Eine erfolgreiche Data Culture ist der Schlüssel für Unternehmen, um aus der ständig wachsenden Menge an Daten den größtmöglichen Nutzen zu ziehen. Der Trend, Entscheidungen auf der Basis von Daten zu treffen, ist unaufhaltsam. Doch wie schaffen es Führungskräfte, ihre Teams dazu zu befähigen, Daten effektiv zu nutzen?
Eine lebendige Data Culture: Der Treibstoff für Unternehmenserfolg
Data Culture ist mehr als ein Schlagwort – sie ist die Grundlage für datengestützte Entscheidungen. Wenn alle Abteilungen eines Unternehmens Daten zur Verbesserung von Arbeitsabläufen und zur Entscheidungsfindung nutzen, entsteht eine Atmosphäre, in der kompetenter Umgang mit Daten zum Standard gehört.
Warum ist das so wichtig? Daten sind Treibstoff für den Geschäftserfolg: 76 Prozent der Teilnehmer:innen des BARC Data Culture Survey 22 gaben an, dass ihr Unternehmen eine Datenkultur anstrebt. Und 75 Prozent der Führungskräfte sehen Data Culture als wichtigste Kompetenz.

Die entscheidende Rolle von Führungskräften
Eine etablierte Data Culture ist nicht nur ein Erfolgsfaktor für das Unternehmen, sondern auch ein Weg, um Innovationen zu fördern und Mitarbeiter:innen zu motivieren. Führungskräfte spielen hier eine zentrale Rolle, indem sie als Wegbereiter auftreten und den Wandel aktiv unterstützen. Sie müssen die Vorteile einer Data Culture klar kommunizieren, klare Richtlinien für Datenschutz und Datenqualität aufstellen und gezielte Schulungen sowie regelmäßige Kommunikation über Fortschritte anbieten. Eine klare Verantwortung für die Datenkultur ist entscheidend, denn 31 Prozent der Unternehmen mit schwach ausgeprägter Data Culture haben keine dedizierte Abteilung oder Person mit dieser Verantwortung.
Herausforderungen und Lösungen
Der Weg zur erfolgreichen Data Culture ist mit Hürden gespickt. Führungskräfte müssen sich verschiedenen Herausforderungen stellen:
- Widerstand gegen Veränderungen: Ein Übergang zu einer Data Culture kann auf Widerstand stoßen. Führungskräfte müssen die Vorteile klar kommunizieren und Schulungen anbieten, um ihre Mitarbeiter:innen in den Veränderungsprozess einzubeziehen.
- Fehlende Data-Governance: Richtlinien und Standards für den Umgang mit Daten sind entscheidend. Fehlen diese, verringert sich schlimmstenfalls die Datenqualität. Das führt zu falschen Entscheidungen. Hier sind Methoden zur Datenbereinigung und -validierung sowie regelmäßige Audits vonnöten.
- Bedenken hinsichtlich des Datenschutzes: Datenschutz und Datenzugang stehen oft im Konflikt. Hier müssen klare Richtlinien und Sicherheitsmaßnahmen eingeführt werden, um das Vertrauen der Mitarbeiter:innen zu gewinnen.
- Fehlende Ressourcen und Unterstützung: Ohne die nötigen Ressourcen kann der Aufbau einer Data Culture scheitern. Unternehmen müssen gezielte Schulungen anbieten und den geschäftlichen Nutzen in wirtschaftlichen Kennzahlen darstellen, um die Unterstützung ihrer Führungskräfte zu gewinnen.
Best Practices für eine starke Data Culture
Um eine Data Culture effektiv zu etablieren, können Unternehmen auf folgende Best Practices setzen:
Kritisches Denken: Die Förderung von kritischem Denken und ethischen Standards ist entscheidend. Data- und KI-Lösungen werden überall Werkzeuge des täglichen Lebens werden. Deshalb bleibt menschliche Intelligenz die wichtigste Kompetenz im Umgang mit Technologie.
Messen und Planen: Data Culture kann nur schrittweise aufgebaut werden. Unternehmen sollten datengesteuertes Verhalten messen und evaluieren, um den Fortschritt zu bewerten. Je stärker die Data Culture, desto omnipräsenter ist datengetriebenes Entscheiden.
Etablierung von Schlüsselrollen: Unternehmen sollten spezielle Funktionen bzw. Rollen schaffen für Mitarbeiter:innen, die die Data Strategy mit der Unternehmensstrategie verknüpfen und als zentrale Multiplikator:innen die Datenkultur bei den Mitarbeiter:innen fördern.
Die Entwicklung einer starken Data Culture erfordert klare Führung, klare Richtlinien und das Engagement der gesamten Organisation. Führungskräfte spielen dabei eine entscheidende Rolle, um den Wandel zu einer datengetriebenen Kultur erfolgreich zu gestalten.
Der Aufbau einer starken Datenkultur: Unser strategischer Ansatz
Bei statworx haben wir uns darauf spezialisiert, robuste Datenkulturen in Unternehmen zu etablieren. Unsere Strategie basiert auf bewährten Rahmenwerken, Best Practices und unserer umfangreichen Erfahrung, um die Grundlagen für eine erfolgreiche Datenkultur in Ihrem Unternehmen zu schaffen.
- Data Culture Strategie: Hand in Hand mit den Teams unserer Kunden entwickeln wir die strategische Roadmap, die erforderlich ist, um eine blühende Datenkultur zu fördern. Dies beinhaltet den Aufbau der grundlegenden Strukturen, die für die Maximierung des Potenzials Ihrer Unternehmensdaten unerlässlich sind.
- Data Culture Trainings: Wir setzen auf die Befähigung Ihrer Belegschaft mit den Fähigkeiten und dem Wissen, um im Bereich Daten und KI zu agieren. Unsere Schulungsprogramme zielen darauf ab, Mitarbeiter:innen mit den Kompetenzen auszustatten, die für den Aufbau einer starken Datenkultur unerlässlich sind. Damit können Unternehmen das volle Potenzial von Daten und Künstlicher Intelligenz ausschöpfen.
- Change-Management und Begleitung: Die Verankerung einer Datenkultur erfordert anhaltende Anstrengungen im Change-Management. Wir arbeiten mit den Kunden-Teams zusammen, um langfristige Änderungsprogramme zu etablieren, die darauf abzielen, eine robuste Datenkultur im Unternehmen zu initiieren und zu festigen. Unser Ziel ist es, sicherzustellen, dass die Transformation in der DNA der Organisation verankert bleibt, um anhaltenden Erfolg zu gewährleisten.
Mit unserem umfassenden Serviceangebot sind wir bestrebt, Unternehmen in eine Zukunft zu führen, in der Daten zu einem strategischen Vermögen werden, das neue Chancen erschließt und fundierte Entscheidungsfindung auf allen Ebenen ermöglicht. Darüber haben wir ausführlich in unserem Whitepaper “Data Culture als Führungsaufgabe in Unternehmen” geschrieben, das auch eine Data-Culture-Checklist enthält. Unsere Angebote rund um das Thema Datenkultur sind auf unserer Themenseite Data Culture zu finden.
Wir stehen am Beginn des Jahres 2024, einer Zeit grundlegender Veränderungen und spannender Fortschritte in der Welt der Künstlichen Intelligenz. Die nächsten Monate gelten als kritischer Meilenstein in der Evolution der KI, in denen sie sich von einer vielversprechenden Zukunftstechnologie zu einer festen Realität im Geschäftsleben und im Alltag von Millionen wandelt. Deshalb präsentieren wir gemeinsamen mit dem AI Hub Frankfurt, dem zentralen KI-Netzwerk der Rhein-Main-Region, unsere Trendprognose für 2024, den AI Trends Report 2024.
Der Report identifiziert zwölf dynamische KI-Trends, die sich in drei Schlüsselbereichen entfalten: Kultur und Entwicklung, Daten und Technologie sowie Transparenz und Kontrolle. Diese Trends zeichnen ein Bild der rasanten Veränderungen in der KI-Landschaft und beleuchten die Auswirkungen auf Unternehmen und Gesellschaft.
Unsere Analyse basiert auf umfangreichen Recherchen, branchenspezifischem Fachwissen und dem Input von Expert:innen. Wir beleuchten jeden Trend, um einen zukunftsweisenden Einblick in die KI zu bieten und Unternehmen bei der Vorbereitung auf künftige Herausforderungen und Chancen zu unterstützen. Wir betonen jedoch, dass Trendprognosen stets einen spekulativen Charakter haben und einige unserer Vorhersagen bewusst gewagt formuliert sind.
Direkt zum AI Trends Report 2024!
Was ist ein Trend?
Ein Trend unterscheidet sich sowohl von einem kurzlebigen Modephänomen als auch von einem medialen Hype. Er ist ein Wandelphänomen mit einem „Tipping Point“, an dem eine kleine Veränderung in einer Nische einen großen Umbruch im Mainstream bewirken kann. Trends initiieren neue Geschäftsmodelle, Konsumverhalten und Arbeitsformen und stellen somit eine grundlegende Veränderung des Status Quo dar. Für Unternehmen ist es entscheidend, vor dem Tipping Point die richtigen Kenntnisse und Ressourcen zu mobilisieren, um von einem Trend profitieren zu können.
12 KI-Trends, die 2024 prägen werden
Im AI Trends Report 2024 identifizieren wir wegweisende Entwicklungen im Bereich Künstlichen Intelligenz. Hier sind die Kurzversionen der zwölf Trends mit jeweils einem ausgewählten Zitat aus den Reihen unserer Expert:innen.
Teil 1: Kultur und Entwicklung
Von der 4-Tage-Woche über Omnimodalität bis AGI: 2024 verspricht große Fortschritt für die Arbeitswelt, für die Medienproduktion und für die Möglichkeiten von KI insgesamt.
These I: KI-Kompetenz im Unternehmen
Unternehmen, die KI-Expertise tief in ihrer Unternehmenskultur verankern und interdisziplinäre Teams mit Tech- und Branchenwissen aufbauen, sichern sich einen Wettbewerbsvorteil. Zentrale KI-Teams und eine starke Data Culture sind Schlüssel zum Erfolg.
„Eine Datenkultur kann man weder kaufen noch anordnen. Man muss die Köpfe, die Herzen und die Herde gewinnen. Wir möchten, dass unsere Mitarbeitenden bewusst Daten erstellen, nutzen und weitergeben. Wir geben ihnen Zugang zu Daten, Analysen und KI und vermitteln das Wissen und die Denkweise, um das Unternehmen auf Basis von Daten zu führen.“
Stefanie Babka, Global Head of Data Culture, Merck
These II :4-Tage-Arbeitswoche durch KI
Dank KI-Automatisierung in Standardsoftware und Unternehmensprozessen ist die 4-Tage-Arbeitswoche für einige deutsche Unternehmen Realität geworden. KI-Tools wie Microsofts Copilot steigern die Produktivität und ermöglichen Arbeitszeitverkürzungen, ohne das Wachstum zu beeinträchtigen.
Dr. Jean Enno Charton, Director Digital Ethics & Bioethics, Merck
These III: AGI durch omnimodale Modelle
Die Entwicklung von omnimodalen KI-Modellen, die menschliche Sinne nachahmen, rückt die Vision einer allgemeinen künstlichen Intelligenz (AGI) näher. Diese Modelle verarbeiten vielfältige Inputs und erweitern menschliche Fähigkeiten.
Dr. Ingo Marquart, NLP Subject Matter Lead, statworx
These IV: KI-Revolution in der Medienproduktion
Generative AI (GenAI) transformiert die Medienlandschaft und ermöglicht neue Formen der Kreativität, bleibt jedoch noch hinter transformatorischer Kreativität zurück. KI-Tools werden für Kreative immer wichtiger, doch es gilt, die Einzigartigkeit gegenüber einem globalen Durchschnittsgeschmack zu wahren.
Nemo Tronnier, Founder & CEO, Social DNA
Teil 2: Daten und Technologie
2024 dreht sich alles um Datenqualität, Open-Source-Modelle und den Zugang zu Prozessoren. Die Betreiber von Standardsoftware wie Microsoft und SAP werden groß profitieren, weil sie die Schnittstelle zu den Endnutzer:innen besetzen.
These V: Herausforderer für NVIDIA
Neue Akteure und Technologien bereiten sich vor, den GPU-Markt aufzumischen und NVIDIAs Position herauszufordern. Startups und etablierte Konkurrenten wie AMD und Intel wollen von der Ressourcenknappheit und den langen Wartezeiten profitieren, die kleinere Player derzeit erleben, und setzen auf Innovation, um NVIDIAs Dominanz zu brechen.
