
Nachdem wir in dem vorherigen Artikel eine Einführung in Pandas gegeben haben und somit nun Daten auswählen sowie manipulieren können, soll sich in diesem Artikel alles um die Visualisierung von Daten drehen. Bekanntlicherweise lassen sich mit der passenden Grafik Daten häufig noch besser verstehen und ermöglichen eine andere Art der Interpretation, unabhängig von Mittelwerten und anderen Kennzahlen.
Welche Bibliothek zu Datenvisualisierung in Python?
In dem Bibliotheksdschungel von Python wimmelt es nur so von Bibliotheken, die sich zur Visualisierung eignen. Die Bandbreite reicht von einem einfachen Streudiagramm über die Darstellung der Struktur eines neuronalen Netzes bis zu 3D-Visualisierungen. Die älteste und ausgereifteste Datenvisualisierungs Bibliothek im Python Ökosystem ist Matplotlib. Mit dem Start der Entwicklung im Jahr 2003 hat sie sich kontinuierlich weiterentwickelt und bildet auch die Basis für die Bibliothek seaborn. Sie bietet eine große Fülle an Einstellungs- bzw. Customizing Möglichkeiten und orientiert sich dabei an MATLAB. Der Namenszusammenhang ist offensichtlich ;-).
Start mit Matplotlib
Grafiken mit Matplotlib zu erstellen kann auf zwei Arten erfolgen:
- via
pyplot - Objekt-orientierter Ansatz
An dieser Stelle sei angemerkt, dass es sich bei pyplot um eine Teilbibliothek von matplotlib handelt. Der erste Ansatz ist der meist verbereitete, da dieser einen einfachen Einstieg in Matplotlib ermöglicht. Hingegen bietet sich der zweite für wirklich sehr detailreiche Grafiken an, die viele Anpassungen erfordern, an. In diesem Blog-Beitrag werden die Grafiken ausschließlich mit pyplot erstellen. Die Erstellung orientiert sich dabei an folgender Vorgehensweise:
- Erstellung eines
figure-Objekts inkl.axes-Objekten - Bearbeiten der
axes-Objekte - Ausgabe des Objekts
Folglich bearbeiten wir in Python somit ein Objekt direkt, anstatt wie bei der „Gramma of Graphics“ Schicht für Schicht auf eine Grafik zu legen.
Initialisierung einer Grafik
Der Import von matplotlib typerweise wie folgt:
# Import Matplotlib
import matplotlib.pyplot as plt
Nun gilt es ein figure-Objekt anzulegen. An dieser Stelle sollte man sich zudem überlegen, wie viele Darstellungen man in seinem Objekt integrieren möchte, dies erleichtert den späteren Arbeitsfluss. Im folgenden Codebeispiel wird eine figure mit einer Spalte sowie einer Zeile erstellt.
# Initilaisierung einer Figure
fig, ax = plt.subplots(nrows = 1, ncols = 1)
# Ausgabe der Figure
fig
Die Methode figure liefert zwei Argumente zurück, es handelt sich dabei um die eigentlich figure sowie um ein Axes-Objekt. Dies hängt mit dem objektorientierten Ansatz von Matplotlib zusammen. Umfasst eine figure mehrere Teildarstellungen wie z.B. Histogramme von unterschiedlichen Daten, so kann man die Teildarstellungen einzeln über das Axes-Objekt bearbeiten und das figure-Objekt fasst alle Teildarstellungen zusammen. Die figure umfasst somit die graphische Darstellung und das Axes-Objekt die einzelnen Teildarstellungen. Lässt man sich die erstellte Variable fig ausgeben, so erhält man folgende Darstellung:
Unsere Grafik enthält also bis jetzt nur ein Koordinatensystem. Um den objektorientieren Ansatz noch einmal zu verdeutlichen erstellen wir eine figure mit insgesamt zwei Zeilen und Splaten.
# Erstellen einer Figure mit 4 separaten Grafiken
fig, ax = plt.subplots(nrows = 2, ncols = 2)
Mittels Indexselektion kann man nun die einzelnen Teildarstellungen aus dem Grid auswählen. Somit sollte der objektorientierte Ansatz klar und deutlich geworden sein.
# Auswahl der einzelnen Teildarstellungen
ax[0,0]
ax[0,1]
ax[1,0]
ax[1,1]
Bei der Initialisierung einer Grafik sind natürlich Anpassungen im Hinblick auf die Größe der Grafik denkbar, dies lässt sich wie folgt umsetzen:
# Festlegung der figure Größe
fig, ax = plt.subplots(nrows = 2, ncols = 2, figsize = (10, 12))
Die Grafikgröße wird als Tuple (Breite, Höhe) in Inches angegeben.
