplexe Abhängigkeiten und langfristig kostspielige Wartungsarbeiten entstehen [2]. Die folgenden Risiken sind hierbei besonders hervorzuheben
1. Gewährleistung von Synchronität
Häufig werden im explorativen Kontext Datenaufbereitungs- und Modellierungs-Workflows lokal entwickelt. Unterschiedliche Konfigurationen der Entwicklungsumgebungen oder gar der Einsatz von verschiedenen Technologien erschweren eine Reproduktion von Ergebnissen, insbesondere zwischen Entwickler*innen bzw. Teams. Zusätzlich ergeben sich potenzielle Gefahren hinsichtlich der Kompatibilität des Workflows, sofern mehrere Skripte in einer logischen Reihenfolge exekutiert werden müssen. Ohne einer entsprechenden Versionskontroll-Logik kann der Synchronisationsaufwand im Nachhinein nur mit großem Aufwand gewährleistet werden.
2. Aufwand der Dokumentation
Um die Performance des Modells zu bewerten, werden häufig im Anschluss an das Training Modellmetriken berechnet. Diese hängen von verschiedenen Faktoren ab, wie z.B. der Parametrisierung des Modells oder den verwendeten Einflussfaktoren. Diese Metainformationen über das Modell werden häufig nicht zentral gespeichert. Zur systematischen Weiterentwicklung und Verbesserung eines Modells ist es jedoch zwingend erforderlich, eine Übersicht über die Parametrisierung und Performance aller vergangenen Trainingsläufe zu haben.
3. Heterogenität von Modellformaten
Neben der Verwaltung von Modellparametern und Ergebnissen besteht die Herausforderung das Modell anschließend in die Produktionsumgebung zu überführen. Sofern verschiedene Modelle aus mehreren Paketen zum Training verwendet werden kann das Deployment aufgrund unterschiedlicher Pakete und Versionen schnell umständlich und fehleranfällig werden.
4. Wiederherstellung alter Ergebnisse
In einem typischen Machine Learning Projekt ergibt sich häufig die Situation, dass ein Modell über einen langen Zeitraum entwickelt wird. Beispielsweise können neue Features verwendet oder auch gänzlich neue Architekturen evaluiert werden. Nicht zwangsläufig führen diese Experimente zu besseren Ergebnissen. Sofern Experimente nicht sauber versioniert werden, besteht die Gefahr alte Ergebnisse nicht mehr nachbilden zu können.
Um diese und weitere Herausforderungen im Umgang und Management von Machine Learning Workflows zu lösen, wurden in den vergangenen Jahren verschiedene Tools entwickelt, wie beispielsweise TensorFlow TFX, cortex, Marvin oder MLFlow. Insbesondere letzteres ist aktuell eine der am häufigsten verwendeten Lösungen.
MLflow ist ein Open Source Projekt mit dem Ziel, das Beste aus existierenden ML Plattformen zu vereinen, um die Integration zu bestehenden ML Bibliotheken, Algorithmen und Deployment Tools so unkompliziert wie möglich zu gestalten [3]. Im Folgenden werden die wesentlichen MLflow Module vorgestellt und Möglichkeiten erörtert, mit der Machine Learning Workflows über MLflow abgebildet werden können.
MLflow Services
MLflow besteht aus vier Komponenten: MLflow Tracking, MLflow Models, MLflow Projectsund MLflow Registry. Je nach Anforderung an das Experimental- und Deployment-Szenario können alle Services gemeinsam genutzt, oder auch einzelne Komponenten isoliert werden.
Mit MLflowTracking lassen sich alle Hyperparameter, Metriken (Modell-Performance) und Artefakte, wie bspw. Charts, loggen. MLflow Tracking bietet die Möglichkeit, für jeden Trainings- oder Scoring-Lauf eines Modells Voreinstellungen, Parameter und Ergebnisse für ein kollektives Monitoring zu sammeln. Die geloggten Ergebnisse lassen sich in einer GUI visualisieren oder alternativ über eine REST API ansprechen.
Das Modul MLflow Models fungiert als Schnittstelle zwischen Technologien und ermöglicht ein vereinfachtes Deployment. Ein Modell wird je nach Typ als Binary, z.B, als reine Python-Funktion oder als Keras-, oder H2O-Modell gespeichert. Man spricht hierbei von den sogenannten model flavors. Weiterhin stellt MLflow Models eine Unterstützung zur Modellbereitstellung auf verschiedenen Machine Learning Cloud Services bereit, z.B. für AzureML und Amazon Sagemaker.
MLflow Projects dienen dazu, einzelne ML-Projekte in einem Paket oder Git-Repository abzukapseln. Die Basiskonfigurationen des jeweiligen Environments werden über eine YAML-Datei festgelegt. Über diese kann z.B. gesteuert werden, wie genau das conda-Environment parametrisiert ist, das im Falle einer Ausführung von MLflow erstellt wird. Durch MLflow Projects können Experimente, die lokal entwickelt wurden, auf anderen Rechnern in der gleichen Umgebung ausgeführt werden. Dies ist bspw. bei der Entwicklung in kleineren Teams von Vorteil.
Ein zentralisiertes Modellmanagement bietet MLflow Registry. Ausgewählte MLflow Models können darin registriert und versioniert werden. Ein Staging-Workflow ermöglicht ein kontrolliertes Überführen von Modellen in die Produktivumgebung. Der gesamte Prozess lässt sich wiederum über eine GUI oder eine REST API steuern.
Beispiele für Machine Learning Pipelines mit MLflow
Im Folgenden werden mit Hilfe der o.g. MLflow Module drei verschiedene ML Workflow-Szenarien dargestellt. Diese steigern sich von Szenario zu Szenario hinsichtlich der Komplexität. In allen Szenarien wird ein Datensatz mittels eines Python Skripts in eine Entwicklungsumgebung geladen, verarbeitet und ein Machine Learning Modell trainiert. Der letzte Schritt stellt in allen Szenarien ein Deployment des ML Modells in eine beispielhafte Produktivumgebung dar.
1. Szenario – Die Einsteigervariante
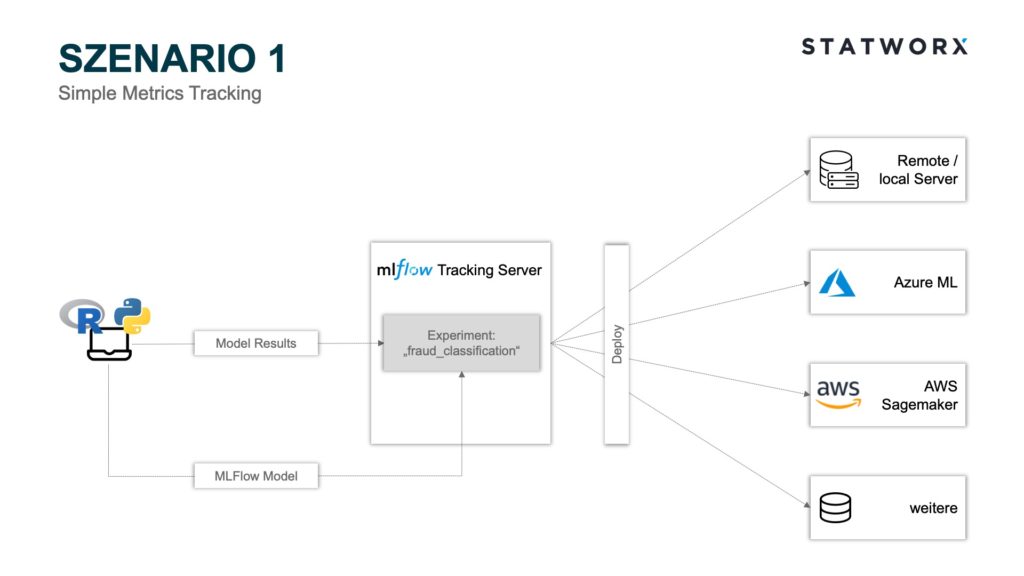 Szenario 1 – Simple Metrics Tracking
Szenario 1 – Simple Metrics TrackingSzenario 1 bedient sich der Module MLflow Tracking und MLflow Models. Hierbei können mittels der Python API die Modellparameter und Metriken der einzelnen Runs auf dem MLflow Tracking Server Backend Store gespeichert und das entsprechende MLflow Model File als Artefakt auf dem MLflow Tracking Server Artifact Store abgelegt werden. Jeder Run wird hierbei einem Experiment zugeordnet. Beispielsweise könnte ein Experiment ‚fraud_classification‘ lauten und ein Run wäre ein bestimmtes ML Modell mit einer Hyperparameterkonfiguration und den entsprechenden Metriken. Jeder Run wird zur eindeutigen Zuordnung mit einer einzigartigen RunID abgespeichert.
