
Management Summary
Machine Learning Projekte zu deployen und zu überwachen ist ein komplexes Vorhaben. Neben dem konsequenten Dokumentieren von Modellparametern und den dazugehörigen Evaluationsmetriken, besteht die Herausforderung vor allem darin, das gewünschte Modell in eine Produktivumgebung zu überführen. Sofern mehrere Personen an der Entwicklung beteiligt sind, ergeben sich zusätzlich Synchronisationsprobleme in Bezug auf die Entwicklungsumgebungen und Versionsstände der Modelle. Aus diesem Grund werden Tools zum effizienten Management von Modellergebnissen bis hin zu umfangreichen Trainings- und Inferenzpipelines benötigt.
In diesem Artikel werden die typischen Herausforderungen entlang des Machine Learning Workflows dargestellt und mit MLflow eine mögliche Lösungsplattform beschrieben. Zusätzlich stellen wir drei verschiedene Szenarien dar, mit deren Hilfe sich Machine Learning Workflows professionalisieren lassen:
- Einsteigervariante:
Modellparameter und Performance-Metriken werden über eine R/Python API geloggt und in einer GUI übersichtlich dargestellt. Zusätzlich werden die trainierten Modelle als Artefakt abgespeichert und können über APIs bereitgestellt werden. - Fortgeschrittenes Modellmanagement:
Neben dem Tracking von Parametern und Metriken werden bestimmte Modelle geloggt und versioniert. Dies ermöglicht ein kontrolliertes Monitoring und vereinfacht das Deployment von ausgewählten Modellversionen. - Kollaboratives Workflowmanagement:
Das Abkapseln von Machine Learning Projekten als Pakete oder Git Repositories und der damit einhergehenden lokalen Reproduzierbarkeit von Entwicklungsumgebungen, ermöglichen eine reibungslose Entwicklung von Machine Learning Projekten mit mehreren Beteiligten.
Je nach Reifegrad Ihres Machine Learning Projektes können die drei Szenarien als Inspiration für einen potenziellen Machine Learning Workflow dienen. Zum besseren Verständnis haben wir jedes Szenario detailliert ausgearbeitet und geben Empfehlungen hinsichtlich der zu verwendeten APIs und Deployment-Umgebungen.
Herausforderungen entlang des Machine Learning Workflows
Das Training von Machine Learning Modellen wird immer einfacher. Mittlerweile ermöglichen eine Vielzahl von Open Source Tools eine effiziente Datenaufbereitung sowie ein immer einfacheres Modelltraining und Deployment.
Der Mehrwert für Unternehmen entsteht vor allem durch das systematische Zusammenspiel von Modelltraining, in Form von Modellidentifikation, Hyperparametertuning und Fitting auf den Trainingsdaten, und Deployment, also dem Bereitstellen des Modells zur Berechnung von Vorhersagen. Insbesondere in frühen Phasen der Entwicklung von Machine Learning Initiativen wird dieses Zusammenspiel häufig nicht als kontinuierlicher Prozess etabliert. Ein Modell kann jedoch nur dann langfristig Mehrwerte generieren, wenn ein stabiler Produktionsprozess vom Modelltraining, über dessen Validierung bis hin zum Test und Deployment implementiert wird. Sofern dieser Prozess korrekt implementiert wird können bei der operativen Inbetriebnahme des Modells komplexe Abhängigkeiten und langfristig kostspielige Wartungsarbeiten entstehen [2]. Die folgenden Risiken sind hierbei besonders hervorzuheben
1. Gewährleistung von Synchronität
Häufig werden im explorativen Kontext Datenaufbereitungs- und Modellierungs-Workflows lokal entwickelt. Unterschiedliche Konfigurationen der Entwicklungsumgebungen oder gar der Einsatz von verschiedenen Technologien erschweren eine Reproduktion von Ergebnissen, insbesondere zwischen Entwickler*innen bzw. Teams. Zusätzlich ergeben sich potenzielle Gefahren hinsichtlich der Kompatibilität des Workflows, sofern mehrere Skripte in einer logischen Reihenfolge exekutiert werden müssen. Ohne einer entsprechenden Versionskontroll-Logik kann der Synchronisationsaufwand im Nachhinein nur mit großem Aufwand gewährleistet werden.