Norman Behrend, Chief Customer Officer, Genesis Cloud
These VI: Datenqualität vor Datenquantität
In der KI-Entwicklung rückt die Qualität der Daten in den Fokus. Statt nur auf Masse zu setzen, wird die sorgfältige Auswahl und Aufbereitung von Trainingsdaten sowie die Innovation in der Modellarchitektur entscheidend. Kleinere Modelle mit hochwertigen Daten können größeren Modellen in der Performance überlegen sein.
Walid Mehanna, Chief Data & AI Officer, Merck
These VII: Das Jahr der KI-Integratoren
Integratoren wie Microsoft, Databricks und Salesforce werden zu den Gewinnern, da sie KI-Tools an Endnutzer:innen bringen. Die Fähigkeit zur nahtlosen Integration in bestehende Systeme wird für KI-Startups und -Anbieter entscheidend sein. Unternehmen, die spezialisierte Dienste oder wegweisende Innovationen bieten, sichern sich lukrative Nischen.
Marco Di Sazio, Head of Innovation, Bankhaus Metzler
These VIII: Die Open-Source-Revolution
Open-Source-KI-Modelle treten in Wettbewerb mit proprietären Modellen wie OpenAIs GPT und Googles Gemini. Mit einer Community, die Innovation und Wissensaustausch fördert, bieten Open-Source-Modelle mehr Flexibilität und Transparenz, was sie besonders wertvoll für Anwendungen macht, die klare Verantwortlichkeiten und Anpassungen erfordern.
Prof. Dr. Christian Klein, Gründer, UMYNO Solutions, Professor für Marketing & Digital Media, FOM Hochschule
Teil 3: Transparenz und Kontrolle
Die verstärkte Nutzung von KI-Entscheidungssystemen wird 2024 eine intensivierte Debatte über Algorithmen-Transparenz und Datenschutz entfachen – auf der Suche nach Verantwortlichkeit. Der AI Act wird dabei zum Standortvorteil für Europa.
These IX: KI-Transparenz als Wettbewerbsvorteil
Europäische KI-Startups mit Fokus auf Transparenz und Erklärbarkeit könnten zu den großen Gewinnern werden, da Branchen wie Pharma und Finance bereits hohe Anforderungen an die Nachvollziehbarkeit von KI-Entscheidungen stellen. Der AI Act fördert diese Entwicklung, indem er Transparenz und Anpassungsfähigkeit von KI-Systemen fordert und damit europäischen KI-Lösungen zu einem Vertrauensvorsprung verhilft.
Jakob Plesner, Rechtsanwalt, Gorrissen Federspiel
These X: AI Act als Qualitätssiegel
Der AI Act positioniert Europa als sicheren Hafen für Investitionen in KI, indem er ethische Standards setzt, die das Vertrauen in KI-Technologien stärken. Angesichts der Zunahme von Deepfakes und der damit verbundenen Risiken für die Gesellschaft wirkt der AI Act als Bollwerk gegen Missbrauch und fördert ein verantwortungsbewusstes Wachstum der KI-Branche.
Catharina Glugla, Head of Data, Cyber & Tech Germany, Allen & Overy LLP
These XI: KI-Agenten revolutionieren den Konsum
Persönliche Assistenz-Bots, die Einkäufe tätigen und Dienstleistungen auswählen, werden zu einem wesentlichen Bestandteil des Alltags. Die Beeinflussung ihrer Entscheidungen wird zum Schlüsselelement für Unternehmen, um auf dem Markt zu bestehen. Dies wird die Suchmaschinenoptimierung und Online-Marketing tiefgreifend verändern, da Bots zu den neuen Zielgruppen werden.
Chi Wang, Principle Researcher, Microsoft Research
These XII: Alignment von KI-Modellen
Die Abstimmung (Alignment) von KI-Modellen auf universelle Werte und menschliche Intentionen wird entscheidend, um unethische Ergebnisse zu vermeiden und das Potenzial von Foundation-Modellen voll auszuschöpfen. Superalignment, bei dem KI-Modelle zusammenarbeiten, um komplexe Herausforderungen zu meistern, wird immer wichtiger, um die Entwicklung von KI verantwortungsvoll voranzutreiben.
Daniel Lüttgau, Head of AI Development, statworx
Schlussbemerkung
Der AI Trends Report 2024 ist mehr als eine unterhaltsame Bestandsaufnahme; er kann ein nützliches Werkzeug für Entscheidungsträger:innen und Innovator:innen sein. Unser Ziel ist es, unseren Leser:innen strategische Vorteile zu verschaffen, indem wir die Auswirkungen der Trends auf verschiedene Sektoren diskutieren und ihnen helfen, die Weichen für die Zukunft zu stellen.
Dieser Blogpost bietet nur einen kurzen Einblick in den umfassenden AI Trends Report 2024. Wir laden Sie ein, den vollständigen Report zu lesen, um tiefer in die Materie einzutauchen und von den detaillierten Analysen und Prognosen zu profitieren.
Die Diskussion um den Einsatz von Künstlicher Intelligenz (KI) am Arbeitsplatz scheint unsere Gesellschaft zu spalten. Aktuell entfaltet sich ein Spannungsfeld: KI wird von den einen als bahnbrechender Fortschritt gefeiert und von anderen als Horrorszenario gefürchtet. Dazwischen scheint es wenig zu geben.
Unsere statworx-Arbeitsgruppe „AI & Society“ hat es sich zur Aufgabe gemacht, dem Diskurs auf den Grund zu gehen, um Antworten auf die drängenden Fragen unserer Gesellschaft zu finden. Dazu führten wir eine nicht-repräsentative Meinungsumfrage – teils online, teils in der Innenstadt von Frankfurt – mit 132 Teilnehmer:innen durch. Wir wollten unter anderem wissen: Was denken die Menschen außerhalb der KI-Bubble über Künstliche Intelligenz im Arbeitsalltag? Wo sehen sie die größten Potenziale und wovor fürchten sie sich? Unser Ziel: Statt nur Meinungen abzufragen, wollen wir die Ängste und Hoffnungen der Menschen verstehen, um daraus Lösungsansätze für einen sozialverträglichen KI-Einsatz ableiten zu können. Dazu untersuchten wir auch andere relevante Studien und Umfragen und die daraus abgeleieteten Empfehlungen.

Was Menschen über KI denken
Geht es um die Nutzung von KI am Arbeitsplatz herrscht eigentlich nur in der Kompetenz-Frage weitestgehend Einigkeit: Unternehmen und Personen, die KI in ihren Arbeitsalltag einsetzen, verschaffen sich Vorteile gegenüber anderen. Darüber hinaus zeigt sich ein undeutliches, teils widersprüchliches Bild auf dem weiten Feld von Studien, Darstellungen der öffentlichen Meinung, persönlicher Ansichten und Emotionen. Ein paar Auszüge daraus:
53 Prozent der von uns befragten Personen wünschen sich, mehr KI-Anwendungen in Studium und Beruf einzusetzen. Gleichzeitig sind sich 45 Prozent der Befragten nicht bewusst, bereits KI-gestützte Services wie Google Maps und Spotify im Alltag zu nutzen. Das zeigt: Es besteht weiter ein großer Aufklärungsbedarf darüber, was der Begriff „Künstliche Intelligenz“ tatsächlich beinhaltet – und was nicht.
Unsere Umfrage zeigt, dass Menschen in verschiedenen Branchen sorgenvoll in die Zukunft von und mit KI blicken. 55 Prozent sagen, dass sie eher besorgt, als begeistert von KI sind. Etwas mehr als die Hälfte der von uns befragten Personen gab sogar an, Angst vor der “allgemeinen Entwicklung” im Bereich KI zu haben. Auch gegenüber dem Institut für Demoskopie Allensbach gaben 40 Prozent an, dass generative KI sie beunruhige. Einer weiteren Studie zufolge finden sogar 58 Prozent der Deutschen KI „unsympathisch“. Das deutet darauf hin, dass ein großer Anteil der Bevölkerung diffuse Ängste und negative Assoziationen in Bezug auf KI hat.
Wenn es um den Einfluss von Künstlicher Intelligenz auf den eigenen Arbeitsalltag geht, vermutet ein Drittel der befragten Personen einen “eher starken” Einfluss. Knapp 60 Prozent wiederum denken, dass KI den eigenen Job “eher wenig” oder “gar nicht” beeinflussen wird. Weniger als ein Drittel erwartet, dass KI die eigene Arbeit interessanter machen wird und nur circa ein Viertel kann sich “mehr Raum für Kreativität” durch KI vorstellen. Diese Tendenzen werden von Ergebnissen einer Onlineumfrage des Marktforschungsinstituts Bilendi unter nichtakademischen Fachkräften mit Berufsausbildung unterstützt: Ein Viertel der Befragten gab an, dass vor allem Unternehmen vom KI-Einsatz profitieren. Beschäftigte würden keine tatsächliche Arbeitsentlastung erfahren, weil durch den technologischen Fortschritt bloß die Menge zu erledigender Aufgaben zunähme. Das zeigt: Die Auswirkungen von KI auf den eigenen Arbeitsalltag werden eher als negativ eingeschätzt. Doch nur ein Fünftel der von Bilendi Befragten glaubt auch, dass KI den eigenen Job irgendwann vollständig ersetzen werde. Auch 58 Prozent unserer Befragten glauben nicht, dass KI zu mehr Arbeitslosigkeit führt, im Gegensatz zu 33 Prozent in der KIRA-Studie, die sich Sorgen um Arbeitsplatzverluste machen.
Worauf wir uns tatsächlich einstellen müssen
Dass die von uns befragten Personen den Impact von Künstlicher Intelligenz vermutlich unterschätzen, zeigt sich in internationalen Vergleichsstudien. Eine Ipsos-Umfrage vom Sommer 2023 illustriert das in Deutschland vorherrschende geringe Bewusstsein für das Transformationspotenzial von KI folgendermaßen:
- 35 Prozent der deutschen Befragten halten es für wahrscheinlich, dass KI ihren derzeitigen Arbeitsplatz in den nächsten 5 Jahren verändern wird (somit vorletzter Platz im Ländervergleich mit einem Durchschnitt von 57 Prozent).
- Nur 19 Prozent der deutschen Befragten glauben, dass KI ihren derzeitigen Arbeitsplatz in den nächsten 5 Jahren ersetzen wird, im Vergleich zu einem Länderdurchschnitt von 36 Prozent.
- Lediglich 23 Prozent der deutschen Befragten denken, dass der verstärkte Einsatz von künstlicher Intelligenz ihre Arbeit in den nächsten 3-5 Jahren verbessern wird, im Gegensatz zum Länderdurchschnitt von 37 Prozent.
- Grundsätzlich vermuten 40 Prozent der Befragten eine Verschlechterung des deutschen Arbeitsmarktes durch die Nutzung von KI, während nur 20% eine Verbesserung erwarten.
Die Ergebnisse zeigen: Unternehmen, aber vor allem ihre Beschäftigten fühlen sich der neuen Herausforderung nicht gewachsen und machen sich kein realistisches Bild von den wirklich erwartbaren Veränderungen durch KI. Es fehlt an Bildungsangeboten und an individuellen Kompetenzen. Ihre diffusen Sorgen gepaart mit Unbedarftheit spitzen sich zu konkreten Herausforderungen für Arbeitgeber zu: Wie sollen Unternehmen mit unterschiedlichen Sichtweisen ihrer Mitarbeitenden auf KI umgehen? Wie (wenn überhaupt) geht man auf die ein, die sich ganz verweigern? Und wie mit jenen, die extrem enthusiastisch bis hin zu übereifrig sind? Wie befähigt man Menschen, souverän mit KI-basierten Tools umzugehen? Welche Abteilung und welche Mitarbeitenden benötigen überhaupt welche KI-Kompetenzen? Und wie bildet man diese individuell passend aus?
