
Bei all dem Hype um KI in den letzten Jahren darf man nicht außer Acht lassen, dass ein Großteil der Unternehmen bei der erfolgreichen Implementierung von KI-basierten Anwendungen noch hinterherhinken. Dies ist gerade in vielen Industrien, wie z.B. in produzierenden Gewerben, recht offensichtlich (McKinsey).
Eine von Accenture 2019 durchgeführte Studie zum Thema Implementierung von KI in Unternehmungen zeigt, dass über 80% aller Proof of Concepts (PoCs) es nicht in Produktion schaffen. Außerdem gaben nur 5% aller befragten Unternehmen an, eine unternehmensweite KI-Strategie implementiert zu haben.
Diese Erkenntnisse regen zum Nachdenken an: Was genau läuft schief und warum schafft künstliche Intelligenz anscheinend noch nicht die ganzheitliche Transition von erfolgreichen, akademischen Studien zu der realen Welt?
1. Was ist data-centric AI?
„Data-centric AI is the discipline of systematically engineering the data used to build an AI system.“
Zitat von Andrew Ng, data-centric AI Pionier
Der data-centric Ansatz fokussiert sich auf eine stärkere Daten-integrierenden KI (data-first) und weniger auf eine Konzentration auf Modelle (model-first), um die Schwierigkeiten von KI mit der „Realität“ zu bewältigen. Denn, die Trainingsdaten, die meist bei Unternehmen als Ausgangspunkt eines KI-Projekts stehen, haben relativ wenig gemeinsam mit den akribisch kurierten und weit verbreiteten Benchmark Datensets wie MNIST oder ImageNet.
Das Ziel dieses Artikels ist, data-centric im KI-Workflow und Projektkontext einzuordnen, Theorien sowie relevante Frameworks vorzustellen und aufzuzeigen, wie wir bei statworx eine data-first KI-Implementierung angehen.
2. Welche Gedankengänge stecken hinter data-centric?
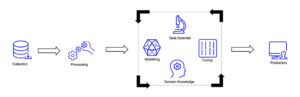
Vereinfacht dargestellt bestehen KI-Systeme aus zwei entscheidenden Komponenten: Daten und Modell(-Code). Data-centric fokussiert sich mehr auf die Daten, model-centric auf das Modell – duh!
Bei einer stark model-centric lastigen KI werden Daten als ein extrinsischer, statischer Parameter behandelt. Der iterative Prozess eines Data Science Projekts startet praktisch erst nach dem Erhalt der Daten bei den Modell-spezifischen Schritten, wie Feature Engineering, aber vor allem exzessives Trainieren und Fine tunen verschiedener Modellarchitekturen. Dies macht meist das Gros der Zeit aus, das Data Scientists an einem Projekt aufwenden. Kleinere Daten-Aufbereitungsschritte werden meist nur einmalig, ad-hoc am Anfang eines Projekts angegangen.
Im Gegensatz dazu versucht data-centric (automatisierte) Datenprozesse als zentralen Teil jedes ML Projekts zu etablieren. Hierunter fallen alle Schritte die ausgehend von den Rohdaten nötig sind, um ein fertiges Trainingsset zu generieren. Durch diese Internalisierung soll eine methodische Überwachbarkeit für verbesserte Qualität sorgen.
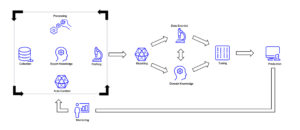
Man kann dabei data-centric Überlegungen in drei übergeordnete Kategorien zusammenfassen. Diese beschreiben lose, welche Aufgabenbereiche bei einem data-centric Ansatz bedacht werden sollten. Im Folgenden wurde versucht, diese bekannte Buzzwords, die im Kontext von data-centric immer wieder auftauchen, thematisch einer Kategorie zuzuordnen.