2. Aufwand der Dokumentation
Um die Performance des Modells zu bewerten, werden häufig im Anschluss an das Training Modellmetriken berechnet. Diese hängen von verschiedenen Faktoren ab, wie z.B. der Parametrisierung des Modells oder den verwendeten Einflussfaktoren. Diese Metainformationen über das Modell werden häufig nicht zentral gespeichert. Zur systematischen Weiterentwicklung und Verbesserung eines Modells ist es jedoch zwingend erforderlich, eine Übersicht über die Parametrisierung und Performance aller vergangenen Trainingsläufe zu haben.
3. Heterogenität von Modellformaten
Neben der Verwaltung von Modellparametern und Ergebnissen besteht die Herausforderung das Modell anschließend in die Produktionsumgebung zu überführen. Sofern verschiedene Modelle aus mehreren Paketen zum Training verwendet werden kann das Deployment aufgrund unterschiedlicher Pakete und Versionen schnell umständlich und fehleranfällig werden.
4. Wiederherstellung alter Ergebnisse
In einem typischen Machine Learning Projekt ergibt sich häufig die Situation, dass ein Modell über einen langen Zeitraum entwickelt wird. Beispielsweise können neue Features verwendet oder auch gänzlich neue Architekturen evaluiert werden. Nicht zwangsläufig führen diese Experimente zu besseren Ergebnissen. Sofern Experimente nicht sauber versioniert werden, besteht die Gefahr alte Ergebnisse nicht mehr nachbilden zu können.
Um diese und weitere Herausforderungen im Umgang und Management von Machine Learning Workflows zu lösen, wurden in den vergangenen Jahren verschiedene Tools entwickelt, wie beispielsweise TensorFlow TFX, cortex, Marvin oder MLFlow. Insbesondere letzteres ist aktuell eine der am häufigsten verwendeten Lösungen.
MLflow ist ein Open Source Projekt mit dem Ziel, das Beste aus existierenden ML Plattformen zu vereinen, um die Integration zu bestehenden ML Bibliotheken, Algorithmen und Deployment Tools so unkompliziert wie möglich zu gestalten [3]. Im Folgenden werden die wesentlichen MLflow Module vorgestellt und Möglichkeiten erörtert, mit der Machine Learning Workflows über MLflow abgebildet werden können.
MLflow Services
MLflow besteht aus vier Komponenten: MLflow Tracking, MLflow Models, MLflow Projectsund MLflow Registry. Je nach Anforderung an das Experimental- und Deployment-Szenario können alle Services gemeinsam genutzt, oder auch einzelne Komponenten isoliert werden.
Mit MLflowTracking lassen sich alle Hyperparameter, Metriken (Modell-Performance) und Artefakte, wie bspw. Charts, loggen. MLflow Tracking bietet die Möglichkeit, für jeden Trainings- oder Scoring-Lauf eines Modells Voreinstellungen, Parameter und Ergebnisse für ein kollektives Monitoring zu sammeln. Die geloggten Ergebnisse lassen sich in einer GUI visualisieren oder alternativ über eine REST API ansprechen.
Das Modul MLflow Models fungiert als Schnittstelle zwischen Technologien und ermöglicht ein vereinfachtes Deployment. Ein Modell wird je nach Typ als Binary, z.B, als reine Python-Funktion oder als Keras-, oder H2O-Modell gespeichert. Man spricht hierbei von den sogenannten model flavors. Weiterhin stellt MLflow Models eine Unterstützung zur Modellbereitstellung auf verschiedenen Machine Learning Cloud Services bereit, z.B. für AzureML und Amazon Sagemaker.
MLflow Projects dienen dazu, einzelne ML-Projekte in einem Paket oder Git-Repository abzukapseln. Die Basiskonfigurationen des jeweiligen Environments werden über eine YAML-Datei festgelegt. Über diese kann z.B. gesteuert werden, wie genau das conda-Environment parametrisiert ist, das im Falle einer Ausführung von MLflow erstellt wird. Durch MLflow Projects können Experimente, die lokal entwickelt wurden, auf anderen Rechnern in der gleichen Umgebung ausgeführt werden. Dies ist bspw. bei der Entwicklung in kleineren Teams von Vorteil.
