
In unserem ersten Blog-Beitrag zum Textmining im tidyverse haben wir uns mit den ersten Schritten zum Einlesen und Bereinigen von Texten mit den Mitteln des tidyverse befasst und bereits erste Sentimentanalysen begonnen. Die Grundlage hierzu bildete das epistemologische Werk The Grammar of Science von Karl Pearson. Im zweiten Teil wollen wir auf diesen Grundlagen aufbauen und damit ein weiteres von Pearsons vielfältigen Interessensgebieten anschneiden: Die deutsche Sprache. Pearson, der nach einem Studienaufenthalt in Heidelberg Karl anstelle Carl genannt werden wollte, verlieh seinem Interesse an Goethe auch in seinem Buch The New Werther Ausdruck.
Um den deutschsprachigen Korpora des Internets gerecht zu werden, wollen wir an dieser Stelle Lexika vorstellen, welche sich für die Bedeutungsanalyse von Texten eignen. Hierzu eignet sich der Sentimentwortschatz SentiWS der Universität Leipzig. In diesem Worschatz finden sich Ratings auf einer Skala von -1 (negatives Sentiment) bis 1 (positives Sentiment). Die aktuellste Version kann als .zip-File hier heruntergeladen werden.
Wie im ersten Blog der Serie beschrieben, ist der Weg zu ersten Analysen relativ kurz: Nach etwas Datenbereinigung und Zerlegung unseres Character-Strings in einzelne Tokens verbinden wir unsere Textdaten (in diesem Fall ein nach Autoren gruppierter Korpus unseres STATWORX-Blogs) mit dem Lexikon unserer Wahl, wodurch wir einen Datensatz von nach Sentiment bewerteten Wörtern erhalten, welche sowohl in unserem Datensatz als auch im Lexikon enthalten sind.
Deutschsprachige Blogs scrapen
Bevor wir beginnen, müssen wir uns allerdings zuerst der Erstellung eines Textdatensatzes widmen. Da wir als Beispiel einen vornehmlich deutschen, aber überschaubaren Korpus wählen möchten und uns das Befinden der STATWORX-Blogger verständlicher Weise sehr am Herzen liegt, möchten wir den STATWORX-Blog als Grundlage nutzen.
Nach dem Laden der relevanten Pakete (auch in diesem Eintrag möchte ich wieder Pakete aus dem tidyverse empfehlen), konstruieren wir mit Hilfe des purrr-Paketes zwei aufgeräumte, kompakte Code-Blöcke zum Sammeln der entsprechenden Blog-Links und zum Auslesen und Präparieren selbiger.
# load packages
library(XML)
library(xml2)
library(tidyverse)
library(tidytext)
library(tokenizers)
Im folgenden Code-Block durchsuchen wir die fünf bisher existierenden Blog-Übersichten auf der STATWORX-Homepage nach Links zu den einzelnen Blogs. Dafür nutzen wir hmtlParse und xpathSApply aus dem XML-Paket um die Übersichtsseiten einzulesen und nach Links zu durchforsten. Mit Hilfe von filter und distinct aus dem dplyr-Paket trennen wir daraufhin Übersichten von den eigentlichen Artikeln und filtern Duplikate aus den Links heraus.