Fakt ist: Gerade die Veränderungen im Bereich generativer KI wirken sich massiv auf die Arbeitswelt aus. Einerseits wächst der Bedarf an Fachkräften, die Data-Kompetenz mit Branchenwissen vereinen, und es entstehen ganz neue Jobs wie der des “Prompt Engineers”, andererseits birgt KI-basierte (Teil-)Automatisierung in vielen Branchen die Gefahr großer Stellenstreichungen. Die Ankündigung der BILD-Zeitung, wegen ChatGPT Personal abzubauen, ist wahrscheinlich nur ein Vorbote. Manche Schätzungen gehen sogar davon aus, dass bis zu 80 Prozent der Arbeitsplätze in den kommenden Jahrzehnten automatisiert werden könnten. Die UN und andere Expert:innen halten das zwar für unrealistisch, doch es zeigt auch: Wir wissen nicht, wohin die Reise wirklich gehen wird. Das liegt auch daran, dass Branchen zu unterschiedlich, Berufsprofile mehrdimensional und Menschen (noch) nicht ohne Weiteres ersetzbar sind. Nur weil ein KI-System einen Arbeitsprozess automatisiert, kann es nicht gleich ein komplettes Jobprofil übernehmen. KI-Forscher:innen stimmen dem noch zu: In einer großangelegten Befragung von mehr als 2.700 Forscher:innen äußerten nur zehn Prozent die Erwartung, dass KI uns bis 2027 in allen Aufgaben überlegen sein könnte. Doch die Hälfte der Befragten glaubt auch, dass dieser technologische Durchbruch bis 2047 erreicht werden könnte. Klar ist nur: In Zukunft werden menschliche Arbeitskräfte überall mit KI zusammenarbeiten.
Nur mangelndes Wissen? Woher die Skepsis gegenüber KI kommt
KI läuft Gefahr zu einem gesellschaftlichen Spaltungsthema zu werden, wenn wir sie nicht sozialverträglich in unsere Arbeitswelt einbetten. Wie sorgen wir dafür, dass das gelingt? Die meisten Studien deuten in die gleiche Richtung: Bildung ist ein wichtiger Schlüssel, um Verständnis für die (rechtlich zulässigen) Fähigkeiten von KI zu schaffen, fundierte Entscheidungen über und mit KI zu treffen und Ängste vor der Technologie abzubauen. Das bestätigt auch unsere Umfrage: Obwohl sie KI bereits häufiger nutzen, haben Führungskräfte den Wunsch nach mehr Wissen; ebenso wie 53 Prozent der Befragten, die gerne mehr KI in ihrer beruflichen Umgebung einsetzen würden. Doch grundlegendes Wissen über die Technologie und ihren verantwortungsvollen Einsatz reicht nicht.
Viele Menschen wollen auch mehr über die Risiken von KI wissen und suchen nach Wegen, sich selbst zu befähigen. Die Aussagen aus dem qualitativen Teil unserer Studie unterstreichen das. Eine Person fordert zum Beispiel, dass der “Umgang mit KI […] allen Altersgruppen verständlich gemacht werden [sollte, damit] keine Wissenskluft entsteht.” Risikobestimmung ist für viele ein kritischer Punkt, wie aus dem Zitat hervorgeht: “Menschen wollen am ehesten mehr zu Risiken von KI wissen – am wenigsten wollen sie wissen, wie KI funktioniert.” Ein hohes Risikobewusstsein attestiert auch die KIRA-Studie. Passend dazu fanden wir in Bezug auf KI-Anwendungen heraus, dass den Befragten hohe Sicherheit am wichtigsten ist. Am wenigsten wichtig ist ihnen schnelle Verfügbarkeit. Interessant ist allerdings: Führungskräfte schätzen “Hohe Sicherheit” etwas niedriger und “Schnelle Verfügbarkeit” etwas höher ein als Angestellte.
Neben den unmittelbaren Risiken durch KI (wie Diskriminierung) sorgen sich Menschen auch aus anderen Gründen, zum Beispiel weil sie Abhängigkeit und Kontrollverlust befürchten, sich überfordert fühlen oder Angst vor Missbrauch und Manipulation haben. Insbesondere die Angst vor möglicher Überwachung durch KI ist prominent: 62 Prozent unserer Befragten und 54 Prozent der Teilnehmer:innen der KIRA-Studie stimmen dem zu. Ähnlich verhält es sich beim Thema Desinformation, das 51 Prozent unserer Befragten und 56 Prozent der KIRA-Studienteilnehmer:innen als mit KI verbunden betrachten. Interessanterweise denken jedoch 59 Prozent unserer Befragten nicht, dass KI die Menschheit bedroht, während 58 Prozent der KIRA-Studienteilnehmer:innen deshalb besorgt sind.
Wer sind die KI-Skeptiker:innen?
Wen die vielen Zahlen und Studien etwas ratlos zurücklassen, der oder die ist nicht allein. Es zeichnet sich kein klares Bild ab. Noch weniger lässt sich ableiten, wie man im Einzelnen vorgehen sollte, um mit KI-Skeptiker:innen umzugehen. Die Diskrepanzen in den Antworten spiegeln die Vielschichtigkeit der Wahrnehmung von KI und ihrer Auswirkungen auf den Arbeitsmarkt wider. Die verschiedenen Perspektiven und Herausforderungen unterstreichen die Notwendigkeit eines umfassenden Dialogs und einer partizipativen Gestaltung der Zukunft im Zeitalter der Künstlichen Intelligenz. Doch mit wem müssen wir wie sprechen?

Eine in der MIT Sloan Management Review veröffentlichten Umfrage unter 140 Führungskräften identifiziert drei Idealtypen von KI-basiertem Entscheidern: Skeptiker, Interagierer und Delegierer. Skeptiker sind nicht bereit, ihre Autonomie im Entscheidungsprozess an KI abzugeben, während Delegierer gerne die Verantwortung der KI überlassen. Intergrierer gehen einen Mittelweg, der je nach Entscheidung eher in die eine oder eher in die andere Richtung tendieren kann. Die drei Typen der Entscheidungsfindung zeigen, dass die Qualität der KI-Empfehlung selbst nur die Hälfte der Gleichung ist bei der Bewertung KI-gestützter Entscheidungsfindung in Organisationen. Der menschliche Filter macht den Unterschied aus, sagen die Autoren Philip Meissner and Christoph Keding. Delegierer sind auch ohne KI eher diejenigen, die Verantwortung an andere übergeben.
Eine EY-Studie kommt zu dem Ergebnis, dass Tech-Skeptiker:innen älter sind und ein geringeres Einkommen haben. Sie sind relativ unzufrieden mit ihrem Leben und befürchten, dass es künftigen Generationen noch schlechter gehen wird. Nur wenige glauben, dass die jungen Menschen von heute ein besseres Leben haben werden als ihre Eltern. Tech-Skeptiker:innen sind besorgt um ihre finanzielle Sicherheit, misstrauen der Regierung und sind nicht von den Vorteilen der Technologie überzeugt. Sie nutzen die Technologie für grundlegende Aufgaben, glauben aber nicht, dass sie die Probleme der Gesellschaft lösen wird. Sie verfügen zwar über grundlegende digitale Fähigkeiten, aber nur wenige sehen einen Sinn darin, diese weiterzuentwickeln. Tech-Skeptiker:innen sind in der Regel gegen die gemeinsame Nutzung von Daten, selbst wenn es einen klaren Zweck gibt.
Daraus können wir auch ableiten: Skepsis ist ein zutiefst menschliches, oft charakterliches Merkmal, das nicht unbedingt für vernunftlogische Argumente zugänglich ist. Ein Eckpfeiler aller Bemühungen muss deshalb transparente, verständnisvolle Kommunikation auf Augenhöhe sein, die das ernst nimmt. Eine Forrester-Umfrage zum Thema KI im Personalwesen identifizierte vier Personengruppen, auf die Führungskräfte ihre Kommunikation abstimmen sollten:
- KI-Skeptiker:innen: am häufigsten in der IT-Branche anzutreffen
- KI-Befürworter:innen: am ehesten im Alter von 26 bis 35 Jahren und im Gesundheitssektor
- KI-Indifferente: am ehesten im Alter von 36-45 Jahren
- KI-Enthusiast:innen: am ehesten 18-25 Jahre alt und arbeiten im Vertrieb
Unabhängig davon, wie zutreffend diese Einteilung für die deutsche Gesellschaft ist, kann die Erstellung von Personas sinnvoll sein, um passende Botschaften zu entwickeln. Jede dieser Gruppen reagiert unterschiedlich auf verschiedene Arten der Kommunikation. So sagt etwa die Hälfte der KI-Befürworter:innen, dass Transparenz in Bezug auf die Frage, ob durch KI Arbeitsplätze im eigenen Unternehmen wegfallen werden oder nicht, ihre Bedenken und Ängste in Bezug auf KI im Personalwesen verringern würde. Nur 18 Prozent derjenigen, die der KI gleichgültig gegenüberstehen, sehen das genauso. Während mehr als die Hälfte der KI-Skeptiker:innen angaben, dass die Kommunikation darüber, wie das Unternehmen KI einsetzt, ihre Bedenken und Ängste lindern würde, sind nur 22 Prozent der KI-Befürworter:innen dieser Meinung. 45 Prozent der vorsichtigen Befürworter:innen und Skeptiker:innen gab an, dass sie das Unternehmen eher verlassen würden, wenn ihre Bedenken über den Einsatz von KI in der Personalabteilung nicht ausgeräumt würden.
Wie schaffen wir KI-Zuversicht?
Was können wir daraus für den Umgang mit KI-Skepsis lernen? Wir befinden uns immer noch an der Spitze des Eisbergs, wenn es um die Nutzung von KI geht. Während Unternehmen ihre KI-Infrastruktur weiter ausbauen, müssen sie auch sicherstellen, dass sich ihre Mitarbeitenden befähigt fühlen, KI in ihren jeweiligen Rollen zu nutzen. Mit anderen Worten: Die Unternehmensführung muss deutlich zeigen, dass sie ihre Mitarbeitenden als Partner:innen und nicht nur als Passagier:innen auf der KI-Reise sieht.

Unsere Einschätzung: Es bedarf der Entwicklung robusterer Richtlinien für verantwortungsvolle KI in Unternehmen und Teams, um Sorgen in Zuversicht umzuwandeln und dem ungewollten Abfluss von Betriebsgeheimnissen oder anderer schutzwürdiger Daten entgegenzuwirken. Dazu gehört maximale Transparenz über den (geplanten) Einsatz von KI. Die Realität ist, dass die meisten Mitarbeiter:innen nicht wirklich verstehen, wie KI funktioniert – viele Entscheidungsträger:innen aber glauben, dass sie es wissen. Upskilling hilft, diese Kluft zu überbrücken. Die gezielte Qualifizierung von Arbeitnehmer:innen fördert einen sicheren und produktiven Einsatz. Wenn Mitarbeiter:innen darüber hinaus auch verstehen – weil es ihnen nachvollziehbar gezeigt wird – wie die Technologie ihr Arbeitsleben verbessern kann, erhöht das ihre Bereitschaft, mitzuziehen. Denn der Großteil von ihnen hofft schon, dass KI ihnen den Zugang zu Informationen erleichtern und ihre Produktivität steigern wird. Und auch diejenigen, die skeptisch sind, sind rationalen Argumenten gegenüber meist aufgeschlossen. Entscheidend ist, wie man sie anspricht. Statt Verständnis und Bereitschaft vorauszusetzen, kann es sich lohnen, sie auf individueller Ebene abzuholen: “Wenn du eine große finanzielle Entscheidung treffen musst, hörst du dann einzig auf dein Bauchgefühl oder versuchst so viele Daten und Informationen wie möglich zu sammeln?” Es muss klar werden, dass es bei (fast allen typischen) KI-Systemen um Technologien geht, die Menschen dienen dazu sollen, bessere, evidenzbasierte Entscheidungen zu treffen – und nicht um irgendeine Roboterdystopie, in der der Mensch zum Mittel wird.
Dafür ist zielgruppengerechte interne Kommunikation wichtig. Unternehmen in denen vornehmlich Tech- und KI-Enthusiasten arbeiten, sind möglicherweise gut beraten, KI als neuen, revolutionären Trend an ihre Mitarbeiter:innen zu kommunizieren. Wenn diese Zielgruppe Wert darauf legt, dass ihr Arbeitgeber modern und hightech ist, sollte sich das auch in der Kommunikation widerspiegeln. Andere Unternehmen, in denen weniger Enthusiasmus und vielleicht stärker konservative, vorsichtige Denkweise herrschen, fahren wahrscheinlich besser damit, KI intern als kontinuierlich Weiterentwicklung und Verbesserung bestehender, bekannter Technologien zu kommunizieren. Möglicherweise sollten sie sogar ganz darauf verzichten, das Label KI zu nutzen und neue Systeme eher an vertraute Namen und Beschreibungen anlehnen. Welche kommunikativen Strategien in welchem Unternehmen (und in welchen Abteilungen) gut funktionieren, lässt sich pauschal nicht sagen. Die oben vorgestellten Personas und ihre Gründe für KI-Skepsis geben jedoch gute Hinweise darauf, wie man interne Stimmungen einfangen und darauf eine passende Kommunikationsstrategie ausrichten kann.
