
The story continues
As Christian and I have already mentioned in part 1 of this simulation study series, pandas and data.table have become the most widely used packages for data manipulation in Python and R, respectively (in R, of course, one may not miss mentioning the dplyr package). Furthermore, at STATWORX we have experts in both domains, and besides having some lovely sweets at our company (Jessica’s blog posts on this topic), we also have discussions about one particular topic: R or Python? Which one is the better language? Well, “better” is quite a broad term, and eventually, it is certainly a matter of taste and depends on the context of your problem. However, when crunching large amounts of data, one criterion needs to be met by any “data language”: speed.
Speed is the central subject of our series. We present performance comparisons between pandas and data.table when being confronted with common tasks in data engineering, and this time, we focus on three of such operations especially:
- Data sorting
- Data column generation
- Data aggregation
The setup (skip if you have read part 1)
The simulation study is rather complex, so some time should be spent on explaining the setup. Each of the above-mentioned operation categories is a simulation in its own right. Independently of the operations, we have created 12 datasets of different sizes — the largest one has 1200 columns and 100.000 rows — whose columns consist of four possible data types: integer, double, string, and boolean. Each column in turn follows a different distribution from which it was generated, depending on the data type it was assigned (for example, an integer column may stem from a zero-inflated poisson distribution, a poisson distribution, or a uniform distribution). For each of the three above data operation categories — sorting, generating, and aggregating — we have defined a set of concrete actions, which we call scenario. One scenario for the data sorting case may, for instance, be “take a pre-specified randomly selected integer column and sort the whole dataset according to that column”. Each scenario is run 100 times and the median computation time in milliseconds computed. In the main plots you see below, we put the median computation times of pandas and data.table in contrast by dividing the former by the latter.