2.1. Integration von SMEs in den Development Prozess als wichtiges Bindeglied zwischen Data- und Model-Knowledge.
Die Einbindung von Domain Knowledge ist ein integraler Bestandteil von data-centric. Dies hilft Projektteams besser zusammenwachsen zu lassen und so das Wissen der Expert:innen, auch Subject Matter Experts (SMEs) genannt, bestmöglich im KI-Prozess zu integrieren.
- Data Profiling:
Data Scientists sollten nicht als Alleinkämpfer:innen die Daten analysieren und nur ihre Befunde mit den SMEs teilen. Data Scientists können ihre statistischen und programmatischen Fähigkeiten gezielt einsetzen, um SMEs zu befähigen, die Daten eigenständig zu untersuchen und auszuwerten. - Human-in-the-loop Daten & Model Monitoring:
Ähnlich wie beim Profiling soll hierbei durch das Bereitstellen eines Einstiegpunktes gewährleistet werden, das SMEs Zugang zu den relevanten Komponenten des KI-Systems erhalten. Von diesem zentralen Checkpoint können nicht nur Daten sondern auch Modell-relevante Metriken überwacht werden oder Beispiele visualisiert und gecheckt werden. Gleichzeit gewährt ein umfängliches Monitoring die Möglichkeit, nicht nur Fehler zu erkennen, sondern auch die Ursachen zu untersuchen und das möglichst ohne notwendige Programmierkenntnisse.
2.2. Datenqualitätsmanagement als agiler, automatisierter und iterativer Prozess über (Trainings-)Daten
Die Datenaufbereitung wird als Prozess verstanden, dessen kontinuierliche Verbesserung im Vordergrund eines Data Science Projekts stehen sollte. Das Modell, anders als bisher, sollte hingegen erstmal als (relativ) fixer Parameter behandelt werden.
- Data Catalogue, Lineage & Validation:
Die Dokumentation der Daten sollte ebenfalls keine extrinsische Aufgabe sein, die oft nur gegen Ende eines Projekts ad-hoc entsteht und bei jeder Änderung, z.B. eines Modellfeatures, wieder obsolet sein könnte. Änderungen sollen dynamisch reflektiert werden und so die Dokumentation automatisieren. Data Catalogue Frameworks bieten hier die Möglichkeit, Datensätze mit Meta-Informationen anzureichern.
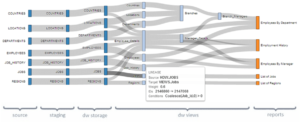
Data Lineage soll im Weiteren dabei unterstützen, bei diversen Inputdaten, verschiedenen Transformations- und Konsolidierungsschritten zwischen roh- und finalem Datenlayer den Überblick zu behalten. Je komplexer ein Datenmodell, desto eher kann ein Lineage Graph Auskunft über das Entstehen der finalen Spalten geben (Grafik unten), beispielsweise ob und wie Filterungen oder bestimmte join Logiken benutzt wurden. Die Validierung (neuer) Daten hilft schließlich eine konsistente Datengrundlage zu gewährleisten. Hier helfen die Kenntnisse aus dem Data Profiling um Validierungsregeln auszuarbeiten und im Prozess zu integrieren.
- Data & Label Cleaning:
Die Notwendigkeit der Datenaufbereitung ist selbsterklärend und als Best Practice ein fester Bestandteil in jedem KI-Projekt. Eine Label-Aufbereitung ist zwar nur bei Klassifikations-Algorithmen relevant, wird aber hier selten als wichtiger pre-processing Schritt mitbedacht. Aufbereitungen können aber mit Hilfe von Machine Learning automatisiert werden. Falsche Labels können es nämlich für Modelle erschweren, exakte patterns zu erlernen.