Über die Arbeitsgruppe AI & Society
Als Arbeitsgruppe mit Einblicken in den aktuellen Forschungsstand führen wir gemeinsam mit Expert:innen aus Wirtschaft, Gesellschaft und Forschung die Diskussion. Unsere Arbeitsgruppe ist nicht nur auf die Analyse beschränkt, sondern handelt auch aktiv. „KI Macht Schule“ und der Girls Day sind nur einige Beispiele unserer Bemühungen, die Gesellschaft in den Dialog einzubeziehen und KI erlebbar zu machen. Die Entwicklung von Responsible-AI-Prinzipien und Workshops sind weitere Maßnahmen, um Innovation verantwortungsvoll voranzutreiben.
Alle Ergebnisse auf einen Blick

Quellen
https://arxiv.org/pdf/2401.02843.pdf
https://blog.workday.com/en-us/2023/how-employees-feel-ai-at-work.html
https://www.elektroniknet.de/halbleiter/wer-hat-angst-vor-ki.207613.html
https://www.ey.com/en_gl/government-public-sector/meet-the-tech-skeptics
https://www.faz.net/aktuell/politik/inland/allensbach-warum-deutsche-die-ki-fuerchten-19060081.html
https://t3n.de/news/ki-prognosen-automatisierung-arbeit-1601598/
Anfang Dezember erzielten die zentralen EU-Institutionen im sogenannten Trilog eine vorläufige Einigung über einen Gesetzesvorschlag zur Regulierung künstlicher Intelligenz. Nun wird der finale Gesetzestext mit allen Details ausgearbeitet. Sobald dieser erstellt und gesichtet wurde, kann das Gesetz offiziell verabschiedet werden. Wir haben den aktuellen Wissensstand zum AI-Act zusammengetragen.
Im Rahmen des ordentlichen Gesetzgebungsverfahrens der Europäischen Union ist ein Trilog eine informelle interinstitutionelle Verhandlung zwischen Vertretern des Europäischen Parlaments, des Rates der Europäischen Union und der Europäischen Kommission. Ziel eines Trilogs ist eine vorläufige Einigung über einen Legislativvorschlag, der sowohl für das Parlament als auch für den Rat, die Mitgesetzgeber, annehmbar ist. Die vorläufige Vereinbarung muss dann von jedem dieser Organe in förmlichen Verfahren angenommen werden.
Gesetzgebung mit globalem Impact
Eine Besonderheit des kommenden Gesetzes ist das so genannte Marktortprinzip: Demzufolge werden weltweit Unternehmen von dem AI-Act betroffen sein, die künstliche Intelligenz auf dem europäischen Markt anbieten, betreiben oder deren KI-generierter Output innerhalb der EU genutzt wird.
Als künstliche Intelligenz gelten dabei maschinenbasierte Systeme, die autonom Prognosen, Empfehlungen oder Entscheidungen treffen und damit die physische und virtuelle Umwelt beeinflussen können. Das betrifft beispielsweise KI-Lösungen, die den Recruiting-Prozess unterstützen, Predictive-Maintenance-Lösungen und Chatbots wie ChatGPT. Dabei unterscheiden sich die rechtlichen Auflagen, die unterschiedliche KI-Systeme erfüllen müssen, stark – abhängig von ihrer Einstufung in Risikoklassen.
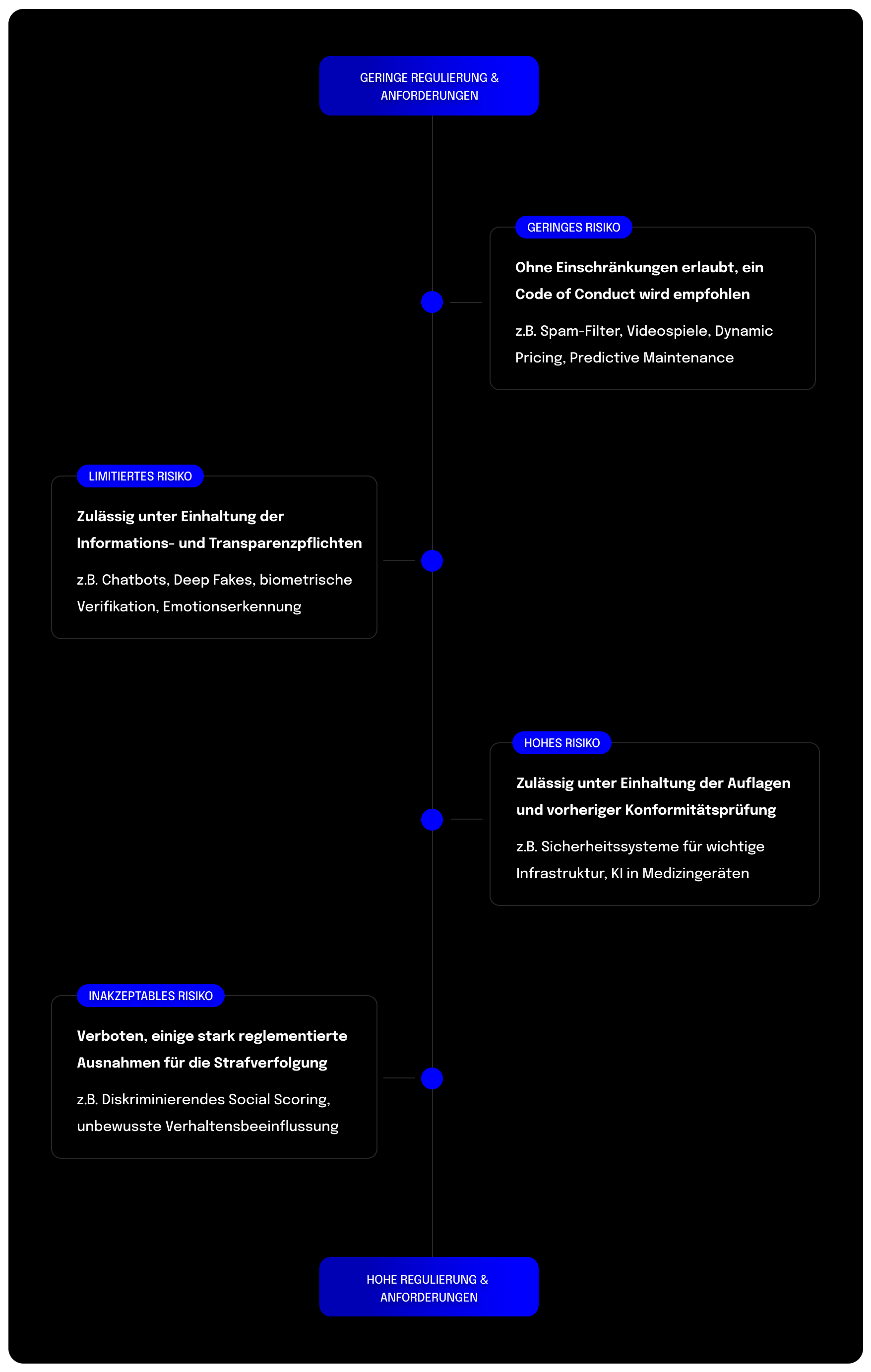
Die Risikoklasse bestimmt die rechtlichen Auflagen
Der risikobasierte Ansatz der EU umfasst insgesamt vier Risikoklassen:
- niedriges,
- begrenztes,
- hohes
- und inakzeptables Risiko.
Diese Klassen spiegeln wider, inwiefern eine künstliche Intelligenz europäische Werte und Grundrechte gefährdet. Wie die Bezeichnung „inakzeptabel“ für eine Risikoklasse bereits andeutet, sind nicht alle KI-Systeme zulässig. KI-Systeme, die der Kategorie „inakzeptables Risiko“ angehören, werden vom AI-Act verboten. Für die übrigen drei Risikoklassen gilt: Je höher das Risiko, desto umfangreicher und strikter sind die rechtlichen Anforderungen an das KI-System. Welche KI-Systeme in welche Risikoklasse fallen und welche Auflagen damit verbunden sind, erläutern wir im Folgenden. Unsere Einschätzungen beziehen sich auf die Informationen aus der Unterlage „AI Mandates“ vom Juni 2023. Das Dokument stellt zum Zeitpunkt der Veröffentlichung das zuletzt veröffentliche, umfassende Dokument zum AI-Act dar.
Verbot für Social Scoring und biometrische Fernidentifikation
Einige KI-Systeme bergen ein erhebliches Potenzial zur Verletzung der Menschenrechte und Grundprinzipien, weshalb sie der Kategorie „inakzeptables Risiko” zugeordnet werden. Zu diesen gehören:
- Echtzeit-basierte biometrische Fernidentifikationssysteme in öffentlich zugänglichen Räumen (Ausnahme: Strafverfolgungsbehörden dürfen diese zur Verfolgung schwerer Straftaten und mit richterlicher Genehmigung nutzen);
- Biometrische Fernidentifikationssysteme im Nachhinein (Ausnahme: Strafverfolgungsbehörden dürfen diese zur Verfolgung schwerer Straftaten und ausschließlich mit richterlicher Genehmigung nutzen);
- Biometrische Kategorisierungssysteme, die sensible Merkmale wie Geschlecht, ethnische Zugehörigkeit oder Religion verwenden;
- Vorausschauende Polizeiarbeit auf Basis von sogenanntem „Profiling“ – also einer Profilerstellung unter Einbezug von Hautfarbe, vermuteten Religionszugehörigkeit und ähnlich sensiblen Merkmalen –, dem geografischen Standort oder vorhergehenden kriminellen Verhalten;
- Systeme zur Emotionserkennung im Bereich der Strafverfolgung, Grenzkontrolle, am Arbeitsplatz und in Bildungseinrichtungen;
- Beliebige Extraktion von biometrischen Daten aus sozialen Medien oder Videoüberwachungsaufnahmen zur Erstellung von Datenbanken zur Gesichtserkennung;
- Social Scoring, das zu Benachteiligung in sozialen Kontexten führt;
- KI, die die Schwachstellen einer bestimmten Personengruppe ausnutzt oder unbewusste Techniken einsetzt, die zu Verhaltensweisen führen können, die physischen oder psychischen Schaden verursachen.
Diese KI-Systeme sollen im Rahmen des AI-Acts auf dem europäischen Markt verboten werden. Unternehmen, deren KI-Systeme in diese Risikoklasse fallen könnten, sollten sich dringend mit den bevorstehenden Anforderungen auseinandersetzen und Handlungsoptionen ausloten. Denn ein zentrales Ergebnis des Trilogs ist, dass diese Systeme bereits sechs Monate nach der offiziellen Verabschiedung verboten sein werden.
Zahlreiche Auflagen für KI mit Risiko für Gesundheit, Sicherheit oder Grundrechte
In die Kategorie „hohes Risiko“ fallen alle KI-Systeme, die nicht explizit verboten sind, aber dennoch ein hohes Risiko für Gesundheit, Sicherheit oder Grundrechte darstellen. Folgende Anwendungs- und Einsatzgebiete werden dabei explizit genannt:
- Biometrische und biometrisch-gestützte Systeme, die nicht in die Risikoklasse „inakzeptables Risiko“ fallen;
- Management und Betrieb kritischer Infrastruktur;
- allgemeine und berufliche Bildung;
- Zugang und Anspruch auf grundlegende private und öffentliche Dienste und Leistungen;
- Beschäftigung, Personalmanagement und Zugang zur Selbstständigkeit;
- Strafverfolgung;
- Migration, Asyl und Grenzkontrolle;
- Rechtspflege und demokratische Prozesse
Für diese KI-Systeme sind umfassende rechtliche Auflagen vorgesehen, die vor der Inbetriebnahme umgesetzt und während des gesamten KI-Lebenszyklus beachtet werden müssen:
- Assessment zur Abschätzung der Effekte auf Grund- und Menschenrechte
- Qualitäts- und Risikomanagement
- Data-Governance-Strukturen
- Qualitätsanforderungen an Trainings-, Test- und Validierungsdaten
- Technische Dokumentationen und Aufzeichnungspflicht
- Erfüllung der Transparenz- und Bereitstellungspflichten
- Menschliche Aufsicht, Robustheit, Sicherheit und Genauigkeit
- Konformitäts-Deklaration inkl. CE-Kennzeichnungspflicht
- Registrierung in einer EU-weiten Datenbank
KI-Systeme, die in einem der oben genannten Bereiche eingesetzt werden, aber keine Gefahr für Gesundheit, Sicherheit, Umwelt und Grundrechte darstellen, unterliegen nicht den rechtlichen Anforderungen. Dies gilt es jedoch nachzuweisen, indem die zuständige nationale Behörde über das KI-System informiert wird. Diese hat dann drei Monate Zeit, die Risiken des KI-Systems zu prüfen. Innerhalb dieser drei Monate kann die KI bereits in Betrieb genommen werden. Stuft die prüfende Behörde es jedoch als Hochrisiko-KI ein, können hohe Strafzahlungen anfallen.