Ein zentralisiertes Modellmanagement bietet MLflow Registry. Ausgewählte MLflow Models können darin registriert und versioniert werden. Ein Staging-Workflow ermöglicht ein kontrolliertes Überführen von Modellen in die Produktivumgebung. Der gesamte Prozess lässt sich wiederum über eine GUI oder eine REST API steuern.
Beispiele für Machine Learning Pipelines mit MLflow
Im Folgenden werden mit Hilfe der o.g. MLflow Module drei verschiedene ML Workflow-Szenarien dargestellt. Diese steigern sich von Szenario zu Szenario hinsichtlich der Komplexität. In allen Szenarien wird ein Datensatz mittels eines Python Skripts in eine Entwicklungsumgebung geladen, verarbeitet und ein Machine Learning Modell trainiert. Der letzte Schritt stellt in allen Szenarien ein Deployment des ML Modells in eine beispielhafte Produktivumgebung dar.
1. Szenario – Die Einsteigervariante
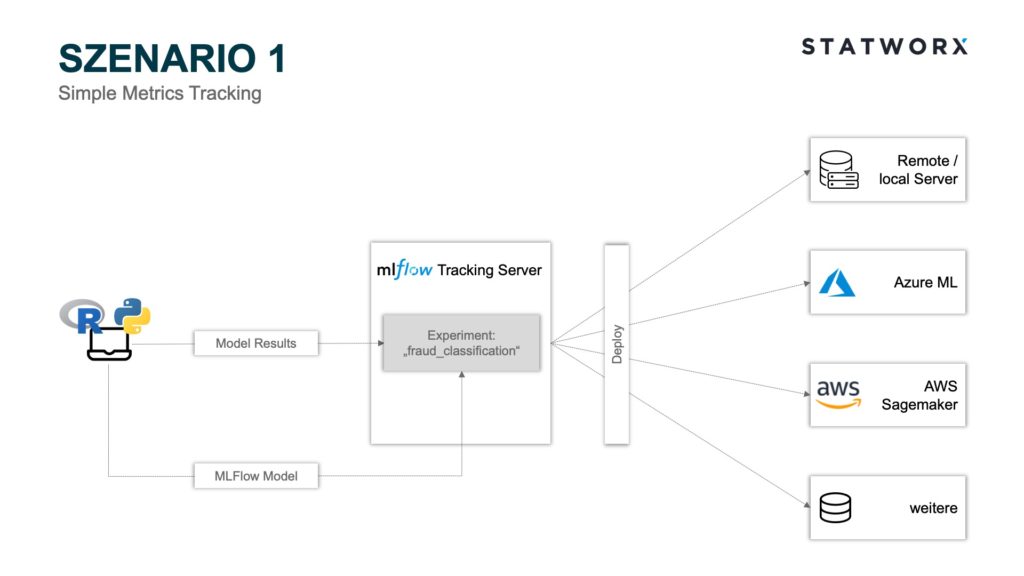 Szenario 1 – Simple Metrics Tracking
Szenario 1 – Simple Metrics TrackingSzenario 1 bedient sich der Module MLflow Tracking und MLflow Models. Hierbei können mittels der Python API die Modellparameter und Metriken der einzelnen Runs auf dem MLflow Tracking Server Backend Store gespeichert und das entsprechende MLflow Model File als Artefakt auf dem MLflow Tracking Server Artifact Store abgelegt werden. Jeder Run wird hierbei einem Experiment zugeordnet. Beispielsweise könnte ein Experiment ‚fraud_classification‘ lauten und ein Run wäre ein bestimmtes ML Modell mit einer Hyperparameterkonfiguration und den entsprechenden Metriken. Jeder Run wird zur eindeutigen Zuordnung mit einer einzigartigen RunID abgespeichert.