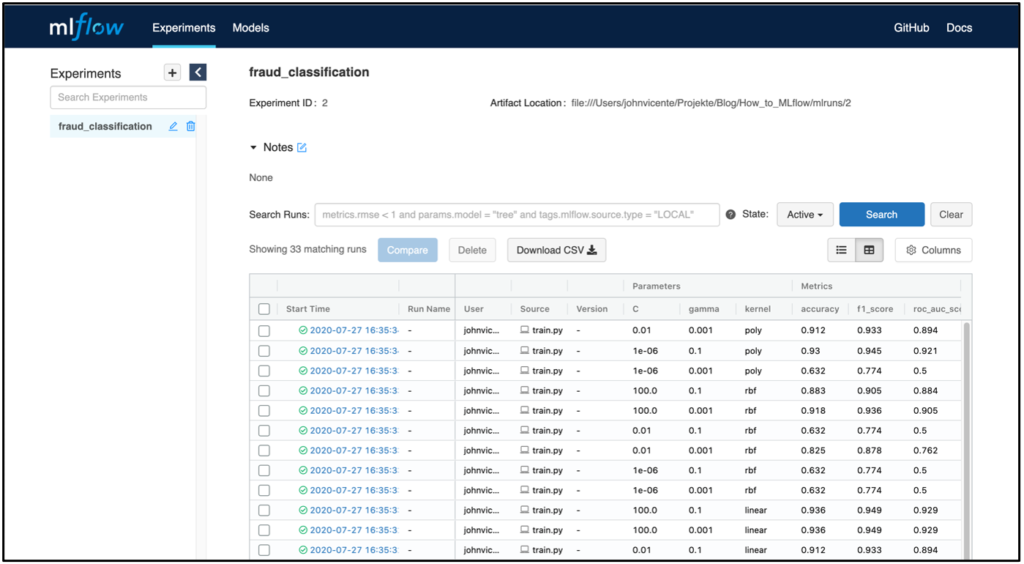
Im Screenshot wird die MLflow Tracking UI beispielhaft nach der Ausführung eines Modelltrainings dargestellt. Der Server wird im Beispiel lokal gehostet. Selbstverständlich besteht auch die Möglichkeit den Server Remote, beispielsweise in einem Docker Container, innerhalb einer VM zu hosten. Neben den Parametern und Modellmetriken werden zudem der Zeitpunkt des Modelltrainings sowie der User und der Name des zugrundeliegenden Skripts geloggt. Klickt man auf einen bestimmten Run werden zudem weitere Informationen dargestellt, wie beispielsweise die RunID und die Modelltrainingsdauer.
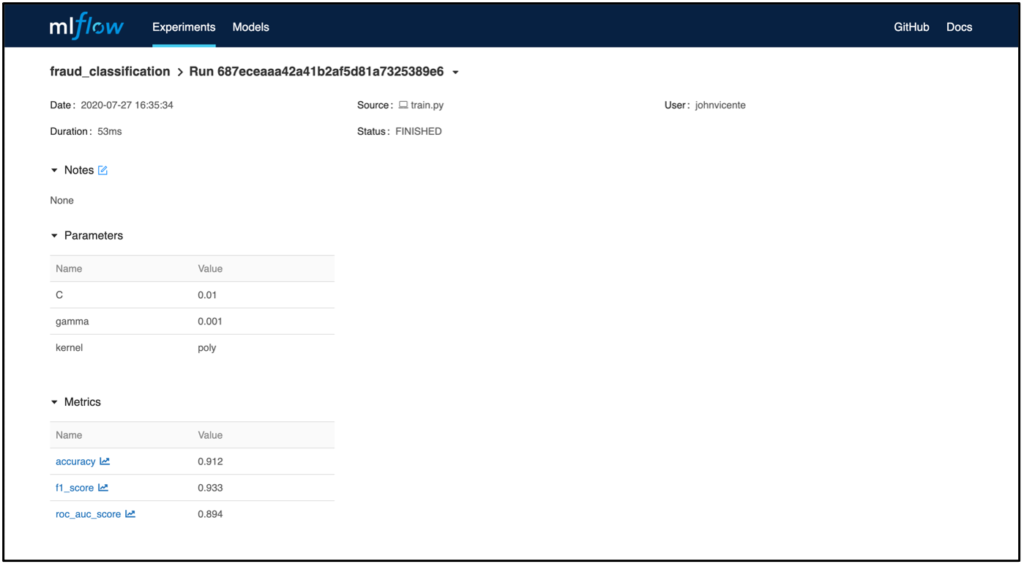
Sofern man neben den Metriken zusätzlich noch weitere Artefakte, wie bspw. das Modell, geloggt hat, wird das MLflow Model Artifact ebenfalls in der Run-Ansicht dargestellt. In dem Beispiel wurde ein Modell aus dem sklearn.svm Package verwendet. Das File MLmodel enthält Metadaten mit Informationen über die Art und Weise, wie das Modell geladen werden soll. Zusätzlich dazu wird ein conda.yaml erstellt, das alle Paketabhängigkeiten des Environments zum Trainingszeitpunkt enthält. Das Modell selbst befindet sich als serialisierte Version unter model.pklund enthält die auf den Trainingsdaten optimierten Modellparameter.
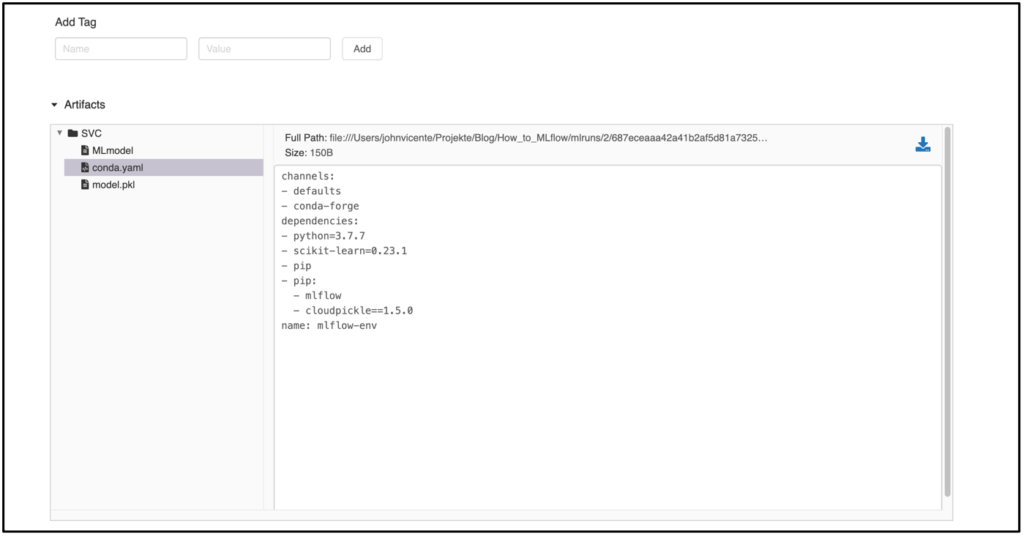
Das Deployment des trainierten Modells kann nun auf mehrere Weisen erfolgen. Möchte man beispielsweise das Modell mit der besten Accuracy Metrik deployen, kann der MLflow Tracking Server über die Python API mlflow.list_run_infos angesteuert werden, um so die RunID des gesuchten Modells zu identifizieren. Nun kann der Pfad zu dem gewünschten Artefakt zusammengesetzt werden und das Modell bspw. über das Python Paket pickle geladen werden. Dieser Workflow kann nun über ein Dockerfile getriggert werden, was ein flexibles Deployment in die Infrastruktur Ihrer Wahl ermöglicht. MLFlow bietet für das Deployment auf Microsoft Azure und AWS zusätzliche gesonderte APIs an. Sofern das Modell bspw. auf AzureML deployed werden soll, kann ein Azure ML Container Image mit der Python API mlflow.azureml.build_image erstellt werden, welches als Webservice nach Azure Container Instances oder Azure Kubernetes Service deployed werden kann. Neben dem MLflow Tracking Server besteht auch die Möglichkeit andere Ablagesysteme für das Artefakt zu verwenden, wie zum Beispiel Amazon S3, Azure Blob Storage, Google Cloud Storage, SFTP Server, NFS und HDFS.