Eine Sonderregelung gilt außerdem für KI-Produkte und KI-Sicherheitskomponenten von Produkten, deren Konformität auf Grundlage von EU-Rechtsvorschriften bereits durch Dritte geprüft wird. Dies ist beispielsweise bei KI in Spielzeugen der Fall. Um eine Überregulierung sowie zusätzliche Belastung zu vermeiden, werden diese vom AI-Act nicht direkt betroffen sein.
KI mit limitiertem Risiko muss Transparenzpflichten erfüllen
KI-Systeme, die direkt mit Menschen interagieren, fallen in die Risikoklasse „limitiertes Risiko“. Dazu zählen Emotionserkennungssysteme, biometrische Kategorisierungssysteme sowie KI-generierte oder veränderte Inhalte, die realen Personen, Gegenständen, Orten oder Ereignissen ähneln und fälschlicherweise für real gehalten werden könnte („Deepfakes“). Für diese Systeme sieht der Gesetzesentwurf die Verpflichtung vor, Verbraucher:innen über den Einsatz künstlicher Intelligenz zu informieren. Dadurch soll es Konsument:innen erleichtert werden, sich aktiv für oder gegen die Nutzung zu entscheiden. Außerdem wird ein Verhaltenskodex empfohlen.
Keine rechtlichen Auflagen für KI mit geringem Risiko
Viele KI-Systeme, wie beispielsweise Predictive-Maintenance oder Spamfilter, fallen in die Risikoklasse „geringes Risiko“. Unternehmen, die ausschließlich solche KI-Lösungen anbieten oder nutzen, werden kaum vom AI-Act betroffen sein. Denn bisher sind für solche Anwendungen keine rechtlichen Auflagen vorgesehen. Lediglich ein Verhaltenskodex wird empfohlen.
Generative KI wie ChatGPT wird gesondert geregelt
Generative KI-Modelle und Basismodelle mit vielfältigen Einsatzmöglichkeiten waren im ursprünglich eingereichten Entwurf für den AI-Act nicht berücksichtigt. Daher werden die Regulierungsmöglichkeiten solcher KI-Modelle seit dem Launch von ChatGPT durch OpenAI besonders intensiv diskutiert. Laut des Pressestatements des Europäischen Rats vom 9. Dezember sollen diese Modelle nun auf Basis ihres Risikos reguliert werden. Grundsätzlich müssen alle Modelle Transparenzanforderungen umsetzen. Basismodelle mit besonderem Risiko – so genannte „high-impact foundation models“ – werden darüber hinaus Auflagen erfüllen müssen. Wie genau das Risiko der KI-Modelle eingeschätzt wird, ist aktuell noch offen. Auf Grundlage des letzten Dokuments lassen sich folgende mögliche Auflagen für „high-impact foundation models“ abschätzen:
- Qualitäts- und Risikomanagement
- Data-Governance-Strukturen
- Technische Dokumentationen
- Erfüllung der Transparenz- und Informationspflichten
- Sicherstellung der Performance, Interpretierbarkeit, Korrigierbarkeit, Sicherheit, Cybersecurity
- Einhaltung von Umweltstandards
- Zusammenarbeit mit nachgeschalteten Anbietern
- Registrierung in einer EU-weiten Datenbank
Unternehmen können sich schon jetzt auf den AI-Act vorbereiten
Auch wenn der AI-Act noch nicht offiziell verabschiedet wurde und wir die Einzelheiten des Gesetzestextes noch nicht kennen, sollten sich Unternehmen jetzt auf die Übergangsphase vorbereiten. In dieser gilt es, KI-Systeme und damit verbundene Prozesse gesetzeskonform zu gestalten. Der erste Schritt dafür ist die Einschätzung der Risikoklasse jedes einzelnen KI-Systems. Falls Sie noch nicht sicher sind, in welche Risikoklassen Ihre KI-Systeme fallen, empfehlen wir unseren kostenfreien AI-Act Quick Check. Er unterstützt Sie dabei, die Risikoklasse einzuschätzen.
Mehr Informationen:
- Lunch & Learn „Done Deal“
- Lunch & Learn „Alles, was du über den AI Act Wissen musst “
- Factsheet AI Act
Quellen:
- Presse-Statement des europäischen Rats: „Artificial intelligence act: Council and Parliament strike a deal on the first rules for AI in the world“
- AI Mandates (June 2023)
- „Allgemeine Ausrichtung“ des Rats der Europäischen Union: https://www.consilium.europa.eu/en/press/press-releases/2022/12/06/artificial-intelligence-act-council-calls-for-promoting-safe-ai-that-respects-fundamental-rights/
- Gesetzesvorschlag („AI-Act“) der Europäischen Kommission: https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX%3A52021PC0206
- Ethik-Leitlinien für eine vertrauenswürdige KI: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
Read next …


… and explore new


Habt ihr euch jemals ein Restaurant vorgestellt, in dem alles von KI gesteuert wird? Vom Menü über die Cocktails, das Hosting, die Musik und die Kunst? Nein? Ok, dann klickt bitte hier.
Falls ja, ist eure Traumvorstellung bereits Realität geworden. Wir haben es geschafft: Willkommen im „the byte“ – Deutschlands (vielleicht auch weltweit erstes) KI-gesteuertes Pop-up Restaurant!
Als jemand, der seit über zehn Jahren in der Daten- und KI-Beratung tätig ist und statworx und den AI Hub Frankfurt aufgebaut hat, habe ich immer daran gedacht, die Möglichkeiten von KI außerhalb der typischen Geschäftsanwendungen zu erkunden. Warum? Weil KI jeden Aspekt unserer Gesellschaft beeinflussen wird, nicht nur die Wirtschaft. KI wird überall sein – in Schulen, Kunst und Musik, Design und Kultur. Überall. Bei der Erkundung dieser Auswirkungen von KI traf ich Jonathan Speier und James Ardinast von S-O-U-P, zwei gleichgesinnte Gründer aus Frankfurt, die darüber nachdenken, wie Technologie Städte und unsere Gesellschaft prägen wird.
S-O-U-P ist ihre Initiative, die an der Schnittstelle von Kultur, Urbanität und Lifestyle tätig ist. Mit ihrem jährlichen „S-O-U-P Urban Festival“ bringen sie Kreative, Unternehmen, Gastronomie- und Menschen aus Frankfurt und darüber hinaus zusammen.
Als Jonathan und ich über KI und ihre Auswirkungen auf Gesellschaft und Kultur diskutierten, kamen wir schnell auf die Idee eines KI-generierten Menüs für ein Restaurant. Glücklicherweise ist James, Jonathans Mitbegründer von S-O-U-P, ein erfolgreicher Gastronomie-Unternehmer aus Frankfurt. Nun fügten sich die Puzzlestücke zusammen. Nach einem weiteren Treffen mit James in einem seiner Restaurants (und ein paar Drinks) beschlossen wir, Deutschlands erstes KI-gesteuertes Pop-up-Restaurant zu eröffnen: the byte!
the byte: Unser Konzept
Wir stellten uns the byte als ein immersives Erlebnis vor, bei dem KI in möglichst vielen Elementen des Erlebnisses integriert ist. Alles, vom Menü über die Cocktails, Musik, Branding und Kunst an der Wand: wirklich alles wurde von KI generiert. Die Integration von KI in all diese Komponenten unterschied sich auch für mich sehr von meiner ursprünglichen Aufgabe, Unternehmen bei ihren Daten- und KI-Herausforderungen zu helfen.
Branding
Bevor wir das Menü erstellt haben, entwickelten wir die visuelle Identität unseres Projekts. Wir entschieden uns für einen „Lo-Fi“-Ansatz und verwendeten eine pixel-artige Schrift in Kombination mit KI-generierten Visuals von Tellern und Gerichten. Unser Hauptmotiv, ein neonbeleuchteter weißer Teller, wurde mit Hilfe von DALL-E 2 erstellt und war in all unseren Marketingmaterialien zu finden.

Location
Wir haben the byte in einer der coolsten Restaurant-Event-Locations in Frankfurt veranstaltet: Stanley. Das Stanley ist ein Restaurant mit etwa 60 Sitzplätzen und einer voll ausgestatteten Bar im Inneren (ideal für unsere KI-generierten Cocktails). Die Atmosphäre ist eher dunkel und gemütlich, mit dunklen Marmorplatten an den Wänden, weißen Tischläufern und einem großen roten Fenster, das einen Blick in die Küche ermöglicht.

Das Menü
Das Herzstück unseres Konzepts war ein 5-Gänge-Menü, welches wir mit dem Ziel entworfen haben, die klassische Frankfurter Küche mit den multikulturellen und vielfältigen Einflüssen aus Frankfurt zu erweitern (für alle, die die Frankfurter Küche kennen, wissen, dass dies keine leichte Aufgabe war).
Mit Hilfe von GPT-4 und etwas „Prompt Engineering“-Magie, haben wir ein Menü erstellt, das von der erfahrenen Küchencrew des Stanley getestet (vielen Dank für diese großartige Arbeit!) und dann zu einem endgültigen Menü zusammengestellt wurde. Nachfolgend findet ihr unseren Prompt, der verwendet wurde, um die Menüauswahl zu erstellen:
„Create a 5-course menu that elevates the classical Frankfurter kitchen. The menu must be a fusion of classical Frankfurter cuisine combined with the multicultural influences of Frankfurt. Describe each course, its ingredients as well as a detailed description of each dish’s presentation.“
Zu meiner Überraschung waren nur geringfügige Anpassungen an den Rezepten erforderlich, obwohl einige der KI-Kreationen extrem abenteuerlich waren! Hier ist unser endgültiges Menü:
- Handkäs-Mousse mit eingelegter Rote Bete auf geröstetem Sauerteigbrot
- „Next Level“ Grüne Soße (mit Koriander und Minze) mit einem frittierten Panko-Ei
- Cremesuppe aus weißem Spargel mit Kokosmilch und gebratenem Curry-Fisch
- Currywurst (Rind & vegan) by Best Worscht in Town mit Karotten-Ingwer-Püree und Pinienkernen
- Frankfurter Käsekuchen mit Äppler-Gelee, Apfelschaum und Hafer-Pekannuss-Streusel
Mein klarer Favorit war die „Next Level“ Grüne Soße, eine orientalische Variante der klassischen Frankfurter 7-Kräuter-Grünen Soße mit dem panierten Panko-Ei. Lecker!
Hier könnt ihr das Menü in freier Wildbahn sehen 🍲

KI-Cocktails
Neben dem Menü haben wir GPT angewiesen, Rezepte für berühmte Cocktail-Klassiker zu erstellen, die zu unserem Frankfurt-Fusion-Thema passen. Hier sind die Ergebnisse:
- Frankfurt Spritz (Frankfurter Äbbelwoi, Minze, Sprudelwasser)
- Frankfurt Mule (Variation eines Moscow Mule mit Calvados)
- The Main (Variation eines Swimming Pool Cocktails)
Mein Favorit war der Frankfurt Spritz – er war erfrischend, kräuterig und super lecker (siehe Bild unten).