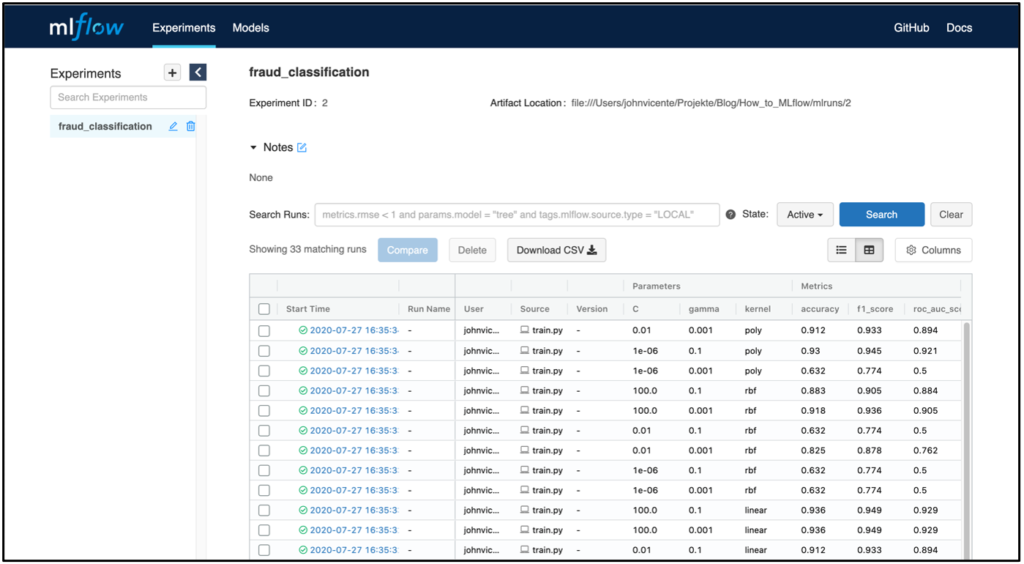
Im Screenshot wird die MLflow Tracking UI beispielhaft nach der Ausführung eines Modelltrainings dargestellt. Der Server wird im Beispiel lokal gehostet. Selbstverständlich besteht auch die Möglichkeit den Server Remote, beispielsweise in einem Docker Container, innerhalb einer VM zu hosten. Neben den Parametern und Modellmetriken werden zudem der Zeitpunkt des Modelltrainings sowie der User und der Name des zugrundeliegenden Skripts geloggt. Klickt man auf einen bestimmten Run werden zudem weitere Informationen dargestellt, wie beispielsweise die RunID und die Modelltrainingsdauer.
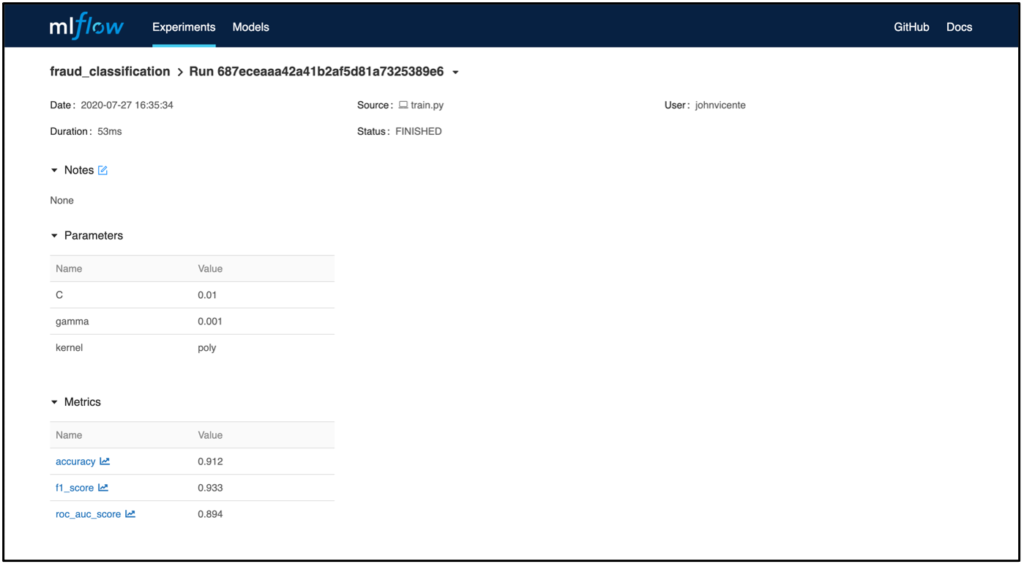
Sofern man neben den Metriken zusätzlich noch weitere Artefakte, wie bspw. das Modell, geloggt hat, wird das MLflow Model Artifact ebenfalls in der Run-Ansicht dargestellt. In dem Beispiel wurde ein Modell aus dem sklearn.svm Package verwendet. Das File MLmodel enthält Metadaten mit Informationen über die Art und Weise, wie das Modell geladen werden soll. Zusätzlich dazu wird ein conda.yaml erstellt, das alle Paketabhängigkeiten des Environments zum Trainingszeitpunkt enthält. Das Modell selbst befindet sich als serialisierte Version unter model.pklund enthält die auf den Trainingsdaten optimierten Modellparameter.