2. Szenario – Fortgeschrittenes Modellmanagement
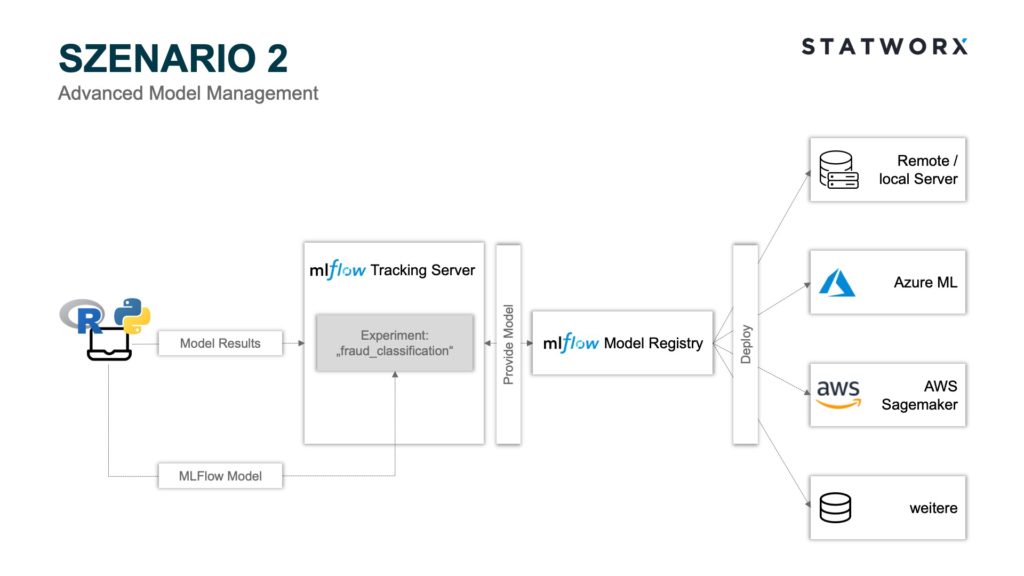 Szenario 2 – Advanced Model Management
Szenario 2 – Advanced Model ManagementSzenario 2 beinhaltet, neben den in Szenario 1 verwendeten Modulen, zusätzlich MLflow Model Registry als Modelmanagementkomponente. Hierbei besteht die Möglichkeit, aus bestimmten Runs die dort geloggten Modelle zu registrieren und zu verarbeiten. Diese Schritte können über die API oder GUI gesteuert werden. Eine Grundvoraussetzung, um die Model Registry zu nutzen, ist eine Bereitstellung des MLflow Tracking Server Backend Store als Database Backend Store. Um ein Modell über die GUI zu registrieren, wählt man einen bestimmten Run aus und scrollt in die Artefakt Übersicht.
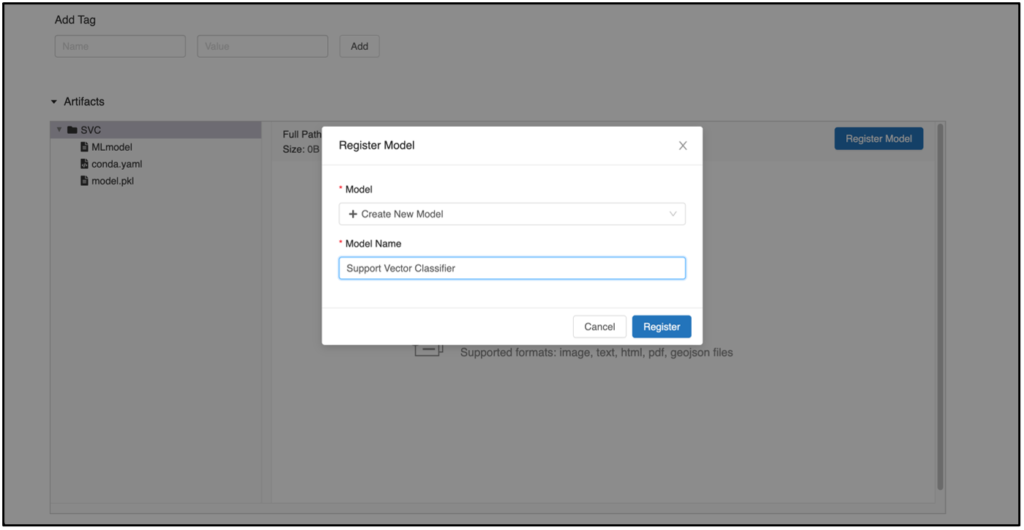
Mit einem Klick auf Register Model öffnet sich ein neues Fenster, in dem ein Modell registriert werden kann. Sofern man eine neue Version eines bereits existierenden Modells registrieren möchte, wählt man das gesuchte Modell aus dem Dropdown Feld aus. Ansonsten kann jederzeit ein neues Modell angelegt werden. Nach dem Klick auf den Button Register erscheint in dem Reiter Models das zuvor registrierte Modell mit einer entsprechenden Versionierung.
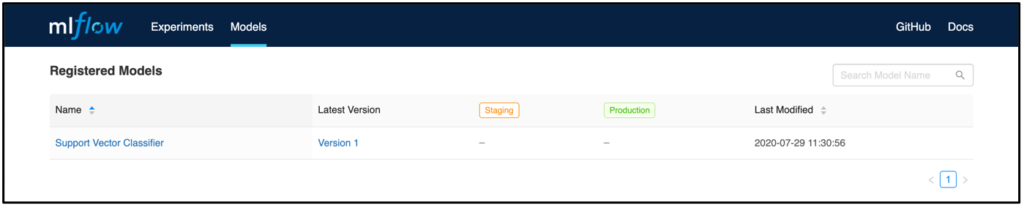
Jedes Modell beinhaltet eine Übersichtsseite, bei der alle vergangenen Versionen dargestellt werden. Dies ist bspw. nützlich, um nachzuvollziehen, welche Modelle wann in Produktion waren.
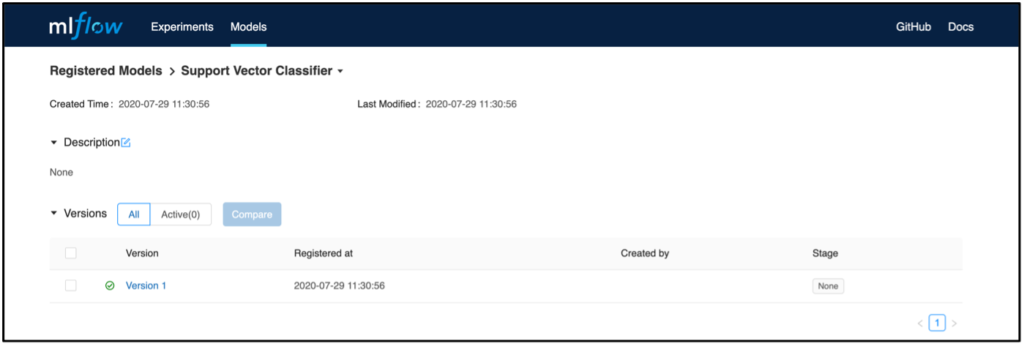
Wählt man nun eine Modellversion aus, gelangt man auf eine Übersicht, bei der beispielsweise eine Modellbeschreibung angefügt werden kann. Ebenso gelangt man über den Link Source Run zu dem Run, aus dem das Modell registriert worden ist. Hier befindet sich auch das dazugehörige Artefakt, das später zum Deployment verwendet werden kann.
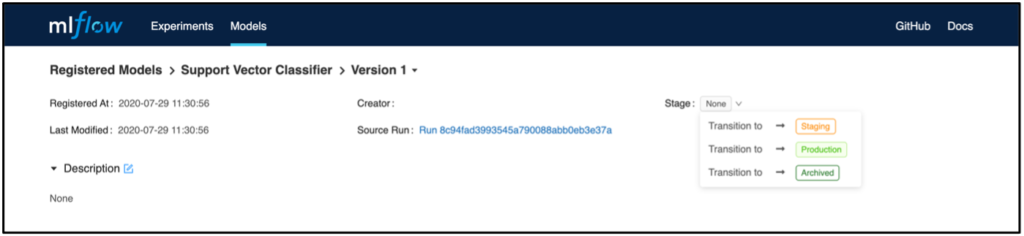
Zusätzlich können einzelne Modellversionen in dem Bereich Stage in festgelegte Phasen kategorisiert werden. Dieses Feature kann beispielsweise dazu genutzt werden, um festzulegen, welches Modell gerade in der Produktion verwendet wird oder dahin überführt werden soll. Für das Deployment kann, im Gegensatz zu Szenario 1, die Versionierung und der Staging-Status dazu verwendet werden, um das geeignete Modell identifizieren und zu deployen. Hierzu kann z.B. die Python API MlflowClient().search_model_versions verwendet werden, um das gewünschte Modell und die dazugehörige RunID zu filtern. Ähnlich wie in Szenario 1 kann dann das Deployment beispielsweise nach AWS Sagemaker oder AzureML über die jeweiligen Python APIs vollzogen werden.