KI-Host: Ambrosia, die kulinarische KI
Ein wichtiger Teil unseres Konzepts war „Ambrosia“, ein KI-generierter Host, die unsere Gäste durch den Abend geführt und das Konzept sowie die Entstehung des Menüs erklärt hat. Es war uns ein wichtiges Anliegen, die KI für die Gäste erlebbar zu machen. Wir engagierten einen professionellen Drehbuchautor für das Skript und verwendeten murf.ai, um Text-zu-Sprach-Elemente zu erstellen, die zu Beginn des Dinners und zwischen den Gängen abgespielt wurden.
Notiz: Ambrosia spricht ab Sekunde 0:15.
KI-Musik
Musik spielt eine wichtige Rolle für die Atmosphäre einer Veranstaltung. Daher haben wir uns für mubert entschieden, ein generatives KI-Start-up, das es uns ermöglichte, Musik in verschiedenen Genres wie „Minimal House“ zu erstellen und zu streamen, und so für eine progressive Stimmung über den gesamten Abend sorgte. Nach dem Hauptgang übernahm ein DJ und begleitete unsere Gäste durch die Nacht. 💃🍸
KI-Kunst
Im gesamten Restaurant platzierten wir KI-generierte Kunstwerke des lokalen KI-Künstlers Vladimir Alexeev (a.k.a. “Merzmensch”). Hier sind einige Beispiele:

KI-Spielplatz
Als interaktives Element für die Gäste haben wir eine kleine Web-App erstellt, die den Vornamen einer Person nimmt und in ein Gericht verwandelt, inklusive einer Begründung, warum dieser Name perfekt zum Gericht passt. Probiert es hier gerne selbst aus: Playground
Launch
the byte wurde offiziell auf der Pressekonferenz des S-O-U-P-Festivals Anfang Mai 2023 angekündigt. Wir starteten auch zusätzliche Marketingaktivitäten über soziale Medien und unser Netzwerk von Freunden und Familie. Als Ergebnis war the byte drei Tage lang vollständig ausgebucht und wir erhielten breite Medienberichterstattung in verschiedenen Gastronomie-Magazinen und der Tagespresse. Die Gäste waren (meistens) von unseren KI-Kreationen begeistert und wir erhielten Anfragen von anderen europäischen Restaurants und Unternehmen, die the byte exklusiv als Erlebnis für ihre Mitarbeiter:innen buchen möchten. 🤩 Nailed it!
Fazit und nächste Schritte
Die Erschaffung von the byte zusammen mit Jonathan und James war eine herausragende Erfahrung. Es hat mich weiter darin bestärkt, dass KI nicht nur unsere Wirtschaft, sondern alle Aspekte unseres täglichen Lebens transformieren wird. Es gibt ein riesiges Potenzial an der Schnittstelle von Kreativität, Kultur und KI, das derzeit erschlossen wird.
Wir möchten the byte definitiv in Frankfurt weiterführen und haben bereits Anfragen aus anderen Städten in Europa erhalten. Außerdem denken James, Jonathan und ich bereits über neue Möglichkeiten nach, KI in Kultur und Gesellschaft einzubringen. Stay tuned! 😏
the byte war nicht nur ein Restaurant, sondern ein fesselndes Erlebnis. Wir wollten etwas erschaffen, was noch nie zuvor gemacht wurde, und das haben wir in nur acht Wochen erreicht. Das ist die Inspiration, die ich euch heute mitgeben möchte:
Neue Dinge auszuprobieren, die einen aus der Komfortzone herausholen, ist die ultimative Quelle des Wachstums. Ihr wisst nie, wozu ihr fähig seid, bis ihr es versucht. Also, geht raus und probiert etwas Neues aus, wie den Aufbau eines KI-gesteuerten Pop-up-Restaurants. Wer weiß, vielleicht überrascht ihr euch selbst. Bon apétit!
Impressionen

Media
Genuss Magazin: https://www.genussmagazin-frankfurt.de/gastro_news/Kuechengefluester-26/Interview-James-Ardinast-KI-ist-die-Zukunft-40784.html
Frankfurt Tipp: https://www.frankfurt-tipp.de/ffm-aktuell/s/ugc/deutschlands-erstes-ai-restaurant-the-byte-in-frankfurt.html
Foodservice: https://www.food-service.de/maerkte/news/the-byte-erstes-ki-restaurant-vor-dem-start-55899?crefresh=1
Die versteckten Risiken von Black-Box Algorithmen
Unzählige Lebensläufe in kürzester Zeit sichten, bewerten und Empfehlungen für geeignete Kandidat:innen abgeben – das ist mit künstlicher Intelligenz im Bewerbungsmanagement mittlerweile möglich. Denn fortschrittliche KI-Techniken können auch komplexe Datenmengen effizient analysieren. Im Personalmanagement kann so nicht nur wertvolle Zeit bei der Vorauswahl eingespart, sondern auch Bewerber:innen schneller kontaktiert werden. Künstliche Intelligenz hat auch das Potenzial, Bewerbungsprozesse fairer und gerechter zu gestalten.
Die Praxis zeigt jedoch, dass auch künstliche Intelligenzen nicht immer „fairer“ sind. Vor einigen Jahren sorgte beispielsweise ein Recruiting-Algorithmus von Amazon für Aufsehen. Die KI diskriminierte Frauen bei der Auswahl von Kandidat:innen. Und auch bei Algorithmen zur Gesichtserkennung von People of Color kommt es immer wieder zu Diskriminierungsvorfällen.
Ein Grund dafür ist, dass komplexe KI-Algorithmen auf Basis der eingespeisten Daten selbstständig Vorhersagen und Ergebnisse berechnen. Wie genau sie zu einem bestimmten Ergebnis kommen, ist zunächst nicht nachvollziehbar. Daher werden sie auch als Black-Box Algorithmen bezeichnet. Im Fall von Amazon hat dieser auf Basis der aktuellen Belegschaft, die vorwiegend männlich war, geeignete Bewerber:innenprofile ermittelt und damit voreingenommene Entscheidungen getroffen. Auf diese oder ähnliche Weise können Algorithmen Stereotypen reproduzieren und Diskriminierung verstärken.
Prinzipien für vertrauenswürdige KI
Der Amazon-Vorfall zeigt, dass Transparenz bei der Entwicklung von KI-Lösungen von hoher Relevanz ist, um die ethisch einwandfreie Funktionsweise sicherzustellen. Deshalb ist Transparenz auch eines der insgesamt sieben statworx Principles für vertrauenswürdige KI. Die Mitarbeitenden von statworx haben gemeinsam folgende KI-Prinzipien definiert: Menschen-zentriert, transparent, ökologisch, respektvoll, fair, kollaborativ und inklusiv. Diese dienen als Orientierung für die alltägliche Arbeit mit künstlicher Intelligenz. Allgemeingültige Standards, Regeln und Gesetzte gibt es nämlich bisher nicht. Dies könnte sich jedoch bald ändern.
Die europäische Union (EU) diskutiert seit geraumer Zeit einen Gesetzesentwurf zur Regulierung von künstlicher Intelligenz. Dieser Entwurf, der so genannte AI-Act, hat das Potenzial zum Gamechanger für die globale KI-Branche zu werden. Denn nicht nur europäische Unternehmen werden von diesem Gesetzesentwurf anvisiert. Betroffen wären alle Unternehmen, die KI-Systeme auf dem europäischen Markt anbieten, dessen KI-generierter Output innerhalb der EU genutzt wird oder KI-Systeme zur internen Nutzung innerhalb der EU betreiben. Die Anforderungen, die ein KI-System dann erfüllen muss, hängen von dessen Anwendungsbereich ab.
Recruiting-Algorithmen werden auf Grund ihres Einsatzbereichs voraussichtlich als Hochrisiko-KI eingestuft. Demnach müssten Unternehmen bei der Entwicklung, der Veröffentlichung aber auch beim Betrieb der KI-Lösung umfassende Auflagen erfüllen. Unter anderem sind Unternehmen in der Pflicht, Qualitätsstandards für genutzte Daten einzuhalten, technische Dokumentationen zu erstellen und Risikomanagement zu etablieren. Bei Verstoß drohen hohe Bußgelder bis zu 6% des globalen jährlichen Umsatzes. Daher sollten sich Unternehmen schon jetzt mit den kommenden Anforderungen und ihren KI-Algorithmen auseinandersetzen. Ein sinnvoller erster Schritt können Explainable AI Methoden (XAI) sein. Mit Hilfe dieser können Black-Box-Algorithmen nachvollzogen und die Transparenz der KI-Lösung erhöht werden.
Die Black-Box mit Explainable AI Methoden entschlüsseln
Durch XAI-Methoden können Entwickler:innen die konkreten Entscheidungsprozesse von Algorithmen besser interpretieren. Das heißt, es wird transparent, wie ein Algorithmus Muster und Regeln gebildet hat und Entscheidungen trifft. Dadurch können mögliche Probleme wie beispielsweise Diskriminierung im Bewerbungsprozess nicht nur entdeckt, sondern auch korrigiert werden. Somit trägt XAI nicht nur zur stärkeren Transparenz von KI bei, sondern begünstigt auch deren ethisch unbedenklichen Einsatz und fördert so die Konformität einer KI mit dem kommenden AI-Act.
Einige XAI-Methoden sind sogar modellagnostisch, also anwendbar auf beliebige KI-Algorithmen vom Entscheidungsbaum bis hin zum Neuronalen Netz. Das Forschungsfeld rund um XAI ist in den letzten Jahren stark gewachsen, weshalb es mittlerweile eine große Methodenvielfalt gibt. Dabei zeigt unsere Erfahrung aber: Es gibt große Unterschiede zwischen verschiedenen Methoden hinsichtlich Verlässlichkeit und Aussagekraft ihrer Ergebnisse. Außerdem eignen sich nicht alle Methoden gleichermaßen zur robusten Anwendung in der Praxis und zur Gewinnung des Vertrauens externer Stakeholder. Daher haben wir unsere Top 3 Methoden anhand der folgenden Kriterien für diesen Blogbeitrag ermittelt:
- Ist die Methode modellagnostisch, funktioniert sie also für alle Arten von KI-Modellen?
- Liefert die Methode globale Ergebnisse, sagt also etwas über das Modell als Ganzes aus?
- Wie aussagekräftig sind die resultierenden Erklärungen?
- Wie gut ist das theoretische Fundament der Methode?
- Können böswillige Akteure die Resultate manipulieren oder sind sie vertrauenswürdig?
Unsere Top 3 XAI Methoden im Überblick
Anhand der oben genannten Kriterien haben wir drei verbreitete und bewährte Methoden zur detaillierten Darstellung ausgewählt: Permutation Feature Importance (PFI), SHAP Feature Importance und Accumulated Local Effects (ALE). Im Folgenden erklären wir für jede der drei Methoden den Anwendungszweck und deren grundlegende technische Funktionsweise. Außerdem gehen wir auf die Vor- und Nachteile beim Einsatz der drei Methoden ein und illustrieren die Anwendung anhand des Beispiels einer Recruiting-KI.
Mit Permutation Feature Importance effizient Einflussfaktoren identifizieren
Ziel der Permutation Feature Importance (PFI) ist es, herauszufinden, welche Variablen im Datensatz besonders entscheidend dafür sind, dass das Modell genaue Vorhersagen trifft. Im Falle des Recruiting-Beispiels kann die PFI-Analyse darüber aufklären, auf welche Informationen sich das Modell für seine Entscheidung besonders verlässt. Taucht hier z.B. das Geschlecht als einflussreicher Faktor auf, kann das die Entwickler:innen alarmieren. Aber auch in der Außenwirkung schafft die PFI-Analyse Transparenz und zeigt externen Anwender:innen an, welche Variablen für das Modell besonders relevant sind. Für die Berechnung der PFI benötigt man zunächst zwei Dinge:
- Eine Genauigkeitsmetrik wie z.B. die Fehlerrate (Anteil falscher Vorhersagen an allen Vorhersagen)
- Einen Testdatensatz, der zur Ermittlung der Genauigkeit verwendet werden kann.
Im Testdatensatz wird zunächst eine Variable nach der anderen durch das Hinzufügen von zufälligem Rauschen („Noise“) gewissermaßen verschleiert und dann die Genauigkeit des Modells über den bearbeiteten Testdatensatz bestimmt. Nun ist naheliegend, dass die Variablen, deren Verschleierung die Modellgenauigkeit am stärksten beeinträchtigen, besonders wichtig für die Genauigkeit des Modells sind. Sind alle Variablen nacheinander analysiert und sortiert, erhält man eine Visualisierung wie die in Abbildung 1. Anhand unseres künstlich erzeugten Beispieldatensatzes lässt sich folgendes erkennen: Berufserfahrung spielte keine große Rolle für das Modell, die Eindrücke aus dem Vorstellungsgespräch hingegen schon.