The computations were performed on a machine with an Intel i7 2.2GHz with 4 physical cores, 16GB RAM and a SSD harddrive. Software Versions were OS X 10.13.3, Python 3.6.4 and R 3.4.2. The respective library versions used were 0.22 for pandas and 1.10.4-3 for data.table.
Sort / Arrange
Here we check the speed of sorting (also referred to as arranging) a data frame on one or two randomly drawn columns. In total, there are 5 scenarios: sorting (1) an integer, (2) a double, (3) a character string, (4) a boolean, and (5) two randomly drawn columns of any data type.
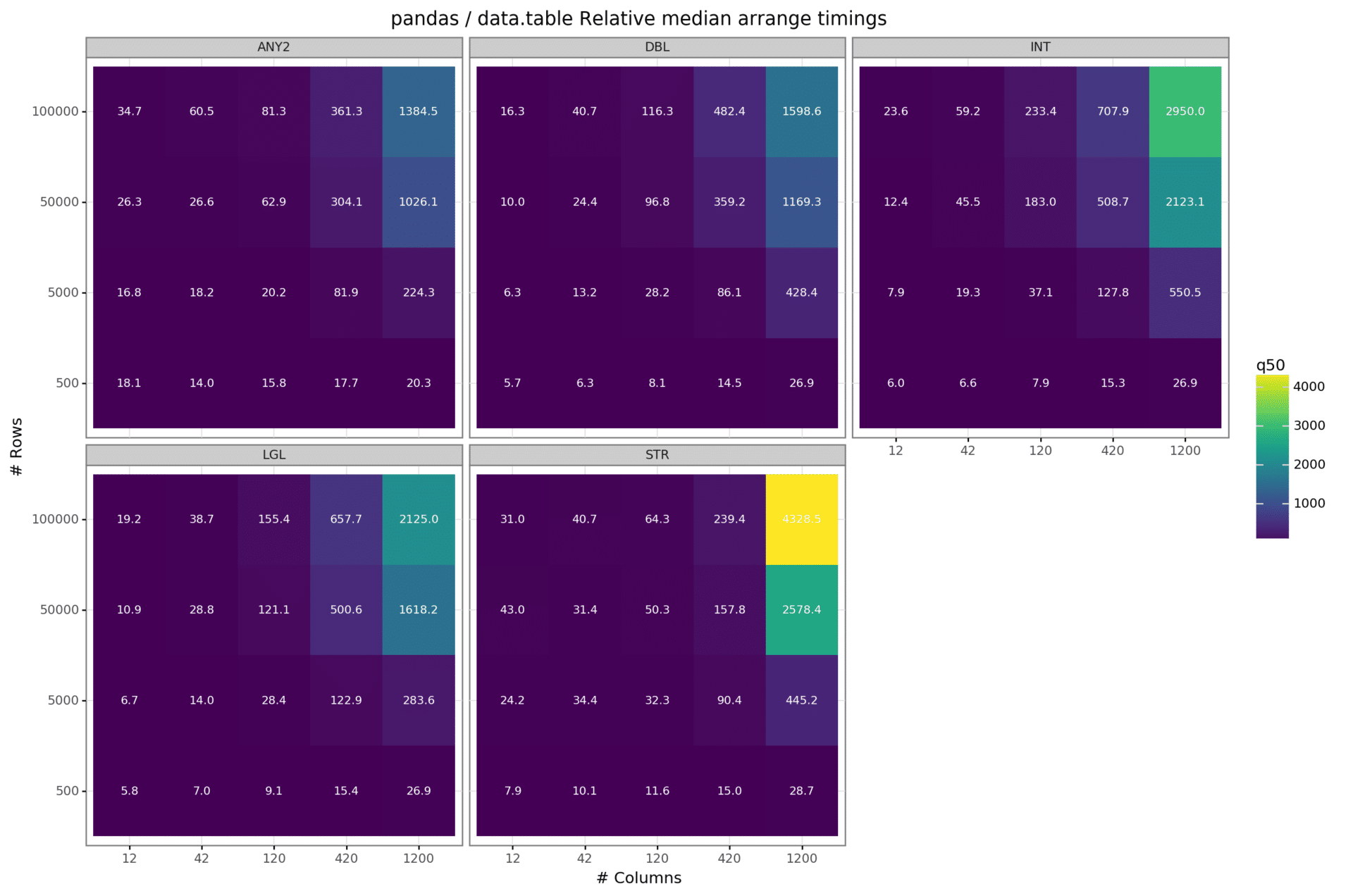
As indicated by the relative median sorting times, it becomes obvious that data.table performs sorting tasks considerably faster than its python counterpart. This difference becomes most prominent when looking at the extreme case where the data set has 1200 columns.
Mutate
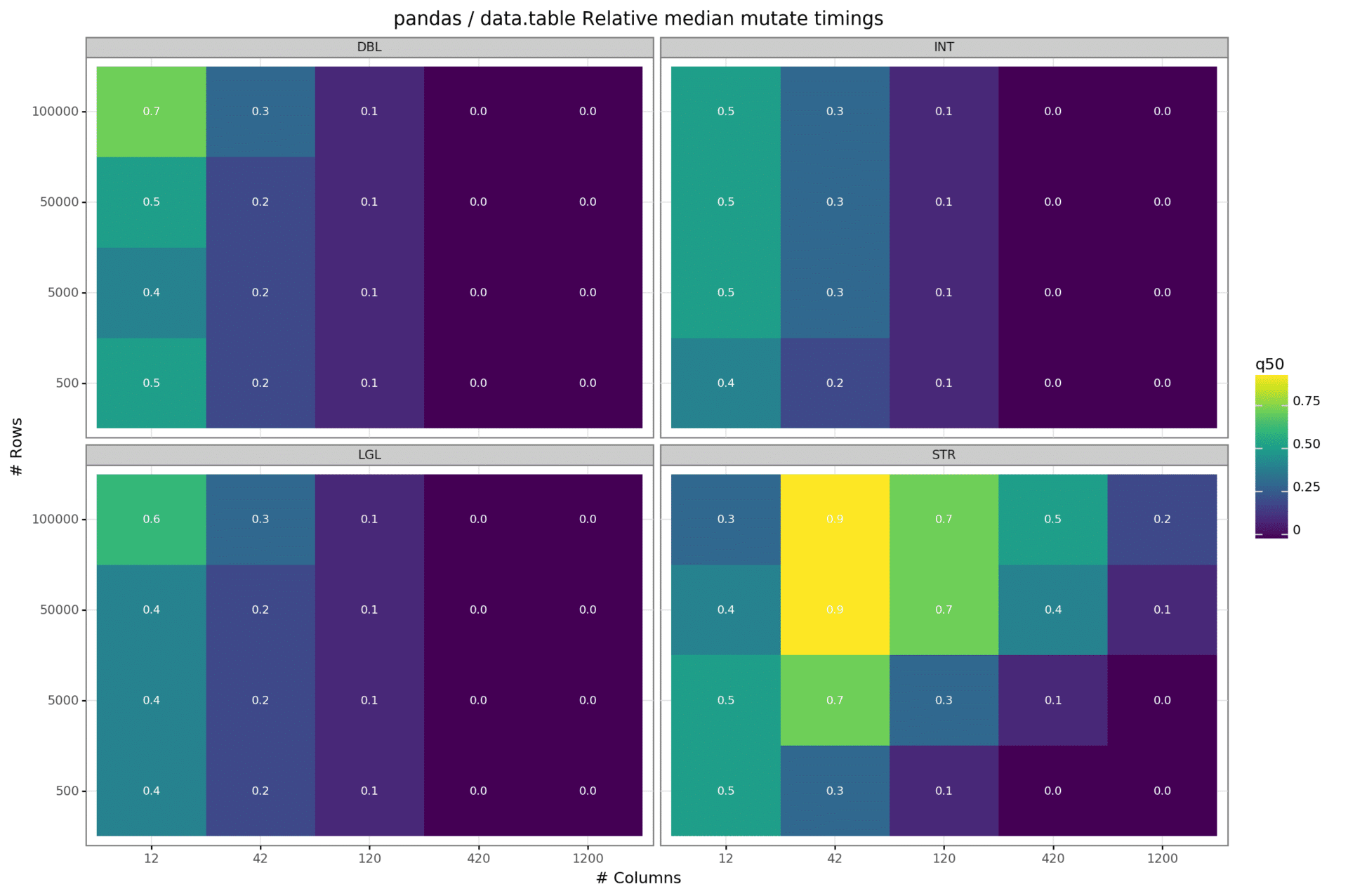
In this setting, we create a new “result” column in our dataset based on some pre-specified operations that depend on the data type we are are considering. In total, we measure the computation time of four scenarios, one scenario per data type (We used the term “mutate” here as a reference to the dplyr package, which has a mutate()-function):
- Take a pre-specified randomly chosen integer column
 and increment each element in by one:
and increment each element in by one: 
- Take a pre-specified randomly chosen double column
 and double each element:
and double each element: 
- Take a string column
 and append each element with the character ‘a’:
and append each element with the character ‘a’: 
- Take a bool column
 and negate it:
and negate it: 
In this operation category, pandas performs very efficiently across all scenarios. In absolute terms, when having to create a column of type integer, double, or bool, pandas never needed more than a millisecond to complete the task, while it took data.table up to 40 milliseconds to do the same thing. This is the reason why — when rounding to one