# Extraction of first five pages of Statworx-Blogs
# Extraction of all links that contain "blog", but filter the overview pages
# get unique blog posts
webpages %
xpathSApply(., "//a/@href") %>%
data_frame(.) %>%
filter(., grepl("/blog", .)) %>%
filter(., !grepl("/blog/$|/blog/page/|/data-science/|/statistik/", .)) %>%
distinct()) %>% unlist
Nun sind wir bereit, mit den entsprechenden Links, den bereits angesprochenen xpathSApply und htmlParse, sowie read_html aus dem xml2-Paket die eigentlichen Blogeinträge auszulesen. Mit Hilfe von paste und gsub bereinigen wir die Absätze im Text. Anschließend nutzen wir unnest_tokens aus dem tidytext-Paket, um einzelne Worte aus den Blogeinträgen zu isolieren. Weiterhin nutzen wir dplyr und das tokenizers-Paket, um mit anti_join und stopwords(„de“) deutschsprachige Stopwords aus dem Text zu entfernen (für genauere Beschreibungen der Begrifflichkeiten und der Natur dieser Bereinigungen möchte ich an dieser Stelle noch einmal auf den ersten Teil unserer Serie Textmining im tidyverse verweisen). Zuletzt fügen wir noch eine Spalte zum Dataframe hinzu (da dieser Block in purrr::map_df eingewickelt ist, erhalten wir als Output unserer Pipe einen Dataframe), welcher den Nachnamen des jeweiligen STATWORX-Bloggers angibt.
# read in blog posts, output should be a dataframe
# parse HTML, extract text, clean line breaks
# unnest tokens (in this case terms) and remove stop words
# add a column with the author name
tidy_statworx_blogs %
htmlParse(., asText = TRUE) %>%
xpathSApply(., "//p", xmlValue) %>%
paste(., collapse = "n") %>%
gsub("n", "", .) %>%
data_frame(text = .) %>%
unnest_tokens(word, text) %>%
anti_join(data_frame(word = stopwords("de"))) %>%
mutate(author = .$word[2]))
Im nächsten Schritt wollen wir unseren Blog-Datensatz mit dem oben genannten Leipziger Sentimentwortschatz verbinden. Wir lesen sowohl die negativen, als auch die positiven Sentimentrating-txt-Files ein, beachten dabei t als Trennzeichen und setzen fill = TRUE. Mit bind_rows aus dem dplyr-Paket verbinden wir beide Rating-Datensätze, selektieren nur die ersten beiden Spalten und benennen diese mit word und value.
setwd("/Users/obiwan/jedi_documents")
sentis %
dplyr::select(., 1:2)
names(sentis) <- c("word", "value")
Anschließend nutzen wir str_to_lower aus dem stringr-Paket, um die character-Daten im Ratingdatensatz komplett in Kleinbuchstaben umzuwandeln und gsub, um die Worttypbeschreibungen aus den Strings zu entfernen. Mit inner_join aus dem dplyr-Paket verbinden wir nun die Blog-Eintragsdaten mit den Sentimentratings und zwar nur für jene Worte, welche sowohl in den Blogs vorkommen, als auch im Leipziger Sentimentwortschatz geratet sind. Für weitere Analysen können wir auch noch in der gleichen Pipe eine Spalte hinzufügen, welche dichotom beschreibt, ob einem Wort ein positives, oder ein negatives Sentiment zugeordnet wird – dazu mehr beim nächsten Mal.
tidy_statworx_blogs_sentis %
mutate(word = stringr::str_to_lower(word)) %>%
mutate(word = gsub("Dnn", "", word)) %>%
inner_join(., tidy_statworx_blogs, by = "word") %>%
mutate(sent_bin = ifelse(value >= 0, "positive", "negative"))
Wir erhalten einen Datensatz mit Ratings, welcher wie folgt aussieht:
tbl_df(tidy_statworx_blogs_sentis)
# A tibble: 360 x 4
word value author sent_bin
1 abhängigkeit -0.3653 darrall negative
2 abhängigkeit -0.3653 darrall negative
3 abhängigkeit -0.3653 darrall negative
4 abhängigkeit -0.3653 moreau negative
5 absturz -0.4739 krabel negative
6 abweichung -0.3462 aust negative
7 abweichung -0.3462 moreau negative
8 abweichung -0.3462 gepp negative
9 angriff -0.2120 bornschein negative
10 auflösung -0.0048 heinz negative
# ... with 350 more rows
Durchschnittliche Sentimentratings – Ein Stimmungsbarometer?