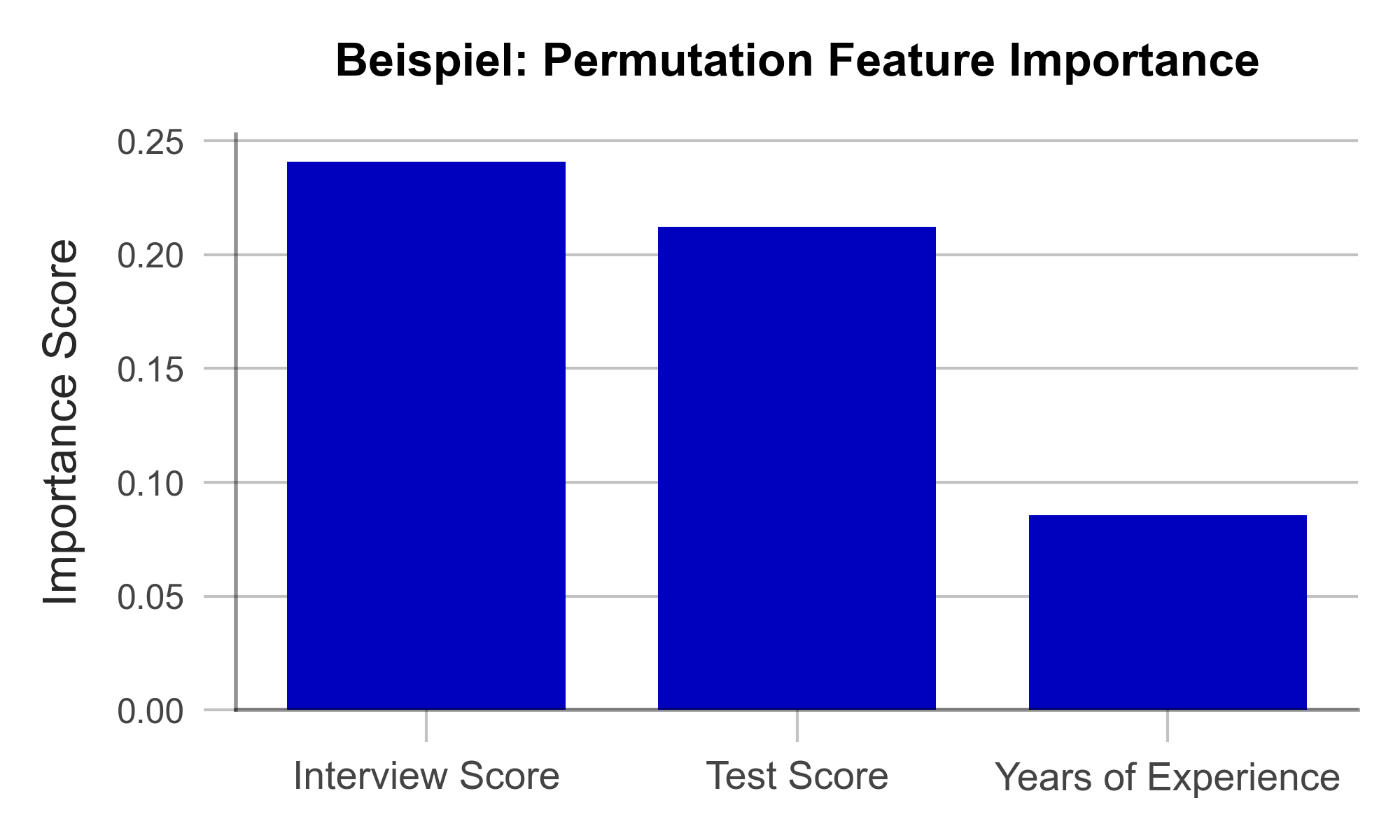
Abbildung 1 – Permutation Feature Importance am Beispiel einer Recruiting-KI (Daten künstlich erzeugt).
Eine große Stärke der PFI ist, dass sie einer nachvollziehbaren mathematischen Logik folgt. Die Korrektheit der gelieferten Erklärung kann durch statistische Überlegungen nachgewiesen werden. Darüber hinaus gibt es kaum manipulierbare Parameter im Algorithmus, mit der die Ergebnisse bewusst verzerrt werden könnten. Damit ist die PFI besonders geeignet dafür, das Vertrauen externer Betrachter:innen zu gewinnen. Nicht zuletzt ist die Berechnung der PFI im Vergleich zu anderen Explainable AI Methoden sehr ressourcenschonend.
Eine Schwäche der PFI ist, dass sie unter gewissen Umständen missverständliche Erklärungen liefern kann. Wird einer Variable ein geringer PFI-Wert zugewiesen, heißt das nicht immer, dass die Variable unwichtig für den Sachverhalt ist. Hat z.B. die Note des Bachelorstudiums einen geringen PFI-Wert, so kann das lediglich daran liegen, dass das Modell stattdessen auch die Note des Masterstudiums betrachten kann, da diese oft ähnlich sind. Solche korrelierten Variablen können die Interpretation der Ergebnisse erschweren. Nichtsdestotrotz ist die PFI eine effiziente und nützliche Methode zur Schaffung von Transparenz in Black-Box Modellen.
| Stärken | Schwächen |
|---|---|
| Wenig Spielraum für Manipulation der Ergebnisse | Berücksichtigt keine Interaktionen zwischen Variablen |
| Effiziente Berechnung |
Mit SHAP Feature Importance komplexe Zusammenhänge aufdecken
Die SHAP Feature Importance ist eine Methode zur Erklärung von Black-Box-Modellen, die auf der Spieltheorie basiert. Ziel ist es, den Beitrag jeder Variable zur Vorhersage des Modells zu quantifizieren. Damit ähnelt sie der Permutation Feature Importance auf den ersten Blick stark. Im Gegensatz zur PFI liefert die SHAP Feature Importance aber Ergebnisse, die komplexe Zusammenhänge zwischen mehreren Variablen berücksichtigen können.
SHAP liegt ein Konzept aus der Spieltheorie zugrunde: die Shapley Values. Diese sind ein Fairness-Kriterium, das jeder Variable eine Gewichtung zuweist, die ihrem Beitrag zum Ergebnis entspricht. Naheliegend ist die Analogie zu einem Teamsport, bei dem das Siegerpreisgeld unter allen Spieler:innen fair, also gemäß deren Beitrag zum Sieg, aufgeteilt wird. Mit SHAP kann analog für jede einzelne Beobachtung im Datensatz analysiert werden, welchen Beitrag welche Variable zur Vorhersage des Modells geliefert hat
Ermittelt man nun den durchschnittlichen absoluten Beitrag einer Variable über alle Beobachtungen im Datensatz hinweg, erhält man die SHAP Feature Importance. Abbildung 2 veranschaulicht beispielhaft die Ergebnisse dieser Analyse. Die Ähnlichkeit zur PFI ist klar ersichtlich, auch wenn die SHAP Feature Importance die Bewertung des Vorstellungsgespräches nur auf Platz 2 setzt.
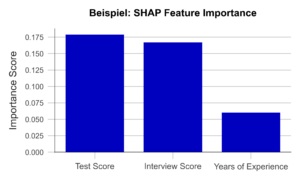
Abbildung 2 – SHAP Feature Importance am Beispiel einer Recruiting KI (Daten künstlich erzeugt).
Ein großer Vorteil dieses Ansatzes ist die Möglichkeit, Interaktionen zwischen Variablen zu berücksichtigen. Durch die Simulation verschiedener Variablen-Kombinationen lässt sich zeigen, wie sich die Vorhersage ändert, wenn zwei oder mehr Variablen gemeinsam variieren. Zum Bespiel sollte die Abschlussnote eines Studiums stets im Zusammenhang mit dem Studiengang und der Hochschule betrachtet werden. Im Gegensatz zur PFI trägt die SHAP Feature Importance diesem Umstand Rechnung. Auch sind Shapley Values, einmal berechnet, die Grundlage einer Bandbreite weiterer nützlicher XAI Methoden.
Eine Schwäche der Methode ist jedoch, dass sie aufwendiger zu berechnen ist als die PFI. Nur für bestimmte Arten von KI-Algorithmen (z.B. Entscheidungsbäume) gibt es effiziente Implementierungen. Es will also gut überlegt sein, ob für ein gegebenes Problem eine PFI-Analyse genügt, oder ob die SHAP Feature Importance zu Rate gezogen werden sollte.
| Stärken | Schwächen |
|---|---|
| Wenig Spielraum für Manipulation der Ergebnisse | Berechnung ist rechenaufwendig |
| Berücksichtigt komplexe Interaktionen zwischen Variablen |
Mit Accumulated Local Effects einzelne Variablen in den Fokus nehmen
Die Accumulated Local Effects (ALE) Methode ist eine Weiterentwicklung der Partial Dependence Plots (PDP), die sich großer Beliebtheit unter Data Scientists erfreuen. Beide Methoden haben das Ziel, den Einfluss einer bestimmten Variablen auf die Vorhersage des Modells zu simulieren. Damit können Fragen beantwortet werden wie: „Steigen mit zunehmender Berufserfahrung die Chancen auf eine Management Position?“ oder „Macht es einen Unterschied, ob ich eine 1.9 oder eine 2.0 in meinem Abschlusszeugnis habe?“. Im Gegensatz zu den vorherigen zwei Methoden trifft ALE also eine Aussage über die Entscheidungsfindung des Modells, nicht über die Relevanz bestimmter Variablen.
Im einfachsten Fall, dem PDP, wird eine Stichprobe von Beobachtungen ausgewählt und anhand dieser simuliert, welchen Einfluss z.B. eine isolierte Erhöhung der Berufserfahrung auf die Modellvorhersage hätte. Isoliert meint, dass dabei keine der anderen Variablen verändert wird. Der Durchschnitt dieser einzelnen Effekte über die gesamte Stichprobe liefert eine anschauliche Visualisierung (Abbildung 3, oben). Leider sind die Ergebnisse des PDP nicht besonders aussagekräftig, wenn korrelierte Variablen vorliegen. Am Beispiel der Hochschulnoten lässt sich das besonders gut veranschaulichen. So simuliert der PDP hierbei alle möglichen Kombinationen von Noten im Bachelor- und Masterstudium. Dabei entstehen leider Fälle, die in der echten Welt selten vorkommen, z.B. ein ausgezeichnetes Bachelorzeugnis und ein miserabler Masterabschluss. Der PDP hat kein Gespür für unsinnige Fälle, woran auch die Ergebnisse kranken.
Die ALE-Analyse hingegen versucht, dieses Problem durch eine realistischere Simulation zu lösen, die die Zusammenhänge zwischen Variablen adäquat abbildet. Dabei wird die betrachtete Variable, z.B. die Bachelor-Note, in mehrere Abschnitte eingeteilt (z.B. 6.0-5.1, 5.0-4.1, 4.0-3.1, 3.0-2.1 und 2.0-1.0). Nun wird die Simulation der Erhöhung der Bachelor-Note lediglich für Personen in der respektiven Notengruppe durchgeführt. Dies führt dazu, dass unrealistische Kombinationen nicht in die Analyse einfließen. Ein Beispiel für einen ALE-Plot findet sich in Abbildung 3 (unten). Hier zeigt sich anschaulich, dass der ALE-Plot einen negativen Einfluss der Berufserfahrung auf die Anstellungschance identifiziert, während dies dem PDP verborgen bleibt. Ist dieses Verhalten der KI erwünscht? Will man zum Beispiel insbesondere junge Talente einstellen? Oder steckt dahinter vielleicht eine versteckte Altersdiskriminierung? In beiden Fällen hilft der ALE-Plot dabei, Transparenz zu schaffen und ungewünschtes Verhalten rechtzeitig zu erkennen.
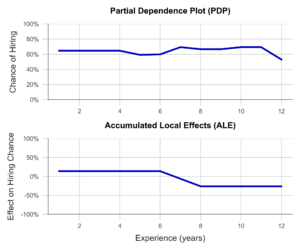
Abbildung 3– Partial Dependence Plot und Accumulated Local Effects am Beispiel einer Recruiting KI (Daten künstlich erzeugt).