3. Szenario – Kollaboratives Workflowmanagement
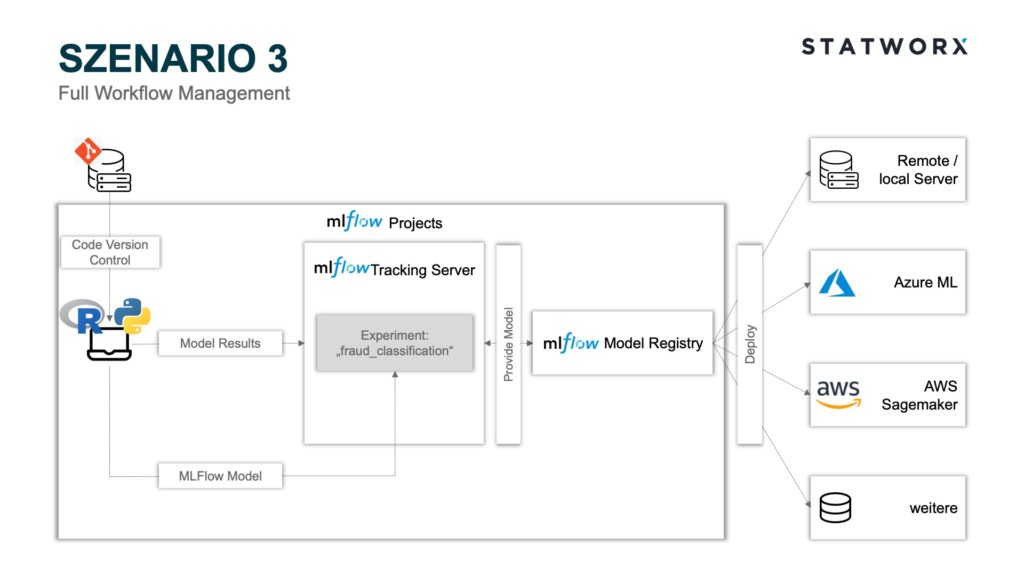 Szenario 3 – Full Workflow Management
Szenario 3 – Full Workflow ManagementDas Szenario 3 beinhaltet, neben denen in Szenario 2 verwendeten Modulen, zusätzlich noch das Modul MLflow Projects. Wie bereits erläutert, eignen sich MLflow Projects besonders gut für kollaborative Arbeiten. Jedes Git Repository oder jede lokale Umgebung kann hierbei als Projekt fungieren und mittels eines MLproject File gesteuert werden. Hierbei können Paketabhängigkeiten in einem conda.yaml festgehalten und beim Starten des Projekts auf das MLproject File zugegriffen werden. Anschließend wird die entsprechende conda Umgebung mit allen Abhängigkeiten vor dem Training und Logging des Modells erstellt. Dies verhindert den Bedarf eines manuellen Angleichens der Entwicklungsumgebungen aller beteiligten Entwickler*innen und garantiert zudem standardisierte und vergleichbare Ergebnisse aller Runs. Insbesondere letzteres ist erforderlich im Deployment Kontext, da allgemein nicht garantiert werden kann, dass unterschiedliche Package-Versionen dieselben Modellartefakte produzieren. Anstelle einer conda Umgebung kann auch eine Docker Umgebung mittels eines Dockerfiles definiert werden. Dies bietet den Vorteil, dass auch von Python unabhängige Paketabhängigkeiten festgelegt werden können. Ebenso ermöglichen MLflow Projects durch die Anwendung unterschiedlicher commit hashes oder branch names das Verwenden verschiedener Projektstände, sofern ein Git Repository verwendet wird.
Ein interessanter Use Case hierbei ist die modularisierte Entwicklung von Machine Learning Trainingspipelines [4]. Hierbei kann bspw. die Datenaufbereitung vom Modelltraining entkoppelt und parallel weiterentwickelt werden, während parallel ein anderes Team einen unterschiedlichen branch name verwendet, um das Modell zu trainieren. Hierbei muss lediglich beim Starten des Projektes im MLflow Projects File ein unterschiedlicher branch name als Parameter verwendet werden. Die finale Datenaufbereitung kann im Anschluss auf denselben branch name gepusht werden, der zum Modelltraining verwendet wird und wäre somit bereits vollständig in der Trainingspipeline implementiert. Das Deployment kann ebenfalls als Teilmodul innerhalb der Projektpipeline mittels eines Python Skripts über das ML Project File gesteuert werden und analog zu Szenario 1 oder 2 auf eine Plattform Ihrer Wahl erfolgen.
Fazit und Ausblick
MLflow bietet eine flexible Möglichkeit den Machine Learning Workflow robust gegen die typischen Herausforderungen im Alltag eines Data Scientists zu gestalten, wie beispielsweise Synchronisationsprobleme aufgrund unterschiedlicher Entwicklungsumgebungen oder fehlendes Modellmanagement. Je nach Reifegrad des bestehenden Machine Learning Workflows können verschiedene Services aus dem MLflow Portfolio verwendet werden, um eine höhere Professionalisierungsstufe zu erreichen.
Im Artikel wurden drei, in der Komplexität aufsteigende, Machine Learning Workflows exemplarisch dargestellt. Vom einfachen Logging der Ergebnisse in einer interaktiven UI, bis hin zu komplexeren, modularen Modellierungspipelines können MLflow Services unterstützen. Logischerweise ergeben sich auch außerhalb des MLflow Ökosystems Synergien mit anderen Tools, wie zum Beispiel Docker/Kubernetes zur Modellskalierung oder auch Jenkins zur Steuerung der CI/CD Pipeline. Sofern noch weiteres Interesse an MLOps Herausforderungen und Best Practices besteht verweise ich auf das von uns kostenfrei zur Verfügung gestellte Webinar zu MLOps von unserem CEO Sebastian Heinz.
Quellen
- https://www.aitrends.com/machine-learning/mlops-not-just-ml-business-new-competitive-frontier/
- Hidden Technical Debt in Machine Learning Systems (2014) von D. Sculley et al., (https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf)
- https://databricks.com/blog/2018/06/05/introducing-mlflow-an-open-source-machine-learning-platform.html
- https://mlflow.org/docs/latest/projects.html#building-multistep-workflows
Im haben wir darüber gesprochen, was ein DAG ist, wie man dieses mathematische Konzept in der Projektplanung und -programmierung anwendet und warum wir bei beschlossen haben, Airflow statt anderer Workflow-Manager einzusetzen. In diesem Teil werden wir jedoch etwas technischer und untersuchen eine recht informative Hello-World-Programmierung und wie man Airflow für verschiedene Szenarien einrichtet, mit denen man konfrontiert werden könnte. Wenn du dich nur für den technischen Teil interessierst und deshalb den ersten Teil nicht lesen willst, aber trotzdem eine Zusammenfassung möchtest, findest du hier eine Zusammenfassung:
- DAG ist die Abkürzung für „Directed Acyclic Graph“ und kann als solcher Beziehungen und Abhängigkeiten darstellen.
- Dieser letzte Aspekt kann im Projektmanagement genutzt werden, um deutlich zu machen, welche Aufgaben unabhängig voneinander ausgeführt werden können und welche nicht.
- Die gleichen Eigenschaften können in der Programmierung genutzt werden, da Software bestimmen kann, welche Aufgaben gleichzeitig ausgeführt werden können oder in welcher Reihenfolge die anderen beendet werden (oder fehlschlagen) müssen.
Warum haben wir Airflow gewählt:
- Kein Cron – Mit Airflows integriertem Scheduler müssen wir uns nicht auf Cron verlassen, um unsere DAG zu planen und verwenden nur ein Framework (nicht wie Luigi).
- Code Bases – In Airflow werden alle Workflows, Abhängigkeiten und das Scheduling in Python Code durchgeführt. Daher ist es relativ einfach, komplexe Strukturen aufzubauen und die Abläufe zu erweitern.
- Sprache – Python ist eine Sprache, die man relativ leicht erlernen kann und Python Kenntnisse war in unserem Team bereits vorhanden.
Vorbereitung
Der erste Schritt war die Einrichtung einer neuen, virtuellen Umgebung mit Python und virtualenv.
$pip install virtualenv # if it hasn't been installed yet
$cd # change into home
# create a separated folder with all environments
$mkdir env
$cd env
$virtualenv airflow
Sobald die Umgebung erstellt wurde, können wir sie immer dann verwenden, wenn wir mit Airflow arbeiten wollen, so dass wir nicht in Konflikt mit anderen Abhängigkeiten geraten.
$source ~/env/airflow/bin/activate
Dann können wir alle Python-Pakete installieren, die wir benötigen.
$ pip install -U pip setuptools wheel \
psycopg2\
Cython \
pytz \
pyOpenSSL \
ndg-httpsclient \
pyasn1 \
psutil \
apache-airflow[postgres]\
A Small Breeze
Sobald unser Setup fertig ist, können wir überprüfen, ob Airflow korrekt installiert ist, indem wir airflow version in Bash eingeben und du solltest etwas wie dieses sehen:
Anfänglich läuft Airflow mit einer SQLite-Datenbank, die nicht mehr als eine DAG-Aufgabe gleichzeitig ausführen kann und daher ausgetauscht werden sollte, sobald du dich ernsthaft damit befassen willst oder musst. Doch dazu später mehr. Beginnen wir nun mit dem typischen Hello-World-Beispiel. Navigiere zu deinem AIRFLOW_HOME-Pfad, der standardmäßig ein Ordner namens airflow in deinem Stammverzeichnis ist. Wenn du das ändern willst, editiere die Umgebungsvariable mit export AIRFLOW_HOME=/your/new/path und rufe airflow version noch einmal auf.