Da uns nun interessieren könnte, welchem Blogger aus dem Team wir besser nicht krumm kommen sollten, könnten wir nun zu unserer Sicherheit das durchschnittliche Sentimentrating pro Autor visualisieren. Wir gruppieren unsere Analyse pro Autor, aggregieren die Sentimentratings als arithemtische Mittel auf Gruppenebene und pipen den entstehenden Dataframe in eine ggplot-Funktion. Letztere erstellt für uns absteigend geordnete Säulen mit dem mittleren Sentimentrating pro Blogger, zeichnet das mittlere Sentimentrating des gesamten STATWORX-Teams ein, dreht die Koordinaten und ändert das ggplot-Theme zu theme_minimal für den optischen Feinschliff.
tidy_statworx_blogs_sentis %>%
group_by(author) %>%
summarise(mean_senti = mean(value, na.rm = TRUE)) %>%
ggplot(.) +
geom_bar(aes(x = reorder(author, mean_senti), y = mean_senti),
stat = "identity", alpha = 0.8, colour = "Darkgrey") +
labs(title = "Mean Sentiment Rating by Author",
x = "Author", y = "Mean Sentiment") +
geom_hline(yintercept = mean(sentis$value, na.rm = TRUE),
linetype = "dashed", colour = "Grey30", alpha = 0.7) +
coord_flip() +
theme_minimal()
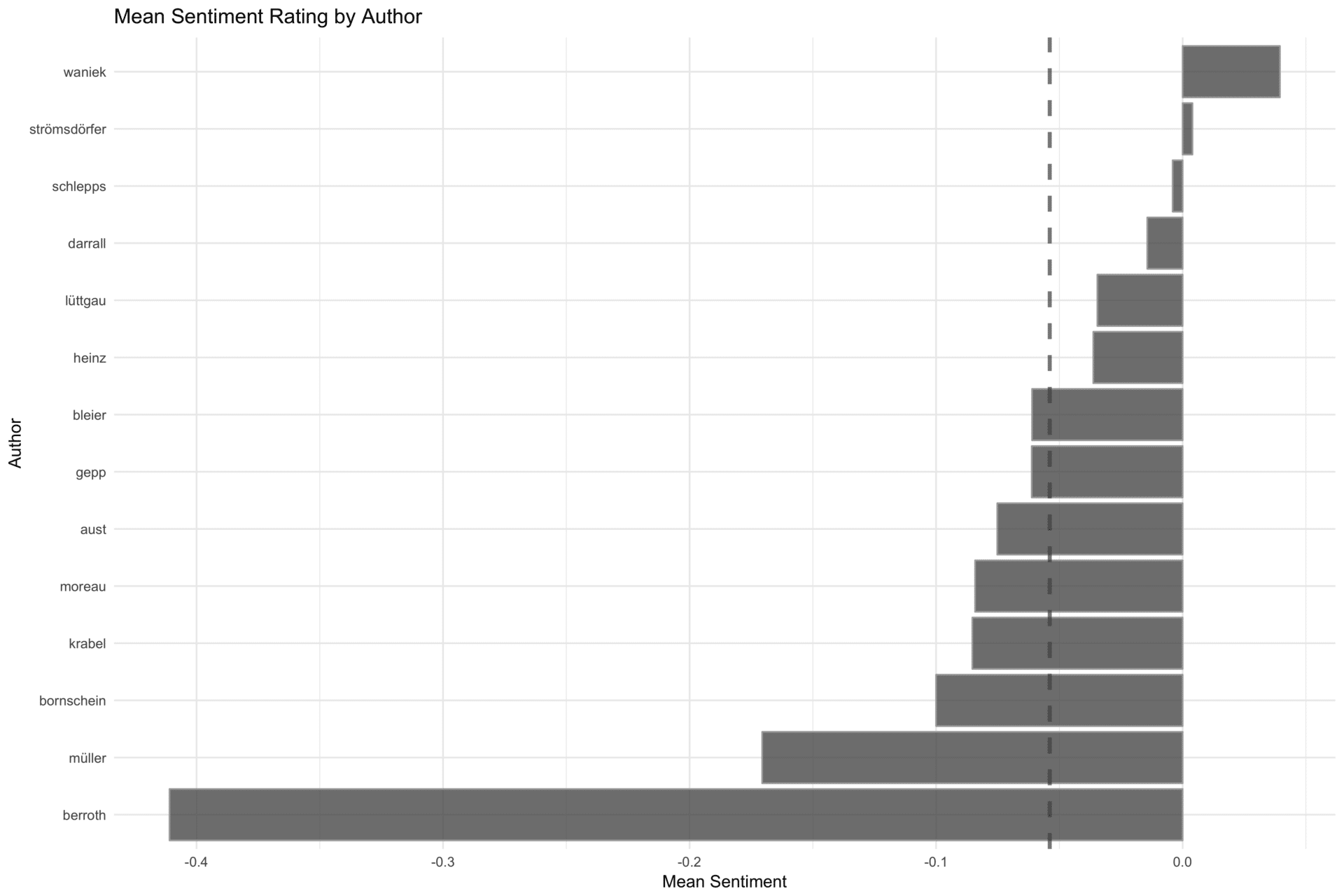