Das Deployment des trainierten Modells kann nun auf mehrere Weisen erfolgen. Möchte man beispielsweise das Modell mit der besten Accuracy Metrik deployen, kann der MLflow Tracking Server über die Python API mlflow.list_run_infos angesteuert werden, um so die RunID des gesuchten Modells zu identifizieren. Nun kann der Pfad zu dem gewünschten Artefakt zusammengesetzt werden und das Modell bspw. über das Python Paket pickle geladen werden. Dieser Workflow kann nun über ein Dockerfile getriggert werden, was ein flexibles Deployment in die Infrastruktur Ihrer Wahl ermöglicht. MLFlow bietet für das Deployment auf Microsoft Azure und AWS zusätzliche gesonderte APIs an. Sofern das Modell bspw. auf AzureML deployed werden soll, kann ein Azure ML Container Image mit der Python API mlflow.azureml.build_image erstellt werden, welches als Webservice nach Azure Container Instances oder Azure Kubernetes Service deployed werden kann. Neben dem MLflow Tracking Server besteht auch die Möglichkeit andere Ablagesysteme für das Artefakt zu verwenden, wie zum Beispiel Amazon S3, Azure Blob Storage, Google Cloud Storage, SFTP Server, NFS und HDFS.
2. Szenario – Fortgeschrittenes Modellmanagement
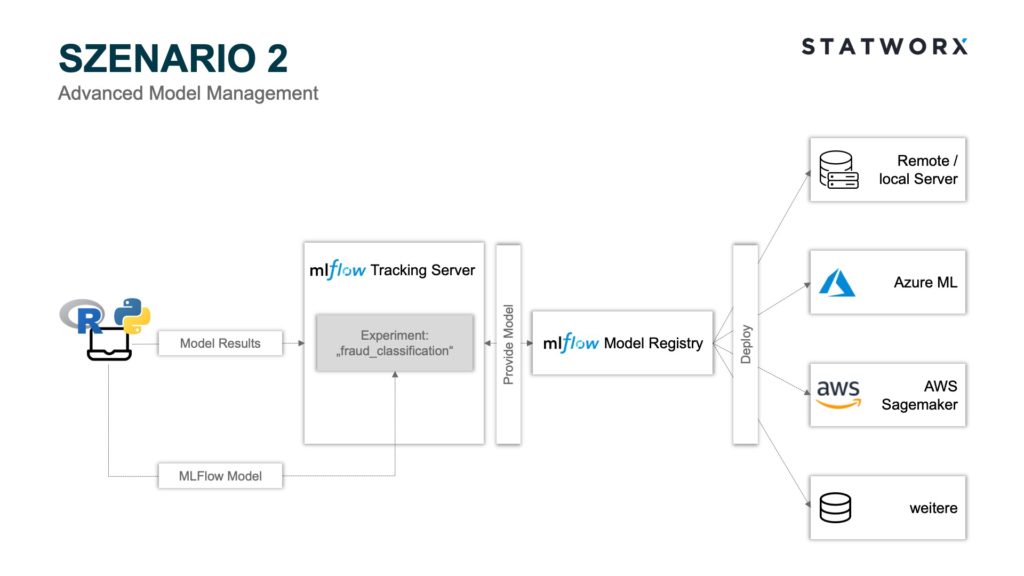 Szenario 2 – Advanced Model Management
Szenario 2 – Advanced Model ManagementSzenario 2 beinhaltet, neben den in Szenario 1 verwendeten Modulen, zusätzlich MLflow Model Registry als Modelmanagementkomponente. Hierbei besteht die Möglichkeit, aus bestimmten Runs die dort geloggten Modelle zu registrieren und zu verarbeiten. Diese Schritte können über die API oder GUI gesteuert werden. Eine Grundvoraussetzung, um die Model Registry zu nutzen, ist eine Bereitstellung des MLflow Tracking Server Backend Store als Database Backend Store. Um ein Modell über die GUI zu registrieren, wählt man einen bestimmten Run aus und scrollt in die Artefakt Übersicht.