# ~/airflow/dags/HelloWorld.py
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def print_hello():
return 'Hello world!'
dag = DAG('hello_world',
description='Simple tutorial DAG',
start_date= datetime.now() - timedelta(days= 4),
schedule_interval= '0 12 * * *'
)
dummy_operator= DummyOperator(task_id= 'dummy_task', retries= 3, dag= dag)
hello_operator= PythonOperator(task_id= 'hello_task', python_callable= print_hello, dag= dag)
dummy_operator >> hello_operator # same as dummy_operator.set_downstream(hello_operator)
Die ersten neun Zeilen sollten einigermaßen selbsterklärend sein, nur der Import der notwendigen Bibliotheken und die Definition der Hello-World-Funktion passieren hier. Der interessante Teil beginnt in Zeile zehn. Hier definieren wir den Kern unseres Workflows, ein DAG-Objekt mit dem Identifier hello _world in diesem Fall und eine kleine Beschreibung, wofür dieser Workflow verwendet wird und was er tut (Zeile 10). Wie du vielleicht schon vermutet hast, definiert das Argument start_date das Anfangsdatum des Tasks. Dieses Datum sollte immer in der Vergangenheit liegen. Andernfalls würde die Aufgabe ausgelöst werden und immer wieder nachfragen, ob sie ausgeführt werden kann, und als solche bleibt sie aktiv, bis sie geplant ist. Das schedule_interval definiert die Zeiträume, in denen der Graph ausgeführt werden soll. Wir setzen sie entweder mit einer Cron-ähnlichen Notation auf (wie oben) oder mit einem syntaktischen Hilfsmittel, das Airflow übersetzen kann. Im obigen Beispiel definieren wir, dass die Aufgabe täglich um 12:00 Uhr laufen soll. Die Tatsache, dass sie täglich laufen soll, hätte auch mit schedule_interval='@daily ausgedrückt werden können. Die Cron-Notation folgt dem Schema Minute - Stunde - Tag (des Monats) - Monat - Tag (der Woche), etwa mi h d m wd. Mit der Verwendung von * als Platzhalter haben wir die Möglichkeit, in sehr flexiblen Intervallen zu planen. Nehmen wir an, wir wollen, dass ein Job jeden ersten Tag des Monats um zwölf Uhr ausgeführt wird. In diesem Fall wollen wir weder einen bestimmten Monat noch einen bestimmten Wochentag und ersetzen den Platzhalter durch eine Wildcard * ( min h d * *). Da es um 12:00 laufen soll, ersetzen wir mi mit 0 und h mit 12. Schließlich geben wir noch den Tag des Monats als 1 ein und erhalten unsere endgültige Cron-Notation 0 12 1 * *. Wenn wir nicht so spezifisch sein wollen, sondern lediglich täglich oder stündlich, beginnend mit dem Startdatum Ausführungen benötigen, können wir Airflows Hilfsmittel verwenden – @daily, @hourly, @monthly oder @yeary.
Sobald wir diese DAG-Instanz haben, können wir damit beginnen, sie mit einer Aufgabe zu füllen. Instanzen von Operatoren in Airflow repräsentieren diese. Hier initiieren wir einen DummyOperator und einen PythonOperator. Beiden muss eine eindeutige id zugewiesen werden, aber dieses Mal muss sie nur innerhalb des Workflows eindeutig sein. Der erste Operator, den wir definieren, ist ein DummyOperator, der überhaupt nichts tut. Wir wollen nur, dass er unseren Graphen füllt und dass wir Airflow mit einem möglichst einfachen Szenario testen können. Der zweite ist ein PythonOperator. Neben der Zuordnung zu einem Graphen und der id benötigt der Operator eine Funktion, die ausgeführt wird, sobald die Aufgabe ausgelöst wird. Nun können wir unsere Funktion hello_world verwenden und über den PythonOperator an unseren Workflow anhängen.
Bevor wir unseren Ablauf schließlich ausführen können, müssen wir noch die Beziehung zwischen unseren Aufgaben herstellen. Diese Verknüpfung wird entweder mit den binären Operatoren << und >> oder durch den Aufruf der Methoden set_upstream und set_downstream vorgenommen. Auf diese Weise können wir die Abhängigkeit einstellen, dass zuerst der DummyOperator laufen und erfolgreich sein muss, bevor unser PythonOperator ausgeführt wird.
Nun da unser Code in Ordnung ist, sollten wir ihn testen. Dazu sollten wir ihn direkt im Python-Interpreter ausführen, um zu prüfen, ob wir einen Syntaxfehler haben. Führe ihn also entweder in einer IDE oder im Terminal mit dem Befehl python hello_world.py aus. Wenn der Interpreter keine Fehlermeldung ausgibt, kannst du dich glücklich schätzen, dass du es nicht allzu sehr vermasselt hast. Als nächstes müssen wir überprüfen, ob Airflow unsere DAG mit airflow list_dags kennt. Jetzt sollten wir unsere hello_world id in der gedruckten Liste sehen. Wenn dies der Fall ist, können wir mit airflow list_task hello_world überprüfen, ob jede Aufgabe ihm zugewiesen ist. Auch hier sollten wir einige bekannte IDs sehen, nämlich dummy_task und hello_task. So weit so gut, zumindest die Zuweisung scheint zu funktionieren. Als nächstes steht ein Unit-Test der einzelnen Operatoren mit airflow test dummy_task 2018-01-01 und airflow test hello_task 2018-01-01 an. Hoffentlich gibt es dabei keine Fehler, und wir können fortfahren.
Da wir nun unseren Beispiel-Workflow bereitstellen konnten, müssen wir Airflow zunächst vollständig starten. Dazu sind drei Befehle erforderlich, bevor wir mit der manuellen Auslösung unserer Aufgabe fortfahren können.
airflow initdbum die Datenbank zu initiieren, in der Airflow die Arbeitsabläufe und ihre Zustände speichert:

airflow webserver, um den Webserver auflocalhost:8080zu starten, von wo aus wir die Weboberfläche erreichen können:
airflow scheduler, um den Scheduling-Prozess der DAGs zu starten, damit die einzelnen Workflows ausgelöst werden können:
airflow trigger_dag hello_worldum unseren Workflow auszulösen und ihn in den Zeitplan aufzunehmen.
Jetzt können wir entweder einen Webbrowser öffnen und zu der entsprechenden Website navigieren oder open http://localhost:8080/admin/ im Terminal aufrufen, und es sollte uns zu einer Webseite wie dieser führen.
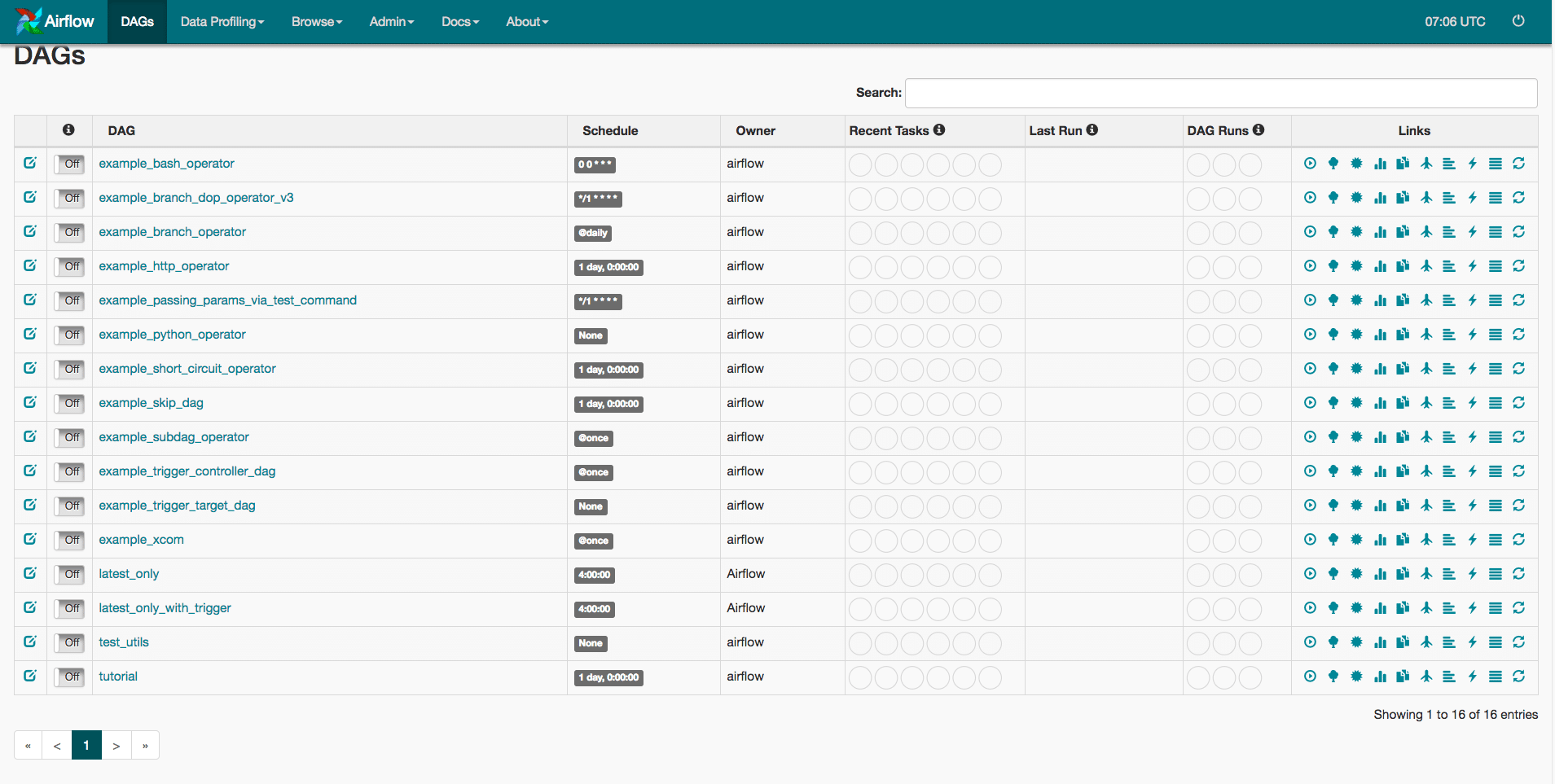
Unten solltest du deine Kreation sehen und der hellgrüne Kreis zeigt an, dass unser Ablauf geplant ist und ausgeführt wird. Jetzt müssen wir nur noch warten, bis er ausgeführt wird. In der Zwischenzeit können wir über das Einrichten von Airflow sprechen und darüber, wie wir einige der anderen Executors verwenden können.