Eine andere Darstellung, welche für uns interessant ist, ist die Verteilung der Sentimentratings pro Autor. An dieser Stelle wählen wir einen gruppierten Densitiyplot, obwohl durchaus viele Darstellungen hier hilfreich sein können:
tidy_statworx_blogs_sentis %>% ggplot(.) +
geom_density(aes(value, fill = author), alpha = 0.7, bw = 0.08) +
xlim(-1,1) +
labs(title = "Densities of Sentiment Ratings by Author",
x = "Sentiment Rating") + theme_minimal()
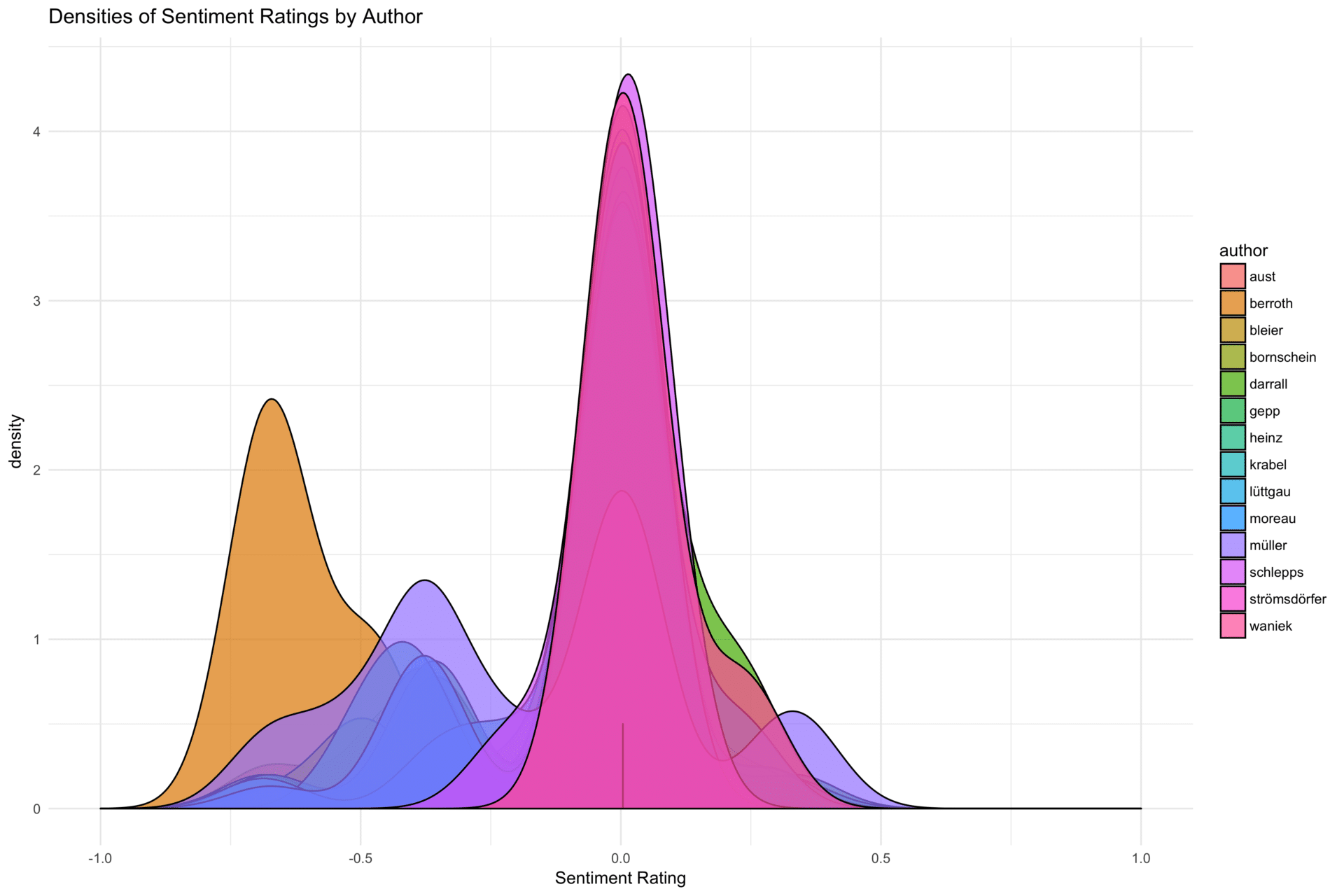
Mit diesen wenigen Handgriffen haben wir nun auch ein paar erste Analysen zu einem deutschsprachigen Textkorpus gemacht. Meine Formulierung verrät wohl bereits: Wir stehen mit dem Textmining trotz ersten Fortschritten noch ziemlich am Anfang. Allerdings haben wir uns nun für deutlich komplexere Aufgaben ausgerüstet: Der näheren Erfassung von Inhalt und Semantik in unseren Korpora. Im nächsten Teil befassen wir uns Term-Dokument-Matrizen, Dokument-Term-Matrizen, sowie der Latent Dirichlet Allocation und verwandten Techniken.
Referenzen
- Duncan Temple Lang and the CRAN Team (2017). XML: Tools for Parsing and Generating XML Within R and S-Plus. R package version 3.98-1.9. https://CRAN.R-project.org/package=XML