digit — most of the fractions in the graph above mainly comprise panels filled with a zero. Interestingly, the relative performance gain of pandas over data.table is constant with respect to the number of rows across all numbers of columns. In the string scenario, the relative mutate time is increasing with an increase in the number of rows, yet pandas beats data.table with a significant margin.
Aggregate
We have tested 16 different scenarios that are a combination of a randomly selected column of a specific data type and a randomly selected grouping variable (provided we are in a grouping scenario) which is in all cases an integer. Pictures are always better than words, so here you go.

The results are illustrated below. There is a lot of information in this graph, so take your time construing the results yourself. I will pinpoint some general patterns that are observable from the graph.
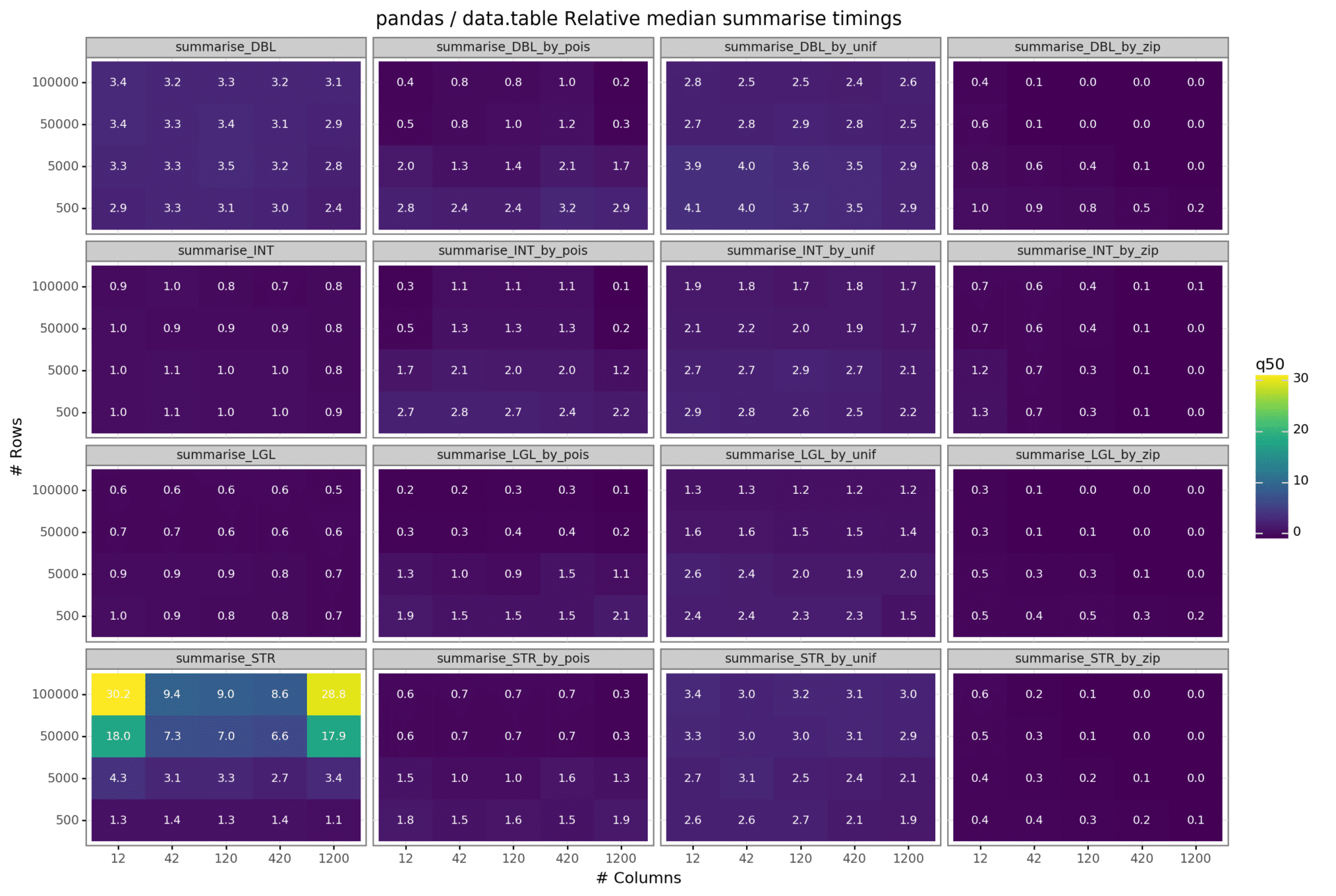
First, let us focus in the aggregation scenarios in which no grouping was applied. In the double and string case, data.table appears to outperform pandas on all data sets. Strangely, in the string summarise case, pandas does way worse than data.table, with no clear pattern explaining why. In the int scenario, their computation time is more akin, with slight wins and losses on both sides. In the case of handling booleans, pandas seems to do a little better, taking half the computation time of data.table at the largest data set with 100.000 rows and 1200 columns. Now, things become more interesting when we look at the grouping scenarios.
When looking at the relative times, you can see that — when only comparing grouping scenarios — data.table performs most efficiently when the number of groups is largest and groups are evenly distributed (“unif”), being faster than pandas across all data types. Then, the relative efficiency declines when grouping by a variable that is less evenly distributed (“pois”), and is the lowest (i.e. data.table is the slowest) when being confronted with a heavily skewed grouping variable that follows a zero-inflated poisson distribution (“zip”). In the latter grouping scenario, pandas does way better than the R counterpart.