Zusammenfassend ist der ALE-Plot eine geeignete Methode, um einen Einblick in den Einfluss einer bestimmten Variable auf die Modellvorhersage zu gewinnen. Dies schafft Transparenz für Nutzende und hilft sogar dabei, ungewünschte Effekte und Bias zu identifizieren und zu beheben. Ein Nachteil der Methode ist, dass der ALE-Plot stets nur eine Variable analysiert. Um also den Einfluss aller Variablen zu verstehen, muss eine Vielzahl von ALE-Plots generiert werden, was weniger übersichtlich ist als z.B. ein PFI- oder ein SHAP Feature Importance Plot.
| Stärken | Schwächen |
|---|---|
| Berücksichtigt komplexe Interaktionen zwischen Variablen | Mit ALE lassen sich nur eine oder zwei Variablen pro Visualisierung analysieren |
| Wenig Spielraum für Manipulation der Ergebnisse |
Mit Explainable AI Methoden Vertrauen aufbauen
In diesem Beitrag haben wir drei Explainable AI Methoden vorgestellt, die dabei helfen können, Algorithmen transparenter und interpretierbarer zu machen. Dies begünstigt außerdem, den Anforderungen des kommenden AI-Acts frühzeitig gerecht zu werden. Denn auch wenn dieser noch nicht verabschiedet ist, empfehlen wir auf Basis des Gesetzesentwurfs sich bereits jetzt mit der Schaffung von Transparenz und Nachvollziehbarkeit für KI-Modelle zu beschäftigen. Viele Data Scientists haben wenig Erfahrung in diesem Feld und benötigen Fortbildung und Einarbeitungszeit, bevor sie einschlägige Algorithmen identifizieren und effektive Lösungen implementieren können. Die weiterführende Beschäftigung mit den vorgestellten Methoden empfehlen wir daher in jedem Fall.
Mit der Permutation Feature Importance (PFI) und der SHAP Feature Importance haben wir zwei Techniken aufgezeigt, um die Relevanz bestimmter Variablen für die Vorhersage des Modells zu bestimmen. Zusammenfassend lässt sich sagen, dass die SHAP Feature Importance eine leistungsstarke Methode zur Erklärung von Black-Box-Modellen ist, die die Interaktionen zwischen Variablen berücksichtigt. Die PFI hingegen ist einfacher zu implementieren, aber weniger leistungsfähig bei korrelierten Daten. Welche Methode im konkreten Fall am besten geeignet ist, hängt von den spezifischen Anforderungen ab.
Auch haben wir mit Accumulated Local Effects (ALE) eine Technik vorgestellt, die nicht die Relevanz von Variablen, sondern sogar deren genauen Einfluss auf die Vorhersage bestimmen und visualisieren kann. Besonders vielversprechend ist die Kombination einer der beiden Feature Importance Methoden mit ausgewählten ALE-Plots zu ausgewählten Variablen. So kann ein theoretisch fundierter und leicht interpretierbarer Überblick über das Modell vermittelt werden – egal, ob es sich um einen Entscheidungsbaum oder ein tiefes Neuronales Netz handelt.
Die Anwendung von Explainable AI ist somit eine lohnende Investition – nicht nur, um intern und extern Vertrauen in die eigenen KI-Lösungen aufzubauen. Vielmehr gehen wir davon aus, dass der geschickte Einsatz interpretationsfördernder Methoden drohende Bußgelder durch die Anforderungen des AI-Acts vermeidet, rechtlichen Konsequenzen vorbeugt, sowie Betroffene vor Schaden schützt – wie im Fall von unverständlicher Recruitingsoftware.
Unserer kostenfreier AI Act Quick Check unterstützt Sie gerne bei der Einschätzung, ob eines Ihrer KI-Systeme vom AI Act betroffen sein könnte: https://www.statworx.com/ai-act-tool/
Quellen & Informationen:
https://www.faz.net/aktuell/karriere-hochschule/buero-co/ki-im-bewerbungsprozess-und-raus-bist-du-17471117.html (letzter Aufruf 03.05.2023)
https://t3n.de/news/diskriminierung-deshalb-platzte-amazons-traum-vom-ki-gestuetzten-recruiting-1117076/ (letzter Aufruf 03.05.2023)
Weitere Informationen zum AI Act: https://www.statworx.com/content-hub/blog/wie-der-ai-act-die-ki-branche-veraendern-wird-alles-was-man-jetzt-darueber-wissen-muss/
Statworx principles: https://www.statworx.com/content-hub/blog/statworx-ai-principles-warum-wir-eigene-ki-prinzipien-entwickeln/
Christoph Molnar: Interpretable Machine Learning: https://christophm.github.io/interpretable-ml-book/
Bildnachweis:
AdobeStock 566672394 – by TheYaksha
Der Europäische Rat hat vergangenen Dezember ein Dossier veröffentlicht, welches den vorläufigen Standpunkt des Rates zum Gesetzesentwurf des so genannten „AI-Act“ darstellt. Dieses neue Gesetz soll künstliche Intelligenz regulieren und wird somit zum Gamechanger für die gesamte Tech-Branche. Im Folgenden haben wir die wichtigsten Informationen aus dem Dossier zusammengetragen, welches zum Zeitpunkt der Veröffentlichung den aktuellen Stand des geplanten AI-Act beschreibt.
Ein rechtlicher Rahmen für KI
Künstliche Intelligenz besitzt enormes Potential, unser aller Leben zu verbessern und zu erleichtern. Zum Beispiel unterstützen KI-Algorithmen schon heute die Krebsfrüherkennung oder übersetzen Gebärdensprache in Echtzeit und beseitigen dadurch Sprachbarrieren. Doch neben den positiven Effekten gibt es auch Risiken, wie die neusten Deepfakes von Papst Franziskus oder der Cambridge Analytica Skandal verdeutlichen.
Um Risiken künstlicher Intelligenz zu mindern, erarbeitet die Europäische Union derzeit einen Gesetzesentwurf zur Regulierung künstlicher Intelligenz. Mit diesem möchte die EU Verbraucher:innen schützen und den ethisch vertretbaren Einsatz von künstlicher Intelligenz sicherstellen. Der sogenannte „AI-Act“ befindet sich zwar noch im Gesetzgebungsprozess, wird jedoch voraussichtlich noch 2023 – vor Ende der aktuellen Legislaturperiode – verabschiedet. Unternehmen haben anschließend zwei Jahre Zeit, die rechtlich bindenden Auflagen umzusetzen. Verstöße dagegen werden mit Bußgeldern von bis zu 6% des weltweiten Jahresumsatzes bzw. maximal 30.000.000 € geahndet. Deshalb sollten Unternehmen sich schon jetzt mit den kommenden rechtlichen Anforderungen auseinandersetzen.
Gesetzgebung mit globaler Wirkung
Der geplante AI-Act basiert auf dem „Marktortprinzip“, wodurch nicht nur europäische Unternehmen von der Gesetzesänderung belangt werden. Somit sind alle Unternehmen vom betroffen, die KI-Systeme auf dem europäischen Markt anbieten oder auch zur internen Nutzung innerhalb der EU betreiben – bis auf wenige Ausnahmen. Private Nutzung von KI bleibt bisher von der Verordnung unangetastet.
Welche KI-Systeme sind betroffen?
Die Definition von KI entscheidet, welche Systeme vom AI-Act betroffen sein werden. Daher wird die KI-Definition des AI-Acts in Politik, Wirtschaft und Gesellschaft seit geraumer Zeit kontrovers diskutiert. Die initiale Definition war so breit gefasst, dass auch viele „normale“ Software-Systeme betroffen gewesen wären. Der aktuelle Vorschlag definiert KI als jedes System, das durch Machine Learning oder logik- und wissensbasierten Ansätzen entwickelt wurde. Ob diese Definition letztendlich auch verabschiedet wird, gilt es abzuwarten.
7 Prinzipien für vertrauenswürdige KI
Die „sieben Prinzipien für vertrauenswürdige KI“ stellen die wichtigste inhaltliche Grundlage des AI-Acts dar. Ein Gremium von Expert:innen aus Forschung, Digitalwirtschaft und Verbänden hat diese im Auftrag der Europäischen Kommission entwickelt. Sie umfassen nicht nur technische Aspekte, sondern auch soziale und ethische Faktoren, anhand derer die Vertrauenswürdigkeit eines KI-Systems eingeordnet werden kann entlang derer eine KI beurteilt werden kann:
- Menschliches Handeln & Aufsicht: Entscheidungsfindung soll unterstützt werden, ohne die menschliche Autonomie zu untergraben.
- Technische Robustheit & Sicherheit: Genauigkeit, Zuverlässigkeit und Sicherheit muss präventiv sichergestellt sein.
- Datenschutz & Data Governance: Umgang mit Daten muss rechtssicher und geschützt erfolgen.
- Transparenz: Interaktion mit KI muss deutlich kommuniziert werden, ebenso die Limitationen und Grenzen dieser.
- Vielfalt, Nicht-Diskriminierung & Fairness: Vermeidung unfairer Verzerrungen muss über den gesamten KI-Lebenszyklus sichergestellt werden.
- Ökologisches & gesellschaftliches Wohlergehen: KI-Lösungen sollten sich möglichst positiv auf die Umwelt auswirken.
- Rechenschaftspflicht: Verantwortlichkeiten für die Entwicklung, Nutzung und Instandhaltung von KI-Systemen müssen definiert sein.
Auf Basis dieser Grundsätze wurde der risikobasierte Ansatz des AI-Acts entwickelt, mit welchem KI-Systeme in eine von vier Risikoklassen eingeordnet werden können: niedriges, limitiertes, hohes und inakzeptables Risiko.
Vier Risikoklassen für vertrauenswürdige KI
Die Risikoklasse eines KI-Systems gibt an, wie stark ein KI-System die Prinzipien vertrauenswürdiger KI bedroht und welche rechtlichen Auflagen das System erfüllen muss – sofern das System grundlegend zulässig ist. Denn zukünftig sind auf dem europäischen Markt nicht alle KI-Systeme willkommen. Beispielsweise werden die meisten „Social Scoring“-Techniken als „inakzeptabel“ eingeschätzt und im Zuge des neuen Gesetzes verboten.
Für die anderen drei Risiko-Klassen gilt die Faustregel: Je höher das Risiko eines KI-Systems, desto höher die rechtlichen Anforderungen an dieses. Die meisten Anforderungen werden Unternehmen erfüllen müssen, welche Hochrisiko-Systeme anbieten oder betreiben. Als solche gelten z.B. KI, die für den Betrieb kritischer (digitaler) Infrastruktur genutzt oder in medizinischen Geräten eingesetzt wird. Um diese auf den Markt zu bringen, müssen Unternehmen hohe Qualitätsstandards bei den genutzten Daten beachten, ein Risikomanagement einrichten, eine CE-Kennzeichnung anbringen und vieles mehr.
KI-Systeme der Klasse „limitiertes Risiko“ unterliegen Informations- und Transparenzpflichten. Demnach müssen Unternehmen Nutzer:innen von Chatbots, Emotionserkennungssystemen oder Deepfakes über den Einsatz und Nutzung künstlicher Intelligenz informieren. Predictive Maintenance oder Spamfilter sind zwei Beispiele für KI-Systeme, welche in die niedrigste Risiko-Klasse „geringes Risiko“ fallen. Unternehmen, die ausschließlich solche KI-Lösungen anbieten oder nutzen, werden kaum von dem kommenden AI-Act betroffen sein. Für diese Anwendungen sind nämlich bisher keine rechtlichen Auflagen vorgesehen.
Was Unternehmen jetzt tun können
Auch wenn sich der AI-Act noch in der Gesetzgebung befindet, sollten Unternehmen bereits jetzt aktiv werden. Ein erster Schritt stellt die Abklärung der Betroffenheit durch den AI-Act dar. Um Sie dabei zu unterstützen, haben wir den AI-Act Quick Check entwickelt. Mit diesem kostenlosen Tool können Sie KI-Systeme kostenfrei und schnell einer Risiko-Klasse zugeordnet und Anforderungen an das System abgeleitet werden. Nicht zuletzt kann auf dieser Basis abgeschätzt werden, wie umfangreich die Realisierung des AI-Acts im eigenen Unternehmen wird und erste Maßnahmen ergriffen werden.
Profitieren auch Sie von unserer Expertise!
Selbstverständlich unterstützen wir Sie gerne bei der Evaluation und Lösungen unternehmensspezifischen Herausforderungen rund um den AI-Act. Sprechen Sie uns dafür gerne an!