- Hadley Wickham, James Hester and Jeroen Ooms (2017). xml2: Parse XML. R package version 1.1.1. https://CRAN.R-project.org/package=xml2
- Hadley Wickham, Romain Francois, Lionel Henry and Kirill Müller (2017). dplyr: A Grammar of Data Manipulation. R package version 0.7.4. https://CRAN.R-project.org/package=dplyr
- Kirill Müller and Hadley Wickham (2017). tibble: Simple Data Frames. R package version 1.3.4. https://CRAN.R-project.org/package=tibble
- Lincoln Mullen (2016). tokenizers: A Consistent Interface to Tokenize Natural Language Text. R package version 0.1.4. https://CRAN.R-project.org/package=tokenizers
- Lionel Henry and Hadley Wickham (2017). purrr: Functional Programming Tools. R package version 0.2.3. https://CRAN.R-project.org/package=purrr
- Pearson, Karl (1880). The New Werther. C. Kegan & Co. https://archive.org/stream/newwertherbylok00peargoog#page/n6/mode/2up
- Pearson, Karl (1892). The Grammar of Science. London: Walter Scott. Dover Publications.
- https://archive.org/stream/grammarofscience00pearrich#page/n9/mode/2up
- Porter, T. (2017). Karl Pearson. In Encyclopædia Britannica. Retrieved from https://www.britannica.com/biography/Karl-Pearson
- Silge, J., & Robinson, D. (2017). Text mining with R: a tidy approach. Sebastopol, CA: OReilly Media.