In general, in the bool, int and double case, pandas seems to get closer to or even overtake data.table in terms of computation time when the number of rows in the data increases, i.e. more data needs to be aggregated. In the string case, it is the opposite.
Conclusion and Outlook
The results from the simulation study are mixed, with no clear winner across all operation categories that needed to be carried out. If sorting happened a lot in your codes, data.table should be the package to go. However, if you wanted to use a package that is fast at creating new data columns, pandas would be your preferred choice. With aggregation, my opinion based on the results is that pandas is more often extremely faster than slower when compared with data.table, but in general, which one is quicker depends on the data type and the nature of the grouping variable you encounter. Having said that, I would not want to dare declare a clear winner.
We are aware that there are numerous points in the study that could be altered in order to improve the validity of our findings. For instance, it would be necessary to investigate the aggregation scenarios in more depth in order to understand what really drives the performance of the packages. If only having looked at the grouping scenarios, I would have concluded that data.table becomes slower than pandas when the number of groups by which it has to carry out aggregations decreases, and vice versa. This conclusion, however, is contradicted by the finding that data.table beats pandas in aggregating a double and string column when no grouping is required.
That being said, we consider this simulation experiment a valuable starting point from which we can start more thorough endeavors into the realm of performance comparisons between data.table and pandas. Please feel free to contribute to this project by sending us an email. We also have a public repo containing all necessary codes on GitHub.
So far, the only thing we can say for sure is that, in the end, it indeed seems that choosing between pandas and data.table is up to your taste (speaking of which: I am going to treat myself with some sweets…).