Das Backend
Wie bereits erwähnt – sobald wir uns ernsthaft mit der Ausführung unserer Graphen beschäftigen wollen, müssen wir das Backend von Airflow ändern. Anfänglich wird eine einfache SQLite-Datenbank verwendet, die Airflow darauf beschränkt, jeweils nur eine Aufgabe sequenziell auszuführen. Daher werden wir zunächst die angeschlossene Datenbank auf PostgreSQL umstellen. Falls du Postgres noch nicht installiert hast und Hilfe dabei brauchst, empfehle ich dir diesen Wiki-Artikel. Ich könnte den Prozess nicht so gut beschreiben wie die Seite. Für diejenigen, die mit einem Linux-basierten System arbeiten (sorry, Windows), versucht es mit sudo apt-get install postgresql-client oder mit homebrew auf einem Mac – brew install postgresql. Eine andere einfache Möglichkeit wäre die Verwendung eines Docker-Containers mit dem entsprechenden image.
Nun erstellen wir eine neue Datenbank für Airflow, indem wir im Terminal psql createdb airflow eingeben, in dem alle Metadaten gespeichert werden. Als nächstes müssen wir die Datei airflow.cfg bearbeiten, die in dem AIRFLOW_HOME-Ordner erscheinen sollte (der wiederum standardmäßig airflow in Ihrem Home-Verzeichnis ist) und die Schritte 1 – 4 von oben (initdb…) neu starten. Starte nun deinen Lieblingseditor und suche nach Zeile 32 sql_alchemy_conn =. Hier werden wir den SQLite Connection String durch den von unserem PostgreSQL-Server und einen neuen Treiber ersetzen. Diese Zeichenkette wird zusammengesetzt aus:
postgresql+psycopg2://IPADRESS:PORT/DBNAME?user=USERNAME&password=PASSWORD
Der erste Teil teilt sqlalchemy mit, dass die Verbindung zu PostgreSQL führen wird und dass es den psycopg2-Treiber verwenden soll, um sich mit diesem zu verbinden. Falls du Postgres lokal installiert hast (oder in einem Container, der auf localhost mappt) und den Standard-Port von 5432 nicht geändert hast, könnte IPADRESS:PORT in localhost:5432 oder einfach localhost übersetzt werden. Der DBNAME würde in unserem Fall in airflow geändert werden, da wir ihn nur zu diesem Zweck erstellt haben. Die letzten beiden Teile hängen davon ab, was du als Sicherheitsmaßnahmen gewählt hast. Schließlich könnten wir eine Zeile erhalten haben, die wie folgt aussieht:
sql_alchemy_conn = postgresql+psycopg2://localhost/airflow?user=postgres&password=password
Wenn wir dies getan haben, können wir auch unseren Executor in Zeile 27 von „Executor = SequentialExecutor“ in einen „Executor = LocalExecutor“ ändern. Auf diese Weise wird jede Aufgabe als Unterprozess gestartet und die Parallelisierung findet lokal statt. Dieser Ansatz funktioniert hervorragend, solange unsere Aufträge nicht zu kompliziert sind oder auf mehreren Rechnern laufen sollen.
Sobald wir diesen Punkt erreicht haben, brauchen wir Celery als Executor. Dabei handelt es sich um eine asynchrone Task/Job-Warteschlange, die auf verteilter Nachrichtenübermittlung basiert. Um den CeleryExecutor zu verwenden, benötigen wir jedoch ein weiteres Stück Software – einen Message Broker. Ein Message Broker ist ein zwischengeschaltetes Programmmodul, das eine Nachricht von der „Sprache“ des Senders in die des Empfängers übersetzt. Die beiden gängigsten Optionen sind entweder redis oder rabbitmq. Verwende das, womit du dich am wohlsten fühlst. Da wir rabbitmq verwendet haben, wird der gesamte Prozess mit diesem Broker fortgesetzt, sollte aber für redis mehr oder weniger analog sein.
Wiederum ist es für Linux- und Mac-Benutzer mit apt/homebrew ein Einzeiler, ihn zu installieren. Tippe einfach in dein Terminal sudo apt-get install rabbitmq-server oder brew install rabbitmq ein und fertig. Als nächstes brauchen wir einen neuen Benutzer mit einem Passwort und einen virtuellen Host. Beides – Benutzer und Host – kann im Terminal mit dem rabbitsmqs Kommandozeilen-Tool rabbitmqctl erstellt werden. Nehmen wir an, wir wollen einen neuen Benutzer namens myuser mit mypassword und einen virtuellen Host als myvhost erstellen. Dies kann wie folgt erreicht werden:
$ rabbitmqctl add_user myuser mypassword
$ rabbitmqctl add_vhost myvhost
Doch nun zurück zur Airflows-Konfiguration. Navigiere in deinem Editor zur Zeile 230, und du wirst hoffentlich broker_url = sehen. Dieser Connection-String ist ähnlich wie der für die Datenbank und wird nach dem Muster BROKER://USER:PASSWORD@IP:PORT/HOST aufgebaut. Unser Broker hat das Akronym amqp, und wir können unseren neu erstellten Benutzer, das Passwort und den Host einfügen. Sofern du nicht den Port geändert hast oder einen Remote Server verwendest, sollte deine Zeile in etwa so aussehen:
broker_url = amqp://myuser:mypassword@localhost:5672/myvhost
Als nächstes müssen wir Celery Zugriff auf unsere airflow-Datenbank gewähren und die Zeile 232 mit:
db+postgresql://localhost:5432/airflow?user=postgres&password=password
Dieser String sollte im Wesentlichen dem entsprechen, den wir zuvor verwendet haben. Wir müssen nur den Treiber psycopg2 weglassen und stattdessen db+ am Anfang hinzufügen. Und das war’s! Du solltest nun alle drei Executors in der Hand haben und die Einrichtung ist abgeschlossen. Unabhängig davon, welchen Executor du gewählt hast, musst du, sobald du die Konfiguration geändert hast, die Schritte 1-4 – Initialisierung der DB, Neustart des Schedulers und des Webservers – erneut ausführen. Wenn du dies jetzt tust, wirst du feststellen, dass sich die Eingabeaufforderung leicht verändert hat, da sie anzeigt, welchen Executor du verwendest.