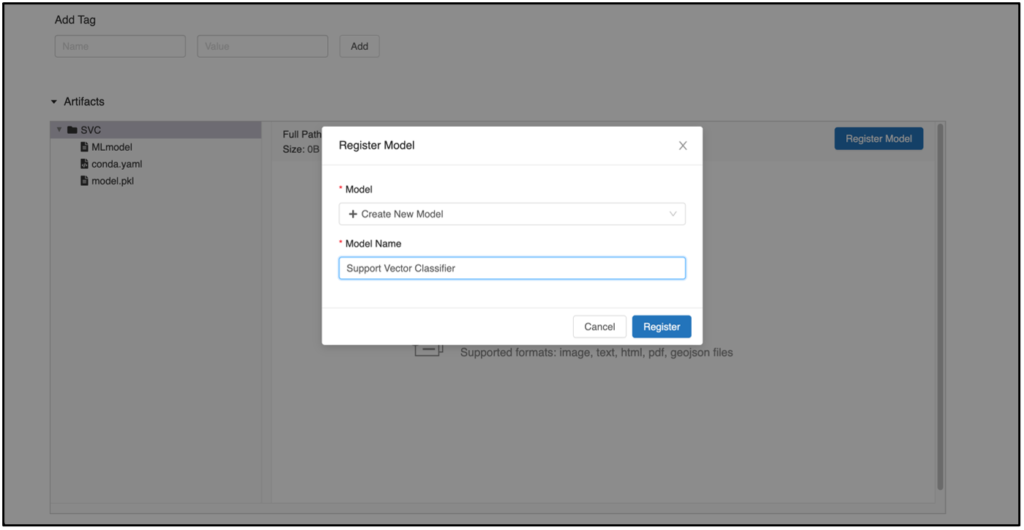
Mit einem Klick auf Register Model öffnet sich ein neues Fenster, in dem ein Modell registriert werden kann. Sofern man eine neue Version eines bereits existierenden Modells registrieren möchte, wählt man das gesuchte Modell aus dem Dropdown Feld aus. Ansonsten kann jederzeit ein neues Modell angelegt werden. Nach dem Klick auf den Button Register erscheint in dem Reiter Models das zuvor registrierte Modell mit einer entsprechenden Versionierung.
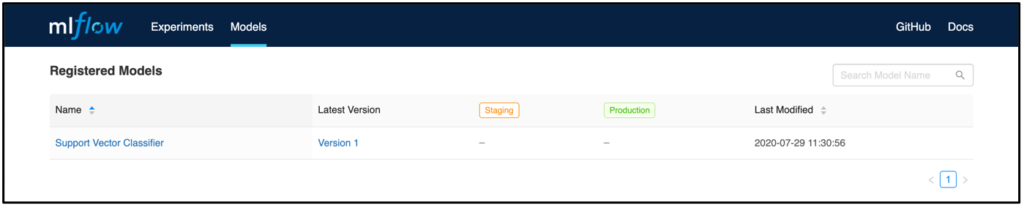
Jedes Modell beinhaltet eine Übersichtsseite, bei der alle vergangenen Versionen dargestellt werden. Dies ist bspw. nützlich, um nachzuvollziehen, welche Modelle wann in Produktion waren.
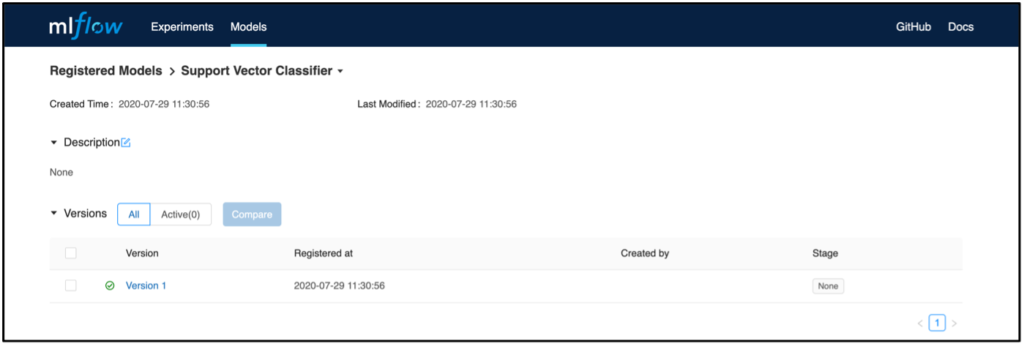
Wählt man nun eine Modellversion aus, gelangt man auf eine Übersicht, bei der beispielsweise eine Modellbeschreibung angefügt werden kann. Ebenso gelangt man über den Link Source Run zu dem Run, aus dem das Modell registriert worden ist. Hier befindet sich auch das dazugehörige Artefakt, das später zum Deployment verwendet werden kann.