Auch sollte man sich bewusst machen, dass solange sich die Trainingsdaten ändern, die Datenaufbereitung kein vollkommen abgeschlossener Prozess sein kann. Neue Daten bedeuten oft auch neue Cleaning-Schritte. - Data Drifts in Produktion:
Eine weit verbreitete Schwachstelle von KI-Applikationen tritt meist dann auf, wenn sich Daten nicht so präsentieren, wie es beim Trainieren der Fall war, beispielweise im Zeitverlauf ändern (Data Drifts). Um die Güte von ML Modellen auch langfristig zu gewährleisten, müssen Daten in Produktion kontinuierlich überwacht werden. Hierdurch können Data Drifts frühzeitig ausfindig gemacht werden, um dann Modelle neu auszurichten, wenn z.B. bestimmte Inputvariablen von ihrer ursprünglichen Verteilung zu stark abweichen. - Data Versioning:
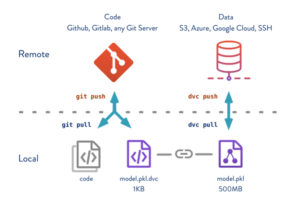
GitHub ist seit Jahren der go to Standard für Code Versionierungen, um mehr Übersicht und Kontrolle zwischen Codeständen zu haben. Aber auch Daten können versioniert werden und so eine ganzheitliche Prozesskontrolle bieten. Ebenfalls können so Code- mit Datenständen verknüpft werden. Dies sorgt nicht nur für bessere Überwachbarkeit, sondern hilft auch dabei, automatisierte Prozesse anzustoßen.
2.3. Generieren von Trainingsdatensätzen als programmatischer Task.
Gerade das Erzeugen von (gelabelten) Trainingsdaten ist einer der größten Roadblocker für viele KI-Projekte. Gerade bei komplexen Problemen, die große Datensätze benötigen, ist der initiale, manuelle Aufwand enorm.
- Data Augmentation:
Bei vielen datenintensiven Deep Learning Modellen wird diese Technik schon seit längerem eingesetzt, um mit bestehenden Daten, artifizielle Daten zu erzeugen. Bei Bilddaten ist dies recht anschaulich erklärbar. Hier werden beispielsweise durch Drehen eines Bildes verschiedene Perspektiven desselben Objektes erzeugt. Aber auch bei NLP und bei „tabularen“ Daten (Excel und Co.) gibt es Möglichkeiten neue Datenpunkte zu erzeugen.
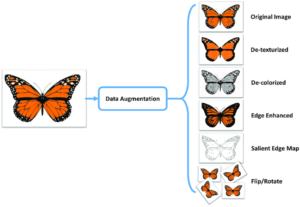
- Automated Data Labeling:
Normalerweise ist Labeling ein sehr arbeitsintensiver Schritt, in dem Menschen Datenpunkte einer vordefinierten Kategorie zuordnen. Einerseits ist dadurch der initiale Aufwand (Kosten) sehr hoch, andererseits fehleranfällig und schwierig zu überwachen. Hier kann ML durch Konzepte wie semi- oder weak supervison Automatisierungshilfe leisten, was den manuellen Aufwand erheblich reduziert. - Data Selection:
Arbeiten mit großen Datensätzen sind im lokalen Trainingskontext schwierig zu handhaben. Gerade dann, wenn diese nicht mehr in den Arbeitsspeicher des Laptops passen. Und selbst wenn, dann dauern Trainingsläufe meist sehr lange. Data Selection versucht die Größe durch ein aktives Subsampling (ob gelabelt oder ungelabelt) zu reduzieren. Aktiv werden hier die „besten“ Beispiele mit der höchsten Vielfalt und Repräsentativität ausgewählt, um die bestmögliche Charakterisierung des Inputs zu gewährleisten – und das automatisiert.
Selbstverständlich ist es nicht in jedem KI-Projekt sinnvoll, alle aufgeführten Frameworks zu bedenken. Es ist Aufgabe eines jedes Development Teams, die nötigen Tools und Schritte im data-centric Kontext zu analysieren und auf Relevanz und Übertragbarkeit zu prüfen. Hier spielen neben datenseitigen Überlegungen auch Business Faktoren eine Hauptrolle, da neue Tools meist auch mehr Projektkomplexität bedeuten.