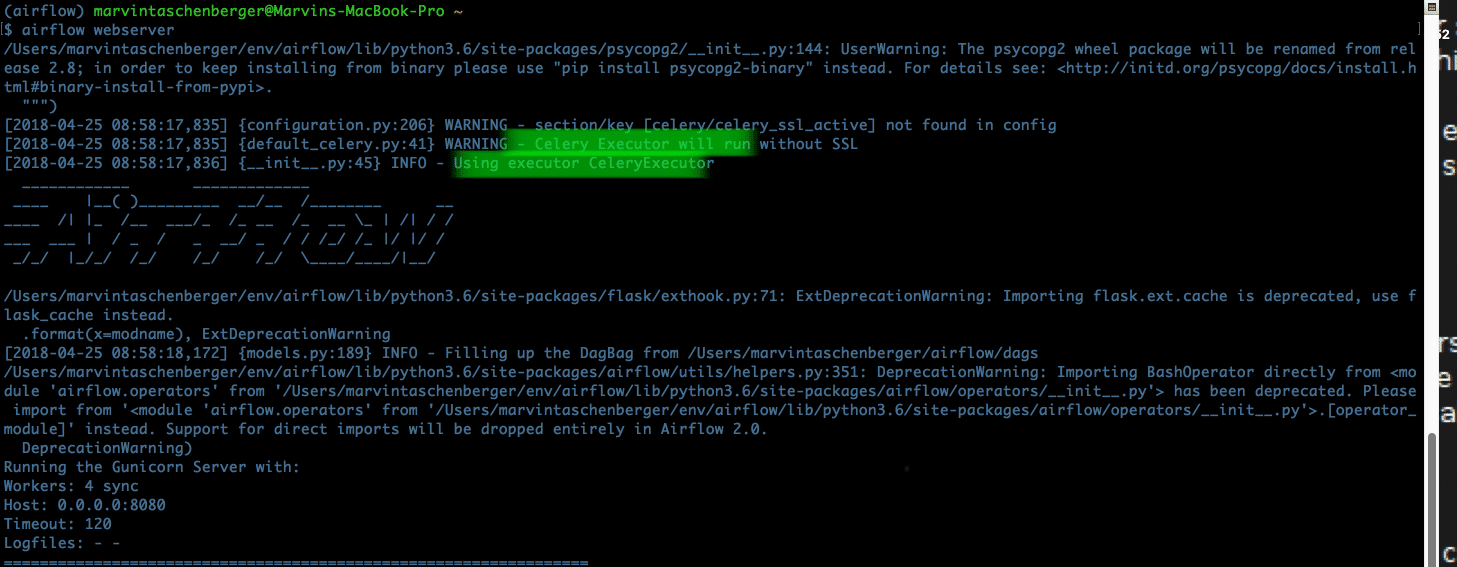
Airflow ist ein einfach zu bedienender, codebasierter Workflow-Manager mit einem integrierten Scheduler und mehreren Executors, die je nach Bedarf skaliert werden können.
Wenn du einen Ablauf sequenziell ausführen willst oder wenn es nichts gibt, was gleichzeitig laufen könnte, sollten die Standard-SQLite-Datenbank und der sequenzielle Executor die Aufgabe erfüllen.
Wenn du Airflow verwenden willst, um mehrere Aufgaben gleichzeitig zu starten und so die Abhängigkeiten zu verfolgen, solltest du zuerst die Datenbank und einen LocalExecutor für lokale Mehrfachverarbeitung verwenden. Dank Celery sind wir sogar in der Lage, mehrere Maschinen zu verwenden, um noch fortgeschrittenere und komplexere Workflows ohne viel Aufwand und Sorgen auszuführen.
Kürzlich standen wir bei vor der typischen Situation, dass wir einen Proof of Concept (POC) in etwas umwandeln mussten, das in der Produktion verwendet werden konnte. Der „neue“ Aspekt dieser Umwandlung bestand darin, dass der PoC mit einer winzigen Menge (ein paar hundert Megabyte) geladen war, aber für eine riesige Datenmenge (Terabyte) vorbereitet werden musste. Der Schwerpunkt lag auf dem Aufbau von Datenpipelines, die alle Einzelteile miteinander verbinden und den gesamten Workflow von der Datenbank über ETL (Extract-Transform-Load) und Berechnungen bis hin zur eigentlichen Anwendung automatisieren. Das einfache Master-Skript, das ein Skript nach dem anderen aufruft, kam also nicht mehr in Frage. Es war relativ klar, dass ein Programm oder ein Framework, das DAG’s verwendet, notwendig war. Daher werde ich in diesem Beitrag kurz darauf eingehen, was eine DAG in diesem Zusammenhang ist, welche Alternativen wir in Betracht gezogen haben und für welche wir uns letztendlich entschieden haben. Außerdem gibt es einen , in dem genauer erklärt wird, wie der Arbeitsablauf mit Airflow aussieht, z.B. ein Hallo-Welt-Programm und das ganze Setup.
Was ist eine DAG?
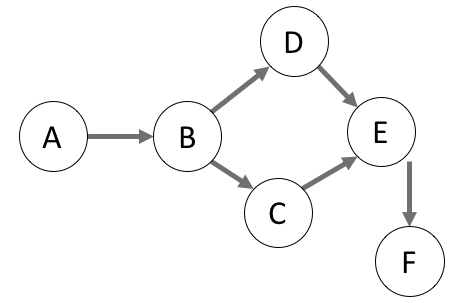
Directed Acyclic Graph
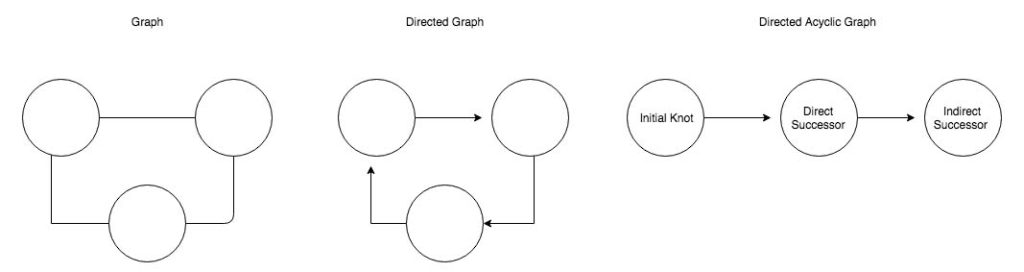
In der Programmierung kann diese spezielle From eines Ausführungsplans verwendet werden, um alle notwendigen Prozessschritte als einen Knoten im Graphen zu definieren. Jede Aufgabe, die selbständig erledigt werden kann, ist ein Anfangsknoten ohne Vorgänger und hat als solcher keine abhängingen, vorgeschalteten Beziehungspunkte. Ausgehend von einem Anfangsknoten werden wir die Aufgaben verknüpfen, die direkt von diesem abhängig sind. Wenn wir diesen Prozess fortsetzen und alle Aufgaben mit dem daraus entstehenden Graphen verbinden, können wir ein ganzes Projekt in einem visuellen Ablaufplan darstellen. Auch wenn dies für einfache Projekte wie „führe erst A aus, dann B und schließlich C“ trivial sein mag, ist dies ab einer gewissen Größe oder Komplexität des Workflows nicht mehr der Fall. Komplexe Arbeitsabläufe, mit mehreren Aufgaben, die wiederum direkte und indirekte Abhängigkeiten aufweisen können, bietet das ideale Szenario die Stärken der DAG-Darstellung auszunutzen. Ein DAG gibt daher nicht nur einen nützlichen Einblick, wie sich Abhängigkeiten auf die eigentlich Ausführung des Prozesses auswirken (welche Aufgben dürfen parallel, welche müssen sequentiell ausgeführt werden). Sondern ist als visuelle Darstellung hilfreich, um diesen Prozess auch für Nicht-Experten leicht verständlich zu machen.
Wonach haben wir gesucht?
Wie bereits erwähnt, waren wir auf der Suche nach einer Software, einem Framework oder zumindest einer Bibliothek als Orchestrator, die auf der Basis von DAGs arbeitet, den Überblick über die gesamten Workflows behält und mit eventuell auftretenden Fehlern (z.B. eine Aufgabe schlägt fehlt) umgehen kann. Darüber hinaus wäre ein eingebauter, „advanced“ Scheduler vorteilhaft, da der Ablauf jede Woche ausgeführt werden muss und eine manuelle Überwachung daher sehr mühsam wäre. Warum advanced? – Es gibt einfache Scheduler wie cron, die sich hervorragend eignen, um einen bestimmten Job zu einer bestimmten Zeit zu starten, die sich aber nicht, oder nur sehr aufwendig in den Workflow nativ integrieren lassen. Ein Scheduler, der auch die DAGs (mit allen Abhängigkeiten und Besonderheiten) im Auge behält, wäre also großartig. Schließlich sollte neben der leichten Erweiterbarkeit des Workflows dieser auch skalierbar sein. Es wäre also hilfreich, wenn wir ein Skript, z. B. zum Bereinigen von Daten, mehrmals nur mit einem anderen Argument (für verschiedene Datenstapel) als verschiedene Knoten im Workflow ohne viel Overhead und Code aufrufen könnten.
Was waren unsere Optionen?