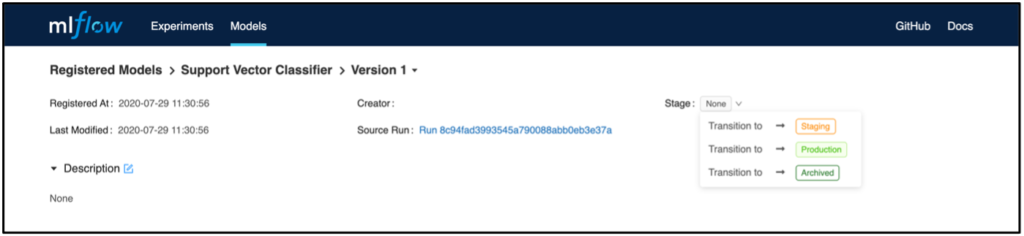
Zusätzlich können einzelne Modellversionen in dem Bereich Stage in festgelegte Phasen kategorisiert werden. Dieses Feature kann beispielsweise dazu genutzt werden, um festzulegen, welches Modell gerade in der Produktion verwendet wird oder dahin überführt werden soll. Für das Deployment kann, im Gegensatz zu Szenario 1, die Versionierung und der Staging-Status dazu verwendet werden, um das geeignete Modell identifizieren und zu deployen. Hierzu kann z.B. die Python API MlflowClient().search_model_versions verwendet werden, um das gewünschte Modell und die dazugehörige RunID zu filtern. Ähnlich wie in Szenario 1 kann dann das Deployment beispielsweise nach AWS Sagemaker oder AzureML über die jeweiligen Python APIs vollzogen werden.
3. Szenario – Kollaboratives Workflowmanagement
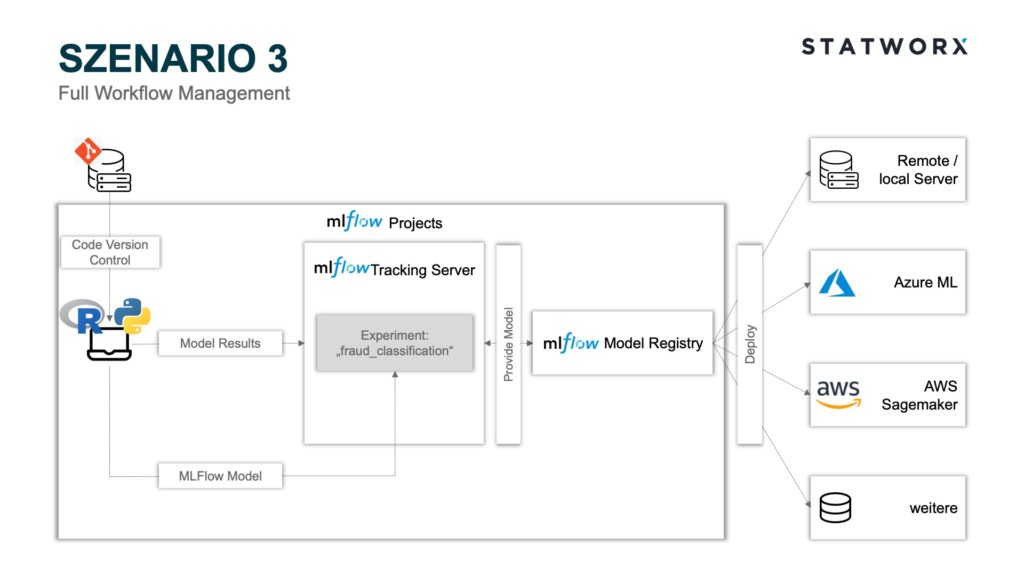 Szenario 3 – Full Workflow Management
Szenario 3 – Full Workflow ManagementDas Szenario 3 beinhaltet, neben denen in Szenario 2 verwendeten Modulen, zusätzlich noch das Modul MLflow Projects. Wie bereits erläutert, eignen sich MLflow Projects besonders gut für kollaborative Arbeiten. Jedes Git Repository oder jede lokale Umgebung kann hierbei als Projekt fungieren und mittels eines MLproject File gesteuert werden. Hierbei können Paketabhängigkeiten in einem conda.yaml festgehalten und beim Starten des Projekts auf das MLproject File zugegriffen werden. Anschließend wird die entsprechende conda Umgebung mit allen Abhängigkeiten vor dem Training und Logging des Modells erstellt. Dies verhindert den Bedarf eines manuellen Angleichens der Entwicklungsumgebungen aller beteiligten Entwickler*innen und garantiert zudem standardisierte und vergleichbare Ergebnisse aller Runs. Insbesondere letzteres ist erforderlich im Deployment Kontext, da allgemein nicht garantiert werden kann, dass unterschiedliche Package-Versionen dieselben Modellartefakte produzieren. Anstelle einer conda Umgebung kann auch eine Docker Umgebung mittels eines Dockerfiles definiert werden. Dies bietet den Vorteil, dass auch von Python unabhängige Paketabhängigkeiten festgelegt werden können. Ebenso ermöglichen MLflow Projects durch die Anwendung unterschiedlicher commit hashes oder branch names das Verwenden verschiedener Projektstände, sofern ein Git Repository verwendet wird.