3. Integration von data-centric bei statworx
Data-centric Überlegungen spielen bei unseren Projekten gerade in der Übergangsphase zwischen PoC und Produktivstellen des Modells vermehrt eine führende Rolle. Denn auch in einigen unserer Projekte ist es schon vorgekommen, dass man nach erfolgreichem PoC mit verschiedenen datenspezifischen Problemen zu kämpfen hatte; meist hervorgerufen durch unzureichende Dokumentation und Validierung der Inputdaten oder ungenügende Integration von SMEs im Datenprozess und Profiling.
Generell versuchen wir daher unseren Kunden die Wichtigkeit des Datenmanagements für die Langlebigkeit und Robustheit von KI-Produkten in Produktion aufzuzeigen und wie hilfreiche Komponenten innerhalb einer KI-Pipeline verknüpft sind.
Gerade unser Data Onboarding – ein Mix aus Profiling, Catalogue, Lineage und Validation, integriert in ein Orchestrations-Framework – ermöglicht uns mit den oben genannten Problemen besser umzugehen und so hochwertigere KI-Produkte bei unseren Kunden zu integrieren.
Zusätzlich hilft dieses Framework dem ganzen Unternehmen, bisher ungenutzte, undokumentierte Datenquellen für verschiedene Use Cases (nicht nur KI) verfügbar zu machen. Dabei ist die enge Zusammenarbeit mit den SMEs auf Kundenseite essenziell, um so effektive und robuste Datenqualitäts-Checks zu implementieren. Die resultierenden Datentöpfe und -prozesse sind somit gut verstanden, sodass Validierungs-Errors vom Kunden verstanden und behoben werden können, was so zu einem langlebigen Einsatz des Service beiträgt.
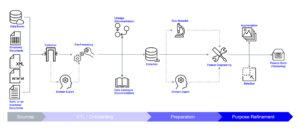
In einer abgespeckten, kundenspezifischen Data Onboarding Integration haben wir mit Hilfe verschiedener Open und Closed Source Tools eine für den Kunden einfach skalierbare und leicht verständliche Plattform geschaffen.
So haben wir beispielsweise Validationchecks mit Great Expectations (GE), einem Open Source Framework, umgesetzt. Dieses Tool bietet neben Python-basierter Integration diverser Tests auch eine Reporting Oberfläche, die nach jedem Durchlauf einen einfach verständlichen Einstiegspunkt in die Resultate bietet.
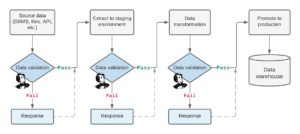
Diese Architektur kann dann in verschiedenen Kontexten laufen, ob in der Cloud, mit einem Closed Source Software wie Azure Data Factory oder on premises mit Open Source Tools wie Airflow – und kann um weitere Tools jederzeit ergänzt werden.
4. Data-centric im Status Quo von KI
Sowohl model- als auch data-centric beschreiben Handlungsansätze, wie man an ein KI-Projekt herangehen kann.
Model-centric ist in den letzten Jahren recht erwachsen geworden und es haben sich dadurch einige Best Practices in verschiedenen Bereichen entwickelt, auf denen viele Frameworks aufbauen.
Dies hat auch damit zu tun, dass in der akademischen Welt der Fokus sehr stark auf Modellarchitekturen und deren Weiterentwicklung lag (und noch liegt) und diese stark mit führenden KI-Unternehmen korreliert. Gerade im Bereich Computer Vision und Natural Langue Processing konnten kommerzialisierte Meta-Modelle, trainiert auf gigantischen Datensets, die Tür zu erfolgreichen KI Use Cases öffnen. Diese riesigen Modelle können auf kleineren Datenmengen für Endanwendungen gefinetuned werden, bekannt unter Transfer Learning.