Nachdem wir die Entscheidung getroffen hatten, dass wir einen DAG basierten Orchestrator implementieren müssen, tauchten in der anschließenden Google-Suche eine Vielzahl von Software, Frameworks und Paketen auf. Es war notwendig, die Menge der Optionen einzugrenzen, so dass nur einige wenige übrig blieben, die wir eingehend untersuchen konnten. Auch stellten wir fest, dass wir ein Tool brauchen, das nicht nur überwiegend GUI basiert ist, da dies die Flexibilität und Skalierbarkeit einschränkt. Es sollte allerdings auch nicht zu code-intensiv oder in einer unbequemen Programmiersprache sein, da die daraus resuliteriende, flache Lernkurve eine rasche Adaption verhindert und es zusätzlich länger dauert alle Projekt Stakeholder an Bord zu holen. Daher wurden Optionen wie Jenkins oder WAF sofort verworfen. Dennoch konnten wir die Auswahl auf drei Optionen eingrenzen.
Option 1 – Native Lösung: Cloud-Orchestrator
Da der PoC in einer Cloud bereitgestellt wurde, war die erste Option auch ziemlich offensichtlich – wir könnten einen der nativen Orchestratoren verwenden. Diese böten uns eine einfache GUI zur Definition unserer DAGs, einen Scheduler und waren darauf ausgelegt, Daten wie in unserem Fall notwendig zu routen. Auch wenn sich das gut anhört, war das unvermeidliche Problem, dass solche GUIs die oben genannte Flexibilität einschränken, man für die Benutzung natürlich bezahlen müsste und es ohne Coden überhaupt keinen Spaß machen würde. Trotzdem behielten wir die Lösung als Backup-Plan bei.
Option 2 – Apaches Hadoop-Lösungen: Oozie oder Askaban
Oozie und Azkaban sind beides Open-Source Workflow-Manager, die in Java geschrieben und für die Integration in Hadoop-Systeme konzipiert sind. Sie sind daher beide für die Ausführung von DAGs entworfen, skalierbar und haben einen integrierten Scheduler. Während Oozie versucht, hohe Flexibilität im Tausch gegen Benutzerfreundlichkeit zu bieten, ist es bei Azkaban genau andersherum. So ist die Orchestrierung im Falle von Azkaban nur über die WebUI möglich. Oozie hingegen stützt sich auf XML-Dateien oder Bash, um Prozesse zu verwalten und zu planen.
Option 3 – Python-Lösung: Luigi oder Airflow
Luigi und Airflow sind beides in Python geschriebene Workflow-Manager, die als Open-Source-Frameworks verfügbar sind.
Luigi wurde 2011 von Spotify entwickelt und sollte so allgemein wie möglich gehalten werden – im Gegensatz zu Oozie oder Azkaban, die für Hadoop gedacht waren. Der Hauptunterschied zu den beiden anderen ist, dass das Definieren von Aufgaben in Luigi ausschließlich code- und nicht GUI-basiert ist. Die ausführbaren Workflows werden alle durch Python Code dargestellt und die Benutzeroberfläche dient nur der Verwaltung. Diese WebUI von Luigi bietet dabei eine hohe Benutzerfreundlichkeit, wie das Suchen, Filtern oder Überwachen der Graphen und Aufgaben.
Ähnlich verhält es sich mit Airflow, das von Airbnb entwickelt und 2015 freigegeben wurde. Außerdem wurde es 2016 in den Apache Incubator aufgenommen. Wie Luigi ist es ebenfalls code basiert und verfügt über eine Benutzeroberfläche, die auch hier wieder die Endnutzerfreundlichkeit erhöht. Außerdem verfügt es über einen integrierten Scheduler, so dass man nicht auf Cron angewiesen ist.
Unsere Entscheidung
Unser erstes Kriterium für die weitere Filterung war, dass wir einen code basierten Orchestrator wollten. Auch wenn grafische Schnittstellen relativ einfach zu handhaben sind und man sich schnell zurechtfindet, würde dies zu Lasten einer langsameren Entwicklung gehen. Außerdem wäre das Bearbeiten und Erweitern zeitaufwändig, wenn jede einzelne Anpassung per Mausklick erfolgen müsste, anstatt Funktionen oder Codeschnipsel wiederzuverwenden. Deshalb haben wir uns gegen Option 1 entschieden – den lokalen Cloud-Orchestrator. Der Verlust an Flexibilität sollte nicht unterschätzt werden. Alle Erfahrungen und Skills, die wir mit einem unabhängigen Orchestrator gewonnen haben, können wahrscheinlich auf jedes andere Projekt übertragen werden. Dies wäre bei einem cloud-nativen Orchestrator nicht der Fall, da er an die spezifische Umgebung gebunden ist.
Der wichtigste Unterschied zwischen den beiden anderen Optionen ist die Programmiersprache, in denen sie arbeiten. Luigi und Airflow sind Python basiert, während Oozie und Azkaban auf Java und Bash-Skripten basieren. Auch diese Entscheidung war leicht zu treffen, denn Python ist eine hervorragende Skriptsprache, die leicht zu lesen, schnell zu erlernen und einfach zu schreiben ist. Unter dem Aspekt der Flexibilität und Skalierbarkeit bot uns Python einen besseren Nutzen als die (kompilierte) Programmiersprache Java. Außerdem musste die Workflow-Definition entweder über eine grafische Benutzeroberfläche (wieder) oder über XML erfolgen. Auf diese Weise konnten wir auch Option zwei ausschließen.
Abschließend bliebt nur zu klären, ob Spotifys Luigi oder Airbnbs Airflow zur Anwendungen kommen sollte. Es war eine Entscheidung zwischen dem ausgereiften und stabilen (Luigi) oder dem jungen Star (Airflow) unter den Workflow-Managern. Beide Projekte wurden nach wie vor gepflegt und sind auf GitHub sehr aktiv, mit über mehreren tausend Commits, mehreren hundert Stars und mehreren hundert Mitwirkenden. Nichtsdestotrotz gab es einen Aspekt, der für unsere Entscheidung ausschlaggebend war – Cron. Luigi kann Jobs (Aufgaben) nur mit Hilfe von cron planen, im Gegensatz zu Airflow, das einen integrierten, advanced Scheduler hat. Aber was ist überhaupt das Problem mit Cron?
Cron funktioniert gut, wenn Sie eine Aufgabe zu einer bestimmten Zeit erledigen wollen. Sobald Sie jedoch mehrere Aufträge planen wollen, die voneinander abhängen, wird es schwierig. Cron berücksichtigt diese Abhängigkeiten nicht. Nehmen wir an, wir brauchen einen Job, der alle fünf Minuten läuft und einige Echtzeitdaten aus einer Datenbank abgreift. Wenn nichts schief geht und die Laufzeit der Jobs bekannt ist (und sich nicht ändert), werden keine Probleme entstehen. Ein Job wird gestartet, er wird beendet, der nächste startet und so weiter. Was aber, wenn die Verbindung zur Datenbank nicht funktioniert? Auftrag eins wird gestartet, aber nie beendet. Fünf Minuten später wird der zweite Job das Gleiche tun, während Job eins noch aktiv ist. Dies kann sich fortsetzen, bis der gesamte Rechner durch nicht beendete Aufträge blockiert ist oder abstürzt. Mit Airflow könnte ein solches Szenario leicht vermieden werden, da es den Start neuer Aufträge automatisch stoppt, wenn die Anforderungen nicht erfüllt sind.
Zusammenfassung unserer Entscheidung
Wir haben uns für Apache Airflow gegenüber den anderen Alternativen entschieden, weil
-
Kein Cron – Mit Airflows integriertem Scheduler müssen wir uns nicht auf Cron verlassen, um unsere DAG zu planen, und verwenden nur ein Framework (nicht wie Luigi).
-
Code-Basierend – In Airflow werden alle Workflows, Abhängigkeiten und das Scheduling in Python Code ausgeführt. Daher ist es relativ einfach, komplexe Strukturen aufzubauen und die Abläufe zu erweitern.
-
Sprache – Python ist eine Sprache, die man leicht erlernen kann und die in unserem Team vorhanden war.
Daher erfüllt Airflow alle unsere Anforderungen. Wir haben damit einen Orchestrator, der den Workflow, den wir mit Python Code definieren, im Auge behält. Daher können wir den Workflow auch leicht in jede Richtung erweitern – mehr Daten, mehr Batches, mehr Schritte im Prozess oder sogar auf mehreren Maschinen gleichzeitig ausweiten, sind kein Problem mehr. Darüber hinaus bietet Airflow auch eine schöne visuelle Oberfläche des Workflows, sodass man ihn auch leicht überwachen kann. Und schließlich erlaubt Airflow den Verzicht auf Cron, da es mit einem nativen (advanced) Scheduler ausgestattet ist. Dieser kann nicht nur eine Aufgabe starten, sondern behält auch den Überblick über alle definierten Abhängigkeiten und ist in seinen Ausführungseigenschaften stark anpassbar, was zusätzliche Flexibilität bedeutet.
Im dieses Blogs schauen wir uns Airflow genauer an, erklären, wie man es verwendet und wie man es für verschiedene Anwendungsfälle konfiguriert.