Darstellung von Daten
Nachdem wir dargestellt haben wie man eine Grafik in Matplotlib initialisieren kann, soll es nun darum gehen, diese mit Daten zu befüllen. Für den Einstieg nehmen wir die erste figure aus dem Blog-Beitrag. Zur Darstellung von Daten greifen wir auf das Axes-Objekt zu und wählen zu Beginn die Funktion plot. Eine Vielzahl von weiteren Funktionen kann unter diesem Link gefunden werden.
# Erstellen der Grafik
fig, ax = plt.subplots(nrows = 1, ncols = 1)
# Erstellen von Beispieldaten
sample_data = np.random.randint(low = 0, high = 10, size = 10)
# Darstellung der Beispieldaten
ax.plot(sample_data)
# Ausgabe der Figure
fig
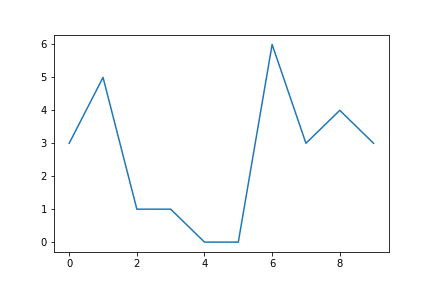
An dieser Stelle sei kurz angemerkt, dass Matplotlib im Hintergrund zwei Vorgänge durchgeführt hat:
- Die Skala wurde automatisch an die Daten angepasst.
- Die Darstellung der Daten erfolgte über den Index, d. h. der eigentliche Wert ist auf der y-Achse.
Ist man der Auffassung, dass z.B. ein Streudiagramm besser geeignet wäre, so lässt sich die Grafik einfach ändern. Anstelle von plot schreibt man scatter. Der Codes zeigt, dass in diesem Fall nicht die Daten automatisch über den Index dargestellt wurden, sondern explizit x und y als Argumente übergeben müssen.
# Erstellen der Grafik
fig, ax = plt.subplots(nrows = 1, ncols = 1)
# Erstellen von Beispieldaten
sample_data = np.random.randint(low = 0, high = 10, size = 10)
# Darstellung der Beispieldaten
ax.scatter(x = range(0, len(sample_data)), y=sample_data)
# Ausgabe der Figure
fig
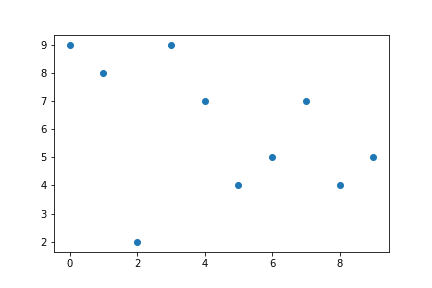
Alle typischen Datenvisualisierungen lassen sich so mit Matplotlib umsetzen.
Beschriftungen und Speichern von Grafiken
Die Darstellung der Daten ist die eine Sache, mit einer passenden Überschrift werden sie dann doch verständlicher.
Als Beispiel wollen wir ein Histogramm mit den Beispieldaten beschriften. Mithilfe der Funktionen set_ kann die Beschriftung einfach vorgenommen werden.
fig, ax = plt.subplots(nrows=1, ncols=1)
sample_data = np.random.randint(low = 0, high = 10, size = 10)
ax.hist(sample_data,width = 0.4)
# Hinzufügen der Beschriftungen
ax.set_xlabel('Beispieldaten')
ax.set_ylabel('Häufigkeiten')
ax.set_title('Histogramm mit Matplotlib')
# Ausgabe der Figure
fig
Wir erhalten folgende Grafik:
Möchte man gerne seine Grafik speichern, so kann man über die Funktion fig.savefig('Pfad der Grafik') dies vornehmen.
Resümee und Ausblick
Dieser Blog Beitrag sollte einen ersten Einstieg in die Python Visualisierungsbibliothek Matplotlib geben und grundlegende Konzepte vermitteln. Die Anpassbarkeit der Grafiken geht weit über die Funktionen, die wir vorgestellt haben, hinaus:
- Anpassung der Farben, Farbverläufe,…
- individuelle Axenbeschriftung/-skalierung
- Annotieren von Grafiken mit Text Boxen
- Änderung der Schriftart
- …
Allgemein ist zu berücksichtigen, die passenden Daten für die Grafiken auszuwählen, wie man das mit Pandas umsetzen kann, lässt sich hier nachlesen. Im nächsten Beitrag in dieser Serie wird es dann um Scikit-Learn gehen, der Einsteiger Machine Learning Bibliothek in Python.