Diese Entwicklung hilft allerdings nur einem Teil der gescheiterten Projekte, da gerade im Kontext von industriellen Projekten fehlende Kompatibilität oder Starrheit der Use Cases die Anwendungen von Meta-Modellen erschwert. Die Nicht-Starrheit findet sich häufig in maschinenlastigen Produktionsindustrien, wo sich das Umfeld, in dem Daten produziert werden, stetig ändert und sogar der Austausch einer einzelnen Maschine große Auswirkungen auf ein produktives KI-Modell haben kann. Wenn diese Problematik nicht richtig im KI-Prozess bedacht wurde, entsteht hier ein schwer kalkulierbares Risiko, auch bekannt unter Technical Debt [Quelle: https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf].
Zu guter Letzt stellen die Distributionen bei einigen Use Cases ein inhärentes Problem für ML dar. Modelle haben grundsätzlich Schwierigkeiten mit edge cases, sehr seltene und ungewöhnliche Beobachtungspunkte (die long tails [Quelle: https://medium.com/codex/machine-learning-the-long-tail-paradox-1cc647d4ba4b] einer Verteilung). Beispielweise ist es nicht ungewöhnlich, dass bei Fault Detection das Verhältnis von fehlerhaften zu einwandfreien Bauteilen eins zu mehreren Tausend beträgt. Die Abstraktionsfähigkeit bei ungesehenen, abseits der Norm liegenden Fehlern ist hier meist schlecht.
5. Schluss – Paradigmenwechsel in Sicht?
Diese Probleme zu bewältigen, ist zwar Teil des Versprechens von data-centric, aber präsentiert sich im Moment noch eher unausgereift.
Das lässt sich auch an der Verfügbarkeit und Maturität von Open Source Frameworks darlegen. Zwar gibt es schon vereinzelte, produktionsfertige Anwendungen, aber keine, die die verschiedenen Teilbereiche von data-centric zu vereinheitlichen versucht. Dies führt unweigerlich zu längeren, aufwendigeren und komplexeren KI-Projekten, was für viele Unternehmen eine erhebliche Hürde darstellt. Außerdem sind kaum Datenmetriken vorhanden, die Unternehmen ein Feedback geben, was sie denn genau gerade „verbessern“. Und zweitens, viele der Tools (bsp. Data Catalogue) haben einen eher indirekten, verteilten Nutzen.
Einige Start-ups, die diese Probleme angehen wollen, sind in den letzten Jahren entstanden. Dadurch, dass diese aber (ausschließlich) paid tier Software vermarkten, ist es eher undurchsichtig, inwiefern diese Produkte wirklich die breite Masse an Problemen von verschiedenen Use Cases abdecken können.
Obwohl die Aufführungen oben zeigen, dass Unternehmen generell noch weit entfernt sind von einer ganzheitlichen Integration von data-centric, wurden robuste Daten Strategien in der letzten Zeit immer wichtiger (wie wir bei statworx an unseren Projekten sehen konnten).
Mit vermehrtem akademischem Research in Daten Produkte wird sich dieser Trend sicherlich noch verstärken. Nicht nur weil dadurch neue, robustere Frameworks entstehen, sondern auch weil durch Uni-Absolvent:innen den Unternehmen mehr Wissen in diesem Gebiet zufließt.
Bild-Quellen:
Model-centric arch: eigene
Data-centric arch: eigene
Data lineage: https://www.researchgate.net/figure/Data-lineage-visualization-example-in-DW-environment-using-Sankey-diagram_fig7_329364764
Historisierung Code/Data: https://ardigen.com/7155/
Data Augmentation: https://medium.com/secure-and-private-ai-writing-challenge/data-augmentation-increases-accuracy-of-your-model-but-how-aa1913468722
Data & AI pipeline: eigene
Validieren mit GE: https://greatexpectations.io/blog/ge-data-warehouse/