Ein interessanter Use Case hierbei ist die modularisierte Entwicklung von Machine Learning Trainingspipelines [4]. Hierbei kann bspw. die Datenaufbereitung vom Modelltraining entkoppelt und parallel weiterentwickelt werden, während parallel ein anderes Team einen unterschiedlichen branch name verwendet, um das Modell zu trainieren. Hierbei muss lediglich beim Starten des Projektes im MLflow Projects File ein unterschiedlicher branch name als Parameter verwendet werden. Die finale Datenaufbereitung kann im Anschluss auf denselben branch name gepusht werden, der zum Modelltraining verwendet wird und wäre somit bereits vollständig in der Trainingspipeline implementiert. Das Deployment kann ebenfalls als Teilmodul innerhalb der Projektpipeline mittels eines Python Skripts über das ML Project File gesteuert werden und analog zu Szenario 1 oder 2 auf eine Plattform Ihrer Wahl erfolgen.
Fazit und Ausblick
MLflow bietet eine flexible Möglichkeit den Machine Learning Workflow robust gegen die typischen Herausforderungen im Alltag eines Data Scientists zu gestalten, wie beispielsweise Synchronisationsprobleme aufgrund unterschiedlicher Entwicklungsumgebungen oder fehlendes Modellmanagement. Je nach Reifegrad des bestehenden Machine Learning Workflows können verschiedene Services aus dem MLflow Portfolio verwendet werden, um eine höhere Professionalisierungsstufe zu erreichen.
Im Artikel wurden drei, in der Komplexität aufsteigende, Machine Learning Workflows exemplarisch dargestellt. Vom einfachen Logging der Ergebnisse in einer interaktiven UI, bis hin zu komplexeren, modularen Modellierungspipelines können MLflow Services unterstützen. Logischerweise ergeben sich auch außerhalb des MLflow Ökosystems Synergien mit anderen Tools, wie zum Beispiel Docker/Kubernetes zur Modellskalierung oder auch Jenkins zur Steuerung der CI/CD Pipeline. Sofern noch weiteres Interesse an MLOps Herausforderungen und Best Practices besteht verweise ich auf das von uns kostenfrei zur Verfügung gestellte Webinar zu MLOps von unserem CEO Sebastian Heinz.
Quellen
- https://www.aitrends.com/machine-learning/mlops-not-just-ml-business-new-competitive-frontier/
- Hidden Technical Debt in Machine Learning Systems (2014) von D. Sculley et al., (https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf)
- https://databricks.com/blog/2018/06/05/introducing-mlflow-an-open-source-machine-learning-platform.html
- https://mlflow.org/docs/latest/projects.html#building-multistep-workflows